Abstract
In this article, we introduce an hp certified reduced basis (RB) method for parabolic partial differential equations. We invoke a Proper Orthogonal Decomposition (POD) (in time)/Greedy (in parameter) sampling procedure first in the initial partition of the parameter domain (h-refinement) and subsequently in the construction of RB approximation spaces restricted to each parameter subdomain (p-refinement). We show that proper balance between additional POD modes and additional parameter values in the initial subdivision process guarantees convergence of the approach. We present numerical results for two model problems: linear convection–diffusion and quadratically non-linear Boussinesq natural convection. The new procedure is significantly faster (more costly) in the RB Online (Offline) stage.
1. Introduction
The certified reduced basis (RB) method is a model-order reduction framework for rapid evaluation of functional outputs, such as surface temperatures or fluxes, for partial differential equations (PDEs) that depend on an input parameter vector, for example, related to geometric factors or material properties. There are four key ingredients to the certified RB framework:
| • | Galerkin projection: optimal linear combination of N pre-computed | ||||
| • | POD/Greedy sampling: POD (in time)/Greedy (in parameter) [Citation3] optimal selection and combination of FE field snapshots; | ||||
| • | a posteriori error estimation: rigorous upper bounds for the error in the RB (output) approximation with respect to the ‘truth’ FE discretization [Citation4,Citation5]; and | ||||
| • | Offline–Online computational decomposition: | ||||
We shall describe each ingredient further in subsequent sections.
We shall assume that the field variable depends smoothly on the parameters. In that case we can expect, and we can rigorously confirm a posteriori, that ; we can then furthermore anticipate rapid Online evaluation of the RB output approximation and associated RB output error bound. The certified RB method is thus computationally attractive in two important engineering contexts: ‘real time’, such as parameter estimation and optimal control; ‘many query’, such as multiscale or stochastic simulation. In both instances, the Offline effort either is unimportant or can be amortized over many input–output evaluations. In both instances, rigorous error control without direct appeal to the ‘truth’ is crucial.
For many problems, the field variable may be quite different in different regions of the parameter domain, and hence a snapshot from one region may be of little value to the RB approximation in another region. To exploit this opportunity, we introduce in [Citation7] an hp-RB method for linear elliptic equations. In the Offline stage, we first adaptively subdivide the original parameter domain into smaller regions (h-refinement); we then construct individual RB approximation spaces spanned by snapshots restricted to parameter values within each of these parameter subdomains (p-refinement). In the Online stage, the RB approximation associated with any new parameter value is then constructed as a (Galerkin) linear combination of snapshots from the parameter subdomain that contains the new parameter value. The dimension of the local approximation space, and thus the Online cost, shall be very low: every basis function contributes significantly to the RB approximation. We note that an alternative ‘multiple bases generation’ procedure is introduced in [Citation8]; a different ‘interpolation’ approach to parametric reduced order modelling with parameter subdomains is described in [Citation9].
In this article, we extend the work in [Citation7] to linear and non-linear parabolic equations through a POD (in time)/Greedy (in parameter) procedure. The POD/Greedy sampling approach [Citation3] is invoked both in the initial partition of the parameter domain (h-refinement) and subsequently in the construction of RB approximation spaces restricted to each parameter subdomain (p-refinement). Much of the elliptic machinery from [Citation7] extends to the parabolic case because we only subdivide the parameter (and not the temporal) domain. The critical new issue for the hp-POD/Greedy algorithm for parabolic problems is proper balance between additional POD modes and additional parameter values in the initial subdivision process.
The hp-POD/Greedy procedure was first introduced in the conference proceedings paper [Citation10]. We extend [Citation10] here in several important ways. First, we introduce an improvement to the algorithm: an additional Offline splitting step that permits direct control of the Online computational cost. Second, we introduce (for a simple but illustrative case) a new a priori convergence theory for the initial subdivision process; we show in particular that the procedure is convergent provided sufficiently many POD modes are included in the RB spaces. Good convergence of the subdivision process is critical to both Offline and Online performances. Third, and finally, we extend our considerations to quadratically non-linear parabolic problems. This class of problems is particularly ‘ripe’ for the hp approach due to the computational cost associated with RB error bound evaluation [Citation11,Citation12]: even a small reduction in N – the number of RB basis functions – will result in significant Online computational savings.
We begin in Section 2 with the problem statement(s). In Section 3, we introduce the hp-RB approximation, the associated RB error bounds and the necessary computational procedures. In Section 4, we present the hp-POD/Greedy algorithm and the new a priori convergence theory. Finally, in Section 5, we present numerical results for two model problems: a linear time-invariant (LTI) convection–diffusion problem and a quadratically non-linear Boussinesq natural convection problem; we focus our discussion on computational cost and Online economization compared with the standard (p-type) RB method.
2. Problem statement
We directly consider a discrete-time parametrized parabolic PDE defined over a spatial domain for discrete time levels
, 0 ≤ k ≤ K; here
, and
is the final time. We further introduce a P-dimensional parameter domain
and denote by
a particular parameter value. For a given
, we shall denote the exact solution to our discrete-time parabolic PDE as
.
We consider Backward Euler () and Crank–Nicolson (
) temporal discretization schemes (more generally, we may consider
; we define
. The exact formulation reads as follows: for any
, find
,
, such that
subject to initial condition . In the sequel, we shall always assume zero initial conditions. We then evaluate our output of interest as
for
. Here, X denotes a Sobolev space over
; typically
, where
,
, where
is the boundary of
,
is the space of square integrable functions over
and d is the dimension of the field. (In our exposition
; later, for the Boussinesq problem,
.)
We suppose that X is equipped with an inner product and induced norm
; we further denote by
the standard
inner product and by
the standard
norm. For any
,
is a coercive and continuous bilinear form over
,
is a coercive and continuous bilinear form over X,
is a continuous trilinear form over X,
is an X-bounded linear functional and
is an
-bounded linear ‘output’ functional. We introduce coercivity constants
under our assumptions and
, respectively, for any
. Note for
our problem is linear and coercive.
To develop efficient Offline–Online computational procedures for the RB field approximation, RB output approximation and RB error bound, we shall suppose that all our forms admit ‘affine’ expansions in functions of . Specifically, for any
where and Q is finite and preferably modest. We suppose that m, b and f admit similar expansions in at most Q terms. Many problems (including the examples of this article) admit an affine expansion; for other problems, approximate affine representations can be developed [Citation13,Citation14].
We now introduce the ‘truth’ spatial discretization of the PDE. We suppose a regular triangulation of
and introduce a corresponding high-resolution FE space
of dimension
. The truth discretization of EquationEquation (1)
(1) reads as follows: for any
, find
,
, such that
subject to initial condition ; then evaluate the truth output approximation as
for
. It is this truth FE approximation that we wish to accelerate by RB treatment. We shall assume that
is rich enough that the exact and truth solutions are indistinguishable at the desired level of numerical accuracy. As we shall observe below, the RB Online computational cost is independent of
, and the RB approximation is stable as
. We can thus choose
conservatively.
3. hp-RB approximation
For a parameter domain , the hp-RB method serves to construct a hierarchical partition of
into M distinct parameter subdomains
,
. Each of these subdomains
has associated nested RB approximation spaces
, where
,
. We define
. The procedure for the construction of the parameter domain partition and associated RB spaces, as well as the form of the ‘identifiers’
, shall be made explicit in Section 4. In this section, we discuss the RB approximation, the RB a posteriori error estimators and the associated computational procedures given the parameter domain partition and associated RB spaces.
3.1. RB approximation
For any new , we first determine
such that
. Given any N, we define
. The RB approximation of EquationEquation (4)
(4) reads as follows: for any
, find
,
, such that
subject to initial condition ; then evaluate the RB output approximation as
for
.
3.2. A posteriori error estimation
A rigorous a posteriori upper bound for the RB error is crucial for the Offline hp-POD/Greedy sampling procedure as well as for the Online certification of the RB approximation and the RB output. The key computational ingredients of the RB error bound are the RB residual dual norm and lower bounds for the stability constants.
Given an RB approximation, ,
, for
, we write the RB residual
,
, as
The Riesz representation of the residual ,
, satisfies
We denote by the residual dual norm.
We next introduce positive lower bounds for the coercivity constants of m and a, and
, respectively, such that for all
We also introduce a lower bound for the (possibly negative) stability constant
which we shall denote :
for
and all
. We further define
.
We can then develop the error bound
for which it can be demonstrated [Citation4,Citation12,Citation11] that ,
,
.Footnote
1
We can furthermore develop an RB output error bound
for which it can be demonstrated that ,
,
.
3.3. Computational procedures
3.3.1. Construction–evaluation
Thanks to the ‘affine’ assumption (3), we can develop Construction–Evaluation procedures for the RB field, RB output and RB error bound. We first consider the RB field and the RB output. In the Construction stage, given the RB basis functions, we form and store all the necessary parameter-independent entities at cost . In the Evaluation stage, we first determine the subdomain to which the given new parameter
belongs: an
binary search suffices thanks to the hierarchical subdomain construction, which we will make explicit in the next section [Citation7]. We next assemble the RB system (5) at cost
(
) in the LTI case [Citation6] and at cost
in the quadratically non-linear case [Citation11,Citation12]; we then solve this system at cost
in the LTI case and at cost
in the quadratically non-linear case. (Here
is the number of Newton iterations required to solve the non-linear equations at each timestep.) Given the RB field, the RB output can be evaluated at cost
.
We next consider the RB error bound (10). We invoke the Riesz representation of the residual and linear superposition to develop Construction–Evaluation procedures for the residual dual norm.Footnote
2
In the Construction stage, we again compute and store all the necessary parameter-independent entities at cost . In the Evaluation stage, we can evaluate the residual dual norm at cost
for LTI problems [Citation6] and at cost
for quadratically non-linear problems [Citation11,Citation12]. (In the sequel, we shall assume
, as is the case in our numerical examples.) We note that the
cost for quadratically non-linear problems compromises rapid evaluation for larger N and in practice limits
– motivation for an hp approach.
3.3.2. Offline–Online decomposition
The Construction–Evaluation procedures enable efficient Offline–Online decomposition for the computation of the RB field approximation, RB output approximation and RB output error bound. The Offline stage, which is performed only once as preprocessing, can be very expensive – -dependent complexity; the Online stage, which is typically performed many times, is comparably inexpensive –
-independent complexity. We note that our RB formulation (5) inherits the temporal discretization of the truth (4); we may thus not choose
arbitrarily small without compromise to RB Online cost.
In the hp-RB Offline stage, we perform the hp-POD/Greedy sampling procedure, which we discuss in the next section and which is the focus of this article: we invoke Construction–Evaluation procedures to identify good RB spaces and to compute and store the Construction quantities required in the Online stage. The link between the Offline and Online stages is the permanent storage of the Online Dataset; the storage requirement for the hp-RB method is in the linear case and
in the quadratically non-linear case. We recall that M is the number of subdomains identified by the hp-POD/Greedy. In the hp-RB Online stage, we perform Evaluation based on the Online Dataset: we calculate the RB field approximation, the RB output approximation and the RB error bound at the given new parameter in
complexity.
4. hp-POD/Greedy sampling
In this section, we discuss the hp-POD/Greedy procedure for the construction of the parameter subdomain partition and the associated RB approximation spaces. We employ a hierarchical parameter domain splitting procedure and hence we may organize the subdomains in a binary tree. Let L denote the number of levels in the tree. For , we introduce Boolean vectors
For any ,
we define the concatenation
,
. The M subdomains of
are associated to the M leaf nodes of the binary tree; we denote by
,
, the Boolean vectors that correspond to the leaf nodes; we can thus label the parameter subdomains as
,
. Similarly, we denote by
the set of nested RB approximation spaces associated to
,
.
4.1. Procedure
The hp-POD/Greedy algorithm introduced here applies to both the linear and non-linear cases. However, we adopt the notation of the linear () and scalar (
) problems for simplicity.
Table
We introduce as Algorithm 4.1 the POD algorithm (the Method of Snapshots [Citation16]). For specified and
, Algorithm 4.1 returns
X-orthonormal functionsFootnote
3
such that
satisfies the optimality property
The set contains the
first POD modes of
.
We next introduce as Algorithm 4.2 the POD/Greedy sampling procedure of [Citation3] (see also [Citation17]). Let . For specified
, an RB space dimension upper bound
, an initial parameter value
, a finite train sample
and an error bound tolerance
, Algorithm 4.2 returns
nested RB spaces
(note that as the spaces are nested by construction, we only specify
as the return argument) and
(μ) such that either
or
. (Note that in the POD/Greedy we may take the
RB error bound
rather than the
RB error bound
[Citation17]; for the linear coercive case,
.)
Table
We initialize the POD/Greedy by setting ,
and
. Then, while the dimension of the RB space is less than
and the tolerance
is not satisfied over
, we enrich the RB space: we first compute the projection error
,
, where
denotes the X-orthogonal projection of
onto
; we next increase the dimension of the RB space by adding the
first POD modes of the projection error to the current RB space; we then greedily determine the next parameter value over
based on the a posteriori error estimator at the final time. We invoke Construction–Evaluation procedures for the computation of the maximum RB error bound over
(line 7 of Algorithm 4.2); as the RB error bound calculation is very fast (
-independent in the limit of many evaluations), we may choose
very dense.
We finally introduce as Algorithm 4.3 the hp-POD/Greedy algorithm. For specified , an RB space dimension upper bound
, error bound tolerances
and
, an initial parameter anchor point
and an initial train sample
of cardinality
, Algorithm 4.3 constructs a hierarchical splitting of
into
subdomains
,
, and associates to each parameter subdomain an RB space
of dimension
such that for each subdomain
, the tolerance
is satisfied over
by
and the tolerance
is satisfied over
by
. We introduce here
as the RB error bound associated with the temporary space
, and we recall that
is the RB error bound associated with the returned space XNmax,Bm,
Bm
. (In the hp-RB Online stage, we may readily extract spaces
of any dimension N,
.)
Table
We now comment on the constant , which in turn determines the dimension R of the temporary spaces
(lines 3–6): we successively increment R and evaluate
until
. For
, the tolerance
is then satisfied by
in a neighbourhood of the anchor point
, and we thus avoid arbitrarily small subdomains. We note that
corresponds to R = K; however, typically
is sufficient and we may thus choose
close to (but larger than) unity.
We next consider the splitting of any particular subdomain into two new subdomains
and
. We suppose that
is equipped with a train sample
. Given a parameter anchor point
, we first compute the truth field
,
, and define the temporary RB space
associated with the subdomain
as discussed above. The next step is to evaluate
for all
in order to identify a second anchor point (line 7)
. We note that the two anchor points
and
are maximally different in the sense of the RB error bound, and thus provide good initial parameter values for two new RB spaces.
We now introduce a distance function, ; for example, we may choose Euclidean distance. We can then implicitly define two new subdomains
and
based on the distance to the two anchor points:
and
. Note that by this definition, parameter values that are equidistant from the two anchor points
and
belong to
. The final step of splitting is to construct a new train sample associated with each of the two new subdomains (line 9). We first enrich (by adding random points, say) the current train sample
such that
has cardinality
; we then define
We note that we may choose the initial train sample for the hp-POD/Greedy to be rather sparse compared with the train sample for the standard POD/Greedy, because we effectively construct an adaptively refined train sample (over ) during the parameter domain partition process. The adaptively generated hp-POD/Greedy train sample associated with a given subdomain is typically much smaller than the (global) train sample associated with the standard POD/Greedy.
We apply this splitting scheme recursively to partition into the final M subdomains; we can thus organize the subdomains in a binary tree. In , we illustrate the procedure, as well as the associated binary tree, for two levels of recursive splitting.
Figure 1. Two levels of h-refinement and associated binary tree; here .
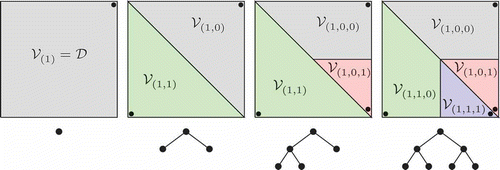
The final step is p-refinement: we identify the nested RB spaces to be associated with the subdomain (line 13). If the POD/Greedy returns with , we discard the generated basis and successively perform additional subdomain splitting and POD/Greedy steps until the tolerance is satisfied with at most
basis functions (lines 15–18). This additional splitting step permits simultaneous control over
and
. We note that
– the number of POD modes to include at each Greedy iteration during p-refinement – is typically chosen small: small
leads to more optimal spaces albeit at a higher (Offline) computational cost.
Under the assumption that is chosen such that R is always smaller than
(note that we can always ‘re-specify’
if at any point
), the hp-POD/Greedy algorithm provides an Online Dataset such that the RB error bound tolerance
is satisfied (over the train samples) with at most
basis functions. We hope to achieve this goal without the expensive execution of lines 15–18: it is our intent that if
is satisfied with R basis functions, then
will be satisfied with at most
basis functions; whenever this is true, we discard only R basis functions at each level of splitting.
We regard lines 15–18 as insurance: if is not satisfied with at most
basis functions – even if
was satisfied with R basis functions – we discard the computed candidate space, split the subdomain and again execute hp-POD/Greedy in a recursive manner. Ideally
is chosen such that the insurance is rarely invoked and
is close to
for most
. If the insurance is invoked too often –
is too large with respect to the target
– the Offline computational cost will be large. If the insurance is rarely or never invoked and
for most
, then
is too small with respect to the target
.
Remark 4.1: We note that as the number of subdomains M increases, the hp-POD/Greedy algorithm in general requires a larger (Offline) computational cost and generates a larger Online Dataset than the standard (p-type) POD/Greedy method. However, in the non-linear case, the cost and storage associated with the RB error bound help to moderate this increase: an increase in M provides a decrease in N such that the product
grows only modestly. We further note that, thanks to the efficient
subdomain search, M can be very large without compromise to the Online computational cost. In practice, we thus seek M to balance Offline cost and Online storage against Online speed.
Remark 4.2: As discussed in [Citation11,Citation12], we must employ a ‘nominal’ lower bound for the stability factor
for non-linear parabolic problems during the POD/Greedy: the SCM, which allows for construction of the rigorous lower bound
, can only be performed after generation of the RB space. In this context,
is a conservatively chosen constant or (say) a linear function of
. Note that the rigour of our error bounds in the Online stage is not compromised: after completion of the POD/Greedy, we perform the SCM,Footnote
4
and subsequently the Online RB error bounds are rigorous.
4.2. A priori convergence analysis
We now introduce an a priori convergence theory for Algorithm 4.3. Selection of relatively few and optimal subdomains – small M for specified – is crucial to reduce both Offline cost and Online cost and storage. We consider here the class of linear scalar problems (
,
). For simplicity, we consider the case of a single parameter (
); we assume a Backward Euler temporal discretization (
); and we consider the case in which
is parameter independent and in particular equal to the
inner product:
.
We recall that the bilinear form a and the linear functional f admit the affine expansions
for all . For our purposes in this section, we shall require that
where is an X-inner product and
is
-continuous in its second argument. Specifically we require, for any
,
,
We also require that the are
-bounded:
For simplicity, we suppose that ; hence
for all
. We further require that the
and
are Lipschitz continuous: for any
,
, there exist constants
and
,
, such that
We introduce lower and upper bounds over for the coercivity and continuity constants of
:
respectively. For simplicity of notation we suppose, for and any
, that
For our theororetical arguments below, we assume and
. The coercivity lower bound
shall be given as
for all
. We emphasize that all our assumptions in this section are satisfied by our convection–diffusion numerical example of
Section 5.1.
We consider Algorithm 4.3 with . Hence p-refinement – execution of POD/Greedy in line 13 – will converge (
) for any specified
. We thus focus here on h-refinement; we show in particular that the hp-POD/Greedy algorithm generates a finite number of parameter subdomains.
To this end, we shall require the following continuity result.
Lemma 4.1:
For any
,
, and any
,
, there exist positive constants
and
such that
Proof: We refer to Appendix A for the proof.
We next define for any and any
,
, the ‘energy-norm’
To this end, we shall require the following stability result.
Lemma 4.2:
For any
, the solution
,
, of (4) for
satisfies
Proof: We refer to Appendix B for the proof.
For and
, we define
. We shall require the following continuity result.
Lemma 4.3:
Assume that
and
belong to the same parameter subdomain (say)
, and let
denote the RB space associated with
. Let
and
,
, satisfy Equation (5) for
. Then
where
Proof: We refer to Appendix C for the proof.
We shall finally require the following continuity result, which is a discrete counterpart of Proposition 11.1.11 of [Citation18].
Lemma 4.4:
Assume that
and
belong to the same parameter subdomain (say)
, and let
denote the RB space associated with
. Let
and
,
, satisfiy
Equation
Equation (5)
(5)
for
. Then the finite difference
is
-bounded in time:
where
Proof: We refer to Appendix D for the proof.
We now claim
Proposition 4.1:
Let
and let
denote the length of
. For specified
, Algorithm 4.3 terminates for finite
subdomains; moreover, the convergence of the h-refinement stage is first order in the sense that
Proof: The proof has two steps. We first show that the RB error bound is Lipschitz continuous. We then relate this result to our particular procedure to prove convergence of the hp-POD/Greedy algorithm.
Step 1: We recall that for , the Riesz representation
of the residual
,
, satisfies
Let ,
. We define
. From EquationEquation (33)
(33), we note that by linearity
for all and for
. For term I, we invoke Lemma 4.1 directly to obtain
For term II, we first write
Then, by the triangle inequality, Lemma 4.1, continuity and EquationEquation (22)(22), we obtain
For term III, we invoke linearity, the Cauchy–Schwarz inequality and the Poincaré inequalityFootnote 5 to obtain
We now insert the expressions for terms I, II and III into EquationEquation (34)(34); for
we then obtain
We divide through in EquationEquation (39)(39) by
, square both sides and invoke the inequality
for
to obtain
We multiply through in EquationEquation (40)(40) by
, substitute k for
and sum over
to obtain
Next, from coercivity and Lemma 4.2 we note that
Furthermore, from coercivity and EquationEquation (22)(22), and Lemmas 4.3 and 4.4, we note that
From EquationEquation (41)(41) with EquationEquations (42)
(42) and (43), we thus obtain
where
By the definition of the RB error bound (recall that we use ) and the reverse triangle inequality, we finally obtain
Step 2: The next step is to relate EquationEquation (46)(46) to the convergence of Algorithm 4.3. The algorithm generates a partition of
into M subdomains. Either
, in which case the proof is complete, or
. We now examine the case
. We consider the splitting of any particular subdomain
into two new subdomains
and
. We denote here by
the anchor point associated with
and
, and by
the anchor point associated with
. We assume that the error tolerance at the final time is not satisfied over (a train sample over)
; hence
. We recall that by construction of our procedure
for specified
. We can thus invoke EquationEquation (46)
(46) for
,
and
replaced by
to conclude that
and hence
We now split into
and
based on Euclidean distance to the two anchor points. It is clear that
The partition procedure generates M > 1 distinct subdomains ,
.Footnote
6
Each of these subdomains is the result of a splitting of a ‘parent’ subdomain
(for some
). As
above was arbitrary, we can successively set
to be the parent of each of the M ‘leaf’ subdomains and conclude that
We define ; hence in particular
.
We complete the proof by a contradiction argument. Assume that . Thus
which is clearly a false statement. We conclude that with
. We finally note that Algorithm 4.3 is convergent because the POD/Greedy (line 13) will be able to satisfy the error bound tolerance
within each of the M final subdomains.
Remark 4.3: The requirement reappears in the proof in EquationEquation (47)
(47). We note that we cannot obtain a positive lower bound for the distance between the two anchor points if
.
Remark 4.4: If we assume only (and not in L
2) and furthermore
only X-continuous in both arguments (and not L2-continuous in the second argument), then we can still obtain Proposition 4.1 albeit with an additional factor
in the ‘constant’ C. However, we note that this
factor is in this case relatively ‘benign’: we cannot in any event let ‘
’ in practice because of the increase in Online computational cost. (In contrast, we can let ‘
’ because larger
affects only Offline cost.)
We recall that all the hypotheses of Proposition 4.1 are satisfied by our numerical example in Section 5.1.
Remark 4.5: Proposition 4.1 guarantees that the partition algorithm (h-refinement) is convergent. However, the convergence is very slow and hence subsequent p-refinement is in practice necessary. But note that with only a global Lipschitz constant c in our proof, our bound (32) is very pessimistic and in particular does not reflect any adaptivity in the partition. In practice, we expect that the algorithm adaptively generates smaller subdomains in areas of for which the field exhibits larger variations with the parameters.
5. Numerical results
We now present numerical results for two model problems. We demonstrate that in both cases the hp-RB method yields significant Online computational savings relative to a standard (p-type) RB approach; we also show that the partitions of may reflect the underlying parametric sensitivity of the problems. All our computational results are obtained via rbOOmit [Citation19], which is an RB plugin for the open-source FE library libMesh [Citation20]. All computations are performed on a 2.66-GHz processor. For the hp-RB approximations below, we have used a ‘scaled’ Euclidean distance for the distance function : we map (a rectangle in both our examples) to
(via an obvious affine transformation) and compute the Euclidean distance on
. For the constant
in Algorithm 4.3, we choose
.
5.1. Convection–[diffusion problem]
We consider the non-dimensional temperature u, which satisfies the convection–diffusion equation in the spatial domain for the discrete time levels
,
; we employ Backward Euler temporal discretization (hence
). We impose a parameter-dependent velocity field
and we prescribe a constant forcing term
. We specify homogeneous Dirichlet boundary conditions and zero initial conditions. We denote a particular parameter value
by
and we introduce the parameter domain
. For this problem, we focus for simplicity on the RB field approximation and thus we do not consider any particular outputs.
We next introduce the forms
for , where
. Our problem can then be expressed in the form (4) with
; note that our only parameter-dependent form is a, which admits an affine expansion (3) with
. We note that this problem satisfies all the theoretical hypothesis of Proposition 4.1.Footnote
7
For our truth approximation, we choose a
FE space
of dimension
.
To obtain a benchmark for comparison, we first perform a standard (p-type) POD/Greedy: we specify for the target tolerance,
for the number of POD modes to include at each greedy iteration,
for the initial parameter value and a train sample
of size 900. We then execute Algorithm 4.2 (we also ‘specify’
such that the POD/Greedy terminates for
satisfied over
). The tolerance is in this case satisfied for
.
We next perform two hp-POD/Greedy computations. In the first, we specify ,
,
,
,
and a train sample
of size 64. In this case, Algorithm 4.3 terminates for M = 22 subdomains with
(recall that
). In the second case, we specify
,
,
,
,
and a train sample
of size 25. In this case, Algorithm 4.3 terminates for
subdomains with
. The maximum RB
error bound
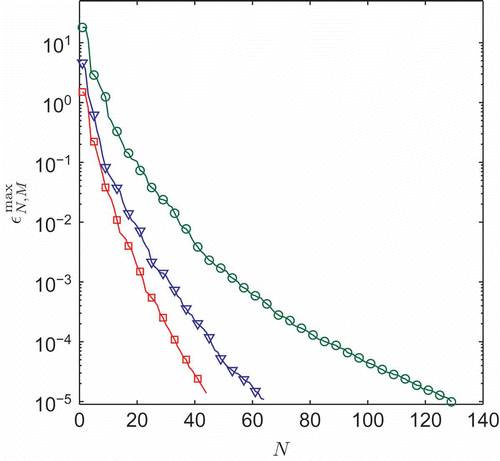
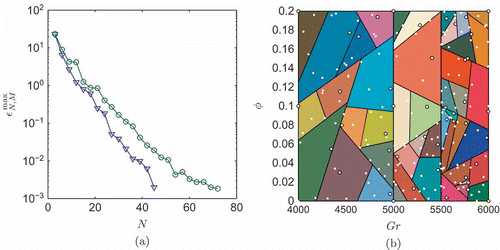
(over the train samples) over all M subdomains for each of the cases M = 22 and 278, as well as the p-type reference case M = 1, are plotted in as functions of N. We note that larger M yields smaller N, as desired.
Figure 2. Convergence: hp-RB (triangles (M = 22) and squares ()) and p-type RB (circles). In the hp-RB cases, the error bound is the maximum over all subdomains for a given N.
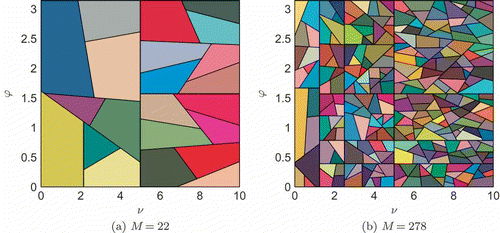
We show the two partitions of in .Footnote
8
Note that the field variable exhibits larger variations with
for larger
, and hence we would expect the subdomain size to decrease with increasing
. However, this is not the case in (b) except for smaller
. By way of explanation, we note that when the field varies significantly with time, which is indeed the case for large
, R – the number of POD modes in the temporary space
– will be larger. We suspect that the additional POD modes included in the
associated with subdomains for
larger than approximately 5 may also represent some parametric variations in the field and hence account for the ‘non-monotonic’ (in
) subdomain size.
Figure 3. Parameter domain partitions ,
, for the convection–diffusion problem.
We note that the hp-RB method indeed yields a significant Online speedup. Online p-type RB calculation of the RB solution coefficients and error bound for basis functions requires
seconds. In contrast, Online hp-RB calculation of the RB solution coefficients and error bound for the case with M = 22 subdomains and
requires
seconds, and for the case with
subdomains and
requires
seconds; in both cases, the search for the subdomain containing the new online parameter is negligible (
seconds). (The timing results are averages over 100 Online calculations for randomly selected
.)
Of course, Offline cost and Online storage are larger for the hp-RB than for the standard (p-type) RB: the Offline stage requires 29.6 minutes and 3.5 hours for the hp-RB computations (M = 22 and , respectively) and only 13.4 minutes for the standard RB; the Online Dataset requires 25.3 MB and 142.9 MB for the hp-RB computations (M = 22 and
, respectively) and only 5.7 MB for the standard RB. In particular, Offline cost for the
computation is admittedly very large compared with the Offline cost for the p-type computation. Of course, even in our ‘real time’ and ‘many query’ contexts, the larger Offline cost associated with the hp-RB method may be an issue; we must thus seek to balance the increase in Offline cost against the decrease in Online cost by appropriate choices of the parameters
and
. We note that for this problem, our M = 22 hp-RB computation provides significant Online speedup at only modest increase in Offline cost.
The additional splitting step – the “insurance” provided by lines 15–18 in Algorithm 4.3 – was never invoked for either hp-POD/Greedy computation. For the computation with specified , the average of
,
, is 57.3. For the computation with specified
, the average of
,
, is 37.9. We conclude that in both cases we could have chosen
somewhat larger (at the risk of invoking insurance) to obtain a more optimal partition with respect to the target
.
We finally note that calculation of the truth (4) for this problem with requires about 0.9 seconds. The average speedup relative to a truth calculation is approximately 64 for the p-type Online calculation with
, and approximately 273 and 500 for the hp-RB Online calculations (
, M = 22 and
,
, respectively).
5.2. Boussinesq problem
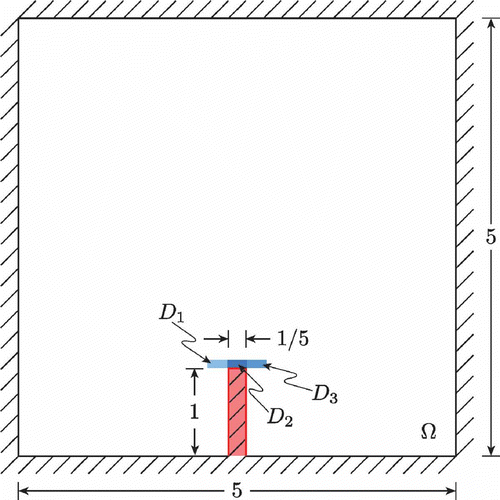
We consider natural convection in the two-dimensional enclosure , where
is the ‘pillar’
, for the discrete time levels
,
; we employ Crank–Nicolson temporal discretization (hence
). The direction of the acceleration of gravity is defined by the unit vector
. We solve for the field variables
(the x and y components of the fluid velocity) and
(the temperature) over
; hence the field has dimension
. The ‘roof’ of the enclosure is maintained at temperature
, the sides and base of the enclosure are perfectly thermally insulated and the top and sides of the pillar are subject to a uniform heat flux of magnitude
(the Grashof number); we impose no-slip velocity conditions on all walls. We denote a particular parameter value
by
and we introduce the parameter domain
. Note that we set the Prandtl number, Pr, here to 0.71 (for air).
Our goal is to study parametric dependence of the temperature in regions at or near the top of the heated pillar (or ‘fin’) in the presence of natural convection, and hence we are interested in local average-temperature outputs. These outputs can be expressed as -bounded functionals of
, namely,
here ,
,
are three small rectangles above the pillar. The domain geometry and output regions are depicted in .
Figure 4. The computational domain; note that does not include the pillar, which is shaded. The output regions
and
are also indicated.
We introduce the forms
for ,
and
; in these expressions,
and
. Here,
, where Z is the divergence-free subspace of
, and
is the subspace of
of functions that vanish on the enclosure roof.
Our problem can then be expressed in the form (4) with (we have used a skew-symmetric form of the non-linear convection operator
to generate certain discrete stability properties [Citation18]); note that all forms satisfy the ‘affine’ assumption. For our truth FE space, we choose
of dimension
, where
denotes a discretely divergence-free
space for the velocity (developed from the
Taylor–Hood velocity–pressure approximation) and
is a standard
FE space for the temperature. For further details on the formulation of this problem, see [Citation11].
We note that for the computational results for this problem, we consider a ‘relative
error bound’ version of Algorithm 4.2 and hence Algorithm 4.3. To obtain a benchmark for comparison, we first perform a standard (p-type) POD/Greedy computation: we specify
for the target tolerance,
for the number of POD modes to include at each Greedy iteration,
for the initial parameter value and a train sample
of size 200. In this case, Algorithm 4.2 terminates for
. Recall that in the quadratically non-linear case, the POD/Greedy terminates when the nominal error bound reaches the prescribed tolerance.
We then perform an hp-POD/Greedy computation: we specify ,
,
,
,
and a train sample
of size 9. In this case, Algorithm 4.2 terminates after generation of
subdomains with
. The maximum relative RB
error bound
(over the train samples) over all subdomains for the hp-RB approximation as well as for the p-type RB approximation are shown in (a). As in the linear case, the hp approach trades reduced N for increased M. We show the hp-RB parameter domain partition in (b).
Figure 5. (a) Convergence: hp-RB (triangles) and p-type RB (circles). (b) Parameter domain partition: we show the anchor point (a circled white dot) and the Greedily selected parameters (white dots) in each subdomain; note that, within a subdomain, parameters are often selected more than once by the POD/Greedy algorithm.
In , we show for the RB output approximations to the three outputs (53) for three parameter values
,
and
. We also indicate the corresponding error bars
,
,
, in which the true result
must reside. We recall that the RB output error bounds
are obtained as the product of the RB field error bound
and the dual norm of the output functional (EquationEquation (11)
(11)).Footnote
9
We remark that the accuracy of these hp-RB outputs is comparable with the accuracy of the p-type RB outputs because the hp-POD/Greedy and p-type POD/Greedy calculations terminate for the same specified tolerance. Note that time is measured in diffusive units and hence the final time of 0.16 is sufficient to observe (at these
) significant non-linear effects.
Figure 6. The RB outputs (bottom, solid line),
(top, solid line),
(middle, solid line), and associated error bars (dashed lines) as functions of time for three values of
. (a)
(b)
(c)
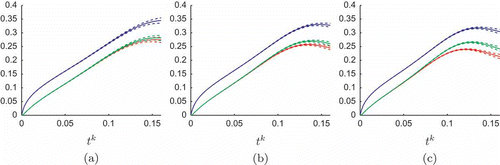
The standard (p-type) RB method yields a significant Online speedup relative to the expensive Boussinesq truth FE solves (one truth solve requires 239 seconds); nevertheless, these p-type RB computations are still rather expensive due to the complexity of the RB error bound for quadratically non-linear problems. The hp-POD/Greedy method of this article provides a significant additional speedup in the hp-RB Online stage due to the direct control of
and hence reduction in N: Online p-type RB calculation of the output and error bound with
basis functions requires 6.48 seconds, whereas Online hp-RB calculation of the output and error bound with
subdomains and
requires only 0.845 seconds. Of course, Offline cost and Online storage are larger for the hp-RB than for the standard RB: the Offline stage requires about 69 hours for the hp-RB and only about 5.2 hours for the standard RB; the Online Dataset requires 2.3 GB for the hp-RB and only 481 MB for the standard RB.
We finally note that the additional splitting step (‘insurance’) was invoked for 10 subdomains for the hp-POD/Greedy computation, and the average of ,
, is 40.1. This suggests that
in this case was reasonably well chosen with respect to the target
.
Appendix A. Proof of Lemma 4.1
From Equations Equation(16)(16), Equation(18)
(18) and Equation(20)
(20), we obtain Equation Equation(24)
(24) with
. From Equations Equation(15)
(15), Equation(19)
(19) and Equation(21)
(21), we obtain Equation Equation(25)
(25) with
.
Appendix B. Proof of Lemma 4.2
From EquationEquation (4)(15) with
, we obtain
We next recall Young's inequality (for
). For the first term on the right, we first invoke the Cauchy–Schwarz inequality and then Young's inequality for
,
and
to obtain
For the second term on the right, we first invoke boundedness of and then Young's inequality with
,
and
to obtain
where the last step follows from coercivity of . We combine Equations (B2) and (B3) with (B1), invoke Equation Equation(22)
(22), substitute
for k and sum over
to obtain EquationEquation (27)
(27).
Appendix C. Proof of Lemma 4.3
From linearity of EquationEquation (5)(5), we obtain, for
,
Next, from Lemma 4.1 we obtain
For the first term on the right, we invoke Young's inequality for ,
and
to note that
where the second inequality follows from coercivity of . For the second term on the right, we invoke Young's inequality for
,
and
to note that
where the second inequality follows from coercivity of . With Equations (C2)–(C4), we obtain for
,
For the first term on the right, we note by the Cauchy–Schwarz inequality and Young's inequality for ,
and
that
Hence
We now substitute for k and sum over
to obtain
We finally note that . Hence, by Lemma 4.2 we obtain Equation Equation(28)
(28) for
given in EquationEquation (29)
(29).
Appendix D. Proof of Lemma 4.4
From linearity of EquationEquation (5)(5) we obtain, for
,
We choose and obtain
From Lemma 4.1 we obtain
and
We thus obtain
We now recall from Equation Equation(16)(16) that
. We may thus write
Next, we apply the Cauchy–Schwarz inequality to the first term on the right and continuity to the second term on the right; we then apply Young's inequality to each term on the right to obtain
or
We then substitute for k and sum over
to obtain
Finally, we first invoke coercivity of , and then Lemmas 4.2 and 4.3 to obtain
The desired result thus follows because .
Acknowledgements
This work was supported by the Norwegian University of Science and Technology, AFOSR Grant No. FA9550-07-1-0425, and OSD/AFOSR Grant No. FA9550-09-1-0613.
Notes
1 In the linear case , and it thus follows from EquationEquation (9)
(9) and the definition of
(we recall that
is coercive) that EquationEquation (10)
(10) simplifies to
.
2 We refer to [Citation12,Citation15] for details on the Construction–Evaluation procedure for the computation of lower bounds for the stability constants – a Successive Constraint Method (SCM).
3 We note that .
4 We note that after completion of the hp-POD/Greedy, we can apply the SCM algorithm independently for each parameter subdomain; we thus expect a reduction in the SCM (Online) evaluation cost because the size of the parameter domain is effectively reduced.
5 We suppose here for simplicity that ; hence
for all
.
6 In fact, we should interpret M here as the number of subdomains generated by Algorithm 4.3 so far; the ,
, are not necessarily the final M subdomains. With this interpretation, we thus do not presume termination of the algorithm.
7
EquationEquation (16)(16) is satisfied with
. We note that
is
continuous in its second argument because by the Cauchy–Schwarz inequality
.
8 To ensure a good spread over of the rather few (25 or 64 for our two examples) initial train points, we use for
a deterministic initial regular grid. (For the train sample enrichment, we use random points.) As some train points belong to a regular grid, the procedure may produce ‘aligned’ subdomain boundaries, as seen in .
9 We note that .
References
- Noor , A.K. and Peters , J.M. 1980 . Reduced basis technique for nonlinear analysis of structures . AIAA J. , 18 : 455 – 462 .
- Almroth , B.O. , Stern , P. and Brogan , F.A. 1978 . Automatic choice of global shape functions in structural analysis . AIAA J. , 16 : 525 – 528 .
- Haasdonk , B. and Ohlberger , M. 2008 . Reduced basis method for finite volume approximations of parametrized linear evolution equations . Math. Model. Numer. Anal. , 42 : 277 – 302 .
- Grepl , M.A. and Patera , A.T. 2005 . A posteriori error bounds for reduced-basis approximations of parametrized parabolic partial differential equations . M2AN Math. Model. Numer. Anal. , 39 : 157 – 181 .
- Rozza , G. , Huynh , D.B.P. and Patera , A.T. 2008 . Reduced basis approximation and a posteriori error estimation for affinely parametrized elliptic coercive partial differential equations . Arch. Comput. Methods Eng. , 15 : 229 – 275 .
- Nguyen , N.C. , Rozza , G. , Huynh , D.B.P. and Patera , A.T. 2010 . “ Reduced basis approximation and a posteriori error estimation for parametrized parabolic PDEs: Application to real-time Bayesian Parameter estimation ” . In Large-Scale Inverse Problems and Quantification of Uncertainty, Wiley Series in Computational Statistics , Edited by: Biegler , L. , Biro , G. , Ghattas , O. , Heinkenschloss , M. , Keyes , D. , Mallick , B. , Tenorio , L. , van Bloemen Waanders , B. and Willcox , K. John Wiley & Sons, Chichester .
- Eftang , J.L. , Patera , A.T. and Ronquist , E.M. 2010 . An ‘hp’ certified reduced basis method for parametrized elliptic partial differential equations . SIAM J. Sci. Comput. , 32 : 3170 – 3200 .
- Haasdonk , B. , Dihlmann , M. and Ohlberger , M. 2010 . A training set and multiple bases generation approach for parametrized model reduction based on adaptive grids in parameter space . Tech. Rep. 28, SRC SimTech ,
- Amsallem , D. , Cortial , J. and Farhat , C. January 2009 . “ On-demand CFD-based aeroelastic predictions using a database of reduced-order bases and models ” . In 47th AIAA Aerospace Sciences Meeting Including The New Horizons Forum and Aerospace Exposition January , Orlando, FL
- Eftang , J.L. , Patera , A.T. and ønquist , E.M.R . 2009 . “ An hp certified reduced basis method for parametrized parabolic partial differential equations ” . In Spectral and High Order Methods for Partial Differential Equations, Lecture Notes in Computational Science and Engineering , Edited by: Hesthaven , J.S. and ønquist , E.M.R . Vol. 76 , 179 – 187 . Trondheim, , Norway : Springer .
- Knezevi , D.J. , Nguyen , N.C. and Patera , A.T. 2010 . “ Reduced basis approximation and a posteriori error estimation for the parametrized unsteady Boussinesq equations ” . In M3AS, Accepted c
- Nguyen , N.C. , Rozza , G. and Patera , A.T. 2009 . Reduced basis approximation and a posteriori error estimation for the time-dependent viscous Burgers’ equation . Calcolo , 46 : 157 – 185 .
- Barrault , M. , Maday , Y. , Nguyen , N.C. and Patera , A.T. 2004 . An ‘empirical interpolation’ method: application to efficient reduced-basis discretization of partial differential equations . C. R. Math. Acad. Sci. Paris , 339 : 667 – 672 .
- Eftang , J.L. , Grepl , M.A. and Patera , A.T. 2010 . A posteriori error bounds for the empirical interpolation method . C. R. Math. , 348 : 575 – 579 .
- Huynh , D.B.P. , Rozza , G. , Sen , S. and Patera , A.T. 2007 . A successive constraint linear optimization method for lower bounds of parametric coercivity and inf-sup stability constants . C. R. Math. Acad. Sci. Paris , 345 : 473 – 478 .
- Sirovich , L. 1987 . Turbulence and the dynamics of coherent structures. Part I. Coherent structures . Quart. Appl. Math. , 45 : 561 – 571 .
- Knezevic , D.J. and Patera , A.T. 2010 . “ A certified reduced basis method for the fokker-planck equation of dilute polymeric fluids: fene dumbbells in extensional flow ” . In SIAM J. Sci. Comput 793 – 817 .
- Quarteroni , A. and Valli , A. 1994 . “ Numerical approximation of partial differential equations ” . In Springer Series in Computational Mathematics , Vol. 23 , Berlin : Springer-Verlag .
- Knezevic , D.J. and Peterson , J.W. 2010 . “ A high-performance parallel implementation of the certified reduced basis method ” . In Comput. Methods Appl. Mech. Eng., Submitted
- Kirk , B.S. , Peterson , J.W. , Stogner , R.M. and Carey , G.F. 2006 . libMesh: a C++ library for parallel adaptive mesh refinement/coarsening simulations . Eng. Comput. , 23 : 237 – 254 .