
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper introduces a novel class of volatility forecasting models that incorporate market realized (co)variances and semi(co)variances within the framework of a heterogeneous autoregressive (HAR) model. Our empirical analysis shows statistically and economically significant forecasting gains. For our most parsimonious market-HAR specification, stock volatility forecasting is improved by 9.80% points. Using a mixed sampling frequency market-HAR variant with low (high) sampling frequency for the stock (market) improves forecasting by a further 6.90% points. Our paper also develops noise-robust estimators to facilitate the use of realized semi(co)variances at high sampling frequencies.
1. Introduction
Comparing financial econometrics and asset pricing studies, Bollerslev (Citation2022) argues that the former remains uninformed about the inherently multivariate issues in finance, such as covariation among multiple assets or systematic risk factors. This paper addresses this gap. We motivate and introduce a model for stock volatility that incorporates a market volatility factor. Our results show that stock volatility forecasting improves significantly, both in statistical and economic terms. Thus market volatility is a significant factor in modeling and forecasting stock volatility.
Asset pricing studies dating back to the model of Sharpe (Citation1964), Lintner (Citation1965) and Black et al. (Citation1972) posit that the market factor is sufficient to explain the cross-section of expected returns. Empirical support for this claim has been futile. Instead, additional factors have been proposed ,Footnote1 such as value and size (Fama and French Citation1993), momentum (Jegadeesh and Titman Citation1993), liquidity (Pástor and Stambaugh Citation2003), and market volatility (Ang et al. Citation2006b).Footnote2 An interrelationship between asset return and volatility dates back to Fama and MacBeth (Citation1973), Campbell and Hentschel (Citation1992) and Glosten et al. (Citation1993). However, the inclusion of market volatility as ‘a priced factor’ suggests that, determining their investment set, investors value both contemporaneous return and future return uncertainty (Campbell Citation1996, Chen Citation2002).
Unlike observed logarithmic returns, risk is latent. Noisy proxies for risk (e.g. squared returns) have been superseded by conditional variance estimators and stochastic volatility models. The advent of high-frequency data marked a paradigm shift in volatility modeling and forecasting.Footnote3 An efficient estimator of return volatility, the realized variance (RV), has been shown to dominate GARCH-type and stochastic volatility (SV) models (Andersen et al. Citation2003). Additionally, the simple and easy-to-estimate HAR model (Corsi Citation2009) has dominated other approaches for modeling and forecasting realized measures.Footnote4 Owing to the vastness of tick-level data and limits in computational power, the financial econometrics literature is largely univariate or small-scale multivariate.Footnote5 Put simply, individual stock volatility modeling and forecasting is agnostic about other stocks or indeed any systematic risk factors.
Our motivation is twofold: on the one hand, we argue that individual stock volatility modeling and forecasting should be informed by dynamics in other stocks or systematic risk factors. The market factor is the most commonly appearing in the asset pricing literature. Hence, it is not unreasonable to assume that a market volatility factor would have explanatory power for individual stock volatilities. Contrarily a case could be made when the market volatility factor would be uninformative. This would require that market wide uncertainties are timely and correctly incorporated within individual stock dynamics. We feel this is unrealistic for two reasons: first, an assumption of market efficiency is required (i.e. all available information is correctly reflected in the stock price) but unlikely to hold. Instead, it may take some time for financial analysts and/or traders to gauge the impact of news on individual stocks, as well as precisely trace the exact effect of a certain macroeconomic announcement (i.e. ‘soft’ news, see Bollerslev (Citation2022)). Second, it assumes investor rationality while ignoring investor biases, technical analysis and algorithmic trading.
On the other hand, ever since the asset pricing literature has been using a timeseries regression, returns are bound to be outperformed by volatilities on informational content alone. In other words, a timeseries model at the daily horizon would explain a much larger fraction of stock volatility than stock return.Footnote6 Therefore, a timeseries volatility model in the spirit of asset pricing factor models has two key advantages: first, there is more informational content to be captured owing to the high persistence feature of the volatility process. Second, as the stock-specific autoregressive components of the HAR model capture a sizeable fraction of the variation in stock volatility, they leave less room for false factors essentially acting as a shield towards the ‘zoo’ of factors criticism. Our proposed model builds on the popular HAR framework for modeling stock volatility. To this we add market volatility and stock-market covariation information from realized measures. We call it the market-HAR. Being a univariate specification, it retains the key features of the HAR, namely its flexibility and estimation simplicity. Resembling the asset pricing models intuition, the market-HAR allows market information reflected in market-volatility to affect stock volatility. However, unlike asset pricing models that assume a constant relation between stock and market returns, the market-HAR allows it to vary across time.Footnote7 Put simply, market-volatility influence on stock volatility forecasting can be higher in specific periods, for instance during financial crisis. To capture this information, market-HAR incorporates realized covariance information between stock and market.
We generalize the market-HAR by (i) incorporating semi-variance and semi-covariance measures; (ii) allowing for different sampling frequencies between firm-specific and market-specific realized measures; and (iii) considering the impact of jumps. That disentangling good from bad volatility improves HAR forecasting performance is well documented (Patton and Sheppard Citation2015). In our market-HAR extensions, we use stock-specific and market-specific realized semi-variances (Barndorff-Nielsen et al. Citation2010) as well as their respective realized semi-covariances (Bollerslev et al. Citation2020). This enhances the capacity of market-HAR models to deal with asymmetries in volatilities and covariances, which is relevant for downside risk management (Grootveld and Hallerbach Citation1999, Ang et al. Citation2006a, Huang Citation2008, Guerard et al. Citation2013). Where realized semi-variances are segregated by their signed returns, realized semi-covariances are split in four components by their concordant and discordant signed returns.
We also consider a mixed sampling market-HAR variant that allows for different sampling frequencies between the firm-specific and market-specific components. To explore potential benefits over a wide range of frequencies, we mitigate the impact of market microstructure noise (MMSN) by the use of noise-robust realized variances (Jacod et al. Citation2009, Christensen et al. Citation2014) and noise-robust realized covariances (Christensen et al. Citation2010). We develop noise-robust realized semi-variance and semi-covariance measures by extending previous work in this area. Our modified noise-robust measures permit the use of realized measures at frequencies higher than the popular 300-second. Previous studies deliver improvements in forecasting when noise-robust measures are used in the presence of MMSN relative to standard volatility measures (Ghysels and Sinko Citation2011, Bu et al.Citation2021).
Jumps are important in forecasting, with mixed evidence to the nature of their contribution (Giot and Laurent Citation2007, Andersen et al. Citation2007, Corsi et al. Citation2010, Busch et al. Citation2011, Patton and Sheppard Citation2015, Nolte and Xu Citation2015, Bu et al. Citation2021). To acknowledge the impact of jumps in our market-HAR model, we introduce individual jumps in the firm-specific and market-specific components, while we also account for the existence of co-jumps.
For the empirical analysis, intraday data for 20 NYSE stocks from 2000 to 2016 across a representative sample of business sectors are used. The SPDR (SPY) S&P 500 ETF acts as a proxy for the market factor over the same period. The main results are that the market-HAR model delivers significant improvements for in-sample and out-of-sample forecasting. As compared with the benchmark HAR model, the most parsimonious market-HAR model enhances individual stock volatility forecasting by 9.80% points on average for the 300-second, 1-day ahead horizon. In accounting for asymmetric effects, market-HAR models enhance forecasting performance by a further 8.40% points. Models that incorporate realized semi(co)variance information deliver superior volatility forecasting over their more parsimonious counterparts. These full-fledged market-HAR models improve volatility forecasting by up to 30.70% points relative to the benchmark HAR model. Forecasting performance is moderated at high sampling frequencies and/or long forecasting horizons. Yet the market-HAR models remain between 19.4 % and 20.9% points superior to the HAR without market information. A mixed sampling market-HAR model also increases forecasting performance when low (high) sampling frequencies of the stock (market) are combined. To underscore the practical relevance of the forecasting improvements of the market-HAR model, we evaluate gains in hypothetical portfolio allocation decisions. Relying on a utility-based framework (Fleming et al. Citation2001, Citation2003, Bernales and Guidolin Citation2014, Christoffersen et al. Citation2014, Nolte and Xu Citation2015) ignoring market information in volatility forecasting can raise the annual cost to risk-averse investors by up to 57 basis points.
Our study offers three contributions to the finance literature. First, we introduce a univariate model that allows for market-specific information to complement stock volatility modeling and forecasting. Second, we develop and utilize noise-robust measures of the realized semi-variances and semi-covariances to exploit the information content of realized measures across a wider range of sampling frequencies. Third, we conduct the first forecasting study using a mixture of sampling frequencies between the firm and market components. While the consensus is that market microstructure noise increases at higher sampling frequencies, our use of noise-robust measures allows us to better explore the informational content across these assets.
The remainder of the paper is organized as follows. Section 2 describes the theoretical background and the new noise-robust realized semi-variances and semi-covariances; Section 3 outlines the forecasting models and evaluation criteria, and sets out the economic value approach; Section 4 describes our data; Section 5 presents and discusses the empirical results. Section 6 reports a robustness exercise that includes the use of jumps and logarithmic transformation of the realized variances. Concluding remarks and directions for future research are provided in Section 7.
2. Theoretical background
We consider a factor-type log price process (Ng et al. Citation1992, Fan et al. Citation2016), defined on some filtered probability space , evolving continuously over time:
(1)
(1)
where
is the log-price of an individual asset,
is the K-dimensional factor process,
is the idiosyncratic component, and β is an
vector of constant factor loadings. To complete the specification, we make similar assumptions to those in Fan et al. (Citation2016) on the dynamics of factors and idiosyncratic components.
Assumption 2.1
Suppose the log asset prices, , follows a factor model given by equation (Equation1
(1)
(1) ), in which
and
are continuous Itô semimartingales:
(2)
(2)
(3)
(3)
where
and
are the respective systematic and idiosyncratic spot volatilities, which are adapted and càdlàg,
and
are two Brownian motions. Whereas
is independent of
, we allow for correlation among factors, that is
for
,Footnote8 where
denotes the quadratic covariation. In addition,
and
are drift terms which are progressively measurable.
To facilitate the exposition, we consider the case of two main factors, the market factor, , and a latent and relevant factor,
, which takes the following form:
(4)
(4)
Under assumption 2.1, we have that the integrated variance of
is defined as
(5)
(5)
The above result suggests that the total integrated variance of an individual asset is related to three componentsFootnote9: idiosyncratic variance, systematic variances, and covariance component. One would expect that each of these components possesses value in a forecasting setting. In this spirit, we propose to model and forecast the asset variance by incorporating proxies for these elements separately in our market-HAR model specifications outlined in Section 3. However, the accurate estimation of idiosyncratic variance has been proven rather difficult in practice, where the literature has identified more than 300 factors that explain the cross-section of stock returns (Harvey et al. Citation2016), and yet the idiosyncratic variance comprises most of the total variance (Ang et al. Citation2009). Moreover, it is custom in the literature to use past total variance in HAR specifications. Given that from a regression point of view a model with past idiosyncratic and systematic variances is observationally equivalent (only regression parameter values would differ) to a model with total and systematic variances, we refrain from obtaining idiosyncratic variance and use common total variance instead, alongside the systematic variance and a covariation term.
The integrated variance and covariance outlined in equation (Equation5(5)
(5) ) can be consistently estimated using the realized variance and covariance (Andersen et al. Citation2001a, Citation2003, Barndorff-Nielsen and Shephard Citation2004). However, these measures are not consistent estimates of the integrated variance and covariance when the observed price contains measurement error. Since, in practice, the observed price process is contaminated with microstructure noise (see Bandi and Russell Citation2006, Hansen and Lunde Citation2006 among others), in the next section we introduce realized measures that are robust to the presence of such contamination.
2.1. Realized measures and market microstructure noise
In the presence of market microstructure noise, the price is observed with a measurement error, which distorts the standard realized measures.Footnote10 In particular, the observed price is the sum of an unobservable efficient price and a noise component due to imperfections of the trading process:
(6)
(6)
where
is the contaminated price,
is the efficient price, and
is the observation error, which is independent and identically distributed with
and
, and
. The contaminated returns are estimated as
, where
represent the number of intraday increments per day and
. As shown by Zhang et al. (Citation2005), Hansen and Lunde (Citation2006), and Bandi and Russell (Citation2006), realized measures estimated from contaminated returns result in noisy measures of volatility since
.Footnote11 To mitigate the impact of the MMSN, we use pre-averaging returns and realized measures (Jacod et al. Citation2009). The pre-averaging returns for day t are defined as
(7)
(7)
where
.
Using the pre-averaged returns, the pre-averaging realized variance (PRV) of Jacod et al. (Citation2009) and Christensen et al. (Citation2014) is defined as
(8)
(8)
where
,
is a small sample correction;
is a bias-correction to remove a leftover effect of noise that is not eliminated by the pre-averaging estimator; following Oomen (Citation2006)
is estimated as
.Footnote12
The constants associated with g are defined as
(9)
(9)
The pre-averaged realized semi-variances are defined as
(10)
(10)
(11)
(11)
where
is the indicator function used to obtain the required sign of the pre-averaged returns. The first term on the right of the equation is a bias-correction factor, scaled to equally affect the positive and negative pre-averaged returns.
The modulated realized covariance (MRC) of Christensen et al. (Citation2010) is a noise-robust estimator of the realized covariance (Barndorff-Nielsen and Shephard Citation2004), and is defined as
(12)
(12)
Using
ensures that the MRC is consistent without a bias-correction, while setting
ensures a
rate of convergence (Christensen et al. Citation2010).Footnote13
We construct noise-robust semi-covariances by decomposing MRC into
(13)
(13)
Each element of equation (Equation13
(13)
(13) ) is estimated as follows:
(14)
(14)
where
and
represent respectively the pre-averaged returns of the stocks and the market.
3. Forecasting models and evaluation
3.1. Forecasting models
With the use of pre-averaged realized variances, the HAR model proposed by Corsi (Citation2009) is defined as
(15)
(15)
where
with
. The main advantages of the HAR model are its simplicity in estimation and its ability to capture long-memory properties observed in realized measures. Our new market-HAR class of models utilize information from both the stock and the market as well as their cross-dependencies; thus aiming to enhance stock volatility modeling and forecasting by harnessing unexplored market information.Footnote14
The market-HAR class features the following models:
HAR-V
(16)
(16)
HAR-Co-V
(17)
(17)
Both models are motivated by the non-linear dependence observed in asset returns. As evidenced by spill-over and financial contagion studies (Forbes and Rigobon Citation2002, Diebold and Yilmaz Citation2009, Bekaert et al. Citation2014), financial market interconnectedness increases significantly during periods of turmoil. Our dataset reflects this. Average correlation across all stocks is 0.45 pre-crisis, and 0.80 during the crisis. Evidence shows that volatility predictability varies across market conditions (Li and Zakamulin Citation2020). By incorporating realized covariance within its specification, HAR-Co-V models signal the ‘calm and crisis’ dichotomy by the varying cross-dependencies, between the stock and the market.
Asymmetric (i.e. ‘leverage’) effects are well established in financial time series. An early approach has been the GJR-GARCH (Glosten et al. Citation1993) that allows conditional variance to respond differently to signed returns. Incorporating asymmetric effects in realized measures can improve volatility forecasting and portfolio variance estimation; see Patton and Sheppard (Citation2015) and Bollerslev et al. (Citation2020) who respectively advocate the use of semi-variances and semi-covariances. We allow for asymmetric dependencies in our market-HAR models by decomposing the and the
. Our approach uses a flexible ‘continuous leverage effect’ (akin to the SHAR model of Patton and Sheppard (Citation2015)) based on the semi-variances for the HAR-V model and both the semi-variances and semi-covariances for the HAR-Co-V model, allowing for more refined responses to positive and negative return shocks.
The asymmetric market-HAR models are outlined asfollows:
HAR-V
(18)
(18)
HAR-V
(19)
(19)
HAR-Co
-V
(20)
(20)
HAR-Co
-V
(21)
(21)
HAR-Co
-V
(22)
(22)
HAR-Co
-V
(23)
(23)
3.2. Forecasting evaluation
Primary interest lies in the out-of-sample forecasting performance of the models. We consider three horizons h = 1 (1 day), h = 5 (1 week), and h = 22 (1 month). An increasing window updates the coefficients, with an initial window of 1000 days (IW = 1000 ). The out-of-sample performance is evaluated using the heteroskedastic mean square error (HMSE) and the quasi-likelihood (QLIKE) loss functions:
(24)
(24)
(25)
(25)
where
and
are respectively the forecasted and estimated
for the pseudo out-of-sample period, and N = T−IW refers to the total number of out-of-sample observations. We consider the QLIKE, which is robust in the sense of Patton (Citation2011), and the heteroskedasticity-adjusted MSE (HMSE) proposed by Bollerslev and Ghysels (Citation1996). Given that volatility is heteroskedastic the HMSE has become a popular loss function, see Diebold and Lopez (Citation1996) and Poon and Granger (Citation2003) among others.Footnote15
We evaluate the statistical significance of the forecast gains via the Conditional Predictive Accuracy (CPA) test of Giacomini and White (Citation2006) relative to the benchmark HAR (i.e. HAR-PRV) model. The CPA test is robust to nested models and its null hypothesis is of equal predictive accuracy conditional on some information set :
(26)
(26)
where
is the difference between two loss functions and
. The test statistic is then defined as
(27)
(27)
where
is a heteroskedasticity and autocorrelation consistent (HAC) estimator of the asymptotic variance.
We evaluate whether there is a subset of models that significantly outperforms the rest. To do so, we use the Model Confidence Set (MCS) of Hansen et al. (Citation2011) and denote by the set of all models (the benchmark HAR-PRV and the market-HAR class). The MCS procedure offers an efficient comparison that avoids multiple pairwise tests of loss functions, which can be both cumbersome and misleading unless appropriately corrected. The test statistic is defined as
(28)
(28)
where
is the average loss difference. The MCS test is then given by
and has a null hypothesis that all models have the same expected loss. Under the alternative, there is some model i that has an expected loss that exceeds the expected loss of all other models
. The surviving models are retained with a confidence level
. We implement the MCS via a block bootstrap using a block length of 10 days and 5000 bootstrap replications.
3.3. Economic value
We assess the value investors derive from using market-HAR models, by constructing volatility timing-based portfolio allocation strategies. Risk-averse investors are assumed to divide their funds between one risk-free asset and one risky asset with their focus on the daily investment horizon. The intuition is that, when volatility is high (low), investors allocate more (less) funds into the risk-free asset. It follows that accurate volatility forecasts would directly affect the investors' asset allocations.Footnote16
Using a mean–variance utility, the investor maximizes the economic utility by optimizing:
(29)
(29)
(30)
(30)
where h indicates the periods ahead, γ is the risk-aversion parameter,
is the conditional expected portfolio return and
is the conditional variance of the portfolio return. The portfolio return is
, where
is the portfolio weight of the risky asset,
is the conditional expected return of the risky asset, and
is the risk-free rate, which we know ex-ante. The risk-free rate is proxied by the 3-month US Treasury bill.
is estimated using a rolling window of 1000 days.
Substituting and taking FOC w.r.t , we obtain the optimal portfolio weight as
(31)
(31)
Two strategies are used depending on the volatility forecasts obtained either from the benchmark HAR-PRV or from the market-HAR models. We constrain our portfolio, so short-selling and leverage are not allowed. We consider different risk aversion levels
in line with Fleming et al. (Citation2003), Marquering and Verbeek (Citation2004), and Nolte and Xu (Citation2015). The sample averaged realized utility for a given strategy may be interpreted as the certain return that provides the same utility to the investor as the risky investment strategy, and is given as
(32)
(32)
As each investment strategy corresponds to an averaged realized utility for a unique sample, we can compare the performance fee that investors are willing to pay to switch strategies. The performance fee is denoted in basis points against the benchmark HAR-PRV strategy. The performance fee, denoted as
, is obtained by equating the sample averaged realized utility of the candidate strategy a to the benchmark b and solving for the performance fee, namely:
(33)
(33)
To ensure that the performance of our volatility-timing portfolio strategies is robust to realistic transaction costs, we follow DeMiguel et al. (Citation2014) and define the transaction cost adjusted portfolio return as
(34)
(34)
where
is the transaction cost adjusted portfolio return and π is the transaction cost parameter. Following Nolte and Xu (Citation2015), we set π to 0.0025, corresponding to a 2.5 cent half spread on a 10 dollar stock.
4. Data
Our sample consists of 20 individual stocks selected by trading volume over the period January 3, 2000, to December 31, 2016, a total of 4277 days, together with the SPDR (SPY) S&P 500 ETF over the same time period which we use as a proxy for the market factor.Footnote17 We consider sampling frequencies ranging from 30 to 300 seconds.
Table provides descriptive statistics for all the stocks and the SPY. The SPY is the least volatile asset in our study with an averaged annualized volatility close to 15%. By contrast, stock volatility is up to three times higher. Amazon displays the highest annualized return and volatility, whilst Arconic (ARNC) has the minimum annualized return and Procter & Gamble (PG) is the least volatile stock.
Table 1. Summary statistics.
Table reports average correlations across the stocks for all the realized measures under analysis. Above (below) the main diagonal the correlations are obtained using realized measures estimated from 30 (300)-second return. The superscripts ‘s’ and ‘m’ represent the realized measures of the stock and the market, respectively. Realized measures estimated at the 30-second frequency display stronger correlations compared with their counterpart estimated at the 300-second frequency. The level of correlation among all stock and market realized measures offers prima facie evidence that valuable information may be extracted from semi-variances and semi-covariances, and could lead to superior volatility forecasts.
Table 2. Average correlations across sampling frequency and realized measures.
Figure depicts the PRV and MRC with their respective signed components, averaged across all the stocks. The left-panel shows that negative semi-variances are more volatile than positive semi-variances, which is consistent with the view that negative returns have a pronounced impact on volatility (Glosten et al. Citation1993, Corsi and Renò Citation2012, Patton and Sheppard Citation2015). The right-panel plots the semi-covariances. Here, the concordant elements () are positive by construction; the discordant (
) are negative. During crisis periods, the concordant elements increase more than the discordant decline; thus confirming that during turbulent periods the correlation between stocks and market increases. Besides we note that the level of covariation is mainly determined by the concordant elements, suggesting that the discordant ones are of lesser importance.
Figure 1. Realized variance/covariance and their elements.
The graph plots the variance and covariance decomposition based on the average of the 20 stocks. The realized measures are estimated at the 300 seconds.
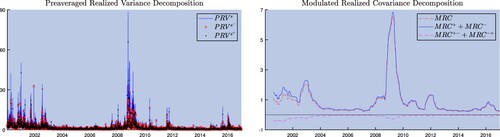
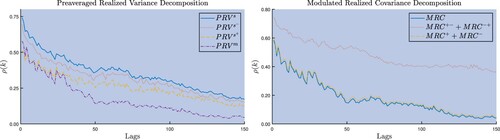
Figure plots the autocorrelation function, averaged across all stocks for the PRV and MRC with their respective signed components. A cursory inspection shows a lower level of persistence when compared to standard volatility measures, which is expected since MMSN induces first-order autocorrelation (Hansen and Lunde Citation2006). The negative semi-variance shows higher persistence than its positive counterpart; thus being aligned with the findings of Patton and Sheppard (Citation2015). Besides, the market is less persistent than the stocks. This may be in part explained by the memoryless large (finite) jumps typically observed in individual stocks (Duffie et al. Citation2000, Andersen et al. Citation2007, Duong and Swanson Citation2015, Bu et al. Citation2021), which however once aggregated at the market level become informative (Duong and Swanson Citation2015, Bu et al. Citation2021); thus reducing the persistence of compared to
. The MRC shows similar patterns as only the concordant elements are affected by co-jump activity (Bollerslev et al. Citation2020, Hizmeri et al. Citation2020).
Figure 2. Autocorrelation function.
The figure graphs the autocorrelation function for the different realized variances and covariances elements. The results presented are for the average across the stocks.
5. Modeling and forecasting with the market-HAR
5.1. In-sample performance
Table presents the estimated coefficients and goodness-of-fit statistics for the HAR-PRV, HAR-V and HAR-Co-V models across three forecasting horizons: 1 day (h = 1), 1 week (h = 5), and 1 month (h = 22) ahead. The null hypothesis of the F-test is that of equal fit between the benchmark HAR-PRV and each of the market-HAR models; with the rejection indicating the latter outperforms the former. The number of stocks where the market-HAR models supersede the benchmark HAR-PRV is reported.
Table 3. Market-HAR prediction regression results.
A first inspection of the results shows that adding market information in the HAR-V model leads to an improvement in the model fit relative to the benchmark model. This improvement ranges from 0.9% to 1.9% points in terms of the adjusted R-squares, and with the exception of two stocks at h = 5, the F-test rejects the null of equal fit for all the stocks across all forecasting horizons. Moreover, the HAR-Co-V model (which incorporates the variance and covariance market information) substantially improves the model fit: relative to the HAR-PRV models R-squares are raised from 1.4% to 3.4% points. The F-test corroborates this result. Market information renders stock-specific variables insignificant, which suggests that idiosyncratic volatility dynamics are of lesser importance. Monthly market volatility in the HAR-V model and the covariance estimates in the HAR-Co-V models are generally negative across all forecasting horizons. For the HAR-V model, negative market variance reduces weights assigned to monthly information; instead it places more emphasis on daily and weekly information.
Tables and present the parameter estimates and goodness-of-fit statistics for the asymmetric market-HAR variants. We discuss these tables in turn. Focusing first on the results in table , we observe that the specification based on the negative semi-variance has better fit than the one with the positive. Besides, the HAR-V outperforms the benchmark HAR-PRV in the majority of stocks. The increase in model fit is readily observed in terms of R-squares, where the HAR-V
model improves between 3.4 % and 4.3% points relative to the HAR-PRV model, and between 1.5 % and 3.3% points relative to the unsigned HAR-V variant, across all forecasting horizons. Our findings here are in line with Patton and Sheppard (Citation2015) who argue that negative semi-variances are more important to predict future volatility.
Table 4. Asymmetric HAR-V prediction regression results.
Table 5. Asymmetric HAR-Co-V prediction regression results.
In table , the asymmetric HAR-Co-V models are presented in two panels. Panel A gives parameter estimates for the HAR-Co-V models based on semi-covariances, but using unsigned volatilities. Across all forecasting horizons F-test values show both models to improve fit relative to the benchmark HAR-PRV model. The general similarity of goodness of fit across these models suggests similar explanatory power for the semi-covariances. Panel B reports the parameter estimates for the asymmetric HAR-Co-V using semi-covariances and semi-variances in the fully positive (HAR-Co-V
) and negative (HAR-Co
-V
) variant. The HAR-Co
-V
outperforms its fully positive counterpart by 6.5–9.0% points in terms of the adjusted R-squared, across all forecasting horizons. Compared to the benchmark HAR-PRV, the HAR-Co
-V
model offers superior fit in most stocks.
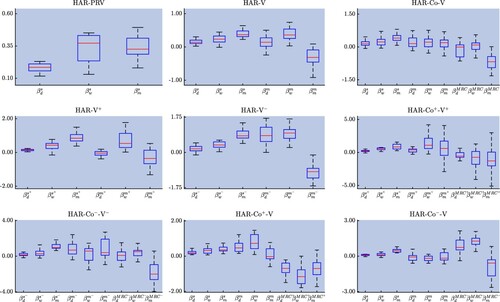
Figure presents the distribution of model coefficients across the stocks using box-plots. The coefficient estimates appear well-behaved with the weekly and monthly components of the HAR-PRV model reflecting the stocks' heterogeneity to a greater extent than the daily component. This may be plausibly related to the mix of investor preferences observed at different stocks and/or business sectors. Across the models that contain both firm-specific and market-specific information, the marginal contribution of the latter varies substantially at the stock level, as evidenced by the higher heterogeneity of the market-specific coefficients vis-à-vis their firm-specific counterparts. A similar finding is observed for the models further allowing for realized covariances.Footnote18
Figure 3. Box plots for 1-day ahead parameter estimates.
Note: The figure depicts the box plot for each coefficient estimated across the nine different models. Each subplot shows the daily weekly and monthly coefficient pertaining to a specific model.
Our general findings are that, by incorporating market information, the market-HAR models deliver superior explanatory power over the benchmark HAR-PRV model. Whether the superior in-sample performance translates into out-of-sample forecasting gains is examined next.
5.2. Out-of-sample forecasting
Table reports out-of-sample relative losses across forecasting horizons and sampling frequencies. Using each loss function, relative loss is computed as the ratio of the market-HAR models to the benchmark HAR-PRV model. For values below unity, market-HAR models outperform the benchmark. The superscript indicates stocks with significantly higher ( level) relative forecasting performance for market-HAR models, under the CPA test of Giacomini and White (Citation2006). In line with the literature, we first discuss results based on the 300-second sampling frequency, 1-day ahead forecasting using the HMSE loss function.Footnote19 We then discuss in turn the impact of sampling frequency and longer forecasting horizon.
Table 6. Out-of-sample ranking performance.
A first inspection of the results shows the most parsimonious of the market-HAR models (i.e. the HAR-V) to outperform the benchmark HAR-PRV model by approximately 9.80% points, and 15 stocks display significant forecasting gains. Asymmetric market-HAR models provide even better out-of-sample forecasting performance: when the negative semi-variance is used, the HAR-V model is relatively superior by 18.20% points, and 17 stocks display significant forecasting gains. Market-HAR models that incorporate realized covariance information outperform by up to 30.70% points the benchmark HAR-PRV model, with significant results for most stocks.
The forecasting gains of market-HAR models are moderated at high sampling frequencies and longer forecasting horizons.Footnote20 Nevertheless, these remain highly significant even at the 30-second sampling frequency and/or the 1-month ahead case. In particular, the HAR-Co-V model outperforms the benchmark by 20.9% points with significant results in 19 stocks when the sampling frequency is set at the 30-second, and by 19.40% points when the forecasting horizon is set to 1-month ahead.
5.3. Model classification and performance
This section presents the results of the Model Confidence Set (MCS) approach, which identifies the subset of models from the many market-HAR specifications with a superior predictive ability across specific forecasting horizons and sampling frequencies. The small variation in the ranking of models, as attributed to noise-robust realized measures, gives confirmation that, after accounting for MMSN, the sampling frequency choice becomes insignificant.
reports MCS ranking information for individual stocks across forecasting horizons when the 300-second sampling frequency is used for the realized measures. Retained models are identified by a ranking number; models excluded from the MCS are identified by a dash. Models ranked higher outperform those ranked lower. The MCS results reported are based on the QLIKE loss function.Footnote21 Focusing on the 1-day ahead results, we observe that for most stocks (i.e. 18/20) there are at least two competing models in the MCS, while only 3/20 stocks include the HAR-PRV model—the main benchmark in the previous part of the analysis. The last two columns show respectively the percentage of times a model has been included in the MCS and its average rank. The HAR-V and HAR-Co
-V models are predominantly selected by the MCS featuring in 70% of the stocks; while the former has an average ranking of 2.86, the latter ranks at 1.86. Therefore the MCS finds the HAR-Co
-V the best model, on average. The 1-month forecasts show that the HAR-Co
-V model expands to 90% of the stocks, with its average ranking dropping to 1.44; thus further dominating the other models.
Table 7. Model confidence set ranking across forecasting horizons.
Table gives MCS rankings for individual stocks across sampling frequencies at the 1-day ahead forecasting horizon. The MCS results obtained with the 150-second sampling frequency show that HAR-Co-V is the best model for 70% of the stocks with an average ranking of 1.64; thus being comparable to the results reported in table . However, as the sampling frequency increases the HAR-V
emerges as the best specification in 80–90.0% of the stocks. It appears that the negative semi-variance dominates at higher frequencies, while the positive one carries no predictive power. In broad strokes, these asymmetric models show superior forecasting performance, which is in line with the findings of Patton and Sheppard (Citation2015) and Bollerslev et al. (Citation2016) among others. The new information that our paper uncovers relates to which signed components contribute to the most significant gains in the presence of both stock-specific and market-specific signed realized measures as well as their signed realized covariances. It further reveals that despite negative semi-variances being regarded as more informative, there is merit in the information content afforded by the positive semi-covariance.
Table 8. Model confidence set across sampling frequencies.
5.4. Mixed sampling frequency market-HAR
In this section, we gauge the forecasting performance of the market-HAR models when we individually vary the sampling frequency on the stock and the market. Our earlier results have shown that the market-HAR models generally outperform the benchmark HAR-PRV and that the forecasting gains are of comparable magnitude across sampling frequencies. However, the results in table reveal different correlation levels across sampling frequencies. Besides, the use noise-robust realized measures enable us to use a wide span of sampling frequencies.
We setup the mixed sampling approach on the HAR-V model for two reasons. First, the HAR-V model is the most parsimonious of the market-HAR class of models, hence our results here would be useful to establish a minimum expected gain. Second, the HAR-Co-V model incorporates the realized covariation that has to be estimated at the same sampling frequency between the stock and the market.Footnote22 The mixed-sampling HAR-V model is constructed by holding constant the stock frequency, while varying the market frequency and vice versa. We use a total of six sampling frequencies ranging from 30 to 300 seconds. The results are compared against the benchmark HAR-PRV and the HAR-V models that are based on the same sampling frequency for the stock and the market.
The results of this exercise are presented in . The forecast evaluation criteria, averaged across all stocks, are presented in Panel A, while the relative losses with respect to the same frequency case (main diagonal) are reported in panel B. Figure plots the relative losses in a 3D plane. The x- and y-axes display respectively the sampling frequency of the market and the stock, while the z-axis displays the loss ratio for the QLIKE (left-panel) and HMSE (right-panel). The darker part of the figure highlights the best performance, while by contrast the lighter part indicates the worst performance.
Figure 4. Mixed sampling HAR-V model.
Note: The figure depicts the out-of-sample average relative loss for a mixed sampling HAR-V model. The model is estimated by varying the sampling frequency used to estimate the stock and index volatility. The left-panel plots the QLIKE loss ratio surface, and the right-panel plots the HMSE loss ratio surface.
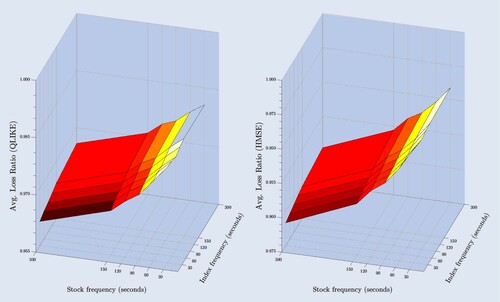
Table 9. Mixed sampling market-HAR.
Interesting observations can be drawn from these results. First, all the sampling frequency combinations outperform the benchmark HAR-PRV model, thus corroborating our previous findings on the benefits of incorporating market information upon volatility forecasting. Second, the relative losses reported in the lower (upper) triangular part of each panel are below (above) unity suggesting that using a mixed sampling frequency market-HAR affects the forecasting performance. We observe that the best forecasting performance is achieved when the market sampling frequency is higher than the stock's. In particular and using the QLIKE (HMSE), the mixed sampling market-HAR shows 1.90% (6.90%) points superior forecasting performance when the 300-second stock sampling frequency is combined with the 30-second market sampling frequency. Forecasting improves proportionally to the differential in sampling frequencies between the stock and the market, while for those cases where stock sampling frequency is lower than the market, forecasting deteriorates. This observation suggests that the use of a mixed-sampling approach better captures variations in the information set of the stock and the market.
5.5. Economic value analysis
Table reports the economic gains of switching from the benchmark HAR-PRV strategy to the market-HAR class of models for the 1-day ahead case.Footnote23 The performance fee represents the amount that an investor is willing to pay to using our new class of forecasting models, and the performance fee is expressed in annual basis points. Statistically significant differentials are evaluated against the null hypothesis of zero performance fee using a one-sided t-test with a robust variance–covariance estimator following Engle and Colacito (Citation2006), Bandi et al. (Citation2008), and Nolte and Xu (Citation2015), namely: and
. Bold numbers highlight the market-HAR models that outperform the benchmark strategy, and starred values indicate significant gains at the 5% significance level.
Table 10. Volatility-timing portfolio performance fee.
A cursory inspection of the results finds that market-HAR models generate positive performance fees across all stocks. The best performance is achieved by the HAR-V, HAR-Co
-V, and HAR-Co
-V
strategies. When
, these significantly outperform the benchmark strategy in at least 50% of our stocks. In contrast, the HAR-V
and HAR-Co
-V
models, that are based on the uninformative positive semi-variance, deliver weak out-of-sample performance. Performance fees at higher levels of risk aversion (
) are positive and comparable to the
case.
To be allowed to switch from the benchmark strategy to the HAR-Co-V strategy, a hypothetical investor would be willing to pay between 57 (
) and 11 (
) basis points. Regardless of the performance of HAR-V
or HAR-Co
-V
, if HAR-V strategies were positioned at
, a fee of 5.627 basis points would be warranted. Alternatively, HAR-Co-V strategies would, on average, warrant a performance fee of 9.357 basis points. These illustrative values highlight the benefits of incorporating market information in stock volatility forecasting; and that utilizing covariance and/or signed realized measures would further enhance the performance.
Table presents the performance fee, averaged across all stocks for 1-day ahead forecasts when transaction costs are considered. These values are slightly smaller than earlier results, so indicating that transaction costs have only marginal impact upon strategies. The superior performance of the market-HAR models is not challenged by realistic transaction costs.
Table 11. Volatility-timing portfolio performance fee with transaction costs.
6. Robustness
In this section, we examine the robustness of market-HAR forecasting gains to the presence of jumps and the choice of functional form.
6.1. Jumps
Accounting for jumps in volatility forecasting has been well documented, yet no consensus exists as to whether jumps increase forecasting performance (Giot and Laurent Citation2007, Andersen et al. Citation2007, Corsi et al. Citation2010, Busch et al. Citation2011, Patton and Sheppard Citation2015, Nolte and Xu Citation2015, Bu et al. Citation2021). In our context, we allow for the presence of jumps in either of the firm-specific and market-specific components, as well as jumps occurring in both components simultaneously (i.e. co-jumps). To separate the jump variation from the total realized variance, we need a measure that is robust to the presence of jumps. Since our framework relies on noise-robust measures, we use the pre-averaged bipower variation (PBV) proposed by Christensen et al. (Citation2014):
(35)
(35)
where
, and
. The jump variable are defined as follows:
Finally, we can create a co-jump measure as follows:
(36)
(36)
Our focus is to ensure that the forecasting gains commanded by the market-HAR are robust to the inclusion of daily jumps, rather than an investigation of whether jumps increase forecasting performance. Table presents out-of-sample relative losses of market-HAR models with jump components against the benchmark HAR-PRV model. The CPA test of Giacomini and White (Citation2006) at the 5% significance level reports the number of stocks that show significantly higher forecasting gains relative to the benchmark HAR-PRV model. For brevity we present results based on the 300-second sampling frequency, and 1-day, 1-week, 1-month ahead forecasting horizons using the HMSE and QLIKE loss functions.Footnote24 Market-HAR models with jumps in the stock-specific and market-specific components are denoted as HAR-V-J
and HAR-V-J
respectively; HAR-V-JJ denotes the inclusion of both jump components, while the HAR-V-CJ further imposes that jumps in the firm-specific and market-specific components occur simultaneously. The lower part of the table repeats the HAR-V (without jumps) for comparison purposes.
Table 12. HAR-V with jump regressors.
Our results suggest that the forecast improvements pertaining to the inclusion of a market component revealed in the main paper are not challenged, on average, by the existence of jumps in either or both of stock-specific and market-specific components. On average and for short horizons, inclusion of jumps appears to offer minor improvements in forecasting performance.
6.2. Functional form
It is sometimes practice that volatility modeling and forecasting is conducted on the logarithmic transformation of the realized measure. To ensure that the forecasting benefits documented by the market-HAR models in the main part of the paper are not reflective of nonlinear dependencies, we proceed to estimate a market-HAR model with the logarithmic transformation, which we denote as Log-HAR-V. To facilitate comparisons, the forecasts of the Log-HAR-V are compared against those of a Log-HAR model. Namely, these models are defined as
Log-HAR
(37)
(37)
Log-HAR-V
(38)
(38)
Table presents out-of-sample relative losses of Log-HAR-V model against the Log-HAR. The CPA test of Giacomini and White (Citation2006) at the 5% significance level reports the number of stocks that show significantly higher forecasting gains relative to the Log-HAR. For brevity, we present results based on the 300-second sampling frequency, and 1-day, 1-week, 1-month ahead forecasting horizons using the HMSE and QLIKE loss functions.Footnote25 The lower part of the table repeats the HAR-V (without logarithmic transformation) for comparison purposes.
Table 13. Out-of-sample results Log HAR-V model.
Our results suggest that the qualitative nature of our findings in the main paper is not challenged by the logarithmic transformation. Put simply, inclusion of the market factor improves individual stock volatility forecasting irrespective of the functional form adopted on the forecasting model.
7. Concluding remarks
The increased availability of high-frequency data has shaped the financial econometrics literature. Yet the inherently multivariate issues in finance, such as the covariation among multiple assets or systematic risk factors, remain largely unaddressed. Our contribution here fills this gap. We show that incorporating the market volatility factor significantly improves stock volatility forecasting in statistical and economic terms. The importance of the market volatility factor suggests of developments that are not fully reflected in individual stock dynamics. For example, it may take some time for financial analysts and/or traders to gauge the impact of news on individual stocks, as well as precisely trace the exact effect of a certain announcement; what Bollerslev (Citation2022) refers to as ‘soft’ news.
Our market-HAR model incorporates market information in a simple-to-estimate and digestible way. It does so by including realized variances and covariances of the market factor within the univariate heterogeneous autoregressive (HAR) model of Corsi (Citation2009). Using a sample of 20 representative stocks from the S&P 500 and the SPDR (SPY) S&P 500 ETF market proxy, in-sample and out-of-sample forecasting improvements are obtained, which are priced at 57 annual basis points. The forecasting gains reported in this paper are robust to a variety of robustness tests.
Our work has implications for future research. The cross-sectional heterogeneity we observe in the market-specific and covariance coefficients (see figure ) leads to ongoing work investigating their financial/economic drivers by potentially making use of the high frequency versions of the Fama–French size and value factors (Bollerslev and Zhang Citation2003, Aït-Sahalia et al. Citation2020). Besides, using our mixed frequency market-HAR design, the largest forecasting gains are attained when using a low (high) sampling frequency for the stock (market). This finding reflects the different informational content present in stocks/market across sampling frequencies. Future work in this direction could be positioned alongside (Giglio et al. Citation2016, Adrian et al. Citation2019, Carriero et al. Citation2020) in seeking to relate the ‘products’ of financial econometrics research to financial and economic outcomes. Finally, our market-HAR model can also be appropriate for modeling multivariate realized volatility, see for example the vech-HAR (Chiriac and Voev Citation2011, Bollerslev et al. Citation2018), the HAR-DRD (Oh and Patton Citation2016), and the HEAVY (Noureldin et al. Citation2012). This would allow us to relax the assumption that all assets share the same covariation dynamics (Chiriac and Voev Citation2011, Bollerslev et al. Citation2018). In such context, multivariate models may benefit from the use of the market factor as shown in this paper to avoid looming curse of dimensionality issues.
Acknowledgments
We thank the editors and two anonymous reviewers for their constructive feedback. The authors have benefited from conversations with Torben Andersen, Jia Li and John Maheu; and they acknowledge Gerry Steele and participants at the 12th International Conference in Computational Statistics and Financial Econometrics in PISA and the CMAF-EMP Research Workshop for helpful comments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 Many factors have been proposed in what (Cochrane Citation2011) refers to this as ‘a zoo of new factors’. Harvey et al. (Citation2016) and Chordia et al. (Citation2020) advocate for multiple hypothesis testing frameworks to minimize false discovery of new factors. Further warranting such rigorous testing procedures is the advent of LASSO-type penalizing regression and machine learning techniques in the field, see Chinco et al. (Citation2019), Gu et al. (Citation2020), and Freyberger et al. (Citation2020).
2 We purposely refer to the paper of Ang et al. (Citation2006b), which introduces an aggregate volatility factor to explain the cross-section of returns. We call this ‘market volatility’ as it provides a smoother transition with the motivation of our model in this paper; the authors refer to it as systematic volatility and it is proxied by the VIX index.
3 Arguably this is the origin of the financial econometrics research field (Bollerslev Citation2022).
4 Alternatively, ARFIMA models may also be used in volatility modeling, see Izzeldin et al. (Citation2019) for a comparison to HAR models.
5 A multivariate investigation within the financial econometrics literature has around 10 stocks over a 20-year period (Bollerslev et al. Citation2018). By comparison in asset pricing literature the Gu et al. (Citation2020) investigation uses 30,000 stocks over a 60-year period.
6 For example, Chinco et al. (Citation2019) using LASSO techniques explain around 2.5% of the variation in the stock return.
7 While this is true in a simple OLS regression, rolling estimation is one way to assume that the relationship can change. Even so, realized covariance in the market-HAR model allows the relation between stock and market to change at the daily and even intraday intervals.
8 Our framework allows for correlation among factors that is motivated by empirical evidence. Using the Fama and French (Citation2015) five-factor model plus the momentum factor obtained from Kenneth French's website https://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html we find that the market factor has a 14% correlation with the size factor SMB (‘small-minus-big’) factor and a correlation with the profitability factor RMW (‘robust-minus-weak’). Similarly, the book-to-market factor HML (‘high minus low’) displays a 43% and
correlation with the investment factor CMA (‘conservative-minus-aggressive’) and momentum factors, respectively.
9 This result is equivalent to that of Fan et al. (Citation2016), with the main distinction that we have restricted our process to be a univariate process and to have only two factors.
10 In the exposition that follows, we use returns and realized measures in the presence of microstructure noise; for an exposition of these measures in a noise-free scheme, see Andersen et al. (Citation2001a), Andersen et al. (Citation2001b), Barndorff-Nielsen and Shephard (Citation2002b), Meddahi (Citation2002), and Andersen et al. (Citation2003) for realized measures, Barndorff-Nielsen et al. (Citation2010) and Patton and Sheppard (Citation2015) for realized semi-variances, and Barndorff-Nielsen and Shephard (Citation2004) and Bollerslev et al. (Citation2020) for realized covariance and semi-covariances.
11 RV and IV denote respectively the realized and integrated variance, see Meddahi (Citation2002) and Barndorff-Nielsen and Shephard (Citation2002a) among others.
12 Oomen (Citation2006) shows that this estimator equals being very closely related to
proposed by Zhang et al. (Citation2005) and Bandi and Russell (Citation2006).
13 To avoid notational clutter we drop the δ onwards, and assume it is equal to 0.1 unless otherwise stated.
14 These models come directly from a vector HAR structure. However, here the interest is only in forecasting the stock volatility rather than the stock and the market volatility. For instance, .
where the first equation gives rise to the HAR-V model.
15 The MSE loss criterion may be a natural choice in evaluating competing estimates for the mean, but this is less obvious in a heteroskedastic environment (Bollerslev et al. Citation1994, Bollerslev and Ghysels Citation1996). The MSE is a symmetric loss function and therefore fails to properly account for the asymmetry observed in variances. Within risk management practices underestimation of variance forecasts is more dangerous than overestimation as it might provide false signals of recovery, which can lead to substantial risk overexposure. However, we confirm that our results are qualitatively similar to the use of MSE.
16 We aim for an intuitive comparison at the stock level to illustrate the benefits of the market-HAR model, similar to Fleming et al. (Citation2001), Fleming et al. (Citation2003), and Marquering and Verbeek (Citation2004). We leave portfolio designs with re-balancing schemes between the risky assets open to future research.
17 In a volatility forecasting application, Liu et al. (Citation2018) show that the SPDR (SPY) S&P 500 ETF and the S&P 500 are similar, and we opt for the former as it is a tradable asset.
18 The factors driving the heterogeneity of market-specific information is an interesting question, which we leave open for a future large sample evaluation.
19 The results using QLIKE are qualitatively similar.
20 Li and Zakamulin (Citation2020) also verify that volatility forecast accuracy diminishes in longer horizons.
21 The results based on the HMSE provide similar conclusions and are omitted for brevity, but are available upon request.
22 As the aim of this exercise is not to produce a horse-race we exclude the signed models and leave this question open to future research.
23 Results for longer horizons are qualitatively similar to those of the 1-day ahead case and are available upon request.
24 Results for other sampling frequencies are qualitatively similar and available from the authors upon request.
25 Results for other sampling frequencies are qualitatively similar and available from the authors upon request.
References
- Adrian, T., Boyarchenko, N. and Giannone, D., Vulnerable growth. Amer. Econ. Rev., 2019, 109(4), 1263–1289.
- Aït-Sahalia, Y., Kalnina, I. and Xiu, D., High-frequency factor models and regressions. J. Econom., 2020, 216(1), 86–105.
- Andersen, T.G., Bollerslev, T. and Diebold, F.X., Roughing it up: Including jump components in the measurement, modeling, and forecasting of return volatility. Rev. Econ. Stat., 2007, 89(4), 701–720.
- Andersen, T.G., Bollerslev, T., Diebold, F.X. and Ebens, H., The distribution of realized stock return volatility. J. Financ. Econ., 2001a, 61(1), 43–76.
- Andersen, T.G., Bollerslev, T., Diebold, F.X. and Labys, P., The distribution of realized exchange rate volatility. J. Am. Stat. Assoc., 2001b, 96(453), 42–55.
- Andersen, T.G., Bollerslev, T., Diebold, F.X. and Labys, P., Modeling and forecasting realized volatility. Econometrica, 2003, 71(2), 579–625.
- Ang, A., Chen, J. and Xing, Y., Downside risk. Rev. Financ. Stud., 2006a, 19(4), 1191–1239.
- Ang, A., Hodrick, R.J., Xing, Y. and Zhang, X., The cross-section of volatility and expected returns. J. Finance, 2006b, 61(1), 259–299.
- Ang, A., Hodrick, R.J., Xing, Y. and Zhang, X., High idiosyncratic volatility and low returns: International and further us evidence. J. Finance Econ., 2009, 91(1), 1–23.
- Bandi, F.M. and Russell, J.R., Separating microstructure noise from volatility. J. Financ. Econ., 2006, 79(3), 655–692.
- Bandi, F.M., Russell, J.R. and Zhu, Y., Using high-frequency data in dynamic portfolio choice. Econom. Rev., 2008, 27(1-3), 163–198.
- Barndorff-Nielsen, O., Kinnebrock, S. and Shephard, N., Measuring downside risk-realised semivariance. In Volatility and Time Series Econometrics: Essays in Honor of Robert F. Engle, pp. 117–136, 2010. New York: Oxford University Press.
- Barndorff-Nielsen, O.E. and Shephard, N., Econometric analysis of realized volatility and its use in estimating stochastic volatility models. J. R. Statist. Soc.: Ser. B (Statistical Methodology), 2002a, 64(2), 253–280.
- Barndorff-Nielsen, O.E. and Shephard, N., Estimating quadratic variation using realized variance. J. Appl. Econ., 2002b, 17(5), 457–477.
- Barndorff-Nielsen, O.E. and Shephard, N., Econometric analysis of realized covariation: High frequency based covariance, regression, and correlation in financial economics. Econometrica, 2004, 72(3), 885–925.
- Bekaert, G., Ehrmann, M., Fratzscher, M. and Mehl, A., The global crisis and equity market contagion. J. Finance, 2014, 69(6), 2597–2649.
- Bernales, A. and Guidolin, M., Can we forecast the implied volatility surface dynamics of equity options? Predictability and economic value tests. J. Bank. Finance, 2014, 46, 326–342.
- Black, F., Jensen, M.C. and Scholes, M., The capital asset pricing model: Some empirical tests. Stud. Theory Capital Markets, 1972, 81(3), 79–121.
- Bollerslev, T., Realized semi (co) variation: Signs that all volatilities are not created equal. J. Financial Econ., 2022, 20(2), 219–252.
- Bollerslev, T., Engle, R.F. and Nelson, D.B., Arch models. Handb. Econ., 1994, 4, 2959–3038.
- Bollerslev, T. and Ghysels, E., Periodic autoregressive conditional heteroscedasticity. J. Bus. Econ. Stat., 1996, 14(2), 139–151.
- Bollerslev, T., Li, J., Patton, A.J. and Quaedvlieg, R., Realized semicovariances. Econometrica, 2020, 88(4), 1515–1551.
- Bollerslev, T., Patton, A.J. and Quaedvlieg, R., Exploiting the errors: A simple approach for improved volatility forecasting. J. Econom., 2016, 192(1), 1–18.
- Bollerslev, T., Patton, A.J. and Quaedvlieg, R., Modeling and forecasting (un) reliable realized covariances for more reliable financial decisions. J. Econom., 2018, 207(1), 71–91.
- Bollerslev, T. and Zhang, B.Y., Measuring and modeling systematic risk in factor pricing models using high-frequency data. J. Empiric. Finan., 2003, 10(5), 533–558.
- Bu, R., Hizmeri, R., Izzeldin, M., Murphy, M. and Tsionas, M., The contribution of jump signs and activity to forecasting stock price volatility, 2021. Available at SSRN 3361972.
- Busch, T., Christensen, B.J. and Nielsen, M.Ø., The role of implied volatility in forecasting future realized volatility and jumps in foreign exchange, stock, and bond markets. J. Econom., 2011, 160(1), 48–57.
- Campbell, J.Y., Understanding risk and return. J. Polit. Econ., 1996, 104(2), 298–345.
- Campbell, J.Y. and Hentschel, L., No news is good news: An asymmetric model of changing volatility in stock returns. J. Finance Econ., 1992, 31(3), 281–318.
- Carriero, A., Clark, T.E. and Marcellino, M.G., Capturing macroeconomic tail risks with Bayesian vector autoregressions. FRB of Cleveland Working Paper, 2020.
- Chen, J., Intertemporal capm and the cross-section of stock returns. In EFA 2002 Berlin Meetings Discussion Paper, 2002.
- Chinco, A., Clark-Joseph, A.D. and Ye, M., Sparse signals in the cross-section of returns. J. Finance, 2019, 74(1), 449–492.
- Chiriac, R. and Voev, V., Modelling and forecasting multivariate realized volatility. J. Appl. Econom., 2011, 26(6), 922–947.
- Chordia, T., Goyal, A. and Saretto, A., Anomalies and false rejections. Rev. Financ. Stud., 2020, 33(5), 2134–2179.
- Christensen, K., Kinnebrock, S. and Podolskij, M., Pre-averaging estimators of the ex-post covariance matrix in noisy diffusion models with non-synchronous data. J. Econom., 2010, 159(1), 116–133.
- Christensen, K., Oomen, R.C. and Podolskij, M., Fact or friction: Jumps at ultra high frequency. J. Financ. Econ., 2014, 114(3), 576–599.
- Christoffersen, P., Feunou, B., Jacobs, K. and Meddahi, N., The economic value of realized volatility: Using high-frequency returns for option valuation. J. Finan. Quant. Anal., 2014, 49(3), 663–697.
- Cochrane, J.H., Presidential address: Discount rates. J. Finance, 2011, 66(4), 1047–1108.
- Corsi, F., A simple approximate long-memory model of realized volatility. J. Finan. Econom., 2009, 7(2), 174–196.
- Corsi, F., Pirino, D. and Renò, R., Threshold bipower variation and the impact of jumps on volatility forecasting. J. Econom., 2010, 159(2), 276–288.
- Corsi, F. and Renò, R., Discrete-time volatility forecasting with persistent leverage effect and the link with continuous-time volatility modeling. J. Bus. Econ. Stat., 2012, 30(3), 368–380.
- DeMiguel, V., Nogales, F.J. and Uppal, R., Stock return serial dependence and out-of-sample portfolio performance. Rev. Financ. Stud., 2014, 27(4), 1031–1073.
- Diebold, F.X. and Lopez, J.A., 8 forecast evaluation and combination. Handb. Statist., 1996, 14, 241–268.
- Diebold, F.X. and Yilmaz, K., Measuring financial asset return and volatility spillovers, with application to global equity markets. Econ. J., 2009, 119(534), 158–171.
- Duffie, D., Pan, J. and Singleton, K., Transform analysis and asset pricing for affine jump-diffusions. Econometrica, 2000, 68(6), 1343–1376.
- Duong, D. and Swanson, N.R., Empirical evidence on the importance of aggregation, asymmetry, and jumps for volatility prediction. J. Econom., 2015, 187(2), 606–621.
- Engle, R. and Colacito, R., Testing and valuing dynamic correlations for asset allocation. J. Bus. Econ. Stat., 2006, 24(2), 238–253.
- Fama, E.F. and French, K.R., Common risk factors in the returns on stocks and bonds. J. Financ. Econ., 1993, 33, 3–56.
- Fama, E.F. and French, K.R., A five-factor asset pricing model. J. Financ. Econ., 2015, 116(1), 1–22.
- Fama, E.F. and MacBeth, J.D., Risk, return, and equilibrium: Empirical tests. J. Political Econ., 1973, 81(3), 607–636.
- Fan, J., Furger, A. and Xiu, D., Incorporating global industrial classification standard into portfolio allocation: A simple factor-based large covariance matrix estimator with high-frequency data. J. Bus. Econ. Stat., 2016, 34(4), 489–503.
- Fleming, J., Kirby, C. and Ostdiek, B., The economic value of volatility timing. J. Finance, 2001, 56(1), 329–352.
- Fleming, J., Kirby, C. and Ostdiek, B., The economic value of volatility timing using ‘realized’ volatility. J. Financ. Econ., 2003, 67(3), 473–509.
- Forbes, K.J. and Rigobon, R., No contagion, only interdependence: Measuring stock market comovements. J. Finance, 2002, 57(5), 2223–2261.
- Freyberger, J., Neuhierl, A. and Weber, M., Dissecting characteristics nonparametrically. Rev. Financ. Stud., 2020, 33(5), 2326–2377.
- Ghysels, E. and Sinko, A., Volatility forecasting and microstructure noise. J. Econom., 2011, 160(1), 257–271.
- Giacomini, R. and White, H., Tests of conditional predictive ability. Econometrica, 2006, 74(6), 1545–1578.
- Giglio, S., Kelly, B. and Pruitt, S., Systemic risk and the macroeconomy: An empirical evaluation. J. Financ. Econ., 2016, 119(3), 457–471.
- Giot, P. and Laurent, S., The information content of implied volatility in light of the jump/continuous decomposition of realized volatility. J. Futures Markets, 2007, 27(4), 337–359.
- Glosten, L.R., Jagannathan, R. and Runkle, D.E., On the relation between the expected value and the volatility of the nominal excess return on stocks. J. Finance, 1993, 48(5), 1779–1801.
- Grootveld, H. and Hallerbach, W., Variance vs downside risk: Is there really that much difference? Eur. J. Oper. Res., 1999, 114(2), 304–319.
- Gu, S., Kelly, B. and Xiu, D., Empirical asset pricing via machine learning. Rev. Financ. Stud., 2020, 33(5), 2223–2273.
- Guerard, J.B., Markowitz, H. and Xu, G., Global stock selection modeling and efficient portfolio construction and management. J. Invest., 2013, 22(4), 121–128.
- Hansen, P.R. and Lunde, A., Realized variance and market microstructure noise. J. Bus. Econ. Stat., 2006, 24(2), 127–161.
- Hansen, P.R., Lunde, A. and Nason, J.M., The model confidence set. Econometrica, 2011, 79(2), 453–497.
- Harvey, C.R., Liu, Y. and Zhu, H., and the cross-section of expected returns. Rev. Financ. Stud., 2016, 29(1), 5–68.
- Hizmeri, R., Izzeldin, M. and Nolte, I., Bolstering the modelling and forecasting of realized covariance matrices using (directional) common jumps. Available at SSRN 3745671, 2020.
- Huang, X., Portfolio selection with a new definition of risk. Eur. J. Oper. Res., 2008, 186(1), 351–357.
- Izzeldin, M., Hassan, M.K., Pappas, V. and Tsionas, M., Forecasting realised volatility using arfima and har models. Quant. Finance, 2019, 19(10), 1627–1638.
- Jacod, J., Li, Y., Mykland, P.A., Podolskij, M. and Vetter, M., Microstructure noise in the continuous case: The pre-averaging approach. Stoch. Process. Their. Appl., 2009, 119(7), 2249–2276.
- Jegadeesh, N. and Titman, S., Returns to buying winners and selling losers: Implications for stock market efficiency. J. Finance, 1993, 48(1), 65–91.
- Li, X. and Zakamulin, V., Stock volatility predictability in bull and bear markets. Quant. Finance, 2020, 20(7), 1149–1167.
- Lintner, J., Security prices, risk, and maximal gains from diversification. J. Finance, 1965, 20(4), 587–615.
- Liu, F., Pantelous, A.A. and von Mettenheim, H.-J., Forecasting and trading high frequency volatility on large indices. Quant. Finance, 2018, 18(5), 737–748.
- Marquering, W. and Verbeek, M., The economic value of predicting stock index returns and volatility. J. Finan. Quant. Anal., 2004, 39(2), 407–429.
- Meddahi, N., A theoretical comparison between integrated and realized volatility. J. Appl. Econom., 2002, 17(5), 479–508.
- Ng, V., Engle, R.F. and Rothschild, M., A multi-dynamic-factor model for stock returns. J. Econom., 1992, 52(1-2), 245–266.
- Nolte, I. and Xu, Q., The economic value of volatility timing with realized jumps. J. Empir. Finance, 2015, 34, 45–59.
- Noureldin, D., Shephard, N. and Sheppard, K., Multivariate high-frequency-based volatility (heavy) models. J. Appl. Econom., 2012, 27(6), 907–933.
- Oh, D.H. and Patton, A.J., High-dimensional copula-based distributions with mixed frequency data. J. Econom., 2016, 193(2), 349–366.
- Oomen, R.C.A., Comment on: ‘Realized variance and market microstructure noise’ by Peter R. Hansen and Asger Lunde. J. Bus. Econ. Stat., 2006, 24(2), 195–202.
- Pástor, L. and Stambaugh, R.F., Liquidity risk and expected stock returns. J. Polit. Econ., 2003, 111(3), 642–685.
- Patton, A.J., Volatility forecast comparison using imperfect volatility proxies. J. Econom., 2011, 160(1), 246–256.
- Patton, A.J. and Sheppard, K., Good volatility, bad volatility: Signed jumps and the persistence of volatility. Rev. Econ. Statist., 2015, 97(3), 683–697.
- Poon, S.-H. and Granger, C.W., Forecasting volatility in financial markets: A review. J. Econ. Lit., 2003, 41(2), 478–539.
- Sharpe, W.F., Capital asset prices: A theory of market equilibrium under conditions of risk. J. Finance, 1964, 19(3), 425–442.
- Zhang, L., Mykland, P.A. and Aït-Sahalia, Y., A tale of two time scales: Determining integrated volatility with noisy high-frequency data. J. Am. Stat. Assoc., 2005, 100(472), 1394–1411.