
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Existing image inpainting algorithms have achieved good results in regular mask inpainting tasks, but there are still many limitations for irregular mask, and the inpainting results lack edge consistency and semantic correctness. To address these problems, we designed a progressive generative adversarial network in this paper. The generative network mainly contains a progressive feature generation module and an adaptive consistent attention module, and the discriminator network uses SN-PatchGAN. The network performs recursive inpainting from the edge to the centre, and the repaired features are used as the conditions for the next feature generation, which makes the constraints of the central content gradually strengthened. In order to obtain distant information from the feature maps as well as to consider the possible problem of inconsistency between feature mappings under different recursions when using attention directly in the progressive inpainting network, we designed an adaptive consistent attention module in this paper, which can adaptively combine scores obtained from different recursions to capture more feature information. The discriminator used in this paper is SN-PatchGAN, which directly calculates the hinge loss of each point on the output graph and can focus on different locations as well as different semantics. Comparing this paper's method on CelebA dataset and CMP Facade dataset with the latest work, the experimental results show that this paper's method performs well in the irregular mask image inpainting task, and the inpainting results have better performance in terms of edge consistency, semantic correctness, and overall image structure.
1. Introduction
Digital image processing is the processing of image information to meet the needs of human visual psychology and practical applications [Citation1]. With the continuous development of science and technology, people have more requirements for image quality, image inpainting has become an important branch in the field of image processing. The purpose of image inpainting is to fill in the missing pixels in a corrupted image with a given mask [Citation2], in order to achieve consistency in the overall texture structure as well as semantic visual realism. This task has received extensive attention and become a valuable and popular research topic for decades [Citation3–5]. High-quality image inpainting can be useful in a wide range of applications, such as inpainting of old photographs, object removal, image inpainting, image processing, image denoising, etc.[Citation6–11]. Currently, image inpainting methods can be divided into traditional image inpainting methods and deep learning-based image inpainting methods.
Traditional methods for image inpainting by mathematical and physical means are divided into structure-based and texture-based methods. Structure-based approaches use geometric methods to recover missing parts of an image. Bertalmio et al. [Citation12] used the BSCB algorithm based on Partial Differential Equation (PDE) for image inpainting for the first time. Chan and Shen proposed the Total Variation (TV) model [Citation13] and the Curvature Driven Diffusions (CDD) model [Citation14], inspired by Bertalmio et al. The TV inpainting model is suitable for repairing small areas of breakage and can effectively remove noise, but it does not connect the repaired part to the background well. The CDD model extends the TV model by better connecting the repaired area to the background, but the resulting interpolated segments are visually blurrier. Texture-based approaches use texture synthesis to restore the area of the image to be repaired. Bertalmio et al. [Citation15] first proposed adding texture information to a structure-based image inpainting algorithm. Criminisi et al. [Citation16] proposed a block-based texture synthesis algorithm, which can restore the texture information of the image well, but cannot maintain the structural consistency of the restored area with the background. Starck et al. [Citation17] proposed an iterative inpainting algorithm based on an analytical dictionary, which achieves inpainting by making a sparse prior on the local smoothness of the image, but the inpainting of the texture and edges of the image is relatively poor. Traditional image inpainting algorithms are robust for small regions of missing images with simple textures, but the inpainting effect gradually deteriorates as the region to be restored becomes larger, and the inpainting results suffer from blurred images and incoherent contextual semantics.
In recent years, with the rapid development of artificial intelligence [Citation18], image inpainting combined with deep learning has gradually become the mainstream direction of research, in which deep Convolutional Neural Networks (CNN) and Generative Adversarial Networks (GAN) [Citation19] are widely used. Pathak et al. [Citation20] proposed the Context Encoder (CE), which uses a fully connected layer so that the network can learn the relationship between all feature locations to deepen the semantic understanding of the whole image. However, this method sometimes misses fine texture details, resulting in visual artefacts around broken areas, and cannot handle high-pixel images. Yang et al. [Citation21] improved on CE by using a texture network to modify the prediction of missing parts to improve the visual quality of the filled image. However, it is difficult to achieve the expected results for image inpainting with a complex background structure. Yu et al. [Citation5] proposed a two-stage image inpainting network and designed a contextual attention layer, but the method is too dependent on the correlation between unknown and known feature blocks and lacks an understanding of the high-level semantics of the image. To address the problem that the model cannot obtain a larger receptive field, Wang et al. [Citation22] proposed a Generative Multi-column Convolutional Neural Networks (GMCNN), where the multi-column structure decomposes the image into components with different perceptual fields and feature resolutions, thus helping the model to obtain a larger receptive field. However, large convolution kernels lead to a large number of model parameters, which makes the computational cost larger and requires a large amount of computational resources. Hui et al. [Citation23] improved on GMCNN by proposing a multi-scale feature fusion network that combines various sparse multi-scale features to obtain dense multi-scale features, so that the features of the generated image at each scale match the ground truth. Multi-scale feature fusion networks can effectively obtain multi-scale information at the expense of spatial detail, making it difficult to strike a balance between spatial detail and contextual information. Thanh et al. [Citation24] proposed an adaptive image inpainting method based on the Eulerian elastic model, which uses structural tensor eigenvalues to estimate the parameters of the inpainting model and implements them using high-order discrete gradients, and the quality of the image inpainting method performs well.
The above methods improve the defects of traditional image inpainting and have a large improvement in inpainting results, but these models are trained on regular mask images and are therefore not suitable for the task of irregular mask image inpainting. To address this problem, Liu et al. [Citation25] proposed a partial convolution method conditional only on valid pixels to handle irregular mask inpainting, which can control the information passed within the network. However, partial convolution makes the invalid pixels disappear gradually and also makes the rule mask information disappear, so it cannot achieve satisfactory inpainting results for images with sparse structures. Nazeri et al. [Citation26] proposed a two-stage adversarial model EdgeConnect, where first an edge generator generates an edge hypothesis map, and then the image inpainting network uses the edge hypothesis map as a prior to fill in the missing regions, which can effectively solve the problem of deep learning that fails to reconstruct reasonable structures due to excessive smoothing. However, the edge hypothesis map generated by this network has not yet met the expectations, and the problem of generating reasonable edges for missing regions, for example, still needs to be addressed in the future. Yu et al. [Citation27] proposed gated convolution, which learns a dynamic selection mechanism by adding an additional standard convolutional layer and a sigmoid activation function that learns a dynamic selection mechanism across all layers for each channel at each spatial location, significantly improving the colour consistency and picture quality of the Inpainting, but there is still room for improvement in terms of image realism, edge consistency, and global semantic structure. Abdulla et al. [Citation28] proposed an example-based algorithm that consists of two phases; in the first phase, the entire image is searched and the most similar features are found and selected using Euclidean distance. In the second stage, the distance between the selected feature block location and the feature block location to be filled is measured. Ahmed et al. [Citation29] proposed an improved search mechanism to select the most similar patches, and the algorithm adds the results of the first two stages and finally selects the patch that obtains the smallest distance value for filling. This method can obtain the best similar blocks to the maximum extent, which results in a higher quality of inpainting results. Mao et al. [Citation30] proposed a self-attentive Wasserstein-based Generative Adversarial Network (WGAN) for single-image inpainting. This network has the ability to mine the global relevance of images by introducing WGAN to ensure the global consistency of the inpainting content and using self-attention to obtain the similarity of local features of images, thus performing well in image inpainting tasks.
For better inpainting of broken images with continuous masks, so that the inpainting results have edge consistency and semantic correctness, we design a Progressive Generative Adversarial Network (PGAN) for irregular masked image inpainting. The progressive feature generation approach is used to strengthen the constraints on the central region. Adaptive Consistent Attention Module (ACAM) is designed to obtain distant features and adaptively combine the scores to solve the inconsistent feature mapping problem between different recursions. To focus on irregular masks with diverse locations and shapes, SN-PatchGAN is used to calculate the hinge loss of each pixel point.
In summary, the main contributions of this paper are as follows:
| (1) | The design of a progressive generative adversarial network (PGAN) that exploits the correlation between neighbouring pixels and progressive feature generation to strengthen the constraints of the central region. | ||||
| (2) | The design of an adaptive consistent attention module (ACAM) which adaptively combines attention scores from different recursions to ensure consistency in feature mapping under different recursions to obtain better results. | ||||
| (3) | The discriminator network uses SN-PatchGAN for irregular mask image repair, which can produce high-quality repair results simply and quickly. | ||||
In this paper, progressive generative adversarial network for irregular masked image inpainting is designed to strengthen the constraints of the image inpainting process. The remaining sections of this paper are organized as follows: in Section 2, the related work of this paper is presented. Section 3 presents the proposed method in this paper. Section 4 carries out the experimental details. Section 5 presents our conclusions.
2. Related work
2.1. Generative adversarial network
Generative adversarial networks are a deep learning model that is one of the most promising approaches to unsupervised learning on complex distributions in recent years. A GAN consists of a generative network and a discriminative network. The generative network takes as input a random sample from a noisy distribution, and its output needs to mimic as much as possible the real samples in a given training set. The discriminant network's input is the output of the generative network or the real sample, and its purpose is to distinguish the output of the generative network from the real sample as much as possible, while the generative network has to deceive the discriminant network as much as possible. The two networks confront each other and continuously optimize and adjust the parameters, with the ultimate goal of making the discriminant network unable to judge whether the output of the generative network is real or not. The structure of GAN is shown in .
Figure 1. The basic structure of GAN.
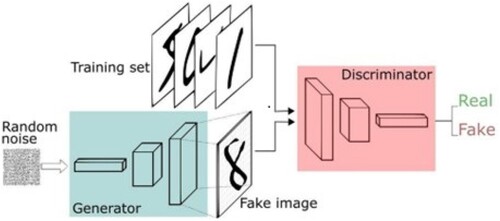
The training process of GAN is shown in Equation (Equation1(1)
(1) ).
(1)
(1) Where E is the expectation,
is the real sample, G is the generator network, and D is the discriminator network. The generator captures the distribution of the sample data and uses the noise z that follows a specific distribution to generate a sample similar to the real training data, and the discriminator is a binary classifier that estimates the probability that a sample is a ground truth.
Compared with other models, GAN can produce clearer, more realistic samples and is applied to scenarios such as super-resolution reconstruction, image editing, data generation [Citation31–33], where complex loss functions can be designed and the two networks will spontaneously confront each other. However, because GAN is derived from the game theory, there is the problem that the gradients of the generator and discriminator cancel each other, which will lead to the difficulty of convergence of the network, and in addition, GAN is less stable and more difficult to train. So the attention module can make the GAN network discard the current irrelevant information and pay more attention to the target information, which can effectively reduce the complexity of training and improve the effect of repair.
2.2. Channel attention module
The Channel Attention Module (CAM) is a feature map compressed in spatial dimension to obtain a 1D vector. Since each channel of the feature map is considered as a feature detector, the CAM focuses on which content has a significant role. To efficiently compute the CAM, the spatial dimensionality method of compressing the input feature map is used, and CAM is shown in .
Figure 2. Diagram of channel attention module.
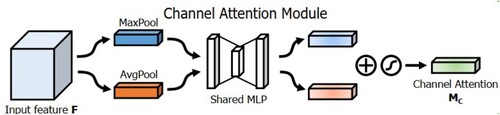
CAM inputs the features into two parallel max-pooling layer and average pooling layer, changes the feature map size from C*H*W to C*1*1, and then goes through a shared fully connected layer, first compresses the number of channels to 1/r times the original number, and then expands to the original number of channels, and gets the two activated results after the ReLU activation function. For the output results, the CAM feature map is obtained after element-by-element summation by the sigmoid activation function.
The channel attention is calculated as shown in Equation (Equation2(2)
(2) ).
(2)
(2) Where, σ is the sigmoid function,
,
,
and
share the weights of the MLP.
2.3. Spatial attention module
The Spatial Attention Module (SAM) is a compression of channels, averaging pooling and max pooling in channel dimensions, respectively, and generating spatial attention maps using spatial relationships between features. Different from CAM, SAM focuses on which parts have important roles, and SAM is shown in .
Figure 3. Diagram of spatial attention module.
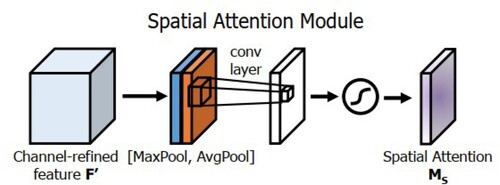
SAM takes the output result of CAM as input, gets two 1*H*W feature maps by max-pooling and average pooling, performs stitching operation on the two feature maps, and then transforms them into 1-channel feature maps by 7*7 convolution, and finally gets the feature maps of SAM by a sigmoid activation function.
The spatial attention is calculated as shown in Equation (Equation3(3)
(3) ).
(3)
(3) Where, σ is the sigmoid function and
is the convolution kernel of size
.
2.4. Perceptual loss
Perceptual loss was first proposed in 2016 by Johnson et al. [Citation34] in the area of image style conversion for comparing two images that look similar but are different, such as the same photo but shifted by one pixel, or the same image across different resolutions. In these cases, the pixel-level loss function outputs a large error value despite the fact that the images are very similar, while the perceptual loss function compares high-level perceptual and semantic differences between the images. The perceptual loss is calculated as shown in Equation (Equation4(4)
(4) ).
(4)
(4) Where, y is the ground truth,
is the predicted image,
,
,
denote the number of channels, length and width of the feature map, and
is the activation of the VGG network in processing the image y at the layer j. The activation of the ground truth y and the predicted image
is compared by the shape normalization of the image using squared L2 loss.
2.5. Style loss
Initially used in the field of style transfer, style loss is now also widely used in tasks such as image inpainting and super-resolution reconstruction. The idea is to use the Gram matrix to perform the computation of feature map differences. A pre-trained model outputs different features in different layers of the feature map, the shallow features are more detailed and the deeper features are more abstract. And the Gram matrix is actually the calculation of the correlation between two vectors. After the Gram matrix calculation of different feature map vectors, the overall image style can better grasp. The style matrix formed by the ground truth is shown in Equation (Equation5(5)
(5) ).
(5)
(5) Where, S is the ground truth, i is the height, j is the width, k is the different channels, and
denotes the positions of i, j, and k in layer l.
is used to measure the correlation coefficient between the activation terms in the k and
channels.
The style matrix formed by the generated images is shown in Equation (Equation6(6)
(6) ).
(6)
(6) Where, G is the generated image.
Two matrices were obtained from S and G, respectively, and the final error between these two matrices is shown in Equation (Equation7(7)
(7) ).
(7)
(7) Where,
is the style loss function defined for layer l.
3. Proposed method
At present, image inpainting using deep neural networks can produce good results, but there are still problems of poor edge consistency and semantic consistency for the inpainting of irregularly masked images. Therefore, in this paper, we designed a progressive generative adversarial network, in which the network shares parameters during the inpainting process, gradually strengthens the constraints on the internally generated content, and performs this progressive process in the feature mapping space, which solves the limitation that the network input and output need to be represented in the same space. Meanwhile, adaptive consistent attention is designed to be used in the generative network, which effectively solves the problem of semantic inconsistency of the restored images.
3.1. Network structure
For the continuous mask with a large area, this paper designed a progressive generative adversarial network, and the network structure is shown in . The input of the network is a mask image, and the mask image is encoded first and then restored using the progressive restore module. The restored feature map is passed through the decoder to obtain the restore result, and then the restored image and the ground truth are input to the discriminator for determination.
Figure 4. The framework of our method.
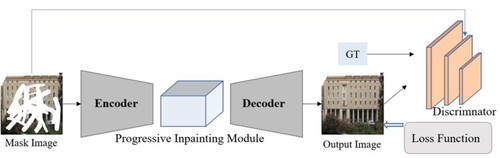
In the progressive generative network, we input the mask image and first restore it from the boundary region of the mask, using the progressive feature values to fill it, and then this part that has been filled as the known content, based on which the next smaller mask boundary region is restored until the mask region restore is completed. Traditional discriminator is mainly designed for single rectangular masks that fill regions with fixed locations. In this paper, we consider the task of repairing irregularly mask images, in which there may be multiple holes with arbitrary shapes at arbitrary locations, so we use a simple and effective GAN loss SN-PatchGAN for irregular image inpainting, whose network structure is shown in .
Figure 5. SN-PatchGAN.
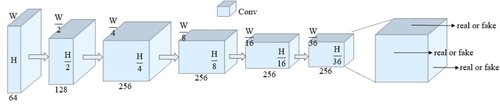
SN-PatchGAN consists entirely of convolutional layers and the input consists of generated image, ground truth and mask. The earliest discriminator was a direct output of 0/1 values, later PatchGAN used 2D tensor output, and in this paper we use 3D output with output size of , h, w and c are the height, width and number of channels, respectively. The network uses 6 convolutions with a kernel size of 5 and a step size of 2. The six convolutions are superimposed to capture the feature statistics of Markov blocks. Then, we apply the GAN directly to each feature element in this feature map, formulating a GAN of
number, focusing on different positions and different semantics of the input image. By using SN-PatchGAN, our network has better performance in the irregular mask image inpainting task.
3.2. Adaptive consistent attention module
The attention mechanism can further enhance the ability of the progressive inpainting module to restore high-quality feature maps, and to enhance the semantic consistency of the images as well as the possibility of capturing distant features, the Convolutional Block Attention Module (CBAM) [Citation35] is used in the feature generation phase, which consists of a channel attention module and a spatial attention module in tandem to extract feature information from both channel and spatial dimensions, but the direct use of the CBAM in progressive network does not work well because it does not consider the problem of consistency between feature mappings in different recursive cases, which may lead to inconsistent semantics of the generated images. To solve this problem, we designed an adaptive consistent attention module in this paper, which is different from previous attention mechanisms that calculate attention scores independently. This attention solves the problem of inconsistent feature mapping brought by considering only the current layer of attention scores by adaptively combining different recursive attention scores, and the repair model in this paper effectively improves the model consistency level with the assistance of adaptive consistent attention module. The attention module in this paper is shown in .
Figure 6. Adaptive consistent attention module.
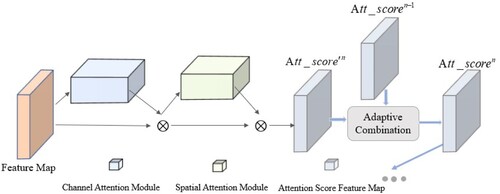
The adaptive consistent attention module in this paper first inputs the feature map and goes through CAM and SAM in turn to calculate the attention score. First, the feature map is input to the CAM for 2D convolution, and the convolution result is multiplied with the input feature map, and the CAM is calculated as , where n is the number of current cycles, F is the input features,
, and CAM 2D convolution. Then the output result of the channel attention is used as input for the 2D convolution of the SAM, and after the convolution, the output result is multiplied with the feature map obtained from the CAM to obtain the original attention score of the current cycle, which is calculated as
. The final attention score is calculated from the original attention score of the current cycle.
To calculate the final attention score for the current cycle, it is necessary to determine whether each pixel on the feature map is a valid pixel, if a pixel is a known region or has been filled, it is a valid pixel, and if a pixel is a masked region and has not been filled, it is an invalid pixel. The final attention score of a pixel is calculated. If a pixel on the feature map was valid in the last cycle, then the final attention score of that pixel in the current cycle is equal to the weighted sum of the original attention score of the current cycle and the final attention score of the previous cycle, as shown in Equation (Equation8(8)
(8) ).
(8)
(8) where n is the number of current cycles, (i,j) is the coordinates of the pixel on the feature map, λ is the weight,
is the original attention score, and
is the final attention score.
If a pixel on the feature map was invalid in the last cycle, then the final attention score for that pixel in the current cycle is equal to the original attention score, as shown in Equation (Equation9(9)
(9) ).
(9)
(9) After calculating the final score, the reconstructed feature map is stitched with the original feature map, and then another pixel-by-pixel convolution is done to obtain the final updated feature map for this cycle.
3.3. Progressive generation network
The pixel correlation within the local area of the image to be repaired is strong, and the missing region pixels can be inferred more accurately from the surrounding pixel information. However, for continuous irregular masks, the pixel correlation is weakened due to its large missing range and the increased distance between known and unknown regions, which leads to insufficient constraints on the centre location of the missing regions. In this paper, we design progressive generative network to solve this problem, which is divided into three main modules: the region identification module (represented by the blue dashed frame in the figure), the feature generation module (represented by the yellow dashed frame in the figure) and the feature merging module (represented by the green dashed frame in the figure), and the network structure is shown in . The region identification module is used to identify the mask boundary and treat the inner part of the boundary as the area to be patched. The feature generation module fills the content based on the results identified by the region identification module, which consists of a U-Net network and uses skip connection. The feature merging module is used to merge the features generated by the intermediate processes. The region identification and feature generation processes are alternated, and the final feature map is generated after the restore by feature merging.
Figure 7. Progressive generation network.
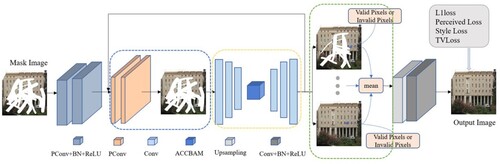
Partial convolution is the basic module for region recognition, the region identification module determines the region to be restored by identifying the mask boundaries. The module needs to cascade multiple partial convolution layers together to update the mask and feature mapping, and the partial convolution is used to identify the region to be updated in each recursion, we can obtain masks with a smaller range of updates after each partial convolution layer. The feature mapping is processed by the normalization layer and activation function after passing through the partial convolution layers and then passed to the feature generation module. The difference between the update mask and the input mask is then defined as the region to be generated in this recursion. The updated mask is retained throughout the recursion until the next recursion when it is reduced.
In the feature generation module, after the image to be restored has been identified in the region identification section as the region to be restored in the current round of recursion, the feature values within the region to be processed are estimated by the feature generation module, which aims at progressive feature values to fill the identified region. Progressive features not only produce better inpainting results but also facilitate subsequent inference. The feature generation module in this paper has a simple structure, consisting of an encoding layer and a decoding layer, which are combined together by a skip connection. After generating the feature values, the feature map is passed to the next recursion. In this paper, the region identification module and the feature generation module are alternated in the network, and the generation module is based on the previous generation of the feature map, which reduces the computation and saves a lot of computational cost. The attention module can be used in image inpainting to synthesize better-quality features, so this paper also designed an adaptive consistent attention module in this part of feature generation, which can adaptively combine different recursion scores to solve the problem of inconsistent feature mapping between different recursions, thus improving the semantic consistency of inpainting results.
When the mask image is completely filled, we use the feature merging module to merge the feature map. If we directly use the result of the last feature map as the output, the gradient will disappear and destroy the signal generated by the previous iteration. To solve this problem, an intermediate feature map merging is required. When the mask image inpainting is completed or the number of cycles has reached the upper limit, the average value of multiple feature maps output by multiple cycles is calculated to obtain the merged final feature map.
3.4. Loss functions
The loss function is an optimization target for the reconstruction accuracy of each pixel as well as the composition. The L1 loss function is used to calculate the absolute sum of the errors between the true and predicted values, using the average value to represent the overall loss value. First, we define the pixel losses in this paper, which are the L1 loss of the mask region and the valid region pixels on the network output, respectively. We input the masked image , the initial binary mask M, the network output image
and the real image
, as shown in Equation (Equation10
(10)
(10) ).
(10)
(10) Where,
is the number of elements in
,
, C, H and W are the number of channels, height and width, respectively.
For image generation learning, we use pre-trained and fixed VGG-16 with perceptual loss and style loss. The perceptual loss and style loss compare the difference between the depth feature map of the generated image and the ground truth. This loss function can effectively convey the structural and textural information of the image to the model, and the perceptual loss is calculated as shown in Equation (Equation11(11)
(11) ).
(11)
(11) Where,
,
and
are the height, weight and channel size of the
feature map, respectively, and
is the feature map from the
pooling layer in the fixed VGG-16.
The style loss uses the Gram matrix to perform the computation of feature map differences. Our pre-trained model, which outputs different layers of feature maps expressing different features, with the shallow layer used to compare details and the deep layer used to compare abstract content. The Gram matrix calculates the correlation of two vectors. By subjecting different feature map vectors to the Gram matrix calculation, we can better grasp the overall image style and make the restored image style more consistent. The style loss is calculated as shown in Equation (Equation13(13)
(13) ).
(12)
(12)
(13)
(13) The last item is Total Variation (TV) loss, whose role is mainly noise reduction. The difference in neighbouring pixel values in the image can be solved to some extent by reducing TV Loss, thus maintaining the smoothness of the image, as shown in Equation (Equation14
(14)
(14) ).
(14)
(14) where
is the most original output image,
is the number of elements in
, R is the mask region 1 pixel expansion region, and TV loss is a smoothing penalty on R, with the main purpose of maintaining the smoothness of the image and eliminating artefacts that may be brought by image inpainting.
In summary, the total loss function of our generative network is shown in Equation (Equation15(15)
(15) ).
(15)
(15) Where, δ, γ, χ, ε and λ are the parameters given to adjust the weights of each loss in the overall loss.
The discriminator uses spectral-normalization, which makes the GAN training more stable and converges faster. The final loss function of the discriminator is the hinge loss and SN-PatchGAN loss. The SN-PatchGAN loss function is calculated as shown in Equation (Equation16(16)
(16) ).
(16)
(16) Where, E is the expectation,
is the true sample, and z is the noise.
4. Experiments
4.1. Experimental settings
All experimental data in this paper are done in the same experimental environment. The hardware devices used for the experiments are 64-bit Windows 10 operating system, Intel(R) Core(TM) i9-10900X CPU @ 3.70GHz processor, and NIVIDIA GeForce RTX 2080Ti graphics card. For software, the framework chosen for this experiment is PyTorch v1.0.0, configured with cuda v10.0, Python v3.7.3, and the compiler used is PyCharm.
The number of training sessions is 160,000, and the pre-training network is trained using Adam optimizer with parameters set to and
. The model is trained using the learning rate of
, Batch_Size is 6, and then the model is fine-tuned using
. The loss function weights are set to
,
,
,
and
.
4.2. Datasets
In the experiments of this paper, two public image datasets and a mask dataset are used for the image inpainting task. And the training of network models and the comparative measurement of image inpainting effects are performed on this dataset.
CelebA Dataset [Citation36]: the image dataset focusing on faces contains 202599 images of 10177 celebrity identities, and all are feature-labelled, this dataset is very good for face-related training tasks.
CMP Facade Dataset [Citation37]: provides a dataset of frontal images collected at the Machine Perception Center, which includes 606 frontal images of buildings from different cities around the world and with different styles, which have been manually annotated.
NVIDIA Irregular Mask Dataset [Citation25]: contains 12,000 masks and a total of six different hole-to-image area ratios, with each category containing 1000 masks with boundary constraints and 1000 masks without boundary restrictions.
4.3. Qualitative comparisons
In the same experimental setting, our method was compared with several classical, state-of-the-art methods, which include Liu et al. [Citation25], Yu et al. [Citation27], Hui et al. [Citation23], Zhao et al. [Citation10], and Li et al. [Citation38]. On the CelebA Dataset [Citation36] and CMP Facade Dataset [Citation37] for the comparative experiments in this paper, and measured qualitative and quantitative results to compare our model with previous methods, and the results are shown in and .
Figure 8. Comparative experimental results on the CelebA Dataset.

Figure 9. Comparative experimental results on the CMP Facade Dataset.

and show the results of the method in this paper compared with the five state-of-the-art methods on two datasets. In most cases, our model restore results are significantly better than the other state-of-the-art methods, especially in the case of large area breakage, where our algorithm generates semantically more reasonable results. All methods produce seemingly reasonable inpainting results on both datasets; however, the inpainting results of Liu et al. method produce visual artefacts and edge response in the transition region between the mask and the surrounding area, colour differences between the restored and known areas can be observed, and the inpainting results on larger mask images suffer from semantic discontinuities. Yu et al.'s method yielded more visually pleasing results without significant colour inconsistencies, but the restored images using the gated convolution method had flaws in edge processing and poor boundary consistency. Hui et al.'s method used multiscale dense fusion blocks and combines multiple losses, and the inpainting results perform well overall, but there are texture structure deficiencies. Zhao et al. used co-modulated generative adversarial networks, that is, given the conditions and introduced noise, to achieve good results in the large mask repair task, but the authenticity of the repair results needs further improvement. Li et al.'s method can produce realistic texture details, but the method is less robust in repairing large irregular masked images. Thanks to the progressive generative adversarial network and the well-designed adaptive consistent attention module, the method in this paper provides significant visual improvements in texture and structure, and our network can produce satisfactory image structure with significant improvements in global semantic continuity and boundary consistency of the image, and the image is free from artefact generation, which can be seen in the figure with smoother connections between the muscle textures and lines of the face, the inpainting of the building has more texture details.
4.4. Quantitative comparisons
We also quantitatively compared the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) of the model in this paper, where the SSIM index evaluates the generated image and the real image in terms of image structure. Quantitative evaluation of restoration results means objective evaluation of restoration results. Subjective evaluation information is influenced by personal opinions, so quantitative indexes are used to evaluate image restoration effects more objectively. Through quantitative analysis of the experimental data, it can be found that our method has better inpainting effect compared with other methods and our inpainting method has stable inpainting capability. and show the results of the two datasets with different methods, and our method produces excellent results and the highest AVE SSIM and AVE PSNR on the CelebA and CMP Facade datasets.
Table 1. PSNR (dB)/SSIM (%) evaluation results of different methods on the CelebA Dataset.
Table 2. PSNR (dB)/SSIM (%) evaluation results of different methods on the CMP Facade Dataset.
shows the analysis results of PSNR and SSIM metrics of our method and other advanced methods on the CelebA dataset, the numbers in bold in the table indicate the optimal values. The data shows that our method has the highest scores in AVE PSNR and AVE SSIM compared with other methods, our method improved by 3.69dB and 0.152, respectively, compared with Liu et al.'s method, compared with Yu et al.'s method improved by 2.09 dB and 0.107, compared with Hui et al.'s method improved by 1.01 dB and 0.055, compared with Zhao et al.'s method improved by 0.64 dB and 0.027, and compared with Li et al.'s method improved by 1.18 dB and 0.040, respectively.
shows the analysis results of PSNR and SSIM indicators of this method and other advanced methods on the CMP Facade dataset, the numbers in bold in the table indicate the optimal values. The data shows that our method has the highest scores in AVE PSNR and AVE SSIM compared with other methods. Compared with the method of Liu et al., our method has improved 3.14dB and 0.190, respectively, compared with the method of Yu et al., 2.03dB and 0.133, respectively, and compared with the method of Hui et al., 1.23dB and 0.057, respectively, compared with Zhao et al.'s method, it is improved by 0.56dB and 0.062, respectively, and compared with Li et al.'s method, it is improved by 1.04dB and 0.079, respectively.
As can be seen from and , our model achieves better results compared with the other five advanced methods. The highest AVE PSNR and AVE SSIM are achieved in both datasets, which is a good indication that our method can obtain better results and a more stable model. The PGAN designed in this paper gradually repairs the masked regions from edge to centre and from easy to difficult, thus generating semantically true and edge-consistent results. PGAN contains ACAM and SN-PatchGAN, which can better ignore unimportant features and extract effective features, thus enhancing the model restore ability and thus generating semantically consistent and visually results with higher degree of realism. We can conclude from the experimental data that the image inpainting model in this paper has stronger and more stable inpainting ability and better inpainting results.
4.5. Ablation studies
In order to verify the effectiveness of each module in the proposed method, we did the ablation study in this paper under the same experimental environment, and the results are shown in . The first column is the ground truth, the second column is the input image, and each other column corresponds to a module of this paper.
Figure 10. Results of ablation studies on CelebA and CMP Facade datasets.

From the ablation study results in , it can be seen that the overall inpainting effect using only the progressive generative network method is poor, and the inpainting results will show semantic discontinuities and insufficient clarity with pixel-level defects. The use of progressive generative network and ACAM can effectively solve the problems of semantic discontinuity and low clarity because of the inclusion of attention mechanism, but the model convergence speed is slower and the generated results will show certain boundary artefacts. Using the full model without style loss, the inpainting results in poor overall style consistency compared to the real image. Finally, using full model(progressive generative network + ACAM + SN-PatchGAN+ style loss) gives the best results, generates more consistent and highest definition restored images, and performs best in terms of semantic content, boundary consistency, style consistency and texture.
shows the analysis results of the PSNR and SSIM metrics of the ablation study of the method in this paper on the CelebA dataset, the numbers in bold in the table indicate the optimal values. The analysis of the experimental data shows that the full model has the best results and gets the highest values on both AVE PSNR and AVE SSIM results, compared with the dual progressive generative network by 2.20dB and 0.118, respectively, compared with progressive generative network and ACAM by 0.84dB and 0.077, respectively, and compared with progressive generative network and SN-PatchGAN by 0.41dB and 0.022, respectively. Compared with the full model without style loss is improved by 0.47dB and 0.024, respectively.
Table 3. PSNR(dB)/SSIM(%) evaluation results of the ablation study on the CelebA Dataset.
shows the analysis results of PSNR and SSIM metrics for the ablation study of the method in this paper on the Paris StreetView dataset, the numbers in bold in the table indicate the optimal values. And the analysis of the experimental data shows that the full model has the best results and gets the highest values on both AVE PSNR and AVE SSIM results, compared with the dual progressive generative network by 1.65dB and 0.125, respectively, compared with progressive generative network and ACAM by 1.15dB and 0.073, respectively, and compared with progressive generative network and SN-PatchGAN by 0.59dB and 0.045, respectively. Compared with the full model without style loss is improved by 0.22dB and 0.021, respectively.
Table 4. PSNR(dB)/SSIM(%) evaluation results of the ablation study on the CMP Facade Dataset.
From and , it can be seen that this paper enhances the consistency between feature mappings by using the ACAM, the consistency between feature mappings is enhanced, the structural applicability of the model is improved, the model's ability to restore semantic information is increased, and the texture detail and edge consistency problems arising from the model restore results are mitigated. In addition, in this paper, by using PGAN and SN-PatchGAN, the model generates images with higher clarity, enhances the quality of the restored images, and improves the learning ability and convergence speed of the model. Based on the experimental data, we can conclude that the inpainting results of this paper using full model can achieve better results compared to using only some of the modules.
5. Conclusion
Image inpainting is an important research branch in the field of digital image processing, which aims to automatically recover the lost information based on the existing information of an image. In this paper, we designed an irregular mask image inpainting algorithm based on a progressive generative adversarial network, which uses correlation of neighbouring pixels and progressive feature generation to gradually enrich the information in the missing regions and give semantically clear and well-structured inpainting results. In addition, an adaptive consistent attention module is designed, which helps the generation process of the feature generation module in the progressive generative adversarial network, adaptively combines the attention scores of different recursions, ensures the feature mapping between different recursions, and makes the inpainting results more consistent. The discriminator network used SN-PatchGAN, which focuses on different locations and different semantics of the input images, allowing our network to have better performance in irregular mask image restoration tasks. In the experimental part, extensive quantitative (PSNR and SSIM) and qualitative comparison and ablation studies are conducted in this paper to demonstrate the advantages of our designed network in terms of performance and effectiveness.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Hong-an Li
Hong-an Li received the M.S. degree in 2009 and the Ph.D. degree in 2014 in computer science and technology from Northwest University, Shaanxi, China. From 2014 to 2023, he was an associate professor of the College of Computer Science and Technology, Xi’an University of Science and Technology. His research interests include computer graphics and computer-aided geometric design, virtual reality and image processing.
Liuqing Hu
Liuqing Hu received the bachelor’s degree in software engineering in 2021 from the College of Computer Science and Technology, Xi’an University of Science and Technology. She is currently studying for a master’s degree in the College of Computer Science and Technology, Xi’an University of Science and Technology. Her research interests include artificial intelligence, image processing and computer vision applications.
Jing Zhang
Jing Zhan received the M.S. degree in computer application technology from Northwest University of Shaanxi Province, China in 2013 and the Ph.D. degree in 2018. From 2018 to 2023, she served as a lecturer in the School of Computer Science and Technology of Xi'an University of Science and Technology. Her research interests include graphics and image processing, intelligent information processing and signal processing and perception.
References
- Li H-a, Zhang M, Chen D, et al. Image color rendering based on Hinge-Cross-Entropy GAN in internet of medical things. Comput Model Eng Sci. 2023;135(1):779–794.
- Isogawa M, Mikami D, Iwai D, et al. Mask optimization for image inpainting. IEEE Access. 2018;6:69728–69741.
- Shih ML, Su SY, Kopf J, et al. 3d photography using context-aware layered depth inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020. p. 8028–8038.
- Zheng C, Cham T J, Cai J. Pluralistic image completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019. p. 1438–1447.
- Yu J, Lin Z, Yang J, et al. Generative image inpainting with contextual attention. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2018. p. 5505–5514.
- Wan Z, Zhang B, Chen D, et al. Bringing old photos back to life. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE; 2020. p. 2744–2754.
- Yi Z, Tang Q, Azizi S, et al. Contextual residual aggregation for ultra high-resolution image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020. p. 7508–7517.
- Zeng Y, Fu J, Chao H, et al. Learning pyramid-context encoder network for high-quality image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019. p. 1486–1494.
- Li J, Wang N, Zhang L, et al. Recurrent feature reasoning for image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020. p. 7760–7768.
- Zhao S, Cui J, Sheng Y, et al. Large scale image completion via co-modulated generative adversarial networks. arXiv preprint arXiv:2103.10428. 2021. p. 1–25.
- Le TT, Dang N, Hue NM, et al. On numerical implementation of the Laplace equation-based image inpainting. IOP Conference Series: Materials Science and Engineering. 2021;1022(1):012034(10pp).
- Bertalmío M, Sapiro G, Caselles V, et al. Image inpainting. Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques; 2000. p. 417–424.
- Shen J, Chan T. Mathematical models for local nontexture inpainting. SIAM J Appl Math. 2002;62(3):1019–1043.
- Chan T, Shen J. Nontexture inpainting by curvature-driven diffusions. J Vis Commun Image Represent. 2001;12(4):436–449.
- Bertalmío M, Vese L, Sapiro G, et al. Simultaneous structure and texture image inpainting. IEEE Trans Image Process. 2003;12(8):882–889.
- Criminisi A, Perez P, Toyama K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans Image Process. 2004;13(9):1200–1212.
- Starck JL, Elad M, Donoho DL. Image decomposition via the combination of sparseRepresentations and a variational approach. Image Process IEEE Trans. 2005;14(10):1570–1582.
- Zhang J, Yan Q, Zhu X, et al. Smart industrial IoT empowered crowd sensing for safety monitoring in coal mine. Digit Commun Netw. 2022;8:2–12.
- Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. Adv Neural Inf Process Syst. 2014;28:1–9.
- Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders: Feature learning by inpainting. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2016. p. 2536–2544.
- Yang C, Lu X, Lin Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2017. p. 6721–6729.
- Wang Y, Tao X, Qi X, et al. Image inpainting via generative multi-column convolutional neural networks. Adv Neural Inf Process Syst. 2018;31:331–340.
- Hui Z, Li J, Wang X, et al. Image fine-grained inpainting. arXiv preprint arXiv:2002.02609. 2020. p. 1–11.
- Thanh DNH, Prasath VBS, Dvoenko S. An adaptive image inpainting method based on euler's elastica with adaptive parameters estimation and the discrete gradient method. Signal Process. 2021;178:1–19.
- Liu G, Reda FA, Shih KJ, et al. Image inpainting for irregular holes using partial convolutions. In: Proceedings of the European conference on computer vision (ECCV); 2018. p. 85–100.
- Nazeri K, Ng E, Joseph T, et al. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv preprint arXiv:1901.00212. 2019. p. 1–17.
- Yu J, Lin Z, Yang J, et al. Free-form image inpainting with gated convolution. In: Proceedings of the IEEE/CVF international conference on computer vision; 2019. p. 4471–4480.
- Abdulla AA, Ahmed MW. An improved image quality algorithm for exemplar-based image inpainting. Multimed Tools Appl. 2021;80(9):13143–13156.
- Ahmed MW, Abdulla AA. Quality improvement for exemplar-based image inpainting using a modified searching mechanism. UHD J Sci Technol. 2020;4(1):1–8.
- Mao Y, Zhang T, Fu B, et al. A self-attention based wasserstein generative adversarial networks for single image inpainting. Pattern Recognit Image Anal. 2022;32(3):591–599.
- Chan KCK, Wang X, Xu X, et al. Glean: generative latent bank for large-factor image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition; 2021. p. 14245–14254.
- Chen Y, Liu S, Wang X. Learning continuous image representation with local implicit image function. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition; 2021. p. 8628–8638.
- Hong S, Marinescu R, Dalca AV, et al. 3d-stylegan: a style-based generative adversarial network for generative modeling of three-dimensional medical images. Deep Generative Models, and Data Augmentation, Labelling, and Imperfections. Cham: Springer; 2021. p. 24–34.
- Johnson J, Alahi A, Fei-Fei L. Perceptual losses for real-time style transfer and super-resolution. In: European conference on computer vision. Cham: Springer; 2016. p. 694–711.
- Woo S, Park J, Lee JY, et al. Cbam: convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV); 2018. p. 3–19.
- Liu Z, Luo P, Wang X, et al. Deep learning face attributes in the wild. In: Proceedings of the IEEE international conference on computer vision; 2015. p. 3730–3738.
- Tyleček R, Šára R. Spatial pattern templates for recognition of objects with regular structure. In: German conference on pattern recognition. Berlin, Heidelberg: Springer; 2013. p. 364–374.
- Li H-a, Hu L, Hua Q, et al. Image inpainting based on contextual coherent attention GAN. J Circuits Syst Comput. 2022;31(12):2250209(21 pages).