?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Spatially varying coefficient (SVC) models are a type of regression models for spatial data where covariate effects vary over space. If there are several covariates, a natural question is which covariates have a spatially varying effect and which not. We present a new variable selection approach for Gaussian process-based SVC models. It relies on a penalized maximum likelihood estimation and allows joint variable selection both with respect to fixed effects and Gaussian process random effects. We validate our approach in a simulation study as well as a real world data set. In the simulation study, the penalized maximum likelihood estimation correctly identifies zero fixed and random effects, while the penalty-induced bias of non-zero estimates is negligible. In the real data application, our proposed penalized maximum likelihood estimation yields sparser SVC models and achieves a smaller information criterion than classical maximum likelihood estimation. In a cross-validation study applied on the real data, we show that our proposed penalized maximum likelihood estimation consistently yields the sparsest SVC models while achieving similar predictive performance compared to other SVC modeling methodologies.
1. Introduction
Improved and inexpensive measuring devices lead to a substantial increase of spatial point data sets, where each observation is associated with (geographic) information on the observation location, say, a pair of latitude and longitude coordinates. Usually, these data sets not only consist of a large number of observations, but also include several covariates. Spatially varying coefficient (SVC) models are a type of regression models which offer a high degree of flexibility as well as interpretability for spatial data. In contrast to classical geostatistical models (see Cressie Citation2011 for an overview), they allow a covariate’s marginal effect, i.e., the corresponding coefficient, to vary over space. Prominent, existing methodologies for SVC modeling are Bayesian SVC processes by Gelfand et al. (Citation2003) and geographically weighted regression (GWR, Brunsdon et al. Citation1998, Fotheringham et al. Citation2002). Fields of application for SVC models are broad and include crime rates modeling (Wheeler and Waller Citation2009), ecological data (Finley Citation2011), air temperature modeling (Kim et al. Citation2021) or real estate price prediction (Gelfand et al. Citation2003, Wheeler et al. Citation2014). When modeling such data with SVC models, the large number of potential coefficients leads to the question: Which of the given covariates do indeed have a non-zero spatially varying coefficients? The motivation behind a viable variable selection approach of SVC models is two-fold. First, possible multicollineartiy between the covariates make the interpretation of regression models difficult and the parameter estimation unstable (Wheeler and Tiefelsdorf Citation2005, Wheeler and Calder Citation2007). Second, SVC models offer a high degree of flexibility which can lead to over-fitting to the data and ultimately results in worse out-of-sample predictive performance. Therefore, variable selection is an integral part of SVC modeling. While the literature on variable selection in general is extensive, it is very limited for SVC models.
Variable selection for SVC models is usually done locally or globally over space. For instance, Smith and Fahrmeir (Citation2007) introduce a local selection procedure for SVC models on lattice data. Reich et al. (Citation2010) proposed a Bayesian method that selects SVC globally, i.e., the coefficient enters the model equation either for all locations or for none. Boehm Vock et al. (Citation2015) present a simultaneous local and global variable selection.
As for GWR, Fotheringham et al. (Citation2013) and Lu et al. (Citation2014a) propose a step-wise information criterion-based variable selection. Joint variable shrinkage and selection algorithms like ridge regression, the least absolute shrinkage and selection operator (LASSO, Tibshirani Citation1996) or the elastic net (Zou and Hastie Citation2005) have been proposed specifically for GWR, too (Wheeler Citation2007, Citation2009, Vidaurre et al. Citation2012, Li and Lam Citation2018). Finally, Mei et al. (Citation2016) introduce a bootstrap approach to globally test for constant coefficients in GWR models.
Concerning frequentist Gaussian process (GP)-based geostatistical models, existing variable selection methods which we list in the following are exclusively for the fixed effects parts. Huang and Chen (Citation2007) proposed a selection method between smoothing splines with deterministic spatial structure and kriging which is GP-based. The method relies on generalized degrees of freedom (Ye Citation1998) to assess the models. Another variable selection for the fixed effects was proposed by Wang and Zhu (Citation2009). Using penalized least squares, variable selection under a variety of penalty functions is conducted. In particular, the penalty function smoothly clipped absolute deviation suggested by Fan and Li (Citation2001) and used in the simulation study performs best for variable selection in spatial models. However, the error term of the spatial models is defined as strong mixing and in all of the numerical examples the sample size is very limited. Chu et al. (Citation2011) provide theoretical results for variable selection in a GP-based geostatistical model using a penalized maximum likelihood. Since maximum likelihood estimation is computationally expensive, Chu et al. (Citation2011) also give results for variable selection under covariance tapering (Furrer et al. Citation2006). Their penalized maximum likelihood estimation procedure – with and without covariance tapering – is a one-step sparse estimation and therefore differs from Fan and Li (Citation2001). The penalty function of choice in Chu et al. (Citation2011) is the smoothly clipped absolute deviation, too.
In Dambon et al. (Citation2021a) a novel type of SVC models, so called GP-based SVC models, as well as a corresponding maximum likelihood estimation approach is presented. The GP-based SVC model can be applied to model and predict spatial data in a similar fashion to the above mentioned other methodologies. So far, GP-based SVC models have been applied on real estate data in order to obtain interpretable models for real estate price predictions and to study spatially varying relationships (Dambon et al. Citation2021a, Citation2022). In a comparison with GWR both in a simulation study and a real estate data application, it has been shown that GP-based SVC models have better predictive performance (Dambon et al. Citation2021a). Furthermore, the novel SVC model defines and estimates a single model in contrast to the GWR-based, location-specific model. Thus, the model and parameter interpretation of the GP-based SVC model is simpler. A disadvantage of the GP-based SVC model is that though the corresponding maximum likelihood approach has been specifically designed to allow large data analyses, the computational cost is still higher than GWR-based modeling.
Like with other SVC models, we assume that multicollinearity or over-fitting may hinder the GP-based SVC model to reach its full potential either with respect to predictive performance or model interpretability. In this article, we present a global variable selection methodology for GP-based SVC models that complements the already existing maximum likelihood approach. So far, such a variable selection methodology is missing. The rest of the article is structured as follows. We introduce GP-based SVC models in Section 2. In Section 3, we propose our implementation of the selection problem. Numeric results of a simulation study are given in Section 4. In Section 5, we present a real data application and assess the predictive performance of our proposed methodology in a cross-validation. In Section 6, we conclude.
2. Variable Selection for GP-based SVC models
2.1. GP-based SVC models
Let n be the number of observations, let p be the number of covariates for a fixed effect, and let q be the number of covariates
with random coefficients, i.e., SVCs. The fixed and random effects covariates do not necessarily need to be identical. Each observation i is associated with an observation location
in domain
Furthermore, let
be the vector of observed responses and
the error term (also called nugget). Here,
denotes an n dimensional multivariate normal distribution, where its mean vector
is an n dimensional vector with only 0 entries and its covariance matrix
We denote the n × n dimensional identity matrix by
Without loss of generality, we assume the random coefficients to have zero-mean and define a GP-based SVC model as
(1)
(1)
Note that the spatial structure of each SVC is described by a zero-mean GP This model assumption covers a broad variety of coefficients. For special interest coefficients such as sign preserving SVCs or spatially clustered coefficients we refer to Kim et al. (Citation2021) and Li and Sang (Citation2019), respectively.
In particular, we assume that each GP is defined by a covariance function c with range parameter ρk and variance
Hence, each SVC is parameterized by the covariance parameters
and potentially a mean effect μj in the case when
We assume additional parameters like the smoothness of the covariance function c to be known and that we can write
(2)
(2)
where
is a correlation function,
is an anisotropic geometric norm defined by a positive-definite matrix
(Wackernagel Citation1995, Schmidt and Guttorp Citation2020). Note that EquationEquation (2)
(2)
(2) covers most of commonly used covariance functions such as the Matérn class or the generalized Wendland class. For instance, the Matérn covariance function is of the form of EquationEquation (2)
(2)
(2) with correlation function
(3)
(3)
where
is the smoothness parameter,
is the Gamma function,
is a scaled anisotropic distance, and
is the modified Bessel function of the second kind and order ν. For
EquationEquation (3)
(3)
(3) reduces to the exponential function
and the corresponding covariance function is therefore given by
Finally, we assume mutual prior independence between the SVCs
as well as the nugget
For the observed data, the GPs reduce to finite dimensional normal distributions with covariance matrices
defined as
Thus, we have
and under the assumption of mutual prior independence the joint effect is given by
with
ie,
is a block diagonal matrix. We denote two data matrices as
and
where we have
such that the jth column is equal to
and
where
denotes a diagonal matrix containing with its diagonal entries defined by a vector
Let
and
be the unknown vectors of fixed effects and covariance parameters. Then the GP-based SVC model is given by
(4)
(4)
and is parametrized by
That is, the parameter of interest
consists of the mean effects
and the covariance parameters
Similarly, the corresponding parameter space Ω is the product of the respective parameter spaces
and
ie,
The response variable
follows a multivariate normal distribution
with covariance matrix
(5)
(5)
where
denotes the Hadamard (or element-wise) product of two matrices. Furthermore, the log-likelihood is defined as
(6)
(6)
Dambon et al. (Citation2021a) provide a computationally efficient maximum likelihood approach to estimate by maximizing (6), which we denote as
We denote the respective mean effects and covariance parameter estimates as
and
Once the parameter has been estimated, one can spatially predict the GPs using the empirical best linear unbiased predictor. That is, for new locations
the spatial predictions of the joint normal distribution
are given by the conditional distribution
In particular, we have
with cross-covariance matrix
and covariance matrix
Both matrices are defined by the maximum likelihood estimated covariance parameters
For further details concerning the estimation and prediction, please refer to Dambon et al. (Citation2021a).
2.2. Penalized likelihood
We introduce a penalized likelihood that will induce global variable selection for the GP-based SVC model (4). Related to this, we say that for an effect of
and for
an effect of
on the response is given. Note that variable selection for the random coefficients corresponds to choosing between
and
For the special case that
for some j, there are three possible cases for each covariate to enter a model (Reich et al. Citation2010):
The jth covariate is associated with a non-zero-mean SVC, i.e., there exist a non-zero fixed effect and a random coefficient.
There only exists a fixed effect
for the jth covariate, but
The jth covariate enters the model solely through the zero-mean SVC, i.e.,
The parameters within that we penalize are therefore μj and
Given some penalty function
we define
where λ acts as a shrinkage parameter. We augment the likelihood function (6) with penalties for the mean and variance parameters. In general, each of the parameters μj and
have their corresponding shrinkage parameter
and
respectively, yielding the penalized log-likelihood:
(7)
(7)
For a given set of shrinkage parameters we maximize the penalized likelihood function to obtain a penalized maximum likelihood estimate:
(8)
(8)
Note the similarity to Bondell et al. (Citation2010) and Ibrahim et al. (Citation2011) who present a joint variable selection by individually penalizing the fixed and random effects in linear mixed effects models. Müller et al. (Citation2013) give an overview of such selection and shrinkage methods.
Finally, one usually assumes the penalty function to be singular at the origin and non-concave on to ensure that
has favorable properties such as sparsity, continuity and unbiasedness (Fan and Li Citation2001). From now on, we will consider the L1 penalty function, i.e.,
(Tibshirani Citation1996).
3. Penalized likelihood optimization and choice of shrinkage parameter
In this section, we show how to find the maximizer of the penalized log-likelihood and how we choose the tuning parameters λj.
3.1. Optimization of penalized likelihood
In the following, we show how a maximizer of the penalized log-likelihood EquationEquation (7)(7)
(7) can be found for given λj. This is equivalent to minimizing the negative penalized log-likelihood. We propose a (block) coordinate descent which cyclically optimizes over the mean parameters
and covariance parameters
ie,
(9)
(9)
(10)
(10)
for
The initial values are given by the maximum likelihood estimate
Algorithm 1 summarizes this block approach. In the following, we show how the component-wise minimizations EquationEquations (9)
(9)
(9) and Equation(10)
(10)
(10) are realized.
Data: shrinkage parameters λj, convergence threshold δ, maximum likelihood estimate objective function
Result:
1Initialize
2repeat
3
4
5
6
7until
8
Algorithm 1: General coordinate descent algorithm for penalized likelihood.
3.1.1. Optimization over mean parameters
We fix the covariance parameters for some
The optimization step for the mean parameter (line 3, Algorithm 1) simplifies to
We note that the first term is a generalized least square estimate for a linear model with Using the Cholesky decomposition
of
and a simple variable transformation
and
the objective function simplifies to
We note that this objective function coincides with a LASSO for a classical linear regression model (Tibshirani Citation1996) with individual shrinkage parameters per coefficient.
3.1.2. Optimization over covariance parameters
We optimize over the covariance parameters with fixed mean parameter
(c.f. Algorithm 1, line 4). We rearrange this optimization problem writing
with the following objective function:
(11)
(11)
We use numeric optimization to obtain In particular, we use a quasi Newton method (Byrd et al. Citation1995) for the numeric optimization. Note that for a
with
the corresponding range
is not identifiable and might induce non-convergence issues. The following proposition ensures that in case described above the optimization is well behaved.
Proposition 3.1.
Let r be a correlation function for a GP-based SVC model as given above. Assume that the derivative of r exists and is bounded, i.e., for some constant
. Let
for
. Then the objective function f defined in (11) fulfills
for all
and
Proof.
The proof is given in the Appendix A.1. □
The additional assumption is quite weak and fulfilled by most of covariance functions used for modeling GP. The partial derivative with respect to
is 0 and therefore the approximation of the gradient function for
yields values very close or identically to 0. Therefore, in the case of
the numeric optimization will stop making any adjustments along the
direction.
3.2. Choice of shrinkage parameters
We use the adaptive LASSO (Zou Citation2006) for the parameters λj given by
(12)
(12)
where we use the maximum likelihood estimates
and
to weight the shrinkage parameters
These two parameters account for the differences between the mean and variance parameters. This leaves us with the task to find a sensible choice of shrinkage parameters
We choose these parameters by minimizing an information criterion which combines the goodness of fit and model complexity, i.e.,
An alternative approach that is computationally more expensive is to use cross-validation. To emphasize the dependency on we introduce the short hand notation
for denoting the penalized maximum likelihood estimate of
for a given
The corresponding mean parameters and variances are given by
and
respectively. We use a Bayesian information criterion (BIC) which is given by
(13)
(13)
where
is the count of non-zero entries. That is, the model complexity is captured via the number of non-zero fixed effects and non-constant random coefficients. Of course, there exist various information criteria like, for instance, the corrected Akaike information criterion (AIC, see Müller et al. Citation2013, for an overview). In our empirical experience the BIC performs best with respect to variable selection which is in line with Schelldorfer et al. (Citation2011).
Our goal is to find a minimizer ie,
A single evaluation of
is computationally expensive, which is why we want the number of evaluations as low as possible. To this end, we use model-based optimization (also known as Bayesian optimization, Jones Citation2001, Koch et al. Citation2012, Horn and Bischl Citation2016). For our objective function
we initialize the optimization by drawing a Latin square sample of size ninit from Λ which we define as
Then we compute
to obtain the tuples
Now we can fit a surrogate model to the tuples. In our case, we assume a kriging model defined as a GP with a Matérn covariance function of smoothness
c.f. EquationEquation (3)
(3)
(3) . That is, given the observed tuples, we have
as our surrogate model. An infill criterion is used to find the next, most promising
We use the expected improvement infill criterion which is derived from the current surrogate model
For a given
this information criterion is defined by
(14)
(14)
where ξmin denotes the current BIC minimum. In the case of a GP-based surrogate model, the expected improvement infill criterion (14) can be expressed analytically. A separate optimization of (14) returns the best parameter
according to the infill criteria and then the BIC is calculated. The tuple
is added to the existing tuples and surrogate model is updated. This procedure is repeated niter times. Finally, the minimizer of the BIC from the set
is returned. For more details regarding model-based optimization refer to Bischl et al. (Citation2017).
3.3. Software implementation
The described penalized maximum likelihood approach is implemented in the package varycoef (Dambon et al. Citation2021b). It contains the discussed model-based optimization which is implemented using the
package mlrMBO (Bischl et al. Citation2017) as well as a grid search to find the best shrinkage parameters. Furthermore, the varycoef package implements our proposed optimization of the penalized likelihood using a coordinate descent. The optimization over the mean parameters is executed using a classical adaptive LASSO with the
package glmnet (Friedman et al. Citation2010). For the optimization over the covariance parameters, we use the quasi Newton method ‘L-BFGS-B’ (Byrd et al. Citation1995) which is available in a parallel version in the
package optimParallel (Gerber and Furrer Citation2019).
4. Simulation
4.1. Setup
We simulate N = 100 data sets consisting of samples with observation locations
from a 15 × 15 perturbed grid, c.f. Appendix A.2 and Furrer et al. (Citation2016), Dambon et al. (Citation2021a). As in Tibshirani (Citation1996) and his suggested simulation setup, which has been assumed (eg Fan and Li Citation2001) or adapted (eg Li and Liang Citation2008, Ibrahim et al. Citation2011) in other simulation studies for variable selection, we use
covariates which are sampled from a multivariate zero-mean normal distribution such that the covariance between
and
is
with
For each simulation run, we sample the covariates
which are both associated with a fixed and random effect. Let
and
be the corresponding data matrices as defined above. Concerning the fixed effects parameters, we assume
(15)
(15)
in order to obtain a balanced design in the sense that for each possible combination of zero and non-zero parameters of both the fixed and random effects there are two cases. Let
for
be the GP-based SVCs defined by an exponential covariance function with corresponding parameters provided in . For
the respective variance
is zero and therefore the respective true SVCs
are constant zero. Hence, the true model contains two of each covariates with a non-zero-mean SVC (k = 1, 5), constant non-zero-mean effects (k = 2, 7), zero-mean SVC (k = 3, 6) and without any effect (k = 4, 8). Adding a sampled nugget effect
with nugget variance
and independent of the GPs we can compute the response
Table 1. True GP parametrization for simulation study.
We compare methodologies for estimating the SVC model, c.f. (4), or the oracle SVC model
(16)
(16)
The latter one is called the oracle model as it assumes the true data generating covariates to be known and excludes all other parameters from their respective estimation. As a reference, we will use two classical maximum likelihood approaches without any shrinkage or variable selection to estimate EquationEquations (4)(4)
(4) and Equation(16)
(16)
(16) labeled
and
respectively. The third methodology is our novel penalized maximum likelihood approach which estimates (4) and we denote it by
For the coordinate descent algorithm, we set a relative convergence threshold of
and a maximum of Tmax = 20 iterations. Note that this upper limit on the number of iterations was never attained in our simulations. Furthermore, the range of shrinkage parameters was set to
ie,
Finally, the shrinkage parameters
are estimated by model-based optimization using ninit = 10 initial evaluations and niter = 10 iteration steps. The infill criterion is the previously defined expected improvement given in EquationEquation (14)
(14)
(14) . The shrinkage parameter ranges as well as the number of initial evaluations and iteration steps was chosen such that we obtain reasonable results under a feasible time and computational resource constraint. The methods
and
are implemented using varycoef (Dambon et al. Citation2021b). Further details are given in Appendix A.3.
4.2. Results
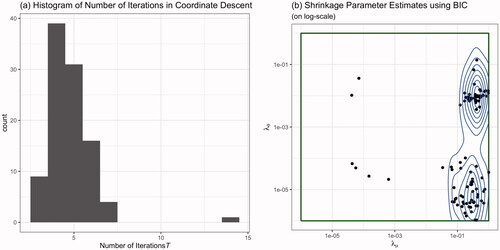
First, we check the convergence properties of the coordinate descent over all simulations. This is depicted in . Facet (a) shows a histogram of the number of evaluated iterations T, where the median over all iterations was 4. This shows that the coordinate descent algorithm converges quickly. Second, the estimated shrinkage parameters are depicted in . We observe that there exist two regimes with respect to The borders of the shrinkage parameter space used in the model-based optimization are depicted darkgreen. There are some estimates very close to the border. Upon closer inspection of actual parameter estimates (see below) we could not find any substantial difference between parameter estimates obtained by
close to the boundary compared to all other
Figure 1. The coordinate descent with (a) the number of iterations steps T and (b) the model-based optimization estimated under the BIC.
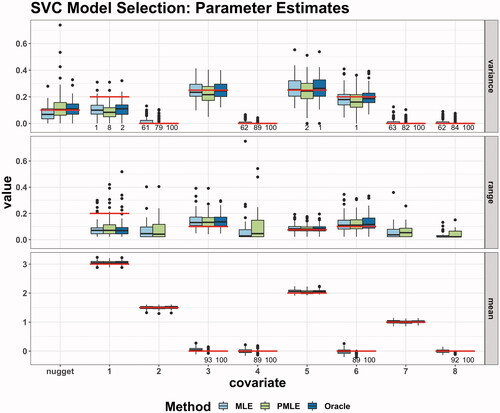
Second, we turn to the actual parameter estimates. They are depicted in and grouped by variances, ranges and means. The true values are indicated by red lines. Furthermore, the number of zero estimates is given, if there are any. As one can see, the returns sparse estimates in the fixed effects as well as the variances. We can clearly observe that for all methods, the estimation of the mean parameters is much more precise compared to the covariance parameters. However, the maximum likelihood estimation is not able to return mean parameters identical to zero. For the variances, we observe that both the
and
are capable of obtaining sparse estimates. Here, the additional penalization of the variances manifests itself in the higher number of zero estimates. On average, we observe an increase of 21.5 correctly zero estimated variance parameters. The penalty has a minor downside as there are some zero estimates, where the true variance is unequal zero. In that case, the nugget compensates for unattributed variation by the covariates which manifests itself in large variance estimates, c.f. outliers of box plot for estimated nugget variance, .
Figure 2. Parameter estimates as box plots and, if any, number of zero estimates. Simulation setup: N = 100 simulation runs, observations on a perturbed 15 × 15 grid. The true values are illustrated by horizontal lines, c.f. (15) and .
Finally, we summarize the results of the simulation study in . For each simulation and methodology m, we compute the relative model error which is defined as
Table 2. Median relative model error (MRME) and average number of correctly (C) and incorrectly (IC) estimated zero parameters, divided into fixed effects and random effects, i.e., the SVCs.
The median relative model error is provided in and is smallest for This comes at no surprise given the high degree of flexibility of an SVC model. It shows that some kind of variable selection is desirable in order to counter over-fitting. The median relative model error for
is similar to the one of
It is not identical as the parameter estimates cannot fully mimic the behavior of the oracle. This is summarized in the second part of , where the number of estimated zero parameters are given both within the mean effects of
and the random effects of
The average number of correctly identified zero parameter and incorrectly identified zero parameters over all simulations is provided.
introduces sparse estimates for the fixed effects while there are no incorrectly identified zero parameters in the fixed effects. Furthermore,
substantially increases the number of correctly identified zero parameters estimates for the random effects by 35% compared to
Meanwhile, the number of incorrectly identified zero parameters remains on a very low level. It is also worth mentioning that both the maximum likelihood and penalized maximum likelihood estimation do not incorrectly estimate any mean parameter as zero.
4.3. Discussion
In this section, we summarize our results of the simulation study. Our first focus is the selection of covariance parameters, where the overall performance is not on par with ones of the mean parameters. However, this comes at no surprise as covariance parameters are known to be more difficult to estimate than mean parameters. Furthermore, we can observe a familiar behavior from variable selection of classical linear models. Increasing the sparsity of the model, i.e., having none or only a few SVC, will increase the variance of the nugget effect.
Overall, our newly suggested penalized maximum likelihood estimation correctly identifies covariates with no effect in over 90% of the fixed and 83% of the random effects. This is notable considering the only drawback is that less than 3% of covariates were incorrectly estimated to have no effect.
5. Application
5.1. Data
As an application, we consider the Dublin Voter data set. It consists of the voter turnout in the 2002 General Elections and 8 other demographic covariates for n = 322 electoral divisions in the Greater Dublin area (Ireland), see . All nine variables are given in percentages and we provide an overview in . The data set was first studied by Kavanagh (Citation2004) and is available in the R package GWmodel. The corresponding articles by Gollini et al. (Citation2015) and Lu et al. (Citation2014b) showcase analyses of this data set using the GWR framework. In particular, a GWR-based selection using a corrected AIC (Hurvich et al. Citation1998) is conducted. The goal of this section is to apply our proposed penalized maximum likelihood estimation on the Dublin Voter data set, compare the results to linear model-based LASSO and GWR-based selections and – in a final step – to assess the predictive performance using cross-validation.
Figure 3. Voter turnout in the 2002 General Elections per electoral division. The black dots represent the observation locations per electoral division used in our analysis. They are provided in the data set, too.
Table 3. Description and summary statistics of Dublin Voter data.
As one can see in , the summary statistics of the variables vary a lot, which can be an issue in numeric optimization. Therefore, without loss of generality and interpretability, we standardize the data by subtracting the empirical mean and scaling by the empirical standard deviation. We annotate the standardized variables by a prefix ‘Z’. Furthermore, the observation locations represent the electoral divisions as depicted in and are provided as Easting and Northing in meters. We transform them to kilometers to ensure computational stability while staying interpretable with respect to the range parameter.
5.2. Models and methodologies
We use two models in our comparison. The first one is a simple linear model
where we apply the adaptive LASSO for variable selection. Since we use the standardized covariate
as our response, we do not expect an intercept in the model. The coefficients are denoted as μj in accordance with our previous notation, i.e., these are only mean effects, and
denotes the adaptive LASSO used to estimate the mean effects. It is implemented using the
package glmnet (Friedman et al. Citation2010), where the corresponding adaptive weights are given by an ordinary least squares estimate and the shrinkage parameter is estimated by cross-validation.
The second model is a full SVC model including an intercept:
The SVCs have yet to be specified according to the method being used to estimate the model, but generally, they do contain mean effects, i.e., the they are not centered around zero. As for the intercept, we expect a zero-mean effect. However, there might be some spatially local structures that can be captured using a SVC.
In the case of the GP-based SVC model as given in (1), the can simply be partitioned into the mean effect μj and the random effect
We estimate the GP-based SVC model by maximum likelihood and penalized maximum likelihood estimation. The results of both procedures are again labeled
and
respectively, and implemented using varycoef. For GWR,
is defined as the generalized least square estimate where observations are geographically weighted. As a kernel to weight the observations based on their distances, we are using an exponential function. The kernel relies on an adaptive bandwidth that is selected using a corrected AIC (Hurvich et al. Citation1998). The method is described in Lu et al. (Citation2014a) and implemented in
package GWmodel. The results are labeled as
5.3. Results
In this section, we present the results for all model-based approaches, i.e., and
as not all comparison measures of
are defined. In terms of variable selection, we provide the estimated shrinkage parameters, number of non-zero estimates of the mean and the variances, the log-likelihood
and the BIC in . As one can see, the
gives a sparse model with only three out of eight selected fixed effects. As expected,
does not provide any sparse fixed effects but selects only six of the potentially nine random effects. With
we obtain a sparser model. Over all, the smallest BIC is achieved by
followed by
and
Table 4. Overview of estimated shrinkage parameters (Shrink. Par.), model complexity (MC), goodness of fit (GoF) in terms of the log-likelihood and combined Bayesian information criterion (BIC) of all model-based approaches.
In , the estimated parameters are provided. For the fixed effects, we observe that results in zero estimates for the intercept and Z.LowEduc. These fixed effects are only a subset of what
estimated to be zero. In the covariance effects, we observe an interesting behavior. We note that
gives zero estimates for one third of the SVCs’ variances even without penalization. This coincides with previous results from the simulation study. As expected, the non-zero variance covariates of
are a subset of the ones of
Further details on the coordinate descent algorithm for
are given in Appendix A.4.
Table 5. Parameter estimates of model-based approaches.
Overall, the penalized maximum likelihood approach results in less zero fixed effects compared to the adaptive LASSO. There is only one variable which does not enter the model at all, namely, Z.LowEduc, and only one other that does have a zero-mean effect, namely, the intercept. However, the linear model does not take the spatial structures into account. Considering the spatial structure apparently triggers the inclusion of additional fixed effects. The model gains complexity but we have to consider that this might be necessary in order to account for the spatial structures within the data. Therefore, SVC model selection remains a trade-off between model complexity and goodness of fit which we will address in the following section using cross-validation.
5.4. Cross-validation
In the last section we examined the goodness of fit combined with model complexity as well as parameter estimation. We now turn to predictive performance. Here, we expect that due to high degree of flexibility of full SVC models, methods without any kind of variable selection could result in over-fitting on the training data in connection with biased spatial extrapolation on the prediction data set.
To examine this, we conduct a classical 10-fold cross-validation. That is, we randomly divide the Dublin Voter data set into 10 folds of size 32 or 33, i.e., each observation i falls into one of the following disjoint sets For each ι
the variable selection and model fitting of all four methods
is conducted on the union of nine sets with set
left out for validation. We report the out-of-sample rooted mean squared errors (RMSE) on
for each method m denoted
This procedure is repeated for each ι. The results are visualized in and .
Figure 4. Bubble plot visualizing the results of the cross-validation. The location of the bubbles corresponds to number of fixed and random effects selected by model. Note that the locations are slightly jittered to ensure overlapping methods are still visible. The size of the bubbles corresponds to per fold ι and method m.
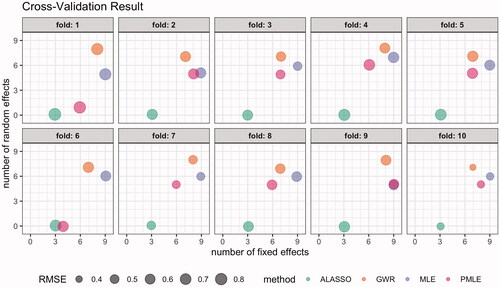
Table 6. Mean and standard deviation (SD) of out-of-sample RMSE per method aggregated over all folds.
First, we observe that the size of the bubbles, i.e., varies more between different folds than between different methods. To analyze the differences in predictive performance, we provide the mean and standard deviation per method in . While the predictive performance of the estimated SVC models are similar,
falls behind.
Second, we address the number of selected fixed and random effects. Upon closer inspection of , we see notable variations of the number of selected fixed and random effects over different folds for all methods but We attribute this to the relatively small sample size. As already observed in Section 5.3, the number of selected mean effects is higher for selection methods
and
on full SVC models than
on a linear model. Furthermore, we note that
consistently selects the smallest number of random effects in SVC models.
Overall, we observe that with decreasing number of selected fixed and random effects, the predictive performance as measured with the out-of-sample RMSE decreases as well. In this particular application, our proposed penalized maximum likelihood estimation yields among the sparsest SVC models while achieving similar predictive performance to the compared maximum likelihood estimated GP-based SVC models and GWR-based variable selection.
6. Conclusion
We present a novel methodology to efficiently select covariates in GP-based SVC models. We propose to perform variable selection for both fixed effects and SVCs by, respectively, penalizing the fixed regression coefficients and the variance of the spatial random coefficients using L1 penalties. Furthermore, we show how optimization of the resulting objective function can be done using a coordinate descent algorithm. The latter can be done efficiently by relying on existing efficient methodology for the fixed effects part and by parallelizing the optimization procedure. Compared to the unpenalized MLE, a potential drawback is a longer computation time due to the shrinkage parameter optimization.
In a simulation study, we show that our method is capable of spatial variance component as well as fixed effect selection. One direct consequence of variable selection is the prevention of over-fitting. We observe that the relative model errors of penalized maximum likelihood estimated SVC models are similar to the errors of the oracle, whereas the maximum likelihood estimated SVC models’ low relative model error indicate over-fitting. In the real data application, we find that our novel method achieves the lowest BIC among the considered approaches. In the cross-validation, the penalized maximum likelihood estimation consistently yields the smallest number of selected random effects, while having a similar predictive performance as the unpenalized maximum likelihood estimation and GWR.
Our novel variable selection methodology has been implemented specifically with SVC models in mind. However, with some adaptions, one can apply it to generalized linear models that fit in our underlying model assumptions. Further future work on our penalized maximum likelihood estimation can include individual weighting of fixed and random effects via the BIC. One could add weights to the specific model complexity penalization as, usually, the addition of another fixed effect to an SVC model is not equal to adding another random effect in terms of, say, computational work load or model complexity.
Data and codes availability statement
The codes for the simulation and application are available online under https://doi.org/10.6084/m9.figshare.16680610. The data used in the application are given in the package GWmodel (Lu et al. Citation2014b, Gollini et al. Citation2015). The new method is implemented in the
package varycoef (Dambon et al. Citation2021b).
Acknowledgment
JD sincerely thanks Lucas Kook for the valuable exchange and help with respect to the model-based optimization implementation. We would like to thank the anonymous reviewers for their valuable comments which improved the quality of this manuscript.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Jakob A. Dambon
Jakob A. Dambon is a Data Scientist at Swiss Re and Lecturer at the Lucerne University of Applied Sciences and Arts. His research interests include spatial statistics and accompanying statistical software, in particular for spatially varying coefficient models.
Fabio Sigrist
Fabio Sigrist is a Professor at the Lucerne University of Applied Sciences and Arts and his research interests include machine learning, spatial statistics and financial econometrics.
Reinhard Furrer
Reinhard Furrer is a Professor at the University of Zurich and his research interest include spatial and spatio-temporal statistics as well as accompanying statistical software for large data analysis.
References
- Bischl, B., et al., 2017. mlrMBO: a modular framework for model-based optimization of expensive black-box functions. Available from: http://arxiv.org/abs/1703.03373 [Accessed 6 Jan 2021].
- Boehm Vock, L.F., et al., 2015. Spatial variable selection methods for investigating acute health effects of fine particulate matter components. Biometrics, 71 (1), 167–177.
- Bondell, H.D., Krishna, A., and Ghosh, S.K., 2010. Joint variable selection for fixed and random effects in linear mixed-effects models. Biometrics, 66 (4), 1069–1077.
- Brunsdon, C., Fotheringham, S., and Charlton, M., 1998. Geographically weighted regression. Journal of the Royal Statistical Society: Series D (the Statistician), 47 (3), 431–443.
- Byrd, R.H., et al., 1995. A limited memory algorithm for bound constrained optimization. SIAM Journal on Scientific Computing, 16 (5), 1190–1208.
- Chu, T., Zhu, J., and Wang, H., 2011. Penalized maximum likelihood estimation and variable selection in geostatistics. The Annals of Statistics, 39 (5), 2607–2625.
- Cressie, N., 2011. Statistics for spatio-temporal data. Wiley series in probability and statistics. Hoboken, NJ: Wiley.
- Dambon, J.A., et al., 2022. Examining the vintage effect in hedonic pricing using spatially varying coefficients models: a case study of single-family houses in the Canton of Zurich. Swiss Journal of Economics and Statistics, 158 (1), 2.
- Dambon, J.A., Sigrist, F., and Furrer, R., 2021a. Maximum likelihood estimation of spatially varying coefficient models for large data with an application to real estate price prediction. Spatial Statistics, 41, 100470.
- Dambon, J.A., Sigrist, F., and Furrer, R., 2021b. varycoef: an R package for Gaussian process-based spatially varying coefficient models. Available from: https://arxiv.org/abs/2106.02364. [Accessed 4 Jun 2021].
- Fan, J. and Li, R., 2001. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association, 96 (456), 1348–1360.
- Finley, A.O., 2011. Comparing spatially-varying coefficients models for analysis of ecological data with non-stationary and anisotropic residual dependence. Methods in Ecology and Evolution, 2 (2), 143–154.
- Fotheringham, A.S., Brunsdon, C., and Charlton, M., 2002. Geographically weighted regression: the analysis of spatially varying relationships. Chichester: Wiley.
- Fotheringham, A.S., Kelly, M.H., and Charlton, M., 2013. The demographic impacts of the Irish famine: towards a greater geographical understanding. Transactions of the Institute of British Geographers, 38 (2), 221–237.
- Friedman, J., Hastie, T., and Tibshirani, R., 2010. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software, 33 (1), 1–22.
- Furrer, R., Bachoc, F., and Du, J., 2016. Asymptotic properties of multivariate tapering for estimation and prediction. Journal of Multivariate Analysis, 149, 177–191.
- Furrer, R., Genton, M.G., and Nychka, D.W., 2006. Covariance tapering for interpolation of large spatial datasets. Journal of Computational and Graphical Statistics, 15 (3), 502–523.
- Gelfand, A.E., et al., 2003. Spatial modeling with spatially varying coefficient processes. Journal of the American Statistical Association, 98 (462), 387–396.
- Gerber, F. and Furrer, R., 2019. optimParallel: an R package providing a parallel version of the L-BFGS-B optimization method. The R Journal, 11 (1), 352–358.
- Gollini, I., et al., 2015. GWmodel: an R package for exploring spatial heterogeneity using geographically weighted models. Journal of Statistical Software, 63 (17), 1–50.
- Horn, D. and Bischl, B., 2016. Multi-objective parameter configuration of machine learning algorithms using model-based optimization. In: 2016 IEEE symposium series on computational intelligence (SSCI). Athens, Greece: IEEE. 1–8.
- Huang, H.C. and Chen, C.S., 2007. Optimal geostatistical model selection. Journal of the American Statistical Association, 102 (479), 1009–1024.
- Hurvich, C.M., Simonoff, J.S., and Tsai, C.L., 1998. Smoothing parameter selection in nonparametric regression using an improved Akaike information criterion. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 60 (2), 271–293.
- Ibrahim, J.G., et al., 2011. Fixed and random effects selection in mixed effects models. Biometrics, 67 (2), 495–503.
- Jones, D.R., 2001. A taxonomy of global optimization methods based on response surfaces. Journal of Global Optimization, 21 (4), 345–383.
- Kavanagh, A., 2004. Turnout or turned off? Electoral participation in Dublin in the 21st century. Journal of Irish Urban Studies, 3 (2), 1–22.
- Kim, M., Wang, L., and Zhou, Y., 2021. Spatially varying coefficient models with sign preservation of the coefficient functions. Journal of Agricultural, Biological and Environmental Statistics, 26 (3), 367–386.
- Koch, P., et al., 2012. Tuning and evolution of support vector kernels. Evolutionary Intelligence, 5 (3), 153–170.
- Li, K. and Lam, N.S.N., 2018. Geographically weighted elastic net: a variable-selection and modeling method under the spatially nonstationary condition. Annals of the American Association of Geographers, 108 (6), 1582–1600.
- Li, R. and Liang, H., 2008. Variable selection in semiparametric regression modeling. Annals of Statistics, 36 (1), 261–286.
- Li, F. and Sang, H., 2019. Spatial homogeneity pursuit of regression coefficients for large datasets. Journal of the American Statistical Association, 114 (527), 1050–1062.
- Lu, B., et al., 2014a. Geographically weighted regression with a non-Euclidean distance metric: a case study using hedonic house price data. International Journal of Geographical Information Science, 28 (4), 660–681.
- Lu, B., et al., 2014b. The GWmodel R package: further topics for exploring spatial heterogeneity using geographically weighted models. Geo-Spatial Information Science, 17 (2), 85–101.
- Mei, C.L., Xu, M., and Wang, N., 2016. A bootstrap test for constant coefficients in geographically weighted regression models. International Journal of Geographical Information Science, 30 (8), 1622–1643.
- Müller, S., Scealy, J.L., and Welsh, A.H., 2013. Model selection in linear mixed models. Statistical Science, 28 (2), 135–167.
- Reich, B.J., et al., 2010. Bayesian variable selection for multivariate spatially varying coefficient regression. Biometrics, 66 (3), 772–782.
- Schelldorfer, J., Bühlmann, P., and van de Geer, S., 2011. Estimation for high-dimensional linear mixed-effects models using ℓ1-penalization. Scandinavian Journal of Statistics, 38 (2), 197–214.
- Schmidt, A.M. and Guttorp, P., 2020. Flexible spatial covariance functions. Spatial Statistics, 37, 100416.
- Smith, M. and Fahrmeir, L., 2007. Spatial Bayesian variable selection with application to functional magnetic resonance imaging. Journal of the American Statistical Association, 102 (478), 417–431.
- Tibshirani, R., 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological)), 58 (1), 267–288.
- Vidaurre, D., Bielza, C., and Larrañaga, P., 2012. Lazy lasso for local regression. Computational Statistics, 27 (3), 531–550.
- Wackernagel, H., 1995. Anisotropy. Berlin: Springer, 46–49.
- Wang, H. and Zhu, J., 2009. Variable selection in spatial regression via penalized least squares. Canadian Journal of Statistics, 37 (4), 607–624.
- Wheeler, D.C., 2007. Diagnostic tools and a remedial method for collinearity in geographically weighted regression. Environment and Planning A: Economy and Space, 39 (10), 2464–2481.
- Wheeler, D.C., 2009. Simultaneous coefficient penalization and model selection in geographically weighted regression: the geographically weighted lasso. Environment and Planning A: Economy and Space, 41 (3), 722–742.
- Wheeler, D.C., et al., 2014. A Bayesian approach to hedonic price analysis. Papers in Regional Science, 93 (3), 663–683.
- Wheeler, D.C. and Calder, C.A., 2007. An assessment of coefficient accuracy in linear regression models with spatially varying coefficients. Journal of Geographical Systems, 9 (2), 145–166.
- Wheeler, D.C. and Tiefelsdorf, M., 2005. Multicollinearity and correlation among local regression coefficients in geographically weighted regression. Journal of Geographical Systems, 7 (2), 161–187.
- Wheeler, D.C. and Waller, L.A., 2009. Comparing spatially varying coefficient models: a case study examining violent crime rates and their relationships to alcohol outlets and illegal drug arrests. Journal of Geographical Systems, 11 (1), 1–22.
- Ye, J., 1998. On measuring and correcting the effects of data mining and model selection. Journal of the American Statistical Association, 93 (441), 120–131.
- Zou, H., 2006. The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101 (476), 1418–1429.
- Zou, H. and Hastie, T., 2005. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67 (2), 301–320.
Appendix A
A.1 Proofs
Proof of Proposition 3.1.
Let be the distance matrix under some anisotropic geometric norm defined by a positive-definite matrix
ie,
Let
be a correlation function whereby
we denote the component-wise evaluation, i.e.,
We have:
With we have
and recall that
is well-defined and invertible. With the identities
and
for some quadratic matrix
we obtain
and therefore
□
A.2 Perturbed grid
A perturbed grid is used to sample the observation locations. It consists of 15 × 15 sampling domains arranged as a regular grid. Each sampling domain is a square surrounded by a thin margin. We sample an observation location uniformly from each square in the sampling domains. The true effect of the SVC is then sampled from an GP at corresponding observation locations. In such an example is provided. This is repeated for all N = 100 simulation runs.
A.3 Numeric optimization
We provide further details for the numeric optimization. In all maximum likelihood and penalized maximum likelihood methods, we use the package optimParallel (Gerber and Furrer Citation2019). In the simulation study, recall that we are on a m × m perturbed grid, where we have m = 15 observations along one side. Here, we set
and
as lower bounds. The lower bounds in the case of the ranges are motivated by the effective range of an exponential GP. It is
where ρ is the corresponding range of the GP. Since the smallest distances between neighbors on a perturbed grid are
on average, it is not feasible to model GPs with ranges smaller than a third of that. This prevents individual SVCs to take on the role of a nugget effect.
A.4 Coordinate descent iterations
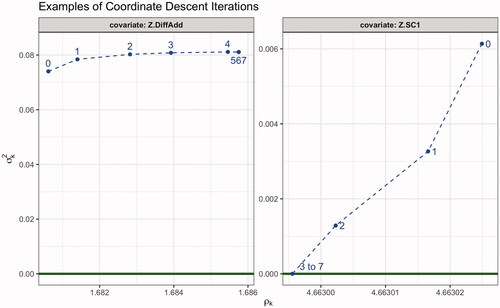
We briefly discuss the coordinate descent in from Sections 5.2 and 5.3. For the two covariates Z.DiffAdd and Z.SC1, we give the covariance parameters for respective SVCs at individual steps t in the coordinate descent in . We have chosen these two covariates as both their variances have the largest absolute difference between the initial and final values. Additionally, one of the variances shrunk to 0 where the other did not. In total, we have T = 7 iterations of the coordinate descent algorithm and the individual covariance parameters
for
and k = 2, 4 are given by the blue dots with annotated iteration step t. Note that for both covariates the covariance parameters of the last three, respectively, five iteration steps are (almost) identical. The lower bound of the variance is indicated by the dark green line. clearly visualizes the effect of adding the penalties on the variance parameters as both optimization trajectories primarily evolve along the variance axis first, before the range is adjusted further on. For
we see that no further adjustments are made beside the fact that ρ4 is unidentifiable under
(Proposition 3.1).
Figure A1. Perturbed grid of size 15 × 15 within the unit square (black border). The gray squares indicate the sampling domain. The colored points are the observation locations with corresponding value of the SVC, i.e.,
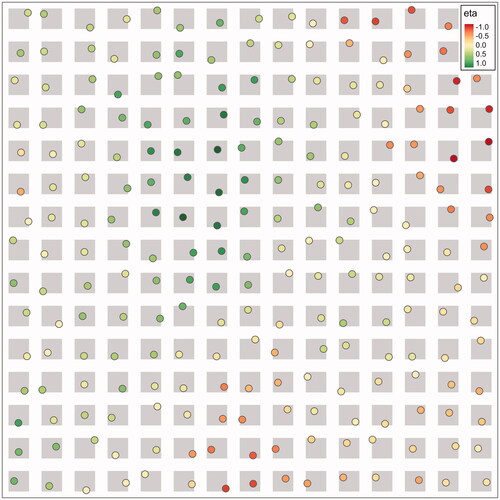
Figure A2. Covariance parameters trajectories of two SVCs for covariates Z.DiffAdd and Z.SC1 in coordinate descent.