
Abstract
One of the principal motivations for the new paradigm in reasoning was a reaction to the old (binary truth functional) paradigm's inability to deal with everyday non-monotonic inference. Within the new paradigm the problem of non-monotonicity is recast as the problem of belief revision or dynamic inference; that is, what happens when the probability distribution over which inferences are made changes from Pr0 to Pr1. Non-monotonicity arises when the new distribution, conditional on new information, I, changes the relevant probabilities, so that Pr0(x) ≠ Pr1(x), i.e., Pr0(x) ≠ Pr0(x|I). In this paper we first introduce the general problem of dynamic inference. We then consider the specific problems for dynamic conditional inference, in particular for modus tollens (MT). We then turn to possible reactions to these problems, looking at Oaksford and Chater's (Citation2007) learning approach and causal Bayes nets. We conclude that most of the recent research on the non-monotonic effects observed in casual conditional inference and the suppression effect require a dynamic approach. However, the rational constraints on the transition from Pr0 to Pr1, when Pr0(x) ≠ Pr0(x|I), remain unclear.
Notes
1 We thank Igor Douven for pointing out that if probability conditionals cannot be regarded as propositions, then this notation can only be interpreted as a pseudo-probability (see CitationDouven & Verbrugge, 2013).
2 If this is a counterexample, the probability of the conclusion, ¬p, is 0 and its uncertainty is maximal at 1, and as the probability of the conditional premise (Pr1(q|p)) must fall, the uncertainty of the conclusion is now greater than the sum of the uncertainties of the premises (0 + 1 – Pr1(q|p)).
3 We should say at this point that the issues here are complex and we are forced to gloss over many important problems. For example, there are pragmatic issues about the context in which ¬q is informative with respect to the conditional.
4 To see the corresponding generalisation we just quantify over “tomorrow”, i.e., if it sunny on day(x), then I will play tennis with you on day(x). You may believe this is highly probable when said by Tom.
5 We henceforth include DA and AC in the set of inferences, for reasons we have discussed.
6 Taken from a meta-analysis by Schroyens and Schaeken (Citation2003).
7 As we remarked in footnote 1, if probability conditionals cannot be regarded as propositions, then this notation can only be interpreted as a pseudo-probability (see CitationDouven & Verbrugge, 2013). We calculate ![]() on the assumption that Pr0(q|p) is the probability of a dependency model (see below). We use this notation because it renders clear one of the assumptions of our learning strategy (see next paragraph).
on the assumption that Pr0(q|p) is the probability of a dependency model (see below). We use this notation because it renders clear one of the assumptions of our learning strategy (see next paragraph).
8 We thank Igor Douven for pointing out that, while this may be the general case, there are special classes of conditionals for which it does not hold. For example, non-interference conditionals: “If it snows in July, the government will fall”, biscuit conditionals: “If you are hungry, there are biscuits on the table” (although here there is a dependency between the antecedent and the “relevance” of the consequent), and Dutchman conditionals: “If John passes the exam, I’m a Dutchman.”
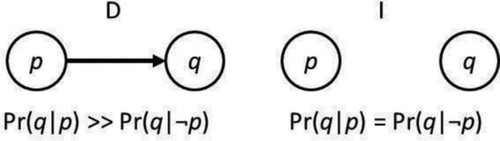
Figure 1 The conditional dependency (D) and the independence model (I) in Causal Bayes Net. The lack of a link between p and q in I indicate they are independent
9 Collinearity is a potential problem in cluster analysis but this is only an issue if it is not expected. Here the constraints derived in (5) above mean that we would expect collinearity because they explicitly show that one variable can be defined in terms of the others.
10 Such a catch-all is closely related to McCarthy's (Citation1980) abnormal predicate in the circumscription approach to non-monotonic logic.
11 Strictly, the case when a new conditional is learnt is when it is introduced sequentially leading to a new distribution. Accessing the new conditional from LTM for world knowledge is perhaps better described as supposing the new conditional applies in this context.
12 For discrete random variables, the Kullback-Leibler distance from Pr0 to Pr1, D(Pr0∥Pr1) = ![]() . As this is the log of a ratio, it is 0 if Pr0 and Pr1 assign the same probability to each event x in the event space over which they assign probabilities. This quantity is also called mutual information.
. As this is the log of a ratio, it is 0 if Pr0 and Pr1 assign the same probability to each event x in the event space over which they assign probabilities. This quantity is also called mutual information.
13 As Douven (Citation2012) observes, there are other distance measures and ways of formulating this problem which require empirical investigation.
14 In Grice's (Citation1975) terms, Barwise and Perry (Citation1983) were proposing that natural meaning, e.g., smoke means fire, could provide the basis for non-natural or linguistic meaning, e.g., “smoke” (i.e., the word) means smoke (the presence of smoke).