
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This note proposes time series models for data where the frequency changes over time. As an example, for many countries, in the past, real GDP growth was observed annually and since a few years or decades, the data are available per quarter. Modifying the time series models allows for the incorporation of these older annual data, without a need for imputation. Illustrations for real GDP growth in China and the Netherlands show the merits of the method.
I. Introduction
For many countries, national statistics institutes collect reliable quarterly data for real Gross Domestic Product (GDP) growth, whereas before they used to collect those data only at the annual level. For example, quarterly real GDP growth in China is made available since 1992Q1 by the National Bureau of Statistics of China (NBSC) (www.stats.gov.cn), while annual real GDP growth rates are available from the World Bank since 1961. Statistics Netherlands makes available their real GDP growth rates per quarter through https://opendata.cbs.nl/statline/, where at the time of writing this paper, the available data start in 1995Q1, whereas the World Bank published annual real GDP growth rates again since 1961.
presents the quarterly and annual data for China, starting in 1961 and ending in 2009Q4, see Franses and Mees (Citation2013) for an analysis. It is the purpose of this note to propose a model for the annual and quarterly data at the same time,Footnote1 that is, to account for the gaps in the quarterly data before 1992Q1. The nominal GDP data in current prices data in China are reported in a format that differs from many other countries but is convenient for the present purposes. That is, NBSC presents the data in cumulated format. Writing GDP in quarter Q in year T as , then the nominal GDP data look like
Figure 1. Quarterly and annual real DGP growth for China, starting in 1961 and ending in 2009Q4
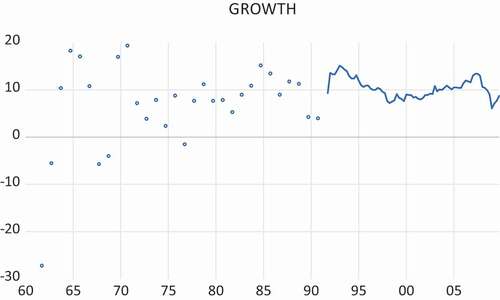
where ‘r’ means the first revision, ‘rr’ the second revision and ‘rrr’ the third revision. The way the data are compiled in the fourth quarter matches with annual GDP. As a consequence, writing as total annual GDP, it is clear that
In other words, the annual data in the years before 1992 for China match with the annual growth rates per quarter, but then only observed in the fourth quarter. In turn, this means that the annual data before 1992 can be treated as quarterly rates with gaps for the quarters Q1, Q2 and Q3, see again .
In Section 2 this paper continues with analysing a first-order autoregression for the quarterly GDP growth dates in China. Section 3 focuses on a second-order autoregression for the quarterly data for the Netherlands, which first have to be turned in the cumulated format like in China. Section 4 concludes with various further research topics.
II. Real GDP growth in China: autoregression of order 1
This section will focus on a first-order autoregression and its formulation in case of gaps in the data. The intention is not to impute newly created data in these gaps, but merely to adjust the expression of the model to accommodate the gaps.
Assume there are quarterly real GDP growth figures, based on quarterly cumulative levels data , and continue with
It is convenient to write a first autoregression as
where is the mean of the variable and where
is a zero mean white noise process with variance
. When this model is fitted to the Chinese data for 1992Q1 to 2009Q4, there are no signs of significant residual autocorrelation, so this autoregression seems to fit the Chinese data well.
Backward substitution of the model in (1) towards results in
This shows that skip-sampling the data with frequency 4 does not introduce additional autocorrelation, that is, is uncorrelated with
. The variance of the error term in the part of the sample that involves the annual data is however larger than
as it is
. One may now want to make use of this explicit expression, but one can also resort to the (Newey and West) HAC estimator for the standard errors of the parameters.
Defining a variable which takes a value of 4 until 1992Q1 and of 1 afterwards, the expressions in (1) and (2) can be combined into
where is a zero mean white noise process with time-varying variance.
Fitting model (3) using the Generalized Method of Moments (GMM) (performed in EViews version 11), the estimation results for the sample 1962Q4 to 2009Q4 (102 effective observations) are
where HAC corrected standard errors are given in parentheses. The Ordinary Least Squares (OLS) based estimate of the standard error would have been 0.035, so indeed the HAC correction takes care of the larger variance in the first part of the sample as the HAC standard error exceeds the OLS standard error.
When model (1) is fitted to the effective sample 1992Q2 to 2009Q4, the following estimation results are obtained:
where now the OLS-based standard errors are reported in parentheses. Comparing the two sets of estimates, it can be seen that the mean growth rate is about the same across the two samples, but the estimates for the first autoregressive parameter differ substantially. In fact, a Dicky Fuller test statistic for the shorter sample is (0.918–1)/0.044 = −1.864, which suggests the presence of a unit root, while the same statistic for the full sample is (0.765–1)/0.045 = −5.222, which suggests a clear rejection of the unit root null hypothesis.Footnote2
Hence, one can now conclude that the longer sample introduces more power to a unit root test. However, looking again at the data in , it may be that the observation in 1961Q4 is influential as it is large and negative. Re-estimating model (3) for the sample 1963Q4 to 2009Q4 (now with 101 effective observations) gives
and clearly the HAC-based estimate of the standard error for almost doubles. The Dicky-Fuller unit root test value now becomes (0.733–1)/0.093 = −2.871, which is close to the 5% critical value. Hence, one still would conclude here that, based on the full sample, the unit root null hypothesis gets rejected.
III. Real GDP growth in the Netherlands: autoregression of order 2
In this section the focus is on real GDP data for the Netherlands. A graph of the (non-cumulated) real GDP data for 1995Q1 to 2019Q4 is presented in . The cumulated levels of real GDP data appear in . presents the annual growth rates when observed quarterly, based on not cumulated and cumulated data. It is clear that the two series do not differ much. Finally, adds the annual data observed in the fourth quarter, starting from 1961 onwards.
Figure 2. Real Gross Domestic Product 1995Q1-2019Q4 for the Netherlands (in billions of Euros)
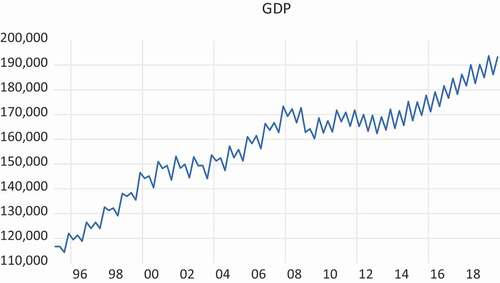
Figure 3. Real Gross Domestic Product 1995Q1-2019Q4 for the Netherlands (in billions of Euros), when cumulated as Q1, Q1+ Q2, Q1+ Q2+ Q3 and Q1+ Q2+ Q3+ Q4
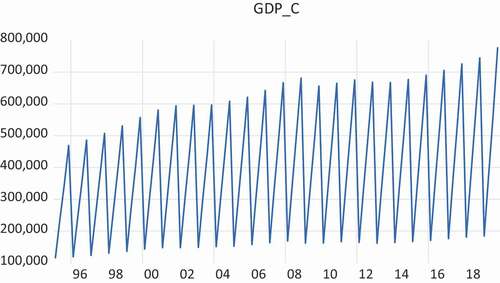
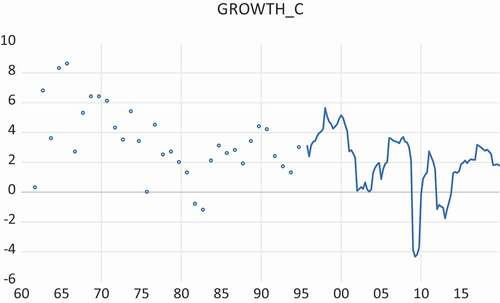
Figure 4. Annual growth rates of Real GDP, 1996Q1-2019Q4, for the Netherlands, based on quarterly GDP figures (GROWTH) and based on cumulative quarterly GDP figures (GROWTH_C), computed as
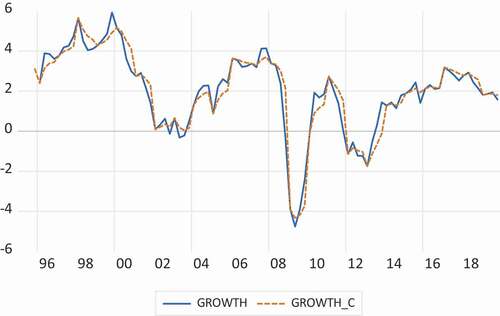
Figure 5. Annual growth rates of real GDP for 1961Q4-2019Q4 for the Netherlands
An analysis of the autocorrelation function of real GDP growth for the last part of the sample involving the actual quarterly data indicates that an autoregression of order 2 describes the data well. To allow for simple backward substitution, as is done in (2), it is convenient to write the second-order autoregression as
Re-arranging terms gives
and this allows to compute the residuals. Again, the parameters can be estimated using GMM. Backward substitution gives
where is a zero mean white noise process with time-varying variance. More generally, if
is variable that takes a value 4 until 1996.1 and 1 afterwards, then the general form of this second-order autoregression is
where still is a zero mean white noise process with time-varying variance.
The estimation results for the sample for the Netherlands that starts in 1963.4 (and has 128 effective observations) are
with the HAC corrected standard errors in parentheses. Clearly, all parameters differ from zero, significantly. The Dicky Fuller test value is (0.854–1)/0.059 = −2.475, which is close to the 10% critical value.
The estimation results for the effective sample 1996Q3 to 2019Q4 (94 observations) are
where again, now the OLS-based estimated standard errors are in parentheses. The Dicky Fuller test value is (0.797–1)/0.099 = −2.051, which is much further away from the 10% critical value. Hence, also here, one can see that including past annual data provides more evidence against the null hypothesis of a unit root.
IV. Conclusion
This paper has proposed a simple method to include past annual data into models for currently available quarterly data. Application to real GDP growth per quarter for China and the Netherlands showed that the method is easy to apply. As there are longer spans of data to analyse, it was also found that there was more evidence against the unit root null hypothesis.
The method can easily be applied to any type of time series and for any frequency. So, if data are available now at the monthly level and before at the quarterly level, the same tools can be used. Note that it is important to write the model such that there is a multiplication of first-order autoregressive terms in order to make the representation easy to handle.
A next step can be to consider vector autoregressive models and autoregressive distributed lag models for data with similar features.
Disclosure statement
No potential conflict of interest was reported by the author.
Notes
1 In a sense, my approach mimics a MIDAS model, where two or more variables observed at different frequencies are correlated, see Breitung and Roling (Citation2015), Clements and Galvão (Citation2008), and Ghysels, Santa-Clara, and Valkanov (Citation2004) for useful references. In the present paper, however, the focus is on mixed frequencies over time, and not across variables.
2 For the case of an intercept and no trend, the 5% critical value of the Dicky-Fuller test for 100 observations is −2.89, and the 10% critical value is −2.58.
References
- Breitung, J., and C. Roling. 2015. “Forecasting Inflation Rates Using Daily Data: A Nonparametric MIDAS Approach.” Journal of Forecasting 34 (7): 588–603. doi:https://doi.org/10.1002/for.2361.
- Clements, M. P., and A. B. Galvão. 2008. “Macroeconomic Forecasting with Mixed-frequency Data: Forecasting Output Growth in the United States.” Journal of Business & Economic Statistics 26 (4): 546–554. doi:https://doi.org/10.1198/073500108000000015.
- Franses, P. H., and H. Mees. 2013. “Approximating the DGP of China’s Quarterly GDP.” Applied Economics 45 (24): 3469–3472. doi:https://doi.org/10.1080/00036846.2012.709604.
- Ghysels, E., P. Santa-Clara, and R. Valkanov. 2004. “The MIDAS touch: mixed data sampling regression models.” CIRANO Working paper.
