
ABSTRACT
In this study we explored factors that determine the knowledge of L2 words with orthographic neighbours in L1 (cognates and false cognates). We asked 150 Polish learners of English to translate 105 English non-cognate words, cognates, and false-cognates into Polish, and to assess the confidence of each translation. Confidence ratings allows us to employ a novel analytic procedure which disentangles knowing cognates and false cognates from strategic guessing. Mixed-effects logistic regression models revealed that cognates were known better, whereas false cognates were known worse, relative to non-cognate controls. The advantage of knowing cognates, but not false cognates, was modulated by the degree of similarity to their L1 equivalents. The knowledge of cognates and false cognates was not affected by the frequency of their formal equivalent in L1. Based on these findings we conclude how cross-linguistic formal similarity affects L2 word learnability, proposing a mechanism by which cognates and false cognates are acquired.
Introduction
Over half a century ago, structuralists claimed that ‘those elements that are similar to [the learner’s] native language will be simple for him, and those elements that are different will be difficult’ (Lado Citation1957, 2). Although it is now clear that apart from L1–L2 similarity relations, there are many more factors that contribute to the language learningFootnote1 process, at the level of vocabulary, the dichotomy: similar-easy/different-difficult is still tempting to explore. Here, we test how the degree of orthographic similarity between L1 and L2 words influences the ease of learning L2 vocabulary items. We do so by measuring the outcome of the word-acquisition process and ‘taking a picture’ of which words are known by our participants at the moment of testing.
Cross-linguistic orthographic similarity in language processing and learning
One of the most salient similarities between the lexicons of two languages are cognates, ie words whose form and meaning considerably overlap across two or more languages, irrespective of whether the similarity results from language typology or borrowing processes (Friel and Kennison Citation2001; Jarvis Citation2009). Another group of words that are similar to their L1 equivalents are false cognates, otherwise called interlingual homographs. In contrast to cognates, these words are only formally similar, but their L1 and L2 meanings differ. Since formal similarity makes both groups of words somewhat ‘special’, cognates and false cognates are within the range of interest of both experimental psycholinguistics and second language acquisition (SLA) studies. The two fields approach cross-linguistically similar words differently, but neither of them have satisfactorily determined whether such words are indeed ‘special’ when it comes to their acquisition.
Psycholinguistic experiments on vocabulary learning methods demonstrate that cognates are faster retrieved from memory and more resistant to forgetting than other words, so they may be particularly easy to learn (eg Ellis and Beaton Citation1993; Lotto and de Groot Citation1998; for an overview see De Groot and Van Hell Citation2005). Cognates are also processed more easily in many other experimental paradigms, a phenomenon called the cognate facilitation effect: In translation tasks, identical or nearly identical cognates are translated faster and more correctly than non-cognates (De Groot Citation1993; Jacobs, Fricke, and Kroll Citation2016). In lexical decision and word identification studies, identical cognates are recognised faster than non-cognate words, particularly when the task is conducted in L2 (Dijkstra et al. Citation2010; Lemhöfer et al. Citation2008; Mulder et al. Citation2014). The cognate advantage is explained as resulting from the architecture of the bilingual mental lexicon. When cognates are processed, the orthographic representations from both languages are activated in parallel, each leading to the activation of a common semantic representation. As a result, the translation or recognition of the word is speeded up via top-down modulations (Dijkstra and Van Heuven Citation2002). It is also claimed that cognates share the same orthographic representation in the bilingual lexicon (Gollan, Forster, and Frost Citation1997). If this is the case, higher cumulative frequency of the shared orthographic representation could also contribute to the cognate advantage (Lemhöfer et al. Citation2008). The advantage does not apply to processing false cognates, though. Their processing also leads to the non-selective activation of two semantic representations (eg Durlik et al. Citation2016), which are, however, divergent. Without common semantics, the common orthographic form alone does not speed up the translation and recognition of false cognates (see eg Dijkstra and Van Heuven Citation2002), and sometimes even slows it down (De Groot, Delmaar, and Lupker Citation2000; Von Studnitz and Green Citation2002).
Thus, psycholinguistic experiments suggest that for language learners the existence of cognates, but not false cognates, should help to bridge the gap between the vocabularies of the known and the target language. However, experiments conducted in laboratory settings can be criticised for lacking ecological validity: They use relatively small subsets of words, or utilise pseudowords and methods of learning that diverge from how words are acquired in real life (for example in classroom conditions, for overview see Otwinowska Citation2015; Rogers, Webb, and Nakata Citation2014). In addition, the experiments on processing cognates and false cognates are often conducted on participants whose proficiency does not reflect that of typical classroom students: either very highly proficient participants (see De Groot and Van Hell Citation2005; Kootstra, Dijkstra, and Starren Citation2015; Van Hell and Tanner Citation2012), or, in the case of experimental studies on novel word-learning, on participants with no proficiency in the target language (eg Rogers, Webb, and Nakata Citation2014). In effect, such experiments may not reveal how cross-linguistically similar words are acquired in natural classroom settings.
SLA studies, often conducted in more real-life conditions, take a different approach to testing the effects of cross-linguistic lexical similarity on word acquisition. SLA research emphasise the role of awareness, and assume that learners can benefit from cognates only when they realise that the L2 word is similar to a known word (Jarvis and Pavlenko Citation2008; Jessner Citation2006; Ringbom Citation2007). Only then can learners guess that the word is cognate, and infer its meaning (eg Berthele Citation2011; Müller-Lancé Citation2003; Vanhove and Berthele Citation2015). Since lexical inferencing is regarded as a beneficial vocabulary learning strategy, this should help learners acquire the cognate (Wesche and Paribakht Citation2010). For false cognates, just the opposite should occur. Once learners assume the similarity to L1 words, they should erroneously infer the meaning of the false cognate, thwarting the process of its acquisition.
Based on the above assumptions, numerous SLA studies conclude that L2 cognates do not turn out easier to learn than non-similar L2 words, because learners often fail to identify them as cognate to L1, especially when the words are embedded in texts (Dressler et al. Citation2011; Nagy et al. Citation1993; Schmitt Citation1997; Singleton Citation2006). Moreover, even when potential cognates are identified, some learners tend to distrust them, having been warned by teachers about the danger of encountering false cognates (Lightbown and Libben Citation1984; Meara Citation1993). It remains an open question, however, whether studying the potential cognate benefit in vocabulary acquisition should rely on learners’ awareness of cognateness, because this assumption has not been verified. It is unclear whether noticing cognates is really necessary for the benefit, when we consider the experiment by (Vanhove Citation2015), where participants benefitted from cross-linguistic similarity in learning cognates in an unknown language, but they were mostly unaware of the rule that had helped them and were unable to verbalise it after the experiment. We also have to bear in mind that the cognate advantage in processing may occur at the automatic, pre-conscious level (Dijkstra and Van Heuven Citation2002). Even less is known about the acquisition and knowledge of false cognates. Thus, it should be worth examining the how cognates and false cognates are acquired without relying on learners’ awareness of the similarity.
To sum up, although psycholinguistic experiments clearly demonstrate that bilingual processing, translating, or memorising cognates seems easy, relative to other words and false cognates, it is not certain whether this benefit holds outside the laboratory, in real-life word acquisition in the L2 classroom, where word learning is more contextualised. SLA research does not help in establishing whether cognates are easier to learn, either. Although results suggest that cognates may not be acquired easier than non-cognate words because they remain unnoticed in texts, SLA studies rely on the unverified assumption that cognates have to be consciously identified. In the present study we aim to fill these gaps by testing whether cross-linguistically similar words are easier to learn in real-life conditions, but without relying on participants’ awareness of L1–L2 similarity.
The present study
Word learnability
In this study we systematically test how the learnability of L2 words formally similar to L1 equivalents (cognates and false cognates) compares to the learnability of control, non-cognate words. We assume that the acquisition of words in a language environment primarily depends on the exposure to the word (Laufer and Rozovski-Roitblat Citation2015). Thus, we operationalise learnability as the ease or difficulty in learning a word (Laufer Citation1990), when the exposure to the word is held constant. When learners encounter word A and word B equally frequently in their lifetime, and at the time of testing, 80% of them know word A, but only 20% know word B, we can say that word A is easier to learn (more learnable) than word B. Therefore, our approach is the following: We select a group of cognates, false cognates and non-cognate control words such that all these words had an equal chance of being encountered by our participants, and we test if they are known by participants. Any differences in the knowledge of these words should reflect differences in their learnability.
We operationalise the knowledge of a word as the ability to translate it confidently from L2 into L1, which corresponds to the middle point of the Vocabulary Knowledge Scale (Paribakht and Wesche Citation1997). To measure word knowledge, we engage Polish learners of English in a simple translation task from L2 to L1, which contains cognate words, false cognates and non-cognate control words. Those words that are more learnable should be translated with high confidence by more participants.
Effectively, in this study we do not examine the word-acquisition process, as is typically done in word-learning experiments, but we measure the outcome of this process by capturing which words our participants already know at the moment of testing. Still, we believe that this is a more ecological way to measure word-learnability than laboratory experiments. No word-learning experiment can control all the possible ways in which words can be acquired in real life conditions (memorising the association of the L2 word form with its L1 equivalent, visualisation, cross-situational statistical learning, fast-mapping, inferring meaning from the context, etc.), and account for how learners further interact with words for their retention (c.f. Laufer and Rozovski-Roitblat Citation2015; Schmitt Citation2008). Thus, it is unlikely that any experimental study testing word-learnability will truly simulate the process. In our study, we circumvent this problem by comparing which words have already been acquired at a point in time. As long as the words have had similar chances to be encountered, we can make inferences about the learnability of those words based on such results.
To ensure that participants had equal chances of exposure to each of the three categories of words to translate (cognates, false cognates and control words), we chose the words typically introduced at the intermediate level on English language courses, and statistically controlled them with respect to their L2 frequency and concreteness and grammatical category.
Word knowledge vs. word guessing
Since many of the words that we test bear a formal similarity to L1 words, in measuring their learnability we must address the risk that that participants develop a ‘guessing strategy’ and translate them based on their form (Berthele Citation2011; Gooskens et al. Citation2012; Vanhove and Berthele Citation2015). While form-based guessing is obvious in the case of translations of false cognates, it is impossible to determine in the case of true cognates. To learn which words were truly known to participants, apart from measuring translation accuracy, we also measured participants’ confidence of each translation, presuming that when strategically guessing, participants translate with lower confidence. This lets us establish individual confidence thresholds below which translations are probably guessed (for details, see Data analysis).
Item-related and participant related factors considered in the study
In this study, we not only want to determine whether formally similar and non-similar words differ in their learnability, but also to establish the factors that affect these differences. Below we briefly introduce several subject- and item-related variables that we consider, and explain how they might inform our understanding of the way cognates and false cognates are acquired.
The degree of cross-linguistic similarity
Three lines of research suggest that cognate processing is affected by their degree of formal similarity. Studies on cognate guessing show that lesser similarity between L1 and Ln cognates makes the formal relationship between them harder to notice (Berthele Citation2011; Gooskens, Kürschner, and Bezooijen Citation2011; Vanhove and Berthele Citation2015). In classroom research, L2 cognates bearing less orthographic overlap with L1 remain unnoticed (Dressler et al. Citation2011) or are recognised worse in texts (Nagy et al. Citation1993). Psycholinguistic experiments show that bilingual participants presented with identical cognates make translations and lexical decisions faster than when cognates differ slightly from L1 equivalents (Comesaña et al. Citation2015; Dijkstra et al. Citation2010; Mulder et al. Citation2014). It thus seems likely that formal similarity may affect cognate learning proportionally to the degree of similarity.
With respect to false cognates, we are not aware of any studies investigating the impact of cross-linguistic similarity on their processing. However, we can presume that if false cognates turn out to be more difficult to learn than non-cognate words, those that are less similar to their formal (misleading) equivalents in L1 might be easier to learn, because the detrimental effect of their misleading similarity will be diminished.
Frequency of L1 form equivalent
If learning cognates benefits from the pre-existing link between the form and the L1 meaning, this benefit should be proportional to the strength of the link. The reverse effect should occur for false cognates. When learners encounter a false cognate, the meaning of its L1 misleading equivalent gets automatically activated. If acquisition of false cognates requires that the irrelevant L1 meaning is first inhibited, then learning false cognates should be hampered proportionally to the strength of the pre-existing link between the form and its L1 meaning.
To index the strength of the pre-existing association between the word form and its L1 meaning, we will use the frequency of the L1 formal equivalent. This relies on the assumption that with the growing number of exposures to the L1 word in L1 contexts, the link between the word form and its L1 meaning becomes stronger.
Learner’s L2 proficiency
Participants’ proficiency might affect the potential benefit in learning cognates, and the potential disadvantage in learning false cognates. First, more proficient learners may become more sensitised to unknown words that bear formal similarity to L1, and strategically start to treat them as valuable cues for meaning (Jessner Citation2006; Ringbom Citation2007). Second, more proficient learners should have more automatised knowledge of morphological rules of L2 (c.f. Segalowitz Citation2007; Segalowitz and Hulstijn Citation2005), as well as better orthography-to-phonology mappings in L2. Thanks to this, they should be able to process even less similar cognates in the same way as identical cognates.
With false cognates, for the same reasons, the increasing L2 proficiency might sensitise learners to orthographic or phonological correspondences between false cognates and their less similar formal equivalents. This sensitivity to similarity might, paradoxically, negatively affect the learning of false cognates by more highly proficient L2 learners. The more similarity they spot, the more misleading some new false cognate forms might be for them.
MethodFootnote2
Participants
A hundred and fifty Polish learners of English (age 20–25 years, 99 female) from the University of Warsaw, Poland participated in the study. One hundred and twenty-two participants took part in the final analyses (28 participants were rejected, 3 because they did not translate any word correctly, and 25 when applying the correction for guessing, see below). Within the group, there were 73 students attending a general English course at B1 level (Footnote CitationCEFR 3), and 49 first-year undergraduate students of the Institute of English Studies attending a course in English grammar at the B2+ level (CitationCEFR). Although English was not the second, but the third language for some participants, for the sake of consistency we will refer to English as L2, and any other language known best by the participant as L3.
The CEFR-level is a rather vague estimate of participants’ L2 proficiency. Although we did not apply an independent proficiency test for English, we also wanted to avoid self-ratings, which often do not correspond to the actual performance of respondents (Lemhöfer and Broersma Citation2012). To quantify proficiency for English, the main language assessed, we measured participants’ vocabulary size using an index interwoven in the translation task: the number of correctly translated non-cognate control words.Footnote4 However, it will only be used to predict translation performance for cognates and for false cognates, to avoid the trap of deriving a predictor and an outcome variable from the same data.
Materials
We used a list of 105 English words: 35 Polish-English cognates (20 nouns and 15 adjectives), 35 Polish-English false cognates (20 nouns and 15 adjectives), and 35 non-cognate control English words (20 nouns and 15 adjectives) extracted from a B1 level course-book,Footnote5 chosen by experimenter judgement. We concentrated on words introduced relatively late on language courses (ie at B1 level CitationCEFR), assuming that using such stimuli would better capture the variance in the lexical knowledge at levels of L2 proficiency represented by our sample of participants. presents examples of the stimuli, while the full list can be found in the online materials.
Table 1. Types of stimuli used in the study.
Cognates and false cognates were statistically controlled for the degree of orthographic similarity to their translation equivalents, as indexed by Levenshtein distance between their L1 and L2 orthographic forms. Levenshtein distance measures the minimal number of substitutions, insertions, and deletions to be made in order to edit one string into another. In the present study, we accounted for differences in word lengths by dividing the LD by the length of the longer of the two words. This yielded a normalised LD (nLD), which is the LD divided by the maximum length of the longer word. It takes values between 0 and 1, where score 0 indicates full formal overlap, and 1 indicates that the two words do not have any letter in common. The 35 cognates and 35 false cognates displayed various degrees of similarity to their Polish form equivalents, but overall, nLD did not differ between the two groups of words (p > .08; see ). The 35 control words bore no formal similarity to Polish words.Footnote6
Figure 1. Box-plots comparing non-cognates, cognates and false-cognates on Concreteness, L2 word length, L2 logFrequency, L1 form-equivalent logFrequency, and nLD.
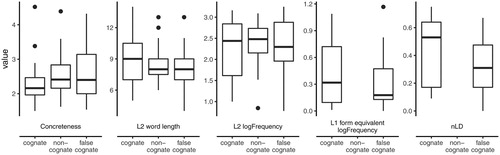
The stimuli were comparable across the three word types in terms of L2 corpus frequency (p > .44; SUBTLEX-US; Brysbaert and New Citation2009) , length (p > .16) , concreteness (p > .08 Brysbaert, Warriner, and Kuperman Citation2014; see ), as well as the corpus frequency of their orthographic L1 neighbour for true and false cognates (p > .36; National Corpus of Polish; Przepiórkowski et al. Citation2012; see ).
Procedure
The study took place at the University of Warsaw, during students’ regular classes. They were not reimbursed for their participation, but were free to resign from. Participants were also informed that the test results would not be considered for their course grade, and that their data would be anonymous and used only for research purposes. After filling in the background questionnaire, participants were given the paper-and-pencil translation task. They were asked to translate the list the 105 English words into L1 Polish. Additionally, they had to indicate the confidence level of each translation on the scale 1–4 (1 – I’m guessing; 2 – I think it might be so; 3 – I’m quite sure; 4 – I know for sure). The confidence level scales were located next to the blank spaces where participants filled in their translations.
We created four lists with the same stimuli in a randomised order. To prevent cheating, the lists were distributed to participants in such a way that no two students with the same version of the list sat next to each other. Participants were asked to translate the words into Polish without much thinking and were instructed to write a dash or leave the slot blank, if they could not translate the word. The task lasted between 20 and 25 min, but no strict time limit was set.
Data analysis
Data coding
Since we operationalised the knowing of a word as the ability to translate it with high confidence, in all the analyses the dependent variable was the correctness of translation. All missing responses were treated as incorrect.
Disentangling guessing and knowing cognates and false cognates
Our main question is whether the orthographic similarity between L1 and L2 affects the likelihood that a word will be known to participants, as opposed to being guessable by them. Such strategic guessing based on form is a serious confound in measuring cognate knowledge: it artificially elevates the number of correctly translated cognates, relative to false cognates and non-cognate words. While guessing is easily detectable for false cognates (it leads to distinctive translation errors), it is impossible to detect for cognates, based on the translation alone. Thus, we treat the knowledge of words as a hidden variable, which for cognates is not available from the test and needs to be reconstructed. To reconstruct the variable and disentangle the knowing and guessing of cognates, we used confidence ratings, applying the following procedure.
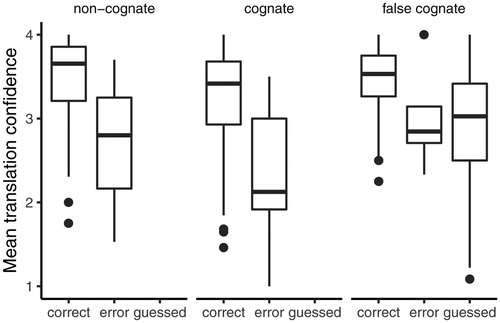
First, for each incorrect false cognate translation we coded whether it had been erroneously translated into its Polish orthographic neighbour. The coding revealed that 56% of the incorrect false cognate translations were guessed. Knowing that participants heavily relied on guessing when translating false cognates, we assumed that they applied the same strategy to cognates. To differentiate between the guessed and non-guessed translations of cognates, we used the confidence ratings that participants provided for each translation: We assumed that participants were less confident when guessing, relative to when they knew the word. Before testing this hypothesis, we removed from further analyses 16 participants who had fewer than 4 confidence ratings for the correct or fewer than 4 confidence ratings for the guessed translations of false cognates, and thus their mean confidence ratings were unreliable. To verify our assumption that the participants were less confident when guessing, for each participant we averaged the confidence ratings for the correctly translated and guessed false cognates. The two averaged ratings proved reliably different: paired t(130) = 13.38, p < .0001, r = .76 (see ). Nine participants violated the assumption that guessing is associated with lower confidence, because they had higher mean ratings for the guessed than for the correct translations of false cognates. They were also removed from further analyses.
Figure 2. Comparison of the mean participant confidence ratings for the correct and incorrect translations of non-cognates, cognates and false cognates. For false cognates, we also show the mean confidence ratings of the guessed translations (form-based).
Now we could use the confidence ratings to identify those translations that appeared to be guessed and to adjust them so that they better reflected participants’ true knowledge of the tested words. To this aim, we established a confidence threshold that best separated the confidence for all correct and guessed translations. To obtain the threshold, for each participant we found the point separating the mean confidence rating of the correct and the guessed translations (ie we averaged the mean confidence ratings for the correct and the guessed translations).
Any correct translations with confidence lower than the threshold were recoded as incorrect,Footnote7 which led to the correcting of 14.2% of responses. The correction was applied to words of all types. The reason is participants might have indicated low confidence of translations not only when guessing, but also when they knew the word, but were not entirely familiar with it. Such situations occurred in all word types. If the correction was applied to cognate words only, they would get over-corrected, relative to non-cognates and false cognates.
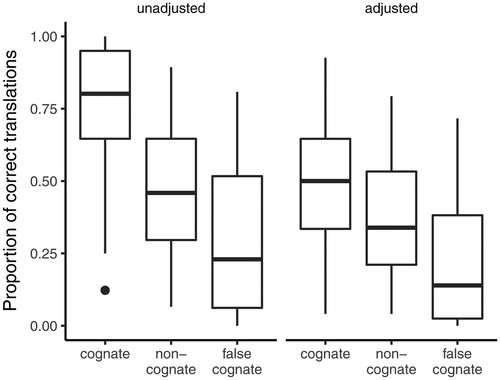
To verify that the correction worked as intended, we checked how it affected the three word types. Because the percentage of the correct, low-confidence translations should be similar across of all three word types, we assumed that false cognates and non-cognate controls should be affected by the correction to a similar degree. However, significantly more correct, low-confidence translations of cognates should be affected, relative to the translations of non-cognate controls and false cognates. This is because the correction should also target those translations of cognates that had been guessed (and done with low-confidence). The actual percentages of corrected translations confirmed our assumptions: 25% of cognates, 10% of non-cognate controls, and 7% of false cognates had been affected by the correction (see also ), reassuring us that the correction worked as intended. From now on, all the analyses will be performed on data corrected for guessing.
Figure 3. Box-plots showing the proportion of the correctly translated words (non-cognate words, cognates, false cognates) before and after adjusting the data for guessing.
Statistical analyses
Due to the binary character of the dependent variable, we used mixed-effects logistic regression in all analyses, employing package lme4 for R (Bates et al. Citation2015). The generalised linear mixed-effects models (GLMM) enabled us to consider learner-related and item-related predictors in a single model, and test for their interaction in a single analysis. GLMM are also generally more robust than classical regressions, and are more likely to detect true effects (Jaeger Citation2008). In all analyses, we adopted maximal random effects structure justified by the data, following the procedure suggested by (Bates et al. Citationin review). The models were fitted using Laplace approximated maximum likelihood. We report p-values based on the Wald Z statistic. All variables were centred (we decentred them for better visualisation in –). Categorical variables were simple-coded. The intercept of the model reflects the grand mean. We reported only the best model, identified by using the backwards-stepwise model selection procedure: Starting with a maximal model (indicated at the description of each analysis) we removed fixed effects until it resulted in the decrease of AIC by 2 or more.
Figure 4. Visualisation of the GLMM estimates of the main effects of Word Type (blue: non-cognate words, green: cognates, red: false cognates) and L2 logFrequency. Error bands represent 95% confidence bands .
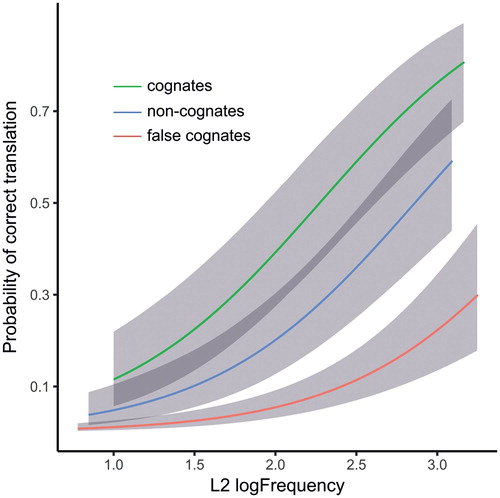
Figure 5. Visualisation of the GLMM estimates for the interaction between L2 Proficiency and nLD for cognates. For visualisation, L2 Proficiency is median-split into high proficiency (solid lines) and low proficiency (dashed lines. Error bands represent 95% confidence bands.
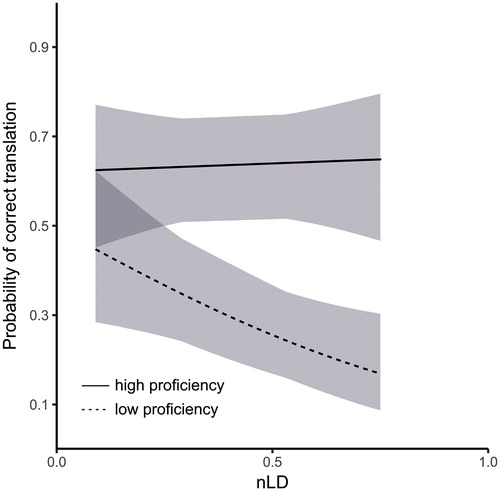
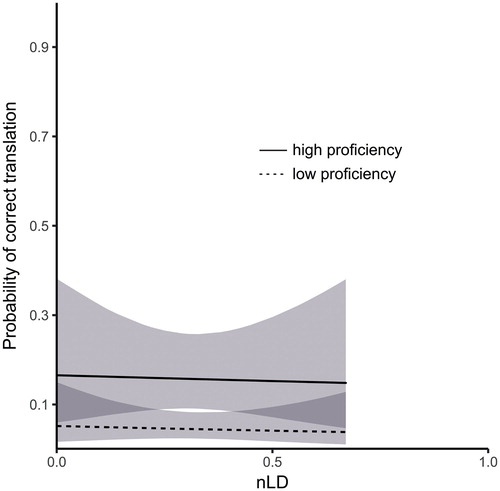
Figure 6. Visualisation of the GLMM estimates for the effects of L2 Proficiency and nLD for false cognates. For visualisation, L2 Proficiency is median-split into high proficiency (solid lines) and low proficiency (dashed lines). Error bands represent 95% confidence.
We fitted three regression models predicting the likelihood that a word is known by a participant: on all words, on cognates, and on false cognates. The first analysis let us compare all three word types. However, it did not allow us to examine the impact of orthographic similarity to L1 orthographic equivalents and L2 proficiency since L1 orthographic similarity does not apply to non-cognates and since the L2 proficiency measure was derived from the participants’ responses to non-cognates. In two separate analyses focused on cognates and on false-cognates we tested contribution of these factors. The item-related predictors included: Word Type (cognate, false cognate, non-cognate control), L2 logFrequency, Concreteness, and in the case of models testing the learning of cognates and false cognates: nLD (normalised Levenshtein Distance to the orthographic neighbour in L1), and L1 form logFrequency (the frequency of the orthographic neighbour in L1). Analyses on cognates and on false cognates also included L2 Proficiency as a learner-related predictor. The actual predictors used in each model are introduced before the respective analyses.
Results
Learnability predictors for all word types
The first analysis tests whether non-cognate words, cognates and false cognates differ in their learnability, while controlling for L2 corpus frequency of these words (serving as a proxy for exposure to these words). We ran a mixed-effects logistic regression estimating the impact of the item-related variables: L2 logFrequency, Word Type (cognate, false cognate, non-cognate control), and Concreteness. The maximal model included these factors, as well as interactions of Word Type with the remaining predictors. As mentioned, the maximal model was subsequently reduced during the model selection process. The final model included random intercepts for subjects and items, and by-subject random slopes for both Word Type effects and for L2 logFrequency. This model is given in and in .
Table 2. Summary of the fixed effects in the best mixed-logit model on all words.
As can be seen, the full effect of L2 logFrequency increased the odds that the word would be correctly translated over 49.5 times,Footnote8 showing that the probability of exposure to a word (L2 frequency) is the most pronounced predictor of its learnability. However, even when controlling for the exposure to the word, we also obtained a significant effect of Word Type. Everything else being equal, cognates had 2.5 times greater odds of being correctly translated, relative to non-cognate controls, whereas false cognates had 3.6 times smaller odds of being correctly translated than control words. Therefore, cognates were easier while false cognates more difficult to translate, relative to non-cognate words.
Now we will focus on cognates and false cognates to examine the effects of formal similarity between L2 words and their orthographic neighbours in L1, the frequency of the orthographic neighbour in L1, and participants’ proficiency in L2 on the translation outcomes.
Learnability predictors for cognate words
The second regression model focused on the predictors that underlie the learnability of cognates. We were primarily interested in how the degree of formal similarity between the English-Polish translation equivalents (indexed by nLD) has an impact on the learnability of cognates. The maximal model included the main effects of: L2 logFrequency, L1 Form Frequency, nLD, Concreteness, and L2 Proficiency, as well as interactions of nLD with each of the remaining predictors. The final model included random intercepts for subjects and items, as well as a by-item random slope for Proficiency, and a by-subject random slope for nLD. This model is shown in , and .
Table 3. Summary of the fixed effects in the best mixed-logit model on cognates.
In parallel to the analysis on all word types, we found a significant main effect of L2 logFrequency. In addition, we found a main effect of Proficiency, qualified by an interaction of Proficiency and nLD. The interaction shows that for the less proficient participants high nLD makes it difficult to benefit from words’ cognateness, while high proficient participants are unaffected by nLD. L1 logFrequency of the orthographic (and semantic) equivalent of the L2 word did not affect the probability of knowing the cognate.
Learnability predictors for false cognates
The third regression model inquired which predictors are significant for the learnability of false cognates. Like in the model focused on cognates, the maximal model included the main effects of L2 logFrequency, L1 form logFrequency (the frequency of the L1 orthographic equivalent of the word, ie its misleading, form-based translation), nLD, Concreteness, and L2 Proficiency, as well as interactions of nLD with each of the remaining predictors. The final model included random intercepts for subjects and items, as well as a random slope for Proficiency. The best-fitting model is given in , and visualised in .
Table 4. Summary of the fixed effects in the best mixed-logit model on false cognates.
In parallel to previous analyses, both L2 logFrequency and L2 Proficiency substantially increased the odds that the false cognate would be correctly translated. The effect sizes are comparable with the previous analyses. Notably, the frequency of the L1 orthographic equivalent and nLD did not affect the knowledge of false cognates.
Discussion
Our study aimed to test whether L2 words having formal neighbours in L1 differ in their ease of acquisition (learnability), in comparison with non-cognate control words. In addition, we explored which factors affect the learnability of these words, in order to better understand the mechanisms by which formally similar words are acquired. We adopted a novel approach to measure word-learnability, in which we tested participants’ knowledge of words, while controlling for their exposure to words (in terms of corpus L2 frequency). We reasoned that when participants had an equal chance to encounter two words, and yet they know one word better than the other, this would indicate that one word is easier to learn than the other (ie they differ in learnability). We operationalised the knowledge of a word as the ability to translate it with confidence (Paribakht and Wesche Citation1997). Thus, we measured whether participants had acquired English (L2) words in a simple paper-and-pencil translation test, by asking them to translate each word into Polish (L1). Since many of the tested words bore a high formal similarity to L1 words, some participants inevitably exploited the similarity to guess their meaning. To tease apart strategic guessing from knowing the word, we measured both the performance and the confidence of translations. As expected, many false cognates were guessed, and based on the confidence ratings, over half the correct translations of cognates appeared to be guessed. Based on the confidence ratings, we filtered out those participants’ translations of cognate words that have likely resulted from guessing. Thanks to these operations, we obtained translation scores that more accurately reflected knowledge of the tested words. We posit that these scores, obtained with the use of ecologically-valid stimuli adjusted to the participants’ language level, reflect the outcomes of word learning in real-life conditions.
The learnability of word types (cognates, false cognates, control words)
The main result of our study is that both cognates and false cognates differ from control non-cognate words in their learnability. Relative to non-cognate words, cognates had a significantly greater chance, whereas false cognates had a significantly smaller chance to be correctly translated. This indicates that cognates may be indeed easiest to learn, while false cognates the most difficult. Interestingly, the effect of false cognate disadvantage in our study was of similar strength to the effect of cognate advantage. This effect looks like a symmetrical hindrance, or enhancement, depending on whether the orthographic similarity goes (or does not go) in pair with semantic congruence.
The advantage of acquiring cognates can be explained by the knowledge of L1 learners already have at the first time they encounter the cognate in an L2 context. Due to language-non-selective access to the mental lexicon, during the initial stages of recognition, word candidates from all languages are co-activated based on the word-form (c.f. Dijkstra and Van Heuven Citation2002; Kroll and De Groot Citation1997; Kroll et al. Citation2010). For the cognates that are yet unknown in L2, this leads to the activation of their semantic representation, thanks to the form-meaning mapping existing in L1. Presumably, then, learning a cognate only requires validating the mapping, which leads to strengthening the form-meaning connection, but does not require establishing new orthographic or semantic representation for the word in L2 (c.f. Ecke Citation2015; Gollan, Forster, and Frost Citation1997).
There are two possible explanations of what makes false cognates harder to learn. They both base on the assumption that each exposure to a false cognate activates an L1 meaning that is invalid in L2 context (Dijkstra and Van Heuven Citation2002). According to the first explanation, in order to learn the meaning of a false cognate, learners must first memorise that the L2 word form does not correspond to the same concept in L2 as in L1, and only then can they start to associate the word form with the L2 meaning of the false cognate. According to the second explanation, on each encounter of the false cognate in the L2 context, learners must inhibit the automatically activated L1 representation of the word, which is necessary to enable learning its L2 meaning. In the next section we will reject one of these explanations by evaluating how other results inform the mechanism of learning formally similar words.
Factors modulating the learnability of cognates and false cognates
Frequency of the L1 formal equivalent
In order to check the impact of the L1 form-meaning association, we tested whether the learnability of words in L2 depends on the frequency of the word’s formal equivalent in L1, ie the true translation equivalent for cognates, and the false equivalent (misleading orthographic neighbour) for false cognates. Following the assumption that the frequency of the formal equivalent in L1 provides us with an index of the strength of the form-meaning association (Lemhöfer et al. Citation2008), we hypothesised that high L1 frequency of the form would increase the learnability of cognates, but decrease the learnability of false cognates, whose false, form-based equivalent would require stronger inhibition in order to facilitate the learning of the true L2 meaning.
However, L1 frequency did not show any impact on the translation of cognates and false cognates. For cognates, there are two possible explanations for the absence of this effect. According to the first explanation, the very existence of the learnt association between form and meaning in L1 yields a learnability bonus, but the strength of this association is not important. Instead of going through the effort of associating the form with its L2 meaning, learners would simply learn that the association pre-existing in L1 is also valid for L2 (Ringbom Citation2007). For cognates, reusing the already existing association between form and meaning would make sense also because the L1 and L2 meanings of cognates are usually very similar, and overlap much more than concepts corresponding to the translation equivalents of non-cognate words (Ecke Citation2015; Van Hell and De Groot Citation1998; Schmitt Citation2010). The second explanation is purely statistical, and pertains to the fact that the lexical frequencies of cognate words in L1 and L2 are highly correlated (r = .75 in our dataset). In regression modelling, high collinearity between two predictors can render them indistinguishable. In consequence, L2 frequency might have accounted for most of the variance that would otherwise be accounted for by the frequency of L1 formal equivalent.
The learnability of false cognates was also unaffected by the frequency of L1 false orthographic neighbour. Here, high correlation between the frequencies of L1 and L2 formal equivalents (ie the false cognate and its false formal equivalent in L1) cannot explain the absence of the effect, because the two frequencies correlate very weakly (r = .14). This leaves us with an explanation parallel to the first explanation proposed for cognates, namely, that the very presence of a competing association between the same form and the meaning of the word in L1 that hinders the formation of a new form-meaning association. Since the strength of the existing association does not appear to be important, we can reject the explanation that false cognates are less learnable because their irrelevant L1 meaning has to be first inhibited before to enable learning them. If this were the case, inhibition would be more difficult for those word pairs in which this irrelevant and competing activation was stronger.
To sum up, we established that the learnability of false cognates and cognates does not depend on the strength of association between form and its L1 meaning. We proposed that in the case of cognates, learners only need to remember that the L2 word carries the same meaning as in L1. In the case of false cognates, before learning begins, students must first remember that this word does not mean what is appears to mean in L2 (ie memorise it is a false cognate), and only then they can associate the form with the true L2 meaning. This two-step process results in lower learnability of false cognates.
Orthographic similarity
One of the main points in our study was testing whether the learnability of cognates and false cognates in L2 is modulated by the degree of orthographic similarity to their formal equivalents in L1. As demonstrated by our results, the more similar the cognates, the easier they are to learn. This is in line with SLA studies indicating higher recognition rates for those cognates that are more orthographically similar (Dressler et al. Citation2011; Nagy et al. Citation1993), and with research on receptive multilingualism showing that it is easier to infer the meaning of an unknown cognate when it is more similar to the equivalent in a known language (Berthele Citation2011; Gooskens, Kürschner, and Bezooijen Citation2011; Vanhove and Berthele Citation2015). In our results, L2 proficiency interacts with orthographic similarity of L1 and L2 forms of cognates. Participants of the lowest L2 proficiency treated the less similar cognates as any other words they do not know. Conversely, participants with higher L2 proficiency took advantage of the cognate status even when L2 words bore moderate orthographic similarity to their L1 equivalents. As we hypothesised in the Introduction, the advantage for highly proficient learners can come about for two reasons. First, learners with high L2 proficiency have a better grasp of English morphology (c.f. Schmitt Citation2010). When the L1 and L2 equivalents of cognates differ formally because of their affixes (eg nerv-ous-ness and nerw-ow-ość), the knowledge of L2 morphology enables learners to automatically decompose the unknown L2 cognate into the stem and affixes, and access the corresponding conceptual representations based on the stem only. Second, proficient learners know the grapheme-to-phoneme mappings in L2 better, which helps them realise that the L1 and L2 equivalents sound the same, even if they the look different (eg v in nerv- is pronounced in the same way as w in nerw-).
The finding that L2 proficiency interacts with the orthographic similarity of L1 and L2 forms of cognates has implications for an understanding of the possible lack of effects in those classroom studies that focused on noticing and awareness of cognates: Participants with low proficiency might simply overlook non-identical cognates. Indeed, the studies by Dressler et al. (Citation2011) and Singleton (Citation2006) found that learners at proficiency levels lower than ours fail to identify non-identical cognates (although again, it is not clear whether learners have to be aware that a word is a cognate to benefit from its cognate status).
The result that the less similar cognates are less learnable might also shed some light on the role of language typology in vocabulary acquisition. Typological relatedness of languages aids L2-Ln acquisition because learners perceive their similarity (Ringbom Citation2007). Also, the closer the languages typologically, the greater the number of orthographically similar and identical cognates that they share (Schepens, Dijkstra, and Grootjen Citation2012). Therefore, it should be easy to grasp the correspondences between the known and new words across languages from the same family, but not necessarily for words from other language families, where the cognate status of words is obscured by orthography. When words are embedded in context, cognates which are less similar to the known language may not be perceptually salient to the L2 learner, especially at lower L2 proficiency levels. If the learner judges two languages to be considerably different, he/she may not even seek crosslinguistic similarities between words (Ringbom Citation2007). Thus, typological factors may prevent less experienced language learners from the benefit in learnability that such less similar cognates afford. This conclusion might be restricted to pairs of languages that share some similarity.
Contrary to our expectations, orthographic similarity did not affect the learnability of false cognates. We assumed that learning false cognates that are identical to their formal equivalents in L1 should be more difficult than learning false cognates that are formally less similar. After all, the degree of orthographic similarity should equally affect learning formally similar words. Yet, for some reason participants were always affected by the similarity of L2 false cognates to their false equivalents in L1, even when the similarity was low. It still remains to be resolved as to why.
Conclusions
To our best knowledge, this is the first study which has compared the learnability of cognates, false cognates, and non-cognate words in an ecologically-valid task and in a methodologically rigorous way. Previous research either studied cognates in artificial conditions, or tested learners’ noticing and guessing, thus yielding answers mediated by awareness. Here, we demonstrated that when adequate measures are used, L2 cognates are easier to learn for students at all L2 proficiency levels, while false cognates are the most difficult. What is more, the degree of L1–L2 similarity modulates cognate learnability in conjunction with L2 proficiency, such that that the less similar cognates are more difficult to acquire for inexperienced learners.
Further, the present study enabled us to disentangle the knowing of formally similar words from the guessing of their meaning based on cross-linguistic similarity, and let us show the magnitude of these effects in vocabulary learning. Finally, we also circumscribed a possible acquisition mechanism for words that have formal equivalents in L1. Learning these words necessarily starts with determining whether their L2 meaning does, or does not overlap with the meaning of the formal equivalent in L1. This concludes the acquisition of cognates, whereas false cognates still need to be acquired as with any other non-homographic words. This two-step process increases their learning difficulty.
Acknowledgements
We would like to thank Aneta Pavlenko and Zofia Wodniecka for their valuable comments on the earlier versions of this paper. We would like to extend special thanks to Jan Vanhove, who went far beyond his duties as a reviewer in discussing some flaws in the previous versions of the manuscript, and in suggesting a correct way of estimating confidence intervals for LMMs.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1 Throughout the paper we use ‘learning’ and ‘acquisition’ interchangeably.
2 Raw data associated with this article, as well as scripts used to run all analyses and obtain all figures can be found at the Open Science Framework: https://osf.io/qsau7/.
3 CEFR (Council of Europe Citation2001) - the Common European Framework of Reference for Languages: Learning, teaching, assessment is a scale used across the European Union to provide a coherent basis for curriculum development, designing teaching materials, and assessing foreign language proficiency. The CEFR describes foreign language proficiency at six levels: A1, A2, B1, B2, C1, and C2 (from beginner to proficient, respectively).
4 Since we use this index as a predictor for the log-odds of correct translation of cognates and false-cognates, we transformed this variable into the logit scale too. L2 proficiency index defined in this way is correlated with mean self-evaluation for reading and writing on 1–6 scale (r = .58), but it may be a better measure of lexical knowledge in L2 than self-evaluation (Lemhöfer and Broersma Citation2012).
5 All the control words were taken form a B1-level coursebook Starightforward. Intermediate Student’s Book by Macmillan. All the words used as stimuli were listed in the Oxford Wordpower Dictionary, in its version specially designed for Polish learners of English at the B1-B2 level. Since our learners were exposed to language both in class and through media (TV, Internet, etc.), we chose such words that are taught at a similar level on English language courses and are also balanced with respect to their frequency (SUBTLEX-US; Brysbaert and New Citation2009).
6 In the case of words with the highest nLD (eg ethical – etyczny), their nLD stems from orthographic conventions of each language visible in the roots (ethi- vs. ety-) and the presence of affixes (-cal vs. -czny). However, speakers with intermediate knowledge of L2 can intuitively map the similarity of both words, especially when their meaning is identical (also see the Discussion).
7 For 4 participants we removed translations with confidence lower than 2, for 40 participants - lower than 3, and for 122 participants - lower than 4.
8 This number was derived in the following way: The full range of L2 logFrequency amounts to 2.47 (3.25 for the most frequent word minus 1.78 for the least frequent word). 2.47 multiplied by the regression coefficient of L2 logFrequency (1.60) gives 3.95 of change in the log-odds of correct translation, between the least and the most frequent L2 word. To obtain the change in the odds (ie remove the logarithm), we must get the exponent of this number (52). This number indicates that, all other factors being equal, the odds for correctly translating the most frequent word are 52 times higher than the odds for correctly translating the least frequent word.
References
- Bates, Douglas, Reinhold Kliegl, Shravan Vasishth, and Harald Baayen. in review. “Parsimonious Mixed Models.” arXiv:1506.04967 [Stat]. http://arxiv.org/abs/1506.04967.
- Bates, Douglas, Martin Maechler, Ben Bolker, Steven Walker, Rune Haubo Bojesen Christensen, Henrik Singmann, and Bin Dai. 2015. “C+ Eigen and LinkingTo Rcpp.” Package “lme4.”
- Berthele, Raphael. 2011. “On Abduction in Receptive Multilingualism. Evidence from Cognate Guessing Tasks.” Applied Linguistics Review 2: 191–220. doi:10.1515/9783110239331.191.
- Brysbaert, Marc, and Boris New. 2009. “Moving Beyond Kučera and Francis: A Critical Evaluation of Current Word Frequency Norms and the Introduction of a New and Improved Word Frequency Measure for American English.” Behavior Research Methods 41 (4): 977–990. doi:10.3758/BRM.41.4.977.
- Brysbaert, Marc, Amy Beth Warriner, and Victor Kuperman. 2014. “Concreteness Ratings for 40 Thousand Generally Known English Word Lemmas.” Behavior Research Methods 46 (3): 904–911. doi:10.3758/s13428-013-0403-5.
- Comesaña, Montserrat, Pilar Ferré, Joaquín Romero, Marc Guasch, Ana P. Soares, and Teófilo García-Chico. 2015. “Facilitative Effect of Cognate Words Vanishes When Reducing the Orthographic Overlap: The Role of Stimuli List Composition.” Journal of Experimental Psychology: Learning, Memory, and Cognition 41 (3): 614–635. doi:10.1037/xlm0000065.
- Council of Europe. 2001. Common European Framework of Reference for Languages: Learning, teaching, assessment. Cambridge: Cambridge University Press.
- De Groot, Annette. 1993. “Word-type Effects in Bilingual Processing Tasks.” In The Bilingual Lexicon, edited by Robert Schreuder and B. Weltens, 27–51. Amsterdam: John Benjamins.
- De Groot, Annette, Philip Delmaar, and Stephen J. Lupker. 2000. “The Processing of Interlexical Homographs in Translation Recognition and Lexical Decision: Support for Non-selective Access to Bilingual Memory.” The Quarterly Journal of Experimental Psychology Section A 53 (2): 397–428. doi:10.1080/713755891.
- De Groot, Annette, and Janet G. Van Hell. 2005. “The Learning of Foreign Language Vocabulary.” In Handbook of Bilingualism. Psycholinguistic Approaches, edited by J. F. Kroll and A. M. B. De Groot, 9–49. Oxford: Oxford University Press.
- Dijkstra, Ton, Koji Miwa, Bianca Brummelhuis, Maya Sappelli, and Harald Baayen. 2010. “How Cross-language Similarity and Task Demands Affect Cognate Recognition.” Journal of Memory and Language 62 (3): 284–301. doi:10.1016/j.jml.2009.12.003.
- Dijkstra, Ton, and Walter J.B. Van Heuven. 2002. “The Architecture of the Bilingual Word Recognition System: From Identification to Decision.” Bilingualism: Language and Cognition 5 (3). doi:10.1017/S1366728902003012.
- Dressler, Cheryl, Maria S. Carlo, Catherine E. Snow, Diane August, and Claire E. White. 2011. “Spanish-speaking Students’ Use of Cognate Knowledge to Infer the Meaning of English Words.” Bilingualism: Language and Cognition 14 (2): 243–255. doi:10.1017/S1366728910000519.
- Durlik, Joanna, Jakub Szewczyk, Marek Muszyński, and Zofia Wodniecka. 2016. “Interference and Inhibition in Bilingual Language Comprehension: Evidence from Polish-English Interlingual Homographs.” PLOS ONE 11 (3): e0151430. doi:10.1371/journal.pone.0151430.
- Ecke, Peter. 2015. “Parasitic Vocabulary Acquisition, Cross-linguistic Influence, and Lexical Retrieval in Multilinguals.” Bilingualism: Language and Cognition 18 (2): 145–162. doi:10.1017/S1366728913000722.
- Ellis, Nick, and Alan Beaton. 1993. “Factors Affecting the Learning of Foreign Language Vocabulary: Imagery Keyword Mediators and Phonological Short-term Memory.” The Quarterly Journal of Experimental Psychology Section A 46 (3): 533–558. doi:10.1080/14640749308401062.
- Friel, Brian M., and Shelia M. Kennison. 2001. “Identifying German–English Cognates, False Cognates, and Non-cognates: Methodological Issues and Descriptive Norms.” Bilingualism: Language and Cognition 4 (3): 249–274. doi:10.1017/S1366728901000438.
- Gollan, Tamar H., Kenneth I. Forster, and Ram Frost. 1997. “Translation Priming with Different Scripts: Masked Priming with Cognates and Noncognates in Hebrew–English Bilinguals.” Journal of Experimental Psychology: Learning, Memory, and Cognition 23 (5): 1122–1139. doi:10.1037/0278-7393.23.5.1122.
- Gooskens, Charlotte, R. Bayley, R. Cameron, and C. Lucas. 2012. “Methods for Measuring Intelligibility of Closely Related Language Varieties.” In Handbook of Sociolinguistics, edited by R. Bayley, and C. Lucas, 195–213. Oxford: Oxford University Press.
- Gooskens, Charlotte, Sebastian Kürschner, and Renée van Bezooijen. 2011. “Intelligibility of Standard German and Low German to Speakers of Dutch.” Dialectologia: Revista Electrònica II: 35–63.
- Jacobs, April, Melinda Fricke, and Judith F. Kroll. 2016. “Cross-language Activation Begins During Speech Planning and Extends Into Second Language Speech.” Language Learning 66 (2): 324–353. doi:10.1111/lang.12148.
- Jaeger, T. Florian. 2008. “Categorical Data Analysis: Away from ANOVAs (Transformation or Not) and Towards Logit Mixed Models.” Journal of Memory and Language 59 (4): 434–446. doi: 10.1016/j.jml.2007.11.007
- Jarvis, Scott. 2009. “Lexical Transfer.” In The Bilingual Mental Lexicon: Interdisciplinary Approaches, edited by Aneta Pavlenko, 99–124. Bristol: Multilingual Matters.
- Jarvis, Scott, and Aneta Pavlenko. 2008. Crosslinguistic Influence in Language and Cognition. London: Routledge.
- Jessner, Ulrike. 2006. Linguistic Awareness in Multilinguals: English as a Third Language. Edinburgh: Edinburgh University Press.
- Kootstra, Gerrit Jan, Ton Dijkstra, and Marianne Starren. 2015. “Second Language Acquisition.” In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed., 349–359. Oxford: Elsevier.
- Kroll, Judith F., and Annette De Groot. 1997. “Lexical and Conceptual Memory in the Bilingual: Mapping Form to Meaning in Two Languages.” In Tutorials in Bilingualism, edited by A. M. B. De Groot and J. F. Kroll, 169–199. Mahwah, NJ, US: Lawrence Erlbaum Associates Publishers.
- Kroll, Judith F., Janet G. Van Hell, Natasha Tokowicz, and David W. Green. 2010. “The Revised Hierarchical Model: A Critical Review and Assessment.” Bilingualism: Language and Cognition 13 (3): 373–381. doi:10.1017/S136672891000009X.
- Lado, Robert. 1957. Linguistics Across Cultures: Applied Linguistics for Language Teachers. Ann Arbour: University of Michigan Press.
- Laufer, Batia. 1990. “Why are Some Words More Difficult than Others? — Some Intralexical Factors that Affect the Learning of Words.” IRAL - International Review of Applied Linguistics in Language Teaching 28 (4): 293–308. doi:10.1515/iral.1990.28.4.293.
- Laufer, Batia, and Bella Rozovski-Roitblat. 2015. “Retention of New Words: Quantity of Encounters, Quality of Task, and Degree of Knowledge.” Language Teaching Research 19 (6): 687–711. doi:10.1177/1362168814559797.
- Lemhöfer, Kristin, and Mirjam Broersma. 2012. “Introducing LexTALE: A Quick and Valid Lexical Test for Advanced Learners of English.” Behavior Research Methods 44 (2): 325–343. doi:10.3758/s13428-011-0146-0.
- Lemhöfer, Kristin, Ton Dijkstra, Herbert Schriefers, R. Harald Baayen, Jonathan Grainger, and Pienie Zwitserlood. 2008. “Native Language Influences on Word Recognition in a Second Language: A Megastudy.” Journal of Experimental Psychology: Learning, Memory, and Cognition 34 (1): 12–31. doi:10.1037/0278-7393.34.1.12.
- Lightbown, Patricia M., and Gary Libben. 1984. “The Recognition and Use of Cognates by L2 Learners.” In Second Languages: A Cross-linguistic Perspective, edited by R. W. Anderson, 393–417. Rowley, MA: Newbury House.
- Lotto, Lorella, and Annette M. B. de Groot. 1998. “Effects of Learning Method and Word Type on Acquiring Vocabulary in an Unfamiliar Language.” Language Learning 48 (1): 31–69. doi:10.1111/1467-9922.00032.
- Meara, Paul. 1993. “The Bilingual Lexicon and the Teaching of Vocabulary.” In The Bilingual Lexicon, edited by Robert Schreuder and Bert Weltens, 279–297. Amsterdam: John Benjamins Publishing.
- Müller-Lancé, Johannes. 2003. “A Strategy Model of Multilingual Learning.” In The Multilingual Lexicon, edited by Jasone Cenoz, Ulrike Jessner, and Britta Hufeisen, 117–132. Dordrecht: Kluwer Academic Publishers.
- Mulder, Kimberley, Ton Dijkstra, Robert Schreuder, and Harald R. Baayen. 2014. “Effects of Primary and Secondary Morphological Family Size in Monolingual and Bilingual Word Processing.” Journal of Memory and Language 72: 59–84. doi:10.1016/j.jml.2013.12.004.
- Nagy, William, Georgia Earnest Garcia, Aydin Durgunoglu, and Barbara Hancin-Bhatt. 1993. “Spanish-English Bilingual Students’ Use of Cognates in English Reading.” Journal of Literacy Research 25 (3): 241–259. doi:10.1080/10862969009547816.
- Otwinowska, Agnieszka. 2015. Cognate Vocabulary in Language Acquisition and Use: Attitudes, Awareness, Activation. Bristol: Multilingual Matters.
- Paribakht, T. Sima, and Marjorie Wesche. 1997. “Vocabulary Enhancement Activities and Reading for Meaning in Second Language Vocabulary Acquisition.” Second Language Vocabulary Acquisition: A Rationale for Pedagogy 55 (4): 174–200.
- Przepiórkowski, Adam, Mirosław Bańko, Rafał Górski L., and Barabara Lewandowska-Tomaszczyk. 2012. Narodowy Korpus Języka Polskiego. Warsaw: Wydawnictwo Naukowe PWN.
- Ringbom, Håkan. 2007. Cross-linguistic Similarity in Foreign Language Learning. Clevedon: Multilingual Matters.
- Rogers, James, Stuart Webb, and Tatsuya Nakata. 2014. “Do the Cognacy Characteristics of Loanwords Make Them More Easily Learned than Noncognates?” Language Teaching Research July, 1362168814541752. doi:10.1177/1362168814541752.
- Schepens, Job, Ton Dijkstra, and Franc Grootjen. 2012. “Distributions of Cognates in Europe as Based on Levenshtein Distance.” Bilingualism: Language and Cognition 15 (1): 157–166. doi:10.1017/S1366728910000623.
- Schmitt, Norbert. 1997. “Vocabulary Learning Strategies.” In Vocabulary: Description, Acquisition and Pedagogy, edited by Norbert Schmitt and M. McCarthy, 199–227. Cambridge: Cambridge University Press.
- Schmitt, Norbert. 2008. “Review Article: Instructed Second Language Vocabulary Learning.” Language Teaching Research 12 (3): 329–363. doi:10.1177/1362168808089921.
- Schmitt, Norbert. 2010. Researching Vocabulary: A Vocabulary Research Manual. New York: Palgrave Macmillan.
- Segalowitz, Norman. 2007. “Access Fluidity, Attention Control, and the Acquisition of Fluency in a Second Language.” TESOL Quarterly 41 (1): 181–186. doi:10.1002/j.1545-7249.2007.tb00047.x.
- Segalowitz, Norman, and Jan Hulstijn. 2005. “Automaticity in Bilingualism and Second Language Learning.” In Handbook of Bilingualism: Psycholinguistic Approaches, edited by J. F. Kroll and Annette M. B. De Groot, 371–388. Oxford: Oxford University Press.
- Singleton, David. 2006. “Lexical Transfer: Interlexical or Intralexical.” In Cross-linguistic Influences in the Second Language Lexicon, edited by J. Arabski, 130–143. Clevedon: Multilingual Matters.
- Van Hell, Janet G., and Annette De Groot. 1998. “Conceptual Representation in Bilingual Memory: Effects of Concreteness and Cognate Status in Word Association.” Bilingualism: Language and Cognition 1 (3): 193–211. doi:10.1017/S1366728998000352.
- Van Hell, Janet G., and Darren Tanner. 2012. “Second Language Proficiency and Cross-language Lexical Activation.” Language Learning 62 (s2): 148–171. doi: 10.1111/j.1467-9922.2012.00710.x
- Vanhove, Jan. 2015. “The Early Learning of Interlingual Correspondence Rules in Receptive Multilingualism.” International Journal of Bilingualism OnlineFirst. doi:1367006915573338.
- Vanhove, Jan, and Raphael Berthele. 2015. “Item-related Determinants of Cognate Guessing in Multilinguals.” In Crosslinguistic Influence and Crosslinguistic Interaction in Multilingual Language Learning, edited by Gessica De Angelis, Ulrike Jessner, and Marijane Kresic, 95–118. London: Bloomsbery Academic.
- Von Studnitz, Roswitha E., and David W. Green. 2002. “Interlingual Homograph Interference in German–English Bilinguals: Its Modulation and Locus of Control.” Bilingualism: Language and Cognition 5 (1): 1–23. doi:10.1017/S1366728902000111.
- Wesche, Marjorie Bingham, and Tahereh Paribakht. 2010. Lexical Inferencing in a First and Second Language: Cross-linguistic Dimensions. Bristol: Multilingual Matters.