
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Stop-and-move semantic trajectories are segmented trajectories where the stops and moves are semantically enriched with additional data. A query language for semantic trajectory datasets has to include selectors for stops or moves based on their enrichments and sequence expressions that define how to match the results of selectors with the sequence the semantic trajectory defines. This article addresses the problem of searching semantic trajectories, using stop-and-move sequence expressions. The article first proposes a formal framework to define semantic trajectories and introduces stop-and-move sequence expressions, with well-defined syntax and semantics, which act as an expressive query language for semantic trajectories. Then, it describes a concrete semantic trajectory model in RDF, defines SPARQL stop-and-move sequence expressions and discusses strategies to compile such expressions into SPARQL queries. Lastly, the article specifies user-friendly keyword search expressions over semantic trajectories based on the use of keywords to specify stop-and-move queries, and the adoption of terms with predefined semantics to compose sequence expressions. It then shows how to compile such keyword search expressions into SPARQL queries. Finally, it provides a proof-of-concept experiment over a semantic trajectory dataset constructed with user-generated content from Flickr, combined with Wikipedia data.
1. Introduction
In the recent years, massive amounts of tracking data have been generated for the benefit of applications that address human or animal mobility, traffic management, etc. Research works in the field (Renso et al. Citation2013b, Bogorny et al. Citation2014) begin with a raw trajectory that consists of spatio-temporal positions extracted from a raw movement track. Then they partition its points into homogeneous segments, that have common properties, such as stops, where the speed of the object is lower than a certain threshold, and moves, where the speed is greater than such threshold (Spaccapietra et al. Citation2008). The subsequent semantic enrichment step enriches the segmented trajectory with additional information (e.g. traffic, weather, etc.) retrieved from external repositories (Parent et al. Citation2013). The final output is a semantic trajectory (Renso et al. Citation2013b).
Given a semantic trajectory dataset, one immediate question arises: how to query the dataset? The query language must include selectors for stops and moves based on their enrichments and must define how to match the selectors with the sequence of stops and moves contained in the semantic trajectory. For example, a query on semantic trajectories of tourists in the city of Pisa can search for ‘walking trajectories that begin with a stop at the Leaning Tower, then at Campo Santo and, later on, stop at a museum’. The intended interpretation of ‘then’ is that the first two stops are consecutive, but ‘later on’ indicates that there might be several stops between Campo Santo and the museum, as long as all moves are by walking (as transportation means).
In this work, we focus on stop-and-move semantic trajectories of humans (Renso et al. Citation2013a). The trajectory segments are rich in information (e.g. stops contain information for Points-Of-Interest – POIs and moves contain information on the transportation means, duration and distance traveled) and may contain information about the moving object. For querying the resulting semantic trajectory dataset, we employ stop-and-move sequence expressions. Although we employ the familiar concepts of stops and moves (Alvares et al. Citation2007a, Spaccapietra et al. Citation2008, Baglioni et al. Citation2008), we support querying more than the stops’ properties. The proposed expressions allow us to search for semantic trajectories using the stops’ and moves’ properties and the intercalation of stops and moves.
The article proposes a formal framework for semantic trajectories, which is based on Description Logic and formally introduces the syntax and semantics of stop-and-move sequence expressions. It also provides a semantic trajectory model in RDF (Resource Description Framework) and defines user-friendly keyword expressions that search for individual stops and moves or their sequences. Finally, it explains how such stop-and-move sequence expressions can be mapped to queries in the SPARQL Protocol and RDF Query Language (or SPARQL for simplicity), taking advantage of the concrete framework.
The main contributions of this research, therefore, are threefold:
It provides a formal representation of semantic trajectories, which for the first time allows sequence queries that combine stops and moves;
It implements a query mechanism for semantic trajectories, which considers in tandem stop-and-move semantics and the semantics of their sequence in the semantic trajectory;
It provides an end-to-end explanation of how keyword search expressions over semantic trajectories are mapped to SPARQL.
The article also includes a proof-of-concept experiment to validate the proposed solution. The experiment adopts a triplified version of the TripBuilder dataset, a semantic trajectory dataset constructed from user-generated content obtained from Flickr, combined with data from Wikipedia. The experiment illustrates how to compile a set of keyword search expressions into SPARQL.
The remainder of this article is organized as follows. Section 2 summarizes related work. Section 3 introduces the use-case trajectory dataset and sample informal queries that help illustrate the discussion in the next sections. Section 4 provides a formal model for semantic trajectories and defines stop-and-move sequence expressions. Section 5 defines an RDF model for semantic trajectories and for stop-and-move sequence expressions. Section 6 introduces keyword search expressions over semantic trajectories and discusses their translation to SPARQL. Section 7 describes the proof-of-concept experiment. Finally, Section 8 contains the conclusions and suggests directions for future research.
2. Related work
The abundance of positioning data and the applications that use them quickly raised the interest in adding semantics to trajectories. The Baquara framework (Fileto et al. Citation2013) was a pioneering approach in the domain of semantically enriched trajectories, that supported a limited amount of Linked Open Data sources. The Athena ontology (Renso et al. Citation2013a) was a step towards an OWL-basedFootnote1 reasoning process for semantic trajectories. This allowed meaningful pattern interpretations of human behavior by combining inductive and deductive reasoning.
In order to take advantage of semantic trajectories, which are represented in an abstract model, it is necessary to develop the appropriate query mechanisms (e.g. in SPARQL). However, the simplicity of keyword-based queries makes them more preferable among non-expert users and raises the need for a SPARQL transcription mechanism (Oliveira et al. Citation2015, Bast et al. Citation2016). Examples of graph-based approaches, which directly explore the RDF dataset for generating and ranking candidate SPARQL queries, are: i) mapping techniques, such as (Zhou et al. Citation2007) and (Rihany et al. Citation2018), which use Wordnet to map keywords to elementary SPARQL query building blocks Zheng et al. (Citation2016), ii) ranking techniques (e.g. (Ghanbarpour and Naderi Citation2019)) that search for the top-k answers of the keyword-based query and iii) graph summarization algorithms of Tran et al. (Citation2009), Le et al. (Citation2014), Lin et al. (Citation2018) and Wen et al. (Citation2018). Another schema-based approach is QUICK (Zenz et al. Citation2009), which employs user feedback on the selection of intermediate queries that will be finally executed. Finally, the compositional approach of Han et al. (Citation2017) uses the keywords to first obtain elementary query graph building blocks and then applies a bipartite graph matching-based best-first search method to assemble the final query.
Baquara2, by Fileto et al. (Citation2015), introduced the concepts of movement segments (e.g. stops and moves), events and movement objects and allowed SPARQL queries over them. The datAcron ontology (Santipantakis et al. Citation2017) conceptualised trajectories as temporal sequences of segments, which relate to a behaviour, event, etc. Every expression results in an iterative execution of parametrized SPARQL queries that collects all the relevant trajectory information. Spaccapietra et al. (Citation2008) defined concepts for Stops, Moves, trajectory Begin and End but ignored stop ordering. The Geo-Ontology (Hu et al. Citation2013) considered the ordering of points in the trajectory (e.g. concepts hasNext, hasSuccessor, etc.) but did not support SPARQL and intercalated stop-and-move sequence queries.
When keyword query expressions target semantic trajectories, it is important to allow trajectory or sub-trajectory matching, either exact or approximate. It is also important to support operations that capture the semantic properties of a trajectory (Alvares et al. Citation2007b, Yan et al. Citation2008, Parent et al. Citation2013), such as stops (or moves) contained in it with or without order (Furtado et al. Citation2016, Petry et al. Citation2019). For this purpose, we aim at retrieving trajectories of interest using approximate criteria and semantic matching operators of increased flexibility compared to exact matching. The semantics of the trajectory refer to various aspects of stops and moves, and the scenario we employ assumes human trajectories in an urban environment.
In this work, we propose an algorithm for converting a keyword-based query into SPARQL, which is composed by: i) restriction clauses that represent keyword matches and ii) join clauses that connect the restriction clauses. The keyword-based query conversion is schema-based since it exploits the RDF schema to compile the final SPARQL query. The generation of the join clauses builds upon the idea of candidate networks (Hristidis and Papakonstantinou Citation2002), following the successful paradigms of (Oliveira et al. Citation2015, Bergamaschi et al. Citation2016). The answer to the SPARQL query is a subgraph of the RDF graph, which contains literal nodes that match the keywords, and paths that connect the literal nodes.
3. A keyword search over semantic trajectories use-case
This section briefly describes the TripBuilder (Brilhante et al. Citation2014) semantic trajectory dataset, an example dataset used in this paper, and provides a set of sample queries that follow our proposed notation for stop-and-move sequence expressions.
TripBuilder contains tourist trajectories from different Italian cities. The trajectories have been constructed by clustering users’ Flickr photos in the spatial dimension and relating them to points-of-interest (POIs). POI semantics (e.g. POI category) have been extracted from Wikipedia. For example, for the city of Pisa, the dataset contains 3,430 trajectories by 1,825 distinct users, from which only 389 trajectories (approximately 11%) have a length between 4 and 20. illustrates two trajectories, both of which have six POIs. This research uses a triplified version of the original TripBuilder dataset (https://doi.org/10.6084/m9.figshare.11559090). The triplification follows the RDF schema described in Section 5.
Table 1. Two illustrative trajectories, based on the TripBuilder dataset
The sample queries defined over the TripBuilder RDF dataset can be expressed using:
a symbolic notation, similar to that of regular expressions, that defines sequences of stop-and-move queries
a reserved terms-based notation, which combines query terms and reserved terms that define the properties and interrelations of stops and moves.
summarises the symbols and reserved terms of the proposed notation, with the list of symbols in the first column, their equivalent terms in the second column, and a description of their meanings in the last column. In , we demonstrate the two notations using a set of example queries for the city of Pisa. Queries are first expressed in natural language, and then written using the symbolic and the reserved terms-based notation. Finally, shows sample query terms used in the TripBuilder RDF dataset, their free-text equivalents and their meaning.
Table 2. Alphabet for keyword queries over semantic trajectories
Table 3. A set of sample queries
Table 4. Terms used on the TripBuilder dataset and the sample queries
Queries 1 to 1 ignore moves and focus only on the semantics of stops and their sequences. Queries 1 to 1 seek for semantic trajectories that combine stops and moves in a specific sequence. In 1 ‘Stop’ indicates that the trajectory may have zero or more stops of any kind between the stop that satisfies ‘Museidipisa’ and the end of the trajectory. In 1 ‘Move’ indicates that the trajectory may have any kind of move between the stop that satisfies ‘Chiesedipisa’ and the end of the trajectory.
We assume that a query is evaluated against some segment of a trajectory
. The segment is required neither to start at the beginning of
nor to terminate at the end of
. If
must be evaluated against the complete trajectory, then the user must resort to the reserved symbols
and
, as in Examples Q5, Q7 and Q10. Section 4.2.2 provides a formal definition of how queries are evaluated against trajectories. Section 5 shows how to write the example queries in SPARQL.
4. A formal framework for querying semantic trajectories
4.1. A formal framework for semantic trajectories
The formal framework for semantic trajectories provides the concepts needed to define the syntax and semantics of the query expressions and to define an RDF model and a SPARQL implementation of such expressions. We present its main concepts in two groups: i) the core model that suffices to formalize semantic trajectories in Description Logic and ii) the extended model that includes concepts for writing query expressions.
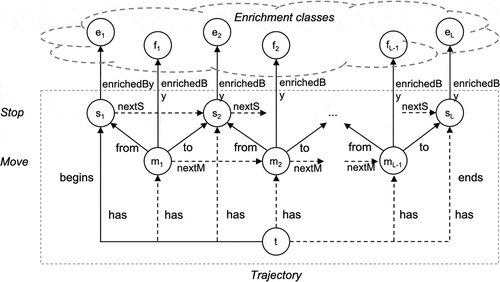
Core model: The core model has three classes, ,
and
, and a set of other classes collectively called enrichment classes. The individuals in
are called trajectory individuals, those in
are called stop individuals, those in
are called move individuals, and those in the enrichment class are called enrichment individuals. Whenever possible, the term ‘individual’ is omitted. The core model also has four binary relationships,
,
,
and
.
schematically depicts a trajectory individual in the core (complete lines) and the extended model (dashed lines). A formalization of the core model reduces to capturing the following assumptions:
Figure 1. Schematic trajectory in the extended model
[A1.] ,
and
are disjoint;
[A2.] ,
and
are disjoint from the enrichment classes;
[A3.] relates a stop or move to one or more enrichments;
[A4.] relates a trajectory to a single stop, called the begin stop of the trajectory, and a begin stop is related to a single trajectory by
;
[A5.] relates a move to a single stop, and a stop is related to a single move by
;
[A6.] relates a move to a single stop, and a stop is related to a single move by
;
[A7.] is defined for a move
iff
is also defined for
;
[A8.] does not map a move to the begin stop of a trajectory.
For example, a pair in ‘ relates stop
to
’, which corresponds to the Leaning Tower of Pisa, and another pair relates move
to
”, which corresponds to the respective transportation mean used in move
.
Using assumptions A4-A8, for a trajectory that begins with
, we define a unique sequence of stops
, the stop sequence of
, and traverse from
to the other stops, using
and
relationships. Likewise, we can define a unique sequence of moves,
, called the move sequence of
, by traversing from stop
to stop
moving by move
, using the
and
relationships, for each
. Following assumption A3, the semantic trajectory
induced by trajectory
will be a pair
, where
is a sequence of sets of stop enrichments,
, and
is a sequence of sets of move enrichments,
. Consequently, the following properties hold:
[P1.] A stop or move belongs to at most one trajectory;
[P2.] A stop or move is not repeated in or
.
Extended model: The extended model adds two more classes, and
, and four binary relationships,
,
,
and
, as follows:
[D1.] is the set of begin stops of the trajectories;
[D2.] is the set of the last stops (end stops) in the stop sequences of the trajectories;
[D3.] relates each pair of consecutive stops of the stop sequence of each trajectory, that is,
is the composition of the inverse of
with
;
[D4.] relates each pair of consecutive moves of the move sequence of each trajectory, that is,
is the composition of
with the inverse of
;
[D5.] relates each trajectory to each stop of the stop sequence of the trajectory, and to each move of the move sequence of the trajectory;
[D6.] relates each trajectory to its end stop.
Additional classes and relationships of the extended model do not increase the expressiveness of the model, from the formal point of view, but they facilitate writing query expressions over semantic trajectories, as well as their SPARQL counterparts.
Description Logic: Before providing the formalization of the proposed framework, we briefly summarize the core Description Logic (DL) (Baader et al. Citation2003) concepts.
The atomic concepts and atomic roles of a DL alphabet capture the classes and properties of the domain of discourse; the universal concept
and the bottom concept
are atomic concepts of
, and the identity relation
is an atomic role of
. The individuals of the domain are denoted using a set of constants in
.
We use to denote the atomic concepts of
,
to denote the atomic roles of
, and
to denote the constants of
. We can then denote concept expressions
and role expressions
over
. The atomic concepts and roles are the simplest expressions.
Based on the above, it is possible to define for concept expressions and
: i) the negation ‘
’, ii) full existential quantifications of the form ‘
’, iii) the union ‘
’, iv) the intersection ‘
’ and v) the product ‘
’. Similarly, for role expressions
,
, we can define: i) the inverse ‘
’, ii) the transitive closure ‘
’, iii) the intersection ‘
’ and iv) the composition ‘
’. Finally we can define axioms ‘
’, ‘
’, ‘
’, or ‘
’ and assertions of the form ‘
’ or ‘
’ for concept and role expressions.
The classes and binary relationships of the core and the extended models are accommodated by considering that alphabet has five special atomic concepts,
,
,
,
, and
, and eight special atomic roles,
,
,
,
,
,
,
and
. The special symbols are called the trajectory symbols of
, and the other symbols the enrichment symbols of
. The axioms of the core model, which correspond to assumptions (A1-A8), and the definitions of the extended model, which correspond to definitions (D1-D6), have been omitted due to space restrictions and can be available upon request.
Trajectories as sequences: Let be an alphabet,
an interpretation for
and
. The stop-and-move sequences over
induced by
is the pair
such that:
● is the sequence of stops of
such that
,
and
, for each
● is the sequence of moves of
such that
, for each
We say that is the length of
. Note that an empty trajectory is allowed, as well as a trajectory with just one stop, in which case
is the empty sequence.
The enrichment sets sequences induced by or simply the enrichments of
, are defined by the pair
, where
is the sequence such that
is the set of pairs in
whose first element is
, called the enrichments of
in
, for
and
is the sequence such that
is the set of pairs in
whose first element is
, called the enrichments of
in
, for
.
Finally, the semantic trajectory over induced by
is a pair
such that
is the stop-and-move sequences over
induced by
and
is the enrichment sets sequences induced by
. Note that
is entirely determined by
and the interpretation that
assigns to
.
4.2. Query expressions over semantic trajectories
This section defines a query language for semantic trajectory datasets that includes: (1) stop-and-move queries that select a stop or a move based on its enrichments; and (2) sequence expressions that define how to match the stop-and-move queries with the sequence of actions (i.e. stops or moves) defined in the semantic trajectory. It first treats stop-and-move expressions as separated sequences, which is convenient from the formal point of view. Then, it introduces expressions that intercalate stop-and-move queries.
In what follows, let be a DL alphabet and
be an interpretation for
, satisfying the assumptions and formalization of Section 4.1.
4.2.1. Enrichment, stop and move queries
An enrichment query is simply a concept expression over the enrichment symbols of
. A stop query over
is either one of the atomic concepts
,
,
, or a concept expression of the form
where is an enrichment query. A stop query then defines the set of stops that have at least one enrichment that satisfies
. Indeed, the interpretation of
is the set of stops of
, and the interpretation of
in
is the set of individuals that
maps to some individual in
. Therefore, the interpretation of
is the set of stops with an enrichment in
.
We recursively expand the set of stop queries to include stop concept expressions of the forms ‘’ and ‘
’, where
and
are stop queries or stop concept expressions.
Likewise, a move query over is either the atomic concept
or a concept expression of the forms
where is an enrichment query. Again, we recursively expand the set of move queries to include move concept expressions defined as above.
The semantics of the enrichment query, as well as those of the stop-and-move queries, need not be explicitly defined, since they result from the standard semantics of DL concept expressions, briefly summarized in Section 4.1.
4.2.2. Stop-and-move sequence expressions
A stop sequence expression is a regular expression of stop queries, a move sequence expression is a regular expression of move queries, and a stop/move sequence expression is a pair , where
is a stop sequence expression and
is a move sequence expression.
More precisely, the set of stop sequence expressions over is recursively defined as:
(1) The empty sequence is a stop sequence expression over
.
(2) Any stop query of over is a stop sequence expression over
.
(3) If is a stop sequence expression over
, then
,
,
, and
are also stop sequence expressions over
.
(4) If and
are stop sequence expressions over
, then
and
are also stop sequence expressions over
.
Parentheses may be omitted if no ambiguity arises. The set of move sequence expressions over is likewise defined, using move queries as a basis.
The definition of the semantics of stop (or move) sequence expressions is simplified if we treat such expressions as specifying a set of sequences of the stop (or move) queries.
Recall that is also a stop query that returns the set of all stops. Let
again denote the empty sequence. Let
denote the concatenation of two sequences
and
, with
, if
, and
, if
. Let
denote the n-fold concatenation
of
with itself, with
.
The expansion of a stop (or move) sequence expression , denoted
, is a set of sequences of stop (or move) queries defined as follows:
(1) If is the empty sequence
, then
(2) If is a stop (or move) query
, then
(3) If is an expression of the form
, then
(4) If is an expression of the form
, then
(5) If is an expression of the form
, then
(6) If is an expression of the form
, then
(7) If is an expression of the form
, then
(8) If is an expression of the form
, then
We immediately derive that:
(9) The expressions ‘’ and ‘
’ are semantically equivalent, since:
from (4), (1), and (5).
(10) The expressions ‘’ and ‘
’ are semantically equivalent, since:
from (8), (1), and (5).
Let be a sequence with
elements, and
be two positive integers. Then,
is the segment of
starting at the
element and ending at the
element of
, if
,
, if
, and
, if
or
.
We extend the notion of segment to a trajectory , with length
, so that
, for any two positive integers
and
. We say that a trajectory
is a segment of
iff there are positive integers
and
such that
.
Let be an interpretation for
and
be a trajectory over
, with length
, where
is a sequence of stops of
and
is a sequence of moves of
. Let
be a stop (or move) sequence expression.
There are at least two options for the semantics of stop (or move) sequence expressions, depending on how is evaluated against
:
● Strong semantics, denoted , when
is evaluated from the beginning to the end of
.
● Weak semantics, denoted , when
is evaluated against a segment of
, which is required neither to start at the beginning of
nor to terminate at the end of
.
This research adopts the weak version as the default semantics. However, note that one can force an expression to be evaluated from the beginning to the end of the trajectories by using
and
at the beginning and at the end of
.
Strong satisfiability is defined as follows. If is a non-empty trajectory, then
strongly satisfies
iff
● (the empty sequence
is in
), or
● There is a non-empty sequence in
such that, for each
,
(or
, for move sequence expressions), and
, where
is the length of the trajectory; in this case, we say that
is the effective length of
induced by its evaluation in
.
If is the empty trajectory, then
strongly satisfy
iff
.
We say that strongly satisfies a stop/move sequence expression
iff
strongly satisfies
,
strongly satisfies
, and
, where
is the effective length of
induced by its evaluation in
and
is the effective length of
induced by its evaluation in
.
We say that weakly satisfies
iff there is a segment
of
such that
.
We conclude this section with examples that illustrate the differences between strong and weak satisfiability. Under the notion of weak satisfiability, the queries in , with their intended interpretation, are expressions over the alphabet , where
● The terms Museidipisa, Cappelledipisa, Torridipisa and Chiesedipisa are atomic concepts of .
● The terms Torre_pendente_di_pisa and Torre_del_Leone are constants of .
Furthermore, the queries 1 to 1 in must be rewritten as follows:
● Each constant is replaced by the concept expression
.
● Each stop query is replaced by the concept expression
, as in the example below, to conform with EquationEq. 1
(1)
(1) .
● Likewise, each move query is replaced by the concept expression
, to conform with EquationEq. 2
(2)
(2) .
For example, Queries 1 and 1 are respective formally rewritten as:
Q1: Stop
enrichedBy.Museidipisa; Stop
enrichedBy.Cappelledipisa
Q5: Begin
enrichedBy.Museidipisa; End
enrichedBy.Cappelledipisa
where and
are specializations of
.
4.2.3. Intercalated stop-and-move sequence expressions
The definition of a stop/move sequence expression as a pair , where
is a stop sequence expression and
is a move sequence expression, is attractive from a formal point of view, but it may hide some complexities. Indeed, if a semantic trajectory
satisfies
, then the effective length of
must be one less than the effective length of
, by definition, to be able to intercalate the two sequences. But this requirement cannot be verified by a syntactical inspection of
and
and is introduced only in the semantic notion of satisfiability.
For example, consider a stop/move sequence expression , where:
and
.
Since uses the ‘+’ operator, it denotes sequences of move queries of arbitrary lengths, but only the sequence ‘
’, which has a length equal to 3, could be properly intercalated with
, which has a length equal to 4.
We therefore define an intercalated stop-and-move sequence expression as an expression of the form:
, where
is a stop sequence expression and
is a move sequence expression, for
and
.
To define the semantics of intercalated stop-and-move sequence expression, we proceed as in Section 4.2.2, attaining only to weak satisfiability. The expansion of , denoted
, is defined as for stop sequence expressions, but respecting the intercalation of stop-and-move expressions.
Let . Assume, without loss of generality, that
is of the form:
, where
is a sequence of stop queries and
is a sequence of move queries, for
and
.
Let and
, for
, and likewise for
. The stop projection of
is the sequence of stop queries
and the move projection of
is the sequence of move queries
such that:
where is the length of
and
is the length of
, for
and
.
An example of an intercalated stop-and-move sequence expression would be:
The following sequences pertain to :
The stop projection of is
and the move projection of
is
, where:
The equalities follow if we observe that . Note that if we intercalate
and
we obtain
again:
Finally, let be a trajectory. If
is the empty trajectory, then
does not weakly satisfy
. If
is a non-empty trajectory then
weakly satisfies
iff there is
such that
weakly satisfies
, where
is the stop projection of
and where
is the move projection of
.
5. An RDF framework for querying semantic trajectories
Based on the formal framework of Section 4, this section introduces a concrete RDF framework for querying semantic trajectories. It first defines an RDF model for representing semantic trajectories. Then, it introduces the SPARQL stop (or move) queries and SPARQL stop (or move) sequence expressions. Next, it discusses how to compile SPARQL stop sequence expressions into equivalent SPARQL queries. Finally, it shows how to process SPARQL intercalated stop-and-move sequence expressions.
5.1. SPARQL query expressions over semantic trajectories
The model is expressed as an RDF schema with classes (Trajectory, Stop, Move, Begin, End), properties (enrichedBy, from, to, nextS, nextM, has, begins, ends) and declarations (see ). The enrichment classes and properties are not part of the proposed RDF model for semantic trajectories, as highlighted in Section 4.1. We assume that they are defined in a knowledge base.
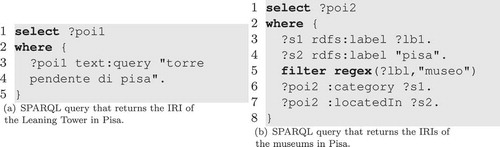
A SPARQL enrichment query is a SPARQL select query over the enrichments knowledge base whose TARGET clause has a single variable and, thus, returns a set of IRIs that identify enrichments. illustrates two SPARQL enrichment queries. The property function http://jena.apache.org/text#query
, in the query of ), combines SPARQL and full-text search via Lucene in Apache Jena. SPARQL enrichment queries such as these may, in fact, be automatically generated from keyword queries, as discussed in Section 6. We stress that a SPARQL enrichment query is not restricted to queries of the forms shown in , but they can be any SPARQL query over the enrichments knowledge base, whose TARGET clause has a single variable.
Figure 2. Examples of two SPARQL enrichment queries
provides a summary of stop expressions and the respective SPARQL queries. The definition of SPARQL move queries is an exact parallel and is omitted.
Table 5. A summary of expressions and their SPARQL equivalent
As in Section 4.2.2, a SPARQL stop sequence expression is a regular expression of SPARQL stop queries, a SPARQL move sequence expression is a regular expression of SPARQL move queries, and a SPARQL stop/move sequence expression is a pair , where
is a SPARQL stop sequence expression and
is a SPARQL move sequence expression. The notion of SPARQL intercalated stop-and-move sequence expressions is defined as in Section 4.2.3. Finally, we introduce the notion of a restricted SPARQL stop sequence expression, defined exactly as a SPARQL stop sequence expression, except that expressions of the forms
and
are allowed only when
is a SPARQL stop query (and not recursively a SPARQL stop sequence expression). The same holds for
and
. Likewise, a restricted SPARQL intercalated stop-and-move sequence expression allows expressions of the forms
and
only when
is a SPARQL stop query, and expressions of the forms
and
only when
is a SPARQL move query.
5.2. Processing of SPARQL stop sequence expressions
This section discusses how to compile restricted SPARQL stop sequence expressions to SPARQL queries. The processing of SPARQL move sequence expressions is entirely similar. The compilation process recursively parses a restricted SPARQL stop sequence expression and replaces each sub-expression of
by a SPARQL graph pattern that depends on the syntax of the sub-expression. The result is a SPARQL graph pattern, which is further post-processed to eliminate redundant triple patterns. The final SPARQL graph pattern is used to construct the WHERE clause of the SPARQL query Q that corresponds to
. The target clause of Q is a list of three variables, ?t, ?begin and ?end. When executed, Q binds ?t to a trajectory
, and ?begin and ?end to stops
and
of
, such that the segment of
from
to
strongly satisfies
, and
weakly satisfies
. Section 6 contains an example of the compilation process.
The compilation process uses templates, which are expressions of the form
Template(;?t,?begin,?end)
where is a restricted SPARQL stop sequence expression, and ?t, ?begin and ?end are SPARQL variables. When called, the template expands to a schematic graph pattern
, in the same way, that a macro expands in traditional programming languages. The schematic graph pattern
may contain calls to other templates, and non-standard SPARQL commands, such as if-then-else’s, as in Template 1. The expansion process replaces the formal parameters by the concrete parameter values passed in the call, renames the other variables used in
to avoid conflicts, and eliminates non-standard SPARQL commands. In the resulting SPARQL graph pattern:
● If is the empty stop sequence expression
, then
is the empty group pattern ‘{}’ that matches any graph (including the empty graph) with one solution that does not bind any variables. This is justified since the empty stop sequence expression matches any trajectory.
● If is not the empty stop sequence expression,
binds ?t to a trajectory
, and ?begin and ?end to a stops
and
of
such that the sequence of consecutive stops of
from
to
satisfies
.
Recall that a stop SPARQL query Q has a single variable ?v in the TARGET clause and let Q[?u] denote Q with ?v replaced by ?u. Two of the most common query templates are presented in the following:
(1) Template (‘S1;S2’;? t,? begin,? end)
1 Template (‘S1’;? t,? begin,? endS1).
2 if bound (? endS1)
3 then { ? endS1 :nextS ? beginS2.
4 Template (‘S2’; ? t , ? beginS2 , ? endS2) }
5 else { Template (‘S2’ ; ? t , ? begin , ? endS2) }
6 bind (IF (bound(? endS2) , ? endS2 , ? endS1) as ? end)
Note: This template uses a non-standard SPARQL if-then-else construct.
First note that the template call for S1 may evaluate to , leaving ?endS1 unbound, and the template calls for S2 may also evaluate to
, leaving ?endS2 unbound. There are therefore four cases to consider:
Case 1: The template calls for S1 and S2 do not evaluate to . Then, they bind ?t to a trajectory
and ?begin, ?endS1, ?beginS2 and ?end to stops
,
,
and
of
, respectively, such that: (1) the sequence of consecutive stops in
from
to
satisfies S1; (2) the sequence of consecutive stops in
from
to
satisfies S2; (3)
and
are consecutive stops of
(by Line 3). Line 6 then makes the binding of ?end equal to that of ?endS2.
Case 2: The template call for S1 does not evaluate to and the template call for S2 evaluates to
. Then, the template call for S1 binds ?t to a trajectory
and ?begin and ?endS1 to stops
and
such that the sequence of consecutive stops in
from
to
satisfies S1. The template call for S2 does not bind ?endS2. Line 6 then makes the binding of ?end equal to that of ?endS1.
Case 3: The template call for S1 evaluates to and the template call for S2 does not evaluate to
. The template call for S1 does not bind ?endS1. Then, by Line 2, the template call for S2 in Line 5 binds ?t to a trajectory
and ?begin and ?endS2 to stops
and
of
such that the sequence of consecutive stops in
from
to
satisfies S2. Line 6 then makes the binding of ?end equal to that of ?endS2.
Case 4: The template calls for S1 and S2 both evaluate to . Then, both ?endS1 and ?endS2 are unbound and Line 6 leaves ?end unbound.
(2) Template(‘Q’;?t,?begin,?end)
1 ? t: has ? begin.
2 ? begin: nextS* ?end.
3 {Q[? begin]}.
4 {Q[?end]}.
5 filter not exists {
6 ? begin: nextS* ?stopM.
7 ? stopM:nextS* ?end.
8 filter not exists {Q[?stopM]}}
This graph pattern binds variable ?t to a trajectory and variables ?begin and ?end to stops
of
of
such that all consecutive stops from
to
in
satisfy Q, including
and
.
Notes:
(a) The actual implementation of the template places Lines 3 and 4 before Lines 1 and 2, for efficiency reasons.
(b) This template applies only when Q is a SPARQL stop query, and not a SPARQL stop sequence expression, in view of the use of the SPARQL path expression ‘:nextS*’.
(c) Lines 5 to 7 explore the fact that is equivalent to
. Thus, the sentence ‘for any stop
between
and
,
satisfies
’ is equivalent to ‘there is no stop
between
and
such that
does not satisfy
.’
The final SPARQL graph pattern is subjected to a simplification process. However, a detailed discussion of the simplification process is outside the scope of this article. Section 6 contains an example that illustrates how to compile a restricted SPARQL stop sequence expression to an equivalent SPARQL query, and how to simplify the query.
5.3. Processing of SPARQL intercalated stop-and-move sequence expressions
A restricted SPARQL intercalated stop-and-move sequence expression allows expressions of the forms and
only when
is a SPARQL stop query, and expressions of the forms
and
only when
is a SPARQL move query. Let S1 and S2 be restricted SPARQL stop sequence expressions as those presented in Section 5.2. Let M, M1 and M2 be SPARQL move queries. Recall that M has a single variable in the TARGET clause, and let M[?u] denote M with this single variable replaced by ?u (and likewise for M1 and M2). The templates that follow are not an exhaustive list, but illustrate the extension process.
(3) Template(‘S1< M1;M2> S2’,?t,?begin,?end)
1 Template(‘S1’ , ? t , ? begin , ? endS1).
2 Template(‘S2’ , ? t , ? beginS2 , ? end) .
3 ?move1: from ? endS1 ;: to ? stop2 .
4 ?move2: from ? stop2 ;: to ? beginS2 .
5 {M1[? move1] } .
6 {M2[?move2] }
The recursive template calls in Lines 1 and 2 bind variable ?t to a trajectory and variables ?begin, ?endS1, ?beginS2 and ?end to stops
,
,
and
of
, respectively, and Lines 3 and 4 bind variables ?move1 and ?move2 to moves
and
of
, respectively, such that: (1) the sequence of consecutive stops in
from
to
satisfies S1; (2) the sequence of consecutive stops in
from
to
satisfies S2; (3)
is from
to a stop
and
from
to
(by Lines 3 and 4); (4)
satisfies M1 and
satisfies M2 (by Lines 5 and 6).
Note: This templates assume that the recursive template calls do not evaluate to . A more elaborated template would include tests for unbound variables, as in Template 1.
(4) Template(‘S1 < M> S2’;?t,?begin,?end)
1 Template(‘S1’ ; ? t , ? begin , ? endS1) .
2 Template(‘S2’ ; ? t , ? beginS2 , ? end) .
3 ?moveB: from endS1 .
4 ?moveE: to beginS2 .
5 ?moveB: nextM* ?moveE .
6 {M[? moveB]} .
7 {M[? moveE]} .
8 filter not exists {
9 ?moveB:nextM* ?moveM .
10 ?moveM:nextM* ?moveE .
11 filter not exists {M[?moveM]}}
The recursive template calls in Lines 1 and 2 bind variable ?t to a trajectory and variables ?begin, ?endS1, ?beginS2 and ?end to stops
,
,
and
of
, respectively, and Lines 3 and 4 bind variables ?moveB and ?moveE to moves
and
of
, respectively, such that: (1) the sequence of consecutive stops in
from
to
satisfies S1; (2) the sequence of consecutive stops in
from
to
satisfies S2; (3)
is from
and
is to
(by Lines 3 and 4); (4) all moves in the sequence of moves of
from
to
satisfy M (by Lines 5–11).
6. Keyword query expressions over semantic trajectories in RDF
This section introduces keyword query expressions over semantic trajectories in RDF as a user-friendly alternative to SPARQL intercalated stop-and-move sequence expressions. It also discusses, with the help of an example, how to process such keyword query expressions, based on the results of Section 5.
As a brief motivation, we observe that keyword search proved to be a popular paradigm under the users’ perspective. From the origins of information retrieval, keyword search was used to retrieve items (usually documents) that are somehow relevant to the search keywords. These techniques evolved to relational and RDF database search, where entities and their attributes are considered to be the documents that must be retrieved. Advanced graph-search algorithms allow us to retrieve relevant entities from a database and also show how these entities relate to each other. This makes such algorithms attractive for searching large collections of semantic trajectory data. However, despite their advantages, graph-based queries are still not convenient for expressing restrictions on the sequence of stops and moves. The keyword query expressions introduced in this section overcome this difficulty.
The definitions that follow are similar to those in Sections 4.2 and 5.1. A keyword stop query is a finite set of literals, called keywords, that defines a set of stops based on their enrichments. These queries would then be applied to the RDF knowledge base to select a set
of enrichments, which are then used to select the set of stops that are related to the enrichments in
by the enrichedBy property. A keyword move query is likewise defined.
Schema-based algorithms (García et al. Citation2017, Izquierdo et al. Citation2018) can then be used to translate keyword stop (or move) queries into SPARQL queries that retrieve resources by their name, such as ‘Torre Pendente di Pisa’, or by their attributes, such as ‘Musei di Pisa’. In the first case, the query would retrieve a single POI id that corresponds to the Leaning Tower of Pisa (see )), while in the second case it would return a list of ids that correspond to the museums in Pisa (see )). One can relax the scope of the query by informing only some keywords, such as ‘Torre di Pisa’, in which case the keyword query could return the ids of the ‘Torre Pendente di Pisa’ and ‘Ristorante La Torre Pisa’. A detailed discussion of the process of translating keyword queries to SPARQL queries is outside of the scope of this article.
A keyword intercalated stop-and-move sequence expression is a regular expression based on keyword stop-and-move queries, as in Section 4.2. The regular expression symbols may be replaced by the reserved terms listed in .
The processing of a keyword intercalated stop-and-move sequence expression to SPARQL has two basic steps:
(1) Translate into a SPARQL intercalated stop-and-move sequence expression
:
(a) If necessary, replace the reserved terms “Stop”, “Move”, “Begin” and “End” by SPARQL queries, as discussed in Section 5.1.
(b) Also, if necessary, replace the reserved terms that denote regular expressions by equivalent symbols, using .
(c) Translate each keyword stop (or move) query into a SPARQL query.
(2) Process as discussed in Section 5.
We illustrate the processing of 1 (see ), in the Jena ARQ SPARQL engine:
Step 1: Translate the keyword queries ‘Cappelledipisa’, ‘Chiesedipisa’ and ‘Torre_pendente_di_pisa’ to SPARQL enrichment queries, as shown in , to retrieve the resources associated with these POIs. Note that variables ?v1, ?v2 and ?v3 bind the IRIs of POIs resources associated with ‘Cappelledipisa’, ‘Chiesedipisa’ and ‘Torre_pendente_di_pisa’, respectively.
Figure 3. The SPARQL enrichment queries of the keyword queries in

Step 2: Process the resulting SPARQL intercalated stop-and-move sequence expression . The process recognizes that
satisfies Template 5.3: Template(‘S1 < M
> S2’; ?t, ?begin, ?end) where:
● S1 is the SPARQL query corresponding to ‘Begin S3’;
● S3 is the SPARQL query corresponding to ‘(Cappelledipisa | Chiesedipisa)’
● S2 is the SPARQL query corresponding to ‘S4 End’
● S4 is the SPARQL query corresponding to Torre_pendente_di_pisa
● M is the SPARQL query corresponding to <Bus>
and combines the different templates to the final template for
Step 3: The compilation process ends by setting the TARGET clause (as a SELECT form) with variable ?t that binds the queried trajectories, and applying some simplifications (indicated after the query). The final synthesized SPARQL query is:
1 select ? t , ? begin , ? end
2 where {
3 ? t: begins ? begin .
4 {
5 { ? begin : enrichedBy ?v1 .
6 ?v1 text : query ‘Cappelledipisa’}
7 UNION
8 { ? begin: enrichedBy ?v2 .
9 ?v2 text :query ‘Chiesedipisa’ }
10}
11 ? t :ends ?end .
12 { ? end: enrichedBy?v3.
13 ?v3 text: query ‘Torre_pendente_di_pisa’ }
14 ?moveE: to ? end ;: enrichedBy ? transpE .
15 filter (?transpE = : Bus)
16 ?moveB: from ?begin ; : nextM* ?moveE;:enrichedBy ?transpB .
17 filter (?transpB = : Bus)
18 filter not exists {
19 ?moveB:nextM* ?moveM .
20 ?moveM:nextM* ?moveE .
21 filter not exists { ? moveM: enrichedBy ? transpM filter (?
transpM = : Bus) }
22}
23}
7. A proof-of-concept experiment
For the construction of the TripBuilder RDF dataset, we wrote a Java program that parses the TripBuilder city data files, extracts data for POIs, stops and trajectories and triplifies the resulting data in RDF. We also included:
The property:length, added to the instances of the:Trajectory class, indicates the length of a trajectory.
The property:move_number, added to the instances of the:Move class, indicates the sequential position of a move in a trajectory.
The class:Transportation whose resources were automatically generated, labeled with a value in the set {“Walk”, “Taxi”, “Bus”, “Subway”}, and randomly linked to resources of the:Move class using the property:enrichedBy. This new class helps exploit the capabilities of the translation algorithm, given that the original TripBuilder dataset does not contain information about moves.
The resulting RDF dataset contains a total of 1,617,582 triples, which break down to 5 rdfs:Class declarations, 255,018 class instances (47% of them corresponding to stops, 30% to moves and 21.5% to trajectories) and 1,973 indexed property values.
We put the RDF dataset on a Jena ARQ SPARQL server (running on a quad-core processor Intel(R) Core(TM) i7-5820 K [email protected] GHz, 64 GB of RAM and SSD 1TB, with GNU/Linux Ubuntu 16.04.6 LTS oS). The string property values, including rdfs:label values, were indexed using Lucene (hosted in the same server) thus allowing both SPARQL queries and full-text search.
The experiments evaluated our approach on the keyword query expressions of , measuring: (1) the templates that the SPARQL stop-and-move sequence expressions satisfy; and (2) the average execution time of 10 repetitions of each synthesized query.
Given that queries Q1 to Q7 are stop sequence expressions, and Q8 to Q10 are examples of intercalated stop-and-move sequence expressions the results can be summarized as:
Q1 and Q2 are quite simple and the equivalent SPARQL queries have a small runtime.
The runtime of the SPARQL query for Q3 is considerably higher due to the nested filter not exists group patterns and the SPARQL Property Path operator “*” inside the stop patterns.
Q7 contains a stop sequence expression similar to Q3, and its SPARQL query has a runtime comparable to that of the SPARQL query for Q3 (about 4 seconds).
However, the SPARQL query for Q9 has a small runtime (similar to Q2). The runtime of its SPARQL query for Q10 is about 3 seconds.
To conclude, we observe that the complexity of the SPARQL query synthesized in each case naturally reflects the complexity of the keyword query expressions. As expected, queries with triple patterns with the property path operator ‘*’ inside nested ‘filter not exists’ group patterns (Q3, Q7), or with complex graph patterns (Q10) had a high runtime. However, unexpectedly, even with a complex graph pattern, Q9 had a small runtime. Queries with less complex graph patterns (Q1, Q2, Q4, Q5, Q8), or with just UNION or OPTIONAL patterns (Q6) had acceptable runtime. Overall, all queries were executed within the specified timeout of 1 minute. The average runtime of the test suite queries, about 1.5 s, was reasonable. Hence, the experiment suggests that the proposed approach, based on keyword query expressions and RDF, is feasible.
8. Conclusions and future work
This article addressed the question of retrieving semantic trajectories with a query language that includes: (1) stop-and-move queries that select sets of stops or moves based on their enrichments; and (2) sequence expressions that define how to match the stop-and-move queries with the sequence of actions defined in the semantic trajectory.
The article first introduced a formal model for semantic trajectories and defined stop-and-move sequence expressions, with well-defined syntax and semantics. Then, it moved to a concrete semantic trajectory model in RDF and described how to process SPARQL stop-and-move sequence expressions, using state-of-the-art, efficient SPARQL query processors. Using keywords to capture stop-and-move queries, and terms with predefined semantics to define sequence expressions it offers a user-friendly query notation that can be compiled into SPARQL queries. Finally, the article described a proof-of-concept experiment using the TripBuilder dataset, a semantic trajectory dataset constructed from user-generated content obtained from Flickr, combined with data from Wikipedia.
In more detail, Section 4.1 formalized the semantic trajectory model adopted, within the tradition of Description Logic. The adoption of Description Logic is justified since it is a well-known formalism, the notions of atomic concept and atomic role suffice to model semantic trajectories, and it has been used before to formalize trajectory models. Section 4.2 covered the syntax and semantics of stop-and-move sequence expressions – the central concept of the article – which, for the first time, explore the richness of intercalated sequences of stops and moves, and not just stop sequences or just move sequences. Since a sequence expression E imposes a complex restriction on a semantic trajectory , this step was required to clarity how E evaluates over
. This article adopted the weak semantics when E is evaluated against a segment of
, which is required neither to start at the beginning of
nor to terminate at the end of
. The formal semantic trajectory model led to a concrete model in RDF and to concrete SPARQL queries, which opened the way to implementations of the concepts on top of standard RDF stores. Section 5 introduced SPARQL stop-and-move sequence expressions, a concrete realization of abstract sequence expressions, and showed how to compile them into standard SPARQL queries. The compilation process is recursive and non-trivial since SPARQL stop-and-move sequence expressions are constructed by composing atomic SPARQL queries and may involve complex operators, such as ‘*’. However, SPARQL has a sophisticated syntax, out of the reach of the typical user. The third step of the article was then to hide such complex syntax under a user-friendly, keyword-based notation. Section 6 introduced the class of keyword query expressions over semantic trajectories in RDF and showed how to compile such expressions into SPARQL stop-and-move sequence expressions, which are then compiled into SPARQL queries. Section 7, the last step, summarized a proof-of-concept experiment, within the space limitations of the article, that showed that the SPARQL queries compilated from stop-and-move sequence expressions have adequate performance. Therefore, the proof-of-concept suggested that stop-and-move sequence expressions, when compiled to SPARQL, are indeed a feasible language to search semantic trajectories and not just an abstract query framework.
As future work, we plan to run large-scale experiments with real-world semantic trajectory datasets, backed up by a robust implementation of the keyword stop-and-move sequence expression SPARQL compiler. A target application would be related to investigations of cargo vessel incidents. The stop-and-move sequence expressions introduced in this article would help, for example, to locate vessel trajectories that match disallowed movement patterns, such as ‘trajectories of oil tankers that sailed from any oil rig port in country , sailed through a high-risk region (e.g. a piracy prone area) and arrived at a port
in another country
’. Such trajectories are sometimes followed by captains at the risk of not been covered by insurance companies in the case of an attack. It could also be used to query for different types of trajectories, such as navigation patterns of interest in an e-shop: ‘customers who visited the product page of a tv-set
(an analogy of stop), then followed a link (a type of move) to another tv-set
(another stop of the same type) and later on their session searched (i.e. a different type of “move” within a website) for a console
’. We also plan to adapt the proposed approach to other types of sequences, such as music playlists. Finally, we will invest in extending the approach to a question-and-answer scenario.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data and codes availability statement
The original TripBuilder dataset was not created by the authors of this article, but the data and codes that support the findings of this study are available at https://doi.org/10.6084/m9.figshare.11559090.
Additional information
Funding
Notes on contributors
Yenier Torres Izquierdo
Yenier Torres Izquierdo is currently studying towards a D.Sc. degree in Informatics at the Department of Informatics of the Pontifical Catholic University of Rio de Janeiro – PUC-Rio, in the database area, with expected completion in 2021. He holds an M.Sc. in Informatics from PUC-Rio (2017), in the area of the database, and had a scholarship “Student Grade 10” in 2016 and 2019 from FAPERJ for his academic results during the M.Sc. and D.Sc. studies. He obtained a B.Sc. in Computer Science from the University of Havana (2012). He is currently a software developer at the Tecgraf Institute – PUC-Rio. His research topics are Process Mining, Data Mining, Databases, Compilation, DSL, Programming Languages, and Artificial Intelligence.
Grettel Monteagudo García
Grettel Monteagudo García obtained a D.Sc. in Informatics from the Pontifical Catholic University of Rio de Janeiro – PUC-Rio (2020), in the area of the database, an M.Sc. in Informatics from PUC-Rio (2016), also in the area of the database, and a B.Sc. in Computer Science from the University of Havana (2012), in the database management systems area. She had a scholarship “Student Grade 10” in 2018 and 2015 from FAPERJ for her academic results during the D.Sc and M.Sc. studies, respectively. She won the HackPUC 2014, hackathon organized by PUC-Rio. She is currently a researcher and software developer at the Tecgraf Institute – PUC-Rio. She worked at the Department of Information Systems at the José A. Echeverría Polytechnic Institute (CUJAE) in Havana, Cuba, in 2013, as a trainee professor and researcher. Her research interests include ontological models, Semantic Web technologies, keyword search, and graph algorithms.
Marco A. Casanova
Marco A. Casanova is a Full Professor at the Department of Informatics and Coordinator of the Central Planning and Evaluation Office of the Pontifical Catholic University of Rio de Janeiro – PUC-Rio. He graduated in Electronic Engineering at the Military Institute of Engineering (1974), obtained an M.Sc. in Informatics from PUC-Rio (1976), and an M.Sc. (1977) and a Ph.D. (1979) in Applied Mathematics from Harvard University. He was Graduate Program Coordinator (2005-2007) and Director (2007-2011) of the Department of Informatics of PUC-Rio. His research interests concentrate on database conceptual modeling and the construction of database management systems. In July 2012, he received the Scientific Merit Award from the Brazilian Computer Society.Luiz André Portes Paes Leme obtained a B.Sc. in Electrical Engineering from the State of Rio de Janeiro University (1989), and an M.Sc. in Informatics (2006) and a D.Sc. in Informatics (2009), both from the Pontifical Catholic University of Rio de Janeiro. He conducted postdoctoral research at the Consiglio Nazionale delle Ricerche (2015). Currently, he is Associate Professor at the Federal Fluminense University. His research interests include data integration, information retrieval, and mobile data analysis.
Luiz André P. Paes Leme
Luiz André P. Paes Leme obtained a B.Sc. in Electrical Engineering from the State of Rio de Janeiro University (1989), and an M.Sc. in Informatics (2006) and a D.Sc. in Informatics (2009), both from the Pontifical Catholic University of Rio de Janeiro. He conducted postdoctoral research at the Consiglio Nazionale delle Ricerche (2015). Currently, he is Associate Professor at the Federal Fluminense University. His research interests include data integration, information retrieval, and mobile data analysis
Christos Sardianos
Christos Sardianos is currently a Ph.D. candidate and research assistant at the Department of Informatics & Telematics at Harokopio University of Athens. He also holds an MSc in the area of Web Engineering and a BSc in Electronics Engineering. The research area of his Ph.D. is “Knowledge Mining from Large Scale Social Networks”, under the supervision of Associate Professor Iraklis Varlamis. His main research topics of interest include Recommender Systems, Data Mining, Machine Learning, and Social Network Analysis. He has participated in numerous EU, international and national funded projects including Fortissimo (FP7), EM3, TEACHING, Palo Analytics, ICT4Growth, DemocracIT and MASTER (H2020).
Konstantinos Tserpes
Konstantinos Tserpes is an Assistant Professor at the Department of Informatics and Telematics of the Harokopio University of Athens. He holds a Ph.D. in the area of Distributed Systems from the school of Electrical and Computer Engineering of the National Technical University of Athens (2008). His research interests revolve around distributed systems, software and service engineering, Big Data analytics, and social systems. He has been involved in several EU and National funded projects leading research for solving issues related to scalability, interoperability, fault tolerance, and extensibility in application domains such as multimedia, e-governance, post-production, finance, e-health, and others. He has served as the scientific or general coordinator in several ICT projects such as +Spaces, SocIoS, Consensus, Fortissimo (FP7), and BASMATI (H2020) and the principal investigator for the projects ACCORDION, TEACHING, COLLABS, MASTER and SmartShip (H2020).
Iraklis Varlamis
Iraklis Varlamis is an Associated Professor of Data Management at the Department of Informatics and Telematics of the Harokopio University of Athens. He holds a Ph.D. in Informatics from the Athens University of Economics and Business, Greece, and an MSc in Information Systems Engineering from UMIST, UK. He has been involved as a technical coordinator in a number of EU funded projects concerning knowledge management, data mining, machine learning, and expert systems. He has also coordinated several national R&D projects concerning data management and personalized delivery of information. He has authored more than 130 articles concerning text and graph mining and intelligent applications in social networks and the web and received more than 2200 citations. He has worked as a scientific coordinator or principal investigator in several collaborative research projects funded by National, EU (e.g. H2020 TEACHING, SustAGE, MASTER, FP7-Fortissimo) and International Funds (e.g. Qatar Funding-EM3).
Lívia C. Ruback Rodrigues
Lívia C. Ruback Rodrigues obtained a D.Sc. in Informatics (2017) and an M.Sc. in Informatics (2013), both from the Pontifical Catholic University of Rio de Janeiro – PUC-Rio, and a B.Sc. in Computer Science from the Federal University of Juiz de Fora (2009). She currently is an Assistant Professor at the Department of Computing of the Federal Rural University of Rio de Janeiro and a member of the AI Inclusive Project. Her research interests include Linked Data, Semantic Web, Social Media, and Social Computing.
Notes
1. OWL stands for Web Ontology Language.
References
- Alvares, L.O., et al. 2007a. Dynamic modeling of trajectory patterns using data mining and reverse engineering. In: 26th international conference on conceptual modeling, poster session. Auckland, New Zealand: ACM, vol. 83, 149–154.
- Alvares, L.O., et al. 2007b. A model for enriching trajectories with semantic geographical information. In: 15th annual ACM international symposium on advances in geographic information systems. Auckland, New Zealand: ACM, 22.
- Baader, F., et al. eds., 2003. The description logic handbook: theory, implementation, and applications. USA: Cambridge University Press.
- Baglioni, M., et al. 2008. An ontology-based approach for the semantic modelling and reasoning on trajectories. In: International conference on conceptual modeling. LNCS. Berlin, Heidelberg: Springer, vol. 5232, 344–353.
- Bast, H., Buchhold, B., and Haussmann, E., 2016. Semantic search on text and knowledge bases. Foundations and Trends® in Information Retrieval, 10 (1), 119–271. doi:10.1561/1500000032
- Bergamaschi, S., et al. 2016. Combining user and database perspective for solving keyword queries over relational databases. Information Systems, 55, 1–19. doi:10.1016/j.is.2015.07.005.
- Bogorny, V., et al. 2014. Constant – a conceptual data model for semantic trajectories of moving objects. Transactions in GIS, 18 (1), 66–88. doi:10.1111/tgis.12011
- Brilhante, I., et al., 2014. TripBuilder: a tool for recommending sightseeing tours. In: 36th European Conf. on Information Retrieval (ECIR’14). Springer, Cham, 771–774.
- Fileto, R., et al. 2013. Baquara: A holistic ontological framework for movement analysis using linked data. In: International conference on conceptual modeling. LNCS. Springer, Berlin, Heidelberg, vol. 8217, 342–355.
- Fileto, R., et al. 2015. The baquara2 knowledge-based framework for semantic enrichment and analysis of movement data. Data & Knowledge Engineering, 98, 104–122. doi:10.1016/j.datak.2015.07.010.
- Furtado, A.S., et al. 2016. Multidimensional similarity measuring for semantic trajectories. Transactions in GIS, 20 (2), 280–298. doi:10.1111/tgis.12156
- García, G.M., et al. 2017. RDF keyword-based query technology meets a real-world dataset. In: 20th International Conference on Extending Database Technology, Venice, Italy. OpenProceedings.
- Ghanbarpour, A. and Naderi, H., 2019. A model-based keyword search approach for detecting top-k effective answers. The Computer Journal, 62 (3), 377–393. doi:10.1093/comjnl/bxy056
- Han, S., et al. 2017. Keyword search on RDF graphs - A query graph assembly approach. In: ACM Conference on Information and Knowledge, CIKM 2017, Singapore, Singapore. ACM Press, vol. Part F1318, 227–236.
- Hristidis, V. and Papakonstantinou, Y., 2002. Discover: keyword search in relational databases. In: 28th International Conference on Very Large Databases (VLDB’02). Hong Kong, China: VLDB Endowment, 670–681. Available from: https://linkinghub.elsevier.com/retrieve/pii/B9781558608696500652
- Hu, Y., et al. 2013. A geo-ontology design pattern for semantic trajectories. In: International Conference on Spatial Information Theory. LNCS. Cham: Springer, vol. 8116. 438–456.
- Izquierdo, Y.T., et al. 2018. QUIOW: A keyword-based query processing tool for RDF datasets and relational databases. In: 30th International Conference on Database and Expert Systems Applications (DEXA’18), Regensburg, Germany. Springer, vol. 11030, 259–269.
- Le, W., et al. 2014. Scalable keyword search on large RDF data. IEEE Transactions on Knowledge and Data Engineering, 26 (11), 2774–2788. doi:10.1109/TKDE.2014.2302294
- Lin, X.Q., Ma, Z.M., and Yan, L., 2018. RDF keyword search using a type-based summary. Journal of Information Science and Engineering, 34 (2), 489–504.
- Oliveira, P.D., Silva, A.D., and Moura, E.D., 2015. Ranking Candidate Networks of relations to improve keyword search over relational databases. In: 31st IEEE International Conference on Data Engineering (ICDE’15), Seoul, S. Korea. IEEE, 399–410.
- Parent, C., et al. 2013. Semantic trajectories modeling and analysis. ACM Computing Surveys (CSUR), 45 (4), 42. doi:10.1145/2501654.2501656
- Petry, L.M., et al. 2019. Towards semantic-aware multiple-aspect trajectory similarity measuring. Transactions in GIS, 23 (5), 960–975. doi:10.1111/tgis.12542
- Renso, C., et al. 2013a. How you move reveals who you are: understanding human behavior by analyzing trajectory data. Knowledge and Information Systems, 37 (2), 331–362. doi:10.1007/s10115-012-0511-z
- Renso, C., Spaccapietra, S., and Zimányi, E., 2013b. Mobility data. Cambridge: Cambridge University Press.
- Rihany, M., Kedad, Z., and Lopes, S., 2018. Keyword search over RDF graphs using wordnet. In: 1st International Conference on Big Data and Cyber-Security Intelligence (BDCSIntell’18), Hadath, Lebanon. CEUR-WS, vol. 2343, 75–82.
- Santipantakis, G.M., et al. 2017. Specification of semantic trajectories supporting data transformations for analytics: the datacron ontology. In: 13th International Conference on Semantic Systems. Amsterdam, Netherlands: ACM, 17–24.
- Spaccapietra, S., et al. 2008. A conceptual view on trajectories. Data & Knowledge Engineering, 65 (1), 126–146. doi:10.1016/j.datak.2007.10.008
- Tran, T., et al., 2009. Top-k exploration of query candidates for efficient keyword search on graph-shaped (RDF) data. In: 25th International Conference on Data Engineering, ICDE 2009, Shanghai, China. IEEE, 405–416.
- Wen, Y., Jin, Y., and Yuan, X., 2018. KAT: keywords-to-SPARQL translation over RDF graphs. In: 23rd International Conference on Database Systems for Advanced Applications (DASFAA’18), Gold Coast, Australia. Springer, vol. 10827, 802–810.
- Yan, Z., et al. 2008. Trajectory ontologies and queries. Transactions in GIS, 12, 75–91. doi:10.1111/j.1467-9671.2008.01137.x.
- Zenz, G., et al. 2009. From keywords to semantic queries-Incremental query construction on the semantic web. Journal of Web Semantics, 7 (3), 166–176. doi:10.1016/j.websem.2009.07.005
- Zheng, W., et al. 2016. Semantic SPARQL similarity search over RDF knowledge graphs. 42nd International Conference on Very Large Databases (VLDB’16), 9 (11), 840–851.
- Zhou, Q., et al. 2007. SPARK: adapting keyword query to semantic search. In: 6th International Semantic Web Conference (ISWC’07), Busan, Korea. Springer, vol. 4825, 694–707.