
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Research on scaling analysis in finance is vast and still flourishing. We introduce a novel statistical procedure based on the generalized Hurst exponent, the Relative Normalized and Standardized Generalized Hurst Exponent (RNSGHE), to robustly estimate and test the multiscaling property. Furthermore, we introduce a new tool to estimate the optimal aggregation time used in our methodology which we name Autocororrelation Segmented Regression. We numerically validate this procedure on simulated time series by using the Multifractal Random Walk and we then apply it to real financial data. We present results for times series with and without anomalies and we compute the bias that such anomalies introduce in the measurement of the scaling exponents. We also show how the use of proper scaling and multiscaling can ameliorate the estimation of risk measures such as Value at Risk (VaR). Finally, we propose a methodology based on Monte Carlo simulation, which we name Multiscaling Value at Risk (MSVaR), that takes into account the statistical properties of multiscaling time series. We mainly show that by using this statistical procedure in combination with the robustly estimated multiscaling exponents, the one year forecasted MSVaR mimics the VaR on the annual data for the majority of the stocks.
1. Introduction
Nowadays, scaling and multiscaling are widely accepted as empirical stylized facts in financial time series. Since they provide important information to risk and asset managers, they need to be properly addressed and analyzed. The (multi)scaling property of time series is particularly important in risk management and has been recently employed as a warning tool for financial events (Antoniades et al. Citation2021). In particular, models that implicitly or explicitly assume independence of asset returns should be tested against long-term dependence alternatives. In fact, if the assumption of independence of price increments is not met, risk measures might be severely biased, especially if the long-range dependence is acting with a different degree across the time series statistical moments. In particular, multiscaling has been adopted as a formalism in two different branches of quantitative Finance, i.e. econophysics and mathematical Finance. The former devoted most of the attention to price and returns series in order to understand the source of multifractality from an empirical and theoretical point of view (Mandelbrot Citation1963, Citation1967; Mantegna and Stanley Citation1995; Lux and Marchesi Citation1999; Mantegna and Stanley Citation1999; Gençay et al. Citation2001; Calvet and Fisher Citation2002; Lux Citation2004; Di Matteo, Aste, and Dacorogna Citation2005; Di Matteo Citation2007; Buonocore et al. Citation2019) and has recently identified a new stylized fact which relates (non-linearly) the strength of multiscaling and the dependence between stocks (Buonocore et al. Citation2019). The latter instead, builds on the work of (Gatheral, Jaisson, and Rosenbaum Citation2018) on rough volatility and has been used to construct stochastic models with anti-persistent volatility dynamics (Gatheral, Jaisson, and Rosenbaum Citation2018; Livieri et al. Citation2018; Fukasawa, Takabatake, and Westphal Citation2019; Takaishi Citation2020). Even if the research question comes from different perspectives, it is important to recognize the relevance that its study has in Finance.
Multiscaling has been understood to originate from one or more phenomenon related to trading dynamics.Footnote1 In particular, it can be attributed to the fat tails, the autocorrelation of the absolute value of log-returns, liquidity dynamics, or (non-linear) correlation between high and low returns generated by the different time horizons at which traders operate and the consequent volumes traded. It can also be caused by the endogeneity of markets for which a given order generates many other orders. This occurs especially in markets where algorithmic trading is frequently adopted. There are different methodologies used to compute scaling exponents from time series (Jiang et al. Citation2019). Among all, let us recall the Multifractal Detrended Fluctuation Analysis (MFDFA) proposed in Kantelhardt et al. (Citation2002), the Wavelet Transform Modulus Maxima (WTMM) introduced by Muzy, Bacry, and Arneodo (Citation1991, Citation1993), the Deep learning approach proposed in Corbetta et al. (Citation2021) and the Structure function approach also known as the Generalized Hurst exponent (GHE) method (Kolmogorov Citation1962; Van Atta and Chen Citation1970; Di Matteo, Aste, and Dacorogna Citation2003; Di Matteo Citation2007). In a recent paper, Barunik and Kristoufek (Citation2010) tested different methodologies against some data specification and empirically showed that the GHE approach outperforms the other models. For this reason, throughout this work, we will use the GHE approach. Notwithstanding the importance of the correct estimation of the Hurst exponent, the analysis has been rarely addressed from a statistical point of view.
In this paper, we propose a step-by-step procedure that provides a robust estimation and that tests the multiscaling property in a statistically significant way. Application to simulated data and empirical data allows us also to demonstrate the impact of bias on these estimations. We show how the use of proper scaling and multiscaling can ameliorate the estimation of risk measures such as Value at Risk(VaR). We also propose a methodology based on Monte Carlo simulation, which we name Multiscaling VaR, which takes into account the statistical properties of multiscaling time series by using a multiscaling consistent data generating process.
The paper is structured as follows. Sections 2 and 3 provide a brief description of multiscaling in Finance and of the statistical procedure proposed to consistently estimate and test the scaling spectrum. Section 4 shows the results of this methodology applied to synthetic data while Section 5 reports the results of an empirical application to real financial time series. Section 6 is devoted to a practical application of scaling and multiscaling property to VaR while Section 7 concludes.
2. Multiscaling in finance
In this section, we explain the importance of the multifractal (multiscaling) formalism in financial markets. Let us first fix the notation by defining the prices time series as and the log-prices
. From this, the log-returns over a time aggregation τ are
, where τ is expressed in days. Financial models are usually based on the assumption that log-prices follow a Brownian Motion and the for this model, the rescaled second moment of the log-returns over time aggregation τ follows
(1)
(1) where
is the standard deviation at aggregation horizon τ while σ is the standard deviation at daily aggregation. This equation is usually referred to as the square root of time rule and it is widely applied in quantitative Finance (Danielsson and Zigrand Citation2006; Wang, Yeh, and Ying-Pin Cheng Citation2011). Examples are the Black and Scholes model in which the volatility evolves as
, or the VaR which under Basel regulatory framework can be computed for higher time aggregation, e.g. the τ days VaR can be computed as the daily VaR multiplied by
. In the analysis of the Nile river, Hurst found that the scaling behavior described by a Brownian Motion was not in line with the empirical data (Hurst Citation1956). Scaling and multiscaling analyses have been later introduced in Finance (Mandelbrot Citation1963, Citation1967, Citation2013; Jiang et al. Citation2019). To detect multiscaling, it is necessary to study the non-linearity of the scaling exponents of the q-order moments of the absolute value of log-returns (Mandelbrot, Fisher, and Calvet Citation1997; Calvet, Fisher, and Mandelbrot Citation1997; Di Matteo Citation2007). In particular, for a process
with stationary increments, the GHE methodology considers a function of increments (Di Matteo Citation2007) of the form
(2)
(2) where
is the set of evaluated moments,
is the set of lags used to compute the log-returns, N and M are the maximum numbers of moments and lag specification, i.e.
,
,
and
,
is the q-moment for
, and
is the so called generalized Hurst exponent which is a function of q. Finally, the function
is concave (Mandelbrot, Fisher, and Calvet Citation1997; Calvet, Fisher, and Mandelbrot Citation1997) and codifies the scaling exponents of the process. A process is uniscaling when the function
does not depend on q, i.e.
(Di Matteo Citation2007), while it is multiscaling otherwise. If
, the process does not behave as a standard Brownian Motion (Wiener process) and neglecting this feature, would significantly bias the estimation of the true risk. In particular, if H<0.5
the process is said to be anti-persistent (persistent) while if H = 0.5 the process can be of two types, i.e. it can have independent increments or it can be a short-term dependent process (Lillo and Farmer Citation2004; Kristoufek Citation2010). Given Equation (Equation2
(2)
(2) ), a possible way to define a multiscaling proxy is by quantifying the degree of non-linearity of the function
. The standard procedure used in order to extract
consists in running a linear regression in log-log scale of Equation (Equation2
(2)
(2) ), which reads as
(3)
(3) where τ is defined in the range
and
(Di Matteo Citation2007). A multiscaling proxy can be obtained by fitting the measured scaling exponent with a second degree polynomial (Buonocore, Aste, and Matteo Citation2016; Buonocore et al. Citation2019) of the formFootnote2
(4)
(4) where A and B are two constants. In this mathematical setting, as for different multifractal models in Finance (Bacry, Delour, and Muzy Citation2001b; Calvet and Fisher Citation2002, Citation2004; Jiang et al. Citation2019), we implicitly assume a quadratic function of
. The measured B,
, represents the curvature of
. If
, the process is uniscaling, while if
, the process is multiscaling (Buonocore, Aste, and Matteo Citation2016; Buonocore et al. Citation2019). In order to widely apply the multiscaling formalism in Finance, it is of vital importance the ability to correctly estimate the value of
and consequently, of A and B.
3. Methodology
As highlighted in the previous section, estimating the Hurst exponent from empirical data is a challenging task and these challenges can be categorized into two different classes:
Those due to the statistical procedure adopted;
Those linked to the financial data themselves.
Within the first class, we identify two main issues related to the following two points:
The statistical model used to compute the scaling exponents;
The input variables used in the statistical procedure.
Within the second class, issues arise mainly from the following question:
If the data contain an anomaly, how is this impacting the estimation of the scaling and multiscaling exponents?
In this work, we address the above challenges. First, we focus on the statistical procedure and the implication on financial time series with and without anomalies. Then, we discuss practical implications related to Finance, with special attention to Value at Risk.
3.1. Statistical procedure
Multiscaling properties of financial time series have been understood to come from one or more phenomena related to trading dynamics. From the point of view of the financial microstructure, scaling can be attributed to liquidity dynamics, endogeneity of markets, or any other dynamic existing in the market. In particular, the superimposition of distinct strategies and investment horizons generates long-range dependence with different degrees of strength when evaluated at different order moments and this is precisely the definition of multiscaling. In this section we propose a methodology to estimate the Hurst exponent and the multiscaling depth (curvature) coefficient B in a robust manner. As specified in Equation (Equation3
(3)
(3) ), the estimation of scaling laws is generally performed through a linear regression in log-log scales. The statistical problem which might arise in this context is that the regression is performed minimizing the squared log-errors instead of the true errors. This procedure might, in case of strong deviation from the assumed statistical model for the errors, severely impact the results. The solution to this problem consists of applying a nonlinear regression to the original (i.e. not transformed) data, comparing the fit of the two specifications to the original data and using the one which performs better. Another issue related to the statistical model is the uncertainty associated to the intercept for the q regressions. In particular, we can exactly compute the value of
rather than estimating it, thus eliminating possible errors and bias. We can define the standardized
as
(5)
(5) based on which, Equation (Equation2
(2)
(2) ) can be rewritten as
(6)
(6) Equation (Equation6
(6)
(6) ) eliminates the possible bias introduced by the estimation of
via regression. To easily exploit and model the multiscaling behavior, we define the q-order normalized moment as
(7)
(7) which transforms Equation (Equation6
(6)
(6) ) in
(8)
(8) Within this new formulation, the analysis is much easier since now, all the q regressions have a 0 intercept and the multiscaling is present only if the regression coefficients
differ for distinct values of q. In fact, for uniscaling time series all regression lines are overlapping while, for multiscaling time series they diverge. Given the formalism introduced by Equation (Equation8
(8)
(8) ), it is easy to check whether a process is multiscaling or not. In addition, we can now rewrite Equation (Equation4
(4)
(4) ) for the normalized and standardized structure function of Equation (Equation8
(8)
(8) ) as
(9)
(9) Even if mathematically equivalent to Equation (Equation4
(4)
(4) ), this equation has a statistical advantage. Eliminating the multiplication by q from both sides of the Equation, we reduce the possibility of spurious results in case q is a dominant factor in the multiplication. Indeed, the interpretation is equivalent, i.e. A is the linear scaling index while B is the multiscaling proxy. Finally, let us define the relative structure function between two consecutive moments, namely
and
(
), as follows
(10)
(10) where
. This formalization has a similar structure as the Extended Self Similarity (ESS) methodology (Jiang et al. Citation2019) since the scaling exponents are computed taking as reference another moment function while it diverges from it as the ESS has a reciprocal effect while Equation (Equation10
(10)
(10) ) has an incremental effect relative to the reference moment. This approach helps in the statistical analysis since we can now test if a process is statistically multiscaling using a significance test on the estimated
. In fact, for uniscaling time series we have that
, which implies that the difference between different order moments is always 0.Footnote3 On the contrary, for multiscaling time series it should be different from 0 for all q. This reduces to a t-test on the regression coefficients estimated using Equation (Equation10
(10)
(10) ). Besides the multi-regression approach, it is possible to perform a multivariate regression by rewriting Equation (Equation10
(10)
(10) ) as
(11)
(11) where M is the maximum number of moments used. This is a multivariate nonlinear regression that can be easily solved via a nonlinear optimization algorithm. Such a methodological approach implies a possible relationship between the q-moments used in the regression. Depending on the model assumptions, one can use Equation (Equation11
(11)
(11) ) or perform M separate regressions for each exponent. In the first case, it is then possible to use an F-test to test if all the coefficients except for the first one (
) are jointly equal to 0 against the alternative that some coefficients are different from 0. This is a less restrictive multiscaling test compared to the multiple t-tests. We call strongly multiscaling processes those processes which reject both the null hypothesis for all the t-tests and the null of the F-test. Conversely, we call weakly multiscaling processes those processes for which the null hypothesis of all the t-tests is rejected but not the null of the F-test.Footnote4 This is quite intuitive since if a process is multiscaling, all the relative increments are statistically significant. However, if the process reconstructed with a single exponent is statistically equivalent to the one reconstructed with the full multiscaling spectrum, this means that such multiscaling behavior is weak. As already mentioned, it is recommended to estimate the model both in the log-log scale and in the original coordinate system, and to base the choice of the model on a goodness of fit measure.
3.1.1. The choice of q and τ
The choice of q and τ is an important step in the statistical evaluation of the multiscaling exponents. They must be selected using specific statistical criteria. In fact, using the wrong values of q and τ can severely bias the evaluation. Regarding q, many research papers about multiscaling systems propose the use of a vast spectrum of qs. This approach has two fallacies. The first one lies in the fact that multiscaling processes are such even for small values of q. Secondly and most importantly, given a distribution of returns with tail exponent α, for ,
diverges (Jiang et al. Citation2019). For empirical data, this effect is characterized by a distortion of the moment function which can be misinterpreted as multiscaling even without the presence of temporal dependence. Hence, to have a robust measure of multiscaling, it is necessary to have
. Any multiscaling behavior found by neglecting or ignoring this fact, is severely biased and possibly false. The method used to set q can derive from two different approaches, i.e. established research results or direct tail exponent computation. Since it has been empirically shown that financial time series have fat tails with tail exponents ranging from
(Weron Citation2001; Scalas and Kim Citation2006; Eom, Kaizoji, and Scalas Citation2019) to
(Jiang et al. Citation2019), a conservative approach would be to use
. Alternatively, it is possible to estimate α on the empirical distribution through a tail estimator (e.g. Clauset, Rohilla Shalizi, and Newman Citation2009; Virkar and Clauset Citation2014) and use it as threshold for q. In this paper, we follow the conservative approach and use
. In fact, if the multiscaling phenomenon is present, it can be extrapolated from this range of moments.
Regarding the time aggregation τ, a general rule would be to use the minimum possible value of τ, denoted as , such that the autocorrelation information of the series is preserved. The autocorrelation ρ of the return series at lag τ is defined as:
(12)
(12) where μ and
are respectively the mean and variance of
. It is a well known stylized fact that returns are expected to be uncorrelated at daily frequency while the absolute and squared returns exhibit long-range persistence (Cont Citation2001; Chakraborti et al. Citation2011). Among the different procedures used to estimate
, it is worth mentioning:
Segmented regression on the structure function (Yue et al. Citation2017);
Autocorrelation significance test (Buonocore, Aste, and Matteo Citation2017).
The first procedure computes the structure function for each q-moment and successfully fits a segmented regression in log-log coordinates between τ and , and finds two slopes: one for the scaling component and one for the non-scaling component (Yue et al. Citation2017). The second approach instead, chooses the value of τ prior to computing the structure function, setting the value of
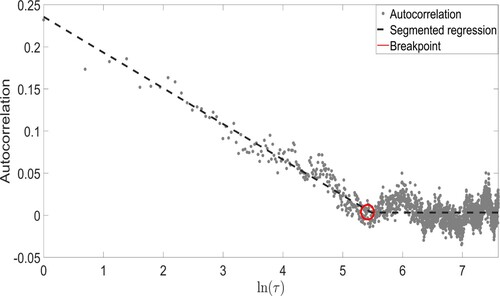
as the minimum value of τ for which the autocorrelation is not statistically significant (Buonocore, Aste, and Matteo Citation2017). In this paper, we propose a new approach which takes the advantages of both methods. We name this Autocorrelation Segmented Regression. The rationale behind this approach is to perform a segmented regression on the autocorrelation (or the autocovariance) function computed on the absolute returns and take
as the value which minimizes the sum of squared residuals for the high autocorrelation state and the random noise state, i.e. plateau.Footnote5 This approach has the advantage of setting the value of τ in advance, avoiding ad-hock solutions and reducing computations. Nevertheless, the method is less sensitive to a unique non-significant lag. In fact, in noisy data it can happen that for a lag the autocorrelation is not significant while it is significant for a considerable number of subsequent lags. The equation for the proposed Autocorrelation Segmented Regression (ACSR) takes the form
(13)
(13) where α is the intercept of the regression and can be fixed to be equal to
with
, β is a slope parameter for the autocorrelation function, τ is the lag at which the autocorrelation is computed, and
is the value of aggregation which maximizes the autocorrelation information.Footnote6 We use
instead of τ for a better detection of
. Figure shows how this method works. We generated a process with known
and run the ACSR to empirically estimate
. As shown in Figure , we get a value of
which corresponds to
.
Figure 1. ACSR methodology computed on the autocorrelation function of the absolute values of the log-returns time series. The red circle shows the breakpoint where the regression line has a break.
3.1.2. Multiscaling estimation and testing procedure
Before turning the attention to the simulation experiment, let us recall the full procedure required to robustly extract the scaling exponents:
Compute
with the Autocorrelation Segmented Regression method;
Compute
Perform the linear and nonlinear regressions with the above parameters (Equation (Equation11
Assess the goodness of fit of the two models and select the one that overperforms;
Compute the multiscaling curvature using Equation (Equation9
Concerning point (5), in this paper we propose a full procedure in order to run what we call the multiscaling test. The testing procedure is divided into four steps. In the first step, we test if each scaling increment is statistically significant through a t-test. The second step is devoted to the F-test. In particular, we perform the F-test using the predicted relative moments from both the regression with the full estimated scaling spectrum, and the regression where only the first scaling is different from 0, i.e.
and
, where
. If the null hypothesis is rejected, that the full spectrum is necessary to recover all the relative moments.Footnote7 The third step of the procedure consists of a random walk (RW) hypothesis. Assuming the multiscaling parameter B = 0, we perform the regression of Equation (Equation9
(9)
(9) ) with only the constant A and test if
with a t-test. In fact, for financial returns
which implies
. Hence, when B = 0 for monoscaling time series, we expect A = 0.5. In case the null hypothesis is rejected, this means that the RW scaling is incorrect and the use of the square-root of time rule severity creates a bias in the risk measures. The last step involves a confirmatory test of the results deriving from the first and second steps of the test procedure. In particular, we perform the full regression of Equation (Equation9
(9)
(9) ) and test for
and
using a t-test. If this test gives a conflicting result with respect to the first and second steps, we cannot assert anything on the process with precision and a deeper analysis is required by controlling for different input specifications.
4. Simulation experiment
In the simulation experiment, we focus on one of the most used models to generate multifractal time series: the Multifractal Random Walk (MRW) proposed by Bacry, Delour, and Muzy (Citation2001a, Citation2001b). This model is capable to generate multifractal time series with a known multiscaling spectrum. In addition, this model is able to generate time series which are consistent with the financial stylized facts. In the discrete version of the MRW, the process is defined as (Bacry, Delour, and Muzy Citation2001b):
(14)
(14) with
where λ is called intermittency parameter and determines the strength of the multifractality, L is the autocorrelation length,
is the variance of the process, and
is the discretization step. The distinctive feature of the MRW is that, even if the
are independent, the
are not, having autocovariance
with
In the continuous limit, the scaling exponents of this model are
(15)
(15) The power of this model is that it encompasses all the major stylized facts using only three parameters (
). In fact, this model is able to reproduce fat tails, volatility clustering and multiscaling spectrum. For the purpose of simulation, we generated 100 paths each of dimension T = 10, 000 and we set the model parameters to L = 250,
and
in accordance to empirical findings (Bacry, Kozhemyak, and Muzy Citation2008, Citation2013; Løvsletten and Rypdal Citation2012). As explained in previous section,
. In particular, we use
with steps 0.02 which converts to 50 evaluated moments. To select
, we use the
estimated by the ACSR. Table shows results for the different specifications of λ. As shown in the table, the procedure is quite accurate and the 95% confidence intervals (C.I.) always contain the value of L = 250 which is the truncation parameter.
Table 1. Results of the ACSR for the estimation of .
is the mean over all the paths and the
C.I. are computed over 200,000 bootstrapped samples.
Once the parameters are estimated, we compute the multiscaling exponents and evaluate their statistical significance. Since Equation (Equation15(15)
(15) ) gives the true multiscaling spectrum, we can easily test the performance of the GHE approach and compare it with the new proposed methodology of this paper. We use the normalized and standardized structure function (NSSF) proposed in Equation (Equation8
(8)
(8) ) and the relative normalized and standardized structure function (RNSSF) proposed in Equation (Equation11
(11)
(11) ), which we name Normalized and Standardized Generalized Hurst Exponent (NSGHE) and the Relative Normalized and Standardized Generalized Hurst Exponent (RNSGHE), respectively. The latter methodology will be used to test the multiscaling spectrum. Tables and present the root mean squared errors (RMSE) of the different methodologies computed over the 100 realizations for both A and B parameters of Equation (Equation4
(4)
(4) ).Footnote8 As it is possible to notice, the RNSGHE generally outperforms with respect to the other specifications. It is important to highlight that by removing the slope ambiguity, results have considerably improved. In fact, the standard GHE approach has the highest RMSE among all the specifications. This result was expected since the new methodology helps to remove uncertainty and thus, to ameliorate the estimation performance.
Table 2. RMSE for the parameter A for the different methodologies.
Table 3. RMSE for the parameter B for the different methodologies.
Tables and show a better performance of the RNSGHEL and RNSGHENL compared to the other models, in terms of RMSE. For this reason, we use these models in the paper. Now, we show the nature of the process by performing the multiscaling test. Figure shows the p-values of all the 50 coefficients related to the q moments equations for a realization of the MRW model, assuming the same parameters specification as above and . What we can observe is that by choosing a confidence level of
, the null hypothesis of scaling increments equal to 0 for all the evaluated moments is rejected. However, if we set a more stringent confidence level, for example
, the null hypothesis is not rejected for some coefficients, resulting in a uniscaling process.
Figure 2. p-Values of all the 50 coefficients related to q moments equations for a multifractal random walk with T = 10, 000, , L = 250 and
.
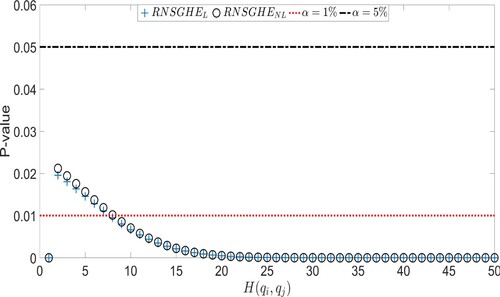
For all the p-values are almost 0. Since we generated processes with a non-negligible amount of multiscaling, this was expected. Once the t-test has been carried out, we perform an F-test on the overall scaling spectrum (Equation (Equation11
(11)
(11) )). Results are reported in Table . It is possible to infer that the process generated with
does not reject the null for which all the scaling increments are equal to 0 while, for
the null is rejected and the full scaling spectrum is necessary to reconstruct the relative moments. By combining this result with the outcome of the t-test, we can conclude that the process generated with
is weakly multiscaling at
confidence level but it is not multiscaling at
confidence level. The other two specifications are strongly multiscaling at any reasonable confidence level.
Table 4. p-Values of the F-test for the null that only is different from 0.
Since these processes have been generated such that they have a specific multiscaling spectrum, the last two tests of the multiscaling test procedure have trivial results.
5. Empirical application
In this section, we perform the empirical application of the proposed statistical methodology on financial data described in Section 5.1, and produce a statistical analysis of their multiscaling properties in Section 5.2. In Section 5.3, we also study how anomalies impact these estimation.
5.1. Data
The dataset used for the analyses is composed of stocks listed in the Dow Jones (DJ). In particular, close prices of stocks are recorded on a daily basis from 3 May 1999 to 20 November 2019, i.e. 5363 trading days. We use 27 over the 30 listed stocks since they are the ones for which the entire time series is available. For the purpose of our analysis, we use log-prices and log-returns. Table reports the summary statistics of the data.
Table 5. Summary statistics of the log-returns of the analyzed stocks.
As shown in this table, all the empirical stylized facts can be observed. Indeed, log-returns are centered at 0, the Skewness is (in most of the cases) different from 0, while the high value of the Kurtosis clearly depicts fat tails of the log-returns distributions.
5.2. Multiscaling test
In this section, we report results of the multiscaling test.Footnote9 We report the results of all the steps of the testing procedure described at the end of Section 3.1.2. Results are presented using the RNSGHEL because as explained in the previous section, it has the best performance in the correct estimation of the scaling spectrum.Footnote10 Results are summarized in Table . The second column of the table presents the calculated using the ACSR methodology, which is presented in Section 3.1.1. For its estimation, we fix a maximum value for the choice of τ equal to
in order not to bias the scaling estimation with too few values. We notice that several stocks reach the boundary value, suggesting a very high rate of persistency in the time series. The third column of this table reports the response to the weak multiscaling (weak M-S) process hypothesis, i.e. hypothesis that a single scaling exponent is enough to approximate the full scaling spectrum but individual scaling increments are statistically significant. As we can observe, none of the analyzed stocks are weakly multiscaling. In fact, as reported in the fourth column, all the stocks pass both the tests and result in strong multiscaling processes. The fifth column of the table reports the result of the RW hypothesis. To perform this analysis we run the regression
and test if the estimated A,
, is equal to 0.5.Footnote11 We note that only for two stocks the null hypothesis is not rejected, namely Cisco and Pfizer. However, this is a first order approximation of the process and do not check if the process is multiscaling. The sixth column summarizes results of the confirmation test, which is equivalent to test
and
in the full regression model of Equation (Equation9
(9)
(9) ). Finally, the last three columns of the table report the estimated Hurst exponent
computed for the RW test, the linear scaling index
, and the multiscaling proxy
. These results point out that multiscaling is a stylized fact and can be statistically tested by rewriting the structure function in a convenient way.
Table 6. Results of the multiscaling estimation and testing procedure.
5.3. Effect of anomalies in the multiscaling estimation
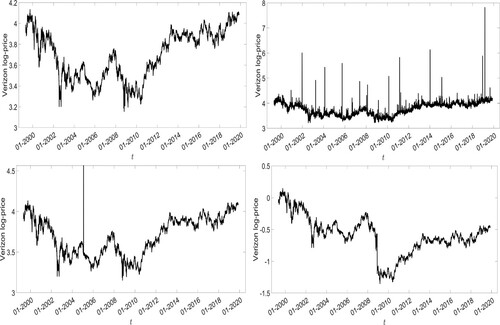
Multiscaling time series are generated from trading dynamics. One of the fundamental aspects of systems exhibiting multiscaling properties is the strong endogeneity of the sample paths, an aspect which is considered to be originated by financial trading dynamics. For this reason, transient exogenous shocks only distort the analysis and consequently, the estimation procedure. Hence, the statistical procedure used to analyze multiscaling systems are highly sensitive to exogenous shocks. In this context, we refer to an exogenous shock as an unexpected and transient behavior of the stock price, not explainable by the market conditions or by the price path. In addition, anomalies in the time series can occur due to errors or algorithmic trading crashes. Anomalies in financial time series can be grouped into three main categories: spikes, jumps and contamination errors. Figure shows these possible anomalies. The top left panel is dedicated to the original log-price time series for Verizon. This time series is quite volatile and in fact, the log-returns have a Kurtosis index equal to 9. However, although the distribution of log-returns is fat-tailed, there are not clear anomalies. The top right panel of Figure depicts the same log-price time series to which a strong fat-tailed series (Kurtosis larger than 1000) is added. This is the case of contamination error. This is generally due to machine errors in the data transmission process. The bottom left panel reflects the Verizon log-price time series with a random spike added. The spike can arise from multiple sources, among all algorithmic trading errors or contamination errors due to data manipulations. The last panel in the bottom right corner represents the log-price series with an added jump. Jumps per se can arise from endogenous or exogenous shocks. However, if they derive from an endogenous driving force, they persist in the jump direction. Conversely, if they come from an exogenous source instead, they tend to be transient. In a relatively recent paper (Sornette, Malevergne, and Muzy Citation2003), the authors explain that huge financial crashes can be originated from endogenous shocks which have a huge persistence behavior. These kinds of shocks are inherent in the price process so they are not transient anomalies.
Figure 3. Verizon log-prices time series and some anomalies of financial time series.
In a mostly technical paper, Katsev and L'Heureux (Citation2003) show both theoretically and experimentally that such data anomalies can strongly bias results, especially for short datasets. In particular, the paper shows that under certain circumstances, these irregularities can generate spurious scaling. For these reasons, it is suggested to analyze the time series and eliminate such anomalies before proceeding with the scaling estimation. In order to do so, we propose a methodology based on financial stylized facts. More precisely, we use volatility clustering and long-range dependence of asset returns (Cont Citation2001; Chakraborti et al. Citation2011). In this empirical context, the quantities that we name Cumulative Variance (CV) and Cumulative Auto-Covariance (CAV):Footnote12
(16)
(16) and
(17)
(17) should be very similar, except when an exogenous (unexpected) anomaly exists. The volatility clustering drives the similarity in the short period since
and
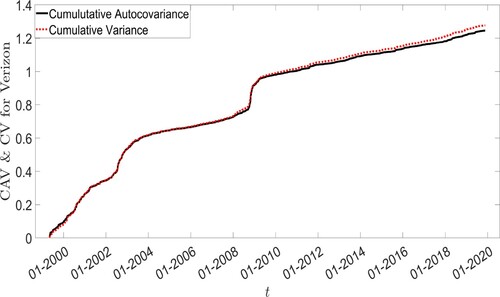
are expected to be very similar (same cluster), while the long-range dependence drives the similarity of the two measures over the long-run. Figure represents the two quantities for the Verizon stock. These two quantities are approximately equal, confirming that even with high volatility and many tail events, the time series does not contain exogenous shocks.
Figure 4. Cumulative Variance (CV) and Cumulative Auto-Covariance (CAV) for the Verizon time series.
The difference between the two cumulative series is given by . By running a change-point detection in the intercept and slope of
, it is possible to detect the anomalies in the price series and replace the corresponding values on the original series according to a specific rule, e.g. the mean of previous and subsequent data points. Top panels of Figures and reflect the case in which a spike and a jump have been added to the log-price time series of Verizon, respectively. As shown in the figures, the two measures start to diverge significantly exactly in correspondence of the anomaly point. The bottom panels instead, represent the change point detection performed on the quantity
. The panel shows that the procedure correctly identifies the position of the anomaly.
Figure 5. Cumulative Variance () and Cumulative Auto-Covariance (
) for the Verizon time series (top panel) and the measure
(bottom panel) in case of the added spike.
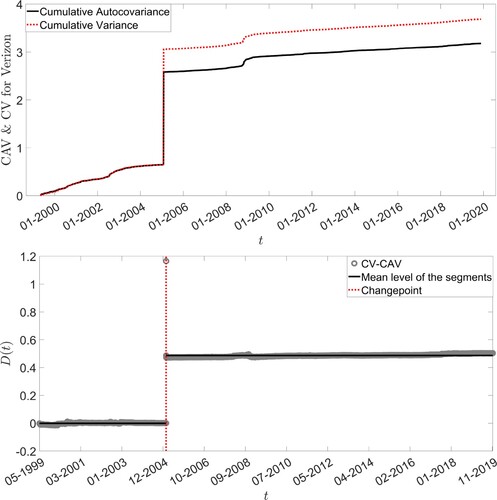
Figure 6. Cumulative Variance () and Cumulative Auto-Covariance (
) for the Verizon time series (top panel) and the measure
(bottom panel) in case of the added jump.
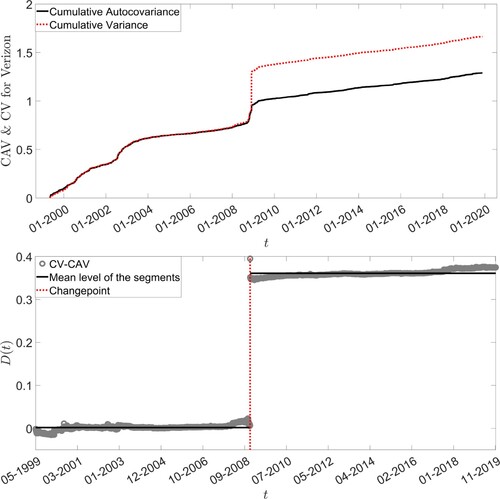
Given the fact that such events (spikes or jumps) are rare and have unconventional magnitude, their removal can only benefit the analysis. Let us estimate the multiscaling exponent for the Verizon stock when the anomalies reported in Figure (bottom panels) are not removed by the time series. Table reports the results. The estimated values change considerably, especially in the scenario where a spike is added.
Table 7. Results of the multiscaling estimation on the times series reported in Figure (bottom panels) with anomalies not removed.
For completeness, we also perform a t-test with the null hypothesis of no difference between the estimates with anomalies and the estimates reported in Table . The null hypothesis for all the coefficients is strongly rejected at any confidence level.
To show how these anomalies can generate spurious multiscaling, we generate 100 fractional Brownian motions (uniscaling process) of length 1000 with Hurst exponent H = 0.47 (the one estimated for Verizon). To these simulated time series we add a spike and a jump and estimate ,
and
for both the series with and without the anomalies. Results are reported in Table . As we can see, when the anomalies are not present in the time series, the average values for
,
and
are in line with the true values and not statistically different from them. In the scenario with the added spike, we can see that
,
and
are severely biased. In particular, due to the spike, the times series look multiscaling, while it is not. Finally, for the case of the added exogenous jump, we have that the scaling exponent curves and the parameter B is not equal to 0. Also the other two estimated coefficients are upward biased and statistically different from the theoretical ones.
Table 8. Average of the 100 estimated ,
and
for a fractional Brownian motion with H = 0.47.
C.I. computed over 200,000 bootstrapped samples are reported in parenthesis.
These results clearly show that the scaling exponents are sensitive to such anomalies and estimates can be biased if such anomalies are not carefully analyzed.
5.4. Jump test on the empirical data
We performed the jump detection analysis on the 27 stocks used for the analysis and found that 6 of them exhibited jumps. Table summarizes the results. We report the date(s) in which the jump is identified by the change point detection algorithm,Footnote13 as well as the estimated ,
and
when the jump(s) have been removed.Footnote14
Table 9. Results of the jump detection analysis and estimated exponent parameters.
From Table , we can notice the following: when removal of the jump increases the estimate of and
, multiscaling is reduced, while the opposite is true apart for UTX stock. Furthermore, we can see that, apart for
for the MRK stock, all the other estimates fall outside of the confidence intervals of the same parameters' estimates reported in Table . This means that the estimated coefficients reported in Table are statistically different (at
significance level) from the ones estimated without the jumps. Results make clear that in case of abrupt jumps or spikes, the estimates of the scaling exponent parameters can be severely impacted.
6. Practical application of scaling and multiscaling to VaR
In this section, we show that by using a simple VaR configuration without a scaling or multiscaling consideration might bias the VaR estimation at higher aggregation scales. We use daily stocks data from the Dow Jones index to estimate the multiscaling spectrum and to carry out the multiscaling test described in Section 5. After the procedure is concluded, we estimate the two most common VaR models, i.e. the Historical and Gaussian VaR at 1 day. Successively, we use these estimates to compute the yearly VaR using the square root of time rule.Footnote15 We then compare them with the fractional VaR with proper scaling and highlight eventual biases. To conclude, we propose a methodology to compute a multiscaling consistent VaR.
6.1. Value at risk
VaR is an easy and intuitive way to quantify risk for assets and portfolios. Let be the Value at Risk at frequency τ for a confidence level equal to
which satisfies
(18)
(18) where
are the log-returns at frequency τ. Several methodologies are used to compute the VaR. Among all, we recall the Historical VaR (HVaR) and the Gaussian VaR(GVaR).Footnote16 The former is a non-parametric approach that uses historical data to compute the VaR, while the latter assumes a Gaussian distribution of stock returns and applies the Gaussian formula for the percentiles computation to extract the VaR at a given confidence level. The issue faced in applied Finance is that the square root of time rule works only under the assumption of iid Gaussian returns. However, this technique is widely adopted regardless of its assumptions.
In our analysis, VaR is computed using the two aforementioned approaches at day, and
confidence level (
). Annual VaR (
) is calculated with the scaling exponent equal to 0.5, i.e.
and to the estimated H, i.e.
Footnote17. We further estimate the true
using annual returns (
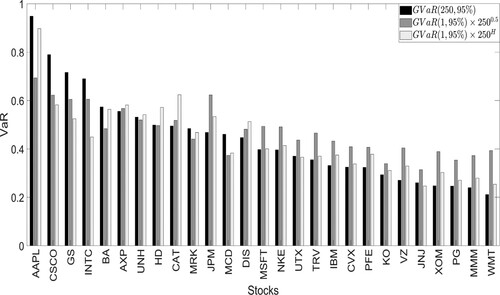
days) and compare them. Results are shown in Figures and . These figures show that when we compare the VaR calculated using the H scaling time rule and the VaR with the square root of time rule, the deviation from the true VaR is lower when the former approach is used. In fact, for the VaR with H scaling time, the bias with respect to the true VaR is considerably lower for most of the stocks in both the HVaR and GVaR settings. This is due to the fact that over the long-run, even a small divergence from the assumption of scaling exponent equal to 0.5 can have a substantial impact.
Figure 7. HVaR using annual data and using daily data rescaled by the factor and by
. Stocks are sorted by the magnitude of the annual Historical VaR.
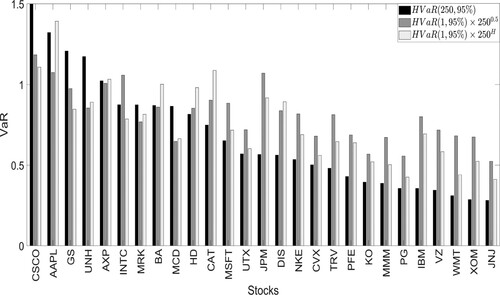
Figure 8. GVaR using annual data and using daily data rescaled by the factor and by
. Stocks are sorted by the magnitude of the annual Gaussian VaR.
To conclude the analysis with a quantitative assessment of the performance of the different methodologies, we also report the relative error (RE), i.e.
where K is equal to 0.5 for the VaR computed with the square root of time rule or equal to the estimated H,
, as reported in Table . This helps to identify the magnitude of the deviation from the true VaR and to compare the two scaling approaches. Figure shows the results.
Figure 9. Relative error between the true VaR calculated using annual data, HVaR and GVaR computed using daily data scaled by the factor 0.5 and by the estimated factor H. The red line is the 45 degrees reference line.
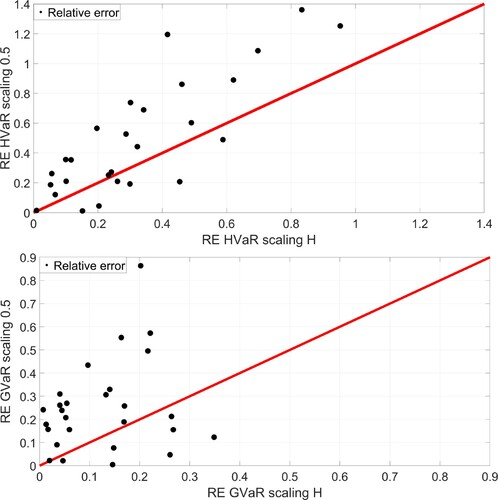
As the figure shows, using the correct scaling results in a smaller relative error. This confirms that the choice of a proper scaling exponent should not be neglected by the financial community, considering that its estimation and testing are relatively simple.
6.1.1. Multiscaling consistent VaR
In the previous subsection, we showed that using the correct scaling contributes to reduce the computation error for VaR at smaller frequencies. However, as explained in Section 5.2, all time series analyzed are strongly multiscaling. To deal with such situations, we discuss a possible solution. While VaR is related to the log-returns, multiscaling is a property of the moments of the log-returns. For this reason, there is not a straightforward formula to compute VaR which takes into account multiscaling. An exception to this is the Multifractal VaR proposed in Lee, Wook Song, and Chang (Citation2016), where the author introduces a VaR consistent with the multifractality of financial time series using the Multifractal Model of Asset Returns (MMAR). In a previous paper (Batten, Kinateder, and Wagner Citation2014), a similar analysis is performed but it relies on the MMAR Monte Carlo simulations and it computes the VaR on the simulated time series. The Monte Carlo approach has the advantage of letting the researcher use the model that best depicts the data. In fact, one can calibrate the MRW or the MMAR and generate a large number of sample paths which can be used to compute VaR. In the case of moderate multiscaling, the difference can be low but for multiscaling processes with a , neglecting such a feature can strongly distort the VaR. In this work, we use the MRW to simulate 250 trading days (i.e. 1 year) of log-returns and compute the VaR of the simulated paths. For this purpose, three parameters need to be estimated: the variance
, the autocorrelation scale parameter L and the intermittency parameter λ. The variance can be estimated from the log-returns time series as
with
, the parameter L is set to be equal to
, while the intermittency parameter λ can be extracted by equating the estimated coefficients of Equation (Equation4
(4)
(4) ) to the parameters in Equation (Equation15
(15)
(15) ) and getting two (possibly different) estimates of λ, i.e.
and
.Footnote18 For each stock, we estimate the three parameters,
, L and λ. Hence, we generate 100, 000 independent paths of daily returns for a year (i.e. 250 days). Finally, we quantify the VaR, which we name Multiscaling VaR (MSVaR), by computing the
percentile on these simulations. Results are depicted in Figure .
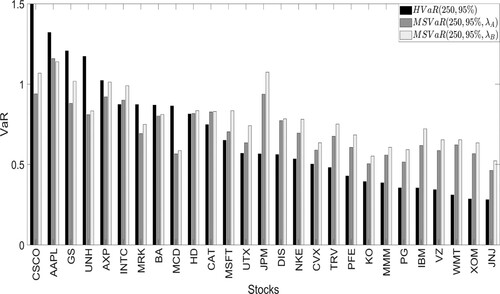
Figure 10. Annual Historical VaR (HVaR) and Multiscaling VaR (MSVaR). Confidence level . Stocks are sorted according to the magnitude of the Historical VaR.
It is possible to appreciate that the MSVaR computed on the simulated paths has a comparable size to the Historical VaR computed on annual data. It is also important to note that the values predicted using and
are very similar, suggesting that the stocks log-returns can be adequately approximated by the MRW model. Nevertheless, we remark on the importance of the full multiscaling estimation and testing procedure which lead to the MSVaR. In fact, if the previous analysis is bypassed the estimated risk metrics can be severely biased and inconsistent.
7. Conclusions
In this paper, we propose a step-by-step procedure to robustly estimate and test multiscaling in financial time series. By rewriting the structure function in a convenient way we perform multiple tests on the scaling spectrum and assess the statistical significance of multiscaling, discriminating between weak and strong multiscaling. We have shown the effect of anomalies in financial time series and studied the impact on the estimated scaling exponents. Moreover, we have shown how the use of proper scaling can help to reduce the error in the VaR forecasting at a smaller frequency with respect to the commonly used square root of time rule. Finally, we have proposed a Multiscaling consistent VaR using a Monte Carlo MRW simulation calibrated to the data and on which the VaR is then computed. Results are encouraging and confirm the goodness of the proposed methodological approach. Multiscaling is a stylized fact which can make a difference in the assessment of risk measures and in building quantitative models. It can be easily extrapolated from data and should not be overlooked by risk managers and authorities.
Acknowledgments
We would like to thank the anonymous referees who provided useful and detailed comments on a previous version of the manuscript. Their comments significantly improved the quality of this work. We want to thank the ESRC Network Plus project ‘Rebuilding macroeconomics’. We are grateful to NVIDIA corporation for supporting our research in this area with the donation of a GPU. We thank Bloomberg for providing the data.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 We refer as trading dynamics the results of the set of actions undertaken by investors in buying and selling financial instruments.
2 Technical details of the choice of this functional form can be found in Buonocore, Aste, and Matteo (Citation2016); Buonocore et al. (Citation2019).
3 Excluding the special case .
4 If the null hypothesis for one or more t-tests is not rejected but the F-test rejects the null hypothesis, the process is a non-stable multiscaling process.
5 Valsamis, Husband, and Ka-Wai Chan (Citation2019) review different segmented regression specifications.
6 It is important to notice that the segmented regression in the structure function and the ACSR method yields similar results.
7 For the non-linear regression, in order to use the F-test we have to use and
.
8 For the linear regression case, the NSGHE and RNSGHE are equivalent models, so we report only the result for the RNSGHE.
9 All the tests are performed using a confidence level of unless differently stated.
10 It is important to highlight that if the other methods proposed in this paper are adopted, results remain qualitatively unchanged.
11 This is the standard procedure to estimate the Hurst exponent for uniscaling processes, i.e. .
12 In the financial High-frequency literature, these quantities are strongly related to the Realized Variance and Bipower Variation.
13 For the change point detection we used as penalty.
14 We imputed the value corresponding to the jump with the average between previous and subsequent data points.
15 Theoretically, this is only valid with the Gaussian formulation. Nevertheless, it is commonly used also for Historical VaR time aggregation.
16 Besides the common knowledge of non-Gaussianity of stocks' log-returns, the Gaussian VaR is widely adopted both in academia and industry.
17 We will discuss the multiscaling case later in the paper.
18 If the data generating process is not a fully MRW, the estimation of λ by using A or B can differ substantially. In our case, for most of the stocks analyzed the intermittency parameter computed with the two estimated coefficients, i.e. and
, are very similar.
References
- Antoniades, I. P., Giuseppe Brandi, L. Magafas, and T. Di Matteo. 2021. “The Use of Scaling Properties to Detect Relevant Changes in Financial Time Series: A New Visual Warning Tool.” Physica A: Statistical Mechanics and Its Applications 565: 125561.
- Bacry, Emmanuel, Jean Delour, and Jean-François Muzy. 2001a. “Modelling Financial Time Series Using Multifractal Random Walks.” Physica A: Statistical Mechanics and Its Applications 299 (1): 84–92.
- Bacry, Emmanuel, Jean Delour, and Jean-François Muzy. 2001b. “Multifractal Random Walk.” Physical Review E 64 (2): 026103.
- Bacry, Emmanuel, Alexey Kozhemyak, and Jean-François Muzy. 2008. “Continuous Cascade Models for Asset Returns.” Journal of Economic Dynamics and Control 32 (1): 156–199.
- Bacry, Emmanuel, Alexey Kozhemyak, and Jean-François Muzy. 2013. “Log-Normal Continuous Cascade Model of Asset Returns: Aggregation Properties and Estimation.” Quantitative Finance 13 (5): 795–818.
- Barunik, Jozef, and Ladislav Kristoufek. 2010. “On Hurst Exponent Estimation Under Heavy-Tailed Distributions.” Physica A: Statistical Mechanics and Its Applications 389 (18): 3844–3855.
- Batten, Jonathan A., Harald Kinateder, and Niklas Wagner. 2014. “Multifractality and Value-at-Risk Forecasting of Exchange Rates.” Physica A: Statistical Mechanics and Its Applications 401: 71–81.
- Buonocore, Riccardo J., Tomaso Aste, and T. Di Matteo. 2017. “Asymptotic Scaling Properties and Estimation of the Generalized Hurst Exponents in Financial Data.” Physical Review E 95: 042311.
- Buonocore, Riccardo J., Tomaso Aste, and T. Di Matteo. 2016. “Measuring Multiscaling in Financial Time-Series.” Chaos, Solitons & Fractals 88: 38–47.
- Buonocore, R. J., G. Brandi, R. N. Mantegna, and T. Di Matteo. 2019. “On the Interplay Between Multiscaling and Stock Dependence.” Quantitative Finance 20 (1): 133–145.
- Calvet, Laurent E., and Adlai J. Fisher. 2002. “Multifractality in Asset Returns: Theory and Evidence.” Review of Economics and Statistics 84 (3): 381–406.
- Calvet, Laurent E., and Adlai J. Fisher. 2004. “How to Forecast Long-Run Volatility: Regime Switching and the Estimation of Multifractal Processes.” Journal of Financial Econometrics 2 (1): 49–83.
- Calvet, Laurent E., Adlai J. Fisher, and Benoit B. Mandelbrot. 1997. “Large Deviations and the Distribution of Price Changes.” Cowles Foundation Discussion Papers 1165. Cowles Foundation for Research in Economics, Yale University.
- Chakraborti, Anirban, Ioane Muni Toke, Marco Patriarca, and Frédéric Abergel. 2011. “Econophysics Review: I. Empirical Facts.” Quantitative Finance 11 (7): 991–1012.
- Clauset, Aaron, Cosma Rohilla Shalizi, and Mark E. J. Newman. 2009. “Power-Law Distributions in Empirical Data.” SIAM Review 51 (4): 661–703.
- Cont, Rama. 2001. “Empirical Properties of Asset Returns: Stylized Facts and Statistical Issues.” Quantitative Finance 1 (2): 223–236.
- Corbetta, Alessandro, Vlado Menkovski, Roberto Benzi, and Federico Toschi. 2021. “Deep Learning Velocity Signals Allows to Quantify Turbulence Intensity.” Science Advances 7 (12): eaba7281.
- Danielsson, Jon, and Jean-Pierre Zigrand. 2006. “On Time-Scaling of Risk and the Square-Root-of-Time Rule.” Journal of Banking & Finance 30 (10): 2701–2713.
- Di Matteo, T. 2007. “Multi-Scaling in Finance.” Quantitative Finance 7 (1): 21–36.
- Di Matteo, T., Tomaso Aste, and Michel M. Dacorogna. 2003. “Scaling Behaviors in Differently Developed Markets.” Physica A: Statistical Mechanics and Its Applications 324 (1): 183–188.
- Di Matteo, T., Tomaso Aste, and Michel M. Dacorogna. 2005. “Long-Term Memories of Developed and Emerging Markets: Using the Scaling Analysis to Characterize Their Stage of Development.” Journal of Banking & Finance 29 (4): 827–851.
- Eom, Cheoljun, Taisei Kaizoji, and Enrico Scalas. 2019. “Fat Tails in Financial Return Distributions Revisited: Evidence from the Korean Stock Market.” Physica A: Statistical Mechanics and Its Applications 526: 121055.
- Fukasawa, Masaaki, Tetsuya Takabatake, and Rebecca Westphal. 2019. “Is Volatility Rough?” arXiv preprint arXiv:1905.04852.
- Gatheral, Jim, Thibault Jaisson, and Mathieu Rosenbaum. 2018. “Volatility is Rough.” Quantitative Finance 18 (6): 933–949.
- Gençay, Ramazan, Michel Dacorogna, Ulrich A. Muller, Olivier Pictet, and Richard Olsen. 2001. An Introduction to High-Frequency Finance. San Diego: Elsevier.
- Hurst, Harold Edwin. 1956. “Methods of Using Long-Term Storage in Reservoirs.” Proceedings of the Institution of Civil Engineers 5 (5): 519–543.
- Jiang, Zhi-Qiang, Wen-Jie Xie, Wei-Xing Zhou, and Didier Sornette. 2019. “Multifractal Analysis of Financial Markets: A Review.” Reports on Progress in Physics 82 (12): 125901.
- Kantelhardt, Jan W., Stephan A. Zschiegner, Eva Koscielny-Bunde, Shlomo Havlin, Armin Bunde, and H. Eugene Stanley. 2002. “Multifractal Detrended Fluctuation Analysis of Nonstationary Time Series.” Physica A: Statistical Mechanics and Its Applications 316 (1): 87–114.
- Katsev, Sergei, and Ivan L'Heureux. 2003. “Are Hurst Exponents Estimated from Short or Irregular Time Series Meaningful?” Computers & Geosciences 29 (9): 1085–1089.
- Kolmogorov, Andrey Nikolaevich. 1962. “A Refinement of Previous Hypotheses Concerning the Local Structure of Turbulence in a Viscous Incompressible Fluid at High Reynolds Number.” Journal of Fluid Mechanics 13 (1): 82–85.
- Kristoufek, Ladislav. 2010. “Long-Range Dependence in Returns and Volatility of Central European Stock Indices.” Bulletin of the Czech Econometric Society 17: 50–67.
- Lee, Hojin, Jae Wook Song, and Woojin Chang. 2016. “Multifractal Value at Risk Model.” Physica A: Statistical Mechanics and Its Applications 451: 113–122.
- Lillo, Fabrizio, and J. Doyne Farmer. 2004. “The Long Memory of the Efficient Market.” Studies in Nonlinear Dynamics & Econometrics 8 (3): 1–1.
- Livieri, Giulia, Saad Mouti, Andrea Pallavicini, and Mathieu Rosenbaum. 2018. “Rough Volatility: Evidence from Option Prices.” IISE Transactions 50 (9): 767–776.
- Løvsletten, O., and M. Rypdal. 2012. “Approximated Maximum Likelihood Estimation in Multifractal Random Walks.” Physical Review E 85: 046705.
- Lux, Thomas. 2004. “Detecting Multi-Fractal Properties in Asset Returns: The Failure of the Scaling Estimator.” International Journal of Modern Physics C 15 (04): 481–491.
- Lux, Thomas, and Michele Marchesi. 1999. “Scaling and Criticality in a Stochastic Multi-Agent Model of a Financial Market.” Nature 397 (6719): 498–500.
- Mandelbrot, Benoit B. 1963. “The Variation of Certain Speculative Prices.” The Journal of Business 36 (4): 394–419.
- Mandelbrot, Benoit. 1967. “The Variation of Some Other Speculative Prices.” The Journal of Business40 (4): 393–413.
- Mandelbrot, Benoit B.. 2013. Fractals and Scaling in Finance: Discontinuity, Concentration, Risk. Selecta Volume E. New York: Springer.
- Mandelbrot, Benoit B., Adlai Fisher, and Laurent E. Calvet. 1997. “A Multifractal Model of Asset Returns.” Cowles Foundation Discussion Papers 1164. Cowles Foundation for Research in Economics, Yale University.
- Mantegna, Rosario N., and H. Eugene Stanley. 1995. “Scaling Behaviour in the Dynamics of an Economic Index.” Nature 376 (6535): 46–49.
- Mantegna, Rosario N., and H. Eugene Stanley. 1999. Introduction to Econophysics: Correlations and Complexity in Finance. Cambridge: Cambridge University Press.
- Muzy, Jean-François, Emmanuel Bacry, and Alain Arneodo. 1991. “Wavelets and Multifractal Formalism for Singular Signals: Application to Turbulence Data.” Physical Review Letters 67 (25): 3515–3518.
- Muzy, Jean-François, Emmanuel Bacry, and Alain Arneodo. 1993. “Multifractal Formalism for Fractal Signals: The Structure-Function Approach Versus the Wavelet-Transform Modulus-Maxima Method.” Physical Review E 47 (2): 875–884.
- Scalas, Enrico, and Kyungsik Kim. 2006. “The Art of Fitting Financial Time Series with Levy Stable Distributions.” arXiv preprint physics/0608224.
- Sornette, Didier, Yannick Malevergne, and Jean-François Muzy. 2003. “What Causes Crashes?” Risk (Concord, NH) 16: 67–71.
- Takaishi, Tetsuya. 2020. “Rough Volatility of Bitcoin.” Finance Research Letters 32: 101379.
- Valsamis, Epaminondas Markos, Henry Husband, and Gareth Ka-Wai Chan. 2019. “Segmented Linear Regression Modelling of Time-Series of Binary Variables in Healthcare.” Computational and Mathematical Methods in Medicine 2019 (3478598): 1–7.
- Van Atta, C. W., and W. Y. Chen. 1970. “Structure Functions of Turbulence in the Atmospheric Boundary Layer over the Ocean.” Journal of Fluid Mechanics 44 (1): 145–159.
- Virkar, Yogesh, and Aaron Clauset. 2014. “Power-Law Distributions in Binned Empirical Data.” The Annals of Applied Statistics 8 (1): 89–119.
- Wang, Jying-Nan, Jin-Huei Yeh, and Nick Ying-Pin Cheng. 2011. “How Accurate is the Square-Root-of-Time Rule in Scaling Tail Risk: A Global Study.” Journal of Banking & Finance 35 (5): 1158–1169.
- Weron, Rafał. 2001. “Levy-Stable Distributions Revisited: Tail Index > 2 Does Not Exclude the Levy-Stable Regime.” International Journal of Modern Physics C 12 (2): 209–223.
- Yue, Peng, Hai-Chuan Xu, Wei Chen, Xiong Xiong, and Wei-Xing Zhou. 2017. “Linear and Nonlinear Correlations in the Order Aggressiveness of Chinese Stocks.” Fractals 25 (5): 1750041.