
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
With the rapid development of information, decision making problems in various fields have presented multidimensional, complex and uncertain characteristics. Nested probabilistic-numerical linguistic term set (NPNLTS) is an effective tool to describe complex information due to the nested structure and diverse variables. This paper extends the concept of NPNLTS, and defines an improved form, i.e., nested probabilistic linguistic term set (NPLTS), and then proposes a novel VIKOR method with nested probabilistic linguistic information to solve the model. Within the context of empirical corporate finance, a case study related to corporate investment decision is presented and handled by the novel VIKOR method. After that, comparative analysis is carried out considering other decision-making methods, decision coefficient in VIKOR, and weights of attributes. As a result, the proposed method not only provides a rational and effective solution, but also reveals the rule in the case when decision coefficient and weights of attributes change, respectively. Finally, we discuss the proposed method from the theoretical and application aspects with a view to guiding future research. To a certain extent, this study provides a new decision environment to deal with multidimensional problems.
JEL Codes:
1. Introduction
With the rapid development of the social economy, decision making problems have become complex and multidimensional due to the uncertain information and diverse structure in various fields. How to describe the information accurately is one of the most important issues in the decision-making field. The father of fuzzy logic, Pro. Zadeh, proposed the idea (1975) that linguistic expression is one of the most consistent means of human cognition and thinking, as well as situations in real life. Scholars have proposed several classical linguistic models to express the preference precisely and effectively, and also promote the development of fuzzy theory. The first linguistic model was proposed by Pro. Zadeh (Citation1975), and it could handle the part of uncertain information by using a certain linguistic term to present human perception. In order to describe continuous linguistic term information, some linguistic models are established, such as the 2-tuple fuzzy linguistic model (Herrera & Martínez, Citation2000), the virtual linguistic model (Xu, Citation2004), and the Type-2 fuzzy linguistic model (Türkşen, Citation2002). Later, due to the fact that people tend to hesitate between different linguistic terms in the process of evaluating objective things, and thus using a single linguistic term cannot express people’s views fully. Rodríguez et al. (Citation2012) proposed the hesitant fuzzy linguistic term set (HFLTS) to represent uncertain information by multiple linguistic terms. The drawbacks are that it can neither represent the weight information from multiple experts, nor describe the complex information of binary linguistic structure. To improve these issues, Pang et al. (Citation2016) proposed the probabilistic linguistic term set (PLTS), which can be regarded as a comprehensive linguistic expression based on the unigram linguistic structure, and it has been widely applied in different fields (Wei et al., Citation2020a; Liu et al., Citation2020; Wei et al., Citation2020b, Wu & Liao, Citation2019; Lei et al., Citation2020; Wei et al., Citation2020c).
Faced with more complex and uncertain linguistic information, like ‘a little too much’ and ‘just a little bad’, aforementioned linguistic models cannot express the information environment fully and effectively. Under such circumstances, information is basically a binary linguistic structure, and people could break such complex information down and then describe objective things accurately (Zadeh, Citation2012). To accurately represent such uncertain information, some models based on binary linguistic structure have been proposed, such as the linguistic terms with weakened hedges (Wang et al., Citation2018), the double hierarchy hesitant fuzzy linguistic term set (DHHFLTS) (Gou et al., Citation2017) and the nest probabilistic-numerical linguistic term set (NPNLTS) (Wang et al., Citation2019). Specifically, the form of double linguistic term set is ‘adverb and adjective’ that can express preference precisely because double linguistic terms are both ordinal variables, but it cannot represent the weight information from experts or alternatives, as well as describing the nominal linguistic information. Another linguistic term set, the NPNLTS, can describe the above information due to its nested structure and linguistic types. According to two types (ordinal or nominal) of linguistic variable, NPNLTS, as an effective tool, can handle various types of problems, such as decision making, optimization, and discrimination, and it has been applied in multi-sensor target tracking (Wang et al., Citation2020), medical plan evaluation (Wang et al., Citation2019) and water resources allocation (Wang et al., Citation2020).
Since scientific and comprehensive linguistic models conform to human cognitive and thinking, they have played essential roles in the natural language processing and decision-making. Specially, decision making methods based on linguistic models not only ensure the scientific results by improving the accuracy of description information, but also have a strong application value in different fields. For example, Cheng et al. (Citation2018) proposed an effective interaction approach based on PLTSs for venture capital multiattribute group decision making (MAGDM) under linguistic environment, and gave a beneficial supplement to MAGDM. A Bayesian best-worst method (BWM) was introduced by Mohammadi and Rezaei (Citation2020) to find the aggregated final weights of criteria for a group of decision makers at once. The BWM framework is meaningfully viewed from a probabilistic angle, and a Bayesian hierarchical model is tailored to compute the weights in the presence of a group of decision makers. Abdel-Basset et al. (Citation2019) defined a novel T2NN-TOPSIS strategy combining type 2 neutrosophic numbers and TOPSIS under group decision making, and applied in supplier selection. In addition, decision making methods have also developed based on some popular methods, such as TOPSIS (Hu et al., Citation2020), VIKOR (Joshi, Citation2020), and TODIM (Mahdiraji et al., Citation2020). In recent years, VIKOR or improved VIKOR methods have been widely used in some fields, such as innovation policies in banking sector (Dincer et al., Citation2020), green supply chain management (Rahman et al., Citation2020), renewable energy system schemes in tourist resorts (Zheng & Wang, Citation2020) and corporate sustainability (Tseng, Citation2017).
According to the current situation of linguistic models and decision-making methods, the motivation for our work is based on two aspects. On the one hand, due to that numerical information in NPNLTS could be further calculated or normalized as probabilistic information, a more extensive concept, as well as an improved NPNLTS, can be proposed to use more conveniently in practice, called as the nested probabilistic linguistic term set (NPLTS). On the other hand, because of wide application in decision making, we intend to establish the framework of VIKOR based on the nested probabilistic linguistic information, and apply to a common scenario in corporate investment. Considering the issues discussed above, this paper aims to propose a novel VIKOR method with NPLTSs and apply to the corporate investment problem. The contributions of this paper mainly lie in the following aspects: (1) In the uncertain and complex environment, a more extensive form, i.e., NPLTS, is presented from the original concept of NPNLTS that suits to describe a wide variety of uncertain information from the aspects of structure and type. (2) As a more objective and rational method, a novel VIKOR with the nested probabilistic linguistic information is proposed to deal with the multidimensional decision-making problems. (3) A case study related to corporate investment is provided to show the process of solution by the proposed method that gives a reference of the framework in decision making. Moreover, the comparative analysis is carried out not only to verify the effectiveness of the proposed method, but also show the characteristics and trends of key parameters, such as decision coefficient, and weights of attributes. (4) In the context of the current environment, some further discussions of the proposed method are made for future research considering the theoretical aspect and application prospect.
The rest of this paper is organized as follows: Section 2 introduces materials and methods, i.e., NPLTSs and VIKOR with the nested probabilistic linguistic information. In Section 3, a case study related to the corporate investment is presented containing problem description, solution, and comparative analysis. In Section 4, some further discussions are provided from the views of theory and application. Section 5 ends the paper with some conclusions.
2. Materials and method
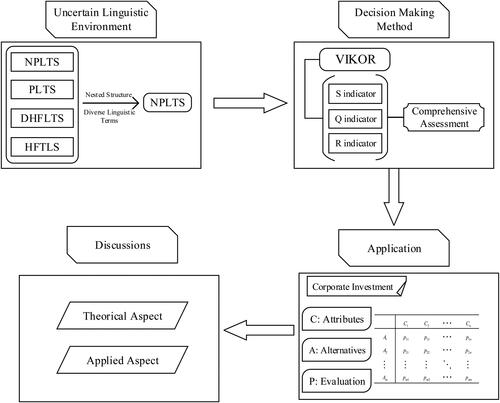
In our real life, there is uncertain and complex information in a variety of aspects, such as evaluation, management and decision making. Considering that there are two obvious advantages of NPLTSs, i.e., nested structure and diverse linguistic terms, we use it to describe attributes with respect to each alternative. In addition, VIKOR is a classical decision-making method, proposed by Opricovic (Citation1998), as well as an expansion of the TOPSIS method that is also a popular decision approach, from three indicators to help decision makers choose the best alternative. In this paper, NPLTSs and VIKOR are main tool and method to handle the decision-making problem, shown in .
Figure 1. The research framework of this study.
Source: The Authors.
2.1. Nested probabilistic linguistic term sets
In 2019, Wang et al. (Citation2019) proposed the nest probabilistic-numerical linguistic term sets (NPNLTSs), where the element of outer probabilistic linguistic term set (OPLTS) is probability, and it is the number in inner numerical linguistic term set (INLTS). In general, numerical information can be further calculated or normalized as probabilistic information, including confidence, likelihood, proportion, preference or weights. Therefore, we improve NPNLTS to be a more extensive form, i.e., nested probabilistic linguistic term set (NPLTS).
The construction of the nested linguistic term set (NLTS) is composed of the outer linguistic term set (OLTS) and the inner linguistic term set (ILTS) that are completely independence denoted as and
respectively. Noted that
is used for describing
By merging the expressions, the NLTS is defined as
where
is called the nested linguistic term. In the increasingly complex environment, people's cognition with respect to objective things has become more uncertain, which often appears in the indecision among various OLTSs or ILTSs. Besides, the weight of each linguistic term derived from experts is crucial to obtain precise results in the group decision making. Inspired by the probabilistic linguistic term set (Pang et al., Citation2016), which represents the weights through probability, NPLTS is defined combined with a finite set
and NLTS
to help people express information accurately and effectively, and it is a mapping function from
to a subset of
denoted as:
(1)
(1)
where
is the element of the nested probabilistic linguistic terms in
expressed as:
(2)
(2)
where
is the number of the elements in
as well as the number of the nested probabilistic linguistic terms;
is the number of the elements in
Specifically, the normalized NPLTS (N-NPLTS) is satisfied with
and
Under such a circumstance, decision experts describe objective things completely using all outer linguistic terms and inner linguistic terms.
As illustrated in Introduction, NPLTS has four cases according to types of OLTS and ILTS. (1) When the elements are ordinal in OLTS and ILTS, NPLTS is used for decision makers to express preferences accurately. Specifically, NPLTS is reduced to DHHFLTS (Gou et al., Citation2017) when there are adjectives and adverbs in OLTS and ILTS, respectively. (2) When the elements are ordinal and nominal in OLTS and ILTS, respectively, representational information taking the form of “adjective plus noun”, is not only limited to describe preferences of objective things, but also includes the diversity of information, which is applicable to practical problems that need to evaluate the degree from the overall situation and judge the local characteristics. (3) When the elements are nominal and ordinal in OLTS and ILTS, respectively, NPLTS is used to describe information like “noun plus adjective” containing characteristics and preference of objective things. In this case, people usually first identify the local features and then give their preferences. (4) When the elements are nominal in OLTS and ILTS, like the form of “noun plus noun”, NPLTS is suitable to evaluate features or attributes of things from whole to parts used to identify or select the certain thing. In this paper, due to that the selection of corporate investment firstly considers individual features (nominal factors) and obtains their preferences (ordinal factors), the third case of NPLTS is used in this paper, and in the following parts, we only discuss for this situation.
In order to prevent the subscripts of linguistic terms from falling out of a given range during calculation, motivated by the concept of conversion function (Gou et al., Citation2017), we define equivalent conversion function from NPLTS to [0,1] for computing reasonably and conveniently. As for a continuous NLTS
is the continuous NPLTS, where
is the number of outer linguistic terms, as well as nested linguistic terms in
Let
be the membership set of continuous nested probabilistic terms, membership can be obtained from terms by the function
as follows:
(3)
(3)
where
represents the positive length of a linguistic term in OLTS. Specifically, when the linguistic term
is a benefit type,
otherwise, that is,
is a cost type,
Note that EquationEq. (3)(3)
(3) satisfies boundedness, which is proved as follows: Since
and
then
and
thus,
Considering
and
then
and
Therefore,
In practical problems, it is necessary and important to compare alternatives with a certain linguistic information. In the following, we define the score function and the variance function based on the idea of expectation and variance in statistics. Let be a NPLTS, where
is the number of the nested linguistic terms in
the score function and the variance function are denoted as:
(4)
(4)
(5)
(5)
According to EquationEq. (4)(4)
(4) and EquationEq. (5)
(5)
(5) , any two NPLTSs,
and
can be compared by the following rules:
If
then
If
If
if
if
if
2.2. VIKOR with nested probabilistic linguistic information
VIKOR is a popular method applied to the decision-making problems, because it compares the gap between alternatives and the ideal alternatives by three indicators, i.e., the maximum group benefit value, the minimum individual regret value and the benefit ratio value, which are on the basis of the positive and negative ideal solutions. Compared with another classical decision-making approach, the TOPSIS method, the VIKOR takes more into account the relative importance of the distance between different alternatives (Opricovic & Tzeng, Citation2004). Next, a novel VIKOR method with the nested probabilistic linguistic information is proposed to handle the multidimensional decision-making problems.
A multi-attribute decision making problem with NPLTS is briefly described as follows: Assume that decision makers need to select the best plan according to a set of attributes among a set of alternatives
The weight vector of attributes is
and satisfies
Let
and
be an OLTS and an ILTS in the NLTS
respectively. Decision makers evaluate each alternative with respect to attributes according to the natural language, and NPLTSs can be obtained and listed in the corresponding matrices
(6)
(6)
where
is a NPLTS, indicates that decision makers evaluate each of the alternatives
considering the attributes
Based on which, the process of VIKOR with the NPLTS is provided step by step and also shown in .
Figure 2. The process of VIKOR with nested probabilistic linguistic information.
Source: The Authors.
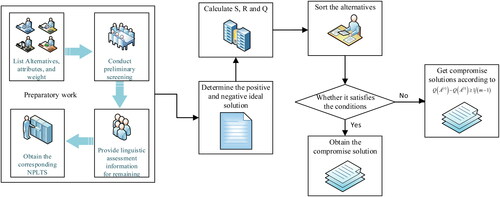
Step 1. Give a set of alternatives and attributes, and determine the NLTS and the weight of each attribute.
Step 2. Establish matrix with the NPLTSs.
Step 3. Calculate the membership transformed from the NPLTSs in the matrix according to EquationEq. (3)
(3)
(3) .
Step 4. Determine the positive ideal solution and the negative ideal solution
for
by EquationEq. (7)
(7)
(7) .
(7)
(7)
Step 5. Calculate the maximizing group utility and the individual regret
for each of the alternatives
by EquationEq. (8)
(8)
(8) and EquationEq. (9)
(9)
(9) , respectively.
(8)
(8)
(9)
(9)
Step 6. Calculate the benefit ratio values by EquationEq. (10)
(10)
(10) .
(10)
(10)
where
is the decision coefficient and belongs to [0,1]. If
then the decision maker prefers to group utilities; If
then the decision maker prefers to individual regrets; If
then the decision is made according to the decision making mechanism reached by the decision maker through consultation. In general,
(Ikram et al., Citation2020).
Step 7. Sort the alternatives according to from small to large.
Step 8. Obtain the compromise solution which satisfies the following conditions:
Condition 1. Acceptable advantages:
Condition 2. Acceptable stability:
If the result of one alternative cannot satisfy both two conditions, there is at least two compromise solution. In addition, if only Condition 2 does not hold, and
are both compromise solutions. If only Condition 1 does not hold,
are all the compromise solutions, when
satisfies the condition
3. A case study
The most important objective of firms is to maximize their profit, and hence how to choose investment projects are crucial for firms’ operating decisions. Basically, different industries show heterogeneous returns, for instance, financial industry and information and technology (IT) industry usually have higher returns than other traditional manufacturing industries, so firms should decide which industries they would like to enter according to their competitive advantages when conducting investment decisions. Meanwhile, within each industry, firms should also decide which type of projects they will invest. Firstly, firms can invest their available capital in real economy projects, such as purchasing and updating equipment, building factories or improving research and development (R&D), and these investments can extend the production and acquire returns. However, such kind of long-term projects are irreversible (Bernanke, Citation1983), and business environments have substantial impact on their success, uncertainties about economic policies and future returns may restrict firms’ investment enthusiasm. As a substitute, firms can invest their capital in risky financial assets, such as risky securities, and this type of short-term investments are prevalent in United States (Duchin et al., Citation2017), China (Shu et al., Citation2020) and other emerging markets (Demir, Citation2009). Financial asset investments usually have high returns, but such projects are also illiquid and subject to the regulation of financial regulatory authority, the great risks of these projects can affect firms’ investment incentives. In addition, firms can use liquid assets to finance their preferred investment projects if external funding are expensive or not available, so they have incentives to hold cashes (Opler et al., Citation1999). Therefore, firms should optimally allocate their capital between different industries and different investments projects (real sector investment, cash holding or risky financial asset) to maximize potential returns under complex economic environments, simultaneously. We would like to use the VIKOR method with NPLTS we proposed in this paper to study how firms improve their investment decisions.
3.1. Problem description
In real economy, there exist different types of firms, but all of their investment projects need capital and labour as inputs, so their investment decisions will be affected by financing cost, the price of capital, and wage, the price of labour. Besides, all projects’ expected returns are uncertain, then risks in future profit will affect firms’ decisions on the allocation of their capital between different projects. To what extent firms’ investment decisions are affected by the economic environments depend on the attributes (e.g., low, middle or high) of inputs price and return risks. Without loss of generality, we assume that there exist four alternative industries in the market, information and technology (IT) industry,
new energy vehicle industry,
real estate industry, and
textile industry. For all firms of these industries, they can invest their available capitals in three alternative projects,
real sector investment,
cash holding, and
risky financial asset.
3.2. Solve the problem
According to the process of the VIKOR method with the NPLTS introduced in 2.1, the specific steps to deal with the investment problem are as follows:
Step 1. Alternatives and attributes have been given in Subsection 3.1, and determine the weight vector of attributes that is Given an OLTS and an ILTS in the NLTS
that are
and
respectively.
Step 2. Decision makers evaluate the alternative industries with respect to the projects
using NLTSs. lists the evaluation information with NPLTSs after calculation and integration.
Table 1. The evaluation information with NPLTSs.
Step 3. According to EquationEq. (3)(3)
(3) , the membership
is calculated as:
Step 4. The positive ideal solution and the negative ideal solution
are obtained by EquationEq. (7)
(7)
(7) :
Step 5. Calculate the maximizing group utility and the individual regret
by EquationEq. (8)
(8)
(8) and EquationEq. (9)
(9)
(9) :
Step 6. According to EquationEq. (10)(10)
(10) , the benefit ratio value
is calculated with
Step 7. Sort alternatives in terms of listed in .
Table 2. Ranking results of alternatives with S, R, Q.
Step 8. is the compromise solution which satisfies two conditions. One is the acceptable advantages:
Another is acceptable stability:
ranks the first in both S and R.
3.3. Comparative analysis
In this subsection, comparative analysis is carried out to verify the proposed method effectively and scientifically by comparing it with another method, and also reveal the rule when key parameters change, like the decision coefficient and the weights of attributes.
(1) TOPSIS, as another classical decision-making method, has also been widely used in many fields, because it involves less subjective thoughts of decision experts and can measure alternative information objectively. In the following, the TOPSIS method with NPLTSs is used to handle the same problem in Subsection 3.1. Firstly, the distance between the alternative and the positive ideal solution is calculated as:
Similarly, the distance between the alternative and the negative ideal solution is also calculated as:
Then, the minimum distance between the alternative and the positive ideal solution and the maximum distance between the alternative and the negative ideal solution are obtained:
According to the above distance measures, the closeness degree of each alternative can be calculated:
Finally, the ranking is and the best investment plan is
The rankings are the same by using two decision making methods, and the optimal alternative is which further demonstrates the rationality of the proposed method to a certain extent. As for the final values, the gap is greater by the proposed method than the TOPSIS method. The reason may be that the VIKOR method amplifies the differences among alternatives in terms of three indicators. It would be convenient to distinguish alternatives when the number of alternatives is large. In addition, the TOPSIS method has one best alternative in general except for having the same closeness degree, while VIKOR may have more than one compromise solution due to the conditions of compromise solution. In this case, the proposed method takes more practical factors into consideration and fits the actual situation better, because there are always compromise solutions in practice.
(2) The coefficient balances the relationship between group utility and individual regret. With the increase of the coefficient
the sort is inclined to group utility. On the contrary, the sort tends to the individual regret. Considering that the rank is closely related to the coefficient
this part studies that how would be the results when the decision coefficient
of the proposed method changes. Firstly, let the coefficient
be 0.25, 0.5, and 0.75, respectively, the results are obtained by the proposed method, listed in .
Table 3. Ranking results of alternatives with changed coefficient v.
As we can see, the results vary with the changed coefficient Specifically, the sort is
when
while the sort is
when
and the sort is
when
Although ranks change with different values of the coefficient
the optimal alternative is
under three situations. In particular,
is also a compromise solution when
is superior to
when
and
while
is superior to
when
It indicates that the coefficient
not only impacts the decision conditions, but also decides the sort of alternatives. In practice, the composition and structure of experts would affect the coefficient
and it is also an important factor that decides the final result.
In order to further reveal the rule between the coefficient and the value of Q, we make a simulation when the coefficient varies from 0 to 1, and the step length is 0.1, shown in .
Figure 3. The trend of values (Q) of alternatives when coefficient varies from 0 to 1.
Source: The Authors.
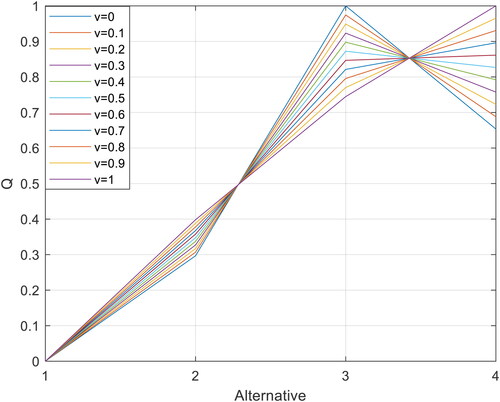
In , there are obvious and regular trends values (Q) of alternatives. Specifically, is always 0 no matter how the coefficient
changes, indicating that
has good enough evaluation information so that the coefficient
cannot impact the optimal alternative. When the coefficient
increases, the values of
and
are increase gradually, while
decreases continuously, which shows that the coefficient
impacts the above three alternatives that
and
prefer to group utility, and
prefers to individual regret. In addition, there is a threshold of the coefficient
that decides the order of
and
When
indicating that it is a balance between
and
in the case, and decision makers can choose the suitable preference in the actual situation.
(3) Another key factor that may impact the results is the weights of attributes. With respect to corporate investment, board of directors in different firms may have different preferences to attributes. In this part, we also make a simulation to reveal the rule between the weights of attributes and the value of Q. Let
and
vary from 0 to 1, and the step length is also 0.1, which satisfy that
As a result, there are 66 weight sets, listed in .
Table 4. The weight of attributes in various cases.
With each weight vector of attributes, there is a sort according to the values of Q. shows the contour by values of Q between alternatives and cases of weights. According to the legend, the yellower the color, the higher the value, and the bluer the color, the lower the value.
Figure 4. The contour by values of Q between alternatives and cases of weight.
Source: The Authors.
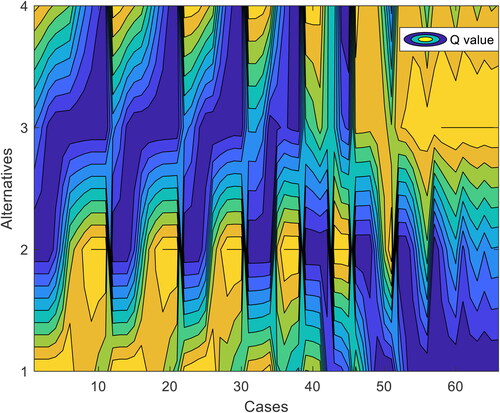
In , the values of Q vary regularly during the certain period of cases. For example, in the first 11 groups,
increases by 0.1 from 0 to 1, and
decreases by 0.1 from 1 to 0. The best alternative in terms of the values of Q changes from
to
gradually, indicating that
relies more on higher
while
pays more attention to higher
and
prefers to the intermediate statuses.
is always the worst alternative no matter how weights vary, showing that there is little influence on
in terms of
and
From an overall perspective,
is the best alternative as long as
is large enough, and in such a case,
is the worst alternative. Therefore, it can be concluded that the change of attribute weights has a great impact on alternatives in decision making, and the weights of attributes often depend on the company's condition and the actual market situation.
4. Further discussion
A novel framework of VIKOR method provides a perspective of uncertain and the nested information to deal with multidimensional decision making problems, like the case study in corporate investment. In the following, we make further discussions in terms of theoretical aspect and application prospect.
4.1. Theoretical aspect
The proposed approach combines a linguistic model, i.e., NPLTS and a classical decision making method that is VIKOR. The characteristics of the method mainly reflect in two aspects. One is that multidimensional decision making problems could be better represented and experts express their preferences more accurately. The other is that the framework and solution form of the proposed method are more in accordance with the actual situation. Compared with traditional VIKOR method, the proposed approach with NPLTSs considers multiple information, i.e., outer layer and inner layer, to describe objective things accurately. Nested structure of linguistic information could help decision makers to handle multidimensional and complex problem from whole to part or conversely. In addition, the method with NPLTS could not only reveal the relationship between the outer layer and the inner layer, but also grasp the connection between the attributes and the nested layer. Another feature is about the VIKOR method that Q value and conditions decide the compromise solution. Under such circumstances, there may be not only one optimal alternative, but have multiple compromise alternative, especially when the number of alternatives is large, such as talents selection. On the one hand, three indicators measure the alternatives jointly, and there exists a balance group utility and individual regret. On the other hand, there may be not the optimal selection for many decision cases in practice, but choose one or more compromise alternatives. For example, location problem is related to the efficiency of logistics distribution and chain benefits and costs, and the optimal location may not on a road or in a river. Overall, as a qualitative method, the proposed method is useful for identifying and characterising multidimensional and uncertain information to deal with large-scale decision making problems in real life.
With advances in technology, practical problems have become more complex and abstract. Therefore, emerging techniques, such as neural network, support vector machine, and deep learning methods, are supposed to combine with classical methods, especially in the era of big data.
4.2. Application prospect
The case study of this paper explores corporate investment project decisions between four different industries and three distinct investment projects in an environment with complex information. We focus on the optimal industry choice firms that can benefit the most if they decide to enter, and our results indicate that the weights of different asset projects have substantial impact on the final choice of industries.
Our application can be extended in several ways. First of all, we can modify the framework and explore the determinants of firms’ financialization. In corporate finance research field, economists begin to study why firms hold excess risky assets (Demir, Citation2009; Duchin et al., Citation2017; Shu et al., Citation2020), but they neglect the important impacts of multidimensional, complex and uncertain factors. In current study, we arbitrary keep the weight vector of asset investments fixed and try to choose the most profitable industry. Once we rotate the industries and projects matrix, keep the weight vector of industries fixed and set our ultimate objective to choose the most profitable investment, we can understand to what extent industrial policies and financial market or labour market policies can affect firms’ incentives in holding risky financial assets.
Secondly, we can also examine how to motivate firms to conduct R&D activities in one modified version of our analysis framework. It is widely acknowledged that innovation can help firms establish competitive advantages (Porter, Citation1992) and promote the overall economic growth (Romer, Citation1990), but not all firms engage in such kind of activities. We can keep the industrial composition or regional composition constant, and study how firms choose among R&D investment and other investment projects. We can then simulate the impacts of different industrial policies or factor markets policies on firms’ R&D investment decisions, figuring out the most effective policy package in promoting innovative activities.
5. Conclusions
Nested probabilistic linguistic term set (NPLTS) is an extended concept based on the nested probabilistic-numerical linguistic term set (NPNLTS) that is suitable for describing the nested and diverse information under complex and uncertain environment. Due to the advantages and features of NPLTS, this paper has defined the basic operation of NPLTS and proposed a novel VIKOR method with the nested probabilistic linguistic information. According to the framework of the proposed method, a case study about corporate investment has been presented and handed by the novel VIKOR method. To show the effectiveness and scientifically of the proposed method, a comparative analysis has been carried out from three aspects, i.e., another decision making method (TOPSIS), decision coefficient in VIKOR, and weights of attributes. The results not only verify the proposed method rationally, but also reveal the rule when decision coefficient and weights of attributes change, respectively. In addition, according to the analysis and the above-mentioned results, further discussions have been conducted from the views of theoretical aspect and application prospect. In the future, we will further study the advanced and emerging decision-making methods with NPLTSs and popular technologies, like machine learning, to handle practical problems in economic fields.
Acknowledgments
The work was supported by the National Natural Science Foundation of China (Nos. 71571123, 71771155), the Fundamental Research Funds for the Central Universities (No. YJ202063), and the Opening Project of Sichuan Province University Key Laboratory of Bridge Non-destruction Detecting and Engineering Computing (No. 2019QYJ03).
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Abdel-Basset, M., Saleh, M., Gamal, A., & Smarandache, F. (2019). An approach of TOPSIS technique for developing supplier selection with group decision making under type-2 neutrosophic number. Applied Soft Computing, 77, 438–452. https://doi.org/https://doi.org/10.1016/j.asoc.2019.01.035
- Bernanke, B. S. (1983). Irreversibility, uncertainty, and cyclical investment. The Quarterly Journal of Economics, 98 (1), 85–106. https://doi.org/https://doi.org/10.2307/1885568
- Cheng, X., Gu, J., & Xu, Z. S. (2018). Venture capital group decision-making with interaction under probabilistic linguistic environment. Knowledge-Based Systems, 140, 82–91. https://doi.org/https://doi.org/10.1016/j.knosys.2017.10.030
- Demir, F. (2009). Financial liberalization, private investment and portfolio choice: Financialization of real sectors in emerging markets. Journal of Development Economics, 88(2), 314–324. https://doi.org/https://doi.org/10.1016/j.jdeveco.2008.04.002
- Dincer, H., Yuksel, S., & Martinez, L. (2020). A comparative analysis of incremental and disruptive innovation policies in the European banking sector with hybrid interval Type-2 fuzzy decision-making models. International Journal of Fuzzy Systems, 22 (4), 1158–1176. https://doi.org/http://doi.org/10.1007/s40815-020-00851-8
- Duchin, R., Thomas, G., Jarrad, H., & Christopher,. (2017). Precautionary savings with risky assets: When cash is not cash. The Journal of Finance, 72(2), 793–852. https://doi.org/https://doi.org/10.1111/jofi.12490
- Gou, X. J., Liao, H. C., Xu, Z. S., & Herrera, F. (2017). Double hierarchy hesitant fuzzy linguistic term set and MULTIMOORA method: A case of study to evaluate the implementation status of haze controlling measures. Information Fusion, 38, 22–34. https://doi.org/https://doi.org/10.1016/j.inffus.2017.02.008
- Gou, X. J., Xu, Z. S., & Liao, H. C. (2017). Multiple criteria decision making based on Bonferroni means with hesitant fuzzy linguistic information. Soft Computing, 21(21), 6515–6529. https://doi.org/https://doi.org/10.1007/s00500-016-2211-1
- Herrera, F., & Martínez, L. (2000). A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Transactions on Fuzzy Systems, 8 (6), 746–752. https://doi.org/https://doi.org/10.1109/91.890332
- Hu, M. M., Liu, M. K., & Lan, J. B. (2020). Decision making with both diversity supporting and opposing membership information. Economic Research-Ekonomska Istraživanja, 33 (1), 3427–3452. https://doi.org/https://doi.org/10.1080/1331677X.2020.1774790
- Ikram, M., Zhang, Q. Y., & Sroufe, R. (2020). Developing integrated management systems using an AHP-Fuzzy VIKOR approach. Business Strategy and the Environment, 29 (6), 2265–2283. https://doi.org/https://doi.org/10.1002/bse.2501
- Joshi, R. (2020). A novel decision-making method using R-Norm concept and VIKOR approach under picture fuzzy environment. Expert Systems with Applications, 147, 113228. https://doi.org/https://doi.org/10.1016/j.eswa.2020.113228
- Lei, F., Wei, G. W., Gao, H., Wu, J., & Wei, C. (2020). TOPSIS method for developing supplier selection with probabilistic linguistic information. International Journal of Fuzzy Systems, 22 (3), 749–759. https://doi.org/https://doi.org/10.1007/s40815-019-00797-6
- Liu, X. D., Wang, Z. W., Zhang, S. T., & Liu, J. S. (2020). Probabilistic hesitant fuzzy multiple attribute decision-making based on regret theory for the evaluation of venture capital projects. Economic Research-Ekonomska Istraživanja, 33 (1), 672–697. https://doi.org/https://doi.org/10.1080/1331677X.2019.1697327
- Mahdiraji, H. A., Zavadskas, E. K., Skare, M., Kafshgar, F. Z. R., & Arab, A. (2020). Evaluating strategies for implementing industry 4.0: a hybrid expert oriented approach of BWM and interval valued intuitionistic fuzzy TODIM. Economic Research-Ekonomska Istraživanja, 33 (1), 1600–1620. https://doi.org/https://doi.org/10.1080/1331677X.2020.1753090
- Mohammadi, M., & Rezaei, J. (2020). Bayesian best-worst method: A probabilistic group decision making model. Omega, 96, 102075. https://doi.org/https://doi.org/10.1016/j.omega.2019.06.001
- Opler, T., Lee, Pi, René, S., & Rohan, W. (1999). The determinants and implications of corporate cash holdings. Journal of Financial Economics, 52(1), 3–46. https://doi.org/https://doi.org/10.1016/S0304-405X(99)00003-3
- Opricovic, S. (1998). Multicriteria optimization of civil engineering systems. Faculty of Civil Engineering Belgrade, 2, 5–21.
- Opricovic, S., & Tzeng, G. H. (2004). Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. European Journal of Operational Research, 156 (2), 445–455. https://doi.org/https://doi.org/10.1016/S0377-2217(03)00020-1
- Pang, Q., Wang, H., & Xu, Z. S. (2016). Probabilistic linguistic term sets in multi-attribute group decision making. Information Sciences, 369, 128–143. https://doi.org/https://doi.org/10.1016/j.ins.2016.06.021
- Porter, M. E. (1992). Capital disadvantage: America’s falling capital investment system. Harvard Business Review, 70(5), 65–82.
- Rahman, T., Ali, S. M., Moktadir, M. A., & Kusi-Sarpong, S. (2020). Evaluating barriers to implementing green supply chain management: An example from an emerging economy. Production Planning & Control, 31(8), 673–698. https://doi.org/https://doi.org/10.1080/09537287.2019.1674939
- Rodríguez, R. M., Martínez, L., & Herrera, F. (2012). Hesitant fuzzy linguistic terms sets for decision making. IEEE Transactions on Fuzzy Systems, 20 (1), 109–119. https://doi.org/https://doi.org/10.1109/TFUZZ.2011.2170076
- Romer, P. M. (1990). Endogenous technological change. Journal of Political Economy, 98(5, Part 2), S71–S102. https://doi.org/https://doi.org/10.1086/261725
- Shu, J. X., Zhang, C. S., & Zheng, N. (2020). Financialization and sluggish fixed investment in Chinese real sector firms. International Review of Economics & Finance, 69, 1106–1116. https://doi.org/https://doi.org/10.1016/j.iref.2018.12.008
- Tseng, M. L. (2017). Using social media and qualitative and quantitative information scales to benchmark corporate sustainability. Journal of Cleaner Production, 142, 727–738. https://doi.org/https://doi.org/10.1016/j.jclepro.2016.05.062
- Türkşen, I. B. (2002). Type 2 representation and reasoning for CWW. Fuzzy Sets and Systems, 127 (1), 17–36. https://doi.org/https://doi.org/10.1016/S0165-0114(01)00150-6
- Wang, H., Xu, Z. S., & Zeng, X. J. (2018). Linguistic terms with weakened hedges: A model for qualitative decision making under uncertainty. Information Sciences, 433-434, 37–45. https://doi.org/https://doi.org/10.1016/j.ins.2017.12.036
- Wang, X. X., Xu, Z. S., & Gou, X. J. (2019). Nested probabilistic-numerical linguistic term sets in two-stage multi-attribute group decision making. Applied Intelligence, 49 (7), 2582–2602. https://doi.org/https://doi.org/10.1007/s10489-018-1392-y
- Wang, X. X., Xu, Z. S., & Gou, X. J. (2020). Allocation of fresh water recourses in China with nested probabilistic-numerical linguistic information in multi-objective optimization. Knowledge-Based Systems, 188, 105014. https://doi.org/https://doi.org/10.1016/j.knosys.2019.105014
- Wang, X. X., Xu, Z. S., Gou, X. J., & Trajkovic, L. (2020). Tracking a maneuvering target by multiple sensors using extended kalman filter with nested probabilistic-numerical linguistic information. IEEE Transactions on Fuzzy Systems, 28 (2), 346–360. https://doi.org/https://doi.org/10.1109/TFUZZ.2019.2906577
- Wang, X. X., Xu, Z. S., Gou, X. J., & Xu, M. (2019). Distance and similarity measures for nested probabilistic-numerical linguistic term sets applied to evaluation of medical treatment. International Journal of Fuzzy Systems, 21 (5), 1306–1329. https://doi.org/https://doi.org/10.1007/s40815-019-00625-x
- Wei, G. W., He, Y., Lei, F., Wu, J., Wei, C., & Guo, Y. F. (2020a). Green supplier selection with an uncertain probabilistic linguistic MABAC method. Journal of Intelligent & Fuzzy Systems, 39 (3), 3125–3136. https://doi.org/https://doi.org/10.3233/JIFS-191584
- Wei, G. W., Lu, J. P., Wei, C., & Wu, J. (2020c). Probabilistic linguistic GRA method for multiple attribute group decision making. Journal of Intelligent & Fuzzy Systems, 38 (4), 4721–4732. https://doi.org/https://doi.org/10.3233/JIFS-191416
- Wei, G., Lei, F., Lin, R., Wang, R., Wei, Y., Wu, J., & Wei, C. (2020b). Algorithms for probabilistic uncertain linguistic multiple attribute group decision making based on the GRA and CRITIC method: application to location planning of electric vehicle charging stations. Economic Research-Ekonomska Istraživanja, 33 (1), 828–846. https://doi.org/https://doi.org/10.1080/1331677X.2020.1734851
- Wu, X. L., & Liao, H. C. (2019). A consensus-based probabilistic linguistic gained and lost dominance score method. European Journal of Operational Research, 272 (3), 1017–1027. https://doi.org/https://doi.org/10.1016/j.ejor.2018.07.044
- Xu, Z. S. (2004). A method based on linguistic aggregation operators for group decision making with linguistic preference relations. Information Sciences, 166(1-4), 19–30. https://doi.org/https://doi.org/10.1016/j.ins.2003.10.006
- Zadeh, L. A. (1975). Concept of a linguistic variable and its application to approximate reasoning-Part I. Information Sciences, 8(3), 199–249. https://doi.org/https://doi.org/10.1016/0020-0255(75)90036-5
- Zadeh, L. A. (2012). Computing with Words: What is computing with words (CWW)?. Springer. 2012.
- Zheng, G. Z., & Wang, X. (2020). The comprehensive evaluation of renewable energy system schemes in tourist resorts based on VIKOR method. Energy, 193, 116676–116153. https://doi.org/https://doi.org/10.1016/j.energy.2019.116676