
ABSTRACT
It has been shown that pure Pavlovian associative reward learning can elicit value-driven attentional capture. However, in previous studies, task-irrelevant and response-independent reward-signalling stimuli hardly competed for visual selective attention. Here we put Pavlovian reward learning to the test by manipulating the extent to which bottom-up (Experiment 1) and top-down (Experiment 2) processes were involved in this type of learning. In Experiment 1, the stimulus, the colour of which signalled the magnitude of the reward given, was presented simultaneously with another randomly coloured stimulus, so that it did not capture attention in a stimulus-driven manner. In Experiment 2, observers performed an attentionally demanding RSVP-task at the centre of the screen to largely tax goal-driven attentional resources, while a task-irrelevant and response-independent stimulus in the periphery signalled the magnitude of the reward given. Both experiments showed value-driven attentional capture in a non-reward test phase, indicating that the reward-signalling stimuli were imbued with value during the Pavlovian reward conditioning phases. This suggests that pure Pavlovian reward conditioning can occur even when (1) competition prevents attention being automatically allocated to the reward-signalling stimulus in a stimulus-driven manner, and (2) attention is occupied by a demanding task, leaving little goal-driven attentional resources available to strategically select the reward-signalling stimulus. The observed value-driven attentional capture effects appeared to be similar for observers who could and could not explicitly report the stimulus–reward contingencies. Altogether, this study provides insight in the conditions under which mere stimulus–reward contingencies in the environment can be learned to affect future behaviour.
In everyday life an abundance of visual input reaches the retina. However, only a small part of the incoming information is processed in order to play a role in guiding behaviour. Because our processing resources are limited, stimuli in the visual world constantly compete for representation in the brain. Selective attention is the cognitive mechanism that resolves this competition, by enhancing the representation of stimuli that are behaviourally relevant and suppressing the representation of stimuli that are potentially distracting. It is well established that selective attention can be voluntarily controlled by the current goals of the observer and involuntarily driven by the physical salience of stimuli in the environment. The stimulus-driven factors are referred to as bottom-up and the goal-driven factors are referred to as top-down (for reviews see Corbetta & Shulman, Citation2002; Desimone & Duncan, Citation1995; Itti & Koch, Citation2001; Theeuwes, Citation2010). For example, when driving, controlled goal-directed attention is needed in order to process relevant stimuli on the road directly ahead, while ignoring irrelevant stimuli in the distance. Nonetheless, the sudden appearance of a fire truck will automatically capture attention in a stimulus-driven manner due to its physical salience (i.e., big, red and moving fast). However, a recent body of literature has demonstrated that attention is influenced by the learned significance that certain stimuli acquired over time through experience, that cannot be explained in terms of goal-driven and stimulus-driven processes (for reviews see Anderson, Citation2013, Citation2015; Awh, Belopolsky, & Theeuwes, Citation2012; Chelazzi, Perlato, Santandrea, & Della Libera, Citation2013; Chun, Golomb, & Turk-Browne, Citation2011; Kristjánsson & Campana, Citation2010; Le Pelley, Mitchell, Beesley, George, & Wills, Citation2016). Awh et al. (Citation2012) termed this third attentional control mode “selection history” as it includes attentional priority for stimuli that have been previously selected (i.e., priming) or have been associated with reward (e.g., value-driven attentional capture), independent of their physical salience and behavioural relevance. The general idea is that the subjective salience of previously selected or reward associated stimuli is enhanced in such a way that stimuli that are recently selected or stimuli that signal reward will receive greater attentional priority. For example, an ordinary silver car in traffic might grab your attention if it happens to be your best friend’s car that you have seen (and selected) often. In addition, billboards advertising your favourite food or clothing brand might automatically grab your attention as they are associated with a rewarding experience. This suggests that the deployment of attention can be changed as a result of learning about stimuli and learning about stimulus–reward contingencies.
In experimental settings, it has been shown that stimuli enjoy increased priority when a relatively high reward is directly coupled to that stimulus or a feature of that stimulus (e.g., Bucker & Theeuwes, Citation2016; Kiss, Driver, & Eimer, Citation2009; Krebs, Boehler, Egner, & Woldorff, Citation2011; Munneke, Hoppenbrouwers, & Theeuwes, Citation2015). Thus, when reward is congruent with the current task demands, the reward outcome that is associated with a stimulus can increase its attentional priority to improve behavioural performance. In addition, several studies have shown that stimuli that have been associated with a high, compared to low, reward receive attentional priority even if they become completely task-irrelevant and rewards are no longer delivered (e.g., Anderson, Laurent, & Yantis, Citation2011a, Citation2011b; Bucker, Silvis, Donk, & Theeuwes, Citation2015; Della Libera & Chelazzi, Citation2006, Citation2009; Failing & Theeuwes, Citation2014; MacLean, Diaz, & Giesbrecht, Citation2016; Moher, Anderson, & Song, Citation2015; Pool, Brosch, Delplanque, & Sander, Citation2014; Roper, Vecera, & Vaidya, Citation2014; Theeuwes & Belopolsky, Citation2012). Typically, these studies make use of a training-test phase design, such that certain target stimulus features are coupled to the delivery of high and low reward in the training phase, while that same stimulus features are presented as distractors in the following test phase during which rewards are no longer delivered. The general finding in the test phase is then that high compared to low reward-value associated stimuli capture attention more strongly. This suggests that otherwise neutral stimuli can be imbued with reward-value through associative learning in a training phase, such that they capture attention more strongly in a non-reward test phase, completely independent of their physical salience and the current goals of the observer.
More recently, it has been questioned whether value-driven attentional capture (see Anderson, Citation2013) as described above is a consequence of instrumental or Pavlovian associative learning (see Le Pelley et al., Citation2016). In the previously mentioned studies, reward was always associated with target stimuli that needed to be selected in the training phase in order to give a correct response. Consequentially it is possible that value-driven attentional capture, as observed in the test phase, is simply a carryover of an overlearned attentional orienting response. Therefore, one cannot distinguish whether the act of selecting the reward associated stimulus or the mere co-occurrence of the stimulus and reward delivery is responsible for value-driven attentional capture. In other words, when target stimuli are associated with rewards, it is unclear whether instrumental or Pavlovian associative reward learning is responsible for value-driven attentional capture. In order to explicitly differentiate between instrumental and Pavlovian learning, Le Pelley and colleagues designed a task in which rewards were delivered based on the identity of a task-irrelevant distractor (Le Pelley, Pearson, Griffiths, & Beesley, Citation2015). Unlike the previously mentioned experiments, rewards were administered throughout the entire experiment and attentional orienting towards the reward-signalling distractor stimulus needed to be suppressed in order to give a correct response in time and receive that trial’s reward. The results of Le Pelley et al. (Citation2015) and similar studies (e.g., Bucker, Belopolsky, & Theeuwes, Citation2015; Failing, Nissens, Pearson, Le Pelley, & Theeuwes, Citation2015; Le Pelley et al., Citation2015; McCoy & Theeuwes, Citation2016; Mine & Saiki, Citation2015; Pearson, Donkin, Tran, Most, & Le Pelley, Citation2015) repeatedly showed that high compared to low reward-signalling distractors captured attention more strongly. This suggests that the mere co-occurrence of a stimulus and reward administration increases its attentional priority.
However, in all previous studies reward administration was response dependent, as only fast and correct responses were followed by reward delivery. To rule out any sort of task and response dependence (i.e., instrumental aspects) on associative reward learning underlying value-driven attentional capture, in a recent study we automatically distributed rewards independent of the participants’ task and response (Bucker & Theeuwes, Citation2017). In two experiments a genuine Pavlovian reward conditioning phase was separated from a non-reward test phase. During the Pavlovian conditioning phase, participants performed an easy fixation change task at the middle of the screen while coloured stimuli could appear in the periphery (Experiment 1) or at fixation (Experiment 2). Crucially, the mere presentation of one coloured stimulus resulted in the delivery of a high reward, while the presentation of the other coloured stimulus resulted in the delivery of a low reward. The delivery did not depend on the response of the observer, nor was the stimulus in any way relevant for the task. In a subsequent non-reward test phase, value-driven attentional capture was assessed using the additional singleton paradigm (Theeuwes, Citation1992). The results showed that the colours of the distractors that previously signalled the magnitude of the reward given had a significant impact on performance, with stronger attentional capture for distractors that previously signalled the delivery of a high compared to a low reward. This implies that the reward associated stimuli were imbued with their respective reward value during the Pavlovian reward conditioning phase, which led us to conclude that genuine Pavlovian associative reward learning can elicit value-driven attentional capture.
Although the above-mentioned studies provide compelling evidence that Pavlovian learning underlies value-driven attentional capture, it is unclear what role stimulus-driven and goal-driven attentional processes play during Pavlovian learning of the stimulus–reward contingencies. For example, in our previous study (Bucker & Theeuwes, Citation2017) we could not rule out the role of either bottom-up or top-down attentional processing, so that it was indistinguishable how the reward-signalling stimuli were prioritized during Pavlovian learning. First, in the previous experiments, the reward-signalling stimulus was the only (coloured) stimulus in the display, so that there was (almost) no competition in the visual scene to be resolved. This makes it very likely that the reward-signalling stimulus was automatically prioritized, possibly in a stimulus-driven manner (Theeuwes, Citation1992, Citation2010). Second, observers performed a fairly easy fixation change detection task that did not demand much attentional effort, which means that observers should have had enough attentional resources to strategically attend the reward-signalling stimuli. To investigate how (and if) stimulus-driven and goal-driven attentional resources are involved in Pavlovian reward learning underlying value-driven attentional capture, we manipulated the extent to which bottom-up and top-down processes could be deployed, while task-irrelevant and response-independent reward-signalling stimuli competed for visual selective attention. In Experiment 1, we ensured that the reward-signalling stimulus did not automatically capture attention in a stimulus-driven manner by presenting the reward-signalling stimulus simultaneously with another randomly coloured stimulus. In Experiment 2, we let participants perform a reward-independent and attentionally demanding rapid serial visual presentation (RSVP) task at the centre of the screen to minimize the availability of attentional resources to process the reward-signalling stimuli in the periphery (see Joseph, Chun, & Nakayama, Citation1997). Altogether, the present study examines the limits of Pavlovian associative reward learning that underlies value-driven attentional capture. This provides insight in the conditions under which mere stimulus–reward contingencies can be learned from the environment to guide future behaviour.
Experiment 1
In Experiment 1, we examined whether Pavlovian reward learning would occur when the reward-signalling stimuli competed for visual selective attention with other task-irrelevant and response-independent stimuli, such that they could not automatically capture attention in a stimulus-driven manner. Participants performed a fixation change task at the centre of the screen, while two equally salient stimuli were presented simultaneously to the left and right side of fixation (see ). One of the peripherally presented stimuli was always presented in the high or low reward-signalling colour, while the other peripherally presented stimulus was presented in a random colour that did not resemble the high or low reward-signalling colour. The magnitude of the reward given depended on the colour of the reward-signalling stimulus only. To ensure pure Pavlovian reward learning, reward delivery was completely response-independent. Crucially, as the reward-signalling stimulus was presented simultaneously with a non-reward associated distractor on either side of fixation, it is expected not to attract any attention in an exogenous way (Theeuwes, Citation1995a), unlike in previous studies (e.g., Bucker & Theeuwes, Citation2017; Le Pelley et al., Citation2015). Following the reward conditioning phase, we examined value-driven attentional capture in the non-reward test phase using the additional singleton paradigm (Theeuwes, Citation1992). If Pavlovian associative reward learning occurs even when we prevent that one of the stimuli in the display captures attention in a stimulus-driven manner, we expect to observe value-driven attentional capture in the non-reward test phase. However, the introduced competition for visual selective attention between the reward-signalling stimuli and the randomly coloured stimuli might prevent Pavlovian associative reward learning to occur, especially as the introduced competition occurs at a task-irrelevant spatial location, indicating that there is no need to attend to these stimuli. Thus, if automatic attentional guidance towards the reward-signalling stimuli in the reward conditioning phase is necessary in order for observers to show the same attentional response (i.e., value-driven attentional capture) in the test phase during which the reward associated stimuli are no longer signalling reward delivery, then we expect no value-driven attentional capture in the non-reward test phase. To examine whether explicit knowledge about the colour–reward contingencies plays a role in Pavlovian reward learning while the task-irrelevant stimuli compete for visual selective attention, we assessed whether observers could explicitly report the stimulus–reward contingencies.
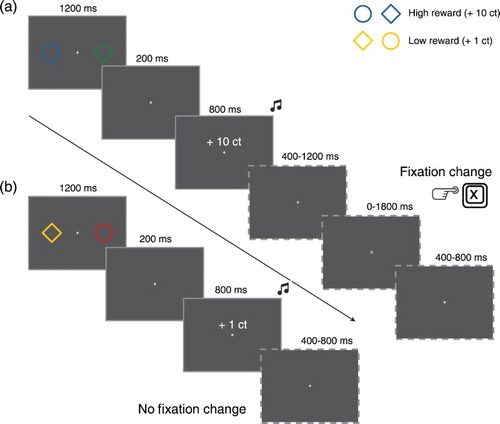
Figure 1. Schematic representation of the trial sequence and timing of the reward conditioning phase of Experiment 1. (a) Fixation change trial, starting with a stimulus display with a high reward-signalling stimulus (blue circle) and another randomly coloured stimulus (green diamond), followed by an inter stimulus interval, the feedback display with accompanying sound indicating a 10 ct win and (in dashed outlines) a variable inter stimulus interval, after which the fixation changed (from + to x) so that participants had to press the keyboard “X” button within 1800 ms, followed by the inter trial interval. (b) No fixation change trial, starting with a stimulus display with a low reward-signalling stimulus (yellow diamond) and another randomly coloured stimulus (red circle), followed by an inter stimulus interval, the feedback display with accompanying sound indicating a 1 ct win and (in dashed outlines) no fixation change (fixation remained +) so that no response was required, followed by the inter trial interval.
Method
Participants
A group of 32 participants (13 male, 18–34 years of age, mean = 24.8 years, standard deviation = 3.6 years) was tested at the Vrije Universiteit Amsterdam. All participants reported having normal or corrected-to-normal vision and gave written informed consent before participation. Participants earned €7.04 reward during the reward conditioning phase and were paid at a rate of €8.00 per hour to compensate for participation. All research was approved by the Vrije Universiteit Faculty of Psychology ethics board and was conducted according to the principles of the Declaration of Helsinki.
Apparatus
All participants were tested in a sound-attenuated, dimly-lit room, with their head resting on a chinrest at a viewing distance of 75 cm. A computer with a 3.2 GHz Intel Core processor running OpenSesame (Mathôt, Schreij, & Theeuwes, Citation2012) generated the stimuli on a 22-inch screen (resolution 1680 × 1050, refreshing at 120 Hz). The necessary response data were acquired through the standard keyboard and all auditory stimuli were presented through headphones.
Stimuli
Reward conditioning phase
Throughout the reward conditioning phase a white (CIE: x = .312, y = .332, 120 cd/m2) fixation cross (.30° × .30°) was presented on a black (< 1 cd/m2) background at the centre of the screen (see ). On fixation-change trials (25% of the trials) the fixation cross (+) rotated 45° angular degrees (x) for a brief period, but the fixation cross never disappeared from the screen. The reward stimulus display contained one circle (r = 1.45°) and one diamond (45° angular degrees rotated square with sides of 2.2° visual degrees), presented on the horizontal meridian of the screen at a distance of 5.1° visual degrees left and right from fixation. One of the stimuli (randomly selected to be the circle or the diamond on each trial) was always presented in either blue (rgb = 85, 155, 255; CIE: x = .193, y = .203, 37 cd/m2) or yellow (rgb = 162, 161, 0; CIE: x = .419, y = .504, 37 cd/m2). The blue and yellow stimuli were coupled to the delivery of high and low reward and the colour–reward contingencies were counterbalanced across participants. The stimulus that was not presented in one of the reward associated colours (i.e., blue or yellow) was presented in a random colour, with the restriction that it could not resemble the blue or yellow stimulus colours that were associated with reward. To do so, the randomly picked colour could not have red, green and blue components (i.e., the “r”, ”g” and “b”) that all differed less than 85 units from the red, green and blue components of the blue and yellow colours that were associated with reward. Furthermore, if the blue reward colour was presented, the randomly presented colour could not have a blue component that was larger than 170 (255 maximum blue component value minus 85 units), and if the yellow colour was presented the difference between the red and green components could not be smaller than 85 units (as similar values for the red and green components produce a yellowish colour). The location of the reward associated coloured shape was randomly assigned to be left or right of the fixation cross on each trial. The reward feedback display contained the written text “ + 1 ct” or “+ 10 ct” (∼.5° × 3.0°) presented in white, 0.50° visual degrees above the white fixation cross at the centre of the screen. Simultaneously with the visually presented feedback the sound of one or more dropping coins was played in low and high reward trials, respectively.
The reward stimulus display was presented for 1200 ms followed by a 200 ms interval during which the fixation cross was shown. Then the reward feedback display was presented for 800 ms. In no fixation change trials, the fixation cross was presented for a random inter trial interval of 400–800 ms whereafter the next reward stimulus display was shown. In fixation change trials the reward feedback display was followed by a random 400–1200 ms interval after which the fixation cross rotated 45° angular degrees. When this change occurred, participants had to press the “X” button on the keyboard within a 1800 ms response window. Directly after button press or after 1800 ms, the fixation cross rotated back to normal and the standard 400–800 ms inter trial interval was followed by the presentation of the next reward stimulus display.
Non-reward test phase
For the non-reward test phase we utilized the additional singleton task (Theeuwes, Citation1992). Accordingly, six shapes, randomly one diamond (2.95° × 2.95°) among five circles (r = 1.45°) or one circle among five diamonds, were presented at equal distances on an imaginary circle (r = 5.90°) (see ). All stimuli were presented in grey (CIE: x = .312, y = .330, 37 cd/m2) or all were presented in grey except for the colour singleton that was presented in either blue (CIE: x = .193, y = .203, 37 cd/m2) or yellow (CIE: x = .419, y = .504, 37 cd/m2). The shape singleton was never coloured and always presented in grey. All shapes contained a grey (CIE: x = .312, y = .330, 37 cd/m2) horizontal or vertical line (0.50°, width = 3 pixels). At all times a white (CIE: x = .312, y = .332, 120 cd/m2) fixation cross (.30° × .30°) was presented at the centre of the screen. Feedback consisted of the written words (∼.5° × 2.0°), “correct”, “incorrect” or “too slow” presented in white (CIE: x = .312, y = .332, 120 cd/m2). Visual feedback for incorrect and too slow trials was accompanied by a pure tone of 400 Hz and 800 Hz, respectively.
Figure 2. Schematic representation of the trial sequence and timing of the non-reward test phase of both Experiment 1 and Experiment 2. (a) The stimulus display of the additional singleton paradigm with a high reward-value colour singleton distractor (blue circle) and a diamond shape singleton target containing a horizontal line element for which a “Z” key press within 1800 ms resulted in the correct feedback screen, followed by the inter trial interval. (b) Overview of the three different distractor type conditions, with the high reward-value condition (blue distractor circle), the low reward-value condition (yellow distractor diamond) and the no distractor condition (no coloured distractor shape).
The stimulus display was presented for a maximum period of 1800 ms and disappeared as soon as a response was given. The stimulus display was directly followed by the visual feedback for 500 ms occasionally accompanied by the auditory feedback that was played for 200 ms. All trials were separated by a random 1200–1600 ms inter trial interval.
Procedure and design
Participants were instructed to remain fixated on the central fixation cross at all times and respond as quickly and accurately as possible. In the reward conditioning phase, the task for participants was to press the “X” keyboard button as soon as the fixation cross rotated 45° angular degrees. They were instructed that other stimuli would appear in the periphery but that these were not related to their task and could be ignored. Furthermore, they were told that they would automatically receive rewards while doing the fixation task, and that reward delivery was independent of their task and response. The reward conditioning phase consisted of four separate blocks with 32 trials each. Within each block the high and low reward stimulus display were both shown 16 times in random order. The fixation cross changed eight times per block (25% of the time) randomly between presentations of the reward stimulus display. Between blocks of the reward conditioning phase, participants were shown how much reward they earned and on how many occasions they missed the fixation change.
At the start of the non-reward test phase, participants were explicitly told that rewards were no longer delivered. Furthermore, they were told that the fixation change task was over, but that fixation needed to be maintained. The task in the non-reward test phase was to discriminate the orientation of the target line within the shape singleton and press the “Z” or “M” keyboard button (with their left and right index finger, respectively) as fast and accurate as possible for horizontal or vertical lines, respectively. The test phase consisted of eight blocks with 36 trials each. Within each block there were 12 trials in which the colour singleton distractor was presented in the colour that was previously associated with high reward, 12 trials in which the colour singleton distractor was presented in the colour that was previously associated with low reward and 12 trials in which no coloured distractor singleton was presented. The shape singleton contained a horizontal or vertical target line equally often within each block. Between blocks, participants were informed about their mean response time and mean accuracy in that particular block and their overall accuracy. In total, 128 reward displays were shown and 32 fixation changes occurred during the reward condition phase. The non-reward test phase consisted of 288 trials. Including breaks between blocks all participants were able to finish the experiment within approximately 45 minutes.
Exit questionnaire explicit knowledge
After the experiment, participants filled out the exit questionnaire in which they were asked to answer one question regarding their knowledge about the stimulus–reward contingencies in the Pavlovian reward conditioning phase of the experiment. They were explicitly instructed to give their response with regard to the first phase of the experiment only. The following question was written down: “If I told you that one color was signaling a high chance on high reward and another color was signaling a high chance on low reward, could you tell me which color signaled what reward?” and the options “High reward … .. ” and “Low reward … .. ” were provided. As participants were exposed to many different random colours in the training phase of Experiment 1, we considered participants to have obtained explicit knowledge about the stimulus–reward contingencies if they were able to correctly report the high reward-signalling colour. Participants who did not fill out the correct high reward-signalling colour were considered to have no explicit knowledge about the stimulus–reward contingencies.
Preprocessing
Accuracy was calculated as the percentage correct of all trials. All correct responses that were made within the 1800 ms response window were included in the accuracy analysis. For the reaction time analysis, only correct trials were analysed. Furthermore, trials on which reaction time deviated more than 2.5 standard deviations from the participant’s individual mean correct reaction time were excluded from the analysis.
Exclusions
Participants were excluded from the analyses if performance in one or more conditions of the non-reward test phase was at or below chance level. The cumulative binomial distribution indicated that performance significantly (p < .041) deviated from chance (50%) if participants responded correctly on more than 56 trials out of a total of 96 trials per condition. Thus, participants who scored below 59% correct in one or more conditions were excluded from the analyses. In Experiment 1, two participants scored at or below chance level (i.e., below 59% correct) in one or more conditions and were therefore replaced by others to keep the counterbalancing scheme intact.
Results
Fixation change task
All participants were very much able to detect the fixation changes as only two out of the 30 participants missed the fixation change once. As reward was independent of performance on the fixation task and any response, all participants earned €7.04 extra reward in the reward conditioning phase.
Value-driven attentional capture
To investigate whether Pavlovian learning of the colour–reward contingencies occurred, even though the task-irrelevant and non-salient reward signalling colours competed for visual selective attention, we compared mean reaction time and accuracy between the high reward-value, low reward-value and no distractor condition of the non-reward test phase (see ). A repeated measures ANOVA on mean reaction time with distractor type (high reward-value/low reward-value/no distractor) as factor showed a significant main effect, F(2, 58) = 39.482, p < .001, = .577. Crucially, a two-tailed t-test showed that reaction times were longer in the high reward-value (mean = 822 ms) compared to the low reward-value (mean = 813 ms) distractor condition, t(29) = 2.325, SE = 4.013, p = .027. Furthermore, planned paired samples t-tests showed that reaction times were shorter in the no distractor condition (mean = 773), compared to both the high (mean = 822 ms), t(29) = 7.395, SE = 6.664, p < .001 and low (mean = 813 ms), t(29) = 6.048, SE = 6.605, p < .001 reward-value distractor condition.
Figure 3. Mean reaction time (A) and accuracy (B) per distractor type condition of Experiment 1. (A) Participants responded slower on high compared to low reward-value distractor trials and slower on both high and low reward-value distractor trials compared to no distractor present trials. (B) Participants responded equally accurate on high and low reward-value distractor trials and better on no distractor trials compared to both high and low reward-value distractor trials.
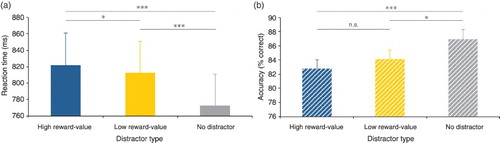
A repeated measures ANOVA on mean accuracy with distractor type (high reward-value/low reward-value/no distractor) as factor showed a significant main effect, F(2, 58) = 8.656, p < .001, = .230. Subsequent paired samples two-tailed t-tests showed that accuracy was similar for trials in which a high (mean = 82.8% correct) or low (mean = 84.1% correct) reward-value distractor was present, t(29) = 1.369, SE = .989, p = .181, and that accuracy was higher in the no (mean = 86.9% correct) distractor condition compared to both the high t(29) = 4.287, SE = 0.964, p < .001 and low, t(29) = 2.570, SE = 1.081, p = .016, reward-value distractor condition.
The reaction time and accuracy results were consistent with each other, showing that search was fastest and most accurate in the distractor absent condition. Furthermore, participants reacted significantly slower if a high compared to a low reward-value distractor was present, without showing a performance difference in accuracy. These effects did not differ for participants who had the blue or yellow colour coupled to high reward, as a between subjects counterbalancing factor showed no significant interaction with distractor type for both reaction time and accuracy, both Fs < 1.
Explicit knowledge about the stimulus–reward contingencies
In Experiment 1, nine out of 30 participants were considered to have explicitly knowledge about the stimulus–reward contingencies. To investigate whether explicitly knowing the stimulus–reward contingencies modulated the value-driven attentional capture effect, we split the participants into two groups. An ANOVA on mean reaction time with distractor type (high reward-value/low reward-value) as within subject factor and explicit knowledge (yes/no) as between subject factor showed a significant main effect of distractor type, F(1, 28) = 4.936, p = .035, = .150. Crucially, no significant interaction effect between distractor type and explicit knowledge was observed, F < 1, indicating that the distractor type effect (longer reaction times for high compared to low reward-value distractor trials) did not significantly differ between participants that were able to explicitly report the stimulus–reward contingencies (mean = 11.3 ms) and those that were not (mean = 8.5 ms). As the group that explicitly knew the stimulus–reward contingencies only contained nine participants, the null result of the interaction between distractor type (high reward-value/low reward-value) and explicit knowledge (yes/no) might reflect a lack of power. Therefore, to further investigate whether explicit knowledge about the stimulus–reward contingencies genuinely did not modulate the value-driven attentional capture effect, we pooled the data of Experiment 1 and Experiment 2 (see Pooled analysis for Experiment 1 and Experiment 2).
Discussion
Experiment 1 shows that reaction times in the non-reward test phase were slower when high compared to low reward-value distractors were present, indicating that high compared to low reward-value distractors captured attention more strongly. This implies that the high and low reward-signalling stimuli were imbued with their respective reward-value in the Pavlovian reward conditioning phase to elicit value-driven attentional capture in the non-reward test phase. Thus, value-driven attentional capture was observed after Pavlovian reward learning, even though the reward-signalling stimuli competed for selection and did not automatically capture attention in a stimulus-driven manner. Although the reward associated colour was presented concurrently with another randomly picked task-irrelevant and response-independent colour, the mere co-occurrence of the high and low reward associated colours and reward delivery was enough to imbue them with their respective value, such that the high compared to the low reward associated stimulus remained to capture attention more strongly in the non-reward test phase. This suggests that pure Pavlovian reward learning of colour–reward contingencies can elicit value-driven attentional capture even when two equally salient and task-irrelevant stimuli (of which one signals the amount of reward that will be obtained) compete for visual selective attention. In addition, the data of Experiment 1 suggests that the explicit knowledge that participants have about the stimulus–reward contingencies does not play a role in modulating the value-driven attentional capture effect.
Experiment 2
In Experiment 2, we examined whether pure Pavlovian reward learning would occur if observers performed a reward-independent but engaging and attentionally demanding task at the centre of the screen. By introducing competition between the primary task at the centre and the reward-signalling stimulus in the periphery, we intended to leave little goal-driven attentional resources in place for participants to strategically select the reward-signalling stimulus. Indeed, Joseph et al. (Citation1997) showed that when observers were engaged in an attentionally demanding RSVP-task at the centre, they were unable to detect the presence of a pop-out feature in the periphery. This indicates that little resources, if any, are available for processing stimuli in the periphery when observers are engaged in a centrally presented RSVP-task. To that end, we let participants perform an attentionally demanding RSVP-task at the centre of the screen, while a peripherally presented ring could either have the high or low reward-signalling colour (see ). The ring was task-irrelevant and response-independent. Participants responded whether an initially presented target letter was present or absent within the RSVP-stream of 16 letters, while high and low rewards were automatically distributed depending on the colour of the reward-signalling ring. Similar to Experiment 1, following the reward conditioning phase, we examined value-driven attentional capture in the non-reward test phase using the additional singleton paradigm (Theeuwes, Citation1992). If Pavlovian associative reward learning of task-irrelevant and response-independent stimuli occurs when goal-driven attention is largely occupied with an attentionally demanding task at a different spatial location, we expect to observe value-driven attentional capture in the non-reward test phase. However, if goal-driven processes are needed to guide attention towards the stimulus–reward contingencies, then we expect no value-driven attentional capture in the non-reward test phase. Again, as in Experiment 1, we examined whether explicit knowledge about the colour–reward contingencies played a role in Pavlovian reward learning that underlies value-driven attentional capture.
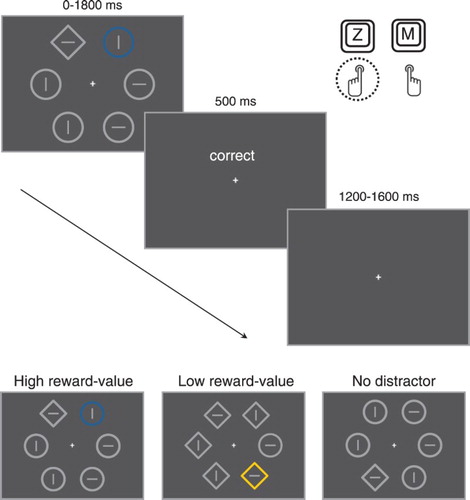
Figure 4. Schematic representation of the trial sequence and timing of the reward conditioning phase of Experiment 2. (a) A randomly chosen target letter was presented, followed by an inter stimulus interval, the RSVP-stream (16 letters were presented for 33 ms with 42 ms inter stimulus intervals in between), a response delay period of 750 ms, after which participants responded whether the target letter was absent (“A” keyboard button) or present (“P” keyboard button) within 1800 ms, followed by the feedback screen. (b) The colour of the grey ring in the periphery changed to one of the reward-signalling colours (here the low reward colour [i.e., yellow]) during the presentation of the 3rd until the 14th letter of the RSVP-stream. The ring remained grey during the presentation and intervals of the first two and last two letters. After the presentation of the complete RSVP-stream a sound indicated whether a low or high reward was delivered.
![Figure 4. Schematic representation of the trial sequence and timing of the reward conditioning phase of Experiment 2. (a) A randomly chosen target letter was presented, followed by an inter stimulus interval, the RSVP-stream (16 letters were presented for 33 ms with 42 ms inter stimulus intervals in between), a response delay period of 750 ms, after which participants responded whether the target letter was absent (“A” keyboard button) or present (“P” keyboard button) within 1800 ms, followed by the feedback screen. (b) The colour of the grey ring in the periphery changed to one of the reward-signalling colours (here the low reward colour [i.e., yellow]) during the presentation of the 3rd until the 14th letter of the RSVP-stream. The ring remained grey during the presentation and intervals of the first two and last two letters. After the presentation of the complete RSVP-stream a sound indicated whether a low or high reward was delivered.](/cms/asset/8fd5c4bd-aef9-4574-b859-aef9dbac576e/pvis_a_1399948_f0004_c.jpg)
Method
The overall methods used in Experiment 2 were similar to those used in Experiment 1, with a number of small changes. Crucially, the reward conditioning phase was adjusted such that participants had a more attentionally demanding task at the centre of the screen. The non-reward test phase was identical to that in Experiment 1.
Participants
A new group of 35 participants (12 male, 20–34 years of age, mean = 24.4 years, standard deviation = 3.1 years) was tested at the Vrije Universiteit Amsterdam. All participants reported having normal or corrected-to-normal vision and gave written informed consent before participation. Participants earned €9.90 reward during the reward conditioning phase and received this reward as a compensation for their participation. All research was approved by the Vrije Universiteit Faculty of Psychology ethics board and was conducted according to the principles of the Declaration of Helsinki.
Apparatus
Experiment 2 and Experiment 1 were conducted with the same equipment under the same experimental conditions.
Stimuli, design and procedure
Reward conditioning phase
In the reward conditioning phase participants were instructed to remain fixated at the centre of the screen and respond as quickly and accurately as possible. A white (CIE: x = .312, y = .332, 120 cd/m2) fixation cross was presented at the centre of the screen for the majority of time to help them fixate. While participants performed an RSVP-task at the centre of the screen, the colour of a peripherally presented ring indicated whether a high or low reward was distributed on that trial. The task for participants was to detect whether an initially presented target letter was presented within a following stream of letters or not. At all times, the ring (r = 5.2° centred around fixation, width = 0.75°) was presented on a black background (<1 cd/m2). The ring was coloured grey (CIE: x = .312, y = .330, 37 cd/m2) for the majority of time, but the colour could change to blue (CIE: x = .193, y = .203, 37 cd/m2) or yellow (CIE: x = .419, y = .504, 37 cd/m2) depending on the reward that was distributed on that trial. The blue and yellow colour were coupled to the delivery of high and low reward and the colour–reward contingencies were counterbalanced across participants. At the start of a trial, a white (CIE: x = .312, y = .332, 120 cd/m2) target letter (1.0° tall) was presented at the centre of the screen for 250 ms, followed by an inter stimulus interval of 1000 ms during which the fixation cross was presented. Then, 16 white (CIE: x = .312, y = .332, 120 cd/m2) letters (1.0° tall) were consecutively presented at the centre of the screen. The letters were randomly chosen from the alphabet and each letter was presented for 33 ms followed by a 42 ms inter stimulus interval in which nothing was presented at the centre of the screen. On half of the trials the target letter was presented at a random position within the stream. On the other half of the trials no target letter was presented within the stream. During the presentation of the 3rd until the 14th letter and the inter stimulus intervals between those letters, the grey ring in the periphery changed colour to blue or yellow depending on the amount of reward that was distributed on that trial. The blue or yellow reward-associated colour was presented simultaneously with the presentation of the RSVP stream, such that the demanding task at the centre of the screen would occupy most attentional resources, leaving minimal resources in place to attend the reward-associated colour in the periphery. Following the presentation of all 16 letters within the RSVP stream, a white fixation cross was shown at the centre of the screen for 750 ms. The sound of one or multiple dropping coins was played for approximately 200 ms on low and high reward trials, respectively. When the fixation cross was replaced by a fixation dot (r = 0.2°), participants had 1800 ms to indicate whether the target letter was present or absent within the RSVP stream, by pressing the “P” keyboard button with their right index finger or the “A” keyboard button with their left index finger, respectively. As the rewards were delivered before a response was given, we ensured that reward delivery was response-independent and that no coincidental instrumental learning could occur. When a response was given or after a maximum period of 1800 ms, the grey (CIE: x = .312, y = .330, 37 cd/m2) feedback text “incorrect”, “correct” or “too slow” appeared above the fixation cross for 250 ms. All trials were separated by a random inter trial interval of 750–1250 ms.
The reward conditioning phase consisted of six separate blocks with 30 trials each. In half of the blocks high rewards were delivered more often than low rewards (2:1 ratio) and in the other half of the blocks low rewards were delivered more often than high rewards (2:1 ratio) such that participants did not earn the exact same amount of reward every block. High and low reward blocks were alternatingly presented and it was counterbalanced between participants whether they started with a high or low reward block. Between blocks of the reward conditioning phase, participants were shown how much reward they earned in addition to their mean response time and mean accuracy on the RSVP-task. In total, 180 trials were performed in the reward conditioning phase, during which the grey circle changed 90 times to the high and 90 times to the low reward-signalling colour.
Non-reward test phase
The stimuli, timings and procedure used in the non-reward test phase of Experiment 2 were identical to those used in Experiment 1 (see ). In total, 288 trials were performed in the non-reward test phase. Including breaks between blocks, all participants were able to finish the experiment within one hour.
Exit questionnaire about explicit knowledge
The exit questionnaire for Experiment 2 was identical to that of Experiment 1. Again, we considered participants to have obtained explicit knowledge about the stimulus–reward contingencies if they were able to correctly report the high reward-signalling colour, whereas participants who did not fill out the correct high reward-signalling colour were considered to have no explicit knowledge about the stimulus–reward contingencies.
Preprocessing
The data of the reward conditioning phase and the non-reward test phase were analysed separately. Accuracy was calculated as the percentage correct of all trials in the corresponding phase. Trials on which the reaction time was more than 2.5 standard deviations away from the participants’ mean correct reaction time per phase were excluded from the reaction time analyses (2.8% in the reward conditioning phase and 2.2% in the non-reward test phase).
Exclusions
Participants were excluded from the analyses if performance in one or more conditions of the non-reward test phase was at or below chance level. In Experiment 2, three participants scored at or below chance level (i.e., below 59% correct, as indicated by the cumulative binomial distribution). To keep the counterbalancing scheme intact these participants were replaced by others such that the data of 32 participants in total were included in the analyses.
Results
RSVP-task performance
On the RSVP-task in the reward conditioning phase, participants were on average 78.9% correct (standard deviation = 7.7%) and responded on average in 302 ms (standard deviation = 85 ms). All participants scored above chance level (> 56% correct, as indicated by the cumulative binomial distribution). As reward was independent of the participants’ response and performance, all participants received €9.90 in the reward conditioning phase.
Value-driven attentional capture
To investigate whether Pavlovian learning of the peripherally presented colour–reward contingencies occurred, while the reward-signalling stimuli competed for visual selective attention with the attentionally demanding RSVP-task at the centre of the screen, we compared mean reaction time and accuracy between the different conditions of the non-reward test phase (see ). A repeated measures ANOVA on mean reaction time with distractor type (high reward-value/low reward-value/no distractor) as factor showed a significant main effect, F(2, 62) = 38.836, p < .001, = .556. Crucially, a two-tailed t-test showed that reaction times were longer in the high reward-value (mean = 826 ms) compared to the low reward-value (mean = 813 ms) distractor condition, t(31) = 2.728, SE = 4.673, p = .010. Furthermore, planned paired samples t-tests showed that reaction times were shorter in the no distractor condition (mean = 776), compared to both the high, t(31) = 7.537, SE = 6.635, p < .001 and low, t(31) = 6.008, SE = 6.202, p < .001 reward-value distractor condition.
Figure 5. Mean reaction time and accuracy per distractor type condition. (a) Participants responded slower on high compared to low reward-value distractor trials and slower on both high and low reward-value distractor trials compared to no distractor trials. (b) Participants responded equally accurate on high and low reward-value distractor trials and better on no distractor trials compared to both high and low reward-value distractor trials.
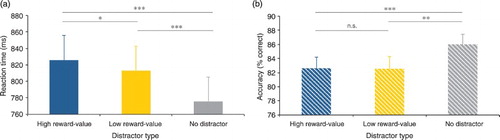
A repeated measures ANOVA on mean accuracy with distractor type (high reward-value/low reward-value/no distractor) as factor showed a significant main effect, F(2, 62) = 6.573, p = .003, = .175. Subsequent paired samples two-tailed t-tests showed that accuracy was similar for trials in which a high (mean = 82.6% correct) or low (mean = 82.6% correct) reward-value distractor was present, t(31) < 1, and that accuracy was higher in the no (mean = 86.0% correct) distractor condition compared to both the high, t(31) = 3.642, SE = 0.933, p < .001 and low, t(31) = 2.767, SE = 1.243, p = .009, reward-value distractor condition.
The reaction time and accuracy results of Experiment 2 were consistent with each other, showing that search was fastest and most accurate in the distractor absent condition. Furthermore, participants reacted significantly slower if a high compared to a low reward-value distractor was present, without showing a difference in accuracy. These effects did not differ for participants who started with the high compared to the low reward conditioning block and for participants who had the blue or yellow colour coupled to high reward, as the between subjects counterbalancing factor showed no significant interaction with distractor type for both reaction time, F < 1, and accuracy, F < 1.
Explicit knowledge about the stimulus–reward contingencies
In Experiment 2, 12 out of 30 participants were considered to have explicitly knowledge about the stimulus–reward contingencies. To investigate whether explicitly knowing the stimulus–reward contingencies modulated the value-driven attentional capture effect, we split the participants into two groups. An ANOVA on mean reaction time with distractor type (high reward-value/low reward-value) as within subject factor and explicit knowledge (yes/no) as between subject factor showed a significant main effect of distractor type, F(1, 30) = 6.630, p = .015, = .181. Crucially, no significant interaction effect between distractor type and explicit knowledge was observed, F < 1, indicating that the distractor type effect (longer reaction times for high compared to low reward-value distractor trials) did not significantly differ between participants that were able to explicitly report the stimulus–reward contingencies (mean = 12.2 ms) and those that were not (mean = 13.1 ms). As the group that did explicitly know the stimulus–reward contingencies only contained 12 participants, the null result of the interaction between distractor type (high reward-value/low reward-value) and explicit knowledge (yes/no) might reflect a lack of power.
Pooled analysis for Experiment 1 and Experiment 2
As the observed results for Experiment 1 and Experiment 2 were very similar, and as the non-reward test phases of both experiments were identical, we pooled the data of Experiment 1 and Experiment 2 to further investigate whether explicit knowledge about the stimulus–reward contingencies genuinely did not modulate the value-driven attentional capture effect. An ANOVA on mean reaction time of the pooled data of Experiment 1 and Experiment 2 with distractor type (high reward-value/low reward-value) as within subject factor and explicit knowledge (yes/no) and experiment (Experiment 1/Experiment 2) as between subject factors showed a significant main effect of distractor type, F(1, 58) = 11.304, p = .001, = .163, confirming the value-driven attentional capture effect for the pooled data. Furthermore, there was no main effect of explicit knowledge, nor experiment, both Fs < 1.695. In addition, the interaction between distractor type and experiment was not significant, F < 1. Crucially, identical to the results of the individual ANOVAs for Experiment 1 and Experiment 2, the ANOVA on the pooled data did not show a significant interaction between distractor type and explicit knowledge either, F < 1. This indicates that explicit knowledge did not modulate the effect of distractor type and that value-driven attentional capture was similar for participants that explicitly knew (10.7 ms) and did not know (11.8 ms) the stimulus–reward contingencies.
To explicitly test for the null effect that explicit knowledge plays no role in modulating value-driven attentional capture, we performed a Bayesian repeated measures ANOVA on mean reaction time of the pooled data with distractor type (high reward-value/low reward-value) as within subject factor and explicit knowledge (yes/no) and experiment (Experiment 1/Experiment 2) as between subject factors. The results indicate that the data can be best explained by a model that only included the main effect of distractor type (with participants responding slower in high compared to low reward-value trials), compared to the null model (Bayes factor = 40.2). Crucially, the best model including the interaction between distractor type and explicit knowledge (Distractor Type + Explicit knowledge + Distractor Type * Explicit knowledge + Experiment) was worse than the absolute best model that only included the main effect of distractor type (Bayes factor = 4.3). Both the conventional and the Bayesian analysis suggest that value-driven attentional capture is most likely not modulated by the explicit knowledge that participants have about the stimulus–reward contingencies.
Discussion
Experiment 2 shows that reaction times in the non-reward test phase were slower when high compared to low reward-value distractors were present, indicating that high compared to low reward-value distractors captured attention more strongly. This implies that the high and low reward-signalling stimuli were imbued with their respective reward-value in the Pavlovian reward conditioning phase to elicit value-driven attentional capture in the non-reward test phase, even though participants needed to strategically attend the letters of the RSVP-stream in order to perform the primary task. Thus, although the reward-signalling stimuli in the periphery competed for selection with the central RSVP-task that was designed to strongly tax attentional resources (as in Joseph et al., Citation1997), the stimulus–reward contingencies were nevertheless learned. This suggests that pure Pavlovian reward learning of colour–reward contingencies can occur even if goal-driven attentional processes are very much occupied with an attentionally demanding task at a different spatial location. In addition, the data of Experiment 2 and the pooled data of Experiment 1 and Experiment 2 suggest that value-driven attentional capture is similar for observers who can and cannot explicitly report the stimulus–reward contingencies.
General discussion
In the present study, we put Pavlovian associative reward learning to the test by examining whether value-driven attentional capture would be observed following a Pavlovian reward conditioning phase in which the reward-signalling stimuli competed for attention. In two experiments, the associative reward learning phase was separated from the test phase in which value-driven attentional capture was assessed, to rule out any form of response-dependency or task-relevance. In the Pavlovian reward conditioning phase, we manipulated the extent to which bottom-up (Experiment 1) and top-down (Experiment 2) processes were involved in selecting the task-irrelevant and response-independent reward-signalling stimuli. In Experiment 1, the reward-signalling stimulus was presented together with another randomly coloured stimulus, ensuring that the competition between the two stimuli would prevent attention being automatically drawn to the stimulus signalling reward delivery. In Experiment 2, the reward-signalling stimulus was presented in the periphery while participants were engaged with a demanding RSVP-task at the centre, such that goal-driven attentional processes would be very much occupied by the central task, leaving minimal resources to attend the periphery. The results of both experiments showed that that high compared to low reward associated stimuli captured attention more strongly in the non-reward test phase. This indicates that Pavlovian reward learning under strong competitive conditions can elicit value-driven attentional capture. In addition, the results show that the observed value-driven attentional capture effect was similar for observers who could and observers who could not explicitly report the stimulus–reward contingencies in the Pavlovian reward conditioning phase. This provides insight in the conditions under which mere stimulus–reward contingencies can be learned from our visually rich environment in order to affect future attentional deployment.
The findings of the present study are in line with previous studies suggesting that Pavlovian reward learning underlies value-driven attentional capture (Bucker & Theeuwes, Citation2017; Failing et al., Citation2015; Le Pelley et al., Citation2015; Mine & Saiki, Citation2015; Pearson et al., Citation2015). However, unlike most previous studies, in the current study the reward-signalling stimuli were completely task-irrelevant and response-independent during learning. Although it has been shown that pure Pavlovian reward learning can elicit value-driven attentional capture (Bucker & Theeuwes, Citation2017), the reward-signalling stimuli in that study were always the most physically salient stimuli on the screen. In one experiment the coloured reward-signalling stimulus was presented among grey distractors, having the ability to automatically attract attention in a stimulus-driven manner (Theeuwes, Citation1992), while in a follow-up experiment the reward-signalling stimuli were presented alone, such that there was no competition for visual selective attention to resolve. In Experiment 1 of the present study we put this finding to the test by letting the task-irrelevant and response-independent reward-signalling stimuli compete for visual selective attention with another randomly coloured stimulus. Hereby we ensured that the reward-signalling stimulus was not automatically selected in a stimulus-driven manner as it was not the only or the most physically salient stimulus in the display. Nonetheless, the current results replicate the results of Bucker and Theeuwes (Citation2017), even though the reward-signalling stimulus in the current study could not automatically capture attention because it was the most salient stimulus in the display (as was the case in our previous study). This confirms the idea that the value-driven attentional capture effect does not necessarily rely on repeating (i.e., training) an automatic attentional orienting response towards the reward-signalling stimuli during conditioning. In addition, it implies that value-driven attentional capture that is observed in a non-reward test phase does not merely reflect the inability to suppress a lingering automatic attentional response that is trained in an earlier reward conditioning phase. Instead, the present results confirm that the Pavlovian signal-value of reward associated stimuli elicits value-driven attentional capture (see Le Pelley et al., Citation2016). Furthermore, the present results provide new evidence showing that pure Pavlovian stimulus–reward contingencies can be learned even if the reward-signalling stimuli compete for visual selective attention and are not automatically attended due to their physical salience.
While the reward-signalling stimulus competed with one other task-irrelevant stimulus in Experiment 1, the reward-signalling stimulus in Experiment 2 competed for visual selective attention with a task-relevant RSVP-stream of letters. By letting observers perform an engaging and attentionally demanding task at the centre while the reward-signalling stimuli were presented in the periphery, we manipulated the extent to which goal-driven attention could be directed towards the reward-signalling stimuli. The RSVP-task is in general considered to be attentionally demanding (see Joseph et al., Citation1997), but the RSVP-task that we used was especially considered to tax strategic goal-driven attentional resources. First, because the initially presented probe letter that had to be detected within the RSVP-stream of 16 letters was randomly selected from the 26 letters of the alphabet on each trail, observers had to continuously update their search template from trial-to-trial, which is known to be more attentionally demanding than repeatedly searching for the same target (e.g., Bravo & Nakayama, Citation1992; Carlisle, Arita, Pardo, & Woodman, Citation2011). Second, because the target letter (the one that matched the probe letter) was presented in the same font, size and colour as the non-target letters (unlike for example in Raymond, Shapiro, & Arnell, Citation1992), it was non-physically salient and did not pop-out automatically. Third, the target letter could appear at any time in the stream of the 16 rapidly (33 ms) presented letters, such that participants could not anticipate it. Because of these carefully chosen features of our RSVP-task, it is likely that observers needed to devote all resources to the centrally presented task leaving little, if any, resources available for processing the peripheral stimuli. In addition, we ensured that the reward-signalling stimuli in the periphery could not automatically capture attention in a stimulus-driven manner because of their physical salience. That is, the ring was presented in grey at all times and only changed to the high or low reward-signalling colour during the presentation of the 3rd to the 14th letter of the RSVP-stream. As the reward associated colours and the grey colour were isoluminant, this colour change cannot evoke a stimulus-driven shift of attention (Theeuwes, Citation1995b). Although the reward-signalling ring did not automatically capture attention and goal-driven attentional resources were largely, if not completely, occupied with the primary RSVP-task, the high and low reward-signalling colours were imbued with their respective reward value during the Pavlovian reward conditioning phase, such that they elicited value-driven attentional capture in the non-reward test phase. This suggests that task-irrelevant and non-salient stimulus–reward contingencies can impact future behaviour, even if the reward-signalling stimuli strongly compete for visual selective attention with a demanding primary task.
Although we ensured that the reward-signalling stimuli in both experiments could not capture attention in a stimulus-driven manner, we cannot rule out that the reward-signalling stimuli were never attended. Especially during the fixation change task of Experiment 1, observers had enough time to strategically attend both the reward-signalling stimulus and the other randomly coloured stimulus. Furthermore, although the RSVP-task in Experiment 2 was designed to maximally tax the goal-driven attentional resources of the observer, we cannot rule out that the reward-signalling stimuli received some attention. However, here we did not intend to show that Pavlovian reward learning could occur in the absence of attention, as it is highly likely that some sort of attentional prioritization is needed to trigger associative learning processes of task-irrelevant stimuli (see Failing & Theeuwes, Citation2017). Rather, the goal was to examine the role that stimulus-driven and goal-driven attentional processes play in Pavlovian reward learning when task-irrelevant and response-independent reward-signalling stimuli compete for attention. To that end, the results show that Pavlovian reward learning can occur completely independent of a primary task, when the reward-signalling stimuli are non-salient and the primary task largely taxes the observers’ goal-driven attentional resources. This suggests that, under competitive conditions, stimulus–reward can be picked up from the environment to affect the deployment of attention in the future, even when the stimulus–reward contingencies are no longer in place.
In the present study we show in two experiments that value-driven attentional capture evoked by Pavlovian reward learning is similar for participants who could explicitly report the stimulus–reward contingencies and those who could not. This finding is similar to the results of Le Pelley et al. (Citation2015) in which participants responded to the orientation of a line element in a shape-singleton while the colour of a colour-singleton indicated whether a high or low reward could be earned on that trial. The results showed slower responses for trials on which the high compared to the low reward-signalling stimulus was present, indicating that value-driven attentional capture occurred due to Pavlovian reward learning of the distractor colour–reward contingencies. The results not only show value-driven attentional capture at the group level, but participants who knew the stimulus–reward contingencies showed value-driven attentional capture that was statistically no different from participants who did not know them. These findings are similar to the present results, as we observe that value-driven attentional capture is not modulated by explicit knowledge about the stimulus–reward contingencies in both Experiment 1 and Experiment 2 separately, and for the data of Experiment 1 and Experiment 2 together. However, in the present study more participants reported the incorrect (N = 41) than the correct (N = 21) stimulus–reward contingencies, whereas this was the opposite in Le Pelley et al. (Citation2015) with seven incorrect and 17 correct reports. The fact that the majority knew the stimulus–reward contingencies in Le Pelley et al. (Citation2015) is not surprising as participants had many (N = 1728) trials to learn the contingencies between two colours and two possible reward outcomes. In addition, in that study the reward-signalling stimuli automatically attracted attention in a stimulus-driven manner due to their physical salience. Here however, it was more difficult for participants to know the specific colour–reward contingencies as the stimuli did not capture attention in a stimulus-driven manner (Experiment 1) and goal-driven attentional resources were largely occupied (Experiment 2). Especially in Experiment 1, participants were exposed to a lot of random colours in addition to the two reward associated colours, which most likely made it more difficult to get to know the specific colour–reward contingencies. Regardless of the majority being unable to correctly report the stimulus–reward contingencies, the current results suggest that mere stimulus–reward contingencies in the environment can have an impact on future behaviour without observers being able to explicitly report the exact stimulus–reward relations.
In two experiments we investigated the role of stimulus-driven and goal-driven processes in Pavlovian associative reward learning, while task-irrelevant and response-independent reward-signalling stimuli competed for visual selective attention. The results of both experiments showed that pure Pavlovian reward conditioning can elicit value-driven attentional capture in a separate non-reward test-phase, even when the reward-signalling stimuli are unable to capture attention in a stimulus-driven manner and observers largely devote their goal-driven attentional resources to a demanding primary task. In addition, the results suggest that the value-driven attentional capture effect is not modulated by the explicit knowledge that observers have about the specific stimulus–reward contingencies. This increases our understanding of reward learning processes in real-life situations in which reward-signalling stimuli are present that are not explicitly searched for or do not automatically attract attention. For example, when driving, can billboard commercials affect future behaviour if they are not physically salient and therefore not able to automatically capture attention in a stimulus-driven manner? Or similarly, can billboard commercials affect future behaviour when goal-driven attentional processes are very much occupied with the driving-task such that there are little attentional resources left in place to strategically attend them? The present study examined the role that stimulus-driven and goal-driven attentional processes play during Pavlovian associative reward learning that underlies value-driven attentional capture to provide insight in the conditions under which mere stimulus–reward contingencies can be learned from the environment to guide future behaviour
Disclosure Statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Anderson, B. A. (2013). A value-driven mechanism of attentional selection. Journal of Vision, 13(3), 7, 1–16. doi: 10.1167/13.3.7
- Anderson, B. A. (2015). The attention habit: How reward learning shapes attentional selection. Annals of the New York Academy of Sciences, 1369, 24–39.
- Anderson, B. A., Laurent, P. A., & Yantis, S. (2011a). Value-driven attentional capture. Proceedings of the National Academy of Sciences, 108(25), 10367–10371. doi: 10.1073/pnas.1104047108
- Anderson, B. A., Laurent, P. A., & Yantis, S. (2011b). Learned value magnifies salience-based attentional capture. PLoS One, 6(11), e27926. doi: 10.1371/journal.pone.0027926
- Awh, E., Belopolsky, A. V., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences, 16(8), 437–443. doi: 10.1016/j.tics.2012.06.010
- Bravo, M. J., & Nakayama, K. (1992). The role of attention in different visual-search tasks. Attention, Perception, & Psychophysics, 51(5), 465–472. doi: 10.3758/BF03211642
- Bucker, B., Belopolsky, A. V., & Theeuwes, J. (2015). Distractors that signal reward attract the eyes. Visual Cognition, 23(1-2), 1–24. doi: 10.1080/13506285.2014.980483
- Bucker, B., Silvis, J. D., Donk, M., & Theeuwes, J. (2015). Reward modulates oculomotor competition between differently valued stimuli. Vision Research, 108, 103–112. doi: 10.1016/j.visres.2015.01.020
- Bucker, B., & Theeuwes, J. (2016). Appetitive and aversive outcome associations modulate exogenous cueing. Attention, Perception, & Psychophysics, 78(7), 2253–2265. doi: 10.3758/s13414-016-1107-6
- Bucker, B., & Theeuwes, J. (2017). Pavlovian reward learning underlies value driven attentional capture. Attention Perception & Psychophysics, 79(2), 415–428. doi: 10.3758/s13414-016-1241-1
- Carlisle, N. B., Arita, J. T., Pardo, D., & Woodman, G. F. (2011). Attentional templates in visual working memory. Journal of Neuroscience, 31(25), 9315–9322. doi: 10.1523/JNEUROSCI.1097-11.2011
- Chelazzi, L., Perlato, A., Santandrea, E., & Della Libera, C. (2013). Rewards teach visual selective attention. Vision Research, 85, 58–72. doi: 10.1016/j.visres.2012.12.005
- Chun, M. M., Golomb, J. D., & Turk-Browne, N. B. (2011). A taxonomy of external and internal attention. Annual Review of Psychology, 62, 73–101. doi: 10.1146/annurev.psych.093008.100427
- Corbetta, M., & Shulman, G. L. (2002). Control of goal-directed and stimulus-driven attention in the brain. Nature Reviews Neuroscience, 3(3), 215–229. doi: 10.1038/nrn755
- Della Libera, C., & Chelazzi, L. (2006). Visual selective attention and the effects of monetary rewards. Psychological Science, 17(3), 222–227. doi: 10.1111/j.1467-9280.2006.01689.x
- Della Libera, C., & Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses. Psychological Science, 20(6), 778–784. doi: 10.1111/j.1467-9280.2009.02360.x
- Desimone, R., & Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18(1), 193–222. doi: 10.1146/annurev.ne.18.030195.001205
- Failing, M., Nissens, T., Pearson, D., Le Pelley, M., & Theeuwes, J. (2015). Oculomotor capture by stimuli that signal the availability of reward. Journal of Neurophysiology, 114(4), 2316–2327. doi: 10.1152/jn.00441.2015
- Failing, M., & Theeuwes, J. (2017). Don’t Let It distract You: How information about the availability of reward affects attentional selection. Attention, Perception, & Psychophysics, 79(8), 2275–2298. doi: 10.3758/s13414-017-1376-8
- Failing, M. F., & Theeuwes, J. (2014). Exogenous visual orienting by reward. Journal of Vision, 14(5), 1–9. doi: 10.1167/14.5.6
- Itti, L., & Koch, C. (2001). Computational modelling of visual attention. Nature Reviews Neuroscience, 2(3), 194–203. doi: 10.1038/35058500
- Joseph, J. S., Chun, M. M., & Nakayama, K. (1997). Attentional requirements in a’preattentive’feature search task. Nature, 387(6635), 805–807. doi: 10.1038/42940
- Kiss, M., Driver, J., & Eimer, M. (2009). Reward priority of visual target singletons modulates event-related potential signatures of attentional selection. Psychological Science, 20(2), 245–251. doi: 10.1111/j.1467-9280.2009.02281.x
- Krebs, R. M., Boehler, C. N., Egner, T., & Woldorff, M. G. (2011). The neural underpinnings of how reward associations can both guide and misguide attention. The Journal of Neuroscience, 31(26), 9752–9759. doi: 10.1523/JNEUROSCI.0732-11.2011
- Kristjánsson, Á, & Campana, G. (2010). Where perception meets memory: A review of repetition priming in visual search tasks. Attention, Perception, & Psychophysics, 72(1), 5–18. doi: 10.3758/APP.72.1.5
- Le Pelley, M. E., Mitchell, C. J., Beesley, T., George, D. N., & Wills, A. J. (2016). Attention and associative learning in humans: An integrative review. Psychological Bulletin, 142(10), 1111–1140. doi: 10.1037/bul0000064
- Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T. (2015). When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General, 144(1), 158–171. doi: 10.1037/xge0000037
- MacLean, M. H., Diaz, G. K., & Giesbrecht, B. (2016). Irrelevant learned reward associations disrupt voluntary spatial attention. Attention, Perception, & Psychophysics, 78(7), 2241–2252. doi: 10.3758/s13414-016-1103-x
- Mathôt, S., Schreij, D., & Theeuwes, J. (2012). Opensesame: An open-source, graphical experiment builder for the social sciences. Behavior Research Methods, 44, 314–324. doi: 10.3758/s13428-011-0168-7
- McCoy, B., & Theeuwes, J. (2016). The effects of reward on oculomotor control. Journal of Neurophysiology, 116(5), 2453–2466. doi: 10.1152/jn.00498.2016
- Mine, C., & Saiki, J. (2015). Task-irrelevant stimulus–reward association induces value-driven attentional capture. Attention, Perception, & Psychophysics, 77(6), 1896–1907. doi: 10.3758/s13414-015-0894-5
- Moher, J., Anderson, B. A., & Song, J. H. (2015). Dissociable effects of salience on attention and goal-directed action. Current Biology, 25(15), 2040–2046. doi: 10.1016/j.cub.2015.06.029
- Munneke, J., Hoppenbrouwers, S. S., & Theeuwes, J. (2015). Reward can modulate attentional capture, independent of top-down set. Attention, Perception, & Psychophysics, 77(8), 2540–2548. doi: 10.3758/s13414-015-0958-6
- Pearson, D., Donkin, C., Tran, S. C., Most, S. B., & Le Pelley, M. E. (2015). Cognitive control and counterproductive oculomotor capture by reward-related stimuli. Visual Cognition, 23(1–2), 41–66. doi: 10.1080/13506285.2014.994252
- Pool, E., Brosch, T., Delplanque, S., & Sander, D. (2014). Where is the chocolate? Rapid spatial orienting toward stimuli associated with primary rewards. Cognition, 130(3), 348–359. doi: 10.1016/j.cognition.2013.12.002
- Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 18(3), 849–860.
- Roper, Z. J., Vecera, S. P., & Vaidya, J. G. (2014). Value-driven attentional capture in adolescence. Psychological Science, 25(11), 1987–1993. doi: 10.1177/0956797614545654
- Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51(6), 599–606. doi: 10.3758/BF03211656
- Theeuwes, J. (1995a). Temporal and spatial characteristics of preattentive and attentive processing. Visual Cognition, 2(2–3), 221–233. doi: 10.1080/13506289508401732
- Theeuwes, J. (1995b). Abrupt luminance change pops out; abrupt color change does not. Perception & Psychophysics, 57(5), 637–644. doi: 10.3758/BF03213269
- Theeuwes, J. (2010). Top–down and bottom–up control of visual selection. Acta Psychologica, 135(2), 77–99. doi: 10.1016/j.actpsy.2010.02.006
- Theeuwes, J., & Belopolsky, A. V. (2012). Reward grabs the eye: Oculomotor capture by rewarding stimuli. Vision Research, 74, 80–85. doi: 10.1016/j.visres.2012.07.024