
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Multiple experts decision-making (MEDM) can be regarded as a situation where a group of experts are invited to provide their opinions by evaluating the given alternatives, and then select the optimal alternative(s). As a useful linguistic expression model, linguistic preference orderings (LPOs) were established in which the order of alternatives and the relationships between two adjacent alternatives are fused well. Considering that prospect theory has the superiority in depicting risk attitudes (risk seeking for losses and risk aversion for gains) during the uncertain decision-making process, this paper develops a consensus model based on prospect theory to deal with MEDM problems with LPOs. Firstly, each LPO provided by expert is transformed into the responding DHLPR with complete consistency. Then, the reference point of expert is determined and the prospect preference matrix is established. Moreover, we can obtain the overall prospect consensus degree for a MEDM problem by calculating the similarity degree between individual and collective prospect preference matrix. Furthermore, a consensus improvement method is developed to complete the consensus reaching process. Finally, we apply the proposed method to deal with a practical MEDM problem involving the construction project investment, and make some comparative analyses with existing methods.
1. Introduction
Multiple experts decision-making (MEDM) can be regarded as a situation in which a group of experts are invited to provide their individual opinions by evaluating the given alternatives, and then select the optimal alternative(s) by aggregating their opinions or using some decision-making methods (Gou et al., Citation2020c). Obviously, the first and most important step of MEDM is to acquire the assessment information of experts, and the preference ordering (PO) structures are usually used by experts to express their opinions considering that people prefer to rank the alternatives according to their own ideas or common sense (Chiclana et al., Citation1998; Hervés-Beloso & Cruces, Citation2018; He & Xu, Citation2018; Tanino, Citation1984; Zhang et al., Citation2018). Meanwhile, there are lots of PO structures such as POs (Chiclana et al., Citation1998; Zhang et al., Citation2018), hesitant PO sets (He & Xu, Citation2018), continuous POs (Hervés-Beloso & Cruces, Citation2018), fuzzy POs (Tanino, Citation1984), etc.
However, there exist two critical problems when using the existing POs. Firstly, the existing POs can only reflect the orderings of alternatives, but lack the research on the precise relationship between any two adjacent alternatives in the POs. In fact, some experts may prefer a more detailed sentence to express their opinions, such as “ is very faster than
, and
is slightly faster than
”, instead of only using an order
In addition, the existing methods are more inclined to aggregate the POs and obtain the final ordering of alternatives directly (He & Xu, Citation2018), but ignore the unbalanced relationship between any two adjacent alternatives. To overcome the first shortcoming, primarily, we can utilize the double hierarchy linguistic terms (DHLTs, the basic elements of double hierarchy linguistic term set (DHLTS) (Gou et al., Citation2017)) to express the relationship between any two adjacent alternatives. The reason is that the DHLTS can be used to handle complex linguistic information well by dividing them into two simple linguistic hierarchies, where the first hierarchy linguistic term set (LTS) is the main linguistic hierarchy and the second hierarchy LTS is the linguistic feature or detailed supplementary of each linguistic term in the first hierarchy LTS (Gou et al., Citation2017). Then, Gou et al. (Citation2020c) developed a new concept of linguistic preference ordering (LPO) which is composed of PO and DHLTs, and they also focused on dealing with two kinds of LPOs, respectively. To overcome the second shortcoming, Gou et al. (Citation2020c) transformed the LPOs into the corresponding double hierarchy linguistic preference relations (DHLPRs) with complete consistency (2020 b), and then obtained the decision-making result by handling these DHLPRs.
In the past decision-making processes, some existing methods are only used to deal with the experts’ assessments (Fan et al., Citation2006; Liu et al., 2019) and do not consider the experts’ psychological behaviors. What is more, lots of empirical evidences (Camerer, Citation1998; Kahneman & Tversky, Citation1979; Tversky & Kahneman, Citation1992) have shown that the experts’ psychological behaviors would play an important role in decision analysis (Dong et al., Citation2015). As we know, Kahneman and Tversky (Citation1979) proposed the concept of prospect theory, and it has the superiority in depicting risk attitudes (risk seeking for losses and risk aversion for gains) during the uncertain decision-making process (Tversky & Kahneman, Citation1992). Meanwhile, a lot of scholars have devoted to this aspect research and demonstrated the usefulness of behavioral decision-making revealed by the prospect theory (Abdellaoui, Citation2000; Birnbaum, Citation2005; Bleichrodt et al., Citation2009; Gonzalez & Wu, Citation1999; He & Zhou, Citation2011; Lu et al., Citation2020; Wu & Gonzalez, Citation1999; Zhou et al., Citation2019). In recent years, prospect theory has been applied to deal with some decision-making problems such as behavioral decision-making (Fan et al., Citation2013; Wang et al., Citation2015), multi-attribute decision-making (Fan et al., Citation2013; Liu et al., Citation2014; Tian et al., Citation2018, Citation2020) and MEDM (Yan & Liu, Citation2014), etc.
However, as far as we know, there is no research about the extension of prospect theory in consensus reaching process (CRP) of MEDM problems with LPOs. Therefore, the purpose of this paper is to develop a consensus model based on prospect theory to deal with MEDM problems with LPOs. Firstly, the LPOs provided by experts can be transformed into DHLPRs with complete consistency, which can ensure the integrity of the original assessment information (Gou et al., Citation2020c). Then, we can determine the reference point of expert considering that it is the demarcation point of the positive and negative DHLTs, and establish the prospect preference matrix by calculating the gains and losses with respect to alternatives for each expert based on the equivalent transformation function (Gou et al., Citation2017) and the prospect value function introduced by Kahneman and Tversky (Citation1979). Moreover, by calculating the similarity degree between individual prospect preference matrix and the collective prospect preference matrix, we can obtain the overall prospect consensus degree for a MEDM problem, and check whether the consensus is reached or not. If not, we develop a consensus improvement method which consists of identifying the experts and the pairs of alternatives that need to improve their consensus degrees, and feeding the suggestions back to the corresponding experts and telling them how to adjust their preferences. Finally, a model is set up to obtain the priority vector of each expert, and then the rank of alternatives is obtained based on the collective priority vector which is got by aggregating these individual priority vectors.
The main innovation points of this paper are highlighted as follows:
By fusing LPOs and prospect theory, we cannot only obtain more comprehensive assessment information of expert, but also have the superiority of prospect theory in depicting risk attitudes (risk seeking for losses and risk aversion for gains) during the decision-making process.
The prospect preference matrix of each expert is established by calculating the gains and losses with respect to alternatives.
A consensus improvement method is developed, which consists of the identification rules and the direction rules.
The final rank of alternatives can be obtained by establishing and solving a model which can be used to calculate the priority vector of each expert and the collective priority vector.
The remainder of the paper is organized as follows: Section 2 reviews some related concepts of DHLPR, LPOs and prospect theory. Section 3 develops a MEDM resolution framework with LPOs based on prospect theory. Section 4 applies the proposed method to deal with a practical MEDM problem involving the construction project investment, and makes comparative analysis with the existing methods. Some concluding remarks are summarized in Section 5.
2. Preliminaries
As the basis of this paper, some related concepts are reviewed in this section including DHLPR, LPOs and prospect theory.
2.1. Double hierarchy linguistic preference relation
For dealing with natural languages, Zadeh (Citation2012) provided the concept of Computing with Words (CW). Based on CW, lots of linguistic representation models were developed (Juang & Chen, Citation2013; Pang et al., Citation2016; Rodríguez et al., Citation2012; Wang et al., Citation2018; Wei et al., Citation2020; Wei & Gao, Citation2020; Xu & Wang, Citation2017). However, the above linguistic representation models usually have some gaps when expressing some more complex and detailed linguistic information such as “only a little fast” and “slightly high”. By splitting complex linguistic term into two parts with the form of “adverb + adjective” and expressing them by different kinds of linguistic terms respectively, Gou et al. (Citation2017) defined the concept of DHLTS. Let and
be the first hierarchy LTS and the second hierarchy LTS of linguistic term
in
respectively. A DHLTS,
can be expressed by
(1)
(1)
where the basic element
is called DHLT, and
expresses the second hierarchy linguistic term of the linguistic term
in
For convenience, EquationEq. (1)
(1)
(1) can be rewritten by a unified form
In recent years, many scholars began to pay attention to the research of double hierarchy linguistic information and developed a lot of research results including preference relations (Gou et al., Citation2018a, Citation2019, Citation2020a, Citation2020b, Citation2020c, Citation2020d), measure methodologies (Fu & Liao, Citation2019; Gou et al., Citation2018b) and decision methodologies (Fu & Liao, Citation2019; Gou et al., Citation2017, Citation2018a, Citation2018b, Citation2019, Citation2020a, Citation2020b, Citation2020c; Krishankumar et al., Citation2019; Liu et al., Citation2019a, Citation2019b; Wang et al., Citation2020), etc.
Let be a continuous DHLTS, then the numerical scale
and the subscript
of the DHLT
which expresses the equivalent information to the membership degree
can be transformed to each other by the following functions
and
(2)
(2)
(3)
(3)
To get the concept of DHLPR, some operational laws of DHLTs were developed (Gou et al., Citation2017). Suppose that
and
are three different DHLTs, and
is a real number. Then,
if
Definition 1
(Gou et al., Citation2020b). Let be a DHLTS. A DHLPR
is presented by a matrix
where
is a DHLT, indicating the degree of the alternative
over
For all
satisfies the conditions
and
In addition, a DHLPR can be called an additively consistent DHLPR (Gou et al., Citation2020c) if it satisfies
(4)
(4)
To obtain the additively consistent DHLPR conveniently, Gou et al. (Gou et al., Citation2020c) proposed the following theorem:
Theorem 1
(Gou et al., Citation2020c). Let be a DHLPR. If
for all
, then
is an additively consistent DHLPR.
2.2. Linguistic preference orderings
In MEGM processes, when experts evaluate alternatives and provide their POs, two forms of LPOs are very familiar. One is to rank all alternatives using a LPO in continuous form directly, and the other one is to give the relationship between any two alternatives and then all these relations make up a set of POs (2020c).
The LPO in continuous form
Let and
be a DHLTS and a set of alternatives, respectively. Suppose that an expert
provides his/her linguistic preference information by a LPO denoted by:
(5)
(5)
where
the
denotes the
largest alternative, and the linguistic preference, denoted as a DHLT
means that the degree of the
largest alternative is better than the
largest alternative.
The LPO in decentralized form
Considering that the complexity of things and the fuzziness of people’s cognition, sometimes some experts prefer to give some pairwise comparisons between any two alternatives rather than provide a complete PO. Therefore, in this case, the preference information provided by an expert on
can be called a LPO in decentralized form, which is a set of PO pairs and can be shown as follows:
(6)
(6)
where
expresses the relationship between
and
Next, two examples are given to show these two LPOs. Let be a set of alternatives, then
is a LPO in continuous form, and
is a LPO in decentralized form.
Remark 1.
For a LPO in continuous form, considering that the evaluation between the alternative ranked in the first position
and that in the final position
must be less than
and the sum of all evaluations in the LPO should be equal to
Therefore, we have
For a LPO in decentralized form, to obtain the preference information more completely and transform the LPO into DHLPR successfully and exactly, the original preference pairs should contain all alternatives and should also have some relations among alternatives directly or indirectly. Therefore, the number of the PO pairs should not be less than
As we know, the LPOs can express linguistic information more completely and correctly, but it is very difficult to make calculations among them. Therefore, Gou et al. (Citation2020c) developed a transformation model to transform the LPOs into a unified form, namely, a completely consistent DHLPR. The model consists of equations, which can be used to obtain the remaining elements of the upper triangular matrix of DHLPR
(7)
(7)
By deleting some repeating the elements EquationEq. (7)
(7)
(7) is changed to the following form:
(8)
(8)
2.3. Prospect theory
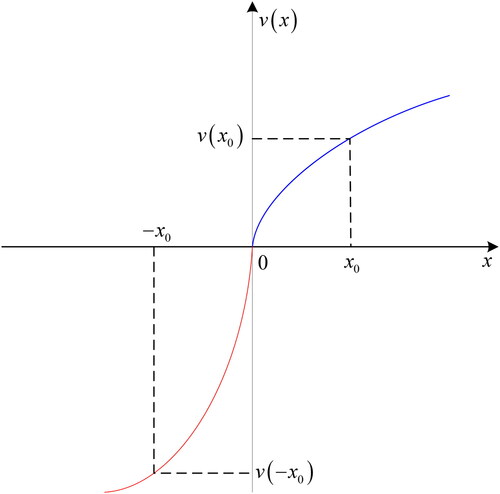
Tversky and Kahneman (Citation1992) proposed the prospect theory, which can be used to describe the bounded rational behavior of experts when dealing with decision-making problems. The key point of prospect theory is that the risk seeking for losses and risk aversion for gains are unsymmetrical (Tian et al., Citation2018). Based on the prospect theory, the prospect value function can be obtained:
(9)
(9)
In EquationEq. (9)(9)
(9) , the
is the assessment value of a project or an alternative. Specially, the
is called as reference point and it can be used to determine the assessment value belongs to the gain or the loss. If
then the possible assessment value
means a gain; Otherwise, the possible assessment value
represents a loss. The parameters
and
are the risk attitudes of expert for gains and losses respectively, and
is a loss aversion coefficient. Generally,
and it means that the graph of the value function for losses is steeper than gains. Based on (Tversky & Kahneman, Citation1992), we obtain
and
Suppose that the reference point
for any an assessment value
the prospect value function is shown in .
Figure 1. The prospect value function.
Source: The Authors.
3. Prospect consensus with LPOs
In MEDM processes, it is common that experts usually have different education background, cognition and experience of practical decision-making problem. Therefore, it is necessary to reach group consensus before obtaining the final decision-making result. Considering that prospect theory has been demonstrated as a common phenomenon in decision-making because it can express the behavior of risk aversion for gains and risk seeking for losses. Thus, In this section, we develop a MEDM resolution framework and propose a consensus model based on prospect theory with LPOs.
A MEDM problem can be described as: Let be a set of experts, and
be a set of alternatives. Each expert
evaluates all alternatives and provides his/her individual LPO. Based on EquationEq. (7)
(7)
(7) or Equation(8)
(8)
(8) , each LPO can be transformed into the corresponding completely consistent DHLPR
3.1. The selection process
Based on the prospect theory and the DHLPR transformed from the LPO provided by the expert
the prospect preference matrix
is established:
(10)
(10)
where
is a real number and determined by the following formula:
(11)
(11)
where the function
is the equivalent transformation function,
is the reference point. In this paper, considering that the element is positive when
and the element is negative when
so we can let
Therefore, the
is the prospect preference element of the alternative
to the alternative
from the expert
For each prospect preference matrix we can obtain the individual priority vector
of the expert
by establishing and solving the following model:
Then, the collective priority vector can be obtained by aggregating all experts’ priority vectors, where
(12)
(12)
Obviously, the bigger value of is, the higher ranking order of the alternative
will be. Therefore, the rank of all alternatives and the optimal alternative can be obtained.
3.2. The consensus processes
In MEDM processes, the other important step is that all experts should reach group consensus before making decision. Therefore, this subsection researches the consensus process in the MEDM framework with LPOs based on prospect theory, which consists of consensus measure and feedback adjustment method.
Generally, we can utilize the distance or similarity degree between individual preferences and the collective preference to express the consensus degree for the decision-making problem (Dong et al., Citation2010). Similarly, next we will propose a prospect consensus degree (PCD) for the MEDM problem with LPOs based on prospect theory.
Firstly, by aggregating all prospect preference matrices the collective prospect preference matrix
is obtained, where
Then, the PCD of the expert is obtained by measuring the similarity degree between the prospect preference matrix
and collective prospect preference matrix
Definition 2.
Let and
be the prospect preference matrix of
and the collective prospect preference matrix, respectively. The PCD of the expert
is defined by
Then, the overall prospect consensus degree (OPCD) among experts is obtained by
(14)
(14)
Obviously, the larger the value of OPCD is, the higher the consensus degree among all experts will be. Specially, means that all experts have full and unanimous agreement. Suppose that
is the given threshold, if
then the consensus is achieved; Otherwise, if
then the consensus is not achieved and it is necessary to improve the consensus degree.
We develop a consensus improvement method, which consists of two steps: Firstly, we need to identify the experts and the pairs of alternatives that need to improve their consensus degrees, this step is called identification rules; Secondly, we also need to feedback the suggestions to the corresponding experts and tell them how to adjust their preferences, this step is called direction rules.
(I) Identification rules
Suppose that then we can obtain a set of experts whose prospect consensus degrees are less than the given threshold
(15)
(15)
Then, for any an expert we need to identify the pairs of alternatives that should be adjusted and they are included in a set as follows:
(16)
(16)
(II) Direction rules
Suppose that the adjusted preference relation of the expert is
Based on EquationEqs. (15)
(15)
(15) and Equation(16)
(16)
(16) , the direction rules are designed as follows:
If
If
If
When the experts have got the direction rules discussed above, the next step is to determine the extent of the adjustments. Suppose that the and
are the preferences of the expert
in the
and the
iterations, respectively. Accordingly, we can obtain the prospect preference matrix
and the prospect preference matrix
Then the general range is
(17)
(17)
In fact, we can always find a parameter EquationEq. (17)
(17)
(17) can be equivalently transformed into
(18)
(18)
3.3. The consensus process
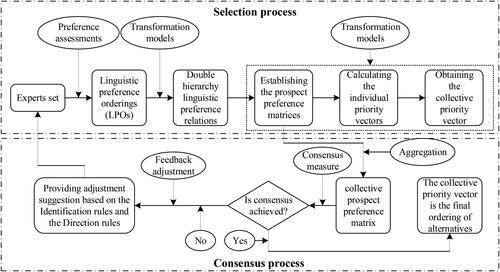
Based on the selection process and consensus process discussed above, a MEDM consensus model with LPOs based on prospect theory is established as follows:
Algorithm 1.
A MEDM consensus model with LPOs based on prospect theory
Input: The LPOs of all experts, the consensus threshold the parameters
and
and the maximum number of iterations
Output: The number of iterations the final consensus degree, and the ranking order of all alternatives.
Step 1. Transform all the LPOs of experts into the corresponding DHLPRs
Step 2. Based on EquationEqs. (10)(10)
(10) and Equation(11)
(11)
(11) , we calculate and establish the prospect preference matrices
of expert
Step 3. Based on EquationEqs. (13)(13)
(13) and Equation(14)
(14)
(14) , we calculate the PCD of each expert and the OPCD among all experts, respectively. If
then go to Step 5; If
then go to Step 4.
Step 4. Identify the experts and the pairs of alternatives that need to improve their consensus degrees based on EquationEqs. (15)(15)
(15) and Equation(16)
(16)
(16) . Then we feedback the adjustment suggestions to the corresponding experts according to the direction rules. The experts provide their novel LPOs or preferences on the basis of the adjustment suggestions. Go back to Step 1 or Step 2.
Step 5. Based on Model 1 and EquationEq. (12)(12)
(12) , calculate the priority vectors of all experts and the collective priority vector, respectively. Then the rank of all alternatives is obtained.
This MEDM consensus framework with LPOs based on prospect theory is described in .
Figure 2. The MEDM consensus framework with LPOs based on prospect theory.
Source: The Authors.
4. The application of the MEDM consensus model with LPOs based on prospect theory
In this section, firstly we apply the method proposed in this paper to deal with a practical MEDM problem involving the construction project investment, and then make some comparative analyses between the proposed method and the existing methods (Gou et al., Citation2018a, Citation2020c).
4.1. The background of construction project investment with prospect theory
Construction project investment is a complex system engineering, the managers will face many risk factors and decision-making problems from project initiation to delivery. For a certain construction project, although its objective risk size and degree are certain, for different construction project investment, decision makers may choose different risk decision-making methods because of their different risk interest preferences. In the actual investment activities of construction projects, the attitudes of risk decision makers towards risk interests are not invariable. They may prefer risk interests in the face of some risks, but dislike risk interests in the face of other risks. Even in the same investment activity, no one will go to completely favor risk return, and do not consider risk loss; At the same time, no one is completely risk-averse without thinking about risk-return. Prospect theory (Kahneman & Tversky, Citation1979; Tversky & Kahneman, Citation1992), as a major discovery in the field of decision-making, introduces psychological knowledge and integrates the value feeling factors of decision-makers into the analysis of decision-making behaviors, which hides the deficiency of expected utility theory and better explains decision makers’ behaviors under uncertain conditions. Therefore, by introducing the risk attitudes and preferences of decision makers into the investment risk decision of construction projects through prospect theory, it can better reflect the decision-making behavior of the finite rational person under the condition of uncertain risk, thus improving the scientificity and objectivity of construction project investment.
Suppose that one real estate development company is facing five investment projects and four experts
are invited to evaluate these investment projects. Let
be a DHLTS, where
and
Then four invited experts provide their preferences by
shown as follows:
4.2. Solving the MEDM problem with the proposed method
In this subsection, we can use the consensus framework with LPOs based on prospect theory proposed in this paper to deal with the above practical MEDM problem.
Step 1. Transform all LPOs of experts into the corresponding DHLPRs
Step 2. Based on EquationEqs. (10)
Step 3. Based on EquationEqs. (13)
Table 1. The results of the prospect consensus degrees and the overall prospect consensus degree.
Obviously, the consensus is not achieved. Therefore, the experts should adjust their preferences and improve the group consensus.
Step 4. Based on EquationEqs. (15)–(17), the experts
Based on EquationEqs. (10)(10)
(10) and Equation(11)
(11)
(11) , calculate and establish the new prospect preference matrices
of the experts
Then, based on EquationEqs. (13)
(13)
(13) and Equation(14)
(14)
(14) , calculate the new PCD (PCD(1)) of each expert and the new OPCD (OPCD(1)) among all experts. The results are shown in .
Table 2. The results of the prospect consensus degrees and the overall prospect consensus degree.
Obviously, so the consensus is achieved.
Step 5. Based on Model 1 and EquationEq. (12)
Table 3. The results of the prospect consensus degrees and the overall prospect consensus degree.
Therefore, the ranking order of all alternatives is
4.3. Comparative analysis
In this subsection, we can make some comparative analyses between the proposed method and some existing methods.
(1) The comparative analysis about the CRP
Firstly, based the multi-stage interactive consensus reaching algorithm with LPOs developed by Gou et al. (Citation2020c), the above MEDM problem can be solved after two times of iterations, and the ranking of alternatives is also
Secondly, we can use the consensus reaching method proposed by Gou et al. (Citation2018a) to solve the above MEDM problem. Firstly, we obtain the overall consensus degree Therefore, we need to improve the preferences of the experts
and
and they provide their adjusted preferences:
Then, we obtain the overall consensus degree Therefore, the consensus is achieved, and the synthetical value of each alternative is also
Based on the above three methods, some comparative analyses can be summarized as follows:
The fundamentals of these three methods are different. Firstly, the method proposed in this paper mainly utilizes prospect theory to calculate the prospect preference matrices, the prospect consensus degree of each expert and the overall prospect consensus degree, and then checks whether the group consensus is achieved or not. Considering that the risk seeking for losses and risk aversion for gains are unsymmetrical in decision-making, so the proposed method is more in line with the bounded rational behavior of experts. Secondly, the method developed by Gou et al. (Citation2020c) mainly consists of three stages consensus optimization processes. Therefore, this method can be used to achieve consensus using minimal changes in the size of the change, the number of modifications, and the number of individuals who need to revise their preferences. Finally, the method proposed by Gou et al. (Citation2018a) makes the CRP only based on the DHLPRs instead of the LPOs. Therefore, it has limitation when dealing with group consensus reaching method with LPOs.
Even though the proposed method fully considers the risk seeking for losses and risk aversion for gains of experts, the extent of the changes is not effectively controlled. In contrast, the methods proposed by Gou et al. (Citation2020c) develops optimization models to decrease the modification amplitudes of different aspects, and the method proposed by Gou et al. (Citation2018a) also decreases the modification amplitudes of experts and preferences. However, both of them do not consider the bounded rational behavior of experts. The extent of the changes of these three methods are listed in . Clearly, the modification number of the DHLTs of the proposed method is larger than that of the other methods (Gou et al., Citation2018a, Citation2020c), and the number of experts that have to change their preferences of the method of this paper, Gou et al. (Citation2020c), and Gou et al. (Citation2018a) are 3, 4 and 2, respectively.
In specific decision-making processes, the determination of reference points is the main obstacle to be solved urgently in prospect theory, and it is influenced by the decision makers themselves, objective environment and other factors, so it is very difficult to accurately locate and evaluate them. In this paper, we suppose that
Table 4. The priority vectors of all experts and the collective priority vector.
(2) The comparative analysis about decision-making methods without prospect theory
When the consensus is reached, this paper mainly obtains the ranking order of alternatives by calculating the priority vectors of all experts and the collective priority vector. In fact, without considering the prospect theory, there exist some other decision-making methods in other decision-making environment. However, there exist no decision-making method under double hierarchy linguistic preference environment. In order to show the advantages of the proposed method, we can make some comparative analyses between the proposed method and some methods provided in other decision-making environment such as the synthetical value-based method (Gou et al., Citation2018a, Citation2019) and the TOPSIS method (Gou et al., Citation2018b), etc.
Firstly, let be a set of DHLTs,
be the weight vector of them. Based on (Gou et al., Citation2018a, Citation2019), the double hierarchy linguistic weighted average (DHLWA) operator can be shown as follows:
(19)
(19)
Based on EquationEq. (9)(9)
(9) , for DHLPRs
the group DHLPR
can be calculated. Then we can aggregate the values of each row of
by
and obtain the overall values of all alternatives:
Therefore, the ranking order of alternatives is
Secondly, based on the traditional TOPSIS methods, the above MEDM problem can be solved. Firstly, the positive ideal solution and the negative ideal solution
of the group DHLPR
can be obtained, where
and
Then, based on the following formula and let
(20)
(20)
The satisfaction degree of each alternative can be got as Therefore, the ranking order of alternatives is
(3) The comparative analysis about decision-making methods with prospect theory
Different from the second part, we can make some comparations about decision-making methods with prospect theory.
Firstly, based on the prospect preference matrices
of the experts
we can also use the synthetical value-based method to solve this MEDM problem, and the overall values of all alternatives are
Therefore, the ranking order of alternatives is
Secondly, based on the traditional TOPSIS methods and prospect theory, we can obtain the satisfaction degree of each alternative as Therefore, the ranking order of alternatives is
Combining the second and the third parts, some discusses can be summarized as follows:
The ranking order of alternatives of all methods is
In second part, the synthetical value-based method and the TOPSIS method do not consider the prospect theory. Even though the decision-making result is same, it is more line with the bounded rational behavior of experts if we consider the risk seeking for losses and risk aversion for gains in decision-making. In addition, the methods in third part consider the prospect theory, but the models need more uncertain parameters and the decision-making processes are more complex.
5. Conclusions and future research directions
Considering that prospect theory has superiority in depicting risk attitudes during the uncertain decision-making process, and LPOs have the advantage of reflecting the ranking ordering of alternatives and the precise relationship between any two adjacent alternatives in the POs simultaneously. Therefore, this paper developed a consensus model based on prospect theory to deal with MEDM problems with LPOs. Firstly, to ensure the integrity of the original assessment information, the LPOs provided by experts was transformed into DHLPRs with complete consistency. In addition, the reference point of expert was determined and the prospect preference matrix was established by calculating the gains and losses with respect to alternatives for each expert. Moreover, the overall prospect consensus degree for a MEDM problem was developed based on the similarity degree between individual prospect preference matrix and the collective prospect preference matrix. Furthermore, a consensus improvement method was developed to complete the CRP. When all experts reach consensus, a model was set up to obtain the priority vector of each expert, and then the ranking of alternatives can be obtained. Finally, we applied the proposed method to deal with a practical MEDM problem involving the construction project investment and then made some comparative analyses with the existing methods.
As the future study, we will devote ourselves to the research of the prospect theory under different uncertain decision-making environment. Meanwhile, as some interesting topics, we will also study applications of LPOs in large-scale group decision-making or large-scale alternatives decision-making problems.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abdellaoui, M. (2000). Parameter-free elicitation of utility and probability weighting functions. Management Science, 46(11), 1497–1512. https://doi.org/https://doi.org/10.1287/mnsc.46.11.1497.12080
- Birnbaum, M. H. (2005). Three new tests of independence that differentiate models of risky decision making. Management Science, 51(9), 1346–1358. https://doi.org/https://doi.org/10.1287/mnsc.1050.0404
- Bleichrodt, H., Schmidt, U., & Zank, H. (2009). Additive utility in prospect theory. Management Science, 55(5), 863–873. https://doi.org/https://doi.org/10.1287/mnsc.1080.0978
- Camerer, C. (1998). Bounded rationality in individual decision making. Experimental Economics, 1(2), 163–183. 96. https://doi.org/https://doi.org/10.1023/A:10099443261
- Chiclana, F., Herrera, F., & Herrera-Viedma, E. (1998). Integrating three representation models in fuzzy multipurpose decision making based on fuzzy preference relations. Fuzzy Sets and Systems, 97 (1), 33–48. https://doi.org/https://doi.org/10.1016/S0165-0114(96)00339-9
- Dong, Y. C., Luo, N., & Liang, H. M. (2015). Consensus building in multiperson decision making with heterogeneous preference representation structures: A perspective based on prospect theory. Applied Soft Computing, 35, 898–910. https://doi.org/https://doi.org/10.1016/j.asoc.2015.03.013
- Dong, Y. C., Xu, Y. F., Li, H. Y., & Feng, B. (2010). The OWA-based consensus operator under linguistic representation models using position indexes. European Journal of Operational Research, 203(2), 455–463. 2009.08.013. https://doi.org/https://doi.org/10.1016/j.ejor
- Fan, Z. P., Ma, J., Jiang, Y. P., Sun, Y. H., & Ma, L. (2006). A goal programming approach to group decision making based on multiplicative preference relations and fuzzy preference relations. European Journal of Operational Research, 174(1), 311–321. https://doi.org/https://doi.org/10.1016/j.ejor.2005.03.026
- Fan, Z. P., Zhang, X., Chen, F. D., & Liu, Y. (2013). Multiple attribute decision making considering aspiration-levels: a method based on prospect theory. Computers & Industrial Engineering, 65(2), 341–350. https://doi.org/https://doi.org/10.1016/j.cie.2013.02.013
- Fu, Z. G., & Liao, H. C. (2019). Unbalanced double hierarchy linguistic term set: The TOPSIS method for multi-expert qualitative decision making involving green mine selection. Information Fusion, 51, 271–286. https://doi.org/https://doi.org/10.1016/j.inffus.2019.04. 002. https://doi.org/https://doi.org/10.1016/j.inffus.2019.04.002
- Gonzalez, R., & Wu, G. (1999). On the shape of the probability weighting function. Cognitive Psychology, 38(1), 129–166. https://doi.org/https://doi.org/10.1006/cogp.1998.0710
- Gou, X. J., Liao, H. C., Wang, X. X., Xu, Z. S., & Herrera, F. (2020a). Consensus based on multiplicative consistent double hierarchy linguistic preferences: Venture capital in real estate market. International Journal of Strategic Property Management, 24 (1), 1–23. https://doi.org/https://doi.org/10.3846/ijspm.2019.10431
- Gou, X. J., Liao, H. C., Xu, Z. S., & Herrera, F. (2017). Double hierarchy hesitant fuzzy linguistic term set and MULTIMOORA method: A case of study to evaluate the implementation status of haze controlling measures. Information Fusion, 38, 22–34. https://doi.org/https://doi.org/10.1016/j.inffus.2017.02.008
- Gou, X. J., Liao, H. C., Xu, Z. S., & Herrera, F. (2020b). Consensus model handling minority opinions and non-cooperative behaviors in large-scale group decision-making under double hierarchy linguistic preference relations. IEEE Transactions on Cybernetics, 51(1), 283–296. https://doi.org/https://doi.org/10.1109/TCYB.2020.2985069.
- Gou, X. J., Liao, H. C., Xu, Z. S., Min, R., & Herrera, F. (2019). Group decision making with double hierarchy hesitant fuzzy linguistic preference relations: Consistency based measures, index and repairing algorithms and decision model. Information Sciences, 489, 93–112. https://doi.org/https://doi.org/10.1016/j.ins.2019.03.037
- Gou, X. J., Xu, Z. S., & Herrera, F. (2018a). Consensus reaching process for large-scale group decision making with double hierarchy hesitant fuzzy linguistic preference relations. Knowledge-Based Systems, 157, 20–33. https://doi.org/https://doi.org/10.1016/j.ins.2019.03.037. https://doi.org/https://doi.org/10.1016/j.knosys.2018.05.008
- Gou, X. J., Xu, Z. S., Liao, H. C., & Herrera, F. (2018b). Multiple criteria decision making based on distance and similarity measures with double hierarchy hesitant fuzzy linguistic term sets. Computers & Industrial Engineering, 126, 516–530. https://doi.org/https://doi.org/10.1016/j.cie.2018.10.020
- Gou, X. J., Xu, Z. S., & Zhou, W. (2020c). Managing consensus by multi-stage optimization models with linguistic preference orderings and double hierarchy linguistic preferences. Technological and Economic Development of Economy, 26(3), 642–674. https://doi.org/https://doi.org/10.3846/tede.2020.12013
- Gou, X. J., Xu, Z. S., & Zhou, W. (2020d). Identification critical factors in developing lung cancer based on interval consistency repairing method for double hierarchy hesitant fuzzy linguistic preference relation. Economic Research-Ekonomska Istraživanja, https://doi.org/https://doi.org/10.1080/1331677X.2020.1801485.
- Hervés-Beloso, C., & Cruces, H. V. (2018). Continuous preference orderings representable by utility functions. Journal of Economic Surveys, 33(1), 179–194. https://doi.org/https://doi.org/10.1111/joes.12259.
- He, Y., & Xu, Z. S. (2018). A consensus framework with different preference ordering structures and its applications in human resource selection. Computers & Industrial Engineering, 118, 80–88. https://doi.org/https://doi.org/10.1016/j.cie.2018.02.022
- He, X. D., & Zhou, X. Y. (2011). Portfolio choice under cumulative prospect theory: an analytical treatment. Management Science, 57(2), 315–331. https://doi.org/https://doi.org/10.2139/ssrn.1479580
- Juang, C. F., & Chen, C. Y. (2013). Data-driven interval type-2 neural fuzzy system with high learning accuracy and improved model interpretability. IEEE Transactions on Cybernetics, 43(6), 1781–1795.https://doi.org/https://doi.org/10.1109/TSMCB. 2012.2230253.
- Kahneman, D., & Tversky, A. (1979). Prospect theory: an analysis of decision under risk. Econometrica, 47(2), 263–291. https://doi.org/https://doi.org/10.2307/1914185
- Krishankumar, R., Subrajaa, L. S., Ravichandran, K. S., Kar, S., & Saeid, A. B. (2019). A framework for multi-attribute group decision-making using double hierarchy hesitant fuzzy linguistic term set. International Journal of Fuzzy Systems, 21(4), 1130–1143. https://doi.org/https://doi.org/10.1007/s40815-019-00618-w
- Liu, Y., Fan, Z. P., & Zhang, Y. (2014). Risk decision analysis in emergency response: a method based on cumulative prospect theory. Computers & Operations Research, 42, 75–82. https://doi.org/https://doi.org/10.1016/j.cor.2012.08.008
- Liu, N. N., He, Y., & Xu, Z. S. (2019a). Evaluate public-private-partnership’s Advancement using double hierarchy hesitant fuzzy linguistic PROMETHEE with subjective and objective information from stakeholder perspective. Technological and Economic Development of Economy, 25(3), 386–420. 2019.7588. https://doi.org/https://doi.org/10.3846/tede
- Liu, Z. M., Zhao, X. H., Li, L., Wang, X. Y., & Wang, D. (2019b). A novel multi-attribute decision making method based on the double hierarchy hesitant fuzzy linguistic generalized power aggregation operator. Information, 10, 339. https://doi.org/https://doi.org/10.3390/info10110339
- Lu, J. P., He, T. T., Wei, G. W., Wu, J., & Wei, C. (2020). Performance evaluation of government purchases of home-based elderly-care services using the Pythagorean 2-tuple linguistic TODIM method. International Journal of Environmental Research and Public Health, 17(6), 1939. https://doi.org/https://doi.org/10.3390/ijerph17061939
- Pang, Q., Wang, H., & Xu, Z. S. (2016). Probabilistic linguistic term sets in multi-attribute group decision making. Information Sciences, 369, 128–143. https://doi.org/https://doi.org/10.1016/j.ins.2016.06.021
- Rodríguez, R. M., Martínez, L., & Herrera, F. (2012). Hesitant fuzzy linguistic terms sets for decision making. IEEE Transactions on Fuzzy Systems, 20(1), 109–119. https://doi.org/https://doi.org/10.1109/TFUZZ.2011.2170076
- Tanino, T. (1984). Fuzzy preference orderings in group decision making. Fuzzy Sets and Systems, 12(2), 117–131. https://doi.org/https://doi.org/10.1016/0165-0114(84)90032-0. https://doi.org/https://doi.org/10.1016/0165-0114(84)90032-0
- Tian, X. L., Niu, M. L., Zhang, W. K., Li, L. H., & Herrera-Viedma, E. (2020). A Novel TODIM based on Prospect Theory to Select Green Supplier with Q-rung Orthopair Fuzzy Set. Technological and Economic Development of Economy, 0(0), 1–27. https://doi.org/https://doi.org/10.3846/tede.2020.12736
- Tian, X. L., Xu, Z. S., & Fujita, H. (2018). Sequential funding the venture project or not? A prospect consensus process with probabilistic hesitant fuzzy preference information. Knowledge-Based Systems, 161, 172–184. https://doi.org/https://doi.org/10.1016/j.knosys.2018.08. 002. https://doi.org/https://doi.org/10.1016/j.knosys.2018.08.002
- Tversky, A., & Kahneman, D. (1992). Advances in prospect theory: cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5(4), 297–323. https://doi.org/https://doi.org/10.1007/BF00122574
- Wang, X. D., Gou, X. J., & Xu, Z. S. (2020). Assessment of traffic congestion with ORESTE method under double hierarchy hesitant fuzzy linguistic environment. Applied Soft Computing, 86, 105864. https://doi.org/https://doi.org/10.1016/j.asoc.2019.105864
- Wang, H., Xu, Z. S., & Zeng, X. J. (2018). Linguistic terms with weakened hedges: A model for qualitative decision making under uncertainty. Information Sciences, 433–434, 37–45. https://doi.org/https://doi.org/10.1016/j.ins.2017.12.036
- Wang, L., Zhang, Z. X., & Wang, Y. M. (2015). A prospect theory-based interval dynamic reference point method for emergency decision making. Expert Systems with Applications, 42(23), 9379–9388. https://doi.org/https://doi.org/10.1016/j.eswa.2015.07.056
- Wei, G. W., & Gao, H. (2020). Pythagorean 2-tuple linguistic power aggregation operators in multiple attribute decision making. Economic Research-Ekonomska Istraživanja, 33(1), 904–933. https://doi.org/https://doi.org/10.1080/1331677X.2019.1670712
- Wei, G., Lei, F., Lin, R., Wang, R., Wei, Y., Wu, J., & Wei, C. (2020). Algorithms for probabilistic uncertain linguistic multiple attribute group decision making based on the GRA and CRITIC method: application to location planning of electric vehicle charging stations. Economic Research-Ekonomska Istraživanja, 33(1), 828–846. https://doi.org/https://doi.org/10.1080/1331677X.2020.1734851
- Wu, G., & Gonzalez, R. (1999). Nonlinear decision weights in choice under uncertainty. Management Science, 45(1), 74–85. 45.1.74. https://doi.org/https://doi.org/10.1287/mnsc
- Xu, Z. S., & Wang, H. (2017). On the syntax and semantics of virtual linguistic terms for information fusion in decision making. Information Fusion, 34, 43–48. https://doi.org/https://doi.org/10.1016/j.inffus.2016.06.002
- Yan, S. L., & Liu, S. F. (2014). Group grey target decision making based on prospect theory. Control Decision, 29(4), 673–678. https://doi.org/https://doi.org/10.13195/j.kzyjc.2012.1901.
- Zadeh, L. A. (2012). Computing with Words: What is computing with words (CWW)?. Springer. 1–40.
- Zhang, B. W., Liang, H. M., Zhang, G. Q., & Xu, Y. F. (2018). Minimum deviation ordinal consensus reaching in GDM with heterogeneous preference structures. Applied Soft Computing, 67, 658–676. https://doi.org/https://doi.org/10.1016/j.asoc.2017.06.016
- Zhou, X. Y., Wang, L. Q., Liao, H. C., Wang, S. Y., Lev, B., & Fujita, H. (2019). A prospect theory-based group decision approach considering consensus for portfolio selection with hesitant fuzzy information. Knowledge-Based Systems, 168, 28–38. https://doi.org/https://doi.org/10.1016/j.knosys.2018.12.029