Abstract
This paper discusses the accuracy of different types of models. Statistical models are based on process data and/or observations from lab measurements. This class of models are called black box models. Physical models use physical relationships to describe a process. These are called white box models or first principle models. The third group is sometimes called grey box models, being a combination of black box and white box models. Here we discuss two examples of model types. One is a statistical model where an artificial neural network is used to predict NO x in the exhaust gases from a boiler at Mälarenergi AB in Västerås, Sweden. The second example is a grey box model of a continuous digester. The digester model includes mass balances, energy balances, chemical reactions and physical geometrical constraints to simulate the real digester. We also propose that a more sophisticated model is not required to increase the accuracy of the predicted measurements.
1. Introduction
This article considers the use of mathematical models for online applications in the pulp and paper industry. The models are included in the distributed control system (DCS) at a very low level. The mathematical models are unobtrusive, as the operators only see the interface at the process display. The output to the operator appears the same whether a value relates to a single signal or is the result of a sophisticated calculation. This has both advantages and disadvantages.
Nevertheless there is great potential to widen the use of mathematical models, as the algorithms in current use are relatively rudimentary. The accuracy of the measurements does not justify the use of more sophisticated models, and sensor measurements are often noisy or unreliable due to fouling, drift, etc.
In this paper we discuss the accuracy of different types of models, and how mathematical models can be used to improve the quality of measurements.
2. Different types of mathematical models
Mathematical models can be divided into statistical or physical models. Statistical models are based solely on process data from the DCS system and/or lab measurements and do not consider the physics of the process. Whether the process is a paper machine, a water treatment plant or a boiler, the structure of the model is still exactly the same. This type of model is often called a black box model. The advantage of using this type of model is that an in-depth knowledge of the process is not required. In principle, the methods can be used by anyone, and the results should be easy to implement.
ABB developed a method called SIMCA-P in collaboration with SIMCA [Citation1] for process applications at the beginning of the 1990s, with partial least square (PLS) and principal component analysis models for online applications. Pavillion and Gensym [Citation2] also developed neural net software during the 1990s. Both these types of statistical models have been used extensively in many applications. Transfer functions combined with process identification have been used by control engineers for decades. For example, the Swedish Institute of Computer Science introduced Hierarchical Graph Mixtures for handling complex time series of process data [Citation3]. These have also been implemented in a number of other applications.
The other types of models are the physical models. These are sometimes also called white models, and aim to describe processes using first principles of physics. For a separation process, this means taking into account gravity, centrifugal forces, geometry and so on. As far as possible, constants from natural laws are used, but in most cases some tuning with process data is also needed to compensate for the shortage of computing power. When the computing power has reached a level where models with a high accuracy can be used in real time, the purely physical model should not need tuning.
Physical models have been used extensively, especially in training simulator applications, and also in diagnostics and optimization. Some models have been quite detailed, while others have been very unsophisticated, but still based primarily on first physical principles. One of the applications of physical models is in controlling the processes in a model predictive controller (MPC). An MPC is a multivariable model predictive control technology [Citation4]. The main advantage of MPC is its ability to handle multivariable processes with strong interactions between process variables and with constraints involving both process and state variables. The potential of the methodology is dependent on the quality of the process model and of the measured variables. In a good simulation of a process, the MPC is less dependent on the measured variables. This kind of model can be used to check the DCS system in a green field mill. This was applied successfully by ABB in Visy pulp and paper mill in Australia and at MNI in Malaysia [Citation5].
The third group of models are sometimes called grey models. These combine the features of the black box and the white models. They still use basic physical principles, but only to a limited extent. Statistical data from the process is used to tune the models. This may make the models more robust than pure black box models as basic physics is included, but the models are still of low complexity.
3. Statistical models
This section considers a few examples of physical models.
The first example involves the application of an artificial neural network (ANN) using the NeurOn-LineTM software from Gensym, which we consider to be one of the best ANN software packages on the market [Citation6]. Pre-existing data was used to develop the soft sensor model to predict NO x in the exhaust gases from a boiler at Malarenergy in Vasteras.
The input variables for the model were (1) coal flow, (2) feed water flow (3), gas flow before SCR (catalytic reactor), (4) air flow and (5) steam temperature after super heater. The output is NO x in the gas that comes out of the boiler.
The first model was built using all the data without any pre-preparation or removal of outliers. In the second model, values not following the trend of neighbouring values were removed from the output data. In the third model, outliers were removed from both input and output. In the fourth model, values that did not follow the trend of neighbouring values were removed from the input.
The influence of the input variables on the prediction polynomial is shown in .
Table 1. Impact values for input variables
Here we can see that feed water flow and air flow were stable, whereas gas flow and coal flow alternated between high positive and high negative values. This shows that there was no positive contribution from the two variables, though it might have been expected from the high impact values.
shows the root mean square error (RMSE) for the test data and the validation data respectively together with the correlation coefficient and the error.
Table 2. Root mean square error (RMSE) for the models
In we can see that the data treatment had very little impact – all the tested models produced similar accuracy. Model 1, based on data without any pre-preparation had a validation error of 12.4%. Model 3, which had pre-preparation on both input and output data, had an 11.4% validation error.
We also tested the influence of training time of the ANN on the accuracy of the model ().
Table 3. Accuracy of the models depending on the training time
shows that overtraining resulted in less accurate predictions. Excessive noise produced the same effect as real data. shows the effect of having different numbers of variables in the model.
Table 4. Accuracy of the models depending on the number of input variables
The data show that the optimum accuracy may be achieved using just a few important variables and may not be improved by increasing the number of input variables. This assumes that the additional variables would have little influence on the NO x content.
This example demonstrates the difficulty of using statistical models without considering the details of the process. It is easy to build noise or disrupting data into a model, and quite difficult to see when this has been achieved using purely statistical representations of the model accuracy. In all the cases considered the models produced similar statistical significance even though they were very different in reality if the process physics were considered.
A second example is a model for predicting paper quality from measurements along a complete fibre line at ASSI Dynas [Citation7]. PLS models were developed using SIMCA and Unscrambler. Data from 254 sensors along the fibre line and the paper machine were used in the initial models. Predictions from models that used these data directly were very poor. Following an inspection by mill staff it was found that only 50 of the sensors were reliable enough to be used, as the rest were either not calibrated, showed excessive drift or had some other problem. Of these 50, 12 were judged to have a major influence on the final paper quality. After going through the process data more in detail, and using knowledge of the process for the first time at this stage, five of the sensors were considered to be of greater importance than the others. It was also possible to vary these in a systematic way. A reduced factorial experiment was designed where these were varied while the rest were kept as stable as possible. As a complement to the existing plant measurements, near-infra red (NIR) spectra was also produced from pulp at several positions along the production line. New prediction models were produced for 15 different paper properties. Some of these turned out to be very good, with Q-values (a measure of prediction power) above 80% [Citation7].
However, after a month of using this model, reliability of predictions by the model was significantly lower. After 4 months it had fallen below 60% from an initial value above 80%. This is a major problem with pure statistical models, in that it is very difficult to predict all the variables that impact the results. New information cannot easily be added to compensate for factors such as different permeability of the paper machine wire or swings in wood properties, as the statistical significance demands that the variables should be varied in a systematic way, which is normally not possible in real mills. Instead the model must be rebuilt from scratch every time it is altered, and new factorial experiments must be performed. This is not an impossible task, but the work needed to keep the models up to date reduces the advantage of pure statistical models over the other types of models.
4. Physical models
The purely physical models, based on first principles, are illustrated by the following examples. The first example is a model of a recovery boiler that contains a bed bottom made out of melted sodium carbonate and sodium sulphate plus sulphide, solidified by water tubes in the bed bottom. At the surface of the melt, unburnt carbon reduces sulphates to sulphides, which is one of the major functions of the recovery boiler. In order to achieve this, the primary air supply in this part of the boiler has to be controlled in order to maintain the reducing atmosphere. Higher up in the boiler secondary air is introduced, and further up tertiary air, to combust all gases, as emissions of carbon monoxide and hydrocarbons are not permissible. NO x content must also be controlled, as there may be a tax penalty for excessive emissions. This example therefore has the same requirements as the preceding black box example with the NO x soft sensor using the ANN.
To obtain a good model we need a good understanding of all the chemical reactions taking place in the boiler and a detailed fluid dynamics model for how droplets, particles and gas behave in the boiler. This requires that knowledge of fluid dynamics, thermodynamics and chemical reactions can be combined. In addition, the detailed geometry of the boiler also needs to be defined. To accurately set up the equations for the model, the boiler has to be discretized into small volume elements, and reasonable boundary conditions have to be formulated for each volume element. To account for the motion of the gas and of the particles within the gas, we need to integrate a Lagrangian solution for the particles with an Eulerian solution for the fluid dynamics problem of the gas. If the heat transfer at the series of heat exchangers in the exhaust gas channel is added to the equation, as well as consideration of how particles stick to these, the task of solving the problem exceeds current computing capacity, although it may be possible 50 years from now. Executions have been performed using supercomputers that consider very short time periods and very small parts of the problem, demonstrating that purely physical modelling is possible in principle.
Because of these limitations, instead of using the full equations as described, simplifications have to be made. In order to achieve this, we have to identify the key variables. Only a few of the known reactions in combustions of this type are slow enough to be limiting. Therefore, rather than having to consider every one of the more than 500 known reactions it is possible to achieve similar results by considering between 5 and 10 reactions. From the fluid dynamics point of view, much larger volume elements have to be used, and a semi steady state must be assumed to achieve calculation times that are reasonable with the computing power available today.
This of course limits the potential to make white models for online usage. All physical models used today are grey to some extent. The most common application of these is in design of specific detail processes or in training simulators, where no data from the process is available and statistical models cannot therefore be used.
Despite this, white models are expected to dominate in the future. However, they are not discussed here as their use in online applications is not imminent.
5. Combining statistical and physical models
The conclusion from this consideration of statistical and physical models is that a combination of these appears most attractive. The question then arises how this should be performed.
Our opinion is that we must start with an as complete an understanding as possible of what takes place inside the process. When this has been achieved, a hypothesis should be formulated and a model developed that takes the hypothesis into account. The basic principles should be accounted for in a reasonable way and a few key tuning parameters identified. These should be both relevant from a process point of view and possible to determine from the process measurements or by manual sampling and laboratory analysis.
Once this has been achieved we have to consider how the process is operated. Among the questions that have to be addressed are – Where do variations occur? What are the parameters that are beyond our control? Which parameters cannot presently be measured? Which changes do we have to control, for example grade changes or rate changes in production? How can these dynamics be modelled?
The other question is how the statistical and physical models should be combined. Either the statistical models can be used to tune the physical models or the statistical and physical models can be used in parallel. How do we make use of the models for the online applications? These questions will be discussed here and we will try to formulate answers to at least some of them.
6. Illustrating example
Here we use a continuous digester as an example. The model is mainly based on first principles, but parts of the model are based on data from experiments. Constants in different equations are experimentally determined. This is therefore a grey model, lying somewhere between a white and a black box model.
What is taking place inside the digester? The digester may be 60 m high and 10 m in diameter. In the centre there is a pipe from which liquid is introduced at different levels. At the outer periphery there are large sieves through which liquid is taken out of the digester. At the bottom, where wash water is introduced, there are scrapers. Liquid in the digester diffuses in and out of the wood chips, and lignin reacts with sulphides. Lignin is transferred from the wood chips into the liquid. The liquid and wood chips flow through the digester. The flow pattern is due to the balance between forces such as buoyancy and gravity for example.
The digester model is built on the same principle as the Purdue model [Citation8]. However, unlike the Purdue model, this model contains a pressure flow network. The digester is discretized into a two-dimensional array with a number of volume elements both from top to bottom and outwards from the centre. Each volume element is of a specific size and the flow resistance between two volume elements is determined by the size of the open volume between the chips. The reaction rates Ri for dissolution of fast lignin, slow lignin and hemicelluloses are calculated by the following equation:
Here Ri is the reaction rate for each component – fast lignin, slow lignin and hemicelluloses, Ai is the Arrhenius constant for each component, Ei is the specific energy, U is the gas constant and T is the temperature. Z is the concentration of hydroxide (OH) and hydrogen sulphide (HS), respectively. The final term relates to the free void (ε) between the chips. ρ is the density of the liquid in the volume element V.
The chemical consumption of hydroxide and hydrogen sulphide is calculated from the reaction rates (R) for fast and slow reacting lignin and for hemicelluloses and the stoichiometric coefficient (α) for liquid and for wood chip (2).
The temperature (T
c) not only controls the reaction rate but is also used in the calculation for the diffusion rate R
D in EquationEquation (3)(3) where λm is the diffusion constant.
The diffusion rate is used to calculate the exchanges between the chips and the trapped liquor in the chips in mass balance (4) and the free liquor mass balance (5).
The parameters and
represent the flow of chips in and out of the volume element respectively, while F
l is the corresponding liquid flow rate. When calculating the temperature, it is assumed to be the same for both balances (6)
Here ρ is the density, c p is the heat capacity and T is the temperature. The subscript l denotes liquid and subscript c is for chip.
The pressures and the flows of the liquid are calculated from the dynamic and static pressures (7). The degree to which the chip column is compacted must be taken into consideration when calculating the dynamic pressure. The compaction η is calculated from the size of the chips (9) and how soft the chips are EquationEquation (8)(8). The wood chips become softer as the lignin dissolves, thereby increasing the compaction and therefore the flow resistance in the free space between the chips. With larger chips the space between the chips also becomes larger than with smaller chips due to the geometry.
In EquationEquation (7)(7), P is the pressure in a volume element, P
in is the pressure of an adjacent volume element, ρl is the density of the liquid, A is the open area of the liquid flowing between the volume elements, h is the elevation between the centres of gravity of the volume elements, g is gravity and F
in is the flow between the volume elements. ηlignin is the compaction factor due to the dissolution of lignin from the chips, Z
chips is the original amount of lignin in the wood chips entering the digester and Z
lignin is the amount in the chips leaving the volume element. ηflakes represents the geometric impact of small flakes in between the larger chips causing an increased pressure drop, and Z
flakes is the amount of flakes in the actual volume element.
To validate the model we tested whether the chips reacted according to the predictions. Here the primary focus was to investigate how the flow resistance changed as a result of compaction as lignin dissolved from the chips. The effect of introducing more flakes and therefore producing less free space between the chips was also investigated. After 2000 seconds the average size of the incoming chips in the top of the digester was reduced, effectively increasing the number of flakes. After 4000 seconds the temperature inside the digester was increased. The results and explanations are shown in .
Figure 1. Calculated flow rate values inside the digester as function of time.
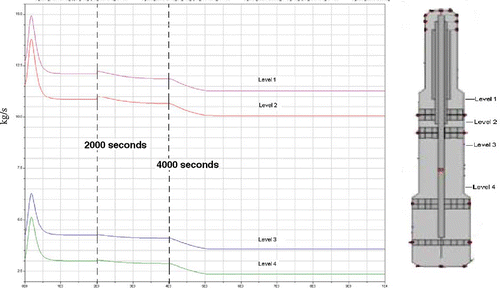
shows the flow between the different levels inside the digester. The maximum flow rate was at level 1. The flow decreased as the chips moved downwards through the digester. This is an effect of the compaction of chips inside the digester. The compaction is the free space in the chip column inside the digester and increases the flow resistance for the liquor. The compaction depends on how many flakes the chips contain and how long the delignification has proceeded. The initial delignification rate was high because of the high concentration of lignin in the chips and the high concentration of white liquor. After 2000 seconds the concentration of flakes was reduced. This increased the space between the chips and thus lowered flow resistance, thereby increasing the flow. After 4000 seconds the temperature inside the digester was increased and the delignification proceeded more quickly. This increased the compaction and decreased the flow.
Once the model is running, we can tune the constants in the equations using process data for different operational conditions by measuring concentrations, temperatures and flows as a function of time. If a sensor is faulty, it can be recalibrated or the values can be adjusted. If the deviation between the predicted and measured values is above a certain level, adjustment can be made iteratively until the prediction is good enough for the operating conditions. Thereafter the conditions are changed and the model is retuned for the new conditions. This proceeds in a systematic way according to a pre-prepared scheme. The tuning can be performed using different algorithms, but are basically different versions of the same principles. shows the deviations between the predicted value and the measured value for five different flows. The sensor status is valid as long as the deviation is stable and parallel to the x-axis. A change in direction of the line indicates that there is a problem with the sensor, as for FL1 in .
Figure 2. Deviation between the model prediction and measured values for a number of related sensors (flow meters).
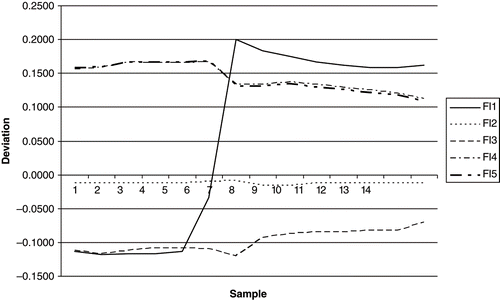
As previously mentioned, it is difficult for the model to produce reliable output for both tuning the model and using the model to pinpoint different process or sensor problems. A number of different methods are used to achieve reliable values. Among these are filters, moving windows and related methods [Citation9]. Other methods relate to data reconciliation, where material and energy balances are determined and used primarily to determine sensor faults when combined with sequential processing [Citation10]. In this method sensors are removed from the system one at a time, and the best fit for each single signal is calculated. In this way the faulty sensor can be identified with relatively high certainty.
In this way, it is possible to build a good model showing how the process behaves during normal operation. This is set up for the types of wood normally used. The type of material entering the system is identified either by operator input or by measurements of NIR spectra of incoming wood chips to determine their chemical properties. From this and from the operational conditions one can predict the kappa number of the wood leaving the digester and the yield. The operations can be optimized and any problems in the process can be identified by following specific variables such as the chemical composition of the liquid in the extraction line and the kappa number of the pulp produced. This information can be used by the operators to increase both the production capacity and the quality of the fibres produced. The model can also be used to determine the best way to perform a fast grade change.
These results are unlikely to be achieved with a black box model, as the number of measurable parameters is not sufficient to produce a robust model. Many black box models are unable to deal with dynamics, and in particular grade changes. With a grey model, dynamics are relatively easy to add to an existing steady-state model. It is also possible to model grade changes, which is important especially for feed-forward control. Even when there is a large range of operations, some of which lie outside the range tested in previous experiments, a physical model can still be valid, although it would probably be less accurate in the range where no measurements are available. Predictions by black box models are generally totally unreliable outside the range used to construct the model.
If either the input data or the handling of the data between the sensors and the output to the operator is of poor quality, there is no reason to make further calculations. On the other hand, if we try to assure the quality of the sensor readings and treat the signals correctly, the information can be further treated using different algorithms to achieve diagnostics, optimization and decision support. This can increase both the production rate and the quality of the fibres produced.
7. Conclusions
There are many possibilities to use physical models in combination with statistical models. Among potential applications are diagnostics, optimization, MPC and decision support for operators. In the long term, purely physical models are expected to be used in such applications to increase the production volume and quality. In the shorter term, however, combined models are the most robust and are normally the best suited for use in online control. Pure statistical models may on the other hand be suitable for specific tasks and where there is a lack of understanding of the process.
References
- Thompson , D. R. , Kougoulos , E. , Jones , A. G. and Wood-Kaczmar , M. W. 2005 . Solute concentration measurement of an important organic compound using ATR-UV spectroscopy . J. Cryst. Growth 276 , : 230 – 236 .
- Lopez , J. P. 1998 . Supervision and diagnosis of pharmaceutical processes with NeurOnLine . Gensym Users Society Conference Proceedings . 1998 , Newport, Wales.
- Holst , A. , Ekman , J. and Gillblad , D. 2004 . Deviation detection of industrial processes . Eur. Res. Consort. Inform. Math. , 56 : 13 – 14 .
- Morari , M. , Lee , J. and Garcia , C. 2000 . Model Predictive Control Prentice Hall, Englewood Cliffs
- Dahlquist , E. and Ryan , K. 2002 . MNI – experience with process simulation . Asia Paper Technical Conference, Proceedings, Singapore . 2002 , Singapore.
- Avelin , A. 2001 . Fysikalisk samt empirisk modellering av panna 4 Vasteras KVV , Vasteras, , Sweden : MSc thesis (in Swedish), Malardalen University .
- Liljenberg , T. , Backa , S. , Lindberg , J. , Ekwall , H. and Dahlquist , E. 1999 . On-line characterization of pulp – stock preparation department . SPCI Conference . 1999 , Stockholm, Sweden.
- Bhartiya , S. , Dufour , P. and Doyle , F. J. 2001 . Thermal-hydraulic modeling of a continuous pulp digester . Proceedings from Conference on Digester modeling . 2001 , Annapolis, USA.
- Latva-Käyrä , K. and Ritala , R. . Dynamic validation of multivariate linear soft sensors with reference laboratory measurements . Proceedings of Model Validation Workshop, VTT Symposium . COST ACTION E36, Modeling and Simulation in Pulp and Paper Industry , Edited by: Kappen , J. , Manninen , J. and Ritala , R. Vol. 238 , pp. 57 – 64 .
- Karlsson , C. , Dahlquist , E. and Dotzauer , E. 2004 . Data reconciliation and gross error detection for sensors in the flue gas channel in a heat and power plant , Iowa, , USA : PMAPS, Proceedings .