
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Variational inequalities (VIs) are pervasive in mathematical modelling of equilibrium and optimization problems in engineering and science. Examples of applications include traffic network equilibrium problems, financial equilibrium, obstacle problems, lubrication phenomena and many others. Since these problems are computationally expensive to solve, we focus here on the development of model order reduction techniques, in particular the reduced basis technique. Reduced basis techniques for the approximation of solutions to elliptic VIs have been developed in the last few years. These methods apply to VIs of the so-called first kind, i.e. problems that can be equivalently described by a minimization of a functional over a convex set. However, these recent approaches are inapplicable to VIs of the so-called second kind, i.e. problems that involve minimization of a functional containing non-differentiable terms. In this article, we evaluate the feasibility of using the reduced basis method (RBM) combined with the empirical interpolation method (EIM) to treat VIs. In the proposed approach, the problem is approximated using a penalty or barrier method, and EIM is then applied to the penalty or barrier term. Numerical examples are presented to assess the performance of the proposed method, in particular the accuracy and computational efficiency of the approximation. Although the numerical examples involve only VIs of the first kind, we also evaluate the feasibility of using the RBM combined with the EIM to treat VIs of the second kind.
1. Introduction
Many problems in engineering and science can be described as elliptic variational inequalities (VIs). Before addressing such problems in function spaces, we first give the reader a simple example. It is inspired by [Citation1] and addresses a scalar minimization problem.
Let ,
be an interval and f :I →
be a continuously differentiable function. Since f is continuous, it has a minimum in I. The minimum x is characterized in the following way:
The last characterization can be reformulated into a single statement
which is a VI-problem in . In the following, we generalize the problem to the Banach space setting. There the minimum of a functional does not lie in an interval but in a convex set.
In particular, we consider ‘elliptic VI-problems of the first kind’. Such problems are defined as a minimization of a sum of a bilinear and linear functional over a convex set X (see, e.g., [Citation2]): , or equivalently
. This class of problems includes, among other problems, obstacle problems, lubrication phenomena and two-dimensional flows of perfect fluids or wake problems.
In this article, we focus on minimizing functionals with a bilinear and (non)linear part, such as obstacle-like problems. The problem’s underlying physics is described by parameters: material, geometry and boundary properties. For a fixed parameter, the solution procedure for VIs, in practice, often relies on Lagrange-, barrier- or penalty-based methods (see, e.g., [Citation3]) and is often costly. Especially, in real-time (e.g. parameter-estimation) and many-query (e.g. design optimization) contexts, it is necessary to find faster ways to solve VIs for many parameters. One key ingredient is exploring the parameter-induced solution-manifold and trying to resolve it with only a few functions.
The reduced basis method (RBM) was successfully applied in [Citation4,Citation5], and [Citation6] to the Lagrange-based approach for VIs of the first kind with bilinear and linear functional parts only. In [Citation5] the computation of surrogate solutions, and a posteriori error bounds with a partial offline-online computational decomposition are presented. The idea of such a decomposition is to pre-compute offline costly terms in advance and then, online, rapidly – without high-dimensional computations – compute a surrogate solution and its error estimator.
In this paper we focus primarily on solving VIs in which the ‘cost’ function is a sum of a bilinear and a nonlinear functional. We investigate the feasibility of solving these VIs by applying the empirical interpolation method (EIM) to the barrier- and penalty-based formulations. Although the problems considered here involve differentiable nonlinear functions, our ultimate goal is to evaluate the proposed method’s practicability for VIs of the second kind, i.e. VIs involving non-differentiable functionals. VIs of the second kind play an important role in friction and contact (see, e.g., [Citation7]) and are even more difficult to handle.
We focus on the development of rapidly convergent reduced basis surrogates and associated a posteriori error estimators, following three steps. First, we eliminate the Lagrange multiplier by applying the barrier or penalty method. This adds a non-linear term to the functional. Second, we apply EIM to the latter non-linear term, in order to evaluate it rapidly yet accurately. Third, we reduce the dimension of the problem through a Galerkin projection onto a low-dimensional reduced basis space and an efficient evaluation of the non-linearity by EIM. Using these three steps, we rapidly compute a surrogate. Moreover, this surrogate is used to evaluate a non-rigorous a posteriori error estimator. More precisely, this estimator approximates the error but does not bound it rigorously.
We start with the general problem setting. Let be the physical domain and
represent parameters. The VI is described by a minimization problem on a convex subset X(μ) of a separable Hilbert space V. Find
, such that
We assume that a(∙,∙) is a symmetric, continuous and coercive bilinear form. Furthermore, we distinguish two cases for a bounded functional f(∙): In Section 2, we consider a linear f(∙), whereas in Section 4, we consider an example with a non-linear f(∙). Here, for simplicity, we only allow the parameter μ to influence the admissible space X(μ) by the means of , where
. However, our approach is easily extendable to parameter-dependent a(∙,∙) and f(∙). Note that here
since for
and
, the Sobolev embedding theorem implies
(see, e.g., [Citation2]). Since u is continuous, the restriction
is well defined. However, for higher spatial dimensions, the continuity of u is not ensured, but we can define an embedding
and so consider the order relation ≥ in the weak L2-sense.
We state the main contributions of this article:
We investigate the feasibility of solving (non-linear) VIs by applying the EIM to the barrier- and penalty-based formulations.
We study the quality of error estimators provided by the EIM-RB reduction.
We successfully apply our methods to VIs including convex differentiable terms, such as
.
In Section 2, we introduce two solution procedures, a barrier method and an exponential penalty method (exp-penalty method), and derive the equivalence of a VI and a non-linear elliptic equation. In Section 3, we (i) briefly introduce the application of EIM and RBM to non-linear elliptic equations and (ii) derive two a posteriori error estimators. In Section 4, we present numerical results for an one-dimensional (1D) model problem with an obstacle-type constraint.
2. Barrier method and exponential penalty method
We first introduce a regularization with a barrier method with an obstacle-like, parameter-dependent constraint . The idea of the barrier methods is to substitute the constraint by a smooth and monotone so-called barrier functional that raises to infinity if the solution approaches the constraint. Therefore, the constraint is incorporated in the barrier functional
, where
is necessary for the well-posedness. Overall, the new functional
is still convex in u for all
and therefore a minimizer
exists.
The discretized problems of and Equation (1) can be treated by non-linear convex programming, for which the authors of [Citation8] show convergence for a decreasing parameter
. More precisely, the solution of the discretized problem
converges to the solution of the discretized problem (Equation (1)).
Further, we characterize the minimizer u(∙; μ, ) for a linear f(∙) by the first order necessary (here, also sufficient) condition:
In order to approach a solution of Equation (1), we solve Equation (2) for a sequence of decreasing homotopy parameters and follow a continuation procedure combined with Newton’s method. More precisely, we start to solve Equation (2) with the Newton’s method for a relatively large
0 ≈ 0.2. This
0 is chosen such that the Newton’s method converges in a few steps and u(
0) is relatively close to the unconstrained problem of Equation (1). Once the Newton’s method has converged, we decrease
by a fixed factor γ (e.g. we take γ = 2/3) such that
1 = γ ·
0. Then, we solve Equation (2) for u(
1) using u(
0) as the initial guess in the Newton’s method. We eventually stop when we obtain the solution of Equation (2) for the final homotopy parameter
final = 1E – 3. The convergence of the Newton’s method for all
> 0 is ensured for the discretized setting (see Chapter 11.2 in [Citation8]). The construction of the
-sequence, here, is based on the following observations: (i) for
0 the Newton’s method converges in a few steps, (ii) the factor γ = 2/3 was sufficient to provide on the one side a good initial guesses for solving Equation (2) for the next
and on the other side not to include too many intermediate
-solutions and (iii) we choose
such that the regularization error caused by the
-sequence is close to the discretization error (see Section 4). In our model problems, we did not encounter any convergence problems. For a detailed discussion on the initial parameter
0 and the construction of the
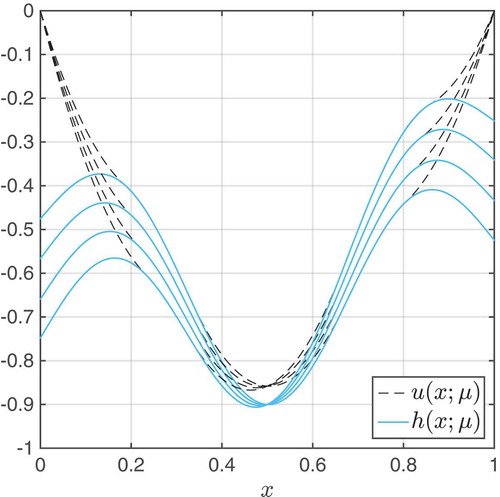
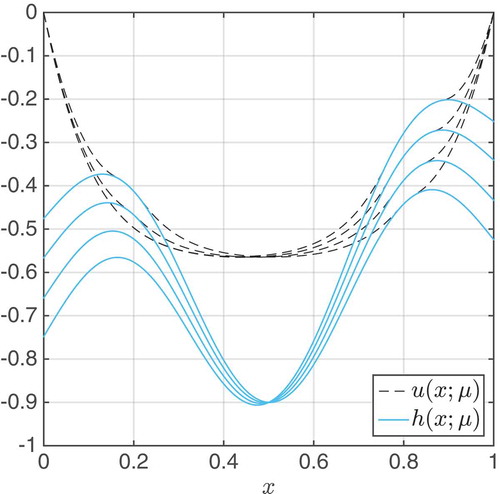
-array, we refer to Chapter 11.3.1 in [Citation8]. In , we anticipate the numerical example in Section 4 and show solutions for the obstacle problem.
Figure 1. Solutions u(x; μ) and the corresponding obstacles h(x; μ) of the first numerical example in Section 4.
Second, we introduce a penalty approach. The standard penalty method with a quadratic penalization functional is widely used and has been analysed (see, e.g., [Citation9,Citation7]). Since the quadratic penalty term is only once-differentiable, we introduce a smoother penalization with an exponential term. This penalization has been already proposed for non-linear convex programming in n, (see, e.g., [Citation10,Citation11]). In this work, we extend the exp-penalty method to the function space setting.
Analogously to the barrier method, we define an additional penalizing term with
→ 0. The term E(u; μ,
) becomes larger, if u violates h(μ). Since for all fixed
> 0 the term E(u; μ,
) is convex, we can identify a
-dependent minimization problem: find u(
) minimizing
. Again, we characterize u(
) by the first-order optimality condition
We then solve this non-linear elliptic equation for a fixed
by using a damped Newton’s method and a decreasing
-sequence in a homotopy. In practice, we use the same sequence as in the barrier method.
Based on the convergence results of the exp-penalty method for discrete spaces in [Citation10,Citation11], we carry out finite-dimensional calculations in Section 4.
3. Empirical interpolation method and reduced basis method
In this section, we introduce well-known reduction techniques and combine them to explore one way to (i) rapidly compute accurate approximations to parametrized VIs and (ii) explore the parameter-induced solution manifold.
We will focus on the barrier method only in this section; all the results can be directly transferred to the exp-penalty method. We start by introducing a discrete and computable framework for the barrier method. Let Ωh be a discrete domain space and Vh a high fidelity finite element method-space that is fine enough to resolve the parameter-dependent solution sufficiently well. In this article, we use P1 piecewise linear hat basis functions. In order to reduce the computational cost, we first, introduce EIM to reduce the complexity of the non-linear term in Equation (2) and, second, apply RBM to reduce the complexity of the linear and bilinear terms. Based on these two steps, we derive a reduced Newton’s method and an error indicator that estimates the quality of the reduced solution.
3.1. EIM
The formulation of the barrier method in Equation (2) involves a μ-dependent non-linear term , which we need to efficiently approximate for a fixed, here, final
. EIM provides such an approximation by a coefficient function approximation
with
. We define
in Algorithm 1 and restate major results from [Citation12] and [Citation13].
EIM is based on a greedy approach to successively construct so-called interpolation points and a sample set
with the associated reduced space
. The approximation
lies in the latter space
. The EIM approach consists of the following three steps:
First, we choose a maximal dimension of the space WM : , and define a finite parameter training set
for which we compute u(μ) and
for all
Second, we compute the first basis function of the coefficient function approximation by the following four ingredients: (i) choose one parameter , (ii) set
, (iii) determine the first interpolation point by
and (iv) set the first basis function of WM as
.
Third, we perform Algorithm 1 that uses data from M previous steps to generate data for M + 1.
Algorithm 1
EIM induction
for
define
solve
compute
interpolation error
determine
set
define
end for
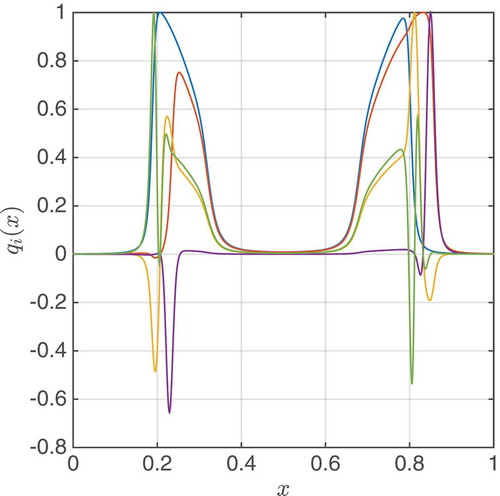
Note that in Algorithm 1, the matrix BM is lower triangular with unity diagonal and hence invertible. Further, using the EIM approach, we depict the first five basis functions of WM for the first numerical example in . It is worth mentioning that if the functional f(∙) has non-linear parts, they can be simply included in the functional g(∙) and also treated by the proposed EIM reduction. We can thus assume in the subsequent sections that f(∙) is linear. We now turn to the RB method.
Figure 2. The first five basis vectors forming gM’s space WM in the numerical example for the barrier method in Section 4. The basis is constructed by EIM.
3.2. RBM
It has been shown that RBM efficiently reduces the complexity for many parametrized problems, such as elliptic [Citation14], transport dominated [Citation15], parabolic [Citation16] and even hyperbolic problems [Citation17,Citation18].
Based on the RBM results for elliptic problems, we give the following reduced basis setting. We introduce a nested sample ; see later for construction of samples obtained by the greedy approach. Further, we define the associated nested reduced basis space
, where
is the solution of the barrier method for the final and smallest homotopy parameter
. Further, we orthonormalize
with respect to the inner product
such that the Newton’s Jacobian matrix (to be defined in Section 3.5) is better conditioned. Subsequently, we apply a Galerkin projection for the non-linear elliptic Equation (2), for the final homotopy parameter
final, onto the space
and search for a surrogate solution
for any
. The resulting non-linear reduced problem is given by
. By considering the representation of
, we get a smaller algebraic system
. We see immediately that the latter system cannot be solved online efficiently, since
is non-linear in uN and therefore cannot be decomposed in the offline stage. Consequently, we apply the EIM-approximation to the latter term, which leads to a reduced problem with the unknown
:
We can rapidly access , which completes the online–offline decomposition. Through this decomposition, we can now solve Equation (3) and obtain a surrogate
for the original problem (Equation (1)). Note that here we do not consider
as a parameter for the RBM, but include implicitly the final homotopy parameter
final in gM, in Equation (3).
3.3. Greedy procedure
In this subsection, the sample set and the corresponding RB-space
are constructed for the final homotopy parameter
final in four steps: First, let
be a training set, which is usually larger than
, since from our experience we need more training parameters to sufficiently explore the μ-induced solution manifold. If
, then choose an initial parameter
and set μ* = μ1. Second, add μ* into
and the corresponding solution u(·; μ*) into
. Third, compute with M = Mmax for all
the surrogate
and its approximate relative error estimator
. The derivation of
and
est is introduced in the following Sections 3.4 and 3.5. Fourth and finally, having
est, we determine the parameter μ* with the largest
est to be added into
.
The second, third and fourth steps are repeated until the maximal estimator falls below a tolerance, or a maximal number of reduced basis functions Nmax is reached; for a detailed description of the greedy method, see, e.g., [Citation19]. Using the greedy approach, we depict the first five basis function of for the first numerical example in .
Figure 3. First five basis vectors forming the reduced basis space in the numerical example for the barrier method in Section 4. The basis
is constructed by greedy procedure based on the a posteriori error estimator (only the residual part
NM).
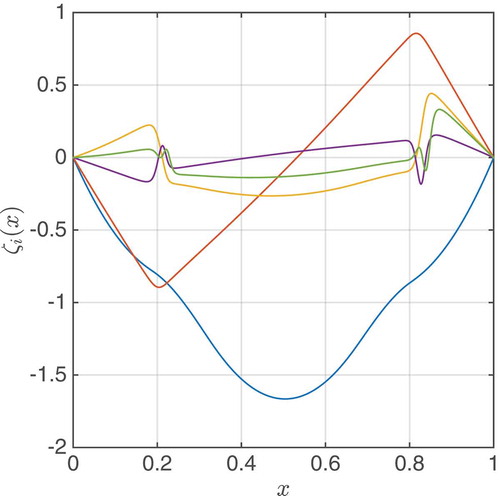
It is worth mentioning that in , we see, in the transition area between non-contact and contact, steep gradients. These gradients are hard to approximate for the EIM. The gradients become even steeper for smaller final such that an inaccurate gM causes inaccurate approximations for u (see and ).
Figure 4. Relative convergence of barrier/exp-penalty solutions to the reference solution, depending on the homotopy parameter , measured in V-norm.
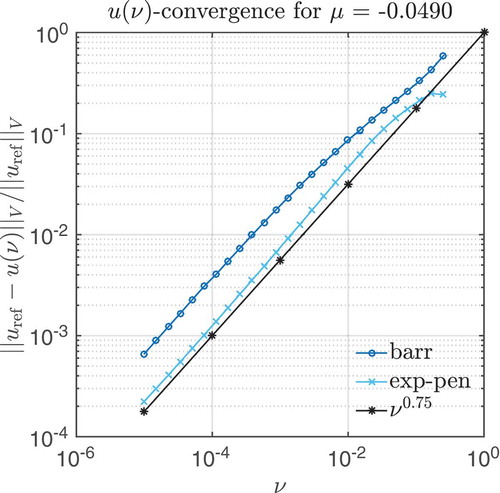
Figure 5. Barrier method: maximal relative error and estimator decay (only residual part) for different N, M values.
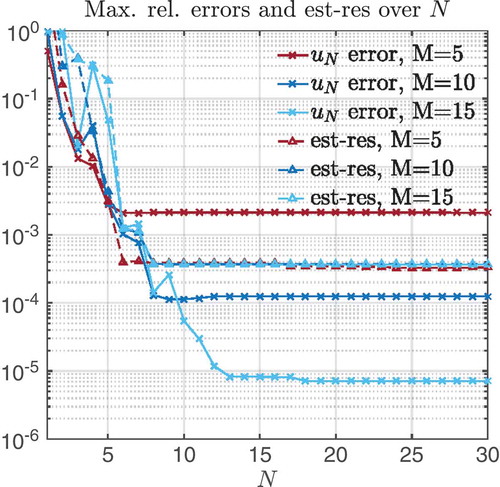
Figure 6. Exp-penalty method: maximal relative error and estimator decay (only residual part) for different N, M values.
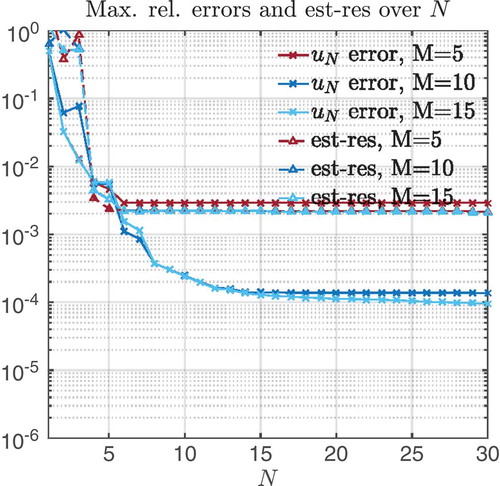
Figure 7. Barrier method: Numerical instabilities for the case when the homotopy parameter is very small (final = 1E – 4). Maximal relative error and estimator decay (only residual part) for different M, N values.
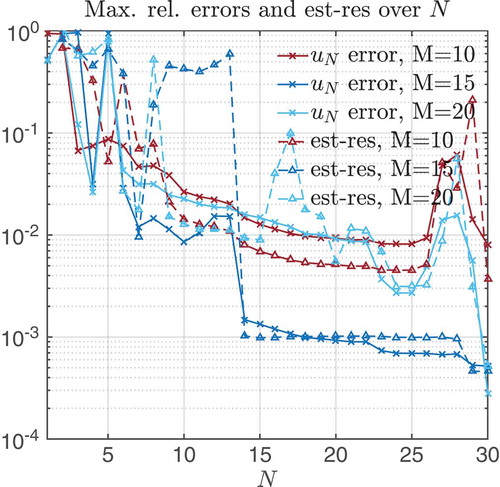
Figure 8. Exp-penalty method: Numerical instabilities the case when the homotopy parameter is very small (final = 1E – 4). Maximal relative error and estimator decay (only residual part) for different M, N values.
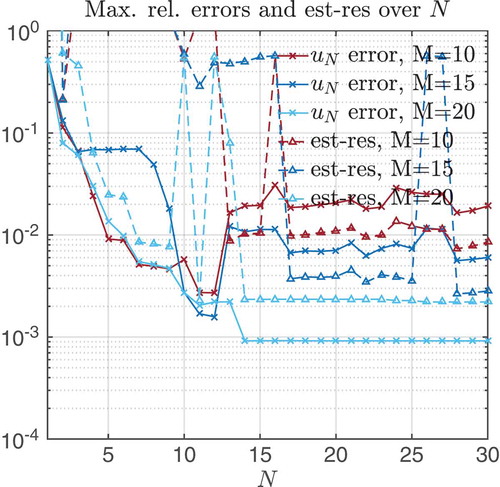
In the next part of this section, we give the formulation of the a posteriori error estimator and the explicit construction of Newton’s method in the reduced setting.
3.4. A posteriori error estimator
In order to derive an error estimator, we define the residual term
. Then we define three auxiliary terms that are used in the estimator derivation: (i)
, (ii)
and (iii)
, where
. We go back to Equation (2), use its full solution u(μ) and conclude
Note that is continuous and monotonically decreasing in u. From that we infer that
and therefore
. Next we substitute
in Equations (4) and (5) with
and conclude
.
At this point, we already derive the first error estimator by neglecting . Using (i)
and (ii)
, where α is the coercivity constant of a(∙,∙), we conclude
In Section 4, we illustrate in the numerical examples that this term is already a good indicator for the error. However, for completeness, we go one step back and consider the neglected term . In order to estimate that term we use a special property of EIM: If M + 1 ≤ Mmax and
, then
(see, e.g., in [Citation12]). Of course, this condition
is generally not satisfied. Therefore, we make a common EIM assumption that
. Thus, we deduce
. We infer from
≥ 0 and coercivity of a(∙,∙) that
Here, α = 1, since we did not include any μ dependence for a(∙,∙) and defined (∙,∙)V = a(∙,∙). If a(∙,∙;μ) is ‘parametrically coercive’, the simple ‘min-θ’ approach can be applied to determine α (see [Citation14]). For even more general bilinear, and even non-symmetric forms, the Successive Constraint Method provides an α (see [Citation14]).
3.5. Reduced Newton’s method
We solved the full problem (Equation (2)) by a continuation procedure with the Newton’s method. We apply exactly the same approach with the same -sequence also for the reduced problem (Equation (3)) for
final. For the Newton’s method, we need the following two ingredients: first, the reduced Equation (3), which we drive close to zero, and second, the gradient of Equation (3).
Let be an initial guess, where – except for the first homotopy solution
– the initialization is given by
. We denote the representation
, where
stores the RB vectors and
is the coefficient vector. Using that representation, we define three algebraic parts: (i) a matrix
, (ii) a vector
and (iii) determine
at the interpolation points
and store the values in
. In order to evaluate
, we evaluate the basis ζi at the xm and store them in
. Then, we define
. Using the definition of
, we derive a new representation of the last term of Equation (3)
We define two matrices, and
, and thus rewrite Equation (3) algebraically into
For the gradient of the last expression, we take derivatives of Equation (3) with respect to the unknown uNM. This results in the following expression of the gradient where diag(vector) is a matrix with the vector’s entries on the diagonal.
Having now the evaluation of Equation (3) and its gradient, we state the Newton’s iteration: (i) start with a guess uNM and (ii) compute δuNM by solving:
(iii) update , where
is an additional damping parameter, in order to achieve better results; (iv) go to (ii) with the current uNM.
We discuss the well-posedness of the Newton’s iteration. It mainly depends on a good choice of the starting point and on the properties of the reduced matrix . The solvability can be theoretically ensured by the so-called inf-sup-condition (see, e.g., [Citation15], Section 3). In practice, we check the invertability of the gradient especially for the final homotopy parameter
final and discovered that the smallest eigenvalue of the reduced Newton’s matrix was always
(1).
We now give a short overview of the computational cost of the reduced barrier method. We define H as the size of the -sequence and I as the average number of Newton’s iteration steps during the homotopy. The cost mainly depends on the computation of the gradient
with
(MN2) and the inversion of it. In summary, the cost is given by
. In addition, the evaluation of the error estimator for uNM(μ) is comparably cheap with only
(M2 + N2).
As mentioned in the beginning, all results of this section can be directly applied to the exp-penalty method by using for a fixed, final
=
final.
Here we want to comment on the fact that we only consider basis functions ξi for the final parameter final. Of course, this causes less accurate intermediate results during the homotopy steps; however, we encountered that the accuracy suffices to have a converging Newton’s method. However, for too small
, we encounter both (i) a less accurate EIM approximation gM(μ) and (ii) less accurate RB approximation uNM(μ) (see and .
4. Numerical example: 1D obstacle problem
In this section, we apply the proposed methods to two examples and investigate their performance. We first define the framework of the problem and afterwards show the numerical results of the barrier method and the exp-penalty method applied to linear and non-linear functionals.
4.1. A quadratic cost functional
We set and
. Let Ωh be an equidistant mesh with
= 999 dofs (1000 cells) and let Vh consist of first-order Lagrange FE. We define a minimization problem, given in [Citation5], by
, where
is the elasticity parameter. We impose
, with the parametrized obstacle
and
We utilize the routine quadprog of MATLAB, with TolFun = 1E – 12 to compute very accurate reference solutions uref (∙; μ). Solving the problem with this method for a P1 FE basis on the mesh with
= 999 gives an approximate relative discretization error ≈ 2E – 3. We computed this error estimate by employing nested meshes, where the finest discretization has 4000 elements. Further, for the barrier and the exp-penalty methods, we need to consider not only the discretization error but also the regularization error caused by the homotopy in
.
We start with the regularization error. Here, we need to choose a sequence of barrier/penalty parameters with a sufficiently small final parameter. The latter is chosen depending on the relative error between the accurate reference solution uref and the full barrier/exp-penalty solutions ubarr(
final) and uexp(
final). The dependence on the final homotopy parameter is depicted in . As a result, we choose for both methods the final homotopy parameter
final = 1E–3, such that the relative error to the reference solution is ≈ 2% for the barrier method and ≈ 1% for the exp-penalty method. The construction of the
-sequence with
final = 1E–3 is already stated in Section 2.
Having this -sequence we can now approximate the discretization error. Here it is the same as for the routine quadprog, namely ≈ 0.2%. We now describe the reduction process for RB and EIM. We start with constructing the EIM quantities qi(x) and xi (see ). This is done by using a training set
, constructed by choosing 60 equidistant values for μ in the interval [0.05, 0.5]. We note that for constructing the vectors qi(x), we need to compute u(μ) for all
. Therefore, it is not prudent to take a very large number of training points here.
Having an EIM approximation with up to Mmax = 60 functions, we continue to construct the RB with ζi (see ). Again we construct a set , but now with far more points, 300 equidistant values for μ in the interval [–0.05, 0.5]. We run the greedy procedure based on the error estimator, see Equation (6), and EIM with M = 60 basis elements in order to construct N = 30 RB functions. The resulting maximal error estimator for (N,M) = (30,60) is around 4E – 4 for the barrier method and 11E – 4 for the exp-penalty method. This is below the expected discretization and regularization errors, such that we can stop the enrichment of RB here.
For testing the reduced methods, we choose another set by taking 148 equidistant values for μ in the interval [–0.049, 0.49637] with
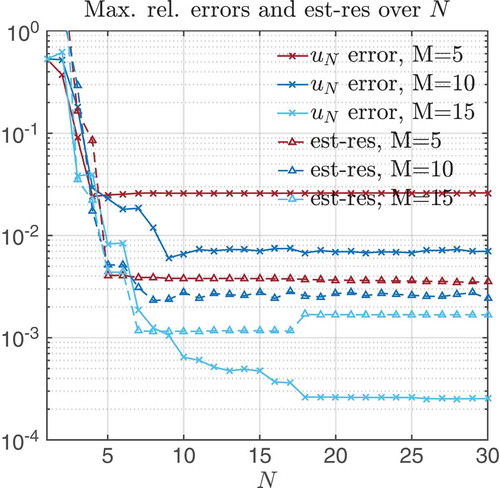
In and , we display the maximal relative errors (solid) and the maximal relative error estimators from Equation (6) (dashed) in V-norm for the barrier method and the exp-penalty method. We note that for (N,M) = (10,10), both methods already reach a relative error below 1%. This is important since the accuracy of the reduced method should be better than the one caused by the homotopy error: 2% (barrier) and 1% (exp-penalty) (see ). Further, we observe for both methods that already with M = 5 the error estimators reach a plateau for N = 6, which means that adding more basis function for gM does not improve the estimator. However, increasing M until M = 5 does improve the error visibly. Using the error estimator given in Equation (7) results in similar results only with slightly less accurate estimators (see also and ).
Table 1. Barrier method.
Table 2. Exp-penalty method.
We present in and relative errors and different relative estimators for different N, M. We denote the estimator from Equation (6) with (est-res) and from Equation (7) with (est), where the latter estimator gives less accurate results due to the inaccurate term . Furthermore, we display in the average effectivity
and the speed-up ratio between the computational times of the reduced method and the full method without reduction. The full time for the barrier method is around ≈ 0.1s and for the exp-penalty method is ≈ 0.05s.
We can clearly see in that the error decays with growing N, M, while the mean effectivity is strongly varying. The speed-up ratio for (N, M) = (10, 10) is around 27.2, which means that the reduced approach is around 27 times faster than the original one. We stress two notable results: (i) taking a too small M, as in (N, M) = (10, 5), might result in an underestimating error estimator (6) and (ii) the error estimator in Equation (7) is likely to overestimate the error.
In we see a similar behaviour, except that the effectivity is more stable and saturates at 20. The speed-up ratio is now roughly twice as small as before, since the RB-time stayed the same, whereas the full time for running the exp-penalty method is half as large as for the barrier method. Again, it is worth mentioning that the second estimator, given by Equation (7), is likely to overestimate the error.
We comment on an implementational issue. In order to resolve the non-linearity in g(u, x; μ) and to achieve reliable results in EIM, it is necessary to carefully consider the role of quadrature points in the computation of integrals such as . More precisely, by involving in the offline stage a more accurate quadrature rule we improve the approximation quality (see, e.g., [Citation20], p. 132 and [Citation13]). In the previous example, we used 2 quadrature points on each element. By using 5 quadrature points, the offline time increases with the factor of ≈ 1.3, whereas the online cost stays the same (compare speed-up ratios in and ). The accuracy of the integration improves and we achieve better error estimators for both the barrier method and the exp-penalty method. As a result, we show the improved results for the barrier method in .
Table 3. Barrier method.
Comparing the computational times of the proposed reduced methods with the method proposed in [Citation5], we observe some differences. As suggested in [Citation5], we use on the one hand an out-of-the box routine quadprog and on the other hand our implementation of the barrier and exp-penalty method. For finding a reduced solution uN with roughly the same error estimator, we note that the method from [Citation5], using quadprog, is as fast as our reduced methods. For evaluating the error bound or error estimator, we observe for all approaches almost the same time. Here, the reason lies probably in the small model problem size. Theoretically, the difference lies in the computational effort for the a posteriori error bound and error estimator. In fact, our estimator is independent of the high problem dimension .
We give a short remark on the application of the reduction to a two-dimensional (2D) problem. Independently of the problem, the speed-up of the reduction is again dependent on the dimension of the true problem and the EIM- and RB-basis dimension M, N. Since
is usually larger for 2D problems than for 1D problems, we observed for a model problem with an obstacle-like constraint larger speed-up.
In the next part, we comment on the influence of the final homotopy parameter final on the numerical stability of the reduced barrier and the exp-penalty methods. We keep all specifications of the previous example – with 2 quadrature points – but only change
final = 1E – 4. Recomputing EIM and RB for both methods, results in an outcome that is depicted in and . We can observe instabilities, which appear due to larger slopes of the non-linearity caused by the smaller homotopy parameter. The smaller parameter results in a less accurate Newton’s iteration and causes more damping steps with some outliers. We investigated the influence of three different quantities: (i) M, Mmax in order to change accuracy of EIM, (ii) the number of quadrature points in order to change accuracy of the evaluation of non-linearities and the (iii) stepsize in the homotopy array in order to improve initial guesses for Newton’s method. Only the last quantity provides some improvement. Through refining the stepsize around
final, we only observed a tighter error estimator; however, we could not improve the errors. The instabilities occur for the last homotopy steps (here, for
final and
final−1), although (i) the previous
are reasonably good with an error of 1E – 3, and (ii) the Newton’s method converges in few steps. It seems that the EIM approximation of the non-linearity is too inaccurate to provide reliable gM(μ) for too small
final over
. In order to avoid instabilities, we suggest to choose
final such that the regularization error (see ) lies above (i) the expected discretization error (2E – 3) and (ii) the greedy error (barrier 0.4E – 3 and exp-penalty 1.1E – 3). Although this is not sufficient to rule out instabilities, we could follow this heuristic with good results.
4.2. Non-linear cost functionals
We extend the previous obstacle problem by adding a convex non-linearity to the cost functional. The existence and uniqueness of this class of problems is discussed in detail in Chapter 4 in [Citation2]. Here, we consider a differentiable cubic non-linearity that represents a cubic pull-back force to the rest position. Thus, the overall functional is given by
, where we now choose
.
On the one side, this class of problems cannot be treated by the Lagrange-based approach of [Citation5], since is no longer linear. Nonetheless, one could apply EIM to the non-linear part of f(∙) and then apply the Lagrange-based approach. The clear advantage of our approaches is that it is relatively easy to incorporate the non-linearity into the reduced methods.
Next, we display different parameter-dependent solutions of the problem, with non-linear f(∙), in .
Figure 9. Solutions u(x; μ) and the corresponding obstacles h(x; μ) of the second numerical example; using the exp-penalty method (final = 1E – 3).
We apply the exp-penalty method to a VI with non-linear f(∙). Again, we choose the final parameter final = 1E – 3, such that the relative error to the reference solution is
. We apply the proposed reduction methods with the same parameters and sets as in the previous example and show its performance in . The error and estimator curves are now higher as for the previous example because of the additional non-linearity. In fact, the non-linearity leads to a more diverse parameter-induced solution manifold and consequently to a more difficult problem to be reduced.
Figure 10. The exp-penalty method applied to a VI with non-linear f(∙): Maximal relative error and estimator decay (only residual part) for different N, M values.
Finally, we comment on the application of our approaches to VIs of the second kind, i.e. VIs that involve minimization of functionals with non-differentiable non-linearities such as . Adding
to the minimizing functional adds a very hard non-linearity to the minimization problem. The full problem can be solved, e.g., through application of a Newton’s method to a regularization-approach of the
term or through a Gauss–Seidel method (see Chapter 5 in [Citation2]). Applying these methods to the non-differentiable problem not only takes more computational time but also produces solutions with low accuracy. Subsequent application of RBMs using the barrier and exp-penalty methods described earlier and a regularization of the
-term resulted in further magnification of the inaccuracy. Efforts at stabilizing the iteration by investigating the influence of M, Mmax, the number of quadrature points, stepsize in the homotopy and different regularizations for the
-term were unsuccessful.
In summary, this work evaluates the feasibility of solving VIs with non-linear functionals f(∙) by applying the EIM to the barrier- and penalty-based formulations. These formulations enabled the computation of reduced basis approximations albeit with error estimators only (i.e. not error bounds). Furthermore, the proposed method allows for a full offline–online decomposition of the computation of the approximation and error estimates. We apply our methods to VIs of the first kind involving functionals that are convex, differentiable and non-linear. Our results seem to indicate, however, that the proposed methods are unsuitable for use on the (even more difficult) variational inequalities of the second kind which involve non-differentiable functionals. Other approaches therefore need to be considered to tackle such problems.
Acknowledgments
We would like to acknowledge M. A. Grepl and M. Herty for fruitful discussions. Further, we are truly thankful to the anonymous referees for their comments and valuable feedback. This work was supported by the German Research Foundation through Grant GSC 111 and the Excellence Initiative of the German federal and state governments.
Disclosure statement
The authors have no potential conflicts of interest to disclose.
Additional information
Funding
Related Research Data
References
- S. Antman, The influence of elasticity on analysis: modern developments, Bull. Amer. Math. Soc. 9 (1983), pp. 267–291. doi:10.1090/S0273-0979-1983-15185-6
- R. Glowinski, Numerical Methods for Nonlinear Variational Problems, Springer, Berlin, 1984.
- T. Laursen, Computational Contact and Impact Mechanics, Springer, Berlin, 2002.
- S. Glas and K. Urban, On noncoercive variational inequalities barrier methods for optimal control problems with state constraints, SIAM J. Numer. Anal. 52 (5) (2014), pp. 2250–2271. doi:10.1137/130925438
- B. Haasdonk, J. Salomon, and B. Wohlmuth, A reduced basis method for parametrized variational inequalities, SIAM J. Numer. Anal. 50 (5) (2012), pp. 2656–2676. doi:10.1137/110835372
- Z. Zhang, E. Bader, and K. Veroy, A slack approach to reduced basis approximation and error estimation for variational inequalities, C. R. Math. 354 (3) (2016), pp. 283–289. doi:10.1016/j.crma.2015.10.024
- N.A. Kikuchi and J.T. Oden, Contact Problems in Elasticity: A Study of Variational Inequalities and Finite Element Methods, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1988.
- S. Boyd and L. Vandenberghe, Convex Optimization, Cambridge University Press, Cambridge, 2009.
- E. Cancès, V. Ehrlacher, and T. Lelièvre, Convergence of a greedy algorithm for high-dimensional convex nonlinear problems, Math. Models Meth. App. Sc. 21 (12) (2011), pp. 2433–2467. doi:10.1142/S0218202511005799
- F. Alvarez, Absolute minimizer in convex programming by exponential penalty, J. Convex Anal. 7 (1) (2000), pp. 197–202.
- R. Cominetti and J.P. Dussault, Stable exponential-penalty algorithm with superlinear convergence, J. Opt. Theory Appl. 83 (2) (1994), pp. 285–309. doi:10.1007/BF02190058
- M. Barrault, Y. Maday, N. Nguyen, and A. Patera, An ‘empirical interpolation’ method: application to efficient reduced-basis discretization of partial differential equations, C. R. Math. 339 (9) (2004), pp. 667–672. doi:10.1016/j.crma.2004.08.006
- M. Grepl, Y. Maday, N. Nguyen, and A. Patera, Efficient reduced-basis treatment of nonaffine and nonlinear partial differential equations, ESAIM: Math. Model. Num. 41 (3) (2007), pp. 575–605. doi:10.1051/m2an:2007031
- G. Rozza, D. Huynh, and A. Patera, Reduced basis approximation and a posteriori error estimation for affinely parametrized elliptic coercive partial differential equations, Arch. Comput. Methods Eng. 15 (3) (2008), pp. 229–275. doi:10.1007/s11831-008-9019-9
- W. Dahmen, C. Plesken, and G. Welper, Double greedy algorithms: Reduced basis methods for transport dominated problems, SIAM M2NA 48 (3) (2014), pp. 623–663.
- M. Grepl and A. Patera, A posteriori error bounds for reduced-basis approximations of parametrized parabolic partial differential equations, ESAIM: Math. Model. Num. 39 (1) (2005), pp. 157–181. doi:10.1051/m2an:2005006
- R. Abgrall and D. Amsallem, Robust model reduction by L1-norm minimization and approximation via dictionaries: application to linear and nonlinear hyperbolic problems, (2015). Available at http://arxiv.org/pdf/1506.06178.pdf.
- B. Haasdonk and M. Ohlberger, Reduced basis method for finite volume approximations of parametrized linear evolution equations, ESAIM: Math. Model. Num. 42 (02) (2008), pp. 277–302. doi:10.1051/m2an:2008001
- C. Prud’homme, D.V. Rovas, K. Veroy, L. Machiels, Y. Maday, A.T. Patera, and G. Turinici, Reliable real-time solution of parametrized partial differential equations: reduced-basis output bound methods, J. Fluid. Eng. 124 (1) (2002), pp. 70–80. doi:10.1115/1.1448332
- M. Grepl, Reduced-basis approximation and a posteriori error estimation for parabolic partial differential equations, PhD thesis, Massachusetts Institute of Technology, 2005.
- D.P. Bertsekas, Constrained Optimization and Lagrange Multiplier Methods, Athena Scientific, Belmont, MA, 1996.