
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The paper solves the problem of optimal portfolio choice when the parameters of the asset returns distribution, for example the mean vector and the covariance matrix, are unknown and have to be estimated by using historical data on asset returns. Our new approach employs the Bayesian posterior predictive distribution which is the distribution of future realizations of asset returns given the observable sample. The parameters of posterior predictive distributions are functions of the observed data values and, consequently, the solution of the optimization problem is expressed in terms of data only and does not depend on unknown quantities. By contrast, the optimization problem of the traditional approach is based on unknown quantities which are estimated in the second step, and lead to a suboptimal solution. We also derive a very useful stochastic representation of the posterior predictive distribution whose application not only gives the solution of the considered optimization problem, but also provides the posterior predictive distribution of the optimal portfolio return which can be used to construct a prediction interval. A Bayesian efficient frontier, the set of optimal portfolios obtained by employing the posterior predictive distribution, is constructed as well. Theoretically and using real data we show that the Bayesian efficient frontier outperforms the sample efficient frontier, a common estimator of the set of optimal portfolios which is known to be overoptimistic.
1. Introduction
The fundamental goal of portfolio theory is to allocate optimally investments between different assets. Mean–variance optimization is a quantitative tool which allows one to make this allocation by considering the trade-off between the risk of a portfolio and its return. The basic concepts of modern portfolio theory were developed by Markowitz (Citation1952) who introduced a mean–variance portfolio optimization procedure in which investors incorporate their preferences towards the risk and the expected return to seek the best allocation of wealth. This is attained by selecting portfolios that maximize expected portfolio return subject to achieving a prespecified level of risk or, equivalently, that minimize the variance subject to achieving a prespecified level of expected return. The mean–variance analysis of Markowitz is an important tool for both practitioners and researchers in the financial sector today.
The classical problems and pitfalls of mean–variance analysis are mainly related to extreme weights that often occur when the sample efficient portfolio is constructed. This point was discussed in detail by Merton (Citation1980) who presented an estimator of the instantaneous expected return on the market in a log-normal diffusion price model and showed its slow convergence. Moreover, it was proved that the estimates of the variances and covariances of the asset returns are more accurate than the estimates of the means. Best and Grauer (Citation1991) argued that optimal portfolios are very sensitive to the level of expected returns. Therefore, improving the technique of mean estimation has recently become a key issue of the portfolio optimization problem. The same challenge is also present when the covariance matrix needs to be estimated. To this end, Broadie (Citation1993) showed that the estimated efficient frontier, the set of all mean–variance optimal portfolios, overestimates the expected returns of portfolios for different levels of estimation error. A similar conclusion has also been drawn in more recent studies by Basak et al. (Citation2005), Siegel and Woodgate (Citation2007) and Bodnar and Bodnar (Citation2010).
An alternative approach to deal with the parameter uncertainty in portfolio analysis is to employ the methods of Bayesian statistics (cf. Barry Citation1974, Brown Citation1976, Klein and Bawa Citation1976, Frost and Savarino Citation1986, Aguilar and West Citation2000, Rachev et al. Citation2008, Avramov and Zhou Citation2010, Sekerke Citation2015, Bodnar et al. Citation2017, Bauder et al. Citation2018, Citation2019). It is remarkable that the Bayesian approach is potentially more attractive since: (i) it uses prior information about quantities of interest; (ii) it facilitates the use of fast, intuitive, and easily implementable numerical algorithms in order to simulate complex economic quantities; (iii) it accounts for estimation risk and model uncertainty in the portfolio choice problem. First applications of Bayesian statistics to portfolio analysis during the 1970s were completely based on noninformative or data-based priors. Bawa et al. (Citation1979) provided an excellent early survey of such applications. The Bayesian approaches based on the diffusion prior are usually comparable with the classical methods of portfolio selection. However, if some of the risky assets have longer histories than others, then the Bayesian approaches under the diffuse prior lead to different results (see Stambaugh Citation1997). Jorion (Citation1986) introduced the hyperparameter prior approach in the spirit of the Bayes–Stein shrinkage prior, whereas Black and Litterman (Citation1992) defended an informal Bayesian analysis with economic arguments and equilibrium relations. They derived the Black–Litterman model which leads to more stable and more diversified portfolios than simple mean–variance optimization. Unfortunately, the application of this model requires a broad variety of data, some of which may be hard to find. Recent studies by Pástor (Citation2000) and Pástor and Stambaugh (Citation2000) centred prior beliefs around values implied by asset pricing theories. In particular, Pástor and Stambaugh (Citation2000) investigated the portfolio choices of mean–variance–optimizing investors who use sample evidence to update prior beliefs centred on either the risk-based or characteristic-based pricing models. Tu and Zhou (Citation2010) argued that the investment objective provides a useful prior for portfolio selection and proposed an optimal combination of the naive equally weighted portfolio rule with one of the four sophisticated strategies—the Markowitz (Citation1952) rule, the Jorion (Citation1986) rule, the MacKinlay and Pástor (Citation2000) rule, or the Kan and Zhou (Citation2007) rule—as a way to improve performance. Finally, Kacperczyk and Damien (Citation2011) and Kacperczyk et al. (Citation2013) discussed the application of Bayesian semi-parametric models, while Brandt and Santa-Clara (Citation2006) considered the Bayesian approach in the multi-period optimal portfolio choice problem.
We contribute to the existing literature on optimal portfolio selection by formulating an optimization problem in terms of the posterior predictive distribution and solving it. Using the available information about the development of asset returns which is present in their historical observations, the aim is to construct an optimal portfolio by taking into account investor's preferences. The conventional approach consists of two steps: (i) first, the optimization problem is solved with the solution depending on the unknown parameters of the asset return distribution; (ii) second, the optimal portfolio weights, which are the solutions of the optimization problem, are estimated by applying the historical observations of the asset returns. The second step is always needed in practical applications, since the expression of optimal portfolio weights resulting from the first step usually involve the unknown population parameters of the asset return distribution. Replacing these parameters by their sample estimators leads to additional uncertainty in the decision process which has been ignored for a long time in financial literature. It is important to note that following this two-step approach, the obtained solution is only suboptimal and it can deviate considerably from the optimal (population) portfolio obtained in the first stage.
In this paper, we propose a new approach, where the solution of the investor's optimization problem is obtained by employing the posterior predictive distribution which takes parameter uncertainty into account before the optimal portfolio choice problem is solved. As a result, its solution is presented in terms of historical data and is independent of the unknown parameters of the asset returns distribution. Consequently, it can be directly applied in practice and, in contrast to the conventional approach, it is optimal.
The rest of the paper is organized as follows. Main theoretical results are given in Section 2. Here, we characterize the posterior predictive distribution of the asset returns by developing a very helpful stochastic representation (Theorem 1). This stochastic representation provides not only a way how the future realization of portfolio returns can be simulated, but it is also used to derive the first two moments needed for the considered optimization problem. Section 2.2 deals with constructing optimal portfolios by maximizing the posterior mean–variance utility function, while the expression of the Bayesian efficient frontier is derived in Section 2.3. In Section 2.4 the optimal portfolio choice problem is solved by employing the informative conjugate prior, that can be considered as an extension of the Black–Litterman model, a popular approach in the financial literature. Section 3 presents a numerical comparison of the two Bayesian approaches between each other as well as to methods based on frequentist statistics. The theoretical results are implemented in an empirical study in Section 4, while Section 5 provides a conclusion. The technical derivations are given in an appendix.
2. Mean–variance analysis under parameter uncertainty
2.1. Posterior predictive distribution
Let denote the k-dimensional vector of returns on asset at time t. Assume that a sample of size n of asset returns
, realizations of
, is available which provides the information set
and let
be the observation matrix at time t−1. Consequently, an investor makes a decision by optimizing preferences using information
.
Before the decision problem is formulated in Section 2.2, we first derive the predictive posterior distribution of
given the previous observation of asset returns summarized in
. The derivation of
is based on the methods of Bayesian statistics which provide well-established techniques for providing inferences of future realizations of asset returns given information
.
In the following we assume that the asset returns are infinitely exchangeable and multivariate centred spherically symmetric (see, Bernardo and Smith Citation2000, Section 4.4 for the definition and properties). This assumption is very general and it implies that neither the unconditional distribution of the asset returns is normal nor that they are independently distributed. Moreover, the unconditional distribution of the asset returns appears to be heavy-tailed which is usually observed for financial data (see, e.g. Bradley and Taqqu Citation2003).
Parameterizing the density function of by the parameter
, the posterior distribution of
is obtained by applying the Bayes theorem and it is given by
(1)
(1) where
denotes the prior and
is the likelihood function of
. The posterior distribution
is then used to derive the posterior predictive distribution of the portfolio return at time t expressed as
(2)
(2) where
is the k-dimensional vector of portfolio weights.
The posterior distribution (Equation1(1)
(1) ) is employed in the derivation of the posterior predictive distribution as follows:
(3)
(3) Due to the integration present in the definition of the posterior predictive distribution, it is possible to obtain the analytical expression of
only in very rare cases. Moreover, the integration in (Equation3
(3)
(3) ) could also be high-dimensional, which makes the application of numerical methods very time consuming and also questions the quality of their numerical approximation. In Theorem 1, we derive a stochastic representation for the posterior predictive distribution
which can be very easily used to draw samples from this distribution as well as to compute its expected value and variance analytically. Finally, it has to be noted that the application of the stochastic representation describing the distribution of random quantities has been used both in the frequentist statistics (see, e.g. Givens and Hoeting Citation2012, Gupta et al. Citation2013) and in the Bayesian statistics (cf. Bodnar et al. Citation2017).
Theorem 1
Let be infinitely exchangeable and multivariate centred spherically symmetric. Let
be Jeffreys' prior where
denotes the determinant of a square matrix
and
is the Fisher information matrix. Assume n>k. Then the stochastic representation of the random variable
whose density is the posterior predictive distribution (Equation3
(3)
(3) ) is given by
where
(4)
(4) and
,
are independent with
and
. The symbol ‘
’ denotes the equality in distribution.
The proof of Theorem 1 is given in the appendix. Its results provide an easy way how a random sample from the posterior distribution of can be simulated as summarized in Algorithm 1:

The generated sample is used to calculate important characteristics of the distribution
, like the mean, the variance, the credible interval, etc. To this end, we note that the condition n>k ensures that
is positive definite and, hence, it is invertible.
Another important application of Theorem 1 provides us with the analytical expression of the expected value and the variance of the posterior predictive distribution . These findings are formulated in Corollary 1.
Corollary 1
Under the conditions of Theorem 1, let n−k>2. Then:
(5)
(5) and
(6)
(6)
The proof of Corollary 1 is given in the appendix. Its results are used in the next section where the expressions of optimal portfolio weights are given.
2.2. Mean–variance optimal portfolios
The mean–variance investor constructs an optimal portfolio at time t−1 for the next period by maximizing the mean–variance utility function given by
(7)
(7) under the constraint that the whole wealth is invested into the selected assets, i.e.
where
denotes the k-dimensional vector of ones. The quantity
stands for the coefficient of the investor's risk aversion and describes the investor's attitude towards risk.
In contrast to the conventional approach that involves the unknown parameters of the asset return distribution in its formulation, the optimization problem in (Equation7(7)
(7) ) already incorporates the parameter uncertainty by using the available information summarized in the data matrix
. As a result, the output of solving (Equation7
(7)
(7) ) is the formula for optimal portfolio weights that could be directly applied in practice, while the estimation of optimal portfolio weights is required in the conventional methods that leads to the suboptimality of the resulting portfolio.
The optimization problem in (Equation7(7)
(7) ) is similar to the optimization problem in the conventional approach (see Ingersoll Citation1987, Okhrin and Schmid Citation2006) with the exception that the risk aversion coefficient is multiplied by the constant
. As a results, the solution of (Equation7
(7)
(7) ) is given by
(8)
(8) together with the expected return and the variance expressed as
(9)
(9) and
(10)
(10) respectively, where we use that
and
in (Equation10
(10)
(10) ).
Additionally to the formulae of the optimal portfolio weights, the expected return and the variance of the mean–variance optimal portfolios presented in (Equation8(8)
(8) )–(Equation10
(10)
(10) ), the Bayesian approach allows to characterize the posterior predictive distribution of the constructed optimal portfolio. This is achieved by applying the results of theorem 1 where the weights of an arbitrary portfolio are replaced by the optimal portfolio weights given in (Equation8
(8)
(8) ). Then, the posterior predictive distribution of the optimal portfolio return is obtained via simulations as described after theorem 1 by replacing
with
as in (Equation8
(8)
(8) ). This is a very important result which allows the whole characterization of the stochastic behaviour of optimal portfolio return and is a great advantage with respect to the conventional approach where the point estimator is only present.
We conclude this section by noting that the original Markowitz problem (see Markowitz Citation1952, Citation1959) is solved in the same way. In the mean variance analysis of Markowitz, the optimization problem is given by: (i) minimizing the portfolio variance for a given level of the expected return or (ii) maximizing the expected return for the given level of the variance
. In the first case the optimal portfolio weights are given by (Equation8
(8)
(8) ) with
(11)
(11) while in the second case the weights are obtained from (Equation8
(8)
(8) ) with
(12)
(12)
2.3. Bayesian efficient frontier
Equations (Equation9(9)
(9) ) and (Equation10
(10)
(10) ) determine the set of all optimal portfolios obtained as solutions of (Equation7
(7)
(7) ) for
. Solving these two equation with respect to γ leads to a set in the mean–variance space where all mean–variance optimal portfolios lie. We call this set the (objective) Bayesian efficient frontier since the non-informative Jeffreys prior is employed in its derivation. It is given by
(13)
(13) where
(14)
(14) are the expected return and the variance of the global minimum variance portfolio, i.e. the mean–variance optimal portfolio with the smallest variance, whose weights are expressed as
(15)
(15)
The quantity is the slope parameter of the efficient frontier which is equal to the amount of the excess squared return with respect to the return of the global minimum variance portfolio when the variance is increased by one. Finally, we note that the Bayesian efficient frontier is a parabola in the mean–variance space which is the same finding as obtained by the conventional approach (see Merton Citation1972).
2.4. Subjective Bayesian approach: extended Black–Litterman model
The results of Sections 2.1–2.3 were obtained by assigning the non-informative Jeffreys prior to the model parameter and
corresponding to objective Bayesian inference in statistical literature. In this section we discuss an alternative Bayesian approach which is based on the (extended) Black–Litterman model (cf. Black and Litterman Citation1992). The latter model corresponds to the application of an informative prior for
and
and, thus, it is referred as the subjective Bayesian approach.
In order to incorporate expert knowledge in the construction of an optimal portfolio, Black and Litterman (Citation1992) suggested to employ the normal prior for the mean vector . This approach is known in financial literature as the Black–Litterman model. Below we consider an extension of this model by also including a prior on
in the decision process. To this end, it leads to the application of the informative conjugate prior for
and
given by
(16)
(16)
(17)
(17)
where
,
,
,
are additional model parameters known as hyperparameters. The symbol
denotes the k-dimensional normal distribution with mean vector
and covariance matrix
, while
stands for the inverse Wishart distribution with
degrees of freedom and parameter matrix
. The prior mean
reflects the prior expectation about
, while
determines the prior beliefs about
. The other two hyperparameters
and
are known as precision parameters for
and
, respectively.
In Theorem 2 we present a stochastic representation from the posterior predictive distribution of the portfolio return derived under the application of the prior (Equation16(16)
(16) )–(Equation17
(17)
(17) ). The proof of the theorem is presented in the appendix.
Theorem 2
Let be infinitely exchangeable and multivariate centred spherically symmetric. Assume
. Then, under the application of the informative prior (Equation16
(16)
(16) )–(Equation17
(17)
(17) ), the stochastic representation of the random variable
whose density is the posterior predictive distribution (Equation3
(3)
(3) ) is given by
where
(18)
(18) and
and
are independent with
and
.
Similarly to Theorem 1, the findings of Theorem 2 allow to simulate samples from the posterior distribution of in a simple way given by:

Furthermore, the closed-form expressions of the expected value and of the variance of the posterior predictive distribution is computed as shown in Corollary 2 whose proof is given in the appendix.
Corollary 2
Under the conditions of Theorem 2, let . Then:
(19)
(19) and
(20)
(20) with
Substituting (Equation19(19)
(19) ) and (Equation20
(20)
(20) ) in (Equation7
(7)
(7) ) we find the weights of the optimal portfolios in the case of the extended Black–Litterman model expressed as
(21)
(21) with the expected return and the variance expressed as
(22)
(22) and
(23)
(23)
Although the expression of the optimal portfolio weights obtained from the (extended) Black–Litterman model looks similar to the one obtained in the case of the (objective) Bayesian optimal portfolio (Equation8(8)
(8) ), they are in fact completely different due to the definition of
and
in (Equation18
(18)
(18) ). In contrast to the latter approach which is based on the observed sample only, the weights resulting from the Black–Litterman model incorporate the expert knowledge about the asset returns. As a result, the Black–Litterman Bayesian optimal portfolios do not obviously belong to the efficient frontier as given in (Equation13
(13)
(13) ), but they create their own set of optimal portfolios (see (Equation24
(24)
(24) )), which we call the Black–Litterman efficient frontier. This frontier is obtained by solving (Equation22
(22)
(22) ) and (Equation23
(23)
(23) ) with respect to γ resulting in a set in the mean–variance space where all mean–variance optimal portfolios lie following the (extended) Black–Litterman model. It is given by
(24)
(24) where
(25)
(25) are the expected return and the variance of the Black–Litterman global minimum variance portfolio, whose weights are given by
(26)
(26)
Also, in the case of the (extended) Black–Litterman model, the efficient frontier is the parabola in the mean–variance space. However, its location also depends on the expert knowledge, that is on and
as well as on the beliefs on this knowledge expressed by
and
. As a result, it might significantly deviate from the Bayesian efficient frontier given by (Equation13
(13)
(13) ). On the other side, the application of the Bernstein–von Mises theorem (cf. Bernardo and Smith Citation2000) ensures that as the sample size increases the differences between the two efficient frontiers (Equation13
(13)
(13) ) and (Equation24
(24)
(24) ) as well as between the optimal portfolios (Equation8
(8)
(8) ) and (Equation21
(21)
(21) ) become negligible.
3. Numerical study
The results of Section 2 are obtained from the viewpoint of Bayesian statistics. In this section we compare these two Bayesian approaches of the construction of optimal portfolios between each other as well as to the method based on the frequentist statistics (see, e.g. Jobson and Korkie Citation1981, Okhrin and Schmid Citation2006, Bodnar et al. Citation2018, Citation2019).
3.1. Conventional approach
Let and
be the mean vector and the covariance matrix of the asset returns. Then the traditional approach to construct an optimal portfolio consists of two steps (see, e.g. Ingersoll Citation1987, Okhrin and Schmid Citation2006):
The optimization problem
(27)
The unknown population quantities are replaced by their sample counterparts, i.e. by the sample mean vector and the sample covariance matrix given by
In the similar way, the sample efficient frontier is constructed by (see Bodnar and Schmid Citation2008, Citation2009, Kan and Smith Citation2008) and it is expressed as
(32)
(32) where
(33)
(33) Formula (Equation32
(32)
(32) ) presents the sample estimator of the population efficient frontier.
3.2. Comparison of the three estimators of the efficient frontier
It is remarkable that the expression of the sample optimal portfolio weights has the same structure as the weights of the optimal portfolios obtained following the (objective) Bayesian approach. The only difference is that in (Equation8
(8)
(8) ) is replaced by
in (Equation30
(30)
(30) ). Similar results are also obtained in the case of the efficient frontier which is fully determined by three parameters: the mean and the variance of the global minimum variance portfolio and the slope parameter. While the formulae in the case of the mean of the global minimum variance portfolio coincide, this is not longer true for the variance of the global minimum variance portfolio and the slope coefficient. The (objective) Bayesian approach leads to a larger value of the variance and to a smaller value of the slope parameter. The difference between the corresponding expressions obtained by the sample estimation or derived from the Bayeian posterior distribution as in Section 2 can be considerable when the portfolio dimension is comparable to the sample size as shown in figure , where we plot the ratio
as a function of k/n for
. We observe that when the number of assets k gets closer to the sample size, even for a moderate ratio of
, the (objective) Bayesian estimator and the sample estimator deviate. If the number of assets corresponds almost to the sample size, the estimators deviate considerably. Since it is sometimes necessary to restrict an estimation to a smaller sample size, e.g. after a structural break in the data, the difference in the estimators has to be considered. To this end, we note that such a simple comparison of the estimated efficient frontiers cannot be performed in the case of the Black–Litterman efficient frontier due to a more complicated structure of the latter which also depends on the expert knowledge about the parameters of the asset return distribution.
Figure 1. The ratio plotted as a function of k/n for
and
.
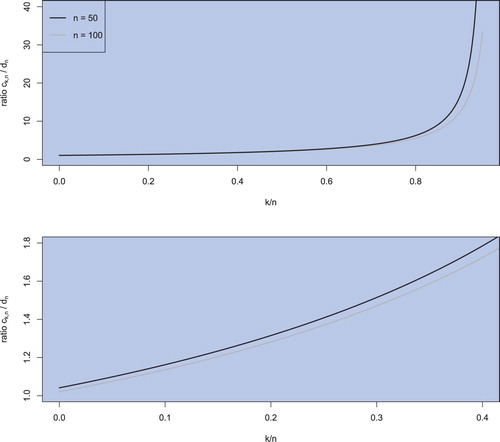
It is a well-known fact that the sample efficient frontier is overoptimistic and overestimates the location of the population efficient frontier in the mean–variance space (cf. Basak et al. Citation2005, Siegel and Woodgate Citation2007, Bodnar and Bodnar Citation2010). In contrast, the Bayesian approach provides an improved procedure which shrinks the sample efficient frontier by increasing the estimated variance of the global minimum portfolio and reducing the slope parameter. We will illustrate this point in Section 4 on real data described in Section 4.1.
3.3. Simulation study
We provide a detailed comparison of the estimators of the optimal portfolio weights, namely the suggested (objective) Bayesian approach, the estimator resulting from the (extended) Black–Litterman model, and the sample estimator, via simulations in this section. In the comparison study we also include two robust estimators of optimal portfolio weights (see, Chapter 20 in Würtz et al. Citation2015), which are based on the robust estimation of the mean vector and of the covariance matrix known as the minimum volume ellipsoid (MVE) estimator (see, e.g. Rousseeuw Citation1984) and the minimum covariance determinant (MCD) estimator (see, e.g. Rousseeuw and Driessen Citation1999). The aim of the Monte Carlo study is to assess the performance of each strategy in the estimation of the expected return and the variance of optimal portfolios. Such results will provide a better understanding about potential improvements which can be obtained by employing the new Bayesian approach.
The results of Proposition 4.6 of Bernardo and Smith (Citation2000) ensure that the conditional multivariate normal distribution satisfies the imposed assumptions of infinitely exchangeability and of multivariate centred spherically symmetry. For that reason, we assume that the asset returns are independently and identically distributed given mean vector and covariance matrix
with the conditional distribution given by
. In order to avoid any restriction to specific values of
, the elements of this vector were generated from the uniform distribution on
in each simulation run, that is
. For the covariance matrix we consider its decomposition into the correlation matrix
and the diagonal matrix with standard deviations
, i.e.
. Two choices of volatility are considered: (i) low volatility with
and (ii) high volatility with
. The correlation matrix is set to
with
, k-dimensional identity matrix
, and the k-dimensional matrix of ones
. We put
,
, and
. In the case of the (extended) Black–Litterman model the precision parameters are
and
, while
and
are obtained by perturbing
and
as
and
with
and
where
and
. The results in the tables are based on
independent repetitions.
As a measure of performance, the average absolute deviation from the resulting estimator to the corresponding true population value was computed for the portfolio expected return and the portfolio variance. The values are summarized in table in the case of low volatilities and in table for high volatilities. We observe that the application of the new objective Bayesian estimation strategy leads to the considerable improvements in terms of both performance measures meaning a better point estimation of both the portfolio expected return and the portfolio variance. The impact of the improvement increases as the portfolio dimension becomes larger. Especially, when k = 40 and n = 50 the new Bayesian estimator results in the values of the average deviation which are 12 times smaller than the one computed for the sample portfolio in the case of the portfolio expected return and about 11.7 times smaller in the case of the variance when the volatilities are low, while both these values are above 12.2 for high volatilities. These findings are in line with the results presented in figure . Also, a slightly better performance is observed in the case of the (extended) Black–Litterman estimation strategy when the portfolio dimension is large. In this case, it is ranked on the second place by using both criteria when k = 40 and n = 50, while it is on the third place in all other cases showing that the influence of the expert knowledge could have a great impact when the sample size is not large. Similar findings are also present for two robust portfolio selection strategies, which are ranked on the fourth and on the fifth places. Also, in these cases, the sample size is not large enough with respect to the portfolio dimension, which causes a bad performance of these two strategies. Finally, we point out that with the increase of the sample size, the values of the two performance measures becomes smaller and in the case of k = 5 and n = 130 they are almost the same for the new Bayesian approach and the sample method while the Bayesian approach is still more preferable.
Table 1. Average absolute deviation (AD) of the estimated portfolio expected return and of the estimated portfolio variance from their population values.
Table 2. Average absolute deviation (AD) of the estimated portfolio expected return and of the estimated portfolio variance from their population values.
3.4. Robustness analysis
Next, we investigate how robust are the numerical findings obtained in the previous section to the deviation from the conditional normality. For this purposed, we employ the conditional multivariate t-distribution with 5 degrees of freedom, which has the same mean vector and the same covariance matrices
as in the case of the model from Section 3.3. Furthermore, it is noted that in contrast to the conditional multivariate normal distribution, the conditional multivariate t-distribution does not belong to the family of infinitely exchangeability and multivariate centred spherically symmetrical distributions.
The replacement of the conditional multivariate normal distribution by the conditional multivariate t-distribution influences the values of the average absolute deviation computed in both cases of the portfolio expected return and of the portfolio variance. All these values become considerably larger which is explained by the heavy-tailed nature of the multivariate t-distribution (see tables and ). On the other side, the ranking between the five estimation strategies does not change. The new (objective) Bayesian approach outperforms the other four competitors in all of the considered cases similarly when the observation data were generated from the multivariate normal distribution. Also, in the case of the large-dimensional portfolio consisting of 40 assets and the sample size equal to n = 50, the (extended) Black–Litterman approach is ranked on the second place for both low and high volatilities, while the sample estimator performs better in the rest of the considered cases.
Table 3. Average absolute deviation (AD) of the estimated portfolio expected return and of the estimated portfolio variance from their population values.
Table 4. Average absolute deviation (AD) of the estimated portfolio expected return and of the estimated portfolio variance from their population values.
4. Empirical illustration
4.1. Data
For the first empirical illustration, we use weekly returns from a collection of assets of the S&P500, allowing for portfolios ranging from 5 to 40 assets. A similar setup is also used in the second empirical illustration where monthly returns instead of weekly returns are used. The parameters are estimated with sample sizes of , corresponding to one year up to two and a half years of weekly data or to approximately four and a half up to eleven years of monthly data. All the data end on the 8th of October 2017. The constructed portfolios consist of
assets. The hyperparameters in the extended Black–Litterman model are obtained by employing the empirical Bayes approach (see, e.g. Gelman et al. Citation2014, Bauder et al. Citation2020). This allows us to analyse the behaviour of the proposed model not only in terms of economic risk but also regarding statistical estimation uncertainty.
4.2. Results for weekly data
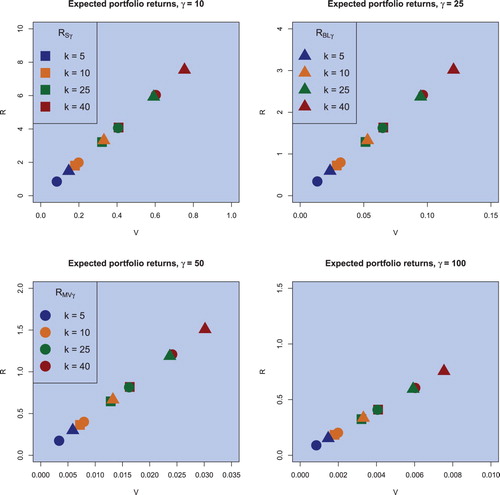
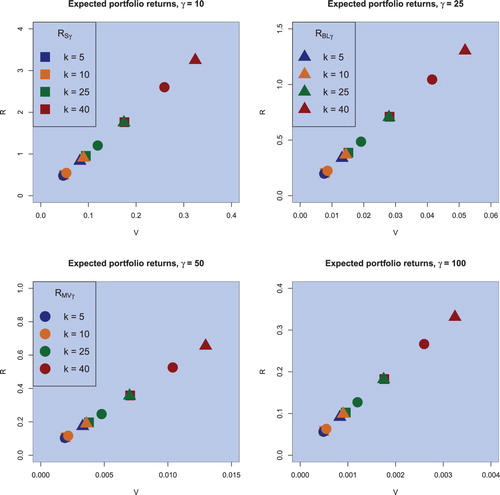
As mentioned in Section 3, there is a distinct difference between the classical sample estimators and the (objective) Bayesian estimators proposed in this paper. With this conclusion and the fact that the sample efficient frontier overestimates the population efficient frontier, we expect the estimators for the expected return and the variance to be larger in the Bayesian case compared to the sample estimators indicating that the (objective) Bayesian approach also takes the estimation risk into account in its construction which in practice automatically leads to smaller values of the risk aversion coefficient in comparison to the conventional case. Figure illustrates this presumption: fixing n = 130 and considering different portfolio sizes for different risk attitudes
, we find that for the same value of the risk coefficient γ and for the same portfolio size, the (objective) Bayesian estimator performs as expected compared to the sample estimator, whereas the Black–Litterman optimal portfolios exhibit a more exaggerated behaviour. The latter results are related to the usage of the additional information in the construction of the Black–Litterman optimal portfolios which, in particular, can lead to the increase of uncertainty especially when the hyperparameters differ considerably from the corresponding population values as shown in the simulation study of Section 3. Furthermore, the difference in the estimators increases if the number of assets gets closer to the sample size, as illustrated in figure or when γ decreases, i.e. for less risk averse investors the impact of parameter uncertainty becomes larger.
Figure 2. Sample optimal portfolios (squares), (objective) Bayesian optimal portfolios (circles), and the Black–Litterman optimal portfolios (triangulares) for the risk aversion coefficient of , for the sample case of n = 130 and for the portfolio dimension of
in the case of weekly data.
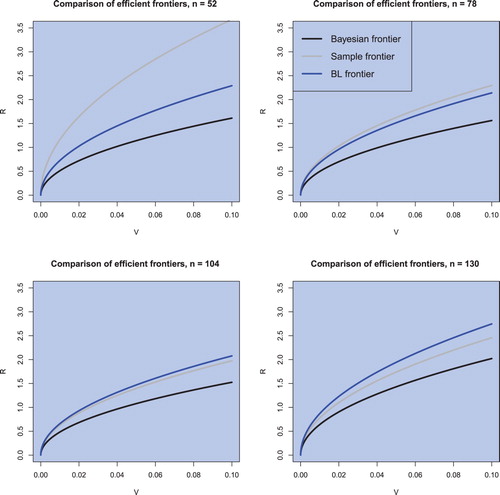
Regarding the efficient frontier, figure shows the estimated efficient frontiers for a fixed sample size of n = 130 and varying portfolio sizes in all three cases, namely the sample efficient frontier, the (objective) Bayesian efficient frontier, and the Black–Litterman efficient frontier. The (objective) Bayesian efficient frontier lies always below the sample efficient frontier and therefore exhibits less overestimation of the population efficient frontier. In contrast, the Black–Litterman frontier exhibits even a stronger overestimation compared to the population efficient frontier due to the uncertainty related to hyperparameters which are present in the model. Furthermore, figure also illustrates the finding shown in figure . The estimators of the efficient frontier deviate stronger when the portfolio size gets closer to the sample size. This fact is also illustrated in figure for fixed k = 40 and varying
. The (objective) Bayesian and the sample estimated efficient frontiers coincide more the larger the sample size n is, whereas the Black–Litterman efficient frontier appears to exhibit stronger overestimation with growing sample size. This is in line with the theoretical implications. Finally, we also observe the increase in the slope parameter of the efficient frontier when the portfolio dimension increases indicating the well-documented positive effect of portfolio diversification.
Figure 3. The sample efficient frontier, the (objective) Bayesian efficient frontier, and the Black–Litterman efficient frontier for n = 130 and in the case of weekly data.
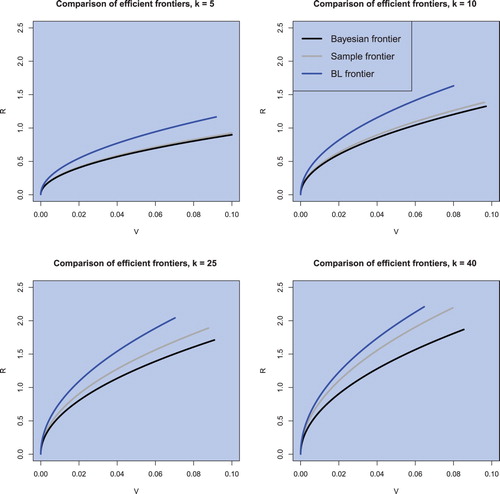
Figure 4. The sample efficient frontier, the (objective) Bayesian efficient frontier, and the Black–Litterman efficient frontier for k = 40 and in the case of weekly data.
4.3. Results for monthly data
Figure shows the location of the sample optimal portfolios, of the (objective) Bayesian optimal portfolios, and of the Black–Litterman optimal portfolios computed for the same values of the risk aversion coefficient γ, portfolio dimension k, and sample size n as in figure in the case of monthly data. The distinct difference between the classical sample estimators, the (objective) Bayesian estimators, and the Black–Litterman optimal portfolios is also identified for monthly data. In contrast to figure we observe a considerable reduction in both the expected returns and the variances of all constructed optimal portfolios, while their ordering with respect to the location in the mean–variance space is the same as the one observed in figure . For the same value of the investor risk aversion coefficient the sample optimal portfolios exhibit smaller values of the expected return and the variance following by the (objective) Bayesian optimal portfolio which incorporate the parameter uncertainty into account in their construction. Finally, the uncertainty about the hyperparameters move the Black–Litterman optimal portfolios futher in the direction of larger values of the expected return and variance.
Figure 5. Sample optimal portfolios (squares), (objective) Bayesian optimal portfolios (circles), and the Black–Litterman optimal portfolios (triangulares) for the risk aversion coefficient of , for the sample case of n = 130 and for the portfolio dimension of
in the case of monthly data.
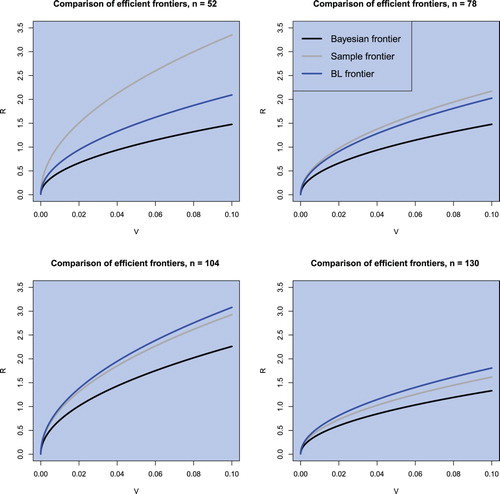
Similar findings are also present in figures and where the sample efficient frontier, the (objective) Bayesian efficient frontier, and the Black–Litterman efficient frontier are drawn for several values of portfolio dimension k and sample size n. Both the sample efficient frontier and the Black–Litterman efficient frontier lie above the (objective) Bayesian efficient frontier tending to provide a considerable overestimation of the population efficient frontier especially when the portfolio dimension is large in comparison to the sample size. In figure we also observe that sample efficient frontier is located above the other two estimators when the sample size is only slightly larger than portfolio dimension k = 40 indicating its poor performance in such situations independently of the data frequency used in the estimation. On the other side, the Black–Litterman efficient frontier demonstrates its dependence on the chosen hyperparameters used in its construction. The considerable sample sizes in both figures and seem to be not large enough to reduce the effect of the hyperparameters on the resulting estimator of the efficient frontier. Better results are expected for larger sample sizes following the Bernstein–von Mises theorem (cf. Bernardo and Smith Citation2000).
Figure 6. The sample efficient frontier, the (objective) Bayesian efficient frontier, and the Black–Litterman efficient frontier for n = 130 and in the case of monthly data.
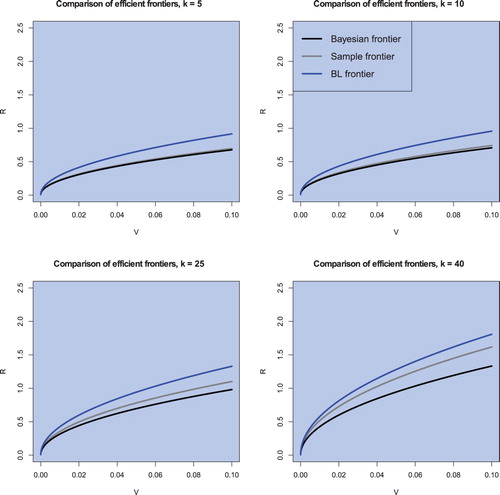
Figure 7. The sample efficient frontier, the (objective) Bayesian efficient frontier, and the Black–Litterman efficient frontier for k = 40 and in the case of monthly data.
4.4. Posterior interval prediction
In contrast to the conventional procedure, both the (objective) Bayesian approach and the application of the Black–Litterman model provide also the whole posterior predictive distribution of the optimal portfolio return and not only the point estimator of its weights. Using data described in Section 4.1, we calculate in this section the prediction intervals for the optimal portfolio returns for several values of the risk-aversion coefficient , for
, and for
in the case of weekly data (see, figures for the (objective) Bayesian approach and for the Black–Litterman model) and in the case of monthly data (see, figures for the (objective) Bayesian approach and figure for the Black–Litterman model).
Figure 8. Credible intervals for the return of optimal portfolios with varying risk attitudes for weekly data obtained by employing the (objective) Bayesian approach. The sample sizes are chosen to be and the portfolio dimension is fixed to k = 25. The confidence level is set to
.
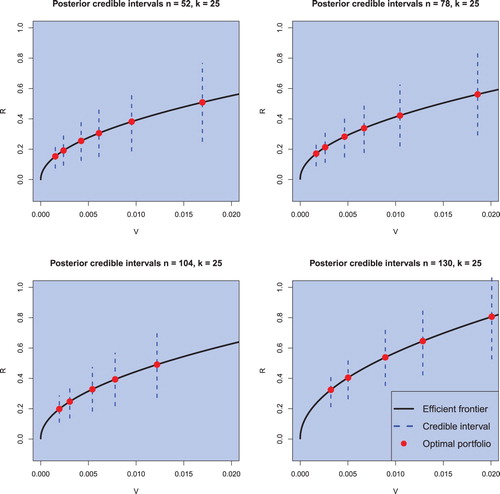
Figure 9. Credible intervals for the return of optimal portfolios for the Black–Litterman model with varying risk attitudes for weekly data. The sample sizes are chosen to be and the portfolio dimension is fixed to k = 25. The confidence level is set to
.
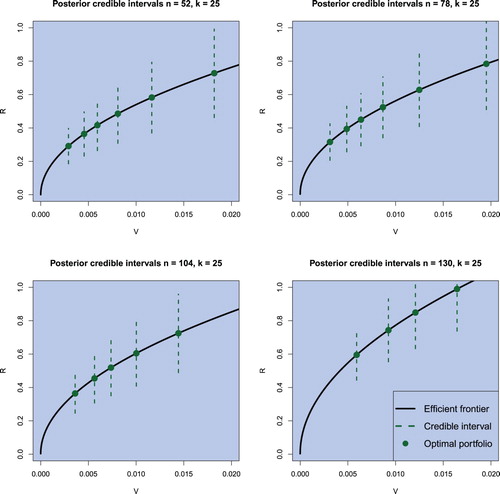
Figure 10. Credible intervals for the return of optimal portfolios with varying risk attitudes for monthly data obtained by employing the (objective) Bayesian approach. The sample sizes are chosen to be and the portfolio dimension is fixed to k = 25. The confidence level is set to
.
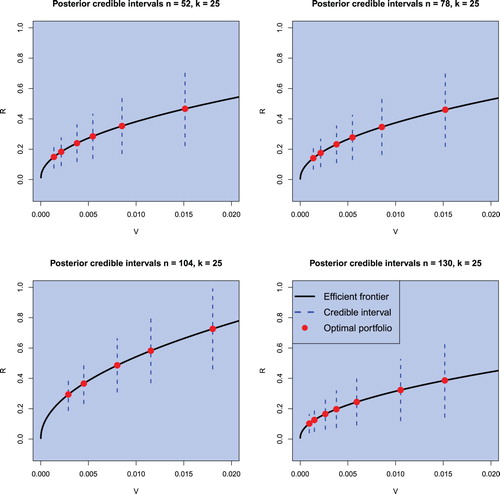
Figure 11. Credible intervals for the return of optimal portfolios for the Black–Litterman model with varying risk attitudes for monthly data. The sample sizes are chosen to be and the portfolio dimension is fixed to k = 25. The confidence level is set to
.
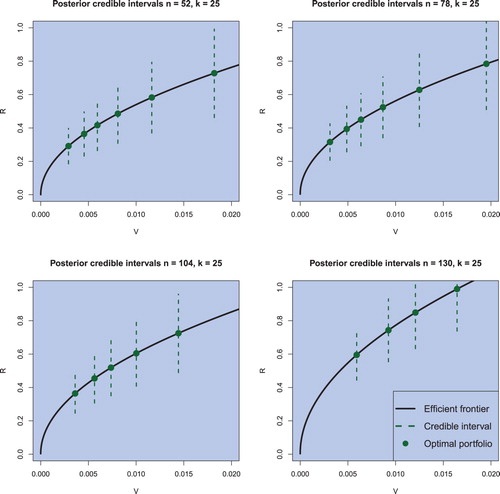
The prediction intervals in figures – are obtained by using the following procedure:
Fix γ and calculate the expected return and the variance of the corresponding mean–variance optimal portfolio as given (Equation9
For chosen γ, compute the weights of the optimal mean–variance portfolio
In using
Fix the significance level of the prediction interval α and compute the
For the computed value of
The order of the efficient portfolios given in figures – is directly determined by the risk aversion coefficient. The smaller γ, the riskier is the portfolio and lies therefore more right on the efficient frontier. We observe that the optimal efficient portfolios are shifted to the right for growing sample sizes. But the focus lies here on the credible intervals for a confidence level of . The first observation is that no credible interval covers negative values, implying positive portfolio returns with probability of
. The second observation is that the credible intervals become larger the more risky an efficient portfolio becomes—which is in line with the theory. And the third observation is that these credible intervals for riskier efficient portfolios become larger regardless of the increased sample size. Hence, the decrease in estimation risk resulting from a larger sample is outweighed by the economic risk.
As in the previous section, no differences between the results obtained by using weekly data or monthly data are detected. Most noteworthy is the case of n = 130 for monthly data as shown in figures and , covering the financial crisis of 2008, showing a drastic drop in returns compared to different periods but also exhibiting credible intervals which do not cover negative values. To this end, we note that the optimal Black–Litterman portfolios are located further on the efficient frontier in comparison to the (objective) Bayesian optimal portfolio computed for the same value of the risk aversion coefficient and they also have larger prediction intervals indicating larger amount of uncertainty which is present when the optimal Black–Litterman portfolios are constructed.
5. Conclusion
The mean–variance analysis of Markowitz presents a fundamental method of portfolio construction which is very popular in the financial literature today. It provides an investor with the portfolio weights which determine the structure of the optimal portfolio. However, the investor faces a number of difficulties in implementing this procedure in practice. One of the main pitfalls of the mean–variance analysis is that its solution is presented in terms of unobservable quantities, the parameters of the asset returns distribution. As a result, the optimization problem is performed in two steps. After finding the analytical solution, the optimal portfolio is constructed by replacing the unknown parameters with their estimates. Due to the considerable influence of parameter uncertainty on the investment process, this procedure leads only to sub-optimal portfolios.
We deal with the problem from the viewpoint of Bayesian statistics. The optimization problem is formulated in terms of the posterior predictive distribution which does not involve unknown quantities. Consequently, we deal with parameter uncertainty before solving the optimization problem. This approach allows us to find optimal portfolio weights which now depend only on historical observations of the asset returns. The advantages of the approach are shown both theoretically and empirically. In particular, we show that the constructed Bayesian efficient frontier improves on the overoptimism present in the sample efficient frontier. Another important advantage of the suggested procedure is that it allows us not only to construct an optimal portfolio based on the posterior predictive distribution, but also leads to an intelligent technique by performing an interval forecast of future realizations of optimal portfolio returns which are obtained by employing the derived stochastic representation of the posterior predictive distribution.
Acknowledgments
The authors would like to thank Professor Michael Dempster, Professor Jim Gatheral and two anonymous Reviewers for their helpful suggestions. This research was partly supported by the German Science Foundation (DFG) via the projects BO 3521/3-1 and SCHM 859/13-1 ‘Bayesian Estimation of the Multi-Period Optimal Portfolio Weights and Risk Measures’ and by the Swedish Research Council (VR) via the project ‘Bayesian Analysis of Optimal Portfolios and Their Risk Measures’.
Disclosure statement
No potential conflict of interest was reported by the author(s).
ORCID
Nestor Parolya http://orcid.org/0000-0003-2147-2288
Additional information
Funding
References
- Aguilar, O. and West, M., Bayesian dynamic factor models and portfolio allocation. J. Bus. Econ. Stat., 2000, 18, 338–357.
- Avramov, D. and Zhou, G., Bayesian portfolio analysis. Annu. Rev. Financ. Econ., 2010, 2, 25–47. doi: 10.1146/annurev-financial-120209-133947
- Barry, C., Portfolio analysis under uncertain means, variances, and covariances. J. Financ., 1974, 29, 515–522. doi: 10.1111/j.1540-6261.1974.tb03064.x
- Basak, G.K., Jagannathan, R. and Ma, R., Estimating the risk in sample efficient portfolios. Technical report, Northwestern University, Evanston, IL, 2005.
- Bauder, D., Bodnar, R., Bodnar, T. and Schmid, W., Bayesian estimation of the efficient frontier. Scand. J. Stat., 2019, 46(3), 802–830. doi: 10.1111/sjos.12372
- Bauder, D., Bodnar, T., Mazur, S., Okhrin, Y., et al., Bayesian inference for the tangent portfolio. Int. J. Theor. Appl. Financ., 2018, 21(8), 1850054. doi: 10.1142/S0219024918500541
- Bauder, D., Bodnar, T., Parolya, N., Schmid, W., Bayesian inference of the multi-period optimal portfolio for an exponential utility. J. Multivar. Anal., 2020, 175, 104544. doi: 10.1016/j.jmva.2019.104544
- Bawa, V.S., Brown, S.J. and Klein, R.W., Estimation Risk and Optimal Portfolio Choice, 1979 (North-Holland Pub. Co: Amsterdam).
- Bernardo, J.M. and Smith, A.F.M., Bayesian Theory, 2000 (Wiley: Chichester).
- Best, M.J. and Grauer, R.R., On the sensitivity of mean–variance–efficient portfolios to changes in asset means: Some analytical and computational results. Rev. Financ. Stud., 1991, 4, 315–342. doi: 10.1093/rfs/4.2.315
- Black, F. and Litterman, R., Global portfolio optimization. Financ. Analysts J., 1992, 48, 28–43. doi: 10.2469/faj.v48.n5.28
- Bodnar, O. and Bodnar, T., On the unbiased estimator of the efficient frontier. Int. J. Theor. Appl. Financ., 2010, 13, 1065–1073. doi: 10.1142/S021902491000611X
- Bodnar, T., Dmytriv, S., Parolya, N. and Schmid, W., Tests for the weights of the global minimum variance portfolio in a high-dimensional setting. IEEE Trans. Signal Process., 2019, 67(17), 4479–4493. doi: 10.1109/TSP.2019.2929964
- Bodnar, T., Mazur, S. and Okhrin, Y., Bayesian estimation of the global minimum variance portfolio. Eur. J. Oper. Res., 2017, 256, 292–307. doi: 10.1016/j.ejor.2016.05.044
- Bodnar, T., Parolya, N. and Schmid, W., Estimation of the global minimum variance portfolio in high dimensions. Eur. J. Oper. Res., 2018, 266(1), 371–390. doi: 10.1016/j.ejor.2017.09.028
- Bodnar, T. and Schmid, W., Estimation of optimal portfolio compositions for gaussian returns. Stat. Decis., 2008, 26, 179–201.
- Bodnar, T. and Schmid, W., Econometrical analysis of the sample efficient frontier. Eur. J. Financ., 2009, 15, 317–335. doi: 10.1080/13518470802423478
- Bradley, B.O. and Taqqu, M.S., Financial risk and heavy tails. In Handbook of Heavy Tailed Distributions in Finance, edited by S.T. Rachev, Volume 1 of Handbooks in Finance, pp. 35–103, 2003 (North-Holland: Amsterdam).
- Brandt, M.W. and Santa-Clara, P., Dynamic portfolio selection by augmenting the asset space. J. Financ., 2006, 61(5), 2187–2217. doi: 10.1111/j.1540-6261.2006.01055.x
- Broadie, M., Computing efficient frontiers using estimated parameters. Ann. Oper. Res., 1993, 45, 21–58. doi: 10.1007/BF02282040
- Brown, S., Optimal portfolio choice under uncertainty: A Bayesian approach. PhD thesis, University of Chicago, 1976,
- Frost, P. and Savarino, J., An empirical Bayes approach to efficient portfolio selection. J. Financ. Quant. Anal., 1986, 21, 293–305. doi: 10.2307/2331043
- Gelman, A., Carlin, J.B., Stern, H.S. and Rubin, D.B., Bayesian Data Analysis, Vol. 2, 2014 (Chapman & Hall/CRC Boca Raton: FL, USA).
- Givens, G.H. and Hoeting, J.A., Computational Statistics, 2012 (John Wiley & Sons: New York).
- Gupta, A. and Nagar, D., Matrix Variate Distributions, 2000 (Chapman and Hall/CRC: Boca Raton).
- Gupta, A., Varga, T. and Bodnar, T., Elliptically Contoured Models in Statistics and Portfolio Theory, 2nd ed., 2013 (Springer: New York).
- Ingersoll, J.E., Theory of Financial Decision Making, 1987 (Rowman & Littlefield Publishers: Lanham, MD).
- Jobson, J. and Korkie, B.M., Performance hypothesis testing with the Sharpe and Treynor measures. J. Financ., 1981, 36, 889–908. doi: 10.1111/j.1540-6261.1981.tb04891.x
- Jorion, P., Bayes–Stein estimation for portfolio analysis. J. Financ. Quant. Anal., 1986, 21(3), 279–292. doi: 10.2307/2331042
- Kacperczyk, M., Damien, P. and Walker, S.G., A new class of bayesian semi-parametric models with applications to option pricing. Quant. Financ., 2013, 13(6), 967–980. doi: 10.1080/14697688.2012.712212
- Kacperczyk, M. and Damien, P., Asset allocation under distribution uncertainty. In McCombs Research Paper Series No. IROM-01-11, 2011 (Citeseer).
- Kan, R. and Smith, D.R., The distribution of the sample minimum-variance frontier. Manage. Sci., 2008, 54, 1364–1380. doi: 10.1287/mnsc.1070.0852
- Kan, R. and Zhou, G., Optimal portfolio choice with parameter uncertainty. J. Financ. Quant. Anal., 2007, 42, 621–656. doi: 10.1017/S0022109000004129
- Klein, R. and Bawa, V., The effect of estimation risk on optimal portfolio choice. J. Financ. Econ., 1976, 3, 215–231. doi: 10.1016/0304-405X(76)90004-0
- MacKinlay, A.C. and Pástor, L., Asset pricing models: Implications for expected returns and portfolio selection. Rev. Financ. Stud., 2000, 13, 883–916. doi: 10.1093/rfs/13.4.883
- Markowitz, H., Portfolio selection. J. Financ., 1952, 7, 77–91.
- Markowitz, H., Portfolio Selection: Efficient Diversification of Investments, 1959 (John Wiley: New York).
- Merton, R.C., An analytic derivation of the efficient portfolio frontier. J. Financ. Quant. Anal., 1972, 7, 1851–1872. doi: 10.2307/2329621
- Merton, R.C., On estimating the expected return on the market: An exploratory investigation. J. Financ. Econ., 1980, 8, 323–361. doi: 10.1016/0304-405X(80)90007-0
- Muirhead, R.J., Aspects of Multivariate Statistical Theory, 1982 (Wiley: New York).
- Okhrin, Y. and Schmid, W., Distributional properties of portfolio weights. J. Econom., 2006, 134, 235–256. doi: 10.1016/j.jeconom.2005.06.022
- Pástor, L., Portfolio selection and asset pricing models. J. Financ., 2000, 55, 179–223. doi: 10.1111/0022-1082.00204
- Pástor, L. and Stambaugh, R.F., Comparing asset pricing models: An investment perspective. J. Financ. Econ., 2000, 56, 335–381. doi: 10.1016/S0304-405X(00)00044-1
- Rachev, S.T., Hsu, J.S.J., Bagasheva, B.S. and Fabozzi, F.J., Bayesian Methods in Finance, 2008 (Wiley: New Jersey).
- Rousseeuw, P.J., Least median of squares regression. J. Amer. Statist. Assoc., 1984, 79(388), 871–880. doi: 10.1080/01621459.1984.10477105
- Rousseeuw, P.J. and Driessen, K.V., A fast algorithm for the minimum covariance determinant estimator. Technometrics, 1999, 41(3), 212–223. doi: 10.1080/00401706.1999.10485670
- Sekerke, M., Bayesian Risk Management: A Guide to Model Risk and Sequential Learning in Financial Markets, 2015 (Wiley: New Jersey).
- Siegel, A.F. and Woodgate, A., Performance of portfolios optimized with estimation error. Manage. Sci., 2007, 53, 1005–1015. doi: 10.1287/mnsc.1060.0664
- Stambaugh, R.F., Analyzing investments whose histories differ in length. J. Financ. Econ., 1997, 45, 285–331. doi: 10.1016/S0304-405X(97)00020-2
- Tu, J. and Zhou, G., Incorporating economic objectives into bayesian priors: Portfolio choice under parameter uncertainty. J. Financ. Quant. Anal., 2010, 45, 959–986. doi: 10.1017/S0022109010000335
- Würtz, D., Chalabi, Y., Chen, W. and Ellis, A., Portfolio Optimization with R/Rmetrics, 2015 (Rmetrics: Zurich).
Appendix
Proof of Theorem 1.
Proof of Theorem 1
The assumptions of infinitely exchangeability and multivariate centred spherically symmetry implies (see, e.g. Bernardo and Smith Citation2000, Proposition 4.6) that the asset returns are independently and identically distributed given the mean vector and the covariance matrix
with the conditional distribution given by
(k-dimensional normal distribution with mean vector
and covariance matrix
). Under this model with
, Jeffreys' prior is given by
(A1)
(A1) which leads to the posterior expressed as
(A2)
(A2) where
and
are given in the statement of the theorem.
From (EquationA2(A2)
(A2) ) we obtain that the posterior distribution of
is the inverse Wishart distribution (see Gupta and Nagar Citation2000 for the definition and properties) given by
(A3)
(A3) Furthermore, integrating out
we get the marginal posterior for
expressed as
where the last equality follows by observing that the function under the integral is the density function of the inverse Wishart distribution with n + k + 1 degrees of freedom and parameter matrix
. The application of Silvester's determinant theorem leads to
(A4)
(A4) which proves that
(k-dimensional multivariate t-distribution with n−k degrees of freedom, location vector
, and scale matrix
).
Because are independent given
and
as well as conditionally normally distributed, we get that the conditional distribution
coincides with
is given by
where the last equality proves that
depends on
,
, and
only over
and
.
The application of Theorem 3.2.13 in Muirhead (Citation1982) leads to
(A5)
(A5) where
and is independent of
and
. Then the stochastic representation of
is given by
where
is independent of
and
.
Finally, from the properties of the multivariate t-distribution, we obtain
and, consequently,
where
and
are independent with
and
.
Proof of Corollary 1.
Proof of Corollary 1.
In using the stochastic representation given in Theorem 1 and the properties of the t-distribution, we get
and
Proof of Theorem 2.
Proof of Theorem 2.
Following the proof of Theorem 1, the marginal posterior of under the informative prior (Equation16
(16)
(16) )–(Equation17
(17)
(17) ) is given by (see, e.g. Bauder et al. Citation2020, Proposition 2)
while the conditional posterior of
given
is expressed as
Because
are independent given
and
as well as conditionally normally distributed, we get that the conditional distribution
coincides with
and is given by
where the last equality proves that
depends on
,
, and
only over
and
.
From Muirhead (Citation1982, Theorem 3.2.13) we get
(A6)
(A6) where
and is independent of
and
.Hence,
where
is independent of
and
.
Finally, from the properties of the multivariate t-distribution, we obtain
and, consequently,
where
and
are independent with
and
.
Proof of Corollary 2.
Proof of Corollary 2.
The application of Theorem 2 leads to
and