
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We model the hardware and software architecture for generalized Internet of Things (IoT) by quantum cloud-computing and blockchain. To reduce the measurement error and increase the efficiency of quantum entanglement (i.e. the capability of fault tolerance) in the current quantum computers and communications, we design a quantum-computing chip by modelling it as a multi-input multi-output (MIMO) quantum channel and obtain its channel capacity via our recently derived mutual information formula. To capture the internal qubit data flow dynamics of the channel, we model it via a deep convolutional neural network (DCNN) with generalized stochastic pooling in terms of resource-competition among different quantum eigenmodes or users. The pooling is corresponding to a resource allocation policy with two levels of competitions as in cognitive radio: the first one is on users’ selection in a ‘win–lose’ manner; the second one is on resourcesharing among selected users in a ‘win–win’ manner. To wit, our scheduling policy is the one by mixing a saddle point to a zero-sum game problem and a Pareto optimal Nash equilibrium point to a nonzero- sum game problem. The effectiveness of our policy is proved by diffusion modelling with theory and numerical examples.
1. Introduction
With the emergence of quantum-computing (see, e.g. Courtland [Citation1], Dai [Citation2], Deutsch [Citation3], Feynman [Citation4], Gibney [Citation5], Nielsen and Chuang [Citation6]), the currently implementing Industrial 4.0 (IR 4.0, see, e.g. Schwab [Citation7]) will be quickly evolving to Industrial 6.0 (IR 6.0, see, e.g. SIR (Sixth Industrial Revolution) Forum [Citation8]). SIR Forum is an U.S. Los Angeles based Forum and was founded in February of 2018. It foresaw that the quantum computing and blockchain will be the core technology of IR 6.0. Comparing with the today’s system, the future quantum system will have extremely powerful processing, storage, tracing and management capability with strong artificial intelligence (AI), which makes the future (strong or generalized) Internet of Things (IoT) possible. This generalized IoT can be called as Internet of Every Thing (see, e.g. ; Dai [Citation2] and Santucci [Citation9]).
Figure 1. Evolution of industrial revolution and internet of every thing (IoT).
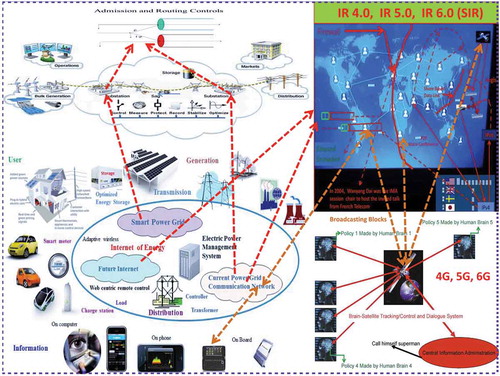
Conceptually, an IoT consists of two parts: Internet and Things. However, the most important feature in an IoT is the efficient interaction between Internet and Things. To reach the efficiency, it requires high-performance network hardware and intelligent softwares with effective integration to realize the future Internet as designed in . More precisely, inside the IoT network system, there is an interactive hardware and software system as structured in . To realize the interaction between Internet and Things, hardware quantum computing centres and physical Things must be integrated together as in through a data storage and software managing system called quantum blockchain as in with flow chart in . Note that, in , we consider the Thing as the future quantum MIMO wireless channel, which reflects the trend of future advancements on mobile cloud-computing (see, e.g. Dai [Citation10]).
Figure 2. Blockchain protocol evolution and quantum network architecture.
In the current era of Industrial 4.0, Things in an IoT (see. e.g. the left-hand side in ) represent the real-world application systems that can be the intelligent end-user’s devices or their generalized forms such as a power and energy system or a supply chain system (see, e.g. Artemis [Citation11] and Dai [Citation2]). However, in the defined Industrial 5.0 of human–machine interactions, Things in an IoT can even be our own human beings (see, e.g. the lower-right graph in ; Dai [Citation12] and Haykin [Citation13]). The interactions between Internet and Things in an IoT can be realized through optical fibre linkages or wireless multi-input multi-output (MIMO) communication (e.g. 4G, 5G or even the future 6G) channels as shown in and as discussed in Dai [Citation2]. In an IoT, Internet is the major information processing and transmission system (see, e.g. its network architecture in and the study in Dai [Citation14]).
It was originated from the U.S. based ARRP (Advanced Research Projects Agency) and initially implemented in U.S. Navy around the late 1960s (see, e.g. Comer [Citation15]) and then went to civil usage. Traditionally, the transmitted IP packet in each node is not stored or not fully stored due to the limitation of processing and storage capacity. Nevertheless, with the increasing of the service capacity, the blockchain technology with data storage at each node becomes implementable and is even predicted its usage in the U.S. Navy Aegis communication system with the encryption of 256 bit Hashes (see, e.g. ). Furthermore, to further its efficiency and security, quantum computers come up such as IBM 50-qubit, Google 72-qubit and Rigetti 128-qubit quantum computers. With the enhancements of these quantum computers, the new quantum-computing Moore’s law (see, e.g. Bertels [Citation16]) targeting the realization of a -qubit based quantum computing for a continuously increasing number
is emerging. When
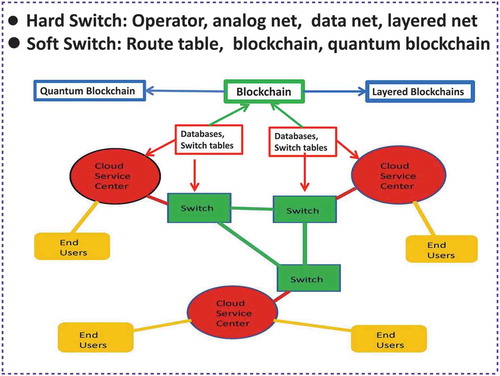
is larger, the corresponding computation power will meet the needs of many real-world applications, e.g. 30-qubit = 10 trillion floating-point operation and 50-qubit = 10 billions of billion floating-point operation (see, e.g. Fan [Citation17]). Thus, we can predict that the current internet protocol (IP) and MIMO communication network will be replaced by quantum IP and quantum MIMO based ones around the next 25 years. Moreover, they will be powered by quantum-cloud-computing and quantum blockchain with the storage capability in each service centre and switch node (see, e.g. and Dai [Citation14]). From one end-user to another one, the user’s quantum data flow consists of qubit data packets will be transmitted from one quantum cloud-computing centre to another one via quantum IP managed by network quantum blockchain software management system (see, e.g. the quantum IP network in with embedded blockchain in , and the discussions in Dai [Citation2], Rajan and Visser [Citation18]). For future references, we call this quantum IP network as a QBP internet (a quantum-blockchain-protocol based internet).
Figure 3. Quantum-blockchain evolution and processing chart.
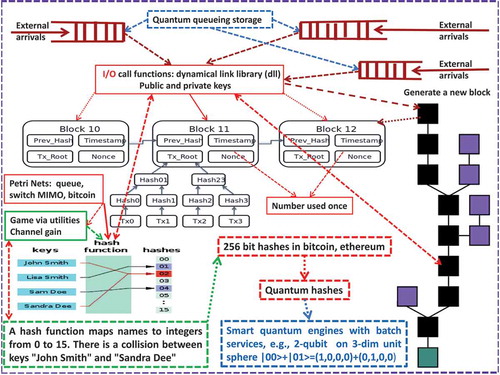
Blockchain is a quickly developing data storage and service technology, which is widely used in IoT, FinTech, Bitcoin/Ethereum, and other applications (see, e.g. Dai [Citation2], Buterin [Citation19], Iansiti and Lakehani [Citation20], Nakamoto [Citation21]) with the functionalities of blockchain management, transaction generation, node communication and block mining. More precisely, blockchain is an orderly distributed database (or called a ledger) system with processing chart of software architecture as presented in . With the appearance of real quantum computers built from IBM, Google, Rigetti, D-Wave, etc., it is recently evolving to the quantum-blockchain by substituting the standard cryptographic Hash functions to quantum cryptographic Hash functions (see, e.g. Rajan and Visser [Citation18]). Unchangeable data history and highly secured signature procedure make each trading transaction more safe than ever. Smart contracts in conducting block mining and flexible node communications make it realizable for the blockchain management to be decentralized and can be realized by implementing strategies through running various algorithms aided with AI. In doing so, the efficient interaction between blockchain and its supporting high-performance quantum-computing hardware facilities is a necessity (see, e.g. and Dai [Citation2]).
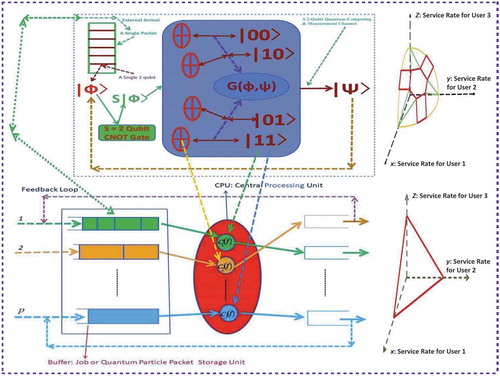
Figure 4. A quantum computing platform with parallel-queues and multiple pools. The upper-left blockchain is from Dai [Citation2] and is detailed in . The lower-right graph is a quantum MIMO wireless channel.
![Figure 4. A quantum computing platform with parallel-queues and multiple pools. The upper-left blockchain is from Dai [Citation2] and is detailed in Figure 3. The lower-right graph is a quantum MIMO wireless channel.](/cms/asset/307df98a-dcba-4b85-b787-221527a2c5cc/nmcm_a_1677725_f0004_oc.jpg)
Currently, there are numerous physical realizations of quantum computers (e.g. those announced by IBM, Google, Rigetti and D-Wave), which are mainly based on four quantum computing models of practical importance besides the theoretical quantum Turing machine (see, e.g. see, e.g. Deutsch [Citation3], Feynman [Citation4], Nielsen and Chuang [Citation6]). However, the performance of these quantum computers still has much more room to improve in terms of error measurement, computing efficiency, energy consumption and cost. Hence, in this paper, we first propose a quantum-computer chip by modelling it as an MIMO channel. This design was originally announced by Dai [Citation22] as a keynote speech in an IEEE conference. Here, we further formalize it and try to make it publicly available. Then, by the mutual information formula derived in Dai [Citation23], we can study the quantum entanglement and fault tolerance concerning signal measurements and determine the service capacity for our proposed quantum channels. During the procedure, there are two types of problems involved: how to allocate power (or rate) resource to different eigenmodes in a quantum-computing channel and how to allocate the rate resource to different users in quantum-cloud-computing service centres. To solve these problems, we model the internal qubit data flow dynamics of the quantum channel through a deep convolution neural network (DCNN) with generalized stochastic pooling in terms of resource-competition users (see, e.g. ).
Figure 5. An DCNN with quantum processor and generalized stochastic pooling. The upper graph is adapted from .
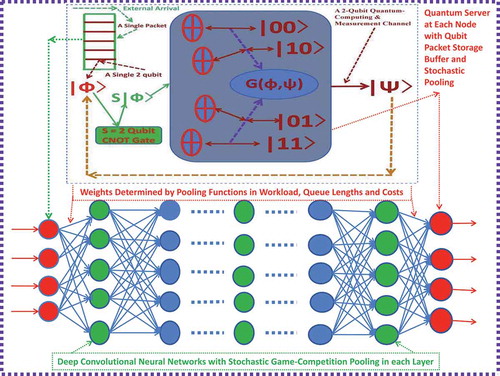
This dynamical system is corresponding to a so-called game platform that was initially studied in Dai [Citation2,Citation24]. To be consistent with the study in the current AI era, we here use the terminology ‘DCNN with stochastic pooling’ (see, e.g. Zeiler and Fergus [Citation25]) to replace the original one to describe the data flow dynamics in our ‘game platform’. Furthermore, in the studies of Dai [Citation2,Citation24], only a ‘win–win’ non-zero-sum Pareto optimal Nash equilibrium policy was designed dynamically. However, in this paper, we extend this policy to allow the stochastic pooling in our DCNN to have one more competition level with ‘win–lose’ users. In other words, our generalized policy is the one by mixing a saddle point to a zero-sum game problem and a Pareto optimal Nash equilibrium point to a non-zero-sum game problem, which can also be used in more other applications, such as, cognitive radio (see, e.g. Akyildiz et al. [Citation26], Haykin [Citation13]), Internet of Energy (IoE, see, e.g. Artemis [Citation11] and Dai [Citation2]) and FinTech (see, e.g. Buterin [Citation19], Nakamoto [Citation21]).
More precisely, in our game platform, we use the triply stochastic renewal reward process (TSRRP) studied in Dai [Citation2] to model the random dynamics of the input quantum qubit data packet flows (or called big data flows, see, e.g. De Mauro et al. [Citation27], Dedić and Stanier [Citation28], Snijders et al. [Citation29]). Furthermore, as in Dai [Citation2], we model the dynamical rate capacity available for resource-competing users at each channel or service pool as a randomly evolving capacity region driven by a finite state continuous Markov chain (FS-CTMC). The parallel-queues in this platform (see, e.g. and ) are used to storage and buffer quantum qubit data packets from their corresponding users. Each queue may be served simultaneously by multiple intelligent quantum-computing channels or service pools while each channel or pool may also serve multiple queues at the same time via running smart policies in the blockchain (see, e.g. ). However, to reflect the dynamic evolving nature of real-world systems and to realize the decentralized operation in a blockchain, the users to be selected at a time is random, the number of pools to serve a particular queue is random, and the number of queues to be served by a particular pool is also random. The efficiency or optimization concerning our designed policy is in terms of system delay, revenue, profit, cost, etc. We will model them through certain utility functions with respect to the performance measures of their internal quantum qubit data flow dynamics such as queue length and workload processes. To illustrate the effectiveness of our policy, we establish a reflecting diffusion with regime-switching (RDRS) model for the performance measures under our proposed policy in order to offer services to different users in an optimal and fair way. Based on this RDRS model, our designed policy is effectively implemented with numerical examples.
The remainder of the paper is organized as follows. In Section 2, we present the quantum system formulation modelled by MIMO channels, fault tolerance by quantum mutual information, quantum storage and particle queueing dynamics. In Section 3, we present the RDRS model and the performance modelling for its internal quantum qubit data flow dynamics of the modelled quantum channel by the RDRS model. Main DCNN and game-competition based scheduling policy together with theoretical modelling results are presented. Numerical simulation examples are also given in this section. In Section 4, we formally prove our main theoretical results. In Section 5, we conclude the paper with remarks.
2. Quantum system formulation modelled by MIMO channels
This section consists of two subsections: qubit presentation and quantum mutual information, quantum storage and particle queueing dynamics.
2.1. Qubit presentation and quantum mutual information
In a quantum-computing-based computer or communication system, the basic information unit is a -qubit with
and can be expressed through the conventional complex column-vector oriented ket-notation. More precisely, a state
of
-qubit register is represented by
where, for each
and
is called an eigenstate and there are total number
of them. In the meanwhile, the basis of bit strings
is known as the computational basis with the corresponding complex coefficients denoted by
. For example, a special case corresponding to the expression in (2.1) with
and
can be realized via the Hadamard gate
(see, e.g. Deutsch [Citation3], Feynman [Citation4], Nielsen and Chuang [Citation6]) as follows,
The sum of the squares of the coefficients’ absolute values in (2.1) must be the unity, i.e.
For each bit string, ,
gives the probability of the system being found in the
state after a measurement. However, because a complex number encodes not just a magnitude but also a direction in the complex plane, the phase difference between any two coefficients (states) denotes a meaningful parameter. This is a fundamental difference between quantum computing and probabilistic classical computing. Under this computational basis, a state
of
-qubit register can be represented by its coefficients
. For examples, if
,
and if
,
while
, where, the prime denotes the transpose of a vector. Note that, if
, a single qubit can be used to denote a particle spinning up and down at the same time. The possible quantum states for a single qubit is visualized by the so-called Bloch sphere as in the left-upper graph of , where
. Note that, the Bloch sphere is the surface of a ball and hence is a two-dimensional manifold since it can be represented by a collection of two-dimensional maps. In the sequel, we just simply call it a 2-sphere by mathematical convention. A pure qubit state can be represented by any point on such a 2-sphere with corresponding angles
and
. More precisely,
is the angle between
-axis and
, and
is the angle between
-axis and the projection of
onto
-plane.
Figure 6. Qubit representation and random walk.
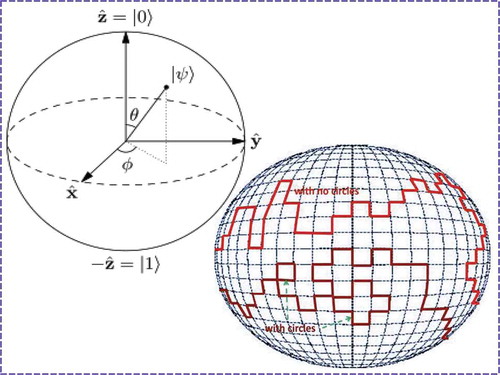
In the future quantum cloud-computing and communication system (see, for a newly designed example), the traditional binary (zero or one) bit based data packets will be replaced by quantum data packets. Each of them will consist of user’s data payload and packet head that indicates the service requirements managed by system software called quantum blockchain in Dai [Citation2] (see, for detail). The length of a quantum data packet is the number of qubits randomly walking over the Bloch sphere as shown in the lower-right graph of . Note that, the random step size for each walk along a particular direction over the sphere may be greater than the unity. Furthermore, the packet length is also random from one quantum data packet to another one. However, no matter whether in a quantum computer or in a quantum communication channel, the service time and quality for a quantum data packet depends on the measurement of each single source qubit. Currently, there are numerous physical realizations of quantum computers, which are mainly based on four quantum computing models of practical importance besides the theoretical quantum Turing machine (see, e.g. Deutsch [Citation3], Feynma [Citation4], Nielsen and Chuang [Citation6]). However, the error from the measurement or unitary operation is still the issue. In general, due to the non-cloning theorem (see, e.g. Niestegge [Citation30], Wootters and Zurek [Citation31]), unknown pure quantum states cannot be copied unless they are orthogonal. Nevertheless, according to Niestegge [Citation30] and references therein, the approximate or imperfect cloning of quantum states is possible, e.g. via a generalized non-Gaussian mutual information formula (see, e.g. Dai [Citation23]) by developing a quantum channel between quantum states and their measurements (or their received states) in a probabilistic way. Furthermore, the quantum Zeno effect or called Zeno’s paradox (i.e. the inhibition of transitions between quantum states by frequent measurements, see, e.g. Itano et al. [Citation32], Misra and Sudarshan [Citation33]) is the other concerned issue. Nevertheless, inside the recently realized IBM 50 qubit quantum computer, the quantum coherence time (the time gap to keep a channel stable (i.e. to keep the number of quantum states the same)) can last up to 90 μs to reduce the influence of Zeno effect, which is enough for the quantum computer to perform the required operation and realize one 20-qubit quantum entanglement in 187 ns (see, e.g. the latest announcement in Song et al. [Citation34]). Therefore, with the hope to reduce the error, we develop a quantum channel method in performing the measurement and computation, which is evolved from the one currently being implemented in MIMO wireless channel (see e.g. Dai [Citation2,Citation24]). An example of such a quantum channel is presented in the lower graph of and illustrated via a comparison with an MIMO channel in the upper-left graph of the figure.
More precisely, consider a quantum state as a wave-packet and suppose that there is an eigenmode corresponding to each eigenstate
with
and
in the
-qubit register of (2.1). The processing based on a single
-qubit chip (e.g. the one designed in the lower graph of ) is more like the one in a single-user MIMO wireless broadcast channel (currently used for 4G/5G wireless communications, see, e.g. Dai [Citation2,Citation24]).
Figure 7. A comparison between -qubit quantum chip in the lower graph and OAM MIMO channel in the upper-left graph, which is illustrated via an intermediate double-slit experiment in the upper-right graph. Channel function
is derived in (2.10). The two upper graphs are not parts of our designed quantum channel, which are presented only for the purpose of comparison and illustration.
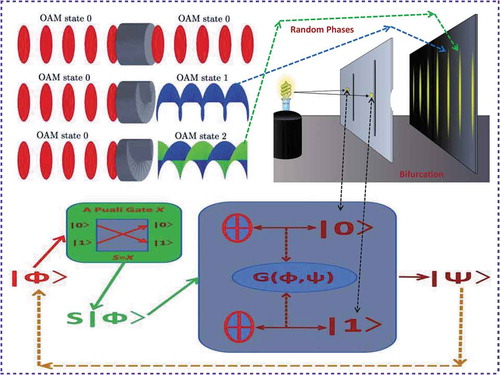
In the upper-left graph of , an orbital angular momentum (OAM) channel (i.e. a particular MIMO channel) is pictured, where, each output wave is with given deterministic frequency and phase. However, to be more illustrative, let us observe the upper-right graph (enhanced from Chang [Citation35]) of for a double-slit experiment, bifurcation occurs along the moving paths of quantum particles (see, e.g. Dai [Citation23]). In other words, the output wave is uncertain due to the random phases associated with different quantum particles, which is also related to quantum walks with random phase shifts (see, e.g. Košík et al. [Citation36]). Therefore, the input/output waves in this quantum-computing system form a probabilistic MIMO channel (see, e.g. in the lower graph of ) and it can be modelled in a generalized way as follows.
Each eigenmode is with power allocation and the total power allocation on the chip processing is subject to a constraint
such that
A -qubit may be measured in a quantum computer or a quantum communication network. In the later case, some switch functionality may also be involved (e.g. for an entanglement between two qubits and see Sawerwain and Wiśniewska [Citation37] for a reference). Thus, we add a switch gate
to our quantum channel. For a quantum state
with complex coefficients
, its corresponding state after switching is denoted by
. If the quantum gate
takes an identity matrix
, this gate placed in a quantum circuit does not perform any operation on the
-qubit, e.g.
. However, in a general situation, the gate
will do the required switch operations. For examples, we can take
to be a
-qubit Pauli gate
or a
-qubit
gate to perform the switch functionality,
Then, we have the following switch results corresponding to and
, respectively,
Furthermore, let be the column vector formed by
and
be its associated row vector formed by the conjugate complex numbers
. To be more illustrative, we use an index
to denote its corresponding index
in (2.1) for an integer
and each number
as follows,
Then, and
can be explicitly expressed by
Furthermore, let be the
matrix given by
where, with an
is a column vector corresponding to a
for an integer
and each number
. Thus,
-qubits
and
can be denoted by
Thus, under the assumption that the matrix is invertible, we can conclude that
Furthermore, by the expressions in (2.1), (2.8) and (2.9), we can derive a quantum-computing and measurement channel (i.e. a quantum communication channel with an example in ) between the original -qubit
and the measured
-qubit
as follows,
Figure 8. A 2-qubit quantum-computing and measurement channel with channel function derived in (2.10).
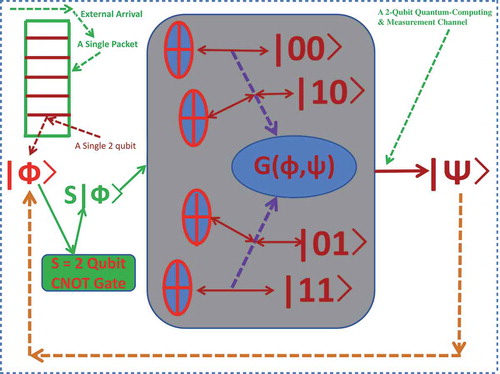
Thus, we are aimed to measure through
in (2.10) as accurate as possible. The ideal case is such that the measurement has the closest quantum entanglement properties between
and
in terms of position, momentum, spin and polarization (see, e.g. Deutsch [Citation3], Feynman [Citation4], Nielsen and Chuang [Citation6]). Since
in (2.10) is random with distribution
, we use
to denote its covariance matrix and let
be its trace. If we endow each eigenmode with the power
, i.e.
, an MIMO MAC channel will be related (see, e.g. Dai [Citation24] and Goldsmith et al. [Citation38]). However, if we endow the whole quantum computer chip with the total power
, i.e.
, an MIMO BC channel will be concerned (see, e.g. Dai [Citation24] and Goldsmith et al. [Citation38]). In both cases, the maximal transmission rates or minimal error measurements can be reached by applying mutual information formulas and water-filling coding techniques (see, e.g. Cover and Thomas [Citation39], Dai [Citation23], Goldsmith et al. [Citation38]).
2.2. Quantum storage and particle queueing dynamics
In this subsection, we assume that the quantum cloud-computing and communication system has service pools (indexed by a set of positive integers
) and
queues in parallel (indexed by
and corresponding to
users) as shown in . Each pool is equipped with
number of flexible quantum-computer based parallel-servers, where
is an integer in
. Associated with the queues, there is an
-dimensional quantum data packet arrival process
, where
with
and
is the number of
-qubit data packets that arrive at the
th queue during
. Note that, here and elsewhere in the paper, the prime denotes the transpose of a vector or a matrix. The size of the quantum data packet is supposed to be a random number
. In other words, each quantum data packet can be denoted by a sequence of
-qubits
, where,
for each
denotes a
-qubit. For example, the single packet shown in the upper-left corner of consists of seven
-qubits including the two green ones, i.e.
. The whole system is supposed to be driven by a stationary FS-CTMC
with a finite state space
. The generator matrix of
is denoted by
with
, and
where, is the holding rate for the chain staying in a state
and
is the transition matrix of its embedded discrete-time Markov chain (see, e.g. Resnick [Citation40]). Furthermore, let
for each nonnegative integer
be defined by
In other words, is a random jump time of the Markovian process
. As in Dai [Citation2], we model the arrival process
for each
by an TSRRP, and for convenience, we recall the definition of an TSRRP as follows.
Definition 2.1 A process with
is called an TSRRP if
for each
is the counting process corresponding to a (conditional) delayed renewal reward process with arrival rate
and mean reward
associated with finite squared coefficients of variations
and
during time interval
.
In addition, we let be the sequence of times between the arrivals of the
th and the
th reward batches of packets at the
th queue. The corresponding batch reward is denoted by
and all the packets arrived with it are indexed in certain successive order. Then, we can define the renewal counting process associated with the inter-arrival time sequence
for each
by
Hence, we can present the TSRRP via
Each -qubit based packet will first get service in the system and then leave it. The service is managed by a quantum blockchain as designed in and , which is the future version of the current blockchain (see, e.g. Dai [Citation2], Rajan and Visser [Citation18]). In this blockchain, the service for a quantum packet consists two parts: security checking and policy computation (or real data payload transmission). After the service, the security information and the policy (or the transmission result) will be stored and copied to all the participating partner nodes for storage. In Dai [Citation2], we call the service corresponding to the policy computation as a virtue big data service and the service corresponding to the data payload transmission as a real big data service. Furthermore, we let
be the sequence of successive arrived packet lengths at queue
, which is supposed to be a sequence of strictly positive i.i.d. random variables with average packet length
and squared coefficient of variation
. In addition, we assume that all inter-arrival and service time processes are mutually (conditionally) independent when the environmental state is fixed. For each
and each nonnegative constant
, we use
to represent the renewal counting process associated with
, i.e.
Let be the
th queue length with
at each time
and
be the number of packet departures from the
th queue in
. Then, the queueing dynamics governing the evolving of data in and data out in the platform can be modelled by
where, each queue is supposed to have an infinite storage capacity to buffer real or virtue data packets (jobs) arrived for a given user. Furthermore, let denote the cumulative amount of service given to the
th queue up to time
, i.e.
where, for each
and
is the summation of all service rates allocated to the
th user at time
from all possible pools and servers. Note that,
is given in a feedback control form and depends on both the current queue length
and the system state
at a time
. Thus, if we use
to denote the total number of jobs (packets) that finishes service in the system by time
, we know that
. Finally, we let
and
denote the (expected) total workload in the system at time
and the one corresponding to user
at time
, i.e.
In the following study, we will employ and
as performance measures and design a rate scheduling policy
for different service pools and servers to all the users in order that the total workload
and its associated total cost are minimized. Furthermore, as in the study of Dai [Citation2], the available resources in our current system are generally transformed into service rates although they can be interpreted as other forms, e.g. power in an MIMO wireless channel or in a quantum-computing and measurement channel. In addition, we assume that the available resources from different pools and servers can be flexibly allocated and shared between the system and users, i.e. the system operates under a concurrent resource occupancy service regime.
3. The RDRS model and performance modelling
As pointed out in Dai [Citation2] that, although TSRRPs can exactly model big data arrival streams, it is hard to directly analyse the corresponding physical queueing model in (2.16) or the physical workload model in (2.18) owing to the non-Markovian characteristics of TSRRPs. Hence, in Dai [Citation2], we have used diffusion models to approximate and
in (2.16) and (2.18) under different scheduling policies. In this paper, we will continue to employ this scheme to identify the RDRS model corresponding to our newly designed mixed zero-sum and non-zero-sum game-competition oriented scheduling policy by considering our queueing system under the asymptotic regime, where it is heavily loaded, i.e. under the so-called heavy traffic (load balance) condition. Furthermore, we will conduct model justification via diffusion approximation. In addition, we present a simulation case study to show the effectiveness of the identified RDRS model for our newly proposed scheduling policy. The corresponding simulation results are displayed in and their interpretations are presented in Subsection 3.4.
Figure 9. In this simulation, the number of simulation iterative times is N = 96,000, the simulation time interval is with
, which is further divided into
subintervals as explained in Subsection 3.4. Other values of simulation parameters introduced in Definition 3.1 and Subsubsection 3.2.1 are as follows:
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
.
![Figure 9. In this simulation, the number of simulation iterative times is N = 96,000, the simulation time interval is [0,T] with T=30, which is further divided into n=10000 subintervals as explained in Subsection 3.4. Other values of simulation parameters introduced in Definition 3.1 and Subsubsection 3.2.1 are as follows: λ1=85/3, λ2=85, m1=3, m2=1, μ1=1/10, μ2=1/20, α1=10, α2=20, β1=10, β2=20, ζ1=1, ζ2=2, ρ1=ρ2=1000, c12=c21=1500, θ1=−1, θ2=−1.2.](/cms/asset/d2822e6a-c303-43db-81a7-423f912a864b/nmcm_a_1677725_f0009_oc.jpg)
3.1. Main claim on RDRS modelling via AI decision
In this subsection, we first present our main claim concerning our RDRS modelling via AI decision. Then, we recall the definition of RDRS model as introduced in Dai [Citation2] for convenience. In doing so, for each and
, we define two sequences of diffusion-scaled processes
and
by
where, is assumed to be a strictly increasing sequence of positive real numbers and tends to infinity. Thus, we can present our main claim as follows.
Under the heavy traffic condition described in Section 4, the sequence of -tuple scaled processes in (3.1) corresponding to an DCNN and game-competition based AI scheduling policy that is proposed in the following subsection, converges jointly in distribution, i.e.
where, is presented by an RDRS model and
is an asymptotic mixed saddle point and Pareto minimal-dual-cost Nash equilibrium policy process globally over
.
Definition 3.1 A -dimensional stochastic process
with
is called an RDRS with oblique reflection if it can be uniquely represented as
where
Furthermore, is a
-dimensional vector,
and
are
matrices, and
for each
is a
matrix. In addition,
is continuous a.s. and is a solution of (3.3) with the properties for each
,
1. ;
2. Each component of
is non-decreasing;
3. Each component can increase only at a time
that
, i.e.
In addition, a solution to the RDRS in (3.3) – (3.4) is called a strong solution if it is in the pathwise sense and is called a weak solution if it is in the sense of distribution.
Concerning the well-posedness of an RDRS, readers are referred to a general discussion in Dai [Citation23]. Moreover, in Definition 3.1, the processes and
are respectively two
-dimensional standard Brownian motions, which are independent each other. For each state
and a time
, the nominal arrival rate vector
, the mean reward vector
, the nominal throughput vector
, and a constant parameter vector
are defined as follows,
Furthermore, the covariance matrices are defined as
In addition, the Itô’s integrals in terms of the Brownian motions are defined as
3.2. The DCNN and game-competition based AI scheduling policy
In this subsection, we design an AI based scheduling strategy by combining DCNN with mixed zero-sum and non-zero-sum myopic game-competition policy for the purpose as stated in the previous subsection and as shown in . To be easy, we begin with an illustrative example.
3.2.1. A scheduling policy example
In this subsection, we focus our study on a single-pool system served by a single -qubit quantum computer as shown in the lower graph of .
Figure 10. Two capacity regions for users with cooperation and zero-sum game competition.
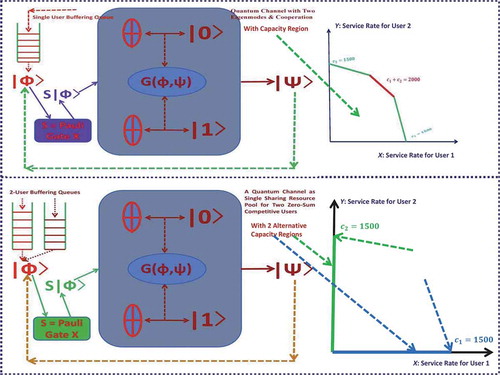
Thus, we will omit the related pool index in our discussion of this subsection for simplicity. Related to this system, two cases will be concerned as shown in . The first case is corresponding to the upper graph in , where only single user is allowed. However, we can pretend to allocate the user’s arrival packets into two separate storage buffers with certain proportions as in the lower graph of . In this case, we are interested in the issue concerning the rate (i.e. power) resource allocation cooperatively between the two eigenmodes inside the quantum computer. More precisely, in , we take
and
(i.e. we think of the single-pool system with two eigenmodes as a two user MIMO channel). Furthermore, we assume that the state space of the FS-CTMC
defined in Subsection 2.2 consists only of a single state 1 (i.e.
for all
). In an MIMO wireless environment, such a case is corresponding to the so-called pseudo static channels (see, e.g. Dai [Citation24] and Bhardwaj et al. [Citation41]). Then, the capacity region denoted by
is assumed to be a non-degenerate convex one confined by five boundary lines including the two ones on
-axis and
-axis as shown in the upper-right graph of . The capacity upper bound of the region satisfies
. This region is corresponding to a degenerate fixed MIMO wireless channel of the generally randomized one in Dai [Citation24]. For each rate vector
, we take the utility functions for user 1 and user 2, respectively, by
where, is the logarithm function with the base
. Furthermore, the vector
is a given queue length of 2-users and it corresponds to the queue length process
defined in (2.16) at a particular time point. The utility functions
and
are called proportionally fair and minimal potential delay allocations respectively, which are widely used in the design of communication protocols (see, e.g. Ye and Yao [Citation42]). Based on these utility functions, we can propose our rate-scheduling policy at each time point
by a Pareto maximal-utility Nash equilibrium point to the non-zero-sum game problem for the case of two eigenmode cooperation. This case is a special situation as studied in Dai [Citation2] and hence we will omit the remaining details here. Nevertheless, in the following discussion, we will present our new findings in a zero-sum game case study or called the second case as shown in the lower graph of , which also comes up in recent smart power and energy switching system, i.e. IoE (see, e.g. Artemis [Citation11] and Dai [Citation43]).
More precisely, in this second zero-sum game case, only a single user (either user 1 or user 2) is allowed to get into service at each time point . Furthermore, we suppose that the service capacity is already determined as shown in the lower graph of , i.e.
for user
and
for user
. Then, based on the above given utility functions, we can design our rate-scheduling policy at each time point
by a saddle point to the zero-sum game problem
for each and a fixed
, where,
and
. In other words, if
with is a solution to the game problem in (3.14), we can conclude that
for a fixed . Furthermore, for each
,
3.2.2. General capacity region
In our platform, the jobs in the th queue for each
can be served simultaneously by a random but at most
(
) number of service pools at a given time point. It can be realized by processors-sharing techniques or through multiple users’ and antennas’ cooperation in MIMO wireless channels, i.e. base stations can perform joint beamforming and/or power control at a particular time period. Under this simultaneous service mechanism, the total service rate for the jth queue at the time point is the summation of the rates from all the pools possibly to serve the jth queue. For convenience, we index such pools by a subset
of the set
, i.e.
where, for each
indexes the
th pool in
.
In the same way, a pool indexed by can possibly serve at most
number of job classes indexed by a subset
of the set
, i.e.
where, for each
indexes the
th job class in
. The pool
is equipped with
number of flexible parallel-servers with rate allocation vector
where, for each
is the assigned service rate to the
th user at pool
and time
. In the sequel, we will also denote the rate
by
for an index
that corresponds to the
. The vector in (3.20) takes values in a capacity region
driven by the FS-CTMC
.
Figure 11. A 3-user capacity set in for a cooperative MIMO wireless channel in the left graph. A degenerate 3-user capacity set in
for a cloud-processors-sharing system in the right graph. The upper graph is adapted from .
For each and
, the set
is a convex region consisting of the origin and owns
boundary pieces (see, e.g. the left graph of is an example in Dai [Citation24], the right graph of is an example of Ye and Yao [Citation42], and the detailed explanations for these two graphs are presented at the end of this subsubsection). In the region, each point is defined according to the corresponding users, i.e.
. On the boundary of
for each
,
of them are
-dimensional linear facets along the coordinate axes. The other ones are located in the interior of
and form the so-called capacity surface represented by
, which has
linear or smooth curved facets
on
for
, i.e.
If let denote the sum capacity upper bound for
, the facet in the centre of
is linear and is assumed to be a non-degenerate
-dimensional region. More precisely, it can be expressed by
where, is the index corresponding to
. Furthermore, we assume that any one of the
linear facets along the coordinate axes forms an
-user capacity region associated with a particular group of
users when the queue corresponding to the other user is empty. By the same way, we can interpret the
-user capacity region for each
.
In the allocation of the service resources over the capacity regions to different users, we adopt the so-called head of line service discipline. In other words, the service goes to the packet at the head of the line for a serving queue where packets are stored in the order of their arrivals. The service rates are determined through a function of the environmental state and the number of packets in each of the queues. For each state and a given queue length vector
, let
for each
denote the rate vector (in bps) of serving the
th queue at all its possible service pools, i.e.
where,
In the meanwhile, let for each
denote the rate vector for all the users possibly served at service pool
, i.e.
Obviously, if the pool index for an integer
with
, we have that
Thus, for each
, the total rate used in (2.17) can be expressed as
Finally, we impose the convention that an empty queue should not be served. Thus, for each and
(e.g. a set as given by (3.24)), we can define
Hence, for all such that
corresponding to each
, if
is on the boundaries of the capacity region
, we have the following observation that
where, and
denotes the empty set.
Typical examples of our capacity region include those for -user MIMO multiple access uplink and broadcast downlink wireless channels, two-way or future quantum communication channels, and
-user cloud-processors-sharing centres or links (see, e.g. Goldsmith et al. [Citation38], Jindal [Citation44], Dai [Citation24], Shapiro et al. [Citation45], Childs et al. [Citation46], Ye and Yao [Citation42]). In a cooperative wireless channel, the inequalities in (3.30) and (3.31) are both strict, which leads to a capacity region (e.g. with three users) as displayed in the left graph of . Note that, in this three-user case, there are 3 linear facets along the coordinate axes and 13 linear or smooth curved facets on the capacity surface. Furthermore, for such an MIMO channel, the capacity region reflects the cooperation property that the maximum of the sum of the rates is achieved only when all of the queues are non-empty. However, in a general cloud-processors-sharing service system, the equalities in (3.30) and (3.31) may be both true, which leads to a degenerate capacity region as shown in the right graph of .
3.2.3. The DCNN and game-competition based scheduling policy
To integrate the decision processes in cognitive radio (see, e.g. Akyildiz et al. and Haykin [Citation13]), FinTech, IoE (see, e.g. Artemis [Citation11] and Dai [Citation43]), etc. into our AI based scheduling system, we classify the users into two types (e.g. primary users and secondary users as in the cognitive radio). In this situation, we first need to smartly select the users (e.g. among the secondary users) to be served, i.e. at each time point and for each pool , we smartly choose a set
of users with
and
for a given
to get into service. Among these selected users, we need to dynamically realize the optimal and fair resource allocation. Therefore, we design a strategy by mixing a saddle point and a static Pareto maximal-utility Nash equilibrium policy myopically at each time point
to a mixed zero-sum and non-zero-sum game problem for each state
and a given queue length vector
. The saddle point corresponds the users’ selection while the Pareto optimality represents the full utilization of resources in the whole game system and the Nash equilibrium represents the fairness to all the selected users. More precisely, in this game, there are
users (players) corresponding to the
queues and each of them has his own utility function
with
and
. The utility functions may also depend on some additional parameters such as prices. Nevertheless, in the current paper, we assume that they are pre-negotiated and are given. Every selected user chooses a policy to maximize his own utility function at each service pool
while the summation of all the users’ utility functions and the summation of the utility functions corresponding to the selected users are also maximized. In other words, we can formulate the following generalized user-selection and resource-scheduling game problem by extending the one in Example 3.4,
while we have that
Note that, the rate vector in (3.32)–(3.36) is given by
and the objective functions are defined by
Note that, the total utility function does not have to be a constant (e.g. zero). In other words, the game is not necessarily a zero-sum one. Thus, by unifying the concepts of Nash equilibrium and Pareto optimality in Nash [Citation47] and Rosen [Citation48], we have the definition concerning a static Pareto maximal-utility Nash equilibrium policy myopically at a particular time point for the dynamic scheduling game as follows.
Definition 3.2 For each state and a queue length vector
, the rate vector
is called a mixed saddle-point and static Pareto maximal-utility Nash equilibrium policy to the mixed zero-sum and non-zero-sum game problem in (3.35) if, for each and any given
, we have that
3.3. Identifying an RDRS model under the policy
In this subsection, we identify the exact expression of an RDRS model corresponding to the CNN and game-competition based AI scheduling policy designed in the previous subsection.
3.3.1. The obtained model by asymptotic approximation
To state our main theorem, we need to introduce another concept of the so-called mixed saddle point and static Pareto minimal-dual-cost Nash equilibrium policy myopically at a particular time point. In doing so, we formulate a minimal-dual-cost game problem corresponding to the maximal-utility game problem in (3.35). More precisely, for each given , a rate vector
, and a parameter
, the problem can be stated as follows:
subject to
where, the cost function for each
and
is defined by
and is an index set corresponding to the non-zero rates and non-empty queues, i.e.
In other words, when the environment is in state , we try to identify a queue state
corresponding to a given
and a given parameter
such that the individual user’s dual-costs and the total dual-cost over the system are all minimized at the same time while the (average) workload meets or exceeds
. In addition, the total dual-cost function
does not have to be a constant. Then, we have the following definition.
Definition 3.3 For each state and a rate vector
, the queue length vector
with
if
is called a mixed saddle point and static Pareto minimal-dual-cost Nash equilibrium policy to the mixed zero-sum and non-zero-sum game problem in (3.42) if, for each
,
, and any given
with
when
, we have that
Based on Definition 3.3 and the concept concerning the asymptotic optimality widely used in heavy traffic analysis (see, e.g. Ye and Yao [Citation42], Dai [Citation24]), we can develop some new concept about the asymptotic Pareto minimal-dual-cost Nash equilibrium policy as follows.
Definition 3.4 Let and
denote the diffusion-scaled queue length and workload processes respectively under an arbitrarily feasible rate scheduling policy
. A process
is called a mixed asymptotic saddle point and Pareto minimal-dual-cost Nash equilibrium policy globally over the whole time horizon if
for any ,
, and
Now, let be the mixed saddle point and Pareto minimal-dual-cost Nash equilibrium policy to the game problem in (3.42) with respect to each given
and
at time
. Then, our main theorem can be presented as follows.
Theorem 3.1 For the game scheduling policy determined by (3.35) with and conditions (4.7) – (4.12) (that will be detailed in Section 4), the sequence of
-tuple processes converges jointly in distribution, i.e.
Furthermore, the limit queue length and total workload
have the relationship
where, is a
-dimensional RDRS in strong sense with
for and some constant
for each
. In addition, there is a common supporting probability space, under which and with probability one, the limit queue length
is an asymptotic mixed saddle point and Pareto minimal-dual-cost Nash equilibrium policy globally over time interval
. Finally, the limit workload
is also asymptotic minimal in the sense that
Note that, the process in (3.49) is directly corresponding to the physical queueing process of
-quibt quantum data packets as defined in Subsection 2.2. However, the diffusive approximation limit process
is a continuous one in both time and space. Based on the
-qubit quantum computing myopically at each time point, it can be used as an approximating model to measure the system performance in the macro-flow level. Furthermore, due to the zero-sum and non-zero-sum two level competition involved, our current results are different from those in Dai [Citation24], especially, the drift and diffusion coefficients presented in (3.51) and (3.52), respectively. The proof of Theorem 3.1 will be provided in Subsection 4.2. Instead, in the following subsection, we first present a simulation case study that based on a simulation procedure proposed for the RDRS in the theorem. More precisely, for a constant
, we divide the interval
equally into
subintervals
with
,
, and
. Furthermore, let
for each process . Then, we can develop an iterative procedure similar to Simulation Procedure 3.1 in Dai [Citation2] to simulate the RDRS model derived in Theorem 3.1.
3.4. A simulation case study via RDRS model
In this subsection, we consider a single-pool system with two-users as presented in Subsubsection 3.2.1 and hence will omit all the related pool index for simplicity. Note that, in a corresponding real-world system, the parameter vector
in (3.14) is the randomly evolving queue length process
in (2.16). Furthermore, it is our concern about how to use the RDRS performance model in Definition 3.1 to evaluate the effectiveness of our designed myopic service policies for the scheduling example in Subsubsection 3.2.1 globally over the whole time horizon
. As mentioned in Subsubsection 3.2.1, the effectiveness of the myopic non-zero-sum game based policy for the case in the upper graph of has been numerically justified in Dai [Citation2]. Thus, in this subsection, we numerically illustrate the effectiveness of the myopic zero-sum game policy designed in (3.14) for the case in the lower graph of . In this case, there are two competing users: user 1 and user 2 with utility functions
and
, respectively. They try to get into the quantum computing service channel through competition according to the policy in (3.14), i.e. only one user can get access to the channel through bids reflected in their utility functions at each particular time point as shown in .
Figure 12. An illustration of simulation case study concerning its importance and applications.
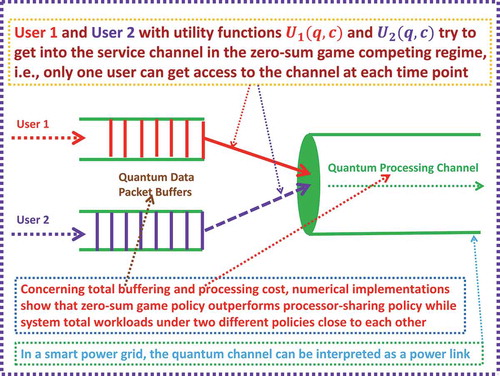
Therefore, our main task in this subsection is to apply the zero-sum game policy in (3.14) to conduct numerical experiments with computational results as displayed in . From the figure, we can see that our policy outperforms processor-sharing policy in terms of total buffering and processing costs while the system total workloads under two different policies close to each other. It is worth to point out that our zero-sum game scheduling policy implemented in this section is a generic one. Besides the application in quantum computation, it also has the importance in other real-world problems such as smart power grid scheduling as shown in .
To illustrate our numerical implementations, we first identify the associated dual-cost functions as defined in (3.42) with
for corresponding
given in (3.13) . More precisely,
where with
are average packet lengths corresponding the two users as explained just after the equation in (2.14) . Then, we can formulate the corresponding minimal dual-cost zero-sum game problem as
for a fixed constant , a fixed
, and all
with
. Note that, both
for
are strictly increasing in terms of
. Thus, a dual-cost saddle point can be expressed as follows
In other words, for any , we have
Furthermore, for the purpose of comparison, we also design an alternative scheduling policy associated with a uniformly generated random number over interval
as follows,
In addition, it follows from the inequalities in (3.60)–(3.62) that the cost of a dual-cost game player with
cannot be reduced if he unilaterally changes his bid’s policy
.
Based on these properties, we can illustrate the effectiveness of our designed policy by the dual-cost game problem in (3.58). More precisely, in our Theorem 3.1 and the following RDRS modelling demonstration in Subsection 4, we have the claim that the physical workload in (2.18) for this single pool case can indeed be modelled by an RDRS as introduced in Definition 0.2 if certain load balance condition holds. Moreover,
is asymptotically minimal at any time
almost surely along any sample path in some supporting probability space. In the meanwhile, the queue length process
in (2.16) is also minimized in the sense that it is asymptotically dual-cost saddle point process given by
where
is given in (3.59). Note that, for this example, it follows from Theorem 3.1 that the coefficients of the 1-dimensional RDRS under our game-based scheduling policy for the physical workload process
can be denoted by
where, for , we have that
Thus, by the -dimensional RDRS corresponding to (3.64) and (3.65) and the saddle point policy
in (3.59), we can apply the iterative formula (called Simulation Procedure
in Dai [Citation2]) to conduct our workload based numerical simulation. Here, we point out that all the processes related to the workload processes will be covered with a ‘hat’.
Next, based on the given parameters as shown in the bottom of , we present the simulation results for our case study as summarized in the graphs of the figure. In this example, the number
of simulation iterative times is 96,000. The simulation time interval is
with
and it is divided into n = 10,000 subintervals. Furthermore, all the ‘simulated means’ used in the graphs are in the average sense, e.g. the simulated mean workload is given by
where, denotes the used
th sample paths of
and
with
and
is the time index. Note that, in , we give the performance evaluation and comparisons with respect to the workload process
. The red curve displayed in the first graph of the left column is the simulated mean workload function with respect to time point
under the saddle point policy. The result presented in the second graph of this column shows the difference between the simulated mean workload directly through the RDRS model associated with the coefficients in (3.64) and (3.65) and the corresponding one obtained by the saddle point policy displayed in (3.59), i.e.
Based on the curves in this graph, we can observe that the two workload processes are quite consistent. The curves shown in the third graph of this column are the decision paths of the saddle point policy given in (3.59) for the two users. The curve in the fourth graph of this column displays the difference of the workloads under the saddle point policy in (3.59) and the arbitrarily selected alternative policy in (3.63). Actually, under this alternative policy, the corresponding system is a single-server polling system with two job classes, the workload process can also be approximated by the RDRS model when our load balance condition is applied (see, e.g. Coffman et al. [Citation49]). Thus, from the workload perspective, the workloads under these two scheduling policies should be close to each other as shown in the graph. However, if we conduct one more deep-level study concerning the system total cost as displayed in the red curve of the fourth graph on the second column, we see that our saddle point policy outperforms the alternative one. In this graph, the other two curves are the errors corresponding to different users. The curves in the first graph of the second column display the decision paths of the alternative policy. The curve in the second graph of this column presents the simulated mean total cost under saddle point policy. The curves in the third graph of this column state the costs for different users under the saddle point policy. The curves in the graphs of the third column display the evolutions of queueing lengths for different users and their comparisons under the saddle point policy and the alternative policy.
4. RDRS modelling demonstration
In this section, we demonstrate the RDRS modelling presented in Theorem 3.1.
4.1. The conditions and assumptions
The utility functions can be either simply taken as the well-known proportionally fair and minimal potential delay allocations as used in (3.13) for Example 3.4 or generally taken such that the existence of a mixed saddle point and Pareto maximal-utility Nash equilibrium policy to the game problem in (3.35) is guaranteed. More precisely, we can suppose that for each
and
is defined on
. It is second-order differentiable and satisfies
Furthermore, we assume that satisfies the so-called radial homogeneity condition at each time point
, i.e. for any scalar
, each
,
,
, and each
with corresponding
, its Pareto maximal utility Nash equilibrium point for the game has the radial homogeneity
In addition, we introduce a sequence of independent Markov processes indexed by , i.e.
. These systems all have the same basic structure as described in the last section except the arrival rates
and the holding time rates
for all
, which may vary with
. Here, we assume that they satisfy the heavy traffic condition
where, is some constant for each
. Moreover, we suppose that the nominal arrival rate
is given by
and in (4.8) for
with
is the nominal throughput determined by
with that is corresponding to the dimension
. In addition,
and
are an
-dimensional constant vector and a reference service rate vector, respectively, at service pool
, satisfying
Remark 4.1 By (3.22), for each
and
can indeed be selected, which satisfy the second condition in (4.11) . Thus, the nominal throughput
in (4.8) can be determined. One simple example that satisfies these conditions is to take
for all
and
. Then, the conditions in (4.8) – (4.11) mean that the system manager hopes to maximally and fairly allocate capacity to all users. Furthermore, the system design parameters
for all
and each
can be determined by (4.8) .
Now, we suppose that the inter-arrival time corresponding to the th arriving job batch to the system indexed by
is given by
where, the does not depend on
and
. Furthermore, it has mean one and finite squared coefficient of variation
. In addition, the number of packets,
, and the packet length
are assumed not to change with
. Furthermore, it follows from the heavy traffic condition in (4.7) for the
th environmental state process
with
that
and
are equal each other in distribution since they own the same generator matrix (see, e.g. the definition in pages 384–388 of Resnick [Citation40]). Hence, in the sense of distribution, all of the systems indexed by
in (3.1) share the same random environment over any time interval
.
4.2. Proof of theorem 3.1
First, from the second condition in (4.7), we know that the processes for each
and
are equal in distribution. Thus, without loss of generality, we can suppose that
Then, for each ,
and by the radial homogeneity of
of the policy in (4.6), we can define the fluid and diffusion scaled processes as follows,
Thus, by (2.16), (4.13), and the assumptions among arrival and service processes, we know that
Furthermore, let
for each with
and define
In addition, we use ,
,
, and
to denote the corresponding vector processes. Then, corresponding to the processes in (4.14)–(4.19), we can define the following fluid limit related processes,
where, for each and
, we have that
Then, we can present a lemma about the weak convergence to a stochastic fluid limit process under our DCNN and game-competition based scheduling strategy.
Lemma 4.1 Suppose that the initial queue length along
. Then, the joint convergence in distribution along a subsequence of
is true under the conditions required by Theorem 3.1,
In addition, if , the convergence is true along the whole
and the limit satisfies
where, is defined in (4.25),
, and
is defined by
Proof. By the proofs of Lemma 4.2 in Dai [Citation2] and Lemma 7 in Dai [Citation24], we only need to prove the claim that in (4.30) to be true for our current purpose. In fact, for each
and
, we define
It follows from the proof in Dai [Citation24] that all the limits in (4.30) are absolutely continuous and differentiable at almost all . In other words, almost every
is a regular point of these limits. Hence, for each regular time
of
over time interval
with a given
, we have the observation that
where, the second equality follows from the concavity of the utility functions and the fact that is the Pareto maximal Nash equilibrium policy to the utility-maximal game problem in (3.35) when the channel is in a particular state. Thus, for any given
and each
,
where, is a positive constant given by
Then, it follows from the fact in (4.34) that for all
. Hence, we complete the proof of the lemma. □
Finally, by considering a specific state and by the index way as used in proving Lemma 0.1, we can provide proofs for Lemma 4.3 to Lemma 4.5 in Dai [Citation2] to be true in the current setting. Then, by applying the results in these lemmas to the proof for Theorem 1 in [Citation24], we can complete the proof for Theorem 3.1 in the current paper. □
5. Conclusion
In this paper, we have modelled the hardware and software architecture for generalized IoT by quantum cloud-computing and blockchain. To reduce the measurement error and increase the efficiency of quantum entanglement (i.e. the capability of fault tolerance) in the current quantum computers and communications, we have designed a quantum-computing chip by modelling it as an MIMO quantum channel and obtain its channel capacity via our recently derived mutual information formula. To capture the internal qubit data flow dynamics of the channel, we model it by an DCNN with generalized stochastic pooling with respect to resource-competition among different quantum eigenmodes or users. The pooling is corresponding to a dynamic resource allocation policy with two levels of competitions as in cognitive radio: the first one is on users’ selection in a ‘win–lose’ manner; the second one is on resource-sharing among selected users in a ‘win–win’ manner. In other words, our policy is the one by mixing a saddle point to a zero-sum game problem and a Pareto optimal Nash equilibrium point to a non-zero-sum game problem. The effectiveness of our policy is proved by diffusion modelling with theory and numerical examples. The applications of our study in more fields such as FinTech and IoE are also provided.
Disclosure statement
No potential conflict of interest was reported by the author.
Additional information
Funding
References
- R. Courtland, China’s 2,000-km Quantum Link Is Almost Complete, IEEE Spectr. Technol. Eng. Sci. News. 53 (11) (2016), pp. 11–12.
- W. Dai, Platform modelling and scheduling game with multiple intelligent cloud-computing pools for big data, Math. Comput. Model. Dyn. Syst. 24 (5) (2018), pp. 506–552. doi:10.1080/13873954.2018.1516677.
- D. Deutsch, Quantum computational networks, Proc. R. Soc. Lond. A 425 (8 September 1989), pp. 73–90. doi:10.1098/rspa.1989.0099.
- R.P. Feynman, Quantum mechanical computers, Opt. News 11 (1985), pp. 11. doi:10.1364/ON.11.2.000011.
- E. Gibney, Chinese satellite is one giant step for the quantum internet, Nat. 535 (7613) (27 July 2016). pp. 478C479. Bibcode:2016Natur.535.478G. PMID 27466107. doi:10.1038/535478a
- M. Nielsen and I. Chuang, Quantum Computation and Quantum Information, Cambridge University Press, 2000, Cambridge, UK.
- K. Schwab, The Fourth Industrial Revolution. World Economic Forum, Cologny, Switzerland (2016).
- SIR Forum. The Six Industrial Revolution. Available at https://www.sirforum.net/, 2018.
- G. Santucci, The Internet of Things: Between the Revolution of the Internet and the Metamorphosis of Objects, Forum American Bar Forum (2010), pp. 1–23, doi:10.2759/26127
- W. Dai, Systems software and hardware: The unification and interaction of quantum-cloud-computing and MIMO wireless communication aided with AI and blockchain. Invited Keynote Speech at 2019 International Conference of Future Advancements in Mobile Cloud Computing and Applications, October 23-24, 2019, Toronto, Canada.
- Artemis, Internet of energy for electric mobility. 2018. Available at http://www.artemis-ioe.eu/
- W. Dai, On the traveling neuron nets (human brains) controlled by a satellite communication system. Proceedings of IEEE 3rd International Conference on Bioinformatics and Biomedical Engineering. Beijing, China. 2009, pp. 1–4.
- S. Haykin, Cognitive Radio: Brain-empowered Wireless Communications, IEEE J. Sel. Areas Commun. 23 (2) (2005), pp. 201C220. doi:10.1109/JSAC.2004.839380.
- W. Dai, Product-form solutions for integrated services packet networks and cloud computing systems, Math Probl Eng. 2014 (Regular Issue) (2014), pp. 16. Article ID 767651. doi:10.1155/2014/767651
- D.E. Comer, Internetworking with TCP/IP, Prentice Hall, New Jersey, 1995.
- K. Bertels, Quantum computing: How far away is it? IEEE 2015 International Conference on High Performance Computing & Simulation (HPCS). Amsterdam, Netherlands. 2015, pp. 557–558. doi:10.1177/1753193414566554.
- H. Fan, The market and prospect of quantum-computing. Invited Kenote Speech at SIR Forum Nanjing Summit-2018, Nanjing, China, November 29, 2018.
- D. Rajan and M. Visser, Quantum Blockchain using entanglement in time. 2018. Available at https://arxiv.org/abs/1804.05979.
- V. Buterin, Ethereum: A next-generation smart contract and decentralized application platform. 2013. Available at http://ethereum.org/ethereum.html.
- M. Iansiti and K.R. Lakehani, The truth about Blockchain, Harv. Bus. Rev. January-February Issue (2017), Features: Article 7.
- S. Nakamoto, A peer-to-peer electronic cash system. 2013.
- W. Dai, BestGo resource allocations for quantum-cloud-computing services and MIMO communications with blockchain and big data. Invited Keynote Speech at 7th IEEE International Conference on Communications, Networks and Satellite, Medan, Indonesia, November 15-17, 2018.
- W. Dai, A unified system of FB-SDEs with Levy jumps and double completely-S skew reflections, Commun. Math. Sci. 16 (3) (2018), pp. 659–704. doi:10.4310/CMS.2018.v16.n3.a4.
- W. Dai, Optimal rate scheduling via utility-maximization for J-user MIMO Markov fading wireless channels with cooperation, Oper. Res. 61 (6) (2013), pp. 1450–1462. with 26 page online e-companion (Supplemental). doi:10.1287/opre.2013.1224
- M. Zeiler and R. Fergus, Stochastic Pooling for Regularization of Deep Convolutional Neural Networks. Proc. of the International Conference on Learning Representations, Scottsdale, Arizona, pp. 8. 2013.
- I.F. Akyildiz, W.Y. Lee, M.C. Vuran, and S. Mohanty, NeXt Generation/Dynamic Spectrum Access/Cognitive Radio Wireless Networks: A Survey, Comput. Networks (Elsevier) J. 50 (2006), pp. 2127–2159. doi:10.1016/j.comnet.2006.05.001.
- A. De Mauro, M. Greco, and M. Grimaldi, A formal definition of big data based on its essential features, Library Rev. 65 (2016), pp. 122–135. doi:10.1108/LR-06-2015-0061.
- N. Dedić and C. Stanier, Towards Differentiating Business Intelligence, Big Data, Data Analytics and Knowledge Discovery, Vol. 285, Springer International Publishing, Berlin, Heidelberg, 2017.
- C. Snijders, U. Matzat, and U.D. Reips, ‘Big Data’: Big gaps of knowledge in the field of Internet, Int. J. Int. Sci. 7 (2012), pp. 1–5.
- G. Niestegge, Non-classical conditional probability and the quantum no-cloning theorem, Phys. Scr. 90 (9) (2015), pp. Paper ID: 095101. doi:10.1088/0031-8949/90/9/095101.
- W.K. Wootters and W.H. Zurek, A single quantum cannot be cloned, Nat. 199 (5886) (1982), pp. 802–803. doi:10.1038/299802a0.
- W.M. Itano, D.J. Heinzen, J.J. Bollinger, and D.J. Wineland, Quantum Zeno effect, Phys. Rev. A 41 (5) (1990), pp. 2295–2300. doi:10.1103/PhysRevA.41.2295.
- B. Misra and E.C.G. Sudarshan, The Zeno’s paradox in quantum theory, J. Math. Phys. 18 (4) (1977), pp. 756–763. doi:10.1063/1.523304.
- C. Song, et al., Generation of multicomponent atomic Schrödinger cat states of up to 20 qubits, Sci. 365 (9 August 2019), pp. 574–577. doi:10.1126/science.aay0600
- C.Z. Chang, Quantum-computing, Artificial Intelligence, and Blockchain Lecture Note in IT Leaders' Summit.Shenzhen, China, (2018).
- J. Košík, V. Bužek, and M. Hillery, Quantum walks with random phase shifts, Phys. Rev. A 74 (2) (2006), pp. 022310. doi:10.1103/PhysRevA.74.022310.
- M. Sawerwain and J. Wiśniewska, Quantum qubit switch: Entropy and entanglement, ArXiv 1709.02407v1 (2017), pp. 1–22.
- A. Goldsmith, S.A. Jafar, N. Jindal, and N. Vishwanath, Capacity limits of MIMO Channels, IEEE J. Sel. Areas Commun. 21 (5) (2003), pp. 684–702. doi:10.1109/JSAC.2003.810294.
- T.M. Cover and J.A. Thomas, Elements of Information Theory, John Wiley & Sons, Inc., Chichester, 1991.
- S.I. Resnick, Adventures in Stochastic Processes, Birkhäuser, Boston, 1992.
- S. Bhardwaj, R.J. Williams, and A.S. Acampora, On the performance of a two-user MIMO downlink system in heavy traffic, IEEE Trans. Inf. Theory 53 (5) (2007), pp. 1851–1859. doi:10.1109/TIT.2007.894662.
- H. Ye and D.D. Yao, Heavy traffic optimality of a stochastic network under utility-maximizing resource control, Oper. Res. 56 (2) (2008), pp. 453–470. doi:10.1287/opre.1070.0455.
- W. Dai, Internet of Energy with Multiple Cloud-Computing Service Centers and Artificial Intelligence. Invited Plenary Talk at IEEE 7th International Conference on Power and Energy Systems, Toronto, Canada (2017).
- N. Jindal, S. Vishwanath, and A. Goldsmith, On the duality of Gaussian multiple-access and broadcast channels, IEEE Trans. Inf. Theory 50 (5) (2004), pp. 768–783. doi:10.1109/TIT.2004.826646.
- J.H. Shapiro, et al., Quantum Computation and Communication - Optical and Quantum Communications-20, RLE Prog. Rep. 145 (2003), pp. 20–21.
- A.M. Childs, D.W. Leung, and H.K. Lo, Two-way quantum communication channels, Int. J. Quantum Inf. 4 (1) (2005), pp. 63–83. doi:10.1142/S0219749906001621.
- J.F. Nash, Equilibrium Points in N-person Games, Proc. Natl. Acad. Sci. 36 (36) (1950), pp. 48C9. doi:10.1073/pnas.36.1.48.
- J.R. Rosen, Existence and uniqueness of equilibrium points for concave N-person games, Econom. 33 (3) (1965), pp. 520–534. doi:10.2307/1911749.
- E.G. Coffman, A.A. Puhalskii, and M.I. Reiman, Polling systems in heavy traffic: A Bessel process limit, Discrete Appl Math 23 (2) (1998), pp. 257–304. doi:10.1287/moor.23.2.257.