Abstract
We consider a two-country endogenous growth model where an economic follower absorbs part of the knowledge generated in a leading country. To solve a suitably defined infinite horizon dynamic optimization problem an appropriate version of the Pontryagin maximum principle is developed. The properties of optimal controls and the corresponding optimal trajectories are characterized by the qualitative analysis of the solutions of the Hamiltonian system arising through the implementation of the Pontryagin maximum principle.
1. Introduction
An endogenous growth model linking a smaller follower country to a larger autarkic leader through ‘absorptive capacities’ enabling it to tap into the knowledge generated in the leading country was introduced by Hutschenreiter et al. [Citation1]. We shall refer to this model as the ‘leader – follower’ model. It is built along the lines of the basic endogenous growth model by Grossman and Helpman [Citation2] with horizontal product differentiation, where technical progress is represented by an expanding variety of products. Based on a comprehensive analysis of the dynamic behaviour of the leader – follower model, a particular class of asymptotics was singled out. Any trajectory characterized by this asymptotics was shown to be a perfect-foresight equilibrium trajectory analogous to that found for the basic Grossman – Helpman model. For this type of trajectory, explicit expressions in terms of model parameters for key variables such as the rate of innovation, the rate of output and productivity growth, the ratio of the stocks of knowledge of the two countries, or the amounts (shares) of labour devoted to research and development (R&D) and manufacturing were given in [Citation1]. The evolution of the economy represented by this model is the result of decentralized maximizing behaviour of economic agents. A perfect-foresight equilibrium trajectory generated by the model can therefore be referred to as ‘decentralized’ or ‘market’ solution. However, a market solution is not necessarily an optimal solution.
The present paper is concerned with the dynamic model of optimal allocation of labour resources to R&D introduced by Aseev et al. [Citation3,Citation4]. An important feature of this model is that the goal functional is defined on an infinite time interval. In problems with infinite time horizons the Pontryagin maximum principle [Citation5], the key instrument in optimal control theory, is, in general, less efficient than in problems with finite-time horizons. In particular, for the case of infinite-time horizons the natural transversality conditions, providing as a rule essential information on the solutions, may not be valid [Citation6]. Additional difficulties arise owing to a logarithmic singularity in the goal functional.
In [Citation3], using an approximation approach to the investigation of optimal control problems with infinite-time horizons developed by Aseev et al. [Citation7], the existence of optimal control was proved and an appropriate version of the Pontryagin maximum principle for the problem under consideration was developed. Moreover, a particular case when the amount of labour allocated to R&D in the leading country exceeds the total labour force in the follower country was investigated.
In the present paper, we qualitatively analyse the solutions of the Hamiltonian system, arising through the implementation of the version of the Pontryagin maximum principle developed in [Citation3] in the case when the elasticity of substitution between any two products equals 2 while the other parameters of the model can take all possible values. Namely, we find that in this case the global optimizers are characterized by specific qualitative behaviours; this allows us to select the optimal regimes in the pool of all local extremals.
2. Statement of the problem and the Pontryagin maximum principle
In the model that we analyse, the economy's labour resources can be used in two different ways, either for manufacturing intermediate goods (which enter final output) or in the production of blueprints for new intermediate goods which permanently raises productivity in final goods production. The optimization problem (P) faced by a fictitious social planner maximizing utility allocating resources to R&D or manufacturing is the following:
Here x ∈ R 1, y ∈ R 1; the model parameters ρ, κ, b, a, γ, υ, x 0, y 0 are positive and an admissible control u is identified with any measurable function u(t) : [0,∞)→R 1, which is bounded on arbitrary finite time interval [0, T], T > 0.
Note that the objective function (Equation1) is equivalent to the objective function used in the social planning problem by Grossmann and Helpman [Citation2]. In the above optimal control problem, (Equation2) describes the dynamics of the knowledge stock x of the follower country, and the control parameter u in (Equation2) is a labour resource which is involved in the production of new knowledge (in the production of blueprints for new intermediate goods). A distinguishing feature of the model is that the knowledge stock available in the following country at time t is assumed to consist of the sum of the knowledge accumulated in the follower country, which is represented by the number of differentiated inputs developed so far domestically, x(t), and a term consisting of externally produced knowledge appropriated by the follower. More specifically, a fraction 0 < γ ⩽ 1 of the knowledge stock y(t) produced in the leading country is absorbed into the knowledge stock of the following country. From (Equation3) it can be seen that the autarkic leading country's stock of knowledge grows exponentially at the steady rate of innovation υ > 0. Initial conditions are fixed by (Equation4). Finally (see (Equation5)), it is assumed that the following country's R&D labour does not exhaust its total labour force and thus manufacturing activity does not vanish at any instant of time.
An important feature of problem (P) consists in the non-closedness of the interval [0,b) for admissible controls (see (Equation5)). This prevents us from referring to standard theorems stating the existence of optimal controls (see, for example, [Citation8]) and from using the modified Pontryagin maximum principle for infinite horizon optimal controls, suggested in [Citation7], directly. The existence of an optimal admissible control u *(t) in problem (P) has been proved in [Citation3].
Let
Theorem 1 (maximum principle): Let u *(t) be an optimal control in problem (P) and x *(t) be the corresponding optimal trajectory. Then there exists an absolutely continuous vector function ψ(t):[0,∞) →R 2, ψ(t) = (ψ 1(t), ψ 2(t)) such that the following conditions hold.
The vector function ψ(t) is a solution to the adjoint system | |||||
For almost all t ∈ [0,∞) the maximum condition takes place: | |||||
The condition of the asymptotic stationarity of the Hamiltonian is valid: | |||||
The vector function ψ(t) is strictly positive, that is | |||||
The proof of theorem 1 has been given in [Citation3].
Corollary: The following transversality conditions hold:
3. Problem reformulation and construction of the associated Hamiltonian system
Now we simplify the problem formulation by reducing the dimension of the state variable for 1. Set
Lemma: Problem (P) is equivalent to the optimal control problem (
Let us introduce a new adjoint variable p(t) = e pt ψ 1(t)y(t), where ψ 1(t) is the adjoint variable corresponding to the optimal trajectory x *(t) in problem (P) via the Pontryagin maximum principle (theorem 1), and let
The following result is a reformulation of theorem 1 in terms of variables z(t) and p(t).
Theorem 2: Let u*t be an optimal control in problem (
The function p(t) is a solution to the adjoint system | |||||
For almost all t ∈ [0,∞) the maximum condition occurs | |||||
The boundedness condition is valid: | |||||
Let us construct the Hamiltonian system associated with the optimal control problem (
For this we introduce the function g(z) : (0,∞) → (0,∞),
Obviously, G 1 ∪ G 2 = G where
Define functions r(z, p) : G → R 1 and s(z, p) : G → R 1,
Theorem 3: A pair (z *(t), u *(t)) is an optimal control process in problem
There exists a strictly positive function p(t) defined defined on [0,∞) such that (z *(t), p *(t)) solves the equations | |||||
For almost all t ⩾ 0, | |||||
For all t ≅ 0 | |||||
In what follows we assume that κ = 1. This case corresponds to the situation when the elasticity of substitution between any two products equals 2 [Citation3,Citation4].
4. Design of optimal control: The first case
Consider the case when inequality υ + ρ > b takes place.
In this case the structure of the vector field of the Hamiltonian system (Equation7), (Equation8) in G (see (Equation6)) may vary slightly depending on the values of parameters b and υ. Two subcases are possible: υ > b or υ + p > b ⩾ υ.
In the case when υ > b the structure of the corresponding vector field is shown in . In the case when υ + p > b = ⩾ υ the structure of the corresponding vector field is shown in . In both cases the Hamiltonian system (Equation7), (Equation8) has a unique rest point in G 1:
Fig. 1. The vector field of the Hamiltonian system (Equation7), (Equation8) for υ = 4, b = 2, κ = 1, ρ = 0.1, γ = 0.5 (a Maple simulation).
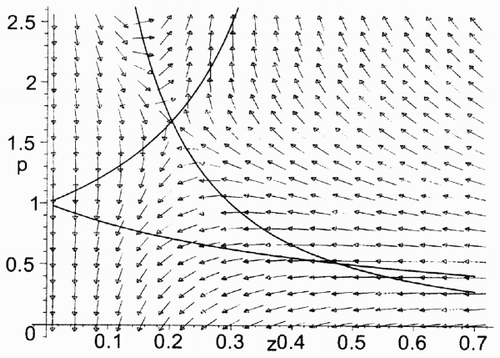
Fig. 2. The vector field of the Hamiltonian system (Equation7) (Equation8) for υ = 4, b = 4, κ = 1, ρ = 0.2, γ = 0.5 (a Maple simulation).
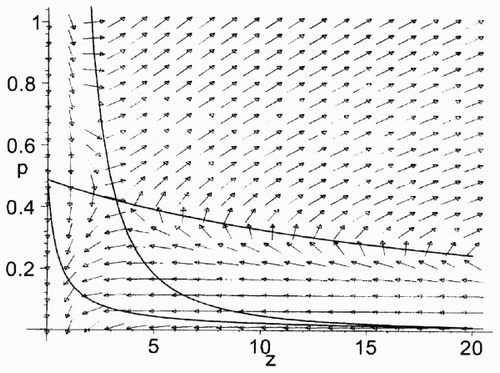
We call a solution (z(t), p(t)) of the Hamiltonian system (Equation7), (Equation8) an equilibrium solution if it is defined on [0,∞) and converges to the rest point (z*, p*). For any z 0 > 0 there exists a unique equilibrium solution to system (Equation7), (Equation8) such that z(0) = z 0.
Theorem 4: Let (z(t),p(t)) be the equilibrium solution of the Hamiltonian system (Equation7), (Equation8) which is determined by z 0. A control process (z *(t), u *(t)) is optimal in problem (
Thus in the case when υ + ρ > b the optimal asymptotic growth rate of the knowledge stock of the following country coincides with the growth rate of the leader. It is exactly the same result that was obtained for the market solution in the leader – follower model [Citation1]. Nevertheless, the corresponding absolute values of the knowledge stocks may be different [Citation3].
5. Design of optimal control: The second case
Consider now the opposite case when b ⩾ υ + ρ.
In this case, to simplify the analysis, let us introduce new variables (q, p) where q = pz.
Let us introduce the function
Obviously,
Define functions
Now we reformulate theorem 3 in terms of the variables q, p.
Theorem 5: A pair (z *(t), u *(t)) is an optimal control process in problem (
There exists a non-negative function p(t) defined on [0,∞) such that (q(t), p(t)), where q(t) = p(t)z *(t) solves the equations | |||||
For almost all t ⩾ 0, | |||||
For all t ⩾ 0, | |||||
The structure of the vector field of system (Equation10), (Equation11) is shown in . There exists a unique rest point of the Hamiltonian system (Equation10), (Equation11) in cl
Fig. 3. The vector field of the Hamiltonian system (Equation7) (Equation8) for υ = 2, b = 3, κ = 1, ρ = 0.4, γ = 0.5 (a Maple simulation).
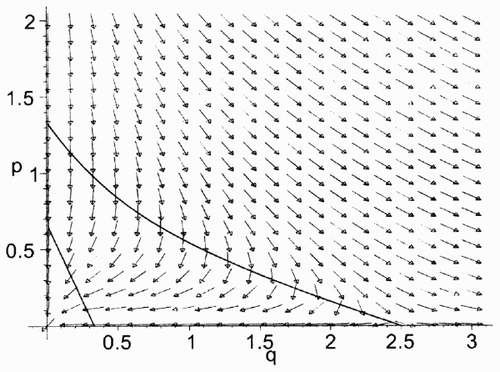
We call a solution (q(t), p(t)) of the Hamiltonian system (Equation10) an equilibrium solution if it is defined on [0,∞) and converges to the rest point (
Theorem 6: Let q(t), p(t)) be the equilibrium solution of the Hamiltonian system (Equation10), (Equation11), which is determined by z 0. A control process (z *(t), u *(t)) is optimal in problem (
6. Conclusions
For the leader – follower model examined, we conclude that, for the case of quite a small follower country (υ + p > b), the optimal asymptotic growth rate of its knowledge stock coincides with the growth rate of the leader. It is exactly the same result that was obtained for the market solution in the leader – follower model [Citation1]. However, we have shown [Citation3] that in the market solution the long-run allocation of labour resources to R&D is less than the optimal and that the optimal ratio of knowledge stocks is larger than the corresponding ratio in the market solution. This implies that the level of productivity of the follower country relative to that of the leader is less than optimal.
The situation is different in the case of the relatively large follower country (υ + p ⩽ b). In this case the ratio of optimal knowledge stocks in the follower country to that of the leader tends to infinity. This means that the follower country overtakes the leader.
Our example shows that R&D-based endogenous optimal growth models may well produce uniform long-run growth rates across countries.
References
References
- Hutschenreiter G Kaniovski Yu.M Kryazhimskii AV 1995 Endogenous growth, absorptive capacities, and international R&D spillovers IIASA Working Paper WP-95-92, International Institute for Applied Systems Analysis, Laxenburg, Austria
- Grossman GM Helpman E 1991 Innovation and Growth in the Global Economy Cambridge Massachusetts MIT Press
- Aseev S Hutschenreiter G Kryazhimskii A 2002 Dynamical model of opimal allocation of resources to R&D IIASA Interim Report IR-02-016. International Institute for Applied Systems Analysis, Laxenburg, Austria
- Aseev S Hutschenreiter G Kryazhimskii A 2002 Optimal investment in R&D with international knowledge spillovers WIFO Working Paper WP-175, Austrian Institute of Economic Research, Vienna, Austria
- Pontryagin LS Boltyanskii VG Gamkrelidze RV Mischenko EF 1962 The Mathematical Theory of Optimal Processes New York Wiley – Interscience
- Halkin , H . 1974 . Necessary conditions for optimal control problems with infinite horizons . Econometrica , 42 : 267 – 272 .
- Aseev SM Kryazhimskii AV Tarasyev AM 2001 First order necessary optimality conditions for a class of infinite-horizon optimal control problems IIASA Interim Report IR-01-007. International Institute for Applied Systems Analysis, Vienna, Austria
- Balder , EJ . 1983 . Existence result for optimal economic growth problems . Journal of Mathematical Applications , 95 : 195 – 213 .