
Abu-Mostafa, Magdon-Ismail and Lin have written a very interesting and useful book on learning from data. Commendably, they have refrained from using the trendy words ‘Big Data’ in the title (and, indeed, in the text) despite the fact the method they write about can be directly applied to large amounts of data. Had the book no other virtues, this by itself would put it at the top of my reading list. However, there is a lot more to like about this slim volume. It has obviously been written with a university course in mind (‘This is a short course, not a hurried course’, the Authors warn the readers—and they are quite right about this!), but the readership that will (or should) find this book very interesting is far wider than a cohort of undergraduate or first-year graduate computer scientists. Anybody who creates reduced-form financial models, anybody who engages in model fitting, anybody who studies excess returns and hunts for return-predicting factors, anybody who frets about over-parameterized models … anybody, in short, who comes in touch in her work with data (big, small or otherwise) will benefit immensely from this book. It is clear, precise, and well written. It demands more concentration and subtle thinking than mathematical pyrotechnics (the mathematical requisites are kept as simple as possible, and a lot is achieved with very simple probability). I enjoyed it a lot, and I will use it even more.
Before delving into a discussion of the topics covered, it is important to understand what the book is about, and what, strictly speaking, it is not about. Its domain is what Prof. Leslie Valiant called in a recent book (Probably Approximately Correct, reviewed in these pages in XXXX) ‘theoryless learning’; the inelegant but expressive term is meant to distinguish this form of learning from theory-driven learning—those types of learning, that is, where a theory about how the world is supposed to work plays an important role. Maxwell equations or the CAPM model are examples of theory-driven approaches to learning. Theoryless learning arises, instead, in domains such as credit scoring, guessing of buying preferences, or, according to Prof. Valiant, biological evolution—in situations, that is, where no guiding theory exists to recognize a good outcome (say, credit decision, book recommendation and genetic mutation) from a bad one.
Now, this type of theoryless learning is becoming more and more common, but most of the finance and economics practitioners and researcher who work with data usually engage in strongly theory-driven activities. Are the teachings of this book therefore inapplicable? Not at all. Some of the quantitative results obtained in the book (about confidence levels, error bounds, etc.) and some of the most draconian recommendations are not strictly applicable. However, the discipline in working with data that the book instils, and the conceptualization that it affords, are very transferable, and all too frequently forgotten. As a motivation, here are the words (in the context of fixed-income return-predicting factors) from a researcher (Prof. Cochrane) who certainly uses a very theory-driven approach in his work:
Really, the problem is, that we could have found so many other similar variables [to explain the findings]. If the data had a significant V shaped pattern, we could have found that. If they were higher on even vs. odd years, we would have found that. That’s the sense in which it is ‘easy’ to find these results. This is really a specification problem, not an econometric problem. Traditionally, the main guard against this kind of fishing has been an economic interpretation of the forecasting variable. But that discipline is dying out, with the result that we have hundreds of claimed forecasting variables.Footnote 1
We shall come back to this quote by the end of this review.
So, what are the ideas presented in Learning from Data? A good place to start is to illustrate the simplest example the Authors discuss, that of a hypothetical theoryless approach to credit scoring. In this setting, a learner has many training examples, i.e., couples (x, y) of input vectors, x (e.g., FICO score, years in residence at present address, renting or owner-occupier, etc.), and outcomes, y (whether the borrower returned the money she had borrowed). There is an unknown target function, f, from the training set to the outcomes: f: X → Y. This function, which we would like to discover (or approximate), produces the best possible mapping between the inputs and the outputs. It is, alas, unknown to us. We search for approximations to the prefect function f in a set, H, of candidate functions, using a learning algorithm, A. The outcome of our search will be a function, g, which, we hope, will approximate well the unknown function, f.
This schema can be considerably enriched, but constitutes the simplest example of supervised learning—of the setting, that is, where the training data contains ‘explicit examples of what the correct output should be for given inputs’. Matters become a bit more complex with reinforcement learning: in this case we do not have access to a binary outcome (success and failure) for each input vector, but ‘the training example […] contains some possible output together with a measure of how good that output is.’ Finally, the greatest challenge is with unsupervised learning, in which we are just given input examples, x 1, x 2, …, x n , but no outputs. (Yes, even in this direst of cases, not all is lost: we may still try, for instance, classification, cluster identification and pattern recognition—see Example 1.6: this is the area of ‘knowledge discovery’, a murkier field sometimes referred to as ‘finding interesting patterns’.Footnote 2 )
Given supervised, reinforcement and unsupervised learning and a truly unknown target function f, the first question is whether learning is at all possible. The stumbling block seems to be that any finite training set, D, is in principle compatible with many unknown functions f that may generate exactly the same data we observe, but which may behave differently in the new instances we are interested in.
The way out of the impasse is to settle for a probabilistic answer to the question of whether learning is possible. This the authors do with admirable clarity by first taking a detour based on elementary probability (draws from an urn with an unknown fraction of red and green balls) and then showing that this ball-drawing setting can be made equivalent to the learning environment we are interested in. In the case of draws from an urn, the result is the deceptively simple Hoeffding inequality, which says that, if the population mean is μ and the recorded sample average is m, then the error in estimating the mean can be probabilistically bounded as
Chapter 1 then explains how this result can be extended to the learning setting, and, in doing so, introduces the fundamental concepts of in-sample and out-of-sample errors. In-sample error is the error our candidate function incurs in fitting the data we know already. Out-of-sample error is the error the candidate function will make when used in anger with not-yet-seen data. In a nutshell, learning from data boils down to finding an optimal trade-off between the in-sample error and out-of-sample error. Fit what you know already too well, and your out-of-sample performance will deteriorate—this is the curse of over-fitting. Fit your training set too coarsely, and you are giving up in predicting power. Much of what is presented in the rest of the book is a mathematically principled approach to evaluating this trade-off.
The reader new to the subject may hope by the end of Chapter 1 that the first version of Hoeffding inequality will have most, if not all, of the answers needed. Matters, alas, are not quite as simple as that, and the accompanying theory of generalization is the topic of Chapter 2. This chapter constitutes the mathematically most demanding part of the book (this, by the way, is the only chapter that cannot be skipped, read out of order or studied in a ‘modular’ fashion, as it contains the foundations for the rest of the book). The problem is that, when the Hoeffding inequality is applied to the learning problem, the error bound depends also on the size, M, of the hypothesis set, H. When the set H is infinite (which is very often the case), the bound becomes meaningless.
To get out of the impasse the Authors first explain the union bound—which gives a mathematically true, but practically useless, result, because the bounds it produces are too loose; and then introduce the effective number of hypotheses—roughly speaking, a combinatorial quantity ‘that captures how different the hypotheses in H are’.Footnote 3 The most important result of Chapter 2 (and, in a sense, the foundation for the rest of the book) is found in Equation 2.12, which states that the out-of-sample error must be smaller of equal to the in-sample-error plus a (positive) quantity, which is a function of the number of observations and of the growth function (which is related to the effective number of hypotheses). Once this result is obtained, a number of useful, intuitive and, sadly, often-forgotten quantities (such as the penalty for model complexity) can be easily derived.
With these results under the belt, Chapter 3 gives a treatment of linear models, and linear and logistic regressions (Sections 3.2 and 3.3) appear as special members of this class.
Chapter 4 contains some of the most useful applications of the foundations laid in Chapter 2, as it deals with overfitting; in particular it provides practical answers to the questions: ‘When does overfitting occur? What are the tools to combat overfitting? How can one estimate the degree of overfitting and ‘certify’ that a model is good, or better than another?’Footnote 4 One of the more surprising results of this chapter is that overfitting does not necessarily arise when the learning model has been endowed with too many bells and whistles in the foolish attempt to reduce the in-sample error, and goes crazy out-of-sample with its turbo-charged capabilities. More surprisingly, ‘[o]verfitting can occur even when the hypothesis set contains only functions that are far simpler than the target function, and so the plot thickens.’Footnote 5
Finally, Chapter 5 deals with three general learning principles, namely, Occam’s razor, sampling bias, and data snooping’. The discussion of Occam’s razor is refreshingly clear and down-to-earth. The concreteness of their treatment is particularly welcome, as Occam’s principle possibly vies with Heisenberg’s principle for being the most-misunderstood-yet-widely-quoted scientific sound-byte, and its description is often shrouded in quasi-mystical terminology. So how do the authors explain Occam’s prescription?
First, they restate it asFootnote 6 ‘The simplest model that fits the data is also the most plausible’,Footnote 7 and then provide an operative answer to the questions ‘what does it mean for a model to be simple?’ and, most importantly, ‘how do we know that simple is better?’
The explanation the Authors provide is based on the concept of complexity introduced in Chapters 2 and 4, and on the important distinction between the complexity of a set, and the complexity of an individual object—so, for instance, entropy is a measure of complexity for a family of objects, while the minimum description length relates to the complexity of a member of the family. The key insight here is that a simple object is not just simple in itself (in the sense that it requires few ‘bits’ to describe it), but must also be a member of a ‘simpler’ family, in the sense that it must be one of few: 3rd-order polynomials are not only individually simpler than, say, 17th-order polynomials, but, in some sense to be made precise, there are also ‘more’ 17th-order polynomials to start with.
Having made this distinction clear, the authors explain that requiring a model to be ‘simpler’ has no aesthetic connotations, but just means that it has more chances of being right. Why so? In a nutshell, just because there are fewer simple hypotheses than complex ones. If one of these few simple candidate hypothesis does a good job at explaining the data at hand, then it is more likely that we have stumbled on something interesting than if the same (or a somewhat better) fit had been obtain by one of the zillion candidate hypotheses of the complex set. The nice example the Authors present about interviewing for a job potentially coin-flipping tradersFootnote 8 provides a nice illustration: ‘[a] perfect predictor always exists in [the] group [of 2 n coin-flipping traders], so finding one doesn’t mean much. If we were interviewing only two traders, and one of them made perfect predictions, that would mean something’.Footnote 9
Finally, the treatment of sampling bias contains an extremely interesting example, which I discuss at some length because I think it is very instructive. It relates to the ‘back-testing’ of a trading strategy for the USD/GBP exchange rate, with 75% of the data used for training and the remaining 25% set aside to test the trading rule. In the back-test, the trading strategy seems to perform very well out-of-sample (i.e., the 25% of the test data). However, when used in real trading, it performs much worse—so much so, that it actually loses money. See Figure . What happened is that, without realizing we were doing so, we were actually data-snooping.
Figure 1. The USD/GBP trading strategy discussed in the text with and without ‘snooping’ (red and blue line, respectively).
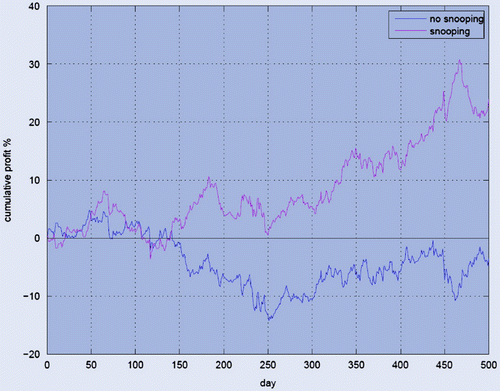
What exactly went wrong? The difficult-to-spot occurrence of data-snooping was that, prior to the analysis proper, the data had been standardized to have zero mean and unit variance—nothing wrong with this. What was wrong was that the normalization was carried out using not just the learning set, but the whole data-set. ‘Therefore, the test data that was extracted had already contributed to the choices made by the learning algorithm by contributing to the values of the mean and the variance that were used in the normalization. […] It is not the normalization that was a bad idea. It is the involvement of test data in that normalization, which contaminate this data and rendered its estimate of final performance inaccurate’.Footnote 10
The relevance of this example goes well beyond the apparently contrived example of the FX trading strategy, and sent a shiver down my spine. The sin of data-snooping is insidious and its wages may not be death, but are still nefarious. It is far more ubiquitous than most researchers (including this reviewer) often realize. The continuous reuse of the same data by a researcher to obtain a statistically significant result, for instance, has ‘data snooping’ written all over. However, there are more ‘covert’ instances of data-snooping. For example, often some financial data are the public domain, as are used by literally dozens (if not hundreds) of researchers who all look at pretty much the same problems. (Think for instance of the equity premium puzzle investigated using the CRSP data-set, or of the excess-return studies carried out using the panel data of discount factors by Gurkaynak et al. (Citation2007)). In this situation, ‘[b]efore you download the data, you read about what other people did with this data-set using different techniques. You naturally pick the most promising technique as a baseline, then try to improve on it and introduce your own ideas. Although you haven’t seen the data-set yet, you are already guilty of data snooping. Your choice of baseline technique was affected by the data-set, through the actions of others […] since the techniques you are using have already proven well-suited to this particular data-set’.Footnote 11 In quantitative terms, this means that the effective (VC) dimension of the problem relates to bigger set of hypotheses than the restricted hypothesis set, H, which the algorithm used in the ‘new’ study employs. The statistical conclusions drawn from the restricted hypothesis set, H, would only apply if you were the first researcher to use those data in that way. The quote by Cochrane about ‘excess-return-predicting-factor fishing’ at the start of this review is particularly apt in this context.
The very ‘purist’ position the Authors embrace may strike some readers as unrealistic. What is wrong, one might say, about looking at a plot of your data first, and then deciding that carrying out, say, a quadratic transformation of variables before attempting a linear regression may be good idea? Nothing, the authors would probably reply, as long as you are willing and capable to account for the degree of data-snooping when you quote the confidence in your R 2 and your t-statistics.
There would be many more interesting topics dealt with in the book to discuss, but I hope I have both conveyed the gist of the authors’ arguments, and given an idea how deftly they present them. The book is very nicely written, with a style of presentation that, much as the models the Authors recommend, is ‘as simple as can be but not any simpler’. It is thoughtful, stimulating and clear. Surprisingly, given the quality of the work, the book was not produced by a publishing house, and was presumably the output of a self-publication effort. If this is the case, the editing care the Authors have devoted to equations, language, style and figures can put many reputable publishing houses to shame (including some University Presses).
If I were to look for a blemish, I would point to the almost complete absence of any reference to Bayesian statistics or probability: I checked the index, in case I missed something in my reading, and the only reference to Bayes’ theorem points to an exercise; as for Bayesian learning, it is only mentioned in one paragraph on page 181 of 182. This absence is all the more surprising because books in closely related areas, such as Murphy’s Machine Learning (Citation2012) or MacKay’s Information Theory, Inference and Learning Algorithms (Citation2003) can give the impression that machine learning is just an application of Bayesian techniques. Perhaps a more balanced approach could have helped the intended readers better?
Notes on contributor
Riccardo Rebonato is Professor of Finance at EDHEC, and sits on the Board of Directors of GARP. He has worked in the financial industry for 25 years, as head of research, trading and risk management. His latest book, Portfolio Management under Stress, has been published by CUP.
EDHEC, France
© 2016, Riccardo Rebonato
Notes
1 Cochrane, J.H., (2015), Comments on “Robust Risk Premia” by Michael Bauer and Jim Hamilton, working paper, University of Chicago, November 2015. Available online at: http://faculty.chicagobooth.edu/john.cochrane/research/Papers/bauer_hamilton_comments.pdf (last accessed 27 November 2015, emphasis added).
2 See, e.g., Murphy (Citation2012), page 2.
3 Page 41.
4 Page 119.
5 Page 119.
6 By the way, a far as I know, what Occam actually wrote was ‘Entia non sunt multiplicanda praeter necessitatem’—roughly speaking, ‘One should not keep on inventing more entities then strictly needed’. I often wonder whether he would recognize, or at all make sense, of the modern versions of his dictum.
7 Page 167.
8 Page 170–171.
9 Ibid.
10 Page 175.
11 Ibid
References
- Gurkaynak, R.S. , Sack, B. and Wright, J.H. , The US treasury yield curve: 1961 to the present. J. Monetary Econ. , 2007, 54 , 2291–2304.10.1016/j.jmoneco.2007.06.029
- MacKay, D. , Information Theory, Inference and Learning Algorithms , 2003 (Cambridge University Press: Cambridge,).
- Murphy, K.P. , Machine Learning: A Probabilistic Perspective , 2012 (MIT Press: Cambridge, MA).