
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The aim of image inpainting is to fill in damaged areas according to certain rules based on information about the adjacent positions of missing areas and the overall structure of the image, a technique that plays a key role in various tasks in computer vision. With the rapid development of deep learning, researchers have combined it with image inpainting and achieved excellent performance. To gain insight into the techniques involved, this paper summarizes the latest research advances in the field of image inpainting. Firstly, existing classical image inpainting methods are reviewed, and traditional image inpainting methods and their advantages and disadvantages are introduced. Secondly, three classical network models are outlined, and the image inpainting methods are classified into single-stage, multi-stage and a priori condition-guided approaches according to different network types and model structures. Representative algorithms among them are selected and their important technical improvement ideas are analyzed and summarized. Then, the common datasets commonly used in image inpainting tasks and the evaluation metrics used to evaluate inpainting results are introduced. The paper presents a comprehensive summary of the various algorithms in terms of network models and inpainting methods, and selects representative algorithms for quantitative and qualitative comparative analysis. Finally, the future development trends and research directions have prospected, and the current problems of image inpainting are summarized.
1. Introduction
Digital image processing is the processing of image information to meet the needs of human visual psychology and practical applications [Citation1–4]. With the increasing development of science and technology, the speed of updating hardware devices, and the demand for image quality, image inpainting has gradually become an important research branch in digital image processing [Citation5–10].
The purpose of image inpainting is to automatically recover the missing information based on the known information of the image, i.e. to restore an image that has been damaged in some way or to remove unwanted objects from the image [Citation11,Citation12]. Image restorers often need to use the most appropriate method to restore the image to its original state, while at the same time ensuring that the artistic effect achieved is optimal. Current image inpainting tasks have a wide range of applications, including rectangular mask inpainting, irregular mask inpainting, object removal, watermark removal, text removal, scratch removal, and old photo coloring [Citation13–17], and examples of these inpainting tasks are shown in .
Figure 1. Example of inpainting for different distortion types.

Traditional image inpainting algorithms are mainly divided into structure-based image inpainting algorithms and texture-based image inpainting algorithms. The former is primarily for implementing the partial differential equation-based PDE process, also known as the diffusion-based image inpainting method. The first PDE equation-based method was proposed in [Citation18] to perform diffusion-based image inpainting on a pixel-by-pixel basis. And because this method does not consider the consistency of the semantic information of the broken regions of the image and the global semantic information, and lacks a constraint process for the higher-level semantic information of the image, it is only applicable to the inpainting of small localized broken images. However, for the inpainting of the large areas of damaged images, there are usually problems such as texture dislocation. Compared with the diffusion-based method, the patch-based method extracts feature blocks from the background region and then pastes them into the mask region. This method can better preserve the texture and structure information in the image. The image block-based Criminisi algorithm was proposed in [Citation19], which significantly improves the repair speed by searching for information about the target pixel blocks around the broken region. However, this method is also not applicable to images with large damaged areas and damaged regions containing important semantics. On the basis of the Criminisi algorithm, Abdulla and Ahmed [Citation20] proposed an example-based algorithm that consists of two phases, in the first phase, the entire image is searched and the most similar features are found and selected using Euclidean distance. In the second stage, the distance between the selected feature block location and the feature block location to be filled is measured. Ahmed and Abdulla [Citation21] proposed an improved search mechanism to select the most similar patches, and the algorithm adds the results of the first two stages and finally selects the patch that obtains the smallest distance value for filling. This method can obtain the best similar blocks to the maximum extent, which results in a higher quality of inpainting results. Improved conventional methods facilitate image inpainting in different ways, yet the results are still poor for high definition and geometrically complex images.
In recent years, as the core technology of artificial intelligence, deep learning has been highly valued because of its powerful learning algorithms and rich application scenarios, and has achieved remarkable success in the field of computer vision. Inpainting technology based on deep learning has been well developed [Citation22–25], and the development of deep learning technology has promoted the significant improvement of inpainting performance. Since the concept of Auto-Encoder [Citation26] was proposed, the evolving and advancing neural networks have been applied to image inpainting, and researchers have tried to use the encoding and decoding structure in Auto-Encoder networks to image inpainting tasks. By capturing the contextual information around the missing regions of an image and encoding it through an encoder to extract the potential feature representation of the image, and a decoder to restore the original image data to generate content of the missing region, while continuously optimizing the inpainting result by adding various constraints. Subsequently, LeNet [Citation27], ResNet [Citation28], and VGG [Citation29] has constantly been proposed, which have performed well in image inpainting. 2014 Goodfellow et al. [Citation30] proposed Generative Adversarial Network (GAN), which computer image inpainting development went further [Citation31–43]. In the training process, the goal of the generator is to try to generate real images to deceive the discriminator, while the goal of the discriminator is to try to distinguish the images generated by the generator from the real ones.
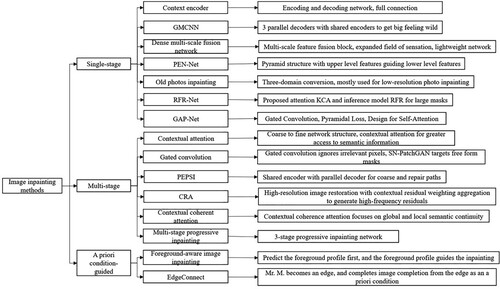
With the proposal and application of a large number of deep learning-based image inpainting algorithms, urgent problems and challenges emerge, such as extracting suitable features, finding similar blocks, and obtaining high-level semantics. To address these problems, researchers have analyzed methods to improve the quality of image inpainting from the perspectives of backbone networks, increasing visual perceptual fields, residual aggregation, and feature fusion based on the work above. This paper provides a more comprehensive and detailed summary of the network models related to image inpainting based on deep learning in recent years, aiming to provide a more comprehensive and in-depth learning perspective for subsequent research in related fields. Through an extensive survey of the literature, this paper further categorizes deep learning-based image inpainting methods into single-stage image inpainting methods, multi-stage image inpainting methods, and a priori condition-guided image inpainting. In addition, this paper presents a generic dataset for image inpainting and analyzes the image inpainting results using evaluation metrics.
2. Traditional image inpainting methods
2.1. Structure-based image inpainting methods
The structure-based approach used geometric methods to recover the missing parts of an image, assuming that the damaged and known parts of the image have similar content. It finds the best matching feature block in the known region of the image and then copies the information to fill the missing region at the pixel level. The first BSCB algorithm based on Partial Differential Equation (PDE) was used for digital image inpainting in [Citation18]. The algorithm treats the input image as three independent channels and fills the region to be restored for each channel by transferring information from outside the missing region using iso-illumination lines. Inspired by [Citation18], Chan and Shen proposed the Total Variation (TV) model [Citation44] and the Curvature Driven Diffusions (CDD) model. Diffusions (CDD) model [Citation45]. The TV inpainting model used the Euler-Lagrange equation, and within the restored area, the model used Anisotropic diffusion based only on the contrast of the iso-illumination lines. The TV inpainting model is suitable for inpainting small areas of breakage, and although it does an excellent job of removing noise, it does not do an excellent job of connecting the restored portion to the background. The CDD model extends the full-variance inpainting model, which better combines the restored region to the background, but the resulting interpolated segments look blurry. Ruzic and Pizurica [Citation46] proposed a method to search for well-matched patches in texture components using Markov Random Field (MRF). Liu et al. [Citation47] proposed a non-local extension of TV regularization. Taking advantage of the non-local similarity of natural images, the proposed approach estimates the image gradient statistics at a particular pixel from a group of nonlocally searched patches which are similar to the patch located at the current pixel, leading to more accurate gradient estimation. Kawai et al. [Citation48] proposed an approach based on selecting the target object and using the background to restrict the search around it for removing objects from the image. Liu et al. [Citation49] used statistical regularization and similarity between regions to extract the main linear structure of the target region, and then used MRF to repair the missing regions. Ding et al. [Citation50] proposes a method using nonlocal texture matching and nonlinear filtering.
Traditional methods usually require much computational power to calculate the similarity scores between points. Barnes et al. [Citation51] demonstrates its practical value in image processing applications by using a fast nearest-neighbor algorithm that reduces the memory and computational overhead of the search process. However, the contents of missing regions in images are often small, completely independent, or unstructured with local missingness. In such cases, traditional structure-based methods may be challenging to solve. Therefore, some researchers have proposed image-to-image reconstruction, which focuses on finding semantically similar images to the degraded target image from existing image libraries and then selecting the appropriate patch information for transfer and retrieval. Hays and Efros [Citation52] used a multi-million dollar database to find the images that are most similar to the target image to be recovered, and then extracted information from the relevant regions to enhance the degraded image. This approach may be more suitable for restoring degraded images when a large amount of image data is available for a particular domain. Still, it often requires retrieving a large amount of domain data and finding the best match [Citation53,Citation54]. Therefore, in practical scenarios, these methods apply to fewer scenarios, and their applications are relatively limited.
2.2. Texture-based image inpainting methods
Texture-based image inpainting is performed using texture synthesis for the area of the image to be restored. Bertalmio et al. [Citation55] first proposed to include texture information in a structure-based image inpainting algorithm. Sharma and Mehta [Citation19] proposed a block-based texture synthesis algorithm that considers a random pixel point on the boundary of the reconstructed region as the center, then selected blocks of a specific size based on image texture features, searched for the block that best matches the damaged image region, and finally used the best matching block to reconstruct the region. This algorithm can repair the texture information of the image well, but it cannot maintain the structural consistency of the repaired region with the background well. In [Citation56], an iterative inpainting algorithm based on an analytical dictionary is proposed to achieve the inpainting by making a sparse prior to the local smoothness of the image. To make the sparse coefficients as non-negative as possible, sparse coding is done first to improve the efficiency of coding. Then the complete dictionary is constructed to achieve the effect of inpainting by signal reconstruction, but the inpainting of texture and edges of the image is relatively poor. Li et al. [Citation57] identifies the restored region by identifying the local texture of the restored region, and then constructs feature sets based on the local variations within and between channels. Another texture based inpainting method proposed in the recent research of [Citation58], which used the distance between damaged pixels and their adjacent pixels and calculates the diffusion coefficient. Sridevi and Kumar [Citation59] proposed an image inpainting method based on fractional order derivatives and Fourier transform. Jin et al. [Citation60] proposed a Canonical Correlation Analysis (CCA) based sparse image detection inpainting method. A search-based dictionary learning of sparse representations was proposed in [Citation61].
Texture-based image inpainting focuses on gradually spreading pixel information around the damaged pixels in an image and synthesizing new textures to fill this missing part. Texture-based reconstruction of missing regions is usually limited by the loss of information around the pixels, difficulty in reasonably learning distant feature information, and lack of high semantic understanding of the image to recover meaningful texture structure of the missing regions. In addition, the scattering distance of pixel information around the missing region increases, and the larger the defect, the less effective pixel information is obtained at the center. Therefore, texture-based approaches are more suitable for recovering backgrounds with structural textures and removing small objects from images, but have limited effectiveness in recovering larger deficits in real natural scenes with complex textures.
Traditional image inpainting algorithms perform well in regular mask and small area mask inpainting tasks with simple texture structures. Still, their inpainting results are inversely proportional to the size of the area to be restored. With the rapid development of artificial intelligence technology, researchers have applied deep learning to a wide range of fields. Deep learning has been applied to image inpainting using network models such as Convolutional Neural Networks (CNN), Generative Adversarial Networks (GAN), Variational Auto-Encoders (VAE), and other network models such as attention mechanisms and residual networks.
3. Deep learning-based image inpainting methods
With the excellent results of deep learning in the field of vision, image inpainting methods based on deep learning have also started to be effective. In this section, we summarize the representative methods of deep learning-based image inpainting by analyzing various methods, as shown in . Comparing and summarizing the methods listed in , we can find that in terms of network selection, CNN-based image inpainting methods are still the mainstream methods for research on deep learning image inpainting applications. As far as generative networks are concerned, VAE and GAN can effectively learn and model real data distribution from training data. The training of VAE-based image inpainting methods is usually more stable, but the generated results are easily blurred. GAN-based image inpainting methods can improve the quality of image inpainting generation, but are difficult to train. The increased network width and depth can better fit the data features, but the network depth can cause the model gradient explosion when it is too deep. Therefore, current image inpainting network models use a thin and deep network structure to reduce and control the number of parameters, and use multi-scale features or jump-connected residual structures to solve the gradient disappearance problem. The use of partial convolution or gated convolution can alleviate the problem that ordinary convolution treats all input pixels as valid pixels, which leads to artifacts, so convolution-based improvements are also a feasible breakthrough direction in image inpainting. Networks are usually complex when using multi-stage image inpainting models, so researchers have tried to investigate how to effectively reuse specific network layers of encoders and decoders to control the number of model parameters and thus improve the training efficiency of the models. Inpainting methods by adding inferred image contours or structural priors can take advantage of prior knowledge of visible regions for more accurate finished texture inpainting.
Figure 2. Typical algorithm for image inpainting.
3.1. Network models overview
3.1.1. CNN
CNN is a neural network whose artificial neurons can respond to a portion of the surrounding units within the coverage area and are excellent for processing large images. CNN is an effective recognition technology developed in recent years, which has attracted great attention, especially in the field of pattern classification. This technology avoids complex image preprocessing and can be directly incorporated into the original image, making it widely used [Citation27–29,Citation62].
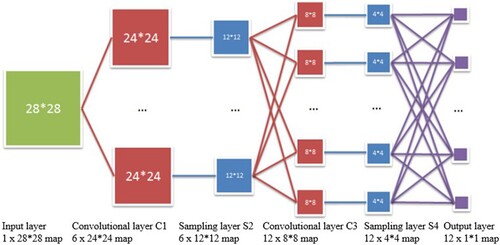
In general, the basic structure of CNN consists of two layers, one of which is the feature extraction layer, where the input of each neuron is mapped to the local receptive area of the previous layer, and features are extracted from this local region. In addition to the local features, its relative position with respect to other features is also determined. The second is the feature mapping layer, where each computational layer of the network consists of several feature mappings, each of which is a plane in which all neurons have the same weights. The mapping function used a sigmoid function with an influence function kernel as the activation function of the convolutional network, so the feature mappings are variable. In addition, the number of free parameters in the network is reduced because the neurons on the mapping plane have common weights. Each convolutional layer of the CNN is followed by a computational layer for local averaging and secondary extraction, which reduces the feature resolution due to the unique feature structure of the secondary extraction. The network structure of the CNN is shown in .
Figure 3. Structure of the CNN.
Recently, the powerful potential of CNN has been demonstrated in all computer vision tasks [Citation63], especially in image inpainting. The purpose of using CNN is to use large-scale training data to improve the expected results in this area. A number of CNN-based image inpainting methods have been proposed [Citation64,Citation65]. The use of CNN allows sharing of convolutional kernels, efficient processing of high-dimensional data, and automatic feature extraction, but when the network level is too deep, modifying parameters using BP propagation results in slower changes in parameters close to the input layer. Moreover, CNN requires a large sample size, and using a gradient descent algorithm can easily make the training results converge to a local minimum. A large amount of valuable information may be lost in the pooling layer, thus ignoring the correlation between the local and the whole and not knowing the features extracted from each convolutional layer.
3.1.2. GAN
GAN is a deep learning model [Citation30], which has been one of the most promising approaches for unsupervised learning on complex distributions in recent years. The GAN model produces quite good outputs by playing the Generative Model and Discriminative Model in the framework to learn each other. Since the idea was proposed, GAN has become one of the hottest concepts in deep learning, and the structure of the GAN model is shown in .
Figure 4. Structure of the GAN.
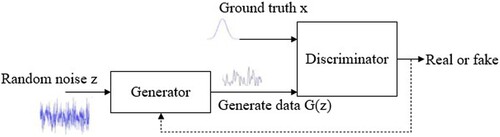
GAN is divided into three parts: generation, discrimination, and adversarial. Generation and discrimination refer to two independent modules, where the generator is responsible for generating content based on a random vector. The discriminator is responsible for determining whether the received content is true or not, and it usually gives a probability that represents the degree of truthfulness of the content. Confrontation refers to the alternate training process of the GAN.
The GAN model can produce clearer and more realistic samples, and the model adopts unsupervised learning, which is widely used in unsupervised learning and semi-supervised learning. However, because GAN comes from the idea of a zero-sum game in game theory, there is the problem that the gradients of the generator and discriminator cancel each other, which will lead to the difficulty of convergence of the network. In addition, GAN itself is less stable, more difficult to train, and the model is easy to collapse.
3.1.3. VAE
VAE is a generative network structure based on Variational Bayes (VB) inference proposed by Kingma et al. [Citation66] in 2014. Unlike the traditional Auto-Encoder, which describes the latent space by numerical methods, the Auto-Encoder describes the observation of the potential space by probability, which has excellent application in data generation. Once proposed, VAE has rapidly gained wide attention in the field of deep generative models, and is considered one of the most valuable methods in the field of unsupervised learning with GAN, and has been increasingly used in the field of deep generative models.
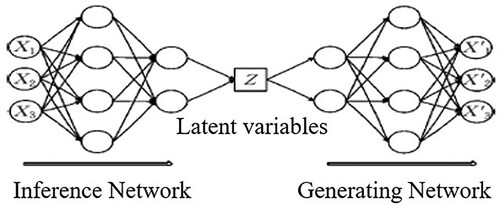
The traditional self-encoder model consists of two parts, encoder and decoder, and the VAE composition is similar to that of the Auto-Encoder. The VAE used two neural networks to build two probability density distribution models, one of which is used for variational inference of the original input data to generate the variational probability distribution of the hidden variable, called the inference network. The other one is used to recover the approximate probability distribution of the original data based on the generated variational probability distribution of the hidden variable and is called the generative network. The network structure of VAE is shown in .
Figure 5. Structure of the VAE.
VAE can handle high-resolution images with simple parameters and a scalable network structure that makes it easy to repair any region of the image if trained to generate a network of the same resolution. The model can directly compare the differences between the reconstructed image and the original image, thus ensuring the generative power. However, since no adversarial network is used, the generated results may be ambiguous.
With the emergence of network models such as CNN, GAN, and VAE, various deep-learning image inpainting methods based on these network models have become popular directions for further improvement by scholars. Pathak et al. [Citation15] proposed a single-stage context encoder structure applied to a large range of missing image inpainting tasks. Since then, single-stage-based image inpainting methods have proliferated and become one of the leading models for image inpainting. Given that the image inpainting results are closely related to the obtained contextual information, some researchers have proposed multi-stage image inpainting methods to obtain more contextual information, and [Citation41] proposed a coarse-to-fine multi-stage network architecture for progressive image inpainting, which can generate better prediction results. To address the problem that single-stage and multi-stage methods do not fully utilize the prior knowledge of visible regions, some researchers proposed new and improved methods to guide network models to make inpainting results with more reasonable texture structure and accurate semantic information by reasoning about image contours and adding structural priors. For different needs and various network-based deep learning image inpainting methods, this paper classifies them into three categories, which are: single-stage image inpainting methods, multi-stage image inpainting methods, and a priori condition-guided image inpainting methods.
3.2. Single-stage image inpainting methods
3.2.1. Context encoder
Pathak et al. [Citation15] proposed an image inpainting network called Context Encoder (CE), which applies an unsupervised visual feature learning algorithm driven by contextual pixel-based prediction to a large-scale missing image inpainting task. The context encoder network structure is shown in . The overall is a simple encoder-decoder. The encoder extracts the feature representation of the input image, and the decoder restores the compressed feature map to the size of the original image. The encoder consisting of convolutional layers does not allow the information to pass directly into the feature map because the convolutional layers cannot directly connect all positions in a particular feature map. In the paper, a fully connected layer to propagate information across channels is proposed as an intermediate connection between the encoder and decoder to ensure feature delivery in each feature map.
Figure 6. Structure of context encoder.
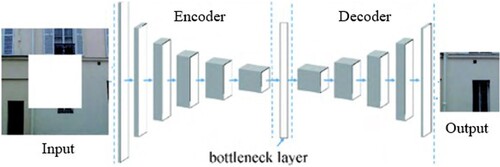
The context encoder used reconstruction loss L2 and adversarial loss to handle continuity in the context and multiple patterns in the output. Reconstruction loss is responsible for capturing the overall structure of the restored region as well as maintaining consistency with the surrounding known regions, and adversarial loss makes the prediction of the restored region look realistic. By keeping them in balance, good inpainting results can be produced. The context encoder understands the semantics of the image to some extent and generates new content based on the predicted pixels based on the information around the hole. The model was a very cutting-edge technology at the time and laid the foundation for subsequent research work.
3.2.2. Generative multi-column convolutional neural networks
There are three significant challenges in the image inpainting process: extracting the appropriate features of the image, finding similar blocks, and synthesizing the auxiliary information. And [Citation67] proposed a Generative Multi-column Convolutional Neural Network (GMCNN) for these three challenges, and the network structure is shown in . The network is divided into three sub-networks: the prediction result generator, the global and local discriminators trained against, and the pre-trained VGG19 network that computes the Implicit Diversified Markov Random Fields (ID-MRF) loss.
Figure 7. Structure of GMCNN.
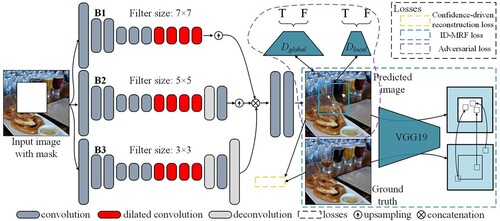
To acquire features, the paper proposed a GMCNN structure consisting of three parallel encoder-decoder branches. The multicolumn structure can decompose the image into components with different perceptual fields and feature resolutions for extracting different levels of features. To solve the semantic structure matching and computationally heavy iterative MRF optimization problem, the ID-MRF term is used to find similar blocks, but only as a regularization term. To impose constraints on the spatial locations, a confidence-driven reconstruction loss is designed, where unknown pixels near the filling boundary are subject to stronger constraints than regions far from the boundary. Weights are applied to the loss function to solve the boundary consistency problem.
3.2.3. Dense multi-scale fusion network
The use of large convolutional kernels leads to a large number of model parameters while obtaining a large perceptual field. Hui et al. [Citation68] proposed a Dense Multi-scale Fusion Block (DMFB) based on the GMCNN, and the network structure is shown in . The overall framework of the network consists of a generator and a discriminator with two branches to combine various sparse multi-scale features to obtain dense multi-scale features, so that the features of the generated image at each scale match with the ground truth.
Figure 8. Structure of dense multi-scale fusion network.
The generation network introduces a Dense Multi-scale Fusion Block (DMFB), which uses dilated convolution to expand the perceptual field without increasing the parameters. The discriminator used a global discriminator and a local discriminator design similar to GMCNN. This approach allows the information of both the complete image and the complementary part to be obtained simultaneously, avoiding misclassification caused by the model focusing only on the complementary region. The paper adds two types of losses to reflect the feature matching between the generated image and the ground truth at each scale.
3.2.4. Pyramid-context encoder network
The current stage of image inpainting methods usually lack the understanding of the high-level semantics of the image, and by searching for similar features in known regions of the image and transplanting them to the damaged regions for texture synthesis, the generated structures usually lack semantic rationality, and the recovered images do not have high resolution. To address this problem, Zeng et al. [Citation42] proposed the Pyramid-Context Encoder Network (PEN-Net) with the network structure shown in . The training is assisted by the pyramid-context encoder, multi-scale decoder, and adversarial training loss to fill the missing regions at pixel level and feature level, thus improving the image inpainting quality.
Figure 9. Structure of PEN-Net.
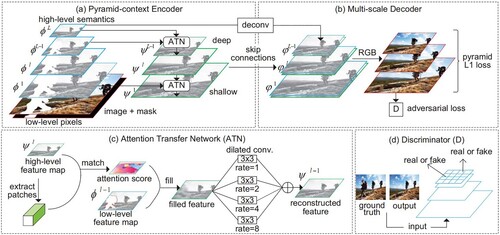
PEN-Net is built with the U-Net network as the backbone structure. The core of PEN-Net is to apply the regional similarity between the damaged and undamaged regions calculated by the attention mechanism on the high-level feature map to the feature completion on the next layer of the low-level feature map. The completed feature map continues to guide the missing regions on the next layer of the feature map regions up to the shallowest pixel layer. In this process, the network performs multiple feature completions at different levels. Finally, the decoding network combines the complemented features and features with high-level semantics to generate the final completed image, which makes the completed image not only semantically reasonable but also has clearer and richer texture details in the complemented content. The paper proposes a deeply supervised pyramidal L1 loss to refine the prediction of missing regions at each scale progressively.
3.2.5. Old photo inpainting network
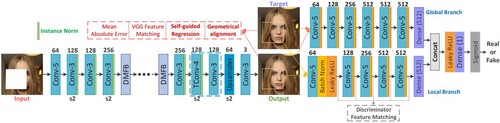
There are many image processing problems faced in old photo inpainting, such as hole filling, scratch removal, coloring, noise removal, etc., which means that multiple image degradation problems are included. While training using deep learning often requires the fabrication of sample pairs, real low-quality data contains multiple degradation problems, and it is almost impossible to simulate a low-quality image that perfectly matches the data distribution by normal images. To avoid the problem of sample fabrication, Wan et al. [Citation16] proposed to simulate the old photo inpainting as a three-domain conversion problem, and the three domains are the domain of the real old photo, the domain of the synthetic low-quality photo, and the domain of the real high-quality photo. The network model is shown in .
Figure 10. Structure of old photo inpainting network.
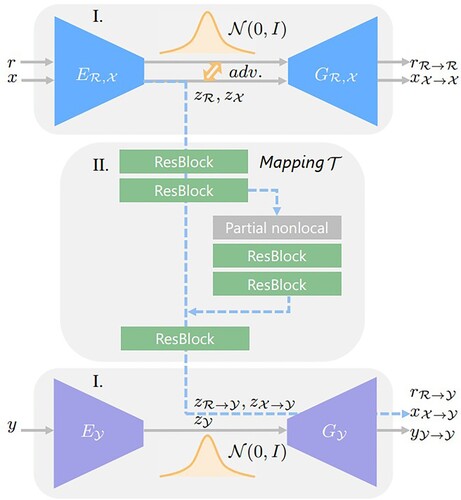
The network model consists of two VAEs and a latent space translation network, and each part can be regarded as a separate module. VAE contains the KL regular term of the latent space, which can help align the latent space of old photo and the latent space of synthetic data, thus reducing the domain interval. The network is based on weakly supervised learning, and the main problems are as follows: (1) Time-consuming, in terms of preprocessing, the paper used three networks trained separately, which can indicate that the network is more time-consuming than pix2pix. (2) The weakly supervised task is often difficult to use on high-resolution images. (3) The problem of the mask, if the model is to be applied practically, how to obtain the mask is a problem. The paper used a specially trained U-Net structure to predict the mask, which in turn additionally increases the computational effort.
3.2.6. Recurrent feature reasoning network
To address this problem of easy semantic ambiguity due to insufficient constraints and artifacts in the inpainting of images for the current inpainting of continuous masks with large areas, a new deep image inpainting structure, namely Recurrent Feature Reasoning Network (RFR-Net), was proposed in [Citation33]. The network structure is shown in . The whole network consists of three main parts: the region identification part, the feature inference part, and the adaptive feature merging part.
Figure 11. Structure of RFR-Net.
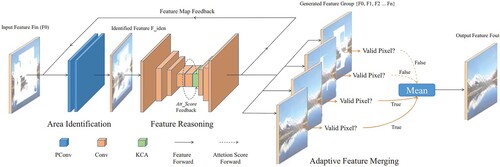
The model, when repairing large defects, can start with the boundary region of the mask, fill it with the highest quality feature values possible, and then use this part as known content to repair the next smaller mask boundary region, and so on, until the mask region is completely restored recursively. Finally, the structure of each repair is weighted and summed to generate the final feature mapping. There are two main innovations in the paper. First, a new attention, Knowledge Consistency Attention (KCA) module, is proposed, which adaptively combines the scores of different recursions to ensure the consistency of the feature exchange process between recursions, making the results more realistic and refined in detail. Then there is a new plug-and-play recurrent feature reasoning model that exploits the correlation between pixels and strengthens the constraints of deeper pixels.
3.2.7. Gated and self-attention based pyramid network
To address the problems of defective inpainting edges, mismatched inpainting contents, and slow training due to the high requirements of image inpainting edge consistency and semantic integrity, Li et al. [Citation69] proposed a gated and self-attention based Pyramid network (GAP-Net), and the network structure is shown in . The network is based on U-Net, fusing the gated convolutional method and the pyramid loss in the pyramid network to change the feature extraction strategy. In addition, the network is designed with a self-attention module and an attention transfer module. It adds content loss and perceptual loss to add a new data distribution between the generated and ground truth.
Figure 12. Structure of GAP-Net.
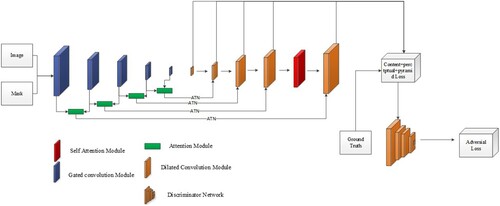
The GAP-Net structure consists of two parts, discriminator and generator. The generator is a modified encoding-decoding network that encodes the input broken image into a latent feature space and then decodes the reconstructed image features to get the output image. The encoding network of the model used gated convolution to reduce the computation of useless information in the convolution process of the broken image, thus reducing the negative impact of useless information in the network for image inpainting, and adding a self-attention to the previous layer of the decoding network output to guide the feature transformation process of the feature map from the potential feature space to the image information, and reconstructs the image more realistically. The decoding network part of the framework of the whole network is a pyramid structure, and the multilayer feature maps, which are stitched together by collecting the output of each layer of the pyramid network and fed directly into the loss calculation module, are used to correct the output of each layer of the image generation network to improve the final inpainting results.
3.3. Multi-stage image inpainting methods
3.3.1. Contextual attention
To address the problem that restored images have visually reasonable structure and texture. Still, the structure and texture are usually distorted or blurred, a method based on a deep generative model is proposed in [Citation41] that can explicitly use the surrounding image features as a reference for image inpainting during network training, which in turn generates better predictions. The network is a feed-forward fully convolutional neural network that can repair missing images at arbitrary locations and of arbitrary shapes. The network is a two-stage network architecture from coarse to fine. The first stage is a null convolutional network trained using reconstruction loss to obtain a rough restored image. The second stage used the proposed contextual attention layer to accomplish fine inpainting, and the network structure is shown in .
Figure 13. Two-stage image inpainting network.
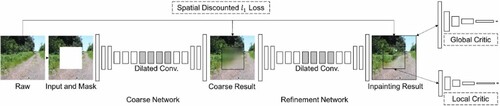
In the first coarse stage, the approximate outline of the missing region is repaired using the reconstruction loss, and the second stage performs two branches of convolution based on the repair map of the first stage, with Contextual Attention (CA) added to the convolution path of one of the branches, and finally, the convolution results of the two branches are combined for repair. The contextual attention layer works by refining this fuzzy inpainting result by using the features of known feature blocks as convolution kernels to process the generated feature blocks. Spatially decaying reconstruction loss is proposed in the paper, with smaller and smaller weights as the pixel points get closer to the center, as a way to reduce the weight of the central region so that the loss value is calculated without misleading the training process because the gap between the central result and the original image is too large.
3.3.2. Gated convolution
In previous inpainting methods, traditional convolution treats both valid and invalid regions in the same way and computes them, leading to many artificial and unnatural effects. To solve this problem, Liu et al. [Citation14] proposed a partial convolution-based method that gives the valid and invalid regions for all layers in a convolutional neural network. For partial convolution, the invalid pixels gradually disappear layer by layer, while the rule-based mask disappears all at the deeper layers. However, in order to synthesize the pixels within the mask, these deep layers may also need to know the information whether the current position is in the masked or known region. Partial convolution of masks with all 1's cannot provide such information. To address this problem, Yu et al. [Citation40] proposed a method based on Gated Convolution (GConv), which is easy to implement, the input mask can be of arbitrary shape and embedded in many intermediate layers. The network structure is shown in .
Figure 14. Image inpainting network based on gated convolution.
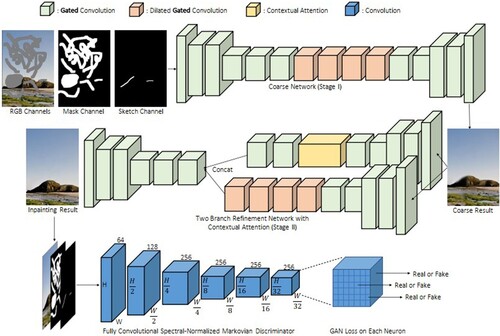
The network proposes an end-to-end generative network based on gated convolution and a new GAN loss freeform image inpainting system. There are three main innovations: (1) Gated convolution is introduced to learn a dynamic selection mechanism that spans every channel at every spatial location in all layers, significantly improving the color consistency and picture quality of free-form masks and inputs. (2) A more practical PatchGAN-based discriminator, SN-PatchGAN, is proposed for free-form image inpainting. The method is simple, fast, and produces high-quality inpainting results. (3) Extending the inpainting model to an interactive inpainting model to obtain more user-desired inpainting effects with user hand-painting as the guide. However, over-smoothing or blurring may occur when the inpainting mask area is large; and there is no color in the sketch, and the final restored image color can only depend on the training set assignment.
3.3.3. Parallel decoding network
The GAN-based method using a coarse-to-fine network with Contextual Attention Module (CAM) has shown outstanding performance in image inpainting. However, the method requires a large number of computational resources due to the feature encoding in two stages. To solve this problem, a new network structure PEPSI was proposed in [Citation38]: fast image inpainting with parallel decoding structure, and the network structure is shown in . PEPSI used a structure consisting of a shared encoding network and a parallel decoding network with coarse and inpainting paths, which can reduce the number of convolutional operations.
Figure 15. Structure of PEPSI.
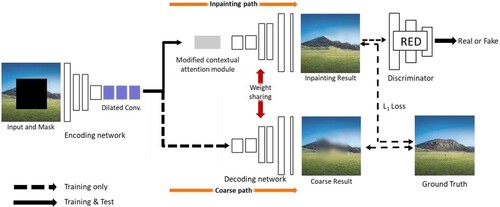
PEPSI extracts features through a single encoding network and generates high-quality inpainting results through a single decoding network. To enable a single shared encoding network to handle two different tasks simultaneously, the authors propose a joint learning approach using a parallel decoding network with a rough path and a repair path. The rough path generates an initial repair result, which trains the encoding network to predict contextually focused features. At the same time, the repair path utilizes fine features from CAM reconstruction to create higher-quality repair results. Compared to traditional coarse-to-fine networks, PEPSI not only reduces convolutional operations by nearly half, but also outperforms other models in terms of test time and quality scores.
3.3.4. Contextual residual aggregation
Data-driven image inpainting-based methods have made great progress, and such methods have more potential than traditional methods in the field of image editing. However, due to memory limitations, they can only handle low-resolution images, and the image size is usually smaller than 1K, which is difficult to meet the demand for high-definition image editing. Based on this, Yi et al. [Citation17] proposed the Contextual Residual Aggregation (CRA), which can generate high-frequency residuals of lost content by weighted aggregation of residuals in the context, and thus can obtain various high-definition details in images, The network structure is shown in .
Figure 16. Structure of CRA.
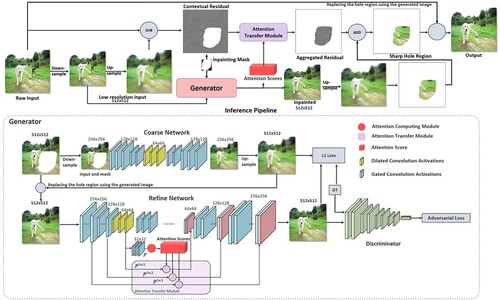
The CRA mechanism can generate high-frequency residuals of lost content by weighted aggregation of residuals in contextual patches, so the network only needs low resolution for training. Since the convolutional layers of the neural network only need to operate on low-resolution inputs and outputs, the cost of memory and computational power is reduced. The model achieves the high-resolution image inpainting in 3 stages. First, the low-resolution repair result is obtained by the generator, then the high-resolution residuals are obtained by the residual aggregation module, and finally, the high-resolution repair image is obtained by merging the high-resolution residuals and the low-resolution repair result. This method achieves for the first time the use of a neural network for 8K image inpainting, which not only obtains high-quality results, but also has less storage space and time consumption. High-resolution images are processed with this method, and the obtained images still have very realistic and perfect details in them.
3.3.5. Contextual coherent attention
In response to the problems of traditional inpainting algorithm models that cannot automatically identify the specific location of the area to be restored, the cost of inpainting and the difficulty of inpainting, and the problems of structural and texture discontinuity and poor model stability in deep learning-based image inpainting, Li et al. [Citation70] proposed an image inpainting method based on the Contextual Coherent Attention (CCA). The method designed a network model based on generative adversarial networks, and in order to improve the global semantic continuity and local semantic continuity of images in image inpainting, a contextually coherent attention layer is added to the network, and a cross-entropy loss function is used to solve the problems of slow convergence of the model and insufficient training stability, and the network structure is shown in .
Figure 17. Structure of contextual coherent attention.
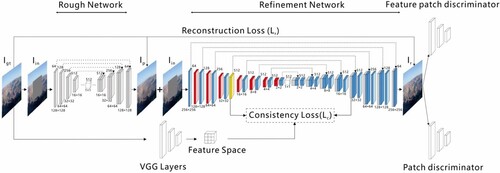
The network model of this method is divided into two steps, coarse repair network and fine repair network, such that the structure can be trained stably. The generator is designed based on the U-Net network, and unlike the traditional U-Net network, the convolutional kernel of this network is expanded from 3×3 to 4×4, and the expanded convolutional kernel makes the overall feeling field of the model expand consequently. The inclusion of contextual coherent attention in the network not only maintains the contextual structure, but also allows more effective prediction of the missing part by modeling the semantic correlation between the features of the missing regions.
3.3.6. Multi-stage progressive inpainting
Image inpainting tasks require a complex balance between spatial detail and contextual information when restoring images. Encoding and decoding networks can efficiently acquire multi-scale information at the expense of spatial detail, and images obtained from single-scale feature channels have good spatial detail but poor semantic robustness due to small perceptual fields. To address the shortcomings of the traditional framework, Zamir et al. [Citation71] proposed a multi-stage network architecture that gradually learns the inpainting function of degraded inputs, thus decomposing the whole inpainting process into more manageable steps, and the network structure is shown in . The network is designed by combining the features of codec networks and single-scale networks, and attention is introduced in each module of the network. And the information exchange between stages is proposed.
Figure 18. Structure of multi-stage progressive inpainting network.
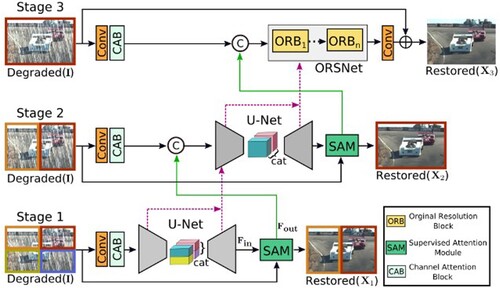
The network model consists of three stages to restore the image progressively; the first two stages are encoder-decoder-based subnetworks used to learn contextual information about the larger sensory fields. Since image inpainting is a position-sensitive task, the subnetwork used in the last stage operates on the original input image resolution without subsampling, thus preserving the desired texture in the final output image. Between every two stages, a supervised attention module is added. The feature maps from the previous stage are rescaled before being passed to the next stage under the supervision of the ground truth. A cross-stage feature fusion mechanism is also introduced, where the multi-scale contextual features in the middle of the previous sub-network help to consolidate the intermediate features in the latter sub-network.
3.4. A priori condition-guided image inpainting methods
3.4.1. Foreground-aware image inpainting
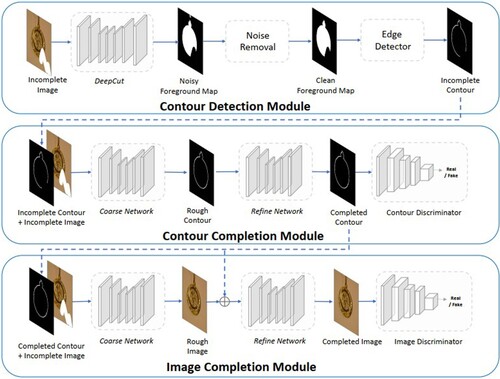
To address the existing image inpainting methods usually fill holes by borrowing information from the surrounding image area. When the hole overlaps or touches the foreground object, it produces poor results due to the lack of information about the actual extent of the foreground and background regions within the hole. Xiong et al. [Citation72] proposed a foreground-aware image inpainting system in which the model first predicts the foreground contour and then uses the predicted obtained contour as a guide to repairing the missing region.
The general framework of the foreground-aware inpainting system proposed by this method is shown in . It consists of three modules, contour detection module, contour inpainting module, and image inpainting module. First, the foreground contour of the damaged image is detected. Then the contour inpainting module comes on the scene to predict what the foreground contour of the complete image should look like. Finally, the completed contour is fed into the image inpainting module together with the damaged image as a guide to repair the damaged part of the image to generate the final image. The innovation of this method is to decouple the image structure inference and content-completion process to obtain the natural contour of the target object, and then use the complemented contour as an a priori guide for the incomplete image. The use of structural before explicitly guide the image inpainting task is proposed and verified as a very meaningful research direction.
Figure 19. Network model based on foreground-aware image inpainting.
3.4.2. EdgeConnect
To address the problem that existing image inpainting methods fail to reconstruct reasonable structures due to excessive smoothing and blurring, a two-stage adversarial model EdgeConnect was proposed in [Citation73], which consists of an edge generator and an image complementation network. The edge generator generates an edge hypothesis map for the edges of the missing regions of the image, and the image complementation network uses the edge hypothesis map as a prior to filling the missing regions. The network structure is shown in .
Figure 20. Structure of EdgeConnect.
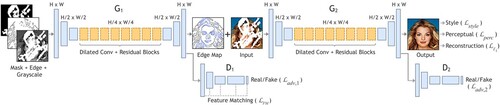
EdgeConnect uses an edge generator to generate rough contours in the missing regions and provides a priori information about the image structure for the second stage of the image complementation network. The image complementation network only needs to combine a priori fuzzy structure for filling and repairing details to obtain complementary images with good structure and texture. Compared with the approach in [Citation72] that combines several different network models to obtain a complete image finally, the network model structure of EdgeConnect is more concise and reasonable in design, and easier to train.
4. Discussion and analysis
4.1. Datasets
Datasets are essential for deep learning-based image inpainting algorithms during training and testing. Some of the more common datasets are the CelebA face dataset [Citation74], which contains more than 200,000 images of celebrities representing 10,000 identities with large pose variations. The Places2 dataset [Citation75], has more than 10 million images, which contains more than 400 unique scene categories. The Paris Street View dataset [Citation76], contains 15,000 high-quality street view images focusing on buildings in cities. The CMP Facade dataset [Citation77], with 606 highly structured elevation images from buildings in multiple cities worldwide. The ImageNet dataset [Citation78], with each subnet, has thousands of images. Each subnet is represented by 1000 images, and the current version of this dataset contains more than 14,197,122 images, of which 1,034,908 human images are annotated with borders. Since real damaged images are difficult to collect, researchers add masks to real samples to form mask datasets, and the most widely used mask dataset is the NVIDIA Irregular Mask Dataset test dataset [Citation14], which contains 12,000 masks and a total of six different hole-to-image area ratios, with each category containing 1,000 masks with boundary constraints and 1000 masks without boundary constraints. shows some example data from the commonly used datasets, and describes the various datasets used for the image inpainting method.
Figure 21. Example of common datasets.

Table 1. Image inpainting datasets.
4.2. Image quality evaluation
Image quality evaluation is divided into subjective and objective evaluations. Subjective evaluation relies entirely on the qualitative assessment of human observers, who give subjective, qualitative judgments about graph image characteristics. Observers are usually selected from untrained amateurs or trained insiders. The method is based on statistical significance, and a sufficient number of observers must be involved in the evaluation to ensure that the subjective evaluation of the images is statistically significant.
The main goal of objective image quality assessment is to develop computational models that can accurately and automatically determine image quality. The ultimate goal is to replace the human visual system for viewing and perceiving images with a computer. Internationally, objective assessment of image quality is usually performed by testing several factors that affect image quality and by checking how well the quantitative values of image quality from computer models correspond to subjective human observations, and several common measures of image quality assessment are described below.
(1) PSNR
Peak-Signal to Noise Ratio (PSNR) [Citation79] is used to calculate the ratio between the peak signal power and the background noise that affects the signal quality. The ratio between the two images is usually calculated from decibels. The signal generally has a wide dynamic range, so PSNR is usually calculated as a logarithmic expression on a decibel scale, with the maximum and minimum values depending on the signal quality. PSNR is often used to measure the reproduction quality of a noisy image compression code, where the signal is the original data, and the noise is the error due to compression or distortion. PSNR is an estimate of the human-perceived reproduction quality of the compression code. PSNR is measured in dB. The PSNR is calculated as shown in Equation (Equation2(2) (2)
(2) (2) ).
(1)
(1)
(2) (2)
(2) (2) Where, H and W are the width and height of the image respectively,
is each pixel point of the image,
is used to denote the pixel information value after the missing region is generated, for the missing region itself the pixel information value is denoted by
, MSE is the mean squared error obtained,
is the maximum pixel point color value. The smaller the MSE, the larger the PSNR, the larger the PSNR value. A larger value means less distortion.
(2) SSIM
Structural Similarity Index Measurement (SSIM) [Citation80] is a new method to measure the structural similarity between two images, with higher values up to 1. The SSIM is a perception-based model that treats image degradation as a change in the perception of structural information, emphasizing the importance of image perceptual quality. SSIM estimates the perceptual quality of an image by calculating the similarity between the original image and the reconstructed image in three dimensions: brightness, contrast, and structure. The SSIM is calculated as shown in Equation (Equation3(3)
(3) ).
(3)
(3) Where,
is the mean of the X image,
is the mean of the Y image,
is the variance of the X image,
is the variance of the Y image,
is the covariance of X and Y, and
,
and
are constants. SSIM has a value in the range [0,1], and a larger value means that the difference between the output image and the real image is smaller, the image quality is better. When the two images are identical, SSIM = 1.
(3) LPIPS
Learned Perceptual Image Patch Similarity (LPIPS) [Citation81], also known as loss of perception, is used to measure the difference between two images. The metric learns the reverse mapping of the generated image to the ground truth, forcing the generator to learn the reverse mapping of reconstructing the ground truth from the fake image and prioritizing the perceptual similarity between them. LPIPS is more consistent with human perception than traditional methods. The LPIPS is calculated as shown in Equation (Equation4(4) (4)
(4) (4) ).
(4) (4)
(4) (4) Where, d is the distance between
and x. H and W are the channel height and width respectively. l is the number of layers, from which the feature stack is extracted and unit-normalized in the channel dimension.
is the vector, which is used to deflate the number of activated channels and finally calculate the
distance. The lower the value of LPIPS, the more similar the two images are, and vice versa, the greater the difference.
4.3. Typical algorithm results analysis
With the help of deep learning techniques, any task in computer vision can be performed by automatic learning using different unsupervised functions. Learning using CNN can lead to further improvements in robustness and simplicity in the functionality of each computer vision task. Since the birth of the two major generative models, VAE and GAN, various deep learning network models based on generative models have emerged, further leading to the booming development of computer vision as a whole. shows the results of some representative image inpainting methods.
Figure 22. Inpainting effect of different methods.

Current research on image inpainting has focused on rectangular and irregular mask images. shows the quantitative comparison of the latest research methods based on rectangular masks on the CelebA-HQ face dataset [Citation74], Places2 dataset [Citation75], and Paris Street View dataset [Citation76], which are trained on images with a central rectangular mask of 128×128 to compare their PSNR and SSIM quantitatively. experimental results are taken from the relevant paper.
Table 2. PSNR (dB) and SSIM for different methods of rectangular mask inpainting on the three datasets.
The comparison results in show that the current rectangular mask-based image inpainting can achieve good results, and [Citation15] for the first time applied unsupervised visual feature learning algorithms based on contextual pixel prediction-driven image inpainting tasks, which can successfully restore high-quality images. Wang et al. [Citation67] used convolutional neural networks that generate multiple columns to extract more features, resulting in better semantic consistency. Yu et al. [Citation41] proposed a coarse-to-fine network architecture to restore missing image regions incrementally and proposes a contextual attention layer to accomplish fine inpainting, generating more visually realistic results. Li et al. [Citation69] proposed a gated convolution-based pyramidal coding and decoding network with better edge consistency and semantic integrity in the inpainting results. These methods perform well on both PSNR and SSIM metrics.
shows the quantitative comparison of the latest research methods based on irregular masks on the CelebA-HQ face dataset, Places2 dataset, and Paris Street View dataset, which are trained on irregularly masked images to compare their PSNR and SSIM quantitatively. The experimental results in are taken from the related paper.
Table 3. PSNR (dB) and SSIM for different methods of irregular mask inpainting on the three datasets.
The results in show that the PSNR and SSIM quantifiers of image inpainting results also vary significantly when the mask rate of irregular image inpainting varies. Taken together, the current methods can basically achieve good inpainting results when the mask rate is low. When the mask rate is above 50%, most of the models can hardly achieve good inpainting results. Relatively speaking, face-based image inpainting is easier to obtain satisfactory results, while image inpainting in natural scenes with complex textures still has more room for improvement.
5. Conclusion and outlook
5.1. Conclusion
This paper firstly briefly describes the background significance and current research status of image inpainting. Then summarizes two traditional image inpainting methods based on structure and texture, and summarizes their advantages and disadvantages. Then introduces three mainstream network models, categorizes deep learning-based image inpainting methods into single-stage image inpainting methods, multi-stage image inpainting methods, and a priori condition-guided image inpainting methods, and presents a review of the representative algorithms. Finally, we compare and analyze the experimental results of common datasets and related algorithms on mainstream datasets, and analyze and outlook at five hot research methods in this field. It is hoped that the research and summary in this paper can better help researchers understand image inpainting methods and thus promote the development of the field.
5.2. Future research directions
With the growing trend of digitization in society and the dramatic increase in the number of images, image inpainting techniques have become an important branch in the field of vision research. Deep learning is gaining more and more attention in image inpainting, and deep learning image inpainting based on generative networks and convolutional neural networks has gradually developed into a mainstream approach. Researchers continue to innovate and make significant progress in network structure design, model selection, loss function optimization, discriminator design, and optimizer selection. However, deep learning in image inpainting can still have broader and deeper attempts, and the following describes the research value and prospects of image inpainting.
| (1) | High-quality inpainting. Current image inpainting methods have achieved good results for simple structures, regular mask inpainting, small region missing inpainting, and low-resolution image inpainting. However, further research is still needed on improving the inpainting of complex textures, large region missing, and high-resolution images. | ||||
| (2) | Network selection and design. CNN, GAN, and VAE based image inpainting and the combination of these three networks are the main frameworks for image inpainting. Therefore, it is necessary to investigate how other deep learning models can be used for image inpainting. In addition, in general, the deeper the network structure, the better the inpainting effect, but with a deeper network structure also comes problems such as training and convergence difficulties. How to balance the conflict between network complexity and inpainting image quality is an exciting research direction. | ||||
| (3) | Loss function optimization. The loss function of the image inpainting network is directly related to the evaluation criteria of inpainting results. Currently, the commonly used loss functions include reconstruction loss, adversarial loss, etc. The change of these loss function representations can affect the semantic information and boundary structure of image inpainting. Therefore, the study of loss functions of image inpainting networks can not only improve the convergence speed of network training, but also improve the quality of image inpainting. | ||||
| (4) | Combining a priori conditions. A priori knowledge is the experience and guidelines obtained from long-term human research in related fields. Deep learning can use big data to train models and automatically select and learn effective features, and if a priori knowledge can be used to guide deep learning models, not only can high-level semantic features containing contextual information be acquired, but it also can further improve deep learning-based inpainting capabilities. Therefore, it is a worthwhile direction to explore how to use prior knowledge and deep learning framework to improve the performance of existing image inpainting. | ||||
| (5) | Designing training samples. For specific application areas of image inpainting, such as the inpainting of cultural relics and frescoes, there are few common datasets for such problems because such tasks are very different in terms of their own characteristics, texture details, content structure, and color features, etc. In order to accomplish different inpainting tasks, it is necessary to design training samples in a targeted manner. | ||||
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Hong-an Li
Hong-an Li received the M.S. degree in 2009 and the Ph.D. degree in 2014 in computer science and technology from Northwest University, Shaanxi, China. From 2014 to 2023, he was an associate professor of the College of Computer Science and Technology, Xi'an University of Science and Technology. His research interests include computer graphics and computer-aided geometric design, virtual reality and image processing.
Liuqing Hu
Liuqing Hu received the bachelor's degree in software engineering in 2021 from the College of Computer Science and Technology, Xi'an University of Science and Technology. She is currently studying for a master's degree in the College of Computer Science and Technology, Xi'an University of Science and Technology. Her research interests include artificial intelligence, image processing and computer vision applications.
Jun Liu
Jun Liu graduated from the School of Computer Science and Technology, Chengdu University of Technology, for the degree of Bachelor in 1995. He received his M.S. degree in the School of Computer Science and Technology, Northwest University in 2009. Since 2011 he worked toward his Ph.D. degree at Northwest University and received his Ph. D. degree in computer science from Northwest University in 2018. He entered the National-Local Joint Engineering Research Center of Cultural Heritage Digitization in Northwest University, as a researcher from 2016 to 2019. He is a member of China Computer Federation. His current research interests include cultural heritage digitization, pattern recognition and machine learning.
Jing Zhang
Jing Zhang received the M.S. degree in computer application technology from Northwest University of Shaanxi Province, China in 2013 and the Ph.D. degree in 2018. From 2018 to 2023, she served as a lecturer in the School of Computer Science and Technology of Xi'an University of Science and Technology. Her research interests include graphics and image processing, intelligent information processing and signal processing and perception.
Tian Ma
Tian Ma (Member, IEEE) was born in Henan, China, in 1982. He received the B.S. degree in measurement and control technology and instrument, the M.S. degree in software engineering, and the Ph.D. degree in information and communication engineering from Northwestern Polytechnical University, Xi'an, China, in 2003, 2006, and 2011, respectively. Since 2014, he has been an Associated Professor with the College of Computer Science and Technology, Xi'an University of Science and Technology, China. He is currently the author of more than 20 articles and more than ten software copyrights. His research interests include image processing, computer graphics, and 3D simulation and visualization. He has served as the Organizing Committee Co-Chair for the 14th International Conference on Verification and Evaluation of Computer and Communication Systems (VECoS 2020) and a common Reviewer for the IEEE International Conference on Signal Processing, Communication and Computing (ICSPCC).
References
- Li HA, Wang D, Zhang J, et al. Image super-resolution reconstruction based on multi-scale dual-attention. Conn Sci. 2023:1–19.
- Ma T, An J, Xi R, et al. Tpe: lightweight transformer photo enhancement based on curve adjustment. IEEE Access. 2022;10:74425–74435.
- Yu J, Tao D, Wang M, et al. Learning to rank using user clicks and visual features for image retrieval. IEEE Trans Cybern. 2015;45(4):767–779.
- Zhang J, Yu J, Tao D. Local deep-feature alignment for unsupervised dimension reduction. IEEE Trans Image Process. 2018;27(5):2420–2432.
- Abbad A, Elharrouss O, Abbad K, et al. Application of meemd in post-processing of dimensionality reduction methods for face recognition. IET Biometrics. 2019;8(1):59–68.
- Elharrouss O, Abbad A, Moujahid D, et al. A block-based background model for moving object detection. ELCVIA: Electronic Letters on Computer Vision and Image Analysis. 2016;15(3):17.
- Hong C, Yu J, Tao D, et al. Image-based three-dimensional human pose recovery by multiview locality-sensitive sparse retrieval. IEEE Trans Industrial Electron. 2015;62(6):3742–3751.
- Hong C, Yu J, Zhang J, et al. Multimodal face-pose estimation with multitask manifold deep learning. IEEE Trans Industrial Inform. 2018;15(7):3952–3961.
- Moujahid D, Elharrouss O, Tairi H. Visual object tracking via the local soft cosine similarity. Pattern Recognit Lett. 2018;110:79–85.
- Yu J, Zhang B, Kuang Z, et al. Iprivacy: image privacy protection by identifying sensitive objects via deep multi-task learning. IEEE Trans Inform Forensics Security. 2017;12(5):1005–1016.
- Isogawa M, Mikami D, Iwai D, et al. Mask optimization for image inpainting. IEEE Access. 2018;6:69728–69741.
- Muddala SM, Olsson R, Sjöström M. Spatio-temporal consistent depth-image-based rendering using layered depth image and inpainting. EURASIP J Image Video Process. 2016;2016(1):1–19.
- Du W, Chen H, Yang H. Learning invariant representation for unsupervised image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2020. p. 14483–14492.
- Liu G, Reda FA, Shih KJ, et al. Image inpainting for irregular holes using partial convolutions. In: Proceedings of the European Conference on Computer Vision (ECCV). ECCV; 2018. p. 85–100.
- Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders: feature learning by inpainting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2016. p. 2536–2544.
- Wan Z, Zhang B, Chen D, et al. Bringing old photos back to life. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2020. p. 2747–2757.
- Yi Z, Tang Q, Azizi S, et al. Contextual residual aggregation for ultra high-resolution image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2020. p. 7508–7517.
- Bertalmio M, Sapiro G, Caselles V, et al. Image inpainting. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques. ACM; 2000. p. 417–424.
- Sharma N, Mehta N. Region filling and object removal by exempeler based image inpainting. IEEE Trans Image Process. 2004;13(9):1200–1212.
- Abdulla AA, Ahmed MW. An improved image quality algorithm for exemplar-based image inpainting. Multimed Tools Appl. 2021;80(9):13143–13156.
- Ahmed MW, Abdulla AA. Quality improvement for exemplar-based image inpainting using a modified searching mechanism. UHD J Sci Technol. 2020;4(1):1–8.
- Shih ML, Su SY, Kopf J, et al. 3D photography using context-aware layered depth inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2020. p. 8028–8038.
- Wang N, Li J, Zhang L, et al. Musical: multi-scale image contextual attention learning for inpainting. In: Twenty-Eighth International Joint Conference on Artificial Intelligence IJCAI-19. IJCAI; 2019. p. 3748–3754.
- Zhao L, Mo Q, Lin S, et al. Uctgan: diverse image inpainting based on unsupervised cross-space translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2020. p. 5741–5750.
- Zheng C, Cham TJ, Cai J. Pluralistic image completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2019. p. 1438–1447.
- Rumelhart DE, Hinton GE, Williams RJ. Learning representations by back propagating errors. Nature. 1986;323(6088):533–536.
- Lecun Y, Bottou L. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–2324.
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2016. p. 770–778.
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. Computer Sci. 2014;1556:1–14.
- Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. In: Neural Information Processing Systems. arXiv; 2014. p. 1–9.
- Iizuka S, Simo-Serra E, Ishikawa H. Globally and locally consistent image completion. ACM Trans Graphics (TOG). 2017;36(4CD):1–14.
- Li HA, Hu L, Zhang J. Irregular mask image inpainting based on progressive generative adversarial networks. Imaging Sci J. 2023:1–14.
- Li J, Wang N, Zhang L, et al. Recurrent feature reasoning for image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2020. p. 7760–7768.
- Liu H, Jiang B, Song Y, et al. Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. In: European Conference on Computer Vision. Cham: Springer; 2020. p. 725–741.
- Liu H, Jiang B, Xiao Y, et al. Coherent semantic attention for image inpainting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. IEEE; 2019. p. 4170–4179.
- Ning X, Duan P, Zhang S. Real-time 3d face alignment using an encoder-decoder network with an efficient deconvolution layer. IEEE Signal Process Lett. 2020;27:1944–1948.
- Ning X, Gong K, Li W, et al. JWSAA: joint weak saliency and attention aware for person re-identification. Neurocomputing. 2021;453:801–811.
- Sagong MC, Shin YG, Kim SW, et al. Pepsi: fast image inpainting with parallel decoding network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2020. p. 11360–11368.
- Xie C, Liu S, Li C, et al. Image inpainting with learnable bidirectional attention maps, 2019.
- Yu J, Lin Z, Yang J, et al. Free-form image inpainting with gated convolution. In: Proceedings of the ICCV. ICCV; 2018. p. 4471–4480.
- Yu J, Lin Z, Yang J, et al. Generative image inpainting with contextual attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2018. p. 5505–5514.
- Zeng Y, Fu J, Chao H, et al. Learning pyramid-context encoder network for high-quality image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2019. p. 1486–1494.
- Zeng Y, Lin Z, Yang J, et al. High-resolution image inpainting with iterative confidence feedback and guided upsampling. In: European Conference on Computer Vision. Springer; 2020. p. 1–17.
- Shen J, Chan TF. Mathematical models for local nontexture inpaintings. SIAM J Appl Math. 2002;62(3):1019–1043.
- Chan TF, Shen J. Nontexture inpainting by curvature-driven diffusions. J Vis Commun Image Represent. 2001;12(4):436–449.
- Ruzic T, Pizurica A. Context-aware patch-based image inpainting using markov random field modeling. IEEE Trans Image Process. 2015;24(1):444–456.
- Liu H, Xiong R, Zhang X, et al. Nonlocal gradient sparsity regularization for image restoration. IEEE Trans Circuits Syst Video Technol. 2016;27(9):1909–1921.
- Kawai N, Sato T, Yokoya N. Diminished reality based on image inpainting considering background geometry. IEEE Trans Vis Comput Graph. 2015;22(3):1236–1247.
- Liu J, Shuai Y, Fang Y, et al. Structure-guided image inpainting using homography transformation. IEEE Trans Multimedia. 2018;20(12):3252–3265.
- Ding D, Ram S, Rodriguez JJ. Image inpainting using nonlocal texture matching and nonlinear filtering. IEEE Trans Image Processing. 2018;28(4):1705–1719.
- Barnes C, Shechtman E, Finkelstein A, et al. Patchmatch: a randomized correspondence algorithm for structural image editing. ACM Trans Graph. 2009;28(3):1–24.
- Hays J, Efros AA. Scene completion using millions of photographs. Acm Trans Graph. 2008;51(10):87–94.
- Xiao B, Hancock ER, Wilson RC. Graph characteristics from the heat kernel trace. Pattern Recognit. 2009;42(11):2589–2606.
- Bai X, Yan C, Yang H, et al. Adaptive hash retrieval with kernel based similarity. Pattern Recognition: The J Pattern Recognition Soc. 2018;75:136–148.
- Bertalmio M, Vese L, Guillermo ST, et al. Simultaneous structure and texture image inpainting. In: IEEE Computer Society Conference on Computer Vision & Pattern Recognition, Vol. 12. IEEE; 2003. p. 882–889.
- Starck JL, Elad M, Donoho DL. Image decomposition via the combination of sparse representations and a variational approach. IEEE Trans Image Process. 2005;14(10):1570–1582.
- Li H, Luo W, Huang J. Localization of diffusion-based inpainting in digital images. IEEE Trans Inform Forensics Security. 2017;12(12):3050–3064.
- Li K, Wei Y, Yang Z, et al. Image inpainting algorithm based on tv model and evolutionary algorithm. Soft Comput – A Fusion Foundations, Methodol Appl. 2016;20(3):885–893.
- Sridevi G, Kumar SS. Image inpainting based on fractional-order nonlinear diffusion for image reconstruction. Circuits Syst Signal Process. 2019;38(8):3802–3817.
- Jin X, Su Y, Zou L, et al. Sparsity-based image inpainting detection via canonical correlation analysis with low-rank constraints. IEEE Access. 2018;6:49967–49978.
- Mo J, Zhou Y. The research of image inpainting algorithm using self-adaptive group structure and sparse representation. Cluster Comput. 2018;22(3):1–9.
- Zhang J, Yan Q, Zhu X, et al. Smart industrial iot empowered crowd sensing for safety monitoring in coal mine. Digital Commun Netw. 2022:1–10.
- Ma T, Zhou X, Yang J, et al. Dental lesion segmentation using an improved icnet network with attention. Micromachines. 2022;13(11):1–15.
- Ma Y, Liu X, Bai S, et al. Coarse-to-fine image inpainting via region-wise convolutions and non-local correlation. In: Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19). IJCAI; 2019. p. 3123–3129.
- Su YZ, Liu TJ, Liu KH, et al. Image inpainting for random areas using dense context features. In: IEEE International Conference on Image Processing (ICIP). IEEE; 2019. p. 4679–4683.
- Kingma DP, Welling M. Auto-encoding variational bayes. arXiv.org. 2014. p. 1–14.
- Wang Y, Tao X, Qi X, et al. Image inpainting via generative multi-column convolutional neural networks. In: Advances in neural information processing systems. Advances in Neural Information Processing Systems; 2018. p. 331–340.
- Hui Z, Li J, Wang X, et al. Image fine-grained inpainting, 2020.
- Li HA, Wang G, Gao K, et al. A gated convolution and self-attention-based pyramid image inpainting network. J Circuits Syst Computers. 2022;31(12):2250208.
- Li HA, Hu L, Hua Q, et al. Image inpainting based on contextual coherent attention gan. J Circuits, Syst Computers. 2022;31(12):2250209.
- Zamir SW, Arora A, Khan S, et al. Multi-stage progressive image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE; 2021. p. 14821–14831.
- Xiong W, Yu J, Lin Z, et al. Foreground-aware image inpainting, 2019.
- Nazeri K, Ng E, Joseph T, et al. Edgeconnect: generative image inpainting with adversarial edge learning. preprint arXiv:1901.00212, 2019. p. 1–17.
- Liu Z, Luo P, Wang X, et al. Large-scale celebfaces attributes (celeba) dataset. Retrieved August. 2018;15(2018):11.
- Zhou B, Lapedriza A, Khosla A, et al. Places: a 10 million image database for scene recognition. IEEE Trans Pattern Anal Machine Intell. 2018;40(6):1452–1464.
- Doersch C, Singh S, Gupta A, et al. What makes paris look like paris? ACM Trans Graph. 2012;31(4):1–9.
- Tyleček R, Šára R. Spatial pattern templates for recognition of objects with regular structure. In: German Conference on Pattern Recognition. Springer; 2013. p. 364–374.
- Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge. Int J Comput Vis. 2015;115(3):211–252.
- Wang X, Yu K, Dong C, et al. Recovering realistic texture in image super-resolution by deep spatial feature transform. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2018. p. 606–615.
- Liu Q, Jia R, Liu Y, et al. Infrared image super-resolution reconstruction by using generative adversarial network with an attention mechanism. Appl Intell: The International Journal of Artificial Intelligence, Neural Networks, and Complex Problem-Solving Technologies. 2021;51(4):2018–2030.
- Zhang R, Isola P, Efros AA, et al. The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2018. p. 586–595.
- Yang C, Lu X, Lin Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2017. p. 6721–6729.
- Ren Y, Yu X, Zhang R, Structureflow: image inpainting via structure-aware appearance flow. In: Proceedings of the IEEE International Conference on Computer Vision. IEEE; 2019. p. 181–190.
- Yan Z, Li X, Li M, et al. Shift-net: image inpainting via deep feature rearrangement. In: Proceedings of the European Conference on Computer Vision (ECCV). ECCV; 2018. p. 1–17.
- Li J, He F, Zhang L, et al. Progressive reconstruction of visual structure for image inpainting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. IEEE; 2019. p. 5962–5971.