
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In the classification calculation, the data are sometimes not unique and there are different values and probabilities. Then, it is meaningful to develop the appropriate methods to make classification decision. To solve this issue, this paper proposes the machine learning methods based on a probabilistic decision tree (DT) under the multi-valued preference environment and the probabilistic multi-valued preference environment respectively for the different classification aims. First, this paper develops a data pre-processing method to deal with the weight and quantity matching under the multi-valued preference environment. In this method, we use the least common multiple and weight assignments to balance the probability of each preference. Then, based on the training data, this paper introduces the entropy method to further optimize the DT model under the multi-valued preference environment. After that, the corresponding calculation rules and probability classifications are given. In addition, considering the different numbers and probabilities of the preferences, this paper also uses the entropy method to develop the DT model under the probabilistic multi-valued preference environment. Furthermore, the calculation rules and probability classifications are similarly derived. At last, we demonstrate the feasibility of the machine learning methods and the DT models under the above two preference environments based on the illustrated examples.
1. Introduction
With the development of artificial intelligence, machine learning plays a vital role in it. Machine learning is used in addressing data set containing a lot of messy information (Blum & Langley, Citation1997), and it can be widely applied in various fields, such as the sales (Sun et al., Citation2008; Tsoumakas, Citation2019; Wong & Guo, Citation2010), the credit assessment (Kruppa et al., Citation2013; Pal et al., Citation2016), and the autonomous vehicles (Qayyum et al., Citation2020), etc. Moreover, machine learning is commonly be divided into two different types including the unsupervised learning and the supervised learning. The unsupervised learning is a method that classifies samples through data analysis of a large number of samples without the category information (Barlow, Citation1989; Goldsmith, Citation2001). The most common unsupervised learning algorithm is the k-means method (Capó et al., Citation2020; Han et al., Citation2020). The supervised learning is a kind of method to learn a function from a given training data. Next, when new data comes, it can predict the result based on the former function (CitationFigueiredo, 2003; Gerfo et al., Citation2008). The supervised learning contains many algorithms, such as the decision tree (DT) (Pal & Mather, Citation2003; Polat & Güneş, Citation2007), the k-nearest neighbor (Zhang & Zhou, 2007; Lee et al., Citation2019), the random forests (Mantas et al., Citation2019), and the support vector machines (Utkin, Citation2019; Yuan et al., Citation2010). Obviously, we can conclude that the machine learning method is not only widely used but also has many kinds of extended algorithms. Based on this, the machine learning method can be developed by fusing some new conditions according to the actual requirements.
In the above machine learning methods, the DT is a basic machine learning classification, regression (Galton, Citation1889), and data mining (Han & Micheline, Citation2006) method. Hunt (Citation1965) proposed the Concept Learning System (CLS) which introduces the concept of the DT. Based on the ID3 algorithm, the DT was formally proposed and defined (Quinlan, Citation1986, Citation1987). After that, some scholars continued to research and improve this method based on the ID3 algorithm, resulting in many classic classification algorithms such as the CART (Crawford, Citation1989; Rutkowski et al., Citation2014), the C4.5 (Quinlan, Citation1996), and the SLIQ (Narasimha & Naidu, Citation2014). In addition, these methods have a large number of extended applications (Bhargava et al., Citation2013; Hardikar et al., Citation2012; Ruggieri, Citation2002; Santhosh, 2013). Although the above algorithms with inductive properties used to construct the DTs can make classification and regression in the single-valued attributes environment, the operation results are not satisfactory when the environment changes (Chen et al., 2003).
According to the above analysis, the multi-valued concept and the multi-valued environment were presented (Miao & Wang, Citation1997). Some scholars built the models by using the similarity (Clarke, Citation1993; Santini & Jain, 1999; Tversky,Citation1977) to solve the problem under the defined multi-valued and multi-labeled environments (Chen et al., Citation2010; Cheng, 2014; Chou & Hsu, Citation2005; Hsu, Citation2021; Yi et al., Citation2011; Zhao & Li, Citation2007). Obviously, they realized the transition from the single-valued to the multi-valued environments. This lays a research foundation for the proposal of a decision classification algorithm under the multi-valued preference environment. However, in the decision-making process, the numbers and weights of the preferences are sometimes different. Therefore, it also provides a research direction for this paper to extend the multi-valued preference environment to the probabilistic multi-valued preference environment.
To achieve the above aims, this paper is organized as follows: This paper briefly reviews the traditional DT models in Section 2. The weight and quantity matching method and the DT algorithm under the multi-valued preference environment are proposed in Section 3. In Section 4, we further propose a machine learning model under the probabilistic multi-valued preference environment and demonstrate the operation process with an example. Section 5 gives the derived conclusions.
2. Preliminaries
The concept of the probabilistic multi-valued attributes environment can be divided into two perspectives to understand. The first perspective is the environment with the multi-valued preferences; the second perspective is the environment with the probabilistic multi-valued preferences. It is found that both of these environments are established based on the traditional single-valued attributes environment. Therefore, before introducing the two new environments in detail, we first briefly review machine learning in the traditional single-valued attributes environment. Then, this paper introduces the construction process of the DT model under the traditional single-valued attributes environment. Finally, we describe the multi-valued and probabilistic multi-valued preference environments. By comparing the three environments through examples, this paper can intuitively present the changes.
2.1. The DT model in a traditional single-valued attributes environment
The traditional DTs include the ID3, C4.5, and CART methods. In this paper, the ID3 algorithm is selected as the basic technique. This method uses the entropy method and information gain to construct a DT, where the information gain is the difference between the information entropy and conditional entropy, and then selects the attribute with the largest information gain as the optimal attribute to form a classification node. The main construction steps of the DT model are shown below:
Assume that a training data set is where
denotes the sample number, and these samples have
classes labeled
and
represents the number of samples belonging to the class
If a discrete attribute
has
possible values, and then
divides the training data set
into
training data subsets and each training data subset can be labeled as
where
is the number of samples in
Note that the set
belongs to the class
in the subset
and
is its sample number of
The corresponding calculation formula of the information gain is given as follows:
(1)
(1)
EquationEq. (1)(1)
(1) denotes the information gain of the attribute
in the training data set
it is used to measure the degree of information uncertainty reduction.
EquationEq. (2)(2)
(2) represents the information entropy of the training set
(2)
(2)
EquationEq. (3)(3)
(3) denotes the conditional entropy of the attribute
in the training data set
Generally, the classification ability of an attribute is enhanced with the increase of the information gain. Then, we can select the attribute with the largest information gain as the optimal attribute.
(3)
(3)
According to this idea, this paper traverses the entire training data set and finds out all the attributes to construct the probabilistic DT. Note that the study in this subsection is only based on the traditional single-valued attributes environment, and then we study the multi-valued and probabilistic multi-valued preference environment in the next section.
2.2. The multi-valued and probabilistic multi-valued preference environment
As we know, there are some situations which show the multi-valued preference and probabilistic multi-valued preference characters in real life. However, few models are developed based on the multi-valued and probabilistic multi-valued preference environments. Therefore, we try to study these two new environments and propose the feasible probabilistic classification and machine learning models in this paper.
It is noted that the original data are derived from the DT cases (Quinlan, 1987). –3 respectively represent the above three environments in this reference. We can find that there are four attributes in each table, namely “outlook, temperature, humidity, windy”. Each attribute has its sub attributes. For example, “outlook” contains three sub attributes of “sunny, overcast, rain”; “humidity” contains three sub attributes of “hot, mild, cool”; “temperature” contains two sub attributes “high, normal”, and “windy” contains two sub attributes “true, false”. Among them, denotes the sample of day
The attributes “outlook, temperature, humidity, windy” means that there are four attributes in the data set; each attribute contains different sub attributes such as “sunny, overcast, rain”. According to these setting, we have
and
represent the probability values of the
th attribute in the
th sample. Classes
and
represent the positive and negative instances.
and
denote the probability values of
and
in the
th sample. Therefore, we can further describe these three environments in detail.
Table 1. A single-valued preference sample.
shows a single-value preference environment. Extract sample from as an illustration, we can find that
shows each attribute only retains one attribute value as the final state. For example, the attribute “outlook” selects the attribute of “overcast”, “temperature” selects the attribute of “hot”, “humidity” selects the attribute of “high”, and “windy” selects the attribute of “false”. In this single-valued preference environment, each rule corresponds to only one classification result
or
which is called the absolute classification.
shows a multi-valued preference environment. We can find that the preference values of the sample have the multi-valued forms. Take the sample in as an illustrated example,
shows that its each attribute contains one or more preferences. In this example, the attribute “outlook” selects three preferences, namely “overcast, sunny, rain”, which means that three different preferences of “outlook” appeared on this day. Obviously, this situation is common in real life. In this paper, we focus on these three preferences but not the order that they occur. Based on this, a multi-valued preference environment can be shown as follows:
Table 2. A multi-valued preference sample.
Definition 1. Let be the
th sample with
attributes, and each attribute contains
preferences, and then this case can be defined as the multi-valued preference environment, where the probability of each preference is equal,
and
According to Def. 1, we can obtain the multi-valued preference environment. Then, it is found that all the attributes in the data retain the single and multiple preferences. The weight of each preference in the same sample and the same attribute is equal. Furthermore, we can find that the probability of preference is not involved here.
shows the multi-valued preference environment with the probability. Taking in as an example, we can find that this is different from and each preference have their probability. Moreover,
and
respectively represent the possible probabilities. Taking the attribute “temperature” in
as an example, this shows that the occurrence probability of preference “hot” is
“mild” is
and “cool” is
on the same day, and the sum of the probabilities of these three preferences is 1.
Table 3. A probabilistic multi-valued preference sample.
Moreover, the attribute “humidity” just has one attribute value “high”. Obviously, the occurrence probability of the attribute value “high” in this day can be set as 100%, and the occurrence probability of the other attribute “normal” can be set as 0%. Finally, by observing the three small samples in , we can find that the number of attribute in each sample can be set as the different values, which means that the attribute situation that occurs every day is also different. We think that this situation including the multi-valued preference and its probability is closer to real life.
The three different environments aforementioned are three kinds of presentations and show the different relationships. The multi-valued preference is a development of the single-valued attribute, while the probabilistic multi-valued preference is a development of the multi-valued preference. Therefore, this paper develops the DT model based on these different environments and analyzes them according to these two situations which are the main innovations of this paper.
3. The machine learning model in the multi-valued preference environment
As aforementioned in Section 2.1, the ID3 algorithm is used to calculate the single-valued discrete data. Then, this method directly selects the optimal attribute by calculating their information gains and constructs the machine learning model. The hypothesis of the ID3 algorithm is that the weight of each sample in each column of attributes is 1. However, the multi-valued and probability multi-valued data sets studied in this paper have the main characteristics, which are the different numbers of attribute values in the same attribute and sample. Thus, these two types of data cannot be directly embedded in the information gain formula to select the optimal attribute in the calculation process.
With respect to the above discussion, we can find that the build of the DT in the multi-valued preference environment includes two main steps. The first step is to solve the aforementioned problem by preprocessing the original training data. In this step, the numbers and weights of the preferences in the original training data should be re-matched to balance them. The second step is to construct a DT using the new training data. Compare with the optimal degree of each attribute and its preference based on the bifurcation criterion, we can find that the optimal attribute is different. Based on this, we first propose the weight and quantity matching method under the multi-valued preference environment in the next subsection.
3.1. The weight and quantity matching in the multi-valued preference environment
In the multi-valued preference environment, the training data set contains
samples for the multi-dimensional attributes which presents a multi-dimensional matrix. Suppose the attribute
in
th sample contains
preferences can be expressed as
Then, the preferences that are selected for the attribute
in the training data set
can be shown as a matrix below:
where
represents a matrix includes the different preferences in the attribute
of all the samples, which is a combination of the
sets
and
denotes the
th sample selects the
th preference in the attribute
and
is defined as the weight of the preference
Moreover, let
denotes the number of preferences belonging to the attribute
in the
th sample. However, since each sample exists independently, each
can be unequal. Therefore, different preferences have different weights under the attribute
To address the issue of uneven weights caused by the unequal numbers, this paper proposes a weight and quantity matching method. This method is to use the least common multiple to match the quantity of data. This principle of the least common multiple can change the amounts of data into the same one. Assume the least common multiple is marked In this multi-valued training data set
the least common multiple of the attribute
can be calculated as
The original training data set
can be expanded accordingly and the expansion multiple is marked with
Here, we make the number of preferences in each sample with respect to the attribute
become
Therefore, the weight reduction of each preference is a multiple of
where
Similarly, the preferences of other attributes can also obtain new weights using the given weight and quantity matching method. Then, we can get a new multi-valued preference data set
and assume
as the new weight of each preference.
Based on this, we finish the process of quantity matching and give a weight and quantity matching method. Therefore, we complete the weight and quantity matching in the multi-valued preference environment. Further, we can analyze how to use the weight and quantity matching method to develop the DT algorithm under the multi-valued preference environment.
3.2. The DT algorithm in the multi-valued preference environment
As we know, the DT model under the single-valued environment uses the information gain to select bifurcation nodes. Similarly, under the multi-valued attribute environment, we also construct the DT model based on the bifurcation nodes. However, with respect to the different environments, the selection criterion for the bifurcation nodes are changed accordingly. In this paper, we develop a new method of selecting nodes under the multi-valued preference environment as the bifurcation criterion.
The following content explains these concepts in conjunction with the mathematical expressions and modeling process of the new DTs and machine learning. We also introduce the notations that are used in the following Sections, which are shown in .
Table 4. The main notations in the multi-valued preference environment.
Due to the different environments, this paper optimizes the algorithm in the single-valued preference environment and improves the information gain as a bifurcation criterion that can handle the multi-valued preferences. Moreover, this paper divides the node selection into two steps, which are the selection of the root node and the other nodes. The reason is that the selection of the root node only considers the changing relationship between the preference and classification. However, the selection of other nodes needs to be based on the known conditions of the previous node. Therefore, the weight modification should be considered, as well as the previous node's weights.
With respect to these principles, the calculation of the root node bifurcation criterion in the multi-valued preference environment is summarized as follows:
(4)
(4)
Then, the bifurcation information entropy of the root node is shown as
(5)
(5)
Furthermore, the conditional information entropy of the root node is presented as follows:
(6)
(6)
Similarly, the calculation of the sub node bifurcation criterion in the multi-valued preference environment is summarized as follows:
(7)
(7)
Then, the bifurcation information entropy of the sub node is
(8)
(8)
Moreover, the conditional information entropy of the sub node is presented as
(9)
(9)
Therefore, we can obtain the root node and sub node bifurcation criterion in the multi-valued preference environment. As we know, after the numbers of attributes are matched, the preference weights can be changed. When calculating the bifurcation criterion values of the nodes, the previous nodes should be considered again. Generally, the larger bifurcation criterion, the more information contained in the data, and the greater uncertainty.
However, the classification result of the DT can be not accurate at this stage and the same attribute branch can appear the different classification results. Then, the final result can be a multi-class result containing probabilities. Therefore, we should calculate the corresponding probabilities of the classification results in all branches to help decision-making. Assume that the preference set corresponds to a branch and the classification results are
and
Then, we can obtain the probability
that the classification result is
by EquationEq. (10)
(10)
(10) . Similarly, we also can get
(10)
(10)
Thus, the main construction process of the probabilistic DT and machine learning in the multi-valued preference environment is given. Obviously, we can make a decision based on the above classification results correspond to each branch. Here, we choose a classification with a probability greater than 50%. To further demonstrate the calculation steps, we give the following pseudo-code.
Table
To understand the above algorithm and its steps, we use an illustrated example to prove its feasibility in the next subsection.
3.3. An illustrated example
To show the above machine learning model, a simple example is given in this section to show the operation process. For an intuitive comparison, this section follows the example in Section 2.2, retains 10 samples, namely We consider four attributes, which are outlook
temperature
humidity
and windy
The training data set
is shown in and it is further expanded and shown in . The final classification DT is shown in .
Figure 1. The DT generated based on the information gain and the data set
Source: The Authors.
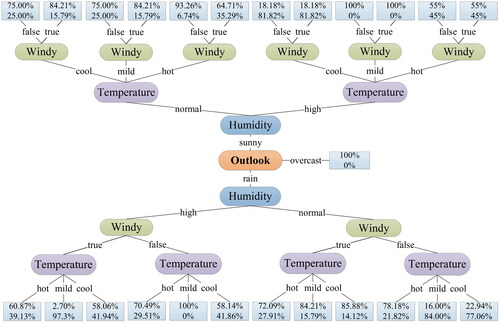
Table 5. A multi-valued training set containing 10 samples.
Table 6. A new training sample set after quantity expanding.
According to the steps to build a multi-valued DT, this subsection first performs the quantity matching in the original data set and then calculates the least common multiple of the four attributes, then we can obtain their matching values when
and
Then, based on the result of quantity matching, the original data set
is expanded to a new data set
as shown in . It is found that the number and weights of attribute values in the same attribute are kept consistent. Further, we use the bifurcation criterion to select the optimal attributes and construct a DT.
In the following content, we only show the selection process of the first node. The calculation processes of other nodes are the same and the results are shown in .
Table 7. The bifurcation criterion value in the multi-valued preference environment.
First, we calculate the bifurcation information of the training data set and compute the bifurcation criterion of four attributes, and then select the attribute with the largest bifurcation criterion value as the root node. The main process is given as follows:
From the above calculation results, we can find that the attribute has the largest bifurcation criterion value, which is selected as the optimal attribute. Specifically, the attribute
contains three branch nodes “sunny”, “overcast”, and “rain”, which divides the data set
into three preferences
and
Furthermore, we calculate the classifications under the two branches of “sunny” and “rain”. The results are shown in .
In , the left part shows the classification process under the attribute value is “sunny”. The right part shows the classification process under the attribute value is “rain”. Obviously, under the two branches, the bifurcation criterion value of is greater than the values of
and
Thus, the attribute
is selected as the optimal node. Since the classification with respect to the attribute
still contains
and
then,
is only used as a bifurcation node. The two preferences “high” and “normal” of attribute
can divide the data set again. Thus,
is divided into
and
These two sets select the attributes from the remaining attributes
and
respectively as the next bifurcation node. shows the more detailed results.
From the calculation results in , it can be seen that in the bifurcation criterion value of the attribute
is greater than the value of
Thus,
is selected as the bifurcation node in both sets. The last attribute
is left as a stop node. Furthermore, in
the bifurcation criterion value of the attribute
is greater than the value of
and then
is selected as the bifurcation node. Thus, only the last attribute
is left as a stop node. Based on this, we temporarily get a DT that lacks classification results. Since the classification results also contain probabilities, we need to calculate them again.
is a probabilistic DT derived from the training data set. The ellipse represents the attribute of the bifurcation node, the better the classification performance is, the closer the attribute is to the root of the tree. The line denotes the division preference, and the rectangle shows the probability of the classification result. The upper and lower numbers represent the probabilities of the classification results respectively under the bifurcation, which are and
For example, when the preferences are “rain, high, false, mild”, we can find that the corresponding classification result is
and
Obviously,
is better than others under this branch. If preferences are “sunny, high, cool, false”, we can find that the corresponding classification result is
and
Then,
is better than others under this branch. If preferences are “sunny, high, hot, true”, we can find that the corresponding classification result is
and
There is very little difference in the classification probabilities between
and
under this branch. Then, both the alternatives are equal.
As aforementioned, to develop a DT model in machine learning under the multi-valued preference environment, this section first proposes a weight and quantity matching method in the multi-valued preference environment. Then, the corresponding DT algorithm is proposed and applied to an illustrated example. In the next section, we develop a machine learning model in the probabilistic multi-valued preference environment.
4. The machine learning model in the probabilistic multi-valued preference environment
It is found that the probability of each preference is the same in the machine learning models under the multi-valued preference environment. However, in the real classification calculation process, the probability of each preference may be different. Therefore, in this section, we propose a machine learning model in the probabilistic multi-valued preference environment. First, we propose a DT algorithm under this environment in the following subsection.
4.1. The DT algorithm in the probabilistic multi-valued preference environment
The probabilistic multi-valued preference environment is a situation based on the expansion of the multi-valued preference. The training data set in the probabilistic multi-valued preference not only contains multi-valued preferences, but also each preference contains the different probability instead of the equal weight values.
In Section 3.1, to re-match the numbers and weights of the preferences under all the attributes, the original data in the multi-valued preference environment needs to be preprocessed. Then, we can ensure that each attribute is balanced during the calculation process. However, each preference in the probabilistic multi-valued environment contains a probability. It is unnecessary to preprocess the data in this environment and we can directly calculate the bifurcation criterion of each attribute. Based on this, we can select the optimal bifurcation node and bifurcation sub node. Additionally, in the probabilistic multi-valued preference environment, it is noted that since each preference contains the probability, the preference probability need to be added in the entire calculation process. Therefore, we can build a DT model in the probabilistic multi-valued preference environment, which is also a machine learning model. Some related notations used in this section are given in .
Table 8. Some main notations in the probabilistic multi-valued preference environment.
Although this environment does not require preprocessing of the original training data set, we need to consider the probability contained in each preference. Then, we subdivide this modeling process into two steps, namely the selection of the root node and the other nodes.
The selection of the optimal root node is done individually, and each branch only considers a certain attribute. We calculate the bifurcation criterion of each attribute separately, and the attribute with the largest bifurcation criterion is the optimal one. There is only one optimal root node in a DT, while there may be multiple optimal sub nodes. The selection principle of all the sub nodes is the same. In this case, the sub node not only considers the current attribute and its belonging preference, but also considers all the previous nodes including the root node. Then, we can take the conditional probability in this environment as the probabilities of other sub nodes when the root node is known, and the corresponding probabilities are multiplied in the calculation process.
With respect to these principles, the calculation of the root node bifurcation criterion in the probabilistic multi-valued environment can be shown as
(11)
(11)
Then, the bifurcation information entropy of the root node is shown as
(12)
(12)
Furthermore, the conditional information entropy of the root node is presented as follows:
(13)
(13)
Similarly, the calculation of the sub node bifurcation criterion in the probabilistic multi-valued preference environment is summarized as follows:
(14)
(14)
Then, the bifurcation information entropy of the sub node is
(15)
(15)
Moreover, the conditional information entropy of the sub node is presented as follows:
(16)
(16)
Therefore, we can obtain the root node and sub node bifurcation criterion in the probabilistic multi-valued preference environment. Furthermore, we need to calculate the probability of each branch in the DT, and then obtain the probability that the classification result is
by EquationEq. (17)
(17)
(17) . Similarly, we also can get
(17)
(17)
Thus, we construct the DT model in machine learning under the probabilistic multi-valued preference environment, and the DT shows the probabilistic character. The above calculation process can be further shown by the following pseudo-code.
Table
4.2. An illustrated example
In this section, to show the effectiveness and feasibility of the above algorithm in the probabilistic multi-valued preference environment, we give the detailed calculation process based on an illustrated example. To present the advantages, we follow the example in Subsection 3.2 and expand the data set to 60 samples which are shown in . We can find that the entire data set is divided into two parts, the first 50 samples are taken as the training data sets, and the last 10 samples are taken as the prediction data sets. In addition, the preference in each sample contains the probability and the sum of the preference probabilities is 1 in the same sample and attribute.
Table 9. The probabilistic multi-valued training set containing 60 samples.
In this example, we only show the calculation process of the root node selection. Similarly, the selection of other sub nodes can be calculated. The calculation results are shown in .
Table 10. The bifurcation criterion value about sub nodes in the probabilistic multi-valued environment.
The above calculation shows the selection process of the root node. From the results, we can find that the attribute has the largest bifurcation criterion value, and then the attribute
can be selected as the optimal attribute. Specifically, the three preferences “sunny”, “overcast”, and “rain” in the attribute
divided data set
into three kinds of preferences
and
When the preference contained in the branch is “overcast”, we can find that all the classification results are unique and the category is In this case, there is no need to further divide this node, and then the classification process is end.
Then, we calculate the bifurcation criterion of other attributes in the two kinds of preferences and
namely “sunny” and “rain”, to find all the sub nodes. This calculation process involves more multi-attribute bifurcation criterion. The bifurcation criterion values and node selection results are given in . Then, we can find that the attribute selection order is
and
Based on this, we can get a DT in machine learning. At last, we use EquationEq. (17)
(17)
(17) to calculate the probability of each branch in the tree and get a probabilistic DT, which are shown in .
Figure 2. The DT based on the information gain and the data set
Source: The Authors.
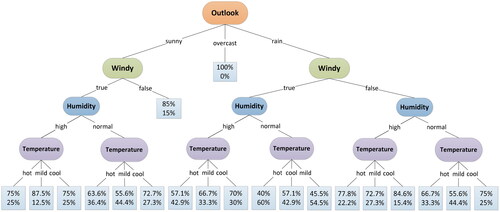
Based on , we can obtain the probabilities of all the branches in the DT and their corresponding classification results. As shown in , the ellipse represents the bifurcation node, the line represents the division preference, and the rectangle denotes the probability of the classification result. The upper and lower numbers in the rectangle refer to the probabilities of the classification results, which are and
respectively. According to this, we can further obtain the classification results of the prediction data set. Moreover, shows all the probabilities of the classification results for
and
As aforementioned, in this section, we propose a DT model in machine learning under the probabilistic multi-valued preference environment. In addition, we apply them to an illustrated example which reflects their feasibility and effectiveness.
5. Conclusions
In the classification process, the data are often not unique, there may be multiple values and probabilities, and then it is meaningful to develop an appropriate method to make a classification decision in this situation. To do this, this paper has given the multi-valued preference environment and probabilistic multi-valued preference environment, and then constructed two optimization machine learning methods based on the new DT models. First, in the multi-valued preference environment, a training data set with matching quantity and weight has been obtained through data preprocessing, and a DT model in the multi-valued preference environment has been proposed by using the entropy to generate several branches and probabilistic classifications. Then, according to the different probabilities, we have developed a DT model in the probabilistic multi-valued preference environment, and the branches and their corresponding probabilities have been similarly generated. Meanwhile, we have given two illustrated examples to show the calculation process and proved the feasibility of the proposed machine learning methods. Therefore, there are three contributions of this paper: (1) This paper has proposed a data preprocessing method to match the weights and numbers in the multi-valued preference environment; (2) This paper has developed a machine learning method and a DT algorithm in the multi-valued preference environment to obtain the corresponding probability classification; (3) This paper has constructed a machine learning method and a DT algorithm in the probabilistic multi-valued preference environment, and the corresponding probability classification has been obtained.
The machine learning methods and the DT algorithms in the multi-valued preference and probabilistic multi-valued preference environments have been proposed in this paper. These can show the practical significance and provide decision makers with reasonable classification decision suggestions. However, these methods also have some limitations in data preprocessing. For example, they are only suitable for the small samples. These limitations are also the focus of our future research.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Barlow, H. B. (1989). Unsupervised learning. Neural Computation, 1(3), 295–311. https://doi.org/10.1162/neco.1989.1.3.295
- Bhargava, D. N., Sharma, G., Bhargava, R., & Mathuria, M. (2013). Decision tree analysis on j48 algorithm for data mining. Proceedings of International Journal of Advanced Research in Computer Science and Software Engineering, 3(6), 22–45.
- Blum, A. L., & Langley, P. (1997). Selection of relevant features and examples in machine learning. Artificial Intelligence, 97(1–2), 245–271. https://doi.org/10.1016/S0004-3702(97)00063-5
- Capó, M., Pérez, A., & Lozano, J. A. (2020). An efficient K-means clustering algorithm for tall data. Data Mining and Knowledge Discovery, 34(3), 776–811. https://doi.org/10.1007/s10618-020-00678-9
- Chen, B., Gu, W., & Hu, J. (2010). An improved multi-label classification method and its application to functional genomics. International Journal of Computational Biology and Drug Design, 3(2), 133–145. https://doi.org/10.1504/IJCBDD.2010.035239
- Chen, Y.-L., Hsu, C.-L., & Chou, S.-C. (2003). Construction a multi-valued and multi-label decision tree. Expert Systems with Applications, 25(2), 199–209. https://doi.org/10.1016/S0957-4174(03)00047-2
- Cheng, J. (2014). A study of improving the performance of mining multi-valued and multi-labeled data. Informatica, 25(1), 95–111.
- Chou, S., & Hsu, C. L. (2005). MMDT: A multi-valued and multi-labeled decision tree classifier for data mining. Expert Systems with Applications, 28(4), 799–812. https://doi.org/10.1016/j.eswa.2004.12.035
- Clarke, K. R. (1993). Non‐parametric multivariate analyses of changes in community structure. Austral Ecology, 18(1), 117–143. https://doi.org/10.1111/j.1442-9993.1993.tb00438.x
- Crawford, S. L. (1989). Extension to the CART algorithm. International Journal of Man-Machine Studies, 31(2), 197–217. https://doi.org/10.1016/0020-7373(89)90027-8
- Figueiredo, M. A. T. (2003). Adaptive sparseness for supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(9), 1150–1159. https://doi.org/10.1109/TPAMI.2003.1227989
- Galton, F. (1889). Co-relations and their measurement, chiefly from anthropometric data. Proceedings of the Royal Society of London, 45, 135–145.
- Gerfo, L. L., Rosasco, L., Odone, F., Vito, E. D., & Verri, A. (2008). Spectral Algorithms for Supervised Learning. Neural Computation, 20(7), 1873–1897. https://doi.org/10.1162/neco.2008.05-07-517
- Goldsmith, J. (2001). Unsupervised learning of the morphology of a natural language. Computational Linguistics, 27(2), 153–198. https://doi.org/10.1162/089120101750300490
- Han, J. W., & Micheline, K. (2006). Data mining: Concepts and techniques. In Data mining concepts models methods & algorithms (2nd ed., Vol. 5, pp. 1–18). Morgan Kaufmann.
- Han, Q. Q., Liu, J. M., Shen, Z. W., Liu, J. W., & Gong, F. K. (2020). Vector partitioning quantization utilizing K-means clustering for physical layer secret key generation. Information Sciences, 512, 137–160. https://doi.org/10.1016/j.ins.2019.09.076
- Hardikar, S., Shrivastava, A., & Choudary, V. (2012). Comparison between ID3 and C4.5. International Journal of Computer Science, 2(7), 34–39.
- Hsu, C. L. (2021). A multi-valued and sequential-labeled decision tree method for recommending sequential patterns in cold-start situations. Applied Intelligence, 51(1), 506–526. https://doi.org/10.1007/s10489-020-01806-0
- Hunt, E. (1965). Selection and reception conditions in grammar and concept learning. Journal of Verbal Learning and Verbal Behavior, 4(3), 211–215. https://doi.org/10.1016/S0022-5371(65)80022-6
- Kruppa, J., Schwarz, A., Arminger, G., & Ziegler, A. (2013). Consumer credit risk: Individual probability estimates using machine learning. Expert Systems with Applications, 40(13), 5125–5131. https://doi.org/10.1016/j.eswa.2013.03.019
- Lee, T. R., Wood, W. T., & Phrampus, B. J. (2019). A machine learning (KNN) approach to predicting global seafloor total organic carbon. Global Biogeochemical Cycles, 33(1), 37–46. https://doi.org/10.1029/2018GB005992
- Mantas, C. J., Castellano, J. G., Moral, G. S., & Abellán, J. (2019). A comparison of random forest based on algorithms: Random credal random forest versus oblique random forest. Soft Computing, 23(21), 10739–10754. https://doi.org/10.1007/s00500-018-3628-5
- Miao, D. Q., & Wang, J. (1997). Rough sets based on approach for multivariate decision tree construction. Journal of Software, 8(6), 425–431.
- Narasimha, P. L. V., & Naidu, M. M. (2014). CC-SLIQ: Performance enhancement with 2k split points in SLIQ decision tree algorithm. IAENG International Journal of Computer Science, 41(3), 163–173.
- Pal, M., & Mather, P. M. (2003). An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sensing of Environment, 86(4), 554–565. https://doi.org/10.1016/S0034-4257(03)00132-9
- Pal, R., Kupka, K., Aneja, A. P., & Militky, J. (2016). Business health characterization: A hybrid regression and support vector machine analysis. Expert Systems with Applications, 49, 48–59. https://doi.org/10.1016/j.eswa.2015.11.027
- Polat, K., & Güneş, S. (2007). Classification of epileptiform EEG using a hybrid system based on decision tree classifier and fast Fourier transform. Applied Mathematics and Computation, 187(2), 1017–1026. https://doi.org/10.1016/j.amc.2006.09.022
- Qayyum, A., Usama, M., Qadir, J., & Al-Fuqaha, A. (2020). Securing future autonomous & connected vehicles: Challenges posed by adversarial machine learning and the way forward. IEEE Communications Surveys & Tutorials, 22(2), 998–1026.
- Quinlan, J. R. (1986). Induction of decision trees. Machine Learning, 1(1), 81–106. https://doi.org/10.1007/BF00116251
- Quinlan, J. R. (1987). Simplifying decision trees. International Journal of Man-Machine Studies, 27(3), 221–234. https://doi.org/10.1016/S0020-7373(87)80053-6
- Quinlan, J. R. (1996). Improved use of continuous attributes in C4.5. Journal of Artificial Intelligence Research, 4(1), 77–90. https://doi.org/10.1613/jair.279
- Ruggieri, S. (2002). Efficient C4.5 classification algorithm. IEEE Transactions on Knowledge and Data Engineering, 14(2), 438–444. https://doi.org/10.1109/69.991727
- Rutkowski, L., Jaworski, M., Pietruczuk, L., & Duda, P. (2014). The CART decision tree for mining data streams. Information Sciences, 266(1), 1–15. https://doi.org/10.1016/j.ins.2013.12.060
- Santhosh, K. (2013). Modified C4.5 algorithm with improved information entropy. International Journal of Engineering Research & Technology, 2(14), 485–512.
- Santini, S., & Jain, R. (1999). Similarity measures. IEEE Transactions on Pattern Analysis & Machine Intelligence, 21(9), 871–883.
- Sun, Z. L., Choi, T. M., Au, K. F., & Yu, Y. (2008). Sales forecasting using extreme learning machine with applications in fashion retailing. Decision Support Systems, 46(1), 411–419. https://doi.org/10.1016/j.dss.2008.07.009
- Tsoumakas, G. (2019). A survey of machine learning techniques for food sales prediction. Artificial Intelligence Review, 52(1), 441–447. https://doi.org/10.1007/s10462-018-9637-z
- Tversky, A. (1977). Features of similarity. Psychological Review, 84(4), 327–352. https://doi.org/10.1037/0033-295X.84.4.327
- Utkin, L. V. (2019). An imprecise extension of SVM-based machine learning models. Neurocomputing, 331, 18–32.
- Wong, W. K., & Guo, Z. X. (2010). A hybrid intelligent model for medium-term sales forecasting in fashion retail supply chains using extreme learning machine and harmony search algorithm. International Journal of Production Economics, 128(2), 614–624. https://doi.org/10.1016/j.ijpe.2010.07.008
- Yi, W., Lu, M., & Liu, Z. (2011). Multi-valued attribute and multi-labeled data decision tree algorithm. Pattern Recognition & Artificial Intelligence, 2(2), 67–74.
- Yuan, R. X., Li, Z., Guan, X. H., & Xu, L. (2010). An SVM-based machine learning method for accurate internet traffic classification. Information Systems Frontiers, 12(2), 149–156. https://doi.org/10.1007/s10796-008-9131-2
- Zhang, M. L., & Zhou, Z. H. (2007). ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognition, 40(7), 2038–2048. https://doi.org/10.1016/j.patcog.2006.12.019
- Zhao, R., & Li, H. (2007). Algorithm of multi-valued attribute and multi-labeled data decision tree. Computer Engineering, 33(13), 87–89.