
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The relations between the mechanical properties, heat treatment, and compositions of elements in aluminum alloys are extracted by a materials informatics technique. In our strategy, a machine learning model is first trained by a prepared database to predict the properties of materials. The dependence of the predicted properties on explanatory variables, that is, the type of heat treatment and element composition, is searched using a Markov chain Monte Carlo method. From the dependencies, a factor to obtain the desired properties is investigated. Using targets of 5000, 6000, and 7000 series aluminum alloys, we extracted relations that are difficult to find via simple correlation analysis. Our method is also used to design an experimental plan to optimize the materials properties while promoting the understanding of target materials.
GRAPHICAL ABSTRACT

CLASSIFICATION:
1. Introduction
Data-driven techniques are essential in materials science. Applying supervised machine learning to a material’s database can predict the properties of unknown materials from the compositions, structures, and processes without synthesizing the material. As demonstrated in the literature, the predicted properties are helpful for materials discovery [Citation1–Citation14]. On the other hand, it is important to know which compositions, structures, and processes largely affect properties. Hence, one of the original problems in materials science is to extract relations in the databases. This can be tackled by applying correlation analysis [Citation15–Citation18], evaluating the contributions of a prediction model [Citation19–Citation23], and performing a feature selection method [Citation24–Citation29], and applying data-driven techniques to improve the understanding of materials [Citation30].
Recently, the amount of data in public material’s databases based on simulations is increasing. Some databases contain over hundreds of thousands of records [Citation31–Citation33]. Thus, many relations have been elucidated via data-driven techniques applied to materials simulation databases. On the other hand, the results significantly change when focusing on experimental databases. Compared to simulations, experiments in materials science require an enormous amount of time and money, and it is difficult to generate a large amount of experimental data. Furthermore, existing public databases contain little experimental data if the focused property is limited [Citation34]. In many cases, it is difficult to extract relations between properties, compositions, structures, and processes from materials databases based on experiments.
For alloys, calculating the mechanical properties using only simulations is challenging due to the necessity of a macroscopic viewpoint. Consequently, experiments are relied on to determine the mechanical properties in alloys. Because the mechanical properties strongly depend on the dominant element, the number of data in an experimental database for each type of alloy is limited [Citation35]. As a target for data-driven techniques to extract relations, an alloy is one of the representative examples. However, since the dependences of the mechanical properties on processes and element compositions are remarkable, extracting the relations is essential in the development of new alloys. To date, this task has relied on experience and feelings of professional researchers, but alloy development should be accelerated, if such relations are clarified using pure data-driven techniques.
Using data-driven techniques, herein we propose a new strategy to extract relations from alloy experimental databases with small data sizes. First, we train a machine learning prediction model for the mechanical properties when process parameters and compositions of elements are inputted. Here, the prediction model with the highest prediction performance is selected from some supervised machine learning models. Second, the distributions of the process parameters and element compositions based on the prediction model are investigated to obtain the desired mechanical properties. Our strategy employs the Markov chain Monte Carlo (MCMC) method as a generator of new data by the prediction model. Third, we extract factors for the desired mechanical properties, including the influence degree at a glance, to promote the understanding of alloys. Herein we focus on aluminum alloys [Citation36–Citation38] to demonstrate our technique. Our technique finds the relations hidden in the aluminum alloy databases, which are difficult to discover by simple correlation analysis. The most important characteristic of aluminum alloys is their lightness, which contributes to energy-saving practical materials for airplanes and automobiles. These are categorized by some series where the mixed elements differ, and by performing heat treatments, various properties are obtained.
The rest of this paper is organized as follows. Section 2 shows the target aluminum databases for the 5000, 6000, and 7000 series as well as our strategy, which combines a machine learning prediction model and MCMC to search for relations in the database. Section 3 shows the results for the 5000, 6000, and 7000 series using our strategy. We discuss the extracted relations to realize high or low mechanical properties. Section 4 is the discussion and summary.
2. Dataset and data analysis method
2.1. Aluminum alloys dataset
The target aluminum alloy data are the 5000, 6000, and 7000 series which are summarized in . The letter in the sample name denotes the alloy shape: (P) plate, (BD) bar-drawn, (T) tube, (BE) bar-extruded, (FH) forging-hand, (S) shape, and (B) brazing. Furthermore, three types of mechanical properties are examined: 0.2% proof stress, tensile strength, and elongation. The data are collected from two databases [Citation39,Citation40]. If an alloy number has multiple data listed, we use the mean value of these data.
Table 1. Target aluminum alloys in the 5000, 6000, and 7000 series. Alloy number and temper types are shown.
The 5000 series aluminum alloys are classified into alloys that cannot be heat treated, where Mg is added to increase the strength. In addition to Al (94.25–99.19 wt%) and Mg (0.40–5.05 wt%), Fe (0.13–0.35 wt%), Mn (0.01–0.75 wt%), Si (0.08–0.23 wt%), Ti (0.00–0.10 wt%), Cu (0.02–0.10 wt%), Cr (0.00–0.25 wt%), and Zn (0.015–0.125 wt%) are mixed in the alloys. The two-dimensional temper designations HXn (X = 1, 2, 3, 4 and n = 1, ..., 9) are used to distinguish the applied combination of basic operations X and the degree of strain-hardening n. Table S1 summarizes the meanings of these temper designations [Citation41,Citation42]. The temper designations are used for explanatory variables as well as for the compositions of the elements above. When the mechanical properties are predicted, an integer value of the temper designations is adopted.
The 6000 and 7000 series aluminum alloys are the heat-treatable alloys. For these alloys, the temper designation is given as TX (X = 1, ..., 10) [Citation41,Citation42] (Table S2). In the 6000 series, Fe (0.18–0.50 wt%), Mn (0.02–0.70 wt%), Si (0.40–1.00 wt%), Al (96.16–98.63 wt%), Mg (0.48–1.00 wt%), Ti (0.00–0.08 wt%), Cu (0.05–0.43 wt%), Cr (0.00–0.25 wt%), and Zn (0.05–0.13 wt%) elements are contained, while Fe (0.06–0.35 wt%), Mn (0.03–0.45 wt%), Si (0.05–0.35 wt%), Al (87.05–98.10 wt%), Mg (0.05–2.75 wt%), Ti (0.00–0.17 wt%), Cu (0.05–2.30 wt%), Cr (0.00–1.15 wt%), V (0.00–0.05 wt%), Zr (0.00–0.15 wt%), and Zn (1.05–7.80 wt%) elements are mixed in the 7000 series. The one-dimensional integer temper designation is used as an explanatory variable for the 6000 and 7000 series. The detailed databases for the 5000, 6000, and 7000 series are 5000.csv, 6000.csv, and 7000.csv, respectively.
2.2. Materials informatics technique
From the explanatory variables (i.e., temper designations and element compositions), which are expressed by vector x, supervised machine learning models are created to predict the mechanical properties using the dataset , which includes N training datapoints. Here, xi is the ith explanatory variables and fi is its mechanical property. That is, the prediction function of fpred(x), which depends on x is trained using D. Although many regression models have been proposed to train fpred(x) in the machine learning community, here, six representative types of methods are utilized: linear regression, ridge regression, elastic net regression, support vector regression, random forest regression, and Gaussian process regression. For the first five methods, we use scikit-learn [Citation43], while the COMBO package [Citation44] is used for the Gaussian process regression. The hyperparameters in these methods are determined so that the leave-one-out cross validation error is minimized. In addition, the prediction performances of machine learning models are compared using the root mean square error (RMSE) for the leave-one-out cross validation, and the most reliable method is selected after optimizing the hyperparameters.
Our strategy () investigates the distributions of the explanatory variables in the most reliable machine learning model to understand the influence of the explanatory variables and to obtain the desired mechanical properties. We utilize the MCMC method to draw the distribution, which is performed by the emcee package [Citation45,Citation46]. Although this package implements several approaches to update the state, herein the stretch move [Citation47] is adopted. In each Monte Carlo update, all explanatory variables are simultaneously updated. Conventionally, MCMC is used in materials informatics research to analyze the posterior distribution in Bayes statistics [Citation48–Citation50]. Unlike conventional research, MCMC is used as a generator of new data by a prediction model.
We perform MCMC samplings with the probability distribution, P(x) given in advance. For example, when the probability distribution with positive T is set to
where f+ and f- are the maximum and minimum values in the training dataset , respectively, explanatory variables with a high predicted mechanical property are actively sampled. Introducing f+ and f- in EquationEq. (1)
(1)
(1) means the standardization of mechanical properties. Thus, our strategy can be applied to different target datasets with the common value of T. By adopting this probability distribution, the distribution of the explanatory variables to obtain high properties is drawn. On the other hand, explanatory variables with low mechanical properties appear when the probability distribution is set to
These distributions drawn by MCMC with EquationEqs. (1)(1)
(1) and (Equation2
(2)
(2) ) include information about the values of the temper designations and compositions to obtain higher or lower mechanical properties, respectively.
Furthermore, the width of the histogram calculated by the obtained distributions shows the robustness of each explanatory variable, which should reflect important heat treatments and elements for each mechanical property. Based on such information, the relations between explanatory variables and mechanical properties can be understood quickly via an MCMC-based method. Supplemental note A discusses the probability distribution when the target value of the property is determined in advance. Note that in our implementation of MCMC, the sampling space is limited. It must fall between the minimum and maximum values of the explanatory variables obtained in D because predictions by the regression model become meaningless for extrapolated points and extraneous relations will be extracted if this limitation is not imposed. Therefore, in this paper, MCMC draws an interpolation distribution between the minimum and maximum values of the explanatory variables.
Setting the value of T is important to obtain reliable relations because the drawn distributions easily fluctuate by changing T. To determine the appropriate value of T to properly extract relations, we address the dependency of the distributions on T by targeting the proof stress and elongation for the 5000 series (Figure S1). If the value of T is sufficiently large, an almost random walk is performed, and the distributions for high or low mechanical properties do not differ from using EquationEqs. (1)(1)
(1) and (Equation2
(2)
(2) ). For a random walk, the distributions against each explanatory variable by the emcee package have a higher probability at the center and a lower one at the edges (Figure S2). To clearly capture relations from the distributions, we conclude that
is an appropriate value of T for the condition in this paper. Note that theoretically, 99.9% of the sampling points are included in the upper 95% or the lower 95% between f+ and f- when EquationEqs. (1)
(1)
(1) and (Equation2
(2)
(2) ) are used, respectively.
Since the appropriate value of T should depend on motivations, (i.e., whether the obtained distributions of the mechanical properties are acceptable), this conclusion is a guide to determine T. This ambiguity of T means that the absolute evaluation of the robustness for each explanatory variable is difficult via our proposed strategy. On the other hand, the MCMC method should promote visualization of the relations relative to other variables.
Figure 1. Flow of our strategy to extract the relations by combining a regression model and MCMC.
3. Results by data-driven analysis
We show the results by our data-driven technique for the 5000, 6000, and 7000 series aluminum alloys. Here, the 0.2% proof stress, tensile strength, and elongation are used as mechanical properties of aluminum alloys. Then the results are compared.
3.1. 5000 series aluminum alloys
For the 5000 series, there are 11 dimensions of explanatory variables due to two temper designations X and n and nine elements, and 115 data are collected. To compare our strategy to conventional analysis, we used a simple correlation analysis as the conventional one. shows pair plots between the mechanical properties and the explanatory variables and the values of the Pearson correlation coefficient, r, which is a measure of the linear association between two variables [Citation51]. Here, r is evaluated by the Python package pandas.DataFrame.corr [Citation52].
According to Guilford’s informal interpretations [Citation53], relations can be categorized depending on the value of r as (very high correlation),
(high correlation),
(moderate correlation),
(low correlation), and
(slight correlation). Herein we assume that the relations exist when
. In , correlation coefficients in red, blue, and black indicate positive, negative, and no relations, respectively. From the results of the correlation coefficients, the second temper designation n will increases the proof stress and tensile strength while the elongation decreases. Since the second digit of the temper designation stands for the degree of strain-hardening and it is well known that there is a strong correlation between the hardness and strength of aluminum alloys [Citation54], the obtained trends are reasonable.
On the other hand, shows that the very strong positive relations between n and tensile strength are limited to each alloy. However, if the value of r evaluated by the whole data is not large, the overall relation is judged to be weakly positive. This is because that the values of the tensile strength strongly depend on the alloy type and the data deviates largely. Compared with n, the first temper designation X has a negligible effect on the mechanical properties. From a viewpoint of element composition, Al and Mg compositions have outstanding relations for the proof stress. The tensile strength is related with the Al, Mg, Cu, and Cr compositions. However, elongation does not have a clear relation with the element composition.
Figure 2. Dependence of the mechanical properties of (a) 0.2% proof stress, (b) tensile strength, and (c) elongation on the temper designations X and n, and the compositions of nine types of elements in the 5000 series. Values of r denote the correlation coefficient. Correlation coefficients in red, blue, and black indicate positive, negative, and no relations, respectively. Each type of aluminum alloy is distinguished by the color of the points.

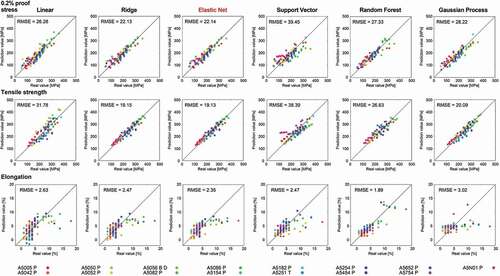
Next, our strategy is applied to the 5000 series aluminum alloys. Machine learning prediction models are constructed to predict the mechanical properties from the explanatory variables. shows the scatter plots between the real and predicted mechanical properties for the test data by various machine learning regression models. Here, the test data is prepared and the prediction results are plotted using the leave-one-out cross validation. The RMSE is evaluated for the test data corresponding to the leave-one-out cross validation error, which is denoted in . For the proof stress and tensile strength, the prediction is highly efficient regardless of the machine learning model. On the other hand, the prediction performance for elongation is poor compared with the proof stress and tensile strength. Hence, it is more difficult to predict the elongation than the proof stress or tensile strength in 5000 series aluminum alloys. In particular, in the high elongation region, the prediction becomes worse. Among these machine learning models, the elastic net regression has a relatively higher prediction accuracy for the three mechanical properties.
Figure 3. Prediction results by machine learning models for the 0.2% proof stress, tensile strength, and elongation in the 5000 series aluminum alloys. These points are predictions for the test data when the leave-one-out cross validation is performed, that is, for the prediction of each point, target data is not included in the training of the machine learning model. Root mean square error (RMSE) for the test data by the leave-one out method is also denoted. As highlighted in red, the elastic net regression provides a relatively higher prediction accuracy for the three mechanical properties.
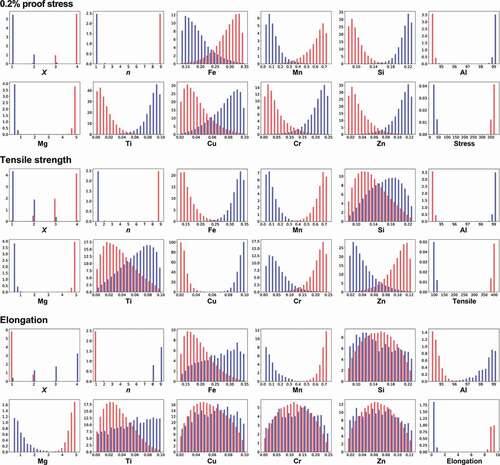
In the second step of our strategy, the distributions of explanatory variables, x, by MCMC samplings to obtain the desired properties are investigated based on the reliable trained machine learning model. shows the normalized frequency histograms obtained by MCMC sampling as explained in Sec. 2.2, where the number of sampling points is about 170,000. The vertical axis means the frequencies. Here, the cases where high or low mechanical properties are desired, and EquationEqs. (1)(1)
(1) and (Equation2
(2)
(2) ) are used as the probability distributions in MCMC, respectively. The proof stress remarkably depends on the temper designation n, Al, and Mg compositions. For a high proof stress, a smaller Al composition around 95 wt% but a larger Mg composition around 5 wt% are desirable for high temper designation n. The opposite conditions are necessary for a low proof stress. Furthermore, all the remaining explanatory variables are slightly related to the proof stress. To increase the proof stress, a large temper designation X, higher compositions of Fe and Mn, but lower compositions of Si, Ti, Cu, Cr, and Zn are preferred. Except for n, Al, and Mg, these relations are not extracted from the simple correlation analysis shown in , demonstrating a benefit of our proposed analysis.
Next, we focus on the tensile strength. Temper designation n and the correlations of Mn, Al, Mg, and Cu for the tensile strength exhibit similar behaviors as those for the proof stress. On the other hand, Fe, Cr, and Zn compositions show the opposite behaviors. Unlike in the proof stress, Si and Ti compositions are not strongly related with the tensile strength because the histogram is widespread and their distributions overlap in a wide range. Although both the proof stress and tensile strength are related to material strength, the extracted relations against the element compositions differ slightly.
Finally, we consider the elongation. The behaviors differ drastically from the above properties. The distributions against temper designations show the opposite behaviors as those for the proof stress and tensile strength. Generally, there is a common trend in metals where the elongation decreases as the tensile strength increases [Citation55,Citation56]. Our analysis derives the same trend from the data of aluminum alloys. It also implies that it is difficult to improve these three properties simultaneously. On the other hand, slight relations are observed for the Mn, Al, and Mg compositions, similar to the behaviors for the proof stress and tensile strength.
To increase the three mechanical properties simultaneously, the compositions of Mn and Mg should be increased, while decreasing the Al composition. If scatterplots are drawn between these element compositions of the MCMC sampling points, the relations between explanatory variables and whether simultaneous change of these variables is needed to obtain three high mechanical properties can be visualized. Figure S3 shows the scatterplots for the Mn, Al, and Mg compositions. Simultaneously changing all three compositions is important in this case. The other element compositions are not strongly related with the elongation, suggesting that it is difficult to correlate these element compositions directly to elongation in aluminum alloys. summarizes these relations between the three mechanical properties and each explanatory variable.
Table 2. Extracted relations between mechanical properties and each explanatory variable for the 5000 series. White and black triangles denote whether to increase or decrease for high (upper table) or low (lower table) mechanical properties, respectively. Bar indicates almost no relation.
The elastic net regression is based on the linear regression, and the coefficients for each explanatory variable can be addressed. MCMC confirms that the distributions are directly reflected by these coefficients. In particular, the coefficients for Si, Cr, and Zn compositions are zero for the elongation in the regression model. For such cases, MCMC performs a random walk in the limited space between the minimum and maximum values of these compositions. In fact, the distributions of Si, Cr, and Zn are similar to the distribution by a random walk (Figure S2). On the other hand, our strategy shows a true effect for the regression model where coefficients cannot be easily understood, as addressed in Sec. 3.3.
Figure 4. Distributions of temper designations X and n and compositions of elements to obtain high (red) or low (blue) mechanical properties by MCMC sampling for the 5000 series aluminum alloys. Elastic net regression is used as a machine learning prediction model. Temper designations X and n have a discrete value, while others have continuous values.
3.2. 6000 series aluminum alloys
For the 6000 series, there are 10 dimensions of explanatory variables because there is one temper designation X and nine elements, and 34 data are collected. Figure S4 shows the pair plot between mechanical properties and explanatory variables. The machine learning prediction results (Figure S5) show that the random forest regression has the highest prediction performance for the three mechanical properties.
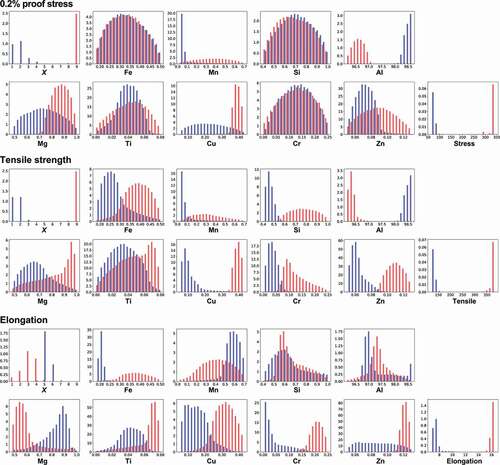
Based on the random forest regression, the frequency histogram is calculated by MCMC sampling (). summarizes the extracted relations between the three mechanical properties and each explanatory variable from the frequency histograms. The proof stress is remarkably dependent on the temper designation X and Al composition to obtain high or low values, but the others do not exhibit strong relations for the proof stress. In particular, the distributions for high and low values nearly overlap for Fe, Ti, Si, and Cr. These distributions are similar to those obtained by a random walk (see Figure S2), indicating that these elements are not related to the proof stress. For the tensile strength, many parameters except for the Fe, Mg, and Ti compositions are related when the tensile strength decreases. On the other hand, a large temper designation X is preferred along with a low Al and high Cu and Zn compositions to increase the tensile strength. In addition, an optimum value for the Cr composition exists around 0.1 wt%.
Table 3. Extracted relations between mechanical properties and each explanatory variable for the 6000 series. White and black triangles denote whether to increase and decrease for high (upper table) or low (lower table) mechanical properties, respectively. Bar indicates almost no relation, while asterisk denotes an optimum value exists.
As an interesting relation which can be revealed by our strategy, there is a relation in the lower property region, but in the higher property region there is no relation against the explanatory variable or vice versa. One such example is the Mn composition for the proof stress and tensile strength. For such cases, a simple correlation analysis is not useful as it will indicate weak relations exist in the whole region. This means that our strategy can capture the nonlinear relations between the mechanical properties and explanatory variables. This is a clear advantage compared with simple correlation analysis.
Furthermore, to realize a high elongation, the Ti, Cu, Cr, and Zn compositions should be increased when X is fixed to 3 or 4. Conversely, to decrease elongation, the Fe, Cu, and Cr compositions should be decreased while the Mn and Mg compositions are increased when X is fixed to 5. Note that our strategy can extract a lot of relations for the elongation compared to a simple correlation analysis (Figure S4). If three high mechanical properties are desired, then Cu should be increased as it is the only common relation for the three properties.
Figure 5. Distributions of temper designation X and compositions of elements to obtain high (red) or low (blue) mechanical properties by MCMC sampling in the 6000 series aluminum alloys. Random forest regression is used as a machine learning prediction model. Temper designation X has a discrete value, while others have continuous values.
3.3. 7000 series aluminum alloys
For the 7000 series, there are 12 dimensions of explanatory variables because there is one temper designation X and eleven elements, and 24 data are collected. Figures S6 and S7 show the pair plots and machine learning prediction results, respectively. The support vector regression has the highest prediction performance for the three mechanical properties. However, the prediction performances are worse than those for the 5000 and 6000 series. In particular, the prediction performance for elongation is insufficient.
Based on the support vector regression, the frequency histogram is calculated by MCMC sampling (). summarizes the extracted relations between the mechanical properties and each explanatory variable from the frequency histogram. In many cases, an optimum value exists to obtain high or low mechanical properties, which cannot be understood via simple correlation analysis using correlation coefficients. For a high proof stress and a tensile strength, the relations are the same. That is, the compositions of Mg and Cu should be increased, while the Mn, Al, Cr, and V compositions are decreased. On the other hand, almost the opposite relations are observed for high elongation, demonstrating that it is difficult to obtain alloys with the three high mechanical properties in the 7000 series.
Figure 6. Distributions of temper designation X and compositions of elements to obtain high (red) or low (blue) mechanical properties by MCMC sampling in the 7000 series. Support vector regression is used as a machine learning prediction model. Temper designation X has a discrete value, while others have continuous values.
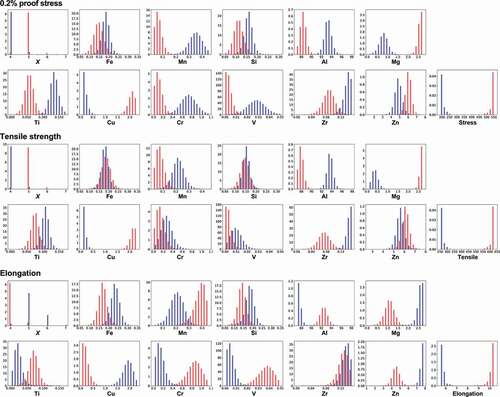
Table 4. Extracted relations between the mechanical properties and each explanatory variable for the 7000 series. White and black triangles denote whether to increase and decrease for high (upper table) or low (lower table) mechanical properties, respectively. Bar indicates almost no relation, while asterisk denotes an optimum value exists.
4. Discussion and summary
We have proposed a materials informatics technique that combines a machine learning prediction model and MCMC to extract the relations in materials databases. Our strategy can visually understand relations between the properties of materials and explanatory variables such as the compositions of elements, structures, and processes to obtain the desired properties. Our implementation of the strategy is available on GitHub [Citation57]. Herein we target aluminum alloys of 5000, 6000, and 7000 series and show that relations, which are difficult to understand using simple correlation analysis, can be extracted. For example, in the 5000 series, aluminum alloys with high proof stress, tensile strength, and elongation may be realized by increasing the Mn and Mg compositions and decreasing the Al composition. In the 6000 series, temper designation X and Al composition are predominantly related to the proof stress and tensile strength, while the others have small relations. Furthermore, if three high mechanical properties are desired, the Cu composition should be large. For the 7000 series, almost the opposite relations are observed between the proof stress/tensile strength and elongation against the compositions of elements. Thus, it is difficult to optimize the mechanical properties simultaneously. Such information is useful to develop new aluminum alloys that meet the needs of industry.
It should be noted that these extracted relations are for the prepared dataset. It is possible that the extracted relations will differ if the dataset is expanded. Thus, to extract reliable relations, a certain amount of reliable data is required so that a machine learning prediction model with sufficient prediction accuracy can be trained. If the prediction accuracy is low, the reliability of the drawn distribution by MCMC will be poor. Accordingly, the reliability of the extracted relations will be low. For example, in our demonstration, the prediction accuracy of the regression model used in the 7000 series is insufficient, and the reliability of the extracted relations is not high. Therefore, to extract reliable relations by our strategy, we should prepare a certain amount of reliable data.
The main advantage of our proposed strategy is that it can be applied to all regression methods to extract relations in the dataset. Conventionally, regression methods (e.g., linear and random forest regressions) are limited when attempting to obtain the contributions of each explanatory variable in the prediction model. In contrast, our strategy can obtain the dependencies of the predicted properties on explanatory variables for every regression method. Compared with conventional techniques, our strategy is universal and can extract the relations without limitations due to the machine learning model.
Moreover, our technique can be used to design an experimental plan to optimize the properties while promoting the understanding of target materials. That is, our strategy can be used to find the direction of the explanatory variables which will realize the desired mechanical properties. This can work not only for a single target property but also for multiple target properties with completely positive relations. On the other hand, if we want to improve some properties with opposite relations (e.g., the proof stress and elongation in the 7000 series) simultaneously, it is difficult to determine the appropriate setting of the next experiment. However, through our data-driven analysis, such difficulties in the experimental design can also be understood. Since our technique has diverse uses, we believe that it is a valuable tool to develop new materials, including alloys.
Supplemental Material
Download Comma-Separated Values File (7.6 KB)Supplemental Material
Download Comma-Separated Values File (2.3 KB)Supplemental Material
Download Comma-Separated Values File (1.8 KB)Supplemental Material
Download PDF (2.2 MB)Acknowledgments
We thank Norio Maruyama for the useful discussions. This article is based on the results obtained in NIMS-TOYOTA Materials Center of Excellence for Sustainable Mobility.
Disclosure statement
No potential conflict of interest was reported by the authors.
Supplementary material
Supplemental data for this article can be accessed https://doi.org/10.1080/14686996.2020.1791676.
Related Research Data
References
- Pilania G, Wang C, Jiang X, et al. Accelerating materials property predictions using machine learning. Sci. Rep. 2013;3:1–6.
- Meredig B, Agrawal A, Kirklin S, et al. Combinatorial screening for new materials in unconstrained composition space with machine learning. Phys. Rev. B. 2014;89:094104.
- Seko A, Togo A, Hayashi H, et al. Prediction of low-thermal-conductivity compounds with first-principles anharmonic lattice-dynamics calculations and Bayesian optimization. Phys. Rev. Lett. 2015;115:205901.
- Ikebata H, Hongo K, Isomura T, et al. Bayesian molecular design with a chemical language model. J. Comput. Aided. Mol. 2017;31:379–391.
- Ju S, Shiga T, Feng L, et al. Designing nanostructures for phonon transport via Bayesian optimization. Phys. Rev. X. 2017;7:021024.
- Kim E, Huang K, Jegelka S, et al. Virtual screening of inorganic materials synthesis parameters with deep learning. npj Comput. Mater. 2017;3:1–9.
- Pilania G, Gubernatis JE, Lookman T. Multi-fidelity machine learning models for accurate bandgap predictions of solids. Comput. Mater. Sci. 2017;129:156–163.
- Dieb TM, Ju S, Yoshizoe K, et al. MDTS: automatic complex materials design using Monte Carlo tree search. Sci. Technol. Adv. Mater. 2017;18:498–503.
- Yang X, Zhang J, Yoshizoe K, et al. ChemTS: an efficient python library for de novo molecular generation. Sci. Technol. Adv. Mater. 2017;18:972–976.
- Gómez-Bombarelli R, Wei JN, Duvenaud D, et al. Automatic chemical design using a data-driven continuous representation of molecules. ACS Cent. Sci. 2018;4:268–276.
- Sawada R, Iwasaki Y, Ishida M. Boosting material modeling using game tree search. Phys. Rev. Mater. 2018;2:103802.
- Sumita M, Yang X, Ishihara S, et al. Hunting for organic molecules with artificial intelligence: molecules optimized for desired excitation energies. ACS Cent. Sci. 2018;4:1126–1133.
- Sakurai A, Yada K, Simomura T, et al. Ultranarrow-band wavelength-selective thermal emission with aperiodic multilayered metamaterials designed by Bayesian optimization. ACS Cent. Sci. 2019;5:319–326.
- Wu S, Kondo Y, Kakimoto M, et al. Machine-learning-assisted discovery of polymers with high thermal conductivity using a molecular design algorithm. npj Comput. Mater. 2019;5:1–11.
- Robeson LM. Correlation of separation factor versus permeability for polymeric membranes. J. Memb. Sci. 1991;62:165–185.
- Rajan K. Materials informatics. Mater. Today. 2005;8:38–45.
- Balachandran PV, Theiler J, Rondinelli JM, et al. Materials prediction via classification learning. Sci. Rep. 2015;5:1–16.
- Pilania G, Mannodi-Kanakkithodi A, Uberuaga BP, et al. Machine learning bandgaps of double perovskites. Sci. Rep. 2016;6:1–10.
- Svetnik V, Liaw A, Tong C, et al. Random forest: A classification and regression tool for compound classification and QSAR modeling. J. Chem. Inf. Comput. Sci. 2003;43:1947–1958.
- Carrete J, Li W, Mingo N, et al. Finding unprecedentedly low-thermal-conductivity half-heusler semiconductors via high-throughput materials modeling. Phys. Rev. X. 2014;4:011019.
- Attarian Shandiz M, Gauvin R. Application of machine learning methods for the prediction of crystal system of cathode materials in lithium-ion batteries. Comput. Mater. Sci. 2016;117:270–278.
- Stanev V, Oses C, Kusne AG, et al. Machine learning modeling of superconducting critical temperature. npj Comput. Mater. 2018;4:1–14.
- Toyao T, Suzuki K, Kikuchi S, et al. Toward effective utilization of methane: machine learning prediction of adsorption energies on metal alloys. J. Phys. Chem. C. 2018;122:8315–8326.
- Ghiringhelli LM, Vybiral J, Levchenko SV, et al. Big data of materials science: critical role of the descriptor. Phys. Rev. Lett. 2015;114:105503.
- Ghiringhelli LM, Vybiral J, Ahmetcik E, et al. Learning physical descriptors for materials science by compressed sensing. New J. Phys. 2017;19:023017.
- Ouyang R, Curtarolo S, Ahmetcik E, et al. SISSO: a compressed-sensing method for identifying the best low-dimensional descriptor in an immensity of offered candidates. Phys. Rev. Mater. 2018;2:083802.
- Igarashi Y, Ichikawa H, Nakanishi-Ohno Y, et al. ES-DoS: exhaustive search and density-of-states estimation as a general framework for sparse variable selection. J Phys Conf Ser. 2018;1036:012001.
- Igarashi Y, Takenaka H, Nakanishi-Ohno Y, et al. Exhaustive search for sparse variable selection in linear regression. J. Phys. Soc. Jpn. 2018;87:044802.
- Sodeyama K, Igarashi Y, Nakayama T, et al. Liquid electrolyte informatics using an exhaustive search with linear regression. Phys. Chem. Chem. Phys. 2018;20:22585–22591.
- Schmidt J, Marques MRG, Botti S, et al. Recent advances and applications of machine learning in solid-state materials science. npj Comput. Mater. 2019;5:1–36.
- Materials Project. [cited 2020 Jan 1]. Available from: https://materialsproject.org/
- Organic Materials Database. [cited 2020 Jan 1]. Available from: https://omdb.mathub.io/
- Stevanović V, Lany S, Zhang X, et al. Correcting density functional theory for accurate predictions of compound enthalpies of formation: fitted elemental-phase reference energies. Phys. Rev. B. 2012;85:115104.
- NIMS materials database (MatNavi). [cited 2020 Jan 1]. Available from: https://mits.nims.go.jp/index_en.html
- NIST alloy data. [cited 2020 Jan 1]. Available from: https://www.nist.gov/mml/acmd/trc/nist-alloy-data
- Mondolfo LF. Aluminum alloys. London: Butterworths; 1976.
- Davis JR. Aluminum and aluminum alloys. Netherlands: ASM International; 1993.
- Hirsch J, Skrotzki B, Gottstein G. Aluminium alloys: the physical and mechanical properties. New York: John Wiley & Sons; 2008.
- Total Materia. [cited 2018 Apr 1]. Available from: https://www.totalmateria.com/page.aspx?ID=Home&LN=EN
- Aluminum database. [cited 2018 Apr 1]. Available from: http://metal.matdb.jp/JAA-DB/
- ISO 2107. Aluminium and aluminium alloys - Wrought products - Temper designations.
- JIS H 0001. Aluminium, magnesium and their alloys - Temper designation.
- scikit-learn. Available from: https://scikit-learn.org/stable/
- Ueno T, Rhone TD, Hou Z, et al. An efficient Bayesian optimization library for materials science. Mater. Discovery. 2016;4:18–21.
- emcee. [cited 2019 Apr 1]. Available from: https://emcee.readthedocs.io/en/stable/
- Foreman-Mackey D, Hogg DW, Lang D, et al. emcee: the MCMC Hammer. Publ. Astron. Soc. Pac. 2013;125:306. .
- Goodman J, Weare J. Ensemble samplers with affine invariance. Commun. Appl. Math. Comput. Sci. 2010;5:65–80. .
- Tamura R, Hukushima K. Method for estimating spin-spin interactions from magnetization curves. Phys. Rev. B. 2017;95:064407.
- Obinata K, Katakami S, Yue Y, et al. Ising model parameter estimation with confidence evaluation using the exchange Monte Carlo method. J. Phys. Soc. Jpn. 2019;88:064802.
- Shinotsuka H, Nagata K, Yoshikawa H, et al. Development of spectral decomposition based on Bayesian information criterion with estimation of confidence interval. Sci. Technol. Adv. Mater. 2020;21:402–419.
- Boslaugh S. Statistics in a Nutshell. Sebastopol: O’Reilly Media, Inc; 2012.
- pandas.DataFrame.corr. [cited 2018 May 1]. Available from: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.corr.html
- Durrheim K, Tredoux C. Numbers, hypotheses & conclusions: a course in statistics for the social sciences. Cape Town: Juta and Company Ltd; 2004.
- Sato S, Endo T. Relation between tensile strength and hardness of aluminum alloys. J. Jpn. Inst. Light. Met. 1986;36:29–35.
- Kim JG, Baek SM, Lee HH, et al. Suppressed deformation instability in the twinning-induced plasticity steel-cored three-layer steel sheet. Acta Materialia. 2018;147:304–312.
- Liu R, Tian YZ, Zhang ZJ, et al. Exploring the fatigue strength improvement of Cu-Al alloys. Acta Materialia. 2018;144:613–626.
- IE-MCMC. [cited 2020 Jun 1]. Available from: https://github.com/rtmr/IE-MCMC