
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Qilou (arcade building) is a particular type of Chinese historical architecture combined with western and eastern building elements, which plays a significant role in the history of modern Chinese architecture. However, the recognition and classification of the qilou mainly rely on manual inspection, suppressing the cultural dissemination and protection of qilou relics. In this paper, we present a new framework that adopts multiple image processing algorithms and a deep learning network to automate qilou classification. First, image dataset of the qilou is enhanced based on the Contrast Limited Adaptive Histogram Equalization (CLAHE) algorithm. Then, an improved Faster R-CNN with ResNet50 (Faster R-CNN-R) is deployed for qilou image recognition. A total of 760 images captured in Guangzhou were used for training, validation, and accuracy check of the proposed framework and several contrastive networks under the same conditions. Compared to other networks, the proposed framework works better than Faster R-CNN with VGG16 (Faster R-CNN-V) and FCOS. The accuracy of the proposed framework embedded with the Faster R-CNN-R, Faster R-CNN-V, and FCOS are 80.12%, 65.17%, and 66.35%, respectively. Based on digital images captured under different lighting conditions, the proposed framework can be used to classify nine different types of qilous, with high robustness.
1. Introduction
Qilou, also known as arcade, arcade building, or veranda in some literature, is a common type of historical architecture found in Southeast China, especially in the Guangdong Province (Lin Citation2006). Qilou has a colonial-veranda style combined with the European and South-East Asian styles (Chen and Wang Citation2013; Chen et al. Citation2011). A qilou has more than two floors: the first floor is a commercial unit with sidewalks front, and the residential area is overhang (Zhang Citation2015). Qilou was named differently in Asia until its official nomenclature was released in 1912 (Li Citation2013). It had various historical backgrounds during the 1920s–1930s, but a decline afterwards (Li Citation2018). With more measures brought by the Guangdong provincial government in China since 1998, the qilou was being protected formally for cultural heritage purposes (Li Citation2018).
With state-of-the-art sensing and artificial intelligence technology, parts of the conservation of qilou can be achieved digitally and automatically. For example, the structure of the qilou can be recorded by using digital photogrammetry and laser scanners (Lerma et al. Citation2010; Liang et al. Citation2018). As shown in , the details of the qilou blocks, including façades consisting of pediments, parapets, decorations, and balconies, are captured with cameras. The qilou block’s design patterns and building types can be analyzed by inspecting the photo, which is useful for qilou’s conservations and documentations (Yilmaz et al. Citation2007). However, manual inspection of qilou photos is labour intensive and time consuming (Lin Citation2002, Citation2006). Besides, qilou façade style classification may be misclassified even by experienced experts (Lin Citation2006; Yang, Hu, and Pan Citation2012). As a result, a convenient and robust recognition framework for the qilou façade style is always desired to document and thus conserve qilou.
Figure 1. Typical qilous in Guangzhou, China.

To recognize qilou styles, it could be possible to employ the Computer Vision (CV) algorithm to identify radiometric and geometric features for heritage purposes (Pintus et al. Citation2016). In recent years, Machine Learning (ML) methods and Deep Learning (DL) methods have been used to detect features and structures of buildings (Maskeliūnas et al. Citation2022; Xia et al. Citation2020; Xu et al. Citation2014; Zhao et al. Citation2018). DL was also broadly used for building structure monitoring, such as crack detection, corruptions, and delamination detected by Convolutional Neural Network based (CNN-based) methods (Beckman, Polyzois, and Cha Citation2019; Cha et al. Citation2018; Cha, Choi, and Büyüköztürk Citation2017). For cultural heritage purposes, the CV, ML, and DL methods were used for historical building classification (Fiorucci et al. Citation2020; Llamas et al. Citation2017). The CNN-based methods were proven to be robust in feature recognition and building classification (Llamas et al. Citation2016; Wang et al. Citation2022; Ye Citation2022; Yi, Zhang, and Myung Citation2020). However, these methods focused on recognizing distinctive styles on decorations adhered to building façades, rather than the entire façades. Since the qilou can be broadly classified into more than nine architectural styles, manual classification is not trivial. The CNN-based networks can be adapted to reduce manual intervention for cultural heritage and other related studies.
In recent years, many CNN-based deep learning networks such as Faster Regions with CNN features (Faster R-CNN), You Only Look Once (YOLO), and Single Shot Multibox Detector (SSD) have become more popular for building classification (Liu et al. Citation2016; Redmon et al. Citation2016; Ren et al. Citation2015). These networks focus on different strategies in feature extraction. For example, the Residual Network (ResNet) or Visual Geometry Group (VGG) is used in Faster R-CNN, and Darknet or CSP Darknet is used for YOLO. Faster R-CNN is a two-stage network that uses a more accurate strategy for generating proposals. The two-stage network has lower speed in training and is more complex than the one-stage network (Huang et al. Citation2017). The performance in classification varies with the building styles (Chen et al. Citation2022; Jiang, Noguchi, and Ahamed Citation2022; Yang et al. Citation2022).
In this paper, we propose a framework based on the Faster R-CNN along with the backbone of ResNet50 (Faster R-CNN-R) to classify qilou’s styles accurately using façade images captured by digital cameras. The framework involves a preprocessing stage that improves the capability of the Faster R-CNN and also the accuracy of feature detection and style classification, with recourse to the CLAHE algorithm. The CLAHE reduces the impact caused by different lighting conditions during image capturing, so that the features can be more accurately extracted from the images for training the networks. Compared to the NASNet (Yoshimura et al. Citation2019) and SB-GoogleNet (Obeso et al. Citation2017), which classify images of regular buildings, the proposed framework focused only on qilou image classification with an improved feature extraction and enhancement method. A recent study using Faster R-CNN with the tubularity flow field (TuFF) and the distance transform method (DTM) algorithms for crack detection and segmentation had achieved a high level of accuracy (Kang et al. Citation2020), inspiring our work for the qilou classification. It has a structure that builds more network layers to process the classified results.
Several other networks, the Faster R-CNN with the backbone of VGG16 (Faster R-CNN-V) and the Fully Convolutional One-Stage Object Detector (FCOS) are compared with the proposed framework. The paper has been organized as follows: Section 2 describes the study area and the qilou style for the classification, Section 3 presents the framework’s main components, Section 4 delineates the experiment. Section 5 describes the classification results, and Sections 6 and 7 are the discussion and conclusions, respectively.
2. Study area and qilou styles
2.1. Study area
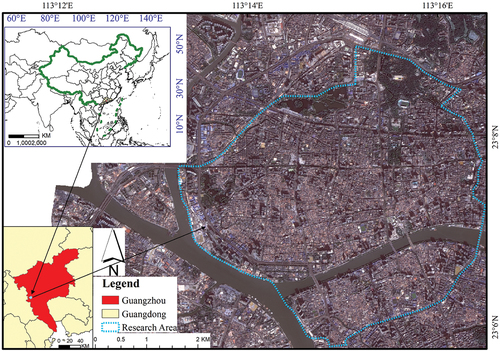
As our chosen area, Guangzhou has the largest number and styles of the qilou in China. According to statistics, thousands of the qilous exist in Guangzhou, with 10–14 architectural styles. Those qilous are mainly gathered within Haizhu, Yuexiu, and Liwan Districts (bounded by blue lines), as shown in .
Figure 2. Research area (bounded by blue lines in the figure), among the Haizhu, Yuexiu, and Liwan Districts in Guangzhou, Guangdong Province, China.
2.2. Styles of the qilou
Among all the qilou styles, the Veranda style combined with the Chinese style of qilou first appeared in the Guangdong Province of China, having diffused and independent architectural styles. According to Lin (Lin Citation2006), there were two main styles of qilou characterized by their façade, including the Early Modern style and Modern style. Then, five medium categories of qilou styles were defined as the Traditional Chinese style, Western style, Chinese-Western style, Chicago School style, and Modern style, comprising the two main styles and nine categories illustrated below. Similar to Lin, Yang (Yang, Hu, and Pan Citation2012) classified the qilous into seven styles: Ancient Greek style, Ancient Roman style, Gothic style, Baroque style, Nanyang style, Traditional Chinese style, and Modern style.
Styles of the qilou can be recognized and classified based on different features in each section described in . Pediments and parapets in the upper section can be for recognition of the Nanyang style. In the middle section, columns can be found in the Classicism style, and windows are exceptionally decorated in the Gothic style. The lower section can be inspected to distinguish the Ancient Roman style. As for the Baroque style, features such as balconies and pediments appear in both the upper and middle sections. Nevertheless, the proposed framework mainly deals with the nine styles of qilou. Those styles are introduced in Sections 2.2.1 to 2.2.5, and their features are summarized in .
Figure 3. Some features for classification of different styles of qilous.
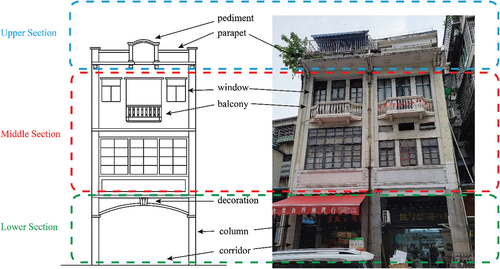
Table 1. Details of different styles of the qilou.
2.2.1. Traditional Chinese style
The Traditional Chinese style can be further classified as the Chinese-palace and Chinese-dwelling styles. The unique feature of the Chinese-palace style is that a Chinese-palace roof is prominent in the qilou’s upper section. As for the Chinese-dwelling style, red or grey bricks on the qilou façades can be identified as one of the features, and their roof is often decorated as an overhanging or flush gable roof (Lin Citation2006).
2.2.2. Western style
The Western styles of qilou can be further categorized as the Gothic, Renaissance, Baroque, and Classic styles, depending on their architectural features. The Gothic style of qilou mostly lies in narrow walls, which are unique features in qilou façades (Smith Citation1890). The Renaissance style emphasizes symmetry, proportion, geometry, and the regularity of the qilou’s components, as demonstrated in the architecture of classical antiquity and ancient Roman architecture (Anderson Citation2013). The Renaissance styles of qilou often have classical orders combined with ancient Roman styles, which show in the structure of the façade.
Besides, the Baroque style is a highly decorative and theatrical style that first appeared in Italy in the early seventeenth century and gradually spread across Europe (Martin Citation2018). Baroque style is usually shown in the structure of pediments, balconies, and columns in qilou (Yang, Hu, and Pan Citation2012). Lastly, the Classicism style of qilou is often accompanied by large columns between the second and third floors, which shows elegance for Classicism (Babinovich and Sitnikova Citation2021).
2.2.3. Chinese-Western style
The Nanyang style is predominantly the Chinese-Western (Li and Ying Citation2021). This type of qilou is usually two or three floors in height. A unique feature of the Nanyang style is that one or multiple (circular) holes are carved on the parapets and pediments to allow wind to pass through, reducing typhoons’ influence (Yang, Hu, and Pan Citation2012). The shape of these holes is not restricted, they can be arbitrary. Circular shape is almost the most popular though.
2.2.4. Chicago school style
Chicago’s architecture has a representative style, namely, the “Chicago School” (Condit Citation1964). When the qilou became popular in the 1930s, the Chicago School style was learned and replicated as the basic type. The structure of Chicago windows may help distinguish them from other styles. Besides, the Chicago School style qilou is mostly the tallest among all other types of qilou. Most of the Chicago School style qilou are hotels, such as the Oi Kwan Hotel and the East Asia Hotel in Guangzhou (Lin Citation2006).
2.2.5. Modern style
The Modern style of qilou is the most commonly found nowadays as most of them are built in a more recent period (e.g., within 30–40 years). These qilou façades are as concise as other modern architecture, with rare decorations and similar structures (Zhao Citation2020). Moreover, the Modern style is the most popular qilou style in Guangzhou.
3. Methods
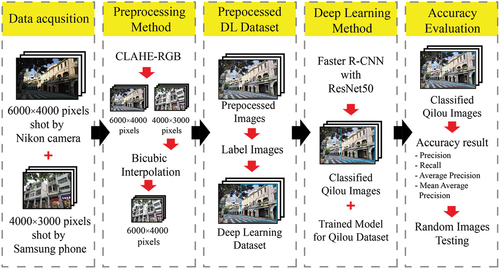
The proposed method improved the qilou classification accuracy by blending CLAHE-RGB and Faster CNN with ResNet50, inspired by the RCNN network previously developed for structural monitoring (Kang et al. Citation2020), to form a new image processing framework, making use of the advantage that the CLAHE-RGB stabilizes the image contrast to improve the robustness of the overall framework. The proposed framework’s classification process can be divided into four parts, as illustrated in . First, digital images of the qilou are captured and stored. Then, a CLAHE-RGB (Contrast Limited Adaptive Histogram Equalization-red-green-blue) method is used to minimize the difference in contrast of digital images, while the Bicubic Interpolation method is used to reduce the differences of pixels in images. Next, the preprocessed images are labelled. After that, a deep learning method based on Faster R-CNN is trained and then used to classify styles of qilou with the processed digital images. Advanced DL semantic segmentation methods such as SDDNet, IDSNet, and STRNet (Ali and Cha Citation2022; Choi and Cha Citation2019; Kang and Cha Citation2022) focused on processing large image size input videos in real time, which provided inspiration for the current study.
Figure 4. Workflow of the proposed framework.
3.1. Preprocessing methods
The CLAHE method (Hitam et al. Citation2013) is mainly used to reduce the contrast between the images as the images are contaminated with shadows to different extents. This method is robust and straightforward for the masked images. To handle RGB images, a CLAHE-based method, named CLAHE-RGB, is implemented in this paper. The main steps are as follows:
Preprocess the input RGB images. First, normalize all images into either portrait or landscape format (e.g., 4000 × 3000 or 6000 × 4000 pixels). Then, split images into multiple small pieces (e.g., 8 × 8 pixels for each piece) under each color channel.
Find the histogram equalization of each piece, and clip the histogram at a user-defined value called ClipLimit. As shown in , the underneath part of the gray value (GV) will be evenly expanded along the count-axis and used to translate the entire histogram upward. The ClipLimit will be recalculated cyclically for each piece using the following equation:
(1)
Figure 5. Transformation of the histogram using the ClipLimit value.
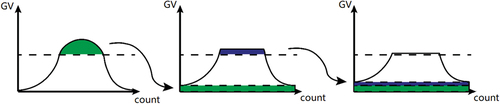
Where S represents the square of each piece. The initial value of ClipLimit is set as 2 based on empirical knowledge and will be recalculated after each clip until it equals 2.
After the histogram balances the gray value of each piece, combine all pieces into a complete image using the Bilinear Interpolation to smooth the gray value between two pieces in each color channel (Castleman Citation1996). The Bilinear Interpolation in CLAHE method can be implemented as follows:
Finally, in order to equalize the pixels of each photo (to 6000 × 4000 pixels), the Bicubic Interpolation method (Keys Citation1981) is used to improve the quality of those images. Similar to Bilinear Interpolation, the color value of the target pixel is calculated by color values of pixels around, but 16 pixels in Bicubic Interpolation. The Bicubic Interpolation proves a better image processing method in upscaling an image, but it requires higher computational power (Han Citation2013).
3.2. Faster R-CNN algorithm
Due to the numerous features and noise in qilou façade images, state-of-art CV methods embedded with DL and ML are used to achieve high accuracy classification. A CNN-based method can be trained to recognize features by leveraging their robustness in handling images with complex information. Furthermore, the effectiveness of CNN-based method in building classification has been well established in the recent decade (Abed, Al-Asfoor, and Hussain Citation2020; Ćosović and Janković Citation2020). We utilize the Faster R-CNN (Ren et al. Citation2015) for qilou façade image classification for this work.
The Faster R-CNN is a two-stage network combined with Region Proposal Network (RPN) and Fast R-CNN (Girshick Citation2015). The flowchart for the adapted network in our framework is shown in . In this research, the Faster R-CNN algorithm can be divided into four parts: feature extraction layers, RPN, ROI pooling layers, and classification layers (Liu, Zhao, and Sun Citation2017).
Figure 6. Layout of the adapted Faster R-CNN in the proposed framework.
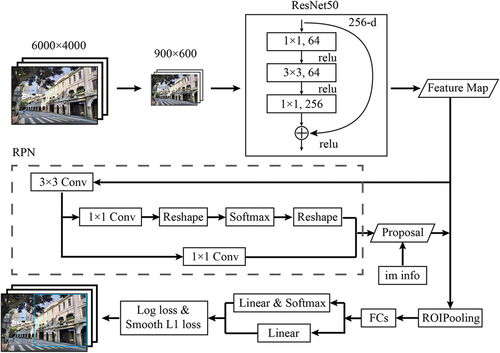
To ensure that most of the qilou’s façade features are detected and classified, the feature extraction layer is indispensable. In this regard, a Residual Network with 50 layers (ResNet50) model is employed to extract features from qilou facade images. ResNet50 is a deep convolutional neural network that incorporates residual connections, as depicted in . This structure enables ResNet to learn from both the input layer and output layer, instead of just from the output layer, resulting in a more comprehensive representation of qilou façade images. For qilou classification, since qilou’s features in each style are complicated, the ResNet50 model is better equipped to extract meaningful information from qilou images. Besides, the ResNet50 model has a better performance compared with VGG16 model in Faster R-CNN’s feature extraction layers (Theckedath and Sedamkar Citation2020; Wen, Li, and Gao Citation2019).
Within the proposed framework, the Faster R-CNN-V is used as follows. Firstly, all the images are resized to 900 × 600, the ResNet50 model is used to extract features in images. Secondly, the feature map’s data flows to RPN for a better proposal. After the data passes the 3 × 3 convolution layer in RPN, it calculates bounding box regression by using a 1 × 1 convolution layer while using softmax (a type of activation function) and reshape features for positive or negative classifications. Results of the RPN and image information (“im info” in , denoting the ratio resolution between the resized image and the original image) decide the proposal layer. The feature maps and proposals are combined for the ROI (region of interest) pooling that will evaluate the features of targets in the images and resize them to the same shape. After the fully connected layers (FCs in ), the classification and regression are performed to calculate the result and label the best suitable area according to the confidence percentage.
4. Experiments
4.1. Data acquisition
About 1000 qilou images were captured in the study area described in Section 2.1 in May 2022, with different shot distances spanning from 10 to 20 m, using a NIKON D5600 camera () with a photograph size of 6000 × 4000 pixels and a Samsung Galaxy S21 Ultra cell phone () of 4000 × 3000 pixels.
Figure 7. Cameras used for the experiment: (a) NIKON D5600; (b) Samsung Galaxy S21 Ultra Camera system.

4.2. Data processing
About 760 images were selected randomly as training and validation datasets from all the collected images. A total of 684 images were used as the training dataset, while 76 images were used for validation. The experiment was conducted on a personal computer with an AMD core Ryzen 9 5950X and an NVIDIA RTX 3070 (8GB), having the CUDA 11.3 and CUDNN 10.8 for the software environment.
For labeling a qilou image, façades of qilou were marked on a web page called “MakeSense” developed by Piotr (Skalski Citation2019). Whole façades of all single qilou in images were labeled as boxes and saved as text or an XML file. Different networks might need a different label format. Transformations among these networks were required in this work.
After labeling the images, a dataset of qilou façades was fully prepared. The Faster R-CNN with VGG16 and FCOS was chosen to compare with Faster R-CNN-R. The FCOS network is a one-stage anchor-free network (Tian et al. Citation2019). The anchor box of FCOS is provided by a point and four distances predicted by FCOS which are between boundaries and the point. The ResNet50 was used in FCOS backbone in this study for comparison. The VGG model is a fully convolutional network with multiple layers (Simonyan and Zisserman Citation2014). Faster R-CNN was first proposed with the backbone of VGG16. Then, the VGG model was replaced by ResNet, a deep residual network, which mostly worked well in different situations (He et al. Citation2016). In this study, we provided the backbone of VGG16 in Faster R-CNN for another experiments.
The implement of the Faster R-CNN and FCOS was based on the famous open-source framework for DL called Pytorch, which is operated as a Python project for users (Paszke et al. Citation2019). The optimizer of the Faster R-CNN was Adam, and the batch size was set as 4. The learning rate of the Faster R-CNN equalled to 10−4, which would go down by using Cosine Annealing Learning Rate. The parameters are set based on empirical knowledge and preliminary testing (depending on the capacity of the computer’s RAM). The same parameters were used in Faster R-CNN-V and FCOS, as well as their framework with CLAHE method.
4.3. Evaluations
In order to measure the performance of training in DL classification tasks, series evaluation metrics, such as Precision, Recall, Average Precision (AP), and mean Average Precision (mAP), are used in this research. The Precision can evaluate the probability among all detected positive predictions (including true positive and false positive), while Recall reflects the probability of true positives among all actual positive instances (including true positive and false negative). Higher Precision and Recall imply that the models occupied in this task perform better, which may lead to an increment in the overall performance. These evaluation metrics (Precision, Recall, AP, and mAP) are, respectively, defined as follows:
where TP (True Positive) is the number of predictions that accurately recognize the ground truths. TN (True Negative) represents predictions that are true but do not belong to this variation. FP (False Positive) is the predictions that are not true but are shown in pictures. FN (False Negative) is denoting that the network cannot identify the ground truth. AP (Average Precision) is an evaluation indicator to the single class prediction, calculated by precision and recall, which can be directly visualized by fitting the Precision–Recall Curve (P-R Curve). P(k) is the precision, and R(k) is the recall. mAP (mean Average Precision) is the valuation of a network, calculated by using average precision.
After the evaluations, a group of test images that do not belong to any of the training data is used to examine the accuracy of each framework. The accuracy in this part of the test is calculated as:
5. Results
5.1. Image preprocessing
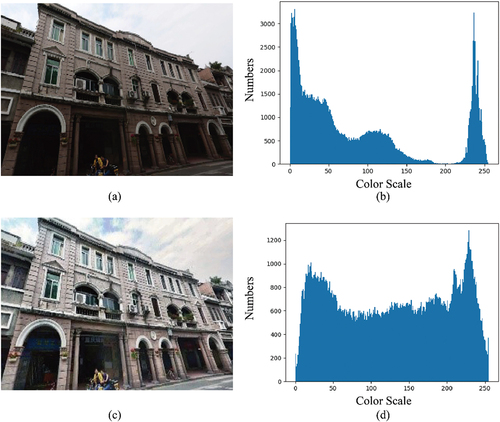
The image contrast improvement for the original images can be realized in after applying the CLAHE-RGB method. show that a very high GV is caused by sunlight and shadow in the histogram, corresponding to the black shadow appearing in the image. After using the CLAHE-RGB method, show that the shadow and sunlight are equalized, and the color transition between pixels becomes more natural for the visualization. The chiaroscuro caused by light radiation is weakened. Differences in the contrast in images captured on cloudy days and sunny days were reduced. Similar results can be found in .
Figure 8. CLAHE-RGB method was applied to Image 1 in the datasets. (a) Original image, (b) histogram of the original image, (c) CLAHE-RGB processed image, (d) histogram of the CLAHE-RGB processed image.
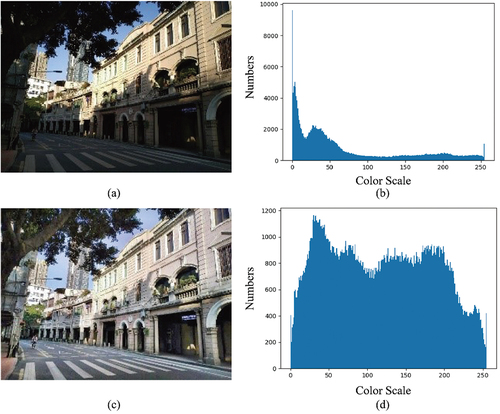
Figure 9. CLAHE-RGB method application to Image 2 in the datasets. (a) Original image, (b) histogram of the original image, (c) CLAHE-RGB processed image, (d) histogram of the CLAHE-RGB processed image.
5.2. Results for the neural networks
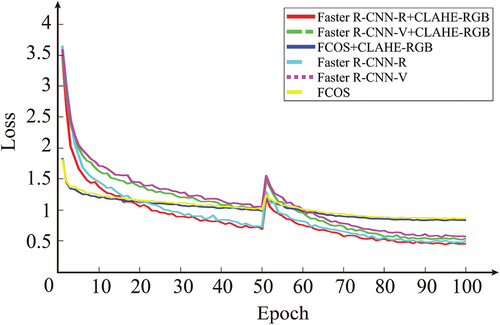
The networks used in this research were trained 100 epochs, respectively; 50 epochs were frozen, and 50 epochs were unfrozen. Training loss of each network is shown in . It can be seen that the “loss curves” of all networks are lower than one after 100 epochs, which represents well training in each network. The reason for the existence of the “loss curve” is that there is a small difference found between the same network with different preprocessing methods used by the common structures. The FCOS network’s losses are different from the Faster R-CNN network. FCOS had a lower loss in the beginning but higher in the end. These results show that the loss is mainly determined by the network, then the backbone, after that preprocessing.
Figure 10. Epochs of different neural networks in this study.
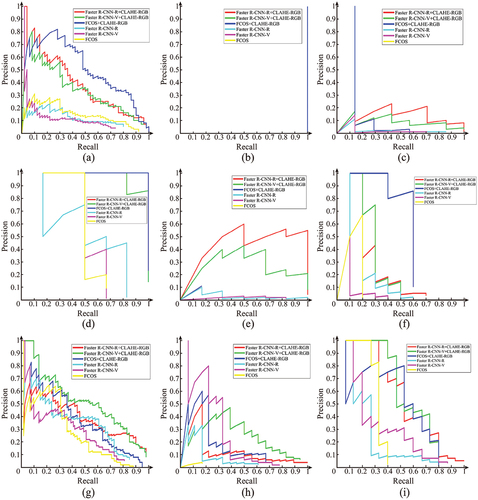
Precisions and recalls can be combined and shown in a graph, namely, the Precision–Recall Curve (P-R Curve). The P-R curve is a vital chart describing the relationship between precisions and recalls, and calculating average precision. Average precision is usually calculated by using the area beneath the P-R curve. The P-R curves of the Faster R-CNN-R, Faster R-CNN-V, and FCOS are compared in . It can be seen that P-R curve lines in the network with CLAHE-RGB method were more than lines in network without preprocessing. Three networks’ P-R curves seem quite the same, but a few various curves are different.
Figure 11. P-R Curves of different neural networks in this study. (a) Faster R-CNN-R with CLAHE-RGB, (b) Faster R-CNN-R, (c) Faster R-CNN-V with CLAHE-RGB, (d) Faster R-CNN-V, (e) FCOS with CLAHE-RGB, (f) FCOS.
Meanwhile, the corresponding AP/mAP for each network is shown in . The table shows that the framework combined with the CLAHE-RGB method and the Faster R-CNN-R has the best performance in classification, as the mAP is the highest. The mAP of Faster R-CNN with CLAHE-RGB seems inferior compared to Faster R-CNN mAP in UA-DETRAC datasets (58.45%). The mAP comparison between Faster R-CNN with ResNet50 and VGG16 shows that the ResNet50 model is advantageous in qilou classification, but performs less accurately without preprocessing. The FCOS network with preprocessing method performs properly in detecting Baroque style, Chicago School style, and Gothic style in training. Some styles have “zero percent” of average precision in networks, which means that such styles of qilou cannot be detected at that time in training. Three networks cannot recognize the Chicago School style in training without preprocessing.
Table 2. AP and mAP of the tested neural networks for model training (best results highlighted in bold font).
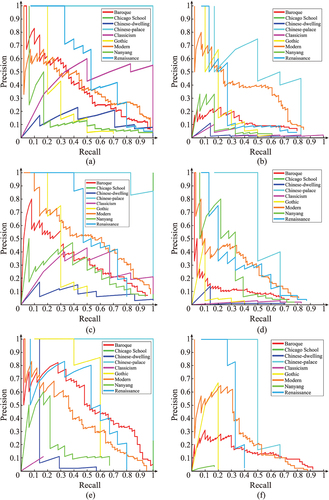
The P-R curves of the qilou style classification for the networks are shown in . As shown in , networks with CLAHE-RGB method are better than those without preprocessing in detecting Baroque style and Chicago School style, for they have the highest precisions. In , Faster R-CNN-R and FCOS perform well in Chinese-palace style with CLAHE-RGB, then Faster R-CNN-V with preprocessing method. It seems suitable for Faster R-CNN with CLAHE-RGB for detecting Classicism style and FCOS with CLAHE-RGB method in Gothic style according to . In , Faster R-CNN-V framework has larger area in Modern style, Nanyang style, and Renaissance style. Both FCOS and Faster R-CNN-R framework have their own merits in recognizing Modern style, Nanyang style, and Renaissance style.
Figure 12. P-R Curves of different styles in this study. (a) Baroque style, (b) Chicago School style, (c) Chinese-dwelling style, (d) Chinese-palace style, (e) Classicism style, (f) Gothic style, (g) Modern style, (h) Nanyang style, (i) Renaissance style.
5.3. Results of the overall framework
One hundred images from all the collected images were selected randomly to verify the factual accuracy of style classifications. As can be seen in , the Faster R-CNN-R can detect qilou more than Faster R-CNN-V and FCOS with CLAHE-RGB method. The ResNet50 model has fewer misidentifications or misses than VGG16, which is a crucial factor in calculating accuracy. This is likely due to the fact that the sum of the false negatives and positives is much less than that of the Faster R-CNN-V. As for FCOS, with the same backbone as ResNet50, detection and classification of qilou façades performed mediocrely. The number of correctly recognized qilou in FCOS is less than Faster R-CNN, indicating that the classification of qilou façade is challenging for the one-stage networks due to the complicated qilou’s geometric features, but less misguidance was found in the results.
Table 3. Accuracy of the tested neural networks for the qilou classification (bold font represents our method’s results).
show the detections and classifications of qilou façades using different methods. In , these four qilous are Modern style, Chinese-dwelling style, and another two Modern styles (from left to right in ). As in , all of them are Modern styles. It can be seen in that the styles of qilou can be recognized correctly, but two missed detections in 13(b) and a misidentification in 14(b). Though Faster R-CNN-V with CLAHE-RGB method can recognize correctly in , false positives often occur in some types of qilou with similar façades, such as Modern style, Chinese-dwelling style, and Baroque style. Faster R-CNN-V detection in shows that four false positives are detected and one qilou is missed. In , the false positives in FCOS with CLAHE-RGB are less than Faster R-CNN-V with CLAHE-RGB, but false negatives are more than those. The FCOS algorithm can recognize Chinese-dwelling style and Modern style in , but none of qilou is detected in . It is worth noting that the high detection and innovations are mainly related to the structure of the two-stage network. The two-stage network is more suitable than the one-stage network, whatever the model of the feature map used. The one-stage network also has the process of feature extraction, but confusion may occur when training with many heterogeneous qilou images. Another reason for the better performance is that the structure of the two-stage network can extract features more effectively as it is associated with the CLAHE-RGB method that increased the entropy of the images.
Figure 13. Images of qilou classification by using different neural networks. (a) Faster R-CNN-R with CLAHE-RGB, (b) Faster R-CNN-R, (c) Faster R-CNN-V with CLAHE-RGB, (d) Faster R-CNN-V, (e) FCOS with CLAHE-RGB, (f) FCOS.

Figure 14. Images of qilou classification by using different neural networks. (a) Faster R-CNN-R with CLAHE-RGB, (b) Faster R-CNN-R, (c) Faster R-CNN-V with CLAHE-RGB, (d) Faster R-CNN-V, (e) FCOS with CLAHE-RGB, (f) FCOS.

6. Discussion
In this study, Faster R-CNN-R, Faster R-CNN-V, and FCOS were applied for qilou style classifications, and a preprocessing CLAHE-RGB method for enlighting the features of qilou was provided. The results demonstrated that networks did approve the accuracy with the CLAHE method, for the pediments, parapets, columns, and decorations were more specific than before. Faster R-CNN-R showed superior performance in qilou classification due to its deeper architecture and advantages in recognizing more complex features by using ResNet50. The two-stage mechanism of Faster R-CNN allowed it to create proposals of potential features on qilou façades, and then the second stage of network classified the matched features. Compared to the result of another Faster R-CNN applications, the accuracy of our results proved to be useful for qilou classification. It was also shown that Faster R-CNN algorithm could handle diverse features on single qilou façade, and higher accuracy than others (Xia et al. Citation2020; Yi, Zhang, and Myung Citation2020). The role of ResNet50 is for qilou feature extraction. ResNet50 is a model with unique residual blocks, which is more generalized compared to VGG model.
However, qilou classification was more complicated than we thought. Some qilou façades were partly covered with pipelines, electric lines, or hidden behind woods, as . Some façades of qilou in commercial streets were blocked by enormous advertising boards, as shown in . If the height of the façade was higher than the bridge in certain streets, features were not able to be recorded on the front, a weird angle of photo was shot, as shown in ; thus, the accuracy could not be guaranteed.
Figure 15. Examples of complicated scene in qilou classification tasks. (a) features are hidden behind woods and electric lines, (b) façades are inundated with advertisements, (c) the bridge is in close proximity to the façades, (d) a shot for recording qilou upper sections.

7. Conclusion
In this paper, we proposed a qilou image classification framework based on the Faster RCNN-R for which its input is first processed by the CLAHE-RGB algorithm that reduces the discrepancy of contrast for the images. The qilou styles were mainly classified into nine categories in Guangzhou, China. The detection results for the nine main styles of qilou from the digital images using the proposed framework integrated the CLAHE-RGB. For training and evaluation, the Faster R-CNN-R with CLAHE-RGB framework had less training loss and better mAP than other frameworks or networks. With the CLAHE-RGB image processing method, the mAP of Faster R-CNN-R, Faster R-CNN-V, and FCOS were 51.66%, 51.15%, and 47.30%, respectively. The mAP of Faster R-CNN-R, Faster R-CNN-V, and FCOS trained by original images was 18.46%, 21.51%, and 20.69%, respectively.
The test also investigated the effectiveness of the CLAHE-RGB preprocessing method and ResNet50 feature extraction model for qilou façade image detection using Faster R-CNN-R, Faster R-CNN-V, and FCOS. The results demonstrated a significant improvement in detection accuracy when employing the CLAHE-RGB method, with Faster R-CNN-R, Faster R-CNN-V, and FCOS achieving accuracies of 80.12%, 65.17%, and 66.35%, respectively. In contrast, without the application of CLAHE-RGB, the accuracies were notably lower at 62.24%, 53.65%, and 50.63%, respectively. These findings highlight the importance of the CLAHE-RGB preprocessing technique in enhancing the performance of the detection algorithms. The use of a deep residual network (e.g. ResNet50) as the backbone proved to be more effective than a deep convolutional network (e.g. VGG) in this research context. Furthermore, the study establishes the superiority of the Faster R-CNN-R algorithm in the proposed framework, emphasizing the benefits of a two-stage network over a one-stage network (e.g. FCOS) for qilou façade style classification. As a direction for future research, the exploration of qilou façade style classification using images or videos captured by Unmanned Aerial Vehicles (UAV) has the potential to attract widespread interest and further advance the field, as the UAV has been widely used for structural inspections (Ali et al. Citation2021; Kang and Cha Citation2018; Waqas, Kang, and Cha Citation2023).
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Notes on contributors
Ming Ho Li
Ming Ho Li, who just finished his master degree in Sun Yat-sen University, specializing in the structural of modern cultural architectures.
Yi Yu
Yi Yu, an Associate Professor in East China Normal University, who experts in emotional labor, care ethics, and biopolitics.
Hongni Wei
Hongni Wei, a Lecturer in Guangdong University of Foreign Studies, who specializes in culture and geography.
Ting On Chan
Ting On Chan, is an Associate Professor in Sun Yat-sen University. His research area is on the field of LiDAR and photogrammetry applications.
References
- Abed, M. H., M. Al-Asfoor, and Z. M. Hussain. 2020. “Architectural Heritage Images Classification Using Deep Learning with CNN.”
- Ali, R., and Y. Cha. 2022. “Attention-Based Generative Adversarial Network with Internal Damage Segmentation Using Thermography.” Automation in Construction 141:104412. https://doi.org/10.1016/j.autcon.2022.104412.
- Ali, R., D. Kang, G. Suh, and Y. Cha. 2021. “Real-Time Multiple Damage Mapping Using Autonomous UAV and Deep Faster Region-Based Neural Networks for GPS-Denied Structures.” Automation in Construction 130:103831. https://doi.org/10.1016/j.autcon.2021.103831.
- Anderson, C. 2013. Renaissance Architecture. England: OUP Oxford.
- Babinovich, N. U., and E. V. Sitnikova. 2021. “Features of Wooden Buildings in Tomsk.“ Journal of Physics: Conference Series 1926 (2021): 12042.
- Beckman, G. H., D. Polyzois, and Y. Cha. 2019. “Deep Learning-Based Automatic Volumetric Damage Quantification Using Depth Camera.” Automation in Construction 99:114–124. https://doi.org/10.1016/j.autcon.2018.12.006.
- Castleman, K. R. 1996. Digital Image Processing. New York: Prentice Hall Press.
- Cha, Y. J., W. Choi, and O. Büyüköztürk. 2017. “Deep Learning‐Based Crack Damage Detection Using Convolutional Neural Networks.” Computer‐Aided Civil and Infrastructure Engineering 32 (5): 361–378. https://doi.org/10.1111/mice.12263.
- Cha, Y. J., W. Choi, G. Suh, S. Mahmoudkhani, and O. Büyüköztürk. 2018. “Autonomous Structural Visual Inspection Using Region‐Based Deep Learning for Detecting Multiple Damage Types.” Computer‐Aided Civil and Infrastructure Engineering 33 (9): 731–747. https://doi.org/10.1111/mice.12334.
- Chen, J., J. P. Liu, L. J. Wang, Y. Y. Wang, and F. Wang. 2011. “Qilou Building Climate Adaptation in Tropical Climate Zone of China: A Study on Haikou Qilou Buildings.” Advanced Materials Research 243-249:6503–6513. https://doi.org/10.4028/www.scientific.net/AMR.243-249.6503.
- Chen, J., and F. Wang. 2013. “Haikou QiLou Historical and Artistic Value, Applied Mechanics and Materials.” Applied Mechanics & Materials 409-410:404–409. https://doi.org/10.4028/www.scientific.net/AMM.409-410.404.
- Chen, M., L. Yu, C. Zhi, R. Sun, S. Zhu, Z. Gao, Z. Ke, M. Zhu, and Y. Zhang. 2022. “Improved Faster R-CNN for Fabric Defect Detection Based on Gabor Filter with Genetic Algorithm Optimization.” Computers in Industry 134:103551. https://doi.org/10.1016/j.compind.2021.103551.
- Choi, W., and Y. Cha. 2019. “SDDNet: Real-Time Crack Segmentation.” IEEE Transactions on Industrial Electronics 67 (9): 8016–8025. https://doi.org/10.1109/TIE.2019.2945265.
- Condit, C. W. 1964. The Chicago School of Architecture: A History of Commercial and Public Building in the Chicago Area, 1875–1925. Chicago, IL, USA: University of Chicago Press.
- Ćosović, M., and R. Janković 2020. “CNN Classification of the Cultural Heritage Images.” 2020 19th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 1–6. IEEE.
- Fiorucci, M., M. Khoroshiltseva, M. Pontil, A. Traviglia, A. Del Bue, and S. James. 2020. “Machine Learning for Cultural Heritage: A Survey.” Pattern Recognition Letters 133:102–108. https://doi.org/10.1016/j.patrec.2020.02.017.
- Girshick, R. 2015. “Fast r-cnn.” Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 1440–1448.
- Han, D. 2013. “Comparison of Commonly Used Image Interpolation Methods.” Conference of the 2nd International Conference on Computer Science and Electronics Engineering (ICCSEE 2013), Hangzhou, P.R. China, 1556–1559. Atlantis Press.
- He, K., X. Zhang, S. Ren, and J. Sun 2016. “Deep Residual Learning for Image Recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, USA, 770–778.
- Hitam, M. S., E. A. Awalludin, W. N. J. H. Yussof, and Z. Bachok 2013. “Mixture Contrast Limited Adaptive Histogram Equalization for Underwater Image Enhancement.” 2013 International conference on computer applications technology (ICCAT), Sousse, Tunisia, 1–5. IEEE.
- Huang, J., V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, and S. Guadarrama 2017. “Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors.” Proceedings of the IEEE conference on computer vision and pattern recognition, Hawaii, USA, 7310–7311.
- Jiang, A., R. Noguchi, and T. Ahamed. 2022. “Tree Trunk Recognition in Orchard Autonomous Operations Under Different Light Conditions Using a Thermal Camera and Faster R-CNN.” Sensors-Basel 22:2065. https://doi.org/10.3390/s22052065.
- Kang, D., S. S. Benipal, D. L. Gopal, and Y. Cha. 2020. “Hybrid Pixel-Level Concrete Crack Segmentation and Quantification Across Complex Backgrounds Using Deep Learning.” Automation in Construction 118:103291. https://doi.org/10.1016/j.autcon.2020.103291.
- Kang, D. H., and Y. Cha. 2022. “Efficient Attention-Based Deep Encoder and Decoder for Automatic Crack Segmentation.” Structural Health Monitoring 21 (5): 2190–2205. https://doi.org/10.1177/14759217211053776.
- Kang, D., and Y. J. Cha. 2018. “Autonomous UAVs for Structural Health Monitoring Using Deep Learning and an Ultrasonic Beacon System with Geo‐Tagging.” Computer‐Aided Civil and Infrastructure Engineering 33 (10): 885–902. https://doi.org/10.1111/mice.12375.
- Keys, R. 1981. “Cubic Convolution Interpolation for Digital Image Processing.” IEEE Transactions on Acoustics, Speech, and Signal Processing 29 (6): 1153–1160. https://doi.org/10.1109/TASSP.1981.1163711.
- Lerma, J. L., S. Navarro, M. Cabrelles, and V. Villaverde. 2010. “Terrestrial Laser Scanning and Close Range Photogrammetry for 3D Archaeological Documentation: The Upper Palaeolithic Cave of Parpalló as a Case Study.” Journal of Archaeological Science 37 (3): 499–507. https://doi.org/10.1016/j.jas.2009.10.011.
- Li, Q. 2018. “Preserving Historic Qilou Districts in Southern China: Consideration of Western Models.“ Historic Preservation Theses. https://docs.rwu.edu/hp_theses/15.
- Li, Y. 2013. A Typo-Morphological Enquiry into the Evolution of Residential Architecture and Urban Tissues of the Guangfunan Area of Guangzhou, China. Concordia University. https://spectrum.library.concordia.ca/977412/1/Li_MSc_F2013.pdf.
- Liang, H., W. Li, S. Lai, L. Zhu, W. Jiang, and Q. Zhang. 2018. “The Integration of Terrestrial Laser Scanning and Terrestrial and Unmanned Aerial Vehicle Digital Photogrammetry for the Documentation of Chinese Classical Gardens–A Case Study of Huanxiu Shanzhuang, Suzhou, China.” Journal of Cultural Heritage 33:222–230. https://doi.org/10.1016/j.culher.2018.03.004.
- Lin, C. 2002. “Research on the Development and Form of Qilou-Style Street Houses.” South China University of Technology.
- Lin, L. 2006. Hong Kong, Macau and Pearl River Delta Regional Architecture: Guangdong Qilou. Beijing, China: Science Press.
- Liu, W., D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Fu, and A. C. Berg 2016. “Ssd: Single Shot Multibox Detector.” Computer Vision–ECCV 2016: 14th European Conference, 21–37. Amsterdam, The Netherlands, Springer. October 11–14, 2016, Proceedings, Part I 14.
- Liu, B., W. Zhao, and Q. Sun. 2017. “Study of Object Detection Based on Faster R-CNN.“ 2017 Chinese Automation Congress (CAC), Shandong, China. 6233–6236.
- Li, S., and H. Ying. 2021. “Study on the Traditional Architectural Forms of Huangcuo Village in Fujian Province from the Perspective of Regional Culture.“ 3rd International Conference on Architecture: Heritage, Traditions and Innovations (AHTI 2021), Moscow, Russia. Vol. 600. 99–110. Atlantis Press.
- Llamas, J. M., P. Lerones, R. Medina, E. Zalama, and J. Gómez-García-Bermejo. 2017. “Classification of Architectural Heritage Images Using Deep Learning Techniques.” Applied Sciences 7:992. https://doi.org/10.3390/app7100992.
- Llamas, J., P. M. Lerones, E. Zalama, and J. Gómez-García-Bermejo 2016. “Applying Deep Learning Techniques to Cultural Heritage Images within the INCEPTION Project, Digital Heritage.” Progress in Cultural Heritage: Documentation, Preservation, and Protection: 6th International Conference, EuroMed 2016, 25–32. Nicosia, Cyprus, Springer. October 31–November 5, 2016, Proceedings, Part II 6.
- Martin, J. R. 2018. Baroque. Routledge.
- Maskeliūnas, R., A. Katkevičius, D. Plonis, T. Sledevič, A. Meškėnas, and R. Damaševičius. 2022. “Building Façade Style Classification from UAV Imagery Using a Pareto-Optimized Deep Learning Network.” Electronics 11 (21): 3450. https://doi.org/10.3390/electronics11213450.
- Obeso, A. M., M. S. G. Vázquez, A. A. R. Acosta, and J. Benois-Pineau 2017. “Connoisseur: Classification of Styles of Mexican Architectural Heritage with Deep Learning and Visual Attention Prediction.” Proceedings of the 15th international workshop on content-based multimedia indexing, Florence, Italy, 1–7.
- Paszke, A., S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, and L. Antiga. 2019. “Pytorch: An Imperative Style, High-Performance Deep Learning Library.” Advances in Neural Information Processing Systems, Vancouver. 32.
- Pintus, R., K. Pal, Y. Yang, T. Weyrich, E. Gobbetti, and H. Rushmeier. 2016. A Survey of Geometric Analysis in Cultural Heritage, 4–31. England: Computer Graphics Forum, Wiley Online Library.
- Redmon, J., S. Divvala, R. Girshick, and A. Farhadi 2016. “You Only Look Once: Unified, Real-Time Object Detection.” Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, USA, 779–788.
- Ren, S., K. He, R. Girshick, and J. Sun. 2015. “Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks.” Advances in Neural Information Processing Systems, Montreal, Canada 28.
- Simonyan, K., and A. Zisserman. 2014. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” Arxiv Preprint Arxiv:1409.1556.
- Skalski, P. 2019. “Make Sense.”
- Smith, T. R. 1890. “Architecture, Gothic and Renaissance, Low.”
- Theckedath, D., and R. R. Sedamkar. 2020. “Detecting Affect States Using VGG16, ResNet50 and SE-ResNet50 Networks.” SN Computer Science 1 (2). https://doi.org/10.1007/s42979-020-0114-9.
- Tian, Z., C. Shen, H. Chen, and T. He 2019. “Fcos: Fully Convolutional One-Stage Object Detection.” Proceedings of the IEEE/CVF international conference on computer vision, California, USA, 9627–9636.
- Wang, B., S. Zhang, J. Zhang, and Z. Cai. 2022. “Architectural Style Classification Based on CNN and Channel–Spatial Attention.” Signal, Image and Video Processing 17 (1): 1–9. https://doi.org/10.1007/s11760-022-02208-0.
- Waqas, A., D. Kang, and Y. Cha. 2023. “Deep Learning–Based Obstacle-Avoiding Autonomous UAVs with Fiducial Marker–Based Localization for Structural Health Monitoring.” Structural Health Monitoring. https://doi.org/10.1177/14759217231177314.
- Wen, L., X. Li, and L. Gao. 2019. “A Transfer Convolutional Neural Network for Fault Diagnosis Based on ResNet-50.” Neural Computing & Applications 32 (10): 6111–6124. https://doi.org/10.1007/s00521-019-04097-w.
- Xia, B., X. Li, H. Shi, S. Chen, and J. Chen. 2020. “Style Classification and Prediction of Residential Buildings Based on Machine Learning.” Journal of Asian Architecture & Building Engineering 19 (6): 714–730. https://doi.org/10.1080/13467581.2020.1779728.
- Xu, Z., D. Tao, Y. Zhang, J. Wu, and A. C. Tsoi 2014. Architectural Style Classification Using Multinomial Latent Logistic Regression, Computer Vision–ECCV 2014: 13th European Conference, 600–615. Zurich, Switzerland, Springer. September 6-12, 2014, Proceedings, Part I 13.
- Yang, H., W. Hu, and G. Pan. 2012. Sai Kuan Mansion and Qilou. Guangzhou, China: Jinan University Press.
- Yang, Y., Y. Jiang, Q. Zhang, F. Zou, and L. Du. 2022. “A Mixed Faster R-CNN and Positioning Coordinates Method for Recognition of Suit Button Arrangement with Small Sample Sizes.” International Journal of Clothing Science and Technology 34 (4): 532–548. https://doi.org/10.1108/IJCST-10-2020-0165.
- Ye, Y. 2022. Arcade Detection and Mapping Based on a Deep Learning Model Constructed Using Street View Images and Object Semantic Relations. National Taiwan University. https://doi.org/10.6342/NTU202202527.
- Yilmaz, H. M., M. Yakar, S. A. Gulec, and O. N. Dulgerler. 2007. “Importance of Digital Close-Range Photogrammetry in Documentation of Cultural Heritage.” Journal of Cultural Heritage 8 (4): 428–433. https://doi.org/10.1016/j.culher.2007.07.004.
- Yi, Y. K., Y. Zhang, and J. Myung. 2020. “House Style Recognition Using Deep Convolutional Neural Network.” Automation in Construction 118:103307. https://doi.org/10.1016/j.autcon.2020.103307.
- Yoshimura, Y., B. Cai, Z. Wang, and C. Ratti. 2019. “Deep Learning Architect: Classification for Architectural Design Through the Eye of Artificial Intelligence.” International Conference on Computers in Urban Planning and Urban Management, Wuhan, China. Vol. 16. 249–265.
- Zhang, J. 2015. “Rise and Fall of the“Qilou”: Metamorphosis of Forms and Meanings in the Built Environment of Guangzhou.” Traditional Dwellings and Settlements Review 26(2): 25–40.
- Zhao, J. 2020. “Influencing Factors of Urban Architectural Style in China: A Case Study of Danzhou City.” IOP Conference Series: Earth and Environmental Science China, 62003. IOP Publishing. https://iopscience.iop.org/article/10.1088/1755-1315/510/6/062003/pdf.
- Zhao, P., Q. Miao, J. Song, Y. Qi, R. Liu, and D. Ge. 2018. “Architectural Style Classification Based on Feature Extraction Module.” IEEE Access 6:52598–52606. https://doi.org/10.1109/ACCESS.2018.2869976.