
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This research provides insights for the separation of cryptocurrencies from other assets. Using dimensionality reduction techniques, we show that most of the variation among cryptocurrencies, stocks, exchange rates, commodities, bonds, and real estate indexes can be explained by the tail, memory and moment factors of their log-returns. By applying various classification methods, cryptocurrencies are categorized as a separate asset class, mainly due to the tail factor. The main result is the complete separation of cryptocurrencies from the other asset types, using the Maximum Variance Components Split method. Additionally, we show that cryptocurrencies tend to exhibit similar characteristics over time and become more distinguished from other asset classes (synchronic evolution).
1. Introduction
Cryptocurrencies, seen as new digital currencies, have attracted much attention from investors and academics. A search for ‘cryptocurrencies’ on Google Scholar returns more than 39,000 items, as of 28 April 2021. Most research articles focus on Bitcoin (BTC), as it is considered the first cryptocurrency and has the largest capitalization since its inception; see, for example, Dyhrberg (Citation2016a) and Bariviera et al. (Citation2017). More recently, an extensive literature review on Bitcoin can be found in Corbet et al. (Citation2019), whereas a more technical demonstration of the technology behind the Bitcoin is presented in Berentsen and Schar (Citation2018). Along with this growing popularity, the market capitalization of cryptocurrencies was increasing substantially; the total capitalization of cryptocurrencies market was around US$ 2000 billion as of 28 April 2021, from around US$ 10 billion as of 1 January 2014 (https://coinmarketcap.com).
Despite their growing popularity, there is no widely accepted definition of cryptocurrencies which would allow one to identify them within the existing economic theory (Núñez, Contreras-Valdez, and Franco-Ruiz Citation2019). In general, cryptocurrencies are defined as ‘digital representations of value, made possible by advances in cryptography and distributed ledger technology (DLT)’ (I.M.F. Treatment of Crypto Assets in Macroeconomic Statistics Citation2019). A related, ongoing topic of discussion, is the instrument classification of cryptocurrencies in macroeconomic statistics (I.M.F. Treatment of Crypto Assets in Macroeconomic Statistics Citation2019; Zwijnenburg, De Queljoe, and Ynesta Citation2020).
Since it appears to be difficult to reach consensus on a standard definition of cryptocurrencies, one can define cryptocurrencies by investigating whether their returns behave similarly to other asset classes (Liu and Tsyvinski Citation2018).
One of the approaches is to compare cryptocurrencies to classical assets via statistical properties of log-returns distribution. Most of the research shows that cryptocurrencies present long-range memory (Bariviera et al. Citation2017; Caporale, Gil-Alana, and Plastun Citation2018; Jiang and Han Citation2018), multifractality (Takaishi Citation2018) higher volatility, skewness, and kurtosis compared to classical assets (Klein, Pham Thu, and Walther Citation2018; Härdle, Harvey, and Reule Citation2020). Borri (Citation2019) shows that cryptocurrencies exhibit large and volatile return swings and are riskier than most of the other assets, while Zhang et al. (Citation2018) find that cryptocurrencies exhibit heavy tails, quickly decaying returns auto-correlations, slowly decaying auto-correlations for absolute returns, strong volatility clustering, leverage effects, long-range dependence, and power-law correlation between price and volume.
Another approach used to separate cryptocurrencies from classical assets is to develop models able to explain the specificity of cryptocurrencies. For example, Manavi et al. (Citation2020), using the matrix correlation method, compare 7 cryptocurrencies with a sample of three types of monetary systems: 28 exchange rates, 2 commodities, 2 commodity-based indices, and 3 financial market indices. Their results show that the cryptocurrency market and Forex market belong to different system communities.
Using a different approach, Liu and Tsyvinski (Citation2018) analyzed the relationship between cryptocurrencies and each of the following asset classes: stocks, precious metals, and currencies. They show that the risk-return trade-off of three major cryptocurrencies (Bitcoin, Ripple, and Ethereum) is distinct from that of the above asset categories. They also show that the cryptocurrency returns can be predicted by factors which are specific to cryptocurrency markets: momentum and investor attention.
Recently, Liu, Tsyvinski, and Wu (Citation2019) and Liu, Liang, and Cui (Citation2020) developed a three-factor model using the CAPM approach (Fama and French Citation1996) and showed that the cross-sectional expected cryptocurrency returns can be captured by three factors: the market factor, the size factor and the momentum factor. A similar approach can be found in Shen, Urquhart, and Wang (Citation2020), who developed a three-factor pricing model, consisting of market, size and reversal factors.
In this paper, we provide a classification of the assets' universe, based on which cryptocurrencies pose unique statistical features, allowing their complete separation from classical assets.
Unlike the three-factor model from Liu, Tsyvinski, and Wu (Citation2019), we are using dimensionality reduction techniques (Factor Analysis) applied to a dataset of risk indicators related to the empirical distribution of daily log-returns (following Bariviera et al. Citation2017; Chan et al. Citation2017; Caporale, Gil-Alana, and Plastun Citation2018; Jiang and Han Citation2018; Takaishi Citation2018; Klein, Pham Thu, and Walther Citation2018; Zhang et al. Citation2018; Borri Citation2019; Härdle, Harvey, and Reule Citation2020). We are also using a much larger data set, in terms of the number of assets used, than in Liu, Tsyvinski, and Wu (Citation2019): 234 cryptocurrencies, 635 stocks, 13 exchange rates, 17 commodities, 5 bonds, and 2 real estate indexes. Liu and Tsyvinski (Citation2018) use only 3 cryptocurrencies (Bitcoin, Ripple, and Ethereum), 354 industries in the US, 137 industries in China, 5 exchange rates, and 3 commodities.
A first result of our research is that most of the variation among cryptocurrencies, stocks, exchange rates, commodities, bonds, and real estate indexes can be explained by three factors: the tail factor, the memory factor and the moment factor. These factors are different from the ones obtained in Liu, Tsyvinski, and Wu (Citation2019), Shen, Urquhart, and Wang (Citation2020) or Liu, Liang, and Cui (Citation2020), and allow us to validate the complete separation of cryptocurrencies from other asset types.
The main result of our paper is the complete separation of cryptocurrencies from classical asset types in finance, by using the Maximum Variance Components Split (MVCS) method. The application of other benchmark classification methods (Binary Logistic Regression, Support Vector Machines (SVM), K-means clustering) provides also an almost complete separation. Our results add to the current literature on this topic by showing that the most important factor which differentiates cryptocurrencies from classical assets is the tail behaviour of the log-returns distribution.
Another important result is the discovery of synchronic evolution of cryptocurrencies, compared to classical assets types. Synchronicity refers to the fact that individual cryptocurrencies tend to develop certain similar characteristics over time that make them fully distinguishable from classical assets, i.e. they tend to behave like a homogeneous group, with certain characteristics that individualize them in the assets ecosystem. By using an expanding window approach, we are able to show that cryptocurrencies have a convergent dynamic, which is mainly driven by the tail behaviour of the log-returns distribution. A related analysis can be found in ElBahrawy et al. (Citation2017), where the cryptocurrency market is seen as an evolutive system with several characteristics which are preserved over time.
The importance of the topic analyzed in this study can be defined by three points of interest, depending on the reader's point of view: (i) exploratory interest in the newly arising asset class of cryptocurrencies, as they behave significantly different from the rest of the financial ecosystem; (ii) statistical interest in utilizing existing methodologies for new data, assessing their validity in a high dimensional scope; (iii) Regulatory interest in order to understand which statistical tools are necessary to grasp the major drivers of the new asset class.
This paper is subsequently organized as follows: Section 2 describes the methodology used; Section 3 describes the datasets and interprets the results of the classification; Section 4 describes the synchronic evolution of cryptocurrencies; Section 5 provides a numerical risk example and discuss more on policy implications, while Section 6 concludes. The data and codes used to obtain the results in this paper are available via  Quantlet.com.
Quantlet.com.
2. Methodology
The methodology used in this paper has four layers: Layer 1, where we describe the multidimensional dataset used to assess the behaviour of the time series of assets' daily log-returns; Layer 2, where we apply data dimension reduction and orthogonalization methods (Factor Analysis) on the dataset described in Layer 1, to retain the orthogonal factors which maximize the explained variance and could discriminate between cryptocurrencies and classical assets (for some methods using the factors estimated in Layer 2); Layer 3, where we use classification techniques to separate cryptocurrencies from classical assets: Binary Logistic Regression, Support Vector Machine, and K-means clustering applied on the factors estimated in Layer 2 and Maximum Variance Components Split methods applied on the entire dataset; Layer 4, where we confirm the validity of the synchronic evolution property of cryptocurrencies, showing their specific characteristics that differentiate them over time from classical assets, using the projection of the multidimensional dataset described in Layer 1 on the 3D space defined by the factors extracted in Layer 2.
2.1. Layer 1 -- multidimensional dataset
The initial dataset consists of daily log-returns of the assets. To properly classify the assets within the assets universe, we need a dataset of variables-indicators that have the statistical power to differentiate between cryptocurrencies and classical assets (stocks, exchange rates, bonds, real estate and commodities). These indicators are estimates of model parameters associated with the daily log-returns. We denote by n the number of assets in the dataset, by t the time index, , where T is the time of the last record in the dataset and by p = 24 is the number of indicators. The daily log-return for asset i in day t, is denoted as
, with
,
, where
is the closing price for asset i in day t. The dataset of indicators can be seen as a tensor
, where
is the number of time points. The components of the matrix
, detailed below, are estimates for the time interval
, with
, where
(the integer part of T/3). Most of the variables-indicators used for the taxonomy are selected from the indicators already validated in the literature to differentiate between cryptocurrencies and classical assets.
First, we took into account the central moments of the log-returns distribution, through the following parameters: variance (), skewness (
) and Kurtosis (
) (used in Bariviera et al. Citation2017; Härdle, Harvey, and Reule Citation2020; Takaishi Citation2018).
Second, we estimated the following parameters of the α-stable distribution, fitted to daily log-returns, to capture heavy tail behaviour: the tail exponent (Stable_, with lower values indicating heavier tails) and the scale parameter (Stable_
). The α-stable distributions are a well-known class of distributions used in financial modeling (Rachev and Mittnik Citation2000), capturing the fat tails and the asymmetries of the real-world log-returns distributions (for their use in cryptocurrencies market, see Li et al. Citation2019; Schnaubelt, Rende, and Krauss Citation2019; Muvunza Citation2020). The α-stable parameters were estimated using the empirical characteristic function method, following Koutrouvelis (Citation1980, Citation1981) and Koutrouvelis and Bauer (Citation1982).
Third, we estimated the quantiles and the conditional tail expectations for the distribution of log-returns, to capture the tail behaviour (Trucíos, Tiwari, and Alqahtani Citation2020): left-side quantiles , right-side quantiles
, conditional left tail expectation
and conditional right tail expectation
, for
. From a market risk perspective, the left tail quantiles can be assimilated to Value-at-Risk, the conditional left tail expectation can be regarded as Expected Shortfall, while the conditional right tail expectation can be seen as the Expected Upside.
Fourth, we estimated a model, as in Mensi, Al-Yahyaee, and Kang (Citation2019), to capture the long memory effect of volatility. Thus, from the following variance equation of the
model estimated from daily log-returns:
(1)
(1)
where L is the lag operator, we retain in our dataset the estimates of fractional differencing parameter
(Baillie, Bollerslev, and Mikkelsen Citation1996).
Fifth, we estimated the first-order auto-correlation coefficient and the Hurst exponent
of the time series of daily log-returns. The Hurst exponent (Hurst Citation1951) was estimated based on the discrete second-order derivative in the wavelet domain (Istas and Lang Citation1997).
In our dataset, the 24 indicators are skewed toward risk measures, which may not fairly justify the role of cryptocurrencies. Similarly to traditional currencies, cryptocurrencies can be used for transaction payment and one can enjoy anonymity in the process of transaction. Although this may be an argument to consider a broader range of indicators, not only from risk measures, the scope of our research scope is to properly separate cryptocurrencies based on the properties of the underlying log-returns distribution.
2.2. Layer 2 -- dimensionality reduction
The most popular methods used to synthesize and extract relevant information from large datasets are Principal Components Analysis (PCA) and Factor Analysis (FA) (Bartholomew Citation2011). Factor Analysis has been extensively used in cryptocurrencies modeling for classification purposes, e.g. Liu, Tsyvinski, and Wu (Citation2019), who use it to develop the cryptocurrency 3-factor model: the market factor, the size factor and the momentum factor. PCA itself is a linear combination of variables, while FA is a measurement model of a latent variable. The aim of Factor Analysis is to explain the outcome of the p variables of a data matrix using fewer variables, the so-called factors (Härdle and Simar Citation2019). In our paper, the initial factor pattern is extracted using the principal component method, followed by a Varimax rotation to insure orthogonality of the factors.
2.3. Layer 3 -- separating cryptocurrencies
To separate cryptocurrencies from classical assets, we are using several classification techniques: Binary Logistic Regression, Support Vector Machines, K-means clustering and Maximum Variance Components Split (technical details regarding these techniques can be found in Appendix 1), that can gradually provide complete separation of cryptocurrencies from classical assets. Binary Logistic Regressions have been successfully applied in building statistical arbitrage strategies for cryptocurrencies market (Fischer, Krauss, and Deinert Citation2019) and to identify and analyze cryptocurrency manipulations in social media (Mirtaheri et al. Citation2009). Support Vector Machines proved to be a reliable method for price movement prediction of cryptocurrencies (see, for example, Valencia, Gómez-Espinosa, and Valdés-Aguirre Citation2019 or McNally, Roche, and Caton Citation2018), while K-means clustering is a classical classification method (MacQueen Citation1967), which was used in James, Menzies, and Chan (Citation2021) to analyse the impact of Covid-19 on cryptocurrencies market. These methods do not provide complete separation of cryptocurrencies, but they can highlight the main factors that have the ability to discriminate between cryptocurrencies and classical assets. The novelty of our paper is the use of Maximum Variance Component Split methods to completely separate the cryptocurrencies data from the data of other assets. Advantage of MVCS is the unusual analysis of variance with between-group variations only, that depend on the distance between potential clusters and the difference of their means.
2.4. Layer 4 -- synchronic evolution of cryptocurrencies
For observing the synchronic evolution of cryptocurrencies, we are using an expanding window approach, allowing to distinguish the convergence over time of cryptocurrencies. In fact, for , where
, the p-dimensional matrix
is projected on the 3-dimensional space defined by the tail, memory and moment factors extracted through the Factor Analysis applied on the dataset
. Looking at the evolution of the Likelihood Ratio from the Logistic Regression model defined in Layer 2, we can observe the ability of the tail factor to discriminate between cryptocurrencies and classical assets. In other words, cryptocurrencies develop over time a similar tail behaviour, pointing out the validity of the synchronic evolution.
3. Data and results
3.1. Multidimensional dataset
The initial dataset consists of daily log-returns of n = 906 assets (cryptocurrencies, commodities, bonds, real estate, exchange rates and stocks -- see Table ), covering the period 03/01/2014 - 30/11/2020 (1740 trading days). The reason for choosing this time span for the analysis is that before 2014 the liquidity in the cryptocurrency market had been relatively low, their total market capitalization being less than US$16 billion (Feng, Wang, and Zhang Citation2018). As described in Layer 1 of the methodology, Section 2.1, the multidimensional dataset used for analysis is , where n = 906 is the number of assets, p = 24 is the number of indicators, T = 1740 (corresponding to 30/11/2020),
(corresponding to 22/04/2016) and
is the number of time points. The components of the matrix
, are estimates for the time interval
, with
.
Table 1. Assets used for analysis.
The first component of the datasetFootnote1 consists of a representative sample of 234 cryptocurrencies selected from the top 1000 cryptocurrencies sourced from https://coinmarketcap.com/, accounting for 98% of the total market capitalization, as of 01/12/2020. The cryptocurrencies were selected according to their market capitalization and data availability for at least 750 trading days. The second component consists of a sample of the most traded commodities indexes, the third component consists of a sample of the most liquid exchange rates, the fourth component consists of a sample of bonds, the fifth component consists of two real estate indexes, while the sixth component contains the constituents of the S&P500 Index, Euro Stoxx 50 Index and FTSE 100 Index, recorded at 30/11/2020 (the complete list of assets used in the analysis can be found in Appendix 2). For robustness purposes, only the assets with at least 750 daily historical observations (three trading years) were kept in the analysis. As cryptocurrencies daily data are available at all times, while the classical assets data observe market closure days (weekends and public holidays), the cryptocurrencies data were pre-processed and their closing prices on these particular days were discarded, insuring a homogeneous sample frequency for all assets' types. A detailed analysis regarding data comparability and analysis of cryptocurrencies can be found in Alexander and Dakos (Citation2020).
3.2. Factor analysis
Factor Analysis is a classical method used to find latent variables or factors among observed variables, by grouping variables with similar characteristics. For this purpose, we are using the matrix , estimated for the period 03/01/2014 -- 30/11/2020. Three steps are involved: estimation of the correlation matrix for all p = 24 indicators/columns of the matrix
, shown in Figure ; extraction of the factors from the correlation matrix, based on the correlation coefficients of the variables; factor rotation, to maximize the relationship between the variables and relevant factors.
Figure 1. Correlation matrix.
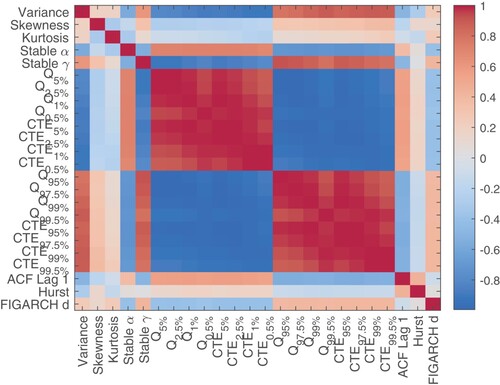
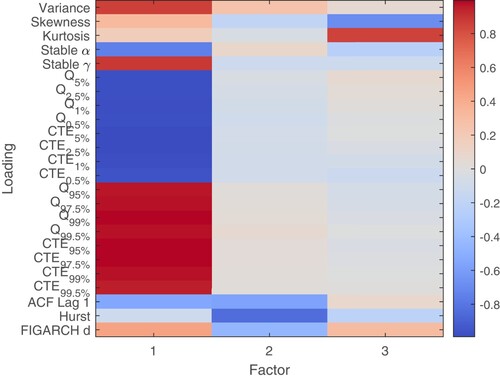
Based on the eigenvalues criteria, three factors were selected, accounting for 88% of the total variance (see Figure ). In order to test the sampling adequacy of the Factor Analysis, we are using the Kaiser–Meyer–Olkin (KMO) test (Cerny and Kaiser Citation1977; Kaiser Citation1974, Citation1981), which should be greater than 0.5 for a satisfactory Factor Analysis (Tabachnick and Fidell Citation2013). In our sample, the KMO value is 0.92, pointing out that the Factor Analysis is suitable for structure detection. For the factor rotation, we used the Varimax method, which outputs orthogonal factors, while also minimizing the number of variables that have high loadings on each factor. Based on the rotated factors pattern, the following conclusions can be drawn (see Figure ):
First factor: the tail factor, accounting for 76% of the total variance, is highly correlated with the following parameters: the lower and upper quantiles of the distribution of log-returns, the conditional tail expectations, variance, the tail parameter alpha and the scale parameter gamma of the α-stable distribution of log-returns.
Second factor: the memory factor, accounting for 6% of the total variance, is highly correlated with the Hurst exponent, the first-order auto-correlation coefficient of log-return and the FIGARCH(1,1) long memory volatility parameter.
Third factor: the moment factor, accounting for 6% of the total variance, is highly correlated with the skewness and kurtosis of log-returns distribution.
Figure 2. Scree plot.
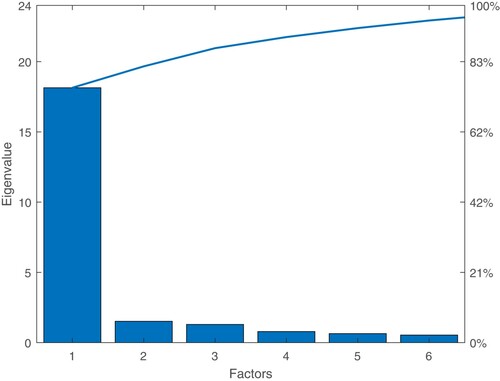
Figure 3. Loadings of the three factors.
Based on the data revealed in Table , one can synthesize few characteristics of cryptocurrencies that differentiate them from the other assets. First, cryptocurrencies have higher variance compared to classical assets, with a scale factor of about 60, on average. Second, as indicated by the values of quantiles and conditional tail expectations, cryptocurrencies have higher propensity for extreme values, in both tails of the log-returns distribution. Third, as indicated by the low values of the alpha-stable tail index, cryptocurrencies log-returns distribution has a larger departure from normality and a higher likelihood for extreme events. These findings extend the results from the literature, for example, Borri (Citation2019), who argues that cryptocurrencies exhibit large and volatile return swings and are riskier than most of the other assets. Fourth, cryptocurrencies exhibit significant negative serial correlation, in line with the results from Griffin and Shams (Citation2020), who documented asymmetric auto-correlations in Bitcoin returns. Fifth, cryptocurrencies have long-term memory, both in log-returns and volatility, as previously shown in related researches (see, for example, Tan, Huang, and Xiao Citation2021). Sixth, we confirm the results from Momtaz (Citation2021), by showing that cryptocurrencies are the only asset class with substantial positive skewness, so cryptocurrencies have longer left tail of log-returns distribution.
Table 2. Asset classes profile based on the averages of the 24 indicators.
Next, we map cryptocurrencies and classical assets on the 3D space defined by the factors estimated through the Factor Analysis, to derive some clustering effect. Figures and show the assets universe projected onto the 3D space defined by the tail, memory and moment factors; the colour code is the following: green: cryptocurrencies, black: stocks, red: commodities, blue: exchange rates, purple: bonds, yellow: real estate. Moreover, in Figure , a confidence region is estimated for cryptocurrencies, based on the Bivariate Kernel Density. The axis represent the scores estimated for each factor, trough Factor Analysis.
Figure 4. Assets projections on the factors space: (a) tail and memory factors; (b) tail and moment factors.
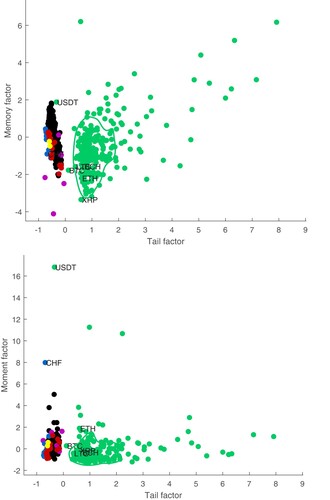
Figure 5. Assets classification: (a) Support Vector Machines; (b) K-means.
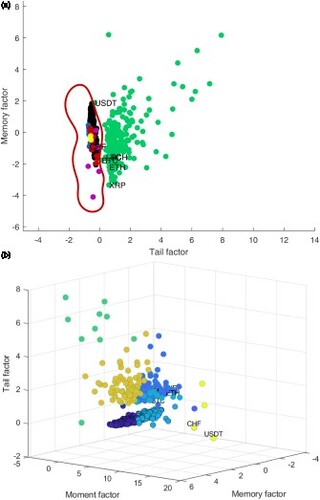
As shown in Figure , it appears to be a separation between cryptocurrencies and classical assets, mainly due to the tail and memory factors, while the moment factor is of subliminal importance. The projection on the space defined by the Factor Analysis reveals some cryptocurrencies with atypical behaviour. Thus, Bitcoin (BTC), the oldest and the most traded cryptocurrency, is closer to classical stocks and commodities, i.e. Bitcoin can be considered at the border between the classical assets and cryptocurrencies. This result augments the findings of Dyhrberg (Citation2016b), who concludes that Bitcoin is somewhere in between a currency (USD) and a commodity (Gold). On the other hand, Tether (USDT), a token that attempts to be tied to the US dollar, has a similar profile with the Swiss currency (CHF). Another group of cryptocurrencies (Paxos Standard, TrueUSD, USD Coin, Stasis Euro, Gemini Dollar and sUSD, the so called ‘stable coins’) are closer to exchange rates, from the point of view of the tail factor. These findings build on the results from James, Menzies, and Chan (Citation2021), where Tether (USDT) and TrueUSD (TUSD) are identified as outliers among cryptocurrencies market, using a different data structure, in the context of Covid-19 pandemic.
3.3. Separating cryptocurrencies
In this section, we list the results of the methods presented in Section 2.3. A related question answered is the ability of the factors produced through the Factor Analysis to separate cryptocurrencies from classical assets.
First, for each of the three factors, we estimated the Binary Logistic Regression model
(2)
(2)
where
for cryptocurrencies,
for classical assets, and
are the orthogonal factors retrieved through the Factor Analysis. Table lists the estimated
of the Binary Logistic Regression model (Equation2
(2)
(2) ), with the performance measure defined by Equation (EquationA2
(A2)
(A2) ).
Table 3. Estimates of binary logistic regression model
As seen in Table , the most important factors regarding the separation between cryptocurrencies and classical assets are the tail factor (having the highest for the Binary Logistic Regression model) and the memory factor, while the moment factor has no significant influence.
Second, we employed Support Vector Machines on the space defined by the two first factors (tail and moment) and K-means clustering on the 3D space defined on the tail, memory and moment factors (see Figure ). None of these methods provides complete separation of cryptocurrencies from classical assets, the overall accuracy of the Support Vector Machines non-linear classifier being 99.56%, while the accuracy of the K-means classifier, with 6 clusters, is 98.45%. When using the Support Vector Machines non-linear classifier, the only cryptocurrencies miss-classified are Bitcoin (BTC) and Tether (USDT).
The results when applying the Maximum Variance Component Split (MVCS) method strengthen those of Binary Logistic Regression, Support Vector Machines and K-means clustering, by providing complete separation of cryptocurrencies. The following notation is used: M is the number of positive equidistant angles of [0, π] (we divide [0, π] in M equal intervals and use the intervals' left endpoints as projecting angles), S is a subset of the 24 columns, is the number of projection directions giving perfect classification when S is used,
is the percentage of the projection directions examined that provided perfect classification, while
are the minimum and the maximum index I value for perfect classification, respectively. The critical value for significance of the I index for
and n = 906 is 0.0108. The order of the 24 indicators is as the order of rows in Table .
In the following, we present the results of the MVCS method for perfect classification of cryptocurrencies from the other assets. For all five other asset structures (stocks, exchange rates, commodities, bonds and real estate indexes), none of the combinations of M and S examined below provided perfect classification.
Due to processing power constraints, we first split the data in two subsets: the first subset consists of columns/indicators 1–12 of matrix and the second includes columns/indicators 1–12 of matrix
. For the same reason, projection directions are used only for M = 3, 6 (the number of projection directions used is
for each case). Results are shown in .
Table 4. Results of the MVCS method.
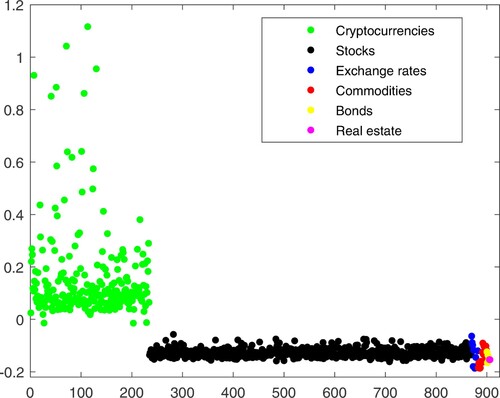
The projection direction that provided the largest index value for columns 1–12 (obtained for M = 6) is: . The projected values in this case are shown in Figure . As shown in this Figure, the projected values of all cryptocurrencies are greater than the projected values of all other assets, and a vertical hyperplane in the middle of the gap will separate cryptocurrencies from the other assets in the space of the data. Therefore, separation is evident. Also, all 181618 projection directions that achieved perfect classification provided also a statistically significant index values for the normal model.
Figure 6. Projections of a subset of the data (the first 12 indicators) for M = 6 on the projection direction that gave the largest index value among those that gave perfect classification of the cryptocurrencies.
These results indicate that columns 1–12 are more important for separation of cryptocurrencies than columns 13–24, since only the former confirm separation. Following this, we next applied the MVCS method to columns 1–12, which we further split to columns 1–6 and 7–12. Here, we used and 18. For columns 7–12, no
value provided perfect classification for the cryptocurrencies. On the other hand, for columns 1-6 and M = 9, 12, 15 and 18, cryptocurrencies were completely separated from all the other assets; see Table . Therefore, we can conclude that the most important columns for complete separation are the first six.
Table 5. Results of the MVCS method, columns 1–6.
Next, the first six indicators/columns are further examined. The MVCS method is applied to all six quintets (each derived by omitting in turn one of the six columns). Higher values of M are used (M = 18, 24 and 32), and the results are reported in Table . It can be concluded that the most important indicator/column for perfect separation of cryptocurrencies is the fourth (Stable α), since its omission resulted in not obtaining perfect classification for the cryptocurrencies. The least important among these six columns for separation of cryptocurrencies are Skewness and Kurtosis, since the quintets without these give the largest number of projection directions that provide perfect classification (), for all values of M used. Therefore, the corresponding combinations of columns are more suitable for separating the cryptocurrencies from the other assets.
Table 6. Results for cryptocurrencies, all leave-one-out quintets of columns 1–6.
Finally, we applied the MVCS code for specific combinations of indicators/columns, in order to further examine the importance of the three factors obtained before (tail, moment and memory). Results for M = 3 are shownFootnote2 in Table .
Table 7. Results of the MVCS method, various indicator combinations, M = 3.
From the above, it is further established that tail components are necessary for the separation of cryptocurrencies from the other asserts, since their omission leads to no perfect classification. Another indication is that left tail components seems more important that the corresponding right tail ones. Next, moment components seem to contribute slightly to the perfect classification of cryptocurrencies, whereas memory components do not seem to have any effect on this separation.
We can conclude that cryptocurrencies are financial instruments whose specific difference is the tail behaviour of the distribution of daily log-returns. In other words, based on the tail factor profile, we can conclude that a random asset is likely to be a cryptocurrency if it has the following properties: very long tails of the log-returns distribution (in terms of left and right quantiles and conditional tail expectations), high variance, high value of the α-stable scale parameter and value of the α-stable tail index close to 1.
4. Synchronic evolution of cryptocurrencies
In order to observe the assets dynamics, we are using an expanding window approach, allowing to distinguish the evolution of the clusters. In particular, for , the p-dimensional dataset is projected on the k-dimensional space defined by the main factors extracted through the Factor Analysis applied on the matrix
. By using this projection instead of a time-varying factor model, we are avoiding situations like changes in factors loadings, causing inconsistencies over time.
In the expanding window approach, first, the 24-dimensional dataset is estimated for the time interval
; second, the time window is extended on a daily basis, up to T=30/11/2020 and for each step in time, the dataset is projected on the 2-dimensional space defined by the tail factor and the memory factor, estimated for the entire period.Footnote3
Figure presents a snapshot of the evolution of the assets universe using the expanding window approachFootnote4. Looking at the evolution of the assets universe, it appears that individual cryptocurrencies tend to develop over time similar characteristics (synchronic evolution) that make them fully distinguishable from classical assets. To test this behaviour, we are using the Likelihood Ratio associated to binary logistic model (Equation2(2)
(2) ), estimated using the expanding window approach described above. The Likelihood Ratio for this model can be defined as:
(3)
(3)
where
is the maximum likelihood of a saturated model that fits perfectly the sample, while
is the maximum likelihood of the estimated model. In the language of Binary Logistic Regression, the Likelihood Ratio from Equation (Equation3
(3)
(3) ) is called deviance (Hosmer and Lemeshow Citation2010) and is a measure of model goodness-of-fit, with large values indicating models with poor classification power. The deviance is always positive, being zero only for perfect fit. To derive the statistical significance of the classification, we compare the Likelihood Ratios of the estimated model and of the intercept-only model. Thus, we compute the difference of the likelihood ratios
(4)
(4)
where asymptotically
,
being the likelihood ratio of the intercept-only model. In fact, we are estimating m models, where
. For each model, we report the Likelihood Ratio (Figure ) and the p-value associated to Equation (Equation4
(4)
(4) ) (see Figure ). Large p-values indicate that the model might not differ statistically from an intercept-only model.
Figure 7. The evolution of the assets universe using the expanding window approach. The colour code is the following: green -- cryptocurrencies, black -- stocks, red -- commodities, blue -- exchange rates, purple -- bonds, yellow -- real estate.
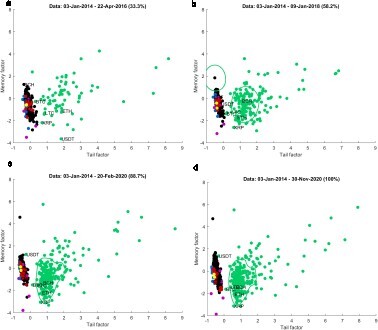
Figure 8. Likelihood Ratios for model (Equation2(2)
(2) ), estimated for the period 22/04/2016-30/11/2020, using an expanding window approach.
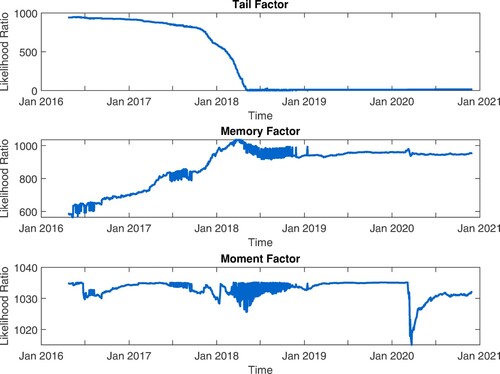
Figure 9. p-values for Equation (Equation4(4)
(4) ), estimated for the period 22/04/2016-30/11/2020, using an expanding window approach.
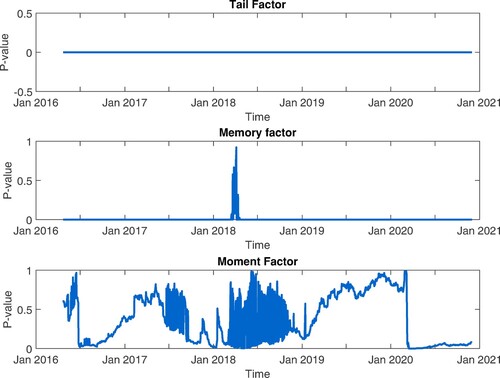
By examining the evolution of the Likelihood Ratios, we can observe a trend change for the tail factor, starting January 2018, when the cryptocurrencies market collapsed after the historical maximum of Bitcoin in December 2017. Thus, the Likelihood Ratio converges to zero, pointing out the ability of the tail factor to discriminate between cryptocurrencies and classical assets. Moreover, as shown by the p-values for the Equation (Equation4(4)
(4) ) (see Figure ), one can conclude that the tail factor can differentiate between cryptocurrencies and classical assets for the entire time-period.
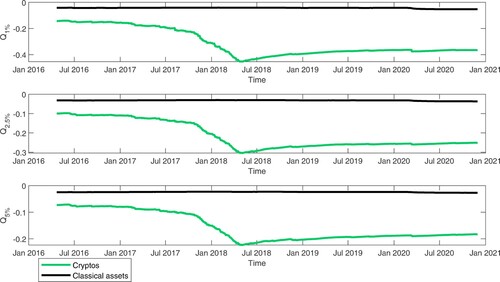
The memory factor lacks significance during the cryptocurrencies crash in January 2018 while the moment factor became significant after February 2020, when the indicators of log-returns distribution for classical assets had a significant shift, capturing the impact of Covid-19 on financial markets. As shown in Figure , the varianceFootnote5 and kurtosis of classical assets increased significantly during the Covid-19 period, while the skewness decreased, pointing out that the left tail of log-returns distribution became longer than the right tail, during 2020. As the cryptocurrencies are highly exposed to tail risk, the traditional inference based on normal distribution may became very inappropriate, as illustrated in Figure , where the empirical ,
and
quantiles are plotted for cryptocurrencies and classical assets.
Figure 10. Variance, skewness and kurtosis dynamics by assets class.
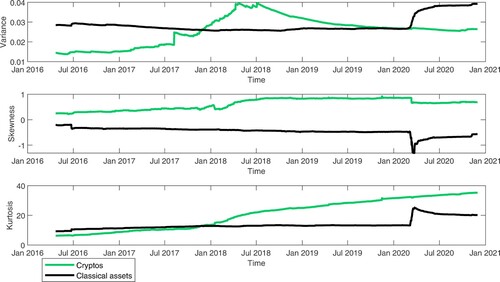
Figure 11. Quantiles dynamics by assets class.
The most important implication of this analysis is the validity of synchronicity phenomenon among cryptocurrencies: in their evolution, the individual cryptocurrencies have developed similar characteristics (longer tails, higher volatility, higher propensity to extreme returns), that differentiate them from classical assets and position them as a new, different species in the ecosystem of financial instruments. The synchronic evolution of cryptocurrencies can explain their co-jumping behaviour, documented by Bouri, Roubaud, and Shahzad (Citation2020): over time, they tend to behave like a homogeneous group, with certain characteristics that individualize them in the assets ecosystem. Also, our result is in line with the findings from Apergis, Koutmos, and Payne (Citation2021), who proved the convergence in prices for several cryptocurrencies and this convergence behaviour can be driven by changes in market microstructure. A similar conclusion regarding convergence in prices can be found in Papadamou et al. (Citation2021), this convergence being stronger during periods of market growth.
5. Market risk and policy implications
In this section, we provide a numerical risk example, that may be beneficial for practitioners in the field. As the results in Section 3 show that the most important factor separating cryptocurrencies from classical assets is the tail factor, we are investigating the impact of adding cryptocurrencies in a classical assets portfolio, from the point of view of market risk measures like VaR (Value-at-Risk), volatility and Sharpe Ratio. The classical assets portfolio is an equally weighted portfolio constructed using the classical assets in our sample (672 assets, covering the period 03/01/ 2014–30/11/2020), while the mixed portfolio is constructed by adding to the benchmark portfolio all the cryptocurrencies in our sample.
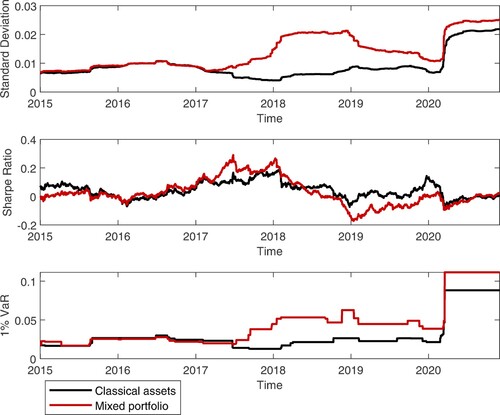
Figure shows the cumulative returns, cumulative standard deviations and cumulative Sharpe Ratios for the classical assets portfolio and the mixed portfolio, computed for the period 03/01/2014-30/11/2020. The portfolio Sharpe Ratio was estimated using the classical formula: , where
and
are the mean and standard deviation of portfolio returns respectively (Liu and Tsyvinski Citation2018). The notable impact of adding cryptocurrencies to the classical assets portfolio is a significant increase of volatility and a significant increase in cumulative return until 2019, while the Sharpe Ratios remains stable for the two portfolios. In terms of Value-at-Risk, Figure reports the evolution of Historical Standard deviation, Sharpe ratio and 1% VaR, estimated using a rolling window of w = 250 observations. VaR at significance level α is defined by the following equation:
(5)
(5)
As illustrated in this Figure, adding cryptocurrencies in the classical assets portfolio leads to an increased volatility and higher VaR; thus, during the Covid-19 pandemic, the 1% VaR increased from 8% in case of classical assets portfolio to 11% in case of mixed portfolio. At the same time, there is no improvement in the evolution of Sharpe Ratio, as a result of adding cryptocurrencies in the classical assets portfolio. These findings are in line with the results from Naimy, El Chidiac, and El Khoury (Citation2020), who showed that volatility and Value-at-Risk of cryptocurrencies are significantly higher, compared to fiat currencies.
We augment these findings by estimating 1% VaR using several classical methods: Historical VaR, four moment VaR, Normal GARCH(1,1), Student's t GARCH(1,1), Normal GJR-GARCH(1,1,1) and Student's t GJR-GARCH(1,1,1). Historical VaR is estimated as , where
is the α quantile of the empirical distribution of log-returns. The four moment VaR (proposed by Favre and Galeano Citation2002 and applied to cryptocurrencies market by Conlon, Corbet, and McGee Citation2020) is estimated as
, with
(6)
(6)
is the α quantile of standard normal distribution,
is the portfolio skewness,
is the portfolio kurtosis,
and
are the mean and standard deviation of portfolio returns respectively.
Figure 12. Cumulative average returns, volatility and Sharpe Ratio for classical assets portfolio and the mixed portfolio.
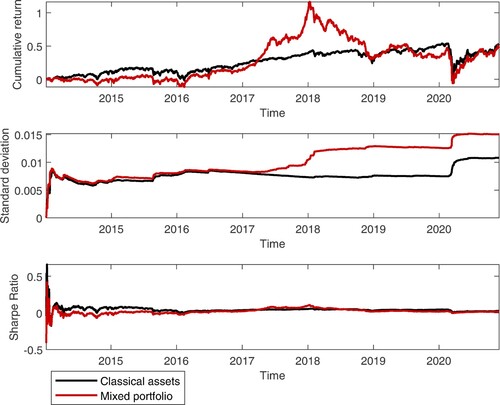
Figure 13. Standard deviation, Sharpe Ratio and Historical 1% VaR for the classical assets portfolio and mixed portfolio, using a rolling window approach.
The Glosten-Jagannathan-Runkle GARCH (1,1,1) (GJR-GARCH (1,1,1)) model (Glosten, Jagannathan, and Runkle Citation1993; Zakoian Citation1994) allows for informational asymmetry in the equation of conditional variance. In GJR-GARCH(1,1,1) model, the log-return is written as , where μ is the expected return,
,
are i.i.d. with zero mean (for example, standard Gaussian or Student's t), and the conditional variance follows the equation:
(7)
(7)
For GARCH models, VaR is estimated as
, where
is the estimated portfolio conditional volatility,
is the portfolio mean return and
is the α quantile (standard normal or Student's t). Table reports the average risk exposure, measured through 1% VaR, estimated for the classical assets portfolio, cryptocurrencies only portfolio and mixed portfolio. As shown in this Table, there is a clear difference in average VaR of classical assets portfolio, compared to cryptos only portfolio or to the mixed portfolio. By including cryptocurrencies in the classical assets portfolio, the average 1% VaR may increase from 4.00% to 6.82%, in case of the four moment VaR, and from 2.16% to 3.48% in case of Student's t GJR-GARCH(1,1,1).
Figure shows the estimated Student's t GJR-GARCH(1,1,1) volatility for the classical assets portfolio, cryptocurrencies portfolio and the mixed portfolio. The maximum volatility of cryptocurrencies portfolio is almost 10 times higher than the maximum volatility of the classical assets portfolio, while the maximum volatility of the mixed portfolio is almost three times higher than the maximum volatility of the classical assets portfolio.
Figure 14. Estimated volatilities from Student's t GJR-GARCH(1,1,1) model, using a rolling window approach.
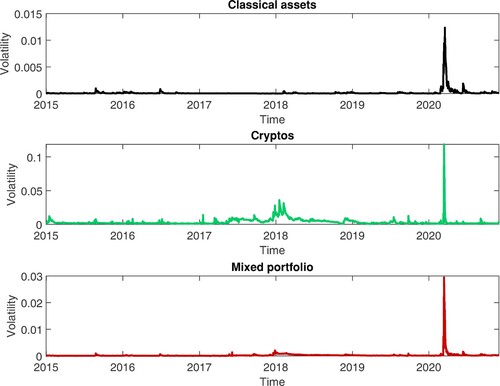
Table 8. Average 1% VaR.
This result confirms the findings from Naimy et al. (Citation2021), who showed that the most stable cryptocurrency is ten times more volatile than the most unstable fiat currency.
Several implications arise from this exercise and from the findings of our study. First, given cryptocurrencies' unpredictable and highly volatile behaviour, investors may be exposed to higher risks than investing in classical assets. Second, cryptocurrencies can be seen as an alternative for portfolio diversification, if investors are looking for higher compensation from riskier assets (a more in-depth analysis can be found in Naimy, El Chidiac, and El Khoury Citation2020). Third, as shown in Conlon, Corbet, and McGee (Citation2020), cryptocurrencies may not be suitable for risk-averse investors, especially in bear market circumstances. Because of their high exposure to tail risk, conventional inference based on normal distribution appears to be inappropriate when it comes to the prudential treatment of cryptocurrencies. Furthermore, since the volatility of cryptocurrencies and traditional assets differs by a factor of about 10, cryptocurrencies may require extra attention and monitoring, as their high volatility could jeopardize overall financial stability.
Further research is needed to unveil any theoretical or economical foundation to explain the differences in the statistical properties of cryptos vs. traditional assets. As shown in Giudici, Milne, and Vinogradov (Citation2020), cryptocurrencies are severely affected by uncertainty, arising from two sources: the embedded technology and the ambiguity regarding their fundamental value. Under these conditions, cryptocurrencies would be even more affected by behavioural biases than the classical assets; for example, cryptos may be prone to herding behaviour and bubbles (Cheah and Fry Citation2015; Papadamou et al. Citation2021). Technology and market microstructure can explain the convergence behaviour of prices (Apergis, Koutmos, and Payne Citation2021) and this convergence may facilitate bubble formation. Regarding the fundamental value of cryptocurrencies, most of the researchers agree on the ‘intangible nature of the cryptocurrency value’ (see Giudici, Milne, and Vinogradov Citation2020). More knowledge on the price dynamics of cryptocurrencies is required to derive the fundamental factors of their statistical behaviour.
6. Conclusions
In this paper, we applied various classification techniques to discriminate between cryptocurrencies and classical assets, like stocks, exchange rates, bonds, real estate indexes, and commodities. Through the means of dimensionality reduction and classification techniques, we proved that most of the variation among cryptocurrencies and classical assets can be explained by three factors: the tail factor, the memory factor and the moment factor. These factors are different from the ones obtained in Liu, Tsyvinski, and Wu (Citation2019) and our analysis revealed that the main difference between cryptocurrencies and classical assets, in terms of properties of the distribution of daily log-returns, is the tail behaviour.
Based on the factors profile, we can conclude that a random asset is likely to be a cryptocurrency if it has the following properties: very long tails of the log-returns distribution (in terms of left and right quantiles and conditional tail expectations), high variance and low values of the α-stable tail parameter, indicating large departure from normality.
Our results provide a series of insights, based on which researchers and practitioners can differentiate cryptocurrencies from classical assets, using the methods presented here. Although classical classification methods (Binary Logistic Regression and Support Vector Machines, K-means clustering) do not provide a complete separation of cryptocurrencies, the Maximum Variance Components Split method achieves this goal.
By looking at the assets universe as a complex ecosystem, we provide empirical evidence that cryptocurrencies exhibit a synchronic evolution, i.e. individual cryptocurrencies develop similar statistical characteristics over time, allowing them to differentiate from classical assets.
From the point of view of the prudential treatment of cryptocurrencies, the traditional inference based on normal distribution seems to be inappropriate, due to their high exposure to tail risk. Moreover, as the volatility of cryptocurrencies is significantly higher then the volatility of classical assets, cryptocurrencies may require special attention and supervision, as their high volatility could have a significant impact on the overall financial stability.
Cryptocurrencies can be seen as digital payment mediums and are also used for speculation. In this research, we are looking at the statistical properties of cryptocurrencies, compared to classical assets; however, this approach can be extended, by including in the analysis some indicators taking into account the payment factors, such as payment techniques, transaction benefits and transaction costs.
Acknowledgments
The authors would like to thank the editor and the anonymous referees for their valuable comments on this article. D. T. Pele would like to thank Dr Lucian Visinescu (Texas State University), for valuable comments and suggestions to improve the quality of the paper. Financial support of the Deutsche Forschungsgemeinschaft's IRTG 1792 grant, the Yushan Scholar Program of Taiwan, the Czech Science Foundation's grant no. 19-28231X / CAS: XDA 23020303 are greatly acknowledged. Y. G. Yatracos would like to thank Professor Dr. Wolfgang K. Härdle and the members of the Ladislaus von Bortkiewicz Chair in Statistics for the warm hosting during his sabbatical, and acknowledges the support of Deutsche Forschungsgemeinschaft's IRTG 1792 grant. All remaining errors are our sole responsibility. The information and views set out in this article are those of the authors and do not necessarily reflect the official opinion of the Central Bank of Cyprus.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes on contributors

Daniel Traian Pele
Prof. Daniel Traian Pele graduated Mathematics (2000) and got his Master in Stochastic Processes and Theoretical Statistics at the University of Bucharest (2002). He got his Ph.D. in Statistics (2007) and habilitation in Statistics (2019) at the Bucharest University of Economic Studies. He currently serves as a Professor at the Department of Statistics and Econometrics, the Bucharest University of Economic Studies, Romania, teaching Statistics of Financial Markets and Time Series. He is an author of more than 20 scientific publications in internationally refereed journals. The corresponding research profile is that of a data scientist, focused on statistical modelling of financial markets. He was a postdoctoral researcher at ICMA Centre, Reading University, United Kingdom (2011) and a Guest Researcher at Research Data Center from Department of Statistics, Humboldt University from Berlin (2014) and International Research Training Group 1792 “High Dimensional Nonstationary Time Series”, Humboldt University from Berlin (2018, 2019). He is the co-founder of SAS Centre of Excellence in the Bucharest University of Economic Studies (2009), aiming to use SAS as a platform for analytics with applications in economy and finance. He is also a World Bank and European Investment Bank consultant in Romania and he taught courses of Statistics, Econometrics and SAS for the employees of the Romanian National Bank (BNR), National Statistical Institute (INS) and other financial institutions. Publication list can be found at: Google Scholar or ResearchGate.

Niels Wesselhöfft
Dr. Niels Wesselhöfft did his Ph. D. in statistics on “Utilizing self-similar stochastic Processes to model rare Events in Finance” under Prof. Dr. Wolfgang K. Härdle. He is focusing on financial markets, having worked for Deutsche Bank, Veritas Institutional and S-Kreditpartner. His research interests cover robustness in non-stationary environments, high-frequency data and heavy-tailed distributions beyond Gaussianity.

Wolfgang Karl Härdle
Prof. Wolfgang Karl Härdle did 1982 his Dr.rer.nat. in Mathematics at Universität Heidelberg and took his Habilitation at Universität Bonn in 1988. He is Ladislaus von Bortkieviecz chair professor of statistics, Humboldt-Universität zu Berlin. Moreover, he is director of the Sino German International Research Training Group IRTG1792 “High dimensional non stationary time series analysis” (WISE, Xiamen University). His research focuses on dimension reduction techniques, computational statistics and quantitative finance. He has published over 30 books and more than 300 papers in top statistical, econometrics and finance journals, being one of the 1% most ranked researchers on Google Scholar, REPEC and SSRN. He has professional experience in financial engineering, smart data analytics, machine learning and cryptocurrency markets. Innovation: Prof. Hardle has created a financial risk meter FRM and a cryptocurrency index CRIX hu.berlin/frm and a cryptocurrency index CRIX hu.berlin/crix. His web page is: hu.berlin/wkh.

Michalis Kolossiatis
Dr. Michalis Kolossiatis obtained a Bachelor's Degree in Mathematics and Statistics (2003) and a Master's Degree in Statistics (2005) at the University of Cyprus and a PhD in Statistics at the University of Warwick (2009). The PhD Thesis title was “Modelling Via Normalisation for Parametric and Nonparametric Inference” and it was under the guidance of Professors Mark F. J. Steel and Jim E. Griffin. He currently works as a Statistics Officer at the Central Bank of Cyprus. Previous work experience includes: Teaching and Research Fellow at Cyprus University of Technology, Lecturer of Statistics at the University of Kent, UK and at the University of Lancaster, UK, and Visiting Lecturer of Statistics at the University of Cyprus. During his employment at the Universities of Kent and Lancaster, he also served in the Department's Statistical Consultancy Unit. Initially, his research work was mainly on Bayesian nonparametric modelling and density estimation, whereas in the last years, he is more focused on econometric modelling. His main interest in terms of applications is on financial data. He has published articles, among others, in Journal of the Royal Statistical Society (Series B) and Journal of Applied Econometrics. Current research interests consist of: Bayesian nonparametric modelling, density estimation, econometrics and machine learning.

Yannis G. Yatracos
Prof. Yannis G. Yatracos obtained his Ph.D. in Statistics from UC Berkeley under Lucien Le Cam, after the BSc in Math (U. of Athens), MSc in Stat (LSE), DEA and Doctorat de 3eme Cycle in Stat/OR (Paris 6). He is currently Professor of Statistics at Yau Mathematical Sciences Center, Tsinghua University and at BIMSA. Previous regular appointments include the National University of Singapore, Rutgers, Columbia, UC Santa Barbara, University of Montreal and Cyprus U. of Technology. Yannis started his research in density estimation using a Minimum Distance approach, extended the results in non-parametric regression and continued in other areas of Statistics, Mathematical Finance, Matching and in Actuarial Science. He investigated in particular pathologies of plug-in-methods, like the bootstrap and the MLE. His current interests include Learning with Matching, Fiducial ABC, Option Pricing with Le Cam's Experiments, Unmasking in Linear Regression, Cluster and Structures Detection in Big Data. Yannis is IMS and ASA Fellow, Elected ISI member and was Associate of the Society of Actuaries (U.S.A.). His research results have been published, among others, in the Annals of Statistics, JASA, Biometrika, IEEE Transactions on Information Theory, Journal of Classification and Annals of Applied Probability.
Notes
1 The complete list of the assets included in the analysis can be found in the file https://github.com/QuantLet/Genus_proximum_cryptos/blob/master/list.xlsx.
2 Again, this relatively low value of M was used for computational reasons.
3 In this approach, only the first two factors are used, as a 3D evolutionary dynamic would be difficult to read.
4 The daily evolution of the assets universe, for the period 22/04/2016-30/11/2020, is depicted in the video Crypto_movie, attached to this paper as supplementary material.
5 In Figure , for classical assets, the variance is multiplied by .
References
- Alexander, C., and M. Dakos. 2020. “A Critical Investigation of Cryptocurrency Data and Analysis.” Quantitative Finance 20 (2): 173–188. doi:10.1080/14697688.2019.1641347
- Apergis, N., D. Koutmos, and J. E. Payne. 2021. “Convergence in Cryptocurrency Prices? The Role of Market Microstructure.” Finance Research Letters 40: 101685. ISSN 1544-6123. doi:10.1016/j.frl.2020.101685
- Baillie, R. T., T. Bollerslev, and H. O. Mikkelsen. 1996. “Fractionally Integrated Generalized Autoregressive Conditional Heteroskedasticity.” Journal of Econometrics 74 (1): 3–30. ISSN 0304-4076. doi:10.1016/S0304-4076(95)01749-6
- Bariviera, A. F., M. J. Basgall, W. Hasperué, and M. Naiouf. 2017. “Some Stylized Facts of the Bitcoin Market.” Physica A: Statistical Mechanics and its Applications 484: 82–90. ISSN 0378-4371. doi:10.1016/j.physa.2017.04.159
- Bartholomew, D. J. 2011. Analysis of Multivariate Social Science Data, Chapman & Hall/CRC Statistics in the Social and Behavioral Sciences. 2nd ed. Boca Raton, FL: CRC Press.
- Berentsen, A., and F. Schar. 2018. “A Short Introduction to the World of Cryptocurrencies.” Federal Reserve Bank of St. Louis Review 100 (1): 1–16. doi:10.20955/r.2018.1-16
- Borri, N. 2019. “Conditional Tail-risk in Cryptocurrency Markets.” Journal of Empirical Finance 50: 1–19. ISSN 09275398. doi:10.1016/j.jempfin.2018.11.002
- Bouri, E., D. Roubaud, and S. J. H. Shahzad. 2020. “Do Bitcoin and Other Cryptocurrencies Jump Together?.” The Quarterly Review of Economics and Finance 76: 396–409. ISSN 1062-9769. doi:10.1016/j.qref.2019.09.003
- Caporale, G. M., L. Gil-Alana, and A. Plastun. 2018. “Persistence in the Cryptocurrency Market.” Research in International Business and Finance 46: 141–148. ISSN 0275-5319. doi:10.1016/j.ribaf.2018.01.002
- Cerny, B. A., and H. F. Kaiser. 1977. “A Study of a Measure of Sampling Adequacy for Factor-Analytic Correlation Matrices.” Multivariate Behavioral Research 12 (1): 43–47. ISSN 0027-3171. doi:10.1207/s15327906mbr1201_3
- Chan, S., J. Chu, S. Nadarajah, and J. Osterrieder. 2017. “A Statistical Analysis of Cryptocurrencies.” Journal of Risk and Financial Management 10 (2): 12. doi:10.3390/jrfm10020012
- Cheah, E.-T., and J. Fry. 2015. “Speculative Bubbles in Bitcoin Markets? An Empirical Investigation Into the Fundamental Value of Bitcoin.” Economics Letters 130: 32–36. ISSN 0165-1765. doi:10.1016/j.econlet.2015.02.029
- Conlon, T., S. Corbet, and R. J. McGee. 2020. “Are Cryptocurrencies a Safe Haven for Equity Markets? An International Perspective From the COVID-19 Pandemic.” Research in International Business and Finance 54: 101248. ISSN 0275-5319. doi:10.1016/j.ribaf.2020.101248
- Corbet, S., B. Lucey, A. Urquhart, and L. Yarovaya. 2019. “Cryptocurrencies As a Financial Asset: A Systematic Analysis.” International Review of Financial Analysis 62: 182–199. ISSN 10575219. doi:10.1016/j.irfa.2018.09.003
- Cristianini, N., and J. Shawe-Taylor. 2000. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. Cambridge: Cambridge University Press. doi:10.1017/CBO9780511801389
- Dyhrberg, A. H. 2016a. “Bitcoin, Gold and the Dollar -- A GARCH Volatility Analysis.” Finance Research Letters 16: 85–92. ISSN 1544-6123. doi:10.1016/j.frl.2015.10.008
- Dyhrberg, A. H. 2016b. “Hedging Capabilities of Bitcoin. Is it the Virtual Gold?.” Finance Research Letters 16: 139–144. ISSN 1544-6123. doi:10.1016/j.frl.2015.10.025
- ElBahrawy, A., L. Alessandretti, A. Kandler, R. Pastor-Satorras, and A. Baronchelli. 2017. “Evolutionary Dynamics of the Cryptocurrency Market.” Royal Society Open Science 4 (11): 170623. ISSN 2054-5703. doi:10.1098/rsos.170623
- Fama, E. F., and K. R. French. 1996. “Multifactor Explanations of Asset Pricing Anomalies.” The Journal of Finance 51 (1): 55–84. ISSN 00221082. doi:10.1111/j.1540-6261.1996.tb05202.x
- Favre, L., and J.-A. Galeano. 2002. “Mean-modified Value-at-risk Optimization with Hedge Funds.” The Journal of Alternative Investments 5 (2): 21–25. ISSN 1520-3255. doi:10.3905/jai.2002.319052
- Feng, W., Y. Wang, and Z. Zhang. 2018. “Can Cryptocurrencies Be a Safe Haven: a Tail Risk Perspective Analysis.” Applied Economics 50 (44): 4745–4762. ISSN 0003-6846. doi:10.1080/00036846.2018.1466993
- Fischer, T., C. Krauss, and A. Deinert. 2019. “Statistical Arbitrage in Cryptocurrency Markets.” Journal of Risk and Financial Management 12 (1): 31. doi:10.3390/jrfm12010031
- Giudici, G., A. Milne, and D. Vinogradov. 2020. “Cryptocurrencies: Market Analysis and Perspectives.” Journal of Industrial and Business Economics 47 (1): 1–18. ISSN 1972-4977. doi:10.1007/s40812-019-00138-6
- Glosten, L. R., R. Jagannathan, and D. E. Runkle. 1993. “On the Relation Between the Expected Value and the Volatility of the Nominal Excess Return on Stocks.” The Journal of Finance 48 (5): 1779–1801. ISSN 00221082, 15406261. http://www.jstor.org/stable/2329067
- Griffin, J. M., and A. Shams. 2020. “Is Bitcoin Really Untethered?.” The Journal of Finance 75 (4): 1913–1964. doi:10.1111/jofi.12903
- Härdle, W., and L. Simar. 2019. Applied Multivariate Statistical Analysis: [R
Matlab Codes]. 5th ed. Berlin and Heidelberg: Springer.
- Härdle, W. K., C. R. Harvey, and R. C. G. Reule. 2020, February. “Understanding Cryptocurrencies.” Journal of Financial Econometrics 18 (2): 181–208. ISSN 1479-8409. doi:10.1093/jjfinec/nbz033
- Hosmer, D. W., and S. Lemeshow. 2010. Applied Logistic Regression. A Wiley-Interscience publication. 2nd ed. New York: John Wiley. [repr.].
- Hurst, H. E. 1951. “Long-term Storage Capacity of Reservoirs.” Transactions of the American Society of Civil Engineers 116: 770–808.
- I.M.F. Treatment of Crypto Assets in Macroeconomic Statistics. 2019. International Monetary Fund, Statistics Department. https://www.imf.org/external/pubs/ft/bop/2019/pdf/Clarification0422.pdf.
- Istas, J., and G. Lang. 1997. “Quadratic Variations and Estimation of the Local Hölder Index of a Gaussian Process.” Annales de l'Institut Henri Poincare (B) Probability and Statistics 33 (4): 407–436. ISSN 02460203. doi:10.1016/S0246-0203(97)80099-4
- James, N., M. Menzies, and J. Chan. 2021. “Changes to the Extreme and Erratic Behaviour of Cryptocurrencies During COVID-19.” Physica A: Statistical Mechanics and its Applications 565: 125581. ISSN 0378-4371. doi:10.1016/j.physa.2020.125581
- Jiang, H., and L. Han. 2018. “Does Income Diversification Benefit the Sustainable Development of Chinese Listed Banks? Analysis Based on Entropy and the Herfindahl-Hirschman Index.” ENTROPY 20 (4): 255. ISSN 1099-4300. doi:10.3390/e20040255
- Kaiser, H. F. 1974. “An Index of Factorial Simplicity.” Psychometrika 39 (1): 31–36. ISSN 0033-3123. doi:10.1007/BF02291575
- Kaiser, H. F. 1981. “A Revised Measure of Sampling Adequacy for Factor-Analytic Data Matrices.” Educational and Psychological Measurement 41 (2): 379–381. ISSN 0013-1644. doi:10.1177/001316448104100216
- Klein, T., H. Pham Thu, and T. Walther. 2018. “Bitcoin is Not the New Gold – A Comparison of Volatility, Correlation, and Portfolio Performance.” International Review of Financial Analysis 59: 105–116. ISSN 10575219. doi:10.1016/j.irfa.2018.07.010
- Koutrouvelis, I. A. 1980. “Regression-Type Estimation of the Parameters of Stable Laws.” Journal of the American Statistical Association 75 (372): 918. ISSN 01621459. doi:10.2307/2287182
- Koutrouvelis, I. A. 1981. “An Iterative Procedure for the Estimation of the Parameters of Stable Laws.” Communications in Statistics -- Simulation and Computation 10 (1): 17–28. ISSN 0361-0918. doi:10.1080/03610918108812189
- Koutrouvelis, I. A., and D. F. Bauer. 1982. “Asymptotic Distribution of Regression Type Estimators of Parameters of Stable Laws.” Communications in Statistics -- Theory and Methods 11 (23): 2715–2730. doi:10.1080/03610928208828417
- Li, M.-Y., Q. Cai, G.-F. Gu, and W.-X. Zhou. 2019. “Exponentially Decayed Double Power-law Distribution of Bitcoin Trade Sizes.” Physica A: Statistical Mechanics and its Applications 535: 122380. ISSN 0378-4371. doi:10.1016/j.physa.2019.122380
- Liu, Y., and A. Tsyvinski. 2018. “Risks and Returns of Cryptocurrency.” NBER Working Paper No. 24877. doi:10.3386/w24877.
- Liu, Y., A. Tsyvinski, and X. Wu. 2019. “Common Risk Factors in Cryptocurrency.” NBER Working Paper No. 25882. doi:10.3386/w25882.
- Liu, W., X. Liang, and G. Cui. 2020. “Common Risk Factors in the Returns on Cryptocurrencies.” Economic Modelling 86: 299–305. ISSN 0264-9993. doi:10.1016/j.econmod.2019.09.035
- MacQueen, J. 1967. “Some Methods for Classification and Analysis of Multivariate Observations.” In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, 281–297. Calif. University of California Press: Berkeley; https://projecteuclid.org/euclid.bsmsp/1200512992.
- Manavi, S. A., G. Jafari, S. Rouhani, and M. Ausloos. 2020. “Demythifying the Belief in Cryptocurrencies Decentralized Aspects. A Study of Cryptocurrencies Time Cross-correlations with Common Currencies, Commodities and Financial Indices.” Physica A: Statistical Mechanics and its Applications 556: 124759. ISSN 0378-4371. doi:10.1016/j.physa.2020.124759
- McNally, S., J. Roche, and S. Caton. 2018. “Predicting the Price of Bitcoin Using Machine Learning.” In 2018 26th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), 339–343. doi:10.1109/PDP2018.2018.00060.
- Mensi, W., K. H. Al-Yahyaee, and S. H. Kang. 2019. “Structural Breaks and Double Long Memory of Cryptocurrency Prices: A Comparative Analysis From Bitcoin and Ethereum.” Finance Research Letters 29: 222–230. ISSN 15446123. doi:10.1016/j.frl.2018.07.011
- Mirtaheri, M., S. Abu-El-Haija, F. Morstatter, G. V. Steeg, and A. Galstyan. 2009. “Identifying and Analyzing Cryptocurrency Manipulations in Social Media.” http://arxiv.org/pdf/1902.03110v1.
- Momtaz, P. P. 2021. “The Pricing and Performance of Cryptocurrency.” The European Journal of Finance 27 (4–5): 367–380. doi:10.1080/1351847X.2019.1647259
- Muvunza, T. 2020. ‘An α-Stable Approach to Modelling Highly Speculative Assets and Cryptocurrencies.” http://arxiv.org/pdf/2002.09881v1.
- Nagelkerke, N. J. 1991. “A Note on a General Definition of the Coefficient of Determination.” Biometrika 78 (3): 691–692. ISSN 0006-3444. doi:10.1093/biomet/78.3.691
- Naimy, V., J. El Chidiac, and R. El Khoury. 2020. “Volatility and Value at Risk of Crypto Versus Fiat Currencies.” In International Conference on Business Information Systems, 145–157. Springer.
- Naimy, V., O. Haddad, G. Fernández-Avilés, and R. El Khoury. 2021. “The Predictive Capacity of GARCH-type Models in Measuring the Volatility of Crypto and World Currencies.” PloS One 16 (1): e0245904. ISSN e0245904. doi:10.1371/journal.pone.0245904
- Núñez, J. A., M. I. Contreras-Valdez, and C. A. Franco-Ruiz. 2019. “Statistical Analysis of Bitcoin During Explosive Behavior Periods.” PloS One 14 (3): e0213919. doi:10.1371/journal.pone.0213919
- Papadamou, S., N. A. Kyriazis, P. Tzeremes, and S. Corbet. 2021. “Herding Behaviour and Price Convergence Clubs in Cryptocurrencies During Bull and Bear Markets.” Journal of Behavioral and Experimental Finance 30: 100469. ISSN 2214-6350. doi:10.1016/j.jbef.2021.100469
- Rachev, S. T., and S. Mittnik. 2000. Stable Paretian Models in Finance. Series in financial economics and quantitative analysis. Chichester: J. Wiley.
- Schnaubelt, M., J. Rende, and C. Krauss. 2019. “Testing Stylized Facts of Bitcoin Limit Order Books.” Journal of Risk and Financial Management 12 (1): 25. doi:10.3390/jrfm12010025
- Shen, D., A. Urquhart, and P. Wang. 2020. “A Three-factor Pricing Model for Cryptocurrencies.” Finance Research Letters 34: 101248. ISSN 1544-6123. doi:10.1016/j.frl.2019.07.021
- Tabachnick, B. G., and L. S. Fidell. 2013. Using Multivariate Statistics. 6th ed. Boston: Pearson Education.
- Takaishi, T. 2018. “Statistical Properties and Multifractality of Bitcoin.” Physica A: Statistical Mechanics and its Applications 506: 507–519. ISSN 0378-4371. doi:10.1016/j.physa.2018.04.046
- Tan, Z., Y. Huang, and B. Xiao. 2021. “Value At Risk and Returns of Cryptocurrencies Before and After the Crash: Long-run Relations and Fractional Cointegration.” Research in International Business and Finance 56: 101347. ISSN 0275-5319. doi:10.1016/j.ribaf.2020.101347
- Trucíos, C., A. K. Tiwari, and F. Alqahtani. 2020. “Value-at-risk and Expected Shortfall in Cryptocurrencies’ Portfolio: a Vine Copula–based Approach.” Applied Economics 52 (24): 2580–2593. ISSN 0003-6846. doi:10.1080/00036846.2019.1693023
- Valencia, F., A. Gómez-Espinosa, and B. Valdés-Aguirre. 2019. “Price Movement Prediction of Cryptocurrencies Using Sentiment Analysis and Machine Learning.” Entropy (Basel, Switzerland) 21 (6): 589. doi:10.3390/e21060589
- Yatracos, Y. G. 1998. “Variance and Clustering.” Proceedings of the American Mathematical Society 126 (04): 1177–1179. ISSN 00029939. doi:10.1090/S0002-9939-98-04524-9
- Yatracos, Y. G. 2009. “The Asymptotic Distribution of a Cluster-index for I.i.d. Normal Random Variables.” The Annals of Applied Probability 19 (2): 585–595. ISSN 1050-5164. doi:10.1214/08-AAP553
- Yatracos, Y. G. 2013. “Detecting Clusters in the Data From Variance Decompositions of Its Projections.” Journal of Classification 30 (1): 30–55. ISSN 0176-4268. doi:10.1007/s00357-013-9124-9
- Zakoian, J.-M. 1994. “Threshold Heteroskedastic Models.” Journal of Economic Dynamics and Control 18 (5): 931–955. ISSN 0165-1889. doi:10.1016/0165-1889(94)90039-6
- Zhang, W., P. Wang, X. Li, and D. Shen. 2018. “Some Stylized Facts of the Cryptocurrency Market.” Applied Economics 50 (55): 5950–5965. ISSN 0003-6846. doi:10.1080/00036846.2018.1488076
- Zwijnenburg, J., M. De Queljoe, and I. Ynesta. 2020, June. “The Recording of Crypto Assets in the System of National Accounts – Interim Guidance, 2020.” In Paper Prepared for the Meeting of the Informal Advisory Group on Measuring GDP in a Digitalised Economy.
Appendices
Appendix 1.
Classification methods
Binary logistic regression
The Binary Logistic Regression model quantifies the performance of each of the orthogonal factors extracted through the Factor Analysis to discriminate between cryptocurrencies and classical assets. Thus, we are estimating the following family of models:
(A1)
(A1)
where
for cryptocurrencies,
for classical assets, and
are the k orthogonal factors retrieved through the Factor Analysis. Based on the explanatory power and the significance of model (EquationA1
(A1)
(A1) ), we can derive the most important factors contributing to the specific difference of cryptocurrencies. As a performance measure for Model (EquationA1
(A1)
(A1) ), we are using
(Nagelkerke Citation1991), where:
(A2)
(A2)
In Equation (EquationA2
(A2)
(A2) ),
is the maximum likelihood of the intercept-only model,
is the maximum likelihood of the full model, and
is the vector of Maximum Likelihood estimated parameters.
Support vector machines
Support Vector Machines (SVM) is a data classification technique, its goal being to produce a model which predicts target values based on a set of attributes (Cristianini and Shawe-Taylor Citation2000). The goal is to find a projection that maximizes margin in a hyperplane of the original data, without any parametric assumptions on the underlying stochastic process. The support vectors are determined via a quadratic optimization problem i.e. given a training data set D with n samples and 2 dimensions ,
, the aim is to find a hyperplane that maximizes the margin:
(A3)
(A3)
K-means clustering algorithm
This clustering method was first popularized by MacQueen (Citation1967), who acknowledged a couple of other researchers that independently used that method around the same time. The aim is to allocate each observation of a data set in one of clusters, where k is predefined, so as to minimize the within-cluster sums of squares. In brief, the algorithm proceeds as follows:
Take k data points and set them as the cluster centres.
Iteratively, for each data point, assign it to the cluster which centre is closer to the data point (the Euclidean distance is usually used, but other distance metrics have been proposed). Update the cluster centre for the selected cluster.
Repeat until convergence (i.e. the allocations do not change).
Maximum variance components split methods: MVCS, GMVCS
These methods aim to separate, respectively, the components of a structure like the types of assets herein or the types of Iris flowers, and clusters defined as the components of a mixture distribution. They are based on an unusual variance decomposition in between-group variations (Yatracos Citation1998, Citation2013). To describe the sample version of the decomposition, let be i.i.d. random variables.
is the j-th order statistic,
Consider the groups and
with averages, respectively,
and
then
(A4)
(A4)
The summands on the right side of Equation (EquationA4
(A4)
(A4) ) measure between-groups variations. The standardized sample variance components
(A5)
(A5)
(A6)
(A6)
indicate the relative contribution of the groups
and
in the sample variability. The index
(A7)
(A7)
determines two potential clusters or parts of a structure and is based on averages and inter-point distances. When
these clusters are
The observed
-value is significant at α-level for the normal model when it exceeds the critical value
(Yatracos Citation2009);
is used herein.
When is the n by r data matrix of r-dimensional observations,
is the jth row of
. The coefficients of the orthogonal projection of
along the unit norm r-row vector
are
.
The split in the sorted values of , where
(A8)
(A8)
is attained, determines along
the groups
and
in the
-rows which are potential clusters and parts of a structure. For example, if for the data herein
consists of rows 1-14, cryptocurrencies (a component) among the assets (the structure) are completely separated along
The Maximum Variance Component Split (MVCS) method compares known components of a structure, e.g. cryptocurrencies herein, with data splits for a set of unit projection directions usually determined by M positive equidistant angles of
e.g. when r = 2 and M = 3 the angles used are
When one of the data split along projection direction
coincides with a component of the structure we have complete separation of this component along
A set of projection directions can be
(A9)
(A9)
where
takes values in
The number of projection directions to be used is . The method is thus computationally intensive for large r and M values, thus it may be used on subsets of the
-columns. The importance of a subset S of
-columns in the separation of a structure's component is measured by the number
of projection directions (EquationA9
(A9)
(A9) ) completely separating the component. Indications for the importance of a specific column c in S in the separation of the same component are obtained by comparing
with the number of projection directions
separating the component when c is left out and also by comparing all
Similar indications of importance can be used for subgroups of S-columns.
The Global Maximum Variance Component Split (GMVCS) along all projection vectors to be obtained from
, determines two clusters. In practice, its approximation is obtained using
. The splitting of these clusters may continue (Yatracos Citation2013).
Appendix 2.
Assets list
Table C1. aaa