
ABSTRACT
We spontaneously orient our attention towards people whose gaze we have led (the “gaze leading” effect). Here, we investigated whether this orienting effect is sensitive to the social and emotional content of the stimuli within the interactions. Experiment 1 replicated the gaze leading effect but found no reliable influence of facial dominance or object valence. Experiment 2, where only object valence was manipulated, replicated Experiment 1. Thus, the gaze leading effect appears reliable but insensitive to the properties of the shared referent object. Experiment 3 varied only facial dominance; a marginally significant interaction indicated that attention was deployed towards high-dominant faces more than low-dominant gaze followers. Experiment 4 varied the social information relating to the social status that participants hold regarding the faces with which they interacted, but statistical support for an influence of biographical information on gaze leading was weak. Overall, the gaze leading effect appears generally reliable, and may vary when information about the individuals following our gaze is manipulated, though it is not yet fully clear which socio-evaluative features are most relevant. Future investigations may therefore require more powerful or sensitive designs to better evaluate the role of socioemotional factors and processes on this social orienting effect.
Humans can use the social attention cues of others to learn about our environment (see Emery, Citation2000; Frischen et al., Citation2007 for reviews). The intent to have a conspecific follow our gaze and “share” attention towards a common referent has been suggested to be uniquely human (Tomasello & Carpenter, Citation2007; Saxe, Citation2006). The social facilitation associated with sharing attention may even be the mechanism by which humans maintain such large social groups. Joint attention involves an initiator who leads a gaze follower to look at a common object (Mundy & Newell, Citation2007). The basis of the attention shift involved in gaze following has been elucidated in recent years using the gaze cueing paradigm that shows that orienting in the direction in which someone else is looking appears to occur in a rapid and robust manner (e.g., Driver et al., Citation1999; Friesen & Kingstone, Citation2003; see Frischen et al., Citation2007, for review). More recent work has shown that the distribution of spatial attention of the gaze leader is also affected by being followed. Specifically, our attention shifts to the face of the person who has followed our gaze (Edwards et al., Citation2015). This indicates that people who follow our gaze to engage in shared attention are prioritized for visual processing, and this attention shift could assist with the maintenance and evaluation of an ongoing social exchange. Here, we aim to extend the findings of Edwards et al. (Citation2015), assessing the general hypothesis that the gaze leading effect reflects an attentional outcome of a social process wherein the shared attention state is evaluated as a social exchange. Therefore, this attentional effect should be influenced by the social context of the stimuli involved including face identity and object valence.
Gaze leading
Recent headway has been made regarding our understanding of gaze leading processes. For example, using interactive paradigms whereby stimuli respond in real time to a participant’s own gaze direction (hence placing the participant as the gaze leader) has revealed that gaze leading influences cognitive and affective processing (see Stephenson et al., Citation2021, for review). For example, in a virtual environment, Kim and Mundy (Citation2012) showed that recognition memory for pictures that participants and virtual agents jointly attended was higher when the participant had initiated shared attention than when the participant had responded to observed gaze. Memory for the face identities involved in social attention is also influenced by gaze leading, as shown in two social learning studies. Dalmaso et al. (Citation2016) showed that faces whose gaze participants had led in phase 1 of an experimental session were subsequently less effective as gaze cueing faces in phase 2 – participants did not follow the eyes of the people they had earlier led. Remarkably, this effect seems to extend to the observation of gaze leading, where faces who are observed to follow the gaze of other faces also do not drive gaze cueing very strongly (Capozzi et al., Citation2016). These processes that relate to memory and social learning in gaze leading may be related to affective processes. For example, in interactive fMRI studies, initiating joint attention engaged neural reward systems more than responding to joint attention (Gordon et al., Citation2013; Schilbach et al., Citation2010). The socio-affective reward associated with initiating social attention has also been shown to enhance the likability of faces whose gaze has been led (Bayliss et al., Citation2013; Grynszpan et al., Citation2017).
Most pertinent to the current work however is the finding that a gaze leader, once followed, will rapidly orient their own visual attention towards the face of the follower (the gaze leading effect, Edwards et al., Citation2015). This novel social attention response can thus be seen as a mechanism in the human attention system by which humans are prompted to develop joint gaze encounters into the more high-level instance of shared attention that requires awareness of mentalistic agents (see Emery, Citation2000). The original demonstration of the gaze leading effect (Edwards et al., Citation2015) showed that this effect is reliable, replicating across three experiments, while also illustrating a number of key and interesting boundary conditions in three additional experiments. Specifically, the first experiment we conducted involved the participants maintaining central fixation on a fixation cross flanked by faces to the left and to the right. The faces would open their eyes and all look left or right prior to a target appearing on one of the faces for speeded discrimination. In this first experiment, contrary to Edwards et al.’s hypothesis of attention prioritization of faces that look where we look, a basic gaze cueing effect was found – attention oriented in the direction of observed peripherally-presented gaze. The second experiment was more “active,” with the participant looking from one fixation cross at the bottom of the screen, then to a central fixation cross, an action that would gaze contingently trigger the faces to “respond.” This more active design led to a null effect on attention orienting. The third experiment (Experiment 1 in Edwards et al., Citation2015) enhanced the ecological context further by retaining the active, gaze-contingent element of the design, but replaced the central fixation cross with an image of an everyday household object. Now, we observed the gaze leading effect, with attention orienting to the face engaging in joint attention. This final gaze leading effect was then replicated twice (3 demonstrations in total), confirming its presence. Finally, another supplementary experiment showed that replacing the faces with arrows led to a cueing effect (not a leading effect). Together the results over 6 experiments described by Edwards et al. (Citation2015) already tell us many things: (1) Context modulates the attentional consequences of observing averted gaze in complex, dynamic ways, (2) At least two orienting effects are triggered in these experiments that directly oppose each other – gaze cueing and gaze leading. The first observation motivates our overall study in the present manuscript – to investigate other contextual factors beyond the importance of object presence and participant engagement as an active agent. The second speaks to a more nuanced point about the spatial distribution of attention in such experiments. Specifically, as argued in Edwards et al. (Citation2015) and note here that the difference in performance between the two critical conditions (joint attention vs. non-joint attention) in these experiments reflect the relative strength of two orienting responses triggered by observing averted gaze in the periphery. One is gaze cueing and the other is gaze leading – an advantage for targets at the non-joint attention face reflects the dominance of gaze cueing (or gaze following) as in the first experiment conducted by Edwards et al. (Citation2015; i.e., passive, no object). The second supplementary study showed a null effect, reflecting an equilibrium between the two orienting effects. When objects are introduced in an active task, however, gaze leading is stronger than gaze cueing, and therefore dominates the orienting response, showing an advantage for targets on the face who engaged in joint attention. Therefore, from the start of the original project to find evidence of a gaze leading effect on attention, we were cognizant that it might be challenging to find evidence for its presence given the strength of gaze cueing. Nevertheless, further extensions to this paradigm could be highly informative as attempts are made to pick apart the underlying nuances of the social attention mechanisms relating to gaze leading, much in the same way that manipulations of the gaze-cueing paradigm allowed us to learn so much about gaze following (see Frischen et al., Citation2007 for review).
The object of shared attention
The distribution of spatial attention is driven in part by the objects that occupy space (e.g., Tipper et al., Citation1991). Similarly, social attention seems to be object-based. It is only once the developmental milestone of working out what others are looking at, as opposed to where, that we can begin to jointly attend with others by following their gaze (Butterworth, Citation1991). Object-based joint attention is what distinguishes mere gaze following from joint attention (Emery, Citation2000) and jointly attending objects with others can be seen as critical to language acquisition (Baldwin, Citation1995). Further, infants appear to prefer gaze that is directed towards objects, than gaze directed elsewhere (Senju et al., Citation2008), possibly evidencing an early preference of, and expectation that, other’s will look at interesting objects. Indeed, our perception of observed gaze is biased towards nearby objects (Lobmaier et al., Citation2006). In adults, gaze cueing is stronger towards coherent target objects than incoherent patterns (Bayliss & Tipper, Citation2005; see also Marotta et al., Citation2012, for evidence of differences between how objects influence arrow – and gaze cueing of attention), and our own affective evaluation of objects is influenced by seeing another person gaze at that object – we like things more when others look at them (e.g., Bayliss et al., Citation2006; Manera et al., Citation2014). Thus, objects can be seen as crucial for social gaze-based interactions (Becchio et al., Citation2008).
Given the above, it is perhaps not surprising that objects appear to be influenced by gaze leading encounters too. Bayliss et al. (Citation2013) showed that when forced to choose which of two objects one prefers, people will more consistently choose the same objects as their “preferred” across trials, if that object was the recipient of joint gaze in which they had been the gaze leader, suggesting that having one’s gaze followed to an object helps solidify affective preference judgements. Further, one of the key boundary conditions highlighted by Edwards et al. (Citation2015; noted above) in the original demonstration of the gaze leading effect was the sensitivity of this orienting response to the presence of an image of a real-world object. Thus, we can expect that manipulating various properties relating to the shared referent object of a joint gaze encounter may result in interesting modulations of the gaze leading effect, thus revealing more information regarding the underlying mechanisms of gaze leading.
Previous work has explored the affective content of target images in gaze cueing paradigms. For example, Bayliss et al. (Citation2010) showed boosted gaze cueing for pleasant target images cued by smiling faces, illustrating some evidence for contextual congruency boosting social attention. More recently, it has been shown that the valence of the looked at the object in a gaze cueing task has consequences for our perception of the cueing face–face identities that happen to cue our attention towards positive images are rated as more trustworthy than faces that cue attention towards unpleasant images (Shirai & Ogawa, Citation2020). Therefore, it appears that there is a complex array of protentional bidirectional effective influences within such triadic interactions. Therefore, in the current work, being the first to modulate the affective content of objects in a gaze leading study, comparing the influence of object valence on the observability of the gaze leading effect seemed a potentially fruitful starting point.
Cue face characteristics in social attention
We have also learned a great deal about joint gaze encounters, from the perspective of the gaze follower, by manipulating the faces in the gaze-cueing paradigm. For example, physical, static facial information in the cueing face can influence the amount of attention orienting that face elicits (e.g., dominance, Jones et al., Citation2010). Our exposure to faces similarly impacts cueing such that we are cued more by more familiar faces (e.g., Deaner et al., Citation2007). Subsequent work has also revealed that changeable features of the face such as emotional expression (e.g., Tipples, Citation2006) and social knowledge relating to the faces can modulate the cueing elicited by those faces (Dalmaso et al., Citation2012; Dalmaso et al., Citation2014; Hudson et al., Citation2012). As noted in the previous section, there is further evidence of interplay between facial – and object-based information. For example, Kuhn and Tipples (Citation2011) found that an expectedly larger gaze cueing magnitude for fearful over happy faces was sensitive to target valence, disappearing when a looked at object was pleasant. Thus, a nuanced sensitivity to social information relating to and signalled by the face can be seen to be highly linked to the rapid social orienting response of gaze cueing.
The gaze leading effect may offer similar advances in our understanding of social attention, if for example modulations relating to the faces and objects in the interaction are revealed. Given the socio-evolutionary importance of dominance hierarchies (e.g., Chance, Citation1967; Shepherd et al., Citation2006) and the advantage that gaze following allows for threat detection (see Emery, Citation2000), we decided to focus on physical dominance cues and signals of potential threat. Indeed, attention orienting to high-dominant conspecifics has been linked to threat assessment (Lansu & Troop-Gordon, Citation2017). Dominance seems to be a relatively consistent modulatory factor in social attention studies overall and specifically may pertain directly to the actions involved in gaze leading. We know, for example, that in primates social hierarchies moderate gaze cueing such that dominant individuals only follow the gaze of other dominant individuals and ignore the gaze of low-ranking individuals (Shepherd et al., Citation2006). Moreover, in humans, there is evidence that being a follower of gaze leads to one’s gaze being a less powerful gaze cue (Capozzi et al., Citation2016; Dalmaso et al., Citation2016). Finally, we also know that implicit and explicit signatures of control are triggered when successfully leading gaze (Stephenson et al., Citation2018). Therefore, we can hypothesize that the strength of attentional response to registering that a dominant vs. non-dominant individual has followed one’s gaze could be different. Specifically, being followed by a dominant person should be registered as a more socially consequential event than being followed by a non-dominant individual and therefore a stronger gaze leading effect should emerge from observing a dominant person following one’s gaze.
The present study
Here we conducted four experiments to investigate the potential for gaze leading paradigms to extend our knowledge of human social attention systems by varying object and facial properties within the joint gaze interaction. Experiment 1 varied both the facial and object properties within the gaze leading encounter. Experiment 2 varied only the object properties, while Experiment 3 varied only the face properties Finally, in Experiment 4 we varied the social knowledge that participants had about the faces that followed their gaze, in order to investigate how higher-level social knowledge (as opposed to physical characteristics) can impact the way in which having one’s gaze followed is interpreted.
Experiment 1
Our first experiment was a replication of the general procedure of Edwards et al. (Citation2015, Experiment 2) wherein participants are instructed to move their eyes from one location to another when an object appears at the second location. Once this eye movement has occurred, two on-screen faces shift their gaze – one follows the participant’s gaze and the other face looks elsewhere. To extend beyond Edwards et al., here we varied two socio-emotional factors that might affect the strength of this social orienting response. The on-screen faces varied in their facial dominance, and the referent objects varied in their potential threat value. On each trial, both on-screen faces (follower and non-follower) were presented as either physically high- or low in perceived dominance. The images serving as objects were either neutral or threat-related in content, allowing us to examine whether the content of the jointly attended object might modulate the gaze leading effect; a stronger gaze leading effect was expected with high-threat stimuli. Further, manipulating both dominance and object valence may be important as past work has demonstrated that the difference in social attention responses to high- and low- dominance faces is sensitive to the threat-related context of the interaction (Cui et al., Citation2014). We predicted that high-dominance faces would command stronger gaze leading effects, especially in high-threat contexts due to previous research suggesting that the gaze of high-dominance individuals is monitored more consistently (Shepherd et al., Citation2006). In this and each subsequent experiment, we varied the stimulus onset asynchrony between the participants gaze fixation of the central object and target onset (100 or 400 ms) as we did in Edwards et al. (Citation2015). This was to replicate the study directly by affording participants a similar temporal experience of stimulus progression (i.e., to maintain unpredictability in the cue-target temporal gap). However, due to the introduction of new variables of interest not studied in Edwards et al. (Citation2015), we decided not to analyse the SOA factor because it was not the focus of our investigation here and did not previously elicit findings of sufficient interest to justify the required increase in trial numbers to maintain an adequate number of observations per cell at the participant level.
Method
In all experiments, we have reported how we determined our sample size, all data exclusions (if any), all manipulations, and all measures we have collected (see Simmons et al., Citation2012). All experiments were approved by the School of Psychology ethics committee at the University of East Anglia. The data on which statistical analyses were performed can be found here: https://mfr.osf.io/render?url=https%3A%2F%2Fosf.io%2Fue36k%2Fdownload
Participants. We aimed for a final sample size of 32 to match that of most experiments in our previous work (Edwards et al., Citation2015). We stopped collecting data at n=35 (3 men) for convenience at the end of a block of booked testing sessions. Participants from the University of East Anglia completed the experiment in return for course credit or payment. Four participants were excluded due to eye-tracking difficulties, hence N=31 (Age; M=22.3 years, SD=7.6 years), of which 6 participants completed only 3 blocks and a further 3 completed only 2 blocks due to eye-tracking problems. All reported normal or corrected-to-normal vision.
Apparatus and stimuli. Face stimuli were selected from Todorov et al. (Citation2013; see also see Oosterhof & Todorov, Citation2008), which contains a validated set of male faces of different computer-generated identities that are morphed along a continuum of “dominance” (ranging from −3 to +3). We selected 32 images: +2 and −2 “dominance” versions of 16 identities (117 × 186 pixels). Each participant saw only one version (high or low dominance) of each identity, counterbalanced. A version of each face was created such that the face’s gaze could be displayed as “direct,” “leftward” or “rightward.”
The referent stimuli were created by trimming 16 affective pictures (resulting size: approximately 150 × 130 pixels), 8 containing potential threat, 8 without threat (see Lang et al., Citation1997), selected based on prior ratings of pleasure and arousal. The threatening (negative) object pictures were chosen based on low pleasure (M=3.76) and high arousal (M=5.76) and contained pictures such as weapons and animals with teeth bared. The nonthreat (neutral) object pictures were chosen based on medium levels of rated pleasure (M=5.13) and low in arousal (M=3.41), for example, a mug, a clock, and a towel.
On a given trial, two faces were displayed on the midline of the screen, each 33mm to the left or right of centre (see ). Face identities were randomly assigned to each position on each trial, with the constraint that a given identity could only appear in one location per trial. Target letters (N or H) were size 18 bold purple Arial text (4mm × 4mm), on a white background (6mm × 6mm) on the bridge of the nose of the target face. Stimulus presentation was controlled by a standard desktop computer running E-Prime (Psychology Software Tools, Pittsburgh, USA), with an 18′ screen (pixel resolution 1024 × 768) and manual responses were made on a standard keyboard.
Figure 1. Panel A: Example timecourse of displays presented in a single trial, progressing from left to right. The faces are examples of “low dominance” stimuli used in Experiments 1–3, and the example trial represents a congruent “joint attention” condition because the target appears on the face that followed the participant’s eyes to the object. Panel B: The left image illustrates an example of high physical-dominance faces and a threat related object, and the right image contains examples of the faces from Experiment 4.
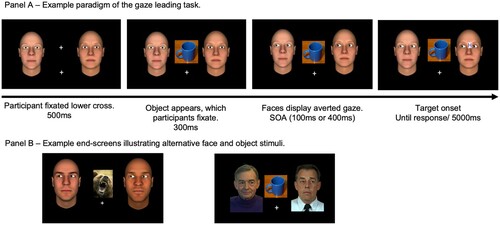
To allow for gaze-contingent progression during the trial sequence, right eye position was tracked using an infrared eyetracker (Eyelink 1000, SR Research, Ontario, Canada; spatial resolution 0.1°, 500 Hz). Head stability was maintained using a chin rest 70 cm from the monitor. Finally, in this and subsequent experiments, the Autism Spectrum Quotient (AQ) questionnaire was used to measure autistic-like traits of participants (Baron-Cohen et al., Citation2001), which has previously been shown to share a relationship with social orienting of attention (e.g., Bayliss et al., Citation2005; Bayliss & Tipper, Citation2005; Edwards et al., Citation2015). We discuss the findings of the AQ in Supplementary Material.
Design. A 2 (Target Location: “Joint Attention Face”; “Non-Joint Attention Face”) × 2 (Facial dominance: High; Low) × 2 (Object valence: Neutral; Negative) within subject design was employed. Here and in each experiment, stimulus onset asynchrony (SOA) was also varied but was not statistically analysed (SOA: 100ms; 400ms).
Procedure. Each trial began with a central fixation cross and a second fixation cross, located 65 mm below. Two faces were also presented, located on either side of the central fixation cross along the midline with direct gaze. The two faces were always the same level of dominance. Each session began with six practice trials to familiarize participants with the gaze leading task. Following this, participants completed four blocks of 64 trials. The entire session took approximately 1 hour. Participants had to fixate on the lower fixation cross for 500 ms thereby triggering an object to appear and replace the central fixation cross. The appearance of the object was their cue to saccade from the lower fixation cross to the object. Following a fixation on the object for 300 ms, both faces would avert their gaze in the same direction, either left or right. Thus, one face would look towards the central object (jointly attending with the participant) while the other face looked away from the participant’s referent. After either 100 or 400 ms SOA a target would appear on the bridge of the nose of one face, to which participants made speeded manual identification on a standard keyboard, pressing the “H” key with the index finger of their dominant hand for the target H and the space bar with their thumb on the same hand for the target letter N. The trial would timeout after 5000 ms if the participant made no response. A feedback screen was presented for 1500 ms after each trial: if a correct response was made the screen remained black, if an incorrect or non-response occurred then a red cross appeared centrally. The importance of speed and accuracy of responses were impressed on participants. The experiment comprised a total of 256 trials over four blocks. The experimenter was present for the duration of the session.
Results
Trials in which an incorrect response was made (2.2%) were removed as were trials where the eyetracker failed to register fixation of the correct location preventing gaze-contingent trial progression (0.98%). Trials with correct reaction times 3SDs above or below the participant’s mean were removed (1.59%) before the means for each condition were calculated. Percentage accuracy for each condition was also calculated. The same exclusion criteria were used in all experiments.
Accuracy. On average correct responses were made on 97.8% of trials (SD = 1.83%). A 2 (Target Location: “Joint Attention Face”; “Non-Joint Attention Face”) × 2 (Facial dominance: High; Low) x 2 (Object valence: Neutral; Negative) repeated measures ANOVA was conducted on participants’ mean accuracy. There were no significant main effects Face dominance, F(1,30) = .97, p=.334, η2p = .03; Object valence F(1,30) = 2.67, p=.112, η2p = .08, Target Location, F(1,30) = 1.09, p=.306, η2p = .04, or interactions, F’s<1.
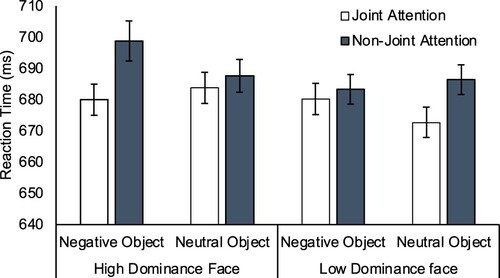
Reaction times. A 2 (Target Location: “Joint Attention Face”; “Non-Joint Attention Face”) × 2 (Facial dominance: High; Low) × 2 (Object Valence: Neutral; Negative) repeated measures ANOVA was conducted on mean reaction times. There was a main effect of Target Location, F(1,30) = 4.293, p = .047, η2p=.125, as targets were more quickly identified when appearing on the joint attention face (M = 679ms, SE = 23.75) than the non-joint attention face (M = 689ms, SE = 23.71), replicating the gaze leading effect on attention reported by Edwards et al. (Citation2015). There was no main effect of Facial Dominance, F(1,30) = 2.281, p = .141, η2p=.071, or Object Valence, F(1,30) = 0.516, p = .478, η2p=.017. No interaction effect was observed between attention Target Location and Facial Dominance, F(1,30) = 0.136, p = .715, η2p=.005, between attention Target Location and Object Valence, F(1,30) = 0.108, p = .744, η2p=.004, or between Facial Dominance and Object Valence, F(1,30) = 0.050, p = .824, η2p=.002. Finally, the three-way interaction was not significant, F(1,30) = 1.950, p = .173, η2p=.061 (see ). For completeness we also conducted planned contrasts exploring the gaze leading effect in each of the four conditions, comparing Target Location in the four different face/object combinations. None of these four contrasts were statistically significant (p’s > .09, dz < 0.32), meaning that while the main effect was significant overall, there was insufficient stability in any given condition in isolation to yield a reliable effect.
Figure 2. Mean reaction times (ms) in each condition in Experiment 1. Error bars are within-subjects standard error for the 3-way interaction term (Loftus & Masson, Citation1994).
Discussion
Participants were faster to correctly identify targets appearing on faces that followed their gaze, compared with faces that looked elsewhere. Thus, participants preferentially shifted their attention towards the onscreen face that had followed the gaze of the participant. This experiment showed that the gaze leading effect replicated with a new stimulus set. We note that, as per Edwards et al. (Citation2015) and our reading of the extant literature on gaze cueing, we did not aim to distinguish between overt or covert attention orienting – our instructions requested participants to maintain central fixation but we did not measure or enforce this. Covert shifts of attention can be viewed as preparatory for overt shifts (e.g., Smith et al., Citation2010). Nevertheless, future work may wish to investigate whether attention orienting during gaze leading encounters is at all limited to covert or overt attention. Indeed, when instructed to overtly look back at a face after looking away, participants do execute these voluntary saccades more rapidly under unspeeded conditions (Bayliss et al., Citation2013), so there will likely be further informative outcomes from future gaze leading paradigms that focus on overt and covert attention. It is somewhat surprising however that the gaze leading effect was not reliably modulated by the valence of the object or the dominance of the on-screen faces. However, previous gaze leading research indicates that it may not be straightforward for the gaze leader to encode and learn both the consistency of the referent object and the gaze follower within the same interaction (see Bayliss et al., Citation2013, Experiment 4, where manipulating multiple contingencies disrupted affective evaluation effects, and also Rogers et al., Citation2014 for a similar impact in a gaze cueing paradigm). Therefore, the following experiments included modulations of the gaze leading effect by varying only one key stimulus-display feature at a time (i.e., manipulating facial appearance or object characteristics in different experiments).
Experiment 2
Here we replicated Experiment 1, but we did not vary the facial dominance of the on-screen faces (i.e., all faces appeared as neutral in physical dominance). Now that only one aspect of the interaction is consistently varied – object valence – participants may be better able to code and track this manipulation, which could result in a modulated gaze leading effect. Here we predict a stronger gaze leading effect in the context of a threatening stimulus. Although one may predict that less attention will be paid to the faces on trials with threatening images – as the threat-image may capture attention over and above the faces – one may also reasonably expect that social referencing in threatening situations may be heightened because knowing who else has registered the threat may aid in mitigating the potentially dangerous situation.
Method
Participants. In this experiment, we increased our target sample size to 40 in order to increase statistical power given the null effect of stimulus categories in Experiment 1. We recruited n=42 participants and terminated testing for convenience at the end of a block of laboratory bookings. Three participants were excluded due to tracking difficulties, leaving a sample of n=39 (six men) for statistical analysis. The participants (age; M=19.5 years, SD=0.9 years) were given course credit and had normal or corrected-to-normal vision. Due to calibration and eye-tracking difficulties one participant completed only three of the four blocks.
Apparatus and stimuli. The stimuli were the same as in Experiment 1 except that the faces were not varied in terms of dominance. Accordingly, the same identity of faces were selected, but we used the morphed version of these identities that were halfway between the high- and low-dominant faces on the dominance scale from Experiment 1 (see Todorov et al., Citation2013).
Design & procedure. The experimental design was the same as Experiment 1, except that the face-type was not varied – hence a 2 (Object Valence: negative; neutral) × 2 (Target Location: joint attention; non-joint attention) repeated measures design. The procedure differed from Experiment 1 only in that there were half as many trials (128 trials, because one factor was dropped compared with Experiment 1).
Results
Accuracy. On average, correct responses were made on 97.18% of trials (SD = 3.04%). There was no significant main effect of Target Location, F(1,38) < 1, or Object Valence F(1,38) = 1.45, p=.24, η2p = .037, and no significant interaction, F(1,38) < 1.
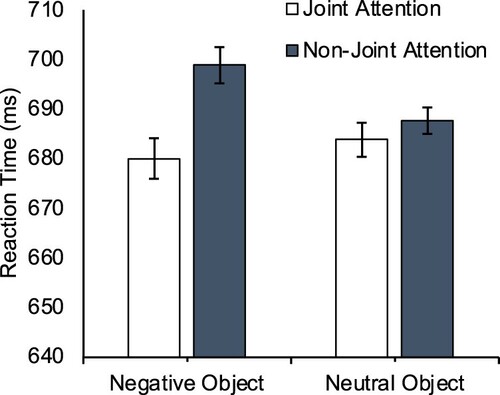
Reaction times. 1.5% of trials were discarded as outliers. The main effect of Target Location was significant F(1,38) = 4.14, p = .049, η2p = .10, with faster responses to targets appearing on the joint attention face (603ms) vs the non-joint attention face (612ms). There was no significant effect of Object Valence, F(1,38) = .18, p=.678, η2p=.005, nor an interaction F(1,38) = 1.48, p=.231, η2p=.038. For completeness, we report planned contrasts between the Joint Attention and Non-Joint Attention face target locations for each object valence; these showed that gaze leading was significant for trials containing a negative object, t(38)=−2.07, p=.046, dz = .33, but not for trials containing neutral objects, t(38)=-.70, p=.49, dz = .11 (see ).
Figure 3. Mean reaction times (ms) for each condition in Experiment 2. Error bars represent within-subjects standard error of the interaction term.
Discussion
This experiment again replicated the overall gaze leading effect, but again showed no reliable influence of contextual factors such as object valence. Thus, the gaze leading effect appears to be somewhat robust to modulations relating to the referent object. However, it is notable that, although there was no gaze leading effect by object valence interaction, the planned comparisons of the gaze leading effect show that the effect was confined to the negative valenced object condition. Thus, future work may look to further assess the extent to which information relating to the referent object of a joint gaze encounter can influence the gaze leader’s perception of and attention to that interaction, as well as more broadly suggesting that the valence information within a gaze leading encounter may modulate the gaze leader’s attentional orientating within that interaction.
Experiment 3
In this Experiment we turn our attention to the other agent within the joint attention interaction, manipulating the facial dominance while keeping the object valence neutral to explore whether social information from the face can modulate gaze leading when manipulated in isolation.
Method
Participants. In order to maintain cross-experiment comparison, we maintained the same final target sample size as in Experiment 2 (i.e., n=40), erring on the side of over-sampling in anticipation of full- or part-session data quality issues. Forty-seven participants (ten men) at the University of East Anglia (age; M=20.2 years, SD=3.0 years) completed the study in return for course credit. All had normal or corrected-to-normal vision. Due to calibration and tracking difficulties six participants completed only three blocks of the four, but were retained for analysis. An additional participant was excluded from analysis due to significant problems maintaining attention during the task (i.e., they fell asleep).
Apparatus and stimuli. In this experiment, one of sixteen images of kitchen objects (taken from Bayliss et al., Citation2006) were randomly presented as the joint attention referent (as in the original illustration of the gaze leading effect; Edwards et al., Citation2015). The faces from Experiment 1 were used, such that each trial contained either two high- or low-dominant faces.
Design and procedure. The design was a 2 (Target Location) × 2 (Facial Dominance) repeated-measures design. The procedure was otherwise identical to Experiment 2.
Results
Accuracy. On average correct responses were made on 96.69% of trials (SD = 5.36%). There was no significant main effect of Target Location, F(1,46) = .12, p=.734, η2p=.003, or Face Type, F(1,46) = 0.01, p=.926, η2p>.001, and no significant interaction F(1,46) = 3.387, p=.072, η2p = .069.
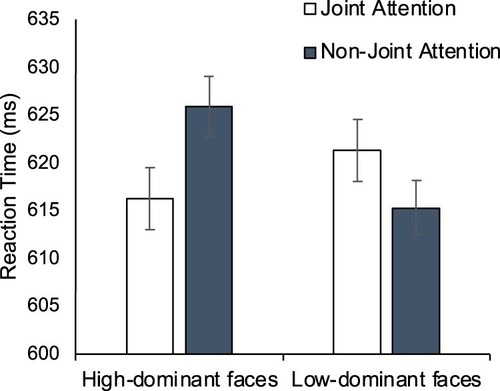
Reaction times. 1.5% of trials were discarded as outliers. There was no significant main effect of Face Type, F(1,46) = 0.79, p=.378, η2p=.017, or Target Location, F(1,46) = 0.24, p=.628, η2p=.005. However, there was a marginally significant interaction, F(1,46) = 4.06, p=.05, η2p=.081. This was due to a larger gaze leading effect for high-dominance trials (10 ms) than for low-dominance trials (−6 ms). However, planned contrasts showed that neither the gaze leading effect for high-dominance trials nor the reverse for low-dominance trials were significant, t(46)=−1.73, p=.091, dz=.25, t(46) = 1.16, p=.254, dz=.17, respectively (see ).
Figure 4. Mean reaction times (ms) for each condition in Experiment 3. Error bars represent within-subjects standard error of the interaction term.
Discussion
In this experiment, there was no overall gaze leading effect, but this was explained by the significant interaction showing a stronger gaze leading effect in response to high compared with low-dominance faces. Further work to confirm this finding and specify the reason for its emergence is required. For example, it could be that participant’s differing responses to the two face types are dominance-specific. However, as discussed in the introduction, dominance is related to a threat, and so it may be that the mechanism by which the current findings emerge is better explained by threat than by dominance. To attempt to generalize our tentative findings to the social construct of dominance more generally, we note that Dalmaso et al. (Citation2012) showed that the social information that we know about a person (e.g., their social status as described in vignettes) influences how our attention is cued by them. Similarly, then, it is possible that our registration of other’s responses to our own gaze behaviour may be similarly sensitive to non-visual social information such as person knowledge related to status/dominance.
Experiment 4
In this experiment we manipulated the social status of people in stimulus photographs by assigning the faces high- or low-status biographies, allowing us to keep visual cues controlled across participants. We predicted that stronger joint attention processes would be revealed in interactions with high-status individuals, which would be in line with both the significant interaction observed in Experiment 3 but also with prior work on gaze cueing in humans and other primates (e.g., Dalmaso et al., Citation2012; Shepherd et al., Citation2006).
Method
Participants. We again targeted a final sample size of approximately 40 participants and over-sampled to account for anticipated data loss. In this experiment, we followed the face-biography learning procedure of Dalmaso et al. (Citation2014), wherein participants who fail to hit a learning threshold are excluded. Data collection, therefore, targeted an initial sample of 60 and was terminated when this was reached. Therefore, an initial sample of sixty participants volunteered in return for course credit. After removing sixteen participants that did not pass the manipulation check, our final sample on which statistical analyses were performed comprised 44 adults (mean age 19.9 years, 7 men).
Apparatus and stimuli. The face stimuli consisted of 6 colour photographs of older Italian male adults aged between 50 and 60 years old with a neutral expression (see Dalmaso et al., Citation2014). The faces were manipulated to be looking either left, right or straight ahead. Half of the face identities, counterbalanced, were paired with short CV’s which were high-status (e.g., Dean of a Faculty of Medicine) and the other half paired with low-status CV’s (e.g., Retired factory worker) (Dalmaso et al., Citation2014). The objects were those used in Experiment 3.
Design and procedure. A 2 (Social status of faces: High status, low status) × 2 (Target Location: Joint attention, non-joint attention) within-subjects design was used. Our procedure followed closely that of Dalmaso et al. (Citation2014) with the gaze leading task placed between a face-biography learning task and a manipulation check.
During the learning phase, each face was presented on the screen along with a short descriptor relating to the social status of that face. For each participant, half of the faces were paired with high-status descriptors and the other half were paired with low-status descriptors. Face identity – social status pairings were counterbalanced between participants. Participants were asked to memorize the faces and the statements in their own time, pressing the spacebar when they wanted to move onto the next face. To check that the face identity – social status pairing had been learned, participants next completed a categorization task. Each face was presented in isolation for 900 ms and participants were required to correctly categorize each face as either high or low status, pressing the Z and M keys, respectively. A green “correct” would appear for a correct response and a red “incorrect” would appear for an incorrect response and a white “too slow” would appear for any response not registered in time. Each face was presented twice in a random order totalling 12 trials. Participants were required to correctly identify all 12 face presentations before moving on to the main gaze leading task. Sub-100% performance resulted in a repeat of the 12-trial categorization cycle. If a participant could not reach 100% performance within 8 cycles, they would return to the initial learning phase.
Participants then completed the gaze leading task identical to Experiment 3 aside from the different face stimuli. Then, participants completed a manipulation check in which each face identity was re-presented in isolation and participants were asked to categorize the face as either high or low status; 16 participants who made at least one error in this manipulation check were removed from analyses. The sessions took approximately 1 hour.
Results
Accuracy. A 2 (Social Status: High, Low) × 2 (Target Location: Joint, Non-joint) ANOVA on accuracy revealed no main effect of Social Status, F(1,43) = .70, p=.407, η2p = .02, nor of Target Location, F(1,43) = .07, p=.788, η2p <.01. There was also no significant interaction, F(1,43) < .01, p=.951, η2p <.01.
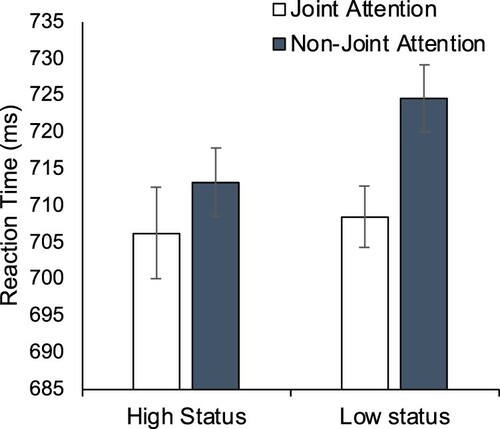
Reaction times. A 2 (Social Status: High; Low) × 2 (Target Location: Joint; Non-joint) ANOVA on mean reaction times revealed no main effect of Social Status, F(1,43) = 1.90, p=.176, η2p = .04. The main effect of Target Location revealed only a trend towards a gaze leading effect, F(1,43) = 3.97, p=.053, η2p = .084, with responses to targets appearing on the Joint Attention face being quicker (707 ms) than to those on the Non-joint Attention faces (719 ms). There was no significant interaction, F(1,43) = .53, p=.471, η2p = .012. Planned contrasts that show that the gaze leading effect was robust in response to low-status faces, t(43)=−2.21, p=.032, dz = .33, but not for high-status faces, t(43)=-.71, p=.48, dz = .11 (see ), the opposite pattern to that of Experiment 3 that compared visual cues of dominance instead of biographically driven knowledge of social status.
Figure 5. Mean reaction times (ms) for each condition in Experiment 4. Error bars represent within-subjects standard error of the interaction term.
Discussion
In this experiment, the gaze leading effect was not significant overall and did not interact significantly with the social status manipulation. We had predicted greater attention orienting to faces that follow gaze that are high (compared to low status). If anything, the data followed the converse pattern with gaze leading observed on low-status trials. Given the failure to replicate the overall gaze leading effect in this context, it appears clear that a more substantial sample is required for future investigations and suggests that should any social-status modulations related to gaze leading exist, they may be more challenging to detect than those associated with gaze cueing (c.f. Dalmaso et al., Citation2012). An alternative explanation for the weak gaze leading effect in the high status condition is that the strength of the initial gaze cueing effect (counter to the gaze leading effect) is stronger for high status individuals (Dalmaso et al., Citation2012; Citation2014), meaning that the subsequent gaze leading effect was unable to dominate the orienting of spatial attention (see Edwards et al., Citation2015). A design with neutral trials capable of describing costs and benefits of attentional orienting could help evaluate this interesting possibility.
General discussion
This study aimed to explore the contextual factors that might influence the strength of the attentional orienting response towards someone who follows our gaze (the gaze leading effect; Edwards et al., Citation2015). The first two experiments replicated the gaze leading effect, while showing no reliable impact of varying both facial dominance and object valence, or varying only object valence, respectively. However, when only facial dominance was varied but the object features were not, Experiment 3 suggests that we orient our attention more to high-dominant faces that follow our gaze compared with low-dominant faces. Finally, Experiment 4 showed that social status does not appear to robustly modulate the extent to which we deploy attention to those that follow our gaze.
Effect sizes and evidence quality
It may be helpful to note and discuss the effect sizes of the gaze leading effect in both Edwards et al. (Citation2015) and those observed here in order to explore the overall size and reliability of the gaze leading effect itself. In Edwards et al. (Citation2015) we suggested and presented evidence that the gaze leading effect was present in the context of an opposing force of gaze cueing – when participants orient to the face that followed their gaze, their attention is relatively distributed in the opposite direction to the direction of those observed eyes. That is, the gaze leading effect emerges in direct opposition to the gaze cueing effect. We may therefore expect this effect to be small due to the requirement for the mechanism underpinning gaze leading to hold a stronger influence over the attention system than the mechanisms underpinning gaze cueing. In both the present study and Edwards et al., we observe effect magnitudes on the order of ∼10 ms or so, with 9/10 conditions with numerical differences in the predicted direction. In terms of statistical effect size, Edwards et al. (Citation2015) reported a mean Cohen’s dz of 0.38 (range 0.25–0.61) whereas in this study we observed a mean dz = 0.18 (range −0.17–0.33). One might conclude therefore that while gaze leading is an observable effect, it might not be sufficiently stable to afford straightforward manipulations to be applied without much larger samples than other paradigms investigating joint attention initiation might require. Although we anticipated our initial sample size of Experiment 1 to be sufficient, at the time the data was collected we did not perform an a priori power analysis. However, a sensitivity power analysis conducted with G*Power (Version 3.1) has since revealed that a sample size of 31 provides .80 power (alpha = .05) to detect effects in either direction of effect size dz= .56. While this does fall within the range of previously reported effect sizes for the gaze leading effect, it is larger than the mean effect size previously observed. Furthermore, and speaking to the general issue of power and anticipated effect sizes, we calculated Bayes Factors (BF10), comparing the evidence in support of the alternative hypothesis vs the null-hypothesis, using JASP (Citation2021; Version 0.14.1). First, we note that the main effect of Target Location showed substantial evidence for H1 when collapsing all four experiments together into one analysis, BF=13.6, lending strong support to the detectability of the gaze leading effect per se. However, none of the individual Experiments produced strong evidence in favour of the gaze leading effect when analysed alone, both in the cases of observed significant main effects using frequentist statistics, Experiment 1 BF=.73 and Experiment 2 BF=1.14, and where these main effects were non-significant using frequentist statistics, Experiment 3 BF=.15; Experiment 4 BF=.72. Moreover, for the interactions of interest, each Bayes Factor across experiments provided evidence for H0 (all BF’s < .17). The overall evidence provided when combining the data contrasts with the experiment-level Bayes analysis and supports our above assertion that while there is good evidence in support of the gaze leading effect, more powerful designs will be needed to assess the effect in the future, especially when the aim is to examine variables that may impact its detectability.
Speaking to the generalizability of the gaze leading effect, it is noteworthy that in the current work Experiments 1 and 2 further illustrate the gaze leading effect and show that it extends beyond the stimuli used in the initial demonstration (cf. Edwards et al., Citation2015). The effects were overall smaller than the original demonstration (as outlined above), which is likely do to the manipulations employed in the current work. We did not observe the gaze leading effect overall in Experiment 3, but this is clearly qualified by the interaction with face-type – therefore the physical characteristics of the face following our gaze, at least in terms of physical dominance, appears to modulate the amount of attention we will pay to the person that has followed our gaze. The data are less clear in Experiment 4: here the gaze leading effect was only a trend (p=.053) and despite hints from the planned comparisons that the information that we know about the gaze follower matters for our attentional deployment, the qualifying interaction was not statistically reliable. We, therefore, suggest that similar investigations may be warranted but note that strong conclusions from these data are difficult to draw.
Contextual modulation of gaze leading
We turn now to evaluating the modest modulatory effects our manipulations had in Experiments 1 through 4. The effect appears to be relatively uninfluenced by manipulations to the objects and faces in the interaction (Experiment 1) and when only the object is manipulated (Experiment 2). However, it is noteworthy that the planned comparisons (in Experiment 2) comparing the gaze leading effect on trials of each object type indicated that the gaze leading effect was reliable for joint gaze towards negative (threat) images, but not towards neutral images. This is particularly intriguing as Experiment 3 suggests that faces that may be more threat-related also result in a stronger gaze leading effect. Of course, the lack of a clear pattern with respect to conditions involving negative images across Experiments 1 and 2, combined with the lack of a significant interaction underpinning this trend, make conclusions challenging to draw.
In Experiment 3, where only the faces in the paradigm were manipulated, the gaze leading effect was not statistically reliable overall. However, this was qualified by the key face type by gaze leading effect interaction, whereby the gaze leading effect was reliable for the high-dominant, but not low-dominant faces. Importantly, this suggests that the physical characteristics of the faces that follow our gaze is important to how we register such responses to our own gaze re-orientations – a finding which fits very well with dominance-hierarchy theories (see Cheng et al., Citation2013). The physical dominance of the on-screen faces was manipulated such that on a given trial both were either high- or low-dominant faces. Participants oriented their attention towards the face that followed their gaze to a greater extent on trials where both faces were high-dominant faces, compared to those trials where both faces were low-dominant. It, therefore, appears that having one’s gaze followed by a highly dominant conspecific may be more salient than having one’s gaze followed by a lower-dominant other. This could be due to threat assessment, as high-dominant others may be more likely to cause negative outcomes than lower-dominant conspecifics (Lansu & Troop-Gordon, Citation2017). Conversely, when considered in the context of social-hierarchy formation and development, having one’s gaze followed by a highly-dominant other may be interpreted as surprising (and therefore salient) and even a signal that one’s self is perceived by that other to be “dominant.”
The present data might indicate that in gaze leading encounters, who follows our gaze is more important than towards what our gaze is followed. That is, Experiment 3 revealed that the physical dominance of the face of a follower of gaze modulates the gaze leader’s reorienting of attention towards that face. However, Experiment 4 showed if anything the reverse relationship whereby the faces linked with a low-status biography elicited the strongest gaze leading effect. Here it is helpful to consider the concept of social prestige (Henrich & Gil-White, Citation2001). The social status manipulation included in Experiment 4 is likely to tap into “prestige” and therefore be somewhat separate from our physical manipulations of “dominance” in prior Experiments (see Dalmaso et al., Citation2020 for review). Indeed, when viewed this way the somewhat “opposite” data patterns can be viewed congruently – our data overall point to attention prioritization of negative stimuli during gaze leading encounters, in line with prior work on gaze cueing (Dalmaso et al., Citation2012; Carraro et al., Citation2017). That is, the threat value lies in the low social status individuals when prestige/esteem is manipulated.
In the present work, we manipulated the physical dominance of the on-screen faces as well as the threat related to the referent objects. It is noteworthy that we did not confirm by way of questionnaire that our participants did view the physically different faces to have differing socio-evaluative qualities – though the faces were from a validated set, independent verification would have enhanced this aspect of our design (Todorov et al., Citation2013). Future work may look to further investigate the underlying mechanism of such face-based effects. Indeed, we thank a reviewer for suggesting that our biographical manipulation in Experiment 4 may have been generally a more appropriate means of investigation as it manipulates conceptual rather than perceptual aspects of social cognition. Future work is, therefore, necessary to pin down whether the modulations herein are related to dominance per se (e.g., for the faces), threat-assessment (c.f. Lansu & Troop-Gordon, Citation2017), or merely valence. In doing so, future work can also tackle important and interesting questions such as how other features of the referent object (e.g., likability) and faces (e.g., attractiveness) might modulate a gaze leader’s registration of and response to having their gaze followed.
Conclusion
Overall, the gaze leading effect is generally replicable across stimulus sets and is somewhat robust. It seems that it is possibly sensitive to the physical social information available in the faces of those that respond to them and jointly attend a shared referent with them. Being sensitive to such information may be critical to properly assessing the ongoing interaction and responding accordingly.
Author contributions
S. G. Edwards, M. Rudrum and A. P. Bayliss conceived the idea and experimental design. S. G. Edwards and M. Rudrum developed and programmed the experiments. S. G. Edwards (E3) and M. T. Rudrum (E1 and E2) collected the data. S. G. Edwards and M. Rudrum analysed the data. All authors interpreted the results. S. G. Edwards, A. P. Bayliss and K. L. McDonough wrote the paper. All authors approved the final version for submission.
Supplemental Material
Download PDF (9.3 KB)Acknowledgement
The authors thank Taylor Marshall-Nichols, Adam Wren, and Daniel Schofield for assistance with data collection for Experiment 4.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Baldwin, D. A. (1995). Understanding the link between joint attention and language. In C. Moore & P. J. Dunham (Eds.), Joint attention: Its origins and role in development (pp. 131–158). Lawrence Erlbaum Associates, Inc.
- Baron-Cohen, S., Wheelwright, S., Skinner, R., Martin, J., & Clubley, E. (2001). The autism-spectrum quotient (AQ): Evidence from Asperger syndrome/high-functioning autism, males and females, scientists and mathematicians. Journal of Autism and Developmental Disorders, 31(1), 5–17. https://doi.org/https://doi.org/10.1023/A:1005653411471
- Bayliss, A. P., di Pellegrino, G., & Tipper, S. P. (2005). Sex differences in eye gaze and symbolic cueing of attention. The Quarterly Journal of Experimental Psychology Section A, 58(4), 631–650. https://doi.org/https://doi.org/10.1080/02724980443000124
- Bayliss, A. P., Murphy, E., Naughtin, C. K., Kritikos, A., Schilbach, L., & Becker, S. I. (2013). ‘Gaze leading’: Initiating simulated joint attention influences eye movements and choice behavior. Journal of Experimental Psychology: General, 142(1), 76–92. doi:https://doi.org/10.1037/a0029286
- Bayliss, A. P., Paul, M. A., Cannon, P. R., & Tipper, S. P. (2006). Gaze cuing and affective judgments of objects: I like what you look at. Psychonomic Bulletin & Review, 13(6), 1061–1066. https://doi.org/https://doi.org/10.3758/BF03213926
- Bayliss, A. P., Schuch, S., & Tipper, S. P. (2010). Gaze cueing elicited by emotional faces is influenced by affective context. Visual Cognition, 18(8), 1214–1232. https://doi.org/https://doi.org/10.1080/13506285.2010.484657
- Bayliss, A. P., & Tipper, S. P. (2005). Gaze and arrow cueing of attention reveals individual differences along the autism-spectrum as a function of target context. British Journal of Psychology, 96(1), 95–114. https://doi.org/https://doi.org/10.1348/000712604X15626
- Becchio, C., Bertone, C., & Castiello, U. (2008). How the gaze of others influences object processing. Trends in Cognitive Sciences, 12(7), 254–258. https://doi.org/https://doi.org/10.1016/j.tics.2008.04.005
- Butterworth, G. (1991). The ontogeny and phylogeny of joint visual attention. In A. Whiten (Ed.), Natural theories of mind: Evolution, development and simulation of everyday mindreading (pp. 223–232). Basil Blackwell.
- Capozzi, F., Becchio, C., Willemse, C., & Bayliss, A. P. (2016). Followers are not followed: Observed group interactions modulate subsequent social attention. Journal of Experimental Psychology: General, 145(5), 531–535. https://doi.org/https://doi.org/10.1037/xge0000167
- Carraro, L., Dalmaso, M., Castelli, L., Galfano, G., Bobbio, A., & Mantovani, G. (2017). The appeal of the devil’s eye: Social evaluation affects social attention. Cognitive Processing, 18(1), 97–103. https://doi.org/https://doi.org/10.1007/s10339-016-0785-2
- Chance, M. R. A. (1967). Attention structure as the basis of primate rank orders. Man, 2(4), 503–518. https://doi.org/https://doi.org/10.2307/2799336
- Cheng, J. T., Tracy, J. L., Foulsham, T., Kingstone, A., & Henrich, J. (2013). Two ways to the top: Evidence that dominance and prestige are distinct yet viable avenues to social rank and influence. Journal of Personality and Social Psychology, 104(1), 103–125. https://doi.org/https://doi.org/10.1037/a0030398
- Cui, G., Zhang, S., & Geng, H. (2014). The impact of perceived social power and dangerous context on social attention. PLoS ONE, 9(12), e114077. https://doi.org/https://doi.org/10.1371/journal.pone.0114077
- Dalmaso, M., Castelli, L., & Galfano, G. (2020). Social modulators of gaze-mediated orienting of attention: A review. Psychonomic Bulletin & Review, 27(5), 833–855. https://doi.org/https://doi.org/10.3758/s13423-020-01730-x
- Dalmaso, M., Edwards, S. G., & Bayliss, A. P. (2016). Re-encountering individuals who previously engaged in joint gaze modulates subsequent gaze cueing. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(2), 271–284. https://doi.org/https://doi.org/10.1037/xlm0000159
- Dalmaso, M., Galfano, G., Coricelli, C., & Castelli, L. (2014). Temporal dynamics underlying the modulation of social status on social attention. PLoS One, 9(3), e93139. https://doi.org/https://doi.org/10.1371/journal.pone.0093139
- Dalmaso, M., Pavan, G., Castelli, L., & Galfano, G. (2012). Social status gates social attention in humans. Biology Letters, 8(3), 450–452. https://doi.org/https://doi.org/10.1098/rsbl.2011.0881
- Deaner, R. O., Shepherd, S. V., & Platt, M. L. (2007). Familiarity accentuates gaze cuing in women but not men. Biology Letters, 3(1), 65–68. https://doi.org/https://doi.org/10.1098/rsbl.2006.0564
- Driver, J., Davis, G., Ricciardelli, P., Kidd, P., Maxwell, E., & Baron-Cohen, S. (1999). Gaze perception triggers reflexive visuospatial orienting. Visual Cognition, 6(5), 509–540. https://doi.org/https://doi.org/10.1080/135062899394920
- Edwards, S. G., Stephenson, L. J., Dalmaso, M., & Bayliss, A. P. (2015). Social orienting in gaze leading: A mechanism for shared attention. Proceedings of the Royal Society B: Biological Sciences, 282(1812), 20151141. https://doi.org/https://doi.org/10.1098/rspb.2015.1141
- Emery, N. J. (2000). The eyes have it: The neuroethology, function and evolution of social gaze. Neuroscience & Biobehavioral Reviews, 24(6), 581–604. https://doi.org/https://doi.org/10.1016/S0149-7634(00)00025-7
- Friesen, C. K., & Kingstone, A. (2003). Abrupt onsets and gaze direction cues trigger independent reflexive attentional effects. Cognition, 87(1), B1–B10. https://doi.org/https://doi.org/10.1016/S0010-0277(02)00181-6
- Frischen, A., Bayliss, A. P., & Tipper, S. P. (2007). Gaze cueing of attention: Visual attention, social cognition, and individual differences. Psychological Bulletin, 133(4), 694–724. https://doi.org/https://doi.org/10.1037/0033-2909.133.4.694
- Gordon, I., Eilbott, J. A., Feldman, R., Pelphrey, K. A., & Van Der Wyk, B. C. (2013). Social, reward, and attention brain networks are involved when online bids for joint attention are met with congruent versus incongruent responses. Social Neuroscience, 8(6), 544–554. https://doi.org/https://doi.org/10.1080/17470919.2013.832374
- Grynszpan, O., Martin, J. C., & Fossati, P. (2017). Gaze leading is associated with liking. Acta Psychologica, 173, 66–72. https://doi.org/https://doi.org/10.1016/j.actpsy.2016.12.006
- Henrich, J., & Gil-White, F. J. (2001). The evolution of prestige: Freely conferred deference as a mechanism for enhancing the benefits of cultural transmission. Evolution and Human Behavior, 22(3), 165–196. https://doi.org/https://doi.org/10.1016/S1090-5138(00)00071-4
- Hudson, M., Nijboer, T. C., & Jellema, T. (2012). Implicit social learning in relation to autistic-like traits. Journal of Autism and Developmental Disorders, 42(12), 2534–2545. https://doi.org/https://doi.org/10.1007/s10803-012-1510-3
- JASP Team. (2021). JASP (Version 0.14.1) [Computer Software].
- Jones, B. C., DeBruine, L. M., Main, J. C., Little, A. C., Welling, L. L., Feinberg, D. R., & Tiddeman, B. P. (2010). Facial cues of dominance modulate the short-term gaze-cuing effect in human observers. Proceedings of the Royal Society B: Biological Sciences, 277(1681), 617–624. https://doi.org/https://doi.org/10.1098/rspb.2009.1575
- Kim, K., & Mundy, P. (2012). Joint attention, social-cognition, and recognition memory in adults. Frontiers in Human Neuroscience, 6, 1–11. https://doi.org/https://doi.org/10.3389/fnhum.2012.00172
- Kuhn, G., & Tipples, J. (2011). Increased gaze following for fearful faces. It depends on what you’re looking for!. Psychonomic Bulletin & Review, 18(1), 89–95. https://doi.org/https://doi.org/10.3758/s13423-010-0033-1
- Lang, P. J., Bradley, M. M., & Cuthbert, B. N. (1997). International affective picture system (IAPS): Technical manual and affective ratings. NIMH Center for the Study of Emotion and Attention, 1(39-58), 3.
- Lansu, T. A., & Troop-Gordon, W. (2017). Affective associations with negativity: Why popular peers attract youths’ visual attention. Journal of Experimental Child Psychology, 162, 282–291. https://doi.org/https://doi.org/10.1016/j.jecp.2017.05.010
- Lobmaier, J. S., Fischer, M. H., & Schwaninger, A. (2006). Objects capture perceived gaze direction. Experimental Psychology, 53(2), 117–122. https://doi.org/https://doi.org/10.1027/1618-3169.53.2.117
- Loftus, G. R., & Masson, M. E. (1994). Using confidence intervals in within-subject designs. Psychonomic Bulletin & Review, 1(4), 476–490. https://doi.org/https://doi.org/10.3758/BF03210951
- Manera, V., Elena, M. R., Bayliss, A. P., & Becchio, C. (2014). When seeing is more than looking: Intentional gaze modulates object desirability. Emotion, 14(4), 824–832. https://doi.org/https://doi.org/10.1037/a0036258
- Marotta, A., Lupiáñez, J., Martella, D., & Casagrande, M. (2012). Eye gaze versus arrows as spatial cues: Two qualitatively different modes of attentional selection. Journal of Experimental Psychology: Human Perception and Performance, 38(2), 326–335. https://doi.org/https://doi.org/10.1037/a0023959
- Mundy, P., & Newell, L. (2007). Attention, joint attention, and social cognition. Current Directions in Psychological Science, 16(5), 269–274. https://doi.org/https://doi.org/10.1111/j.1467-8721.2007.00518.x
- Oosterhof, N. N., & Todorov, A. (2008). The functional basis of face evaluation. Proceedings of the National Academy of Sciences, 105(32), 11087–11092. https://doi.org/https://doi.org/10.1073/pnas.0805664105
- Rogers, R. D., Bayliss, A. P., Szepietowska, A., Dale, L., Reeder, L., Pizzamiglio, G., Czarna, K., Wakeley, J., C, P. J., & Tipper, S. P. (2014). I want to help you, but I am not sure why: Gaze-cuing induces altruistic giving. Journal of Experimental Psychology: General, 143(2), 763–777. https://doi.org/https://doi.org/10.1037/a0033677
- Saxe, R. (2006). Uniquely human social cognition. Current Opinion in Neurobiology, 16(2), 235–239. https://doi.org/https://doi.org/10.1016/j.conb.2006.03.001
- Schilbach, L., Wilms, M., Eickhoff, S. B., Romanzetti, S., Tepest, R., Bente, G., & Vogeley, K. (2010). Minds made for sharing: Initiating joint attention recruits reward-related neurocircuitry. Journal of Cognitive Neuroscience, 22(12), 2702–2715. https://doi.org/https://doi.org/10.1162/jocn.2009.21401
- Senju, A., Csibra, G., & Johnson, M. H. (2008). Understanding the referential nature of looking: Infants’ preference for object-directed gaze. Cognition, 108(2), 303–319. https://doi.org/https://doi.org/10.1016/j.cognition.2008.02.009
- Shepherd, S. V., Deaner, R. O., & Platt, M. L. (2006). Social status gates social attention in monkeys. Current Biology, 16(4), R119–R120. https://doi.org/https://doi.org/10.1016/j.cub.2006.02.013
- Shirai, R., & Ogawa, H. (2020). Affective evaluation of images influences personality judgments through gaze perception. PloS one, 15(11), e0241351. https://doi.org/https://doi.org/10.1371/journal.pone.0241351
- Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2012). A 21 word solution. http://ssrn.com/abstract=2160588
- Smith, D. T., Ball, K., Ellison, A., & Schenk, T. (2010). Deficits of reflexive attention induced by abduction of the eye. Neuropsychologia, 48(5), 1269–1276. https://doi.org/https://doi.org/10.1016/j.neuropsychologia.2009.12.028
- Stephenson, L. J., Edwards, S. G., & Bayliss, A. P. (2021). From gaze perception to social cognition: The shared-attention system. Perspectives on Psychological Science, 16(3), 553–576. https://doi.org/https://doi.org/10.1177/1745691620953773
- Stephenson, L. J., Edwards, S. G., Howard, E. E., & Bayliss, A. P. (2018). Eyes that bind us: Gaze leading induces an implicit sense of agency. Cognition, 172, 124–133. https://doi.org/https://doi.org/10.1016/j.cognition.2017.12.011
- Tipper, S. P., Driver, J., & Weaver, B. (1991). Object-centred inhibition of return of visual attention. The Quarterly Journal of Experimental Psychology Section A, 43(2), 289–298. https://doi.org/https://doi.org/10.1080/14640749108400971
- Tipples, J. (2006). Fear and fearfulness potentiate automatic orienting to eye gaze. Cognition & Emotion, 20(2), 309–320. https://doi.org/https://doi.org/10.1080/02699930500405550
- Todorov, A., Dotsch, R., Porter, J. M., Oosterhof, N. N., & Falvello, V. B. (2013). Validation of data-driven computational models of social perception of faces. Emotion, 13(4), 724. https://doi.org/https://doi.org/10.1037/a0032335
- Tomasello, M., & Carpenter, M. (2007). Shared intentionality. Developmental Science, 10(1), 121–125. doi:https://doi.org/10.1111/j.1467-7687.2007.00573.x