
ABSTRACT
Algorithmic profiling has become increasingly prevalent in many social fields and practices, including finance, marketing, law, cultural consumption and production, and social engagement. Although researchers have begun to investigate algorithmic profiling from various perspectives, socio-technical studies of algorithmic profiling that consider users’ everyday perceptions are still scarce. In this article, we expand upon existing user-centered research and focus on people’s awareness and imaginaries of algorithmic profiling, specifically in the context of social media and targeted advertising. We conducted an online survey geared toward understanding how Facebook users react to and make sense of algorithmic profiling when it is made visible. The methodology relied on qualitative accounts as well as quantitative data from 292 Facebook users in the United States and their reactions to their algorithmically inferred ‘Your Interests’ and ‘Your Categories’ sections on Facebook. The results illustrate a broad set of reactions and rationales to Facebook’s (public-facing) algorithmic profiling, ranging from shock and surprise, to accounts of how superficial – and in some cases, inaccurate – the profiles were. Taken together with the increasing reliance on Facebook as critical social infrastructure, our study highlights a sense of algorithmic disillusionment requiring further research.
Introduction
Profiling describes the ‘systematic and purposeful recording and classification of data related to individuals’ (Büchi et al., Citation2020, p. 2). While surveillance and profiling have traditionally been viewed as government activities, private companies are increasingly incentivized by the competitive advantage of the surveillance-based economy to profile individuals’ private and social lives (West, Citation2019; Zuboff, Citation2019). Furthermore, sophisticated dataveillance techniques – surveillance based on digital traces – help foster such profiling activities (Sax, Citation2016; Van Dijck, Citation2014).
While algorithmic profiling as a key element of surveillance capitalism has received ample attention in critical literature in recent years, the user perspective is still under-reflected. Some empirical studies have confronted users with algorithms more generally (e.g., Eslami et al., Citation2015, Citation2016; Rader et al., Citation2018), yet what users know about algorithmic profiling and what perceptions, opinions, and imaginaries they have remains largely unexplored. By allowing corporations to make inferences about individuals’ lives, algorithmic profiling goes beyond privacy or data protection, and extends a potential threat to individual autonomy (Wachter, Citation2020). Such inferences entail predictions about future actions, inactions, general characteristics, and specific preferences. These inferences create substantial power asymmetries between users and corporations (Kolkman, Citation2020; Zuboff, Citation2019) and can lead to discrimination in areas such as credit scoring, pricing, and job screening (Noble, Citation2018).
To better understand the user perspective, we designed a survey with the following research question: What reactions and rationales do Facebook users have towards algorithmic profiling for targeted advertising? We explored such reactions and rationales in concrete terms, by confronting Facebook users with their own algorithmically derived profiles. Thus, within the larger research field of empirical algorithm studies focused on ethnographic perspectives, our primary contribution is on the reception, or user, side as opposed to the construction/developer side or other forms of algorithm audits and historical critiques (Christin, Citation2020).
In an attempt to signal transparency and potentially increase user trust, Facebook’s ad preferences include two sections, ‘Your Interests’ and ‘Your Categories’, where users can see their algorithmically inferred attributes used for targeted advertising. What do users feel about and how do they make sense of these attributes, attributes that they unknowingly contributed to? What models, folk theories, and imaginaries of algorithmic profiling do users derive? While initial research has found low levels of awareness and relatively high levels of discomfort about such algorithmic profiling in the context of Facebook (Hitlin & Rainie, Citation2019), a deeper understanding about specific thoughts (rationales) and feelings (reactions and emotions) is needed. This article goes beyond awareness and concern and offers a broader and deeper mapping of the reasoning and perceptions users have towards algorithmic profiling.
The open-ended nature of the questionnaire allowed for a thematic analysis, bringing new aspects to light; for example, many users are underwhelmed by the sophistication of algorithmic profiling, are only mildly surprised by inaccuracies in the inferences, but display greater concern when confronted with accurate inferences. Some users might have internalized the belief that Facebook collects and knows ‘everything’, only to be surprised when shown the limitations of algorithmic profiling in practice. Other users still display surprise or shock by how much Facebook is able to infer. More broadly, a theme of algorithmic uncertainty and disillusionment permeated the responses. Such algorithmic disillusionment, which describes the perception that ‘algorithms appear less powerful and useful but more fallible and inaccurate than previously thought’ (Felzmann et al., Citation2019, p. 7), can have adverse effects: if users overestimate the extent of algorithmic profiling, they might constrain themselves preemptively (‘chilling effects’, see Büchi et al., Citation2020); underappreciation, on the other hand, may lead to carelessness, privacy infringements and undue surveillance. Therefore, a realistic and balanced view of algorithmic profiling practices is particularly important as digital platforms have become critical social infrastructure (i.e., abstaining is often not an option; Lutz et al., Citation2020; West, Citation2019). Yet, the allocation of responsibilities in leading such efforts is contested (data protection authorities, governments, local authorities, industry), as are the measures (campaigns, ads, legislation) to inform and protect users. In this sense, understanding user voices is instrumental to creating awareness mechanisms that can allow users to reflect on companies’ and their individual practices and ultimately empower users to develop a self-determined and responsible approach towards using platforms. At the same time, how users perceive algorithms can inform platform practices and shape their transparency efforts. Thus, our article not only contributes to academic research on profiling, targeted advertising, and algorithms in the context of social media but also provides interesting insights for policy and practice.
Literature review
Based on lived experiences, experiential everyday use of technologies, and even regulator and media opinions, users create imaginaries and folk stories: lay theories to explain the outcomes of technical systems (DeVito et al., Citation2017). Yet, when these informal and intuitive approaches to understanding algorithmic profiling are confronted with more information about a system’s technical underpinnings that violate their expectations and imaginaries, users are faced with discomfort, triggering them to reflect on their previously accepted imaginaries. This reflection on the accuracy of their imaginaires may result in self-inhibited behavior (Büchi et al., Citation2020), in surprise or disbelief in particular when the algorithmic inferences are irrelevant, outdated, or have no apparent connection to an online activity (Hautea et al., Citation2020), as well as in disillusionment pertaining to a technology’s sophistication (e.g., De Graaf et al., Citation2017; Felzmann et al., Citation2019).
Users’ awareness through imaginaries, folk theories, and intuitions
Perceptions of algorithms should be understood in a broader sense since algorithms are not isolated technologies, but socio-technical systems within larger data assemblages (Kitchin & Lauriault, Citation2014; Siles et al., Citation2020). Data assemblages consist of ‘many apparatuses and elements that are thoroughly entwined’ and entail the ‘technological, political, social, and economic apparatuses that frame their nature and work’ (Kitchin & Lauriault, Citation2014, p. 6). To analyze algorithms through a data assemblages perspective, user imaginaries (Bucher, Citation2017) and folk theories (Eslami et al., Citation2015; Siles et al., Citation2020; Ytre-Arne & Moe, Citation2021) have been used.
Existing research has focused on understanding what and how much individuals know about profiling and the inner workings of algorithms (Powers, Citation2017; Schwartz & Mahnke, Citation2021), as well as users’ evaluation or feelings towards such practices (Hautea et al., Citation2020; Lomborg & Kapsch, Citation2020; Lupton, Citation2020; Ruckenstein & Granroth, Citation2020; Siles et al., Citation2020). Swart’s (Citation2021) experiential approach shows that users build a perceived awareness of algorithms through lived emotional experiences, everyday use of social media, and media coverage of data and privacy scandals, creating folk theories of how algorithms operate (Bucher, Citation2018; Swart, Citation2021).
The idea of an algorithmic imaginary is used to better understand the ‘spaces where people and algorithms meet’ (Bucher, Citation2017, p. 42), focusing not only on how humans think about what algorithms are, what algorithms should be, and how algorithms function, but also on how human perceptions of algorithms can play a ‘generative role in moulding the algorithm itself’ (p. 42). Lupton’s (Citation2020) more-than-human theoretical approach to algorithms seeks to understand humans and data/technologies as inseparable, thus focusing on human experiences and agency when understanding algorithmic profiling. Using a stimulus of a ‘data persona’ as an algorithmic imaginary to unpack how users view profiling algorithms as a representation of themselves, Lupton (Citation2020) found that most participants believed that their real selves ‘remain protected from the egresses of datafication’ (p. 3172) and that data profilers do not know everything about them.
Eslami et al. (Citation2016) used the concept of folk theories to better understand user perceptions of the automated curation of content displayed on Facebook’s news feed. Folk theories are ‘intuitive, informal theories that individuals develop to explain the outcomes, effects, or consequences of technological systems’ (DeVito et al., Citation2017, p. 3165). These theories may differ considerably from expert theories, as they require users to generalize how these algorithms work based on their own experiences. Siles et al. (Citation2020) utilized folk theories on Spotify recommendation algorithms to help broaden our understanding of human and machine agency. They argued that folk theories illustrate not only how people make sense of algorithms, their expectations of and values for data that emerge, but also how folk theories can ‘enact data assemblages by forging specific links between their constitutive dimensions’ (p. 3).
Discomfort with algorithmic profiling
Being aware of data collection activities does not prevent participants from feeling discomfort when faced with algorithmic practices (Bucher, Citation2017). For instance, a user can be very much aware of Facebook’s data collection practices but still not feel at ease, for example if that user is unexpectedly confronted with images of their ex-partner on their news feed. In other words, algorithms that unearth past behavior can cause unpleasant sensations of being surveilled, undermining personal autonomy and privacy (Ruckenstein & Granroth, Citation2020).
This also holds true for online tracking and targeted advertisements (Lusoli et al., Citation2012; Madden & Smith, Citation2010; Turow et al., Citation2005, Citation2009). If a user finds an advertisement relating to something dear to them that they did not make explicitly public, they may feel as if their phone was listening to them (Facebook, Citation2016). The most probable truth is that such targeted advertising has been presented to the user thanks to the combination of Facebook data and other sources (Kennedy et al., Citation2017). This discomfort indicates that users have certain expectations of appropriate information flow or contextual integrity and may decide on a case-by-case basis which practices are permissible (Nissenbaum, Citation2010), creating a sense of discomfort when those imaginaries and reality mismatch.
However, instead of discomforted, users might feel disappointed or disillusioned about the real capabilities of algorithmic profiling. Algorithmic disillusionment refers to the cognitive state of underwhelm or disenchantment when individuals are confronted with the actual technological capabilities of a system (De Graaf et al., Citation2017). Some individuals may express mere annoyance about the rigidness, rule-bound, and limited substantiality of profiling algorithms that seem to rely mostly on age, gender, and location data for profiling (i.e., ‘crude sorting mechanisms’) (Ruckenstein & Granroth, Citation2020, p. 18) without much else to add. As Ruckenstein and Granroth (Citation2020) state, these emotional reactions to targeted ads extend to dissatisfactions and preferences connected with ‘datafication, surveillance, market aims, identity pursuits, gender stereotypes, and self-understandings’ (p. 17) that may result in general disillusionment. Similarly, Ytre-Arne and Moe (Citation2021) found that many users in Norway perceived algorithms as generally irritating, but ultimately unavoidable, showing the inevitability of an algorithmic-based society.
Ytre-Arne and Moe (Citation2021), in a large-scale survey of Norwegian adults, identified five folk theories in relation to algorithms: algorithms as confining, practical, reductive, intangible, or exploitative. Across these five folk theories, ‘digital irritation’ emerged as an overarching attitude towards algorithms. The authors situate digital irritation in relation to adjacent, but slightly different, concepts such as digital resignation (Draper & Turow, Citation2019) and surveillance realism (Dencik & Cable, Citation2017). Compared to digital resignation and surveillance realism, digital irritation assumes a more active and agentic user role, while acknowledging the problematic aspects of algorithms. Our article draws on these perspectives and extends existing research by offering a more holistic perspective on perceptions of algorithmic profiling on Facebook. We set out to answer the following research questions: What reactions and rationales do Facebook users have towards algorithmic profiling for targeted advertising? How do they react when confronted with their algorithmically derived interests and categories?
Methods
Data collection
This study is based on an online survey launched in late November 2019 and programed in Qualtrics. We limited participation to active Facebook users in the US and obtained 292 valid responses. The participants were recruited via Prolific due to its sophisticated screening functionality, ethical participant remuneration, and ease of use (Palan & Schitter, Citation2018). The median completion time was 19.28 minutes (SD = 9.75 minutes) and the average payment was 8.5 USD/hour. Participants were 39 years old on average (SD = 12.64). 55% identified as female, 44% as male, and 1% had a different gender identity. 55% had obtained a college or university degree and the median annual household income was between 50,000 and 60,000 USD before taxes. A majority (59%) indicated being online ‘almost constantly.’ These demographic characteristics are remarkably close to those of the U.S. Facebook-using population according to market research firms (Statista, Citation2020a).Footnote1
Procedure and measures
The survey included closed-ended questions on demographics, data privacy concerns, privacy protection behavior, social media and internet use, and an in-depth section on respondents’ perceptions of profiling, based on Facebook’s ‘Your interests’ and ‘Your categories’ sections in the Ad Preferences menu (Hitlin & Rainie, Citation2019). The respondents received detailed instructions on how to access ‘Your interests’ and ‘Your categories’ in Facebook desktop and the Facebook app. For the desktop version, we presented them with stepwise screenshots that explained where this information is located. ‘Your interests’ and ‘Your categories’ are both relatively hidden within Facebook (it takes at least seven steps from the home screen) and respondents were asked whether they had ever visited this section of the settings before. Hitlin and Rainie (Citation2019), in a Pew survey of 963 US-based Facebook users with a similar research design to ours, found that 74% of respondents did not know that Facebook maintained this information. Even if respondents were familiar with the existence of these sections, the content might have changed since they last checked and few users can be expected to be completely aware of the full scope of the information.
Crucial for the exploration of folk theories, we additionally used six open text fields to elicit the narratives, imaginaries, and reactions to Facebook’s algorithmic profiling. The following phrasing was used for the first two questions: ‘How do you think Facebook determines which ads to display to you?’ and ‘What kind of data do you think Facebook has about you?’ Two questions then queried users on their reactions to the terms listed in their ‘Your interests’ and ‘Your categories’ sections (both worded in the same way but in different parts of the survey): ‘What are your first impressions? Please write down what you think, what you find interesting, and what surprises you.’ Finally, two questions asked respondents to engage with specific categories in more depth after being asked to select up to three categories they find particularly interesting or surprising: ‘Why do you find these categories particularly interesting or surprising?’ and ‘How do you think Facebook inferred these categories?’
Analysis
We relied on thematic analysis and iterative coding to make sense of the responses. Coding was done in a spreadsheet with the respondents’ answers for each of the six open text answers in one-column and first-order codes in a separate column. We paid particular attention to recurring responses and indicators, such as surprise, and justifications for these indicators. Statements were also coded based on certain concepts, such as ‘privacy’, and emotional themes and words, such as ‘creepiness’, ‘anger,’ ‘weirdness’ or ‘apathy’. From the initial coding, further developed themes helped group together patterns of interactions between codes. These second-order themes refer to the relationship between surprise and accuracy. They reflect how this interaction between perceived accuracy of a category and level of surprise relates to participants responding with certain emotions and feelings, such as concern being associated with negative emotions and surprise, or how unconcerned behavior is associated with positive or neutral emotions and surprise. In the following, we report the main results of our analysis and use direct quotes from the respondents to illustrate key tendencies. The selection of quotes was guided by suitability. Thus, we looked at all quotes for a specific theme and then selected the ones that capture a specific point best and are most meaningful to the reader in case there were several ‘competing’ quotes. We also opted for longer and more elaborate quotes over one-word or few-word quotes if they captured the same point.
Results
Awareness and emotional reactions
In line with Hitlin and Rainie (Citation2019), we found that few respondents had ever visited these settings pages: 21% for ‘Your Interests’ and 13% for ‘Your Categories.’ Some respondents explicitly commented on this, for example, ‘Interesting. I didn’t know that was there. Not very concerned though. I imagine they know a lot more than that page shows’. As such, this study raised awareness with participants and was able to elicit genuine first reactions. Nearly a third (31.2%) was ‘very unaware’ that Facebook linked interests to them. As a reaction, many respondents were curious how Facebook inferred these (e.g., ‘This is interesting and kind of creepy’), resulting in uneasiness or feeling overwhelmed, reflected for instance in the following response: ‘I was shocked how much information they have about me geared towards ads. It makes me feel unsettled’. In addition, a subset was surprised that the interests listed were inaccurate or did not reflect their personality: ‘[…] many do not align with my preferences. It’s surprising to see so many brands and places that are recommended without them being appealing to me’.
Among those who were less shocked, different degrees of surprise were experienced. Some characterized Facebook as data-hungry: ‘They’ve gotten this information from what I’ve clicked, liked, shared, etc. Nothing surprises me about Facebook and what info they have at this point’ and ‘On Facebook, people need to be aware that THEY are the product and that the customers are information-hungry advertisers’. Others were also not surprised by the fact that Facebook collects a lot of data, but rather by how these inferences are curated and by specific inferences:‘I did not know they had all these interests tracked. Some of them are surprising because it looks like they were taken from private conversations’. In some cases, the interests were perceived as outdated and respondents were curious about the data collection process: ‘It seems to contain interests that I don’t remember ever using in FB itself. I’m curious about where the data came from and whether FB shares it with other companies’.
Nearly half (47.3%) of respondents were ‘very unaware’ that Facebook linked categories to them, an even larger proportion compared to interests. When analyzing the responses to ‘Your categories’, we found that 47.6% of users thought that these reflected them accurately, and a minority (27.7%) thought that these categories reflected them inaccurately (). Some were amused rather than concerned at inaccurate profiling: ‘Bwahaha – they think I’m a black male. Raises hand, white female here’, ‘It says Some of my interests are motherhood (I’m not a parent) and cats (I hate cats, dogs are where it’s at)’, or ‘Hilarious in it’s inaccuracy’. In some instances, respondents found the amount or value of the inferred attributes limited which curbed concerns: ‘It has very little of my information in it, so I’m really not concerned.’
Figure 1. Responses to ‘How accurately would you say these categories reflect you as a person?’.
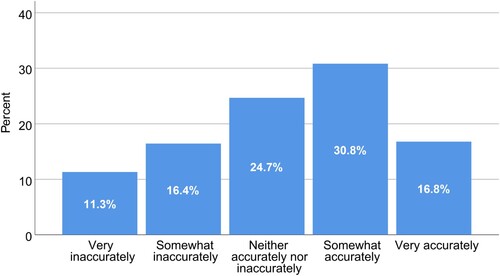
For those who thought the inferences were somewhat or very accurate, we also noticed a spectrum of surprise-related feelings, from ‘I am not surprised at all by what I found here’ to ‘It is very surprising that they know this much stuff about me in the first place’. Some users explicitly commented on accuracy (‘How well I was described!’), whereas others also acknowledged the categories’ accuracy, but again questioned their value: ‘I am not sure how useful it would be for advertising purposes’. Other respondents were surprised that their personal information, for instance about education, relationship status, and employment, was used for advertising without their knowledge. We noticed a disproportionate presence of feelings of anger when users were confronted with their profiles, as reflected by the following two quotes:‘I am angry that there is so much information on my friends’; ‘I find it very upsetting that Facebook made the decisions for me’. A few respondents also expressed a strong sense of concern or fear:‘I think the amount of data Facebook collects is terrifying’.
Sense-making: users’ rationales, thoughts, and folk theories
Thinking generally about the kind of data Facebook may have about them, some respondents seemed to rationalize the type and amount of data by referring to individual control. These users ‘blame’ themselves for the data Facebook has by claiming that Facebook has ‘everything that I have uploaded’. Users largely said they had either purposefully given Facebook the data or that they are able to reconstruct how Facebook got the data. The following quotes illustrate this sentiment: ‘Everything I have searched online’; ‘Whatever I choose to let it have’; ‘Anything that I’ve ever posted, clicked or viewed’. A majority thus rationalized that targeted ads reflect their own voluntary online behaviors including activity outside of Facebook (e.g., ‘What I do online’; ‘Based on my purchases and other searches’) and their actions on Facebook (e.g., ‘Based on your likes and the likes of your friends, quizzes’).
Similarly indicative of perceived control, but in another direction, some believed that their individual actions could limit the data that Facebook has:‘I limit what I do on facebook. I cut the number of people I follow to only those I really know. I limit the groups I follow’. Trying to explain how Facebook tracks users online beyond the app or website itself, a few participants mentioned data exchanges, either with Facebook-related applications (e.g., ‘all of the sites that are linked to Facebook through granted app permissions’) or with other big tech companies such as Google, Amazon, and eBay (e.g., ‘They use your search history and items you view on sites like amazon to display ads targeting items you searched’).
Few participants expressed their deep distrust of Facebook while trying to make sense of specific experiences where profiling became visible:
They listen in to me through the messenger app that I have on my smartphone. There have been NUMEROUS times that I have been talking to my husband about an article or book that I read and then gone on FB and there was an ad for that product/item.
When respondents were asked how they thought Facebook inferred the categories that they identified as particularly interesting or surprising, we again encountered a variety of attempts to explain what data Facebook has and how ads are displayed. Browsing history (‘Probably takes info from google search history’), device meta-data (‘based on GPS and the devices that I use’), one’s own Facebook activities (‘Probably by what I’ve shared, liked, and posted’), and others’ activities (‘I think my wife tagged me in a post for the travel which is way better than them finding out where I accessed the internet. I hope that’s the case’) were mentioned as data categories that feed into profiling algorithms. Many respondents also conjectured that Facebook integrates data from various sources: ‘Some of these categories seem like they could be roughly gathered on websites I have visited’; ‘These were obtained through other means than me willingly putting that information out’. Data brokerage was only a minor theme and none of the respondents mentioned other Facebook-owned platforms such as Instagram or WhatsApp. When data brokerage and aggregation were mentioned, Google was the most frequent reference. Few respondents referred to specific technologies, such as cookies. Similarly, respondents rarely mentioned algorithms: only 10 respondents mentioned the term, either without explanation (e.g., ‘by algorithm’, ‘Algorithms!’, ‘From their algorithms’) or embedded in a narrative of uncertainty, opacity, and inaccuracy (‘I guess Facebook uses some algorithm, but it wasn’t very accurate this times’).
A few participants provided detailed rationales for their statements. Some of the most sophisticated accounts were tied to specific life events and situations:
I think Facebook probably infers my political viewpoints based off of half the people I went to school with constantly posting political stuff all the time, including my age group and the Twin Cities is overall liberal too. Not sure how Facebook determines who is multicultural. I have black family members and a few close black friends that I interact with on Facebook, so I suppose that’s why.
Taken together, these findings indicate a scattered landscape of folk theories and rationales behind respondents’ perceptions of Facebook’s profiling activity. In line with folk theories of technological systems literature (e.g., DeVito et al., Citation2017), when algorithmic outcomes are made visible, we found users combine personal experiences and pre-existing assumptions to ‘reverse-engineer’ the inner workings of Facebook’s profiling. The rationales are predominantly mono-thematic and based on one key way of data accumulation that is directly visible and apparent – for example, the infrequent mentions of algorithms, data brokerage, and Facebook-owned platforms (Instagram, WhatsApp) suggests that most users are not aware of and do not question the underlying data assemblages. This lack of more elaborate and ‘big-picture’ accounts could also be partially due to the context of the survey, where time constraints and wording might have prevented more detailed rationales. Nevertheless, the consistent absence of discussion around underlying data assemblages seems to indicate that in general users lack a systemic understanding of algorithmic profiling.
Discussion
In addition to surprise about the extent of personalized attributes offered to advertizers, our findings also point to an opposing theme of algorithmic disillusionment in users’ reactions to seeing their ‘Your Interests’ and ‘Your Categories’. Many reacted to their profiles with a sense of disenchantment and feeling underwhelmed (see De Graaf et al., Citation2017). This theme captures a perception that algorithms are less powerful and useful, but instead more fallible and inaccurate than originally thought (Felzmann et al., Citation2019). Such algorithmic disillusionment can be connected to the machine heuristic (Sundar & Kim, Citation2019) and overtrust (Wagner et al., Citation2018), where users overestimate technologies and see them as more capable than they actually are, especially compared with human behavior as a benchmark. ‘When the perceived locus of our interaction is a machine, rather than another human being, the model states that we automatically apply common stereotypes about machines, namely that they are mechanical, objective, ideologically unbiased and so on’ (Sundar & Kim, Citation2019, p. 2). Previous research has shown that such a machine heuristic is relatively common and can be fostered by design cues (Adam, Citation2005; Sundar & Kim, Citation2019; Sundar & Marathe, Citation2010). Given that Facebook is frequently portrayed as extremely data-rich, powerful, technologically sophisticated, and manipulative – both in popular culture (e.g., the Netflix movie ‘The Social Dilemma’, which was heavily criticized by scholars and digital activists) and academic discourse (Zuboff, Citation2019) – many users might have developed an internal image of Facebook that was more advanced than what they were actually confronted with.
Although buried deep in the user preferences, these lists of inferred interests and categories seem to reflect Facebook’s attempts at transparency and simplify the practice of algorithmic profiling substantially. And despite serving the purpose of stimulating respondents’ reflections on algorithmic profiling, the information in these profiles is without much doubt only a curated list with an opaque origin deemed ‘presentable’ by Facebook. In this sense, algorithmic disillusionment should be understood in the context of the experience of uncertainty. Many respondents were unsure about Facebook’s profiling practices in general (what data does Facebook have about them) and in specific instances (how Facebook decides to display ads; how Facebook came up with the categories). Uncertainty has been discussed in the context of privacy cynicism (Hoffmann et al., Citation2016; Lutz et al., Citation2020), which conceptualizes such cynicism as an ‘attitude of uncertainty, powerlessness, and mistrust toward the handling of personal data by digital platforms, rendering privacy protection subjectively futile’ (Hoffmann et al., Citation2016, p. 2). Similarly, when confronted with their algorithmically derived profiles, many users expressed mistrust and powerlessness against Facebook’s profiling practices (see Dencik & Cable, Citation2017).
Hautea et al. (Citation2020) identified surprise as a key theme when users were confronted with their algorithmic profiles from Facebook and Google. Four types of inaccurate inferences fueled such surprise: irrelevant inferences, outdated inferences, inferences unrelated to online activities, inferences about friends and family (rather than the respondents themselves). However, their research did not investigate negative surprise as an outcome of accurate inferences. In our study, uncertainty, mistrust, and powerlessness were, in some cases, coupled with surprise, mostly negative surprise. Negative surprise can manifest as shock and outrage at how much Facebook actually knows (the information is perceived as very accurate) or, more prominently, as disillusionment: how little Facebook knows or how useless the data seems to be for Facebook (the information is perceived as mostly inaccurate).
Furthermore, these findings point to a widening gap between the goals of data protection law and other regulatory developments, the socio-legal academic discourse, and layperson perceptions of data-driven realities. Even specialists, experts, and policymakers, struggle to understand algorithms’ functioning, corporate data trading, and what is and is not permissible (Brevini & Pasquale, Citation2020). People’s uncertainty about the uses and value of user data contributes to unawareness of the potential impacts platform practices have on users’ lives. If users base their subsequent imaginaries and intuitions upon incomplete public information, they may misjudge the magnitude of this reality. This false narrative may serve corporations to continue to normalize their data practices and blur the lines of what users think is permissible under various regulations including data protection law. Online targeted advertising is only one example of corporate profiling and one where the stakes are arguably small compared to other sectors. When these profiling activities support ulterior decision-making processes in medical, criminal justice, or tax contexts, the consequences may be more severe for users.
Beyond these theoretical implications, our findings also point to social and practical implications. For users, digital skills and literacy could be improved. For example, the European Commission’s DigComp framework considers being able to ‘vary the use of the most appropriate digital services in order to participate in society’ (Carretero Gomez et al., Citation2017, p. 28) as an advanced proficiency, and explicitly addresses algorithmic decision-making (European Commission Directorate-General for Communications Networks Content and Technology, Citation2018). However, skills related to interacting with applications of algorithmic profiling will continue to reflect existing inequalities (e.g., Cotter & Reisdorf, Citation2020). Yet, it is clear, based on our findings, that the way users perceive the inaccuracy of algorithmic profiling is confined to what they know or think they know about the inner workings of algorithms and platforms. It remains unclear, however, whether this disillusionment would change if users were confronted with further information or with a scenario where more personally significant decisions were made based on inaccurate information (e.g., if the white woman quoted above who was misgendered and misclassified was denied a service or a loan, showing how much context plays a role; see Fosch-Villaronga et al., Citation2021).
For policymakers, a greater response to algorithmic disillusionment is necessary. In response to increasing platform power, privacy infringements, and large amounts of disinformation in the context of social media, policymakers have started calling for stronger regulation, especially regarding personal data processing, profiling for advertisement and recommendation of content, and the removal of illegal content. In Europe, aside from the General Data Protection Regulation, the European Commission issued on 15 December 2020 a proposal of the Digital Service Act (DSA) and Digital Market Act (DMA) to establish ‘responsible and diligent behavior by providers of intermediary services’ and to promote a ‘safe, predictable and trusted online environment’ (Rec. 3). Such legislation calls for greater predictability and transparency that could play well as a remedy for disillusionment. For instance, very large online platforms displaying advertising, such as Facebook, will have to ensure the content of the advertisement and the main parameters used for that purpose are made public (Art. 30 DSA).
Other efforts pointing in a similar direction are apparent in the DMA, which target ‘gatekeepers,’ i.e., service providers with significant impact on the internal market or operating a core platform such as Facebook. The DMA establishes obligations for gatekeepers to refrain from combining personal data sourced on one platform with other platforms (e.g., between Facebook and WhatsApp) (Art. 5 DMA). The DMA also aspires to provide effective portability of data generated by users as well as real-time access to the data. Knowing about these obligations and being able to have real-time access to these data could increase awareness among users and encourage reporting; how these acts will effectively alter the business models and impact users has yet to be seen.
Conclusion
In this article, we studied perceptions of algorithmic profiling based on an in-depth exploratory study of US-based Facebook users. We relied on Facebook’s algorithmically attributed interests and categories to elicit user reactions and reflection on Facebook’s profiling practices. Extending research on the perception of algorithmic systems (Bucher, Citation2017; Eslami et al., Citation2015, Citation2016; Siles et al., Citation2020; Ytre-Arne & Moe, Citation2021), the study spotlights algorithmic profiling, a key part of surveillance capitalism (Zuboff, Citation2019). In our analysis of open and closed questions, we found a mixed picture of emotional reactions and a broad range of folk theories, where uncertainty and speculation about Facebook’s practices dominated. Many users reported surprise or violations of expectations, because they were underwhelmed with the sophistication of the inferred profiles and unimpressed with the salient outcomes of Facebook’s ostensible technological superiority, or conversely because they were overwhelmed with the detail and invasiveness of Facebook’s profiling and data collation (‘creep factor’ and anger).
Given that social media platforms, such as Facebook, are increasingly a critical social infrastructure (Van Dijck et al., Citation2018; West, Citation2019), users either are faced with the difficult choice to give up on an important part of their social life, or to have their privacy and personal autonomy expectations violated. In the long run, feelings of apathy (Hargittai & Marwick, Citation2016) or cynicism (Hoffmann et al., Citation2016; Lutz et al., Citation2020) could make users more passive and resigned (Draper & Turow, Citation2019). Further, chilling effects have been demonstrated as a result of state surveillance (Stoycheff et al., Citation2019; see Büchi et al., Citation2020 for an overview) and in light of our results, future research could empirically investigate whether awareness of Facebook’s and other corporations’ algorithmic profiling deters users from freely using social media. Our study has shown that being confronted with their algorithmic profiles leads some users to adapt their behavioral intentions (e.g., delete their interests and categories and avoid leaving certain traces in the future), but how strongly this applies in general and how much the awareness of algorithmic profiling has free speech implications needs to be tested with further research, for example with experimental, longitudinal, and observational approaches.
Our study has several limitations that may motivate future research. First, we only investigated one platform, whereas algorithmic profiling frequently occurs across platforms and contexts (Festic, Citation2020; Zuckerman, Citation2021). Our choice of Facebook was pragmatic and allowed for some generalization, given its widespread use and importance, but future research should expand the scope, looking at other major players such as Google (including YouTube), Microsoft (including LinkedIn), and Amazon in comparison. Second, we opted for an online survey and were thus limited to how strongly we could engage participants in conversations. Face-to-face interviews could capture respondents’ perceptions more broadly, engage them in follow-up questions, and contextualize the findings more. Nevertheless, we were able to elicit meaningful and detailed responses, and the approach allowed us to sample a much larger number of respondents than would have been possible with traditional qualitative interviews. Future research could use a combination of methods to study user perceptions of algorithmic profiling more holistically, including diaries, walkthroughs, or other user-centered qualitative approaches. Finally, the study of algorithms and profiling should also consider the actors designing and employing the profiling architecture (Christin, Citation2020). Future research could combine user-centered data collection with information from those developing and working with algorithmic profiling systems.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Moritz Büchi
Moritz Büchi, PhD (University of Zurich, Switzerland), is a Senior Research and Teaching Associate in the Media Change & Innovation Division at the Department of Communication and Media Research, University of Zurich and Digital Research Consultant for the UNICEF Office of Research – Innocenti. His research interests include digital media use and its connections to inequality, well-being, dataveillance, algorithmic profiling, privacy, and skills.
Eduard Fosch-Villaronga
Eduard Fosch-Villaronga (Dr., Erasmus Mundus Joint Doctorate in Law, Science, & Technology) is an Assistant Professor at the eLaw Center for Law and Digital Technologies at Leiden University (NL), where he investigates legal and regulatory aspects of robot and AI technologies, with a special focus on healthcare, diversity, governance, and transparency. Currently, he is the PI of PROPELLING, an FSTP from the H2020 Eurobench project, a project using robot testing zones to support evidence-based robot policies. In 2019, Eduard was awarded a Marie Skłodowska-Curie Postdoctoral Fellowship and published the book Robots, Healthcare, and the Law (Routledge).
Christoph Lutz
Christoph Lutz (Dr., University of St. Gallen, Switzerland) is an associate professor at the Nordic Centre for Internet & Society within the Department of Communication & Culture, BI Norwegian Business School (Oslo). His research interests include digital inequality, online participation, privacy, the sharing economy, and social robots. Christoph has published widely in top-tier journals in this area such as New Media & Society, Information, Communication & Society, Big Data & Society, Social Media + Society, and Mobile Media & Communication.
Aurelia Tamò-Larrieux
Aurelia Tamò-Larrieux (Dr., University of Zurich, Switzerland) is currently a postdoctoral fellow and lecturer at the University of St. Gallen in Switzerland. Her research interests include privacy, especially privacy-by-design, data protection, social robots, automated decision-making, trust in automation, and computational law. Aurelia has published her PhD research on the topic of data protection by design and default for the Internet of Things in the book Designing for Privacy and its Legal Framework (Springer, 2018).
Shruthi Velidi
Shruthi Velidi (Bachelor Cognitive Science, Rice University) is a responsible technology, artificial intelligence, and data policy expert based in New York. Shruthi Velidi was awarded a Fulbright Scholarship in 2018 by the US-Norway Fulbright Fellowship Foundation, spending a one-year fellowship at the Nordic Centre for Internet and Society, BI Norwegian Business School (Oslo). Her research interests include privacy, algorithmic and corporate profiling, as well as artificial intelligence and policy.
Notes
1 While we did not find an up-to-date source for the average age of US-based Facebook users, the age distribution is reported in Statista (Citation2020b). Together with the fact that about 69% of US adults use Facebook (Pew, Citation2019) and that the median age in the US in general is 38.4 years (Statista, Citation2021), an average age of Facebook users of about 40 years seems realistic.
References
- Adam, A. (2005). Delegating and distributing morality: Can we inscribe privacy protection in a machine? Ethics and Information Technology, 7(4), 233–242. https://doi.org/10.1007/s10676-006-0013-3
- Brevini, B., & Pasquale, F. (2020). Revisiting the black box society by rethinking the political economy of big data. Big Data & Society, 7(2), 1–4. https://doi.org/10.1177/2053951720935146
- Bucher, T. (2017). The algorithmic imaginary: Exploring the ordinary affects of Facebook algorithms. Information, Communication & Society, 20(1), 30–44. https://doi.org/10.1080/1369118X.2016.1154086
- Bucher, T. (2018). If … then: Algorithmic power and politics. Oxford University Press.
- Büchi, M., Fosch-Villaronga, E., Lutz, C., Tamò-Larrieux, A., Velidi, S., & Viljoen, S. (2020). The chilling effects of algorithmic profiling: Mapping the issues. Computer Law & Security Review, 36, 105367. https://doi.org/10.1016/j.clsr.2019.105367
- Carretero Gomez, S., Vuorikari, R., & Punie, Y. (2017). DigComp 2.1: The digital competence framework for citizens with eight proficiency levels and examples of use (JRC106281). Publications Office of the European Union. https://doi.org/10.2760/00963(ePub)
- Christin, A. (2020). The ethnographer and the algorithm: Beyond the black box. Theory and Society, 1–22. https://doi.org/10.1007/s11186-020-09411-3
- Cotter, K., & Reisdorf, B. C. (2020). Algorithmic knowledge gaps: A new dimension of (digital) inequality. International Journal of Communication, 14, 745–765. https://ijoc.org/index.php/ijoc/article/view/12450
- De Graaf, M., Allouch, S. B., & Van Dijk, J. (2017, March 6–9). Why do they refuse to use my robot? Reasons for non-use derived from a long-term home study. In 2017 12th ACM/IEEE international conference on Human-Robot Interaction (HRI) (pp. 224–233).
- Dencik, L., & Cable, J. (2017). The advent of surveillance realism: Public opinion and activist responses to the Snowden leaks. International Journal of Communication, 11, 763–781. https://ijoc.org/index.php/ijoc/article/view/5524
- DeVito, M. A., Gergle, D., & Birnholtz, J. (2017, May). “Algorithms ruin everything”: #RIPTwitter, folk theories, and resistance to algorithmic change in social media. In Proceedings of the 2017 CHI conference on human factors in computing systems (pp. 3163–3174). ACM. https://doi.org/10.1145/3025453.3025659
- Draper, N. A., & Turow, J. (2019). The corporate cultivation of digital resignation. New Media & Society, 21(8), 1824–1839. https://doi.org/10.1177/1461444819833331
- Eslami, M., Karahalios, K., Sandvig, C., Vaccaro, K., Rickman, A., Hamilton, K., & Kirlik, A. (2016). First I “like” it, then I hide it: Folk theories of social feeds. In Proceedings of the 2016 CHI conference on human factors in computing systems (pp. 2371–2382). ACM. https://doi.org/10.1145/2702123.2702556
- Eslami, M., Rickman, A., Vaccaro, K., Aleyasen, A., Vuong, A., Karahalios, K., Hamilton, K., & Sandvig, C. (2015, April, 18–23). I always assumed that I wasn’t really that close to [her]: Reasoning about invisible algorithms in news feeds. In CHI’15: Proceedings of the 33rd annual ACM conference on human factors in computing systems (pp. 153–162). ACM. https://doi.org/10.1145/2702123.2702556
- European Commission’s Directorate-General for Communications Networks, Content and Technology (EC DG Communication Network, Content, and Technology) (2018). Algo:Aware. Raising awareness on algorithms. European Commission. https://platformobservatory.eu/app/uploads/2019/06/AlgoAware-State-of-the-Art-Report.pdf.
- Facebook (2016) Facebook does not use your phone’s microphone for ads or news feed stories. https://about.fb.com/news/h/facebook-does-not-use-your-phones-microphone-for-ads-or-news-feed-stories/
- Felzmann, H., Villaronga, E. F., Lutz, C., & Tamò-Larrieux, A. (2019). Transparency you can trust: Transparency requirements for artificial intelligence between legal norms and contextual concerns. Big Data & Society, 6(1), 1–14. https://doi.org/10.1177/2053951719860542
- Festic, N. (2020). Same, same, but different! Qualitative evidence on how algorithmic selection applications govern different life domains. Regulation & Governance, 1–17. https://doi.org/10.1111/rego.12333
- Fosch-Villaronga, E., Poulsen, A., Søraa, R. A., & Custers, B. H. M. (2021). A little bird told me your gender: Gender inferences in social media. Information Processing & Management, 58(3), 102541. https://doi.org/10.1016/j.ipm.2021.102541
- Hargittai, E., & Marwick, A. (2016). “What can I really do?” Explaining the privacy paradox with online apathy. International Journal of Communication, 10, 3737–3757. https://ijoc.org/index.php/ijoc/article/view/4655
- Hautea, S., Munasinghe, A., & Rader, E. (2020). ‘That’s not me’: Surprising algorithmic inferences. In Extended abstracts of the 2020 CHI conference on human factors in computing systems (pp. 1–7). ACM. https://doi.org/10.1145/3334480.3382816
- Hitlin, P., & Rainie, L. (2019, January 16). Facebook algorithms and personal data. Pew Research Center: Internet & Technology Report. https://www.pewresearch.org/internet/2019/01/16/facebook-algorithms-and-personal-data/
- Hoffmann, C. P., Lutz, C., & Ranzini, G. (2016). Privacy cynicism: A new approach to the privacy paradox. Cyberpsychology: Journal of Psychosocial Research on Cyberspace, 10(4). https://doi.org/10.5817/CP2016-4-7
- Kennedy, H., Elgesem, D., & Miguel, C. (2017). On fairness: User perspectives on social media data mining. Convergence: The International Journal of Research into New Media Technologies, 23(3), 270–288. https://doi.org/10.1177/1354856515592507
- Kitchin, R., & Lauriault, T. (2014). Towards critical data studies: Charting and unpacking data assemblages and their work. SSRN Electronic Journal. https://papers.ssrn.com/sol3/papers.cfm?Abstract_id=2474112
- Kolkman, D. (2020). The (in)credibility of algorithmic models to non-experts. Information, Communication & Society, 1–17. https://doi.org/10.1080/1369118X.2020.1761860
- Lomborg, S., & Kapsch, P. H. (2020). Decoding algorithms. Media, Culture & Society, 42(5), 745–761. https://doi.org/10.1177/0163443719855301
- Lupton, D. (2020). Thinking with care about personal data profiling: A more-than-human approach. International Journal of Communication, 14, 3165–3183. https://ijoc.org/index.php/ijoc/article/view/13540
- Lusoli, W., Bacigalupo, M., & Lupianez, F. (2012). Pan-European survey of practices, attitudes and policy preferences as regards personal identity data management. http://is.jrc.ec.europa.eu/pages/TFS/documents/EIDSURVEY_Web_001.pdf
- Lutz, C., Hoffmann, C. P., & Ranzini, G. (2020). Data capitalism and the user: An exploration of privacy cynicism in Germany. New Media & Society, 22(7), 1168–1187. https://doi.org/10.1177/1461444820912544
- Madden, M, Smith, A (2010). Reputation management and social media: How people monitor their identity and search for others online. http://pewinternet.org/~/media/Files/Reports/2010/PIP_Reputation_Management.pdf
- Nissenbaum, H. (2010). Privacy in context: Technology, policy, and the integrity of social life. Stanford University Press.
- Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. New York University Press.
- Palan, S., & Schitter, C. (2018). Prolific.ac – A subject pool for online experiments. Journal of Behavioral and Experimental Finance, 17, 22–27. https://doi.org/10.1016/j.jbef.2017.12.004
- Pew. (2019). Social media fact sheet. Pew Research Center: Internet & Technology. https://www.pewresearch.org/internet/fact-sheet/social-media/
- Powers, E. (2017). My news feed is filtered? Awareness of news personalization among college students. Digital Journalism, 5(10), 1315–1335. https://doi.org/10.1080/21670811.2017.1286943
- Rader, E., Cotter, K., & Cho, J. (2018). Explanations as mechanisms for supporting algorithmic transparency. In Proceedings of the ACM 2018 CHI conference on human factors in computing systems (pp. 1–13). ACM. https://doi.org/10.1145/3173574.3173677
- Ruckenstein, M., & Granroth, J. (2020). Algorithms, advertising and the intimacy of surveillance. Journal of Cultural Economy, 13(1), 12–24. https://doi.org/10.1080/17530350.2019.1574866
- Sax, M. (2016). Big data: Finders keepers, losers weepers? Ethics and Information Technology, 18(1), 25–31. https://doi.org/10.1007/s10676-016-9394-0
- Schwartz, S. A., & Mahnke, M. S. (2021). Facebook use as a communicative relation: Exploring the relation between Facebook users and the algorithmic news feed. Information, Communication & Society, 24(7), 1041–1056. https://doi.org/10.1080/1369118X.2020.1718179
- Siles, I., Segura-Castillo, A., Solís, R., & Sancho, M. (2020). Folk theories of algorithmic recommendations on Spotify: Enacting data assemblages in the global South. Big Data & Society, 7(1), 1–15. https://doi.org/10.1177/2053951720923377
- Statista. (2020a). Distribution of Facebook users in the United States as of November 2020, by gender. Statista.com. https://www.statista.com/statistics/266879/facebook-users-in-the-us-by-gender/
- Statista. (2020b). Distribution of Facebook users in the United States as of November 2020, by age group and gender. Statista.com. https://www.statista.com/statistics/187041/us-user-age-distribution-on-facebook/
- Statista. (2021). Median age of the resident population of the United States from 1960 to 2019. Statista.com. https://www.statista.com/statistics/241494/median-age-of-the-us-population/
- Stoycheff, E., Liu, J., Xu, K., & Wibowo, K. (2019). Privacy and the Panopticon: Online mass surveillance’s deterrence and chilling effects. New Media & Society, 21(3), 602–619. https://doi.org/10.1177/1461444818801317
- Sundar, S. S., & Kim, J. (2019). Machine heuristic: When we trust computers more than humans with our personal information. In Proceedings of the 2019 CHI conference on human factors in computing systems (paper no. 538). ACM. https://doi.org/10.1145/3290605.3300768
- Sundar, S. S., & Marathe, S. S. (2010). Personalization versus customization: The importance of agency, privacy, and power usage. Human Communication Research, 36(3), 298–322. https://doi.org/10.1111/j.1468-2958.2010.01377.x
- Swart, J. (2021). Experiencing algorithms: How young people understand, feel about, and engage with algorithmic news selection on social media. Social Media + Society, 7(2). https://doi.org/10.1177/20563051211008828
- Turow, J., Feldman, L., & Meltzer, K. (2005). Open to exploitation: American shoppers, online and offline. http://www.annenbergpublicpolicycenter.org/Downloads/Information_And_Society/Turow_APPC_Report_WEB_FINAL.pdf
- Turow, J., Hoofnagle, C. J., & King, J. (2009). Americans reject tailored advertising and three activities that enable it. http://www.ftc.gov/bcp/workshops/privacyroundtables/Turow.pdf
- Van Dijck, J. (2014). Datafication, dataism and dataveillance: Big Data between scientific paradigm and ideology. Surveillance & Society, 12(2), 197–208. https://doi.org/10.24908/ss.v12i2.4776
- Van Dijck, J., Poell, T., & De Waal, M. (2018). The platform society: Public values in a connective world. Oxford University Press.
- Wachter, S. (2020). Affinity profiling and discrimination by association in online behavioural advertising. Berkeley Technology Law Journal, 35(2), 1–74. https://doi.org/10.15779/Z38JS9H82M
- Wagner, A. R., Borenstein, J., & Howard, A. (2018). Overtrust in the robotic age. Communications of the ACM, 61(9), 22–24. https://doi.org/10.1145/3241365
- West, S. M. (2019). Data capitalism: Redefining the logics of surveillance and privacy. Business & Society, 58(1), 20–41. https://doi.org/10.1177/0007650317718185
- Ytre-Arne, B., & Moe, H. (2021). Folk theories of algorithms: Understanding digital irritation. Media, Culture & Society, 43(5), 807–824. https://doi.org/10.1177/0163443720972314
- Zuboff, S. (2019). The age of surveillance capitalism: The fight for a human future at the new frontier of power. Profile Books.
- Zuckerman, E. (2021). Why study media ecosystems? Information, Communication & Society, 24(10), 1495–1513. https://doi.org/10.1080/1369118X.2021.1942513
