
ABSTRACT
This article introduces a data-intensive approach to visualizing political ideologies as text networks. The methodology combines network theory with collocation analysis from corpus linguistics. Its similarities and differences to Michael Freeden’s morphological approach are highlighted. The prospects are examined by focusing on the case study of Finnish socialism in the early 20th century. Primary sources consist of printed labor newspapers, handwritten newspapers produced by ordinary working people, and parliamentary speeches. The empirical part demonstrates that the network approach is useful for (1) locating key political words based on centrality in the network, (2) identifying clusters of words related to each other more strongly than to the rest of the network, and (3) seeing the structure of an ideological network. The main contribution of the article is methodological for the approach can be applied to other machine-readable sources, both at small and large scales, to automatically extract information on the linguistic patterns characteristic of a political ideology under investigation.
Introduction
What do ideologies look like? If one cannot visualize a phenomenon at all, perhaps one cannot fully understand it either. This article stems from the question I have been struggling with for many years: how to represent a political ideology visually. Many ideas have emerged along the way: word clouds based on simple term frequency, tables showing the most unique words for a specific ideology, or time-series charts describing changes in the use of individual words – all good for highlighting one aspect of an ideology, but unable to reveal the main features of an ideology at once.Footnote1 In this article, one data-intensive approach to visualize complex structures inherent in any political language is introduced. Methodologically, the guiding idea is to combine network theory with collocation analysis from corpus linguistics. This approach can be used not only to operationalize some classical ideas in the study of ideologies, such as the conceptual structures of political languages, but also to shed a new light on thoroughly researched historical phenomena such as early-twentieth century socialism.Footnote2
The idea of representing political concepts visually as networks is not completely new. In corpus linguistics, larger collocational networks have usually been analyzed by first choosing the node word and then building the surrounding lexical network, whereas the approach taken here is more data-driven – the starting point is to count all the strong associations between words.Footnote3 In the field of intellectual history, Peter de Bolla and his team have studied and visualized the structures of individual concepts based on lexical profiles.Footnote4 Recently, Kimmo Elo has utilized a broader text network approach to identify shared topics in European political speeches in the 21st century.Footnote5 Instead of similarities across political speeches, the network approach taken here tries to flesh out linguistic patterns specific to one political ideology. All the approaches mentioned above have been based on the lexis directly available in texts, but there have been attempts to go beyond words. For example, Paul Thagard introduced a method for constructing Cognitive-Affective Maps (CAMs), i.e. diagrams that show how concepts and emotions attached to concepts relate to each other.Footnote6 Building CAMs requires a lot of manual labor; connections between concepts and emotions are made by the researcher after a qualitative analysis, such as close reading interviews done with groups under study. The goal in this article is to find a ‘sweet spot’ between automation and more human-intensive methods; an approach that can applied to large-scale data but would not too primitive for the study of ideologies. In general, the value of text networks for the study of political ideologies remains underexplored. Thus, the main contribution is to reflect on and show how network analysis can enrich historical ideology studies by extracting useful information from machine-readable sources.
It seems that the field of ideology studies is now ripe for data-intensive visual representations. First, there are several off-the-shelf datasets – historical newspapers, books, pamphlets, and parliamentary debates – that form a machine-readable record of political languages used in the past, and if the current selection feels too limited, DIY-digitalization is easier than ever before.Footnote7 Second, a wide arsenal of text mining methods has emerged during the last decades,Footnote8 and as will be shown in the following, at least some of the novel tools can be applied to the questions relevant for the study of ideologies. Third, we have theories that can guide us when transforming fuzzy concepts, such as ‘ideologies’, first into measurable quantities and then into visualizations. Take Michael Freeden, who might be the most influential thinker in the study of ideologies. He defines ideologies as macroscopic structural arrangements that attribute ‘meaning to a range of mutually defining political concepts’.Footnote9 For example, Finnish socialism can be understood as a specific configuration of political concepts selected from an unlimited range of possible combinations. From this notion arises the key feature of all ideologies; if concepts can be arranged in an infinite number of ways, then political languages are ultimately struggles over dominant conceptual arrangements. Thus, the most important property of political languages is what Freeden calls ‘decontestation’: prioritization of one conceptual combination above others.Footnote10 In addition, not all concepts are equal within an ideology, but their positions can vary; there are core, adjacent and peripheral concepts.Footnote11 It does not take much imagination to visualize Freeden’s definition of an ideology as a large network of concepts, some closer to the center and some further, but perhaps surprisingly, the link between his theory and quantitative network analysis cannot be found in previous research. In his magnum opus Ideologies and Political Theory: A Conceptual Approach, the idea of a network appears frequently: ‘ideological network’, ‘structural network’, ‘network of conceptual components’, and ‘network of mutually informing and influencing concepts’, to name a few examples.Footnote12
Freeden himself seems to be rather skeptical toward quantification of political ideologies,Footnote13 but this alone cannot explain the missing link. There are both historical, technical, and epistemological reasons for the relative lack of text mining approaches in the study of ideologies. First, in the humanities and social sciences, non-textual networks have dominated the practice of network analysis. Most of research has traditionally focused on social networks.Footnote14 Second, basic introduction to text mining for the students in the humanities and social sciences is still rare in university curricula which means that computational skills required for text mining need to be acquired independently. Luckily, there are great on-line resources for self-studying,Footnote15 and the future looks even better; for example, if one is interested in studying ideologies as networks, there are several on-going projects building easy-to-use tools for text network analysis.Footnote16 However, there is still a great epistemological gap to be crossed. So far, text mining approaches have focused on counting words, instead of concepts or ideas, although at the level of interpretation this difference is often blurred.Footnote17 The networks presented in this article are based on clusters of words and not clusters of concepts as in Freeden’s theory. However, using words as a starting point of conceptual analysis is not exclusive to text mining; it is also prevalent in the more traditional method of close reading where words in direct quotations act as indicators of conceptual evolution. The link between words and concepts is acknowledged in the study of ideologies. ‘Political concepts are expressed, or signified, in the form of words’, as Freeden writes.Footnote18 There is always going to be a gap between the unit of interest and the unit of measurement (e.g. ‘conceptual patterns’ and ‘lexical patterns’) when applying computational text mining to complex research questions.Footnote19 This gap should not be crossed carelessly, but with serious reflection, which is one of the primary goals in what follows.
The problem of explicit words as the basis for describing an ideological network is at least two-fold: (1) not all the lexical patters are ideological in nature but based on, e.g. syntax of a specific language, and (2) not all the ideological patterns are explicitly visible in language, i.e. what we believe is already known by others tends to be omitted in social communication. The first challenge can be solved by filtering ideological patterns from non-ideological patterns by using any method that works in a specific case, but the second one is more difficult; text mining approaches are ultimately based on counting objects that are visible to the machine, but what is important in political thinking is not necessarily tied to frequency of a word or even a concept. For example, in Freeden’s interpretation of conservatism, the underlying core concepts include the ideas of supporting ‘natural’ change and resisting ’unnatural’ change, extra-human origin of the order, and mirror-like reaction to progressive ideologies.Footnote20 These core concepts are often expressed indirectly, through adjacent and peripheral concepts, e.g. conservatism might sometimes oppose socialism, sometimes the hippie movement, sometimes LGBT rights, depending on the historical juncture. Thus, in the analysis based purely on frequency, adjacent and peripheral concepts might become more visible than the more important concepts in the core of the conservative ideology.Footnote21
This article does not try to transform Freeden’s theory directly into the language of numbers and reproduce his results with a novel data-intensive approach. Rather, the similarities and differences to Freeden’s morphological approach are highlighted and discussed. Hopefully some of the reflections are useful for those who want to explore the possibilities of data-intensive methods for the study of ideologies. First, I briefly introduce what text mining methods have been used to analyze political languages and relate text networks to the state-of-the-art. Then, the text network method itself will be described in-depth, especially in the context of Freeden’s ideology theory. Once the idea has been properly introduced, a small case study showing the method in action will be presented. In the conclusions, the advantages and limitations of text network analysis are examined, along with an exploration of promising areas for future research.
From words to ideologies: the methodology of text network analysis
To understand the potential of text networks better, it is useful to compare them against other text mining approaches used in the study of ideologies. Quantitative analysis of political languages has a long history before the most recent rise of digital humanities. For example, the guiding idea of Harold Lasswell’s Language of Politics (1948) was to advance the study of politics ‘by quantitative analysis of political discourse’.Footnote22 Counting individual words and manually classified categories (such as topics) in the style of Lasswell is one of the most established quantitative methods in the study of political texts.Footnote23 Sophisticated techniques to find statistically significant differences in word use between different text collections have been developed especially in the field of corpus linguistics.Footnote24 These techniques, available through simple graphical user interfaces like AntConc, can be used for example to map out the distinctive key words between political ideologies.Footnote25 In the study of political polarization, a typical approach for extracting political positions automatically from texts measures lexical differences between parties or politicians and then places them onto a single dimension, e.g. left-right axis. The distance between positions is interpreted to indicate the intensity of polarization.Footnote26
The problem of counting individual words in isolation is that a single word has a broad semantic field and can refer to many different concepts depending on the context. For example, the word ‘justice’ can refer to economic, environmental, or criminal justice. Counting relations between words can give a richer semantic representation of political texts. For relations between two words, there is the well-established collocation method that measures the strength of association between two words.Footnote27 For relations between multiple words, various topic modeling algorithms can automatically identify ‘topics’, defined as clusters of multiple words that occur together in texts.Footnote28 The Latent Dirichlet allocation (LDA) has been the standard technique of topic modeling. In LDA, it is first assumed a priori that a text document consists of n number of topics. Then the algorithm tries to iteratively guess which topics could have generated the document under investigation.Footnote29 One potential limitation of topic modeling approaches based on machine learning is that in order to deliver meaningful results they usually require large-scale datasets which are not always available in the study of ideologies.Footnote30
The networks introduced in the following are based on collocations, but they could also be built on topic models or ‘word embeddings’, i.e. words are mapped as numbers in multidimensional vector space. In the field of digital humanities, word embeddings based on word2vec-model have been popular.Footnote31 The model uses a shallow neural network architecture to produce a vector representation of each word in the dataset.Footnote32 Once vectors have been constructed, it is possible to compare the similarity of words in the vector space.Footnote33 Recently, language models based on the transformer architecture have outperformed word2vec in most text mining tasks. Compared to word2vec and collocations, large language models consider a much broader linguistic context and offer a more nuanced representation of a text. The major problem with both word2vec and newer language models for the study of ideologies is that they are ‘black boxes’. In other words, it is difficult to explain why the results are what they are because models are so complex internally. For example, the features that these models use to decide which words are most similar are not transparent for human beings. However, there is a growing interest in research on explainable AI which could potentially lead to breakthroughs in text mining in the humanities and social sciences if high performance can be combined with good interpretability.Footnote34
Thus, the most obvious benefit of collocation-based text networks at the moment lies in transparency; unlike in the case of LDA, word2vec, LLMs, and other complex machine-learning approaches, a researcher knows precisely which lexical features form a link between words. Compared to the conventional use of collocations, i.e. collocates of individual terms visualized as a table, text networks can offer more relational information at one glance, i.e. a visual representation of interrelations between several words. The basic ideas of network theory can be intuitively understood by any scholar: a network consists of objects (‘nodes’) and their interconnections (‘edges’). For example, if words A and B co-occur in our political texts frequently together, we can draw a line between these two nodes to represent an edge. In fact, we can draw lines between all the words that appear together in the sources. Once the complete network has been constructed, we can count, for example, which word has most connections to other words; if word A co-occurs with four other words in , its ‘degree centrality’ is four.Footnote35 In the visualization, we can place words with higher degree values closer to the core of the network, whereas words with less connections can be situated in the periphery.
Figure 1. Simple network visualization. Node a has four edges, node C and E two edges, and nodes B, D, G and F only one edge.
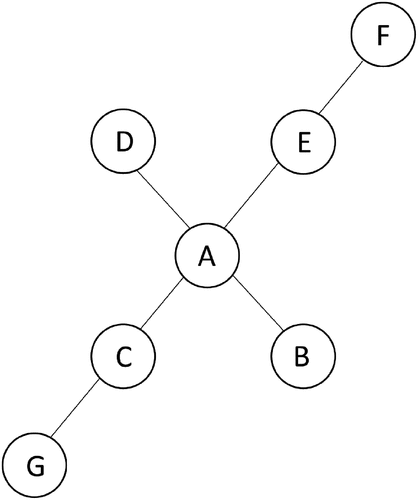
There are some obvious similarities between network analysis and Freeden’s ideology theory. First, the idea of the words with most connections to other words at the center of a text network seems to resemble the idea of the core concepts at the center of a political ideology. In a way, network analysis is compatible with the morphological approach by allowing more than one central concept to lie in the core of an ideology; there can be one or many, depending on what emerges from the dataset.Footnote36 However, besides the basic difference between words and concepts touched upon in the introduction, criteria for centrality are completely different. In the case of network analysis based on degree centrality, it is the nodes with most connections to other nodes that are located at the center, whereas in Freeden’s theory, the core concepts are ‘indispensable to holding the ideology together’ and ‘present in all known cases of the ideology in question’.Footnote37 It is not entirely clear what this definition means if operationalized for the purpose of text mining; at the very least, it contains a temporal requirement that a key concept must be present in the long-term within the ideology and not just momentarily.
In addition to using distance to the core as a measure of importance, both the morphological and text network approaches emphasize the relationships between internal components. The difference comes from what counts as a relationship between words or concepts. In the morphological approach, links between concepts depend ultimately on the researcher’s chosen criteria.Footnote38 The role of these relationships is crucial for the morphological understanding of ideologies; the mutual ordering of concepts creates the ideological network, ‘conferring specific meaning on each concept in an ideology’s domain’.Footnote39 The relationships between concepts are about their proximity inside a network which ultimately defines their meaning. In text network analysis, the relationships between words are more ‘objective’ in the sense that they do not depend as strongly on subjective interpretation but also more ‘superficial’ in the sense that links are based on linguistic co-occurrence. Hidden assumptions and implications embedded in language are ignored in this approach; only the tip of the ideological iceberg counts, whereas ideological contents below the linguistic waterline remain invisible. This contradicts Freeden’s focus on a ‘surplus of meaning’, i.e. both ‘the intended and unintended meanings attached to the employment of a concept are part of its baggage and draw upon wide ranges of assumptions and ideas, though these are not spelt out in the paucity of the spoken or written language’.Footnote40
Networks in the following are based on linguistic co-occurrences between words, but there are many alternative ways to count co-occurrences, each leading to different results. The two big decisions to be made in the very beginning of network analysis are as follows: (1) how to define the window size in which words have to co-occur and (2) how to quantify the strength of connection between co-occurring words? These are both questions without any universally correct answers; the choices should be based on the research questions. For this paper, the co-occurrences in a window of five words were counted. This window size is common in corpus-based discourse analysis, but the window sizes can vary wildly in different research designs.Footnote41 To my knowledge, there is currently no broad linguistic theory to explain the effects of window sizes on the nature of co-occurrences identified in the computational analysis. However, in general, the narrowest windows are better for capturing syntactic relations, whereas wider window sizes are needed to uncover semantic relations in the data.Footnote42
If we count only absolute co-occurrences, the resulting networks can become gigantic very quickly. Networks with too many nodes and edges lead easily to infamous ‘hairballs’, messy visualizations with too much information for human brain to make sense of. Of course, the number of edges can be reduced by raising the threshold of absolute co-occurrences higher, but this does not solve the main problem; the most frequent co-occurrences contain common words such as ‘to be’, ‘which’, ‘and’, and ‘that’, and these do not reveal any relevant information on the key features of a political ideology. Fortunately, there are methods that rank co-occurrences based on the difference between observed and expected co-occurrences. Pointwise Mutual Information (PMI) is one widely used measure of association between two words in corpus linguistics, and it compares the frequency of the co-occurrence to the frequency of its individual parts.Footnote43 For example, it is not surprising to see that ‘immigrant’ and ‘to be’ appear together in a political text for ‘to be’ appears with virtually every word because of its commonness, but the frequent co-occurrence between ‘immigrant’ and ‘illegal’ would be more surprising from the statistical perspective because ‘illegal’ has a lower overall frequency than ‘to be’. The power of PMI is that it finds these strong links between words automatically.
Once the co-occurrences have been defined and counted, the first version of a visual network can be constructed. There are several layout algorithms for visualization, and each produces different results.Footnote44 Nodes are words and edges are defined as statistically strong relations between two words. An interesting alternative approach would be to count the similarity of co-occurrences between all the words in a corpus. For example, if ‘the proletariat’ and ‘the people’ would have very similar immediate linguistic contexts, they would form an edge although they would rarely appear close to each other in any of the texts analyzed. Compared to the first-order co-occurrence used in this article, this kind of ‘second-order co-occurrence’ similarity network should highlight paradigmatic relations in language such as synonyms and antonyms.Footnote45
While counting PMI values for each word pair in the text corpus is enough to represent an ideology as a network, there are other statistical tricks in the trade to extract more information on the network – its nodes, clusters, and relations to other networks – than simply eyeballing its visual representation. In addition to counting node-level measures such as degree centrality, it is also possible to group individual words into topics, i.e. clusters of words that have more connections with each other than with the rest of the network. Clustering based on PMI can be seen as an alternative to topic modeling such as LDA. While the idea of interconnections as the basis of cluster is relatively easy to understand, there is no easy algorithmic solution to decide which node goes to which cluster in a large network. One of the most common solutions is the Louvain method, which is used, for example, in Gephi, the open-source network tool used for visualization in this article. The algorithm tries to maximize ‘modularity’, i.e. the relative density of edges inside clusters compared to edges outside clusters, by first optimizing modularity locally and then recursively merging clusters into a single node.Footnote46 One difference between the Louvain method and topic modeling based on LDA is that the latter requires the user to pre-define the number of topics to be identified in the document, whereas the Louvain method can automatically calculate the optimal number of clusters.Footnote47
Now that text network method has been presented in general terms, it is time to put the idea into practice. The primary sources in the case study consist of political texts produced by the supporters and sympathizers of the Finnish Social Democratic Party in the early 20th century. According to Freeden, ‘while an ideology and a party sharing the same name are never identical, they are mutually supportive’.Footnote48 There was obviously ideological variation inside the party and the labor movement more broadly, but generally Finnish social democracy has been interpreted as one version of ‘Kautskyite socialism’ that dominated the Second International, the main organization of European socialist parties. The core ideas the Finnish SDP originated from Karl Kautsky’s writings, including (1) economic theory of exploitation, (2) materialist conception of history, and (3) the independent organization of working classes into political parties as the main strategy.Footnote49 The ideological variant became incredibly popular in the Grand Duchy of Finland which had the largest socialist party in Europe in the early 20th century.Footnote50
There were many reasons for the rapid breakthrough of socialism, but according to both the supporters and opponents of socialism, the labor press played a key role in the transmission of new political ideas.Footnote51 Here the high level of literacy, even among the rural proletariat, was the lurking factor that enabled socialism to spread so quickly to all corners of the Grand Duchy.Footnote52 The most important socialist newspaper was Työmies, established in the capital Helsinki in 1895 and closed at the end of the Civil War in 1918. It has been said to have had the most educated labor journalists. In 1917, Työmies was the most widely read paper in Finland.Footnote53 In order to improve the geographical coverage, the dataset is supplemented with the second-most important Finnish socialist newspaper from the industrial city of Tampere (Kansan Lehti) and two smaller regional newspapers (Vapaa Sana from Vaasa and Savon Työmies from Kuopio).Footnote54 Although there was some variation in ideological positions taken by individual labor newspapers, in general, group consciousness and common objectives ‘cleared the way for the gradual emergence of uniformity in the press group on the larger political issues’.Footnote55
The National Library of Finland has digitized all the newspapers, including labor press, until around the 1940s.Footnote56 I have chosen four labor newspapers to represent socialist ideology, and this choice has both pros and cons. Labor papers contained not only socialist messages, but also unambiguously nonsocialist texts such as advertisements, direct quotes from political opponents, and even election propaganda from the competing parties if the price was right. Unfortunately, these nonsocialist texts could not be filtered out as the Finnish newspaper corpus currently lacks a sophisticated article segmentation, i.e. quantifications cannot yet be restricted to a specific text genre such as editorials. However, it seems the quantity of newspaper data is so vast that nonsocialist ‘outliers’ do not destroy the big picture. Computational analysis is also hampered by OCR noise, i.e. the quality of automatic text recognition is far from perfect.Footnote57 However, the final analysis of socialism in this article is not based on patterns found in the printed newspapers but patterns found simultaneously in three different source groups. Compared to the standard materials used in the study of ideologies such as texts from leading thinkers or party programmes, digitized newspapers offer a rougher but, in a way, more honest picture of political language because daily newspapers had to react to the world around them impromptu, lacking the time to refine and fine-tune their ideological messages. Furthermore, there are certain ideological patterns that can only be found in big datasets where the large amount of repetition makes conceptual structures visible in statistical analysis.Footnote58
While printed labor newspapers represent the ideological mainstream of Finnish socialism, other sources are needed to sketch socialist ideology at the grassroots of political thinking. Luckily, there existed a flourishing proletarian culture of handwritten newspapers in the early-twentieth century Finland.Footnote59 I have manually coded five handwritten newspapers produced by two trade unions (Tehtaalainen from Tampere, Palveliatar from Helsinki), one workers’ association (Nuija from Savonlinna), one proletarian orator society (Kuritus from Niinivedenpää), and one social-democratic youth organization (Yritys from Vaasa).Footnote60 If printed labor newspapers are compared with handwritten newspapers, they seem ideologically more orthodox, more official and closer to the top of the labor movement, whereas handwritten newspapers represent a less controlled and more heterogeneous manifestation of the socialist ideology at the grassroots of the labor movement.Footnote61
Printed and handwritten newspapers represent public discourses, but the third source used in the article is produced by what has traditionally been understood as the ‘political elite’: parliamentary politicians. All the speeches given by the members of the Social Democratic Party in the Finnish Parliament have been included in the case study.Footnote62 Unlike newspapers, parliamentary debates usually have direct decision-making power. However, considering the historical context, the differences between ideological language in the parliament and newspapers should perhaps not be overdramatized. Many labor journalists became socialist MPs, many parliamentary speeches were re-printed and circulated in the press, and political debate in the early-twentieth century parliament was generally fierce because of its structural dysfunctionality, i.e. the Finnish Parliament resembled more an ‘agitation forum’ for national matters than a real legislative body.Footnote63
By using three different groups of sources, I want to flesh out the shared ideological features of socialism that appear in different fields of political thought. The challenge of using lexical patterns to find ideological patterns is partly solved by demanding strong connections between words to appear simultaneously in various contexts; this criterion should eliminate much of the random noise, i.e. anecdotal co-occurrences caused by the specifics of one source group. summarizes the sources used, their volume, years, and information extracted from each dataset. For pre-processing, all the datasets were first lemmatized, i.e. each word in the texts was changed to its base form.Footnote64 PMI extracted useful results from newspapers and parliamentary debates, but the problem with purely quantitative approach applied to a single dataset was that many word pairs contained words that were not at all political in nature.Footnote65 For visualizations based only on one dataset (), I decided to use a binary ad hoc solution to sidestep the problem; based on my knowledge of Finnish socialism, the words were manually labeled into two categories, ‘political’ or ‘not-political’.Footnote66 Then, those word pairs that did not contain at least one political word were excluded from the network.Footnote67 However, the network visualization based on all three datasets () is unfiltered.
Table 1. Datasets used in the article.
The case study below is not comprehensive but rather a proof of concept that shows the feasibility of the method for the study of ideologies. First, I create a text network from printed newspapers, focusing on analyzing key words and word clusters. Then, I evaluate the similarities and differences between text networks based on printed and handwritten newspapers. Lastly, I identify, visualize and interpret the patterns between words that are consistent across all datasets. The general argument is that a simple text network representation can be useful for revealing lexical units related to the core concepts at the center of political ideologies. In addition, a text network representation can produce basic information on the inter-relations between multiple concepts. Freeden has compared ideologies to ‘rooms that contain various units of furniture in proximity to each other’.Footnote68 This means that concepts are like units in the sense that it is not the units themselves but the organization of the units that defines ideological rooms. Thus, there are many individual socialist rooms, none of which are identical in detail, but they all share a similar arrangement of furniture.Footnote69 Extending the metaphor, one could argue that what text network analysis can add to the study of ideologies is an empirical snapshot of an ideological room from the past. This snapshot is not authentic but rather an artificial representation of the past; text networks intentionally reduce information in order to highlight patterns in the datasets that are difficult to observe with the naked eye, e.g. most central nodes or nodes that together form clusters. Next the snapshot of Finnish socialism will be examined to see if the method can provide a fresh perspective on a much-studied phenomenon.
Case study: network of Finnish socialism
shows the network representation of socialism based on four printed socialist newspapers. The first observation is that the results – based primarily on simple quantification of co-occurring words with human intervention in the filtering phase – seem to make sense. Of course, this is partly because filtering deleted nonpolitical words, but filtering did not determine the location of political words in the network visualization. In the core of socialist network, there are words such as the proletariat, working people, struggle, work, class, capital, party and to organize, all the usual suspects from the dominant international Marxist discourses at the turn of the 20th century. Note that in only words with at least 32 connections to other words in the whole dataset are visualized, meaning that in reality the visible words have even more connections to words outside the network.Footnote70 Thus, these visualizations show the words that have the most connections to other central words of socialism. The visualization omits infrequent words and highlights those words that have broader semantic fields, i.e. they are used in various linguistic contexts. Just like ‘animal’ is more versatile but less precise than ‘dog’ in the variety of contexts it can be applied to, ‘struggle’ is present in but the more specific ‘class struggle’ is not. Perhaps we could conceptualize the words at the core of the visualization as the key words of socialism, words that are frequently needed to make ideological utterances regardless of the topic. ‘The proletariat’ (köyhälistö), ‘struggle’ (taistelu), and ‘work’ (työ) simply emerge when speaking the political language of socialism. Of course, one could argue that networks such as are presenting only words and not concepts at all. This criticism would question the straightforward connection between words and concepts, whereas advocates of text network approach would argue that political concepts can be analyzed through their lexical manifestations.Footnote71
Figure 2. Network representation of printed socialist newspapers, 1895–1910. Different colors represent different clusters based on the Louvain method. Only nodes with at least 32 edges in the whole dataset are visualized.
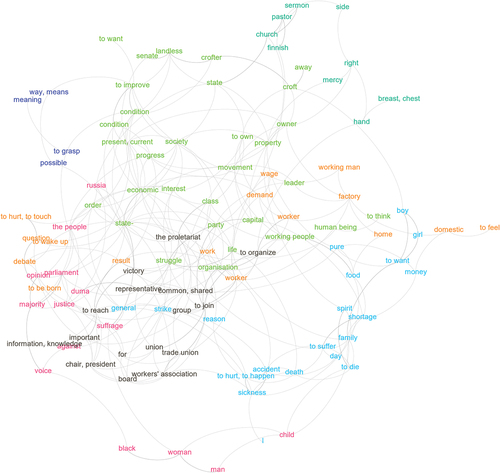
Figure 3. Network representation of handwritten newspapers, 1899–1917. Words in red are unique to the visualized handwritten network compared to the network visualization based on printed newspapers in . Only nodes with at least 13 edges in the whole dataset are visualized.

The position of individual words indicates their relative importance inside the network, whereas colors can be used to highlight words that appear with each other more frequently than expected by chance. In , the largest word cluster consists of 31 words, and most of its words represent a classical understanding of socialist ideology, including many key concepts of Marxist societal analysis (e.g. ‘capital’ (pääoma), ‘class’ (luokka), and ‘struggle’ (taistelu). The second largest cluster is 20 words, and it is clearly related to socialist misery, e.g. ‘to suffer’ (kärsiä), ‘sickness’ (sairaus), and ‘shortage’ (puute). Then, there are two clusters with 16 words. The third cluster is related to ‘organizational jargon’ of the labor movement with words such as ‘to organize’ (järjestyä), ‘workers’ association’ (työväenyhdistys), and ‘trade union’ (ammattiosasto). The fourth cluster seems to be about concrete work with words such as ‘factory’ (tehdas), ‘working man’ (työmies), and ‘wage’ (palkka). The fifth major cluster in the network seems to concern parliamentary politics with words such as ‘parliament’ (eduskunta), ‘duma’ (duuma), and ‘suffrage’ (äänioikeus). In addition to these clusters, there are also minor topics in with less than five words.
In a more content-oriented text network investigation of a historical ideology, the topics identified with clustering should be validated by close reading as many concrete examples as possible. In this methodological experiment, only a few observations are highlighted and compared to Freeden’s interpretation on the key features of socialist ideology. Freeden has defined socialism based on five core concepts shared by ‘all socialisms’: (1) the constitutive nature of human relationship, (2) human welfare as a desirable objective, (3) active human nature, (4) equality of human beings and (5) history as the arena of ultimately beneficial change.Footnote72 The first concept emphasizes human inter-relationships; the socialist unit of analysis is not an atomistic individual but rather social groups or communities consisting of many people.Footnote73 It could be suggested that in the largest cluster of , words like ‘class’, ‘society’ and ‘working people’ refer to this core feature of socialism, whereas in the organizational cluster, the same idea exists in the form of collective singulars ‘the proletariat’ and ‘group’ (joukko) and in the verbs denoting many becoming one such as ‘to join’ (liittyä) and ‘to organize’. Here, it would be extremely interesting to compare socialist newspapers against their liberal opponents; what kind of political subjects would lie in the core of liberalism?
The second core concept of socialism, human welfare, can be found in the largest cluster too, not only in the central presence of ‘human being’ (ihminen) but also in ‘to improve’ (parantaa) and ‘condition’ (both olo and asema) that together form a powerful argument; in the socialist language, ‘to improve the condition of the working people’ is synonymous to reaching universal human welfare, both material and spiritual, which is only achievable by removing the shackles of capitalism. A good individual example of this idea can be found in a letter dedicated to sauna workers, published in the main organ Työmies: ‘I say here to sauna workers that you must begin to improve your conditions, for you do not have to live on alms. Rise up and elevate your humanity!’Footnote74 Lack of human welfare under the prevailing conditions is also visible in the misery cluster which shows many sufferings of the Finnish working people. The difference is that the misery cluster describes the effects, whereas the largest cluster rather gives causal explanations for the effects.
The third core concept in Freeden’s morphology means that all socialist ideologies understand human nature as productive and elevate human work to the important motor of social life.Footnote75 The work cluster is certainly relevant for this key idea of socialism; it was the hard experience of manual labor that united ‘workers’ (both työläinen and työntekijä) and ‘working men’ (työmies), and if their labor was the ultimate driving force of societal progress, as claimed by the Marxist theory, then they should reclaim the fruits of their labor, e.g. by demanding higher wages. A stereotypical utterance in socialist newspapers would highlight how factory as the embodiment of industrial capitalism would prevent the human inside the worker fulfilling his or her true nature: ‘But in the hands of the capitalists the machines transformed into powerful weapons which factory owners used to rob surplus value from the labor of the working man.’Footnote76
The fourth core concept, the socialist ideal of equality, is especially connected to the cluster of parliamentary politics. In the political language of Finnish socialism, the primary goal before the parliamentary reform was winning the universal ‘suffrage’ (äänioikeus) for both men and women. This goal was reached after the general strike in 1905.Footnote77 The socialists believed that ‘justice’ (oikeus) could be brought upon earth for ‘the people’ (kansa). This term usually referred to the working people proper in their own political language, for they formed the ‘majority’ (enemmistö) of Finns. However, the socialist idea of equality did not settle for equal rights to participate in formal political processes but wanted to expand the range of the concept to all spheres of human life: ‘Thus, we strive for elsewhere, towards a socialist society in which even the worker’s economic income and complete equality have been secured and guaranteed, toward a society in which the chances to exploit workers exist no more and the class system ends simultaneously.’Footnote78
The fifth core concept points to the temporality of socialism. According to Freeden, socialists take a ‘massive leap of faith and imagination’ when they maintain their vision of the better socialist future based on their grim analysis of capitalism in the present.Footnote79 The only clearly temporal words in are ‘progress’ (kehitys) and ‘present’/‘current’ (nykyinen). The former is the concept that shows the positive road from the miserable present to the better future in the socialist world explanation, whereas the latter is the most important individual dimension of time in the political language of Finnish socialism. This visualization suggests to me that future-orientation is not what makes socialism so unique compared to other political ideologies; rather, socialism was the ideology mastering the use of the present in its political rhetoric.Footnote80
While there is clearly some overlap between Freeden’s core features of socialism and the data-intensive visualization above, there are insurmountable differences between the two approaches. In general, the data-intensive approach seems to miss some important features of ideologies and to emphasize concepts that are adjacent and peripheral in Freeden’s theory. In the case of Finnish socialism, it is surprising that the words referring to the bourgeoisie, the main political enemy, are not more strongly present in . Perhaps the bourgeoisie is discussed within too narrow linguistic contexts to be included in the visualization which, as explained earlier, requires a multitude of connections to other central words of socialism. The core concept of history is not visible at all, most likely because its lexicalized forms ‘history’ (historia) and ‘historical’ (historiallinen) are rare in the political language of Finnish socialism, blocking its possibilities to make multiple strong connections to other words.Footnote81 This example shows the limits of a lexicon-based approach; extending text mining to the use of tenses would likely improve the analysis. If adjacent concepts are defined as those concepts that do not appear in all instances of an ideology, but are ‘crucial in finessing the core and anchoring it – at least temporarily – into a more determinate and decontested semantic field’,Footnote82 then it could be argued that the core concept of equality is missing from the network but its adjacent concept of parliamentary politics is strongly present.Footnote83 If peripheral concepts are those that change faster in different diachronic and cultural contexts and function as an interface between an ideology and social practices,Footnote84 one clear candidate for a peripheral concept in would be the land question. There are several words referring to the agrarian proletariat: ‘landless’ (tilaton), ‘crofter’ (torppari), and ‘croft’ (torppa). The Finnish SDP became the largest socialist party in Europe in the first parliamentary election of 1907, and their stunning election victory was based on votes from the countryside.Footnote85 The condition of the tenant farmers especially raised criticism in the Grand Duchy of Finland; they and their families could easily be evicted out of their homes if landowners were not satisfied with their performance or simply wanted to return the rented land for their own personal benefit.Footnote86 The socialist newspapers kept the discussion on crofter evictions active, especially for agitational reasons, which pushed the crofters and landless toward the core of the network in . This example shows how the network method can capture at least some of both specific (the land question) and general features (abstract Marxist concepts) of political ideologies.
Interpreting the nodes and clusters of an ideological network in relation to previous research is interesting, but to get maximum benefits from the network analysis, one should compare the structures of many networks. shows the socialist ideology in handwritten newspapers produced by ordinary working people. The nodes in red are unique to the visual network representation based on five handwritten papers () compared to the representation based on four printed newspapers (). Note that this does not mean that the words in red and their strong connections did not appear in the print at all; this means that they are not close enough to the core of the network to be included in the visualization.
At least three interesting differences can be found when looking at the distinctive words in red. First, has more words related to poetic language, where as had more words referring to formal structures. To illustrate this difference, contains words such as ‘heart’ (sydän), ‘soul’ (sielu), ‘nature’ (luonto), ‘god’ (jumala), ‘sun’ (aurinko), and ‘slave’ (orja), but ‘capital’, ‘class’, and ‘society’ from are missing. Second, the bottom half of is filled with many words describing important events in the daily life of a proletarian activist, including ‘meeting’ (kokous), ‘soiree’ (iltama), ‘association/company’ (seura), and ‘orator society’ (puhujaseura). Third, there are many more political action verbs and nouns in compared to : ‘to try’ (koettaa), ‘to rise’ (nousta), ‘to fight’ (taistella), ‘to demand’ (vaatia), and ‘action’ (toiminta).
The distinctive patterns can be explained with differences in the social contexts between handwritten and printed newspapers. Poetry and personal reflection were more common in the handwritten medium. Many working people who contributed to handwritten newspapers in the early 20th century were at the same time entering the public sphere for the first time in their lives. Presumably, they had to face the same difficult ideological questions that had already been reflected and ‘solved’ in the more official labor press years before ordinary workers formulated their own political positions in the handwritten newspapers. The print had diverse objectives – not only sending ideological messages but also spreading news and selling ads – whereas the texts of the handwritten newspapers were much closer to the audience for they were published by reading aloud in a shared physical space.Footnote87 The importance of local context explains why there are so many words related to the daily life sphere in . Finally, the influx of verbs and nouns demanding political action make sense, considering the papers were primarily written by local grassroots activists of the labor movement who tried to encourage each other and more passive members to work toward the goal of socialism. It is no coincidence that ‘responsibility’ (velvollisuus) is close to the core of the network.
Even the short comparison above leads me to the fundamental question in the study of ideologies; how can we define the central features of an ideology if interesting differences can be found just by comparing two networks of socialism derived from very similar contexts, i.e. from the same period and from the same country? One suggestion could be that the ideological core of Finnish socialism is actually somewhat visible in , in those black words that unite both the printed and handwritten discourses. Following once again Freeden, if the core features of an ideology are those that can be found in each case analyzed, then the ideological skeleton of socialism could be operationalized as those strong connections between words that can be found not only in major socialist newspapers and handwritten newspapers but in all important political contexts from the period under investigation. includes both printed newspapers, handwritten newspapers, and parliamentary speeches and shows which lexical connections appear simultaneously in all three ‘genres’Footnote88 of political thinking.
Figure 4. Network representation based on identical edges in printed socialist newspaper, 1895–1910, handwritten newspapers, 1899–1917, and parliamentary speeches by the socialist MPs, 1907–1917. Only nodes that have at least 5 edges and belong to the largest connected community in the center of the network are visualized.
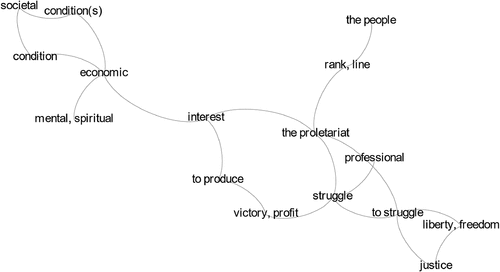
Especially and partly suffered from too much information in a single image, but is visually simpler and more effective; only words that have at least 5 edges and belong to the largest connected component in the core of the network are visualized. Not much of a socialist ideology is left in this visualization made of 16 unique words (nodes) and 19 strong connections (edges) between them. What remains are the most basic ‘snippets’ of socialist thinking, word pairs that convey some key ideas of socialism. ‘The proletariat’ remains in the core of socialism, encompassing the broader vision of the proletariat, synonymous to the people, joining ranks to promote their class interests and to struggle for ‘liberty, freedom’ (vapaus) and ‘justice’ (oikeus). Interesting is also the cluster of societal conditions(s) on the left that covers both material and immaterial aspects; the two are always complementary in the political language of socialism. While this visualization is the best so far for showing the key ingredients of Finnish socialism, it is still far from perfect and demonstrates some limitations related to the word-based approach. The Finnish word ‘voitto’ can refer to two different concepts, i.e. political victory and economic profit, and these distinct meanings are conflated in a text network representation. In general, the method introduced above is good at identifying strongest patterns in datasets, but weaker ideological signals are easily lost when transforming textual sources into visual networks. Considering that the network visualization above is based on messy historical data, plagued by technological noise (variation in OCR quality) and strong biases in content (e.g. nonsocialist ads published in the newspapers), the results seem somewhat promising. Of course, no single text network representation can show the full complexity of an ideology, for this would be impossible to achieve in one visualization. According to the famous and appropriate quote, ‘All models are wrong, but some are useful’.Footnote89
Conclusion
The article has shown that text network analysis can be beneficial for (1) locating key political words based on centrality in a network, (2) identifying clusters of words that are related to each other more strongly than to the rest of the network, and (3) seeing the overall structure of ideological networks. If visualization means mapping properties in the dataset to observable variables such as size, color, and position, then text networks seem superior compared to traditional word clouds which merely scale words based on their frequency. Unlike word clouds, text network representations provide richer information on the connections between words. The main limitation of analyzing political ideologies through network analysis stems from a common critique of quantitative methods; raw numbers cannot capture context-specific nuances.Footnote90 Obviously, careful close reading of political texts cannot be replaced by network analysis, but it should be equally obvious that the two approaches are not mutually exclusive. Given the impracticality for scholars to read all material relevant to their research, quantitative methods like network analysis can direct limited human attention to the repeated patterns in the sources. Network analysis not only highlights linguistic patterns for deeper human analysis but also contextualizes individual speech acts by placing them against the background of a wider conceptual system. In other words, text network analysis can enrich our understanding of the relationship between individual utterances and wider discursive structures.
One could conclude that the use of network analysis for the study of ideologies is always a collaborative effort between machine and human. While word frequencies are coming from computations, elevating raw lexical networks into conceptual networks with meaning requires interpretative labor in two dimensions: (1) reading words in their immediate contexts in the corpus and (2) connecting the findings based on a quantitative analysis to the world beyond the corpus itself using supplementary primary sources and prior scholarship related to the network under study. Both interpretative tasks present their own specific challenges. Especially in the case of large datasets, it is impossible to read manually through all sentences that form a network and its properties. The complexity escalates rapidly as the relations between words multiply exponentially when the number of words increases. If everything cannot be read, a practical approach is to select a random sample of sentences that illustrate the computational patterns of human interest. When connecting the results to knowledge beyond the corpus, one key challenge is that scholars might focus on those patterns that can explained with their prior knowledge and overlook those findings that are difficult to interpret through existing theoretical frameworks. These challenges lead to an inconvenient question: How would a scholar interpret these networks, the position of nodes and clusters connected by different colors, if she, for example, had no expertise on Finnish socialism or had never heard of Freeden’s morphological ideology theory? The interpretations would certainly be different. However, variations in interpretations does not make network analysis itself unobjective given the researcher is methodologically transparent. If she does not advertise visual representations of networks as objective end results, spewed automatically by machine, but rather openly acknowledges that her argument is based on the human interpretation of network information instead of ‘pure’ word counts, the risk of quasi-scientific argumentation can be avoided. One could suspect that two researchers would arrive at similar conclusions if they had similar background knowledge on the ideological phenomenon under investigation and if they read the same number of concrete examples.
While this article translated some classical ideas into an empirical research design with some concrete findings, many tempting areas remain unexplored. First, the evolution of an ideological network over time could be studied. The static ideological networks presented in the article could be transformed into dynamic ones since edges can be easily enriched with timestamps. To discern stable structures of political ideologies from short-lived patterns, time-based criteria could be established; the strong connections between words cannot be limited to individual moments in time, but they should appear, if not every year, at least throughout most of the years under study. As Freeden has written, ‘we have to insist on some structural, empirically ascertainable common features over time and space before we bestow the same name on different ideological genre’.Footnote91 Theoretically, this approach should bring stable features of ideological morphologies alive as visual text networks. Conversely, for those interested in ideological shifts rather than continuities, time-based metadata can be used to automatically pinpoint moments of significant internal changes in the structure of a network. Practically, this could involve calculating similarity values for each yearly network and then identifying which successive years show the least similarity when compared to one another.Footnote92
Second, it is also possible to compare many competing networks against each other, which is fundamental for any serious attempt to study ideologies. By contrasting a single text network with others, one can distinguish what is unique and what is general, e.g. between socialist, liberal, and conservative ideologies. Various properties can be compared, but among the most important for the ideology studies are identifying nodes or edges unique to the network analyzed and determining networks that are most (or least) similar in their overall structure. If one is interested in how political languages diverge or converge over time, this synchronic, inter-ideological perspective (‘comparing the structure of many ideologies in a specific moment’) can be combined with the diachronic, intra-ideological perspective (‘comparing the structure of one ideology over time’). Extending the focus from one ideology as an independent network to many ideologies as interacting networks would potentially represent ideological evolution from a fresh angle, showing smaller networks embedded within larger networks. It could be hypothesized that the success of individual ideological networks depends on their location in the grand network of political debating. For example, one could argue that the decline of socialist parties post-Cold War can be partly explained by their ‘outdated’ political language which failed to address the core topics of the twenty-century political debates like migration or environmentalism. Meanwhile, ideological networks that might appear diametrically opposed, like the anti-racist Greens and far-right Finns Party, can end up benefitting from each other by engaging in heated debates over hot topics like burqas or vegetarianism, thus generating public interest and potentially attracting new followers for both parties. Such hypotheses could be empirically tested by linking text network analyses with electoral data.
It is this third aspect of future research – connecting ideological patterns found in text data to the broader contexts in which texts were born – that presents the most complex and inspiring challenge for scholarship. Could we, through trial and error, develop theories that would explain how ideological networks relate to extralinguistic factors such as age (e.g. ‘is there synchronic variation between different generations using political language at the same point in time’), class (e.g. ‘how does class background influence the structure of ideological networks’), gender (e.g. ‘what differences exist between men’s and women’s ideological networks?’), and time (e.g. ‘do ideological networks change faster near elections?’). Ultimately, combining text network analysis with rich metadata on historical individuals and societies in which they once thought politically will help us to better answer the Big Question in the study of ideologies: Why do some features in political ideologies remain stable while others change drastically over time?
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1. R. Turunen, Shades of Red: Evolution of the Political Language of Finnish Socialism from the Nineteenth Century until the Civil War of 1918 (Helsinki: The Finnish Society for Labour History, 2021). http://hdl.handle.net/10138/336197
2. For ideologies, see, e.g. M. Freeden, Ideologies and Political Theory. A Conceptual Approach (Oxford: Oxford University Press, 1996); J. Schwartzmantel, Ideology and Politics (London: SAGE, 2008); A. Vincent, Modern Political Ideologies. Third Edition (Chichester: Wiley-Blackwell, 2010). For Finnish socialism, see H. Soikkanen, Sosialismin tulo Suomeen (Porvoo: WSOY, 1961); E. Blanc, Revolutionary Social Democracy. Working-Class Politics Across the Russian Empire (1882–1917) (Leiden; Boston: Brill, 2021).
3. V. Brezina, V., T. McEnery, T., & S. Wattam, ‘Collocations in Context: A New Perspective on Collocation Networks’, International Journal of Corpus Linguistics, 20 (2015), pp. 139–173; P. Baker, ‘The Shapes of Collocation’, International Journal of Corpus Linguistics, 21 (2016), pp. 139–164.
4. P. de Bolla et al., ‘Distributional Concept Analysis’, Contributions to the History of Concepts, 14 (2019), pp. 66–92.
5. K. Elo, ‘A Text Network Analysis of Discursive Changes in German, Austrian and Swiss New Year’s Speeches 2000–2021’, Digital Humanities Quarterly, 16 (2022), http://www.digitalhumanities.org/dhq/vol/16/1/000598/000598.html.
6. P. Thagard, The Cognitive Science of Science: Explanation, Discovery, and Conceptual Change (Cambridge: MIT Press, 2012).
7. For off-the-self datasets, see, e.g. CLARIN Virtual Language Observatory, https://vlo.clarin.eu/; for DIY-digitalization, see, e.g. A. Akhlaghi, ‘OCR and Machine Translation’, Programming Historian, 10 (2021), https://doi.org/10.46430/phen0091.
8. For a rather comprehensive list of available tools, see https://tapor.ca/home.
9. M. Freeden, Ideologies, op. cit., Ref. 2, p. 54.
10. Freeden, ibid., p. 76–77.
11. M. Freeden, ‘The Morphological Analysis of Ideology’, in M. Freeden & M. Stears (Eds.) The Oxford Handbook of Political Ideologies (New York: Oxford University Press, 2013), pp. 124–126.
12. M. Freeden, Ideologies, op. cit., Ref. 2, pp. 78, 86, 492, 552.
13. M. Freeden, The Political Theory of Political Thinking. The Anatomy of Practice (Oxford: Oxford University Press, 2013), p. 11.
15. See, e.g., https://programminghistorian.org/.
16. For a practical introduction to text network analysis, see E. Segev, ’How to Conduct Semantic Network Analysis’, in E. Segev (Ed.) Semantic Network Analysis in Social Sciences (London: Routledge, 2022), pp. 16–31.
17. J. Marjanen, ‘Quantitative Conceptual History: On Agency, Reception, and Interpretation’, Contributions to the History of Concepts, 18 (2023), p. 63.
18. M. Freeden, Ideologies, op. cit., Ref. 2, p. 49.
19. J. Grimmer, M. Roberts, & B. Stewart, Text as Data: A New Framework for Machine Learning and the Social Sciences (Princeton: Princeton University Press, 2022), p. 175.
20. M. Freeden, Ideologies, op. cit., Ref. 2, p. 344–345.
21. I would like to thank the anonymous Reviewer for pointing out this key difference between text network and morphological approaches.
22. H. Lasswell & N. Leites, Language of Politics: Studies in Quantitative Semantics (New York: George W. Stewart, 1949), p. 40.
23. J. Grimmer, M. Roberts, & B. Stewart, Text as Data, op. cit., Ref. 19, p. 189–190.
24. For an introduction, see P. Baker, Using Corpora in Discourse Analysis (London: Continuum, 2006).
25. H. Froehlich, ‘Corpus Analysis with Antconc’, Programming Historian 4 (2015), https://doi.org/10.46430/phen0043.
26. R. Németh, ‘A Scoping Review on the Use of Natural Language Processing in Research on Political Polarization: Trends and Research Prospects’, Journal of Computer Social Science, 6 (2023), pp. 289–313. https://doi.org/10.1007/s42001-022-00196-2.
27. P. Baker, Using Corpora, op. cit., Ref. 24, p. 95–120.
28. G. Brookes & T. McEnery, ‘The Utility of Topic Modelling for Discourse Studies: A Critical Evaluation’, Discourse Studies, 21 (2019), pp. 3–21. https://doi.org/10.1177/1461445618814032.
29. For an intuitive explanation of topic modeling, see T. Underwood, ‘Topic Modeling Made Just Simple Enough’, Stone and the Shell -blog, 2012, https://tedunderwood.com/2012/04/07/topic-modeling-made-just-simple-enough/.
30. K. Elo, ‘A Text Network Analysis’, op. cit., Ref. 5.
31. M. Gavin et al., ‘Spaces of Meaning. Vector Semantics, Conceptual History, and Close Reading’, in M. Gold & L. Klein (Eds.) Debates in the Digital Humanities 2019 (Minneapolis: University of Minnesota Press, 2019), pp. 243–267. https://doi.org/10.5749/j.ctvg251hk.24.
32. T. Mikolov et al., ‘Efficient Estimation of Word Representations in Vector Space’, arXiv e-print, 2013.
33. For a practical example, see R. Ros, ‘Conceptualizing an Outside World: The Case of “Foreign” in Dutch Newspapers 1815–1914’, Contributions to the History of Concepts, 16 (2021), pp. 27–51.
34. A. Tocchetti & M. Brambilla, ‘The Role of Human Knowledge in Explainable AI’, Data, 7 (2022), https://doi.org/10.3390/data7070093.
35. There are many different ways to count the centrality of nodes. See M. Newman, Networks: Introduction (Oxford: Oxford University Press, 2010), pp. 168–193. The degree centrality is used in this article for it is the most transparent method to interpret.
36. See M. Freeden, ‘The Morphological Analysis’, op. cit., Ref. 11, p. 125.
37. Freeden, ibid.
38. M. Freeden, Ideologies, op. cit., Ref. 2, pp. 84–85.
39. M. Freeden, ‘The Morphological Analysis’, op. cit., Ref. 11, p. 120.
40. M. Freeden, Ideologies, op. cit., Ref. 2, p. 74.
41. P. Baker, Using Corpora, op. cit., Ref. 24, pp. 100–104.
42. A. Kanner, Meaning in Distributions: A Study on Computational Methods in Lexical Semantics (Helsinki University: Doctoral diss., 2022), pp. 139–140.
43. M. Stubbs, ‘Collocations and Semantic Profiles. On the Cause of the Trouble with Quantitative Studies’, Functions of Language, 2 (1995), pp. 23–55.
44. Force Atlas 2 was used for visualization in this article. For more information on the algorithm, see M. Jacomy et al., ‘ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software’, PLoS One, 9 (2014): e98679. https://doi.org/10.1371/journal.pone.0098679.
45. M. Islam & D. Inkpen 2006, ’Second Order Co-occurrence PMI for Determining the Semantic Similarity of Words’, in Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06), Genoa, Italy. European Language Resources Association (ELRA).
46. V.D. Blondel et al., ‘Fast unfolding of communities in large networks’, Journal of Statistical Mechanics: Theory and Experiment, P10008 (2008).
47. G. Brookes & T. McEnery, ‘The Utility of Topic Modelling’, op. cit., Ref. 28.
48. M. Freeden, Ideology: A Very Short Introduction (Oxford: Oxford University Press, 2003), p. 33.
49. H. Soikkanen, Sosialismin tulo, op. cit., Ref. 2, pp. 83–84; D. Sassoon, One Hundred Years of Socialism: The West European Left in the 20th Century, (London: Tauris, 2010), p. 6; [Author], pp. 18, 215–216.
50. G. Eley, Forging Democracy: The History of the Left in Europe, 1850–2000 (Oxford: Oxford University Press, 2002), p. 66.
51. R. Turunen, Shades of Red, op. cit., Ref. 1, p. 84.
52. On Finnish literacy, see P. Leino-Kaukiainen, ’Suomalaisten kirjalliset taidot autonomian kaudella’, Historiallinen Aikakauskirja, 105 (2007), pp. 420–438.
53. T. Nygård, Poliittisten vastakohtaisuuksien jyrkentyminen sanomalehdistössä (Kuopio: Kustannuskiila, 1987), pp. 80, 114, 119.
54. The dataset is described more carefully in R. Turunen, Shades of Red, op. cit., Ref. 1, pp. 80–91.
55. P. Salmelin, ‘The Transition of the Finnish Workers’ Papers to the Social Democratic Press’, Scandinavian Political Studies, 3 (1968), p. 83.
56. The construction of the dataset is described in T. Pääkkönen et al., ‘Exporting Finnish Digitized Historical Newspaper Contents for Offline Use’, D-Lib Magazine, 22 (2016). https://doi.org/10.1045/july2016-paakkonen.
57. The yearly quality of OCR varies between 70–86% in the dataset. The quality of OCR in the noisiest dataset of this article, i.e. the printed newspaper corpus, was evaluated with the LAS command-line tool, see E. Mäkelä, ‘LAS: An Integrated Language Analysis Tool for Multiple Languages’, Journal of Open Source Software, 1 (2016), 35. http://dx.doi.org/10.21105/joss.00035.
58. R. Turunen, Shades of Red, op. cit., Ref. 1, pp. 83–84.
59. K. Salmi-Niklander & C. Berrenberg, ‘Handwritten Newspapers and Community Identity in Finnish and Norwegian Student Societies and Popular Movements’, in K. Salmi-Niklander & H. Droste (Eds.) Handwritten Newspapers: An Alternative Medium During the Early Modern and Modern Periods, (Helsinki: Finnish Literature Society, 2019), pp. 131–146.
60. The dataset is described more carefully in R. Turunen, Shades of Red, op. cit., Ref. 1, pp. 68–80.
61. R. Turunen, Shades of Red, op. cit., Ref. 1, p. 67.
62. The dataset is introduced in E. Hyvönen et al., ‘Plenary Speeches of the Parliament of Finland as Linked Open Data and Data Services’. Proceedings of the International Workshop of Knowledge Generation from Text (TEX2KG), co-located with ESWC 2023, CEUR Workshop Proceedings, 2023. https://ceur-ws.org/Vol-3447/Text2KG_Paper_1.pdf.
63. H. Soikkanen, Kohti kansanvaltaa 1. 1899–1937 (Helsinki: The Social Democratic Party of Finland, 1975), pp. 126–128; P. Ihalainen, The Springs of Democracy. National and Transnational Debates on Constitutional Reform in the British, German, Swedish and Finnish Parliaments, 1917–1919 (Helsinki: Finnish Literature Society, 2017), pp. 62–64. https://doi.org/10.21435/sfh.24.
64. Automatic lemmatization of the printed newspapers and parliamentary debates was done with the LAS command-line tool, see E. Mäkelä, ‘LAS’, op. cit., Ref. 57. In the case of the handwritten newspapers, all the nouns, verbs and adjectives appearing in the texts were manually transcribed in their lemmatized form.
65. Many of the ‘non-political’ word pairs in the printed newspapers seem to be caused by repeated ads: ‘botanical’ – ‘garden’ (kasvitieteellinen – kasvihuone) = PMI 17.97, ‘magnifying glass’ – ‘paper scrap’ (suurennuslasi – kiiltokuva) = PMI 17.61, ‘compass’ – ‘penknife’ (kompassi – linkkuveitsi) PMI = 16.93.
66. I manually labeled political words both (1) in the list of edges based on printed newspapers and (2) in the list of edges based on handwritten newspapers, and then used the combined list of political words to filter both networks. The amount of manual labeling can be reduced by categorizing only those words that appear in at least n edges.
67. The unfiltered network based on the printed newspapers had 97 384 word pairs which had PMI > 3, whereas the filtered network contained 10 954 word pairs.
68. M. Freeden, Ideologies, op. cit., Ref. 2, p. 86.
69. Freeden, ibid., pp. 86–89. See also R. Turunen, Shades of Red, op. cit., Ref. 1, p. 35.
70. This cutoff point was selected so that less than 100 words had to be visualized; in the case of handwritten newspapers in , the cutoff point of 13 connections was used; in the cutoff point of 5 connections was used.
71. On criticism of word-based approach, see J. Fernández-Sebastián & Q. Skinner, ‘Intellectual History, Liberty and Republicanism’, Contributions to the History of Concepts, 3 (2007), pp. 114–115. https://doi.org/10.1163/180793207X209093.
72. M. Freeden, Ideologies, op. cit., Ref. 2, p. 425–426. See also R. Turunen, Shades of Red, op. cit., Ref. 1, pp. 160–161.
73. M. Freeden, Ideologies, op. cit., Ref. 2, p. 426.
74. ‘Ovatko saunottajain olot kiitettävät?’, Työmies, 20.02.1907, p. 5.
75. M. Freeden, Ideologies, op. cit., Ref. 2, p. 429–430.
76. ’Tieteen merkitys köyhälistölle’, Työmies, 17.05.1909, p. 2. Circulated e.g. in Vapaa Sana, 24.05.1909, p. 4.
77. R. Alapuro, State and Revolution in Finland (Berkeley: University of California Press, 1988), pp. 115–117.
78. ‘Vaalisaarna’, Työmies, 27.01.1910, p. 5.
79. M. Freeden, Ideologies, op. cit., Ref. 2, p. 417–418, 433–435.
80. R. Turunen, Shades of Red, op. cit., Ref. 1, pp. 386–443.
81. R. Turunen, Shades of Red, op. cit., Ref. 1, pp. 387–404.
82. M. Freeden, ’The Morphological Analysis’, op. cit., Ref 11, p. 125.
83. I would like to thank the anonymous Reviewer for raising this insight.
84. Freeden, ibid., pp. 125–126.
85. S. Suodenjoki, ‘Mobilising for Land, Nation and Class Interests: Agrarian Agitation in Finland and Ireland, 1879–1918’, Irish Historical Studies, 41 (2017), pp. 214, 217.
86. V. Rasila 1961, Suomen torpparikysymys vuoteen 1909 (Helsinki: Finnish Historical Society, 1961), pp. 58–68.
87. R. Turunen, ‘From the Object to the Subject of History. Writing Factory Workers in Finland in the Early 20th Century’, in K. Salmi-Niklander & H. Droste (Eds.) Handwritten Newspapers: An Alternative Medium during the Early Modern and Modern Periods (Helsinki: Finnish Literature Society, 2019), pp. 173–178.
88. N. Fairclough, ‘A Dialectical-relational Approach to Critical Discourse Analysis in Social Research’, in R. Wodak and M. Meyer (Eds.), Methods of Critical Discourse Studies (Los Angeles: Sage, 2016), pp. 88.
89. The quote is usually attributed to the statistician George Box (1919–2013).
90. P. Baker, Using Corpora, op. cit., Ref. 24, p. 18.
91. M. Freeden, Ideologies, op. cit., Ref. 2, p. 90–91.
92. See, e.g., K. Elo, ‘A Text Network Analysis’, op. cit., Ref. 5.