
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Modern combustion engines require an efficient cycle-by-cycle fuel injection control scheme to optimise the single combustion events during transient operation. The online optimisation of the respective control inputs typically needs accurate while sufficiently simple models of the combustion quantities. Based on a recently presented cycle-by-cycle optimisation scheme with a hybrid model, this paper focuses on two aspects to enhance the accuracy as well as computational efficiency for an online computation. Firstly, the proper calibration of Gaussian processes nested in a combined physics-/data-based model structure is addressed. Respective test bench measurements and a tailored two-step training procedure are presented. Secondly, the computational efficiency of the online cycle-by-cycle optimisation is increased by mapping computationally intensive calculations into the data-based models through offline preprocessing. In addition, a data-driven approximation of the complete optimisation scheme is proposed to further minimise the computational demand. Simulation studies are used to evaluate the performance of these approaches.
1. Introduction
Despite the ongoing electrification of the mobility sector, in the near and mid-term future, diesel driven vehicles will still play an important role in public transportation, especially for heavy-duty and off-road applications [Citation1,Citation2]. Thus, increasing the diesel engine efficiency, i.e. decreasing the emitted , while minimising harmful emissions like nitrogen oxide (
) or soot remains a high priority [Citation3]. Since the transient engine operation offers great optimisation potential, recent governmental legislations enforce diesel engines to fulfil emission limits that were required only for less dynamic scenarios also under highly transient conditions, i.e. Real Driving Emissions (RDE) [Citation4,Citation5].
Focusing on the transient engine operation, sophisticated control schemes aim to optimally regulate the combustion process via the actuated inputs of e.g. the air or the fuel injection system [Citation6,Citation7]. In this field, approaches of cycle-by-cycle control try to optimise the single combustion events during engine transients. For this task, the parameters of the fuel or even water injection [Citation8] are the main manipulated inputs as they directly affect the combustion whereas air system variables, such as intake pressure or oxygen fraction, pertain time-varying boundary conditions [Citation9]. In order to optimally control this system, mathematical models are employed to precisely assess the cross-relations between the various actuated inputs, time-varying conditions, and combustion quantities (emissions and torque). Since accurate physics-based approaches are often too complex for fast-running cycle-by-cycle control schemes, data-based modelling techniques [Citation10–12] are utilised due to their tight mathematical structure [Citation13,Citation14] despite their limited extrapolation capability, e.g., for extreme conditions or unseen transients. Further, also combined physics-/data-based, i.e. hybrid, models [Citation15] are in the scope of research as they aim to unite the advantages of both modelling domains. Based on the modelled relations between the combustion in- and outputs, the actuated signals are determined online or offline through optimisation-based model inversion [Citation11,Citation16,Citation17].
The real-world application of the previously characterised controllers necessitates a consistent calibration of their data-based models as well as a sufficient computational efficiency to satisfy real-time requirements. In detail, the data-based model calibration involves the gathering of reference data that suits the system specifics and the model purpose. Respective approaches discussed in literature range from sophisticated transient measurement procedures to stabilise Homogeneous Charge Compression Ignition [Citation12] towards steady-state approaches to describe the emissions and torque of engines with a conventional combustion [Citation10,Citation18]. According to the discussed concepts, the design of the experiments must also consider the employed data-based modelling approach. In case of neural networks, the authors of [Citation11] e.g. propose a wide-range design with mixed space filling and full factorial parts whereas the local linear models discussed in [Citation10] require a spatially divided concept tailored to their distributed nature. Even if suitable data is available, the overall model structure may further complicate the data-based model generation. For instance, in a hybrid model, the coupling of the physics-/data-based parts must be considered to determine appropriate training data. Respective calibration approaches are yet not widely discussed.
In order to enhance the computational efficiency of cycle-by-cycle control schemes various concepts are discussed in the literature. Approaches of online optimisation are e.g. tuned by their initial conditions (warm vs. cold start), shut-down criteria, or number of iterations [Citation16]. To further reduce the online effort, the optimisation problem is preprocessed offline and the results are stored in surrogate data-based models [Citation11,Citation17,Citation19]. These concepts increase the computational efficiency but also require a suitable sampling of the optimisation problem to properly calibrate the surrogate models. In addition, they shrink the flexibility of the original optimisation as e.g. configurable weights are fixed in the offline solutions. Thus, keeping the online optimisation instead of the data-based approximation but reducing its computational effort through mathematical simplifications seems a promising, yet not well discussed concept.
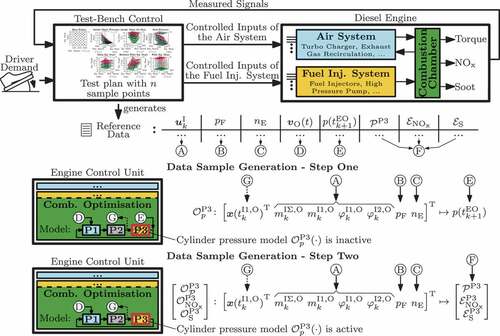
Following the literature overview, this paper focusses on the calibration of data-based models located in a hybrid model structure and discusses enhancements of the computational efficiency of an online optimisation scheme. The papers’ contributions are based on a cycle-by-cycle combustion control scheme that was previously presented in [Citation20]. This approach adapts the fuel injection pattern cycle-by-cycle and includes a hybrid cylinder chamber model [Citation21] where combined physics-/data-based parts predict the emissions and the indicated mean effective pressure (IMEP) per engine cycle. The calibration of the data-based part gets challenging as e.g. one of the models does not predict an output signal but rather is integrated closed-loop into the state space representation. Therefore, the paper extends a mixed space filling / full factorial measurement design similar to [Citation11] by a two-step calibration procedure that separately generates the state space and output data-based models. Furthermore, the computational effort of the online optimisation is induced by certain pre-calculations, parts of the physic-based model, and an equality constraint. To exclude these elements from the online execution, the paper describes a concept to map their characteristics through offline preprocessing into the data-based models. As a result, they still affect the online optimisation although they are not executed individually any more. In addition, the paper discusses the derivation of a full data-based approximation of the online optimisation scheme while keeping its original flexibility e.g. by preserving configurable weights.
The paper is structured as follows. Section 2 recapitulates the hybrid cylinder chamber model of [Citation21] and its application to the combustion optimisation in [Citation20]. Section 3 introduces a calibration procedure for the data-based parts of the hybrid model scheme and discusses the design of test bench measurements in order to gather appropriate reference data. Section 4 describes measures that reduce the computational effort of the original combustion optimisation through adaptations of the optimisation scheme and the data-based models. Section 5 evaluates these improvements by means of simulation studies and the conclusions are discussed in Section 6.
2. Combustion optimisation with a hybrid cylinder chamber model
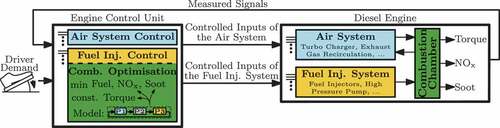
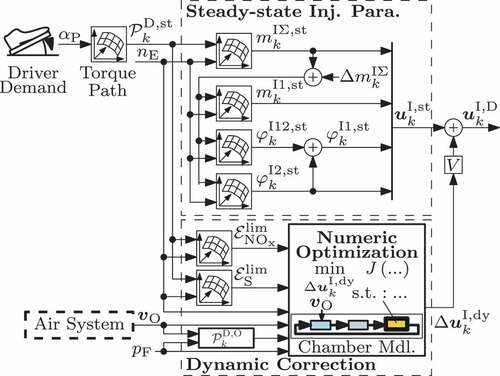
In order to optimally control the combustion during transient engine operation, an optimisation scheme was introduced in [Citation20] to determine correction values for the fuel injection parameters under consideration of their effect on the engine and soot emissions as well as on the IMEP. These adaptations are set cycle-by-cycle in reaction to the current air system state and the fuel pressure which are typically delayed during engine transients. The optimisation-based approach thereby extends the standard fuel injection control as depicted in the system overview of . In course of the optimisation, the considered engine outputs are determined by a combined physics-/data-based, i.e. hybrid, cylinder chamber description from previous work [Citation21]. Since the current paper discusses the calibration of the data-based model part as well as its utilisation for improving the computational efficiency of the optimisation, this section recapitulates relevant aspects of the initial modelling and control approach. Accordingly, Section 2.1 introduces the hybrid cylinder chamber description and Section 2.2 describes its utilisation for the combustion optimisation.
Figure 1. Overview of the diesel engine structure including the engine control unit.
2.1. Description of the physics-/data-based combustion chamber model
The cylinder chamber modelling approach proposed in [Citation21] transforms a conventional, lumped parameter description concept [Citation22–24] into a hybrid approach that combines physics and data-based models. Thereby, the cylinder interior as well as the gas exchange and fuel injection valves define the balance area boundaries, as indicated by the dashed lines in the cylinder sketch in . The model further differentiates between two gas fractions, namely oxygen () and the pseudo-component not-oxygen (
). Overall, it contains the states
Figure 2. Overview of variables to describe the cylinder chamber.
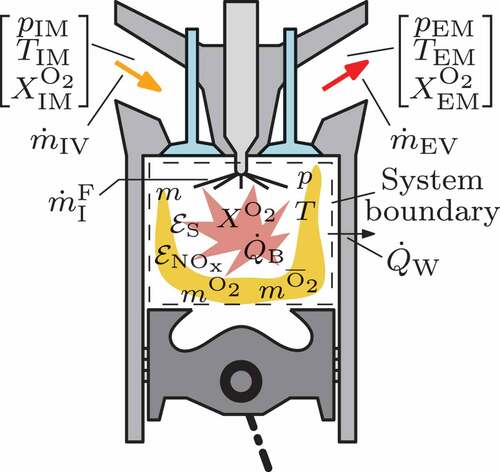
with the total gas mass , the oxygen faction
, and the cylinder pressure
.
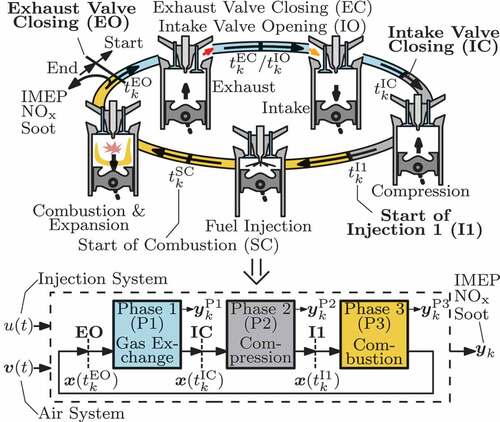
In detail, the physics-/data-based cylinder chamber description separates the combustion cycle into the three stages depicted in , namely gas exchange (blue), compression (grey) and combustion (yellow). The mathematical representation of this arrangement refers to a periodic hybrid automaton [Citation25] that comprises the mentioned phases as well as their transition events, i.e. exhaust valve opening at
, intake valve closing at
and the start of the first fuel injection at
, see . At each transition, the final state of the currently active phase defines the initial state x
of its successor. Except to this requirement, each phase is assumed to be free regarding its specific modelling concept. This generic framework of sequentially connected phases allows to describe the evolution of the cylinder chamber state
by means of
Figure 3. Hybrid automaton-like structuring of the engine cycle into the gas exchange, compression, and combustion phase.
In this approach, the gas exchange and compression phase (phases 1 and 2) are modelled by means of the continuous-time, lumped-parameter cylinder modelling concept [Citation22–24] that is represented by the functions and
, respectively. The input signals
of phases 1 and 2 in (2) consider the external air system dependencies, i.e. the thermodynamic states in the intake (IM) and exhaust (EM) manifold, see , as well as the engine speed . The time-continuous input variables of the gas exchange phase in (3) also enable to attach further models which e.g. describe the air system delay and dead-time effects [Citation26–28].
In contrast to the gas exchange and compression, the complexity of the combustion process requires complex models [Citation29–32] which are, however, inappropriate for the desired combustion optimisation. Thus, at phase 3 in (2), the continuous-time evolution of the states is substituted by the discrete-time approximation
that only determines the final state x of the combustion phase, since it is required for the initialisation of the succeeding gas exchange phase, see . In detail, physics-based surrogate models predict the gas mass
and the oxygen fraction
. They are derived assuming that the injected fuel mass
evaporates completely and combusts stoichiometrically with the oxygen demand described by the stoichiometric factor
. Thus, the overall cylinder gas mass
increases and the oxygen fraction
decreases, respectively. Due to the hard-to-describe combustion physics, a more complex, data-based model
determines the cylinder pressure
in (5). Its input vectorγ
contains the initial state x calculated by the physics-based model of the compression phase (phase 2) of (2), the fuel injection parameters
comprising the start positions and fuel mass distribution of the injection impulses according to as well as the fuel pressure
and the engine speed
. These variables are selected as they affect the cylinder pressure evolution during the combustion phase within the governing differential equation. Further, the data-based model
represents a mapping
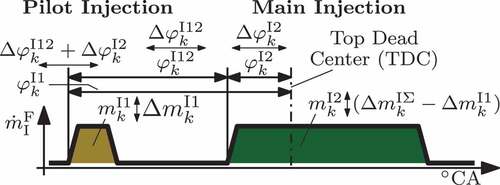
Figure 4. Shape parameter of the fuel mass flow rate and their dynamic correction values.
from the input vector to the scalar pressure signal
. Gaussian process regression with a squared exponential kernel [Citation33] is utilised throughout the paper to set up these data-based mappings as it has proven its suitability in the engine modelling domain [Citation13] and is also supported by recent engine control units [Citation34]. The Gaussian process hyper-parameters are estimated by a maximum likelihood approach utilising the software ASCMO (Advanced Simulation for Calibration, Modelling and Optimization) [Citation35].
At each engine cycle , the cylinder chamber model also describes the output signals
that comprise the IMEP as well as the
and soot emissions
and
. Due to the phase-wise model structure, see , and the integral characteristic of the output signals, the vector
is calculated by the sum
of the individual contributions
of each phase. Similar to the state space description (2), the outputs and
of phases 1 and 2 are derived from the physics-based models. In detail, the IMEP is determined from the in-cylinder pressure trace
according to [Citation36]. Further, no emission components are assumed to be aspirated during the gas exchange. Regarding the combustion phase (phase 3), the single elements of
are determined by the data-based surrogate models
. Similar to (7), they define individual mappings from the input vector
(6) to the respective scalar output signals, which can be summarised in the vector-valued dependency expression
These data-based mappings are also set-up by Gaussian process regression. Thus, they are characterised by the mean values and standard deviations
.
2.2. Fuel injection-based combustion optimisation
The combustion optimisation in [Citation20] determines desired fuel injection parameters that are tailored to the transient engine operation. Therefore, it computes the offsets
to adapt the steady-state fuel injection parameters
under consideration of the actual emission quantities that are e.g. affected negatively by the slow air system and fuel pressure dynamics. Thus, the desired fuel injection parameters for the transient engine operation are calculated on a cycle-by-cycle basis via
This approach considers all degrees of freedom of the two pulse fuel mass flow profile, see , i.e. the adaptations and
for the overall and pilot fuel mass, the shift
of the main injection start, and
for the distance between the pilot and the main injection. To determine the pilot injection shift
, the conversion matrix
sums up its relative offset
and the total shift
of the main injection.
The signal scheme in visualises the integration of the correction approach (16) into the standard fuel injection control concept. This section originally determines the steady-state parameters via the base maps
in dependence of the total fuel mass
and the engine speed
. The offsets
are calculated in addition by the section ”Dynamic Correction“ based on a numeric optimisation approach that utilises the physics-/data-based cylinder chamber model (1)-(13). Further, the optimisation also considers certain
and soot limits
and
, the engine speed
, the air system coupling variables
, the fuel pressure
as well as the desired IMEP
. The inputs
and
thereby introduce the current state of the air system and fuel pressure dynamics to the offset calculation.
Figure 5. Extension of the conventional fuel injection control scheme with a dynamic correction approach to improve the transient engine operation.
The actual corrections (14) are derived by solving the optimisation problem
which consists of the objective function (17a) and the constraints (17b)-(17g). In detail, the objective function (17a) has the structure
and thus weights via between the fuel consumption, the emissions
and soot as well as their uncertainties (standard deviation). To prevent the optimisation from seeking non-physical results, e.g. zero emissions, the emission quantities are further limited smoothly by means of
and
. Due to the max function, emissions are only minimised in case they exceed their limit, see .
Figure 6. Visualisation of the effect of the emission optimisation limit
in the objective function.
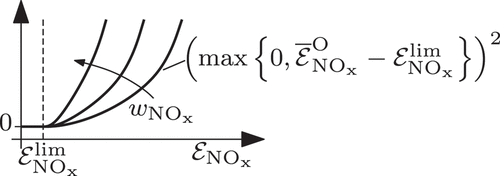
The expressions in (17b)-(17e) comprise the hybrid cylinder chamber model (1)-(13). In detail, (17b) represents the physics-based part, i.e. phases 1 and 2 in (2), and describes the pressure trajectory in the time interval
as well as the state x
at the optimised start time
of the first fuel injection. The data-based models
in (17b)-(17e) represent the combustion phase approximation in (2) and predict the IMEP
, the
and soot emissions
and
, and the pressure
according to (5) and (12). The identifier
denotes the utilisation of the data-based models in the optimisation. Their input vector
is derived from (6) and comprises the cylinder state x calculated by (17b) as well as the optimised fuel injection parameters
determined according to (16). Similar to the dependency relation (13), the data-based models define individual mappings from the input vector
(19) to the scalar outputs, as summarised by
Additionally, the equality constraint in (17f) requires the actual IMEP to match the desired IMEP
. The actual IMEP
is determined in (17e) for the current corrections
according to the combined physics-/data-based calculation approach (9). The reference value
is also estimated by means of (9) via
However, the fuel injection parameters are uncorrected, i.e. the steady-state parameters are utilised without any offset
. Thus, the input vector
of the data-based model only considers the steady-state fuel injection properties, which is also indicated by the identifier
.
Finally, the inequality constraints (17g) limit the value range of the fuel injection corrections . The upper and lower boundaries
ensure that the data-based models (21) are utilised only within the training data range discussed in Section 3.3. The fuel mass offset is restricted indirectly such that the resulting total fuel mass
maintains the lower and upper boundaries (
and
) depicted in . The limits of the other optimisation variables directly originate from their respective value range in the training data.
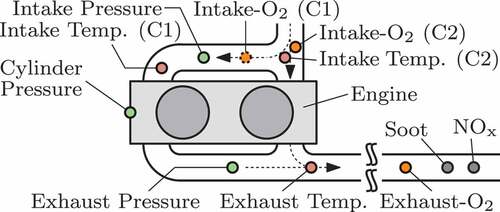
Figure 7. Overview of the test bench structure focussing on the sensors that are located in the intake and exhaust manifold.
3. Generation of data-based models for the combustion optimisation
The combustion optimisation (17) for the transient engine operation utilises the physics-/data-based, i.e. hybrid, cylinder chamber description (1)-(13). The parameters of the physics-based part are typically well known, since they mainly result from geometrical properties. In contrast, the data-based models require tailored reference data of their in- and output signals to fit the generic Gaussian processes (
training) and evaluate their accuracy (
test). Since steady-state test bench measurements are employed to gather this data, their design needs to ensure that the static models
are also valid during engine transients as also discussed in [Citation18,Citation19,Citation37]. The nested location of the data-based models within the hybrid structure further complicates their generation. To solve these issues, Section 3.1 describes a test bench setup that enables the required measurements. Section 3.2 defines the variables to be varied in terms of the measurement campaign while Section 3.3 proposes a concept to shape their variation range. To properly generate the data-based models, Section 3.4 introduces a calibration procedure that processes the steady-state reference data into respective training and test data.
3.1. Description of the test-bench setup
The test-bench setup that is utilised for the gathering of the measurement data comprises all components from the system overview in , i.e. an engine control unit, the air and fuel injection system as well as the core engine with an attached electric break to control its speed. Additional test-bench equipment supervises the overall system, controls the measurement procedure, and manages the sensor signal processing. The utilised sensors are visualised in . They measure the thermodynamic state in the intake and exhaust manifold, i.e. the pressure, temperature, and oxygen fraction, which also correspond to the air system coupling variables required by the optimisation, see . The soot and
emissions as well as the cylinder pressure trace are also measured by this setup.
Figure 8. Visualisation of the main relations between the air system actuators and the cylinder state of the data-based model input
.
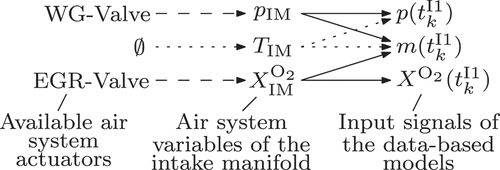
3.2. Determination of the variation variables
Steady-state test bench measurements are executed to gather reference data for the training and test of the data-based models . To ensure the suitability of the data sets, the measurement design ideally varies the signals
of their input vector (19) in a range that fits to the application in the optimisation. However, due to the limited controllability of certain elements of
, the variables
are varied during the test bench measurements. The engine speed , the fuel injection parameters
, and the fuel pressure
are inherited from
since they can be directly set by the test-bench electric break or the engine control unit. In contrast, no actuators are available to control the cylinder pressure
, gas mass
, and oxygen fraction
. However, the air system actuators enable to set these parameters indirectly, e.g. via the intake manifold conditions. Accordingly, visualises a mapping that shows the main dependencies between the air system actuators and the cylinder filling properties. Thus, the EGR valve is aligned with
since it affects the intake manifold oxygen fraction
. Similarly, the waste gate valve allows to vary
by means of the intake pressure
. Since the actual value of
and
are measured by the test bench, see , respective control loops are established to vary both individually. However, no additional air system actuator is available to set the intake temperature
, and consequentially the gas mass
independently from the oxygen fraction
and pressure
. As a result, both induce a certain cylinder gas mass
, which is suboptimal from the measurement design perspective but unavoidable due to the lack of actuators. The previous analysis only considers major dependencies and neglects e.g. the impact of the exhaust manifold state. However, due to the limited number of actuators, they could not be controlled at all.
Figure 9. Visualisation of limits of the variation variables and the desired data points (black dots).
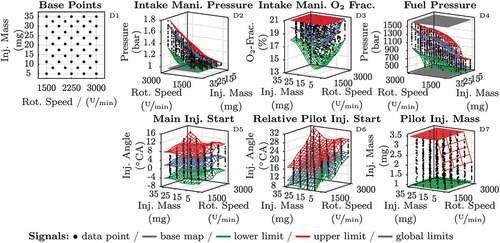
3.3. Design of the parameter variation
The analysis in Section 3.2 defines the signals of (26) to be varied during the steady-state test bench measurements to gather reference data for the training and test of the data-based models
. Now, this section focuses on the derivation of the data points that are actually tested at the measurement campaign.
To derive the list of samples to be measured, the multidimensional variation space defined by must be shaped and filled with data points, respectively. Thus, it needs to be limited to regions aligned with the desired area of application whereas technically inapplicable sections must be dismissed. Accordingly, since the data-based models are utilised in the fuel injection-based combustion optimisation (17), the fuel injection parameters
in
(26) are varied apart from their base value calibration. Further, the models are intended to be used during transient engine operation. Thus, the variation space also needs to include steady-state operating points that represent the conditions during dynamic engine operation, e.g. in the course of a delayed rise of the intake manifold and fuel pressure after a load step. However, this also pinpoints a limitation of the steady-state measurement concept. If an operation point is only reachable by means of transient engine operation, it cannot be considered.
The diagrams in visualise the variation range of the single elements of (26). The black dots represent the desired data points of the measurement procedure. The engine speed and fuel mass in D1 are varied between upper and lower bounds with a slightly modified full factorial design [Citation38], where adjacent data points are shifted to improve space coverage. Further, each engine speed/fuel mass tuple represents a base point at which the remaining variables of
are varied with a space filling design [Citation38]. The diagrams D2 – D4 of show the variation range of the intake pressure
(D2) and the oxygen fraction
(D3) as well as of the fuel pressure
(D4). Since all of them exhibit a delayed or overshooting response during engine transients, the purely steady-state measurement procedure also has to cover these regions of operation. Therefore, base maps (blue) describe the standard value of these parameters in dependence of the engine speed
and fuel mass
. To cover positive and negative deviations during transient engine operation, the green and red maps up- and downwards of the base values further define a certain variation range. For the intake pressure
and the fuel pressure
, the base maps are shifted up- and downwards by a certain offset. However, the positive offset of
is smaller than the negative for engine safety reasons. During engine transients, the intake oxygen fraction
may over- or undershoot the base value. Thus, its upper limit in D3 (red) equals the highest possible value, i.e. the fresh air oxygen fraction. The lower limit (green) is derived from prior measurements where the EGR valve is opened step-by-step to determine the minimal oxygen fraction that ensures save engine operation.
The diagrams D5 – D7 of depict the variation design for the fuel injection parameters, namely of the main injection start in D5, the distance
between the pilot and main injection in D6, and the pilot injection mass
in D7. In order to enable the optimisation of the fuel injection parameters, the green and red limit maps define a certain variation range apart from their base values (blue) that correspond to the steady-state fuel injection parameters
. According to , the base maps are described by
in dependence of the fuel mass
and the engine speed
. For the main injection start, the map is shifted symmetrically by
(D5). The pilot injection start is varied between
and
relative to the main injection (D6). The lower limit is smaller than the upper to avoid interactions of the pilot and main injection. Finally, the pilot injection mass is varied between
and
(D7), whereas for a fuel mass
below
its variation range decreases.
The described experiment design comprises full factorial and space filling parameters varied between non-box shaped boundaries. To determine sets of data points that align with these requirements, the toolbox ExpeDes of the software ASCMO [Citation35] is utilised where the space filling design is determined by a Sobol sequence. To increase the robustness against drifts and measurement failures, the test plan contains six sections that independently describe a complete experiment by 275 data points, respectively. This data point amount is a trade-off between the test bench allocation, space coverage, and total model complexity, i.e. the computational effort of the Gaussian processes.
3.4. Calibration of the data-based models
The test bench measurements designed in Section 3.3 intend to generate appropriate reference data to train and test the data-based models of the combustion optimisation (17). As they are part of the physics-/data-based cylinder chamber model (1)-(13), they are calculated closed-loop with the state space equations of the gas exchange and compression phase. Since this complicates the generation of the data-based models, this section proposes a respective calibration strategy.
The calibration procedure of the data-based models initially assumes, that measurement data is generated in accordance to Section 3.3. The top section in the overview sketch of depicts this prerequisite. Based on this data, the generation of the models follows a two-step procedure, as visualised in the lower section of . Step one generates the approximation model
that determines the cylinder pressure
at the end of the combustion phase. Due to this model, the state space description (2) can be simulated stand-alone. Step two generates the remaining data-based models
while the previously built instance of
is utilised to simulate the cylinder chamber state x
.
Figure 10. Assembly of input-output samples of the training and test data sets at calibration step one and two for the generation of the data-based models of the optimisation problem (17).
The generation of the data-based models requires training and test data sets. Each of them consists of single samples that comprise signals of the inputs and the designated outputs, respectively. The signal flow depicted in visualises the assembly of these data samples at calibration step one and two based on the reference data from test bench measurements. At step one as well as two, the fuel injection parameter
Ⓐ, the fuel pressure
Ⓑ and the engine speed
Ⓒ of the input vector
are inherited from the reference data. In contrast, the derivation of the cylinder state x
Ⓖ requires the evaluation of the cylinder chamber model, since the respective signals are not provided by the measurement data. To execute the respective simulations, the measured air system coupling variables
Ⓓ are required. Further, at step one, the cylinder pressure approximation
within phase 3 is not existing yet (phase 3 is crossed out at step one in ). Thus, the cylinder pressure
at the end of phase 3 is set according to the measured signal Ⓔ. Consequentially, the same signal is also assigned to the output element, since
is trained at step one. During the second calibration step, the previously created model
enables to simulate the cylinder chamber model in a stand-alone fashion. As a result, the cylinder state
in the input
of the data-based models
also contains the unavoidable modelling error that is introduced by the cylinder pressure approximation
. This ensures data consistency compared to a single-step calibration of all data-based models. At step two, the input vector signals are assembled similar to step one. However, the output values for
, soot, and the IMEP of the combustion phase are inherited from the reference data via Ⓕ, respectively.
The measurement procedure designed in Section 3.3 comprises six sections that independently sample the full range of operation. Three of them are selected for the training and test data, respectively. The sections with the highest share of successful runs are utilised for the training. The symmetric split also considers the computational effort of the Gaussian process regression which scales with the training data size. Overall, the training and test data sets comprise 753 and 524 data points, respectively.
4. Improvements of the computational effort of the combustion optimisation
The fuel injection control concept introduced in Section 2.2 calculates the correction values for the fuel injection parameters to optimise the combustion during transient engine operation. However, the proposed approach requires the online optimisation problem (17) to be solved, which may be critical w.r.t. the computational power or timing. Accordingly, this section proposes measures to reduce the computational effort of the correction value calculation. Certain adaptations of the optimisation scheme are proposed taking advantage of the flexibility of the data-based models, e.g., to learn further relations in addition to those of their original training data. In detail, Section 4.1 describes a simplifying restructuring of the original optimisation problem (17) that maps certain calculations into the data of the data-based models to remove them from the optimisation scheme. Section 4.2 extends this concept and also projects the IMEP equality constraint (17f) into the data-based models training data. Finally, Section 4.3 proposes an alternative approach that solves the online optimisation problem offline and stores the results in dedicated correction maps.
4.1. Restructuring of the original optimisation problem
The solution of the optimisation problem (17) requires several time-consuming calculations to be performed multiple times. This refers to the physics-based model in (17b) and (17e) that, e.g., determine the state x and the IMEP
of the compression phase (phase 2). In addition, the total fuel injection parameters
(20) need to be determined from the steady-state parameters
, which requires the base maps
to be evaluated, see . To eliminate this overhead, Section 4.1.1 and 4.1.2 transform the data-based models of the optimisation scheme (17) such that parts of the physics-based model as well as the base maps
are mapped into their training data. Section 4.1.3 updates the optimisation problem accordingly. Finally, Section 4.1.4 discusses the accuracy of the updated data-based models.
4.1.1. Substitution of the physics-based calculations of the compression phase
In the optimisation problem (17), the state x and the IMEP contribution
need to be determined by the physics-based models of the compression phase in (17b) and (17e), respectively. To avoid the explicit calculation of the gas mass
and oxygen fraction
of x
, they are defined to equal the state at intake valve closing, i.e.
and
. However, this simplification does not apply for the pressure
and the IMEP
, since both result from the actual pressure trace
determined by the physics-based model (17b). To substitute these calculations, the approximative data-based mappings
are introduced to directly obtain and
. The input vector
thereby comprises signals that are aligned with the pressure rise during the compression phase, i.e. the initial cylinder state x, the start
of the pilot injection, the engine speed
, and the overall fuel mass
. The identifier
generally denotes that the physics-based calculations of the compression phase (phase 2) are replaced by the mapping (27). Thus, the cylinder chamber state x
can be approximated by
The substitution (29) and the relation from (27) enable to rewrite the input
(19) of the data-based models
to
which does not rely any more on the compression phase model to calculate . This change also requires to update the aligned data-based mappings (21) to
Since the cylinder pressure is replaced by
in
, the calculations of the physics-based models of phase 2 in (17b) are projected into the data-based models (31).
4.1.2. Substitution of the total fuel injection parameters by their correction values
The previous section introduces the data-based models in (31) and
in (27), which both avoid computing the physics-based models of the compression phase in (17b) during the optimisation. However, their input vectors
(28) and
(30) still contain the total fuel injection parameters
(20), which require to determine the steady-state parameters
(15) by the base maps
, see . To save this effort, their dependencies should also be mapped into the training data of the data-based models.
At the input vector (28) of the data-based models
, the pilot injection start
is a function of the corrected fuel mass
, the individual shifts
and
of the pilot and main injection as well as of the engine speed
, see . These known dependencies enable to rewrite the input vector
(28) into
Expanding the dependencies of further turns
into the vector
which does not rely on the total pilot injection start any more. This is also indicated by the identifier
. Further, the vector dimension changes from
to
. The input vector
(30) of the data-based models
is transformed similarly. Due to the dependencies of
resulting from , it is rewritten into
After expanding the dependencies of , the input vector
turns into
which also just relies on the fuel injection parameter corrections .
Due to the input vector transformations (32) and (33), the steady-state fuel injection parameter and consequentially their associated base maps
must not be evaluated during the optimisation any more. In other words, the transformation inherently integrates the base maps
into the training data of the data-based models. As a result, the data-based mappings (27) and (31) are updated to
Since the cylinder pressure mapping in (27) represented an interims result of Section 4.1.1, it is neglected in (34).
4.1.3. Reformulation of the optimisation problem
Section 4.1.1 and 4.1.2 simplify the optimisation scheme (17) as the physics-based calculations of the compression phase as well as the explicit determination of the steady-state fuel injection parameter are both projected into the training data of the data-based models. Accordingly, the optimisation problem (17) is updated to
The physics-based model part in (36b) now only describes the gas exchange (phase 1) to determine x. Furthermore, the data-based model
calculates the compression phase IMEP
in (36e) instead of the physics-based model utilised in (17e).
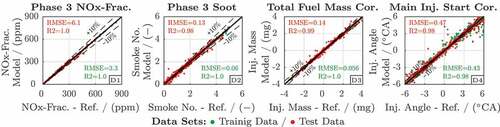
4.1.4. Generation and evaluation of the data-based models
The data-based models and
that are introduced in Section 4.1.2 differ from the models of the original optimisation problem (17). Thus, they need to be generated and tested individually. Their calibration procedure basically follows the approach described in Section 3.4, whereas the input signals of
are used instead of
and the IMEP model
is also trained during step two. The correlation plots in visualise the training (green) and test (red) error of the data-based models that are utilised closed loop in the optimisation. The results for
, soot and the phase 3 IMEP (
) are comparable with the results originally discussed in [Citation20]. Further, the newly introduced IMEP model for phase 2 exhibits a small training as well as test data error (D4).
Figure 11. Evaluation of the data-based models and
.
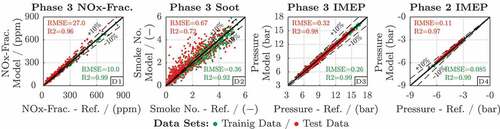
4.2. Elimination of the IMEP equality constraint
Section 4.1 introduced several modifications of the original optimisation problem (17) to reduce the calculation overhead. However, the resulting optimisation scheme (36) still requires a certain computational effort to balance the IMEP equality constraint (36f) at each optimisation iteration. Accordingly, Section 4.2.1 proposes to project this constraint into the data of the data-based models such that their prediction inherently satisfy the constraint thus making its explicit consideration superfluous. Section 4.2.2 reformulates the optimisation problem (36) accordingly. Finally, Section 4.2.3 describes the generation and evaluation of the updated data-based models.
4.2.1. Definition of data-based models with inherent IMEP constraint
The IMEP equality constraint (36f) of the optimisation problem (36) requires the actual IMEP to match the desired value
. According to the governing equation (36e) for
and (22) for
, the constraint (36f) is explicitly described by
The term A, which originates from the desired IMEP (22), only depends on parameters that are constant during a certain optimisation run, i.e. the cylinder state x
at intake valve closing, the engine speed
, the fuel pressure
, and the steady-state fuel injection parameters
. In contrast, term B, which results from the actual IMEP
(36e), also depends on the optimised injection parameter corrections
.
In the course of the optimisation, term A and B of (37) are balanced continuously while the objective function (36a) is minimised. Since the objective purely consists of data-based models, the IMEP constraint may be projected into their training data such that for all of their data points term A and B of (37) are balanced. As the predictions of such data-based models would inherently satisfy the IMEP constraint, its dedicated balancing during the optimisation becomes superfluous.
However, the terms A and B of (37) are unbalanced by default for all training and test data samples created according to Section 3. Hence, a post-processing of the data points is proposed, i.e. a virtual rerun of the test bench measurements, to derive modified samples that inherently satisfy the constraint (37). This data processing approach is visualised in . In detail, the fuel mass of each data sample (green circle) is modified by
into the virtual fuel mass
which causes the equality constraint (black line) to be satisfied. In order to preserve the homogeneous, space filling structure of the data sets, the other fuel injection parameters as well as the engine speed
, fuel pressure
, and cylinder state x
remain unchanged. Since the modified full mass
changes the emissions, the
and soot values
and
of the processed data samples are updated to maintain data consistency. The models
and
from (35) are utilised for these updates.
Figure 12. Concept for processing a data point to inherently satisfy the IMEP constraint equation (37).
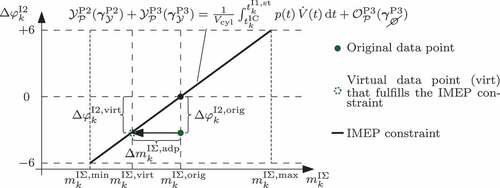
The previous data processing introduces a redundancy in the training and test data. Accordingly, the adapted fuel mass is, e.g., aligned with the shift
of the main injection via the desired IMEP
that equals term A of (37). The redundancy allows to define the data-based mapping
with the input vector
to determine the corrected fuel mass that maintains the desired IMEP
under consideration of the other fuel injection parameter corrections, the engine speed
, the fuel pressure
, and the cylinder state x
. The identifier
indicates that the data of the respective data-based models inherently satisfy the IMEP constraint. The elements of the input vector
(40) originate from
(33), whereas the fuel mass
is replaced by the desired IMEP
(38). The redundancy in the data also allows to define the mapping
with the input vector
to describe the main injection start correction for a certain adapted fuel mass
and desired IMEP
.
Finally, the data-based models and
of the exhaust emissions specified in (35) must be redefined due to the updated data such that their predictions inherently satisfy the IMEP constraint. Their input vector
(33) is extended with the redundancy mapping (41) of the main injection start correction
leading to
The expansion of the dependencies of turns the input vector
into
where is substituted with the desired IMEP
. Accordingly, the data-based mappings (35) of the emission predictions are updated to
Due to the data preprocessing approach of and the adapted input vector (43), the data-based models
and
predict emissions that inherently align with the IMEP constraint (36f).
4.2.2. Reformulation of the optimisation problem without IMEP constraint
Section 4.2.1 introduces the data-based models and
which provide emission predictions that inherently satisfy the IMEP constraint (36f). Hence, the optimisation problem (36) changes to
where the IMEP constraint (36f) is excluded. As the main injection correction is substituted by the desired IMEP
in the input
(43) of the data-based models
and
, it is also removed from the optimisation variables of (45). However, at the end of each optimisation run, the value of
is determined by means of
(41). Hence, the upper and lower limits of
, i.e.
from (24) and (25), still restrict the optimisation through certain lower and upper bounds
and
for the optimised total fuel mass
, see also . These limits are determined by means of the data-based model
(39) with the input vector
in order to determine and
to derive . In order to consider these restrictions within the constraint (45e), the bounds of
from (24) and (25) are adapted to
and
, respectively. The limits
and
from (46) and (47) thereby inherently consider the global fuel mass bounds
and
of (24) and (25). In case only the total fuel mass is optimised via
, i.e. for
and
, the limits (46) and (47) are constant during an optimisation run. Otherwise, they need to be updated at each optimisation iteration.
4.2.3. Generation and evaluation of the data-based models
The data-based models introduced in Section 4.2.1 must be generated and tested. In contrast to the previous models, their data is derived by post-processing existing data sets according to Section 4.2.1. The data of the data-based models from Section 4.1.4 is utilised for this purpose.
The correlation diagrams in visualise the training and test data error of the data-based models. The error of (D1) and soot (D2) is smaller compared with the previous models
in . This results from the smooth training data, that is derived from sampling
and
according to Section 4.2.1. The redundancy models
(D3) and
(D4) also show a small error.
Figure 13. Evaluation of the data-based models .
4.3. Offline learning of the optimisation results
The previous Sections 4.1 and 4.2 introduce approaches to minimise the computational effort of the original optimisation problem (17). However, instead of solving it online during runtime, the following approach determines the corrections offline and stores the results in respective data-based surrogate models, as depicted in the signal flow diagram in . To establish this concept, Section 4.3.1 proposes an input-output structure for these correction models that also preserves the flexibility of the original optimisation problem, e.g., regarding variable weights. As different types can be created, Section 4.3.2 describes the variants investigated by this paper. Finally, Section 4.3.3 describes the generation and evaluation of the surrogate correction models.
Figure 14. Concept for deriving data-based models that substitute the online optimisation to determine the fuel injection correction .
4.3.1. Definition of data-based models for the fuel injection parameter corrections
In order to derive data-based models that substitute the optimisation (17), a set of input signals must be defined to unambiguously describe the correction values
. These signals are selected according to the external dependencies of the original optimisation problem (17) depicted in . In the left part of the diagram in , these relations are restructured to derive the signals
that specify the external dependencies of (17). Hence, both IMEP set points and
, the cylinder filling properties x
at intake valve closing, the engine speed
, the fuel pressure
, and the weights of the objective function (18) are required. For reasons of simplicity, the weights
and
of the model uncertainty terms are neglected. Consequently, the data-based mappings
can be defined to explicitly describe the fuel injection corrections . The identifier
denotes that these data-based models substitute the online optimisation.
4.3.2. Derivation of the data for the data-based correction models
The generation of the substituting data-based models (49) requires certain training and test data. According to Section 3.3, such data sets must contain data samples that vary the input signals in a meaningful range and also provide the output signals, i.e. the fuel injection parameter corrections
. In contrast to the data-based models utilised in the original optimisation problem (17), this input-output data does not originate from measurement data, but from sampling (17) for various boundary conditions. The sketch in shows the concept that is utilised to perform this sampling of the optimisation scheme. Since the data derived according to Section 3.3 already contains a strong variation of the air system conditions, engine speed, fuel pressure, and load, it is used to define a base variation for the boundary conditions of the optimisation. Further, at each data point, the weights are varied in addition. Within this paper, the weight sampling variants V1 and V2 depicted in are investigated. V1 considers a single weight case where
and fuel mass are equally prioritised. In contrast, V2 considers multiple combinations of different
and fuel mass weights. For each of the resulting samples of the input
, the optimisation problem (17) is solved in order to determine the corresponding fuel injection corrections
.
Figure 15. Sampling concept of the optimisation problem to derive training and test data for the data-based models . The weight variation cases V1 and V2 are investigated.

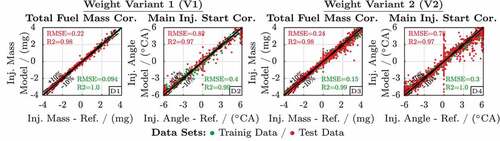
4.3.3. Generation and evaluation of the data-based models
As Section 4.3.2 proposes an approach to determine the training and test data for the data-based correction models (49), this section focusses on their generation and evaluation. In detail, individual models based on Gaussian process regression are created for the weight variants V1 and V2 of . Further, only correction models for the main injection shift and the fuel mass offset
are generated, since both were identified by [Citation20] as the dominant degrees of freedom of the combustion optimisation.
The correlation plots in visualise the training and test data error of the models (D1)/(D3) and
(D2)/(D4) for the weight variants V1 and V2, respectively. Overall, the error measures indicate that all models are fitted very well. However, both weight variants show an increased local error in case no corrections are requested, i.e. in the region of
or
, as well as if the main injection shift
is limited by its lower or upper boundary (17g). Since the fuel injection corrections turn into constant values, i.e. flat surfaces, in these regions, the Gaussian process regression obviously has difficulties to accurately describe that behaviour.
Figure 16. Evaluation of the data-based models of the weight variation cases V1 and V2.
5. Simulation-based evaluation of the improvements in the computational efficiency of the combustion optimisation
Section 4 introduces several concepts to improve the computational efficiency of the fuel injection-based combustion optimisation (17). This section analyses and compares their effects on the accuracy of the fuel injection control as well as on the time required to determine the corrections values .
The comparison is realised in the simulation-based test-bench environment introduced in [Citation20]. Thus, all tested variants are implemented in Simulink via embedded function blocks. Further, the optimisation-based approaches are solved by the Matlab function fmincon with the interior point algorithm. The Gaussian process models are generated by the software ASCMO [Citation35] and are executed as m-code. The run time that is referred to by the following analysis represents the time needed to determine the fuel injection parameter offsets, e.g. via fmincon or the data-based correction models. This measure excludes the effort of the gas exchange calculations since they are executed equally by each approach once per cycle prior to the correction value calculation. In a standard, non-optimised Simulink environment this model part requires to run.
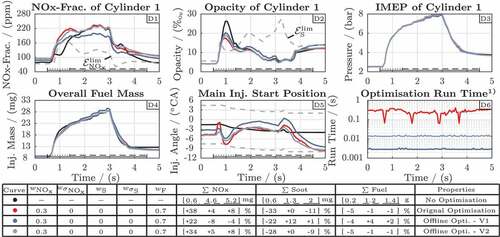
The different variants of the combustion optimisation are compared at a certain transient test cycle. Its engine speed and accelerator pedal trajectory is depicted in the diagrams D7 and D8 of the simulation results overview in . In detail, the engine speed rises as the accelerator pedal is pushed for a certain period of time. The remaining subplots of visualise simulation results, i.e. the emissions and the IMEP generated by cylinder 1 (D1) – (D3), the optimised fuel injection parameters (D4) – (D5) as well as timing measures for the optimisation procedure in D6 and D9.
Figure 17. Comparison of the speed-up measures for the optimisation problem (17). 1) Each approach also simulates the gas exchange phase once per cycle which requires in addition.
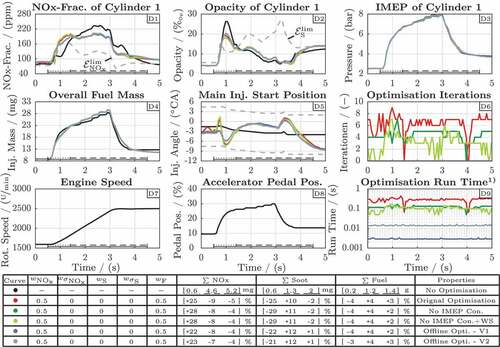
The coloured lines in the plots of indicate the different evaluation cases. Their properties are summarised in the table below the plots. Thus, all variants are configured with the same weight configuration, which equally prioritises and fuel mass. In detail, the black case represents a reference at which the fuel injection parameters are not optimised. The red line shows the behaviour in case the corrections
are calculated according to (36) where certain computational overhead is reduced compared to the original formulation (17). The light and dark green cases both visualise the simulation results of the optimisation problem (45), which utilises data-based models that inherently contain the IMEP constraint. The light green case additionally shows the performance of a warm start procedure, i.e. the optimisation is initialised with the final results of the previous run. The light and dark blue cases both represent approaches where the considered fuel injection adaptations
are determined by the purely data-based correction maps (49). The dark blue line corresponds to the weight variation case V1 of , i.e. it is generated with the data of only one weight configuration. In contrast, the light blue line corresponds to variant V2 which is trained with data from multiple weight configurations.
As the red case in nearly equals the original optimisation formulation (17), it shows the expected behaviour of the combustion optimisation. In the first section, which is marked by the dotted lines (…) in the subplot of , the overall injected fuel mass is decreased by compared to the black case. However, to maintain the IMEP, the main injection start position is shifted forward, since the non-optimised
fraction is below its limit
(D1). As a result, the emitted
mass increases by
. In the second cycle section, which is marked by (- -), the main injection start is mainly shifted backwards compared with the black reference curve in order to decrease the high
emissions. To maintain the IMEP, the fuel mass is increased accordingly. As a result, the emitted
mass decreases by
while the fuel mass increases by
. Overall,
is saved with a
higher invest of fuel mass. Even if soot is neglected by the optimisation due to its zero weight (
), the soot mass is reduced by
. On average, a single optimisation run requires
.
The optimisation results of the green coloured cases, where the IMEP constraint is projected into the data-based models, equal those of the red case very well. Particularly, the IMEP trajectory (D3) remains unchanged. However, both require fewer iterations at each optimisation run (D6). The warm start approach (light green) even further reduces the iteration count and in consequence the overall run time required by the optimisation (D9). Compared to the red reference, the average optimisation run time decreases by for the dark green case and
for the light green variant.
The light and dark blue cases, which both utilise purely data-based correction maps to calculate , cause slightly different simulation results compared with the red and both green cases. Particularly, in the middle of the first section (---) as well as at the end of the second (- -), the determined fuel injection parameter corrections deviate from those of the online optimisation approaches. However, the total reduction of
by
and the fuel mass increase of
or
are nearly equal to the cases with online optimisation. In contrast, the run time (D9) decreases significantly, i.e. the average duration of the light blue case is
below the time required by the light green variant. The dark blue case, which comprises data-based models that are especially tailored for the currently tested weights
, see V1 in , is even
faster compared with the light blue variant. The data-based models of the dark blue case are more complex since they also support weight factor combinations that differs from
, see V2 in . This flexibility is demonstrated by the simulation results depicted in . In contrast to ,
has a lower priority compared to the fuel mass (
). As the light blue case is trained only for the weight combination
, its corrections strongly deviate from those of the online optimisation (red). However, the dark blue case, which is trained with the full range of the
and fuel mass weights, adapts its predictions respectively and shows the same error level that was already discussed for .
Figure 18. Test of the data-based correction models V1 and V2, see , for a weight factor configuration that is not included in their training data. 1) Each approach also simulates the gas exchange phase once per cycle which requires in addition.
6. Conclusion and outlook
In order to improve the transient engine operation, combustion control schemes based on a cycle-by-cycle online optimisation require accurate while sufficiently simple optimisation models. Accordingly, this paper proposes methods to enhance their consistency and computational efficiency. Respective results are discussed based on an online optimisation scheme that contains a hybrid cylinder chamber description where the states and outputs are calculated by coupled physics-/data-based models. To consistently calibrate the data-based parts of this hybrid set-up, the proposed two-step training procedure defines a certain calibration order for the data-based models involved in the state space and output calculations. In detail, the cylinder pressure surrogate model is generated prior to those which predict the emissions and torque of the combustion phase. The additionally suggested test bench measurements further support the generation of the data-based models as the gathered data is tailored to their application in the combustion optimisation. However, in terms of the test bench measurements, further research can be spent in varying the intake manifold temperature in addition to the pressure and oxygen fraction to increase the diversity of the data.
To improve the computational efficiency of the optimisation-based control, time-intensive calculations are moved from the online optimisation scheme into the training data of the data-based models. Different concepts are proposed and compared in a simulation-based test environment. According to the results, projecting the IMEP constraint into the data-based models strongly reduces the computational effort without any loss of accuracy. A warm start strategy even further increases the speed of this approach. Concepts that determine the fuel injection parameter adaptations from purely data-based correction maps are even faster, since they are trained offline with given optimisation results and thus are free of any optimisation overhead during runtime. However, this speed-up is achieved at the expense of a loss of accuracy and lower flexibility, since changes in the emission limit maps or untrained weight values cannot be considered. As the previous results are determined in a simulation-based test environment, they also need to be implemented, tested, and verified in a real-world setup, i.e. in a rapid control prototyping system or in an engine control unit. Consequentially, this will require to improve the computational efficiency of the calculations for the gas exchange phase as well. Even if the changed host environment affects the total run time of the discussed approaches, the identified trends, however, are expected to persist.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- World Energy Council, Global Transport Scenarios 2050, London: World Energy Council, 2011.
- U.S. Energy Information Administration, International Energy Outlook 2019, Washington, DC, USA: U.S. Energy Information Administration, 2019.
- F. Leach, G. Kalghatgi, R. Stone, and P. Miles, The scope for improving the efficiency and environmental impact of internal combustion engines, Transportation Eng. 1 (2020), pp. 100005. doi:10.1016/j.treng.2020.100005.
- European Union, Regulation (ec) 715/2007 of the European parliament and of the council of 20 June 2007, Official J. European Union L, 171, 1–16.
- European Union, Commission regulation (eu) 2018/1832 of 5 November 2018 amending directive 2007/46/ec of the European parliament and of the council, commission regulation (ec) no 692/2008 and commission regulation (eu) 2017/1151, Official J. European Union L, 301, 1–314.
- T. Shen, M. Kang, J. Gao, J. Zhang, and Y. Wu, Challenges and solutions in automotive powertrain systems, J. Control Decision 5 (1) (2018), pp. 61–93. doi:10.1080/23307706.2017.1399092.
- G.P. Merker and R. Teichmann (eds.), Grundlagen Verbrennungsmotoren: Funktionsweise und alternative Antriebssysteme Verbrennung, Messtechnik und Simulation, 8th ed., ATZ/MTZ-Fachbuch, Springer Vieweg, Wiesbaden, 2018.
- M. Wick, J. Bedei, D. Gordon, C. Wouters, B. Lehrheuer, E. Nuss, J. Andert, and C.R. Koch, In-cycle control for stabilization of Homogeneous Charge Compression Ignition combustion using direct water injection, Appl. Energy 240 (2019), pp. 1061–1074. doi:10.1016/j.apenergy.2019.01.086.
- S. Nakayama, T. Ibuki, H. Hosaki, and H. Tominaga, An application of model based combustion control to transient cycle-by-cycle diesel combustion, SAE International Journal of Engines 1 (2008), pp. 850–860.
- M. Grahn, K. Johansson, C. Vartia, and T. McKelvey, A Structure and Calibration Method for Data-driven Modeling of NOx and Soot Emissions from a Diesel Engine, Proceedings of the SAE 2012 World Congress & Exhibition, Detroit, Michigan, USA, 2012.
- R. Finesso, E. Spessa, Y. Yang, G. Conte, and G. Merlino, Neural-network Based Approach for Real-time Control of BMEP and MFB50 in a Euro 6 Diesel Engine, Proceedings of the 13th International Conference on Engines & Vehicles, Capri, Italy, 2017.
- M. Wick, J. Bedei, J. Andert, B. Lehrheuer, S. Pischinger, and E. Nuss, Dynamic measurement of HCCI combustion with self-learning of experimental space limitations, Appl. Energy 262 (2020), pp. 114364. doi:10.1016/j.apenergy.2019.114364.
- B. Berger, F. Rauscher, and B. Lohmann, Analysing Gaussian processes for stationary black-box combustion engine modelling, IFAC Proceedings 44 (2011), pp. 10633–10640.
- S. Hu, S. d’Ambrosio, R. Finesso, A. Manelli, M.R. Marzano, A. Mittica, L. Ventura, Y. Wang, and Y. Wang, Comparison of physics-based, semi-empirical and neural network-based models for model-based combustion control in a 3.0 l diesel engine, Energies 12 (18) (2019), pp. 3423. doi:10.3390/en12183423.
- M. Kang, K. Sata, and A. Matsunaga, Control-oriented cyclic modeling method for spark ignition engines, IFAC-PapersOnLine 51 (31) (2018), pp. 448–453. doi:10.1016/j.ifacol.2018.10.101.
- R. Finesso, O. Marello, E. Spessa, Y. Yang, and G. Hardy, Model-based control of BMEP and NOx emissions in a Euro VI 3.0l diesel engine, SAE International Journal of Engines 10 (2017), pp. 2288–2304.
- M. Grahn, K. Johansson, and T. McKelvey, A diesel engine management system strategy for transient engine operation, IFAC Proceedings 46 (2013), pp. 1–6.
- M. Mrosek, Model-based control of a turbocharged diesel engine with high- and low-pressure exhaust gas recirculation, Ph.D. diss., TU Darmstadt, 2017.
- S. Zydek, Optimale Regelung des Dieselmotors zur Minimierung von Realfahrtemissionen und -verbrauch, Ph.D. diss., TU Darmstadt, 2018.
- T. Makowicki, M. Bitzer, S. Grodde, and K. Graichen, Cycle-by-cycle optimization of the combustion during transient engine operation, IFAC-PapersOnLine 50 (1) (2017), pp. 11046–11051. doi:10.1016/j.ifacol.2017.08.2485.
- T. Makowicki, M. Bitzer, P. Kotman, and K. Graichen, A combustion cycle model for stationary and transient engine operation, IFAC-PapersOnLine 49 (11) (2016), pp. 469–475. doi:10.1016/j.ifacol.2016.08.069.
- R. Pischinger, Thermodynamik der Verbrennungskraftmaschine, 3rd ed., Springer Vienna, Vienna, 2009.
- J.B. Heywood, Internal Combustion Engine Fundamentals, McGraw-Hill, New York, USA, 1988.
- G.P. Merker, C. Schwarz, and R. Teichmann, Combustion Engines Development: Mixture Formation, Combustion, Emissions and Simulation, Heidelberg: Springer Science & Business Media, 2012.
- T.A. Henzinger, The theory of hybrid automata, Proceedings of the 11th Annual IEEE Symposium on Logic in Computer Science, New Brunswick, New Jersey, USA. 1996, pp. 278–292.
- R. S. Benson, The Thermodynamics and Gas Dynamics of Internal Combustion Engines, J. H. Horlock and D. E. Winterbone, eds., Oxford: Clarendon, 1986.
- F. Meddahi, C. Fleck, S. Grodde, A. Charlet, and Y. Chamaillard, Modeling waves in ICE Ducts: Comparison of 1D and low order models, Proceedings of the 12th International Conference on Engines & Vehicles, Capri, Napoli (Italy), 2015.
- P. Kotman, M. Bitzer, K. Graichen, and A. Kugi, Hybrid modeling of a two-stage turbocharged diesel engine air system, Proceedings of the 6th Vienna International Conference on Mathematical Modelling, Vienna (Austria). 2009, pp. 2015–2024.
- J. Warnatz, U. Maas, and R.W. Dibble, Combustion: Physical and Chemical Fundamentals, Modeling and Simulation, Experiments, Pollutant Formation, 4th ed., Springer, Berlin, 2006.
- K. Inagaki, M. Ueda, J. Mizuta, K. Nakakita, and S. Nakayama, Universal Diesel Engine Simulator (Unides): 1st Report: Phenomenological Multi-zone Pdf Model for Predicting the Transient Behavior of Diesel Engine Combustion, Proceedings of the SAE World Congress & Exhibition, Detroit, Michigan, USA, 2008.
- R. Finesso and E. Spessa, Real-time Predictive Modeling of Combustion and NOx Formation in Diesel Engines under Transient Conditions, Proceedings of the SAE 2012 World Congress & Exhibition, Detroit, Michigan, USA, 2012.
- H. Pitsch, H. Barths, and N. Peters, Three-dimensional modeling of NOx and soot formation in DI-Diesel engines using detailed chemistry based on the interactive flamelet approach, Proceedings of the SAE International Fall Fuels and Lubricants Meeting and Exhibition, San Antinio, Texas, USA, 1996.
- C.E.V. Rasmussen and C.K.I.V. Williams (eds.), Gaussian Processes for Machine Learning, MIT Press, Cambridge, Massachusetts, 2006.
- S. Angermaier and M. Gopalakrishnan, Implementation of data-based models using dedicated machine learning hardware (AMU) and its impact on function development and the calibration processes, Proceedings of the International Calibration Conference – Automotive Data Analytics, Methods and Design of Experiments (DoE), Berlin, 2017.
- ASCMO V5.5, ETAS GmbH, Stuttgart, Germany, 2020, Accessed 24 April 2021, Available at https://www.etas.com/de/portfolio/ascmo.php.
- L.V. Guzzella and C.H.V. Onder (eds.), Introduction to Modeling and Control of Internal Combustion Engine Systems, 2nd ed., Springer, Berlin, Heidelberg, 2010.
- D.V. Velmurugan, M. Grahn, and T. McKelvey, Diesel engine emission model transient cycle validation, IFAC-PapersOnLine 49 (11) (2016), pp. 1–7. doi:10.1016/j.ifacol.2016.08.001.
- K. Siebertz, D.V. Bebber, and T. Hochkirchen, Statistische Versuchsplanung: Design of Experiments (Doe), 2nd ed., VDI-Buch, Springer Vieweg, Berlin, Heidelberg, 2017.