
ABSTRACT
Creative AI (notably GANs and VAEs) can generate convincing fakes of video footage, pictures, graphics, etc. In order to conceptualize the societal role of creative AI a new conceptual toolbox is needed. The paper provides metaphors and concepts for understanding the functioning of creative AI. It shows how the role of creative AI in relation to FAT ideals can be enriched by a dynamic and constructivist understanding of creative AI. The paper proposes to use Greimas’ actantial model as a heuristic in the operationalization of this type of understanding of creative AI.
1. Introduction. The era of deepfakes and creative AI.
In the second half of the 2010s technological advances gave Artificial Intelligence (AI) a new capacity: to create. The website www.thispersondoesnotexist.com, created in February 2019 to raise public awareness about creative AI (Paez, Citation2019), is a good point of departure to reflect on its potential societal implications. Every time the site is refreshed, it creates pictures of people that do not exist: fake, yet plausible, faces. ()
Figure 1. Faces of people that do not exist. Generated on 30 January 2020 at https://www.thispersondoesnotexist.com/ Underlying model: StyleGAN, NVIDIA, public release December 2019 (Karras et al., Citation2019).

The endless flow of these synthetic faces, or so-called deepfakes, is both eerie and mesmerizing (Chen, Citation2019; Craig & Kerr, Citation2019; Mizrahi, Citation2019). In this paper I will focus on the civic concern (Chesney & Citron, Citation2018) that creative AI might undermine the distinction between fact and fiction. Will democratic societies be able to handle an infinite source of deepfakes that can be used for political deception (fake news), identity scams (Ghahramani, Citation2019; Harwell, Citation2019) and cyberbullying (for example by using pornographic deepfakes for revenge or extortion, Simonite, Citation2019)? The arms race between deepfake technology and its detection techniquesFootnote1 is not unlike the one between spam and spam detection: newer varieties of deepfakes will go undetected which makes a bans on deepfakes (such as the Facebook ban: Edelman, Citation2020) only effective up to a certain level. How to regulate creative AI, and the vocations and visions expressed in its synthetic outputs?
Creative AI is a new phenomenon. Like with any new phenomenon, the concepts, imagery, analogies and metaphors that we use to understand it will steer how it will be regulated and the societal roles it can fulfill (cf. Larsson, Citation2017). Currently civic concerns with regard to creative AI often build on a limited conceptual understanding of the workings of creative AI, and on underdeveloped notions of agency and of the faction-fiction divide. In this paper I provide a conceptual toolbox to sharpen public and legal debates on creative AI. The first half of the paper (section 2) is devoted to a better understanding of creative AI. I introduce a distinction between classificatory and creative AI, explain the crucial roles of latent space and constrained variation and propose a taxonomy for the various uses of creative AI: understanding, representation and independent creation. In the second half of the paper (section 3) I propose a dynamic, constructivist and societally embedded understanding of creative AI. Firstly, in section 3.1, I show how the dominant ethical approach towards AI, comprising fairness, transparency and accountability (FAT), gets strengthened if it is based in power-sensitive and constructivist valuations. Secondly, in section 3.2, I propose a conceptual heuristic tool to capture the various agency-roles (subject, opponent or helper) which creative AI can play. Finally, I show in section 3.3 how power-sensitive, constructivist valuations and the actantial heuristic can be used to give more bite to the some of the FAT ideals in relation to creative AI.
2. Creative AI.
2.1. AI and ML
While the term AI has become mainstreamed in public debates and policy documents (such as European Commission, Citation2019) its exact meaning is fuzzy. Often when people speak about AI they are actually talking about Machine Learning (ML), which is a particular subfield of AI, or about deep ML (also known as neural networks or deep learning), which is a subfield of the broader field of ML. I will return to deep ML in section 2.3.
From a computer science perspective, ML is as an indirect way of programming (Samuel, Citation1959). Instead of explicitly programming (direct instruction: creating an explicit rule/model), the machine is programmed to create a model from a set of examples (indirect instruction: learning by example). This indirectness allows the programmer to avoid the difficult task of transforming implicit knowledge in an explicit rule: we might know a dog when we see it, but creating a rule that exhaustively describes a dog can be challenging. Despite the fact that ML is in no way autonomous (it depends on the examples and rules for model extraction provided by its programmer: and will therefore replicate any biases present in these) the indirectness of the programming can generate unexpected output that surprises or startles (De Vries, Citation2013, Citation2016).
Within the field of ML there are two dominant types: supervised discriminatory and unsupervised generative ML.Footnote2 These two types of ML are different in two important ways. Firstly, they differ in the type of input on which a model is trained (labeled or unlabeled examples) and, secondly, they differ in what the output of the model does (discriminate or generate).
2.2. An analogy to clarify the distinction between supervised discriminatory and unsupervised generative ML
Imagine that you take a small child to a language fair to teach it about different languages: Japanese, Finnish and French. You could teach it by naming all the languages you hear. Look, that is Japanese, there is another person speaking Japanese, and that person there speaks Finnish. In ML terms your teaching method is supervised discriminatory: you are training the child to infer a rule to classify (that is, to discriminate) between various languages by labeling speech examples. Another teaching strategy would be to refrain from any naming and instead ask open questions such as: Which speech fragments do you think belong to the same language? and Can you identify some structural characteristics that make you think that?. In ML terms this is unsupervised generative learning: you provide uncategorized examples, and ask the child to discover patterns. Pattern discovery can fulfill several functions. They could be a stepping stone for further supervised learning (you are right, those two people do indeed speak the same language: it's Japanese!), or, after some more extensive exposure, allow the child to identify structural characteristics of a language.
The 2010s were the heydays of supervised discriminatory ML in classification tasks: customer segmentation, terrorist profiling, automated speech recognition, object recognition in smart cars, decision support tools in medical diagnosis, etc. all belong to the same classification paradigm that aims to find a simple decision rule to sort out input data. While classification is a goal that potentially could be achieved by both discriminative supervised and unsupervised generative ML (Jebara, Citation2012) using the latter might be like cracking a nut with a sledgehammer.Footnote3 To continue with the language analogy: in order to distinguish between Japanese, Finnish and French, learning a simple decision rule based on a few salient differences is sufficient. Taking extensive courses to actually learn these languages (with the side-effect that one can distinguish between them) would be an extremely inefficient way of achieving the classification goal: you learn a much more complex model than needed to solve the classification task. So why do people make the effort of years of study to learn a language? Probably an important reason it that they want to understand and speak it: that is, to turn understanding into a generative capacity. Until the mid-2010s, this latter capacity was very limited in generative ML, which was predominantly a technique to describe data structures. The capacity to use this data structure to generate or create new output based on a structural understanding was limited. An example of such limited creative ML that has been around since the 1990s is the Autoencoder (AE) where input and output are ideally the same: input is degraded and then reconstructed as close as possible to its original state. In the language analogy this would be the capacity to fill in missing letters in a sentence in a course book that has become partly unreadable due to some staining. When humans learn to speak a new language, they learn how to create new variationsFootnote4: sentences, poems, texts that never existed before but that still make sense in the existing language structure. The ability to speak a new language is the ability to go beyond simply reproducing the exemplary sentences in the course material while staying within the constraints of what makes sense.
2.3. Constrained variation: generative ML going from description to creation
In 2013 and 2014 two important inventions gave generative ML the power of creation: Variational Autoencoders (VAEs) (Kingma & Welling, Citation2013) and Generative Adversarial Networks (Goodfellow et al., Citation2014). The novelty of VAEs and GANs is precisely this: creation through constrained variability. A crucial term here is latent space: it is the possibility space of creation, defining the coordinates of all possible outputs. Pure latent space is unconstrained and meaningless: it is unlimited possibility. However, when a generative model is trained, it narrows the possibility space. If latent space is very narrow, it simply reproduces the input. If it is too wide, the model will produce all kind of nonsensical gibberish. Borges’ famous short story The Library of Babel (Citation1998) is a good example of a latent space that is too unrestrained: the gigantic library contains each possible book made out of 25 characters (22 letters, period, comma and space) and containing 410 pages. The library contains an enormous amount of gibberish and only rarely any sensible sentence is found. If we would train a GAN or a VAE on all existing books, Babel's library would become limited to what is likely to make sense as a book. In the installation Archive Dreaming Footnote5 artist Refik Anadol does precisely this (Miller, Citation2019, pp. 93–93): he used an online library of 1.7 million images, drawings and other archival content relating to Turkey to train a GAN to dream up new archival content, as if from ‘a parallel history’ (p. 93). Like the generative grammar of a language is not limited in the set of utterances it can produce, neither is latent space; it is a generative space, not a database (Klingemann, Citation2020). To understand the role of latent space in generative models such as GANs and VAEs, I will take a closer look at two aspects of their technical functioning.
A first important aspect is that GANs and VAEs both build on neural networks (deep ML). Neural networks are characterized by a layered approach to analysing any given input, where the analysis begins with very basic features (such as edges and angles) to increasingly more high-level ones (such as noses and eyes). In each layer of analysis the input becomes more compressed. The latent space is the most high-level conceptual compression of the input data, the pre-final step before the neural network's output. However, it is hidden from humans because of its complexity: latent space in a neural network typically will be a hypersphere with around 100 dimensions. In section 2.4 I discuss how latent space can nevertheless become a source for human understanding.
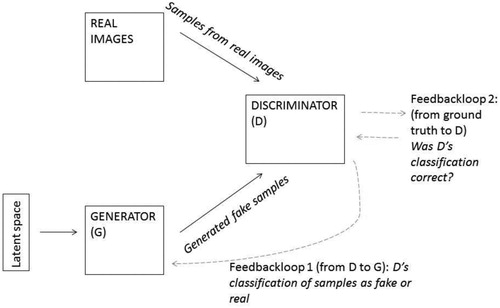
Another crucial aspect in the architecture of GANs () and VAEs () is that they both consist out of two neural networks.
Figure 2. Generator-Discriminator architecture in a GAN.
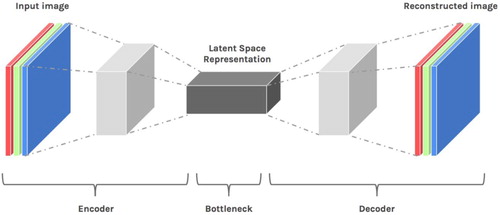
In VAEs the relation between these two networks is a straightforward pipeline: the first neural network is the encoder that compresses input into a latent space (the bottleneck), and then a decoder that reconstructs from latent space into new examples. Input and reconstructed output are not the same because in the latent space structure probabilistic variation is thrown into the mix: hence the ‘V’ of ‘Variation’ in VAEs.
Figure 3. Encoder-Decoder architecture in a VAE. Image source: (Despois, Citation2017).
In GANs the two neural networks are pitched against each other: they have an adversarial relationship. One of the networks is called the Generator and the other one the Discriminator. One of the most common analogies is to describe the adversarial interaction as a cat-and-mouse game where the Generator is a counterfeiter trying to make fake input pass for real, and the Discriminator is a detective who tries to distinguish fake from real. Another way to visualize the adversarial process is to imagine a, slightly sadistic, experiment where a person (the Generator) has to learn to write a novel that could pass for a Jane Austen novel, without ever being shown one of her novels or having been given even the slightest information about her. Another person (the Discriminator), who is equally ignorant about Austen, is randomly shown stuff written by the Generator and excerpts from Austen's work. The Discriminator then has to tell how likely, on a scale from 0 till 1, she thinks that the text is a real one. If she misclassifies she gets punished. The Discriminator soon begins to learn how to better avoid punishment and becomes better in distinguishing Austen texts from the scribbles of the Generator. The Generator gets punished every time the Discriminator correctly exposes her scribbles as fake. Motivated by punishment aversion the Generator begins to learn how to produce increasingly convincing Austen-like texts that fool the Discriminator. So there are two punishment-feedback loops fueling the learning: one ground truth loop (was the input fake or real?) towards the Discriminator, and one classification feedback loop going from Discriminator to Generator. This game continues until, hopefully, an equilibrium is reached and neither Generator nor Discriminator improve their performance. At this stage the Discriminator is send home, while the Generator has internalized a complex formula to generate texts in the style of an author that she has never read. This will be the fate of the Generator for the rest of her life: to produce Austen like texts. The generative formula internalized by the Generator results from variation (Generator) and selection pressure (Discriminator). The success criterion is: how good is the Generator in tricking the discriminator into believing a sample is real? This is a smart but in no way obvious success criterion. For example, evolutionary algorithms, that have recently also received a lot of attention because of their role in designing the first robots made of biological material (Kriegman et al., Citation2020), use a fitness criterion (to which extent does a design solution realize the set aims?) as a measure for success. This means that the GAN process can be characterized as an evolutionary process that is tied up to a representative selection criterion, in a way that organic evolution is not: when birds evolved from dinosaurs nobody judged how good they were at pretending to be dinosaurs – the only thing that mattered is that birds survived in the struggle for existence. Not unlike evolutionary processes GANs are rather volatile and unpredictable. There is no guarantee that an optimal equilibrium is reached: the Discriminator might content herself in accepting very bad Austen imitations as real and the Generator will be satisfied with producing them. Or the Generator might end up in a state of mode collapse: producing texts that are all very similar to Sense and Sensibility, completely ignoring other work by Austen, because the Discriminator does not punish for this limited scope in the Generators creations. Another drawback of GANs is that it is impossible, or at least very difficult (Donahue et al., Citation2016), to generate inverse maps, meaning that the same Austen-like text could have been generated from different points in the latent space and that it is impossible to reconstruct from which of those points it was created. In contrast to VAE output, which results from a neat linear process, there is no direct way of retracing the creation trajectory for individual synthetic examples produced by GANs. Notwithstanding these drawbacks (potentially very bad or limited results, volatility and opacity), GANs have become very popular because of their oftenvery impressive results (Goodfellow, Citation2016).
2.4. Uses of creative AI: a curious mix of understanding, representing and creating.
In this section I propose a taxonomy of three types of use cases for creative AI: understanding, representation and creation.
Firstly there is the use of creative AI for the purpose of understanding (e.g., Chen et al., Citation2016). A trope that often returns is that the latent space allows us to peek into the 'mind', 'brain', 'imagination' or 'dreams' of neural networks (Giles, Citation2018; Mahadevan, Citation2018; Nguyen, Citation2016). One of the intuitions guiding creative AI is that creation somehow equals understanding and representation, and that ‘the ability to synthesize, or "create" the observed data entails some form of understanding’ (X. Chen et al., Citation2016, p. 1). There is a consensus that the data-generating latent space of generative ML ‘can potentially provide interpretable and disentangled data representations’ (Adel et al., Citation2018, p. 1). Here things get tricky. What is a good representation? Is that human representation? While a generative model that recreates convincing non-existing faces might do that based on ‘good’ representations that are akin to those used by humans (hair, nose, eyes, etc.) it could also work equally well based on – at least from the perspective of human understanding – bad representations. Given that the latent space of GANs and VAEs has a much higher dimensionality than human understanding, it is rather likely that human and AI understanding do not converge. Another issue, as discussed above (section 2.3), is that latent space is often not directly accessible for human understanding. In order to access it you will need to visualize the higher dimensional latent space representations into 2D or 3D representations (Tiu, Citation2020) but this will necessarily involve information loss. The capacity of AI to synthetize new data offers another, indirect, way to access latent space: we can query and navigate the structure of latent space by actualizing certain data from it. Let's say that we have the latent space of a GAN or VAE trained on all books contained in the British Library. This latent space is then the deep structure-grammar in which the generative model describes how books can be similar and different from each other on, for example, 100 dimensions: Jane Eyre might be very similar to the Yellow Pages on one dimension, while being very different on another. In order to understand its deep structure, we can ask the model to use its latent space grammar for arithmetic transformations (‘vector arithmetic’: Radford et al., Citation2015) such as: How would the text of Jane Eyre minus Yellow Pages plus Bridget Jones look like? Or we could ask the model to create a path (‘interpolation’) of new generated examples through which the text of Jane Eyre slowly transforms into Yellow Pages. As such we actualize examples that give some indirect insight in the underlying generative structure. This way of creating interpretability could potentially also be useful in achieving the transparency ideal for classificatory AI (see section 3.3).
A second important goal that could be realized with creative AI is representation. For example, in the case of missing data, synthetic data could fill up the gaps. Within statistics such data imputation has existed for a long while. GANs and VAEs, however, allow researchers to make better guesses about what missing data could look like than older statistical methods. The synthetic data mimic the statistical distribution of the real data set. This opens up for a whole new range of use cases. For example, astronomers use synthetic data to guess how uncharted pieces of our universe might look (Castelvecchi, Citation2017). Synthetic data can also be a way of extending an original that is representative of the structure of the original data. Such use cases include adding frames to an existing video sequence, continuing a picture outside its outer boundaries, and repairing images with missing parts. Synthetic data could also be used to complement a lack of fairness in real data sets (Sattigeri et al., Citation2018): a real dataset that has an overrepresentation of white male faces, could be less representative of reality than a dataset that has been supplemented with synthetic data of underrepresented categories of people (see more in section 3.3). Synthetic data are also used for anonymization (Bellovin et al., Citation2019; Jordon et al., Citation2018; Xie et al., Citation2018). Creating synthetic data sets that have the same utility and informativeness as the original while escaping GDPR issues because there is no tie to real people: that is a holy grail that could have a major impact on any research dealing with personal data.
How representative are synthetic data? This is a question that is difficult to answer and that will also depend on the type of data. The more data variability and parameters, the more difficult it becomes to properly represent the data. For example, the fake faces from thispersondoesnotexist.com (see above, section 1) are way more convincing than the fake cats from thiscatdoesnotexist.com (last accessed 20 January 2020): cat pictures have a much larger variability (cats jump around) than human portrait pictures. Convincing is also different from representative: as explained in section 2.3 the phenomenon of mode collapse might result in synthetic data only representing a small part of the original data. And while similarity with the statistical distribution in the original data set is a good indicator of representativeness, it is no more than an educated guess. Especially in the case of missing data there is no ground truth for comparison: who is to say that stars are equally distributed in the unchartered parts of the sky as in the documented ones?
A final important purpose for using creative AI is the creation of novel creations that stand on their own. This includes GANs and VAEs that transform images (let faces age or change into anime drawings; remove glasses from faces; de-rain landscape pictures; etc.), produce text-to-image translations (Zhang et al., Citation2017), and that create new variations on existing recipes, fashion, music, DNA sequences, and graphics. AI-generated works of art and texts are also synthetic outputs that stand on their own. While GANs and VAEs are very popular, some types of output can also be based on other, more domain specific, models. An example is the field of text generation, where enormous advances have been made, showcased by websites like https://talktotransformer.com/ and https://thisarticledoesnotexist.com/ (Zellers et al., Citation2019). Specific generative natural language models such as GPT-2 (Radford et al., Citation2019) currently still often outperform GANs or VAEs in the field of open-ended longer text generation (Holtzman et al., Citation2019).
The uses of creative AI in this tripartite taxonomy (understanding, representation and creation) often overlap. For example, in the Next Rembrandt project (Dutch Digital Design, Citation2018) the goal was to let creative AI dream up new paintings that Rembrandt could have made. In my taxonomy this is a use case that primarily falls into creation that stand on its own. Representativeness is in this case not as important as when creative AI would be used to fill in a missing part of an existing Rembrandt painting. The Next Rembrandt project did not aim to create a comprehensive model to help humans understand what the crucial elements are that constitute a Rembrandt painting. Yet, representativeness and understanding do play a role in the Next Rembrandt. The success of the project partly depended on the representativeness of the synthetic Rembrandts – does the new painting make us think it is a Rembrandt? The creation of new Rembrandts might also give us indirect pointers to better understand Rembrandt's characteristic style. AI-generated art (Miller, Citation2019) sometimes foregrounds the occasions of machinic misunderstandings and misrepresentations: understanding and representation are still important for the value of the work – only in a reversed way. With regard to a series on GAN produced nudes (), that were trained on classical nude paintings, GAN artist Robbie Barrat explains that the output (…) was a misinterpretation by the network. It wasn't fed any art like Francis Bacon or any freaky nude portraits. It was fed very classic nude portraits, but it produced these awful fleshy images instead. (Thompson & Barrat, Citation2018)
Figure 4. Nudes produced by GAN artist Robbie Barrat. Source: https://robbiebarrat.github.io/oldwork.html (last accessed 13 February 2020).
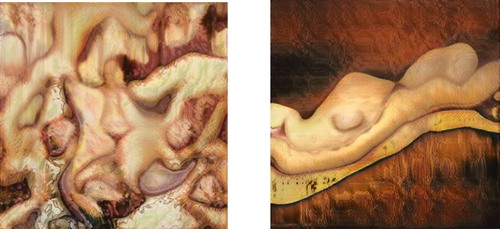
This is a tension at the core of AI-generated works produced by models such as GANs or VAEs: the output aims both for novelty (variation) as well as representation. When the synthetic output is (mainly) valued as a self-sufficient creation this tension might be unimportant: a soup based on a GAN-generated recipe either tastes good or not, its representativeness with regard to other soups is of no importance. However, if AI-generated data are used as stand-in equivalents of real data in research or decision making, misrepresentations and misunderstandings can have disastrous effects.
3. Constructivist and dynamic conceptualizations of creative AI: FAT 2.0
3.1. Beyond FAT and the concern for the dissolution of the fact-fiction divide: constructivist valuations.
The opposition between fact and fiction, between reality and fabrication, between what is true and fake, is one of the big conceptual divides organizing our lives. ‘No, I didn't take that cookie!’, says a young child. ‘Don't make things up, just admit to it!, says the parent. ‘No, really, it's true, I didn't take it’. The ontological discussion about what is fact and fiction begins at an early age and never leaves us. Yet, critical theory has shown over and again that this contrast between a given reality and a fictitious construction is fallacious. From its earliest days photography has failed to live up to its image as a neutral tool to capture reality and has involved construction (Boorstin, Citation1992; Postman, Citation2011; Sontag, Citation2005). Data are never pure or raw but always somehow construed (Gitelman & Rosenberg, Citation2013). Science, fiction and politics have always been intertwined in subtle ways (Latour, Citation1993).
During the 2010s the ever-increasing omnipresence of classificatory AI has been accompanied by a growing importance (European Parliamentary Research Service, Citation2019) attached to the ideals of fairness, accountability and transparency (FATFootnote6) in relation to algorithmic decision making (ADM). One basic definition of fairness is that it is the absence of systematic bias and disadvantage towards particular demographics or social groups. Accountability is a tool that is supposed to contribute to fairness: it is the ideal that the person on organization responsible for an ADM system accounts for its activities and accepts responsibility for the resulting (unfair) outcomes. Transparency has to do with visibility and insight into the system. It is often, falsely, assumed that accountability can be operationalized as transparency (Christensen & Cheney, Citation2015), and that the latter automatically leads to the former. Consequently, accountability is the least studied ideal of the triad of ideals. Yet, transparency is an empty shell if the existing power structures prevent individuals to act on it (Ananny & Crawford, Citation2018). If the necessity of an ADM system and its consequences are not questioned, opening an algorithmic blackbox will stay an empty gesture. In fact, it turns out that interpretability and transparency tools can give a false sense of reliability to classificatory AI systems (Kaur et al., Citation2019), resulting in disempowerment. A similar mechanism can be seen in many interpretations of fairness in ADM that understand bias as a problem that can be solved mathematically (Barocas et al., Citation2018): again it can disempower by distracting from bigger questions, such as the necessity of an ADM system and the power structures supported by it (Powles, Citation2018). The most prevalent interpretations of fairness and transparency ideals are rooted in a belief that also underlies the fact-fiction divide: that access to, and defense of, an untainted, unbiased reality is the ultimate panacea against all injustice. Seen from this perspective, it is not very surprising that the main civic concern with regard to creative AI (see above, section 1) is currently that it will destabilize societies with disinformation. While I’m not arguing in favor of disinformation (or opacity or unfairness), a mere focus on separating fake from real media might become a similarly toothless ideal as fairness and transparency. Detection technology of deepfakes can be very useful, as long as it is not a distraction of the bigger picture: that facts can fall short of reality, and fabricated realities can be more representative of reality than so-called ‘real’ realities. Instead of religiously clinging to the fact-fiction divide, I propose a more constructivist approach to the valuation of synthetic data: ‘Yes, obviously we are dealing with a fabricated reality – the question is whether it is fabricated well!’. Constructivist valuation (cf. De Vries, Citation2016) does not equal to putting everything on the same footing. A tweet by a whimsical president and a serious investigative piece of journalism are not the same because they are both fabrications. Neither are all synthetic data equal. What is needed for the valuation of a particular piece of synthetic data is a set of professional standards derived, firstly, from the practice (journalism, medical research, etc.) in which the data operate, and, secondly, from statistical measures of reliability, representativeness, significance, etc. Moreover the valuation of synthetic output has to be evaluated in the context of its particular use. For example, if a synthetic text is used to report a political event both journalism and statistical standards will be higher than if the synthetic text describes a pair of sneakers on the website of an online shop. This is not to say that synthetic data should be categorically banned from high stake areas such as political journalism or medical research. One could imagine that a synthetic picture to illustrate a political event can be very illuminating as long as it can be shown that it lives up to the necessary professional and statistical standards. A good conceptual understanding of the working of generative ML (see above section 2.3) and the taxonomy of uses of creative AI (see above section 2.4), can be first building blocks to the construction of practice and use-case specific guidelines for the valuation of synthetic data.
3.2. Dynamic agencies of creative AI, humans and classification systems: an actantial model
The image of ourselves as Cartesian free rulers over our tools is alluring. Yet, as McLuhan famously said: ‘We shape our tools and they in turn shape us’ (Culkin, Citation1967, p. 70). Let's take an example from the field of classificatory AI: a security officer in an airport looks at surveillance footage that has been enhanced with a classification algorithm that identifies potential threats and marks them with a red circle. This security officer can give feedback to the system about correct and false classifications. A simple instrumental understanding of this setting places ‘the human in command’ (European Commission, Citation2019; European Economic and Social Committee, Citation2017) as an autonomous arbiter towards the suggestions made by the AI 'tool'. However, while the perception of the security officer is not determined by the suggestions of the system it is likely to be affected and shaped by it (cf. Kaufmann, Citation2019). In turn, the security officer will shape the classification system by providing it with feedback, and possibly perverting and subverting the system by using it in ways that were not anticipated by its designers (Gurses et al., Citation2018; Nissenbaum & Brunton, Citation2015). With the rise of creative AI an important new actant enters into the existing ecologies between humans and classification machines. The semiotic actantial model (Greimas, Citation1983) is a useful heuristic to map how each of these three types of actants can relate to each other. One of the strengts of the Greimasian model is that it is not humanistic: actants can be anything, living or non-living, that steers a set of events or a narative. Greimas identified six types actantial roles: a subject and object (the subject aims to reach the object/goal, which drives the narrative), a sender (triggering the subject to direct itself towards the object), a receiver (who benefits from the junction of subject and object), a helper (an agent supporting the subject in achieving its goal), and an opponent (which can be either a productive or a destructive adversary). When analysing set-ups where human and machinic actants interact, the distribution of roles is open to interpretation. I will explore this in more detail for three roles from the actantial model: subject, opponent and helper. For instance, in the aforementioned case of the security officer and the smart surveillance system, it could be argued that both actants drive the process and as such they are co-creating subjects. Or, that the officer is the subject, and the system the helper. Or, maybe even the other way around: that the system drives the action and that it is the officer who is the subordinate cog. The goal of the tool is to create attentiveness to the power and role distribution that drives such a set-up, and create possibilities for alternative role distributions. How important is it that the officer is in control? How can we support his agency? Who or what could oppose this surveillance set-up? Which actant could be targeted by opposition? How problematic is that? Etc. The actantial model also allows us to ask what would happen if we add creative AI to such set-ups: how could it be an opponent, helper or subject?
Creative AI as opponent. When humans are deceived by deepfakes, creative AI fulfills the role of an opponent to humans. Less in the public limelight is that creative AI is also very suited for fulfilling the role of opponent to classificatory machines, by generating so-called ‘adversarial examples’ (Szegedy et al., Citation2013). Adversarial examples are ‘inputs to machine learning models that an attacker has intentionally designed to cause the model to make a mistake; they’re like optical illusions for machines’ (Goodfellow et al., Citation2017) Such adversarial inputs contain a minor perturbation that is unnoticeable to the human eye while being of crucial significance to a particular classificatory machine. A slight color change in a medical image could lead to a misdiagnosis, placing a tiny sticker on a traffic sign could result in a smart car driving of the lane, and a well-positioned adversarial image on a roof might fool a warfare drone into launching a missile on a hospital instead of a military base (S. Samuel, Citation2019).
Creative AI as subject. In many of the use cases mentioned in section 2.4 creative AI will be the driving subject of the action. Again, it should be noted that the attribution of the subject role depends on the perspective of the one creating the narrative. A regime that uses deepfakes for the goal of political deception might consider itself and the creative AI system to be the co-subjects driving the action. In contrast, the political opponents might attribute the central agency to themselves and caracterize the regime and the creative AI system as the opponents. When creative AI takes the role of subject it will almost always be supported by a human: this can either be a helper, a co-subject or anything in between. Even though creative AI mostly relies on unsupervised learning, which relieves humans of the tedious task of labeling data, it still requires a lot of ‘data wrangling’ to produce anything meaningful, which can be conceptualized in terms such as ‘janitor work’ (Lohr, Citation2014) or, when there is more creativity involved, as ‘curation’. GAN artist Barrat says:
The role that I’m playing is more of a curator than anything else. The first thing I do is curate the data that the network is going to study, and once the network is trained I also curate the output data, deciding which outputs I am going to keep and whether I want to tweak the training sets so that the network learns something different. (…) I’d say that I’m a ‘curator/artist'. (Sicardi, Citation2018)
(c) Creative AI as helper. Finally, creative AI can also take the role of helper in relation to humans as well as classificatory systems. One clear example of a supportive role in relation to classificatory machines is that the generation of synthetic data can increase the learning process of such systems exponentially. Synthetic data functions here as a type of machine imagination (Giles, Citation2018, February 21; Mahadevan, Citation2018) to speed up understanding. An analogy: a child does not need to see a million examples of dogs to understand what a dog is because it can imagine dogs it has never seen and use its imagination to create a concept of a dog. Similarly, the learning rate of AI can be exponentially improved by adding synthetic data into the training data. This means that classificatory AI can become more powerful, and that some of the boundaries between human and AI capacity will shift. For example, the capacity of classificatory AI to solve captchas – a classical Turing test to distinguish humans from AI – increases impressively when trained on a mix of real and AI generated synthetic data (Ye et al., Citation2018). Creative AI can also be used to enhance human agency in relation to AI. In the next section I explore how creative AI could be supportive of FAT ideals, and how to avoid that this support turns into its disempowering opposite.
3.3. Revisting FAT through the constructivism and dynamism of the actantial model.
Currently practical enactments of fairness and transparency with regard to AI often lack real bite, and sometimes can even act in a disempowering way by distracting from more relevant questions and giving a false sense of trustworthiness (above, section 3.1). Knowledge as such is not necessarily empowering. Fairness that cloaks itself in mathematical neutrality obscures that fairness almost involves a normative choice for one type of fairness over another: there is never a free lunch. A FAT 2.0 approach with more normative bite would have to be attentive to whether measures really enhance human agency and shed the pretence of neutrality.
When taking these points in account, synthetic data could be a supportive tool to enhance transparency and fairness of classificatory AI.
Synthetic data supporting transparency. In order for transparency to have some real bite, the gained insights into the logic underlying an ADM system should be actionable knowledge. One aspect that contributes to making knowledge more actionable is if it explains an individual decision and not just the general logic of the system. Synthetic counterfactual data (Wachter et al., Citation2018) can be a way of providing insights in the reasons for a decision in an individual case. For example, if somebody is classified by an ADM system as ‘non-creditworthy’: what are the minimal changes that have to be made to fall in the creditworthy category? Hernandez (Citation2018) shows how the creation of synthetic eBay sellers could be useful in providing reasons to online merchants about why they are banned by an ML classificatory system as a potential fraudulent. By synthesizing the nearest hypothetical seller that would not have been banned, and comparing characteristics with the banned one, the most likely reasons for the ban in this particular instance could be identified.
Synthetic data supporting fairness. While many endeavors to remove bias and discrimination from classificatory AI systems have stranded in logical perplexities (fairness at group level might be unfair at an individual level, fairness towards on demographic might be unfair towards another, etc.), recently some definitions of fairness have been proposed that are open to normative and political aspects in realizing a particular type of fairness in AI (Green & Hu, Citation2018; Selbst et al., Citation2019). Synthetic data could play a role in training classificatory models to classify in a way that is societally considered fair (Xu et al., Citation2018). When parents read stories to their kids about female pirates and black doctors, they do this because they want their kids to perceive the world as a place where a pirate is not necessarily a male and a doctor not necessarily a white middle-aged man. The question is not whether these stories are representative of historical or current realities: they stand for an aspiration of how the world should look like. Similarly synthetic data could be used to train models to perceive the world in ways we think classificatory machines should perceive it. The use of aspirational synthetic data would be a giant step from the currently dominant view that classificatory AI is a neutral tool that merely represents (cf. Foucart, Citation2011). While using aspirational synthetic data for training classificatory machines opens up for a whole array of difficult choices and questions – which flavor of fairness should be preferred? – it is more upfront than pretending that AI classification is a neutral enterprise.
4. Conclusion
To conclude, I return to the mesmerizing synthetic faces of thispersondoesnotexist.com. The website is a powerful tool to showcase what creative AI can do, and yet it also is misdirecting. These non-existing faces do not have a direct practical purpose: they are not there to be sold as art, anonymize a database, fool a classificatory machine or act as fake news. These deepfakes are suspended in a motionless space of meditative encounters between existing persons and non-existing ones. There are no stakes, no dynamic interactions, no practice in which they are operate – everything that makes the crucial difference in any application of creative AI is absent.
Now that creative AI is claiming an increasingly important role in day-to-day life, it is more important than ever to look at AI systems in their operational setting of actantial interactions. What do these AI systems support, oppose or enact? Who or what can support or thwart their doings? An actantial outlook on AI helps to understand, firstly, that transparency is useless if it does not allow for action. Secondly, that fairness is not a mathematical notion but a political stance on the ideal representativeness and distributiveness that an AI system should achieve. In this paper I have shown how explanatory and aspirational synthetic data could help the realization of power-sensitive and constructivist FAT ideals. Simultaneously, I have also problematized the alignment with FAT ideals due to the complex mix of representation, understanding and independent creation that constitutes the outputs of today's dominant models in creative AI.
The conceptual toolbox for understanding creative AI provided in this article is only a first step in a new line of research. This article gives general concepts that will help in the work that still lies ahead of us: the creation of practice and domain specific standards for the various uses of synthetic data.
Acknowledgements:
I would like to express my deepest gratitude to the two anonymous reviewers whose thoughtful comments have been invaluable to this paper. I presented an early draft of this paper in December 2018 at the Data, Security, Values: Vocations and Visions of Data Analysis – Annual Conference of the Nordic Centre for Security Technology and Societal Values (NordSTEVA). A big thank you goes to Mareile Kaufman for inviting me as a keynote, for her unwavering commitment as an editor and her supportive comments. I also would like to express my gratitude for the financial and collegial support I received from the Sociology of Law Department, Lund University (postdoc grant, Cre-AI project; 01/02/2019-01/09/2019) and the Swedish Law and Informatics Research Institute, Stockholm University (postdoc grant, Cre-AI project; 01/09/2019-01/06/2020). Last but not least, I would like to thank my colleague Liane Colonna for taking the time to read and comment during the pressured circumstances caused by covid-19.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes on contributor
Katja de Vries is a postdoctoral legal researcher and philosopher of technology focusing on Machine Learning and Artificial Intelligence. Currently she is working on CRE-AI. CRE-AI is a two year postdoc project (Department of Law, Stockholm University, Sweden, September 2019–2021) on the legal and societal implications of so-called creative or generative Artificial Intelligence, notably Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). She is also affiliated to Lund University (Sociology of Law) and the Vrije Universiteit Brussel (Center for Law, Science, Technology and Society) “[email: [email protected]]”.
Notes
1 See initiatives such as https://weverify.eu/ (last accessed 31 January 2020).
2 Not all supervised learning is discriminative, nor is all unsupervised learning is generative, but a dominant fraction is.
3 It should be noted though that supervised learning is more labor-intensive in terms of labeling than unsupervised learning. The labeling of data requires a lot of human input, exemplified by the emergence of labeling farms where human workers spent all day tagging ML input images.
4 The notion of ‘variation’ is well-developed in music and genetics. Both these notions of variation can provide interesting analogies with the variations produced with creative AI.
5 http://refikanadol.com/works/archive-dreaming/ (last accessed 20 January 2020).
6 Annual FATML conference: https://www.fatml.org/ (last accessed 2 February 2020).
References
- Adel, T., Ghahramani, Z., & Weller, A. (2018). Discovering interpretable representations for both deep generative and discriminative models. 35th International Conference on Machine Learning, Stockholm, Sweden, 10-15 July 2018.
- Ananny, M., & Crawford, K. (2018). Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability. New Media & Society, 20(3), 973–989. https://doi.org/10.1177/1461444816676645
- Barocas, S., Hardt, M., & Narayanan, A. (2018). Fairness and machine learning. Limitations and opportunities (DRAFT). https://fairmlbook.org/
- Bellovin, S. M., Dutta, P. K., & Reitinger, N. (2019). Privacy and synthetic datasets. Stanford Technology Law Review, 22, 1–39. https://doi.org/10.31228/osf.io/bfqh3.
- Boorstin, D. J. (1992, 27–30 January). The image: A guide to pseudo-events in America. Vintage.
- Borges, J. L. (1998). The library of Babel (A. Hurley, Trans. Collected Fictions.) (pp. 112-118). Penguin.
- Castelle, M. (2020, 27–30 January). The social lives of generative adversarial networks. Conference on Fairness, Accountability, and Transparency (FAT*’20), Barcelona, Spain, https://doi.org/10.1145/3351095.3373156.
- Castelvecchi, D. (2017). Astronomers explore uses for AI-generated images. Neural networks produce pictures to train image-recognition programs and scientific software. Nature. https://www.nature.com/news/astronomers-explore-uses-for-ai-generated-images-1.21398
- Chen, A. (2019). Can an AI be an inventor? Not yet. But some campaigners are pushing for the rules to change. MIT Technology Review. https://www.technologyreview.com/s/615020/ai-inventor-patent-dabus-intellectual-property-uk-european-patent-office-law/?utm_source=newsletters&utm_medium=email&utm_campaign=the_algorithm.unpaid.engagement#gid=559908609
- Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Advances in neural information processing systems. arXiv:1606.0365.
- Chesney, R., & Citron, D. K. (2018). Deep fakes: A looming challenge for privacy, democracy, and national security. [draft paper available at SSRN, version July 14, 2018]. http://dx.doi.org/10.2139/ssrn.3213954
- Christensen, L. T., & Cheney, G. (2015). Peering into transparency: Challenging ideals, proxies, and organizational practices. Communication Theory, 25(1), 70–90. https://doi.org/10.1111/comt.12052
- Craig, C. J., & Kerr, I. R. (2019). The death of the AI author. Available at SSRN 3374951.
- Culkin, J. M. (1967). A schoolman’s guide to Marshall McLuhan. The Saturday Review, 51-53, 70–72. http://www.unz.org/Pub/SaturdayRev-1967mar18-00051
- Despois, J. (2017). Latent space visualization — Deep Learning bits #2. Hackernoon. https://hackernoon.com/latent-space-visualization-deep-learning-bits-2-bd09a46920df
- De Vries, K. (2013). Privacy, due process and the computational turn. A parable and a first analysis. In M. Hildebrandt, & K. De Vries (Eds.), Privacy, due process and the computational turn. The philosophy of law meets the philosophy of technology (pp. 9–38). Routledge.
- De Vries, K. (2016). Machine learning/informational fundamental rights. Makings of sameness and difference. Vrije Universiteit Brussel.
- Donahue, J., Krähenbühl, P., & Darrell, T. (2016). Adversarial feature learning. arXiv:1605.09782.
- Dutch Digital Design. (2018). The next Rembrandt: Bringing the old master back to life. Case study: Behind the scenes of digital design. Medium. https://medium.com/@DutchDigital/the-next-rembrandt-bringing-the-old-master-back-to-life-35dfb1653597.
- Edelman, G. (2020). Facebook’s deepfake ban is a solution to a distant problem. Wired. https://www.wired.com/story/facebook-deepfake-ban-disinformation/
- European Commission. (2019). Communication from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of the Regions - Building Trust in Human Centric Artificial Intelligence (COM(2019)168).
- European Economic and Social Committee. (2017). Artificial intelligence: Europe needs to take a human-in-command approach, says EESC. https://www.eesc.europa.eu/en/news-media/press-releases/artificial-intelligence-europe-needs-take-human-command-approach-says-eesc
- European Parliamentary Research Service. (2019). A governance framework for algorithmic accountability and transparency. https://www.europarl.europa.eu/RegData/etudes/STUD/2019/624262/EPRS_STU(2019)624262_EN.pdf
- Foucart, S. (2011, February 14). “Juif" - Une requête très française. Le Monde.
- Ghahramani, A. (2019). Why this person does not exist (and its copycats) need to be restricted. Venture Beat. https://venturebeat.com/2019/03/03/why-thispersondoesnotexist-and-its-copycats-need-to-be-restricted/
- Giles, M. (2018, February 21). The GANfather: The man who’s given machines the gift of imagination. MIT Technology Review. https://www.technologyreview.com/s/610253/the-ganfather-the-man-whos-given-machines-the-gift-of-imagination/
- Gitelman, L., & Rosenberg, D. (2013). “Raw data” is an Oxymoron. MIT Press.
- Goodfellow, I. (2016). Generative adversarial networks. Pros and cons. What is the advantage of generative adversarial networks compared with other generative models? Quora. https://www.quora.com/What-is-the-advantage-of-generative-adversarial-networks-compared-with-other-generative-models
- Goodfellow, I., Papernot, N., Huang, S., Duan, Y., Abbeel, P., & Clark, J. (2017). Attacking machine learning with adversarial examples Open AI. https://blog.openai.com/adversarial-example-research/
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. Advances in neural information processing systems.
- Green, B., & Hu, L. (2018, 10-15 July). The myth in the methodology: Towards a recontextualization of fairness in machine learning. 35th International Conference on Machine Learning, Stockholm, Sweden.
- Greimas, A. J. (1983). Structural semantics: An attempt at a method. University of Nebraska Press.
- Gurses, S., Overdorf, R., & Balsa, E. (2018). POTs: The revolution will not be optimized? 11th Hot Topics in Privacy Enhancing Technologies (HotPETs 2018), Barcelona, Spain.
- Harwell, D. (2019). An artificial-intelligence first: Voice-mimicking software reportedly used in a major theft. Washington Post. https://www.washingtonpost.com/technology/2019/09/04/an-artificial-intelligence-first-voice-mimicking-software-reportedly-used-major-theft/
- Hernandez, J. (2018). Making AI interpretable with generative adversarial networks. Medium. https://medium.com/square-corner-blog/making-ai-interpretable-with-generative-adversarial-networks-766abc953edf
- Holtzman, A., Buys, J., Forbes, M., & Choi, Y. (2019). The curious case of neural text degeneration. arXiv: 1904.09751.
- Jebara, T. (2012). Machine learning: Discriminative and generative. Springer.
- Jordon, J., Yoon, J., & van der Schaar, M. (2018). PATE-GAN: Generating synthetic data with differential privacy guarantees.
- Karras, Tero, Laine, Samuli, & Aila, Timo. (2019). A style-based generator architecture for generative adversarial networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4401–4410. DOI: 10.1109/CVPR.2019.00453.
- Kaufmann, M. (2019). Who connects the dots? Agents and agency in predictive policing. In M. Hoijtink, & M. Leese (Eds.), Technology and agency in international relations (pp. 141–163). Routledge.
- Kaur, H., Nori, H., Jenkins, S., Caruana, R., Wallach, H., & Vaughan, J. W. (2019). Interpreting interpretability: Understanding data scientists’ use of interpretability tools for machine learning. Conference on Human Factors in Computing Systems (CHI 2020), April 25–30, 2020, Honolulu, HI, USA. http://www.jennwv.com/papers/interp-ds.pdf.
- Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv:1312.6114.
- Klingemann, M. (2020). Neurography. Computers, privacy and data protection (CPDP) 2020, Brussels, Belgium.
- Kriegman, S., Blackiston, D., Levin, M., & Bongard, J. (2020). A scalable pipeline for designing reconfigurable organisms. Proceedings of the National Academy of Sciences, 117, 1853–1859. https://doi.org/10.1073/pnas.1910837117
- Larsson, S. (2017). Conceptions in the code: How metaphors explain legal challenges in digital times. Oxford University Press.
- Latour, B. (1993). We have never been modern. Harvester Wheatsheaf.
- Lohr, S. (2014). For big-data scientists, ‘Janitor Work’ Is Key Hurdle to Insights. The New York Times. https://www.nytimes.com/2014/08/18/technology/for-big-data-scientists-hurdle-to-insights-is-janitor-work.html
- Mahadevan, S. (2018, 2-7 February). Imagination machines: A new challenge for artificial intelligence. AAAI Conference, New Orleans, Louisiana, USA. https://pdfs.semanticscholar.org/d3c6/4b2497fb02d496709c4fa8fff00f4581399c.pdf?_ga=2.98735515.469762207.1558014984-957934482.1558014984.
- Miller, A. I. (2019). The artist in the machine. The world of AI-Powered creativity. MIT Press.
- Mizrahi, S. K. (2019, April 11-13). Jack of all trades, master of none: Is copyright protection justified for robotic faux-riginality? We Robot, Miami. https://robots.law.miami.edu/2019/wp-content/uploads/2019/03/SaritKMizrahi_WeRobot_Article.pdf
- Nguyen, A., Dosovitskiy, A., Yosinski, J., Brox, T., & Clune, J. (2016). Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. x, arXiv:1605.09304.
- Nissenbaum, H., & Brunton, F. (2015). Obfuscation: A user’s guide for privacy and protest. MIT Press.
- Paez, D. (2019). ‘This person does not exist’ Creator Reveals His Site’s Creepy Origin Story. Inverse. https://www.inverse.com/article/53414-this-person-does-not-exist-creator-interview
- Postman, N. (2011). Technopoly: The surrender of culture to technology. Vintage.
- Powles, J. (2018). The seductive diversion of ‘solving’ bias in artificial intelligence. OneZero. https://onezero.medium.com/the-seductive-diversion-of-solving-bias-in-artificial-intelligence-890df5e5ef53
- Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv:1511.06434.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. J. O. B. (2019). Language models are unsupervised multitask learners. 1, 8.
- Samuel, A. L. (1959). Some studies in machine learning using the game of checkers. IBM Journal of Research and Development, 3(3), 210–229. https://doi.org/10.1147/rd.33.0210
- Samuel, S. (2019). It’s disturbingly easy to trick AI into doing something deadly. Vox. https://www.vox.com/future-perfect/2019/4/8/18297410/ai-tesla-self-driving-cars-adversarial-machine-learning
- Sattigeri, P., Hoffman, S. C., Chenthamarakshan, V., & Varshney, K. R. (2018). Fairness gan. arXiv:1805.09910.
- Selbst, A. D., Boyd, D., Friedler, S. A., Venkatasubramanian, S., & Vertesi, J. (2019, 29-31 January). Fairness and abstraction in sociotechnical systems. Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA. https://dl.acm.org/doi/10.1145/3287560.3287598.
- Sicardi, A. (2018). Do androids dream Of Balenciaga SS29? Robbie Barrat imagines a future in which the creative director is a computer. SSENSE. https://www.ssense.com/en-se/editorial/fashion/do-androids-dream-of-balenciaga-ss29?utm_term=collabshare
- Simonite, T. (2019). Forget politics. For now, deepfakes are for bullies. Wired. https://www.wired.com/story/forget-politics-deepfakes-bullies/
- Sontag, S. (2005). On photography. RosettaBooks LLC.
- Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2013). Intriguing properties of neural networks. arXiv:1312.6199.
- Thompson, S., & Barrat, R. (2018). The artist, the curator, and the neural net: A conversation with Robbie Barrat. Paprika! https://yalepaprika.com/articles/the-artist-the-curator-and-the-neural-net-a-conversation-with-robbie-barrat/
- Tiu, E. (2020). Understanding latent space in machine learning. Learn a fundamental, yet often ‘hidden,’ concept of deep learning. Medium. Towards Data Science. https://towardsdatascience.com/understanding-latent-space-in-machine-learning-de5a7c687d8d
- Wachter, S., Mittelstadt, B., & Russell, C. (2018). Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harvard Journal of Law & Technology, 31(2), 841–887. https://doi.org/10.2139/ssrn.3063289.
- Xie, L., Lin, K., Wang, S., Wang, F., & Zhou, J. (2018). Differentially private generative adversarial network. arXiv:1802.06739.
- Xu, D., Yuan, S., Zhang, L., & Wu, X. (2018, 10-13 December). Fairgan: Fairness-aware generative adversarial networks. 2018 IEEE International Conference on Big Data, Seattle, WA.
- Ye, G., Tang, Z., Fang, D., Zhu, Z., Feng, Y., Xu, P., Chen, X., & Wang, Z. (2018, 15-19 October). Yet another text captcha solver: A generative adversarial network based approach. Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, Canada.
- Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., Farhadi, A., Roesner, F., & Choi, Y. (2019). Defending against neural fake news. Advances in Neural Information Processing Systems. arXiv:1905.12616.
- Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., & Metaxas, D. N. (2017, 22-29 October). Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy.