?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
There are many well documented behavioral biases in financial markets. Yet, analyzing U.S. equities reveals that less than 1% of returns are predictable in recent years. Given the high number of biases, why are returns not more predictable? We provide new evidence in support of one possible explanation. In the long-run, low correlations across signals that trigger biases may create sufficient antinoise which mutes more sizable patterns in returns. However, in the short-run, correlation spikes coincide with market volatility indicating that behavioral biases may become more visible during crises.
1. Introduction
Numerous empirical observations in financial markets may reflect behavioral biases e.g. Bondt and Thaler (Citation1985), Lakonishok et al. (Citation1994), García (Citation2013) and Bordalo et al. (Citation2019) (among many others). In this paper we examine two main questions. First, given the high number of well-documented biases, how pronounced are systematic patterns in financial markets in recent years? Second, given the weak evidence we find for systematic patterns, why do these biases not show up more clearly in the markets?
Our analysis focuses on U.S. equities. To address the first question, we employ a variety of regression techniques and samples. More specifically, we use a total of 50 popular predictors (signals) and attempt to forecast the cross-section of stock returns in the Russell 1000 with a horizon of 1 month or less. As the functional form of this relation is unclear, we employ Boosted Trees to determine the structure of the data. Conducting a large variety of robustness tests, we find that, out-of-sample, less than 1% of stock returns are predictable—confirming recent findings by Gu et al.(Citation2020).Footnote1
Following on from this result, we address the second question. We focus on a possible explanation that we mainly derive from Friedman (Citation1953), Fama (Citation1965) and De Long et al. (Citation1990): the presence of many uncorrelated signals that trigger biases may cancel out at the aggregate level. To describe this effect, we use an analogy borrowing the term antinoise from the audio signal processing literature.
Studying the empirical correlation structure of our signals, we find that, over the long-run, the correlations are mainly distributed around zero with a much higher kurtosis than a normal distribution. By employing Monte-Carlo methods, we confirm that finding return predictability of more than 1% is an unlikely outcome given such a correlation structure. By contrast, we show that under a bimodal distribution (a counterfactual scenario) with many correlations close to −1 and +1, finding high return predictability is a more likely outcome.
Applying our antinoise analogy to financial markets is straightforward: a trader responding to a two-weeks Momentum signal—one of the predictors in our data—may want to buy a stock matching with another trader responding to a sell signal, thus muting the overall impact of the first signal. With many uncorrelated signals in place, there is a high probability that each signal will face an opposing signal at any given moment in time. As a result of the presence of antinoise, we do not expect to find high return predictability.
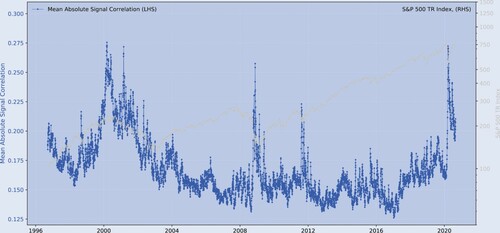
Yet, when we focus on the dynamic behavior of the correlations, figure illustratively shows that correlations become more pronounced (the mean of the absolute correlations increases) during episodes of stock market volatility. For instance, as during the SARS-CoV-2 crisis, the 2008 financial crisis and the Dot-com bubble. In light of our Monte-Carlo simulations, this second piece of evidence indicates that, in the short-run, behavioral biases may become more visible during crises.Footnote2
Figure 1. The S&P 500 index and the mean absolute signal correlations.
Notes: sample period: 1996.06–2020.08; The figure shows the relation between the S&P 500 Index and the mean absolute signal correlations between a collection of market-based and fundamental indicators. is a correlation matrix that contains the cross-correlations between the signals. The mean of the absolute cross-correlations of the signals (the absolute of the elements of
) indicates the strength of the correlations. See Section 3.2 for more detail about the signals (predictors).
What are the limitations of our findings? Our interpretations rest on a number of additional assumptions. First, the set of predictors—although containing many of the standard predictors that the literature employs—does not contain all possible predictors. Could the absence of predictors overturn our conclusions? We think this is unlikely for two reasons: (i) since we already use many of the more correlated predictors, the missing predictors are presumably less correlated with subsequent returns and (ii) finding a high joint correlation across signals is more difficult with a larger basket of weakly correlated predictors.
Second, each of our predictors represents a signal that triggers buying and selling by different types of biased, signal-following traders.Footnote3 By assuming that predictors act as signals which proxy biases, we also make implicit assumptions about the proportions of trades which are triggered by these signals. For example, claiming that a large basket of uncorrelated signals cancels out in the aggregate, rests on the assumption that trades that follow individual signals face a significant number of opposing trades. While we cannot directly provide evidence for this assumption, we think it is reasonable to assume, given the large number of uncorrelated signals and market participants, that no individual signal generates enough trading volume to counter the trading volume generated by other signals.
Our paper primarily relates to the literature on mispricing due to behavioral biases in financial markets. Numerous papers document various individual behavioral biases see, among many others, e.g. Bondt and Thaler (Citation1985), Lakonishok et al. (Citation1994), Coval and Shumway (Citation2005), DellaVigna and Pollet (Citation2009), Mclean and Pontiff (Citation2016), and Chen and Sabherwal (Citation2019) for potential factors in explaining certain price anomalies. Yet, such papers pay little attention to how individual biases interact and create patterns at the aggregate level. Papers that study the interactions of heterogenous traders remain largely theoretical; see, among many others, e.g. Black (Citation1986), Shleifer and Summers (Citation1990), Brock and Hommes (Citation1997), Shleifer and Vishny (Citation1997), Lux and Marchesi (Citation1999), Sandroni (Citation2000), Boswijk et al. (Citation2007), Yan (Citation2010), Xiong and Yan (Citation2010), Eyster et al. (Citation2019), Peress and Schmidt (Citation2020), and Westphal and Sornette(Citation2020).
We contribute to this literature predominantly by empirically studying the effects of signal interactions on overall return predictability. We highlight the two aforementioned findings. Our methodology benefits from recent computational advances in machine learning, which allow us to study the interactions between predictors see, e.g. Moritz and Zimmermann (Citation2016), Gu et al. (Citation2020), and Kozak et al. (Citation2020) among others. These studies are in contrast to older linear studies such as Fama and French (Citation1992, Citation2016) that assume no interactions within the set of predictors, and which may consequently hinder predictability. In contrast to the machine learning papers, which focus on demonstrating that interactions and non-linearities may play an important role in explaining the data, we focus on how the interactions across predictors can help us understand why biased traders may not produce more pronounced patterns in the data.Footnote4
Our findings are further related to studies on herding behavior by investors. As in the literature on ‘style-investing’ (Barberis and Shleifer Citation2003, Teo and Woo Citation2004, Boyer Citation2011), the chosen predictors can be viewed as representative of various styles used by the industry. Thus, our trading signals can proxy for heterogeneous traders that trade on different subsets of such signals. Our empirical findings complement earlier theoretical work on herding by, among many others, Froot et al. (Citation1992), Banerjee (Citation1992), Avery and Zemsky (Citation1998), Dennis and Strickland (Citation2002), Alfarano et al. (Citation2005), Veldkamp (Citation2006), Choi and Sias (Citation2009), Park and Sabourian (Citation2011), Kukacka and Barunik (Citation2013), and Aghamolla and Hashimoto (Citation2020). Like many of these theoretical papers on herding, most empirical studies in this area focus on increasing numbers of traders following the same signals (see, among many others, Grinblatt et al. (Citation1995), Nofsinger and Sias (Citation2002), Peter Chung and Thomas Kim (Citation2017), and Campajola et al. (Citation2020)). By contrast, in our study, herding-like effects do not arise as a result of copy-trading. Rather, we conjecture that, if the correlations between different signals become stronger, herding-like effects may arise and eventually increase market volatility.
Our paper proceeds as follows. Section 2 briefly explains the empirical approach. Section 3 describes the data and the main empirical findings. Section 4 provides a discussion and a theoretical rationale of the empirical evidence. Section 5 concludes. Appendices 1–5 present a variety of robustness tests.
2. Methodology and implementation
At time t, let us define the expected t + 1 response of stock i, , as a function g, of a matrix of predictors
. Formally,
(1)
(1)
As financial returns are noisy, we transform the prediction problem into a classification problem. The procedure is called discretization and lowers the impact of extreme returns, thereby reducing the noise (see e.g. Fayyad and Irani (Citation1993) and Garcia et al. (Citation2013)). We categorize the future realized return of asset i,
, into either one or zero—depending on whether it is positive or negative. More formally, the response variable,
, is coded as
(2)
(2)
We use two main approaches to approximate g—Logit and Boosted Trees. Our strategy is to predict class probabilities and then evaluate how well these probabilities predict subsequently realized returns. Our main goal is to approximate an upper bound of predictability. Appendices present a large variety of further exercises that support the main findings from Section 3.
3. Empirical analysis
3.1. Data
We focus on stocks in the Russell 1000 universe using end-of-day daily data during 1995.12–2020.08. All data are drawn from Bloomberg.Footnote5
To address issues arising from survivorship bias, we make two choices. First, we only include observations from those stocks that are members of the Russell 1000 at a given point in time. For example, on 2020.01.30, our sample includes only those stocks that are members of the Russell 1000 on the day of the last rebalancing. Since stocks enter and exit the index over time, our total sample includes about 3000 stocks. Second, we construct an equally weighted long-only benchmark from the exact same pool of stocks as our machine learning strategies. This benchmark is also rebalanced at the same frequency as our machine learning strategies.
For the forecasting and rebalancing horizon, we choose periods no greater than one month, as longer horizons are notoriously difficult to predict. Trading costs are negligible and affect all strategies and benchmarks symmetrically in our analysis.
Stock prices and volumes are adjusted for spin-offs, stock splits, consolidations, rights offerings, entitlements, stock dividends and bonuses. Historical pricing reflects normal cash dividends including regular cash, interim, income, estimated, partnership distribution, final, prorated, interest on capital, and distribution type dividends. It also reflects abnormal cash dividends including special cash, liquidating, capital gains (both long- and short-term), memorial, return of capital, rights redemption, proceeds/rights, proceeds/shares, proceeds/warrants, and miscellaneous return premia.
We focus on a set of 50 predictors that are available for all stocks. Despite extensive data availability, there are NaN gaps in the data. It is important to mention that the Logit approach cannot deal with NaNs and thus obtains the parameters from a reduced in-sample period. In contrast, Boosting can account for NaNs and estimates from a larger in-sample period. Appendix 4 reports the boosting results from an in-sample period containing only non-NaN observations.
Our sample is split into an in-sample (1995.12–2013.12) and an out-of-sample period (2013.12–2020.08). Since we focus on biases, we choose a rather late cut-off, as patterns and biases are usually arbitraged away when the market learns of them, e.g. Kolev and Karapandza (Citation2017). In Appendix 2, we present results for a different cut-off.
Data scaling is a recommended pre-processing step when working with noisy data. To normalize the predictors, we employ a simple ranking and then scale it between zero and unity. This procedure is equivalent to imposing the empirical cumulative distribution function on the data and converting the actual values to their corresponding probabilities. The advantage of this method is that it linearizes the predictors and thus mitigates the impact of outliers. Formally,
(3)
(3)
where
is an indicator variable denoting the elements smaller than z and
the total number of elements. Appendix 5 provides a robustness test where we use the empirical cumulative distribution instead.
More importantly, we use commonly accepted predictors that have been documented in previous studies. Our interpretation is that these signals have predictive power as they represent either biases or risks. The true source of the predictability is not important since our goal is to measure an upper bound on return predictability. Our main claim is that trader biases cannot account for more than this upper bound. Thus, even if some of the predictors reflect a risk, our central claim is still valid.
3.2. Signals
While smaller than (Gu et al. Citation2020), our set of predictors is sufficient to achieve a similar out-of-sample explanatory power as we will see further below. The predictors we use are motivated by previous studies—although each is specifically calculated, they should be correlated with broad categories of factors that have been shown to explain return variability. These classes include size, value, momentum, crash-risk, and liquidity; see, e.g. Sharpe (Citation1964), Fama and French (Citation1992), Longstaff (Citation1995), Asness et al. (Citation2013), Novy-Marx and Velikov (Citation2015), Farhi and Gabaix (Citation2016), Harvey et al. (Citation2016), Struck and Cheng (Citation2019), Freyberger et al. (Citation2020), among others.
Momentum. We use four different measures of Time Series Momentum with different lags of 10, 20, 60, 180 business days. This is calculated as:
where q denotes the number of workdays and determines the length of the look-back window;
is the level of the excess return series of commodity i at time t.
Volatility. Our second set of predictors measure past daily volatility and is thus similar to the risk measure hypothesized by Sharpe (Citation1964). Formally,
where the look-back window Q, is given by the number of weekdays, and
denotes the average price over that window. By using the levels instead of the changes, we give this measure a little twist drawing on an insight in a recent paper by Shue and Townsend (Citation2020) that emphasizes that price levels may contain valuable information to predict returns. We also consider at-the-money implied volatility of the first listed expiry at least 20 business days from today:
Implied out-of-the-money volatility can also be used to construct a measure of risk reversal. We use the difference between the implied 30-day volatility of the out-of-the-money 95% put and 105% call options. Intuitively, this difference in option implied volatility indicates expectations of market participants in whether the 1-month return risk is skewed above or below the at-the-money strike. Our measure is calculated as:
Finally, we also consider the short term momentum, or change, in implied volatility:
Correlation. Our third set of predictors measures the past daily correlation of each stock with the market. The market correlation is approximated here by the median stock correlation in the sample. We denote that as:
and the look-back window Q, is given by the number of weekdays. Again, relying on the same argument as before, we use the level instead of the change.
Skewness and Kurtosis. We also use the empirical skewness and the kurtosis of the daily returns over the past year. Skewness give us actual realized directional market risks, as compared to the option implied risk-reversal, which measures expected directional risks. Skewness and kurtosis are respectively defined as:
where Q is set to be 260 weekdays. Again, relying on recent findings by Shue and Townsend (Citation2020), we use the level instead of the change.
Size. We compute a measure of size by measuring a moving average of the daily turnover times the share price:
where
is the trading turnover (in USD) of stock i at time t relative to all other stocks j in the Russell 1000. We set Q to be 60 business days.
Value. We use several ratios from the cash-flow statement. Our measures of firm value include the Price Earnings ratio of the firm and the firm's Price Earnings ratio relative to that of the Russell 1000 index:
where
is the trailing 12M earnings per share before extraordinary items. We also include the Price to Sales ratio and the Price to Cash-flow per share ratio:
where
denotes Sales per share and is calculated on a trailing 12 month basis by adding the most recent four quarters.
denotes the cash-flow per share.
From the balance sheet, we use the Price to Book ratio and the Enterprise Value to Book value ratio. The first ratio captures the public market implied growth prospects of the firm, while the second is a measure of how much an acquirer would value the firm:
Liquidity. We include several measures of leverage and liquidity. The Current ratio indicates a company's ability to fulfill its short-term liabilities using short-term assets, and the Cash ratio measures immediate liquidity needs. They are respectively defined as:
where
and
denotes the short term assets and liabilities. Closely related to these ratios is the Interest Coverage ratio, which is used to measure the burden of debt interest payments out of annual operating income (also known as earnings before interest and taxes, or EBIT):
Leverage. If firms cannot meet their liabilities, equity serves as a buffer before liquidation. We consider two measures of leverage: the Tangible Common Equity to Asset ratio, and a liquidation ratio. Using tangible values may be more realistic during a distressed liquidation. In this calculation, both the total assets and the common equity are adjusted downward by the amount of intangible assets (including goodwill, licenses, trademarks, copyrights, etc.).
We also include a liquidation ratio which measures a company's ability to cover debt obligations with its assets, after all short-term liabilities have been satisfied:
Investment and ROIC. To capture predictors of future firm growth and its investment efficiency, we examine two ratios. First, the Operating Cash to Capex ratio, which indicates how much of operating cash is used to service Capex. The intuition here is that growing firms tend to invest more. This measure is also industry specific. For example, for industrials and banks, it is given as
In addition to the dollar value of investment, we are interested in its efficiency. The Return on Invested Capital (ROIC) divided by Weighted Average Cost of Capital (WACC) ratio indicates how efficiently firms are using their investment funds:
Industry Specific Effects. We employ a set of industry dummies to control for differences across industries. More specifically, we use the Industry Classification Benchmark (ICB) super-sector classification which divides companies into 19 super sectors: Automobiles & Parts (3300), Banks (8300), Basic Resources (1700), Chemicals (1300), Construction & Materials (2300), Financial Services (8700), Food & Beverage (3500), Health Care (4500), Industrial Goods & Services (2700), Insurance (8500), Media (5500), Oil & Gas (0500), Personal & Household Goods (3700), Real Estate (8600), Retail (5300), Technology (9500), Telecommunications (6500), Travel & Leisure (5700), Utilities (7500).
3.3. Main findings
Our main results are summarized in table . The table shows the mean, median, max, min, and standard deviation of the correlations between the model predicted probabilities and the realized returns for different samples. It includes (i) an all stocks sample and (ii) samples at the extremes (sorted by predicted probabilities). There are three main takeaways. First, Boosted Trees slightly outperforms the Logistic approach in terms of out-of-sample predictability at the extremes as measured by a higher mean correlation between predicted and realized returns. As the Appendices show, this result passes a number of robustness tests. For instance, in the all top/bottom 10 stocks sample, the mean Pearson correlation is 0.08 for Boosted Trees and 0.06 for the Logistic approach. Second, out-of-sample predictability for both the Logistic approach and Boosted Trees increases at the extremes. For example, under Boosted Trees, the Pearson out-of-sample correlation in the group of the top and bottom 10 stocks is 0.08 while it is only 0.02 in the all stocks sample. Third, the highest out-of-sample (the squared correlation) is less than 1% (Boosted Trees, Top/Bottom 10, Pearson: 0.08). This finding is quantitatively in line with the findings of Gu et al. (Citation2020) using a different sample of U.S. stocks and also a different sample period. In contrast to their results, the linear approach does not lag far behind the tree-based approach in our analysis. This may potentially be due to the fact that our predictor normalization procedure effectively linearizes the data. Appendix 5 shows that the Logistic Classification predictability decreases under an alternative normalization procedure that does not linearize the data.
Table 1. Predicted vs. realized returns (main result, out-of-sample).
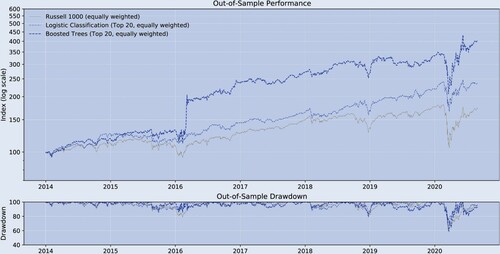
To confirm that the previously shown relatively low out-of-sample predictability contains some information (and is not just noise), table and figure translate the return predictability into long-only trading strategies. All trading strategies are rebalanced bi-weekly at end-of-day prices. The benchmark is the equally weighted long-only Russell 1000. A marketcap-weighted index would have performed similarly. From the Logistic approach and Boosted Trees we form a trading strategy where we sort the universe biweekly by probability, and then take the top 20 of these rankings to form an equally weighted portfolio. The figure shows that the two strategies outperform out-of-sample in terms of absolute returns while exhibiting a drawdown profile similar to the benchmark.
Figure 2. Historical performance (main result, out-of-sample).
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. This figure compares the performance of the different trading strategies.
Table 2. Performance indicators (main result, out-of-sample).
Table confirms this impression. It presents a variety of performance measures. Over the out-of-sample period 2013.12–2020.8, both the Logistic approach and Boosted Trees outperform the long-only Russell 1000. During this period, both strategies feature better drawdown behavior, with the maximum drawdowns being for the Russell 1000,
for the Logistic approach and
for Boosted Trees. The smaller drawdowns and higher returns are reflected in better overall annual risk-adjusted measures, including the return-to-absolute max drawdown ratio and the Sharpe ratio. Our results indicate that the low predictability of
contains valuable information leading to outperformance. This is consistent with (Moritz and Zimmermann Citation2016) whom, using a different stock sample and sample period, find significant improvement in terms of risk-adjusted returns, by employing big-data and non-linear methods over a passive investment approach.
4. Interpretation
Even when we employ advanced regression techniques such as Boosted Trees, we are only able to predict a small fraction of return variation out-of-sample. We now turn to addressing our second main question—given the weak evidence we find for systematic patterns, why do these biases not show up more clearly in the markets? We focus on a possible explanation that we derive from De Long et al. (Citation1990), and Fama (Citation1965): the presence of many uncorrelated signals may lead to biases canceling out at the aggregate level.
The predictability, , can be determined from the cross-correlations. We consider a multiple linear regression problem with N explanatory variables and split their linear correlations into two groups: (i) the predictor-return correlations,
and ii) the predictor correlations,
where
. Define in vector/matrix form these two respectively by:
The vector contains the correlations between the returns and each of the predictor variables. The matrix contains the correlations between each pair of predictor variables. The
of the multiple linear regression problem is given by:
. (We omit the time subscripts to improve readability).
In our context, we split the analysis into two parts. First, we examine the empirical predictor correlation matrix, . Second, we focus on the predictor-return correlations vector,
. Besides investigating the empirical correlation matrix, we conduct Monte-Carlo simulations to generate random correlation matrices under certain distributional assumptions. These simulations serve as a counterfactual from which we can draw conclusions.
For the simulations, we begin by generating strictly positive random eigenvalues from a uniform distribution. To ensure that the sum of the eigenvalues is equal to the number of predictors, we pre-multiply all eigenvalues with a common factor. We then use a numerically fast procedure by Davies and Higham (Citation2000), based on the popular algorithm of Bendel and Mickey (Citation1978), which takes a matrix having the specified eigenvalues and uses a sequence of Givens rotations to introduce ones on the diagonal.
Figure plots the results. Panel A shows the distributions of the elements of estimated from the out-of-sample period 2013.12–2020.08. The correlations are mainly distributed around zero with a much high kurtosis than a normal distribution. Are those weak correlations responsible for the low
? Panel B shows the
's calculated from 1000 simulated matrices. In the simulations, the correlation distribution is assumed to be normal with mean zero, which leads to a higher
by assumption. Yet, despite the normality assumption, the panel clearly shows that most of the generated
s are close to zero. Panels C and D then plot the distributions of the correlations in the case of the (i) lowest generated
and (ii) highest generated
.
Figure 3. Monte-Carlo correlations: varying , normal distribution.
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. Panel A shows the distribution of the empirical predictor correlations . Panel B shows the distribution of the simulated
's. Panel C shows the distribution of the simulated predictor correlations
that yielded the lowest
. Panel D shows the distribution of the simulated predictor correlations
that yielded the highest
.
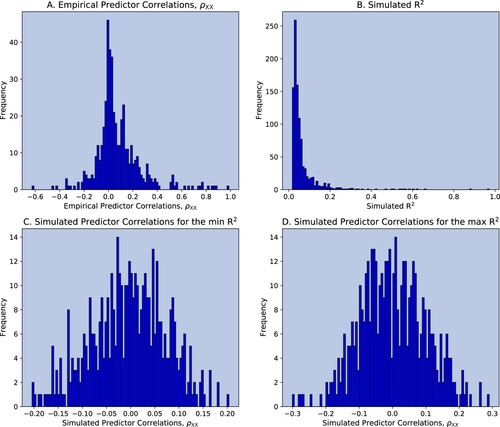
Figure then illustrates that a higher can be generated easily with a distribution of correlations that is very different from the one that is empirically observed.Footnote6 When the predictor correlations are closer to
and
, we are much more likely to find high predictability. This second figure serves as our counterfactual. Combining the information from the two figures, we argue that the empirically weak correlations within the set of predictors support our hypothesis that uncorrelated signals result in a low general predictability of stock returns in the long-run. Intuitively, a noise trader who may respond to a 2-weeks Momentum signal—one of the predictors in our data—may buy a stock matching with another noise trader who may respond to a selling signal thus muting the overall impact of the first signal.
Figure 4. Monte-Carlo correlations: varying , bimodal distribution.
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. Panel A shows the distribution of the empirical predictor correlations . Panel B shows the distribution of the simulated
's. Panel C shows the distribution of the simulated predictor correlations
that yielded the lowest
. Panel D shows the distribution of the simulated predictor correlations
that yielded the highest
.
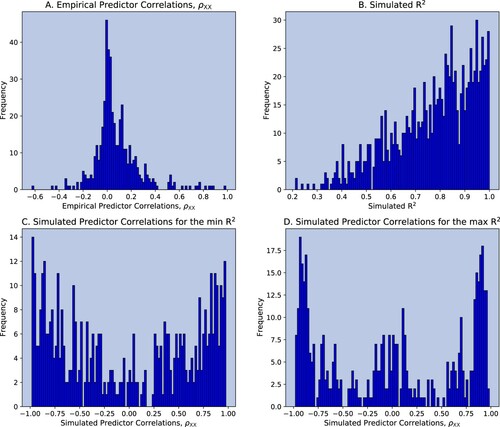
Table (as well as figure in the introduction) then focuses on the time series dynamics of the empirical signal correlation matrix, . The matrix is constructed on a daily basis. To capture both short-term time-series and cross-sectional variation, we use three alternative matrixes. The first contains only the cross section, i.e. trading day t as indicated in the table as Pred Corr (t). The second contains trading day t and the trading day 20 days before as indicated in the table as Pred Corr (t, t-20). The third contains trading day t and the trading day 60 days before as indicated in the table as Pred Corr (t, t-60). It shows that there is a strong positive relation between the market implied volatility and the strength of the correlations between signals (in
).
Table 3. Implied market volatility and signal correlations ( ).
).
Figure in the introduction confirms this impression. It shows that signal correlations becoming more pronounced (the sum of the absolute correlations increases) coincides with episodes of stock market volatility during the SARS-CoV-2 crisis, the 2008 financial crisis, and the Dot-com bubble. In the light of our Monte-Carlo simulations, this second piece of evidence supports the hypothesis that, in the short-run, when noise traders become more correlated, their aggregate behavior may eventually increase volatility (see, e.g. Dennis and Strickland (Citation2002), and Choi and Sias (Citation2009)).
Based on the evidence we obtained from our Monte-Carlo Simulations, we do not expect signal correlations to explain a major part of market volatility. First, there are still many other drivers of volatility such as news. Second, even when the correlations among signals become stronger, this only raises the probability of having noise traders act together in the aggregate. Their actions may still cancel out (thus not raising volatility), even as their signals are more strongly correlated. Third, figure shows that signal correlations never become very strong, with the sum of absolute predictor correlation not increasing by more than 100% during peak times. By contrast, figure emphasizes that signal correlations must be close to and
for a sufficiently high probability of signals to not cancel out.
Our interpretation rests on two additional assumptions. First, the set of predictors—although containing many of the main standard predictors that the literature describes—does not contain all possible predictors. However, we do not think that the presence of other predictors would overturn our conclusions. Given the many predictors that have been studied, and the determination that very few of them are significant, any other predictors would be even more weakly correlated with returns than the ones we use. A larger set of predictors would also result in less correlated actions by signal-following noise traders. As the number of weakly correlated signals grows, it becomes more likely that they cancel out.
Second, each of our predictors represents a signal that triggers buying and selling by different types of biased, signal-following traders. By assuming that predictors reflect signals and biases, we also make implicit assumptions about the proportions of trades which are triggered by these signals. For example, claiming that a large basket of uncorrelated signals cancels out at the aggregate, rests on the assumption that trades triggered by individual signals face a significant number of opposing trades. However, given the large number of uncorrelated signals and market participants, we think it is reasonable to assume that no individual signal generates enough trading volume to overcome trading volume generated by other signals.
5. Conclusions
Behavioral economics makes numerous empirical observations in financial markets that may result from biased, signal-following traders. To what degree do these biases create systematic patterns in the markets? Analyzing U.S. equities, we find that the evidence for systematic patterns is rather small.
More specifically, using over 50 popular predictors (signals) to forecast the cross-section of stock returns in the Russell 1000 over a horizon of 1 month or less, we find that return predictability is less than 1%. This latter piece of evidence warrants explanation given the large number of well-documented behavioral biases.
Our explanation makes an analogy by borrowing the term antinoise from the audio signal processing literature. Studying the empirical correlation structure of our signals, we find that, over the long-run, the correlations are mainly distributed around zero with a much higher kurtosis than a normal distribution. Employing Monte-Carlo methods, we verify that to find predictability of more than is an unlikely outcome given such a correlation structure. By contrast, we show that under a bimodal distribution with many correlations close to −1 and +1, finding high predictability is a more likely outcome.
Applying our antinoise analogy to financial markets is straightforward: a trader responding to a two-weeks Momentum signal—one of the predictors in our data—may want to buy a stock matching with another trader responding to a sell signal thus muting the overall impact of the first signal. With many uncorrelated signals in place, there is a high probability that each signal will face an opposing signal at each point in time. As a result of the presence of antinoise, we do not expect to find high return predictability.
However, focusing on the dynamic behavior of the correlations, we find that correlations become more pronounced during episodes of stock market volatility. For instance, during the SARS-CoV-2 crisis, the 2008 financial crisis, and the Dot-com bubble. In light of our Monte-Carlo simulations, this second piece of evidence indicates that in the short-run behavioral biases may become more visible during crises.
Acknowledgments
We thank Frank Fabozzi, David-Michael Lincke, Stefan Nagel, Andrei Shleifer, Friedrich Wetterling, Karl Whelan as well as the editor, Jim Gatheral, and two anonymous referees for meaningful feedback that helped us improve our work. Annika Sophia Benecke and Ancil Crayton provided outstanding research assistance.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 In the Appendices, we show how this finding is robust to (A) varying the number of long-positions in the portfolio (B) using an alternative in-sample/out-of-sample split (C) rebalancing and forecasting at a weekly or monthly frequency (D) using different sets of boosting parameters (E) employing an alternative predictor normalization procedure.
2 The reason is that the chance of actions canceling out amid strong correlations between signals is lower. Intuitively, with strong correlations between signals, we would need the negative and positive signals to trigger quantitatively identical opposing bets in order for trades to cancel out in the aggregate—a highly unlikely scenario, which we verify in our Monte-Carlo simulations.
3 There is a large literature that argues that return predictability is caused by predictors representing risk premia. This interpretation would only strengthen our argument, as it would imply that the predictability we discover is the result of biases. The current scientific limitations in this field do not allow us to distinguish between these two sources of predictability. This is why we abstain further from investigating the deeper roots of predictability.
4 Our emphasis is on robustness in this context, as non-parametric methods such as Boosted Trees suffer from high variability when applied to noisy data, as with the relation between predictors and returns in financial markets. We also studied neural networks, but had difficulties obtaining robust results that could be replicated. The results from these networks vastly changed when using different random number seeds. Even averaging the results from hundreds of randomly drawn seeds did not ensure stability of the results.
5 As tree estimations are highly sensitive in noisy environments, we average the estimated models several hundred times. The computations are therefore quite demanding. Hence, we rely on a computationally efficient Boosting procedure from Microsoft called LightGBM in combination with an Amazon Web Services (AWS) cluster with 10 instances of 96 virtual CPUs with 768GB RAM each. The code is a mixture of C, C++, and Python. This combination allows us to complete the computations within a single day. For Boosting we use a set of standard parameters. The results under alternative boosting parameters are reported in Appendix 4.
6 To generate a correlation matrix with a bimodal distribution, we follow a simple three step procedure: (i) generate a symmetric random matrix , where each column is drawn from a normal distribution and add a fixed constant premultiplied by a random value from a normal distribution which later governs the shape of the distribution, (ii)
, (iii)
, where
.
References
- Aghamolla, C. and Hashimoto, T., Information arrival, delay, and clustering in financial markets with dynamic freeriding. J. Financ. Econ., 2020, 138(1), 27–52. doi: https://doi.org/10.1016/j.jfineco.2020.04.011
- Alfarano, S., Lux, T. and Wagner, F., Estimation of agent-based models: the case of an asymmetric herding model. Comput. Econ., 2005, 26, 19–49. doi: https://doi.org/10.1007/s10614-005-6415-1
- Asness, C.S., Moskowitz, T.J. and Pedersen, L.H., Value and momentum everywhere. J. Finance, 2013, 68(3), 929–985. doi: https://doi.org/10.1111/jofi.12021
- Avery, C. and Zemsky, P., Multidimensional uncertainty and herd behavior in financial markets. Am. Econ. Rev., 1998, 88(4), 724–748.
- Banerjee, A.V., A simple model of herd behavior. Q. J. Econ., 1992, 107(3), 797–817. doi: https://doi.org/10.2307/2118364
- Barberis, N. and Shleifer, A., Style investing. J. Financ. Econ., 2003, 68(2), 161–199. doi: https://doi.org/10.1016/S0304-405X(03)00064-3
- Bendel, R.B. and Mickey, M.R., Population correlation matrices for sampling experiments. Commun. Statist. Simul. Comput., 1978, 7(2), 163–182. doi: https://doi.org/10.1080/03610917808812068
- Black, F., Noise. J. Finance, 1986, 41(3), 528–543. doi: https://doi.org/10.1111/j.1540-6261.1986.tb04513.x
- Bondt, W.F.M. De and Thaler, R., Does the stock market overreact? J. Finance, 1985, 40(3), 793–805. doi: https://doi.org/10.1111/j.1540-6261.1985.tb05004.x
- Bordalo, P., Gennaioli, N., La Porta, R. and Shleifer, A., Diagnostic expectations and stock returns. J. Finance, 2019, 74(6), 2839–2874. doi: https://doi.org/10.1111/jofi.12833
- Boswijk, H.P., Hommes, C.H. and Manzan, S., Behavioral heterogeneity in stock prices. J. Econ. Dyn. Control, 2007, 31(6), 1938–1970. 10th Workshop on Economic Heterogeneous Interacting Agents. doi: https://doi.org/10.1016/j.jedc.2007.01.001
- Boyer, B.H., Style-related comovement: Fundamentals or labels? J. Finance, 2011, 66(1), 307–332. doi: https://doi.org/10.1111/j.1540-6261.2010.01633.x
- Brock, W.A. and Hommes, C.H., A rational route to randomness. Econometrica, 1997, 65(5), 1059–1095. doi: https://doi.org/10.2307/2171879
- Campajola, C., Lillo, F. and Tantari, D., Unveiling the relation between herding and liquidity with trader lead-lag networks. Quant. Finance, 2020, 20(11), 1765–1778. doi: https://doi.org/10.1080/14697688.2020.1763442
- Chen, H.-S. and Sabherwal, S., Overconfidence among option traders. Rev. Financ. Econ., 2019, 37(1), 61–91. doi: https://doi.org/10.1002/rfe.1048
- Choi, N. and Sias, R.W., Institutional industry herding. J. Financ. Econ., 2009, 94(3), 469–491. doi: https://doi.org/10.1016/j.jfineco.2008.12.009
- Coval, J.D. and Shumway, T., Do behavioral biases affect prices? J. Finance., 2005, 60(1), 1–34. doi: https://doi.org/10.1111/j.1540-6261.2005.00723.x
- Davies, P.I. and Higham, N.J., Numerically stable generation of correlation matrices and their factors. BIT Numer. Math., 2000, 40(4), 640–651. doi: https://doi.org/10.1023/A:1022384216930
- De Long, J.B., Shleifer, A., Summers, L.H. and Waldmann, R.J., Noise trader risk in financial markets. J. Political Econ., 1990, 98(4), 703–738. doi: https://doi.org/10.1086/261703
- DellaVigna, S. and Pollet, J.M., Investor inattention and friday earnings announcements. J. Finance, 2009, 64(2), 709–749. doi: https://doi.org/10.1111/j.1540-6261.2009.01447.x
- Dennis, P.J. and Strickland, D., Who blinks in volatile markets, individuals or institutions? J. Finance, 2002, 57(5), 1923–1949. doi: https://doi.org/10.1111/0022-1082.00484
- Eyster, E., Rabin, M. and Vayanos, D., Financial markets where traders neglect the informational content of prices. J. Finance, 2019, 74(1), 371–399. doi: https://doi.org/10.1111/jofi.12729
- Fama, E.F., The behavior of stock-market prices. J. Bus., 1965, 38(1), 34–105. doi: https://doi.org/10.1086/294743
- Fama, E.F. and French, K.R., The cross-section of expected stock returns. J. Finance, 1992, 47(2), 427–465. doi: https://doi.org/10.1111/j.1540-6261.1992.tb04398.x
- Fama, E.F. and French, K.R., Dissecting anomalies with a five-factor model. Rev. Financ. Stud., 2016, 29(1), 69–103. doi: https://doi.org/10.1093/rfs/hhv043
- Farhi, E. and Gabaix, X., Rare disasters and exchange rates. Q. J. Econ., 2016, 131(1), 1–52. Lead Article. doi: https://doi.org/10.1093/qje/qjv040
- Fayyad, U.M. and Irani, K.B., Multi-interval discretization of continuous-valued attributes for classification learning. In Proceedings of the 13th International Joint Conference on Artificial Intelligence, 28 August–3 September, pp. 1022–1029, 1993 (IJCAI Organization: Chambéry).
- Freyberger, J., Neuhierl, A. and Weber, M., Dissecting characteristics nonparametrically. Rev. Financ. Stud., 2020, 33(5), 2326–2377. doi: https://doi.org/10.1093/rfs/hhz123
- Friedman, M., Essays in Positive Economics, 1953 (University of Chicago Press: Chicago).
- Froot, K.A, Scharftstein, D.S and Stein, J.C., Herd on the street: Informational inefficiencies in a market with short-term speculation. J. Finance, 1992, 47(4), 1461–1484. doi: https://doi.org/10.1111/j.1540-6261.1992.tb04665.x
- García, D., Sentiment during recessions. J. Finance, 2013, 68(3), 1267–1300. doi: https://doi.org/10.1111/jofi.12027
- Garcia, S., Luengo, J., Saez, J.A., Lopez, V. and Herrera, F., A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning. IEEE Trans. Knowl. Data Eng., 2013, 25(4), 734–750. doi: https://doi.org/10.1109/TKDE.2012.35
- Grinblatt, M., Titman, S. and Wermers, R., Momentum investment strategies, portfolio performance, and herding: A study of mutual fund behavior. Am. Econ. Rev., 1995, 85(5), 1088–1105.
- Gu, S., Kelly, B. and Xiu, D., Empirical asset pricing via machine learning. Rev. Financ. Stud., 2020, 33(5), 2223–2273. doi: https://doi.org/10.1093/rfs/hhaa009
- Harvey, C.R., Liu, Y. and Zhu, H., … and the cross-section of expected returns. Rev. Financ. Stud., 2016, 29(1), 5–68. doi: https://doi.org/10.1093/rfs/hhv059
- Kolev, G.I. and Karapandza, R., Out-of-sample equity premium predictability and sample split–invariant inference. J. Banking Finance, 2017, 84, 188–201. doi: https://doi.org/10.1016/j.jbankfin.2016.07.017
- Kozak, S., Nagel, S. and Santosh, S., Shrinking the cross-section. J. Financ. Econ., 2020, 135(2), 271–292. doi: https://doi.org/10.1016/j.jfineco.2019.06.008
- Kukacka, J. and Barunik, J., Behavioural breaks in the heterogeneous agent model: The impact of herding, overconfidence, and market sentiment. Phys. A Stat. Mech. Appl., 2013, 392(23), 5920–5938. doi: https://doi.org/10.1016/j.physa.2013.07.050
- Lakonishok, J., Shleifer, A. and Vishny, R.W., Contrarian investment, extrapolation, and risk. J. Finance., 1994, 49(5), 1541–1578. doi: https://doi.org/10.1111/j.1540-6261.1994.tb04772.x
- Longstaff, F.A., How much can marketability affect security values? J. Finance, 1995, 50(5), 1767–1774. doi: https://doi.org/10.1111/j.1540-6261.1995.tb05197.x
- Lux, T. and Marchesi, M., Scaling and criticality in a stochastic multi-agent model of a financial market. Nature, 1999, 397, 498–500. doi: https://doi.org/10.1038/17290
- Mclean, R.D. and Pontiff, J., Does academic research destroy stock return predictability? J. Finance, 2016, 71(1), 5–32. doi: https://doi.org/10.1111/jofi.12365
- Moritz, B. and Zimmermann, T., Tree-based conditional portfolio sorts: The relation between past and future stock returns. SSRN Working Paper, 03, 2016.
- Nofsinger, J.R. and Sias, R.W., Herding and feedback trading by institutional and individual investors. J. Finance, 2002, 54(6), 2263–2295. doi: https://doi.org/10.1111/0022-1082.00188
- Novy-Marx, R. and Velikov, M., A taxonomy of anomalies and their trading costs. Rev. Financ. Stud., 2015, 29(1), 104–147. doi: https://doi.org/10.1093/rfs/hhv063
- Park, A. and Sabourian, H., Herding and contrarian behavior in financial markets. Econometrica, 2011, 79(4), 973–1026. doi: https://doi.org/10.3982/ECTA8602
- Peress, J. and Schmidt, D., Glued to the TV: Distracted noise traders and stock market liquidity. J. Finance, 2020, 75(2), 1083–1133. doi: https://doi.org/10.1111/jofi.12863
- Peter Chung, Y. and Thomas Kim, S., Extreme returns and herding of trade imbalances. Rev. Finance, 2017, 21(6), 2379–2399. doi: https://doi.org/10.1093/rof/rfx004
- Sandroni, A., Do markets favor agents able to make accurate predictions? Econometrica, 2000, 68(6), 1303–1341. doi: https://doi.org/10.1111/1468-0262.00163
- Sharpe, W.F., Capital asset prices: A theory of market equilibrium under conditions of risk. J. Finance, 1964, 19(3), 425–442.
- Shleifer, A. and Summers, L.H., The noise trader approach to finance. J. Econ. Perspect., 1990, 4(2), 19–33. doi: https://doi.org/10.1257/jep.4.2.19
- Shleifer, A. and Vishny, R.W., The limits of arbitrage. J. Finance, 1997, 52(1), 35–55. doi: https://doi.org/10.1111/j.1540-6261.1997.tb03807.x
- Shue, K. and Townsend, R., Can the market multiply and divide? Non-proportional thinking in financial markets. Working Paper 25751, April 2019. https://www.nber.org/papers/w25751
- Struck, C. and Cheng, E., Time-series momentum: A Monte Carlo approach. J. Financ. Data Sci., 2019, 1(4), 103–123. doi: https://doi.org/10.3905/jfds.2019.1.012
- Teo, M. and Woo, S.-J., Style effects in the cross-section of stock returns. J. Financ. Econ., 2004, 74(2), 367–398. doi: https://doi.org/10.1016/j.jfineco.2003.10.003
- Veldkamp, L.L., Media frenzies in markets for financial information. Am. Econ. Rev., 2006, 96(3), 577–601. doi: https://doi.org/10.1257/aer.96.3.577
- Westphal, R. and Sornette, D., Market impact and performance of arbitrageurs of financial bubbles in an agent-based model. J. Econ. Behav. Organ., 2020, 171, 1–23. doi: https://doi.org/10.1016/j.jebo.2020.01.004
- Xiong, W. and Yan, H., Heterogeneous expectations and bond markets. Rev. Financ. Stud., 2010, 23(4), 1433–1466. doi: https://doi.org/10.1093/rfs/hhp091
- Yan, H., Is noise trading cancelled out by aggregation? Manage. Sci., 2010, 56(7), 1047–1059. doi: https://doi.org/10.1287/mnsc.1100.1167
Appendices
Appendix 1. Robustness: varying the number of long positions
As the first robustness test, we alter the number of long positions of the strategies. In contrast to the main text, where we choose 20 stocks, here we also test for portfolios consisting of 10, and 50 stocks. Figure shows the performance for the Logistic approach and Boosted Trees, respectively. Both figures reveal that the absolute return is highest when the portfolio with only 10 stocks is chosen, followed by 50 stocks. Table shows the performance in more detail. Surprisingly, it reveals that the risk-adjusted returns of the strategies with only 10 stocks is higher than those with 50 stocks. In this context it is important to emphasize that our out-of-sample period is relatively short and does not contain any periods with more than one tail event. Nonetheless, this outperformance may be attributed to our finding that the regression approaches are better able to predict at the extremes of the stock ranking.
Figure A1. Historical performance (Robustness test A, out-of-sample).
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. This figure compares the performance of the different trading strategies.
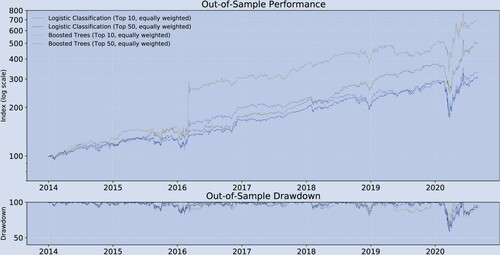
Table B1. Performance indicators (Robustness test A, out-of-sample).
Appendix 2. Robustness: alternative in-sample period
As the second robustness test, we choose a different cut-off between the in-sample and the out-of-sample period. For the in-sample period, we choose 1995.12–2016.12 whereas, in the main text, we use 1995.12–2013.12. With bi-weekly rebalancing, we are still left with 88 out-of-sample observations. Table is broadly in line with the corresponding table from the main text. In comparison to the original table, this table shows that (i) Boosted Trees underperforms the Logistic approach in terms of out-of-sample mean correlations, (ii) the mean out-of-sample correlations for both the Logistic approach and Boosted Trees increases at the extremes, and (iii) the highest out-of-sample (the squared correlation) is less than 1% (Logistic Classification, Top/Bottom 10, Pearson: 0.10). Figure and table are also broadly in line with their counterparts in the main text. Namely, the Logistic approach and Boosted Trees outperform the long-only benchmark both in terms of absolute returns over the entire out-of-sample period. In contrast to the main text, Boosted Trees performance lags behind the Logistic approach.
Figure A2. Historical performance (robustness test B, out-of-sample).
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2016.12; out-of-sample period: 2016.12–2020.08; Stock Sample: Russell 1000. This figure compares the performance of the different trading strategies.
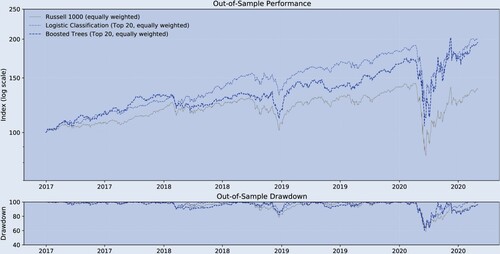
Table C1. Predicted vs. realized returns (robustness test B, out-of-sample).
Table C2. Performance indicators (robustness test B, out-of-sample).
Appendix 3. Robustness: rebalancing and forecasting at alternative frequencies
As the third robustness test, we employ two alternative forecasting and rebalancing horizons: (i) monthly and (ii) weekly. Tables and are broadly in line with the corresponding table from the main text. As in the original table, these tables confirm that (i) Boosted Trees slightly outperform the Logistic approach in terms of mean out-of-sample correlation, (ii) the mean out-of-sample correlation for both the Logistic approach and Boosted Trees increases at the extremes, and (iii) the highest out-of-sample (the squared correlation) is less than 1% (Boosted Trees, Top/Bottom 10, Pearson: 0.07). Figures , and tables , show that the results from monthly rebalancing are broadly in line with their bi-weekly counterparts in the main text. Namely, the Logistic approach and Boosted Trees outperform the long-only benchmark both in terms of absolute and risk-adjusted returns.
Figure A3. Historical performance (robustness test C, out-of-sample, monthly).
Notes: monthly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. This figure compares the performance of the different trading strategies.
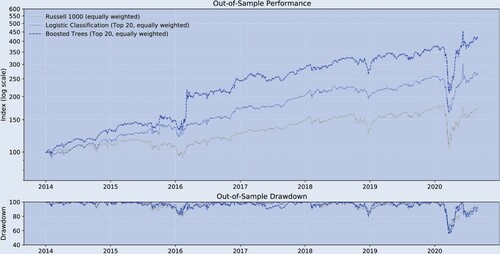
Figure A4. Performance indicators (robustness test C, out-of-sample, weekly).
Notes: weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. This table shows a variety of performance measures for different trading strategies.
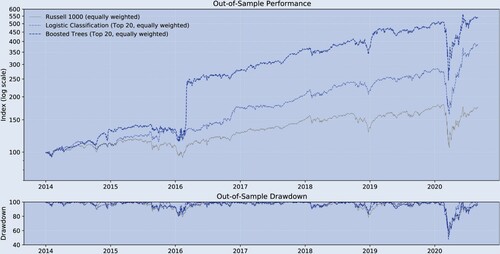
Table D1. Predicted vs. realized returns (robustness test C, out-of-sample, monthly.
Table D2. Predicted vs. realized returns (robustness test C, out-of-sample, weekly).
Table D3. Historical performance (robustness test C, out-of-sample, monthly).
Table D4. Performance indicators (robustness test C, out-of-sample, weekly).
Appendix 4. Robustness: alternative boosting parameters
As the fourth robustness test, we focus on the Boosting parameters. The Logistic approach's parameters are straightforward, but Boosting warrants a variety of additional tests. As there is no theoretical guidance on how to choose these parameters, we present the results for several ad-hoc choices. First, Parameters 1 reduces the subsample of predictors to 50% when constructing each tree. In the main text, each tree is constructed from the entire sample of predictors. Second, Parameters 2 reduces the subsample of predictors to 50% but increases the number of maximum leaves to 400 and sets the maximum tree depth to 20 (in the main text the tree depth is 10 and the maximum number of leaves is 100). Third, Parameters 3 reduces the subsample of predictors to 50% and increases the learning rate to 1 (in the main text the learning rate is 0.1), and uses standard random forests parameters otherwise.
Finally, Parameters Non-NaN runs Boosted Tress from an in-sample period that does not contain any NaNs.
Table is broadly consistent with the corresponding table from the main text. Across Parameters 1, Parameters 2 and Parameters 3, (i) the mean out-of-sample correlation for Boosted Trees increases at the extremes and (ii) the highest out-of-sample (the squared correlation) is less than 1% (Boosted Trees, Top/Bottom 10, Param 1, Spearman: 0.10). Figure and table are also broadly in line with their counterparts in the main text. Under Parameters 1,2 and 3, Boosted Trees outperform the long-only benchmark both in terms of absolute and risk-adjusted returns. Under Parameters Non-NaN out-of-sample performance is also better than long-only and similar to those under Parameters 1,2 and 3.
Figure A5. Historical performance (robustness test D, out-of-sample).
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. This figure compares the performance of the different trading strategies.
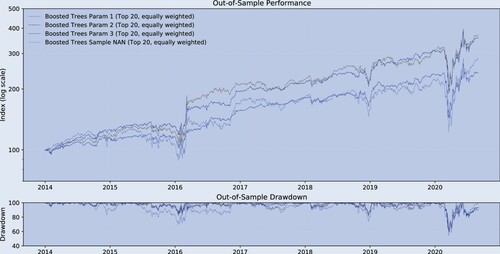
Figure A6. Performance indicators (robustness test D, out-of-sample).
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. This table shows a variety of performance measures for different trading strategies.
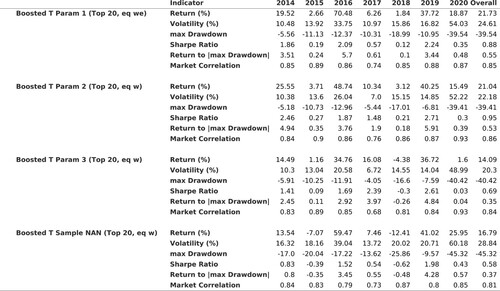
Table E1. Predicted vs. realized returns (robustness test D, out-of-sample).
Appendix 5. Robustness: alternative predictor normalization procedure
As the last robustness test, we employ an alternative normalization procedure for the predictor variables. In the main text, we impose a uniform distribution on the predictors enforcing equidistant steps between observations. A key advantage of this procedure is that it reduces the impact of outliers by effectively linearizing the predictors. In this appendix we will use the following formula to normalize the data:
(A1)
(A1)
where
denotes predictor i. Table is broadly in line with the corresponding table from the main text. As in the original table, this table confirms that (i) Boosted Trees outperforms the Logistic approach in terms of mean out-of-sample correlations, (ii) the out-of-sample correlation for both the Logistic approach and Boosted Trees increases at the extremes, and (iii) the highest out-of-sample
(the squared correlation) is less than 1% (Boosted Trees, Top/Bottom 10, Spearman: 0.08). Figure and table are also broadly in line with their counterparts in the main text. Namely, the Logistic approach and Boosted Trees outperform the long-only benchmark both in terms of absolute and risk-adjusted returns most of the time. The Logistic approach is generally weaker than in the main text. This may be attributed to the fact that the normalization formula used here maintains the non-linearities which are difficult to capture with a linear approach.
Figure A7. Historical performance (robustness test E, out-of-sample).
Notes: bi-weekly forecast horizon and rebalancing; in-sample period: 1995.12–2013.12; out-of-sample period: 2013.12–2020.08; Stock Sample: Russell 1000. This figure compares the performance of the different trading strategies.