
Abstract
Purpose: This study examines the influence of voice quality and multi-talker babble noise on processing and storage performance in a working memory task performed by children using cochlear implants (CI) and/or hearing aids (HA). Methods: Twenty-three children with a hearing impairment using CI and/or HA participated. Age range was between 6 and 13 years. The Competing Language Processing Task (CLPT) was assessed in three listening conditions; a typical voice presented in quiet, a dysphonic voice in quiet, and a typical voice in multi-talker babble noise (signal-to-noise ratio +10 dB). Being a dual task, the CLPT consists of a sentence processing component and a recall component. The recall component constitutes the measure of working memory capacity (WMC). Higher-level executive function was assessed using Elithorn's mazes. Results: The results showed that the dysphonic voice did not affect performance in the processing component or performance in the recall component. Multi-talker babble noise decreased performance in the recall component but not in the processing component. Higher-level executive function was not significantly related to performance in any component. Conclusions: The findings indicate that multi-talker babble noise, but not a dysphonic voice quality, seems to put strain on WMC in children using CI and/or HA.
Introduction
The processing of degraded speech signals seems to require more use of cognitive resources compared to the processing of speech under optimal listening conditions in adults [Citation1–5]. A speech signal that is perceived under optimal listening conditions provides an input, that is processed automatically and fast [Citation2]. This implicit processing means that the speech segments are matched to their long-term representations which allow for immediate access to lexical content which provides building stones for understanding. However, in suboptimal listening conditions where the speech signal is degraded, this process becomes explicit. This explicit processing requires the use of cognitive resources to compensate for the degraded speech signal input. Because more cognitive resources such as working memory are used for auditory processing, fewer resources remain available for the task at hand and also for encoding of information into long-term memory [Citation2]. This suggests that the individual’s intrinsic characteristics such as cognitive abilities and a hearing impairment will influence performance when listening to a degraded speech signal. This degradation is generated by extrinsic factors such as the presence of noise and inadequate reverberation (poor room-acoustics) as well as the presence of a voice disorder [Citation5]. In the present study, we examine the influence of voice quality and multi-talker babble noise on processing and storage performance in a working memory task performed by children using cochlear implants (CI) and/or hearing aids (HA).
Working memory refers to the mental capacity to simultaneously process and store information. Working memory is considered to be one of three core executive functions [Citation6]. The other core executive functions are inhibitory control and cognitive flexibility. These core executive functions are supported by each other and together they constitute the basis for higher-level executive functions such as reasoning, planning, and organisation [Citation6]. According to Miyake et al. [Citation7] and Lehto et al. [Citation8], core executive functions should be considered separate entities, but these entities are interrelated to some extent. The contradictory relationship has been termed the unity/diversity framework [Citation7,Citation8]. For example, planning a response in goal pursuit requires the use of working memory. Inhibitory control is required to maintain focus on the goal by removing task-irrelevant information which facilitates the process of keeping focus on the goal for working memory [Citation6]. When processing speech signals for comprehension, working memory capacity (WMC) can be considered to be a limited system that is used for processing and storing information [Citation9]. Working memory can, therefore, be thought of as a trade-off system because processing of information requires a high amount of activation, fewer resources will be available for storing information and vice versa. The components in a task that requires both sentence processing and storage of words for later recall are not independent from each other; therefore, the WMC measure reflects the capacity to simultaneously process and store information. One such task is the Competing Language Processing Task (CLPT) [Citation10], which is based on the Reading Span Test [Citation11], and can be used to assess verbal WMC in children. The CLPT consists of true and false statements which the listener should judge as such (i.e. sentence processing). After judging a number of sentences, the listener is required to recall the last words in all sentences (i.e. the combination of processing and storing of information that is the measure of WMC). In the present study, we used the CLPT to measure working memory capacity and the non-verbal Elithorn’s mazes to estimate higher-level executive functioning in children using CI and/or HA.
Speech signals can be degraded in several ways. The signal can be degraded already at the source due to a voice disorder, during transmission due to the presence of background noise or inappropriate reverberation, or due to a hearing loss [Citation5]. A hoarse (dysphonic) voice influences language comprehension negatively in both adults and children with normal hearing in comparison with a typical voice [Citation12–15]. Brännström et al. [Citation16] used a task which examined judgements of semantic acceptability of sentences (sentence processing component) and storage of words for later recall (recall component i.e. the measure of WMC) in children with normal hearing. They found that a dysphonic voice seems to have a negative influence on the sentence processing component but not on the recall component causing disturbed sentence processing [Citation16]. Furthermore, they found that children with lower higher-level executive function were more negatively affected by the dysphonic voice quality than children with stronger higher-level executive function. So far, the effect of a dysphonic voice on the sentence processing component and the recall component is unexplored in children with CI and/or HA. The potential interaction with higher-level executive function also calls for further examination in this population.
In listening conditions degraded by background noise, not only intelligibility may be compromised but also word recall [Citation17,Citation18]. Furthermore, a higher use of WMC seems to be required by both adults and children when listening to speech in noise [Citation17–20] indicating that auditory processing needs to be supported by the individual’s WMC. Osman and Sullivan [Citation20] reported for children with normal hearing that multi-talker babble noise reduced working memory performance in the auditory modality in poorer signal-to-noise ratios. The authors used a similar WMC task as in the present study.
It is most likely that a hearing loss provides additional signal degradation also with the use of HA and/or CI [Citation21–24]. This is supported by the findings that children with a hearing impairment seem to require more favourable signal-to-noise ratios to be able to perform at par with their peers with normal hearing [Citation25,Citation26]. Stiles et al. [Citation27] reported that children with a hearing impairment using HA had similar working memory performance in both quiet and in noise (air conditioning noise presented at a better signal-to-noise ratio than +15 dB) as children with normal hearing. In addition, performance did not deteriorate in noise. It is possible that the signal-to-noise ratio was too favourable to elicit an effect.
The aim of the present study was to examine the influence of voice quality and multi-talker babble noise on processing and storage performance in a working memory task performed by children with CI and/or HA and its relation to higher-level executive function. Based on previous studies, we hypothesise that both sentence processing and recall should be poorer when listening to a dysphonic voice or in background noise. Furthermore, we hypothesise that children with poorer higher-level executive function should be more affected by the dysphonic voice and the presence of background noise.
Methods
Participants
Twenty-four hearing impaired (HI) children fitted with CI and/or HA met the inclusion criteria that were set for participation. The children attended different schools in Sweden and were recruited from the summer camp (n = 10) organised by The Swedish Organisation for Children with Cochlear Implants or Hearing Aids (Barnplantorna) or through contact with the children’s schools (n = 14). To be included, the children had to be between 6 and 13 years old (72–156 months), use their CI or HA regularly and be functional speakers of spoken Swedish (not necessarily native speakers). Ten were tested at the summer camp, and 14 children were tested in a quiet setting in their own schools by the same examiner. All children were tested, but one child did not complete a number of tests and was, therefore, excluded.
The final sample of 23 children consisted of 13 girls and 10 boys aged from 06:03 to 13:00 (years:months) with a mean age of 09:03. Twelve children were CI users (11 bilateral and one unilateral). Eight children were HA users (six bilateral and two unilateral). Three children were bimodal users, i.e. CI on one ear and HA on the other. Three children were enrolled in schools for children with a hearing impairment, whereas 20 children were integrated into typical schools with normal hearing peers. Nineteen were native Swedish speakers, and the remaining four children had other native languages and can be considered as multilingual. Seventeen children had former and eight had ongoing contact with a speech-language pathologist (SLP). A note here is that SLP contact is mandatory in Sweden for these children. Eleven children received special services at school due to their hearing impairment. As seen, the sample was heterogeneous. Written informed consent was obtained from the children’s legal guardians. The study was approved by the Regional Ethics Committee in Lund, Sweden (application 2014/408).
Overall procedures
This article presents the results of hearing-impaired children’s decision of semantic acceptability in sentences and recall of words in a working memory task. The task was performed while using their listening devices as they were set at the clinic and are used during their school day. All children were tested individually in a quiet room with two tests in the same predetermined order: first executive function was assessed using Elithorn’s Mazes [Citation28] and second WMC was assessed with the CLPT [Citation10]. The CLPT was performed in three counterbalanced listening conditions: (1) typical voice in quiet, (2) dysphonic voice in quiet, and (3) typical voice in multi-talker babble noise. For the individual child, the three listening conditions used different sentences from the CLPT. In addition, the sentences were counterbalanced among the children. This study is a part of a larger project on listening comprehension, perceived listening effort and cognitive performance in children with a hearing impairment and children with normal hearing. Therefore, additional tests were made by the children that are not reported on here, and the complete test session lasted for approximately 70 min.
Recording of the typical and dysphonic voices
Two recordings of the Swedish version of CLPT (7, Swedish version, 27) were used. In the recordings, the same female speaker (age 49 years old) once spoke with a typical voice and once with a dysphonic voice. The recordings were made at two different sessions in a sound-treated booth [Citation29]. To provoke the dysphonic voice, the speaker read aloud while trying to make herself heard over a background noise presented at 85 dB SPL (Leq) in quasi-free field [Citation29]. The background noise consisted of the International Speech Test Signal (ISTS; Citation30) that had been duplicated and time-shifted eight times [Citation31]. This procedure generated a non-intelligible multi-talker babble noise that was presented through a Fostex SPA 12 speaker (Fostex Corporation, Tokyo, Japan). After reading aloud in this noise at approximately 90–95 dB SPL for 20 min, the dysphonic voice was recorded without rest or intake of fluid.
The typical and the dysphonic voices were recorded in the following manner. The same multi-talker babble noise (ISTS) was presented at 55 dB SPL (Leq). The speaker was instructed to make herself heard over the noise during both the typical and the dysphonic voice recordings. This resulted in speech levels of approximately 60–65 dB SPL (measured with a head-mounted microphone MKE 2, no 09_1, Sennheiser, en-de.sennheiser.com/). The CLPT sentences were recorded with a Lectret HE-747 microphone connected to a Zoom H2 (Zoom Corporation, Tokyo, Japan). A 44.1 kHz/16-bit sampling frequency was used. Sound presentation levels were verified using a Brüel and Kjaer integrating-averaging sound level meter (type 2240) with an integration time of 60 s. Using Adobe Audition (version 6; Adobe Systems, San José, CA), the recordings of the CLPT sentences were normalised to an equal average root-mean-square dB after removing pauses and other silent sections. After this normalisation procedure, the pauses and other silent sections were re-added.
To assess the voice quality authenticity of the two speaker recordings, three experienced SLPs were asked to judge the recorded voice qualities. The analysis software Visual sort and rate – Visor [Citation32] was used, and the recordings were assessed for hyper-function, breathiness, roughness, instability, and the grade of voice disorder. Together, the SLPs listened to the speech signals through computer loudspeakers at a comfortable listening level followed by a consensus discussion. In their assessment, they rated each parameter on an analogue scale ranging from 0 (no occurrence) to 10 (maximum occurrence), scores equal to or higher than 4 were considered as pathological. The dysphonic voice was assessed 7/10 in hyper-function and the typical 1/10. All the other parameters were assessed to 0/10 for both typical and dysphonic voice. In total, the dysphonic voice was assessed 4/10 and the typical voice 0/10 in grade of voice disorder after final judgements in consensus.
Recording of the multi-talker babble noise for the Competing Language Processing Task
A multi-talker babble noise was recorded for the listening condition with background noise present. The recording and generation of this multi-talker babble noise are described in detail by von Lochow et al. [Citation33]. The multi-talker babble noise consisted of recordings of four girls (aged 9–11 years). The recordings were made individually in a sound-treated booth [Citation34]. Each girl was recorded while reading aloud a separate chapter from an age-appropriate book [Citation35]. The recordings were made using a portable microphone JTS (UT16HW) and a receiver JTS (US800ID) connected to a Zoom H2 (Zoom Corporation, Tokyo, Japan). A 44.1 kHz/16-bit sampling frequency was used. The recordings were normalised to the same average root-mean-square dB after removing all pauses and other silent sections using Adobe Audition (version 6; Adobe Systems, San José, CA). After this normalisation procedure, the pauses and other silent sections were re-added.
Generation and presentation of the listening conditions
Three types of listening conditions were generated from these recordings: the first listening condition consisted of the recording of the typical voice presented in quiet. The second listening condition consisted of the recording of the dysphonic voice presented in quiet. The third listening condition consisted of the recording of the typical voice combined with the recorded multi-talker babble noise. The level of the multi-talker babble noise was 10 dB lower (i.e. +10 dB signal-to-noise ratio) than the average root-mean-square dB of the typical voice.
The listening conditions were presented through a Bose Companion 2 loudspeaker located at the level of the listener’s head at 0-degree azimuth at a distance of approximately 1 meter. The speech signal presentation level was at 70 dB SPL at 1 meter. The presentation level was verified using a Brüel and Kjaer integrating-averaging sound level meter (type 2240). The verification was made using a 1000 Hz tone with an average root-mean-square (dB) equal to the speech signals.
The Competing Language Processing Task (CLPT)
The CLPT is a dual task that assesses the ability to simultaneously process and store verbal information, i.e. a measure of the individual WMC [Citation10]. A sentence-based task was selected rather than a number-based task to achieve a more real-life listening task. This choice was also based on the previous extensive experience of testing children at our lab with this task. In the CLPT, the primary task is to judge the semantic acceptability of short sentences presented in blocks. The CLPT consists of true and false statements such as “Birds can fly” (true) or “Horses drive cars” (false). Thus, the task is to decide whether a statement is true or false. There are 63 statements in total, divided into 18 blocks. Each block contains between one and six statements. After the completion of a block, the secondary task is to recall the last word for each sentence in any order (i.e. free recall). Together, these two tasks constitute a measure of the individual’s WMC [Citation10,Citation11]. The original CLPT consists of 12 blocks. In the present study, six additional blocks were created and added to meet the requirements of the experimental design (each child had to complete the task in three different listening conditions). Six blocks were presented with the typical voice in quiet, six blocks with the dysphonic voice in quiet, and six blocks with the typical voice in multi-talker babble noise. In each listening condition, a list consisted of six blocks. In each block, the number of statements before the completion of the secondary task was between 1 and 6. The three lists and the three listening conditions were counterbalanced across the children using a Latin squares design to remove any order and fatigue effects. The new sentences were not tested to assess whether they yielded similar true/false response rates. Because the lists were counterbalanced across subjects, we expect that this potential effect will be largely removed from the present findings. Indeed, a repeated measures ANOVA showed no main effect of list on children’s sentence processing performance. A score of one [Citation1] was awarded for correct judgements of semantic acceptability. No direct control was made regarding the difficulty level of the sentences used in the three listening conditions. However, the counterbalancing of the sentence presentation order among children should account for any differences. A score of one [Citation1] was awarded each correctly recalled word. Hence, the maximum list score for both semantic acceptability and recall was 21. Before the actual testing, the children made two practice blocks with the typical voice in quiet consisting of two statements each to familiarise themselves with the task.
Elithorn’s mazes
The children’s higher-level executive function was assessed with Elithorn’s mazes [Citation28]. This test assesses the individual ability to plan, organise, and process information in the visual modality. It was selected based on our previous experience testing higher-level executive function in children with the present age range. It was also selected to have a complex cognitive task that relies on all stipulated entities in the unity/diversity framework and does not heavily rely on language skills to relate performance on a sentence based task (i.e. CLPT). The task is to find the way out of a printed maze by connecting dots located within the maze using a pen. The test is time-limited and the maximum allowed time is 120 s. Seven mazes are presented one at a time. The maze complexity increases every time a new maze is presented. If the child cannot complete the maze the first time, a second trial is made. A score of four [Citation4] is awarded for each correctly completed maze. Shorter time to complete each maze results in a time bonus awarded a score of 4 for each maze. Hence, the maximum score for the complete test is 56. Initially, two practice mazes were completed to allow for familiarisation with the task.
Statistical analysis
All statistical analyses were performed using SPSS (Statistical Package for the Social Sciences, IBM SPSS Statistics 24, Armonk, NY). All p-values are evaluated at an alpha-level of .05. Multiple tests were corrected using Bonferroni correction. Parametric statistics were used because the distribution in most variables did not differ significantly from the normal distribution as assessed using one-sample Kolgomorov-Smirnov tests. Pearson’s correlation coefficients were used to assess relationships between variables. Two repeated measures analyses of variance (RMANOVA) were used to assess the effect of listening condition, one for semantic acceptability and one for recall in the working memory task (CLPT).
Results
The results reported are semantic acceptability in the different listening conditions, recall in the different listening conditions, and executive function. First, Pearson’s correlation coefficients were calculated between age and semantic acceptability (judgements whether sentences are true or false, i.e. sentence processing) in the different listening conditions, recall (recall the last words in all sentences, i.e. the combination of processing and storing of information—the measure of WMC) in the different listening conditions, and executive function. As no significant relationships were seen between age and any other variable (r ≤ ± 0.363, p ≥ .089), age was excluded as a covariate in the following analyses [Citation36].
A first RMANOVA was conducted to test the effect of listening condition (quiet/typical voice, quiet/dysphonic voice, and multi-talker babble noise/typical voice) on judgements of semantic acceptability. Executive function was added as a covariate. The mean and standard deviations are shown in . No significant effect was seen for listening condition (Wilk’s Lambda = 0.743, F[2,23] = 3.456, p = .051, η2 = 0.257). No interaction effect was seen. The findings show that semantic acceptability was not significantly affected by listening condition, and that performance was not related to executive function.
Figure 1. The mean and standard deviations in the three listening conditions for the sentence processing component (N = 23).
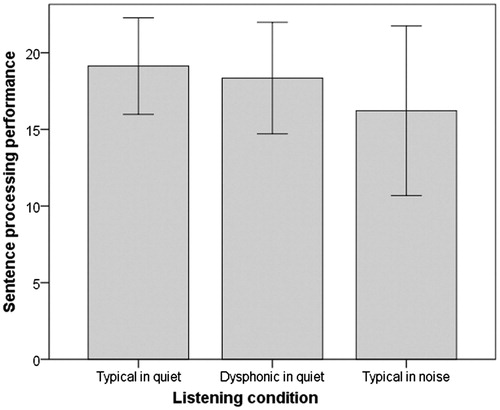
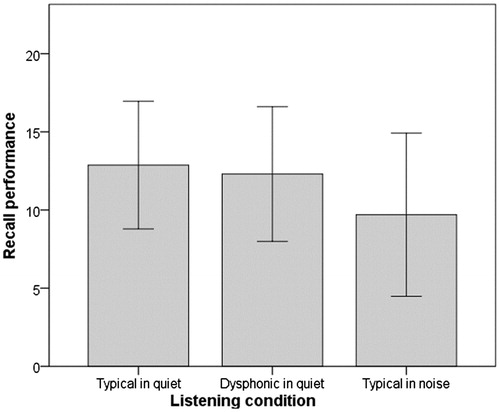
A second RMANOVA was used to test the effect of listening condition (quiet/typical voice, quiet/dysphonic voice, and multi-talker babble noise/typical voice) on recall, our measure of WMC. Executive function was as before added as a covariate. In addition, because the effect in the previous RMANOVA was close to the selected alpha level (0.05), semantic acceptability scores in the three listening conditions were first summed and then added as a second covariate to account for the potential influence of audibility on recall. The mean and standard deviations are shown in . A significant effect was seen for listening condition (Wilk’s Lambda = 0.629, F[2,23] = 5.594, p = .012, η2 = 0.371). No interaction effects were seen. The Bonferroni corrected post-hoc analysis showed that recall was significantly poorer for the listening condition with typical voice and multi-talker babble noise compared to both the typical voice in quiet (p = .004) and the dysphonic voice in quiet (p = .027). The listening conditions with the typical voice in quiet and the dysphonic voice in quiet were not significantly different (p = .908). This finding showed that multi-talker babble noise reduced recall and that the recall was most likely unaffected by audibility and executive function.
Figure 2. The mean and standard deviations in the three listening conditions for the recall component, i.e. the measure of WMC (N = 23).
Discussion
The present study examined the influence of voice quality and multi-talker babble noise on processing and storage performance in a working memory task performed by children with CI and/or HA. The findings show that the recall component is affected by background noise but not by voice quality. The findings also suggest that higher-level executive functioning is not a mediating factor and that audibility most likely have not influenced the results. We found no relationship between age and any of the variables.
Initially, we hypothesised that both sentence processing and recall (the measure of WMC) should be poorer when listening to a dysphonic voice. The sentence processing deterioration was mainly expected from the findings by Brännström et al. [Citation16], who used the same task and found that performance on the sentence processing component deteriorated slightly but significantly when listening to a dysphonic voice in quiet compared to a typical voice in quiet in children with normal hearing. The hypothesised reduction of recall due to the dysphonic voice was based on the assumption that higher activation of the processing component would lessen capacity to store information for later recall [Citation9]. However, the present findings were in contrast to these hypotheses because the findings showed a trend but no significant difference between performance listening to the typical voice in quiet and the dysphonic voice in quiet in neither the sentence processing component nor the recall component of the CLPT. Previous studies indicate that the influence of a dysphonic voice quality on performance in different listening tasks is dependent on task level difficulty [Citation13–15]. Therefore, the present task may provide a task level difficulty that makes it hard to discern any direct effects of a dysphonic voice. It is also possible that the typical voice is already perceived as degraded in children with CI and/or HA. The use of listening devices does not restore hearing to normal. Listening devices may also induce their own speech signal degradation due to signal processing and frequency range. Therefore, the children may not have perceived any differences among the two voice qualities. Furthermore, it may be that the dysphonic voice did not provide a sufficient signal degradation to be discerned by children with CI and/or HA. The provoked dysphonic voice may not have been sufficiently degraded and challenging although it was assessed as a voice disorder grade 4 of 10 by the SLPs. Future studies need to address these issues.
We also hypothesised that performance in both the sentence processing component and the recall component, i.e. the measure of individual WMC, should be poorer when listening to a typical voice in multi-talker babble noise compared to when listening to a typical voice in quiet. This was based on previous findings showing that when listening to speech in noise auditory processing needs to be supported by the individual’s WMC [Citation17–20]. In particular, Osman and Sullivan [Citation20] showed that multi-talker babble noise impaired working memory performance in the auditory modality in poorer signal-to-noise ratios in children with normal hearing. The present findings in children using CI and/or HA lend support to these previous studies. However, the present findings are in contrast to those of Stiles et al. [Citation27] who did not find that working memory performance assessed as backward digit span decreased in air conditioning noise. The differences in findings may be due to the even more favourable signal-to-noise ratio in that study (more than +15 dB) than in the present study (+10 dB).
We found that multi-talker babble noise reduced working memory performance directly and significantly in an online task. This suggests that in a classroom situation with background noise generated by other children, these children with CI and/or HA will have to allocate more WMC to process the incoming signal leaving fewer resources to understand and encode information into long-term representations, which is the basis for learning. To listen, understand and retain verbal information in the classroom is central to learning. If this occurs in background noise, auditory processing will affect working memory performance [Citation1–2]. This will, in turn, lead to fewer resources available to understand and to retain this information. In addition, if the listening becomes too effortful, it is possible that listener motivation drops which in turn affects what is actually perceived by the child [Citation4]. Mainstreaming of children with a hearing impairment into regular classes with peers with normal hearing is common. In Australia, about 83% of the children with a hearing impairment are enrolled in mainstream schools [Citation37]. In Sweden today, the corresponding proportion is about 85% of approximately 10,000 children with a hearing impairment [Statens offentliga utredningar (SOU)] [Citation38]. Only between 10% and 15% of these enter higher education. The corresponding number is about 45% for children with normal hearing (http://www.hrf.se). The present findings suggest that more cognitive resources seem to be required for understanding and learning in children with a hearing impairment. Hence, it is possible that the degraded listening environment in schools today is contributing to the low number of children with a hearing impairment seen in higher education.
The present findings suggest that higher-level executive function is not related to performance in the processing component or the recall component. It is possible that the sample size was too small to discern any relationship. Brännström et al. [Citation16] found a relationship between higher-level executive function and the effect of the dysphonic voice in the processing component for children with normal hearing. It is probable that the lack of association has to do with the fact that higher-level executive functioning is based on the combined processing of three core executive functions. The working memory component in the present executive function task may have had less importance for these children’s performance than inhibitory control and cognitive flexibility. It is, therefore, possible that the sample size was not sufficient to assess this potential relationship in the present population. It could also be that online measures cannot be compared with a measure of higher-level executive function assessed offline. Therefore, assessments of WMC and high-level executive function when listening to a dysphonic voice in quiet or a typical voice in noise may better demonstrate this relationship. Future studies are, however, required.
Study limitations and future directions
In the present study, 23 children with a hearing impairment were tested. The sample was relatively large in comparison with previous Swedish studies [Citation39] and shows similar heterogeneity in many aspects (e.g. age and listening devices). Audibility is always an issue when testing children with a hearing impairment with or without the use of listening devices. We did not directly control for this in the present study. However, because the sentence processing component was not affected by listening condition, it suggests that audibility was not driving the present findings. Furthermore, a favourable signal-to-noise ratio of +10 dB was used to minimise the risk of spectral overlap between the speech signal and the multi-talker babble noise. It is still possible that some amount of overlap occurred. We recognise that there are several additional factors that we failed to control for in this study. It is possible that the time of the hearing impairment onset, identification, and fitting of listening devices along with the type of listening devices, their fitting accuracy, and noise reduction algorithms have influenced the present findings. To reduce the potential influences of these factors, a within-subject design was used where each child is compared with him-/herself. In addition, we argue that the present findings provide an insight into how actual performance is for these children irrespective of listening devices and signal processing. Thus, this present data show how these children actually perform with degraded signals on these types of tasks with their different listening devices. However, future studies need to directly collect and control for these factors’ influence on the studied parameters.
Conclusions
Multi-talker babble noise at a favourable +10 dB signal-to-noise ratio but not a dysphonic voice quality in quiet seems to hamper performance on a working memory task in children using CI and/or HA.
| Abbreviations | ||
| CLPT | = | competing language processing task |
| ISTS | = | international speech test signal |
| SLP | = | speech and language pathologists |
| WMC | = | working memory capacity |
Acknowledgments
The authors thank the participating children, the Swedish Organisation for Children with Cochlear Implants or Hearing Aids (Barnplantorna), and the staff at the participating schools.
Disclosure statement
The authors report no conflicts of interest. The authors alone are responsible for the content and writing of the article.
Additional information
Funding
Notes on contributors
K. Jonas Brännström
K. Jonas Brännström is an associate professor in audiology and a licenced audiologist, Department of Clinical Science Lund, Lund University, Lund, Sweden.
Heike von Lochow
Heike von Lochow, MSc in audiology, is a licenced audiologist, Department of Clinical Science Lund, Lund University, Lund, Sweden.
Viveka Lyberg-Åhlander
Viveka Lyberg-Åhlander is an associate professor in speech and language pathology and licenced speech and language pathologist, Department of Clinical Science Lund, Lund University, Lund, Sweden.
Birgitta Sahlén
Birgitta Sahlén is a full professor in speech and language pathology and a licenced speech and language pathologist, Department of Clinical Science Lund, Lund University, Lund, Sweden.
References
- Rönnberg J. Cognition in the hearing impaired and deaf as a bridge between signal and dialogue: a framework and a model. Int J Audiol. 2003;42:S68–S76.
- Rönnberg J, Lunner T, Zekveld A, et al. The Ease of Language Understanding (ELU) model: theoretical, empirical, and clinical advances. Front Syst Neurosci. 2013;7:31.
- Rönnberg J, Rudner M, Foo C, et al. Cognition counts: a working memory system for ease of language understanding (ELU). Int J Audiol. 2008;47:S99–S105.
- Pichora-Fuller MK, Kramer SE, Eckert MA, et al. Hearing impairment and cognitive energy: the framework for understanding effortful listening (FUEL). Ear Hear. 2016;37:5S–27S.
- Mattys SL, Davis MH, Bradlow AR, et al. Speech recognition in adverse conditions: a review. Lang Cognitive Proc. 2012;27:953–978.
- Diamond A. Executive functions. Annu Rev Psychol. 2013;64:135–168.
- Miyake A, Friedman NP, Emerson MJ, et al. The unity and diversity of executive functions and their contributions to complex “Frontal Lobe” tasks: a latent variable analysis. Cogn Psychol. 2000;41:49–100.
- Lehto JE, Juujärvi P, Kooistra L, et al. Dimensions of executive functioning: evidence from children. Br J Develop Psychol. 2003;21:59–80.
- Just MA, Carpenter PA. A capacity theory of comprehension: individual differences in working memory. Psychol Rev. 1992;99:122–149.
- Gaulin C, Campbell T. Procedure for assessing verbal working memory in normal school-age children: some preliminary data. Percept Mot Skills. 1994;79:55–64.
- Daneman M, Carpenter AC. Individual differences in working memory and reading. J Verb Learning Verb Behav. 1980;19:450–466.
- Rogerson J, Dodd B. Is there an effect of dysphonic teachers’ voices on children’s processing of spoken language? J Voice. 2005;19:47–60.
- Lyberg Åhlander V, Brännström KJ, Sahlén BS. On the interaction of speakers’ voice quality, ambient noise and task complexity with children's listening comprehension and cognition. Front Psychol. 2015;6:871.
- Lyberg Åhlander V, Haake M, Brännström J, et al. Does the speaker’s voice quality influence children's performance on a language comprehension test?. Int J Speech Lang Pathol. 2015;17:63–73.
- Lyberg Åhlander V, Holm L, Kastberg T, et al. Are children with stronger cognitive capacity more or less disturbed by classroom noise and dysphonic teachers? Int J Speech Lang Pathol. 2015;17:1–12. [Epub ahead of print]. doi: 10.3109/17549507.2015.1024172.
- Brännström KJ, Kastberg T, von Lochow H, et al. The influence of voice quality on sentence processing and recall performance in school-age children with normal hearing. Speech Lang Hear. 2018;21:1–9.
- Hygge S, Kjellberg A, Nostl A. Speech intelligibility and recall of first and second language words heard at different signal-to-noise ratios. Front Psychol. 2015;6:1390.
- Pichora-Fuller MK, Schneider BA, Daneman M. How young and old adults listen to and remember speech in noise. J Acoust Soc Am. 1995;97:593–608.
- Rönnberg J, Rudner M, Lunner T, et al. When cognition kicks in: working memory and speech understanding in noise. Noise Health. 2010;12:263–269.
- Osman H, Sullivan JR. Children’s auditory working memory performance in degraded listening conditions. J Speech Lang Hear Res. 2014;57:1503–1511.
- Moore BC. Perceptual consequences of cochlear hearing loss and their implications for the design of hearing aids. Ear Hear. 1996;17:133–161.
- Moore BC. Dead regions in the cochlea: conceptual foundations, diagnosis, and clinical applications. Ear Hear. 2004;25:98–116.
- Moore BC. The role of temporal fine structure processing in pitch perception, masking, and speech perception for normal-hearing and hearing-impaired people. JARO. 2008;9:399–406.
- Moore BC, Glasberg B, Schlueter A. Detection of dead regions in the cochlea: relevance for combined electric and acoustic stimulation. Adv Otorhinolaryngol. 2010;67:43–50.
- Crandell CC, Smaldino JJ. Classroom acoustics for children with normal hearing and with hearing impairment. Lang Speech Hear Serv Sch. 2000;31:362–370.
- Leibold LJ, Hillock-Dunn A, Duncan N, et al. Influence of hearing loss on children’s identification of spondee words in a speech-shaped noise or a two-talker masker. Ear Hear. 2013;34:575–584.
- Stiles DJ, McGregor KK, Bentler RA. Vocabulary and working memory in children fit with hearing aids. J Speech Lang Hear Res. 2012;55:154–167.
- Wechsler D. WISC-IV integrated. Wechsler intelligence scale for children – Fourth edition – Integrated [Manual]. London: Pearson Assessment; 2004.
- ISO. ISO 8253-1. Acoustics: Audiometric test methods part 1: basic pure tone air and bone conduction threshold audiometry. International Organization for Standardization 8253-1. 1998.
- Holube I, Fredelake S, Vlaming M, et al. Development and analysis of an International Speech Test Signal (ISTS). Int J Audiol. 2010;49:891–903.
- Brännström KJ, Holm L, Lyberg Åhlander V, et al. Children’s subjective ratings and opinions of typical and dysphonic voice after performing a language comprehension task in background noise. J Voice. 2015;29:624–630.
- TolvanData. Visual sort and rate - Visor. Elektronisk källa från http://www.tolvan.com/index.php?page=/visor/visor.php, 2014.
- von Lochow H, Lyberg Åhlander V, Sahlén B, et al. The effect of voice quality and competing speakers in a passage comprehension task: performance in relation to cognitive functioning in children with normal hearing. Logoped Phoniatr Vocol. 2018;43:11–19
- ISO. ISO 8253-3. Acoustics: Audiometric test methods part 3: Speech audiometry. International Organization for Standardization 8253-3;1996.
- Thorwall K. Godnattsagor om Anders, nästan 4. Stockholm: Rabén & Sjögren; 1974.
- Tabachnick BG, Fidell LS. Using multivariate statistics. 6th ed. Boston: Pearson Education; 2013.
- Komesaroff L, Komersaroff PA, Hyde M. Ethical issues in cochlear implantation. In: Clausen J, Levy N, editors. Handbook of Neuroethics. Dordrecht: Springer; 2014; p. 815–26.
- 2016:46 S. Coordination, responsibility and communication – the road to increased quality for students with disabilities. Stockholm: Swedish Ministry of Education; 2016.
- Ibertsson T. Cognition and communication in children/adolescents with cochlear implant. Lund: Lund University; 2009.