
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Hedge funds implement elaborate investment strategies that include a variety of positions and assets. As a result, there is significant time variation in the set of risk factors and their respective loadings which in turn introduces severe model risk in any attempt to model and forecast hedge fund returns. In this study, we investigate the statistical and economic value of incorporating heteroscedasticity, non-normality, time-varying parameters, model selection risk and parameter estimation risk jointly in hedge fund return forecasting and fund of funds construction. Parameter estimation risk is dealt with a time-varying parameter structure, while model selection uncertainty is mitigated by model averaging or model selection. We adopt a dynamic model averaging approach along with the conventional Bayesian averaging technique. Our empirical results suggest that accounting for model risk can significantly improve the forecasting accuracy of hedge fund returns and consequently the performance of funds of hedge funds.
1. Introduction
Hedge funds constitute lightly regulated vechicles that promise enchanced performance in all market conditions. To do so, hedge funds employ various sophisticated investment strategies that lead to option-like payoffs and infuse their return distribution with characteristics that differentiate them from traditional asset classes, such as bonds and stocks. Therefore, identifying ways that improve hedge fund return predictability is crucial for optimally defining an investment strategy in hedge funds. To this end, a long list of linear and non-linear risk factors have been proposed, including the Fung and Hsieh asset-based factors, the three Fama-French factors and Carhart's momentum factor, amongst various macroeconomic and financial variables.Footnote1
Predicting hedge funds returns stumbles into obstacles associated with various aspects of model risk. First, there is uncertainty regarding the appropriate set of predictors. This inability of identifying the most appropriate set of factors, or else ‘model uncertainty’, is well established in the traditional asset pricing literature. However, for the hedge funds asset class ‘model uncertainty’ is aggravated by the unique characteristics of their strategies, which call for additional constraints in defining the appropriate set of factors. S. D. Vrontos, Vrontos, and Giamouridis (Citation2008) highlight the magnitude of model uncertainty finding that the posterior probabilities of the ten most probable linear specifications sum to only 18%. Second, hedge fund managers dynamically rebalance their portfolios, thus infusing each factor loading with time-variation, a feature commonly referred to as ‘parameter estimation risk’. Therefore, as stressed by Fung and Hsieh (Citation2004), Fung et al. (Citation2008), Eling and Faust (Citation2010) and Wegener, von Nitzsch, and Cengiz (Citation2010), the parameter estimates and the set of relevant risk factors may change over time. Third, empirical evidence suggests that, due to their characteristics, hedge fund returns exhibit heteroscedasticity, non-normality and fat tails.
To address various sources of model risk, S. D. Vrontos, Vrontos, and Giamouridis (Citation2008) show that a Bayesian Model Averaging approach that accounts for heteroscedasticity improves the pricing of the managers' skills. Similarly, Wegener, von Nitzsch, and Cengiz (Citation2010) employ a specification that recursively excludes the extraneous factors to account for model uncertainty and they use a rolling estimate scheme to account for time variation in parameter estimates. Their results suggest that a non-parametric regression delivers significant gains in returns predictability. From a different perspective, Slavutskaya (Citation2013) employs a panel data approach to overcome the effect of small samples in the estimation process. The author finds an improved out-of-sample accuracy of factor models. Focusing on aggregate data (hedge fund indices), Panopoulou and Vrontos (Citation2015) build on the results of Avramov, Barras, and Kosowski (Citation2013) who find that combining information from single predictor strategies leads to superior selection ability in the presence of inaccurate individual forecasts. Specifically, Panopoulou and Vrontos (Citation2015) account for various model risk sources by implementing a large number of information and forecast combination strategies to unveil significant gains in forecasts accuracy and economic value. Following the respective literature, our paper holds the middle ground between S. D. Vrontos, Vrontos, and Giamouridis (Citation2008) and Panopoulou and Vrontos (Citation2015) as we combine time-varying coefficient models with model averaging/selection schemes and heteroscedastic variance, to account simultaneously for various sources of model risk.
To account for changes in hedge fund strategies, we adopt a time-varying parameter (TVP) model setting with the parameter estimation error assessed by calibrating the posterior distributions of the parameters. Furthermore, to combine or select the most relevant specifications from a set of popular predictors, we utilize the Dynamic Model Averaging (DMA) and Dynamic Model Selection (DMS) methodologies introduced by Koop and Korobilis (Citation2012) in inflation forecasting.Footnote2 Contrary to the simple Bayesian Model Averaging (BMA) methods, the DMA techniques dynamically update the model probability at the end of each period rather than applying a constant model probability.Footnote3 In other words, instead of selecting the appropriate factors, weights are assigned to filtered information (individual forecasts) that arise from the most probable specifications. This approach is in line with the results of Wegener, von Nitzsch, and Cengiz (Citation2010) and Panopoulou and Vrontos (Citation2015), who suggest that reselecting the factors at regular time intervals and combining individual forecasts, respectively, improves accuracy. Another benefit of this approach is that the information update process does not rely on a Markov Chain Monte Carlo (MCMC) algorithm. Therefore, there is a significant decrease in computational time. For all competing specifications, we model the heteroscedasticity of returns via an exponentially weighted moving average (EWMA) approach, to avoid introducing additional estimation risk in our forecasts. Finally, while we do not account directly for the non-normality and excessive kurtosis of returns, any resulting impact on the estimation process is partially treated by the EWMA specification and the non-linear risk factors advocated by Fung and Hsieh (Citation2004) and Agarwal and Naik (Citation2004). To the best of our knowledge, this is the first time that a study addresses all the above issues jointly.
To evaluate the accuracy of our point forecasts, we first forecast the returns of aggregate hedge fund indices and compare the out-of-sample Mean Square Forecasting Error (MSFE) of each competing specification with the MSFE of a simple benchmark autoregressive OLS-AR(1) model. Since gains in point forecast accuracy do not always translate in additional economic value, we assume the position of a risk-averse investor and use utility-based measures to evaluate the economic significance of the gains in forecasting accuracy. In this set-up, the economic evaluation exercise is tantamount to evaluating the predictive density as a whole and not just the point forecasts. Furthermore, we evaluate the performance of our proposed methodology on individual funds by creating hypothetical funds of funds. Our fund selection approach is in line with Agarwal, Green, and Ren (Citation2018), as we focus on the return forecasts instead of chasing past performance in the form of alpha.
As our first contribution, we explore whether our proposed methodology improves the accuracy of point forecasts of hedge fund returns. Our findings suggest that, in terms of point forecast accuracy, simple TVP-AR(1) specifications coupled with heteroscedastic variances can adequately provide significant forecasting improvements. However, when we account for the size of the underlying funds, the BMA, BMS and DMA methods exhibit superior forecasting performance. The negative size-return relationship is well documented in the hedge fund literature. For example, Joenvaara, Kosowski, and Tolonen (Citation2019), Yin and Zhang (Citation2019) and Gao, Haight, and Yin (Citation2019) find that smaller funds yield larger returns. Our findings suggest that the BMA, BMS and DMA models' performance are superior to the TVP-AR(1), once the size-effect is accounted for. Our value weighted indices are more homogeneous compared to the equally weighted ones and driven by a few large size funds. As such, they are more exposed to market factors captured by our predictor list rendering the BMA, BMS and DMA models superior to the simple TVP-AR(1) that does not include any predictors.
Our second contribution builds on the results of the statistical evaluation and investigates whether the forecasting accuracy gains are translated to economic gains. Under the prism of a risk-averse investor, we find that our proposed methods deliver a significantly larger Certainty Equivalent Return (CER) than the benchmark. Our economic evaluation results corroborate the statistical evidence and point towards the superior performance of the TVP specifications coupled with persistent volatility specifications.
Finally, our third contribution emerges from our fund of funds portfolio performance results. Specifically, we find that constructing portfolios based on methods that account for model risk is a superior approach relative to the benchmark. However, these specifications are sensitive to the investor's strategy and the weighting scheme adopted. When we focus on chasing returns, the TVP-AR(1) and DMA methods deliver the best performing portfolios. When we select funds according to the accuracy of forecasts, model averaging/selection methods under mean-variance and mean-CVaR optimization appear superior. Moreover, the crisis evaluation sample highlights the importance of such methods as, depending on the weighting schemes, the TVP and DMA methods select the best performing portfolios.
The rest of the paper is organized as follows: Section 2 describes the forecasting methodologies used in the paper, Section 3 describes the data, and Section 4 presents the empirical results and the predictive ability of the proposed methods. Section 5 presents the portfolio formation strategy and the related findings, while Section 6 concludes.
2. Return prediction models
2.1. Time-varying parameter model
Under the Bayesian framework, the Kalman Filter provides a simple way to recursively forecast the unobservable states (i.e. the coefficients of prediction factors in linear regression models), given new data observations. The normal linear state-space model can be described schematically as a linear regression model with time-varying parameters (Meinhold and Singpurwalla Citation1983; Koop and Korobilis Citation2012). Specifically, the normal linear state-space model is defined as:
(1)
(1)
where
is the hedge fund return at time t,
is the vector of predictors with the first column being 1,
is the vector of coefficients,
is the regression residual of hedge fund returns (with
), and
is the residual of predictive coefficients (with
). The two error terms are assumed to be independent from each other. Equivalently, the above state-space model can be interpreted as a linear hedge fund returns predictive model with time-varying risk exposures
. Contrary to the constant coefficient models, time-varying parameter (TVP) models accommodate the variation of coefficients, by allowing them to vary as new observations are added to the data.
The ordinary Kalman filter begins with the posterior result of parameters that satisfies the following:
(2)
(2)
where
denotes the information set of hedge fund returns from time 0 to time
. Then it proceeds to the following predictive step
(3)
(3)
To simplify the estimation of
, Raftery, Karny, and Ettler (Citation2010) adopt the following approximation
(4)
(4)
where λ acts as a forgetting factor and it is fixed to a number slightly below one (
), so that the coefficients change gradually. Following the model specification, observations that are located m periods in the past would be weighted by
. Raftery, Karny, and Ettler (Citation2010) and Koop and Korobilis (Citation2012) set the forgetting factor to
and
for quarterly data. In the case of
, coefficients evolve relatively slowly, while setting
results in coefficients that are more unstable. For example, when
, the data located at 5 years before time t will receive a weight equal to 80% of the weight assigned to the observation at t−1. However, when
, the respective weight for the observations 5 years ago will be equal to approximately 35% of the weight for the last period observation. To allow for a similar speed of parameter evolution in our monthly dataset we set
for a gradual change to coefficients and
for a more abrupt pattern. In essence, employing the forgetting factors is similar to applying a rolling window regression with a window size of
, which would roughly correspond to rolling window estimations of 20 and 5 years, respectively. The attractive feature of forgetting factors in this context is that they allow controlling the degree of instability in the coefficients. This is important since it is unclear whether rapidly changing coefficients are useful in forecasting as changing coefficients might inflate estimation errors.Footnote4
The important advantage of the simplification in Equation (Equation4(4)
(4) ) is that it eliminates the need to estimate or simulate
. When new data arrives, we proceed to the updating step of the Kalman filter
where
(5)
(5)
In such a set-up, the predictive distribution of returns is given by
(6)
(6)
Therefore, results are analytical, conditional on
, and no MCMC algorithm is required to derive the posterior distribution of parameters and the predictive distribution of hedge fund returns. Hence, there is a significant reduction in computational time. Following Koop and Korobilis (Citation2012), we adopt the Exponentially Weighted Moving Average (EWMA) estimator of
:
(7)
(7)
The above specification suggests that the
forecast, given the information available up to time
, has the following analytical form:
(8)
(8)
where
is the decay factor of the EWMA estimator, which plays a similar role to the forgetting factor λ. We adopt two different values for κ at 0.97 and 0.92, in order to allow for different speeds of decay. The chosen values for the decay factor are guided by RISKMETRICS (Citation1996) who provide an analysis for the specific values and the properties of EWMA estimators in general. Riskmetrics recommend a value of 0.97 for monthly data and 0.94 for daily data. For
, the estimation window roughly corresponds to 150 days (5 months) at a 1% tolerance level, while for the quick decay factor (
), the respective window is 56 days (2 months). Volatility forecasts based on more historical observations (slow decay factor) are smoother than those that rely on fewer data points (fast decay factors). Given that hedge fund returns are quite volatile and exhibit a high degree of heteroscedasticity Giamouridis and Vrontos (Citation2007), we also consider the fast decay factor.
Given all the specifications, the system can be estimated with initial conditions for and
.Footnote5 One important drawback of the TVP model is that the set of predictors remains unchanged throughout time. As a hedge fund manager dynamically adjusts the fund's composition, allowing for time variation of coefficients on a constant set of predictors covers mainly one part of model risk. Implicitly, TVP models can select the most relevant factor by setting its coefficient's value close or equal to zero. However, when the number of selected predictors is large, the problem of in-sample over-fitting is likely to be substantial, which will negatively affect the out-of-sample forecasting performance.
2.2. Model averaging/selection
To account for model uncertainty and time variation of the coefficients, we subject the K possible TVP specifications to model averaging and model selection techniques. This approach is an alternative to combining information via a TVP kitchen sink specification as, instead of focusing on the variables' raw information, it combines the filtered information delivered by each individual forecast. To create forecasts based on the full combination set of the proposed independent variables, we employ the Dynamic Model Averaging (DMA) and Bayesian Model Averaging (BMA) techniques. Contrary to the conventional BMA, the DMA technique allows the weights of each model to evolve dynamically and pays more attention to more recent information.
Consider m potential predictors of hedge funds returns. The model averaging approach evaluates models and predicts the hedge funds returns as:Footnote6
(9)
(9)
where
denotes the predictions made by each candidate model k and
is the predictive probability of model k which also serves as the weight of the forecast made by model k in the prediction result. Unlike the ordinal estimation of
, which requires the estimation of a transition matrix P with
dimensions, Raftery, Karny, and Ettler (Citation2010) replace the model probability prediction equation with
(10)
(10)
where
is a forgetting factor similar to λ in Section 2.1. The approximation is used as it has been shown to be suitable and not too restrictive in other academic areas (Smith and Miller Citation1986; Raftery Citation1995; Koop and Korobilis Citation2012). We assign fixed values close to one, with
to derive the forecasts of the DMA approach. Furthermore, by setting
, we obtain the standard BMA approach. The updated equation of model probability is given as:
(11)
(11)
where
is the predictive density of (Equation6
(6)
(6) ) evaluated conditional on
.
The DMA system is estimated by considering an investor with no preference for specific sources of systemic risk. Hence we select a non-informative prior over the models, i.e. .
In addition to the averaging techniques, we employ the Bayesian Model Selection (BMS) and Dynamic Model Selection (DMS) methods, which predict hedge fund returns by using the forecast of the model with the highest predictive density in each period:
where
denotes the predictions made by the qualified model. Model selection techniques are equivalent to the approach of Wegener, von Nitzsch, and Cengiz (Citation2010), who recursively exclude the non-informative variables to derive the most informative set of factors.Footnote7
2.3. List of prediction models
In our empirical analysis, we employ the OLS-AR(1) model as the benchmark model:
(12)
(12)
The proposed competing models are classified into six categories: DMA, DMS, BMA, BMS, TVP-AR(1) and TVP-ALL models, with different parameter values of α, λ and κ. We estimate 4 different models in each of the DMA, DMS, TVP-AR(1) and TVP-ALL categories, by combining two different values for the time-varying parameters α and λ two different values for the EWMA decay factor κ. Similarly, we estimate 3 different models in each of the BMA and BMS categories, by setting three different values for κ. More specifically, we employ the following models/specifications:
| DMA: | 4 DMA models. Dynamic model averaging over the full combination set of 15 predictors (Number of candidate models | ||||
| DMS: | 4 DMS models. Dynamic model selection models over the full combination set of 15 predictors with time-varying parameter and heteroscedasticity settings identical to the DMA models. | ||||
| BMA: | 2 BMA models. Bayesian model averaging over the full combination set of 15 predictors with constant parameter settings and heteroscedasticity settings equal to (i.e. with forgetting factors) | ||||
| BMS: | 2 BMS models. Bayesian model selection over the full combination set of 15 predictors with constant parameter and heteroscedasticity settings identical to the BMA models. | ||||
| TVP-AR(1): | 4 TVP-AR(1) models with time-varying parameter and heteroscedasticity settings equal to | ||||
| TVP-ALL: | 4 TVP-ALL models. Linear regression models with 15 predictors and AR(1) term with time-varying parameter and heteroscedasticity settings equal to forgetting factors | ||||
3. Data
We obtain data on hedge funds from the BarclayHedge database, with the sample period running from January 1994 to December 2014. The BarclayHedge database reports, among other fields, the monthly returns of hedge funds and a large set of fund-specific characteristics. The initial dataset consists of 6489 alive funds and 16,478 graveyard funds. Consistent with the previous literature, we apply several filters to the original dataset (Avramov et al. Citation2011; O'Doherty, Savin, and Tiwari Citation2015; Joenvaara, Kosowski, and Tolonen Citation2021). First, we keep only funds that are denominated in USD and have Assets Under Management (AUM) greater than $10m. Second, we drop all funds that are closed to new investment and those with non-uniquely listed AUM. These filters result in the final dataset comprising 926 alive funds and 1043 graveyard funds.
In order to mitigate the impact of backfill/selection bias, we exclude the first 12 months of returns data for each fund. Selection bias stems from the fact that hedge funds enter the database voluntarily. Naturally, we would expect that only funds with a good track record would choose to do so, as a means to attract outside investors (Avramov et al. Citation2011). Moreover, since managers are allowed to backfill their fund's past performance, they are unlikely to report poor past performance (O'Doherty, Savin, and Tiwari Citation2015).
We adopt a recursive forecasting scheme, with the in-sample period running until December 2001. This leaves us with an out-of-sample period of 13 years (156 monthly observations). To ensure that sufficient data is available for the estimation period, forecasting starts only when a fund accumulates at least 8 years (96 monthly observations) of historical data. Therefore, after excluding the first 12 months of return data, each fund would need to have at least seven years of data (84 monthly observations) in the estimation period.
We follow Joenvaara, Kosowski, and Tolonen (Citation2021) and classify funds into 11 categories based on their self-reported strategies. These categories are CTA, Emerging Markets, Event Driven, Fund of Funds, Global Macro, Long Only, Long/Short, Market Neutral, Multi-Strategy, Relative Value, Sector. If we exclude Funds of Funds, our final dataset consists of 1388 individual funds (661 alive and 727 graveyard funds). CTA hedge funds engage in managed futures strategies. These funds are directional trend followers by nature and place their bets on the momentum in asset prices. Event-Driven strategies seek investment opportunities based on mispricings surrounding a wide variety of corporate events, such as mergers, acquisitions, bankruptcies, etc. Both Global Macro and Emerging Markets strategies have a broad investment mandate concentrating on the global macroeconomic environment and on emerging markets, respectively. Market Neutral and Long/Short strategies belong to the family of equity hedge strategies. Hedge funds in the Market Neutral strategy take both long and short positions in equity-related securities with the aim to eliminate a fund's exposure to the systematic risk inherent in the overall market. Hedge funds in the Long/Short strategy establish both long and short positions primarily in equity-related securities with the aim to profit from the stock-picking abilities of their managers. On the other hand, Long Only funds take only long positions in undervalued securities reducing downside risk by holding cash and fixed income securities. Sector hedge funds specialize in specific sectors in the economy, mainly energy/basic materials and technology/healthcare. These funds typically hold more than half of their portfolio exposure in a primary sector and attempt to generate profits by identifying pricing opportunities that may not be easily understood by market generalists. Multi-strategy hedge funds engage in a variety of investment strategies in order to deliver consistently positive returns regardless of the directional movement in equity, interest rate or currency markets. The most diverse strategy is the Relative Value one, which targets profit opportunities from risk-adjusted price differentials between financial instruments, such as equity, debt, and derivative securities. Finally, funds of funds invest directly in hedge funds and add value to investors by acting as intermediaries offering access and selection skills to unskilled investors with small net value.
Table Panel A reports the summary statistics of the sample data. The entire sample exhibits negative skewness and excess kurtosis with an average monthly return of 0.72%. The most common trading strategies are Fund of Funds (581 funds) and Equity Long/Short (444 funds). The Fund of Funds category also accounts for the highest proportion of total asset under management ($162.50 billion), followed by Equity Long/Short ($97.89 billion) and CTA ($95.98 billion). Funds in the Emerging Market strategy group earn the highest monthly return (0.91%) and exhibit the highest standard deviation (5.89%), while FoFs earn the lowest monthly return (0.47%) and exhibit the lowest standard deviation (2.02%). Similarly, funds in the Market Neutral strategy group also exhibit a low standard deviation of monthly returns (2.03%). All strategies exhibit negative skewness over the sample period, except for CTA, Global Macro and Market Neutral. Furthermore, the return distributions of all strategies are fat tailed. Panels B and C of Table suggest that alive and graveyard funds have broadly similar profiles, with the possible exception of alive Global Macro funds offering the highest return and alive Market Neutral funds exhibiting the lowest return volatility.
Table 1. Summary statistics of monthly hedge fund returns.
In order to forecast future fund returns, we use a set of factors that are consistent with the existing literature (Amenc, El Bied, and Martellini Citation2003; Agarwal and Naik Citation2004; Fung and Hsieh Citation2004; Wegener, von Nitzsch, and Cengiz Citation2010; I. Vrontos Citation2012; Bali, Brown, and Caglayan Citation2012; Bali, Atilgan, and Demirtas Citation2013; Panopoulou and Vrontos Citation2015). First, we adopt the Fung and Hsieh (Citation2004) asset-based factors, namely bond, currency, commodity, short-term interest rate and stock index lookback straddles. These factors are five trend-following risk factors which are returns on portfolios of lookback straddle options on bonds (BTF), currencies (CTF) commodities (CMTF), short-term interest rates (STITF) and stock indices (SITF) constructed to replicate the maximum possible return on trend-following strategies in their respective underlying assets. Following Fung and Hsieh, we also consider the bond market factor (change in the 10-year bond yield), the return on the S&P 500 index (SP500) and the change in equity implied volatility index (VIX). The next set of factors are related to style investing and to investment policies that incorporate size and value mispricings. Specifically, we employ the HML (High minus Low) and SMB (Small minus Big) Fama–French factors along with the change in the risk free interest rate (3-month T-bill). Accounting for the fact that hedge fund managers might employ trend-following and mean-reversion investment strategies, we also include the Carhart momentum factor. Finally, we include in our set of predictors the annual growth rate of industrial production and the monthly return of the MSCI world index excluding the US.
4. Predictive ability
4.1. Statistical evaluation of forecasts
To assess the predictive ability of each model, we provide a snapshot of the statistical evaluation of self-constructed hedge fund indices on the eleven different trading strategies, namely CTA, Emerging Market (EM), Event Driven(ED), Fund of Funds (FoF), Global Macro (GM), Equity Long Only (LO), Equity Long/Short (LS), Market Neutral (MN), Multi-Strategy (MS), Relative Value (RV), and Sector. Furthermore, to account for possible size effects onto the strategies' return distribution, we perform our analysis for both equal-weighted and value-weighted indices.Footnote8
To measure the forecasting accuracy of each method relative to the benchmark, we employ Theil's U, given by
(13)
(13)
where
is the mean squared forecast error of competing model i over the out-of-sample period, and
is the mean squared forecast error of the benchmark OLS-AR(1) model. A value of Theil's U that is less than 1 indicates superior forecasting accuracy for the competing model relative to the benchmark. Statistical significance is assessed via the Clark and West (Citation2007) test.
Table reports the benchmark's MSFE and the estimated Theil's U of each competing model for each strategy. For the equal weighted case (Table , Panel A), the benchmark's forecasting accuracy differs significantly across the strategies as the reported MSFE ranges from 0.390 for the MN strategy to 12.358 for the LO strategy. Furthermore, we find the benchmark to perform equally well as all the competing methods for the EM strategy, and to surpass the TVP-ALL specifications across all strategies. Turning to the competing methods, we find specifications that improve the forecasting accuracy in almost all strategies. Specifically, we find the TVP-AR(1) family to rank first in eight strategies and to also provide statistically significant results in two strategies, namely FoF and MS. The most notable TVP-AR(1) improvements in MSFE are found in the CTA strategy group, where the ,
specifications show a statistically significant Theil's U of 0.916, 0.915 and 0.912, respectively. Furthermore, we find that TVP-AR(1) delivers the best results for a slower coefficient decay (
) and faster variance decay (
) for five strategies (ED, LO, LS, RV, Sector).
Table 2. Statistical evaluation – Theil's U.
The TVP-AR(1) model does not include any explanatory variables that would potentially absorb the variance dynamics. If the related predictors are not included in the model, a huge portion of unexplained variability is left at the residuals of the process that are modeled through the EWMA process. Since information available to market participants changes with time and is not incorporated in the model (via the mean), variance changes are more abrupt and call for a faster decay factor. On the other hand, for the GM strategy the TVP-AR(1) () specification performs better while for the CTA and MN groups the TVP-AR(1) (
) performs better.
From the GM, CTA, and MN strategies' cross-sectional statistics (Table ), we notice a positive kurtosis while the remaining strategies exhibit negative kurtosis. The positive kurtosis suggests that the variance dynamics depend more on positive deviations from the mean which, in the absence of a leverage effect, do not demand a high decay factor for the variance. Furthermore, CTA and MN comprise a rather small number of funds, which could make them more prone to strategy similarities and/or idiosyncratic characteristics of individual hedge funds return distributions. Hence, in the absence of additional explanatory factors, a low decay parameter () is required. Following the TVP-AR(1) family, the DMA (
) specification ranks first in two strategies (FoF, MS) and also provides statistically significant results in CTA. Furthermore, the BMA, BMS and DMS methods report statistically significant results, but for the ED, GM, LO, LS, MN and Sector strategies, there are no members of the averaging or selection families that significantly outperform the benchmark.
The value weighted results (Table , Panel B) confirm some of the patterns found in the equal weighted case. However, they also highlight specific differences as the impact of the larger funds alters the dynamics of the indices' returns. The benchmark's MSFE increases for the CTA, LO and MN strategies, and decreases for the EM, ED, FoF, LS, MS and RV. Furthermore, we find the benchmark forecasts to perform equally well as the remaining methods for the CTA, LO and EM strategies, and the forecasting accuracy of the DMA/BMA methods to improve in the GM and MN strategy groups. These fluctuations in forecasting accuracy are attributed to the size effects on the strategies that do not enjoy the ‘diversification effect’ of a large number of funds. The value-weighted case indicates that large funds tend to add noise to the returns (CTA) or follow a more homogeneous investment strategy which, when captured by various factors, improves the predictability of their returns (GM, MN). The benchmark's MSFE variation between the weighting schemes verifies this finding as we note a four times increase for the CTA, no significant increase for the GM and a less than two times increase for the MN strategy.
For the competing methods, the TVP-AR(1) specifications remain the most successful ones as they provide the largest statistically significant decrease in four strategies (GM, MN, MS, RV), with the variance persistence parameter set to in all but the MN strategy. The BMS specifications follow, as they rank first in two strategies (ED for
, FoF for
), and also deliver statistically significant results in four (GM, MN, MS, RV), with the consensus on the κ parameter leaning towards 0.92. The BMA ranks first for the LS strategy and also provides significant results in five strategies (ED, GM, MN, MS, RV) for
in all but the GM strategy. The DMA and DMS families' members do not rank first but significantly outperform the benchmark in five (ED, FoF, GM, MN, MS) and three (GM, MN, RV) strategies, respectively. Finally, the TVP-ALL specifications are again found to be consistently outperformed by the benchmark, with Theil's U exceeding 1 in all groups.
Overall, our findings suggest that accounting for model risk leads to distinctive gains in terms of point forecast accuracy. The group of TVP-AR(1) models perform best, followed by BMA models, BMS models and, finally, DMA models. Therefore, time-variant AR(1) coefficient models coupled with heteroscedastic variances provide significant improvements in point forecasts accuracy. This finding is in line with Getmansky, Lo, and Makarov (Citation2004), who argue that illiquidity could be driving the short-term serial correlation in historical hedge fund returns. Accounting for specification risk with (DMA/DMS) or without time-variant probabilities (BMA/BMS) does provide significant gains, especially for the case where the underlying funds follow more homogeneous strategies. Such a result is in line with S. D. Vrontos, Vrontos, and Giamouridis (Citation2008), who find that accounting for specification risk and heteroskedasticity improves the performance of the pricing models significantly, compared to more traditional approaches where the relevant economic factor could be misspecified. Finally, the predictability of point forecast returns seems to benefit more from slow decaying coefficients () and fast decaying variance (
).
4.2. Economic evaluation of forecasts
The statistical evaluation of the proposed methods reveals gains in terms of out-of-sample forecasting accuracy. However, as Leitch and Tanner (Citation1991) suggest, there is a relatively weak relationship between MSFEs and forecast profitability. To assess the economic value of our forecasts, we use profit-based and utility-based measures. Implicitly, such metrics evaluate each method's predictive density performance, under the preferences of a risk averse investor. Therefore, they provide a more direct measure of the forecasts' added value compared to conventional forecast error measures.
Following Campbell and Thompson (Citation2008), Cenesizoglu and Timmermann (Citation2012) and Neely et al. (Citation2014), among others, we measure the economic value of our hedge fund return forecasts via an asset allocation exercise. In more detail, we compute the CER for a mean-variance investor with a portfolio consisting of the risk-free asset and one risky asset (i.e. the hedge fund indices). The optimal solution for the weight of wealth to be invested in the risky asset () in period t + 1 is given by
(14)
(14)
where γ is the relative risk aversion coefficient that reflects the investor's risk appetite,
is the forecast of the hedge fund return, and
is the forecast of its variance. We assume a parameter of risk aversion of
following the extant literature. Specifically, Goetzmann et al. (Citation2007) suggest that the CRSP index is historically optimal for risk aversion levels between 2 and 4, depending on the time period. In general,
is typical for an aggressive investor while
for a conservative investor. Bali, Brown, and Caglayan (Citation2019) set the parameter of risk aversion at
, while Avramov, Barras, and Kosowski (Citation2013) consider a slightly increased relative risk aversion of
. Kandel and Stambaugh (Citation1996), Stambaugh (Citation1999), and Barberis (Citation2000) emphasize the importance of parameter uncertainty in determining the optimal portfolio weights, as historical variation rarely captures the respective uncertainty. To this end, we follow Kandel and Stambaugh (Citation1996) and adopt the variance of the model forecast given by its predictive density. For the benchmark case, we adopt the sample variance since the predictive density of the forecast is not available in non-Bayesian estimation. The optimal weight is subject to the constraints
in order to eliminate short-selling and over-leveraging. Under this specification, the portfolio return over the out-of-sample period
is given by
(15)
(15)
where
denotes the risk-free rate. Following the calculation of the portfolio returns for all the out-of-sample periods, we proceed to calculate the CER of the portfolio as
(16)
(16)
where
and
are the mean and variance, respectively, of the portfolio returns over the out-of-sample period.
Table reports the economic evaluation results. For the case of equal weighted indices (Table , Panel A), the vast majority of the methods outperform the benchmark. Specifically, the MN and CTA strategy groups deliver the highest CER of 151–210 bps and 144–176 bps per month, respectively, whereas LO delivers the lowest maximum CER (around 130bps per month) among all groups. We find the majority of the competing models to significantly outperform the benchmark with, however, small differences between the methods' results. The benchmark proves challenging to outperform in the GM strategy, where only the TVP-AR(1) specification performs better. Overall, the TVP-AR(1) specifications deliver the largest CER in six strategies (CTA, EM, GM, LO, MN, RV) while in ED the reported CER is similar to the best performing one. Furthermore, the dominance of the TVP-AR(1) specification is undisputed only in the MN and RV strategies, where the next best performing family's CER is smaller by approximately nine bps per month (DMA,
) and 24 bps per month (TVP-ALL,
), respectively. Furthermore, we note that the λ parameter does not seem to influence the TVP-AR(1) methods performance since the CERs are similar for the
and
settings.
Table 3. Economic evaluation – CER.
For the rest of the methods, there are members of the DMA, BMA and DMS families whose performance is approximately as good as that of the TVP-AR(1) model. Following the TVP-AR(1) specifications, the DMA methods deliver the largest CER in three strategies (FoF: , LS:
, Sector
), and perform similarly to the best method in three strategies (CTA:
, EM:
, LO:
). Interestingly, the TVP-ALL methods deliver the largest CER in one strategy (ED:
) and similar performance in two (LS:
, Sector:
). Finally, as with the TVP-AR(1) methods, the performance of the best methods depends more on the κ parameter while the α, λ parameters have a minor influence on the CER.
For the value-weighted case (Table Panel B), MN and MS strategies deliver the highest CER of 186–267 bps and 140–252 bps per month, respectively. On the other hand, LO continues to deliver the lowest maximum CER (around 131 bps per month) among all groups. Similar to the statistical evaluation results, the competing models pick up their performance in the GM strategy group, while the ED strategy reports the weakest results. The most significant improvement in terms of CER magnitude is yet again found in the RV strategy, followed by the MS, FoF and Sector strategies. Furthermore, the set of best-performing methods is more heterogeneous as it includes methods from all families. The BMS methods rank first in four strategies (EM: , ED:
, GM:
and LS:
). The DMA methods rank first in three strategies (FoF:
, MS:
and Sector:
), followed by DMS which ranks first in two strategies (CTA:
, MN:
). The TVP-AR(1) specifications produce by far the largest CER in RV (
) and similar CER in three strategies (GM:
, LO:
, LS:
). Finally, TVP-ALL ranks first in one strategy (MS:
).
To sum up, our findings verify the results of the statistical evaluation, as they highlight the gains achieved by accounting for various sources of model risk. Similar to the statistical evaluation results, time variation in the coefficients and heteroscedasticity provide a robust economic added value to our forecasts. Hoverer, when we account for the size of the funds, we find that treating for model uncertainty does indeed improve the asset allocation of a risk averse investor. With respect to the decay parameters settings, we find that the rate of decay of the probability and coefficients add only small value to the forecasts results. On the other hand, the consensus on the variance decay parameter points towards more persistent volatility.
5. Dynamic portfolio construction
5.1. Portfolio construction framework
In this section, we evaluate the performance of the competing methods in forecasting the returns of individual funds via a fund selection and portfolio construction exercise.Footnote9 Common practice in fund selection is to price the funds' abnormal returns and select a portfolio of the best performing ones. This is line with Kosowski, Naik, and Teo (Citation2007) who find that hedge funds that deliver a significant alpha are not just lucky. In our study we follow Panopoulou and Vrontos (Citation2015) and use the out-of-sample predictive densities to select the funds of our portfolio. Using directly the funds' return forecasts, and not their α, is in line with Agarwal, Green, and Ren (Citation2018) who find that investors are either indifferent to the exposures to risk other than than that with respect to the aggregate equity market or they chase them following good performance. Our approach suggests that if the proposed methods deliver more accurate predictive densities, the forecasts will be more successful in identifying the funds that deliver what is expected from them. Hence, a portfolio of such funds should perform better than the benchmark.
Specifically, using the forecasts for each fund over the out-of-sample period Jan 2002–Dec 2014, we select the top-performing funds in two ways. First, we rank the funds according to their return forecasts. In this way we evaluate the ability of the methods to deliver accurate point forecasts for the individual funds. In addition, we follow Avramov, Barras, and Kosowski (Citation2013) and rank the individual funds according to the t-statistics of the forecasts. In this way, we take into account the respective predictive density via point and uncertainty forecasts. These t-statistics are given by
(17)
(17)
where
is the expected hedge fund return in the next period, and
is the standard deviation of the model's return forecast. In all competing models,
is obtained from the predictive density of each forecast. For the benchmark OLS-AR(1) model,
is computed as
(18)
(18)
where
is the observation of predictors (i.e. the constant and the lagged return) at time t, and
is the variance-covariance matrix of the estimated coefficients.
Once the individual funds are ranked, we select the top 30 ones and construct a hypothetical fund of funds by assigning equal, mean-variance and mean-CVaR optimal weights.Footnote10 The mean-variance optimization problem is defined as follows:
(19)
(19)
where
is the expected return of the n-assets portfolio of hedge funds, and
is the variance of the portfolio return. For the variance we have that
where w is the vector which contains the optimal weights
of each fund in the portfolio, and V is the
matrix of sample variance-covariance matrix of fund returns. To account for the non-normalities in the hedge funds returns, we also calculate the mean-CVaR optimal weights. We set the target return equal to
per month, with the upper and lower bounds for
set to [0, 0.1] in order to eliminate short-selling and facilitate diversification (Harris and Mazibas Citation2013; Panopoulou and Vrontos Citation2015). Finally, we perform our analysis for both the full out-of-sample and the crisis period. We assume a holding period of one year in order to simulate the liquidity constraints of the fund of funds. At this point, we note that our goal is to evaluate the ability of the forecasting methods to predict the returns accurately. Hence, we do not consider additional investor constraints in the spirit of Joenvaara, Kosowski, and Tolonen (Citation2019). By doing so, we would have to constrain the investment set pool and therefore invalidate the methods' performance results.Footnote11
5.2. Portfolio performance evaluation criteria
Portfolio performance is evaluated by a set of performance measures. First, we consider the mean realized portfolio return (AR) over the out-of-sample period. Given the weights allocated in each fund across the n-assets portfolio and the realized returns of each fund
, the realized portfolio return at time t + 1 is computed as
(20)
(20)
We also consider the End of Period Value (EPV) measure, which refers to the terminal wealth assuming that we invest 1 unit of wealth at the beginning of the out-of-sample period, and the Fung and Hsieh (Citation2004) 7-factor model α alongside its t-statistic.
Second, we consider various risk-adjusted performance measures, including the Sharpe Ratio (SR), the Sortino ratio and the Upside Potential ratio. The Sharpe Ratio is given by
(21)
(21)
where
denotes the mean realized portfolio return and
denotes the variance of portfolio returns over the out-of-sample period, while
is the expected risk-free rate of return over the period. To match the monthly return data frequency, we adopt the 1-month T-bill rate as a proxy for the risk-free rate.
The Sortino and Satchell (Citation2001) reward to lower partial moment ratio (Sortino ratio) is defined as the excess portfolio return over a threshold value, divided by the standard deviation of negative excessive returns. We use the risk-free rate of return as the threshold value.
(22)
(22)
Sortino, van der Meer, and Plantinga (Citation1999) propose the Upside Potential ratio, which scales the positive excess return of the portfolio (over a threshold return value) with the standard deviation of the negative excess return of the portfolio
(23)
(23)
We also evaluate portfolio performance with the Omega ratio, originally proposed by Keating and Shadwick (Citation2002). The Omega ratio measures performance based on the relationship between positive and negative excess returns, and it can be computed as
(24)
(24)
Finally, we evaluate the tail risk of portfolio returns using the non-parametric historical simulation value-at-risk
. To provide a more concise description of the methods' average ability to select superior portfolios, we average the measures mentioned above for each family of portfolios.
5.3. Top expected returns portfolio performance
Table reports the performance of portfolios constructed on the basis of future expected returns. Overall, our findings for the equal weighted portfolios (Panel A) suggest that the TVP-AR(1) ranks first in AR and EPV, followed by the BMA and DMA portfolios. The benchmark OLS portfolio surpasses the BMS and TVP-ALL portfolios in AR and only the TVP-ALL in terms of EPV. Overall, the difference in average return between the best and worst performing portfolios is about 1.78% per year. A similar ranking is provided by the abnormal returns where the difference between the best performing TVP-AR(1) from the worst performing TVP-ALL is on average around 1.43% per year. Sharpe ratios are quite close for all models ranging from 0.640 (OLS) to 0.779 (TVP-AR(1)). Focusing on the tail of the return's distribution, we find the benchmark to be the riskiest portfolio. At the same time, the TVP-ALL is the least risky one, followed by the BMA and the DMA family. Summarizing the risk and return profiles mentioned above, we find the TVP-AR(1) portfolios to rank first on the basis of all reported measures. The DMA and TVP-ALL portfolios following in the second the third position, respectively, exhibiting similar performance.
Table 4. Out-of-sample performance of top expected return portfolios.
For the mean-variance portfolios (Table Panel B), our results suggest a less risky profile than the equal weighted portfolios, accompanied by reduced returns. We still find the TVP-AR(1) portfolios to rank first in AR, delivering on average 0.983% per month. Following the TVP-AR(1), we have the DMA portfolios offering on average 6 bps less AR than the best-performing ones. The BMA family of portfolios offers about 8 bps less than the best performing portfolios. However, the differences are small for the latter, especially between the TVP-AR(1) and the DMA portfolios. Turning to SRs, we note that these are significantly higher than those of the equal weighted portfolios, exceeding 1 with the exception of the benchmark OLS portfolio. The highest values are attained by BMA (1.250), DMA (1.249) and TVP-AR(1) (1.219). In terms of risk, we find the benchmark portfolio to be the riskiest while the TVP-ALL is the least risky one. The difference between the most and least risky portfolios is about 3.24% in terms of VaR. Following the TVP-ALL portfolios, the BMA portfolios rank the second least risky ones, being about 70 bps on average riskier at the 1% significance level. Turning to the risk-adjusted performance, we find the benchmark portfolio to rank last in each reported measure. In contrast, the BMA and TVP-ALL portfolios outperform the rest with almost equal performance.
For the mean-CVaR portfolios (Table Panel C), we find AR levels to be comparable to the ones from the equal weighted case but with a significantly lower risk profile. In terms of AR, EPV and alpha, the TVP-AR(1) portfolios rank first, the DMA rank second, while the TVP-ALL portfolios rank last. Contrary to the previous cases, the differences between the best and worst performing portfolios are almost 3.08% in AR and 2.86% in abnormal returns per year. Furthermore, in terms of SR, the BMA, DMA, and TVP-AR(1) portfolios are the best performing portfolios with values ranging from 1.219 to 1.250. Our VaR results suggest that the BMA portfolios are the least risky ones, followed by the DMA and TVP-ALL portfolios. The combined effect of the risk-return profile qualifies the BMA, DMA, and TVP-AR(1) portfolios as the best performing portfolios, on average, with practically equal performance.
5.4. T-stat portfolio performance
Table reports the results of portfolios constructed based on the t-statistics of the models' forecasts. We find a significant reduction of the risk and the return levels compared to the top expected return portfolios. For the equal weighted case (Table Panel A), we find the TVP-ALL portfolios to outperform the rest of the portfolios in all AR, EPV and alpha measures, while the benchmark portfolio ranks last. Interestingly, the benchmark ranks first in t-stat, a results that points to least volatile returns. Focusing on the risk profile of the portfolios, we find the TVP-AR(1) portfolios to be the least risky, followed by the BMA. On the other hand, DMS portfolios are the riskiest while the TVP-ALL ones are the second riskiest family of portfolios. Such profiles lead to the TVP-AR(1) portfolios to rank first according to the SR, with the benchmark portfolio ranking second. However, for the Omega and Sortino ratio, we find the second place captured by the DMA portfolios, which then drop third after TVP-AR(1) and TVP-ALL according to upside potential.
Table 5. Out-of-sample performance of top t-statistics portfolios.
For the mean-variance portfolios (Table Panel B), DMA and BMA portfolios rank first and second for AR, EPV and alpha measures, respectively. Similar to the previous cases, the benchmark portfolio ranks last in the returns' performance measures. Interestingly, we find the TVP-ALL portfolios to be the least risky ones while surpassing the DMS and the benchmark in AR. On the other hand, we find the benchmark portfolio to be the riskiest one, followed by the DMS portfolios. The remaining portfolios are, on average, on the same levels of risk. Turning to the risk-adjusted performance, we find that on the basis of SR, the BMA, BMS and TVP-ALL portfolios provide a rather similar return-to-risk reward with improved performance relative to the equal weighted and expected returns cases. Specifically, the respective SRs are all greater than 1.65. According to the Omega ratio, BMA and BMS portfolios provide the superior profile, while the TVP-ALL performance slightly declines. Finally, the downside risk-oriented Sortino ratio and Upside potential point towards the TVP-ALL portfolios ranking first.
For the mean-CVaR portfolios (Table Panel C), we find the DMA portfolios to rank first in all return performance measures, followed by the BMA portfolios. On the other hand, the benchmark portfolio ranks last. Focusing on the risk profile of the portfolios, we find the range of the reported VaR to be similar to the previously mentioned mean-variance portfolios. DMA portfolios rank above the median of the reported VaR, with the BMA ones ranking as the least risky portfolios. As expected, the benchmark is the riskiest one. The risk-adjusted performance measures suggest that the DMA and the BMA portfolios offer the first and second-best SR and Omega, respectively. In contrast, according to the upside potential, DMA and TVP-AR(1) portfolios rank in the top with almost equal performance, while the BMA portfolios rank third, with slightly inferior performance.
5.5. 2007–2009 crisis
In order to assess the competing models' performance in volatile market conditions, we re-evaluate our portfolios during the global financial crisis period (Jan 2007–Dec 2009). Portfolios for this period are first constructed at the end of 2006 and rebalanced at the end of each year. We report the results in Tables -7. For the equal weighted portfolios (Table Panel A), we find the TVP-AR(1) portfolios to rank first in AR, offering almost 36 bps over the worse performing benchmark portfolio. BMA portfolio ranks second, while the remaining families of portfolios seem to provide similar results. Similar patterns are reported for the EPV and alpha measures, while the TVP-AR(1) portfolios are the only ones providing positive but statistically insignificant abnormal returns. In terms of risk, we find the TVP-ALL portfolios to be the least risky ones while the benchmark registers as the riskiest one. Such profiles pave the way for the TVP-AR(1) portfolios to rank first in all risk-adjusted performance measures while the benchmark portfolios rank last.
Table 6. Crisis period – out-of-sample performance of top expected return portfolios.
For the mean-variance portfolios (Table Panel B), we find the TVP-AR(1) portfolios rank first once again, with the BMA portfolio ranking second in both AR and EPV. We also find the families of TVP-AR(1) and BMA portfolios to provide non-negative abnormal returns. The reported VaR suggests that both the TVP-ALL and BMA have, on average, a thinner left tail against the competing portfolios. As expected, the benchmark portfolio ranks as the riskiest one, with the difference from the least risky portfolios exceeding 13% per year. Focusing on the risk-adjusted performance, we cannot select a specific family of portfolios that dominates the rest according to all reported measures. For instance, the BMA portfolios rank first in SR and Sortino ratio, followed by the TVP-AR(1) and the TVP-ALL. However, according to the Upside potential, TVP-ALL ranks first, followed by the TVP-AR(1) and the BMA, with the difference in performance between the latter two families of models quite small. Finally, according to Omega, the BMA portfolios rank first, with the TVP-AR(1) portfolios second best and the TVP-ALL ranking third.
For the mean-CVaR portfolios (Table Panel C), the AR, EPV and alpha measures suggest that the TVP-AR(1) portfolios rank first, with the DMA and BMA portfolios following and the benchmark ranking last. On the other hand, the VaR results suggest that the BMA is the least risky portfolio, followed by the DMA and the TVP-ALL. The benchmark portfolio ranks last, with the difference from the least risky portfolios being equal to almost 11% per year. Finally, according to the risk-adjusted performance results, we find the TVP-AR(1) portfolios to outperform the rest for all categories of measures. However, the performance differences from the overall second best-performing family of DMA portfolios are relatively small.
The results for the equal weighted case of the portfolios created on the basis of their t-stat (Table Panel A) suggest that according to AR, the TVP-ALL portfolios rank first, followed by the DMA portfolios. The AR differential between the best and worst performing (OLS) portfolios is around 3.8% per year. The respective differential between the second-best performing family of portfolios and the benchmark is almost 2.5% per year. Similar rankings are reported by the EPV and alpha measures. Interestingly, the benchmark portfolio delivers the smallest 1% VaR followed by the TVP-ALL. The DMA portfolios surpass only the BMA, BMS and DMS portfolios in terms of risk. Turning to the risk-adjusted performance, we find the benchmark portfolio ranking last according to the SR and Omega measures. However, for the Sortino and the Upside potential, we find the benchmark to perform better than the DMS portfolios, which now rank last. Overall, the TVP-ALL portfolios dominate the portfolios as they rank first according to all risk-adjusted measures, followed closely by the DMA portfolios.
Table 7. Crisis Period -Out-of-sample performance of top t-statistics portfolios.
For the mean-variance portfolios (Table Panel B), we once again find the TVP-ALL portfolios to rank first in terms of the AR, EPV and alpha while TVP-AR(1) and BMS portfolios follow with similar performance. However, for the latter two, the t-stat suggests that the TVP-AR(1) portfolios' returns are significantly less volatile than the BMS ones. This finding is also evident in the VaR results where the second least risky TVP-AR(1) portfolios report a VaR estimate about 1.54% lower than the third least risky BMS portfolios. The TVP-ALL portfolios are the least risky ones, while the benchmark portfolio reports the largest 1% VaR, about 6.34% higher than the best performing one. As expected, the best risk-adjusted performance is dominated by the TVP-ALL portfolios, which rank first according to all reported measures. However, contrary to the previously reported results, the TVP-ALL portfolio performs significantly better than the competing portfolios. For instance, the difference in the Sortino Ratio between the TVP-ALL and the TVP-AR(1) is 42 bps per unit of semi deviation.
Finally, for the mean-CVaR portfolios (Table Panel B), the DMA portfolios rank first in AR, EPV and alpha. In contrast, the BMA and TVP-AR(1) portfolios follow in the rankings but with negligible differences in their performance. Focusing on the reported VaR measure, we find the TVP-AR(1) portfolios to rank first as the least risky portfolios, while the benchmark ranks last followed closely by the BMA portfolios. The TVP-AR(1) portfolios dominate the risk-adjusted performance as they rank first in each reported measure. Contrary to the mean-variance case, the difference from the second-best DMA portfolios is not as pronounced. For instance, we find the difference in Sortino ratios to be around 15 bps per unit of semi deviation, while the respective difference from the overall third best BMA portfolios is 22 bps per unit of semi deviation.
5.6. Portfolio composition
Figures and present the portfolio compositions of selected models at four different rebalancing points, namely in January 2002, January 2006, January 2009 and January 2013. The models we present are the OLS-AR(1), BMA, DMA and TVP-AR(1). In portfolios formed based on expected returns, Equity Long/Short and CTA strategies account for the highest proportion of selected funds, followed by Sector and Emerging Market strategies. There is also an increasing trend of selecting CTA funds and a decreasing trend of selecting LS and Sector funds across the sample period.
Figure 1. Optimal portfolio composition (expected returns).
Note: The figure shows the composition of portfolios selected based on the forecasted expected value of fund returns in Jan 2002, Jan 2006, Jan 2009 and Jan 2013. Selected models are OLS-AR(1) BMA, DMA and TVP-AR(1).
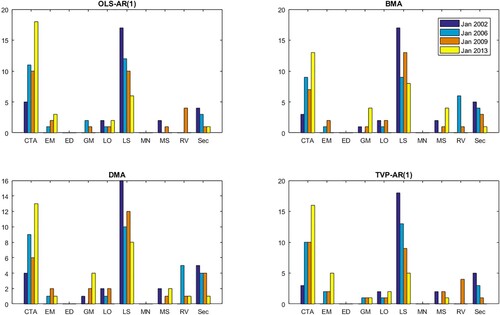
Figure 2. Optimal portfolio composition (t-statistics).
Note: The figure shows the composition of portfolios selected based on t-statistics of expected returns in Jan 2002, Jan 2006, Jan 2009 and Jan 2013. Selected models are OLS-AR(1), BMA, DMA and TVP-AR(1).
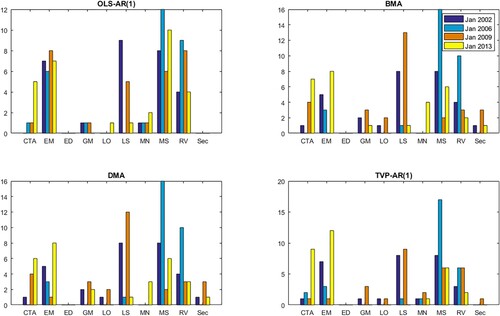
Regarding the portfolios formed based on the forecasts' t-statistics, funds with MS, EM and RV strategies are selected the most. Portfolios selected based on t-statistics are more diversified compared to the portfolios based on expected returns. Interestingly, the ED strategy received a zero weight in all four models, whereas the Sector strategy received a zero weight in the OLS-AR(1) model, but non-zero weights in the other four models. Portfolio composition of the BMA and DMA models seems to show a high degree of similarity when selected based on t-statistics. Finally, the Equity Long/Short strategy attracted a very substantial amount of investment in the crisis period (January 2009). Overall, taking into account model uncertainty in hedge fund return forecasts and portfolio construction is found to lead to a greater degree of diversification when selecting among different trading strategies, compared against the benchmark OLS-AR(1) model. This finding is indicative of the ability of the competing methods to identify the best performing funds from each strategy.
6. Conclusion
In this paper, we jointly investigate the statistical and economic value of incorporating various sources of model risk in forecasting hedge funds returns. Specifically, using an EWMA approach to account for returns' heteroscedasticity, we address parameter uncertainty by applying a time-varying parameter structure while we account for model uncertainty by dynamic model averaging/selection approaches. Our empirical results show that treating for the various sources of model risk significantly improves the forecast accuracy and portfolio performance for both aggregate and fund level returns.
The proposed methods lead to a statistically significant increase in forecast accuracy, as measured by the MSFE, compared to the benchmark OLS-AR(1) model. Specifically, the simplest TVP-AR(1) specification produces the most robust results across the aggregate indices data. However, when we account for the size of underlying funds, we find an increase in the accuracy of the DMA/BMA forecasts. These findings highlight the heterogeneity of the hedge funds investment strategies, which shrinks when we take into account the funds' size. Concerning the decay parameters settings, our results suggest that accuracy benefits more from less persistent volatility, while the coefficients and probability decay rates do not seem to affect the MSFE results significantly.
In the same vein, the economic evaluation results reveal substantial gains from the proposed methods. Furthermore, under the prism of a risk-averse investor, the magnitude of gains is significantly larger than what the statical evaluation suggests. These increased gains are due to the methods' ability to model future uncertainty better than the historical variance of the benchmark. Overall, our findings suggest that TVP-AR(1) specifications provide the most significant gains, while the size effect highlights the need to consider model uncertainty via BMS and DMA specifications. However, a more persistent variance setting is preferable.
Focusing on the individual funds' forecasts, we find that the majority of the competing models select portfolios that significantly outperform the benchmark in average returns and risk-adjusted performance for both evaluation samples. These results provide further support for our approach since we demonstrate that proposed methods provide economic gains by capturing more accurately the predictive density of hedge fund returns.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Christos Argyropoulos
Christos Argyropoulos received his PhD degree in Finance from the University of Kent, United Kingdom, in 2018. He is a Lecturer (Assistant Professor) in Finance at Essex Business School, University of Essex, UK. He has published in various academic journals in the areas financial time series modelling and forecasting.
Ekaterini Panopoulou
Ekaterini Panopoulou received her PhD degree in Financial Econometrics from the University of Piraeus, Greece, in 2004. She is a Professor of Finance at Essex Business School, University of Essex, UK. She has published in various academic journals in the areas of financial econometrics, time series modelling and forecasting.
Nikolaos Voukelatos
Nikolaos Voukelatos received his PhD in Finance from Lancaster University, UK in 2009. He is a Senior Lecturer in Finance at Kent Business School, University of Kent, UK. He has published in various academic journals in the areas of options, implied information, and asset pricing.
Teng Zheng
Teng Zheng received her PhD degree in Finance from the University of Kent, UK, in 2018. Her thesis topic is “Model Risk in Financial Modelling”. She is currently a VP of the Independent Validation Unit in the Barclays Bank PLC.
Notes
1 This article represents the views and analysis of the author only and it should not be taken to represent those of her current employer.
1 Key references of this strand of literature include Fung and Hsieh (Citation2001, Citation2004), Agarwal and Naik (Citation2004), Kosowski, Naik, and Teo (Citation2007), Bali, Gokcan, and Bing (Citation2007), Fung et al. (Citation2008), Jagannathan, Malakhov, and Nomikov (Citation2010), Sadka (Citation2010), Avramov et al. (Citation2011), Bali, Brown, and Caglayan (Citation2011, Citation2012, Citation2014), Buraschi, Kosowski, and Sritrakul (Citation2014) and Agarwal, Arisoy, and Naik (Citation2017).
2 The method has been applied recently in several financial research areas, including gold or copper prices forecasting (Aye et al. Citation2015; Buncic and Moretto Citation2015; Baur, Beckmann, and Czudaj Citation2016); house prices forecasting (Bork and Moller Citation2015; Risse and Kern Citation2016), bond portfolio strategies selection (Caldeira, Moura, and Santos Citation2016); stock return forecasting and portfolio construction (Pettenuzzo and Ravazzolo Citation2016).
3 BMA and BMS specifications are a special case of the DMA and DMS methodologies.
4 Baur, Beckmann, and Czudaj (Citation2016) employ three forgetting factors in forecasting monthly gold returns and find that DMA or DMS with forgetting factors of at least 0.95 provide more accurate forecasts compared to less flexible alternatives such as BMA or DMA with a forgetting factor fixed to unity, i.e. no forgetting. However, the authors show that a fast rate of forgetting produces instantaneous jumps of the estimated parameters and the posterior predictive model probabilities, which inflates the forecast errors. To this end, they suggest comparing results emerging from the implementation of various forgetting factors. Drachal (Citation2016) focuses on monthly spot oil prices and estimates a total of 121 DMA models based on all combinations of forgetting factors
. The author finds that all DMA models with equal forgetting factors except for the one with
produce larger forecast errors than the naïve forecasting benchmark model. Wang et al. (Citation2016) consider time-varying parameter models to forecast the realized volatility of the S&P 500 index using the heterogeneous autoregressive models for realized volatility. In their experiment, they consider DMA with
along with constant coefficient models and find that time-varying parameter models have greater forecasting accuracy than models that use constant coefficients. Finally, Catania, Grassi, and Ravazzolo (Citation2019) focus on the predictability of cryptocurrency time series and compare several alternative univariate and multivariate models for point and density forecasting using a forgetting factor of 0.99 in their baseline experiment.
5 Following Koop and Korobilis (Citation2012), we set and
.
6 This case refers to linear combinations of predictors.
7 We also considered simple combination schemes, such as the mean, median, trimmed mean. Our results, available from the authors upon request, point to superiority of our time-varying approaches.
8 Joenvaara, Kosowski, and Tolonen (Citation2019), Yin and Zhang (Citation2019), Gao, Haight, and Yin (Citation2019) find that smaller funds yield larger returns. Gao, Haight, and Yin (Citation2019) attribute the recorded performance decline to the diseconomies of scale of large size funds.
9 To address any selection/survival bias, we include in our investment opportunity set both alive and graveyard funds. Graveyard data are sourced from the graveyard database of BarclayHedge. We apply identical data filters as stated in Section 3. All graveyard return series are required to have at least five years of in-sample data prior to 2009, but less than six years of out-of-sample data, depending on when the fund exited the database. This approach results in 395 graveyard funds, post-filtering. Finally, we exclude Funds of Funds from the exercise.
10 The literature hints on the number of funds a FoF typically holds. Specifically, Brown, Gregoriou, and Pascalau (Citation2012) study diversification within FoFs and find that the diversification benefits are maximized when the FoF invests in at most 20 funds. Moreover, they find that adding more funds to the portfolio increases left tail risk and lowers returns. Lhabitant (Citation2006) indicates that the typical number is about 40, while Avramov, Barras, and Kosowski (Citation2013) argue that there is a practical limit to the number of individual funds held by funds of funds and limit the minimum and maximum number of funds in the portfolio to 25 and 75, respectively.
11 Joenvaara, Kosowski, and Tolonen (Citation2019) suggest that realistic investor constraints, such as investors' liquidity constraints, can significantly reduce the recorded performance of hedge funds. While such constraints are essential from the perspective of performance persistence, in our paper we focus on the informational advantage of the proposed specifications and whether such methods could extract performance increments compared to a naïve AR(1) benchmark. Applying the complete set of investor constraints in the spirit of Joenvaara, Kosowski, and Tolonen (Citation2019), in conjunction with our sample size and the data intensity of the suggested specifications, could lead to small sample or selection biases, as the pool of funds in our database would decrease significantly for the most realistic cases. Nevertheless, to emulate broadly such constraints, we impose a one-year rebalancing scheme for our theoretical fund of hedge funds portfolios. By doing so, we restrict our investor to be committed to her selection of funds for the whole year, regardless of a fund offering smaller lock up and redemption periods. Hence, while our portfolios may not be entirely realistic in terms of investors' behavior and practices, they provide a consistent platform for evaluating the proposed portfolios against a similarly defined AR(1) benchmark portfolio.
References
- Agarwal, V., Y. E. Arisoy, and N. Y. Naik. 2017. “Volatility of Aggregate Volatility and Hedge Fund Returns.” Journal of Financial Economics 125: 491–510.
- Agarwal, V., T. Green, and H. Ren. 2018. “Alpha Or Beta in the Eye of the Beholder: What Drives Hedge Funds Flows.” Journal of Financial Economics 127: 417–434.
- Agarwal, V., and N. Y. Naik. 2004. “Risks and Portfolio Decisions Involving Hedge Funds.” Review of Financial Studies 17: 63–98.
- Amenc, N., S. El Bied, and L. Martellini. 2003. “Predictability in Hedge Fund Returns.” Financial Analysts Journal 59: 32–46.
- Avramov, D., L. Barras, and R. Kosowski. 2013. “Hedge Fund Return Predictability Under the Magnifying Glass.” Journal of Financial and Quantitative Analysis 48: 1057–1083.
- Avramov, D., R. Kosowski, N. Y. Naik, and M. Teo. 2011. “Hedge Funds, Managerial Skill, and Macroeconomic Variables.” Journal of Financial Economics 99: 672–692.
- Aye, G., R. Gupta, S. Hammoudeh, and W. J. Kim. 2015. “Forecasting the Price of Gold Using Dynamic Model Averaging.” International Review of Financial Analysis 41: 257–266.
- Bali, T., Y. Atilgan, and O. Demirtas. 2013. Investing in Hedge Funds: A Guide to Measuring Risk and Return Characteristics. Massachusetts, MA: Academic Press.
- Bali, T. G., S. J. Brown, and M. O. Caglayan. 2011. “Do Hedge Funds' Exposures to Risk Factors Predict Their Future Returns?.” Journal of Financial Economics 101: 36–68.
- Bali, T. G., S. J. Brown, and M. O. Caglayan. 2012. “Systematic Risk and the Cross Section of Hedge Fund Returns.” Journal of Financial Economics 106: 114–131.
- Bali, T. G., S. J. Brown, and M. O. Caglayan. 2014. “Macroeconomic Risk and Hedge Fund Returns.” Journal of Financial Economics 114: 1–19.
- Bali, T. G., S. J. Brown, and M. O. Caglayan. 2019. “Upside Potential of Hedge Funds As a Predictor of Future Performance.” Journal of Banking and Finance 98: 212–229.
- Bali, T., S. Gokcan, and L. Bing. 2007. “Value At Risk and the Cross-section of Hedge Fund Returns.” Journal of Banking and Finance 31: 1135–1166.
- Barberis, N. 2000. “Investing for the Long Run when Returns are Predictable.” The Journal of Finance55: 225–264.
- Baur, D. G., J. Beckmann, and R. Czudaj. 2016. “A Melting Pot – Gold Price Forecasts Under Model and Parameter Uncertainty.” International Review of Financial Analysis 48: 282–291.
- Bork, L., and S. V. Moller. 2015. “Forecasting House Prices in the 50 States Using Dynamic Model Averaging and Dynamic Model Selection.” International Journal of Forecasting 31: 63–78.
- Brown, S. J., G. N. Gregoriou, and R. Pascalau. 2012. “Diversification in Funds of Hedge Funds: Is it Possible to Overdiversify?.” The Review of Asset Pricing Studies 2 (1): 89–110.
- Buncic, D., and C. Moretto. 2015. “Forecasting Copper Prices with Dynamic Averaging and Selection Models.” The North American Journal of Economics and Finance 33: 1–38.
- Buraschi, A., R. Kosowski, and W. Sritrakul. 2014. “Incentives and Endogenous Risk Taking: A Structural View on Hedge Fund Alphas.” The Journal of Finance 69: 2819–2870.
- Caldeira, J. F., G. V. Moura, and A. A. Santos. 2016. “Bond Portfolio Optimization Using Dynamic Factor Models.” Journal of Empirical Finance 37: 128–158.
- Campbell, J. Y., and S. B. Thompson. 2008. “Predicting Excess Stock Returns out of Sample: Can Anything Beat the Historical Average?.” Review of Financial Studies 21: 1509–1531.
- Catania, L., S. Grassi, and F. Ravazzolo. 2019. “Forecasting Cryptocurrencies Under Model and Parameter Instability.” International Journal of Forecasting 35 (2): 485–501.
- Cenesizoglu, T., and A. Timmermann. 2012. “Do Return Prediction Models Add Economic Value?.” Journal of Banking and Finance 36: 2974–2987.
- Clark, T. E., and K. D. West. 2007. “Approximately Normal Tests for Equal Predictive Accuracy in Nested Models.” Journal of Econometrics 138 (1): 291–311.
- Drachal, K. 2016. “Forecasting Spot Oil Price in a Dynamic Model Averaging Framework–Have the Determinants Changed Over Time?.” Energy Economics 60: 35–46.
- Eling, M., and R. Faust. 2010. “The Performance of Hedge Funds and Mutual Funds in Emerging Markets.” Journal of Banking and Finance 34: 1993–2009.
- Fung, W., and D. A. Hsieh. 2001. “The Risk in Hedge Fund Strategies: Theory and Evidence From Trend Followers.” The Review of Financial Studies 14: 313–341.
- Fung, W., and D. A. Hsieh. 2004. “Hedge Fund Benchmarks: A Risk-based Approach.” Financial Analysts Journal 60: 65–80.
- Fung, W., D. A. Hsieh, N. Y. Naik, and T. Ramadorai. 2008. “Hedge Funds: Performance, Risk, and Capital Formation.” The Journal of Finance 63: 1777–1803.
- Gao, C., T. D. Haight, and C. Yin. 2019. Size, Age, and the Performance Life Cycle of Hedge Funds. Working Paper.
- Getmansky, M., A. W. Lo, and I. Makarov. 2004. “An Econometric Model of Serial Correlation and Illiquidity in Hedge Fund Returns.” Journal of Financial Economics 74: 529–609.
- Giamouridis, D., and I. D. Vrontos. 2007. “Hedge Fund Portfolio Construction: A Comparison of Static and Dynamic Approaches.” Journal of Banking and Finance 31 (1): 199–217.
- Goetzmann, W., J. Ingersoll, M. Spiegel, and I. Welch. 2007. “Portfolio Performance Manipulation and Manipulation-proof Performance Measures.” Review of Financial Studies 20: 1503–1546.
- Harris, R. D., and M. Mazibas. 2013. “Dynamic Hedge Fund Portfolio Construction: A Semi-parametric Approach.” Journal of Banking and Finance 37: 139–149.
- Jagannathan, R., A. Malakhov, and D. Nomikov. 2010. “Do Hot Hands Exist Among Hedge Fund Managers? An Empirical Evaluation.” The Journal of Finance 65: 217–255.
- Joenvaara, J., R. Kosowski, and P. Tolonen. 2019. “The Effect of Investment Constraints on Hedge Fund Investor Returns.” Journal of Financial and Quantitative Analysis 54: 1539–1571.
- Joenvaara, J., R. Kosowski, and P. Tolonen. 2021. “Hedge Fund Performance: are Stylized Facts Sensitive to which Database One Uses?.” Critical Finance Review 10: 271–327.
- Kandel, S., and R. F. Stambaugh. 1996. “On the Predictability of Stock Returns: An Asset-allocation Perspective.” The Journal of Finance 51: 385–424.
- Keating, C., and W. F. Shadwick. 2002. “A Universal Performance Measure.” Journal of Performance Measurement 6: 59–84.
- Koop, G., and D. Korobilis. 2012. “Forecasting Inflation Using Dynamic Model Averaging.” International Economic Review 53: 867–886.
- Kosowski, R., N. Y. Naik, and M. Teo. 2007. “Do Hedge Funds Deliver Alpha? A Bayesian and Bootstrap Analysis.” The Journal of Financial Economics 84: 229–264.
- Leitch, G., and J. E. Tanner. 1991. “Economic Forecast Evaluation: Profits Versus the Conventional Error Measures.” American Economic Review 81: 580–590.
- Lhabitant, F. S. 2006. Handbook of Hedge Funds. London: John Wiley & Sons.
- Meinhold, R. J., and N. D. Singpurwalla. 1983. “Understanding the Kalman Filter.” The American Statistician 37: 123–127.
- Neely, C. J., D. E. Rapach, J. Tu, and G. Zhou. 2014. “Forecasting the Equity Risk Premium: the Role of Technical Indicators.” Management Science 60: 1772–1791.
- O'Doherty, M. S., N. E. Savin, and A. Tiwari. 2015. “Evaluating Hedge Funds with Pooled Benchmarks.” Management Science 62: 69–89.
- Panopoulou, E., and S. Vrontos. 2015. “Hedge Fund Return Predictability; to Combine Forecasts Or Combine Information?.” Journal of Banking and Finance 56: 103–122.
- Pettenuzzo, D., and F. Ravazzolo. 2016. “Optimal Portfolio Choice Under Decision-based Model Combinations.” Journal of Applied Econometrics 31: 1312–1332.
- Raftery, A. E. 1995. “Bayesian Model Selection in Social Research.” Sociological Methodology 25: 111–164.
- Raftery, A. E., M. Karny, and P. Ettler. 2010. “Online Prediction Under Model Uncertainty Via Dynamic Model Averaging: Application to a Cold Rolling Mill.” Technometrics 52: 52–66.
- RISKMETRICS. 1996. “Technical Document–Fourth Edition.” http://www.riskmetrics.com/system/files/private/td4e.pdf.
- Risse, M., and M. Kern. 2016. “Forecasting House-price Growth in the Euro Area with Dynamic Model Averaging.” North American Journal of Economics and Finance 38: 70–85.
- Sadka, R. 2010. “Liquidity Risk and the Cross-Section of Hedge-Fund Returns.” Journal of Financial Economics 98: 54–71.
- Slavutskaya, A. 2013. “Short-term Hedge Fund Performance.” Journal of Banking and Finance 37: 4404–4431.
- Smith, R., and J. Miller. 1986. “A Non-gaussian State Space Model and Application to Prediction of Records.” Journal of the Royal Statistical Society. Series B (Methodological) 48: 79–88.
- Sortino, F. A., and S. Satchell. 2001. Managing Downside Risk in Financial Markets. Oxford, UK: Butterworth- Heinemann.
- Sortino, F. A., R. van der Meer, and A. Plantinga. 1999. “The Dutch Triangle.” The Journal of Portfolio Management 26: 50–57.
- Stambaugh, R. F. 1999. “Predictive Regressions.” Journal of Financial Economics 54: 375–421.
- Vrontos, I. 2012. “Evidence for Hedge Fund Predictability From a Multivariate Student's T Full-Factor Garch Model.” Journal of Applied Statistics 39: 1295–1321.
- Vrontos, S. D., I. D. Vrontos, and D. Giamouridis. 2008. “Hedge Fund Pricing and Model Uncertainty.” Journal of Banking and Finance 32: 741–753.
- Wang, Y., F. Ma, Y. Wei, and C. Wu. 2016. “Forecasting Realized Volatility in a Changing World: A Dynamic Model Averaging Approach.” Journal of Banking and Finance 64: 136–149.
- Wegener, C., R. von Nitzsch, and C. Cengiz. 2010. “An Advanced Perspective on the Predictability in Hedge Fund Returns.” Journal of Banking and Finance 34: 2694–2708.
- Yin, C., and X. Zhang. 2019. Gambling or De-Risking: Hedge Fund Risk-Taking vs. Management Fees. Working Paper.