
Abstract
The focus of this paper is the efficient computation of counterparty credit risk exposure on portfolio level. Here, the large number of risk factors rules out traditional PDE-based techniques and allows only a relatively small number of paths for nested Monte Carlo simulations, resulting in large variances of estimators in practice. We propose a novel approach based on Kolmogorov forward and backward PDEs, where we counter the high dimensionality by a generalization of anchored-ANOVA decompositions. By computing only the most significant terms in the decomposition, the dimensionality is reduced effectively, such that a significant computational speed-up arises from the high accuracy of PDE schemes in low dimensions compared to Monte Carlo estimation. Moreover, we show how this truncated decomposition can be used as control variate for the full high-dimensional model, such that any approximation errors can be corrected while a substantial variance reduction is achieved compared to the standard simulation approach. We investigate the accuracy for a realistic portfolio of exchange options, interest rate and cross-currency swaps under a fully calibrated 10-factor model.
1. Introduction
Managing Counterparty Credit Risk (CCR) has become one of the core activities of financial institutions since the credit crisis in 2008. The Basel III rules introduced Credit Value Adjustment (CVA) which increased counterparty risk capital requirements (Gregory Citation2015) and has significant consequences for the valuation of derivatives. The CVA is the difference between the value of a portfolio without default risk and the true portfolio value which includes default risk of the counterparty (Pykhtin and Zhu Citation2007). By including CVA, one can theoretically hedge away credit risk. More recently, Debt Value Adjustment (DVA), Funding Value Adjustment (FVA) and Capital Value Adjustment (KVA) (Green et al. Citation2014) were defined and this collection of value adjustments is now referred to as XVA. For all these adjustments, Expected Exposure (EE) and Expected Positive Exposure (EPE) are main ingredients that have to be computed from the future distribution of the underlying portfolio. In this paper, we develop an approximation method for these exposures on portfolio level.
Many traded portfolios consist of multiple underlying assets and derivatives on these assets; these are valued by models with multiple risk drivers such as stochastic interest rates, FX rates and stochastic volatility. Computing the future value distributions, for which closed-form solutions are typically not available, is a challenging high-dimensional computational problem. A typical benchmark for methods geared towards high-dimensional problems are basket options, where the pay-off depends on a portfolio of assets, such as stocks, stock indices or currencies. These options serve the purpose of diversification and are therefore popular among investors (Bouzoubaa and Osseiran Citation2010). For the valuation of these options, contributions have been made by, e.g. Jain and Oosterlee (Citation2012) for Monte Carlo estimation under early exercise and Reisinger and Wissmann (Citation2015) for PDE approximations.
In the context of CVA, netting needs to be taken into account and possible negative or positive parts of the exposure distribution are to be considered. This makes CVA estimation for simple plain vanilla instruments similar to the valuation of a series of basket options with different maturity, but is more complex if the instruments themselves are more complex, i.e. no closed-from or semi-closed-form pricing formulae are available. The computational problem in that case can be formulated as the estimation of nested conditional expectations, where the inner expectations are future derivative prices conditional on the underlying risk factors, and the outer expectations, taken over the risk factors, are the expected exposures for the derivative portfolio.
For computing these risk measures, typically, Monte Carlo methods are used to sample the future states of the underlying risk factors by discretization and simulation. Portfolio values for all these states can then be computed in multiple ways, including: fully nested Monte Carlo simulation (Gordy and Juneja Citation2010, Broadie et al. Citation2011), where derivative values along those paths are estimated by an ‘inner’ Monte Carlo simulation; regression-based approaches, introduced for American style options in Longstaff and Schwartz (Citation2001) and applied in the context of exposure in Karlsson et al. (Citation2014) and Joshi and Kang (Citation2016); or a grid or Fourier-based method for the inner expectations and Monte Carlo sampling of the outer expectation (de Graaf et al. Citation2014).
All these different methods have their particular strengths and weaknesses. The naïve nested Monte Carlo method is generically applicable but computationally extremely expensive with a complexity of for root-mean-square error (RMSE)
. This can be improved when the computational budget between inner and outer simulations is optimally balanced, e.g.
when trading off ‘inner’ bias and ‘outer’ variance (Gordy and Juneja Citation2010), and
for arbitrary
for certain non-uniform estimators (Broadie et al. Citation2011). Regression-based approaches have in a sense optimal complexity
as no extra ‘inner’ paths are required (Broadie et al. Citation2015), but an additional bias creeps in when leaving out sets of regression variables in higher dimensions and, in our experience, regression methods still exhibit relatively slow convergence in applications. In practical portfolio CVA computations, only about
to
paths are feasible, giving a high variance of estimators for both of these approaches, in particular for the sensitivities with respect to market factors. PDE schemes, on the other hand, are very efficient for low dimensions but suffer from the ‘curse of dimensionality’—a term used to describe the computational complexity which increases exponentially with the number of risk factors—which made Monte Carlo methods the industry standard technique for problems with dimensions larger than two or three.
Notwithstanding this, we propose a method based on PDEs not just for the inner, but also for the outer expectation. We address the curse of dimensionality by decomposition of the conditional expectations into groups of risk factors, hence breaking the high-dimensional problem up into a sequence of lower dimensional problems, whose solutions are then assembled into a truncated decomposition. For these low-dimensional problems numerical PDE methods are available which give sufficiently accurate approximations in acceptable time. We will find that for practically sufficient accuracy, the approximation requires solving only one one-dimensional base approximation and multiple two- and three-dimensional approximations which are used as corrections. Perhaps practically most relevant, the approximated portfolio dynamics underlying these expansions can be used to construct control variates for Monte Carlo estimators. As such, we do not see this methodology to compete with the above simulation approaches, but to be used in conjunction with them, as it provides a way to combine seamlessly the high accuracy of PDE schemes in low dimensions and the robustness of Monte Carlo schemes in high dimensions. This includes improvements of Monte Carlo schemes using quasi-Monte Carlo sampling (both for regression and nested simulation).
Note that our approach is distinctly different from dimension and variance reduction methods based on conditional sampling as in Dang et al. (Citation2015), Cozma and Reisinger (Citation2017) and Dang et al. (Citation2017).
The method proposed here draws on a variety of related previous work, but requires substantial extensions for the present context:
in terms of application and problem structure, the method extends Reisinger and Wittum (Citation2005) from basket options under Black–Scholes to portfolio risk management under a general class of models;
specifically, for the exposure estimation problem formulated as nested conditional expectations, we solve a combination of forward and backward Kolmogorov equations and carry out numerical integration of the solutions;
compared to the dimension-wise integration method of Griebel and Holtz (Citation2010), the future distribution here is unknown, such that forward PDEs have to be approximated;
compared to Reisinger and Wittum (Citation2005), Reisinger and Wissmann (Citation2015), we use original variables as factors instead of principal components; this makes the results more easily interpretable;
compared to Reisinger and Wissmann (Citation2017) which provides error bounds for the constant coefficient setting, we deal with the case of non-linear SDEs and variable-coefficient PDEs, which requires a generalized definition of the expansion;
instead of theoretical error bounds, we assess the method on a complex real-world example, as outlined in the following.
In actual practical applications, one may want to consider FX and interest rate smiles and a multi-curve framework in which a stochastic basis model should be used. In terms of the latter, however, little is known on how to calibrate the basis vol in an implied measure, and therefore in most pricing models basis is considered as deterministic. In the context of CCR, the problem is even more complex since one can argue that basis is a mixture of credit and liquidity and therefore, it is not clear if it should be modelled as a pure IR component or whether it is a separate risk factor strongly correlated with credit. As such, the question is linked with other modelling complexities such as wrong-way risk.
These modelling aspects are beyond the scope of the paper. We emphasize though that the computational framework presented here is rich enough to incorporate such extensions. We demonstrate the flexibility of the approach by giving results for an extension including stochastic volatility, namely the Heston-2-Hull–White model. For the three chosen currency pairs this leads to a 10-dimensional PDE, where we demonstrate that a relative accuracy of about 1% can be achieved for expected positive exposure computations.
The models are calibrated to market data and for these different portfolios we compute EE and EPE and compare our results with a full-scale Monte Carlo benchmark, demonstrating vastly superior computational complexity.
The outline of this paper is as follows. In the following section 2, we describe the problem set-up. In section 3, we explain the main approximation technique used. (A brief description of the finite difference schemes used for the PDEs in the decomposition is given in appendix 2.) In section 4, we set up our case studies followed by section 5 were we present our results. In section 6, we provide a discussion and concluding remarks.
2. Problem formulation
We consider the general framework of a financial market described by a d-dimensional stochastic process . In our applications, X will be given by a stochastic differential equation of the form:
(1)
where W is a d-dimensional standard Brownian motion with a given correlation matrix , and
a given initial state,
is the drift,
the volatility. We assume that the processes are written under a risk-neutral measure
, which is relevant for derivative valuation as well as regulatory CVA computations.
We now consider derivatives on X. For simplicity, we focus on the European case here. Let the pay-off function determine the amount
to be received by the holder at time
for
. The arbitrage-free value
of this claim for
is then,
where is a discount factor (and we have dropped the subscripts k for simplicity), and satisfies the Kolmogorov backward PDE (see, e.g. Musiela and Rutkowski Citation2005),
(2)
For Counterparty Credit Risk (CCR), not only the time 0 value is important, but also the evolution of this value after the deal has been entered. In this work, we use several measures to quantify CCR. Let
be the value of a portfolio of derivatives at time t that a financial institution holds, where
,
, are derivative portfolio weights. Here, we set
for
, the expiry of the k-th derivative.
First, following Pykhtin and Zhu (Citation2007), Expected Exposure (EE) is defined as the expected value of the portfolio at time ,Footnote†
(3)
where is the filtration at time
. Similarly, the Expected Positive Exposure (EPE) at a future time
is given by,
(4)
Note that the Expected Negative Exposure (ENE) can be computed by taking the minimum instead of the maximum in equation (Equation5(5) ), or from ENE
EE
EPE. In short, EPE (ENE) gives the expected loss of the buyer (seller) of the portfolio in case he or she is in the money and the counterparty defaults, which makes them of prime importance when computing CVA and other XVAs. For example, CVA is defined as,
(5)
where R is the recovery rate, is the discounted EPE and
denotes the default probability of the counterparty at time t (Gregory Citation2010). Note that (Equation6
(6) ) incorporates the debatable but common assumption that the portfolio value is independent of default events (no ‘wrong-way risk’).
In this paper, we focus solely on the computation of EE and EPE. For exposure calculations at time 0, we then consider functionals of the form,(6)
where is an exposure function, e.g.
in the case of EE, or
for EPE. This can be adapted in the obvious way for American or path-dependent options.
Remark 1
To find V(x, 0; t), the expected (positive) exposure at time t as seen from time 0, we could therefore solve backward PDEs in (t, T) for , and then another backward PDE over (0, t) with
as terminal condition. This would however require the solution of a different backward PDE in the second stage for different t. To avoid this, in the following we utilize a forward PDE for the transition densities to compute exposures.
The reason we use the backward PDE to approximate instead of using the density function, is that we need the value of derivatives in the whole state-space reachable by X.
Let p(x, t; a, 0) be the transition density function of at x given state a at
, then
(7)
Here, p is given through an adjoint relation by the Kolmogorov forward equation,(8)
where is the Dirac distribution centred at 0.
Hence, we can obtain expected (positive) exposures by the solution of one forward PDE for the density and one backward PDE for each derivative in the portfolio, plus one integration for each t.
3. Approximation by risk factor decomposition
The principal difficulty in practice arises from the dimensionality d of X in (Equation1(1) ). Although
in (Equation7
(7) ) is typically very large, the computational complexity is linear in
, while it is exponential in d. In this section, we introduce an approximation technique which makes large d computationally manageable.
To introduce the concepts, we focus in section 3.1 on the problem of approximating(9)
(10)
i.e. for simplicity the discount factor is 1, where is the probability density function of
. We first discuss an extension of the anchored-ANOVA concept to PDEs with variable coefficients and the use of a ‘moving anchor’. In section 3.2, we explain how the approximations can be used as effective control variates for unbiased Monte Carlo estimators. The application to the complete expected exposure problem (Equation8
(8) ) will be discussed in section 3.3.
3.1. An anchored-ANOVA-type approximation
The proposed method extends anchored-ANOVA decompositions as considered by Griebel and Holtz (Citation2010) in the context of integration problems. In the setting and notation of (Equation12(12) ), the methodology in Griebel and Holtz (Citation2010) chooses an anchor
and then, for a given index set
, defines projections of the integrand
by
, where
denotes a d-vector such that,
(11)
This leads to a decomposition of f into lower dimensional functions, which can be exploited for successive quadrature approximations (see Griebel and Holtz Citation2010 and the references therein).
In contrast to there, we cannot assume here that the joint probability density function for is analytically known and therefore, we have to consider the dynamics of X directly. To improve the accuracy, e.g. to account for the term-structure of interest rates, here we do not concentrate the measure at a fixed anchor a, but we allow the anchor to move with a certain conditional expectation of the underlying process, as detailed in the following.
We first define a deterministic approximation to X from (Equation1(1) ), (Equation2
(2) ) by,
In Reisinger and Wissmann (Citation2015), a more simplistic approach is used where the drift is first approximated by , and then eliminated by a coordinate transformation
. The above construction takes into account more information about the term structure and also deals systematically with non-constant volatilities.
For given subset , we then define a process,
(12)
where follows the notation from (Equation13
(13) ).
Here, we have replaced a subset of the processes by their conditional expectations. For instance, if is an exchange rate and
and
are the domestic and foreign short rate in a Hull–White model, then
is the expectation of the exchange rate under a constant interest rate model, while
is simply the expectation of the domestic short rate. The point is that the dynamics is effectively of dimension |v|, and the expectation (Equation11
(11) ) can be approximated by lower dimensional problems.
Accordingly, we define(13)
where the right-hand side depends on a implicitly through the definition of in (Equation14
(14) ).
Specifically, the backward PDE for (Equation15(15) ) under (Equation14
(14) ) is,
(14)
The significance of the arguments in the coefficients of (Equation16
(16) ) is that the full information on the coordinates
,
is used, while the solution V(a; a, 0) at the anchor point can be computed solving only a |u|-dimensional PDE in the variables
,
.
Remark 2
The generalization from (Equation15(15) ) to
is straightforward and the corresponding backward PDE instead of (Equation16(16) ) is,
For future reference, we also have the forward PDE,(15)
From here onwards, we can follow the path of Griebel and Holtz (Citation2010) and the references therein, to define a decomposition recursively through a difference operator , by
and, for
,
(16)
where the inclusion in the first summation is strict.
This is indeed a decomposition because,(17)
We note that for ,
only depends non-trivially on the subset of coordinates
, and satisfies (Equation16
(16) ). Therefore,
and hence
can be found by the solution of problems of dimension not higher than |u|.
As an example, consider and
, then
We can now define an approximation by,(18)
where are integer constants, which also depend on s and d (we suppress this to keep the notation simple). The point is that the approximation
at the anchor can be found by solving PDEs of dimension at most s.
Remark 3
The approximations and
have certain similarities with delta and delta-gamma approximations, respectively (see, e.g. Alexander et al. Citation2006). In the latter, the derivative value is approximated by,
where ,
is the gradient or delta and
the Hessian or gamma. One notable difference is that
does not make any approximations if V is two-dimensional or a sum of two-dimensional functions, while delta-gamma always involves linear and quadratic approximations.
An alternative approximation, extending (Equation22(22) ), is given by,
(19)
Here, we always retain the first r coordinates, and apply the splitting only to the remaining coordinates. The approximation
at the anchor can be found by solving PDEs of dimension at most
. It is this approximation that we will use in the numerical computations later on in the paper, with
and
or
. The coordinate
is chosen to capture most of the dynamics, either through prior knowledge or small pilot runs with reduced accuracy.
For instance, for ,
, we have,
(20)
i.e. ,
in (Equation23
(23) ), and, for
,
,
(21)
i.e. ,
,
.
3.2. A control variate
In some situations, the approximation (Equation23(23) ) with small r and s will be sufficiently accurate. There is an expectation—but no guarantee in general—that increasing either r or s will improve the accuracy. The computation of further terms may also be prohibitively expensive due to the high dimensionality and number of PDEs involved. In such cases, it will be valuable to simulate certain corrections by a MC method—instead of computing them by PDEs—to obtain more accurate approximations.
Therefore, we now discuss a way to turn the approximation (Equation23(23) ) into a control variate for a Monte Carlo scheme for (Equation11
(11) ). Denote by
a set of
independent samples of the d-dimensional Brownian motion W, and
the (strong) solution to (Equation1
(1) ) for a given sample path
of W.
The standard estimator of V(x, 0) in (Equation11(11) ) is then,
Denote by the random pay-off, i.e. for event
define
and
(compare with (Equation23
(23) )), then we define the estimator
(22)
where will be determined later to achieve the best variance reduction, and
given by (Equation23
(23) ) will be constructed from numerical PDE solutions. From
we get
i.e. the standard estimator and the control variate estimator are both unbiased.
Typically, we will find that is optimal. Indeed, if
, then
(23)
i.e. we sample the approximation error of the truncated decomposition. The motivation for choosing over the standard estimator
is that for given
,
and
will be close and therefore the variance is much reduced compared to the standard estimator.
The value of which minimizes the variance is determined by the co-variances of the control variate and the standard estimator, which can be approximated by the estimators (see Glasserman Citation2004)
and the optimal value is estimated as . The variance reduction is then approximately,
Summarizing, in situations where the approximation from the previous section is not accurate enough, it can be corrected with a relatively small number of Monte Carlo samples of the correction terms (the right-hand sum) in (Equation27
(27) ).
3.3. Application to derivative portfolios
We now discuss approximations to expected exposures, as per (Equation7(7) ). To benefit from the dimension reduction of risk-factor decomposition, we compute the solutions of all PDEs involved in the spirit of section 3.1.
The general principle is to replace the process X in (Equation7(7) ) by
as defined in (Equation14
(14) ). Thus, we approximate V in (Equation8
(8) ) by,
(24)
where is the transition density function of
, which satisfies the forward PDE (Equation18
(18) ), (Equation19
(19) ) instead of (Equation9
(9) ). Similarly,
is given as the solution to (Equation16
(16) ), with pay-off function
in (Equation17
(17) ). The key point is that we compute
and
by solving |u|-dimensional PDEs, and (Equation28
(28) ) is a |u|-dimensional integration problem, as p is a Dirac measure in dimensions
.
Then is defined by (Equation28
(28) ) and (Equation23
(23) ). The complexity of the whole computation is linear in
, and exponential in
.
For products where model derivative prices are available in closed-form (such as most swaps), we will use those in the computations for speed and accuracy. For others (such as options), we will use numerical PDE approximations as outlined in appendix 2.
4. Case studies
In this section, we present the market set-up for the detailed numerical studies in section 5, where we compute expected exposures (Equation4(4) ) and expected positive exposures (Equation5
(5) ) of portfolios with increasing complexity.
The example consists of various exchange rate and interest rate products, and is chosen to be representative for the scenario where each product in a portfolio is exposed to one or more of a pool of risk factors. So for instance an exchange option of medium term maturity is exposed to interest rate risk in both the domestic and foreign markets, and conversely the domestic interest rate affects an exchange option as well as, say, a domestic zero coupon bond.
4.1. Driving risk factors
We consider a portfolio of FX and interest rate products. Each FX rate is assumed to be governed by a full BS2HW model (see, e.g. Clark Citation2011). Every FX rate , thus, has a stochastic domestic and foreign interest rate. For clarity of exposition, we consider the case where all exchange rates are relative to a single currency, in the case below the EUR, so that we can write the joint dynamics of FX and interest rates as,
(25)
(26)
(27) with given Brownian motions
, with
(28)
and I(i) is the index of the i-th exchange rate and J(i) the index of the i-th foreign rate (e.g. ,
). Here,
is the domestic short rate and
the foreign short rate for exchange rate
,
, with
the total number of markets.
The interest rates are modelled by a mean-reverting Hull–White process with and
,
, designed to fit the forward rate curve in the respective markets. More details on the calibration will be given in Section 4.3.
We defer the discussion of stochastic volatility models to section 5.5, but remark here that it is generally not straightforward to extend these models from a single currency pair to multiple pairs while preserving important FX characteristics like symmetry and the triangle inequality (see Doust Citation2012, De Col et al. Citation2013).
In the numerical examples, we choose EURUSD, EURGBP and EURJPY, i.e. . Together with piecewise constant volatility, the interest rates in the EUR (domestic) and USD, GBP and JPY (all foreign) markets, this gives
risk factors. In the case of stochastic volatility, EURUSD, EURGBP and EURJPY are all modelled with a Heston model such that there are 10 risk factors. This example is complex enough in the sense that a 7- or 10-dimensional PDE solution is not feasible and that we can demonstrate the effect of different decompositions.
4.2. Derivatives
We consider portfolios of cross-currency and interest rate swaps and FX options.
4.2.1. Zero-coupon bonds
Although the portfolios below do not contain any bonds explicitly, the swaps studied here are all based on coupon legs which can be replicated by (and hence valued from the time 0 value of) a string of zero-coupon bonds that pay 1 at different times T. The time t value a zero-coupon bond, P(t, T), under Hull–White for the short rate R is,(29a)
where
and(29b)
see Filipovic (Citation2009).
For simplicity, we assume here a single curve framework and do not make a distinction between discounting and forwarding curves (see the discussion at the end of the introduction).
4.2.2. Cross-currency swap
We consider a series of FX forward swaps settled in arrears, with floating payment and receiving leg. Note that both legs need to be valued in the domestic currency, for which the future exchange rate is used. Following Filipovic (Citation2009), the value of the swap at time
with payment dates
is,
where is the FX rate at time t,
and
are the domestic and foreign floating rate notes, and M is the moneyness as a percentage of the (future) FX rate, e.g. 100% is referred to as At-The-Money (ATM), 105% as In-The-Money (ITM) and 95% as Out of-The-Money (OTM) . The values of the floating rate notes are,
where is the notional in domestic or foreign currency,
.
4.2.3. Interest rate swap
Here, we consider a floating vs. fixed interest rate swap, where the fixed leg is defined as a fixed coupon bond, such that the value with notional equals
where K is the fixed rate and the interval between payment dates (see Filipovic (Citation2009)).
4.2.4. FX option
Finally, we consider an FX call option on the EURUSD FX rate with strike K, notional and maturity T with pay-off
The value of the option at time , under the BS2HW model from section 4.1, is equal to
where follow (29). For more details on these options we refer to Filipovic (Citation2009) and Brigo and Mercurio (Citation2013). We only note that the option value function is the solution of the corresponding three-dimensional backward PDE; see also remark 2.
4.2.5. Contract parameters
The CCYS are driven by the FX rate and the foreign and domestic interest rate processes. The contract specific parameters are shown in table . Note that the trades have different maturity, notional and moneyness.
Table 1. Parameters for the CCYS and IRS.
The interest rate swap is traded on the EUR interest rate, ATM, where the swap rate is such that the initial value of the trade at inception () is equal to zero. The specific parameters can be found in table .
The option strike is set at and the maturity to
. The notional of this option is set to
.
4.3. Market and calibration
As the behaviour and accuracy of the approximation method from section 3 may depend significantly on the model parameters, we perform a careful calibration to market data before undertaking numerical tests.
We use a data-set from 2 December 2014. At this time, the interest rates were low, which resulted in low yields for all markets. Shown in figure (b) are the yields up to five years, computed by polynomial interpolation of the market forward curve f(t) as per (Equation32(32) ). They are used for bond pricing via (Equation31
(31) ) and to calibrate
in (29) by
(29c)
with f(t) from (Equation32(32) ), which gives an exact fit to bond prices (see Filipovic (Citation2009)).
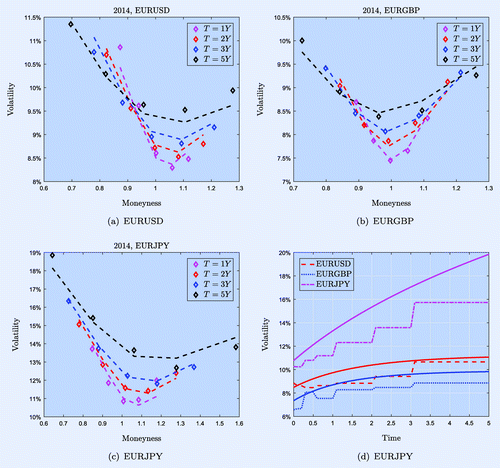
Figure 1. Volatilities and yields over time on 2 December 2014.
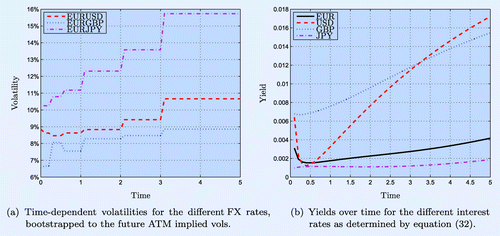
For the FX volatilities in (Equation29a(29a) ), we assume a piecewise constant volatility function which follows the ATM volatilities over time,
where is a partition of the interval
for some maximum maturity
. such that
is the volatility corresponding to the time period
. For simplicity, this partition corresponds to the maturities of available quoted options, hence
is the number of different maturities.
The calibration matches to European At-The-Money (ATM) options’ volatilities assuming constant rates.Footnote†
Denote
the implied volatility of an ATM option with maturity
, then the
can be determined inductively from the system of equations,
The resulting different volatility levels are shown in figure(a).
The Hull–White parameters are calibrated to fit the prevailing yield curve and swaption data using analytic expressions, i.e. is calibrated by (Equation33
(33) ) and
and
by a least-squares fit to co-terminal swaptions that terminate in 10 years (1
9, 2
8, 3
7, 4
6, 5
5, 6
4, 7
3, 8
2 and 9
1), as these swaptions can also be used to replicate the CVA of a swap that matures in 10 years, as is shown in Sorensen and Bollier (Citation1994).
The correlations between the observable factors (exchange and interest rates) are estimated using weekly historical time-series data from the preceding three-year period.
The estimated correlation matrix is regularized to be positive semi-definite by setting any negative eigenvalues in a singular value decomposition to zero (Rebonato Citation1999). The resulting full correlation matrix is shown in appendix 1 together with the other parameters. The yield curve data are provided in a spread sheet at de Graaf et al. (Citation2016).
5. Results
In this section, we analyse the accuracy of the numerical approximations from section 3, applied to the market described in section 4. We compare our results to an accurate approximation computed by a brute-force Monte Carlo method. In particular, we study the relative differences expressed in percentages,(30)
where and
or
to denote two- or three-dimensional corrections (see (Equation23
(23) )). For the computations,
are chosen to coincide with the swap payment dates, so that
is the total number of coupon payments. In addition, we study the mean difference (MD) over time relative to the sum of all notionals (
) in the portfolio expressed in basis points,
Similarly, the normalized standard error for EE is definedas,(31)
where is the standard deviation of the estimator for
, and an analogous definition for EPE.
The settings used for the numerical methods (domain and mesh sizes, time steps, etc) are reported in appendix B.3.
In the following, assuming piecewise constant volatilities, we use up to seven risk factors, , where (see (Equation1
(1) ) and (29))
(32)
are the EURUSD, EURGBP, EURJPY exchange rates (), and EUR, USD, GBP, JPY short rates (
and
, respectively).
To simplify the notation (Equation28(28) ), we will use, e.g. the shorthand
where we suppress the dependence on the anchor and time t, and it is understood implicitly that the arguments identify the function being used. Also note that the function is evaluated at
, since we are interested in exposures conditional on the current state
.
5.1. Case A: single EURUSD CCYS
As a first test case, we focus on the BS2HW model (section 4.1) for a single CCY swap trade on EURUSD. In this case, only the three relevant risk factors ,
and
(the EURUSD exchange rate, the EUR and USD short rates) are used, so effectively
.
In that case(33)
(34)
(35)
The first term in (Equation37(37) ) is a one-dimensional approximation with only the EURUSD rate stochastic, and then the next two brackets correct separately for stochastic domestic (EUR) and stochastic foreign (USD) interest rate, respectively. Note how in this particular case equation (Equation38
(38) ) with the three-dimensional corrections simplifies to the exact solution (Equation39
(39) ).
In figure (a) and (b), the one-, two- and three-dimensional decomposed approximations ,
and
are plotted together with the full-scale Monte Carlo approximation
. The exposure decreases over time, which means that the FX rate drives the expected value of this swap down. The EPE is positive by definition and increases over time.
Figure 2. EE (left) and EPE (right) for a single ATM CCYS ((a) and (b)), for three CCYS ((c) and (d)), and for three CCYS and an IR swap ((e) and (f)). The risk factors are driven by BS2HW and the EURUSD FX rate is taken as a base.
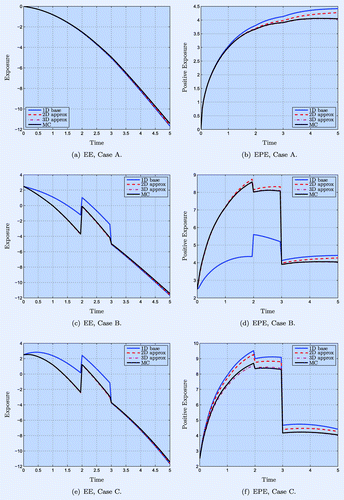
Both the decomposed two- and three-dimensional approximations are reasonably close to the full Monte Carlo estimator, but while the results for Case A in table show that the maximum error is over 5% in the two-dimensional case, it is around 0.5% for the three-dimensional approximation. Note that the latter result should be exact, so that any discrepancy are finite difference errors. These may seem large, but we note that the standard error of Monte Carlo with the industry standard of paths would be approximately
(see table ). While we could certainly improve the finite difference accuracy by finer meshes, we do not investigate this further at this point.Footnote†
Table 2. Errors of exposure approximations for Cases A, B and C. The finite difference approximations are computed with grid points and 500 time steps. The errors are expressed in percentages together with the standard error of the Monte Carlo benchmark with
paths and 1000 time steps. The SE is defined in (Equation35
(35) ) as the root sum squared of the standard errors over time relative to the root sum squared of the sampled EE or EPE.
5.2. Case B: three CCYS (EURUSD, EURGBP and EURJPY)
In the case of three CCYS, there are risk factors, such that adding three-dimensional corrections will no longer yield an exact solution. In this case, we make an a priori choice of the base risk factor, namely the EURUSD FX rate.Footnote‡
The two-dimensional decomposed approximation for the portfolio of three FX swaps now has two extra terms to correct for the other FX rates and two extra terms to correct for the foreign interest rates:
(36)
where the short-hand was used in the last line.
For the three-dimensional corrections, there are in principle extra terms, because in addition to
, we choose two out of the
remaining factors. However, only eight of them are non-zero, as given here:
(37) where the short-hand
was used.
The corrections can be interpreted in the following way. For instance, in the first term in (Equation41(41) ),
treats all exchange rates stochastic but with deterministic interest rates (simple Black–Scholes models); and in the last term,
comes from the full BS2HW model for the EURUSD rate where all other processes are approximated by their expectations (see section 3.1). Similar interpretations can be found for the other correction terms.
In contrast, we have for instance
because in this approximation where (the EURJPY exchange rate) is deterministic, the (JPY) short rate
has no impact on the exposure of the swaps. Similar arguments hold for the other six corrections that vanish.
Figure (c) and (d) show again the one- to three-dimensional decomposed approximations of the exposures together with the full scale Monte Carlo approximation . The different expiries for the different swaps are reflected clearly in the profiles. At
, the EURJPY swap expires, which results in an upwards jump in total EE and EPE whereas at
the EURGBP swap expires and the exposures drop.
Both the two- and especially the three-dimensional approximation are close to the full Monte Carlo estimator; see especially the rows relating to Case B in table . The mean differences are now relative to the sum of all notionals in the portfolio. As none of the correction terms accounts simultaneously for, say, the EURJPY rate, EUR and JPY short rates, even the decomposition with three-dimensional approximations is not exact in this case, such that all errors arise from a combination of truncation error for the expansion and discretization error for the PDE solution (as well as a slightly smaller Monte Carlo error for the benchmark).
We give a table of all the correction terms separately in appendix 4. Table there shows while some terms are dominant, like the one involving the EURUSD and EURGBP rates among the two-dimensional corrections and the one with EURUSD and the associated short rates among the three-dimensional ones, it is certainly not the case that the other terms are negligible. This demonstrates that the problem is genuinely high-dimensional and does not have a lower superposition dimension (see Wang and Sloan Citation2005), by which we mean loosely speaking that the solution cannot be expressed exactly as a linear combination of solutions to low-dimensional problems. Indeed, while the approximations and hence
would be exact for EE here because of its linearity,
is not. For EPE, generally only decompositions involving all risk factors, such as
or any
with
will be exact. The results show, however, that approximations with much smaller r and s and therefore, much lower computational cost can be sufficiently accurate.
In section 5.6 we will show the variance reduction achieved in Case B using the above approximation as control variate.
5.3. Case C: Case B with an additional IRS in EUR
By adding an IR swap to the portfolio, the risk factors do not change, as the EUR interest rate was already modelled as a factor that drives the FX rate in Section 5.2. In figure (e) and (f), one observes the exposure levels are increased because of the interest rate swap. Again, the different profiles match closely over time. In table one sees more clearly that, for all error measures, both the EE and EPE errors improve significantly when we include three-dimensional corrections, as expected.
One thing to note is that the errors for EE are almost exactly the same as in Case B, because the IR swap exposure is valued exactly by all models that have in them, e.g.
.
5.4. Case D: Case C with an additional EURUSD FX call option
We now add an FX option on the EURUSD rate as described in section 4.2. The exposure level increases first, but drops at , as seen in figure (a) and (b).
Figure 3. EE (left) and EPE (right) for a portfolio of CCYS, a call option on the EURUSD FX rate and a floating vs. fixed interest rate swap. The factors are driven by BS2HW and the EURUSD FX rate is taken as the base factor.
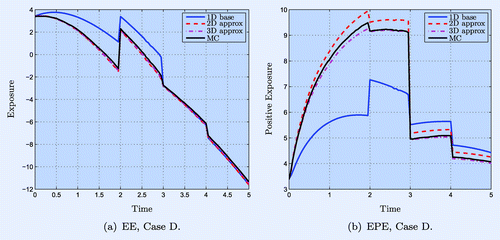
In the previous examples, sections 5.1–5.3, analytical pricing formulas were available for the swaps in the portfolio, which made Monte Carlo estimation of exposures straightforward. With the FX option added, we use the regression-based MC method, similar to the popular Longstaff–Schwartz algorithm (Longstaff and Schwartz Citation2001) for American options. An outline of the algorithm used is given in appendix 3.
Because of this regression, all paths need to be stored and less paths can be used, which results in a higher standard error. We also note that the benchmark in this case is not perfect due to the limited span of the basis functions. The resulting bias is not taken into account in the SE given in table . Nonetheless, the discrepancy between PDE results and Monte Carlo behaves as expected—see table —with a sharp improvement as corrections are added in.
5.5. Stochastic volatility
To investigate the applicability of this method to stochastic volatility, we model all three FX rates with the Heston model (Heston Citation1993), where the stochastic volatility is modelled by a CIR process: (38)
(39)
(40)
(41) with
given, and other notation as earlier. The three sets of Heston parameters are calibrated to volatility smiles from 2 December 2014 and are given with the calibration fit in appendix A.1. It is unclear how to estimate the correlations between the stochastic variance and the other risk factors (apart from its own FX rate). In this test, they are assumed to be zero.Footnote†
The extension to local-stochastic volatility models would not cause any computational difficulty and the accuracy of the approximation is expected to be similar. In this case, there are
risk factors and we again choose the EURUSD FX rate a priori as base risk factor. We consider Case B with three CCYS with different moneyness and maturities.
Table 3. Errors of exposures of a portfolio with three CCYS, a IRS and a FX call option. The errors are expressed in percentages together with the standard error of the Monte Carlo benchmark with paths. The SE is defined in (Equation35
(35) ) as the root sum squared of the standard errors over time relative to the root sum squared of the sampled EE or EPE.
Table 4. Errors of exposure approximations for Case B modelled with the Heston model. The finite difference approximations are computed with grid points and 500 time steps. The errors are expressed in percentages together with the standard error of the Monte Carlo benchmark with
paths and 1000 time steps. The SE is defined in (Equation35
(35) ) as the root sum squared of the standard errors over time relativeto the root sum squared of the sampled EE or EPE.
The two-dimensional decomposed approximation for the portfolio of three FX swaps now has one extra term to correct for the stochastic volatility of the EURUSD base risk factor:
where the short-hand notation from equation (Equation40(40) ) was used.
For the three-dimensional corrections, in this case there are in principle extra terms, because in addition to
, we choose two out of the
remaining factors. In this preliminary test, however, we only add a stochastic volatility factor to the four 2D corrections that contribute the most in the Black–Scholes case.Footnote‡
These include corrections for the volatility in the two additional FX rates (EURGBP and EURJPY):
(42a) where the short-hand notation from equation (Equation41
(41) ) was used.
Note that all the corrections without stochastic volatility treat all exchange rates stochastic but with a time dependent volatility function equal to the expectation of the future volatility, which can be calculated analytically as,(42b)
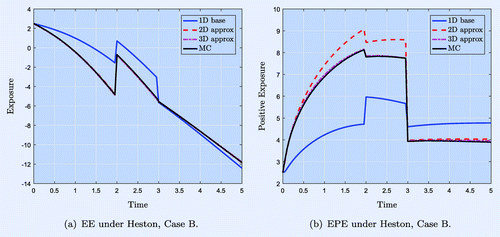
The one- to three-dimensional decomposed approximations of the exposures including stochastic volatility are shown in figure (a) and (b), together with the full-scale Monte Carlo approximation . Again, the profiles reflect the different expiries, and we see that the two-dimensional approximation significantly outperforms the one-dimensional approximation, and for EPE the three-dimensional approximation significantly outperforms the two-dimensional approximation.
Figure 4. EE (left) and EPE (right) for three CCYS under Heston. The EURUSD FX rate is taken as a base risk factor and all FX rates are simulated with stochastic volatility.
This is also clearly visible in table , where we show various error measures as earlier for the different approximations.
In the case of expected exposure, it appears that the two-dimensional decomposed approximation is already close to the full-scale Monte Carlo solution. This is in line with Simaitis et al. (Citation2016), where it is found that for expected exposure, a time-dependent volatility function can be used, whereas only for non-linear exposures (such as expected positive or negative exposure), a full stochastic volatility model should be used.
5.6. Variance reduction
We now correct the bias in the results in the preceding sections by applying the methodology of section 3.2, at much reduced variance compared to the standard estimator. For simplicity, we restrict ourselves to the case where derivatives are priced analytically, so that no regression is required. The obtained variance reduction, calculated as the ratio of the two variances with and without control variate, is shown in figure for the different decomposed approximations and test cases from sections 5.1–5.3. To be clear, a value of, e.g. means that the variance is reduced by a factor of 200, while a value of
implies that no variance reduction at all was achieved.
In figure (a) and (b), the variance reduction factor for EE and EPE in the case of a single CCYS is in the range of 100–1000. For the two-dimensional control variate, the reduction is greater for shorter maturities and increases with time. For the three-dimensional control variate, the variance reduction is constant, which is due to the exactness of the control variate. The only discrepancy between the control variate and the Monte Carlo estimator is the (time) discretization error, which also explains why the variance is not equal to zero.
Table 5. Computational times of the individual solvers in seconds. For the finite difference (FD) solvers, we use grid points and 100 or 500 (in brackets) time steps (see also Appendix B.3). The full Monte Carlo (MC) result is obtained with
paths and 100 or 1000 (in brackets) time steps. For the control variate (CV MC) results, we reduce the number of paths commensurate with the variance reduction. From Figure , Case B, the variance reduction factor is seen to be around 50 in the case of 2D and 200 for the 3D corrections. Therefore, we choose
paths in the case of 2Dcorrections and
for the 3D corrections.
Table 6. Errors of exposures for Case B for different choices of the base risk factor. The errors are expressed in percentages together with the standard error of the Monte Carlo benchmark with paths. The SE is defined in (Equation35
(35) ) as the root sum squared of the standard errors over time relative to the root sum squared of the sampled EE or EPE.
Figure 5. Variance reduction for different test cases with 2D and 3D corrections. The variance with and without control variate is compared. For this computation paths were used.
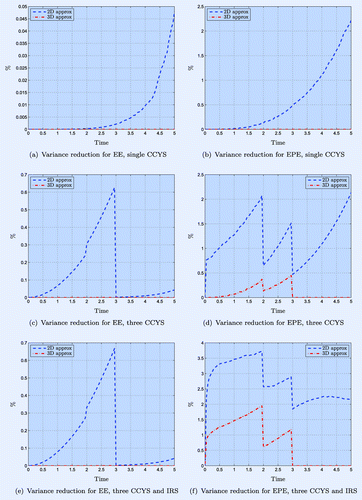
Figure 6. Exposure profiles (EE and EPE) for Case B and variance reduction with different base factors and 2D and 3D corrections. For the variance computations paths were used.
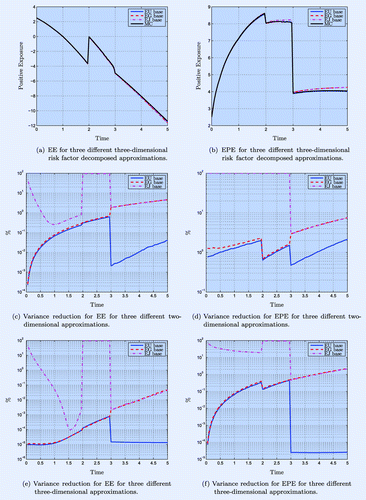
Figure (a) and (b) show the variance reduction in the case of three CCYS. Here, the three-dimensional decomposed approximation is no longer exact and thus, also in the three-dimensional case, the variance increases over time. The sharp drop at and
is due to the expiry of the EURJPY and EURGBP CCYS. The variance reduction is largest between time 3 and 5 because during that time period only the EURUSD CCYS is not terminated. When we use two-dimensional corrections, the reduction is around 200 for EE and 50 for EPE. When three-dimensional corrections are taken into account, we obtain a reduction by a factor of
for EE and 200 for EPE.Footnote†
Figure (c) and (d) show the variance reduction in the case of three CCYS and an IRS. The EE results resemble those for three CCYS alone, because the stochasticity of the IRS due to is modelled exactly by the corrections, as explained at the end of section 5.3. For EPE, the variance is reduced by a factor around 30 for two-dimensional corrections and a factor of 50 for three-dimensional corrections.
The set-up is chosen so that the finite difference accuracy is comparable to the Monte Carlo accuracy. As the finite difference approximation converges at a higher order (for low dimensions, typically up to about 3 or 4) than the Monte Carlo sampling, the computational effort of the Monte Carlo component will become dominant if higher accuracy is required. As a side note, we remark here that the different PDEs and integration problems can be solved by entirely different methods, e.g. Fourier methods could be used for some of the lower dimensional problems or quasi-Monte Carlo methods for some of the medium-dimensional problems.Footnote† The different solutions in the decomposition can also be computed fully in parallel, and parallel to the Monte Carlo runs. We report here sequential run times.
From these run times for Case B, presented in table , we can see that, using the 2D approximation as a control variate, we gain a computational speed-up by a factor 50, as the computation time for the 2D corrections by finite differences is negligible. Using 3D corrections gives us a speed-up factor 12; in spite of the greater variance reduction, the increased time for the PDE solutions eats up any benefit over the 2D corrections.
5.7. Other base risk factors
In the previous sections, the EURUSD FX rate was chosen as the base risk factor a priori, based on the fact that the derivatives driven by this FX rate have the highest maturity. However, there is no guarantee that this choice as a base is optimal in any sense. Often, one may have prior knowledge what the main driving factors are. Failing that, it would be practically feasible to estimate the variance reduction achieved by different factors by a relatively small number of samples in a trial run, and then do the actual large-scale estimation with the best performing base factor. In figure (a) and (b), the different EE and EPE profiles for Case B are shown when we choose the EURGBP or EURJPY FX rate as a base compared to choosing the EURUSD rate. Table shows that the error is indeed smallest for the EURUSD rate.
In figures (e) and (f), we show the resulting variance reductions of the corresponding control variates. Clearly, the EURJPY FX rate as a base does not reduce the variance after , as that is when the base risk factor does not affect any non-terminated derivative in the portfolio. The EURUSD FX rate performs best especially after time
when the EURUSD rate affects the only non-terminated derivative in the portfolio. Note that we use a log scale for better visualization.
6. Conclusion
This paper is motivated by the computation of exposure profiles for portfolios depending on a moderate to large number of risk factors. For this problem, the industry standard technique is to employ forward Monte Carlo sampling to compute future scenarios. This scales linearly in both the number of dimensions (risk factors) and products. However, valuing the whole book across all scenarios is still a big computational challenge and relatively large standard errors have to be tolerated given the relatively low feasible number of sample paths.
We therefore, propose another approach which exploits the accuracy of PDE approximation schemes for low-dimensional estimation problems, through an anchored-ANOVA-style splitting of the high-dimensional problem into a sequence of lower dimensional ones. As the problem is stated in the form of nested conditional expectations, we use a combination of forward and backward PDEs to generate exposure profiles for all future times with a single backward and forward sweep.
This paper provides a proof of concept rather than a fully worked out black box algorithm. The detailed analysis of a moderately sized, realistic and fully calibrated test case showed the scale of the benefits achievable by risk factor decomposition coupled with numerical PDE solutions, used as standalone approximation or—if necessary—employed as a control variate for a Monte Carlo estimator. Some of the computational savings were dramatic, with a speed-up factor of 50 compared to standard Monte Carlo estimation, using a sum of two-dimensional estimators as control variate.
Further tests, not reported here, indicate that for longer maturities (10 years) some three-dimensional terms in the decomposition become significant for an accurate standalone approximation as well as for effective variance reduction.
It remains to investigate in practice the scalability with respect to the number of risk factors and number of products in the derivative portfolio. The PDE-based method, like standard Monte Carlo sampling, scales linearly in the number of derivatives. As for the number of risk factors, the number of 2D correction terms is linear, and the number of 3D ones quadratic in the dimension.
For larger portfolios, one can consider using approximations of the form or
instead of
, or indeed a combination of the two in the sense that only a subset of
with
and
are computed and included in the approximation, chosen adaptively by estimation of the individual terms. We find evidence for this in table , which shows that only a subset of the correction terms are significant. This also suggests that not all terms have to be computed with the same relative accuracy, and one can follow the principle of Griebel and Holtz (Citation2010) to divide the total computational budget optimally between all correction terms. In this process, it is not necessary to use the same numerical method for all terms. Indeed, we have used a combination of closed-form and numerical solutions in the tests, and the framework is rich enough to use the best available method (e.g. Fourier-based methods for affine models, PDEs for early exercise options, or conceivably even a Monte Carlo method for strongly path-dependent derivatives) for a given sub-problem. Moreover, for the computation of a specific correction term only a subset of derivatives has to be considered, namely those affected by the risk factors considered in that correction. So it is conceivable that even for a large derivative portfolio each correction term only requires consideration of a small fraction of the derivatives. For instance, if the portfolio contains derivatives on equities, commodities and FX, the risk factor decomposition may provide a way to decompose the exposure computations into smaller sub-computations.
The practical challenge will be to develop a framework which allows this to happen in a generic way, and which is easily adaptable as different derivatives are entered or the modelling framework changes.
Acknowledgements
The authors would like to thank Dr. Sumit Sourabh for helpful advice and Dr. Shashi Jain for providing the data.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
† Here, we do not include collateralization. This can be added by including a collateral model on top of the exposure dynamics.
† Such a step-by-step calibration is industry practice in CCR modelling.
† See appendix 4 for an analysis of the accuracy of the finite difference schemes used.
‡ See section 5.7 for an assessment of alternative choices.
† After correcting the estimated full correlation matrix for positive-definiteness, these correlations can be slightly non-zero. The full correlation matrix used in this test can be found in equation (A1) in appendix A.1.
‡ See table in appendix 4.
† The extreme variance reduction for EE and 3D is more clearly seen quantitatively from figure later on, where the data are plotted on a log scale.
† Similarly, quasi-Monte Carlo could be used in the benchmark method and offers a potential reduction in simulation paths from to
for simulation-in-simulation (which is rare), or from
to O(n) for regression methods.
† But see Remark 1 why we are not using the backward equation directly to compute exposures.
References
- Alexander, S. , Coleman, T.F. and Li, Y., Minimizing CVaR and VaR for a portfolio of derivatives. J. Banking Finance, 2006, 30 , 583–605.
- Andersen, L.B. and Piterbarg, V.V., Interest Rate Modeling, 2010 (Atlantic Financial Press: London).
- Andreasen, J. and Huge, B., Finite difference based calibration and simulation. 2010. Available online at ssrn.com/abstract=1697545
- Bouzoubaa, M. and Osseiran, A., Exotic Options and Hybrids: A Guide to Structuring, Pricing and Trading, The Wiley Finance Series, 2010 (Wiley: Chichester).
- Brigo, D. and Mercurio, F., Interest Rate Models Theory and Practice, Springer Finance, 2013 (Springer: Berlin Heidelberg).
- Broadie, M. , Du, Y. and Moallemi, C.C., Efficient risk estimation via nested sequential simulation. Manage. Sci., 2011, 57 , 1172–1194.
- Broadie, M. , Du, Y. and Moallemi, C.C., Risk estimation via regression. Oper. Res., 2015, 63 , 1077–1097.
- Capriotti, L. , Jiang, Y. and Macrina, A., Real-time risk management: An AAD-PDE approach. Int. J. Financ. Eng., 2015, 2 , 1550039.
- Clark, I.J., Foreign Exchange Option Pricing: A Practitioner’s Guide, The Wiley Finance Series, 2011 (Wiley: Chichester).
- Cozma, A. and Reisinger, C., A mixed Monte Carlo and PDE variance reduction method for foreign exchange options under the Heston-CIR model. J. Comput. Finance, 2017, 30 , 109–149.
- Dang, D.M. , Jackson, K.R. and Mohammadi, M., Dimension and variance reduction for Monte Carlo methods for high-dimensional models in finance. Appl. Math. Finance, 2015, 22 , 522–552.
- Dang, D.M. , Jackson, K.R. and Sues, S., A dimension and variance reduction Monte-Carlo method for option pricing under jump-diffusion models. Appl. Math. Finance, 2017, 24 , 175–215.
- De Col, A. , Gnoatto, A. and Grasselli, M., Smiles all around: FX joint calibration in a multi-Heston model. J. Banking Finance, 2013, 37 , 3799–3818.
- de Graaf, C.S.L. , Feng, Q. , Kandhai, B.D. and Oosterlee, C.W., Efficient computation of exposure profiles for counterparty credit risk. Int. J. Theor. Appl. Finance, 2014, 17 , 1450024.
- de Graaf, C.S.L. , Kandhai, B.D. and Reisinger, C., Efficient exposure computation by risk factor decomposition. 2016. arXiv preprint arXiv:1608.01197.
- Doust, P., The stochastic intrinsic currency volatility model: A consistent framework for multiple FX rates and their volatilities. Appl. Math. Finance, 2012, 19 , 381–445.
- Filipovic, D., Term-Structure Models: A Graduate Course, Springer Finance, 2009 (Springer: Berlin Heidelberg).
- Glasserman, P., Monte Carlo Methods in Financial Engineering. Applications of Mathematics: Stochastic Modelling and Applied Probability, 2004 (Springer: New York).
- Gordy, M.B. and Juneja, S., Nested simulation in portfolio risk measurement. Manage. Sci., 2010, 56 , 1833–1848.
- Green, A.D. , Kenyon, C. and Dennis, C.R., KVA: Capital valuation adjustment by replication. Risk, 2014, 27 , 82–87.
- Gregory, J., Counterparty Credit Risk: The New Challenge for Global Financial Markets, 2010 (Wiley: Chichester).
- Gregory, J., The xVA Challenge: Counterparty Credit Risk, Funding, Collateral, and Capital, 2015 (Wiley: Chichester).
- Griebel, M. and Holtz, M., Dimension-wise integration of high-dimensional functions with applications to finance. J. Complexity, 2010, 26 , 455–489.
- Haentjens, T. and in ’t Hout, K.J., ADI finite difference schemes for the Heston-Hull-White PDE. J. Comput Finance, 2012, 16 , 83–110.
- Haentjens, T. and in ’t Hout, K.J., ADI schemes for pricing American options under the Heston model. Appl. Math. Finance, 2015, 20 , 207–235.
- Heston, S.L., A closed-form solution for options with stochastic volatility with applications to bond and currency options. Rev. Financ. Stud., 1993, 6 , 327–343.
- Hundsdorfer, W. and Verwer, J.G., Numerical Solution of Time-dependent Advection-diffusion-reaction Equations, 2003 (Springer-Verlag: Berlin).
- in ’t Hout, K.J. and Foulon, S., ADI finite difference schemes for option pricing. Int. J. Numer. Anal. Model., 2010, 7 , 303–320.
- in ’t Hout, K.J. and Welfert, B., Unconditional stability of second-order ADI schemes applied to multi-dimensional diffusion equations with mixed derivative terms. Appl. Numer. Math., 2009, 59 , 677–692.
- Hout, In’t, K.J. and Wyns, M., Convergence of the Modified Craig-Sneyd scheme for two-dimensional convection-diffusion equations with mixed derivative term. J. Comput. Appl. Math., 2016, 296 , 170–180.
- Itkin, A., High-order splitting methods for forward PDEs and PIDEs. Inter. J. Theor. Appl. Finance, 2015, 18 , 1550031.
- Jain, S. and Oosterlee, C.W., Pricing high-dimensional Bermudan options using the stochastic grid method. Int. J. Comput. Math., 2012, 89 , 1186–1211.
- Joshi, M. and Kang, O., Least squares Monte Carlo credit value adjustment with small and unidirectional bias. Available at SSRN, 2016, 2717250 .
- Karlsson, P. , Jain, S. and Oosterlee, C.W., Counterparty credit exposures for interest rate derivatives using the stochastic grid bundling method. Available at SSRN, 2014, 2538173 , 1–25.
- Longstaff, F. and Schwartz, E., Valuing American options by simulation: A simple least-squares approach. Rev. Financ. Stud., 2001, I , 113–147.
- Musiela, M. and Rutkowski, M., Martingal Methods in Financial Modelling, 2nd ed., 2005 (Springer-Verlag: Berlin).
- Pykhtin, M. and Zhu, S., A guide to modelling counterparty credit risk. Global Assoc. Risk Professionals, 2007, 37 , 16–22.
- Rebonato, R., On the simultaneous calibration of multifactor lognormal interest rate models to Black volatilities and to the correlation matrix. J. Comput. Finance, 1999, 2 , 5–27.
- Reisinger, C. and Wissmann, R., Numerical valuation of derivatives in high-dimensional settings via PDE expansions. J. Comput. Finance, 2015, 18 (4), 95–127.
- Reisinger, C. and Wissmann, R., Error analysis of truncated expansion solutions to high-dimensional parabolic PDEs. ESAIM: Mathe. Model. Numer. Anal., 2017, 51 (6), 2435–2463.
- Reisinger, C. and Wittum, G., Efficient hierarchical approximation of high-dimensional option pricing problems. SIAM J. Sci. Comput., 2005, 29 , 440–458.
- Simaitis, S. , de Graaf, C.S. , Hari, N. and Kandhai, D., Smile and default: The role of stochastic volatility and interest rates in counterparty credit risk. Quant. Finance, 2016, 16 , 1725–1740.
- Sorensen, E. and Bollier, T., Pricing swap default risk. Financ. Analysts J., 1994, 50 , 23–33.
- Tavella, D. and Randall, C., Pricing Financial Instruments: The Finite Difference Method, 2000 (Wiley: New York).
- Wang, X. and Sloan, I.H., Why are high-dimensional problems in finance often of low effective dimension? Soc. Ind. Appl. Math., 2005, 27 , 159–183.
Appendix 1 Model parameters
The full correlation matrix for the process from (Equation36
(36) ), used in the tests of section 5, after regularization for positive definiteness (Rebonato Citation1999):
The FX and interest rate SDEs are driven by the parameters in table .
As discussed in Section 4.3, the functions , are calibrated to fit the forward rate curve of the respective markets as seen on 2 December 2014. The ATM volatilities of the FX rates at this date used for
can be found in table .
Table A1. Parameters for the BS2HW model (29).
Table A2. ATM volatilities as seen on 2 December 2014 that are used for bootstrapping the piecewise constant volatility function as explained in section 4.3.
Table A3. Calibrated Heston parameters to 2014 market data. Including mean implied vol errors quoted in percentages. The models are calibrated to 10%-, 25%- and 50%- FX put and call options with maturities 1Y, 2Y, 3Y and 5Y.
A.1. Heston model parameters
In table we give the calibrated Heston parameters together with the mean implied volatility error. As shown in figures (a), (b) and (c), the skew in the EURJPY market is most pronounced (note the different scales on the y-axis). Due to this skew, the bootstrapped ATM volatility is different from the expectation of the future volatility in (Equation44(42a) ). This mean volatility and the bootstrapped volatility over time are presented in figure (d).
The full correlation matrix, including stochastic volatility, for the process used in the tests of section 5.5, after regularization for positive definiteness (Rebonato Citation1999):
(42c)
Note, that due to the regularization the correlation matrix is altered, and correlations are slightly different from the Black–Scholes case.
Figure A1. Implied volatility smiles of FX pairs. The lines are the model fit and the diamonds are the market implied volatilities. The associated errors are presented in table . In figure (d), shown are the piecewise constant volatilities as a function of time, based on bootstrapped ATM volatilities (dashed lines) and the expectations of the model stochastic volatilities (solid lines).
Appendix 2. Numerical approximation of the Kolmogorov PDEs
Here, we outline the finite difference method used for the PDE solutions, as it is somewhat non-standard through the use of forward and backward equations. In particular, we extend the adjoint method from Itkin (Citation2015) from two to three dimensions and use it for the forward component. For a more general introduction to finite difference methods for pricing financial derivatives, see for example Tavella and Randall (Citation2000) and, specifically for interest rate derivatives Andersen and Piterbarg (Citation2010).
As usual, a grid is defined with one dimension per risk factor, and the partial derivatives in the Kolmogorov forward (Equation9(9) ) or backward PDE (Equation3
(3) ) are approximated by finite differences on this grid.
B.1. Backward equations
We use a combination of second order central differences in the centre of the spatial domain, and upwinding for stabilization of large drifts in outer parts of the domain (see appendix B.3), to obtain a system of ODEs in the time variable (in ’t Hout and Welfert Citation2009). Let be the solution to this semi-discrete Kolmogorov backward equation at time
, where
, then we have the following initial value problem
(42d)
with given matrix F, derived from the PDE, and initial vector given by the pay-off at the mesh points. The boundary conditions are also derived from the pay-off function.
We apply an Alternating Direction Implicit (ADI) splitting method. Let be the discretization matrix, as per (B2), at time step
,
,
a uniform step size, then this matrix is first decomposed into
where the individual contains the contribution to F stemming from the first and second order derivatives in the ith dimension. Following in ’t Hout and Foulon (Citation2010), we define one matrix
which accounts for the mixed derivative terms, and treat that fully explicitly. Here we show the scheme for a three-dimensional problem, and the two-dimensional case is obtained as special case by setting
. The Hundsdorfer-Verwer (HV) scheme (Hundsdorfer and Verwer Citation2003),
defines a second order consistent ADI splitting for all , and can be shown to be von Neumann stable for
, see Haentjens (Citation2012). We use
in the computations. Accuracy and stability do not appear to be very sensitive to the choice of
within the above range.
B.2. Forward equations
We use the adjoint relation between the Kolmogorov forward and the backward PDE. It can easily be seen that (for sufficiently smooth coefficients)(43)
with F from above, is a consistent scheme for the Kolmogorov forward equation. The initial datum for the discrete density function P is given by an approximation to the Dirac delta. We choose a mesh such that a mesh point coincides with the location of the Dirac delta. Then
is set to zero for all other mesh points and to a large value at this particular point, chosen such that a numerical quadrature rule applied to
gives 1. At the spatial boundaries, we apply zero Dirichlet conditions.
Hence, following Andreasen and Huge (Citation2010) and Capriotti et al. (Citation2015), we can first set up matrices that approximate the partial derivatives in the Kolmogorov Backward PDE, and use the transpose of these matrices for the Kolmogorov forward PDE.
Now we could apply HV splitting to (B3) and obtain a second order (in time) consistent approximation to the forward PDE. Instead, we follow Itkin (Citation2015) to calculate the exact adjoint of the HV scheme for the backward equation, which results in a different scheme, i.e. the transposition and approximate factorization do not commute. The forward scheme, adapted to the three-dimensional case from the two-dimensional case analysed in Itkin (Citation2015), then is,
Using this scheme, we have the adjoint relation,
i.e. using the backward equation to compute the conditional expectation function and then evaluating it at the location of the Dirac measure (left-hand side), or computing the density and then integrating over the “payoff” function, gives exactly the same result. Apart from the mathematical aestheticism of using the exact adjoint, this scheme has the following stability advantages. As discussed in Hout (Citation2016), splitting schemes do not give stable, and hence convergent, solutions for Dirac initial data. A direct splitting of (B3) is prone to wildly oscillating densities and may give meaningless expectations. Using the above scheme instead, we can be sure that even if we have no guarantee for the stability of the solution, the derived quantity of interest, e.g. EPE, is the same as for the backward equation with regular (for EPE, Lipschitz and piecewise smooth) data.Footnote† The adjoint equation also ensures conservation of discrete probability in the interior of the mesh. The loss of mass at the boundaries is minimized by choosing the domain large enough.
With the grid of discrete transition probabilities, obtained by the numerical solution of the Kolmogorov forward PDE, and a grid of portfolio values from the backward PDE approximations, the exposures can be extracted by numerical quadrature applied to (Equation8(8) ).
B.3. Grid construction and numerical parameters
The grids used for the approximation are non-uniform as in Haentjens (Citation2015), where a transformation is used to place a high density of grid points around the spot values. Moreover, the grid is shifted to include the initial spot value where the non-smooth Dirac delta function for the forward equation is located.
In table the computational domain in ,
and
is chosen. The parameter
controls the fraction of points that lie close to initial spot values (see Haentjens Citation2015).
Table B1. Finite difference grid parameters.
Moreover, we use upwind differences for large absolute interest rates, i.e. , otherwise central differences.
The number of grid points
,
in the three directions is chosen as
; see also appendix 4.
For the F grid, an interval is defined wherein the grid is uniform and dense, similar to Haentjens (Citation2012), while outside the
transformation is used. We set this interval as
.
Appendix 3. Regression-based Monte Carlo algorithm
We use constant, linear and bi-linear basis functions
to account for the correlation between risk factors. The algorithm determines option values along the sample path
, and can be summarized by the following steps:
| (i) | Generate all the paths | ||||
| (ii) | Start from maturity and set | ||||
| (iii) | Set | ||||
| (iv) | Solve the linear regression problem | ||||
| (v) | Set | ||||
| (vi) | Repeat backwards from 2. for all time steps. | ||||
Appendix 4. Finite difference errors and individual terms for Case B
Here we show the individual FD errors for all terms involved for Case B, compared to a Monte Carlo estimate, for both EE (table ) and EPE (Table ).
Remark 4
In the following tables, for instance, BSHW EU-RU refers to from Section 5, i.e. a Black–Scholes–Hull–White model where the EURUSD rate
follows a Black–Scholes-type model but with Hull–White foreign short rate
and deterministic domestic rate, and similarly for the other terms.
Table D1. Finite difference errors of exposures (EE) of a portfolio with three CCYS. The nomenclature of the terms is explained in Remark 4. The errors are measured in (see equation (Equation34
(34) )) in percentages for different number of mesh points. The number of time steps is fixed at 500. Within brackets (for
) the error for a FD solution with 1000 time steps. The Monte Carlo benchmark is computed with
paths and 1000 time steps.
Table D2. Finite difference errors of positive exposures (EPE) of a portfolio with three CCYS. The nomenclature of the terms is explained in Remark 4. The errors are measured in (see equation (Equation34
(34) )) in percentages for different number of mesh points. The number of time steps is fixed at 500. Within brackets (for
) the error for a FD solution with 1000 time steps. The Monte Carlo benchmark is computed with
paths and 1000 time steps.
The results in table (especially) and table show that the FD errors are already in the same order of magnitude as the MC standard error for a larger number of samples (i.e. significantly more samples than are used in practice). We therefore, use mesh points and 500 time steps in most of the computations (unless otherwise stated).
Table D3. Errors of decomposed approximations to exposures of a portfolio with three CCYS (see table , Case B), computed with different numbers of mesh points. The errors are measured in (see equation (Equation34
(34) )) in percentages for different number of grid points in space. The number of time steps is fixed at 500. The Monte Carlo estimator for these approximation errors is computed with
paths and 1000 time steps. Within brackets for MC the error for a MC simulation with identical paths for all estimators, as explained in remark 5. Within brackets for
the error for a FD computation with 1000 timesteps.
Table D4. Contribution of individual corrections for EE and EPE of a portfolio with three CCYS. The nomenclature of the terms is explained in remark 4. The differences are measured in (see equation (Equation34
(34) )) in percentages for
grid points in space.
In table , we report the accuracy of the complete approximations for increasing number of mesh points . For reference, we also compute the approximation with a standard Monte Carlo estimator.
Remark 5
In the first column of Table , we report the results for an estimator where the same Brownian paths are used for the estimation of all in (Equation20
(20) ) for a given
, and in brackets the results if the samepaths are also used across all u. It does not seem generally clear which of the estimators has the smaller variance. Using independent paths for different u results in a summation of the variances of
. Using the same paths for different u is expected to increase the variance if the terms are predominantly positively correlated, and decrease the variance if they are predominantly negatively correlated.