
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Previous captioning methods only rely on semantic-level information considering the similarity of features between image regions in visual space and ignoring the linguistic context incorporated in the decoder for caption generation. In this paper, a transformer-based co-attention network is proposed which uses linguistic information to capture the pairwise visual relationships among objects and significant visual features. We infer the entity words from the visual content of objects, during the caption generation process. Also, we infer the interactive words by focusing on the relationship between entity words, based on the relational context between words generated in the course of caption decoding. We use linguistic contextual information as a guiding force to discover the relationships between objects efficiently. Further, we capture both intra-modal and inter-modal interactions using the multilevel co-attention network. Our model attains 44.1/33.6 BLEU@4, 30.8/25.1 METEOR, 61.9/55.1 ROUGE, 132.1/69.8 CIDEr, and 24.1/17.8 SPICE scores on MSCOCO and Flickr30k datasets, respectively.
Introduction
To describe everything that we see in life, we use natural language. To make the computer enable doing the same task is termed image captioning. But generating descriptions of the scene in a natural language is an extremely challenging job for a machine. Accomplishing this task needs to bridge the domains of image processing, natural language processing, and computer vision. This research area can benefit several applications like video captioning [Citation1,Citation2], visual question answering [Citation3–5], and remote sensing [Citation6,Citation7]. Applications such as human–computer interaction, assisted driving and intelligent navigation for visually impaired people are also benefitted from image descriptions.
Based on the visual understanding of image contents, good quality generated words are desirable for caption generation. Visual understanding involves the relationship between objects (similar and dissimilar) which can be attended to using attention mechanisms. Visual region attention is a common approach to attend features for relating image regions and visual relationship attention attend the pairwise visual relationships of image object that focuses on interactive words. Thus, determining the visual relationships between objects and supplying them to the decoder is of great significance for obtaining good-quality image captions.
The semantic contextual information denotes the association between caption words which guides the process of producing image description. The semantic info contains significant meaningful content that emphasizes the visual relationship between different objects in the image. Better the relationship better the generated words that result in improved quality of captioning. Thus, the task to determine visual relationships is vastly associated with a language decoder for image captioning using the semantic context of the image. The selection of related objects depends on the dynamic semantical context that influences different relationships for producing relevant words. An attention selector attends to related visual relationships as per the dynamic semantics of the image where the relationship attention is used to generate caption words whereas region attention is used to generate image region-based words. It is challenging for the attention selector to switch between different attentions. To handle the issue, in this work we have used a transformer-based co-attention mechanism that takes input from relation-aware attention as well as region-aware attention and aggregates them to find the features in the global context. The global features are then fed into the -
-based decoder to generate the caption words. Thus, we proposed an encoder-decoder-based co-attention mechanism for caption generation. Existing image captioning models mostly used
[Citation8] based decoders. Although used by many models, the computational complexity of
is high due to a large number of network parameters. Instead, we used
[Citation9] decoder that gives an improved performance with few network parameters that ultimately reduced the computational complexity. The hidden layers of the
decoder contain semantic features of the image to determine related visuals for the caption. The proposed decoder is called the
-
model which contains the contextual information between words that produced improved captions where
is used to obtain the features between words that represent the corresponding association. We have proposed
-
encoder-decoder-based image captioning model which is combined with a context-aware co-attention network module and Bottom-up attention mechanism to extract visual features of image regions.
-
decoder is employed to encode and generate a variable-length image caption. Precisely, we have used
decoder and
decoder in our model. First, the
decoder is used to generate the semantic context which is computed on the global region feature, input word, and previous output of the
decoder. Second, we used the Gaussian Error Linear Unit (
) [Citation10] decoder that boosts the semantic context with the region-aware/relation-aware context given by the proposed context-aware co-attention network module that focuses on related image objects to generate the caption words. shows the caption generated by the proposed model using the attention mechanism and
-
encoder-decoder.
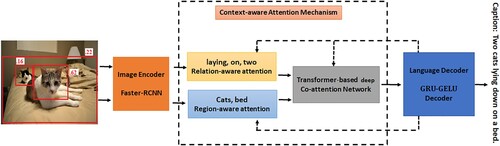
Figure 1. Intuition of our context-aware co-attention-based image captioning model. It consists of relation-aware attention, region-aware attention, transformer-based co-attention module, and -
-based language decoders. The relation-aware attention module is used to generate interactive words based on the relationships between objects. The relation-aware attention module is used to focus on related image regions to generate entity words. Transformer based co-attention module is used to capture the intra-modal and inter-modal interaction between image regions and objects.
The significant contributions of this paper are:
A transformer-based co-attention network for selecting either the region-aware attention or relation-aware attention for generating caption words as a set of entity words or interactive words based on the linguistic information of the caption decoder.
The proposed model captures the pairwise visual relationship between objects by focusing on intra-model and inter-model interactions between relationship features and region features.
To reduce the computational complexity,
decoders are employed by the proposed model. To the best of our knowledge, this is the first work that uses these decoders.
Experiments on
Related works
The task of generating an image caption describes the scene content and detects the visual relationships among objects as well as objects and image regions. Fine-grained visual processing is needed to generate high-quality outputs using linguistic contexts. Consequently, visual attention mechanisms have been widely used in image description [Citation11–14]. The existing works explored the visual relationship for image captioning using encoder-decoder systems [Citation15–18], attention-based models [Citation19–24], and relation-aware models [Citation25–27].
Encoder decoder-based models: Visual relationships for image captioning using the encoder-decoder model have been explored by many researchers in the recent past. Yang et al. [Citation15] proposed a model that incorporates an encoder-decoder framework using a scene graph that connects an object node to adjective and relationship nodes for caption generation. Differently, Hoxha et al. [Citation16] used support vector machines (SVMs) based decoder where a network of SVMs was used instead of RNNs to decrypt the image info into an image caption, particularly with the limited amount of training samples. Al-Malla et al. [Citation17] proposed an attention-based architecture using the Encoder-Decoder approach that used features extracted from a CNN model together with extracted object features using a positional encoding scheme. Yao et al. [Citation18] proposed an encoder-decoder architecture that integrates both semantic and spatial relationships among objects with the region features using an attention mechanism for caption generation.
Co-attention-based models: Many researchers proposed attention-based models that explored visual relationships for image captioning. For example; Anderson et al. [Citation19] proposed an attention mechanism that calculates the attention at the object level and image regions where image regions are associated with feature vectors using Faster R-CNN to determine feature weights for image captioning. Wang et al. [Citation20] explored the associations between image attributes using semantic and region properties which adaptively fuse the region features with attained relationships for caption generation. Xiao et al. [Citation21] proposed an LSTM-based attention model that attends relevant features like spatial, visual, and contextual content which are fused to generate improved image descriptions. Wang et al. [Citation22] exploit the attention variation by integrating a parallel network to increase the model reliability and a balance mechanism to balance channel attention and region attention to generate the image description using a regularization penalty. Huang et al. [Citation24] proposed a model that used attention mechanisms to generate an information vector and an attention gate which is further integrated with another attention to obtaining the attended information for caption generation.
Relational reasoning-based methods: Relational reasoning is crucial in visual understanding which is required along with semantic info of each region for improved image descriptions. It is necessary to combine multiple regions to obtain such a relationship. Zhou et al. [Citation25] detect the relationships between image objects to improve the accuracy of image captioning using a relational network based on semantic context. Wang et al. [Citation26] implicitly model the relationship among image regions using a graph neural network that learns relation-aware visual representations considering contextual information for caption generation. Guo et al. [Citation27] introduced a relational network that implements a concepts-to-sentence memory translator through the fusion and recurrent memory mechanism to encode visual context using info of textual corpus.
Motivation: The above-discussed models encode visual relationships that lack guidance from the linguistic contextual content of the decoder as they still rely on the similarity of visual features of the object to define the relationship between objects. In , we have shown the limitations of the previous methods. In image captioning, similar objects hold a relationship that may not result in interactive words for captioning whereas different objects hold strong visual relationships resulting in interactive words. Consequently, strong guidance from the semantic context in the decoding phase should be used to explore the relationships between different objects. To generate interactive words for similar and dissimilar objects, we have used -
language decoder in this work which is combined with the context-aware co-attention network that focuses on related image objects for generating interactive words using region-aware attention, relation-aware attention, and adaptive attention mechanism is used to decide which features to select and provided to language decoder. We have used the caption loss for training our captioning method.
Table 1. Limitations of previous works.
Proposed method
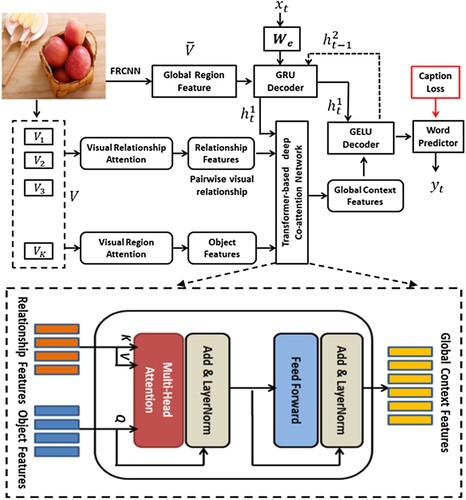
The proposed context-aware co-attention network-based image captioning model is shown in . It is the combination of three major components: Bottom-up attention for extracting visual features, context-aware co-attention network module, and -
language decoder.
Figure 2. An overview of our context-aware co-attention network-based image captioning model which consists of region-aware attention, relation-aware attention, -
decoder pair, and transformer-based co-attention network modules.
The bottom-up attention mechanism is applied to extract a feature set with the size of , where
represents the number of detected regions and each region is represented as
. To be more specific, Faster R-CNN [Citation34] is at the core of the bottom-up attention module to detect regions of interest as
. and
[Citation35] is used to generate feature descriptions corresponding to these regions as
. The
-th object region is represented by
dimensional visual features such that
.
Further, we have employed the -
decoder to encode and produce a variable length caption
with
words by using the obtained image region features
, where
represents
dimensional one-hot feature representation for the
-th word. We have used
decoder and
decoder in our model. First, the
decoder is used to generate the semantic context
which is computed on global region feature
, input word
, and previous output
of
decoder. Second, we used the Gaussian Error Linear Unit
decoder that boosts the semantic context with the region-aware/relation-aware contexts
given by the proposed context-aware co-attention network module.
Based on the dynamic linguistic/semantic context of the decoder, the proposed context-aware co-attention network mechanism focuses on related image objects or pairwise relationships between objects for generating entities or interactive words. To generate the caption words, the proposed model uses three different modules, such as region-aware attention, relation-aware attention, and adaptive attention. (1) The region-aware attention is used to generate entity words by focusing on related image objects and then combining object-based contextual features for language decoder. (2) The relation-aware attention is used to generate interactive words by focusing on related visual relationships between objects and combining relationship-based contextual features for generating these words. (3) The adaptive attention mechanism is used to decide which features to select and provide to the language decoder. The raw semantic information is employed as the semantic information for context-aware co-attention network mechanism to attend to the related visual content. We have used the caption loss for training our captioning method.
In subsequent sections, we will explain the -
language decoder and context-aware co-attention network module.
-language encoder
The proposed model uses the -
language decoder to encode previously generated caption words
to generate the next word
at current time step
. To be precise, at each time step
, the
decoder gives raw linguistic content by using three inputs: global region feature
=
, features corresponding to input word
, and
as the output states of
decoder at previous time step
. We use the previously predicted word
as the current input word
at time step
. The remaining preceding words
are represented as the output states
of
encoder till time step
. Further, we provide the combination of these three features in the
decoder as follows:
(1)
(1) Here,
represents the embedding matrix for a given word
which is used to transform a large dimensional feature representation to a low dimensional dense feature representation. At time step
, the output
represents the hidden states comprising raw content that can be effectively utilized to predict word
. Moreover, the proposed model uses
as the semantic context input for each module of the context-aware co-attention network module, which is used to generate effective interactive/entity words by capturing the related visual relationships/objects.
The proposed context-aware co-attention network module takes and
as inputs and outputs a global contextual feature
according to the varying semantic context contained in
. Precisely, contextual object features are captured by the region-aware attention for predicting the entity word, while a set of relation-aware contextual features is predicted by the relation-aware attention for producing the interactive word. The adaptive attention module decides which attention mechanism should be changed and merges related contextual features as the global contextual feature
for the
decoder.
(2)
(2) As
represents raw semantic content, the global contextual feature
given by the context-aware co-attention network module functions as the complementary visual content that additionally improves
with the significant relationship/object contextual feature which is powerfully associated to the semantic context. To attain this, we feed the concatenation of
and
into the
decoder for enhancing the multi-modal information:
(3)
(3)
We input the output states of
decoder into the word generator for predicting subsequent word
. Our
decoder is an improved language decoder as compared to the
decoder, with the knowledge of precise semantic contextual information and extremely associated visual contextual features for predicting interactive/entity words.
Further, our word predictor utilizes the meaningful and significant linguistic information in the hidden states to predict the conditional probability over likely output words at time step
as shown in Eq. (
). Finally, we compute the distribution overall likely output caption sentences using chain rule using Eq. (
)
(4)
(4)
(5)
(5)
Context-aware co-attention network
In this section, we will describe our proposed context-aware co-attention network module, which operates between -
decoders. It has three major components: visual relation-aware attention, region-aware attention, and attention modulator. Specifically, the nodes are represented by the detected
visual object regions
, and the
edges represent the visual relationships between all object regions. Further, we provide the visual features
as inputs to this module and selectively focus on significantly correlated region-aware (visual object) features or relation-aware (visual relationship) features based on the semantic context of hidden states
.
Relation-aware attention
This attention mechanism aims to capture the visual relationship between the different object regions in a pairwise form, and then obtains visual features for the captured pairwise relationships. We provide the visual features corresponding to
object regions as inputs to this module. To capture the visual relationship between object regions, a self-attention mechanism [Citation36] is employed. Hadamard product-based low-rank bilinear pooling [Citation37] is used to capture second-order interactions between visual object features. Using a bilinear self-attention mechanism, the proposed model performs complex reasoning over image region pairs which in turn represent the power of relation-aware features.
Furthermore, the hidden states of
decoder are used to capture the visual relationships, which are based on linguistic context. Our relation-aware attention mechanism has two sub-modules: (1) pairwise relation-aware attention maps (2) the generation of a relation-aware feature. Both sub-modules use the Hadamard product-based bilinear pooling approach. The attention map generation task is directed by the semantic context incorporated in the hidden states
.
Pairwise relationship attention map generation
For object region features represented as
, we have total
visual relationship pairs. Further, we provide linguistic context
together with the visual region features to generate a
relation-aware matrix
to represent the attention maps for the captured visual relationships. We represent the object regions (
,
as the query nodes and represent all captured relationships for
by a vector
. Further, we represent the softmax-normalized attention weight by
, which depicts the relationship between the object region pair
.
(6)
(6)
(7)
(7)
(8)
(8)
Finally, we compute the normalized relationship value by applying pairwise low-rank bilinear pooling followed by the injection of linguistic context
. First, we compute the outer product
between feature pairs
using the Hadamard product, which gives discriminative features to perform reasoning over the complex relationship. reasoning calculated based on the feature pairs
and linguistic context feature
. Finally, we provide the linguistic context
into the obtained mean-pooled features
to generate the normalized relationship value
(9)
(9)
(10)
(10) where
,
,
represent the embedding matrices used to map region features to a low-rank dimensional feature space, and
represents the pooling matrix,
represents
function, and
represents Hadamard product (element-wise multiplication).
represents the embedding matrix which projects the linguistic context-based feature into the relationship value
.
Visual relationship feature generation
In this module, we generate the features for the captured visual relationships which are denoted by the attention map . For given object region
, we represent the relationship feature
, which is encoded using low-rank bilinear pooling for the associated attention map
.
(11)
(11) Further, we fuse the relationship features with the attention weights to obtain the context-based relationship features using the low-rank Hadamard product.
(12)
(12) Where
represents the pooling matrix and
,
represents the embedding matrices.
represents the
function, and
represents the Hadamard product.
Region-aware attention
Our region-aware attention mechanism focuses on the related object regions for generating entity words at time step and outputs context-based object feature
. Further, the proposed model explores the second-order relations between the context-based query
and object features
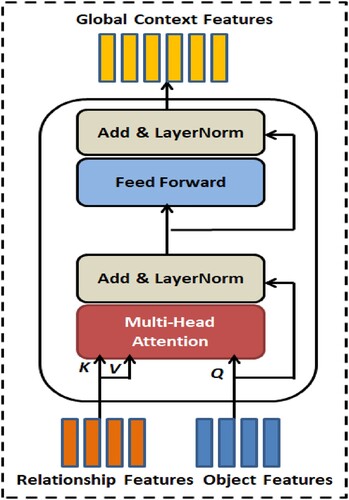
using low-rank bilinear pooling. shows transformer model-based co-attention network with multi-head attention for relationship features and object features to generate context-aware global features.
(13)
(13)
(14)
(14)
(15)
(15)
(16)
(16)
Figure 3. Transformer model-based co-attention network with multi-head attention for relationship features and object features to generate context-aware global features.
Thus, we get raw attention value using activation function
and embedding matrices
and
, which is then fed into
function.
Attention adapter
Our relation-aware attention module is used to generate interactive words by exploring the visual relationships between object regions that are highly related to the linguistic context. Also, visual region-aware attention is needed to generate entity words. Apart from these two tasks, we need a module that selectively switches between these two attention modules based on the need of the language decoder. Thus, our model uses an adaptive attention module to achieve this task.
The relation-aware attention module obtains a set of relation-based features and the region-aware attention module produces context-based object features. Moreover, we fuse both these features to generate one set of complex visual features:
(17)
(17)
(18)
(18) Finally, we fed
into the Sigsoftmax-based [Citation38] adaptive-attention module to select the appropriate attention:
(19)
(19)
(20)
(20)
(21)
(21)
Where
and
are transforming matrices. To improve the representation ability of Softmax function, Sigsoftmax has been introduced where sigmoid function acts as a gating function to make the function smooth.
Caption loss
To train our proposed model, we used both cross-entropy loss and CIDEr score function. First, we train the proposed captioning model by minimizing the cross-entropy loss of the output caption. In the second step, we consider the reward in terms of the CIDEr score and train the model to minimize the negative expected reward of randomly selected captions as the loss:
(22)
(22)
(23)
(23)
Performance analysis
Datasets and evaluation metrics
We have evaluated the proposed image captioning model on dataset [Citation39] and the Flickr30k dataset [Citation40].
dataset contains
images for training purposes,
images for validation purposes, and
images for testing purposes. For each image, it contains
captions. We have used the ‘Karpathy’ data splits [Citation41], for the offline assessment, comprising
images for training, and 5000 images for both validation and testing purposes. Further, we set the maximum caption length to
. There are
words in the word vocabulary, which contains only those words appearing more than
times in the training caption set. The
dataset contains
images taken from
. For each image, there are
reference captions captured from human annotators, and we use
images to train, 1000 for validation, and
to test the proposed model.
We have evaluated the proposed model on widely used evaluation metrics: [Citation42],
[Citation43],
-
[Citation44],
[Citation45] and
[Citation46]. Moreover, we have computed these metric scores using the COCO captioning evaluation tool [Citation39]. Out of these metrics,
and
scores convey the highest-level correlations with human-generated captions.
Hyperparameter settings
We set the input word dimension o . We fixed the hidden states in
decoder to
. The relation-aware attention is represented by a
-dimensional vector. We fixed the head number to
. The region-aware attention is represented by a
-dimensional vector by setting the head number to
. The attention selector dimension is fixed to
. We have used the
optimizer [Citation47] by setting the initial learning rate to
. Every epoch, we are decreasing the learning rate by a factor of
. Further, we used a dropout ratio of
on the o/p states of
decoder and set the dropout ratio to
for relation-aware attention. For the beam search decoding process, we used a beam size of
. Precisely, we initially optimize the entire architecture of the proposed model by adding the cross-entropy loss, similar to the previous models. Similar to existing works [Citation56, Citation57], we employ self-critical sequence training strategy for optimizing our proposed model with CIDEr score during the second stage. shows the values set for important hyperparameters in the proposed model.
Table 2. Hyperparameter values.
Ablation study
This section shows the results of the ablation test conducted to show the role of each module of the proposed model. shows the different variants of the proposed model and their performances. Our variant (Reg-aware Att w/o attention loss) is the baseline model which does not use any attention loss function for training purposes. Our variant 2 (Reg-aware Att w attention loss) is similar to variant
, however, this variant is trained explicitly with attention loss functions such as entity loss and interaction loss. Moreover, this variant is used to verify the role of attention losses in improving the performance of variant
. Also, we have checked whether region-aware attention is sufficient enough to focus on the relationships between different objects effectively. The gain in performance of model
over model
validates that the use of loss functions (either entity or interaction) is beneficial for facilitating the attention model to apply both attention mechanisms. Also, region-aware attention is not able to explore the contribution of relation-aware for interactive words, which leads to poor performances. Our variant
(Reg-aware Att + Rel-aware Att w Att loss) uses a relation-aware attention mechanism in addition to the region-aware attention with attention losses. When we use a relation-aware attention module, the performance of the proposed model is improved significantly. Our variant
(Reg-aware Att + Rel-aware Att w loss + Self-Att) can model intra-model interactions (word-to-word or region-to-region) with entity loss by using the transformer-based self-attention module. Our variant
(Reg-aware Att + Rel-aware Att w loss + Self-Att + Hadamard Product) is used to model inter-model deep interactions (word-to-region) with interaction loss. It can be observed that entity loss is less important as compared to interaction loss. When we do not use entity loss, our model can acquire entity information subtly. When the model does not use interaction loss, it is difficult to learn object relationships by the model. Precisely, we initially optimize the entire architecture of the proposed model by adding the cross-entropy loss, similar to the previous models. Similar to existing works [Citation56, Citation57], we employ self-critical sequence training strategy for optimizing our proposed model with CIDEr score during the second stage.
Table 3. Ablation tests conducted on MSCOCO Karparthy test split.
Quantitative analysis
In and , we have shown the results obtained by our image captioning model and compared the results with the state-of-the-art model on MSCOCO dataset. We have integrated the proposed model with Cross-Entropy Loss and CIDEr Score Optimization settings. In , we have shown the results obtained by our image captioning model and compared the results with the state-of-the-art model on Flickr30k datasets, respectively. For fair comparisons, the proposed model uses similar hyperparameter values as considered by existing image captioning methods.
Table 4. Results of our context-aware co-attention based image captioning model and compared models on MSCOCO Karpathy test split with cross-entropy loss.
Table 5. Results of our context-aware co-attention based image captioning model and compared models on MSCOCO Karpathy test split with CIDEr score optimization.
Table 6. Results of our context-aware co-attention based image captioning model and compared models on the Flickr30k dataset.
demonstrate the effectiveness of the proposed model as it outperforms the state-of-the-art on almost all metrics. Therefore, it can be observed that the proposed model generates high-quality captions by explicitly focusing on the visual relationships between objects based on the robust semantic context. The proposed model explores the intra-model interactions (word-to-word or region-to-region) with entity loss by using the transformer-based self-attention module. Further, the improvement in the performance is achieved by capturing the inter-model deep interactions (word-to-region) with interaction loss. It can be observed that entity loss is less important as compared to interaction loss.
In and , we have shown the superiority of the proposed model, which uses a multilevel co-attention mechanism with region-aware and relation-aware attention mechanisms, over the existing models on almost all the evaluation metrics. On the MSCOCO dataset, the proposed model outperforms the [Citation28] and
-
[Citation23] models by 4.9% and 5.0% on
, 1.4% and 1.6% on
, 2.9% and 3.3% on
-
, 6.6% and 0.9% in CIDEr metrics, respectively. On the Flickr30k dataset, the proposed model outperforms the
[Citation11] and
[Citation28] models by 2.4% and 0.7% on
, 1.6% and 0.5% on
, 3.6% and 0.9% on
-
, 4.2% and 0.5% on
-
respectively. Our model achieved improved results over all other models on the
metric with 24.1 and 17.8 scores on MSCOCO and Flickr30k datasets, respectively.
Using the MSCOCO dataset, we evaluate the computational complexity in terms of average training FLOPs and training time per image. Since training time and FLOPs have a positive correlation, we utilize the FLOPs metric to calculate complexity. In terms of the number of parameters, floating-point operations, training time, and other model parameters, compares the proposed model with the existing methods.
Table 7. Comparison with the existing models in terms of the number of parameters in million (M), training time on GPUs, Flops, layers, width and MLP on MSCOCO.
Qualitative analysis
Qualitative results of our model on MSCOCO and Flickr30k dataset are shown in and respectively. The model attends to the relation between visuals as well as image regions for generating image captions using semantic information about the image. For each test image, the regions and relations are detected for generating the caption words. For region-aware attention, weights are assigned to different identified regions that are further used to establish the relationship among image regions using relation-aware attention.
Figure 4. Qualitative results of our model and other models on MSCOCO. Ours indicates the captions generated by our model. EnsCaption [Citation28] and M2-Transformer [Citation23] are the strong comparative models. For each image, we have shown one interaction and two entity words. Highest attention weights are shown in red colour.
![Figure 4. Qualitative results of our model and other models on MSCOCO. Ours indicates the captions generated by our model. EnsCaption [Citation28] and M2-Transformer [Citation23] are the strong comparative models. For each image, we have shown one interaction and two entity words. Highest attention weights are shown in red colour.](/cms/asset/384c2567-fb0f-4198-8ba1-57fd55a4bef7/yims_a_2179992_f0004_oc.jpg)
Figure 5. Qualitative results of our model and other models on Flickr30k. Ours indicates the captions generated by our model. EnsCaption [Citation28] and Mul_Att [Citation11] are the strong comparative models. For each image, we have shown one interaction and two entity words. Highest attention weights are shown in red colour.
![Figure 5. Qualitative results of our model and other models on Flickr30k. Ours indicates the captions generated by our model. EnsCaption [Citation28] and Mul_Att [Citation11] are the strong comparative models. For each image, we have shown one interaction and two entity words. Highest attention weights are shown in red colour.](/cms/asset/fdfb68b3-ba86-4fd1-9b88-2815b395d17f/yims_a_2179992_f0005_oc.jpg)
For example, in (first row), region-aware attention attended regions ‘cat’ and ‘mirror’ that demonstrate the correct identification of regions whereas relation-aware attention finds the relationships ‘looking’ and ‘at’ between ‘cat’ and ‘mirror’. It results in the caption ‘A cat is looking at its reflection in a mirror’ using -
encoder-decoder. In (first row), ‘players’, ‘long hair’ and ‘softball’ objects are identified by region-aware attention whereas relation-aware attention is accountable to find the relationships ‘two’, and ‘playing’ which generates the caption ‘Two players with long hair are playing softball in a field’ using attention selector. The qualitative results illustrated the effectiveness of our co-attention mechanism using the
-
encoder-decoder.
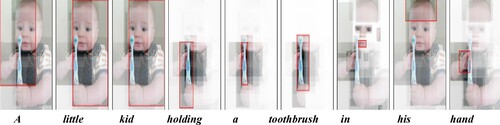
In , we have shown the visualization results of relation-aware attention, region-aware attention, and co-attention mechanism during the caption generation phase. For every word generated during the decoding process, we focus on the salient objects/regions, and capture the relationship between these objects/regions, highlighting the regions in red. Our model can capture the intra-modal and inter-modal interactions between these objects/regions using a transformer-based co-attention mechanism. It validates the capacity of the proposed model for generating quality captions from globally to locally.
Figure 6. Visualization results of attended regions/objects of our context-aware co-attention module during the decoding phase. Higher attention weights are shown in the form of brighter regions. (Best viewed in colour and ).
Limitations and future scope
We analyse the errors made by our model to study the limitations of our method. In some cases, our model fails to give accurate results. One of the limitations identified for our model is that it generates a similar caption for two different images which are visually similar. The reason behind this may be the lack of effective feature extraction of objects in the image. It may be due to not considering the mapping of object relationships and the traits of objects. For example, in (leftmost and middle), our model has generated the same caption ‘A man is riding a bicycle’, for both images. The other limitation of our model is that it sometimes fails to differentiate between similar-looking objects with respect to shape. For example, in (rightmost), our model fails to identify ‘onion’ and ‘orange’, which are similar, and thus generates the wrong caption. The reason behind this may be the lack of detailed descriptions of image objects which results in the captions of less relevance. The future scope of our work may be to use a graph network-based encoder-decoder model to represent the association between properties and relationships of image objects. In this way, we can resolve the first limitation of this work. The other above-mentioned limitation of current work can be handled by using a co-attention mechanism such that it will be able to provide detailed image descriptions for improved caption generation.
Figure 7. Same caption is generated by the proposed model for the left and middle images, as these two images are visually similar. In the rightmost image, our model fails to identify “onion” and “orange” and thus generates the wrong caption.

Conclusion
In this paper, we propose a transformer-based co-attention network that uses linguistic information to capture the pairwise visual relationships among objects and significant visual features to generate entity and interactive words. The proposed model uses both region-aware attention and relation-aware attention to discover and focus on the related pairwise relationship between objects selectively to generate interactive words. Moreover, we can integrate this technique into other vision language tasks such as visual question answering and Image QA. The proposed model obtains the improved results as: scores on the MSCOCO dataset and
scores on the Flickr30k dataset corresponding to
, respectively. The effectiveness of our model is further validated by the ablation tests and visualization.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Himanshu Sharma
Himanshu Sharma is an Associate Professor in the Department of Computer Engineering and Applications, GLA University, Mathura, India. He has done his Ph.D. from GLA University Mathura and M.Tech. from NSIT, New Delhi, India. His area of research is Computer Vision, Image Processing, and Natural Language Processing. He has published many research papers in reputed journals and conferences.
Swati Srivastava
Swati Srivastava is currently working as an Assistant Professor in the Department of Computer Engineering and Applications, GLA University, Mathura, India. She has completed her Ph.D. in Computational Intelligence from HBTU Kanpur, India, and M.Tech. from NIT Allahabad, India. Her area of research includes high-dimensional neurocomputing, computational intelligence, machine learning, and computer vision focused on biometrics. She has published many research papers in reputed journals and conferences.
References
- Wang T, Zhang R, Lu Z, et al. End-to-end dense video captioning with parallel decoding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2021. p. 6847–6857.
- Deng C, Chen S, Chen D, et al. Sketch, ground, and refine: top-down dense video captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021. p. 234–243.
- Sharma H, Srivastava S. Visual question answering model based on the fusion of multimodal features by a two-way co-attention mechanism. Imaging Sci J. 2022: 1–13.
- Sharma H, Jalal AS. Visual question answering model based on graph neural network and contextual attention. Image Vis Comput. 2021;110:104165.
- Sharma H, Jalal AS. Image captioning improved visual question answering. Multimed Tools Appl. 2022;81(24):34775–34796.
- Zhao R, Shi Z, Zou Z. High-resolution remote sensing image captioning based on structured attention. IEEE Trans Geosci Remote Sens. 2021;60:1–14.
- Ye X, Wang S, Gu Y, et al. A joint-training Two-stage method For remote sensing image captioning. IEEE Trans Geosci Remote Sens. 2022;60:1–16.
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735–1780.
- Cho K, van Merriënboer B, Gulcehre B, et al. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar; 2014 Oct; Association for Computational Linguistics. p. 1724–1734.
- Hendrycks D, Gimpel K. (2016). Gaussian error linear units, in arXiv:1606.08415.
- Sharma H, Srivastava S. Multilevel attention and relation network-based image captioning model. Multimed Tools Appl. 2022:1–23.
- Sharma H, Jalal AS. Incorporating external knowledge for image captioning using CNN and LSTM. Mod Phys Lett B. 2020;34(28):2050315.
- Sharma H, Srivastava S. Graph neural network-based visual relationship and multilevel attention for image captioning. J Electron Imaging. 2022;31(5):053022.
- Rennie SJ, Marcheret E, Mroueh Y, et al. Self-critical sequence training for image captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2017. p. 7008–7024.
- Yang X, Tang K, Zhang H, et al. (2019). Auto-encoding scene graphs for image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. p. 10685–10694.
- Hoxha G, Melgani F. A novel SVM-based decoder for remote sensing image captioning. IEEE Trans Geosci Remote Sens. 2021;60:1–14.
- Al-Malla MA, Jafar A, Ghneim N. Image captioning model using attention and object features to mimic human image understanding. J Big Data. 2022;9(1):1–16.
- Yao T, Pan Y, Li Y, et al. Exploring visual relationship for image captioning. In: Proceedings of the European conference on computer vision (ECCV); 2018. p. 684–699.
- Anderson P, He X, Buehler C, et al. Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018. p. 6077–6086.
- Wang C, Gu X. Learning joint relationship attention network for image captioning. Expert Syst Appl. 2023;211:118474.
- Xiao F, Xue W, Shen Y, et al. A new attention-based LSTM for image captioning. Neural Process Lett. 2022;54(4):3157–3171.
- Wang C, Gu X. Dynamic-balanced double-attention fusion for image captioning. Eng Appl Artif Intell. 2022;114:105194.
- Cornia M, Stefanini M, Baraldi L, et al. Meshed-memory transformer for image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020. p. 10578–10587.
- Huang L, Wang W, Chen J, et al. Attention on attention for image captioning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision; 2019. p. 4634–4643.
- Zhou D, Yang J. Relation network and causal reasoning for image captioning. In: Proceedings of the 30th ACM International Conference on Information & Knowledge Management; 2021 Oct. p. 2718–2727.
- Wang J, Wang W, Wang L, et al. Learning visual relationship and context-aware attention for image captioning. Pattern Recognit. 2020;98:107075.
- Guo D, Wang Y, Song P, et al. (2020). Recurrent relational memory network for unsupervised image captioning. arXiv preprint arXiv:2006.13611.
- Yang M, Liu J, Shen Y, et al. An ensemble of generation-and retrieval-based image captioning with dual generator generative adversarial network. IEEE Trans Image Process. 2020;29:9627–9640.
- Liu J, et al. Interactive dual generative adversarial networks for image captioning. In: Proc. AAAI; 2020. p. 11588–11595.
- Kim DJ, Oh TH, Choi J, et al. Dense relational image captioning via multi-task triple-stream networks. IEEE Trans Pattern Anal Mach Intell. 2021;44(11):7348–7362.
- Hu N, Ming Y, Fan C, et al. TSFNet: triple-steam image captioning. IEEE Transactions on Multimedia. 2022:1–14.
- Wang Y, Xu N, Liu AA, et al. High-order interaction learning for image captioning. IEEE Trans Circuits Syst Video Technol. 2021;32(7):4417–4430.
- Liu AA, Zhai Y, Xu N, et al. Region-aware image captioning via interaction learning. IEEE Trans Circuits Syst Video Technol. 2021;32(6):3685–3696.
- Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2017;39(6):1137–1149.
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In: Proc. CVPR; 2016 Jun. p. 770–778.
- Veliçković P, et al. Graph attention networks. In: Proc. Int. Conf. Learn. Representations; 2018. p. 120–132.
- Kim J-H, et al. Hadamard product for low-rank bilinear pooling. In: Proc. 5th Int. Conf. Learn. Representations; 2016. p. 66–78.
- Kanai S, Fujiwara Y, Yamanaka Y, et al. Sigsoftmax: reanalysis of the softmax bottleneck. In: Proc. Adv. Neural Inf. Process. Syst., Ser. Adv. Neural Inf. Process. Syst.; 2018. p. 284–294.
- Lin TY, et al. Microsoft COCO: common objects in context. Lect Notes Comput Sci. 2014;8693:740–755.
- Young P, et al. From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions. Trans Assoc Comput Linguistics. 2014;2:67–78.
- Karpathy A, Fei-Fei L. Deep visual-semantic alignments for generating image descriptions. In: Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR); 2015 Jun. p. 3128–3137.
- Papineni K, et al. Bleu: a method for automatic evaluation of machine translation. In: Proc. 40th Annu. Meet. Assoc. for Comput. Linguistics; 2002. p. 311–318.
- Banerjee S, Lavie A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments. In: Proc. ACL Workshop on Intrinsic and Extrinsic Eval. Meas. for Mach. Transl. and/or Summarization; 2005. p. 65–72.
- Lin CY. Rouge: a package for automatic evaluation of summaries. In: Text summarization branches out. Association for Computational Linguistics; Barcelona, Spain; 2004. p. 74–81.
- Anderson P, Fernando B, Johnson M, Gould S. Spice: semantic propositional image caption evaluation. In: European conference on computer vision. Cham: Springer; 2016. p. 382–398.
- Vedantam R, Zitnick CL, Parikh D. CIDEr: consensus-based image description evaluation. In: Proc. IEEE Conf. Comput. Vis. and Pattern Recognit.; 2015. p. 4566–4575.
- Kingma DP, Ba J. Adam: a method for stochastic optimization. arXiv:1412.6980 (2014).
- Pan Y, Yao T, Li Y, et al. X-linear attention networks for image captioning. In: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit.; 2020. p. 10971–10980.
- Zhang Z, Wu Q, Wang Y, et al. Exploring pairwise relationships adaptively from linguistic context in image captioning. IEEE Trans Multimed. 2021;24:3101–3113.
- Liu X, Li H, Shao J, et al. Show, tell and discriminate: image captioning by self-retrieval with partially labeled data In: Proc. Eur. Conf. Comput. Vis. (ECCV); 2018. p. 338–354.
- Xu K, et al. Show, attend and tell: neural image caption generation with visual attention. Comput Sci. Feb. 2015;2015:2048–2057.
- You Q, Jin H, Wang Z, et al. Image captioning with semantic attention. In: Proc. CVPR; 2016 Jun. p. 4651–4659.
- Chen L, et al. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In: Proc. CVPR; 2017 Jul. p. 6298–6306.
- Lu J, Xiong C, Parikh D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning. In: Proc. CVPR; 2017 Jul. p. 3242–3250.
- Ye S, Han J, Liu N. Attentive linear transformation for image captioning. IEEE Trans Image Process. 2018;27(11):5514–5524.
- Barraco M, Cornia M, Cascianelli S, et al. The unreasonable effectiveness of CLIP features for image captioning: an experimental analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022. p. 4662–4670.
- Li Y, Pan Y, Yao T, et al. Comprehending and ordering semantics for image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022. p. 17990–17999.