Abstract
This article identifies and compares four different methods for dealing with inhomogeneous backgrounds in kernel density estimation. The four methods result from combinations of two bandwidth types (fixed vs. adaptive) and two adjustment sides (site side vs. case side). The fixed and adaptive bandwidths employ different uniform bases in density calculation (spatial extent vs. population support). The adaptive bandwidth's strength lies in identifying spatial extents of density variation. It also produces values that are more comparable between locations and more stable statistically. When making adjustments to address the background, the site-side method makes the adjustment at each site for which the density value is to be estimated, and the case-side method makes the adjustment at each case location. Within a disease-mapping context, the former measures population at risk around each site and the latter measures around each disease case. The case-side adjustment is more justifiable in an application like disease mapping. It is also less sensitive to spatial details of the background (a favorable feature) and considerably more computationally efficient. Lung cancer data from Merrimack County, New Hampshire, USA, are used to demonstrate and compare the results from the four methods, leading to the conclusion that the case-side-adaptive-bandwidth method is most advantageous.
1. Introduction
Kernel density estimation (KDE) is a non-parametric method using local information defined by windows (also called kernels) to estimate densities of specified features at given locations. KDE is an important method for mapping spatial patterns of point events and has applications in ecology (Worton Citation1989, Brunsdon Citation1995), criminology (Chainey and Ratcliffe Citation2005 Chapter 6, Boba Citation2005 Chapter 12), public health and epidemiology (e.g., Bithell Citation1990, Citation2000, Kelsall and Diggle Citation1995a, Citation1995b, Gatrell et al. Citation1996, Rushton and Lolonis Citation1996, Rushton et al. Citation1996, Sabel et al. Citation2000, Han et al. Citation2005), and other fields. KDE over a two-dimensional space can be represented as (adapted from Silverman Citation1986)
Conventional KDE assumes a homogeneous or stationary background. Here background refers to the source of the event points. For example, a population at risk is the background of the patients (disease cases). In this article, within different contexts background is also called background population and background support. The homogenous background assumption is not valid in many geographical applications. Using disease mapping as an example, this assumption means an evenly distributed population at risk, over which the importance of a disease case to a given location is determined only by the geographic distance between them. A disease density map based on this assumption does not indicate whether an elevated local density simply reflects a large local population or results from other causes (Bithell Citation1990, Citation2000). In an environmental health study, it is then meaningless to compare such a map with maps of environmental factors that are potentially related to the disease.
The purpose of this article is to identify and compare the methods of dealing with inhomogeneous backgrounds in kernel estimation that are useful in spatial analysis, particularly in certain applications like disease mapping. To address an inhomogeneous background, a generic approach is to calculate the ratio between the density of the event points and the density of the background (Bithell Citation1990, Citation2000, Kelsall and Diggle Citation1995a, Citation1995b). The mathematical expression of this generic idea results in a variety of methods that will be discussed in Section 2.
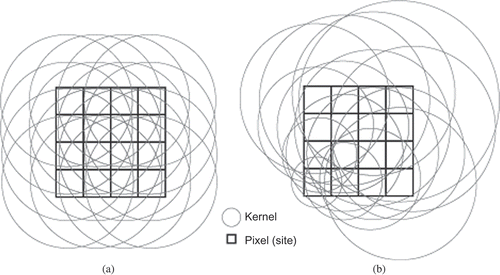
The bandwidth of a kernel estimator can be either fixed across the entire mapping area () or adaptive to suit in local situations (). Each circle in illustrates a kernel and its radius is the bandwidth. In , all the circles have equal radii to illustrate fixed-bandwidth kernels, whereas in , the circles have different radii to illustrate adaptive-bandwidth kernels. All kernels in are centered at the centers of the pixels for which densities are to be estimated, but as discussed later, this is not the only option. Each type of bandwidth has its own strategy to incorporate background information, which will be further discussed in Section 3.
Figure 1. An illustration of the fixed-bandwidth KDE versus the adaptive-bandwidth KDE over raster data.
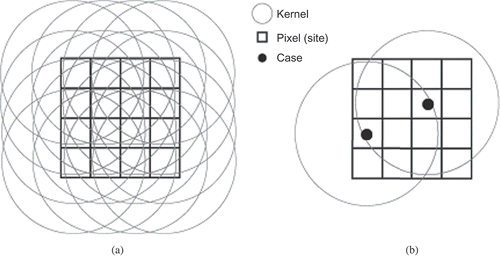
An issue that has not received sufficient attention is where to perform adjustment to address the background. In both the fixed- and adaptive-bandwidth approaches, the background can be evaluated around the place where the density value is to be assigned (e.g., a site where the disease risk is under investigation, and therefore it is called the site-side method herein) or around the location of an event point (e.g., a disease case, and therefore it is called the case-side method herein). A site-side method centers the kernel at a site (), whereas a case-side method centers the kernel at a case (). As in , each circle illustrates a kernel. In , kernels still center at the pixels (sites) for which densities are to be estimated, whereas in , kernels center at cases (represented by the dots). All the kernels in have a fixed bandwidth, but one can also choose where to put the kernel for an adaptive bandwidth. Essentially, the difference between the site-side and the case-side methods can be described as follows: For a group of sites and a group of cases, conceptually KDE needs to calculate value for each and every site-case pair. There are two ways to pair the sites and cases. One is to start with the sites and pair each site with every case, and the other is to start with the cases and pair each case with every site. The former is the site-side method, and the latter is the case-side method. The site-side method puts the kernel at every location (pixel), no matter if there is a case or not; whereas the case-side method puts the kernel only at the case locations. The distinction between these two methods is particularly important over an inhomogeneous background, which will be further discussed in Section 4.
Figure 2. An illustration of the site-side versus case-side calculations over raster data.
This article presents a framework that organizes the methods for dealing with inhomogeneous backgrounds into four categories, which are combinations of two types of bandwidths and two sides of adjustments. Most previous implementations of the widely used case-control method (Bithell Citation1990, Citation2000) belong to the site-side-fixed-bandwidth category in this framework. The other three, namely the case-side-fixed-bandwidth method, the site-side-adaptive-bandwidth method, and the case-side-adaptive-bandwidth method, have not been well reported in the spatial analysis literature. The purpose of this article is to present a preliminary comparison of these four methods, with particular attention to the rationale and advantages of the case-side adjustment. A formal presentation of the framework is given in Section 5.
In this article, the discussion and comparison of the four methods are presented in the context of disease mapping. Lung cancer data from Merrimack County, New Hampshire, USA, are used to demonstrate the four different methods. The case study and further discussions based on the case study are presented in Sections 6 and 7.
It should be noted that because this article is targeting a GIS audience, the literature review and discussion are mainly from the perspective of spatial analysis and geographical applications, rather than non-parametric statistics. The analysis of statistical properties of some of the methods discussed here is challenging and still undergoing. Additional information on the theoretical issues of these methods are found in Silverman (Citation1986), Jones (Citation1990), Jones et al., (Citation1994), Wand and Jones (Citation1995), Sain and Scott (Citation1996), and Sain (Citation2002).
2. A generic approach to addressing an inhomogeneous background
A generic approach to addressing an inhomogeneous background in kernel estimation can be represented as
Within a disease-mapping context, in EquationEquation (2)
(2) can be considered as an indication of the disease risk at location (x, y), c is the density of disease cases, and p is the density of population (herein the word ‘population’ always refers to the population at risk, rather than general population). This generic form corresponds to the derivation of the commonly used rate in epidemiology and public health. It also represents the basic idea of the popular case-control method in disease mapping proposed by Bithell (Citation1990). If both c and p are estimated through their own kernel processes, EquationEquation (1)
(1) can be written as
In disease-mapping and many other geographical applications, our main concern is the relative difference between locations. If this is the case, we can drop the constants from the calculation and EquationEquation (4)(4) becomes
If the background information is about the population itself rather than samples of the population (i.e., controls drawn from the population), like that in the case study presented in this article, it is a common practice to use the total population within the current kernel as the denominator, which is equivalent to the use of a uniform function for Kp
, and EquationEquation (5)(5) becomes
3. Fixed bandwidth versus adaptive bandwidth
Based on EquationEquation (7)(7), a fixed-bandwidth estimator can be represented as follows:
In EquationEquation (8)(8), h becomes a constant, i.e., the estimator applies a fixed bandwidth to every location in the study area. In disease mapping, almost all implementations of the case-control method adopt fixed bandwidths (e.g., Sabel et al.
Citation2000, Han et al.
Citation2005). The spatial filtering technique applied by Rushton and Lolonis (Citation1996) to the study of birth defects and by Rushton et al. (Citation1996) to the study of infant mortality eventually take this approach. In all these application examples, the kernel of Pk
centers at (x, y), but as will be discussed in the next section, the kernel can also center at each case's location.
Different from a fixed bandwidth, an adaptive bandwidth varies across the study area to adapt to either the event points or the background. Bandwidths adapting to event points have been well studied (e.g., Silverman Citation1986, Jones Citation1990, Brunsdon Citation1995, Wand and Jones Citation1995, Sain and Scott Citation1996, Sain Citation2002). In fact, almost all adaptive bandwidths or variable bandwidths discussed in the non-parametric statistics literature are of this type, and it has been proved that such a bandwidth is superior to a fixed bandwidth in estimating probability density of event points (Jones Citation1990). However, over an inhomogeneous background, the background enclosed by such a kernel is likely to be variable from place to place, resulting in inconsistency in the variance of the estimate, and consequently the meaning of using an adaptive bandwidth over an inhomogeneous background is largely lost (see the discussion at the end of this section). For this reason, the current study does not include this type of bandwidth in the analysis and comparison.
In the remainder of this article the term adaptive bandwidth refers only to the bandwidth adapting to the background population. This type of bandwidth aims to have a constant size of population in each of the neighborhoods defined by the bandwidth, which can be represented as follows:
Note that with an adaptive bandwidth, Pk
becomes a constant, and again, if the research interest lies in the relative difference between locations, this constant can be dropped and EquationEquation (9)(9) becomes
The essential difference between the fixed- and adaptive-bandwidth approaches is that they use different uniform bases for comparing the risks at different locations. The fixed-bandwidth approach defines this base in geographical space, whereas the adaptive-bandwidth approach defines it in population. The fixed-bandwidth approach has a disadvantage that the calculated density values may have different statistical variances because the population size used for the adjustment is variable from location to location. The inconstant variance reduces the comparability of the estimate values at different locations. In addition, in a less populous area, the estimate value is subject to high variance and may be considered unstable. By contrast, the adaptive-bandwidth approach assigns each disease case a constant population support, which makes the resulting values more justifiable in health studies and more statistically comparable.
4. Site side versus case side
Over a homogeneous background, EquationEquation (1)(1) can be implemented in two different ways. The first centers the kernel at the location where the density value is to be estimated. Technically, this method measures distance from the location to every event point. Jones (Citation1990) names this method local kernel density estimate. Sain and Scott (Citation1996) call it balloon estimator. In this article it is called the site-side method to reflect the fact that the kernel centers at the site that is under concern (e.g., the site whose disease risk is under investigation). The second way centers the kernel at the location of an event point and calculates the influence of the point on its vicinity. Silverman's variable kernel method takes this approach (Silverman Citation1986, Chapter 2). Jones (Citation1990) and Sain and Scott (Citation1996) call it varying kernel method and sample-point estimator, respectively. In this article it is called the case-side method to favor the application of disease mapping.
Most case-control applications mentioned previously in this article implement the site-side method. Sabel et al. (Citation2000) might be the first to explicitly describe the case-side method for disease mapping. Shi (Citation2007) then compared the computational complexities of the two methods. The computational complexity of the site-side method is O(MN), where M is the number of points of cases (with aggregate data, a single point may represent multiple cases) and N is the number of sites. In the case-side method, because it is known that a site far enough (determined by h) from a case receives little (or zero) influence from that case, it is only needed to perform calculations for the locations within the case's neighborhood. For raster data, with a fixed bandwidth the computational complexity of the case-side method is O(Mh/l), where h is the bandwidth and l is the cell size; with an adaptive bandwidth the complexity is , where Pk
is the user-specified population threshold for defining the bandwidth and pi
is the population density around case i. Because the case-side method over a raster layer avoids dealing with N, which is usually a large number, it can be considerably more efficient. With a fixed bandwidth over a homogeneous background, the site-side and case-side methods are mathematically equivalent, so the difference between the two is mainly about computational efficiency. In Spatial Analyst® of ArcGIS®, the ‘Simple’ option of the ‘Density’ tool implements the site-side calculation, and the ‘Kernel’ option, which includes more sophisticated distance-decaying computation, implements the case-side calculation.
Over an inhomogeneous background, the issue of site-side versus case-side is more profound than just computational efficiency. In the site-side method, Pk
in EquationEquation (8)(8) and p in EquationEquation (10)
(10) refer to the population around (x, y), whereas in the case-side method, these two values refer to the population around case i. When the population is not evenly distributed, the population around a site is likely to be different from that around a case, which makes the results from the two methods different even under a fixed bandwidth. Essentially, in the site-side method the adjustment for addressing the background is constant across the cases but variable across the sites, whereas in the case-side method the adjustment is constant across the sites but variable across the cases. Specifically, the site-side method applies the same kernel population (Pk
in EquationEquation (8)
(8)) or the same bandwidth (h(p) in EquationEquation (10)
(10)) to all the cases when calculating value for a site, ignoring the local situation of each case; meanwhile, it adjusts the same case differently for different sites. In contrast, in the case-side method each case receives an adjustment determined by the case's local situation, and this adjustment remains constant for every site; different cases, however, may be adjusted differently, determined by their local situations.
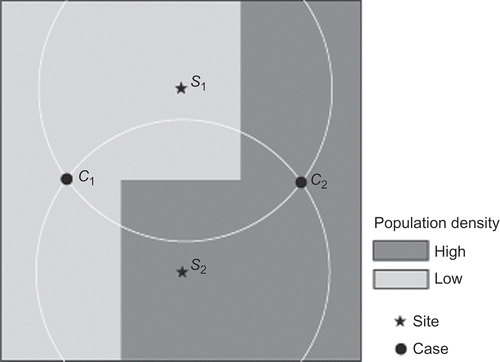
From an epidemiological perspective, it is more reasonable that the importance of a case is determined by the characteristics of the case rather than by the characteristics of the site. This is illustrated by . The distances from the two cases in , c
1 and c
2, to the two sites s
1 and s
2, are all equal (i.e., c
1 − s
1 = c
1 − s
2 = c
2 − s
1 = c
2 − s
2). The equal distances are indicated by the two circles with equal radii centered at s
1 and s
2, respectively. In the site-side method, the two cases are equally important to s
1 and equally important to s
2. However, c
1, which is in a less populous area, should be more important than c
2 in evaluating the risks for the two sites, because c
1 is less likely to result only from the background population. Also, in the site-side method, although each of the two cases has equal distances to the two sites, both cases are less important to s
2 than to s
1, simply because there are more people around s
2. However, the idea that a disease case means less to a site simply because there are more people around that site is hard to justify in epidemiology. In the case-side method, by contrast, c
1 will be more important than c
2 for the two sites – with a fixed bandwidth, Pk
in EquationEquation (8)(8) for c
1 will be smaller than that for c
2, and with an adaptive bandwidth, the lower population density around c
1 results in a larger bandwidth. In the case-side method, s
1 and s
2 will receive equal overall contributions from c
1 and c
2, which is reasonable due to their equal distances to the two cases. Summarily, illustrates that the site-side strategy – if two cases have equal distances to a site then they are equally important to the site – is not so reasonable, because each case may have its own characteristics; meanwhile the case-side strategy – if two sites have equal distances to a case then the case is equally important to them – makes more sense in an application like epidemiology.
Figure 3. Site-side versus case-side: determining the contribution of a case to a site.
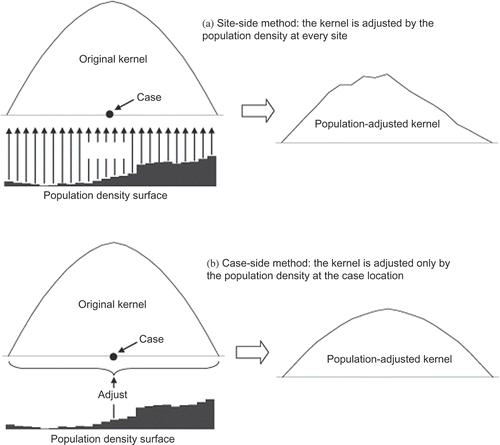
Between the two, the site-side method is more sensitive to spatial variation in the population, as it adjusts the disease density value using the population density value at each site. The effect of this sensitivity is especially clear when there are abrupt spatial changes of population. illustrates this sensitivity in a fixed-bandwidth scenario, but the effect is similar in an adaptive-bandwidth scenario. a shows a site-side process, in which the original kernel function curve is divided by the local population density at every location. The resulting function curve from this process is characterized by sharp turns, which will generate a bumpy density surface. In contrast, with the case-side method illustrated by b, the entire original curve is adjusted by the population density at the location of the case. The function curve remains smooth after this adjustment, leading to a smooth density surface. For a method trying to remove the impact of the background population, the insensitivity of the case-side method is favorable. In a sense, the use of the population density in the case-side-fixed-bandwidth method can be interpreted as a weighting process, in which each case is weighted by the population density at its location. A similar weighting process can be found in Sabel et al. (Citation2000), in which the temporal length of a case is used to determine the height of the kernel.
Figure 4. Case-side versus site-side: sensitivity to the spatial variation of population.
5. The four-estimator framework
Based on the discussion in the previous two sections, four types of estimators can be constructed through the combinations of the two types of bandwidths and the two sides of adjustments, namely the site-side-fixed-bandwidth estimator:
6. Case study
6.1. Data
Data from Merrimack County, New Hampshire, USA, are used to demonstrate results from the methods discussed in previous sections. The disease data, obtained from the New Hampshire Cancer Registry System, are of lung cancer cases that occurred between 1995 and 2003. The total number of cases in the data set is 695. The addresses of these cases were geocoded. Among the 695 cases, 541 (77.8%) were matched to street number locations, and the remaining 154 (22.2%) could only be matched at the zip code level. Those zip code level cases were assigned random locations within their corresponding zip code polygons, and the randomization was controlled by the distribution of the population within those polygons. It is well realized that case completeness and location precision are fundamental to kernel estimation, but a disease registry system is likely to have missing cases and imprecise location data. In addition, issues such as case migration are important for diseases like lung cancer that have a long latency. However, in this study no sufficient information was available for estimating the completeness of the data, finding exact locations of those zip code-level locations, and tracing migration histories of the patients. Fortunately, because the four methods being evaluated used the same data set, the problems with the data should not seriously affect the method comparison. Including the zip code-level cases is necessary, because they account for a considerable percentage in the database and their spatial distribution is not random or even – they tend to occur in rural areas. Without including them the pattern in a disease map would be unrealistic. Randomization controlled by minimum polygons (the zip code polygons in this case) and the background seems to be the best way to maximize the utilization of the location information in these cases, although this process biases to the conservative end, as it assumes that the distribution of these cases is not deviated from the background (Shi Citation2007).
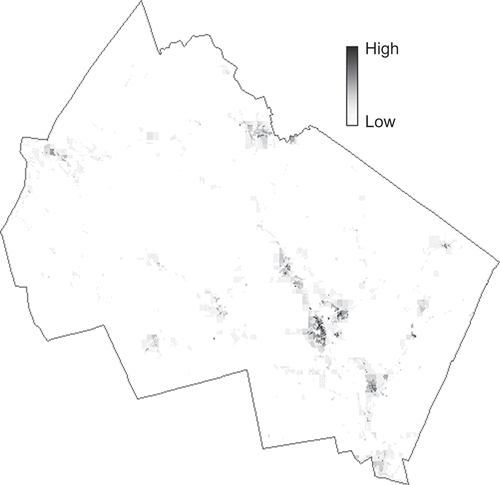
A raster layer was created to detail the spatial distribution of the population in the study area. The value of each cell in this data layer is the expected count of lung cancer cases in the geographical area represented by that cell. Expected count is a measurement in epidemiology for representing the normal situation in a place. It is calculated based on the demographic structure of a place and the normal rates of a disease in a standard population. In other words, the expected count can be considered as the baseline of disease risk in a place. In this study, it is used to substitute the original population value. The expected count data layer was generated by first integrating the US Census 2000 data at the Census Block level and the LandScan Global® 2001 data (http://www.ornl.gov/sci/gist/landscan/), and then calculating the expected count for each cell based on the demographic structure of that cell and the rates of lung cancer in New Hampshire for different age–sex groups. The LandScan Global® data are much more spatially detailed than Census data in rural areas. In urban areas, however, the size of a census block can be much smaller than a cell of the LandScan Global® data. In this research, the resolution of the final expected count layer was set to be 50 m, a compromise between detail level and data size (). With this expected count layer, Pk
and p in EquationEquations (11(11)–
Equation14)
(14) are taken as known.
Figure 5. Population (expected count) of lung cancer cases in Merrimack County, NH.
6.2. Results and discussion
The four estimators presented in Section 4were applied to the data. The implementation needs to specify a function for K in EquationEquations (11(11)–
Equation14)
(14). According to Silverman (Citation1986), however, the choice for K usually does not have significant impact on the result. Therefore, this research adopts a simple function for K as follows:
The value of bandwidth (h) is critical, as it determines the smoothness of the result. Methods for automatically selecting h have been proposed (e.g., Silverman Citation1986, Chapter 3, Chiu Citation1992, Wand and Jones Citation1995, Chapter 3, Gangopadhyay and Cheung Citation2002). However, applying those objective methods to an inhomogeneous-background situation is not straightforward and itself requires substantial research. In this study, h is determined by a process suggested by Silverman (Citation1986, Chapter 3), which consists of a knowledge-based judgment of the results from different bandwidth values. Specifically, a number of different geographic distances (2.5, 5, 7.5, 10, 12.5 km) and expected counts (6, 9, 12, 15, and 18) were tested for the fixed- and adaptive-bandwidth methods, respectively. and present the results of using 5 km as the bandwidth for the fixed-bandwidth methods and using 15 as the expected count for the adaptive-bandwidth methods. They are presented here because first, based on visual inspection, they give good characterizations (in terms of neither over- nor under-smoothing) of the spatial pattern of the lung cancer cases; and second, their calculation settings () are relatively comparable, facilitating the illustration and analysis of the differences between the methods.
Figure 6. Density of lung cancer cases in Merrimack County calculated using different kernel approaches: (a) fixed-bandwidth and site-side; (b) fixed-bandwidth and case-side; (c) adaptive-bandwidth and site-side; (d) adaptive-bandwidth and case-side.
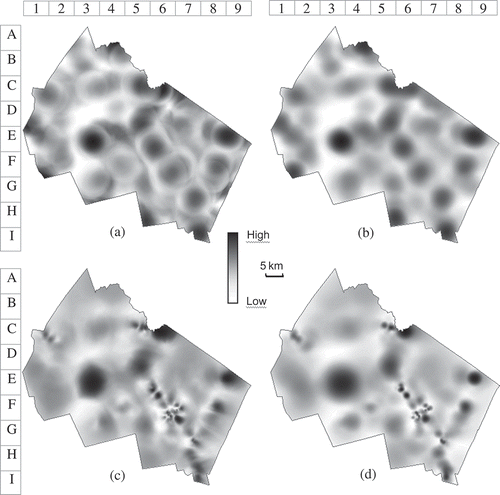
Table 1. Calculation details of the example results
In this study no edge effect correction was performed because first a majority of the study area is not subject to the edge effect and therefore applying edge correction will not significantly affect the method comparison, and second, in practice very often the density map is not the final product but a means for estimating probability through a Monte Carlo process in which the edge effect will be largely removed by repetitive randomizations. It is worth noting, however, that the site-side-fixed-bandwidth method may not really have an edge effect, because in this method both the cases and the population included in the estimation for a site are determined by the same proportion of the kernel that overlaps the study area. The other three methods may have observable edge effects. Specifically, the case-side-fixed-bandwidth method tends to have higher values in border areas; and the two adaptive-bandwidth methods bias toward lower values in those areas.
For comparing the high-density areas identified by different methods, a binary map was created based on each density map (). In the binary map, locations whose estimate values are greater than the mean plus two times the standard deviation of all the estimate values in the corresponding density map are labeled as one (black) and all other locations are labeled as zero (white). It should be noted, however, that the high-density areas identified in this way are not necessary to be statistically meaningful. To evaluate the statistical significance of those high-density values, methods like Monte Carlo should be employed.
Figure 7. High-density areas (>mean + 2 std dev) of lung cancer cases in Merrimack County identified by different kernel approaches: (a) fixed-bandwidth and site-side; (b) fixed-bandwidth and case-side; (c) adaptive-bandwidth and site-side; (d) adaptive-bandwidth and case-side.
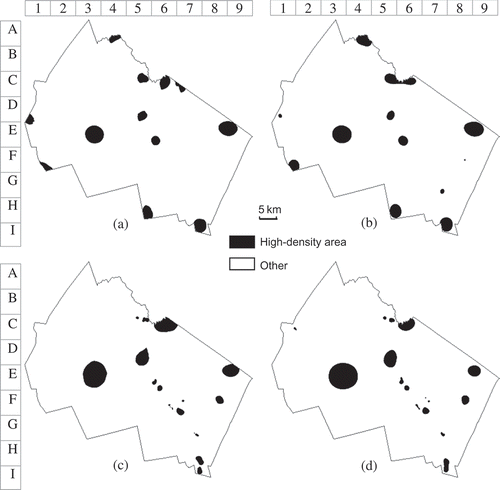
An immediately visible difference between the fixed- and adaptive-bandwidth maps is in the spatial extent of similar density values. The spatial test scale is constant in a fixed-bandwidth method, and therefore it is not surprising that the two fixed-bandwidth maps contain circular bumps of similar sizes ( and ). In contrast, in the two adaptive-bandwidth maps bumps and spikes are of considerably different sizes ( and ). Especially in the Concord–Manchester urban area (E5-G7), the adaptive-bandwidth maps show some spikes: the spikes in the Manchester area (F6-G7) have been concealed by the 5-km fixed bandwidth, but in the Concord area (E5-F6) the spatial extent of the high-density area has been exaggerated by the same 5-km bandwidth. In , several dots in the Manchester area in the adaptive-bandwidth maps do not appear at all in the fixed-bandwidth maps. The two dots in the Concord area in the adaptive-bandwidth maps blend into one bigger dot in the fixed-bandwidth maps. In , the sizes of the high-density areas identified by the fixed bandwidth are less variable, compared with those in the adaptive-bandwidth maps.
The differences between the site-side and the case-site maps are also clearly visible. As expected, the site-side maps ( and ) are considerably less smooth than their corresponding case-side maps ( and ). , a site-side-fixed-bandwidth map, contains many circular phantoms with clear boundaries. These phantoms are artifacts resulting from the high sensitivity of a site-side method to the spatial details in the population distribution. The centers of these phantoms are the locations where the population sizes are either distinctively larger or distinctively smaller than their surrounding areas. In , a site-side-adaptive-bandwidth map, the artifacts from the same source take the form of directional stretches. Examples of such stretches can be seen in E3-E4 and F8-G7. Consequently, the shapes of the high-density areas identified by the site-side methods are generally less compact than their counterparts identified by the case-side methods ().
Another major difference between the site-side and the case-side methods evident from this study is their disparity in computational efficiency. As summarized in , for both fixed and adaptive bandwidths, the running time of a site-side method is more than 200 times that of its corresponding case-side method. This difference is important especially if further geocomputational analysis, such as Monte Carlo simulation, is pursued. Monte Carlo simulation is often employed to find out if the density value at a location is statistically meaningful. It is highly computationally intensive, and therefore the efficiency of the density calculation algorithm is critical to it. Using the numbers in as an example, a Monte Carlo process performing 199 simulations for the site-side-adaptive-bandwidth method would take about 2522 × (1 + 199) = 504,400 s, whereas a process for the corresponding case-side method would take only about 12 × (1 + 199) = 2400 s.
also shows that, under the same bandwidth, the case-side method tends to have a greater expected count within the neighborhood, and under the same pre-specified expected count, a case-side method tends to have a smaller bandwidth. Because disease cases are more likely to occur in areas where the expected count is high these differences are expected.
To get a quantitative sense of the difference between the results from the four methods, Pearson's correlation coefficient was calculated for each pair of the four maps in (). First, the correlation coefficient values confirm the impression that the most obvious difference is due to the type of bandwidth; or in other words, the results from the same type of bandwidth (fixed or adaptive) are more similar than those from different types of bandwidths. Second, the correlation coefficient values reveal some information that is not immediately visible in a visual inspection: (1) The two results from the adaptive bandwidth are less similar than the two from the fixed bandwidth (0.89 vs. 0.94), which indicates that an adaptive bandwidth is more sensitive to the adjustment side. (2) The least similarity is found between the results from the site-side-fixed bandwidth and the case-side-adaptive bandwidth (correlation coefficient = 0.65). As discussed earlier in this article, most previous geographical applications using kernel estimation implement the site-side-fixed bandwidth, but this article argues for the case-side-adaptive bandwidth. Then it is important to know that the results from these two methods are most apart from each other.
Table 2. Correlation coefficients between the results from the four methods
7. Further discussion and summary
Four methods for performing kernel estimation over inhomogeneous backgrounds are discussed within a disease-mapping context. These methods are the different combinations of two bandwidth types (fixed vs. adaptive) and two adjustment sides (site side vs. case side). An essential difference between the fixed and the adaptive bandwidths is that they use different uniform bases to generate comparable local density (risk) values. The fixed-bandwidth approach applies a uniform spatial scale for every location and is suitable for applications in which geographical distance is a primary concern, e.g. distance to a point pollution source. This approach, however, is not good at revealing the spatial extents of the identified interesting areas. It tends to overly smooth density spikes, the consequence of which can be either concealing the spikes or exaggerating the spatial extents of high-density areas. Additionally, the disease density values in low population-density areas calculated by this approach may be unstable. The adaptive-bandwidth approach, on the other hand, uses a uniform population size in the calculation that is better at delineating the spatial extents of the interested areas. In addition, because its calculation is based on a uniform population size, the resulting values have more consistent statistical variances and are therefore more comparable. Furthermore, the user can specify a large enough population size to stabilize the resulting values. A disadvantage of the adaptive bandwidth is that it may overly smooth the values in low population-density areas and thus conceal meaningful geographical patterns in those areas.
No matter which bandwidth is employed, measuring the population around the disease case is advantageous over measuring the population around the site for which the density value is estimated. First, the case-side strategy is more justifiable in health studies as it applies a specific adjustment to a disease case that is determined by the case's local population density, and this adjustment is invariable no matter which site is under estimation. The site-side method gives all the cases the same adjustment when working on a site, but varies the adjustment from site to site. In a health study, it is more reasonable to assume that the contribution of a case to a site should be determined by the characteristics of the case rather than the characteristics of the site. Second, the case-side method is less sensitive to the spatial details in the background than the site-side method, which is a favorable feature, as when the background surface has sharp spikes or deep pits, the output density surface generated by a case-side method remains naturally smooth, whereas the surface from a site-side method contains obvious artifacts. Third, the case-side method is considerably more computationally efficient than the site-side method. The difference in running time between the two methods is determined by the ratio of the number of cases to the number of sites. When the resolution of the output raster is high and/or the number of cases is relatively small, the running times of the two methods can be of different orders. The high computational efficiency of the case-side method makes it preferable in computationally intensive analyses, such as Monte Carlo simulation.
The deductions of EquationEquations (11(11)–
Equation14)
(14) are essentially based on the setting that applies the same bandwidth to both event points and the background. Gatrell et al. (Citation1996) mention the possibility of using a larger bandwidth for the background. Kelsall and Diggle (Citation1995a, Citation1995b) justify the use of same bandwidth for both, but their work is within Bithell's case-control framework (Bithell Citation1990, Citation2000), which belongs to the site-side-fixed-bandwidth category in the framework presented in this article. Whether their conclusion is applicable to the other three categories is still a question.
The ‘Density’ tool in ArcGIS® cannot directly handle inhomogeneous backgrounds, although multistep procedures based on this tool can be designed to implement the two fixed-bandwidth methods. For the site-side-fixed-bandwidth method, one needs to first apply this tool to cases and population separately, and then integrate the results from the two operations. For the case-side-fixed-bandwidth method, one first uses the function to calculate the population density, then attaches the population-density value at a case location to its corresponding case, and finally uses the tool to calculate density for the ‘valued’ cases. There is no way to use the tool to implement the two adaptive-bandwidth methods.
Today, most available disease maps are based on aggregated data and are in vector format, due to the limited availability of spatially detailed data of disease cases and/or population distribution. Two major drawbacks of vector disease maps are the high subjectivity because of subjectively defined polygons, and the low precision because of big polygons. This situation is expected to change with the increasing availability of spatially detailed data in both disease (e.g. Ries et al. Citation2005) and demographic aspects (Bhaduri et al. Citation2002, Mennis Citation2003). Spatially detailed data allow the use of a raster model to overcome the drawbacks associated with a vector model. The kernel methods described in this article are designed for the raster model and can take advantage of the new data. Of all the methods analyzed in this article, the case-side-adaptive-bandwidth method is considered to be the most advantageous.
The case study of New Hampshire lung cancer incidence provides a real-world example demonstrating the significant differences between the four methods. Objectively evaluating the accuracies of these results may be difficult (if not impossible), because there seems to be little agreement on what would be the ‘ground truth’ in modeling the spatial distribution of disease risk. As Openshaw (Citation1996) argued, disease mapping is basically an exploratory approach aiming to bring people's attention to certain areas and formalize hypotheses for further rigorous epidemiological investigations. Nevertheless, subjective examinations may still shed light on the qualities of the results from the different methods. For example, a visual inspection can immediately determine that the circular phantoms in the map generated by the site-side-fixed-bandwidth method are not desired, and a closer examination finds out that they are the artifacts resulted from the peculiarity of the method. The case study in this article also provides empirical evidence on the computational efficiencies of the four methods. Such information may be highly useful when implementing a computationally intensive cluster detection procedure based on kernel estimation.
Finally, although disease mapping provides the context to illustrate and compare the methods analyzed in this article, the discussions and conclusions may be valuable to other applications in which kernel estimation needs to be performed over inhomogeneous backgrounds. For example, they could be useful in crime analysis and mapping in which the distribution of population at risk is also a factor that must be considered (Chainey and Ratcliffe Citation2005, Chapter 6).
Acknowledgements
This work was supported by the National Institutes of Health (Grant # P20 RO18787). The author highly appreciates the helpful comments from the anonymous reviewers. ArcGIS, and Spatial Analyst are registered trademarks of ESRI at Redland, CA, USA.
Related Research Data
References
- Bhaduri , B. 2002 . LandScan: locating people is what matters . Geoinformatics , 5 ( 2 ) : 34 – 37 .
- Bithell , J.F. 1990 . An application of density estimation to geographical epidemiology . Statistics in Medicine , 9 : 691 – 701 .
- Bithell , J.F. 2000 . A classification of disease mapping methods . Statistics in Medicine , 19 : 2203 – 2215 .
- Boba , R. 2005 . Crime analysis and crime mapping , Thousand Oaks, CA : Sage Publications .
- Brunsdon , C. 1995 . Estimating probability surfaces for geographical point data: an adaptive kernel algorithm . Computers & Geosciences , 21 : 877 – 894 .
- Chainey , S. and Ratcliffe , J. 2005 . GIS and crime mapping , Chichester West Sussex, , England : Wiley .
- Chiu , S.-T. 1992 . An automatic bandwidth selector for kernel density estimation . Biometrika , 79 ( 4 ) : 771 – 782 .
- Gangopadhyay , A. and Cheung , K. 2002 . Bayesian approach to the choice of smoothing parameter in kernel density estimation . Journal of Nonparametric Statistics , 14 ( 6 ) : 655 – 664 .
- Gatrell , A.C. 1996 . Spatial point pattern analysis and its application in geographical epidemiology . Transactions of the Institute of British Geographers , 21 ( 1 ) : 256 – 274 . New Series
- Han , D. 2005 . Assessing spatio-temporal variability of risk surfaces using residential history data in a case control study of breast cancer . International Journal of Health Geographics , 4 : 9
- Jones , M.C. 1990 . Variable kernel density estimates . Australia Journal of Statistics , 32 ( 3 ) : 361 – 371 .
- Jones , M.C. , Davies , S.J. and Park , B.U. 1994 . Versions of kernel-type regression estimators . Journal of the American Statistical Association , 89 ( 427 ) : 825 – 832 .
- Kelsall , J.E. and Diggle , P.J. 1995a . Kernel estimation of relative risk . Bernoulli , 1 : 3 – 16 .
- Kelsall , J.E. and Diggle , P.J. 1995b . Non–parametric estimation of spatial variation in relative risk . Statistics in Medicine , 14 : 2335 – 2342 .
- Mennis , J. 2003 . Generating surface models of population using dasymetric mapping . The Professional Geographer , 55 : 31 – 42 .
- Openshaw , S. 1996 . “ Using a geographical analysis machine to detect the presence of spatial clustering and the location of clusters in synthetic data. In ” . In Methods for investigating localized clustering of disease , Edited by: Alexander , F.E. and Boyle , P. 68 – 86 . Lyon : IARC Scientific Publications No. 135 .
- Paulu , C. , Aschengrau , A. and Ozonoff , D. 2002 . Exploring associations between residential location and breast cancer incidence in a case-control study . Environmental Health Perspectives , 110 ( 5 ) : 471 – 478 .
- Ries L.A.G., et al., eds., 2005. SEER cancer statistics review, 1975–2002. Bethesda, MD: National Cancer Institute. Available frombased on November 2004 SEER data submission, posted to the SEER web site 2005 http://seer.cancer.gov/csr/1975_2002/
- Rushton , G. and Lolonis , P. 1996 . Exploratory spatial analysis of birth defect rates in an urban population . Statistics in Medicine , 15 : 717 – 726 .
- Rushton , G. 1996 . The spatial relationship between infant mortality and birth defect rates in a U.S. city . Statistics in Medicine , 15 : 1907 – 1919 .
- Sabel , C.E. 2000 . Modelling exposure opportunities: estimating relative risk for motor neurone disease in Finland . Social Science and Medicine , 50 : 1121 – 1137 .
- Sain , S.R. 2002 . Multivariate locally adaptive density esitmation . Computational Statistics & Data Analysis , 39 : 165 – 186 .
- Sain , S.R. and Scott , D.W. 1996 . On locally adaptive density estimation . Journal of the American Statistical Association , 91 ( 436 ) : 1525 – 1534 .
- Shi , X. 2007 . Evaluating the uncertainty caused byP. O. Box addresses in environmental health studies: a restricted Monte Carlo Approach . International Journal of Geographical Information Science , 21 ( 3 ) : 325 – 340 .
- Silverman , B.W. 1986 . Density estimation for statistics and data analysis , Boca Raton, FL : Chapman & Hall/CRC .
- Talbot , T.O. 2000 . Evaluation of spatial filters to create smoothed maps of health data . Statistics in Medicine , 19 : 2399 – 2408 .
- Turnbull , B.W. 1990 . Monitoring for clusters of disease: application to leukemia incidence in upstate New York . American Journal of Epidemiology , 132 : 136 – 143 .
- Wand , M.P. and Jones , M.C. 1995 . Kernel smoothing , Boca Raton, FL : Chapman & Hall/CRC .
- Worton , B.J. 1989 . Kernel methods for estimating the utilization distribution in home-range studies . Ecology , 70 : 164 – 168 .