
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we discuss downside risk optimization in the context of portfolio selection. We derive explicit solutions to the optimal portfolios that minimize the downside risk with respect to constant targets and random targets. In doing so, we propose using portfolio amplitude, a new measure in the literature, to characterize the portfolio selection under the downside risk optimization. Particularly, we demonstrate a mechanism by which the random target inputs its impact into the system and alters the optimal solution. Our results underpin why investors prefer holding some specific assets in following random targets and provide explanations for some special investment strategies, such as constructing a stock portfolio following a bond index. We present numerical examples of stock portfolio management to support our theoretical results.
1. Introduction
Downside risk has long been commonly used as a tool in portfolio theory. In contrast to the classic Markowitz mean-variance method, in which the risk is measured solely by the variance, downside risk is more concerned with the possibility of returns falling short of a specified target. Such a characteristic fits well with actual investors' attitudes toward risk in practice because it separates the favorable upside deviations from the averse downside ones, whereas the variance takes both into account simultaneously. Among the most studied downside risk measures in the literature, there are the so-called lower partial moment, which is defined as the expectation of nth power of the return's deviation below a pre-specified target that depends on the investor's preference (Harlow and Rao Citation1989). In particular, the first-order lower partial moment is well known as the ‘ target shortfall.’ An investor may prefer to construct his or her portfolio via minimizing downside risk measures, and such an approach is often referred to as downside risk optimization (Harlow Citation1991). Portfolios with optimal downside risk are more attractive in the mean-variance sense because risk can be lowered while expected returns may be maintained or improved and the investor is free to choose a pre-specified target according to his or her own risk appetite. Notably, one can choose to set up the optimal portfolio based on a random target that is correlated with underlying assets. In this regard, the downside risk optimization applies to construct portfolios in both financial and actuarial context such as index funds, pension funds and portfolio insurance etc.
In finance, the rationale behind the notion of an index fund is based on the well known ‘Efficient Market Hypothesis’ (Malkiel and Fama Citation1970) which suggests that the ideal market portfolio should be the most profitable. Therefore, by considering a financial index as the representative of a market portfolio, one can construct portfolios to follow this index as closely as possible with respect to certain measures on the distance between optimal portfolio and the index.Footnote1 In the framework of downside risk optimization, the optimal portfolio minimizes the downside risk with respect to the index. Such downside risk optimization is a particularly compelling method in the case of passive portfolio management,Footnote2 because the risk that portfolio falling short below the index can be minimal. For example, when the expected return of a market index is 10%, a portfolio that guarantees 5% expected return may not be satisfactory, whereas a portfolio with −2% expected return could be favorable if the market index's expected return is −10%. Moreover, as downside risk optimization only minimizes the averse downside parts of the risk, it reserves the potential to be more profitable than the financial index it follows. Therefore, it appears natural to consider portfolios that have minimal downside risk with respect to a financial index. In actuarial context, both pension funds and portfolio insurance utilize models based on the downside risk optimization with constant targets (see, e.g. Haberman and Vigna (Citation2002), and De Franco and Tankov (Citation2011)). Thus, it is also straightforward to motivate the random targets in these applications. For example, the portfolio insurance can set a random target on a bond as the guaranteed return instead of a fixed level.
To determine the composition of the optimal portfolio, one needs to solve the downside risk optimization. Generally speaking, there are two strands on this topic in the literatureFootnote3. One strand focuses on proposing algorithms that solves this complex optimization problem numerically, and the other delves into the optimization models and aims to study the existence and uniqueness of solutions and find the explicit formula of the optimal solution. Since it is usually difficult to calculate downside risk measures explicitly (Markowitz Citation1987), most studies rely on numerical techniques to solve the downside risk optimization. For instance, Rudolf, Wolter, and Zimmermann (Citation1999) defined four types of measures to minimize tracking error between the optimal portfolio and the financial index and found the optimal solution by means of linear programming. Similar models using different numerical techniques are considered in Gharakhani, Zarea Fazlelahi, and Sadjadi (Citation2014). Zhu, Li, and Wang (Citation2009) considered downside risk optimization of the first- and second-order lower partial moments, and used linear programming to obtain numerical solutions. Roman, Mitra, and Zverovich (Citation2013) proposed a numerical method to construct portfolios that are superior to the index with respect to stochastic dominance. Cumova and Nawrocki (Citation2014) studied the downside risk optimization using simulation. Ling, Sun, and Yang (Citation2014) incorporated model uncertainty into the optimization and solved it using semi-definite programming. Notwithstanding the important contributions of these works, the computational challenges and errors are inevitable for numerical solutions.
By contrast, explicit solutions, though usually difficult to obtain, are free of such computational costs. Moreover, it is well known that the portfolio selection is subject to estimation risk. DeMiguel, Garlappi, and Uppal (Citation2009) considered the impact of estimation risk on the efficiency of portfolio selection based on naive portfolio. A more recent study can be found in Platanakis, Sutcliffe, and Ye (Citation2021). Platanakis and Sutcliffe (Citation2017) studied the estimation risk on the asset–liability management in pension scheme based on USS data; see also Platanakis and Sutcliffe (Citation2016). Platanakis and Urquhart (Citation2019) discussed the estimation risk on the portfolio management of cryptocurrencies; see also Platanakis, Sutcliffe, and Urquhart (Citation2018) and Platanakis and Urquhart (Citation2020). In this regard, explicit solutions are also useful for the study of estimation risk because they separate the estimation risk from the computational errors of numerical techniques.
Studies aiming at the explicit solutions of the downside risk optimization are relatively much fewer in the literature. Klebaner et al. (Citation2017) successfully found the explicit solutions to downside risk optimization when the target is a constant. In this paper, we further extend their results and make the following contributions. First, Klebaner et al. (Citation2017) derived the explicit solutions to the first and the second order of the downside risk optimization with respect to a pre-specified constant target. Following the same line, we derive the explicit solutions to the third and the four order of the downside risk optimization with respect to constant targets. The two new orders of downside risk optimization and the explicit solutions provide more alternative objectives for investors in their portfolio management of downside risks. Note that explicit solutions are superior to numerical methods both in terms of computational effort and accuracy; for example, the numerical example in Zhu, Li, and Wang (Citation2009) can be solved analytically using our formulas rather than using linear programming for obtaining the numerical solutions in their paper. Second, we further extend the results of Klebaner et al. (Citation2017) to the context of multivariate elliptical distribution and point out that such framework of downside risk optimization is also applicable in following a random target. Particularly, in addition to the Gaussian model, we consider another two special cases of Student's t model and symmetric variance Gamma model in our elliptical setting. We derive the explicit solutions of the optimal portfolio that minimizes the target shortfall with respect to a random target for those models. Third, by virtue of the explicit solutions, we investigate how following a random target affects the downside risk optimization. More specifically, we first propose using the amplitude of the optimal portfolio weights to characterize the investment strategy. Then, we demonstrate a monotonic relationship between the expected return and the amplitude of the optimal portfolio. The portfolio amplitude, to the best of our knowledge, is new in the literature as a measure for portfolio management. In particular, we prove that when the volatility of the random target increases or the correlation between the random target and underlying assets decreases, the amplitude of the optimal portfolio always ascends, which directly implies more aggressive trading. Finally, we present numerical examples to further clarify and support our theoretical conclusions. We use data from five different stock exchange markets in three years (NASDAQ, NYSE, London stock exchange market, Shanghai stock exchange market and Tokyo stock exchange market) and present several numerical examples.
The remainder of the paper is organized as follows: Section 2 presents our theoretical results. We first introduce the downside risk optimization and derive the explicit solutions to the first four orders of the downside risk optimization with respect to constant targets in Section 2.1. Then, in Section 2.2, we motivate the downside risk optimization approach for portfolio management following a random target. In Section 2.3, we set up models in the context of multivariate elliptical distribution and derive the analytical solutions to optimal portfolio minimizing the target shortfall with respect to a random target. Third, using the derived explicit solutions, we propose the portfolio and amplitude and show its monotonicity with the optimal portfolio following a random target in Section 2.3. Section 3 provides numerical examples to illustrate and support our theoretical results and Section 4 concludes the paper.
2. Main results
2.1. Downside risk optimization with fixed target
In this paper, all expectations are tacitly assumed to exist. All proofs can be found in the appendix. For the stochastic return of a financial asset X, its ith lower partial moment is defined as
(1)
(1) where K is a pre-specified constant target and
is the set of positive integers. The lower partial moment (Equation1
(1)
(1) ) is a well-known measure for the downside risk of X with respect to K, often taken as a fixed or observable target such as the return rate on a long-dated bond or treasury bill. When (Equation1
(1)
(1) ) is applied in portfolio selection, i.e. a portfolio manager selects assets by optimizing the downside risk of his or her portfolio, K can reflect the manager's risk preference. As (Equation1
(1)
(1) ) measures the expected magnitude by which the portfolio falls below the target, a higher K intuitively implies that the portfolio manager would like to have a higher expected return for the portfolio. Formally, we consider n risky assets' stochastic returns
and minimize the ith lower partial moment of the portfolio for a given fixed target K as follows:
Downside risk optimization with fixed target:
(2)
Downside risk optimization is usually computationally cumbersome. Klebaner et al. (Citation2017) provided analytical solutions to downside risk optimization (Equation2(2)
(2) ) for i = 1 and 2 in a multi-normal distribution context. Following their method, we further extend their results to i = 3 and 4. We shall use the following notations to illustrate our results.
Theorem 2.1
Let follow multivariate normal distribution with means
and covariance matrix
. The downside risk optimization (Equation2
(2)
(2) ) has unique optimal solution
, and
where
;
for
for
for
for
2.2. Downside risk optimization with random target
Instead of a fixed target K, we may also consider a random target in the downside risk measure of (Equation1(1)
(1) ). More specifically, let us assume that there are n risky assets and a financial index, whose stochastic returns are given by a random vector
and another random variable
respectively. A portfolio manager would like to invest one unit of wealth in these risky assets such that his or her portfolio's downside risk with respect to the financial index is minimized. Formally, we consider the following downside risk optimizations.
Downside risk optimization with random target (minimizing random target shortfall)Footnote4:
Clearly, instead of prompting expected returns, downside risk optimizations (Equation3(3)
(3) ) focuses on the expected magnitude of downside deviations from the index
. In a nutshell, the objective function of (Equation3
(3)
(3) ) measures how far the portfolio is expected to drop below the index. This type of downside risk optimization is very suitable for passive portfolio managers because they place a higher priority on loss aversion than on gains. By minimizing the downside risk with respect to a financial index, the investor is in effect creating a minimal expectation that his or her portfolio may drop below the index. This is coherent with the idea that in passive portfolio management it is sufficient to follow a benchmark market index. Furthermore, downside risk optimization (Equation3
(3)
(3) ) only minimizes the downside part of the deviation; hence, optimal portfolios have the potential to outperform the random target
with respect to the expected returns.
In addition to its suitability for passive portfolio management, downside optimizations (Equation3(3)
(3) ) is also appealing for more general portfolio management settings. For example, an investor who is interested in a foreign financial market could compose a portfolio using assets from his or her domestic market to follow a foreign market index without investing in this market directly thus avoiding exposure to exchange risk. Such financial behavior is referred as ‘home bias’; see French and Poterba (Citation1991). Furthermore,
does not necessarily have to be an index. It can be a specific stock or fund that is of interest to an investor who is unable or unwilling to invest in it directly.
As aforementioned, moreover, comparing with other methods for constructing index funds, which rely heavily on numerical techniques, analytical solutions for optimizations (Equation3(3)
(3) ) are attainable, and thus it is easy to implement in practice without running the risk of numerical errors. This is particularly advantageous in the case of passive portfolio management, especially when there are more than a few risky assets in the portfolio (as is typically the case in mutual fund management).
Using the explicit solutions of the downside risk optimization with fixed target, we can directly develop analytical solutions to downside risk optimization with a random target (Equation3(3)
(3) ) if we assume that
and
are jointly normally distributed, i.e.
(4)
(4) where
is the covariance matrix for
and
is the covariance between
and
Footnote5. For the computational simplicity, we only consider the first order
for the downside risk optimization.
The following notations are employed to present the analytical solutions:
Theorem 2.2
Using the notations and models defined in (Equation4(4)
(4) ), downside risk optimization (Equation3
(3)
(3) ) has unique analytical solution
where
and
is the solution to the equation
(5)
(5)
and
are the cumulative distribution function and density function of
.
Due to the affine transform of normal distribution, we are able to reformulate downside risk optimizations (Equation3(3)
(3) ) into the framework of downside risk optimization (Equation2
(2)
(2) ). Note that Theorem 2.2 also includes statement (i) of Theorem 2.1 as a special case, where
and
are both 0. Since the market index is a natural candidate for the random target, Theorem 2.2 admits a method to construct an index fund in the framework of downside risk optimization. On the other hand, financial assets' returns may display fatter tails than can be modeled by a normal distribution. In this regard, we further extend Theorem 2.2 to the context of multivariate elliptical distribution. We first introduce the multivariate elliptical distribution family as follows.
Definition 2.3
Multivariate elliptical distribution
A random vector has an elliptical distribution with parameters the
vector
(mean) and the
positive definite matrix
(covariance matrix), if its density function
is of the form
(6)
(6) where
is a normalizing constant.
We denote it as . Here,
is a non-negative measurable function satisfying the condition
(7)
(7)
is called the density generatorFootnote6.
Lemma 2.4
Let . Define the function
Then
has a multivariate elliptical distribution with density generator
and we say it is associated to
.
It is well known that the elliptical distribution family is closed to affine transform and conditioning. For more details, we refer to Landsman and Nešlehová (Citation2008), Landsman, Vanduffel, and Yao (Citation2013, Citation2015) and references therein. We first derive the explicit solution to the optimal expected shortfall with fixed target in the multivariate elliptical context, then the results for random target follows straightforwardly.
Theorem 2.5
For an elliptical vector , using notations in Theorem 2.1, the downside risk optimization of expected shortfall has unique optimal solution
,
where
and
is the solution to the equation
and F is the distribution function of standardized elliptical random variable, i.e.
and f is the density function of the associated elliptical random variable.
Based on Theorem 2.5, we can directly derive the explicit optimal portfolio to the minimization of the expected shortfall with respect to a random target as follows.
Theorem 2.6
For an elliptical vector , using notations in Theorem 2.2, the downside risk optimization of expected shortfall has unique optimal solution
,
where
and
is the solution to the equation
and F is the distribution function of standardized elliptical random variable, i.e.
and fis the density function of the associated elliptical random variable.
Note that, in the multivariate normal context, the associated density function coincides with its original form, i.e. φ, and we have Theorems 2.5 and 2.6 reduce to Theorems 2.1 and 2.2, respectively. For other non-normal classes in the elliptical distribution family, it is also straightforward to derive the explicit optimal portfolio following the same line. In particular, we present, in the following corollaries, two special cases in the elliptical family, namely the multivariate Student's t distribution and the multivariate symmetric variance Gamma (SVG) distribution. The density functions of the two special distributions are present in the appendix.
Corollary 2.7
Let
and use notations in Theorem 2.2, we have
where
and downside risk optimization (Equation3
(3)
(3) ) has unique analytical solution
where
and
is the solution to the equation
(8)
(8) F(x) and
are the cumulative distribution function and density function of
.
Corollary 2.8
Let
and use notations in Theorem 2.2, we have
where
and downside risk optimization (Equation3
(3)
(3) ) has unique analytical solution
where
and
is the solution to the equation
F(x) and
are the cumulative distribution function and density function of
and
respectively.
2.3. On the random target and portfolio amplitude
In this subsection, we demonstrate a mechanism by which the random target plays a role in downside risk optimization. We shall mainly focus on the multivariate normal context for simplicity. Let us recall that in Theorem 2.2, the optimal portfolio is determined by
. As such,
can characterize many features of the optimal portfolio. We first provide the following propositions on
. These propositions are also useful for further analysis in the sequel to this paper.
Proposition 2.9
Using the definitions and notations in Theorem 2.2, satisfies
(9)
(9)
(10)
(10)
Note that
Hence, we are able to compute that
, i.e.
Proposition 2.10
Using the definitions and notations in Theorem 2.2, the expected return of optimal portfolio is
Based on the two propositions above, we can see that characterizes the optimal portfolio weights for given parameters. In other words,
is our key to understanding how the random target influences portfolio selection in the framework of downside risk optimization. First,
indicates the highest expected return the optimal portfolio can reach; as long as
, the optimal portfolio outperforms the random target in the sense of expected returns. Second, it implies that higher expected returns come hand in hand with higher downside risks. Third, when the parameters are not fully known, one may still rely on the lower bound of
to make analysis for the sake of decision-making. For instance,
ensures
, then a higher expected return of the optimal portfolio. Therefore, from an investor's point of view, it is critical to be conscious of the consequences of taking a chosen random target into account in investment strategies. Let us stress that we stick to explicit analysis in this paper. For this purpose, we impose another assumption, namely
, where b is a scale, i.e. the risky assets have identical covariances with the random target.
Remark 2.1
We add this assumption so that we can always maintain explicit mathematical analysis. Although, generally, cannot have identical entries in practice, the explicit analysis can help us understand the impact of the random target. In practice, there are also circumstances where
is unknown or the direct estimation is insensible; for instance,
and
can be taken from markets in different countries and financial sectors, where the data sets are subject different time and geographical factors or might be even unavailable. Moreover, in the case
is unknown, one may simply assume b>0 or b<0. For example, when the random target is taken from the bond market whereas the risky assets are selected from the stock market,
is often assumed to be negative (Singer Citation2010); to follow a random target, investors might be primarily interested in assets that are positively correlated with the random target, thus one may presumed
is positive. We also provide numerical examples (Section 3) showing that all results of our analysis based on this assumption in this section could still empirically hold for non-identical
.
With the aid of such an assumption, we can simplify our model. The risky assets and random target
are jointly normal-distributed
(11)
(11) and
, where
,
and
.
The advantage of assuming that is evident. First, it facilitates analytical computation of formulae. Using the Sherman–Morrison formula and the fact that
and s are all positive, we can establish that
(12)
(12) where
,
,
and
. Second, the assumption allows us to separate the impact of the random target from that of the risky assets in the downside risk optimization. The inputs of random target in the system, i.e. b and
are now summarized into a single variate a; thus we refer it as ‘ target impact’. Third, by investigating on how a alters
, we are able to work out a mechanism regarding random target's role in downside risk optimization, i.e. the random target determines the optimal weights via parameter a. When the target impact a varies, so does
, which results in different optimal portfolio weights. In fact, we can show that
is monotonically increasing with respect to a. Moreover, as we will show in Section 3, we could expect these analyses to a also hold for general cases where we do not need the restrictive assumption
and use
(
, which is the average covariance).
Theorem 2.11
Using the notations in Theorem 2.2, is increasing with respect to a if
.
Remark 2.2
The assumption that is not necessary. Theorem 2.11 still holds for some negative
. However, we are more interested in the circumstance involving positive
because it implies that the expected return of the optimal portfolio is higher than that of the random target (Proposition 2.10), i.e. the optimal portfolio outperforms the random target with respect to expected returns. Moreover, we do not need the assumption on
to prove
is increasing with respect to
; thus we may expect the following analysis could still hold for general setting of
.
As the target impact is quantified as a single scale a, we may have some comparisons according to Theorem 2.11 between the optimal portfolios following a constant and a random target. For instance, it is clear that constant target would have a = 0; thus any random target with a>0 always increases , which results in a different optimal portfolio with possibly higher expected return. To account precisely for the impact of the random target on the optimal portfolio, i.e. to gauge how optimal portfolio weights vary along different a, we need an appropriate measure to account for the changes in optimal portfolio weights when
varies. Note that short-selling is permitted in our model, i.e. some portfolio weights can be negative. Hence, a smaller
does not necessarily mean less investment; on the contrary, the more negative
is, the more investment (short-selling) is implemented. Furthermore, due to the unit constraint on total weights (
), when an investor conducts more short-selling on
, he or she must buy other assets as compensation. An appropriate measure must be capable of characterizing such investment behavior. In this paper, we propose using ‘portfolio amplitude’ to assess quantitatively the random target's impact.
Definition 2.12
The amplitude of a portfolio with weights is defined as
Put simply, the portfolio amplitude is the largest variation in portfolio weights. Although amplitude is a common quantity in mathematics and physics, it has not been much used in portfolio selection, especially as a measure to assess investment strategies. We believe that it is reasonable and advantageous to use portfolio amplitude to assess investment strategies in our framework. In fact, as we will show in Theorem 2.13 and Proposition 2.14, there is also a monotonic relationship between the amplitude of the optimal portfolio and the target impact a.
Theorem 2.13
Using the notations in Theorem 2.2, the amplitude of the optimal portfolio is increasing with respect to
Now, we are ready to provide a mechanism to explain how the random target impacts the optimal portfolio and how the investor's behavior is captured by portfolio amplitude. We present the following proposition as a summary of the results above.
Proposition 2.14
Using the notations in Theorem 2.2, the following statements are true for .
The amplitude of optimal portfolio
The expected return of optimal portfolio
The amplitude of optimal portfolio
The proof of Proposition 4 follows immediately from Theorems 2.11 and 2.13. By virtue of Proposition 2.14, we may conclude as follows:
First, in the context of our downside risk optimization, we are able to compare the strategies of choosing the expected return of an index as a fixed target and following the index directly as a random target. Specifically, we know that the optimal portfolio following a random target directly always has a higher expected return as long as the random target generates a positive target impact a. This observation supports the investment in the stock market following a random target from the bond market because in such cases b is often assumed to be negative, which immediately implies a positive a.
Second, it is intuitive that following a random target could lead to more aggressive investment as there is more randomness involved in the system; however, this is not true in terms of portfolio amplitude. Note that the target impact is . Thus, compared to following a fixed target (a = 0), following a random target could even be less aggressive if the volatility (
) of the random target is low while the correlation (b) is high. In this regard, the portfolio amplitude, as a measure, can indeed provide an alternative perspective on investment behaviors. In particular, following a random target can be a less aggressive investment behavior if the investor is seeking to reduce the likelihood of loss by following a random target that he or she believes to be relatively safe.
Third, in the circumstance in which b cannot be known precisely, the amplitude of a portfolio with 0-correlation (b = 0) could serve us as a bound for our analysis. For example, if we cannot know the optimal portfolio due to unknown b, but we are certain that b<0. Then, the optimal portfolio with b = 0 provides us with information on the lower bound. More specifically, according to Proposition 2.14, it is clear that any portfolio with b<0 could surpass the 0-correlation portfolio in expected return and amplitude. Hence, investors can easily check whether this lower bound is acceptable when deciding whether to follow a random target or to choose another one.
All in all, from a theoretical point of view, the results based on analytical analysis underpin the relationship between investment strategy and random target in the context of downside risk optimization. On the one hand, it is clear from our analysis that following a random target has advantages, as it provides more flexibility for investors in seeking higher profits.
On the other hand, by proposing portfolio amplitude as a new measure for investment strategies, we point out how investors' preferences influence the optimal portfolio construction, and vice versa. Despite the restrictive assumption on , we could still expect that the same monotonicity between the target impact and the portfolio amplitude holds empirically. In particular, we consider
, where
is the vector of average covariance, and our numerical examples in the next section show that the monotonic relationship could still hold for
.
3. Numerical examples
We present several numerical examples on stock portfolio management in the framework of our downside risk optimization to support our theoretical study. All data we use in this section can be found from Yahoo Finance.
3.1. Example 1: optimal portfolios following constant target with minimal ith lower partial moment
We use weekly returns of the 20 largest capitalization stocks in the market for our analysis, and we collect data from five markets in three years (NASDAQ, NYSE, London Stock Exchange, Shanghai Stock Exchange, Tokyo Stock Exchange in 2017, 2018 and 2019), respectively, for comparisons. The numerical results are presented in Tables .
Table 1. Optimal portfolios minimizing the downside risk with given fixed target (NASDAQ stock exchange). Results are based on data of 2017, 2018 and 2019, respectively.
Table 2. Optimal portfolios minimizing the downside risk with fixed target (NYSE). Results are based on data of 2017, 2018 and 2019, respectively.
Table 3. Optimal portfolios minimizing the downside risk with fixed target (London stock exchange). Results are based on data of 2017, 2018 and 2019, respectively.
Table 4. Optimal portfolios minimizing the downside risk with fixed target (Shanghai stock exchange). Results are based on data of 2017, 2018 and 2019, respectively.
We can see from Tables to , when the given fixed target K increases, the optimal portfolios' downside risks, expected returns and standard deviations all increase for the same order i. Moreover, for the same given target, minimizing higher order downside risk (i = 3, 4) leads to lower expected returns and standard deviation, comparing with minimizing the lower order downside risk (i = 1, 2). Both observations are natural and in accord with our intuition because the downside risks and the expected returns increase with respect to the target K, and lower downside risks result in lighter tails, which mainly determine the standard deviation (variance). We may also observe some similarities between NASDAQ and NYSE, and between Shanghai market and Tokyo market (e.g. the results in 2018). Note that, our formulas are analytical and do not suffer from numerical errors. In fact, there are numerical methods available in many software packages to solve the optimization (e.g. ‘optim’ in R). However, as aforementioned, the solution differs from ours due to numerical errors. The deviation can be even more significant when the dimension is high. These numerical methods could also demand a much longer computation time to get the optimal solutions.
Table 5. Optimal portfolios minimizing the downside risk with fixed target (Tokyo stock exchange). Results are based on data of 2017, 2018 and 2019, respectively.
3.2. Example 2: following constant target vs. following random target
In this example, we consider the optimal portfolio that minimizes the target shortfall following the stock market index as random targets and compare it with the one following the expected return of the random targets (i.e. fixed targets). We take the same stock data in Example 1. The random targets are the market indices from the same market of the selected 20 stocks. We consider Gaussian model, Student's t model and symmetric variance Gamma model for the underlying stocks and use our explicit solutions to obtain the optimal portfolios. To see the impact of the underlying distribution, the input mean and covariance matrices are set to be the same for the three models for each market.
From Tables , we can observe that following the random target directly or following the expected return of the random target as a fixed target bring different optimal portfolios under the framework of downside risk optimization, and see how the impact of the random target on the optimal portfolio is determined by the its variance and the covariances between the underlying assets and the random target (we will discuss this in Example 3). Despite the identical input of the mean and covariance matrix, different models generate different results, i.e. the estimation risk and the model risk are issues for the downside risk optimization. Particularly, the results based on the SVG model are distinctly different than those of the other two models. Moreover, comparing the Gaussian model and Student's t model, we can see when the degree of free (the parameter of Student's t model) is high, the results under the two models give close optimal portfolio (e.g. the NYSE-2019 and Shanghai-2018 cases); otherwise, the difference can be more significant (the NYSE-2017, the Tokyo-2018, 2019 cases). In this regard, our methodology can be used to account for such estimation risk and model risk precisely. As the explicit solutions are free of computational errors, we can see exactly to what extent the differences could be without the impacts of the numerical errors. Such an advantage is particularly useful when the number of selected stocks and the required sensitivity is high.
Table 6. Optimal portfolios minimizing the downside risk with fixed targets and random targets (market indices). Results are based on the data from the five market in 2017.
Table 7. Optimal portfolios minimizing the downside risk with fixed targets and random targets (market indices). Results are based on the data from the five market in 2018.
Table 8. Optimal portfolios minimizing the downside risk with fixed targets and random targets (market indices). Results are based on the data from the five market in 2019.
3.3. Example 3: the target's impact and the amplitude of the optimal portfolio
We present Example 3 to support our analysis in Section 2.3. Using the same data of Example 1 and 2, we further show that the monotonic relationship between the amplitude, the expected returns, and the target impacts could still hold. The numerical results are in Tables .
Table 9. The amplitude and target impact of optimal portfolios minimizing the downside risk with respect to fixed targets and random targets (market indices). Results are based on data in 2017.
Table 10. The amplitude and target impact of optimal portfolios minimizing the downside risk with respect to fixed targets and random targets (market indices). Results are based on data in 2018.
Table 11. The amplitude and target impact of optimal portfolios minimizing the downside risk with respect to fixed targets and random targets (market indices). Results are based on data in 2019.
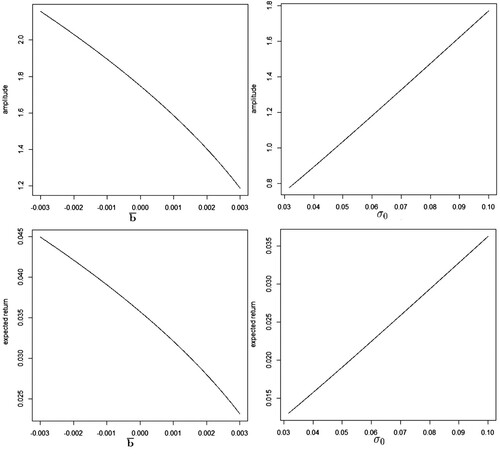
From Tables , we may observe that the numerical results are consistent with our theoretical analysis. When following the market index it generates the higher expected return and the amplitude is the higher too. On the other hand, since the random target is taken as the market index from the same market, it is reasonable to have positive covariances between the underlying assets and the index. This decreases the target impacts. Then, the amplitude, expected returns and target impact are all lowered due to the positive covariances and smaller variances of the indices. In particular, we can observe negative target impacts in this case. As such, the random targets' impact is summarized by a singe scale , and we can use the portfolio amplitude to characterize the optimal portfolio following random targets. If the amplitude of the optimal portfolio is high, then the investor is not only seeking minimal downside risk but also the higher expected returns, which implies more aggressive trading in his/her portfolio. To further demonstrates the monotonicity, we present Figure .
Figure 1. The monotonicity between the expected return, the target impact and the portfolio amplitude.
3.4. Example 4: following random targets when is unknown
In this example, we discuss the downside risk optimization following random target from a different market. We consider two cases using the same data of previous examples in the year of 2019. In particular, in the first case we consider weekly returns of the stocks in NYSE market following the NASDAQ index and the 10-year Treasury bond, respectively. Similarly, we consider weekly returns of stocks in Shanghai stock market following the Tokyo stock market index and the 10-year China government bond, respectively. In both cases, it could be insensible to have direct estimation of between selected stocks and indices ; however, we may assume that the covariances between the stocks and the market index are positive, i.e.
, whilst the covariance between the stocks and the bonds are negative, i.e.
(Singer Citation2010). Then, using our methodology, we can compute the optimal portfolio when
as a bound to decide whether to follow the random target without estimating the covariances.
From Table , we have the optimal portfolio under the downside risk optimization following the random target when is taken as 0. Based on our analysis, such portfolio can be regarded as a bound for investors to decide whether to follow the random targets. For instance, it is reasonable to assume
for stock market index, especially for NASDAQ index as the two markets are both in USA. Then, following the market index should generally result in lower target impact and amplitude than the one in the table. Hence, using Proposition 2.14, we may expect the optimal portfolio following the market index would have lower expected return than the expected returns in the table without knowing the estimation of
. If the investor would like to have minimal target shortfall with higher expected return, then he or she should seek other targets rather than the market index provided in this example. Likewise, we assume negative
between the stocks and the bonds. Then, the optimal portfolios following bonds should have higher expected return than the ones presented in the table. In this regard, our results could explain why investors would construct a stock portfolio following a bond; such investment strategy can have a portfolio that minimizes the target shortfall with respect to the bond and maintains higher expected return simultaneously.
Table 12. Optimal portfolios minimizing the downside risk with random targets when b = 0. Results are based on the data of 2019.
4. Conclusion
Downside risk optimization is an appealing method for portfolio management in both financial and actuarial context. It fits investors' risk averse appetite by minimizing the downside risk and provides flexibility to follow targets based on the investor's preference. In this paper, we derive the explicit solutions to the downside risk optimizations of the first four orders lower partial moments with constant targets. Motivated by the passive portfolio management, we also derive the explicit formulas to the optimal portfolio minimizing the target shortfall with respect to a random target under the multivariate elliptical distributions, and present Gaussian model, Student's t model and symmetric Variance Gamma model as special examples. With some ad hoc assumptions, we analytically prove a mechanism by which the random target influences portfolio selection. In doing so, we propose using portfolio amplitude, as a new measure in the literature, to characterize the impact of following random targets. We present numerical examples based on the data from stock markets across the world to support our theoretical results. In particular, we show that our theoretical analysis could still hold empirically without the ad hoc assumption. Thus, our work in this paper provides new and useful insights into the management of portfolios' downside risk for both financial and actuarial applications. It is our aim to extend the results in this paper to more general models in future research papers.
Acknowledgments
The author wishes to express their indebtedness to the anonymous reviewers and the editor for their many insightful remarks and invaluable comments that helped them improve the paper to a significant extent.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Zinoviy Landsman
Zinoviy Landsman Earned his MA in Probability and Statistics in Tashkent State University (1972) and his PhD in Statistics in Romanovsky Mathematical Institute, Department of Mathematical Statistics, Academy of Sciences of Uzbekistan (1978). He is a professor in University of Haifa (from 2007), and he is now the Director of Actuarial Research Center, University of Haifa and a professor of Holon Institute of Technology, Israel.
Udi Makov
Udi Makov has earned his PhD in Mathematical Statistics from University College London and he is currently a Professor of Statistics at the University of Haifa, Israel.
Jing Yao
Jing Yao obtained his PhD in Economics from Vrije Universiteit Brussel in 2013. He is currently associate professor at Maxwell Institute for Mathematical Science and Heriot-Watt University.
Ming Zhou
Ming Zhou earned his PhD at Nankai University (2006) and did Post-Doctoral Fellow at University of Waterloo (2007). Now he is a Professor in Risk Management and Actuarial Science at Renmin University of China and he is also an Associate (ASA) of Society of Actuaries.
Notes
1 In fact, to completely replicate a market index is possible but costly. A market index often consists of a considerable number of traded assets in the market. Full replication would result in over loaned transaction cost. Moreover, the assets that constitute the market index are not always the same and frequent adaptation is inevitable. Therefore, full replication could be averse for passive portfolio management and many index funds are constructed based on a few selected traded assets (Beasley, Meade, and Chang Citation2003).
2 By contrast, the so-called ‘active’ portfolio management of index tracking is aimed at outperforming the index with frequent trading; see, e.g. Elton, Gruber, and Blake (Citation1995).
3 There is other research strands that study how to invest in the market directly; see for instance (Basak, Shapiro, and Teplá Citation2006).
4 It is usual that one has an additional constraint on the expected return of the portfolio in downside risk optimization, i.e.
where
is the expected returns of
and c is the constant. However, in the context of normal distribution, such optimization has the same optimal solution with the minimization of portfolio variance and has been well-documented in the literature (cf. Corollary 4, Klebaner et al. (Citation2017)). Hence, we focus on (Equation3
(3)
(3) ) in our paper.
5 Note that to ensure that the covariance matrix is positive definite, the components in cannot be identical, i.e.
, where c is a constant.
6 In general, an elliptical distribution does not necessarily has the density function. We focus on the case where the density function exists in this paper.
References
- Basak, S., A. Shapiro, and L. Teplá. 2006. “Risk Management with Benchmarking.” Management Science 52 (4): 542–557.
- Beasley, J. E., N. Meade, and T. J. Chang. 2003. “An Evolutionary Heuristic for the Index Tracking Problem.” European Journal of Operational Research 148 (3): 621–643.
- Cumova, D., and D. Nawrocki. 2014. “Portfolio Optimization in An Upside Potential and Downside Risk Framework.” Journal of Economics and Business 71: 68–89.
- De Franco, C., and P Tankov. 2011. “Portfolio Insurance Under a Risk-Measure Constraint.” Insurance: Mathematics and Economics 49 (3): 361–370.
- DeMiguel, V., L. Garlappi, and R. Uppal. 2009. “Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy?” The Review of Financial Studies 22 (5): 1915–1953.
- Elton, E. J., M. J. Gruber, and C. R Blake. 1995. “Fundamental Economic Variables, Expected Returns, and Bond Fund Performance.” The Journal of Finance 50 (4): 1229–1256.
- French, K. R., and J. M. Poterba. 1991. “Investor Diversification and International Equity Markets (No. w3609).” National Bureau of Economic Research.
- Gharakhani, M., F. Zarea Fazlelahi, and S. J. Sadjadi. 2014. “A Robust Optimization Approach for Index Tracking Problem.” Journal of Computer Science 10 (12): 2450–2463.
- Haberman, S., and E. Vigna. 2002. “Optimal Investment Strategies and Risk Measures in Defined Contribution Pension Schemes.” Insurance: Mathematics and Economics 31 (1): 35–69.
- Harlow, W. V. 1991. “Asset Allocation in a Downside-Risk Framework.” Financial Analysts Journal 47 (5): 28–40.
- Harlow, W. V., and R. K. S. Rao. 1989. “Asset Pricing in a Generalize Mean-Lower Partial Moments Framework: Theory and Evidence.” Journal of Financial and Quantitative Analysis 24: 285–309.
- Klebaner, F., Z. Landsman, U. Makov, and J. Yao. 2017. “Optimal Portfolios with Downside Risk.” Quantitative Finance 17 (3): 315–325.
- Landsman, Z. 2008. “Minimization of the Root of a Quadratic Functional Under a System of Affine Equality Constraints with Application to Portfolio Management.” Journal of Computational and Applied Mathematics 220 (1-2): 739–748.
- Landsman, Z., and J. Nešlehová. 2008. “Stein's Lemma for Elliptical Random Vectors.” Journal of Multivariate Analysis 99 (5): 912–927.
- Landsman, Z., S. Vanduffel, and J. Yao. 2013. “A Note on Stein's Lemma for Multivariate Elliptical Distributions.” Journal of Statistical Planning and Inference 143 (11): 2016–2022.
- Landsman, Z., S. Vanduffel, and J. Yao. 2015. “Some Stein-Type Inequalities for Multivariate Elliptical Distributions and Applications.” Statistics & Probability Letters 97: 54–62.
- Ling, A., J. Sun, and X. Yang. 2014. “Robust Tracking Error Portfolio Selection with Worst-Case Downside Risk Measures.” Journal of Economic Dynamics and Control 39: 178–207.
- Malkiel, B. G., and E. F. Fama. 1970. “Efficient Capital Markets: A Review of Theory and Empirical Work.” The Journal of Finance 25 (2): 383–417.
- Markowitz, H. M. 1987. Mean-Variance Analysis in Portfolio Choice and Capital Markets. Oxford: Blackwell.
- Platanakis, E., and C. Sutcliffe. 2016. “Pension Scheme Redesign and Wealth Redistribution Between the Members and Sponsor: The USS Rule Change in October 2011.” Insurance: Mathematics and Economics69: 14–28.
- Platanakis, E., and C. Sutcliffe. 2017. “Asset–Liability Modelling and Pension Schemes: The Application of Robust Optimization to USS.” The European Journal of Finance 23 (4): 324–352.
- Platanakis, E., C. Sutcliffe, and A. Urquhart. 2018. “Optimal Vs Naïve Diversification in Cryptocurrencies.” Economics Letters 171: 93–96.
- Platanakis, E., C. Sutcliffe, and X. Ye. 2021. “Horses for Courses: Mean-Variance for Asset Allocation and 1/N for Stock Selection.” European Journal of Operational Research 288 (1): 302–317.
- Platanakis, E., and A. Urquhart. 2019. “Portfolio Management with Cryptocurrencies: The Role of Estimation Risk.” Economics Letters 177: 76–80.
- Platanakis, E., and A. Urquhart. 2020. “Should Investors Include Bitcoin in Their Portfolios? A Portfolio Theory Approach.” The British Accounting Review 52 (4): 100837.
- Roman, D., G. Mitra, and V. Zverovich. 2013. “Enhanced Indexation Based on Second-Order Stochastic Dominance.” European Journal of Operational Research 228 (1): 273–281.
- Rudolf, M., H. J. Wolter, and H. Zimmermann. 1999. “A Linear Model for Tracking Error Minimization.” Journal of Banking & Finance 23 (1): 85–103.
- Singer, N. 2010. “Safety-First Portfolio Optimization: Fixed Versus Random Target (No. 113).” Thüen-Series of Applied Economic Theory-Working Paper.
- Zhu, S., D. Li, and S. Wang. 2009. “Robust Portfolio Selection Under Downside Risk Measures.” Quantitative Finance 9 (7): 869–885.
Appendix
Proof to Theorem 2.1.
For i = 1, 2, the proofs can be found in Klebaner et al. (Citation2017). We prove as follows. First note that
(A1)
(A1) and the equation inside the bracket of the right-hand-side is
; thus (EquationA1
(A1)
(A1) ) is increasing at σ. Thus, for a given expected return z, downside risk optimization (Equation2
(2)
(2) ) is equivalent to minimizing
subject to
and
, and the explicit solution is (Landsman Citation2008)
We then need is find the optimal
that determines the optimal weight. To this end, take
. Then, the objective function is
With some tedious calculation, we can show that
is a convex function and has a global minimum at the solution of
. The proof for i = 4 is similar, and we omit it here.
Proof to Theorem 2.2.
By accommodating the notations in (Equation4(4)
(4) ) to Theorem 2.1, we can see Theorem 2.2 follows directly.
Proof to Theorem 2.5.
First note that, for a univariate elliptical random variable ,
where
is the density function of X's standard form, i.e.
, and
. Denoting X's associate as
and using the connection between X and
, i.e.
, we have
It is then easy to verify that
, i.e.
is an increasing function of σ for given μ and K. Thus, similarly with Theorem 2.1, minimising the expected shortfall for given expected return and fixed target has the same solution to minimising the variance for given expected return, and we need to show
is a convex function of c. With some calculation, we can show that
which justify that
is convex and has unique minimum at
. Therefore, we have the theorem holds.
Density function of multivariate Student's t distribution and symmetric Variance Gamma distribution
Student's t distribution:
For , the density function is
In particular, for
the density function is
Symmetric Variance Gamma:
For , the density function is
In particular, for
the density function is
The following Lemma can be easily proved by taking derivatives of the associated functions.
Lemma A.1
The following two statements are true.
Proof to Proposition 2.9.
Due to positive-definite matrices, it holds that ,
and
. Define the equation in (Equation5
(5)
(5) ) as
. It is straightforward to see
is an increasing function based on Theorem 2.2.
For (Equation9(9)
(9) ), note that
and
always hold. Due to the monotonicity of g, we have that (Equation9
(9)
(9) ) is true.
For (Equation10(10)
(10) ), if
, following Lemma A.1, we have
Hence,
. If
thus, again,
, which concludes the proof.
Proof to Theorem 2.11.
We first show that is increasing with respect to
in model (Equation4
(4)
(4) ).
Note that is an implicit function of
according to Equation (Equation5
(5)
(5) ), for which
Theorem 2.2 indicates that
. Thus, we only need to show that
We compute
We can see that
holds because of Proposition 2.9.
Moreover, under the assumption that , we have
, for which
is increasing with respect to a.
Proof to Theorem 2.13.
Note that
With Theorem 2.2, we can rewrite the optimal weights as
(A2)
(A2) where
Let us assume that
and
for some
. Then,
We are able to conclude that
because otherwise
would go negative for large
which cannot be the case. Hence,
is increasing with respect to
.