
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The main practical problems that are faced by portfolio optimisation under the Markowitz model are (i) its lower out-of-sample performance than the naive rule, (ii) the resulting asset weights with extreme values, and (iii) the high sensitivity of those asset weights to small changes in the data. In this study, we aim to overcome these problems by using a computation method that shifts the smaller eigenvalues of the covariance matrix to the space that houses the eigenvalue spectrum of a random matrix. We evaluate this new method using a rolling sample approach. We obtain portfolios that show both more stable asset weights and better performance than the
rule. We expect that this new computation method will be extended to several problems in portfolio management, thereby improving their consistency and performance.
1. Introduction
Portfolio theory, which was developed by Markowitz (Citation1952, Citation1959), is one of the most important pillars of financial theory. Part of the popularity of Markowitz’s model, which is taught in finance courses globally, is due to its simplicity.Footnote1 Nevertheless, despite the model’s popularity, investors’ empirical behaviour tends to differ from its predictions (Benartzi & Thaler, Citation2001).
Portfolio theory addresses the problem of how investors should invest by spreading their money across n + 1 financial assets, where one asset is risk-free and n assets are risky. This shows that investors can achieve higher than expected returns for a given level of risk by investing in efficient portfolios. In , the efficient portfolios are shown by the blue line. This theory indicates that all investors should divide their money between the risk-free asset and a tangent portfolio, which is an efficient portfolio that includes only risky assets Tobin (Citation1958).
Figure 1. Capital market line.
Source: Authors.
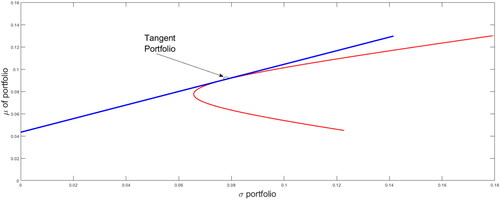
The set of points that contains this linear combination is called the capital market line. Investors choose one of these portfolios in the capital market line according to their degree of risk aversion. To determine the optimal weights of the tangent portfolio, it is necessary to consider expected returns (), the return of the risk-free asset (rf), and the covariance matrix (Σ). The optimal weights (
) are obtained as
where γ is the reduction in an investor’s risk aversion. The practical application depends on obtaining good estimates of
and Σ. However, this approach is not simple in practice. In fact, Markowitz’s model has received serious criticism, including its poor out-of-sample performance (Bloomfield et al., Citation1977; DeMiguel et al., Citation2009; Kritzman et al., Citation2010) and the extreme weights of the resulting optimal portfolios (Black & Litterman, Citation1991, Citation1992; Papp et al., Citation2005). It has also been criticised because its optimal portfolio weights are highly sensitive to the dataset that is used to estimate the parameters, which generates high transaction costs (Best & Grauer, Citation1991; Chopra, Citation1993; Jobson & Korkie, Citation1981).
Several researchers have studied the impact of parameter estimation errors on portfolio optimisation. For instance, Chopra (Citation1993) states that the major problems of the mean/variance (MV) framework are the errors associated with the estimation of the means, variances, and correlations of asset returns, as well as the fact that the optimisation process that underlies this methodology maximises these errors. In addition, Chopra and Ziemba (Citation1993) indicate that the estimation errors in means are approximately 11 times more important than those in variances, and that the estimation errors in variances are about twice as important as those in covariances. Merton (Citation1980) states that a long-term series of data is required to estimate expected returns accurately. Ng et al. (Citation2020) explain the difficulty of improving the accuracy of estimates of the means of returns—even as the sample size increases. Moreover, Best and Grauer (Citation1991) find that for an MV-efficient portfolio weight, both means and variances can be extremely sensitive to changes in asset means; consequently, they have implications for portfolio management. Researchers have also studied the effect of risk estimation on the performance of the Markowitz rule and the conditions required for good performance. For instance, Jobson and Korkie (Citation1981), using Monte Carlo simulations, find that the mean, variance, and covariance parameters do not lend themselves to making inferences in small samples, even when considering 313 months or 26 years to calculate these parameters. Similarly, Jorion (Citation1986) shows that, like local portfolios, the optimal asset allocation is sensitive to estimation risk in international cases. Michaud (Citation1989) states that MV models are highly sensitive to changes in parameters and are hard to estimate; moreover, they also magnify the effect of estimation errors.
Researchers have consequently proposed amendments to the Markowitz model, which can be classified into four categories: the Bayesian approach (Barry, Citation1974; Black & Litterman, Citation1991, Citation1992; Brown, Citation1979; Jorion, Citation1986; Klein & Bawa, Citation1976), models with moment restrictions (MacKinlay & Pástor, Citation2000), models with a portfolio restriction (Best and Grauer, Citation1992), and the optimal combination of portfolios (Garlappi et al., Citation2007; Kan & Zhou, Citation2007).
The most popular approach to managing the effect of estimation risk is the use of Bayesian shrinkage estimators, which shrink the sample estimator towards a certain target under the premise that the resulting shrinkage estimator contains less estimation error than the sample estimator. For example, Jorion (Citation1986) and Frost and Savarino (Citation1986) use a shrinkage estimator of the means vector, Ledoit and Wolf (Citation2003, Citation2004b, Citation2019, Citation2020) and Ollila and Raninen (Citation2019) consider shrinking the covariance matrix, and DeMiguel et al. (Citation2013) consider different combinations of the shrinkage of the means vector and covariance matrix. However, these proposed amendments have not eliminated the main practical drawbacks of the Markowitz model. Despite these amendments, out-of-sample performance is not superior to the naive rule and the weights of optimal portfolios obtained with these amendments remain extremely sensitive.
In this study, we contribute to the literature on this topic by proposing a new approach that largely overcomes all of these drawbacks. In addition to decreasing the effect of the estimation risk of the covariance matrix, we focus on reducing the negative effects of the presence of eigenvalues close to zero in the sample covariance matrix.
Our approach compresses the eigenvalue spectrum of a covariance matrix towards the eigenvalue spectrum of a diagonal matrix, which only contains the estimated values of the variances. This diagonal matrix target represents a multivariate process in which the variables are not correlated. Our approach is based on Ledoit and Wolf (Citation2004b) and Schäfer and Strimmer (Citation2005). In particular, the justification for our approach stems from random matrix theory (RMT). The application of RMT to portfolio optimisation suggests that the estimation risk of the correlation (or covariance) matrix plays an important role in this problem. Using these approaches, Laloux et al. (Citation1999) establish that the smallest eigenvalues of this matrix are sensitive to estimation risk, whereas it is precisely those eigenvectors that correspond to the smallest eigenvalues that determine (in Markowitz’s theory) the least risky portfolios.
To take advantage of this approach, we must determine the optimal shrinkage degree of the covariance matrix before choosing the optimal portfolio. Therefore, we propose a method that makes the smallest eigenvalue of the fitted correlation matrix larger than the minimum corresponding to a random matrix. Next, we compare the performance of our proposed method with the Markowitz method without adjustments, the rule, the Ledoit and Wolf (Citation2003, Citation2004a, Citationb, Citation2020) methods, and the two methods proposed by Ollila and Raninen (Citation2019). We find that the proposed method delivers better out-of-sample performance than all of the other methods for sample sizes larger than 165 months and maintains more stable and less volatile financial asset weights. Our results show that the proposed approach permits the Markowitz rule to clearly overcome the
rule, which shows a notable decrease in the extreme values of the optimal portfolio weights and at the same time a significant decrease in the volatility of the optimal portfolio weights. Moreover, these results are obtained when using relatively small sample sizes to estimate the parameters.
The traditional corrections to the MV model have typically centred on raising its performance by improving the estimations of the parameters and diminishing the risk of the estimation. However, in most of these corrections, the weights of the resulting portfolios continue to be highly volatile. Unfortunately, this makes the practical application of the unrestricted model unviable because of the high transaction costs implied by the extreme changes in the portfolio weights. For example, using the methodologies of Ledoit and Wolf (Citation2003, Citation2004a, b, Citation2020) and Ollila and Raninen (Citation2019), we show that it is possible to improve the performance of the MV model but that the high volatility of the optimal weights prevails. The sensitivity of the optimal weights is only strongly attenuated when near-zero eigenvalues of the covariance matrix are shifted into the space that those of a random matrix occupy.
The following sections are organised as follows. Section 2 presents the eigenvalue shrinkage model. Section 3 describes the procedures that we followed to perform the out-of-sample comparisons of the portfolio selection rules. Section 4 shows the preliminary results, while highlighting the potential advantages. Section 5 presents the advantages of applying a new portfolio selection rule and compares the out-of-sample performance with other covariance matrix shrinkage proposals. Finally, Section 6 concludes.
2. The model
In this section, we will develop a covariance matrix estimate based on the shrinkage of the eigenvalue spectrum.
2.1. Traditional Markowitz approach
Consider that we have a set of T observations of n financial assets with returns rit for with
and a risk-free asset that investors can lend and borrow without limit up to the rate rf.
We assume that investors who wish to determine their optimal portfolios use a fixed sample size of the latest m observations to estimate the parameter values: the risk premiums of each asset (the average return less the return of a risk-free asset) and the covariance matrix Σ.
Typically, in the portfolio selection model, it is assumed that investors have utility functions of the following type:
where μp is the expected return of the portfolio chosen by the investor, σp is the respective variance of the portfolio, and γ represents the risk aversion of the investor. This theory assumes that investors seek to maximise their utility function, with the restriction that the invested money is divided among a set of financial assets that contains n risky assets and one risk-free asset. Hence,
and
where
is the weight assigned to each risky asset and e is the column vector of ones of dimension n. Therefore, the problem for the investor is
(1)
(1)
The solution is
(2)
(2)
Investors can invest money in a risk-free asset that has a return of rf, and in n risky assets that have expected returns and a covariance matrix Σ. They can assign a percentage of their wealth to each risky asset
and
to the risk-free asset.Footnote2 Following this reasoning, Tobin (Citation1958) demonstrates that investors can achieve optimal portfolios by investing a proportion of their wealth in the risk-free asset and the remainder in a portfolio that contains only risky assets
which can be determined as
(3)
(3)
Therefore, using this approach to determine how investors have to invest entails inverting the covariance matrix Σ and multiplying it by the expected excess returns of the risky assets over the risk-free asset However, it is difficult in practice to estimate the true value of these parameters given that they are mainly obtained using limited historical data. Thus, the estimation risk of these parameters sharply affects the performance of the optimal rule of investment proposed by Markowitz (Citation1952).
If investors consider m preview observations of n assets then the means and covariances are estimated using the following expressions:
(4)
(4)
and
(5)
(5)
Consequently, the empirical optimal portfolio weights are determined by
(6)
(6)
2.2. Shrinkage estimation of the eigenvalues of the covariance matrix
In this study, we propose a new approach that compresses the eigenvalue spectrum of a covariance matrix towards the eigenvalue spectrum of a diagonal matrix, which only contains the estimated values of the variances to move the eigenvalues of the covariance matrix away from zero. This diagonal matrix target represents a multivariate process in which the variables are not correlated among themselves. This approach is similar to the approach that was proposed by Ledoit and Wolf (Citation2004b) and Schäfer and Strimmer (Citation2005).
The justification for our approach stems from RMT. The application of RMT to portfolio optimisation suggests that the estimation risk of the correlation (or covariance) matrix plays an important role in this problem. Using this approach, Laloux et al. (Citation1999) find that the smallest eigenvalues of this matrix are sensitive to estimation risk, whereas it is precisely the eigenvectors corresponding to the smallest eigenvalues that determine (in Markowitz’s theory) the least risky portfolios. Thus, as stated by Laloux et al. (Citation1999), ‘one should be careful when using this correlation matrix in applications.’
RMT establishes that for a dataset X that has T observations of n random variables with dimension n × T, where all its components are independent random variables, the spectrum of eigenvalues of its covariance matrix [] will be between a minimum limit ‘
’ and a maximum limit ‘
’ (see Marchenko & Pastur, Citation1967), where
(7)
(7)
As we will show later, the eigenvalues below the lower limit ‘’ contain problematic noise that complicates the portfolio optimisation process. Furthermore, smaller eigenvalues determine (in Markowitz’s theory) the least risky portfolios. Eigenvalues between ‘
’ and ‘
’ are noise belonging to random matrix-type behaviour, whereas values greater than ‘
’ contain useful information. In this study, we propose an adjustment of the covariance matrix by shrinking the covariance matrix eigenvalue spectrum towards a target eigenvalue spectrum. The matrix associated with this target is a diagonal matrix containing the values of the estimated variances on its diagonal. This target matrix mimics a random matrix because the covariances between the variables considered are zero.
This methodology aims to move the part of the eigenvalue spectrum of the covariance matrix that lies between zero and ‘a’ within the eigenvalue spectrum sector given by RMT; that is, the region (a, b). The benefit of applying this adjustment to the covariance matrix is the noticeable reduction in the dispersion of the optimal portfolio weights without any restrictions on them, which allows us to obtain stable portfolios that imply low transaction costs for investors and a considerable improvement in the performance of the Markowitz rule. In fact, the out-of-sample Sharpe ratio surpasses the rule, which permits investors to obtain higher returns for each risk level.
We propose the following correction of the covariance matrix to calculate the optimal weights:
(8)
(8)
where
is the diagonal matrix of
and η is an adjustment factor of the shrinkage. This is the same expression that Schäfer and Strimmer (Citation2005) employ when two models are used to estimate the covariance matrix, the first with many free parameters and the second with little bias.
Consequently, the optimal weights are
(9)
(9)
2.2.1. Shrinkage of the eigenvalue spectrum
Each of the n eigenvalues of the covariance matrix
can be estimated by
(10)
(10)
Furthermore, each of the n eigenvalues of the matrix λY, can be obtained by
(11)
(11)
The eigenvalues of the matrix λY, are those of the matrix Ω when η = 0; as η increases, they approach those of the diagonal matrix S and for η = 1 they are equal to those of the S matrix. Consequently, by changing η, we shift the eigenvalues of the matrix
2.2.2. Eigenvalue spectrum of a typical large covariance matrix
The random matrix eigenvalues have the following distributionFootnote3:
(12)
(12)
where a and b are given by EquationEq. (7)
(7)
(7) and
The red line in shows the theoretical density of the eigenvalues of the random correlation matrix with dimensions equal to 30. The empirical density function of the eigenvalues is shown by the blue line of the correlation matrix of the 30 equally weighted industrial portfoliosFootnote4 considering a sample size of 200 monthly observationsFootnote5 In total, the eigenvalues of the 938 correlation matrices are used to construct this density function.
Figure 2. Density of the eigenvalues of the covariance matrix Σ and of a random matrix.
Source: Authors.
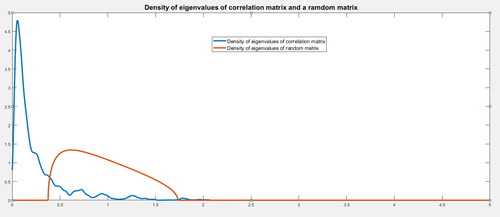
A high proportion of the eigenvalues are below the lower limit of an associated random matrix. As we will show later, the presence of these eigenvalues in this area causes serious problems for the Markowitz model.
Although not shown in , the empirical function of the density of the eigenvalues of Σ reaches values up to 25. According to these observed values and principal component theory, this means that the highest eigenvalue explains around 83% of the variance, while smaller eigenvalues explain a minimal part of the variance of the covariance matrix.
According to RMT, the presence of eigenvalues below the lower limit (a = 0.3754 for n = 30) is highly problematic when determining the optimal portfolio according to Markowitz (Bai et al., Citation2009). By contrast, eigenvalues above the upper limit b = 1.7325 contain valuable information, while eigenvalues within these limits are the products of a random matrix. The proposed approach allows us to move the spectrum of eigenvalues towards a space in which all of these values are above the lower limit of the spectrum corresponding to a random matrix.
2.2.3. Another explanation of the optimal weight sensitivity from the spectral decomposition
A square symmetric matrix such as a covariance matrix can be expressed as
(13)
(13)
where U is defined as
(14)
(14)
Here, represent the eigenvectors of the matrix Σ and D is a diagonal matrix containing the eigenvalues
of the matrix Σ. Therefore, we can express
(15)
(15)
where
are matrices with a rank equal to one. In a similar way, we can express the inverse of a covariance matrix as
(16)
(16)
EquationEq. (16)(16)
(16) shows that when we invert a matrix, smaller eigenvalues and their corresponding eigenvectors are more important than larger eigenvalues. Furthermore, the estimation error of the smallest eigenvalue is greater than that of the highest eigenvalue. This shows the sensitivity of the Markowitz model to errors in the assessment of smaller eigenvalues. shows the eigenvectors associated with eigenvalues with a mean of 0.06, which determine the inverse matrix of EquationEq. (16)
(16)
(16) . The eigenvector associated with the highest eigenvalue, whose value is equal to 25, has minimal importance.
Traditional methodologies aim to reduce the effects of risk in the estimation of the parameters. However, if, after these corrections, the covariance matrix that is finally used continues to have values close to zero, then the high sensitivity of the optimal weights will continue. Thus, for the MV method to be viable, it must try to diminish the estimation risk of the parameters and shift the values of the covariance matrix itself towards the centre in which those of a random matrix are located.
3. Data and experiment
The data correspond to the 1138 monthly observations of excess returns on the risk-free asset of 30 industrial portfolios from July 1926 to April 2021. These are the 30 equally weighted industrial portfolio sectors taken from Kenneth French’s website. We use the series of one-month Treasury bills taken from the Federal Reserve Economic Data as the risk-free rate.
To compare the relative empirical performance of the Markowitz rule with the shrinkage of eigenvalues, we use the naive rule as a benchmark. This investment rule invests a proportion of
of wealth in each of the n assets available for investing in each of the rebalancing dates. We use this naive rule as the benchmark because it is easy to implement given that no parameter estimation is necessary. Hence, this rule has not been outperformed by more complex optimisation rules when small sample sizes are used to estimate the parameters.Footnote6 Furthermore, this rule does not involve any parameter estimation or optimisation process and the data do not matter:
(17)
(17)
We use a rolling sample approach that is similar to the one that was used by DeMiguel et al. (Citation2009). Given a dataset of T = 1138 monthly observations, we use sample sizes () that are equal to 200, 300, 400, and 500 monthly observations. For the case in which the investor uses a sample size of m, we thus have
observations of realised returns obtained using the investment rule suggested by each model.
The observations of out-of-sample returns are used to analyse the performance of these investment rules. The assumptions of the empirical models are as follows:
Investors use the first m observations to estimate the parameter values (mean and covariance matrix).
Using these parameters, investors compute the optimal portfolio weights.
Then, they use this asset allocation to build their portfolios.
Investors hold their investments in these portfolios for one month.
At the end of the month, they calculate their realised returns.
At the beginning of the following month, investors choose the last
months to recalculate the parameters by dropping the earliest return and adding the return of the following month. In this way, the number of monthly observations that is used to calculate the parameters is always equal to m.
Steps from 2 to 6 are repeated until investors take the last assignation in month
As explained earlier, for each sample size of length m, we have observations of realised excess returns, which are calculated as follows:
(18)
(18)
where the value of
depends on the investment rule used:
If we use the Markowitz rule,
If we use the Markowitz rule with the proposed adjustment,
If we use the
Thus, we have observations of realised excess returns for the three rules. Using these realised excess returns, we calculate the out-of-sample Sharpe ratio for the three rules:
(19)
(19)
(20)
(20)
Then, we calculate the realised Sharpe ratio
(21)
(21)
For m = 200, we have 938 observations to compute the out-of-sample Sharpe ratio; for the other extreme (m = 500), we have 638 observations. This allows us to assess the performance of the three investment rules for sample sizes of 200, 300, 400, and 500 months.
Recall that we assume that investors choose their portfolios at the beginning of each month and then rebalance their portfolios by considering the results obtained and the new optimal weightings chosen at the end of the month. It would thus be interesting to explore the optimal length of portfolio rebalancing (e.g. Fahmy, Citation2020).
4. Preliminary results of the shrinkage estimations
4.1. Results using the 30 equally weighted industrial portfolios
shows the results obtained using a rolling sample size of 200 monthly observations.
Figure 3. Out-of-sample Sharpe ratio for different shrinkage levels for a sample size of 200.
Source: Authors.
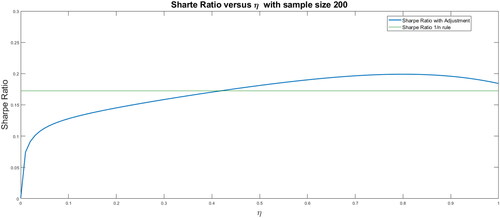
shows the out-of-sample Sharpe ratio for the different investment rules. The green line shows the Sharpe ratio of the naive rule and the blue line shows the out-of-sample modified Markowitz Sharpe ratio for values of η ranging from 0 to 1, with an increment of 0.01. The Markowitz rule without shrinkage corresponds to η equal to zero. The Sharpe ratio of the Markowitz rule without restriction, for a sample size of 200, is 0.011. This is well below that obtained using the
rule, which has an out-of-sample Sharpe ratio of 0.1725. The out-of-sample Sharpe ratio rises by increasing the value of η until it peaks at 0.1990. This optimal adjustment is obtained for η equal to 0.81. Moreover, with the optimum shrinkage, the out-of-sample Sharpe ratio increases from 0.03 to 0.1990 (i.e. an 18-fold increase).
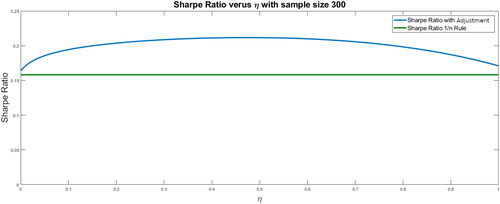
shows the out-of-sample Sharpe ratio for a sample size of 300. The Sharpe ratio without adjustment is 0.1641, which is higher than that obtained using the rule (0.1581). In this case, the optimal adjustment is obtained for η equal to 0.47 with a Sharpe ratio of 0.2117; that is, the out-of-sample Sharpe ratio increases by 29% with respect to the Markowitz rule without adjustment.
Figure 4. Out-of-sample Sharpe ratio for different shrinkage levels for a sample size of 300.
Source: Authors.
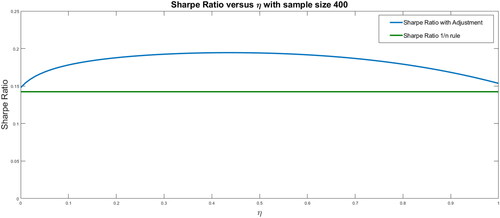
shows that the Sharpe ratio without adjustment is 0.1480, which is higher than that obtained using the rule (0.1424). In this case, the optimal adjustment is obtained for η equal to 0.43, with a Sharpe ratio of 0.1945; that is, the out-of-sample Sharpe ratio increases by 31% with respect to the Markowitz rule without adjustment.
Figure 5. Out-of-sample Sharpe ratio for different shrinkage levels for a sample size of 400.
Source: Authors.
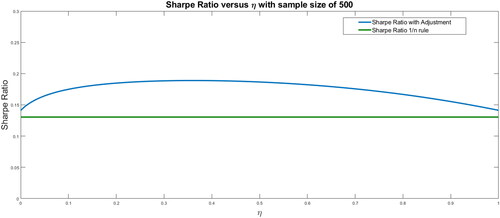
shows that the Sharpe ratio without adjustment is 0.1412, which is higher than that obtained using the rule of 0.1305. In this case, the optimal adjustment is obtained for η equal to 0.37, with a Sharpe ratio of 0.1889; that is, the out-of-sample Sharpe ratio increases by 34% with respect to the Markowitz rule without adjustment.
Figure 6. Out-of-sample Sharpe ratio for different shrinkage levels for a sample size of 500.
Source: Authors.
In summary, the compression of the covariance matrix to a random matrix improves the out-of-sample Sharpe ratio for all of the sample sizes that we considered. However, its effect is stronger for smaller sample sizes.
4.2. Effects of the optimal weights
Recalling that the low performance of the Markowitz rule is only one of its drawbacks, we now focus on the second drawback (i.e. its extreme and volatile portfolio weights).
To illustrate this issue, the following exercise is carried out:
We calculate the 30 portfolio weights obtained with the Markowitz rule without adjustment for each of the
We calculate the 30 portfolio weights obtained with the Markowitz rule with the optimal adjustment for each of the
We calculate the means and standard deviations of each portfolio weight.
shows the means and standard deviations of the optimal weights of the Markowitz rule with and without the adjustment for each of the 30 equally weighted industrial portfolios. Columns 2 and 4 show the means of the optimal weights obtained with the Markowitz rule without adjustment for sample sizes of 200 and 500 monthly observations, and columns 3 and 5 show their respective standard deviations. Similarly, columns 6 and 8 show the means of the optimal weights obtained using the Markowitz rule when setting the optimum adjustment to the covariance matrix for sample sizes of 200 and 500 monthly observations, and columns 7 and 9 show their respective standard deviations.
Table 1. Means and standard deviations of the portfolio weights.
The observed means and standard deviations of the optimal weights obtained using the traditional Markowitz rule show that the weights are extremely high and volatile. For example, for a sample size of 200, the mean of the number 11 portfolio weight of the industrial portfolio is −1.11. Therefore, investors who want to use this rule would have to invest taking the short position in this asset by 1.11 times their wealth. Additionally, the standard deviation of this asset is 5.59 times the value of investors’ wealth, which implies high transaction costs for investors. These facts make it infeasible to use the Markowitz rule under these conditions.
Certainly, these values are the most extreme when the sample size is small. However, the number of observations considered in the sample size does not eliminate these drawbacks. This is consistent with the findings of Jobson and Korkie (Citation1981), Chopra and Ziemba (Citation1993); Chopra (Citation1993), and Best and Grauer (Citation1991)
Instead, using the Markowitz rule with the optimum shrinkage of the eigenvalue spectrum of the covariance matrix, we obtain smaller values with a lower dispersion for each asset weight. For a sample size of 200 monthly observations, the dispersion of some of the weights decreases by more than 416 times.
In conclusion, using this approach improves the out-of-sample Sharpe ratio and at the same time lowers the volatility of the portfolio weights markedly. This could allow the Markowitz rule to overcome its main practical drawbacks.
4.3. Effects of the eigenvalues of the covariance matrix
To assess whether the eigenvalue spectrum is affected using this approach, we calculate the eigenvalues λi for all of the samples and determine the percentage of times that they are within the limits associated with a random matrix. For a sample size of 200 monthly observations, we calculate the 30 eigenvalues of the 938 correlation matrices with and without shrinkage. shows the results, where the values presented are averages. This shows that the main effect of the adjustment is to reduce the percentage of times that the eigenvalues are below the minimum limit.
Table 2. The effect of the eigenvalues of the covariance matrix.
The abundant noise in the estimation of the covariance matrix values triggers the greater presence of eigenvalues below the lower limit, as established in the spectral density of Marchenko and Pastur (Citation1967). Larger eigenvalues remain relatively unaffected by the effect of noise.Footnote7 shows that the eigenvalues spectrum moves towards the right as the compression of the covariance matrix to a random matrix increases. Initially, a large proportion of eigenvalues are below the lower random matrix limit. Meanwhile, as we reach the optimal shrinkage level, no eigenvalues are below the lower limit.
Figure 7. Density of the eigenvalues for different degrees of compression.
Source: Authors.
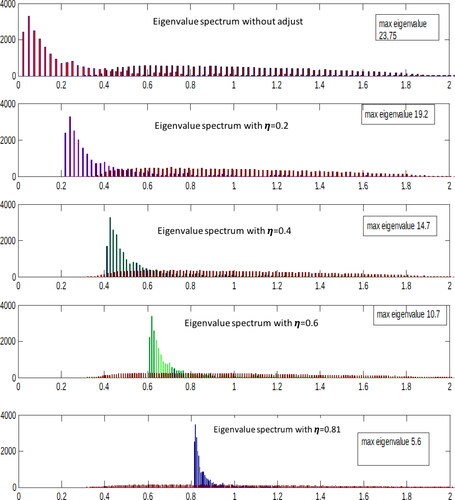
shows the effect of the shrinkage degree (by increasing η) over the eigenvalue spectrum. Random matrix density is shown in brown for all the figures. As the value of η increases, the eigenvalue spectrum of the shrinking matrix shifts towards the interior of a random matrix spectrum. For the lowest eigenvalues of the compressed matrix are all inside the random matrix spectrum.
5. Estimating the optimal covariance matrix ex-ante shrinkage level
So far, we have shown that the shrinkage of the covariance matrix can significantly improve the performance of the Markowitz rule. However, we now want to explore how effective this method is under more realistic conditions. In practice, an investor must simultaneously determine both the degree of compression of the covariance matrix and the portfolio in which they will invest, using only the information available up to that point. Thus, the investor must determine the ex-ante shrinkage level. A comparison with other approaches used to shrink the covariance matrix is also required. For example, we compare our method with the one proposed in Ledoit and Wolf (Citation2004b), followed by a comparison of the optimal shrinkage with other more recent approaches.
5.1. Ledoit–Wolf approach
The Ledoit and Wolf (Citation2004b) method minimises the estimation risk of a set of parameters by shrinking them to a target set value. The logic of this approach relies on the fact that the covariance matrix has a high estimation risk due to the presence of many degrees of freedom. Therefore, this shrinkage to another biased one (with a lower estimation risk and fewer degrees of freedom) reduces the effects of the estimation risk.
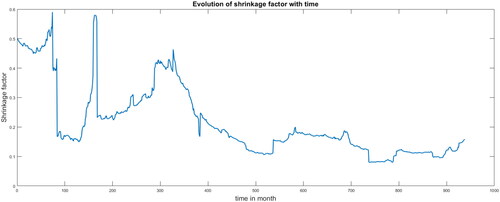
Using Ledoit and Wolf (Citation2004b), we estimate the optimal shrinkage for the 938 samples of size 200.
shows the optimal shrinkage values for each one of the 938 considered samples (of size 200 observations). It shows that the shrinkage degree value decreases when the samples use more recent data. Using these values, we calculate the Markowitz out-of-sample Sharpe ratio and obtain a value of 0.0835 compared with 0.1564 for the rule. This result shows that although the estimation risk decreases, it is not sufficient to ensure that the Markowitz rule performs better than the
rule.
Figure 8. Shrinkage for a sample size of 200 months.
Source: Authors.
5.2. Shrinkage of the eigenvalues of the covariance matrix
Considering this discussion and recalling that the eigenvalues of the covariance matrix below the lower limit of the eigenvalues of a random matrix are those that cause greater problems to the Markowitz rule, we propose an alternative shrinkage approach. This approach consists of moving the smaller eigenvalues within the limits of the respective random matrix. Specifically, we calculate the eigenvalues λi of the correlation matrix. We then take the minimal eigenvalue λmin and move it towards the random matrix spectrum:
(22)
(22)
From Equationequation 22(22)
(22) , we choose the shrinkage factor
as
(23)
(23)
Henceforth, we call this approach the optimal shrinkage of the covariance matrix eigenvalues (OSME). We calculate the optimal for 938 samples and show the result in . Thus, for each of the 938 samples with 200 monthly observations, a new correlation matrix is determined using
Figure 9. Shrinkage for a sample size of 200 months.
Source: Authors.
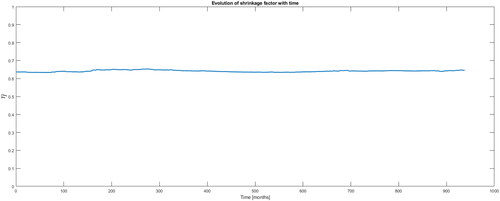
shows that the shrinkage levels have higher and more stable values than the Ledoit and Wolf (Citation2004b) approach. Next, we calculate the out-of-sample performance of the Markowitz rule using this approach. We find that its Sharpe ratio is equal to 0.1928, which is slightly above that of the rule (0.1564).
5.3. Comparison between OSME, Ledoit–Wolf, and the rule
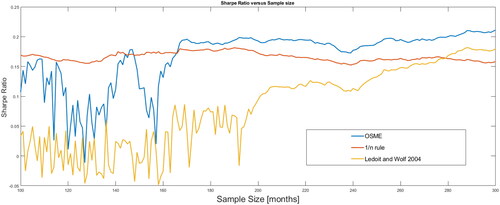
In this subsection, we first compare OSME Ledoit and Wolf (Citation2004a) with the rule. shows the Sharpe ratio of the
rule in red, that obtained using the Ledoit–Wolf method in brown, and that obtained using OSME in blue for the different sample sizes. This figure shows that the
rule is higher for sample sizes of less than 165 months. OSME performs better for sample sizes greater than 165 months. The Ledoit–Wolf method begins to be higher than the
rule for sample sizes over 280 months. However, it is never superior to OSME.
Figure 10. Out of-sample Sharpe ratio versus sample size.
Source: Authors.
shows the means and standard deviations of the optimal weights obtained using these three approaches. Although the standard deviation of the weights decreases, it remains high. The volatility of the optimal weights under the OSME approach is the lowest. The results show notably better performance for the Markowitz rule with OSME adjusted with respect to the naive rule, and not only for a sample size of 200 months. This third approach allows the Markowitz rule to perform better than the
rule for sample sizes greater than 165 monthly observations.
Table 3. Means and standard deviations of the portfolio weights.
5.4. Comparison with other approaches
Finally, to demonstrate the robustness of our results, we compare the proposed approach with recent approaches related to the shrinkage of covariance matrices. The methods that we consider are those of Ledoit and Wolf (Citation2003, Citation2004a,Citationb, Citation2020) and Ollila and Raninen (Citation2019). All of these methods seek to decrease the estimation error in the covariance matrix by compressing the traditional matrix into an identity matrix to decrease the mean squared error. shows the out-of-sample performance of several methods. Two methods developed by Ollila and Raninen (Citation2019) are considered (Ell1-RSCM and Ell2-RSCM). The table shows that the rule predominates for sample sizes less than 200 months. Meanwhile, the OSME approach predominates for sample sizes of 150 months and over. The Ledoit–Wolf and Ollila–Raninen methods exceed the
rule for a sample size greater than 300 months. The Sortino ratio is used as a performance measure to check the robustness of the results (Sortino & Van Der Meer, Citation1991). Whereas the Sharpe ratio considers the standard deviation σ as the risk measure, the Sortino ratio considers as risk only the part of σ whose values are below a minimum acceptable return. shows the performance measures using the Sharpe and Sortino ratios for a sample size of 200 monthly observations. As before, the results continue to show the superior performance of the OSME method. We use the one-month Treasury bills as the minimum acceptable return to calculate the Sortino ratio.
Table 4. Out-of-sample performance.
Table 5. Performance measures using the Sharpe and Sortino ratios.
shows the weights’ standard deviations (for 30 assets) that we obtained using each method. The last row provides the respective mean values. The OSME method decreases the mean volatility 43 times compared with the Markowitz rule. In addition, it decreases mean volatility (on average) by 12.6 times with respect to the Ledoit and Wolf (Citation2003, Citation2004a,b, Citation2020) and Ollila and Raninen (Citation2019) methods. These results are useful for portfolio managers because a portfolio selection method must perform well and incur low transaction costs. High volatility in asset weightings implies high transaction costs when rebalancing portfolios periodically.
Table 6. Standard deviations of the optimal weights.
Therefore, we recommend that portfolio managers (instead of using traditional covariance matrix estimates) should shrink these matrices into a diagonal matrix that only contains the variances of the individual assets. The shrinkage factor must be chosen so that the smallest eigenvalue lies between the lower and upper bounds of the random matrix spectrum (the corresponding shrinkage factor can be calculated by applying equation 23). Consequently, by applying this modified Markowitz rule, better performance and lower transaction costs could be obtained.
6. Conclusions
In the literature, classical methods of covariance matrix shrinkage use a matrix proportional to the identity as a target. In this paper, we propose a modification of the previous method using a diagonal matrix that is generated by the variances of the returns as a target. In addition, we shift the eigenvalue spectrum of the compressed covariance matrix such that its lower part is contained within the spectrum of a random matrix.
Our results suggest that the poor performance of the Markowitz rule is partly driven by the presence of eigenvalues close to zero in the covariance matrix. Using our approach, the corresponding portfolio performance is better than that using the rule. Additionally, the obtained optimal portfolio weights are more stable.
A further comparison with six other methods shows that our approach delivers better out-of-sample performance, while decreasing the volatilities of the optimal weights. Our methodology also works for small sample sizes.
The limitations of this study should be noted. We only used a one-month dataset of 30 equally weighted portfolios in one industry sector from Kenneth French’s database. The performance of this approach using other datasets was not explored (e.g. daily and individual asset data). We also assumed a monthly portfolio rebalancing period with an investment horizon of one month; therefore, different rebalancing and investment periods should also be explored in the future. However, applying optimal portfolio selection with different schemes always faces the problem of correctly estimating the covariance matrices. The effects of considering transaction costs on the out-of-sample performance of this approach should also be explored. This aspect is of particular importance for emerging economies.
These shrinkage methods decrease the correlations between asset returns in the covariance matrix. This improves predictability and decreases the volatility of the optimal portfolio weights, and implies (in part) that the empirical correlations are overestimated; that is, the data contain spurious correlations that alter the estimation process. The causes of this phenomenon remain to be explored.
Although these results are specific to the dataset that we used in this study, they could be considered to be an opportunity to improve the work of portfolio managers, especially those working with small datasets (e.g. oriented towards emerging markets).
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes
1 In this study, we consider that all individuals are risk averse. However, Markowitz’s model could incorporate greater flexibility by allowing useful functions that are considered to be risk-loving individuals. See Georgalos et al. (Citation2021) for a detailed discussion.
2 Here, e is an n-dimensional column vector whose elements consist of ones.
3 See Bai et al. (Citation2009).
4 Taken from Kenneth French’s website.
5 We use the eigenvalues of the correlation matrices as the standardisation criterion because the sum of the eigenvalues of the correlation matrix, with a range equal to n, is equal to n.
6 See, for example, DeMiguel et al. (Citation2009, Citation2013).
7 For details, see Papp et al. (Citation2005).
References
- Bai, Z., Liu, H., & Wong, W.-K. (2009). Enhancement of the applicability of Markowitz’s portfolio optimization by utilizing random matrix theory. Mathematical Finance, 19(4), 639–667. https://doi.org/10.1111/j.1467-9965.2009.00383.x
- Barry, C. B. (1974). Portfolio analysis under uncertain means, variances, and covariances. The Journal of Finance, 29(2), 515–522. https://doi.org/10.1111/j.1540-6261.1974.tb03064.x
- Benartzi, S., & Thaler, R. H. (2001). Naive diversification strategies in defined contribution saving plans. American Economic Review, 91(1), 79–98. https://doi.org/10.1257/aer.91.1.79
- Best, M. J., & Grauer, R. R. (1991). On the sensitivity of mean-variance-efficient portfolios to changes in asset means: some analytical and computational results. Review of Financial Studies, 4(2), 315–342. https://doi.org/10.1093/rfs/4.2.315
- Best, M. J., & Grauer, R. R. (1992). Positively weighted minimum-variance portfolios and the structure of asset expected returns. The Journal of Financial and Quantitative Analysis, 27(4), 513–537. https://doi.org/10.2307/2331138
- Black, F., & Litterman, R. (1992). Global portfolio optimization. Financial Analysts Journal, 48(5), 28–43. https://doi.org/10.2469/faj.v48.n5.28
- Black, F., & Litterman, R. B. (1991). Asset allocation: combining investor views with market equilibrium. The Journal of Fixed Income, 1(2), 7–18. https://doi.org/10.3905/jfi.1991.408013
- Bloomfield, T., Leftwich, R., & Long, J. B. (1977). Portfolio strategies and performance. Journal of Financial Economics, 5(2), 201–218. https://doi.org/10.1016/0304-405X(77)90018-6
- Brown, S. (1979). The effect of estimation risk on capital market equilibrium. The Journal of Financial and Quantitative Analysis, 14(2), 215–220. https://doi.org/10.2307/2330499
- Chopra, V. K. (1993). Improving optimization. The Journal of Investing, 2(3), 51–59. https://doi.org/10.3905/joi.2.3.51
- Chopra, V. K., & Ziemba, W. T. (2013). The effect of errors in means, variances, and covariances on optimal portfolio choice. In Handbook of the fundamentals of financial decision making: Part I (pp. 365–373).
- DeMiguel, V., Garlappi, L., & Uppal, R. (2009). Optimal versus naive diversification: How inefficient is the 1/n portfolio strategy? Review of Financial Studies, 22(5), 1915–1953. https://doi.org/10.1093/rfs/hhm075
- DeMiguel, V., Martin-Utrera, A., & Nogales, F. J. (2013). Size matters: Optimal calibration of shrinkage estimators for portfolio selection. Journal of Banking & Finance, 37(8), 3018–3034. https://doi.org/10.1016/j.jbankfin.2013.04.033
- Fahmy, H. (2020). Mean-variance-time: An extension of markowitz’s mean-variance portfolio theory. Journal of Economics and Business, 109, 105888. https://doi.org/10.1016/j.jeconbus.2019.105888
- Frost, P. A., & Savarino, J. E. (1986). An empirical bayes approach to efficient portfolio selection. The Journal of Financial and Quantitative Analysis, 21(3), 293–305. https://doi.org/10.2307/2331043
- Garlappi, L., Uppal, R., & Wang, T. (2007). Portfolio selection with parameter and model uncertainty: A multi-prior approach. Review of Financial Studies, 20(1), 41–81. https://doi.org/10.1093/rfs/hhl003
- Georgalos, K., Paya, I., & Peel, D. A. (2021). On the contribution of the Markowitz model of utility to explain risky choice in experimental research. Journal of Economic Behavior & Organization, 182, 527–543. https://doi.org/10.1016/j.jebo.2018.11.010
- Jobson, J. D., & Korkie, R. M. (1981). Putting Markowitz theory to work. The Journal of Portfolio Management, 7(4), 70–74. https://doi.org/10.3905/jpm.1981.408816
- Jorion, P. (1986). Bayes-stein estimation for portfolio analysis. The Journal of Financial and Quantitative Analysis, 21(3), 279–292. https://doi.org/10.2307/2331042
- Kan, R., & Zhou, G. (2007). Optimal portfolio choice with parameter uncertainty. Journal of Financial and Quantitative Analysis, 42(3), 621–656. https://doi.org/10.1017/S0022109000004129
- Klein, R. W., & Bawa, V. S. (1976). The effect of estimation risk on optimal portfolio choice. Journal of Financial Economics, 3(3), 215–231. https://doi.org/10.1016/0304-405X(76)90004-0
- Kritzman, M., Page, S., & Turkington, D. (2010). In defense of optimization: the fallacy of 1/n. Financial Analysts Journal, 66(2), 31–39. https://doi.org/10.2469/faj.v66.n2.6
- Laloux, L., Cizeau, P., Bouchaud, J.-P., & Potters, M. (1999). Noise dressing of financial correlation matrices. Physical Review Letters, 83(7), 1467–1470. https://doi.org/10.1103/PhysRevLett.83.1467
- Ledoit, O., & Wolf, M. (2003). Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. Journal of Empirical Finance, 10(5), 603–621. https://doi.org/10.1016/S0927-5398(03)00007-0
- Ledoit, O., & Wolf, M. (2004a). Honey, i shrunk the sample covariance matrix. The Journal of Portfolio Management, 30(4), 110–119. https://doi.org/10.3905/jpm.2004.110
- Ledoit, O., & Wolf, M. (2004b). A well-conditioned estimator for large-dimensional covariance matrices. Journal of Multivariate Analysis, 88(2), 365–411. https://doi.org/10.1016/S0047-259X(03)00096-4
- Ledoit, O., & Wolf, M. (2020). The power of (non-) linear shrinking: A review and guide to covariance matrix estimation. Journal of Financial Econometrics, https://doi.org/10.1093/jjfinec/nbaa007
- Ledoit, O., & Wolf, M. (2019). Quadratic shrinkage for large covariance matrices. University of Zurich, Departmenf of Economics, Working Paper No. 323, Revised version.
- MacKinlay, A. C., & Pástor, L. (2000). Asset pricing models: Implications for expected returns and portfolio selection. Review of Financial Studies, 13(4), 883–916. https://doi.org/10.1093/rfs/13.4.883
- Marchenko, V. A., & Pastur, L. A. (1967). Distribution of eigenvalues for some sets of random matrices. Matematicheskii Sbornik, 114(4), 507–536.
- Markowitz, H. (1952). Portfolio selection. The Journal of Finance, 7(1), 77–91.
- Markowitz, H. (1959). Portfolio Selection, Efficient Diversification of Investments. J. Wiley.
- Merton, R. C. (1980). On estimating the expected return on the market: An exploratory investigation. Journal of Financial Economics, 8(4), 323–361. https://doi.org/10.1016/0304-405X(80)90007-0
- Michaud, R. O. (1989). The Markowitz optimization enigma: Is optimized optimal? ICFA Continuing Education Series, 1989(4), 43–54. https://doi.org/10.2469/cp.v1989.n4.6
- Ng, C. T., Shi, Y., & Chan, N. H. (2020). Markowitz portfolio and the blur of history. International Journal of Theoretical and Applied Finance, 23(05), 2050030. https://doi.org/10.1142/S0219024920500302
- Ollila, E., & Raninen, E. (2019). Optimal shrinkage covariance matrix estimation under random sampling from elliptical distributions. IEEE Transactions on Signal Processing, 67(10), 2707–2719. https://doi.org/10.1109/TSP.2019.2908144
- Papp, G., Pafka, S., Nowak, M. A., & Kondor, I. (2005). Random matrix filtering in portfolio optimization. Acta Physica Polonica. Series B, 35(9), 2757–2765.
- Schäfer, J., & Strimmer, K. (2005). A shrinkage approach to large-scale covariance matrix estimation and implications for functional genomics. Statistical Applications in Genetics and Molecular Biology, 4(1), 32. https://doi.org/10.2202/1544-6115.1175
- Sortino, F. A., & Van Der Meer, R. (1991). Downside risk. The Journal of Portfolio Management, 17(4), 27–31. https://doi.org/10.3905/jpm.1991.409343
- Tobin, J. (1958). Liquidity preference as behavior towards risk. The Review of Economic Studies, 25(2), 65–86. https://doi.org/10.2307/2296205