
Abstract
Purpose
Cochlear implant (CI) recipients struggle to hear in competing background noise. ForwardFocus is a spatial noise reduction setting from Cochlear Ltd. (Sydney) that can simultaneously attenuate noise from multiple sources behind the listener. This study assessed hearing performance with ForwardFocus in an off-the-ear (OTE) sound processor.
Method
Twenty-two experienced adult CI recipients participated. Speech reception data was collected in fixed noise acutely in the clinic. After three to five weeks take home experience, subjective impressions were recorded, and evaluations were conducted for speech reception in quiet and roving noise.
Results
Group mean speech reception thresholds (SRT) were below 0 dB in two spatially-separated noise test conditions when using ForwardFocus in the OTE sound processor. SRT were −8.5 dB (SD 2.9) in 4-talker babble roving in a rear hemi-field (S0Nrearhemi) and −3.9 dB (SD 3.3) in 12-talker babble presented laterally and behind (S0N3). Results in S0N3 were significantly better with ForwardFocus On (p = 0.0018). Subjective ratings with the OTE were comparable to, or better than, with their walk-in BTE or OTE sound processor.
Conclusions
ForwardFocus provides significant benefits for speech recognition in competing background noise in an OTE sound processor. These results support clinicians in counselling CI recipients on potential sound processor options to consider.
Introduction
A cochlear implant (CI) is an implanted hearing device suitable for adults with moderately severe to profound sensorineural hearing loss in the ear to be implanted. It consists of an electrode array inserted into the cochlea, a receiver stimulator located in the mastoid bone and a speech processing device with microphone, which is normally externally worn. Sound processors are often compatible with multiple receiver stimulator and electrode types (from the same manufacturer) and provide an opportunity for CI recipients to receive a technology upgrade without the need for further surgery.
Multiple studies have shown that an upgrade to the sound processor can provide improved speech recognition performance and subjectively reported hearing benefits and access to improved sound-processing capabilities, microphone technology and aesthetics as part of ongoing technology developments (Biever et al., Citation2018; de Ceulaer et al., Citation2015; Dixon et al., Citation2019; Mauger et al., Citation2014; Mosnier et al., Citation2014, Citation2021; Seebens and Diller, Citation2012; Todorov and Galvin, Citation2018; Warren et al., Citation2019).
Variability in hearing performance is observed across CI recipients with understanding speech in competing noise especially challenging for many (Dorman and Gifford, Citation2017; Spahr et al., Citation2007). It is well known that hearing ability and speech recognition degrades with an increase in number of noise sources, the diffusiveness of the noise field and with increased reverberation (van Hoesel and Clark, Citation1995). Directional microphone technologies are provided in more recent sound processors using dual microphones to produce directional algorithms (Dillier and Lai, Citation2015; Hey et al., Citation2019; Mosnier et al., Citation2017; Wolfe et al., Citation2012). These have demonstrated significant improvements for speech recognition in co-located and spatially-separated speech in noise test conditions (Dillier and Lai, Citation2015; Hey et al., Citation2019; Mosnier et al., Citation2017; Wolfe et al., Citation2012).
In addition to directional microphones, overall hearing is improved with access to wireless streaming capabilities and sound processor control via smartphone apps (Warren et al., Citation2019).
Historically, in 1985, the very first wearable sound processor (WSP), a body-worn device, was commercially released by Cochlear LTD Sydney, Australia (Beiter and Nel, Citation2015). A few years later, they released the behind the ear (BTE) sound processor as a more convenient wearer option for many CI recipients (Beiter and Nel, Citation2015). In the last decade, cochlear implant manufacturers have evolved their sound processors further to provide off the ear (OTE) wearer options. These provide the potential for additional wearer convenience relative to the BTE for some participants, pending their lifestyle needs and or use of headwear, whilst continuing to provide adequate hearing performance (Mauger et al., Citation2017; Wimmer et al., Citation2015). The sound processor format may influence the position of the sound processor microphone(s) and hearing benefits obtained. Pending surgical preference for placement of the internal implant of the CI system, some of the inherent physical head shadow benefits provided by the head and pinna may be affected with the sound processor in place. The final location of a single microphone may result in reduced sensitivity to sounds from in front and increased sensitivity to sounds from behind (Flynn et al., Citation2011; Wimmer et al., Citation2015). Directional microphones and directional sound processing algorithms can overcome some of the disadvantages of position of a single microphone potentially experienced in an OTE sound processor, even when positioned more towards the rear of the head (Flynn et al., Citation2011, Citation2012; Mauger et al., Citation2017). However, some limitations for highly directional microphone settings in OTE devices may still be observed (Mauger et al., Citation2017). Researchers have observed that in daily life, CI recipients subjectively reported comparable hearing benefits with OTE sound processors compared to BTE sound processors, while they reported improved wearer comfort with the OTE format (Godey et al., Citation2020; Mauger et al., Citation2017). Furthermore, OTE sound processors were preferred by the majority of participants for lifestyle needs, specifically: wearing glasses or headwear, in the working place, at home, and at social gatherings (Godey et al., Citation2020; Mauger et al., Citation2017). Preference for an OTE versus a BTE sound processor format may also be influenced by retention factors during daily activities, which is thus an important consideration during counselling for choice of sound processor format (Godey et al., Citation2020; Mauger et al., Citation2017).
The CochlearTM Nucleus® 7 Sound Processor (Cochlear Ltd, Sydney, Australia), a BTE sound processor, included a range of established pre-processing technologies, such as ADRO (adaptive dynamic range optimisation), SNR-NR (SNR-based Noise Reduction), WNR (wind noise reduction) and automatic scene classification (SCAN) and the Beam® and zoom dual microphone directional technologies (Hersbach et al., Citation2012; Hey et al., Citation2021; Mauger et al., Citation2014; Warren et al., Citation2019). Beam® is an adaptive dual microphone technology which adaptively steers its point of maximum attenuation, called the null point, towards the dominant noise source in the environment while facing the targeted speaker’s voice (Mauger et al., Citation2014). Zoom is a fixed highly directional microphone technology that uses a consistent null point of ±120° azimuth to provide an optimal directivity index for the listener facing the targeted speaker’s voice (Wolfe et al., Citation2012).
In addition, it newly introduced wireless functionality to accessories and audio sources and a new spatial noise reduction setting called ForwardFocus (Hey et al., Citation2019, Citation2021; Warren et al., Citation2019). ForwardFocus is designed to attenuate multiple noise sources simultaneously arriving from different locations (i.e. spatially separated) behind the listener, including from the sides and directly behind.
In contrast, adaptive and fixed directional microphone technologies, such as Beam and zoom respectively, have a null point that aims to suppress noise levels from a single noise source at any given time, while preserving the level of the desired speech signal in front of the listener. These algorithms effectively create a more favourable signal to noise ratio (SNR) and enable potential improvement in speech recognition ability in competing background noise conditions for the CI recipient over listening without implementing noise reduction algorithms (Mauger et al., Citation2014; Warren et al., Citation2019; Wolfe et al., Citation2012).
ForwardFocus is a clinician enabled, user-controlled technology, recommended for use in noisy environments where the listener is facing the targeted speaker’s voice and multiple, dynamic noise sources are located in the rear hemisphere. When enabled, to attenuate multiple noise sources roving from behind, it is used in combination with fixed directional microphone technology. It has been shown to significantly improve performance in these challenging dynamic noise environments when compared to the adaptive directional dual microphone technology, Beam (Hey et al., Citation2019, Citation2021). In spatially-separated noise, with multiple fixed noise source locations, (90°,180°, 270° (S0N3)), Hey et al. (Citation2019) reported a significant group mean benefit for speech reception thresholds (SRT50%) of 5.8 dB compared to adaptive Beam, using an implementation of ForwardFocus on a research speech processor (Hey et al., Citation2019). Hey et al. (Citation2021) reported statistically significant group mean benefits for SRT50% in co-located speech in noise (S0N0) when using ForwardFocus enabled in the Cochlear Nucleus 7 sound processor of 1.7 dB to 2.8 dB compared to using adaptive Beam in earlier generations of Nucleus sound processors (Hey et al., Citation2021). The use of ForwardFocus as implemented in the Nucleus 7 sound processor is not typically recommended in quiet listening conditions (Hey et al., Citation2019).
The latest version of the OTE ear sound processor, the CochlearTM Nucleus® Kanso 2 sound processor, offers ForwardFocus, which is not available in the earlier CochlearTM Nucleus® Kanso sound processor. The Kanso 2 sound processor includes all of the same sound processing technology and connectivity features that are available in the Nucleus 7 sound processor, while it differs obviously in BTE device format.
The main objective of the study was to clinically assess the functionality of the Kanso 2 sound processor with ForwardFocus enabled versus ForwardFocus disabled by comparing outcomes for speech recognition in noise from multiple sources. A secondary objective was to compare speech recognition in quiet at conversational and soft speech levels in the Kanso 2 sound processor with ForwardFocus off versus the earlier Kanso to confirm no degradation of hearing performance in quiet had been introduced. In addition, after take home trial, a subjective assessment was made of the acceptance of the Kanso 2 sound processor when ForwardFocus was enabled and used by the participant as needed. Finally, speech recognition in noise using roving multiple noise sources located in a rear hemi-field, to further simulate challenging real-world listening conditions, was compared for ForwardFocus enabled in the Kanso 2 sound processor and ForwardFocus enabled in the Nucleus 7 sound processor.
Methods
Participants
Twenty-two adults with a postlingual onset of severe to profound hearing loss, aged 18 years or older with at least three months experience with a compatible cochlear implant (CochlearTM Nucleus® CI500 series or a CochlearTM Nucleus® 24 cochlear implant system) with the Kanso 2 sound processor were enrolled. Participants were approached and recruited via email from Cochlear’s existing research CI recipient pool and via local implant centres. Participants who met the inclusion criteria were enrolled voluntarily based on their willingness and availability to participate. Hearing performance was not used as a criterion for enrolment. All participants signed an informed consent prior to their active participation in the study.
Ages ranged from 36–88 years with a mean of 61.0 years (SD, 12) with 14 females and 8 males. The average age for first cochlear implant surgery was 52 years (SD,15) for the left ear and 51 years (SD,13) for the right ear. The age at first implant in either ear ranged from 26–85 years. The average age of severe high-frequency hearing loss in either ear was self-reported by participants to be 39 years old (SD, 21), range 0–76 years. Thirteen subjects had an acquired progressive loss in at least one ear, three had a sudden loss in both ears and six subjects had some degree of congenital hearing loss. Whilst the onset of hearing loss may have been pre-lingual for these subjects, they were suitable for inclusion given their development of speech and language.
One subject reported a mixed loss on the hearing history form, all others reported a sensorineural hearing loss. Fifteen subjects had bilateral implants, seven had unilateral implants, three of these wore a contralateral hearing aid for bimodal stimulation. The unilateral CI users had a profound loss in the contralateral ear. The three contralateral hearing aid users had mild to moderate (two subjects) and a severe hearing loss (one subject) in the hearing aided ear. The walk-in sound processors and hearing configurations are outlined in .
Table 1 Walk in sound processor configuration for study cohort
Ethics approval was obtained from Bellberry Human Research Ethics Committee, Bellberry Limited, 129 Glen Osmond Road, Eastwood, South Australia 5063. The study is registered publicly via Australia and New Zealand Clinical Trials Registry: ACTRN12619000666123.
Speech perception testing
Testing in quiet and in noise was carried out according to the schedule in .
Table 2. Speech perception testing schedule at the first appointment in the clinic and after 3–5 weeks take home experience with the Kanso 2 sound processor.
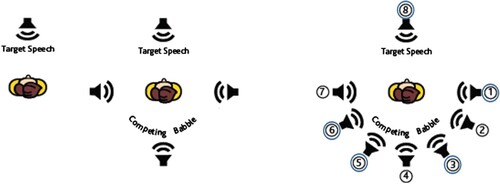
Adaptive speech perception test in noise was conducted using two lists of the Australian Speech Test In Noise (AuSTIN) (Dawson et al., Citation2013). Speech was presented at 65 dB SPL at 0° azimuth with the 4-talker babble noise level presented from the two speaker configurations: speech signal from the front and 4-talker babble noise from three fixed speaker locations (i.e. 12-talker babble), from both sides and rear (S0N3) and speech from the front and 4-independent talkers presented from four dynamic speaker locations roving across seven speakers in the rear hemi-field (S0Nrearhemi) (). The noise level was adjusted until the recipient correctly identified 50% of the words in a sentence and the signal to noise ratio recorded (SRT50%). An average score was recorded for two sentence test lists. A practice list was administered at the beginning of the test session to minimise learning effects of the test material and test situation. In the S0N3 test condition, 4-talker babble was presented at fixed locations, 90°,180° and 270° simultaneously (i.e. 12-talker babble). In the S0Nrearhemi condition, four independent, interfering talkers were presented from four locations simultaneously, randomly chosen from seven speakers between 90° and 270° in a rear hemi-field (). The noise locations remained fixed for the duration of each sentence and changed two seconds before the next sentence was presented (at the same time as the noise level changed).
Figure 1 Test set up with loudspeaker locations. Left figure shows testing for the speech signal in quiet from the front (S0); Middle figure shows the speech signal from the front and 4-talker babble noise from 3 speakers (i.e. 12-talker babble), from both sides and rear (S0N3). Right figure shows the speech from thefront and 4-independent talkers presented from four locations (e.g. from speakers 1,3,5 and 6 shown) roving across 7-speakers in the rear hemi-field (S0Nrearhemi).
Speech perception in quiet was presented from in front (S0) and carried out using a consonant-nucleus-consonant (CNC) monosyllabic word test at 50 dB SPL to represent soft speech and 60 dB SPL to represent conversational level speech using two lists of 50 words per condition (Peterson and Lehiste, Citation1962).
The order of testing of sound processors and test conditions was counter-balanced according to subject number (i.e. odd, and even) to minimise sequence effects.
Noise signals and recorded speech stimuli were played back with no lead time using Matlab at a sampling rate of 44.1 kHz and 32-bit (floating point) bit depth. The signals were generated with a RME Fireface UFX sound card and speech and noise played through speakers positioned at one metre from the subject at head height when in a seated position in an immovable chair. No specific instructions were given on head movement. Sound field calibration of the Average Sound Level (Leq) was performed prior to each test session using a sound level metre using a dB A-weighting (dBA), slow-time weighting. The sound-room equipment was calibrated such that the reference signal was accurate at ear level of a participant seated on the chair. The speech recognition tests were carried out in sound-treated rooms as per ANSI standard S3.1 (2018) and complied with the maximum permissible noise levels stipulated by ISO 8253-2:2009 standard.
Subjective evaluations
Subjective evaluations of the Kanso 2 were assessed using The Sound Processor Experience Questionnaire, which is a non-standardised custom questionnaire. This consisted of five questions where participants were asked to provide ratings to each question in relation to using the Kanso 2 sound processor compared to their own walk-in sound processor in their daily listening configuration. The questions were as follows: 1. Do you feel more or less self-confident? 2. Have you found it easier or harder to deal with conversations in group situations? 3. Do you feel more or less self-conscious? 4. Do you feel better or worse about yourself? 5. Are you more or less inconvenienced by your hearing loss? Participants were asked to select their ratings from a 5-point Likert scale with descriptive ratings ranging from either: much better to much worse or much more to much less.
A custom self-report questionnaire documenting the use of ForwardFocus during the take home period was also included. Situational hearing ability was explored for: conversation with one or two people, kitchen activity, dinner party or restaurant with four or more people, attending church or a lecture.
Procedures
Visit 1
At the initial visit, the ForwardFocus settings were enabled on the Kanso 2 sound processor and participants were tested in the acute condition with ForwardFocus On and ForwardFocus Off with speech and noise from the front. All subjects were tested in the unilateral condition. Bilateral subjects chose their preferred ear for testing, or the first ear was used if there was no preference. Participants’ contralateral ear was blocked using a 3M foam earplug with a reported noise reduction rating of 33dB. There was no randomisation. However, different treatment sequences were assigned to subjects according to their study sequence number (odd/even numbers) so that half of the subjects could be tested with one condition first (for example ForwardFocus On) and the other half could be tested in the other condition (ForwardFocus Off). An AB/BA crossover design was used where A is the treatment and B the control. Subjects were blinded to the use of ForwardFocus during the testing.
Take home trial
During a 3–5 week take home trial of subjects used the study Kanso 2 sound processor with the option to enable ForwardFocus as desired. Participants were asked to provide subjective usability feedback on the Kanso 2 Sound processor via the custom self-report questionnaire. Bilaterally implanted participants were provided with two study Kanso 2 Sound processors for take home trial. All participants were instructed when ForwardFocus would be beneficial and requested to use it as desired for daily listening. No data logging files were collected.
Visit 2
Participants returned to the clinic and were tested in quiet, without ForwardFocus, with the Kanso and Kanso 2 sound processors in the unilateral CI condition as before, with bilateral CI users choosing their preferred ear. The contralateral ear was blocked.
Subjects were then fitted with a study Nucleus 7 sound processor and were tested acutely with the Kanso 2 and Nucleus 7 sound processors with ForwardFocus on in the S0Nrearhemi noise condition. In this condition, bilateral cochlear implant recipients used bilateral sound processors to better represent their daily listening condition. All other subjects were tested unilaterally with the contralateral ear plugged as before.
Different treatment sequences for each sound processor type, based on odd and even subject number and an AB/BA testing sequence, were used as before.
Subjects completed the Sound Processor Experience Questionnaire at the end of the study. All study Kanso 2 sound processors were returned at the end of the study.
Device programming
All devices were programmed using Custom Sound® Pro software (Cochlear LTD., Sydney Australia). The subject’s MAP(s) from their own sound processor was saved in their individual Custom Sound Pro software file and their preferred programmes were written to the study Nucleus 7 and Kanso 2 sound processors used specifically for the study. No changes to T and C levels were made. For speech testing in noise, fixed directionality via zoom, SNR-NR (SNR-based Noise Reduction) and WNR (wind noise reduction) were enabled, and participants used their preferred noise MAP fitted with ADRO (adaptive dynamic range optimisation) and ASC (auto sensitivity control) setting as typically used. Preferred settings and parameters were kept constant for each subject across all test conditions. For speech testing in quiet, standard microphone directionality was used via the SCAN automatic scene analysis programme.
The ForwardFocus setting was enabled in the software to allow the subject to access this feature via the Nucleus Smart App.
Statistics
A minimum of 17 participants was required from a sample size calculation with a clinically important critical difference set at 1 dB for the speech reception threshold (SRT50%) for sentences in noise (based on clinical consensus) for the primary end point (significance level α = 0.05 (two tailed), power of 0.8). Twenty-two participants were enrolled to allow for potential subject withdrawals. Participants with missing paired data were excluded from the analysis. Two lists of sentences were measured per sound processor condition, and the two dB SRT values were averaged to produce a single value per test condition, per subject.
The null hypothesis for the primary objective tested was:
H0: SRT obtained using fixed 4-talker babble noise with the Kanso 2 sound processor with ForwardFocus On (treatment) will be equal to or inferior when compared to the Kanso 2 sound processor with ForwardFocus Off (control).
A non-inferiority margin of 1 dB signal to noise ratio (SNR), based on clinical consensus, was set for the primary objective. If the upper limit of the 95% CI (alpha = 0.025 one-sided) of the mean paired difference of treatment vs control was lower than non-inferiority margin, the treatment condition was regarded as non-inferior to the control.
For the primary and secondary objective endpoints, the statistical significance of the difference between the treatment and comparator was established using a paired t-test. If the assumption of normality was violated, the non-parametric equivalent, a one-sample Wilcoxon signed ranks test, was used.
The paired t-test does not allow for adjustment of any potential carryover effects of the sequence in which test conditions were administered. A Grizzle’s model presents an estimate of the treatment/control difference, adjusting for any potential ‘carryover’ effects and was used to estimate the 95% CI of the paired difference, accounting for the AB/BA cross-over design. The Grizzle’s model was analysed by an Analysis of Variance (ANOVA) model to account for the sequence and period effects when the device treatment effect was compared (Grizzle and Allen, Citation1969).
Normality was assessed using a Shapiro–Wilk test for each speech perception outcome. There was no evidence of departure from normality (assessed at the 5% significance level). Thus, a t-distribution based inference was applicable for all speech perception outcome measures.
All statistical analysis was performed using SAS version 9.4 (SAS Institute, Cary, NC) by an external statistical consultant.
Results
Two participants (both bilateral CI users) did not complete the take home experience and final sound booth evaluations. One of these withdrew during the trial due to COVID-19 social distancing recommendations and did not wish to participate in face-to-face sessions. The other subject was lost to follow-up after accepting the invitation to participate in the study.
Speech perception in noise
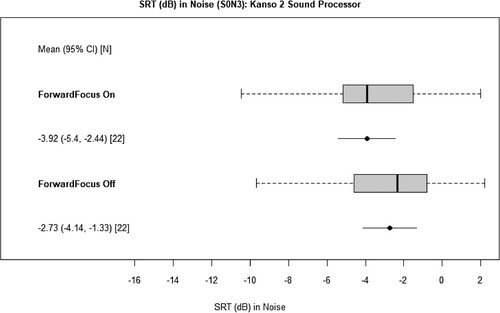
For speech in spatially-separated noise, using12-talker babble from three fixed speaker locations, (S0N3), the group mean SRT50% when using the Kanso 2 sound processor with ForwardFocus Off was −2.7 dB (SD 3.2) and −3.9 dB (SD 3.3) with ForwardFocus On (). ForwardFocus On resulted in a statistically significant improved group mean SRT50% of 1.2 dB (CI: −1.9, −0.5), p-value = 0.0018.
Figure 2 Whisker plots for distribution of speech reception thresholds (dB SRT50%) for the group in the 12-talker babble test condition (S0N3) with mean and 95% confidence intervals shown below each, measured during the Acute test phase with the Kanso 2 sound processor, with the zoom microphone setting, and ForwardFocus On versus ForwardFocus Off for the group (N = 22). All subjects were tested in the unilateral listening condition.
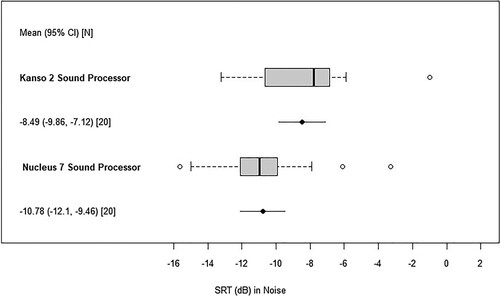
For speech in spatially-separated noise, using 4-talker babble from four speakers roving in a rear hemi-field (S0Nrearhemi), the group mean SRT50% with the Kanso 2 sound processor with ForwardFocus On was −8.5 dB (SD 2.9) (). The mean SRT50% for the 13 bilateral subjects with the Kanso 2 sound processor with ForwardFocus On was −9.23 (SD 2.30) and the seven unilateral subjects was −7.11 (SD 3.61). In S0Nrearhemi, using the Nucleus 7 sound processor with ForwardFocus On, the group mean SRT50% achieved was −10.8 dB, (SD 2.8) (). With ForwardFocus On in both sound processors a statistically significant benefit for the group mean SRT50% of 2.3 dB (95% CI: 1.4, 3.1) was observed with the Nucleus 7 sound processor compared to the Kanso 2 sound processor (p < .0001).
Figure 3 Whisker plots of the distribution of speech reception thresholds in four independent talkers babble roving from the rear hemi-field (S0Nrearhemi) with mean and 95% confidence intervals shown below, after the take-home trial phase (n = 20). The top plot shows the Kanso 2 sound processor with ForwardFocus On. The bottom plot shows the Nucleus 7 sound processor with ForwardFocus On. The 13 bilaterally implanted subjects were tested with their daily use bilateral sound processor configuration and the seven unilaterally implanted subjects were tested in a unilateral sound processor configuration.
Speech perception in quiet
At conversational speech levels of 60 dB SPL, group mean percent correct CNC word scores in quiet were 74.6% (SD 12.05) for the Kanso 2 sound processor and 72.6% (SD10.90) for the Kanso sound processor. There was no statistically significant difference between group mean scores with each sound processor version, p-value = 0.13 ().
Figure 4 Whisker plots show the distribution of group scores for percent correct word scores in quiet at 60 dB SPL (top) and 50 dB SPL (bottom), with mean and 95% confidence intervals indicated below each, after the take-home trial phase (N = 20). All subjects were tested in the unilateral listening condition.
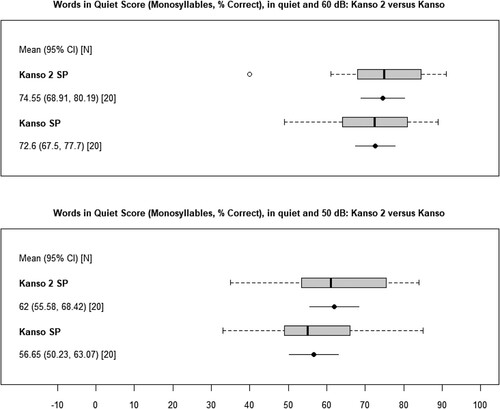
At soft speech levels of 50 dB SPL, group mean percent correct CNC word scores in quiet were 62% (SD13.73) for the Kanso 2 sound processor and 56.7% (SD13.71) for the Kanso sound processor. Group mean percent correct word scores with the Kanso 2 sound processor were significantly higher than with the Kanso sound processor by 5.4% (95% CI: 1.9%, 8.8%), p-value = 0.004 ().
The Grizzle’s model returned estimates of the difference (treatment versus control) that were consistent with the paired t-test for all comparisons conducted, suggesting that there were no notable sequence or period effects.
Subjective evaluations
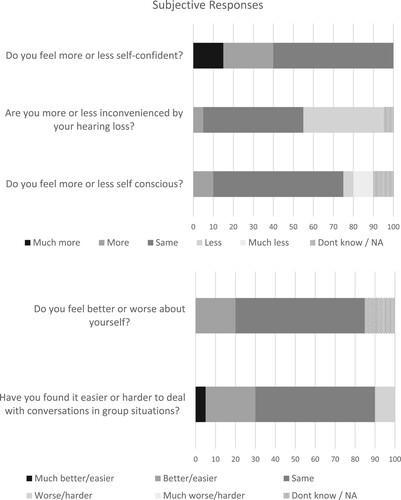
Twenty participants completed the Sound Processor Experience Questionnaire after the take-home trial phase at the final study visit providing subjective ratings for daily use with the Kanso 2 compared to their walk-in sound processor at the start of the study. No statistical analysis was done on the subjective data. For questions 1–4, the majority (60–65%) of participants selected the option suggesting they perceived no difference (‘About the same’) between the sound processors. For question 5, half the group indicated no difference in inconvenience caused by their hearing loss with either sound processor, while 40% indicated they felt less inconvenienced when wearing the Kanso 2 sound processor. When using the Kanso 2 sound processor: Question 1, 40% reported they felt more or much more self-confident; Question 2, 30% reported they found group conversations easier or much easier; and for Question 4, 20% reported they felt better about themselves. Some study participants indicated that the Kanso 2 had a negative impact, with 5–15% of participants reporting they preferred their walk-in sound processor in response to Questions 2, 3 and 5 ().
Figure 5 Percentage of subjects giving each response rating via the Sound Processor Experience Questionnaire, comparing Kanso 2 sound processor to their walk-in sound processor in their daily listening configuration, following the take-home trial phase, N = 20.
The use of ForwardFocus as desired by the participant during take-home trial was monitored through self-report. This was informal, and COVID restrictions severely limited the situations in which the device could be trialled for some recipients. No data logging was available to objectively monitor device use. The questionnaire was completed by a small subset of the study cohort and could not be used to make any meaningful comparisons between processors. The results are therefore not presented here.
Discussion
The ForwardFocus noise reduction setting was implemented in the OTE Kanso 2 sound processor and compared to using directional microphone technologies alone. This study confirmed the potential additional benefits of ForwardFocus for speech recognition in noise in challenging multi-speaker test conditions. Furthermore, it confirmed that when ForwardFocus settings were disabled, no degradation in performance with the Kanso 2 sound processor occurred in quiet relative to its predecessor, the Kanso sound processor.
Daily listening environments will typically have dynamic competing noise conditions with a SNR of somewhere between 0 dB to 20 dB, with SNRs even below zero for less than 10% of the time (Pearsons et al., Citation1977; Smeds et al., Citation2015). This presents significant listening challenges for CI recipients for speech communication in competing background noise and is contrary to the experience of normal-hearing listeners who can use strategies such as glimpsing, an auditory phenomenon where individuals can listen in the gaps in varying noise environments (Nelson et al., Citation2003). Thus, it is important to develop sound processing algorithms that aim to further support CI recipients’ hearing ability in common challenging daily listening situations and to simulate these conditions clinically to assess their benefit (van Hoesel and Clark, Citation1995). Challenging listening environments in the real world may include restaurants, meeting rooms, lecture halls, classrooms, shopping centres, sporting facilities and social gatherings, where multiple noise sources are present, fluctuating, and dynamic in nature.
Unlike adaptive directional sound algorithms which steer a null point of maximum attenuation in the direction of the noise source and can cancel only one noise source at a time, ForwardFocus can attenuate multiple noise sources simultaneously when sound is coming from the rear hemi-field. This is important given that the natural tendency is for individuals to face the desired speaker in the presence of competing background noise sources. These often come from one or more locations and often behind or at the side of the listener. This study attempted to simulate a potential daily noisy condition, where noise sources are fixed in three locations, (S0N3). With ForwardFocus On in the Kanso 2 sound processor, a significant benefit of 1.2 dB SNR for the group mean SRT50% was observed over ForwardFocus Off. The improvement in group mean SRT50% observed reflects the greater degree of attenuation ForwardFocus provides for reducing noise levels from multiple sources located beside and behind the CI-user, compared with a using fixed directional microphone setting alone.
Other researchers have also investigated and published statistically significant benefits of ForwardFocus over directional microphone technologies for SRT50% with fixed noise sources (Hey et al., Citation2019, Citation2021). Nonetheless, the results from these studies cannot be directly compared to our study results with the Kanso 2 sound processor. This is due to several, significant methodological differences to those used in our study, which go beyond the configuration of the sound processor (Hey et al., Citation2019, Citation2021). Methodological differences in their published studies include BTE sound processor formats only; differing numbers of multi-talker babble noise; speech in co-located noise (S0N0); and using an implementation of ForwardFocus on a non-commercial research version of the Nucleus® 6 Sound Processor for customised testing (Hey et al., Citation2019, Citation2021).
By using speech-in-noise tests, with noise generated from multiple speaker lateral and rear locations, in both fixed (S0N3) and roving (S0Nrearhemi) conditions, we attempted to simulate a variety of different challenging noise conditions that may occur in daily life. For example, test set-ups with fixed noise source locations may be most similar to being seated at home around the dinner table or watching TV with a group of people. Roving noise source locations used in a clinical test set up may be more similar to being in a restaurant or café, or social or sporting group meetings, where competing noise sources tend to be more dynamic in nature. Simulations of such daily listening environments is not possible with only one or two speaker set-ups. Hence research examining the effects of speech recognition in noise for CI recipients with an OTE ear sound processor using only a single or two speaker test set-up are less likely to be representative of hearing ability in daily environments (Bayri and Çiprut, Citation2020; Wesarg et al., Citation2018; Wimmer et al., Citation2015).
ForwardFocus is designed to be most effective in improving the SNR for listening in the S0Nrearhemi test condition, with roving independent noise sources presented from multiple locations simultaneously. Group mean SRT50% outcomes with ForwardFocus enabled in the Kanso 2 sound processor and Nucleus 7 sound processor fell well below zero dB SNR, at −8.5 and −10.8 dB respectively. For the bilateral subjects in the group, the low SNR values were derived from a combination of bilateral CI use with bilateral ForwardFocus. For these subjects, this represents their daily listening condition. The sample size did not allow for separate analysis of bilateral and unilateral CI groups, so the relative contributions of ForwardFocus and bilateral CI use could not be evaluated. Nonetheless, these results indicate that irrespective of an on or off the ear sound processor format, with dual microphones and ForwardFocus enabled, substantial noise reduction can be achieved.
Our study also confirmed equivalent performance in quiet between the Kanso 2 sound processor and Kanso sound processor for speech presented at 60 dB SPL. While anticipated, it is important to confirm performance in quiet with the introduction of new noise reduction technologies, even when disabled. A statistically significant group mean improvement of a 5% correct word score at a soft speech level, 50 dB SPL, was observed with the Kanso 2 sound processor compared to the Kanso sound processor. However, this change could be as a result of test/retest variations, and it is debatable whether it is meaningful or perceivable for the recipient in day-to-day life. Mauger et al. (Citation2017) also showed comparable performance between different sound processor configurations, the Kanso sound processor and the Nucleus 6 sound processor for speech recognition in quiet (Mauger et al., Citation2017).
During testing and take-home trial of the Kanso 2 sound processor, participants had access to other noise reduction functions and their preferred MAP settings as available in their walk-in sound processor. With the exception of the ForwardFocus setting enabled or disabled, individual setting options were kept constant within individual participants across test conditions.
Speech recognition in noise with ForwardFocus enabled in the Kanso 2 and Nucleus 7 sound processor resulted in significant group mean differences for SRT50% in favour of the Nucleus 7 sound processor. This may be partly due to the resulting variation in microphone locations, given all other settings were kept constant for intra-participant comparisons. As reported previously, surgical preference for placement of the implant receiver-stimulator may influence the location of the microphone(s) for an OTE ear sound processor relative to a BTE format and subsequent hearing performance (Mauger et al., Citation2017). When comparing directional microphone technologies, Beam and zoom, in the Nucleus 6 sound processor to the newly trialled Kanso sound processor, a relative decline in performance was observed with the Kanso sound processor, but not for the moderately directional standard programme (Mauger et al., Citation2017). Upon further investigation Mauger and colleagues found no correlation between the elevation angle of the Kanso sound processor and SRTs in noise. They concluded that the difference in sound processor position for OTE and BTE devices may be largely compensated for by dual-microphone technology. In contrast, Wimmer et al. (Citation2015) have reported that OTE sound processor configurations with a single microphone showed a greater influence of device position upon speech recognition performance (Wimmer et al., Citation2015). They reported a large variation in placement of the receiver stimulator, with azimuthal position of the OTE sound processor ranging from 93 to 135 degrees (average, 117 degrees). This resulted in a more posterior position having a negative impact upon speech recognition in the S0N180 test condition (r = −0.65) (Wimmer et al., Citation2015).
Subjectively, the group provided largely comparable ratings for the Kanso 2 sound processor compared to their walk-in sound processor for hearing ability in group conversations and with respect to its impact upon their self-confidence, self-consciousness, inconvenience of hearing loss, and self-perception (). The majority of participants (60%−65%) rated the Kanso 2 sound processor equally to their walk-in sound processor. Just over a third (30–40%) rated daily listening more favourably when using the Kanso 2 sound processor in terms of self-confidence, reduced inconvenience caused by their hearing loss, and for small group conversations. However, the interpretation of these results is limited as bias towards the new processor is not controlled for. Similarly, Mauger et al. (Citation2017) reported positive subjective ratings after trialling the Kanso sound processor compared to the walk-in sound processor (BTE format in all cases), particularly for sound quality and wearability, which they concluded was likely due to its discrete format (Mauger et al., Citation2017). Our subjective assessment did not query lifestyle influences related to wireless connectivity, the availability of rechargeable batteries or cosmesis and discretion, however, it is possible that these factors affected the overall ratings with each sound processor. We also observed no cases of discontinued use with the Kanso 2 sound processor, while other studies have observed up to 20% of participants with discontinued use of an OTE sound processor in trial due to dissatisfaction with sound quality (Dazert et al., Citation2017; Mertens et al., Citation2015).
For the individual CI recipient, when deciding between sound processor options, including wearer formats, OTE versus BTE, it is important to consider the potential physical and technical influences on speech recognition outcomes, especially in complex competing background noise. Counselling regarding sound processor options should ideally consider daily lifestyle and hearing needs, including vocationally, educationally, at leisure and socially, to support the CI recipient’s decision process.
Future research investigating the effect of the OTE sound processor position, dual microphones and ForwardFocus on hearing performance in noise in alternate speaker configurations and competing noise types may be beneficial. A view to real world use of ForwardFocus and benefits via datalogs and subjective report is also of value to provide evidence to support clinical recommendations for optimal use. The investigation of hearing benefits relative to the CI recipient’s holistic lifestyle during various activities, including use of wireless connectivity and accessories while using the OTE sound processor, may further complement evidence to support counselling.
Limitations of the study
The study group represents a clinically diverse cohort, and thus outcomes for the cohort are inherently influenced by their diversity. Participants used varying sound processors, device configurations (bilateral, bimodal and unilateral) and sound processor settings at study enrolment which were adopted for the take-home trial of the Kanso 2 sound processor(s) with ForwardFocus enabled for intrasubject comparison. For in clinic tests in quiet and with S0N3, all users only listened with one ear. During the take home trial and for the S0Nrearhemi condition, bilateral CI users had the benefits of bilateral sound processor use and the potential benefits of binaural listening in noise. Thus, the relative contributions of binaural hearing and ForwardFocus in these conditions cannot be assessed. Subjective impressions provided may also have been influenced by pandemic restrictions during the trial due to more limited opportunity to participate in their usual daily activities. It may also have contributed to the lack of feedback from the custom daily use questionnaire. More detailed documentation of hearing levels in each ear, daily device configuration and device settings during the take-home trial may provide additional information for reference and interpretation following real-world experience with test devices. The inclusion of datalogging in future studies to monitor use of new features is recommended. Blinding of the sound processor format in use was not possible. Hence there is potential for bias in subjective impressions of hearing performance related issues due to the appearance of the OTE sound processor. For the test ear, four participants used an OTE sound processor as their walk-in device at the start of the study. An inherent bias towards the Kanso 2 sound processor cannot be discounted for these participants. Differences between potential bilateral and unilateral use of enabled ForwardFocus settings was not assessed and may be of interest for further research.
Conclusion
In a cohort of experienced adult CI-recipients, evaluation with the Kanso 2 sound processor with ForwardFocus On achieved group mean SRT50% thresholds of −3.9 dB and −8.5 dB SNR in spatially-separated, fixed and roving noise respectively. ForwardFocus On resulted in statistically significant benefits over ForwardFocus Off in the Kanso 2 sound processor for group mean SRT50% for speech recognition in noise, when noise was presented from three fixed locations (S0N3). In roving competing background noise (S0Nrearhemi), ForwardFocus implemented in the OTE Kanso 2 sound processor was very effective in achieving group mean SRT50% well below zero (−8.5 dB SNR) for this mixed cohort of unilateral and bilateral CI users. Outcomes with ForwardFocus in the S0Nrearhemi condition with the Nucleus 7 on-the-ear sound processor were even lower at −10.8 dB SNR and were better than with the off-the-ear sound processor. When used in the home environment, subjective ratings with the Kanso 2 were at least equivalent compared with participants walk in sound processors. These results may support clinicians in counselling CI recipients on potential sound processor options to consider, balancing both potential benefits for hearing in noise with advanced sound processing algorithms and the wearability, preferences and user needs for daily hearing and activities.
Disclaimer statements
Contributors: All authors contributed to the interpretation of the data and writing of the manuscript
Funding: This work was supported by Cochlear.
Conflict of interests: MJ, CW, MM and JW are employees of Cochlear and PG acts as a consultant for Cochlear
Ethics approval: Ethics approval was obtained from Bellberry Human Research Ethics Committee, Bellberry Limited, 129 Glen Osmond Road, Eastwood, South Australia 5063. The study is registered publicly via Australia and New Zealand Clinical Trials Registry: ACTRN12619000666123.
Additional information
Notes on contributors
Marian Jones
Marian Jones is a principal research audiologist at Cochlear Limited and has a Bachelor of Arts and Masters in Audiology from Macquarie University.
Chris Warren
Chris Warren holds a Bachelor of Applied Science and Masters of Clinical Audiology from Macquarie University. At the time of contributing, Chris was the Director of Clinical Portfolio Strategy at Cochlear Limited.
Marjan Mashal
Marjan (Emjay) Mashal holds a Bachelor of Speech, Hearing and Language Sciences and Masters of Clinical Audiology from Macquarie University. At the time of contributing to the investigation, Emjay was a Research Audiologist at Cochlear Limited.
Paula Greenham
Paula Greenham is a UK based audiologist with a Bachelor of Physics degree and a Masters in Audiology. She has extensive experience in Cochlear Implants (CI) and as Director of Greenham Research Consulting Limited, she has provided scientific support and writing expertise for a wide range of CI studies.
Josie Wyss
Josie Wyss has many years of experience in hearing devices. She is the Director of Scientific Communications at Cochlear Limited and holds a Diploma in Audiology and Bachelor of Science.
References
- Bayri, M., Çiprut, A. 2020. The effects of behind-the-ear and off-the-ear sound processors on speech understanding performance in cochlear implant users. Auris, Nasus, Larynx, 47(6): 950–957. doi:10.1016/J.ANL.2020.05.025.
- Beiter, A.L., Nel, E. 2015. The history of CochlearTM nucleus® sound processor upgrades: 30 years and counting. Journal of Otology, 10(3): 108. doi:10.1016/J.JOTO.2015.10.001.
- Biever, A., Gilden, J., Zwolan, T., Mears, M., Beiter, A. 2018. Upgrade to Nucleus ® 6 in previous generation CochlearTM sound processor recipients. Journal of the American Academy of Audiology, 29(9): 802–813. doi:10.3766/JAAA.17016.
- Dawson, P.W., Hersbach, A.A., Swanson, B.A. 2013. An adaptive Australian sentence test in noise (Austin). Ear and Hearing, 34(5): 592–600. doi:10.1097/AUD.0b013e31828576fb.
- Dazert, S., Thomas, J.P., Büchner, A., Müller, J., Hempel, J.M., Löwenheim, H., Mlynski, R. 2017. Off the ear with no loss in speech understanding: comparing the RONDO and the OPUS 2 cochlear implant audio processors. European Archives of Oto-Rhino-Laryngology : Official Journal of the European Federation of Oto-Rhino-Laryngological Societies (EUFOS) : Affiliated with the German Society for Oto-Rhino-Laryngology - Head and Neck Surgery, 274(3): 1391–1395. doi:10.1007/S00405-016-4400-Z.
- de Ceulaer, G., Swinnen, F., Pascoal, D., Philips, B., Killian, M., James, C., et al. 2015. Conversion of adult Nucleus® 5 cochlear implant users to the Nucleus® 6 system. Cochlear Implants International, 16(4): 222–232.
- Dillier, N., Lai, W.K. 2015. Speech intelligibility in various noise conditions with the Nucleus® 5 CP810 sound processor. Audiology Research, 5(2): 69–75. doi:10.4081/AUDIORES.2015.132.
- Dixon, P.R., Shipp, D., Smilsky, K., Lin, V.Y., le, T., Chen, J.M. 2019. Association of speech processor technology and speech recognition outcomes in adult cochlear implant users. Otology & Neurotology : Official Publication of the American Otological Society, American Neurotology Society [and] European Academy of Otology and Neurotology, 40(5): 595–601.
- Dorman, M.F., Gifford, R.H. 2017. Speech understanding in complex listening environments by listeners fit with cochlear implants. Journal of Speech, Language, and Hearing Research : JSLHR, 60(10): 3019.
- Flynn, M.C., Hedin, A., Halvarsson, G., Good, T., Sadeghi, A. 2012. Hearing performance benefits of a programmable power baha® sound processor with a directional microphone for patients with a mixed hearing loss. Clinical and Experimental Otorhinolaryngology, 5(Suppl 1): S76–S81. http://www.ncbi.nlm.nih.gov/pubmed/22701154.
- Flynn, M.C., Sadeghi, A., Halvarsson, G. 2011. Benefits of directional microphones and noise reduction circuits for improving Baha® hearing performance. Cochlear Implants International, 12(suppl 1): S139–S141.
- Godey, B., Darrouzet, V., Ruben, H., Mosnier, I., Poncet, C., Schmerber, S., et al. 2020. Comparing behind-the-ear and single-unit cochlear implant audio processors in 83 newly implanted subjects. Journal of Hearing Science, 10(4): 33–39.
- Grizzle, J.E., Allen, D.M. 1969. Analysis of growth and dose response curves. Biometrics, 25(2): 357.
- Hersbach, A., Arora, K., Mauger, S., Dawson, P. 2012. Combining directional microphone and single-channel noise reduction algorithms: a clinical evaluation in difficult listening conditions with cochlear implant users. Ear and Hearing, 33(4): e13–e23. doi:10.1097/AUD.0B013E31824B9E21.
- Hey, M., Böhnke, B., Mewes, A., Munder, P., Mauger, S.J., Hocke, T. 2021. Speech comprehension across multiple CI processor generations: scene dependent signal processing. Laryngoscope Investigative Otolaryngology, 6(4): 807–815. doi:10.1002/LIO2.564.
- Hey, M., Hocke, T., Böhnke, B., Mauger, S.J. 2019. Forwardfocus with cochlear implant recipients in spatially separated and fluctuating competing signals–introduction of a reference metric. International Journal of Audiology, 58(12): 869–878.
- Mauger, S., Jones, M., Nel, E., del Dot, J. 2017. Clinical outcomes with the KansoTM off-the-ear cochlear implant sound processor. International Journal of Audiology, 56(4): 267–276.
- Mauger, S., Warren, C., Knight, M., Goorevich, M., Nel, E. 2014. Clinical evaluation of the Nucleus 6 cochlear implant system: performance improvements with SmartSound iQ. International Journal of Audiology, 53(8): 564–576.
- Mertens, G., Hofkens, A., Punte, A.K., de Bodt, M., van de Heyning, P. 2015. Hearing performance in single-sided deaf cochlear implant users after upgrade to a single-unit speech processor. Otology and Neurotology, 36(1): 51–60.
- Mosnier, I., Marx, M., Venail, F., Loundon, N., Roux-Vaillard, S., Sterkers, O. 2014. Benefits from upgrade to the CP810 sound processor for Nucleus 24 cochlear implant recipients. European Archives of Oto-Rhino-Laryngology : Official Journal of the European Federation of Oto-Rhino-Laryngological Societies (EUFOS) : Affiliated with the German Society for Oto-Rhino-Laryngology - Head and Neck Surgery, 271(1): 49–57.
- Mosnier, I., Mathias, N., Flament, J., Amar, D., Liagre-Callies, A., Borel, S., et al. 2017. Benefit of the UltraZoom beamforming technology in noise in cochlear implant users. European Archives of Oto-Rhino-Laryngology, 274(9): 3335–3342. doi:10.1007/S00405-017-4651-3.
- Mosnier, I., Sterkers, O., Nguyen, Y., Lahlou, G. 2021. Benefits in noise from sound processor upgrade in thirty-three cochlear implant users for more than 20 years. European Archives of Oto-Rhino-Laryngology : Official Journal of the European Federation of Oto-Rhino-Laryngological Societies (EUFOS) : Affiliated with the German Society for Oto-Rhino-Laryngology - Head and Neck Surgery, 278(3): 827–831.
- Nelson, P.B., Jin, S.-H., Carney, A.E., Nelson, D.A. 2003. Understanding speech in modulated interference: cochlear implant users and normal-hearing listeners. The Journal of the Acoustical Society of America, 113(2): 961–968.
- Pearsons, K., Bennett, R., Fidell, S. 1977. Speech levels in various noise environments | science inventory | US EPA. U.S. Environmental Protection Agency, Washington, DC, EPA/600/1-77/025 (NTIS PB270053). https://cfpub.epa.gov/si/si_public_record_Report.cfm?Lab = ORD&dirEntryID = 45786.
- Peterson, G.E., Lehiste, I. 1962. Revised CNC lists for auditory tests. The Journal of Speech and Hearing Disorders, 27: 62–70. doi:10.1044/JSHD.2701.62.
- Seebens, Y., Diller, G. 2012. Improvements in speech perception after the upgrade from the TEMPO+ to the OPUS 2 audio processor. ORL, 74(1): 6–11.
- Smeds, K., Wolters, F., Rung, M. 2015. Estimation of signal-to-noise ratios in realistic sound scenarios. Journal of the American Academy of Audiology, 26(2): 183–196. doi:10.3766/JAAA.26.2.7.
- Spahr, A.J., Dorman, M.F., Loiselle, L.H. 2007. Performance of patients using different cochlear implant systems: effects of input dynamic range. Ear and Hearing, 28(2): 260–275. doi:10.1097/AUD.0B013E3180312607.
- Todorov, M., Galvin, K. 2018. Benefits of upgrading to the Nucleus ® 6 sound processor for a wider clinical population. Cochlear Implants International, 19(4): 210–215.
- van Hoesel, R.J.M., Clark, G.M. 1995. Evaluation of a portable two-microphone adaptive beamforming speech processor with cochlear implant patients. The Journal of the Acoustical Society of America, 97(4): 2498–2503.
- Warren, C.D., Nel, E., Boyd, P.J. 2019. Controlled comparative clinical trial of hearing benefit outcomes for users of the CochlearTM Nucleus ® 7 sound processor with mobile connectivity. Cochlear Implants International, 20(3): 116–126.
- Wesarg, T., Voss, B., Hassepass, F., Beck, R., Aschendorff, A., Laszig, R., Arndt, S. 2018. Speech perception in quiet and noise with an off the ear CI processor enabling adaptive microphone directionality. Otology and Neurotology, 39(4): e240–e249.
- Wimmer, W., Caversaccio, M., Kompis, M. 2015. Speech intelligibility in noise with a single-unit cochlear implant audio processor. Otology & Neurotology : Official Publication of the American Otological Society, American Neurotology Society [and] European Academy of Otology and Neurotology, 36(7): 1197–1202.
- Wolfe, J., Parkinson, A., Schafer, E.C., Gilden, J., Rehwinkel, K., Mansanares, J., et al. 2012. Benefit of a commercially available cochlear implant processor with dual-microphone beamforming: a multi-center study. Otology and Neurotology, 33(4): 553–560. doi:10.1097/MAO.0B013E31825367A5.