
ABSTRACT
In recent years, deep learning algorithm has been used in many applications mainly in image processing of object detection and classification. The use of image processing techniques is becoming more interesting with the existence of drone technology with the employ of deep learning in aerial view image processing because of the high resolution and heaps of images taken. This paper aims to review neural networks specifically on the aerial view image by drones and to discuss the work principles and classic architectures of convolutional neural networks, its latest research trend and typical models along with target detection in object detection, image classification and semantic segmentation. In addition, this study also provided a specific application in the aerial image. Finally, the limitations of the convolutional network and expected future development trends were also discussed. Based on the findings, the deep learning algorithm was observed to provide high accuracy, it outperformed other generally image processing-based techniques.
Introduction
The latest drone technology in acquiring aerial view images has made data analytic in image processing more interesting. The capabilities of the drone to capture high-resolution images contribute to the development of a new method in object classification and detection. Aerial view imaging is a key component in many applications, including building detection [Citation1–3], crack damage [Citation4,Citation5] and earth observation classification [Citation6,Citation7]. Usually, aerial view images are taken using satellite-based instruments with hyperspectral, multispectral, near-infrared, light detection and ranging, synthetic aperture radar and thermal cameras, where the instruments utilize Near-infrared (NIR), Light Detection and Ranging (LIDAR), Synthetic aperture radar (SAR) and thermal cameras [Citation8,Citation9]. In practical applications, large-scale observation is implemented by unmanned aerial vehicles (UAV), aeroplanes and satellites, which provide wide-view snapshots of the earth. All these latest technologies of aerial view image data collection utilize the application of a wide diversity of sensor data, including medium resolution, high resolution, very high resolution (VHR), hyperspectral (HS) images and multispectral (MS) imagery. These advanced sensors possess a wide range of spectrum in order to enable them to be used in various sectors namely agriculture, environment, engineering and construction [Citation10].
Applications such as river bank monitoring or estimating the yield of a plantation usually require information on the earth’s features, like the distribution of houses along the river bank or the number of plants in the plantation, where most of the required data collected through diversity sensing involve images [Citation1,Citation2,Citation4,Citation11,Citation12]. Aerial imagery analysis is a challenging task due to their special feature characteristics like the high resolution and small objective of the images compared to the common images. The key technology in image analysis is extracting and understanding the feature of the image. In general, the ordinary methods employed for image analysis include linear polarization, machine learning (ML), regression analysis, vegetation indices (NDVI) and wavelet-based filtering [Citation13]. The traditional image analysis approach mainly focuses on the design of feature extractor and classifier. However, the development of traditional image analysis methods is constrained due to the poor portability, relatively poor accuracy and the lack of generalization ability of the feature extracted by artificial feature extraction approach [Citation14–17].
The introduction of the latest techniques in machine learning such as deep learning has greatly resolved problems pertaining to image processing in object detection and identification. Hinton proposed the notion of deep learning, and analysed that neural networks with a multiple hidden layer own superior ability of feature learning [Citation16]. Deep learning algorithms like convolutional neural networks, deep belief networks, deep neural networks and recurrent neural networks have been widely exploited in urban planning [Citation18], precision agriculture [Citation19,Citation20], military applications [Citation13] and environmental management [Citation21], wherein some cases they outperformed human experts. The most popular network in deep learning is convolutional neural network (CNN), which learns features from a large number of data, where the learned features describe the rich information inherent in the data. Furthermore, CNN combines feature extraction, feature selection and feature classification into an integrated model to conduct global optimization through end-to-end training, which enhances the distinguishing power of features making it significantly superior to traditional methods in classification and positioning accuracy [Citation20].
This paper discusses and reviews the implementation of deep learning architecture CNN and its applications in aerial imaging, the potential problems for the current CNN algorithm and aerial image processing are also discussed. It’s expected to contribute to the development of deep learning in aerial imagery. The organization of the remaining sections are as follows, section 2 introduces the architectures and working principle of CNN, and also give a summary of the classical CNN architectures; section 3 presents the characteristics of aerial image and the aerial image dataset, and also summarizes the current Deep learning methods in aerial image application; section 4 discusses the problems of CNN and aerial image processing and section 5 gives a conclusion of this paper.
Architectures of CNN
Currently, the deep learning architectures employed in image recognition and analysis studies mainly include Deep Belief Network (DBN) [Citation22], CNN [Citation23] and Stacked Auto-Encoders (SAE) [Citation24]. CNN is perceived to be superior to the others in accuracy detection and speed due to its powerful feature representations, as it is an in-depth research that has become a central issue in the area of image recognition. As shown in , the typical CNN architecture includes input layer, convolutional layer followed by pooling layer and fully connected layer.
Figure 1. Convolutional neural network.
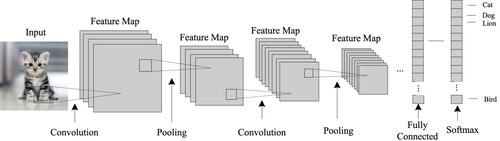
Working principle of CNN
The learning and training of the convolution kernel parameters of CNN are implemented using a supervised learning algorithm named the gradient backpropagation algorithm. It is assumed that the training of the network is not perfect, some errors are bound to occur between the training and the actual outputs. The errors propagate layer by layer in the gradient descent algorithm, whereby the network parameters are updated layer by layer in parallel.
The working principle of CNN can be divided into three phases: network model design, network training and network prediction. Taken the CNN in classification task as an example, the steps are shown below:
Network model design
In the classification task, the objective is to classify the data into several classes. According to the volume of the data and the characteristics of the data itself, the design of the network model needs to design network depth, the function of each layer of the network and the parameters in the network such as λ, η, etc. Among the many studies that conduct experiments on the model design of CNN, are the ones on model depth [Citation25,Citation26], the ride of the convolution [Citation27,Citation28], activation function [Citation29], the parameter selection in the network, etc. [Citation30].
Network training
Parameters are trained in the network through the backpropagation of residuals for CNNs. After the training, the parameters of the network are fixed and the feature of the data is extracted. However, during network training, the overfitting, as well as the vanishing and explosion of gradient problems, greatly affect the convergence performance of the training. Several effective improvements have been proposed to solve the problems, including random initialization network parameters based on Gaussian distribution [Citation31], initialization with pre-trained network parameters [Citation26], and independent and identically distributed initialization for parameters of different layers of CNNs [Citation32]. According to recent research trends, the increased utilization of the CNN model has led to a more challenging complex network model training strategy.
Network prediction
In the classification task, the output of the network is the classification result and the accuracy. The CNN prediction process includes the following three steps. The first step is forward conduction through the input data, followed by the output of the feature map at each layer, and finally using the fully connected network to output the conditional probability distribution. Recent studies have highlighted the high-level features of the forward-conducting CNNs performing with the discriminative ability and generalization performance [Citation33]. In addition, these features can also be applied to a wider range of areas through transfer learning, as the research result is of great significance for expanding the application field of CNNs.
Classical CNN architectures
Based on the 36 latest articles investigated in this paper on deep learning in aerial image processing, the classical network models used in practical applications were usually chosen as the backbone to construct the network, such as the original LeNet-5 network, the classical AlexNet, VGGNet, GoogLeNet and ResNet networks, the object detection framework like Faster R-CNN. Here we describe several commonly used classical networks.
Alexnet
In 2012, Krizhevsky et al. introduced the AlexNet network (), a 5-layer convolutional network with approximately 650,000 neurons and 60 million trainable parameters [Citation31]. These characteristics greatly exceed LeNet-5 in terms of network size [Citation34]. In addition, by choosing the large image classification database ImageNet as the training dataset [Citation35], AlexNet also utilized the dropout technique to reduce the network overfitting problem. In terms of hardware support, it used graphics processing unit (GPU) for training, which increased the training speed of the network by more than 10 times compared to traditional central processing unit (CPU) operations. Therefore, it won the championship in ImageNet’s 2012 image classification competition by achieving an 11% higher accuracy compared to the runner-up. This success has attracted academicians’ attention to utilizing AlexNet to the study of CNN once again.
Figure 2. AlexNet architecture [Citation31].
![Figure 2. AlexNet architecture [Citation31].](/cms/asset/a86c97a7-15a2-442a-9ef9-261b4f42ce86/yims_a_2174651_f0002_oc.jpg)
VGGNet
Given the large convolution kernel problem of AlexNet, Simonyan et al. conducted experiments to discover that it is possible to replace large convolution kernels with several smaller convolution kernels, which obtained better experimental results [Citation26]. In their experiments as shown in , a 7 × 7 convolution kernel was considered as a superposition of 3 layers of 3 × 3 convolution kernels, which had 49 parameters to be learned while only one layer of feature image and one receptive field was provided. The 3 layers of 3 × 3 convolution kernel had 27 parameters, with 3 receptive fields and 3 layers of feature images at different scales. In addition, the network used the 3 × 3 convolution kernel and added a pooling layer after several convolutional layers instead of pooling operation immediately after each convolutional layer, which ensured the network depth. The structure of VGGNet further evidenced that increasing the depth of network is beneficial to enhance the accuracy of image classification. However, the depth of the network should be limited because an excessive number of layers will cause network degradation that will affect the test results [Citation36]. Finally, VGGNet layer number is determined in both the 16 and 19 layers.
Figure 3. VGGNet architecture [Citation26].
![Figure 3. VGGNet architecture [Citation26].](/cms/asset/edc7cabb-55cc-4eea-bd98-52bcbee96126/yims_a_2174651_f0003_oc.jpg)
Googlenet
Different sizes of convolution kernels denote different sizes of receptive fields, whereby VGGNet had proven that different receptive fields help improve classification accuracy. Consequently, GoogLeNet added convolution kernels of different sizes in the same layer [Citation37]. As shown in , three sizes of convolution kernels 1 × 1, 3 × 3, 5 × 5 were inserted in the same layer, where a concatenation operation enables feature images of different scales to be fused together. In addition, a 1 × 1 convolution kernel is added in front of the 3 × 3 and 5 × 5 convolution kernel in order to decrease the dimension and the number of parameters [Citation38]. Inception is an optimization step of CNN structure, where the number of parameters trained by GoogLeNet is only 1/12 than that of AlexNet and obtained more accurate results. GoogLeNet emerged as the champion of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC)2014 classification competition with a network depth of 22 layers.
Figure 4. Inception module with dimension reduction [Citation37].
![Figure 4. Inception module with dimension reduction [Citation37].](/cms/asset/f82047e9-fce7-42cf-9ac9-7198ae482b1f/yims_a_2174651_f0004_oc.jpg)
Resnet
Since gradient exploration and vanish problems exist in network training, He et al. proposed a deep residual learning network [Citation25]. As illustrated in , the residual network directly maps the shallow layer feature map X to the upper layer through shortcut connections, where the output of the high layer becomes the aggregate of the underlying map and the original output. In addition, a priori of the shallow layer network is introduced in the training of the network. Considering the extreme situation, if X is already a near-perfect mapping, the gradient of the current layer will become very small in the subsequent training, and it will continue to affect the coefficient update of the previous layer during the back propagation. As the structure of residual is introduced, the overall gradient does not disappear due to the existence of the output X, and it ensures the performance of deeper networks.
Figure 5. Residual learning: a building block [Citation25].
![Figure 5. Residual learning: a building block [Citation25].](/cms/asset/19c5b3bd-652c-4c69-af13-a619bfae197c/yims_a_2174651_f0005_oc.jpg)
Deep residual network with a 152 layer network depth won the championship with a top-5 error of 3.57% in ILSVRC2015. This result from the residual network exceeded the human eye recognition rate (5.1%) [Citation32]. However, the slimming down of CNN and the optimization of its structure will remain an important topic in the future as the deep residual network model is large and complicated.
Comparison of the classical network
summarizes the aforementioned classical CNN networks in terms of the layers, the parameters, place and the Top-5 error rate when conducted the image classification task in the ILSVRC competition. The dataset is the public ImageNet dataset. The comparison in the table illustrates that with the optimization of the network model, the amount of the parameters decreased with the network depth increased. Meanwhile, the Top-5 error rate has decreased, where ResNet reached the lowest Top-5 error rate of 3.57% with 152 layers and only more than 2 million parameters. The transfer learning method saved much time during the network training and got excellent performance in image classification and object detection. Some applications used the pre-trained network by keeping the convolution layers’ architecture and parameters while changing the full connected layers. VGGNet is the most popular network used in the transfer learning task. AlexNet, GoogLeNet and ResNet also are used as the backbone of the CNN network in specific applications, which reduce the training time and get better results compared to the network trained from scratch.
Table 1. Classical CNN network.
Deep learning in aerial image processing
Characteristics of aerial image
The aerial images obtained from UAV or drone possess high resolution, where the interest targets with less number pixels are sparsely scattered, making it difficult to classify and detect these images. The attribute of the aerial image is summarized as the following: Small objects have less context information, lower resolution and cluttered background; The visual appearance of objects in aerial images differ largely due to the variation of viewpoint, illumination, shadow, occlusion and resolution [Citation39]; High-computational problem due to a large number of heterogeneous images have different temporal resolutions, angular, spectral and spatial; The spectral resolution of VHR images are inherently lower, where the small-scale surface texture and small objects are visible, which lead to low inter-class differences and high intra-class variability of the image; Insufficient aerial image data to train a new CNN network.
In regards to the small object and cluttered background of the image, traditional image processing usually designs a feature extraction approach according to the characteristic of the specific object. However, the feature extraction approach for some objects cannot be used to other category objects, which lacks generalization ability. For deep learning-based method, one network model can be used to extract the feature of different objects, where the approach is not constrained by the characteristic of the object. When considering the high-computational problem, the transfer learning approach applies the parameter trained on public dataset like ImageNet to the new dataset which is similar to the public dataset. Here, the GPU unit is used as the data processing unit, because it is efficient in accelerating the training process. As for the issues of low inter-class dissimilarity and high intra-class variability, Cheng et al. put forward a discriminative CNNs (D-CNNs) model to enhance the accuracy in remote sensing image classification, where a metric learning regularization is used to extract more discriminative CNN features [Citation40]. The experimental result exhibited that the method outperforms the existing three baseline methods with several public benchmark datasets. For the insufficient dataset problem, data augmentation approach is used to enlarge the dataset. Data augmentation increases the amount of data without changing the image category and also improves the generalization ability of the model. There are many ways to augment the data of natural images, such as horizontal flips, a certain degree of displacement, cropping and colour jitter.
Aerial image dataset
Generally, the aerial image is performed by means of UAV, aeroplanes and satellites, which provide wide-view snapshots of the earth. shows several available public aerial image datasets, which are used for semantic segmentation, image classification and object detection. The image resolution for UC Merced Land Use, WHU-RS19, NWPU-RESISC45 and AID are no more than 600 × 600, which are used in the image classification task. WHU-RS19 contains 19 different scene classes and 50 sample sizes of 600 × 600 in each class, while UC Merced Land Use dataset has 2100 images which include 21 classes with 100 images of 256 × 256 sample size for each class. On the other hand, NWPU-RESISC45 dataset established by Northwestern Polytechnical University (NWPU), is a publicly available dataset for Remote Sensing Image Scene Classification (RESISC) which includes 31,500 images, covering 45 scene classes. Among these datasets, AID is the largest annotated aerial image dataset with the images collected from Google Earth imagery, where it contains 10,000 images within 30 scene classes and 200–400 samples in each class with 600 × 600 size. The AID dataset is closer to real aerial image classification tasks due to the large-scale dataset, smaller inter-class dissimilarity and higher intra-class variations images. The remaining datasets consist of high-resolution images, such as NWPU VHR-10, VEDAI, OIRDS and RIT-18 dataset, where NWPU VHR-10 with 10-class is a geospatial object detection dataset containing 800 VHR images collected from Vaihingen and Google Earth dataset, and it has been manually annotated. Besides, the VEDAI, OIRDS and Munich vehicle datasets are vehicle images, which are built for vehicle detection in aerial imagery, where VEDAI dataset contains 1240 images within 9 classes and the vehicles contained in the database displayed different variabilities such as occlusions or specularities, shadowing changes or lighting and multiple orientations. Meanwhile, OIRDS dataset contains 900 annotated images with 1800 targets identified. On the other hand, ISPRS Potsdam, Massachusetts Buildings and Vaihingen datasets consist of aerial imagery with buildings, with Vaihingen datasets and ISPRS Potsdam containing 33 and 38 patches with different sizes, respectively, where each consists of a real orthophoto (TOP) obtained from a broad TOP mosaic. RIT-18 is a high-resolution multispectral dataset collected using a UAV which was annotated with 18 object categories and is used for semantic segmentation.
Table 2. Public aerial image dataset.
Deep learning in aerial image application
A total of 36 latest articles were investigated related to deep learning and their applications on aerial images focused on four categories which are object detection, image classification, image semantic segmentation and other applications. represents the 36 identified relevant works in terms of the aerial image application area and the specific application with related reference. Of the 36 articles, 13 were related to object detection, 13 to classification, 8 to semantic segmentation, 1 to image denoizing and 1 to image matching. Several studies utilized deep learning for building detection [Citation1,Citation3], while a few used it for bottle detection [Citation53], vehicle detection [Citation39,Citation54], etc. In addition to the classification, many studies used deep learning in aerial scene classification while some applied it in agriculture for crop classification and earth observation classification [Citation6,Citation11]. On the other hand, several studies focused on semantic segmentation [Citation51,Citation52,Citation55,Citation56] while some others used deep learning in building and vehicle segmentation [Citation57–59]. Besides, one study focused on the image match issue which tried to find out the same object between two images [Citation60], while another study referred to image denoizing which focused on removing noise in UAV images [Citation61].
Table 3. Specific application of deep learning in the aerial image.
Object detection
Object detection is a crucial research topic in image processing and computer vision, where it focused on detecting a certain class of semantic objects such as buildings, cars or humans in videos and digital images. In recent years, the accuracy of object detection has greatly increased due to the success of deep learning-based CNNs. Currently, deep learning methods used for object detection can be divided into two classes, namely one stage detection and two stage detection [Citation74–77]. The latter involves two steps. First, the regions that potentially contain objects are proposed. Then, the proposed regions obtained in the first step will be classified into different categories. However, the regions proposal step is removed in one stage detection, whereby the object localization and classification are completed at one step, greatly improving the detection speed compared with two stage detection. Examples of well-researched fields for object detection contain pedestrian detection and face detection [Citation39].
enlists the overview of 13 investigations of deep learning-based algorithm used in object detection. It summarizes the investigation in terms of CNN framework used, dataset and other methods used along with the comparisons with other available techniques. Based on , only two investigations [Citation5,Citation62] used General CNN model to train their network while the rest of them employed well-known CNN architectures, such as LeNet-5, Faster R-CNN, SSD, YOLO, VGG-16 and Resnet. Reference [Citation19] reached the highest accuracy at 95.8%, it focused on the vine diseases detection using the LeNet-5 as the CNN network, and the collected data was UAV images. In addition, 5 of the 13 studies utilized VGG architecture with 16–19 weight layers. Together with CNN model, other methods also were employed to improve the performance of detection, in which fine-tuning and transfer learning were the two common methods used in adjusting the pre-trained network in order to be suitable to a specific dataset. In a previous study, two Faster RCNN based models (Inception-Resnet and Resnet) and a one stage Focal Loss network named RetinaNet were used, where the detection accuracy of the models was estimated at 91.3%, 83.1% and 75.6%, respectively [Citation3]. Kasthurirangan et al. and Hilal et al. employed the pretrained deep learning network VGG-16 and fine-tuned the network to a new application with less datasets [Citation4,Citation39]. The experiment implemented by Kasthurirangan et al. achieved 90% accuracy in determining the crack damage detection of civil infrastructure in realistic situations, while Hilal et al. utilized a uniform one stage model, where the proposed method was identified with two public datasets. The results from the latter study outperformed the current result in terms of mean average precision (MAP) and computation time. Recently, the depth of the proposed CNN networks has been increased in ResNet, but the deeper the network the harder it is to train. Therefore, the researchers utilized batch normalization to mitigate the time-consuming problem and avoid gradient vanish [Citation1]. Diogo et al. also employed a multi-resolution feature fusion method, with the results indicating better accuracy and localization capabilities [Citation5]. Besides, Zou et al. used VGG architecture, RAM, small target prior, fisher information and Bayesian statistics to improve the accuracy with the MAP increase of 1%-4% on LEVIR dataset compared to the medium-networks, tiny-networks (TINY-BASE) and VGG-f based networks [Citation2]. Moreover, the multi-task loss function used in a previous study accomplished the improved detection accuracy in small-sized object detection and precise localization, the proposed method obtained the recall at 80.3% [Citation54].
Table 4. Applications of object detection.
Classification
Image classification refers to the task of classifying a number of images into categories in light of the characteristic of the images. It has been widely researched in past decades due to the extensive applications [Citation40]. Recently, deep learning-based aerial image classification has been applied on various areas, including agriculture application like corn classification [Citation11], earth observation classification [Citation6], in estimating plant centres [Citation71], civil infrastructure application like infrastructure quality assessment [Citation68], and urban land use classification [Citation72,Citation73].
represents an overview of image classification in terms of CNN framework used, dataset used, the number of classes, other methods used and comparisons. In total, 13 studies were investigated on the subject of image classification, in which 5 referred to aerial scene classification using publicly available dataset to validate the proposed method, with the UC Merced Dataset as the most commonly used dataset. Of the 5 studies, 2 studies trained their own CNN architecture with the training dataset [Citation64,Citation65] while the remaining 3 employed pre-trained CNN frameworks like AlexNet, VGGNet, GoogLeNet, OverFeat and CaffeNet [Citation40,Citation66,Citation67]. Han et al. used a self-label co-training based SSGF method on AID dataset, NWPU-RESISC45, WHU-RS and UCM datasets [Citation64]. The result indicated that the proposed method improved the classification accuracy compared to supervised learning, Selftraining, SSGA-E and Co-training methods. In addition, a metric learning regularization on CNN features was imposed, and the proposed D-CNN models addressed the problems of inter-class similarity and intra-class diversity by optimizing a new discriminative objective function, the mothed was validated on UC Merced dataset and WHU-RS Dataset with the classification more than 96.9% [Citation67]. Two other studies collected their dataset using the UAV technique [Citation11,Citation71], while the former employed a customised X8-Skywalker frame to obtain data and LeNet to train their CNN architecture [Citation11]. On the other hand, Oshri et al. used transfer learning, fine-tuning and Adam optimiser to improve the classification accuracy, and it was validated on Landsat 8 and Sentinel 1 dataset, and the accuracy reached 84% [Citation71]. Besides, Cao et al. proposed a DNN-based data fusion method using SegNet, which integrate ground feature maps and aerial images together. The experiment on New York City land use maps dataset achieved high accuracy at 78.1% [Citation72]. Similarly, Romero et al. combined sparse features learning, principal component analysis (PCA), greedy layerwise and unsupervised pre-training strategy together [Citation73]. It outperformed PCA and kernel PCA (KPCA) methods when implemented on UC Merced dataset and AVIRIS Indiana’s Indian Pines test site.
Table 5. Applications of image classification.
Semantic segmentation
Image semantic segmentation is a classification at the pixel level, where pixels belonging to the same class are classified into one class, so semantic segmentation is to understand images from the pixel level. The objective of semantic segmentation is to change and simplify the representation of the image to make the image easier for further analyse. Generally, image semantic segmentation is used to locate objects in images. As a popular research domain in aerial image processing, segmentation of high-resolution images plays a crucial role in various applications like forestry and agriculture management, environmental monitoring, land inventory and urban planning. Deep learning algorithms-based CNNs have received an increased amount of attention, where it has been employed in semantic labelling of UAV imagery.
summarizes seven articles that employed deep learning in image segmentation, in which four articles referred to semantic segmentation [Citation51,Citation52,Citation55,Citation56], one article aimed at roof segmentation [Citation57] and another one focused on vehicle instance segmentation [Citation59]. Based on the nature of optical image, the labels of nearby image pixels were strongly correlated for the spatial coherence of the objects, therefore, it was a challenging task to divide these areas effectively. Sun et al. presented a semantic segmentation approach that combined multi-resolution segmentation (MRS) and multi-filter CNN method together, where the multi-filter CNN method is used to aggregate the training data, the multimodal data fusion approach is used to label the imagery, while the MRS method was employed to delineate object boundaries to reduce salt-and-pepper artefacts [Citation55]. In addition to the overfitting problem, dropout and FCRF post-processing methods were employed to improve segmentation performance [Citation56]. With the network depth increasing, the accuracy gets saturated followed by rapid degradation, the Fully Convolutional Network (FCN) based framework with residual learning was used [Citation60], where the experiment on ISPRS Potsdam dataset demonstrated it to outperform the other FCN-based methods. In line with the problem of the internal covariate shift of input layers, stacked convolutional autoencoders (SCAE) and multi-scale independent component analysis (MICA) were utilized to accelerate the training speed [Citation51]. Besides, independent pixel-wise classification by ignoring the high-order regularities has always resulted in spatial inconsistency problems. In order to address the problem, a Building-A-Nets was presented where it successfully detected and rectified the spatial inconsistency on aerial images [Citation58]. Given the complication of benchmark dataset, a new dataset of Aerial Imagery for Roof Segmentation (AIRS) was provided [Citation57], in which several popular applied deep learning based semantic segmentation methods were implanted for the analysis of the proposed dataset and performance evaluation. The results indicated that the dataset served as the benchmark dataset for future study.
Table 6. Applications of image semantic segmentation.
Other applications
Generally, all signal processing devices (both analogue and digital) are susceptible to noise, which can be random or white noise with an even frequency distribution or frequency-dependent noise introduced by a device’s mechanism or signal processing algorithms. summarizes two articles that have applied deep learning in image denoizing and matching. In order to solve the noise problem, a generative adversarial learning framework-based deep neural network approach was proposed to track the relevance between noisy and clean images [Citation61]. The proposed method outperformed the traditional method based on image matching on local features of the denoised UAV images along with corresponding clean UAV images. In the situation that the aerial images on ultra-wide baseline were collected by large camera rotations, the variation of the image exceeded the reach of RANSAC and SIFT methods. Altwaijry et al. introduced a deep learning-based method that sidestepped local correspondence by taking the issue as a classification operation, by incorporating an attention mechanism to generate a group of possible matches [Citation60]. The experiment demonstrated that the proposed models approached human accuracy and outperformed the traditional ultra-wide baseline matching method.
Table 7. Applications in image denoizing and matching.
Discussion
Currently, CNNs based deep learning algorithm is being developed and incorporated rapidly into the field of computer vision, which has achieved amazing results. This paper mainly discussed the structure of CNNs and the research progress in the field of aerial image processing. In short, the success of deep learning depends on three factors, namely big data, large models and big calculations. A large amount of manual annotation data makes supervised training possible, whereby a deeper and larger model improves the recognition ability of the network and with the combination of GPU, the rapid development of computer hardware enables large-scale training time-saving and effective. However, some problems still exist in this field and need to be addressed in future:
It is difficult to determine the most suitable network structure for a specific task, especially the number of layers and neurons for each layer. Hence, it still requires a more detailed knowledge to choose reasonable values such as learning rate and regularization intensity.
The robustness of object detection is mainly affected by inter-class and intra-class diversity, which is reduced by the little inter-class difference and large intra-class diversity. Wang et al. used adversarial learning to address the image recognition problem, where they trained the detection network by generating occlusion and deformation image samples with adversarial network [Citation78], which produced good results. Therefore, building a feature model with generalization capabilities remains an open research problem.
The current theory of CNNs lacks frame mathematical theory. The incorporation of many parameters for a specific model depends more on the experience of the researchers than theory. A complete mathematical explanation is an inevitable problem in the future development of CNNs.
Conclusion
In this systematic review, we conducted a review of deep learning-based research applications in aerial image processing. We investigated 36 relevant articles, examined the problems and particular areas, including the sources of data used, technical details of the network models and performance comparison between the existing techniques and deep learning. In summary, deep learning achieves state-of-the-art performance by outperforming other traditional image processing techniques. In future, we intend to utilize some well-known CNN networks to determine potential methods that can be used to address the problem described in Section 4.
This survey would help future researchers and engineers in conducting experiments with deep learning, and applying it to solve various aerial image processing problems involving object detection, classification, semantic segmentation and other area about image analysis or computer vision. Moreover, the review is expected to contribute to the development of deep learning in aerial imagery.
Acknowledgements
This work was supported by the Research Support Program of Xi’an University of Finance and Economics of China (22FCJH008), and the Social Science Foundation Program of Shaanxi of China (2022M005).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Xinni Liu
Xinni Liu is a senior lecturer at the school of information, Xi’an University of Finance and Economics. She received the PhD degree in electronic engineering and computer science at University Malaysia Pahang, Peken, Malaysia. Her research interest includes computer vision, image processing, machine learning and deep learning.
Kamarul Hawari Ghazali
Kamarul Hawari Ghazali is a professor of faculty of electrical and electronics engineering, University of Malaysia Pahang, Malaysia. His current research interests include Deep Learning, Machine Vision System, Image Processing, Signal Processing, Intelligent System, Vison Control, Computer Control System, Thermal Imaging Analysis. He is a Member of Board of Engineer Malaysia and a Senior Member of IEEE.
Fengrong Han
Fengrong Han is a senior lecturer of Baoji University of Arts and Sciences. Her research interest includes wireless sensor network, optimize algorithm.
Izzeldin Ibrahim Mohamed
Izzeldin Ibrahim Mohamed is a senior lecturer of faculty of electrical and electronics engineering, University of Malaysia Pahang, Malaysia. His research interest includes wireless sensor network, network security.
References
- Wuttichai B, Yumin T, Yinghua Y, et al. A deep learning approach on building detection from unmanned aerial vehicle-based images in riverbank monitoring. Sensors. 2018;18(11):3921–3933.
- Zhengxia Z, Zhenwei S. Random access memories: a new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans Image Proc. 2018;27(3):1100–1111.
- Griffiths D, Boehm J. Rapid object detection systems, utilising deep learning and unmanned aerial systems (UAS) for civil engineering applications. ISPRS TC II Mid-term Sym, Riva del Garda, Italy, Proceedings of ISPRS 2018; 2018, 391–398.
- Kasthurirangan G, Hoda G, Akash V, et al. Crack damage detection in unmanned aerial vehicle images of civil infrastructure using pre-trained deep learning model. Int J Traffic Trans Eng. 2018;8(1):1–14.
- Diogo D, Francesco N, Norman K, et al. Multi-resolution feature fusion for image classification of building damages with convolutional neural networks. Rem Sens. 2018;10(10):1636–1661.
- Dimitrios M, Mihai D, Thomas E, et al. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci Rem Sens Let. 2016;13(1):105–109.
- Xiangtao Z, Yuan Y, Lu X. A deep scene representation for aerial scene classification. IEEE Trans: Geosci Rem Sens. 2019;57(7):4799–4809.
- Lillesand TM, Kiefer RW, Chipman J. Remote sensing and image interpretation. New York (NY): Wiley; 2008.
- Shaw G, Manolakis D. Signal processing for hyperspectral image exploitation. IEEE Sig Proc Mag. 2002;19(1):12–16.
- Ishimwe R, Abutaleb K, Ahmed F. Applications of thermal imaging in agriculture – A review. Adv in Rem Sens. 2014;3(2014):128–140.
- Fedra T, Andres F, Carlos S, et al. Corn classification using deep learning with UAV imagery. An operational proof of concept. IEEE 1st ColCACI, IEEE, Medellin, Colombia, 2018.
- Mohammad R, Yun Z, Rakesh M, et al. Using a VGG-16 network for individual tree species detection with an object-based approach. 10th IAPR Work. Pat. Rec. in Rem. Sensg (PRRS), IEEE, Beijing, China, 2018.
- Calhoon S, Conwell W Y. Image processing methods and arrangements, Google Patents, USA (2018).
- Saxena L, Armstrong L. A survey of image processing techniques for agriculture. Proceedings of AFITA; Perth, Australia, 405–418, 2014.
- Arti S, Baskar G, et al. Machine learning for high-throughput stress phenotyping in plants. Tre Plant Sci. 2016;21(2):110–124.
- Alfatni MSM, Shariff ARM, Shafri HZM, et al. Oil palm fruit bunch grading system using red, green and blue digital number. J App Sci. 2008;8(8):1444–1452.
- Chen C, Baochang Z, et al. Land-use scene classification using multi-scale completed local binary patterns. Sig ima vid Proc. 2016;10(4):745–752.
- Kamusoko Courage. Importance of remote sensing and land change modeling for urbanization studies. Urban development in Asia and Africa. Singapore: Springer; 2017. p. 3–10.
- Kerkech M, Hafiane A, Canals R. Deep leaning approach with colorimetric spaces and vegetation indices for vine diseases detection in UAV images. Comp Electr Agric. 2018;155:237–243.
- Nair V, Hinton GE. Rectified linear units improve restricted Boltzmann machines. Proceedings of International Conference on Mac. Lear (ICML-10); Haifa, Israel, 807–814, 2010.
- White AR. Human expertise in the interpretation of remote sensing data: A cognitive task analysis of forest disturbance attribution. Int J App Ear Obser Geoinformation. 2019;74:37–44.
- Hassan M, Golam R AM, Uddin M Z, et al. Human emotion recognition using deep belief network architecture. Infor Fusion. 2019;51:10–18.
- Rig D, Emanuela P, Emanuele M, et al. Convolutional neural network for finger-vein-based biometric identification. IEEE Trans Infor Forensic Sec. 2019;14(2):360–373.
- Calvo-Zaragoza J, Gallego A. A selectional auto-encoder approach for document image binarization. Com Ver Pattern Rec. 2019;86:37–47.
- He K, Xiangyu Z, Shaoqing R, et al. Deep residual learning for image recognition. IEEE Conference on Computer Vision Pattern Recognition (CVPR), Las Vegas, NV, USA, 770–778, 2016.
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition, arXiv preprint, arXiv:1409.1556 (2014).
- Wenlu Z, Rongjian L, Tao Z, et al. Deep model based transfer and multi-task learning for biological image analysis. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1475–1484, 2015.
- Weixun Z, Zhenfeng S, Chunyuan D, et al. High-resolution remote-sensing imagery retrieval using sparse features by auto-encoder. Rem. Sens Lett. 2015;6(10):775–783.
- Agostinelli F, Hoffman M, Sadowski P, et al. Learning activation functions to improve deep neural networks, arXiv preprint, arXiv:1412.6830, 2014.
- Metin NG, Heang-Ping C. Optimal neural network architecture selection: improvement in computerized detection of microcalcifications. Acad Radiol. 2002;9(4):420–429.
- Krizhevsky A, Sutskever I, Hinton G. Imagenet classification with deep convolutional neural networks. Advances in Neural information Processing System; Lake Tahoe, Nevada, 1097–1105, 2012.
- Kaiming H, Xiangyu Z, Shaoqing R, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. Proceedings of IEEE International Conference on Computer Vision; Santiago, Chile , 1026–1034, 2015.
- Hilal E, Yusuf C A, Mustafa S, et al. Early and late level fusion of deep convolutional neural networks for visual concept recognition. Int J Sema Comp. 2016;10(3):347–363.
- Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–2324.
- Deng J, Dong W, Socher R. Imagenet: a large-scale hierarchical image database. IEEE Conference on Computer Vision Pattern Recognition; New York, IEEE Press, 248–255, 2009.
- Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans Neu Net. 1994;5(2):157–166.
- Szegedy C, Wei L, Yangqing J, et al. Going deeper with convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1–9, 2015.
- Min L, Chen Q, Yan S. Network in network, arXiv preprint, arXiv, 2013. 1312.4400.
- Tayara H, Chong KT. Object detection in very high-resolution aerial images using one-stage densely connected feature pyramid network. Sens. 2018;18(10):3341–3358.
- Gong C, Ceyuan Y, Xiwen Y, et al. When deep learning meets metric learning: remote sensing image scene classification via learning discriminative CNNs. IEEE Trans Geosci Rem Sens. 2018;56(5):2811–2821.
- Marco C, Giovanni P, Carlo S, et al. Land use classification in remote sensing images by convolutional neural networks, arXiv preprint, arXiv:1508.00092 (2015).
- Guofeng S, Wen Y, Tao X, et al. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int J Rem Sens. 2012;33(8):2395–2412.
- Gong C, Junwei H, Xiaoqiang L. Remote sensing image scene classification: benchmark and state of the art. Proc IEEE. 2017;105(10):1865–1883.
- GuiSong X, Jingwen H, et al. AID: a benchmark data set for performance evaluation of aerial scene classification. IEEE Trans Geosci Rem Sens Let. 2017;55(7):3965–3981.
- Gong C, Junwei H, Peicheng Z, et al. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J Photog Rem Sens Let. 2014;98:119–132.
- Razakarivonyb S, Jurie F. Vehicle detection in aerial imagery: a small target detection benchmark. J Vis Commu Ima Rep. 2016;34:187–203.
- Franklin T, Brian C, Craig P, et al. Overhead imagery research data set – an annotated data library & tools to aid in the development of computer vision algorithms. AIPR 2009, DC: Washington IEEE, 2010.
- Rottensteiner F, Sohn G, Jung J, et al. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Anna Photog, Rem Sens Spa Infor Sci. 2012;1(3):293–298.
- Kang L, Gellert M. Fast multiclass vehicle detection on aerial images. IEEE Geosci Rem Sens Let. 2015;12(9):1938–1942.
- Mnih V. Machine learning for aerial image labeling. University of Toronto (Canada); 2013.
- Kemker R, Salvaggio C, Kanan C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J Photog Re Sens Let. 2018;145:60–77.
- Volpi M, Tuia D. Deep multi-task learning for a geographically-regularized semantic segmentation of aerial images. ISPRS J Photog Rem Sens Let. 2018;144:48–60.
- Jinwang W, Wei G, Pan T, et al.: Bottle detection in the wild using low-altitude unmanned aerial vehicles. International Confer. Infor. Fusion (FUSION), Cambridge, UK: IEEE, 2018.
- Jiandan Z, Tao L, Guangle Y. Robust vehicle detection in aerial images based on cascaded convolutional neural networks. Sens. 2017;17(12):2720–2737.
- Ying S, Xinchang Z, Silvano G, et al. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. ISPRS J Photog Rem Sens Let. 2018;143:3–14.
- Marmanis D, Wegner JD, et al. Semantic segmentation of aerial images with an ensemble of CNNs. ISPRS Ann photog. Rem Sens Spa Infor Sci. 2016;3:473–480.
- Qi C, Lei W, Yifan W, et al. Aerial imagery for roof segmentation: a large-scale dataset towards automatic mapping of buildings. ISPRS J Photog Rem Sens Let. 2019;147:42–55.
- Xiang L, Xiaojing Y, Yi F. Building-a-nets: robust building extraction from high-resolution remote sensing images with adversarial networks. IEEE J Sel Top App Earth Obs Rem Sens Let. 2018;11(10):3680–3687.
- Lichao M, Xiaoxiang Z. Vehicle instance segmentation from aerial image and video using a multi-task learning residual fully convolutional network. IEEE Trans Geosci Rem Sens. 2018;56(11):6699–6711.
- Hani A, Eduard T, et al. Learning to match aerial images with deep attentive architectures. IEEE Conference Computer Vision Pattern Recognition (CVPR), 3539–3547, 2016.
- Ruihua W, Xionwu X, Bingxuan G, et al. An effective image denoising method for UAV images via improved generative adversarial networks. Sens. 2018;18(7):1985–2007.
- Benjamin K, Diego M, Devis T. Detecting mammals in UAV images: best practices to address a substantially imbalanced dataset with deep learning. Rem Sens Enviro. 2018;216:139–153.
- Yang L, Peng S, Highsmith M R, et al. Performance comparison of deep learning techniques for recognizing birds in aerial images. IEEE Third International Conference on DSC; Guangzhou, China, 317–324, 2018.
- Amin F, Mohammad E, Babak M. A deep residual neural network for low altitude remote sensing image classification. Ira. Joi. CFIS, IEEE, Kerman, Iran, 2018.
- Wei H, Ruyi F, Lizhe W, et al. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. ISPRS J: Photog Rem Sens Let. 2018;145:23–43.
- Otavio AP, Keiller N, Jefersson AdS, et al. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains. IEEE Conference Computer Vision Pattern Recognition (CVPR) Workshops, 44–51, 2015.
- Fan H, GuiSong X, Jingwen H, et al. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Rem Sens. 2015;7(11):14680–14707.
- Barak O, Annie H, et al. Infrastructure quality assessment in Africa using Satellite Imagery and Deep Learning, arXiv preprint, arXiv:.00894 (2018).
- Vysakh SM, Sowmya V, Soman KP. Deep neural networks as feature extractors for classification of vehicles in aerial imagery. International Conference on SPIN, Noida, India, 105–110, 2018.
- Makantasis K, Karantzalos K, Anastasios D, et al. Deep supervised learning for hyperspectral data classification through convolutional neural networks. IEEE IGARSS; Milan, Italy, 4959–4962, 2015.
- Yuhao C, Javier R, Edward JD. Estimating plant centers using a deep binary classifier. IEEE SSIAI, Las Vegas, NV, USA, IEEE, 2018
- Rui C, Jiasong Z, Wei T, et al. Integrating aerial and street view images for urban land use classification. Rem Sens. 2018;10(10):1553–1575.
- Adriana R, Carlo G, Gustau CV. Unsupervised deep feature extraction for remote sensing image classification. IEEE Trans Geosci Rem Sens. 2016;54(3):1349–1362.
- Jasper R U, Koen EA, Van DS, et al. Selective search for object recognition. Int J Comp Vis. 2013;104(2):154–171.
- Joseph R, Santosh D, Ross G, et al. You only look once: unified, real-time object detection. Proceedings of IEEE Conference on CVPR, 779–788, 2016.
- Shaoqing R, Kaiming H, Ross G, et al. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pat Anal & Mac Int. 2017;39(6):1137–1149.
- Mahyar N, Pouya S, Rama C, et al. Ssh: single stage headless face detector. IEEE ICCV, 4875–4884, 2017.
- Xiaohong W, Abhinav S, and Abhinav G. A-fast-rcnn: hard positive generation via adversary for object detection. Proceedings of IEEE Conference on Computer Vision Pattern Recognition, 2606–2615, 2017.