
ABSTRACT
The present study investigated whether incidental learning of spatial and temporal associations in hybrid visual and memory search enable observers to predict targets in space and time. In three experiments, observers looked for four, previously memorized, target items across many trials. We examined effects of learning target item sequences (e.g., the butterfly always follows the paint-box), target item-location associations (the butterfly is always in the right corner), and target item-location sequences (the butterfly in the right corner always follows the paint-box in the lower middle-left). Learning effects for the sequences of target items alone were weak. By contrast, we found good learning of target item-location associations and a reliable effect of sequence learning for target item-location associations. These findings suggest that spatiotemporal learning in hybrid search is hierarchical: Only if spatial and non-spatial target features are bound, temporal associations bias attention dynamically to the target expected to occur next.
General introduction
The visual environment contains a wide range of associations between objects and their contexts. Associations can be learned incidentally through repeated encounters, which facilitates future information processing and efficient behaviour in complex and dynamic visual environments (Chun & Turk-Browne, Citation2008; Gibson, Citation1963; Shanks, Citation1995). In real-world visual search, multiple sources of foreknowledge could be acquired and used in concert to optimize the allocation of attention during visual search (Egner et al., Citation2008; Kingstone, Citation1992). Specifically, learning spatial and temporal associations may enable the observer to predict the location where an object will occur in space and when it will appear in time (Kahana et al., Citation2008; Postma et al., Citation2008). Incidental associative learning likely alters the “priority map” (Wolfe, Citation1994, Citation2021), a dynamic representation of the search environment that guides selective attention towards task-relevant locations and non-spatial features at a specific point in time (Ferrante et al., Citation2018; Nobre & Stokes, Citation2019; Nobre & Van Ede, Citation2018; Theeuwes et al., Citation2022). However, there is as yet little research on the additive and interactive effects of spatial and temporal associative learning on visual search (Boettcher et al., Citation2022; Nobre & Stokes, Citation2019). Knowing how multiple, co-occurring associative learning mechanisms shape visual search is, however, important for our understanding of the structure of visual associative memory representations that influence attentional priority in complex, dynamic visual tasks.
Object-location memory in visual search
Stable landmarks and objects in the environment offer valuable spatial cues for navigation, orienting, and visual search. Binding object identities to locations is considered a key process of visual working memory (VWM) and episodic long-term memory (LTM) (Postma & De Haan, Citation1996; Postma et al., Citation2008). Associative object-location memory can be learned intentionally and tested explicitly in recall or recognition tests (Postma et al., Citation2004; Shih et al., Citation2012). By contrast, visual search provides a means to demonstrate how incidentally acquired associative memory representations impact attentional processes to optimize behaviour in complex tasks. Imagine you are looking for a specific item on the shelves in your neighbourhood grocery store, where you are familiar with the arrangement of products. Remembering object-location associations allows you to direct your attention to the relevant areas and help you locating the items on your shopping list quickly.
Empirical evidence for visual search facilitation by spatial associations comes from contextual and probability cueing studies (Geng & Behrmann, Citation2005). Observers become faster at finding targets at high-probability as compared to low-probability locations (Geng & Behrmann, Citation2002, Citation2005; Li & Theeuwes, Citation2020; Shaw & Shaw, Citation1977; Walthew & Gilchrist, Citation2006; Yu et al., Citation2023a). Similarly, observers become faster in locating targets in repeating spatial contexts compared to new contexts (Chun, Citation2000; Chun & Jiang, Citation1998). The contextual cueing effect is not limited to locations (Endo & Takeda, Citation2004). Observers who were exposed to repeated configurations of either target and distractor shapes, or locations, or the combination of target shapes and locations, showed faster search times for all three types of repetition (shape, location, shape-location). These findings suggest that spatial and non-spatial target features can be learned incidentally by repeated attentional deployments, guiding visual search towards those learned target properties in the future. Other studies on visual search using naturalistic scenes have further demonstrated that incidentally learned object-location associations can guide attention and enable the observer to find objects at learned locations much faster in the future (Draschkow et al., Citation2021; Draschkow & Võ, Citation2016; Hollingworth, Citation2006, Citation2007; Võ & Wolfe, Citation2015). This is true for contextual information stored in semantic knowledge structures acquired during life-long learning (e.g., if you look for a toaster, you typically find it on a kitchen shelf) as well as recently established episodic memory representations (e.g., in my friend’s kitchen, the toaster is next to the fridge) (Helbing et al., Citation2020; Võ & Wolfe, Citation2015).
Temporal order in visual search
Temporal processing is inherent in natural visual search, where the environment is iteratively sampled across eye and head movements. If events repeatedly unfold over time in the same ways, temporal associations between successive stimuli are formed. These associations, in turn, can guide the serial processing of objects by expectations about what will be seen next (Nobre & Van Ede, Citation2018; Zacks & Tversky, Citation2001). Think about the shopper in the grocery store. Her typical shopping route will follow a temporal sequence through the sections of the store (fruit, cereals, dairy, beverages), so she cannot only anticipate where, but also in which order to look for the items on her shopping list.
Behavioural benefits of learning temporal order sequences have been largely demonstrated in variants of the serial response-time task (SRTT). The original SRTT, introduced by (Nissen & Bullemer, Citation1987), is a four-choice reaction-time task, in which observers respond to a visual cue that appears at one of four positions by pressing a corresponding button. The visual cues can either appear in a repeating sequence of positions or in a random order. Over time, observers’ response times (RTs) become faster in the sequence condition compared to the random condition, even if the participant is unaware of the visuo-motor sequence (Abrahamse et al., Citation2010; Schwarb & Schumacher, Citation2012). Importantly, the sequence learning effect in the SRTT also occurs on purely perceptual and attentional processing stages, independently from motor sequences (Goschke, Citation1998; Mayr, Citation1996). However, learning of pure visual sequences takes longer than learning visuo-motor sequences and is influenced by the complexity of the sequence, learned features, and participants’ awareness (Koch et al., Citation2020; Koch & Hoffmann, Citation2000; Remillard, Citation2003). Sequence learning of non-spatial features has also been reported in statistical learning experiments, where participants become faster in discriminating visual objects that are repeatedly presented in triplets of the same temporal order compared to identifying temporally unassociated objects (Chun & Turk-Browne, Citation2008; Turk-Browne et al., Citation2005).
Recent studies provide some evidence that learning temporal associations between target locations can facilitate visual search. Participants incidentally learned to predict changes in target locations across trials if those were highly probable (Li et al., Citation2022; Li & Theeuwes, Citation2020; Yu et al., Citation2023a). Incidental learning of likely changes in target locations was dependent on awareness in some of the studies (Yu et al., Citation2023a). By contrast, we recently found little evidence of incidental learning of temporal associations of target items (Wiegand et al., Citation2021). Specifically, we investigated whether the sequential order of multiple previously memorized target items influences hybrid search. In “hybrid search” (Schneider & Shiffrin, Citation1977; Wolfe, Citation2012), the observer searches for any instance of multiple target types, held in memory (e.g., find this butterfly, this paint box, or this stroller). Thus, hybrid search is a combination of visual and memory search, which is akin to many of the searches we perform in the real world, such as searching the shelves of a store for items on your mental shopping list (Boettcher et al., Citation2018). In our laboratory version of the task (Wiegand et al., Citation2021; Wolfe, Citation2012), observers first memorized a number of real-world objects, which are easy to commit to memory (Konkle et al., Citation2010; Standing et al., Citation1970). Next, they had to locate one of those target objects across many search displays that also contained unfamiliar distractor objects. We manipulated the sequential order in which the memorized targets appeared across trials. In one block, targets appeared in a repeating sequential order; in the other block, targets appeared in random order. When observers were not told about the target sequence, learning effects on RTs in this task were small and only significant in observers who incidentally acquired explicit knowledge about the sequence. When observers were informed about the sequence in advance, reliable and consistent RT benefits were observed in the sequence relative to the random condition (Wiegand et al., Citation2021). This suggests that target item sequence knowledge in hybrid search can be considered a type of context memory, represented as temporal inter-item associations in a fixed-order series of to-be-remembered items, which help retrieval during memory search (Healey & Kahana, Citation2014; Kahana, Citation2020). While the findings indicate that target item sequence knowledge can facilitate hybrid search by allowing observers to predict the next target, they also demonstrate that this knowledge was not incidentally acquired by most observers. This gives rise to the question under which conditions incidental learning of contextual associations can facilitate hybrid search.
The present study
The goal of the present study was to investigate how incidental learning of different target-context associations could facilitate hybrid search. Coming back to the example of grocery shopping: Following your weekly route through your favorite store, you first look for bananas in the fruit section, then for cornflakes on the shelve with cereals, then for yoghurt in the fridge with dairy products, and lastly for orange juice in the beverages. Shopping in a well-known environment is easier and faster because both learned spatial and temporal associations allow making predictions about what can be expected where and when.
In three experiments administered online, we investigated the unique and combined effects of learning spatial and temporal associations between target items and target locations in groups of healthy younger adults. All experiments were variants of the hybrid search task, in which the observers’ task was to locate any one of four previously memorized target items, among seven or fifteen distractors, as quickly as possible. Observers were not told about regularities that might be present across the search displays. Hence, any potential learning effects would be incidental. In Experiment 1, similar to Wiegand et al. (Citation2021), the four target items appeared in a repeating sequence across trials in one block (target item sequence: the butterfly always follows the paint box) and in random order in the other block. Targets occurred at random locations in both blocks. In Experiment 2, each target item always appeared at the same location in the search display in one block (target item-location association: the butterfly always occurs in the upper right corner), while the target items could appear at any one of four locations in the other block. There was no sequential order of target items or locations in either block. In Experiment 3, target items occurred at the same locations in a repeating sequence in one block (target item-location sequence: the butterfly in the upper right corner always follows the paint box in the lower-middle left). In the other block, target items appeared in random order, but at a repeating spatial sequence of target locations (target location sequence: a target in the upper right corner always follows a target in the lower-middle left). Observers performed 200 trials per block, allowing us to examine potential effects of (1) learning the temporal order of target items, (2) learning target item-location associations, and (3) learning the temporal order of target item-location associations.
Experiment 1: Target item sequence
Wiegand et al. (Citation2021) found little evidence for incidental learning of target sequences in hybrid search and found it only if observers had acquired explicit knowledge about the target order. We concluded that the temporal sequence of target items is not easily encoded into an associative memory representation that would allow observers to use the current target item as a cue to predict the target item occurring in the next trial. However, the participants in the previous study performed only 80 trials, that is, 20 repetitions of a four-target item sequence. One might argue that it simply takes more repetitions of the sequence to learn it. If so, if there were more than 20 repetitions, we might see evidence of learning in the form of faster RTs for the target sequence relative to random order condition. To test whether a high number of repetitions could induce a target sequence effect in hybrid search and to assess learning effects over time, we presented participants with 50 repetitions (200 trials) of the target sequence.
Methods
Participants. Participants were recruited for the online studies via the Radboud Research Participation system SONA (sona-systems.com) and e-mails. Participants were eligible if they were 18–25 years old, had good (corrected) vision, and a good command of English. The research was approved by the local ethics committee of the Faculty of Social Sciences at Radboud University. Participants provided their consent to participate online before the experiment started and any data were collected. Participants received study credits for their participation. Forty-nine participants enrolled in the online study for Experiment 1. Of these, 17 were excluded. Four participants did not do the experiment, five did not complete the experiment, five interrupted and restarted the experiment, one showed >10% trials with exceptionally high RT (>15 s), suggesting distraction, and two did not complete the post-experimental questionnaires. Thus, the final sample consisted of 32 participants ().
Table 1. Sample characteristics.
An a-priori power analyses, run by G*Power (Faul et al., Citation2007), showed that, in order to identify a main effect or interaction effect of moderate size (ηp2 = .06) in a repeated-measures ANOVA with 20 repeated measures (repetition (5) × set size (2) × search condition (2)) correlated (r = .60, expected based on similar experiments, see Wiegand et al., Citation2021) with a Power of .90 and alpha of .05, a sample size of 10 participants would be required. For any follow-up ANOVAs with at least two repeated measures of a within-subject comparison (i.e., learning vs. random condition), a sample size of 36 participants would be required. We invited 50 participants per online experiment, to account for possible drop-out in the online experiments.
Stimulus Material. We used a corpus of 1,430 images from a database of 2,400 distinct real-world objects compiled by (Brady et al., Citation2008). We included only the images of objects which were complete and clearly distinct from the background, were not too similar to other objects, did not contain words, numbers, arrows, landscapes or humans, and were highly unlikely to evoke a feeling of disgust or dislike.
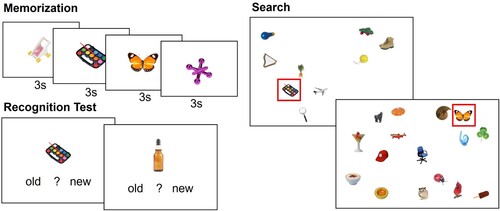
Task. The task was a variant of a hybrid visual and memory search in which participants have to locate any one of the possible targets as quickly as possible (Wolfe, Citation2012). shows example displays of the memorization, recognition, and search phases of the task. In each task block, participants first memorized four target objects, which were serially presented in the centre of the display for three seconds each. This was followed by a recognition memory test, in which the four target objects and four previously unseen objects were presented, one after the other, and participants clicked on either an “old” or “new” button to indicate whether or not the object displayed was one of the memorized target items. If participants failed the recognition test, they were again presented with the target items and completed another recognition test. After having passed the recognition test with an accuracy of 100%, participants continued to the search task. Participants completed 200 search trials per block. Each trial contained one of the four memorized target objects and participants were instructed to localize the target as quickly as possible by clicking on it. After the target was found, the next trial started. Each display had a visual set size of either eight or 16 objects (i.e., one target plus either seven or 15 distractors), which varied randomly across trials. Distractors were drawn randomly from the remaining image set. If the participant erroneously clicked on a distractor object, the search display remained on screen until the correct target was clicked on.
Figure 1. Illustration of the hybrid search task. Participants were presented with each target object for three seconds in the memorization phase. Their memory for the targets was tested in a recognition test with 50% old and 50% new objects. During the subsequent visual search task, each display included one of the target items and participants had to locate this target as quickly as possible.
In Experiment 1, the sequential order of the four target items over the search trials varied between blocks (see also Wiegand et al., Citation2021): In the random condition, target items appeared in random order. In the fixed sequence condition, target items appeared in the same order. The location of the targets varied randomly in both blocks, thus, there was no target item-location association. Each block contained 200 trials. Thus, in the block with the fixed sequential order of target items, the sequence was repeated 50 times. Importantly, the task instructions and physical characteristics of the search displays were the same across search conditions. Thus, the presence of temporal sequences was independent of the explicitly told task goal and the layout of a single search display and any learning effects occurred incidentally. The order of blocks was counterbalanced across participants to control for systematic order effects. Target items were selected randomly from the stimulus set for each participant and could not repeat over search blocks, that is, participants searched for different targets in block one and block two.
Post-experiment questionnaire. After completing the experiment, participants were asked about their subjective experiences in the experiment (https://osf.io/rqgkx). First, we asked participants whether there was anything they have noticed during the experiment. After this, participants were directly asked whether they have noticed the target item sequence. After this, participants had to indicate in which of the two blocks they believed to have noticed the target item sequence.
Procedure, online data collection, and data storage. Participants received a link to the online study via the Radboud Research Participation system SONA or email. When they started the study by clicking the link, they received general information about the study and data management (via Limesurvey, www.limesurvey.org). Only after providing online consent to participate in the research, participants were redirected to the hybrid search task (see below). After having completed the experiment, participants answered demographical questions (age, gender) and answered questions about their subjective knowledge about regularities they may have noticed in the hybrid search task (via Qualtrics, www.qualtrics.com). The online experiment was programmed using jsPsych version 6.3.1 (De Leeuw, Citation2015). Data from the online experiment were temporarily stored in a faculty’s cloud data storage facility (Radcloud Mini). The raw and pre-processed data are available at the Open Science Framework platform (https://osf.io/tc9ej).
Data processing and analyses. Data preprocessing and analyses was done using R, Excel, and SPSS. Trials with incorrect responses were excluded from the analyses. This was 0.2% of the data. We also excluded trials with RTs longer than 15 s. The aim of this outlier correction was to exclude trials in which participants were very likely distracted from the task (something that cannot be easily controlled in an online task). We sought to avoid data trimming that could excessively affect the “true” variance in the RTs. Our conservative criteria were based on inspection of the RT distributions and led to exclusion of 0.5% of the data. In more than 99% of the trials, RTs were <11.3 s, in more than 95% of the trials, RTs were <6.5 s. Analyses were performed on the individual mean RTs for the respective experimental conditions. To analyze learning over time, mean RTs were computed for five consecutive bins of 40 trials each. We performed mixed ANOVAs on mean RTs, with the factors trial bin (40, 80, 120, 160, 200), set size (8, 16), and search condition (target random, target sequence). Interactions were followed-up with post-hoc paired t-tests. We applied the Bonferroni-correction for multiple comparisons where indicated.
We used the responses of the post-experiment questionnaire to evaluate whether participants acquired reportable and correct explicit knowledge about the regularity (sequential order or target item-location association, see target item-location associations, see https://osf.io/rqgkx). Explicit knowledge would be indicated by reporting to have noticed the regularity either spontaneously or after being prompted, and by indicating in which of the two blocks the regularity occurred. We compared the learning effect (RT random – RT sequence) after more than 20 repetitions (80 trials) of the regularity between participants who reported to have noticed a regularity and those who reported to not have noticed a regularity.
Results
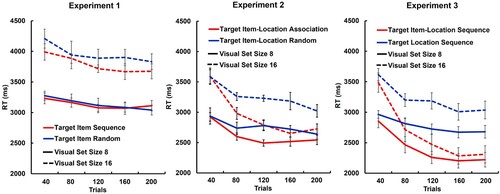
The mean RTs for the different experimental conditions are plotted as a function of repetitions in (left panel). The ANOVA on mean RTs revealed a significant main effect of set size [F(1,31) = 232,07, p < .001, ηp2 = .88]. RTs increased with the visual set size. Furthermore, there was a significant two-way interaction between trial bin and search condition [F(4,124) = 7.153, p < .001, ηp2 = .19] and a marginally significant three-way interaction between trial bin, search condition, and set size [F(4,124) = 2.20, p = .07, ηp2 = .07]. All other main effects and interactions were not significant [all F < 1.81, p > .13, ηp2<.06]. Visual inspection of the mean RTs () suggests a small learning effect over time, which is more pronounced for the larger set size of 16. However, none of the post-hoc t-tests comparing the random and sequence condition across trial bins was significant [all t < 1.49, p > .70, d < 0.18], also not if the comparison was done separately for set sizes 8 and 16 [all t < 1.63, p > .90, d < 0.26]. These findings replicate our previous results (Wiegand et al., Citation2021) and demonstrate only small, if any, sequence learning effects in hybrid search. Even after many trials, target sequence learning does not meaningfully reduce search times.
Figure 2. Search reaction times (RTs). Mean RTs (in milliseconds, ms) and SEM are plotted as a function of search conditions, visual set size (8: solid lines, 16: dashed lines), and number of trials, binned for trials 1–40 (i.e., 1–10 repetitions of a 4-target sequence), 41–80 (11-20 repetitions), 81–120 (21-30 repetitions), 121–160 (31-40 repetitions), and 161–200 trials (41-50 repetitions). In Experiment 1 (left panel), target items appeared either in sequential (Target Item Sequence) or random (Target Item Random) order across trials, and always at random locations. In Experiment 2 (middle panel), target items appeared either at the same target location (Target Item-Location Association) or at random locations (Target Item-Location Random), and always in random order. In Experiment 3 (right panel), target items appeared either at the same location in the same sequential order (Target Item-Location Sequence), or target items appeared at random locations, but target locations followed a sequential order (Target Location Sequence).
Only five out of the 32 participants reported noticing the sequence when asked after the experiment. Three of them reported knowledge about the sequence spontaneously and two reported that they noticed the sequence only after being prompted. Only two of those also indicated the correct block, in which the sequence occurred. The learning effect was not larger in the participants who reported to have noticed a target sequence compared to those who reported to not have noticed a sequence [t(30) = 0.50, p = .96].
Discussion
Experiment 1 provides further evidence that observers do not use temporal order associations between target items in hybrid search to predict when to look for what next. Also in accordance with the previous study (Wiegand et al., Citation2021), only a small proportion of participants seemed to have acquired reportable and correct explicit knowledge about the sequence. By contrast, a reliable sequence learning effect was found in pure visual variants of the SRTT (Mayr, Citation1996) and triplet learning in object identification (Chun & Turk-Browne, Citation2008; Turk-Browne et al., Citation2005), where learning is assumed to be at least partly implicit. Furthermore, the SRTT and statistical learning tasks did not involve a search component. Generally, observers in hybrid search do not easily restrict their memory search based on contextual cues (Boettcher et al., Citation2018; Wiegand & Wolfe, Citation2020). Presumably, the flexible retrieval of temporal target-item associations is, even if possible, too effortful to be an effective strategy for refining the relatively easy memory search. Accordingly, observers in the present task did not use temporal item-item associations to predict the next target and guide attention towards it’s expected non-spatial features. This, however, does not exclude the possibility that other target associations could be incidentally learned during hybrid search and benefit search time. Specifically, the spatial nature of the visual search task may promote the incidental learning of target item-location associations, which we tested in the following experiments.
Experiment 2: Target item-location association
In Experiment 2, we tested if learning target item-location associations could facilitate hybrid search. Observers performed a hybrid search task, in which the same target item always appeared at the same target location in one condition, while the target items appeared randomly at one of four target locations in the other condition. We hypothesized that observers would incidentally learn the target item-location associations over search trials, thus learning to predict where to find what. This would result in shorter RTs over time in the condition with target item-location associations compared to the random condition in which target items and locations varied randomly across trials.
Methods
Participants. Recruitment, inclusion criteria, ethical approval, consent and reimbursement procedure were the same as in Experiment 1. Forty-five participants enrolled in the online study, seven of whom were excluded. Four participants did not complete the experiment and three interrupted and restarted the experiment. Thus, the final sample consisted of 38 participants ().
Stimulus Material. The stimulus material was the same as used in Experiment 1.
Task. Participants completed two blocks of a hybrid visual and memory search task, similar to the one described in Experiment 1. In each block, they first memorized four target objects. After passing a recognition test, they had to localize any one of the four target objects among 7 or 15 distractors over 200 trials. In the random condition, each target item could appear at any one of four target locations (target location random). In the association condition, the same target item appeared always at the same location (target item-location bound). Thus, in both blocks, targets could appear at four possible target locations in the display. None of the four target locations could be occupied by a distractor, that is, it was either empty or contained a target. The target locations were selected randomly for each participant and were different in both blocks. Different from Experiment 1, neither locations nor targets followed an orderly temporal sequence over trials.
Procedure, online data collection, and data storage. The procedures for participation, data collection, and storage were the same as in Experiment 1. The raw and pre-processed data are available at the Open Science Framework platform (https://osf.io/tc9ej).
Data Processing and Analyses. We applied the same criteria for excluding trials as in Experiment 1. Less than 0.2% of the trials were excluded because participants responded incorrectly. Less than 0.2% of the trials were excluded because the RTs were >15 s. In more than 99% of the trials, RTs were < 8.5 s, and in more than 95% of the trials, RTs were <5.2 s. We examined whether learning target item-location associations would affect search times by comparing the mean RTs across search conditions in Experiment 2. Specifically, we analyzed within-subject effects on mean RTs in Experiment 2 with mixed ANOVAs, with the factors trial bins (40, 80, 120, 160, 200), set size (8, 16), and search condition (target-location random, target item-location bound).
Results
The mean RTs for the different experimental conditions in Experiment 2 are plotted as a function of repetitions in , middle panel. The ANOVA on mean RTs revealed significant main effects of search condition [F(1,37) = 13.10, p < .001, ηp2 = .26], trial bins [F(4,152) = 36.21, p < .001, ηp2 = .50], and set size [F(1,38) = 166.96, p < .001, ηp2 = .82]. RTs were shorter in the search condition with target item-location associations compared to the random condition. Besides, RTs increased with the visual set size and decreased over trial bins, significantly from 40 to 80 trials [t(37) = 6,37, p < .005, d = 1.03, [CI: 0.63, 1.42]], but not from 80 to 200 trials [all t(37) < 1.87, p > .34, d < 0.31]. Furthermore, the ANOVA revealed significant two-way interactions between search condition, trial bins, and set size [all F > 9.75, p < .003, ηp2>.21], but no three-way interaction [F(4,152) = 1.60, p = .18, ηp2 = .04]. The effect of target item-location association increased over trials. RTs were faster if the targets appeared at the same locations compared to when they randomly appeared at one of the four locations, from 80 trials marginally significantly [t(37) = 2.65, p = .06, d = 0.43], and significantly from 120 trials onwards [all t(37) > 4.32, p < .005, d > 0.70], but not within the first 40 trials [t(37) = 0.26, p > .99, d = 0.04, [CI:-.36-,.28]]. The RT-benefit of the target item-location association increased with distractor load, but was significant for both set size 8 [t(37) = 2.73, p = .02, d = 0.44, [CI: .11,.77]] and set size 16 [t(37) = 2.73, p = .02, d = 0.64, [CI: .11,.77]].
In the post-experimental questionnaire, all participants reported to have noticed the target item-location association. Twenty-six of them reported knowledge about the association spontaneously and the remaining reported that they noticed the association after being prompted. More than 3/4 (30 out of 38) of them were able to indicate the correct block, in which target items and locations were associated. Thus, most participants seem to have acquired reportable and correct explicit knowledge about the target item-location association. As all participants reported knowledge about the target item-location association, the effect of explicit knowledge on the learning effect could not be evaluated.
Discussion
The results show that observers benefit from learning target item-location associations after 40 trials, that is, 10 repetitions of each target item-location association. This suggests that a few exposures in the hybrid search task suffice to establish the associative memory trace (Gallo & Wheeler, Citation2013). Once the association is established, the location may serve as an effective retrieval cue in the memory search for the associated target, leading to shorter RTs (Sommer et al., Citation2007; Sommer et al., Citation2005). The assumption that the target item-location association is an explicitly-accessible memory representation is supported by participants’ subjective reports about acquired associative knowledge during the experiment. Similarly, Yu and colleagues have recently shown that statistical learning of target locations was dependent on awareness (Yu et al., Citation2023a, Citation2023b).
In comparison to Experiment 1, the results of Experiment 2 indicate that target item-location associations are learned more easily than temporal-order associations between target items. Notably, in the majority of studies that reported temporal learning effects in variants of the SRTT, the target feature that carried the sequential information was spatial, i.e., the target location, not the target identity (Deroost & Coomans, Citation2018; Deroost & Soetens, Citation2006a, Citation2006b; Lum, Citation2020; Mayr, Citation1996; Remillard, Citation2003). Thus, it might be possible that learning a temporal sequence of target item-location associations facilitates hybrid search. This was examined in Experiment 3.
Experiment 3: Target item-location sequence
In Experiment 3, we tested whether learning the temporal order of target item-location associations could facilitate hybrid search. Observers performed a hybrid search task in which target locations followed a temporal sequence over trials. In one condition, each of the four target items appeared at its own, specific location, so that target item-location associations appeared in a temporal sequence. In the other condition, the four target locations followed a temporal sequence, but which target item appeared at which location was random. Based on the results in Experiment 2, we hypothesized that observers would incidentally learn the target item-location associations, leading to faster RT in the condition with target item-location associations compared to when only target locations followed a temporal sequence but not target items.
Methods
Participants. Recruitment, inclusion criteria, ethical approval, consent and reimbursement procedure were the same as in Experiments 1 and 2. Forty-five participants enrolled in the online study. Of these, 11 were excluded. Four participants did not start the experiment, one did not complete the experiment, four interrupted and restarted the experiment, and two showed >10% trials with exceptionally high RT (> 15 s). Thus, the final sample consisted of 34 participants ().
Stimulus Material. The stimulus material was the same as used in Experiments 1 and 2.
Task. Participants completed two blocks of a hybrid visual and memory search task, similar to the ones in Experiment 1 and 2. In each block, they first memorized four target objects. After passing a recognition test, they had to localize any one of the four target objects among 7 or 15 distractors over 200 trials. In Experiment 3, in each block, target locations followed a fixed temporal order sequence. The sequential order of the target items, however, varied between blocks: In the target location sequence (target item random) condition, target items appeared in random order over search trials. In the target item-location sequence condition, both target items and target locations followed the same four-step order over trials. As in Experiment 2, none of the four target positions could be occupied by a distractor, that is, it was either empty or containing a target. Target items and target locations were selected randomly for each participant and were different in the two blocks.
Procedure, online data collection, and data storage. The procedures for participation, data collection, and storage were the same as in Experiment 1 and 2. The raw and pre-processed data are available at the Open Science Framework platform (https://osf.io/tc9ej).
Data Processing and Analyses. We applied the same criteria for excluding trials as in Experiments 1 and 2. Less than 0.3% of the trials were excluded because participants responded incorrectly. Less than 0.6% of the trials were excluded because the RT were >15 s. In more than 99% of the trials, RTs were < 8.5 s, and in more than 95% of the trials, RTs were <5.6 s. We examined the effect of learning temporal sequences of target item-location associations vs. target locations by analyzing within-subject effects on mean RTs with mixed ANOVAs with within-subject factors of trial bins (40, 80, 120, 160, 200), set size (8, 16), and search condition (target location sequence, target item-location sequence). Significant main effects and interactions were followed-up with paired t-tests, applying Bonferroni correction for multiple comparisons where applicable.
Results
The mean RTs for the different experimental conditions in Experiment 3 are plotted as a function of repetitions in , right panel. The ANOVA on mean RTs revealed significant main effects of search condition [F(1,33) = 24.23, p < .001, ηp2 = .42], trial bins [F(1,33) = 42.54, p < .001, ηp2 = .56], and set size [F(1,33) = 62.02, p < .001, ηp2 = .65]. RTs were faster when the target item-location associations appeared in a sequence compared to when only the target locations followed a sequence. Overall, RTs increased with set size and decreased over trial bins, from 40 to 80, and 80 to 120, [both t(33) > 2.7 p < .05, d > 0.47], but not significantly from 120 to 200 trials [both t(33) < 2.60.61, p > .05, d < 0.44]. Furthermore, all two-way interactions [all F > 4.04, p < .005] and the three-way interaction between search condition, trial bins, and set size were significant [F(4,132) = 1.45, p < .001, ηp2 = .04]. As can be seen in , there was a substantial learning effect for the target item-location association, which increased over the first 80 trials (i.e., 20 repetitions of the association). Post-hoc paired t-tests show that RT in both conditions did not differ in the first 40 trials [t(33) = 0.84, p > .99, d = 0.15, CI[−322;102]], but differed significantly from 80 trials onwards [all t(33) > 3.2, p < .02, d > 0.54, CI[−463;202]]. By contrast, only in the search condition with the target item-location sequence, distractor costs shrunk over trials. The set size effect was significant for the first 80 trials [both t(33) > 2.87, p < .05, d > 0.48], but not for the following trials [all t(33) < 2.66, p > .30, d < 0.23]. In the search condition with the target location sequence alone (random order of target items), the set size effect remained significant throughout the whole experiment [all t(33) > 3,61, p < .01, d > 0.78].
Thirty out of the 34 participants reported explicit knowledge about the sequence after the experiment. Twenty-four of them reported knowledge about the sequence spontaneously and the remaining reported that they noticed the sequence only after being prompted. The majority (25 out of 30) of the participants who noticed the target item-location sequence also indicated the correct block in which the sequence occurred. The mean learning effect is quite large in the participants who reported noticing the target sequence (533 ms). It is not evident in those who did not report noticing the target sequence (2 ms). However, due to the imbalance of the number of participants per group (30 vs. 4), there is limited power to statistically evaluate the group differences [t(32) = 1.94, p = .06],
Discussion
In agreement with the results in Experiment 2, Experiment 3 shows that binding of target items and locations happens incidentally and quickly, speeding RTs in hybrid search. Different from Experiment 2, the target locations followed a fixed temporal sequence in Experiment 3. Thus, in the target item-location association condition, the order of both, target items and target locations was fixed and the two factors varied in lockstep, together. The greater RT reduction over time in the target item-location sequence condition compared to the location sequence condition indicates that observers benefit from temporal context if spatial and non-spatial target features are bound. As mentioned above, the target item-location association may allow the observer to refine their memory search at a particular location (Sommer et al., Citation2005, Citation2007). Additionally, learning the temporal order of the target item-location associations may allow the observer to predict which target item appears at a specific location next, rendering visual search highly efficient. The remarkable reduction of distractor costs (i.e., set size effect) over time suggests that observers can strongly guide their attention to the spatiotemporally predictable target. By contrast, temporal predictability of the target location alone did not eliminate the costs of distractor processing.
Finally, the self-reports indicate that many participants acquired reportable and correct explicit knowledge about the target item-location sequence, supporting the assumption that incidentally learned spatiotemporal target associations become explicit, contextual memory representations. This is in line with our previous studies and indicates that awareness contributes to behavioural benefits of incidentally learned regularities (Wiegand et al., Citation2021; Yu et al., Citation2023b).
General discussion
Hybrid search is a combination of visual and memory search, in which observers look for one of several previously memorized target items among distractors. Hybrid search is akin to many real-world searches; for example shopping, in which targets are repeatedly searched for, in a specific spatial and temporal context. The present study investigated effects of incidental learning of spatial and temporal associations in hybrid search to better understand how contextual regularities influence behaviour in such complex, ubiquitous visual tasks (Chun & Turk-Browne, Citation2008; Gibson, Citation1963; Shanks, Citation1995). We found that observers learned target item-location associations (predicting where and what specific target would appear), but not the temporal order of target items (predicting when and what specific target would appear). However, observers learned the temporal order of target item-location associations (predicting when, where and what specific target item would appear).
Learning target item-location associations
Experiments 2 and 3 demonstrate that learning target item-location associations allows observers to effectively reduce their search times (see , middle and right panel). Compared to when targets can occur at any of four locations in the display, RTs are overall faster and the set size effect becomes smaller if target item and location are associated, suggesting that visual search for learned target item-location associations is less prone to distraction. During visual search, each time attention is directed to the target, non-spatial target features are naturally integrated with the target’s spatial location (Eimer, Citation2014). Over repeated searches in the present hybrid search task, item-location associations may thus become represented in the priority map (Egner et al., Citation2008; Wolfe, Citation1994), guiding observers to specific features at specific locations (Ferrante et al., Citation2018).
Alternatively, or additionally, item-location associations become represented in LTM over search trials (Postma & De Haan, Citation1996; Postma et al., Citation2004, Citation2008). The target location may serve as a retrieval cue, speeding memory search for the associated target item. Vice versa, activating a specific target template may serve as a cue to allocate attention to the associated location, speeding visual search. In fact, explicit memory tests demonstrated evidence for symmetric associative memory of object-location associations (Asch & Ebenholtz, Citation1962; Kahana, Citation2002; Sommer et al., Citation2007). Either way, search RT would be faster for target item-location associations than for target items appearing at random locations.
Temporal order of target items and target item-location associations
Our results show that the temporal order of target items alone had little effects on RTs in hybrid search (see , left panel). By contrast, temporal sequence learning of bound target item-location associations resulted in a reliable RT-benefit (see , right panel). This indicates a hierarchical or conditional structure of spatial and temporal associations in hybrid search: only if target item-location associations are established, temporal associations further allow the observer to predict the bound target item and location of the upcoming trial. In a hybrid search task with four target items defined by a unique combination of multiple features, there is a certain dilution of priority states across trials (Bahle et al., Citation2020; Olivers et al., Citation2011; Ort & Olivers, Citation2020). However, learning the temporal order of item-location associations may allow the observer to pre-activate a specific search template of the target item-location association expected to occur next, rendering search highly efficient. Thus, temporal order effects may be understood as dynamic, top-down controlled activations in the priority map, where integrated spatial and non-spatial feature information is increased and decreased on a trial-by-trial basis (Manohar et al., Citation2017). Alternatively, multiple priority maps might be entertained so that the correct one can be turned “on” for the upcoming trial (c.f.Theeuwes et al., Citation2022).
Why are the temporal order effects only observed if items and locations are bound, but not for target items at random positions? We assume that the visual search component of the task promotes a largely automatic integration of target item-location information in the, inherently spatial, priority map (Eimer, Citation2014; Wolfe et al., Citation2004), which becomes represented in VWM (Oberauer & Lin, Citation2017; Pertzov & Husain, Citation2014; Treisman & Zhang, Citation2006). By contrast, the integration of temporal associations is more resource demanding, requiring WM updating and executive control processes (Wiegand et al., Citation2021). Trial-to-trial adaptations of the search template for as yet unbound spatial and non-spatial features might therefore be effortful and less effective than just maintaining a diluted search template, which biases attention to non-spatial target features at all possible target locations. In accordance with this interpretation, RT-benefits of temporal sequences of paired target locations, unrelated to target identity, were only shown for feature search, providing strong bottom-up guidance, but not if search required feature binding of selected items (Li et al., Citation2022; Li & Theeuwes, Citation2020).
An alternative mechanism that could account for the temporal learning effect in Experiment 3 could be a combined space – and memory-based “inhibition of return”-type effect (Posner & Cohen, Citation1984). Specifically, a longer-term inhibition of return may operate at a post-selective stage (Wilson et al., Citation2006), during which the retrieval of the target item associated with its location from the previous trial, would temporally suppress the associated target item and locations in the next trial to prevent re-selection. Consequently, the remaining target items and locations would be prioritized. Assuming that inhibition declines gradually over consecutive trials, such inhibitory processes would produce a gradual space- and memory-based inhibition, which, by association, could reinforce one another to speed search times.
Limitations
The present studies investigated incidental learning without claiming to distinguish between implicit and explicit learning. Our assessments of explicit knowledge of the target item-location association and temporal associations based on self-reports was rather crude as they only provide evidence that participants acquired no or some level of awareness of the regularity. The level of awareness, however, could not further be determined and would require more sophisticated methods (Yu et al., Citation2023b). While the reports suggest that learned associations become represented in a way that can be accessed explicitly, we cannot rule out that implicit processes may have contributed to the learning outcome. It is well possible that associations become stronger until some threshold of associative strength is reached that results in conscious awareness, that is, explicit knowledge, over the course of trials.
Finally, the study faces the common limitations of online studies. The timing accuracy can be expected to be acceptable for the timing requirements of the present experiment (Anwyl-Irvine et al., Citation2021). However, the timing of the online experiment might be slightly less accurate compared to when using experimental software that runs on a stand-alone laboratory computer. Furthermore, the testing conditions, including potentially distracting events in the environment, and the participant’s hardware is unknown, leading to unexplained variability in the data.
Summary and conclusions
In real-world visual search, spatial and temporal target associations often co-occur. Thinking about your shopping-route, you look for distinct items on your shopping list at specific locations where you expect those items, and you collect items in a similar temporal order. Our results show that spatial and temporal associations in hybrid search can be learned without explicit instruction in a manner that reduces search time and increases search efficiency. Spatiotemporal regularities embedded in complex search tasks appear to shape attentional priority in space and time, such that attention can be biased dynamically to task-relevant bound target features and locations based on expectations about the sequential order of search episodes. Our results highlight the notion that the priority landscape guiding selective attention evolves over time and can be controlled flexibly and dynamically based on mnemonic representations (Nobre & Stokes, Citation2019). Future research may further specify the hierarchical structure and time-scales of attention-guiding associative memory traces. Specifically, increasing the task load by higher memory set sizes may increase the reliance on temporal associations that support LTM retrieval processes while selected items are compared to the target templates (Cunningham & Wolfe, Citation2014; Wolfe, Citation2021). Furthermore, it would be interesting to investigate whether and how procedural learning of eye-movement sequences (Seitz et al., Citation2023; Tal et al., Citation2021; Tal & Vakil, Citation2020) contributes to the search time benefits of learning spatio-temporal regularities in hybrid search. Eye-movement data could further provide measures of guidance and distractor rejection processes underlying the spatio-temporal learning effects observed in the search times (Horstmann et al., Citation2017; Zelinsky, Citation2008). Ideally, eye-movement data would be complemented by more sophisticated measures of participants’ awareness of regularities (Yu et al., Citation2023b), for example, by asking them to order target items and target positions or assigning target items to possible target locations.
SupplementaryMaterialBetweenexperimentanalyses.docx
Download MS Word (30.2 KB)Acknowledgements
We would like to thank Philip van den Broek for his help with programming the online experiments and thank Aran van Hout, Frederick Trefz, Emmy Postma, and Aniek Bakker, for their contributions to the data collection.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are openly available in the Open Science Framework (osf.io) at https://osf.io/tc9ej,DOI 10.17605/OSF.IO/TC9EJ
.Additional information
Funding
References
- Abrahamse, E. L., Jiménez, L., Verwey, W. B., & Clegg, B. A. (2010). Representing serial action and perception. Psychonomic Bulletin & Review, 17(5), 603–623. https://doi.org/10.3758/PBR.17.5.603
- Anwyl-Irvine, A., Dalmaijer, E. S., Hodges, N., & Evershed, J. K. (2021). Realistic precision and accuracy of online experiment platforms, web browsers, and devices. Behavior Research Methods, 53(4), 1407–1425. https://doi.org/10.3758/s13428-020-01501-5
- Asch, S. E., & Ebenholtz, S. M. (1962). The principle of associative symmetry. Proceedings of the American Philosophical Society, 106(2), 135–163.
- Bahle, B., Thayer, D. D., Mordkoff, J. T., & Hollingworth, A. (2020). The architecture of working memory: Features from multiple remembered objects produce parallel, coactive guidance of attention in visual search. Journal of Experimental Psychology: General, 149(5), 967. https://doi.org/10.1037/xge0000694
- Boettcher, S. E., Drew, T., & Wolfe, J. M. (2018). Lost in the supermarket: Quantifying the cost of partitioning memory sets in hybrid search. Memory & Cognition, 46(1), 43–57. https://doi.org/10.3758/s13421-017-0744-x
- Boettcher, S. E., Shalev, N., Wolfe, J. M., & Nobre, A. C. (2022). Right place, right time: Spatiotemporal predictions guide attention in dynamic visual search. Journal of Experimental Psychology: General, 151(2), 348. https://doi.org/10.1037/xge0000901
- Brady, T. F., Konkle, T., Alvarez, G. A., & Oliva, A. (2008). Visual long-term memory has a massive storage capacity for object details. Proceedings of the National Academy of Sciences, 105(38), 14325–14329. https://doi.org/10.1073/pnas.0803390105
- Chun, M. M. (2000). Contextual cueing of visual attention. Trends in Cognitive Sciences, 4(5), 170–178. https://doi.org/10.1016/S1364-6613(00)01476-5
- Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36(1), 28–71. https://doi.org/10.1006/cogp.1998.0681
- Chun, M. M., & Turk-Browne, N. B. (2008). Associative learning mechanisms in vision. In S. J. Luck, & A. Hollingworth (Eds.), Visual memory (pp. 209–245). Oxford University Press.
- Cunningham, C. A., & Wolfe, J. M. (2014). The role of object categories in hybrid visual and memory search. Journal of Experimental Psychology: General, 143(4), 1585. https://doi.org/10.1037/a0036313
- De Leeuw, J. R. (2015). jsPsych: A JavaScript library for creating behavioral experiments in a Web browser. Behavior Research Methods, 47(1), 1–12. https://doi.org/10.3758/s13428-014-0458-y
- Deroost, N., & Coomans, D. (2018). Is sequence awareness mandatory for perceptual sequence learning: An assessment using a pure perceptual sequence learning design. Acta Psychologica, 183, 58–65. https://doi.org/10.1016/j.actpsy.2018.01.002
- Deroost, N., & Soetens, E. (2006a). Perceptual or motor learning in SRT tasks with complex sequence structures. Psychological Research Psychologische Forschung, 70(2), 88–102. https://doi.org/10.1007/s00426-004-0196-3
- Deroost, N., & Soetens, E. (2006b). Spatial processing and perceptual sequence learning in SRT tasks. Experimental Psychology, 53(1), 16–30. https://doi.org/10.1027/1618-3169.53.1.16
- Draschkow, D., Kallmayer, M., & Nobre, A. C. (2021). When natural behavior engages working memory. Current Biology, 31(4), 869–874.e5. https://doi.org/10.1016/j.cub.2020.11.013
- Draschkow, D., & Võ, M. L.-H. (2016). Of “what” and “where” in a natural search task: Active object handling supports object location memory beyond the object’s identity. Attention, Perception, & Psychophysics, 78(6), 1574–1584. https://doi.org/10.3758/s13414-016-1111-x
- Egner, T., Monti, J. M., Trittschuh, E. H., Wieneke, C. A., Hirsch, J., & Mesulam, M.-M. (2008). Neural integration of top-down spatial and feature-based information in visual search. Journal of Neuroscience, 28(24), 6141–6151. https://doi.org/10.1523/JNEUROSCI.1262-08.2008
- Eimer, M. (2014). The neural basis of attentional control in visual search. Trends in Cognitive Sciences, 18(10), 526–535. https://doi.org/10.1016/j.tics.2014.05.005
- Endo, N., & Takeda, Y. (2004). Selective learning of spatial configuration and object identity in visual search. Perception & Psychophysics, 66(2), 293–302. https://doi.org/10.3758/BF03194880
- Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146
- Ferrante, O., Patacca, A., Di Caro, V., Della Libera, C., Santandrea, E., & Chelazzi, L. (2018). Altering spatial priority maps via statistical learning of target selection and distractor filtering. Cortex, 102, 67–95. https://doi.org/10.1016/j.cortex.2017.09.027
- Gallo, D. A., & Wheeler, M. E. (2013). Episodic memory. In D. Reisberg (Ed.), The Oxford handbook of cognitive psychology (pp. 189–205). Oxford University Press.
- Geng, J. J., & Behrmann, M. (2002). Probability cuing of target location facilitates visual search implicitly in normal participants and patients with hemispatial neglect. Psychological Science, 13(6), 520–525. https://doi.org/10.1111/1467-9280.00491
- Geng, J. J., & Behrmann, M. (2005). Spatial probability as an attentional cue in visual search. Perception & Psychophysics, 67(7), 1252–1268. https://doi.org/10.3758/BF03193557
- Gibson, E. J. (1963). Perceptual learning. Annual Review of Psychology, 14(1), 29–56. https://doi.org/10.1146/annurev.ps.14.020163.000333
- Goschke, T. (1998). Implicit learning of perceptual and motor sequences: Evidence for independent learning systems. In M. A. Stadler, & P. A. Frensch (Eds.), Handbook of implicit learning (pp. 401–444). Sage Publications, Inc.
- Healey, M. K., & Kahana, M. J. (2014). Is memory search governed by universal principles or idiosyncratic strategies? Journal of Experimental Psychology: General, 143(2), 575. https://doi.org/10.1037/a0033715
- Helbing, J., Draschkow, D., & Võ, M. L.-H. (2020). Search superiority: Goal-directed attentional allocation creates more reliable incidental identity and location memory than explicit encoding in naturalistic virtual environments. Cognition, 196, 104147. https://doi.org/10.1016/j.cognition.2019.104147
- Hollingworth, A. (2006). Visual memory for natural scenes: Evidence from change detection and visual search. Visual Cognition, 14(4-8), 781–807. https://doi.org/10.1080/13506280500193818
- Hollingworth, A. (2007). Object-position binding in visual memory for natural scenes and object arrays. Journal of Experimental Psychology: Human Perception and Performance, 33(1), 31. https://doi.org/10.1037/0096-1523.33.1.31
- Horstmann, G., Becker, S., & Ernst, D. (2017). Dwelling, rescanning, and skipping of distractors explain search efficiency in difficult search better than guidance by the target. Visual Cognition, 25(1-3), 291–305.
- Kahana, M. J. (2002). Associative symmetry and memory theory. Memory & Cognition, 30(6), 823–840. https://doi.org/10.3758/BF03195769
- Kahana, M. J. (2020). Computational models of memory search. Annual Review of Psychology, 71(1), 107–138. https://doi.org/10.1146/annurev-psych-010418-103358
- Kahana, M. J., Howard, M. W., & Polyn, S. M. (2008). Associative retrieval processes in episodic memory. In H. L. Roediger III (Ed.), Cognitive psychology of memory. Vol. 2 of Learning and memory: A comprehensive reference, 4 vols. (J. Byrne, Editor) (pp. 467–490). Elsevier.
- Kingstone, A. (1992). Combining expectancies. The Quarterly Journal of Experimental Psychology Section A, 44(1), 69–104. https://doi.org/10.1080/14640749208401284
- Koch, I., Blotenberg, I., Fedosejew, V., & Stephan, D. N. (2020). Implicit perceptual learning of visual-auditory modality sequences. Acta Psychologica, 202, 102979. https://doi.org/10.1016/j.actpsy.2019.102979
- Koch, I., & Hoffmann, J. (2000). The role of stimulus-based and response-based spatial information in sequence learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(4), 863–882. https://doi.org/10.1037/0278-7393.26.4.863
- Konkle, T., Brady, T. F., Alvarez, G. A., & Oliva, A. (2010). Conceptual distinctiveness supports detailed visual long-term memory for real-world objects. Journal of Experimental Psychology: General, 139(3), 558–578. https://doi.org/10.1037/a0019165
- Li, A.-S., Bogaerts, L., & Theeuwes, J. (2022). Statistical learning of across-trial regularities during serial search. Journal of Experimental Psychology: Human Perception and Performance, 48(3), 262–274. https://doi.org/10.1037/xhp0000987
- Li, A.-S., & Theeuwes, J. (2020). Statistical regularities across trials bias attentional selection. Journal of Experimental Psychology: Human Perception and Performance, 46(8), 860–870. https://doi.org/10.1037/xhp0000753
- Lum, J. A. (2020). Incidental learning of a visuo-motor sequence modulates saccadic amplitude: Evidence from the serial reaction time task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 46(10), 188118-91.
- Manohar, S. G., Pertzov, Y., & Husain, M. (2017). Short-term memory for spatial, sequential and duration information. Current Opinion in Behavioral Sciences, 17, 20–26. https://doi.org/10.1016/j.cobeha.2017.05.023
- Mayr, U. (1996). Spatial attention and implicit sequence learning: Evidence for independent learning of spatial and nonspatial sequences. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22(2), 350–364. https://doi.org/10.1037/0278-7393.22.2.350
- Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of learning: Evidence from performance measures. Cognitive Psychology, 19(1), 1–32. https://doi.org/10.1016/0010-0285(87)90002-8
- Nobre, A. C., & Stokes, M. G. (2019). Premembering experience: A hierarchy of time-scales for proactive attention. Neuron, 104(1), 132–146. https://doi.org/10.1016/j.neuron.2019.08.030
- Nobre, A. C., & Van Ede, F. (2018). Anticipated moments: Temporal structure in attention. Nature Reviews Neuroscience, 19(1), 34–48. https://doi.org/10.1038/nrn.2017.141
- Oberauer, K., & Lin, H.-Y. (2017). An interference model of visual working memory. Psychological Review, 124(1), 21–59. https://doi.org/10.1037/rev0000044
- Olivers, C. N., Peters, J., Houtkamp, R., & Roelfsema, P. R. (2011). Different states in visual working memory: When it guides attention and when it does not. Trends in Cognitive Sciences, 15(7), 327–334.
- Ort, E., & Olivers, C. N. (2020). The capacity of multiple-target search. Visual Cognition, 28(5–8), 330–355. https://doi.org/10.1080/13506285.2020.1772430
- Pertzov, Y., & Husain, M. (2014). The privileged role of location in visual working memory. Attention, Perception, & Psychophysics, 76(7), 1914–1924. https://doi.org/10.3758/s13414-013-0541-y
- Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. G. Bouwhuis (Eds.), Attention and performance: Vol. 10. Control of language processes (pp. 531–556). Erlbaum.
- Postma, A., & De Haan, E. H. (1996). What was where? Memory for object locations. The Quarterly Journal of Experimental Psychology Section A, 49(1), 178–199. https://doi.org/10.1080/713755605
- Postma, A., Kessels, R. P., & van Asselen, M. (2008). How the brain remembers and forgets where things are: The neurocognition of object–location memory. Neuroscience & Biobehavioral Reviews, 32(8), 1339–1345. https://doi.org/10.1016/j.neubiorev.2008.05.001
- Postma, A., Kessels, R. P. C., & van Asselen, M. (2004). The neuropsychology of object-location memory. In G. L. Allen (Ed.), Human spatial memory: Remembering where (pp. 143–160). Erlbaum.
- Remillard, G. (2003). Pure perceptual-based sequence learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29(4), 581–597. https://doi.org/10.1037/0278-7393.29.4.581
- Schneider, W., & Shiffrin, R. M. (1977). Controlled and automatic human information processing: I. Detection, Search, and Attention. Psychological Review, 84(1), 1–66.
- Schwarb, H., & Schumacher, E. H. (2012). Generalized lessons about sequence learning from the study of the serial reaction time task. Advances in Cognitive Psychology, 8(2), 165–178. https://doi.org/10.5709/acp-0113-1
- Seitz, W., Zinchenko, A., Müller, H. J., & Geyer, T. (2023). Contextual cueing of visual search reflects the acquisition of an optimal, one-for-all oculomotor scanning strategy. Communications Psychology, 1(1), 20.
- Shanks, D. R. (1995). The psychology of associative learning. Cambridge University Press.
- Shaw, M. L., & Shaw, P. (1977). Optimal allocation of cognitive resources to spatial locations. Journal of Experimental Psychology: Human Perception and Performance, 3(2), 201–211. https://doi.org/10.1037/0096-1523.3.2.201
- Shih, S.-I., Meadmore, K. L., & Liversedge, S. P. (2012). Aging, eye movements, and object-location memory. PLoS One, 7(3), e33485. https://doi.org/10.1371/journal.pone.0033485
- Sommer, T., Rose, M., & Büchel, C. (2007). Associative symmetry versus independent associations in the memory for object-location associations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(1), 90–106. https://doi.org/10.1037/0278-7393.33.1.90
- Sommer, T., Rose, M., Gläscher, J., Wolbers, T., & Büchel, C. (2005). Dissociable contributions within the medial temporal lobe to encoding of object-location associations. Learning & Memory, 12(3), 343–351. https://doi.org/10.1101/lm.90405
- Standing, L., Conezio, J., & Haber, R. N. (1970). Perception and memory for pictures: Single-trial learning of 2500 visual stimuli. Psychonomic Science, 19(2), 73–74. https://doi.org/10.3758/BF03337426
- Tal, A., Bloch, A., Cohen-Dallal, H., Aviv, O., Schwizer Ashkenazi, S., Bar, M., & Vakil, E. (2021). Oculomotor anticipation reveals a multitude of learning processes underlying the serial reaction time task. Scientific Reports, 11(1), 6190. https://doi.org/10.1038/s41598-021-85842-x
- Tal, A., & Vakil, E. (2020). How sequence learning unfolds: Insights from anticipatory eye movements. Cognition, 201, 104291. https://doi.org/10.1016/j.cognition.2020.104291
- Theeuwes, J., Bogaerts, L., & van Moorselaar, D. (2022). What to expect where and when: How statistical learning drives visual selection. Trends in Cognitive Sciences, 26(10), 860–872. https://doi.org/10.1016/j.tics.2022.06.001
- Treisman, A., & Zhang, W. (2006). Location and binding in visual working memory. Memory & Cognition, 34(8), 1704–1719. https://doi.org/10.3758/BF03195932
- Turk-Browne, N. B., Jungé, J. A., & Scholl, B. J. (2005). The automaticity of visual statistical learning. Journal of Experimental Psychology: General, 134(4), 552–564. https://doi.org/10.1037/0096-3445.134.4.552
- Võ, M., & Wolfe, J. M. (2015). The role of memory for visual search in scenes. Annals of the New York Academy of Sciences, 1339(1), 72–81. https://doi.org/10.1111/nyas.12667
- Walthew, C., & Gilchrist, I. D. (2006). Target location probability effects in visual search: An effect of sequential dependencies. Journal of Experimental Psychology: Human Perception and Performance, 32(5), 1294–1301. https://doi.org/10.1037/0096-1523.32.5.1294
- Wiegand, I., Westenberg, E., & Wolfe, J. M. (2021). Order, please! Explicit sequence learning in hybrid search in younger and older age. Memory & Cognition, 49(6), 1220–1235. https://doi.org/10.3758/s13421-021-01157-2
- Wiegand, I., & Wolfe, J. M. (2020). Age doesn’t matter much: Hybrid visual and memory search is preserved in older adults. Aging, Neuropsychology, and Cognition, 27(2), 220–253. https://doi.org/10.1080/13825585.2019.1604941
- Wilson, D. E., Castel, A. D., & Pratt, J. (2006). Long-term inhibition of return for spatial locations: Evidence for a memory retrieval account. Quarterly Journal of Experimental Psychology, 59(12), 2135–2147. https://doi.org/10.1080/17470210500481569
- Wolfe, J. M. (1994). Guided search 2.0 a revised model of visual search. Psychonomic Bulletin & Review, 1(2), 202–238. https://doi.org/10.3758/BF03200774
- Wolfe, J. M. (2012). Saved by a log: How do humans perform hybrid visual and memory search? Psychological Science, 23(7), 698–703. https://doi.org/10.1177/0956797612443968
- Wolfe, J. M. (2021). Guided Search 6.0: An updated model of visual search. Psychonomic Bulletin & Review, 28(4), 1060–1092. https://doi.org/10.3758/s13423-020-01859-9
- Wolfe, J. M., Horowitz, T. S., Kenner, N., Hyle, M., & Vasan, N. (2004). How fast can you change your mind? The speed of top-down guidance in visual search. Vision Research, 44(12), 1411–1426. https://doi.org/10.1016/j.visres.2003.11.024
- Yu, H., Allenmark, F., Müller, H. J., & Shi, Z. (2023a). Asymmetric learning of dynamic spatial regularities in visual search: Robust facilitation of predictable target locations, fragile suppression of distractor locations. Journal of Experimental Psychology: Human Perception and Performance, 49(5), 709–724. https://doi.org/10.1037/xhp0001120
- Yu, H., Allenmark, F., Müller, H. J., & Shi, Z. (2023b). Learning regular cross-trial shifts of the target location in serial search involves awareness – An eye-tracking study. bioRxiv, https://doi.org/10.1101/2023.12.15.571821
- Zacks, J. M., & Tversky, B. (2001). Event structure in perception and conception. Psychological Bulletin, 127(1), 3–21. doi:10.1037/0033-2909.127.1.3
- Zelinsky, G. J. (2008). A theory of eye movements during target acquisition. Psychological Review, 115(4), 787.