
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The digitalization of news and social media provides an unprecedented source to investigate the role of information on market dynamics. However, the observed sentiment time-series represent a noisy proxy of the true investor sentiment. Moreover, modeling the joint dynamics of different sentiment series can be beneficial for the assessment of their economic relevance. The main methodological contribution of this paper is twofold: (i) we filter the latent sentiment signals in a genuinely multivariate model; (ii) we propose a decomposition into a long-term random walk component, named long-term sentiment, and a short-term component driven by a stationary Vector Autoregressive process of order one, named short-term sentiment. The proposed framework is a dynamic factor model describing the joint evolution of the observed sentiments of a portfolio of assets. Empirically, we find that the long-term sentiment co-integrates with the market price factor, while the short-term sentiment captures transient and firm-specific swings. By means of quantile regressions, we assess the significance of the explanatory power of filtered present sentiment on future returns. Then, we demonstrate how the lagged relation can be successfully exploited in a portfolio allocation exercise.
1. Introduction
Nowadays, as Ignacio Ramonet wrote in The Tyranny of Communication, ‘a single copy of the Sunday edition of the New York Times contains more information than an educated person in the eighteenth century would consume in a lifetime’. This huge amount of information cannot be read by a single person. Recent developments in machine learning algorithms for sentiment analysis help us to categorize and extract signals from text data and pave the way for a new area of research. The use of these new sources of textual data has become popular to analyze the relationship between sentiment and other economic variables using econometric techniques. Algaba et al. (Citation2020) refer to this new strand of literature as Sentometrics. A vast literature focuses on the forecast of future market returns or volatility using sentiment. For instance, Groß-Klußman and Hautsch (Citation2011) study the impact of unexpected news on the displayed quotes in a limit order book, Sun et al. (Citation2016) and Schnaubelt et al. (Citation2020) show that intraday S&P 500 index and constituent returns are predictable using lagged investor sentiment, Peterson (Citation2016) investigates the trading strategies based on sentiment, Tetlock (Citation2007) and Garcia (Citation2013) consider the Dow Jones Industrial Average (DJIA) index predictability using sentiment, Calomiris and Mamaysky (Citation2019) show how the predictability can be exploited in different markets around the world, while Kim and Kim (Citation2014) finds no evidence of predictability coming from messages on Yahoo! Finance. In addition to market returns forecast, sentiment indicators have been used to forecast other market and economic variables. Antweiler and Frank (Citation2004), Borovkova and Mahakena (Citation2015), Allen et al. (Citation2015), Smales (Citation2015), and Jiao et al. (Citation2020) study the impact of sentiment on volatility, Ranco et al. (Citation2015) analyze the impact of social media attention on market dynamics, Borovkova (Citation2015) develops risk measures based on sentiment index, Nyman et al. (Citation2021) and Mai et al. (Citation2019) find predictive power of sentiment indices on financial crisis and firms' bankruptcy respectively, Feuerriegel and Gordon (Citation2019) use financial news to predict macroeconomic indicators and Lillo et al. (Citation2015) show that different types of investors react differently to news sentiment. Huynh et al. (Citation2021) show that media coverage and investor sentiment was able to predict stock returns and volatility during the recent COVID-19 pandemic.
As observed by Zygmunt Bauman in Consuming Life, as the amount of information also increases the amount of useless information increases, and the noise becomes predominant. Two different non-exclusive methods have been explored in the literature to remove or, at least, mitigate the impact of useless information. In the first case, a general-to-specific approach is used directly on the textual data. The amount of information can be reduced by selecting only verified news (i.e. eliminating fake news), considering only the words which are closely related to the topic of interest, considering the importance of any news (e.g. Da et al. Citation2011), selecting only news which appear for the first time (e.g. Thomson Reuters News Analytics engine uses the novelty variable, see Borovkova et al. Citation2017), or weighting a news by means of a measure of attention (e.g. with the number of clicks it receives when published in a news portal Ranco et al. Citation2016). Obviously, the selection of the relevant data is application-specific. For instance, fake news may be irrelevant to forecast the GDP of a country but may be crucial to forecast the results of an election (e.g. Allcott and Gentzkow Citation2017).
In the second case, sentiment time series are directly considered rather than the text source they are built from. The observed sentiment is noisy and various approaches have been proposed to filter it and recover the latent signal. Thorsrud (Citation2018) applies a 60-day moving average, Peterson (Citation2016) uses the Moving Average Convergence-Divergence methodology proposed in Appel (Citation2003), Borovkova and Mahakena (Citation2015), Audrino and Tetereva (Citation2019), and Borovkova et al. (Citation2017) introduce the Local News Sentiment Level model (LNSL), a univariate method that takes inspiration from the Local Level model of Durbin and Koopman (Citation2012). In spite of its convenience from a practical perspective, the moving average approach is not statistically sound and the window length is usually chosen following rules of thumb, which have been tested empirically but lack a clear theoretical motivation. The methods based on the Kalman-Filter techniques present a natural and computationally simple choice to extract an informative signal. Unfortunately, when multiple assets are considered in the analysis, the LNSL model does not exploit the multivariate nature of the data. One goal of this paper is to show that the covariance structure is very informative in sentiment time series analysis.
The first contribution of this paper is to extend the existing time series methods in the latter stream of literature. We propose to model noisy sentiment disentangling two different sentiment signals. In our approach, the observed sentiment follows a linear Gaussian state-space model with three relevant components.Footnote† The first component, named long-term sentiment is modeled as a random walk, the second component is termed short-term sentiment and follows a VAR(1) process, and the last component is an i.i.d Gaussian observation noise process. We name the novel sentiment state-space model Multivariate Long Short Sentiment (MLSS). In the empirical section of the paper, we separately model the sentiment coming from newspapers (news sentiment) and the sentiment extracted from social media (social sentiment). We show that the decomposition provides a better insight on the nature of sentiment time series, linking the long-term sentiment to the long-term evolution of the market—proxied by the market factor—while the short-term sentiments reflect transient swing of the market mood and is more related to the market idiosyncratic components. Specifically, we find that (i) the second news long-term sentiment cointegrates with the first market factor extracted via PCA; (ii) the correlation structure of the short-term sentiment explains a significant and sizable fraction of correlation of return residuals of a CAPM model. Finally, we show that the multivariate local level model provides the best description of the data with respect to alternative models, such as the LNSL.
The second contribution of the paper is to unravel the relation between news and market returns conditionally on quantile levels. We perform various quantile regressions showing that sentiment has good explanatory power of returns. When contemporaneous effects are considered, the result is expected and holds for all models at intermediate quantile levels. However, when the analysis is focused on abnormal days—i.e. days for which returns belong to the 1% and 99% quantiles—neither the noisy sentiment nor the filtered sentiment from an LNSL model explain the observed market returns. The only model achieving statistical significance is the MLSS. This result shows that it is essential to filter the noisy sentiment according to the MLSS, which exploits both the multivariate structure of the data and disentangles the long- and short-term components. Moreover, a test performed on the single components confirms the intuition that the short-term sentiment is the one responsible for the contemporaneous explanatory power. The empirical evidence in favor of the MLSS becomes even more compelling when lagged relations are tested. When a single day lag is considered, i.e. one tests whether yesterday's sentiment explains today returns, the significance of all models, but MLSS, drops to zero. This result holds across all quantile levels. Instead, for quantiles smaller than 10% and larger than 90%, the returns predictability for the MLSS model is highly significant. As before, the decomposition in two time scales is essential and the short-term component is the one responsible of the effect. The analysis extended including lagged sentiment—up to five days—confirms previous findings by Garcia (Citation2013) that past sentiment contributes in predicting present returns. Interestingly, this is true for quantiles between 5% and 10%, both negative and positive, but neither in the median region nor for extreme days. In light of these findings, we finally investigated whether media and social news immediately digest market returns and whether this relation depends on the sign of returns. Our results provide a clear picture showing that (i) the impact of market returns on sentiment is significant up to five days in the future when negative extreme returns—i.e. belonging to quantiles from 1% to 10%—are considered, (ii) when positive returns are considered the impact rapidly fades out and is significant only for quantiles smaller than 5%, (iii) previous findings become not significant if the MLSS sentiment is replaced by the observed noisy sentiment. Consistently with the intuition provided by these results, we test whether the returns predictability of the MLSS model can be exploited in a portfolio allocation exercise. We show that the portfolios generated with the MLSS sentiment series have a higher Sharpe ratio and lower risk than similar portfolios constructed with raw sentiment or sentiment filtered with the univariate LNSL model. Our model outperforms also the benchmark constituted by the buy-and-hold equally weighted portfolio. This result remains true when transaction costs are included.
The rest of the paper is organized as follows. In section 2, we develop the multivariate model for the sentiment and discuss the estimation technique. In section 3, we introduce the TRMI sentiment index and describe the data used in the analysis. In section 4, we report the empirical findings and discuss the advantages of the multivariate approach. In section 5, we compare the various techniques and report the performances of the long-short sentiment decomposition in explaining daily returns. Section 6 describes the portfolio allocation strategies using different filtering techniques and assesses the superiority of the MLSS filter among the others. Section 7 draws the relevant conclusions and sketch possible future research directions.
2. The model
Consider K assets and the corresponding K observed daily sentiment series where
. The observed daily sentiment
quantifies the opinions of investors and consumers about company i. In most cases, the observed sentiment is a continuous number in a compact set.
The Local News Sentiment Level model (LNSL), presented in Borovkova and Mahakena (Citation2015) and subsequently used in Audrino and Tetereva (Citation2019), reads as follows
(1)
(1)
for every
. This model is a univariate specification of the Local Level model of Durbin and Koopman (Citation2012). The latent sentiment series
is considered as slowly changing components, modeled as independent random walks and the parameters
and
are estimated via maximum likelihood (MLE).
Since the LNSL model does not consider the correlations of the innovations among the K assets, we can easily derive its multivariate version as
(2)
(2)
where
and
are K dimensional vectors, Q is a
symmetric matrix and R is a
diagonal matrix. We refer to the multidimensional LNSL model as MLNSL. The synchronous correlation among the innovations of the latent sentiment are described by the covariance matrix Q, while the correlations among the observation noises are assumed to be 0. Clearly, the LNSL model is a special case of the MLNSL model when the matrix Q is diagonal. Since the number of parameters for this model scales as
, the MLE of the MLNSL model is computationally demanding. For this reason, we use the Kalman-EM approach described in Corsi et al. (Citation2015).
The idea of the LNSL and MLNSL models is that the latent sentiment is a slowly changing component with a Gaussian disturbance. In their empirical studies, Audrino and Tetereva (Citation2019) observe that the signal-to-noise ratio , obtained using the LNSL filter, is very small. This finding indicates that the majority of the daily changes in the sentiment series can be considered as noise. One possible explanation for this result is that the Local Level specification of these models is not sufficiently rich to capture all the signals from the observed sentiment. Indeed, in newspapers and social media, there is a consistent amount of articles and opinions which represent fast trends or rapidly changing consumer preferences. Following the recent strand of literature on persuasion (Gerber et al. Citation2011, Hill et al. Citation2013), these fast trends have strong but short-lived effects on consumer preferences. Since the (M)LNSL model, introduced in Borovkova and Mahakena (Citation2015) and Audrino and Tetereva (Citation2019), considers the sentiment as an integrated series, these mean-reverting signals are treated as noise.
The main contribution of this paper is to define a new model which disentangles the slowly changing sentiment from a rapidly changing sentiment, which we name short-term sentiment, and the observation noise. We build our model on the existing approach of Borovkova (Citation2015) and Audrino and Tetereva (Citation2019), and we specify the slowly changing components as a unit root process. In addition, it is reasonable to think that the slowly changing components of a set of firms with common characteristics, for instance, belonging to the same sector, market, or country, should be affected by the same trends and shocks. For this reason, in our model we consider a number of factors driving the slow component of the sentiment dynamics. We name these factors as long-term sentiment. We do not fix the number q a priori, but we select it by means of information criteria.
To provide a more quantitative intuition behind our modeling specification, let us consider the true, but unobserved, daily investor's mood of asset i. We hypothesize today's daily mood can be written as
(3)
(3)
Based on Audrino and Tetereva (Citation2019) and Borovkova and Mahakena (Citation2015), the Long-term Mood is composed of yesterday's Long-term Mood plus a shock
, which is usually small but permanent, i.e.
On the contrary, the Short-term Mood is short-lived, but with a strong and highly influential impact. In particular, the Short-term Mood is composed by a residual part of the yesterday Short-term Mood plus a shock
, i.e.
In this framework, the long-term shocks permanently change the investor's mood while the short-term shocks have an exponentially decaying persistence in the investor's mood. Equation (Equation3
(3)
(3) ) can be rewritten as
(4)
(4)
Considering the whole story and the dynamic of the two sentiments shocks, we can rewrite equation (Equation4
(4)
(4) ) as
where we assumed
to be negligible and equal to zero. In full generality, the multivariate version of model (Equation3
(3)
(3) ) can be formulated as follows
with A and B being
matrices. However, in light of the considerations in the previous paragraph, we restrict the matrix B to be the identity matrix. In this way, the Short-term Mood is purely company-specific. We replace
with the product between a factor loading matrix and a limited number of factors, that is we rewrite the previous equation as
(5)
(5)
where Λ belongs to
with
. It is important to notice that the significance of Λ can be statistically tested and the selection of the number q of factors can be performed by means of AIC and BIC criteria. Following Audrino and Tetereva (Citation2019), we assume that the observed sentiment
is a noisy observation of the investors
, and we formulate a state-space model for
consistent with the intuition provided by model (Equation5
(5)
(5) ). The Multivariate Long Short Sentiment model (MLSS) for the observed sentiment model, assuming a Gaussian specification for the short-term sentiment shock, long-term sentiment shock and the observation noise, reads
(6)
(6)
where
is the diagonal covariance matrix of the observation noise
,
is the matrix of autoregressive coefficients,
is the covariance matrix of the short-term sentiment innovations, and
is the covariance matrix of the random walk innovations. Section B in the online material shows an alternative specification for the long-term component, but the implementation of this model is left for future work. In equation (Equation6
(6)
(6) ),
and
are the latent processes that proxy the Long-term Factor Mood and Short-term Mood in (Equation5
(5)
(5) ), respectively. Please notice that the essential difference between equations (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) is that the observed sentiment, and its components, are noisy versions of the investors' mood and its long and short components. Finally, in this paper, we force a diagonal structure on the matrix Φ, thus neglecting the possible lead-lag effects among sentiments. This restriction is introduced to limit the curse of dimensionality of the model. As an alternative approach allowing for possible lead-lag effects, one should consider to implement well-known regularization techniques. Chen et al. (Citation2017) propose an Expectation Regularization Maximization algorithm to estimate high-dimensional state space model. However, this methodology can not be used in the case of augmented state-space models. A possible extension of regularization techniques for augmented state-space models is an interesting research problem, whose investigation is beyond the scope of the current work. After model (Equation6
(6)
(6) ) is estimated on data (see section 4), we perform the standard tests on the residuals finding that they are approximately normally distributed, serially uncorrelated, as well as their absolute values.Footnote† All these results indicate that a Gaussian state space model is an appropriate specification for the sentiment dataset.
It is worth noticing that, if the observed sentiment lies in a compact set, the LNSL, MLNSL and MLSS models, in their current specification, do not consider the upper and lower bounds. This issue can be accounted for with a non-linear transformation of the data, e.g. by Fisher transforming the data, which maps them on the whole real line as commonly done for correlation time series. In this paper, we do not apply any non-linear transformation since most of the daily sentiment observations are far from the bounds and, as we verified, the Fisher transform mildly affects our analysis. In addition, the definition of unit root processes in presence of bounds is non standard but studied in the literature and it can be tested using ad-hoc unit root tests (Cavaliere and Xu Citation2014).
The estimation of the unknown parameters is based on a combination of the Kalman filter with Expectation Maximization (Kalman Citation1960, Shumway and Stoffer Citation1982, Harvey Citation1990, Wu et al. Citation1996, Jungbacker and Koopman Citation2008, Banbura and Modugno Citation2014). Given that model (Equation2(2)
(2) ) is a special case of model (Equation6
(6)
(6) ), in the next session, we only consider the estimation procedure of model (Equation6
(6)
(6) ).
2.1. Estimation procedure
The estimation of model (Equation6(6)
(6) ) is performed using the Kalman filter (Kalman Citation1960) and the Expectation Maximization (EM) method in Dempster et al. (Citation1977) and Shumway and Stoffer (Citation1982), which was proposed to deal with incomplete or latent data and intractable likelihood. The EM algorithm is a two-step estimator. In the first step, we write the expectation of the likelihood considering the latent process as observed. In the second step, we re-estimate the static parameters maximizing the expectation obtained in the first step. This routine is repeated until some convergence criterion is satisfied. To cast (Equation6
(6)
(6) ) in a standard state-space representation, we use the same procedure as Banbura and Modugno (Citation2014) and define the augmented states
,
,
and
s.t.
(7)
(7)
where
(8)
(8)
The EM renders the approach feasible in high dimension. Indeed, while a direct numerical maximization of the likelihood is computationally demanding, the EM algorithm, thanks to the Kalman filtering and smoothing recursions in appendix 1, can be formulated using the closed-form equations reported in appendix 2. In particular, it allows to disentangle the long-term sentiment
and the short-term sentiment
. To derive the EM steps, we consider the log-likelihood
where θ denotes the set of static parameters
,
,
and R. The EM proceeds in a sequence of steps:
E-step: it evaluates the expectation of the log-likelihood using the estimated parameters from the previous iteration
:
M-step: the parameters are estimated again maximizing the expected log-likelihood with respect to θ:
We initialize the parameters and repeat steps 1 and 2 until we reach the convergence criterion
(11)
(11)
We set
. As observed in Harvey (Citation1990), the dynamic factor model (Equation7
(7)
(7) ) is not identifiable. Indeed, if we consider a non singular invertible matrix M, then the parameters
and
are observationally equivalent, then starting from
we cannot distinguish
from
. We solve this identification problem using the approach proposed by Harvey (Citation1990), imposing the following restrictions
(12)
(12)
where Λ is the
sub-matrix in (Equation8
(8)
(8) ).
The specifications of ,
,
and R in (Equation8
(8)
(8) ), together with (Equation12
(12)
(12) ), impose several constraints to the estimation. The EM procedure allows us to impose restrictions on the parameters in a closed-form. According to Wu et al. (Citation1996) and Bork (Citation2009), we get the constrained
,
,
and R as:
(13)
(13)
where A is defined in (EquationA2
(A2)
(A2) ), M is the
matrix, f is the number of constraints,
is the f vector containing the constraints values such that
Equivalently, for the restricted :
(14)
(14)
where
is defined in (EquationA2
(A2)
(A2) ), G is the
matrix, s is the number of constraints,
is the s vector containing the constraints values such that
.
and R are evaluated using equations (EquationA4
(A4)
(A4) ) and (EquationA5
(A5)
(A5) ) and the restrictions, according to Wu et al. (Citation1996), can be imposed elementwise.
The final estimation scheme reads as follows:
Initialize
Perform the E-step using the estimations
Perform the M-step and evaluate the new estimators
Use the unrestricted estimations and (Equation13
Repeat 2, 3 and 4 above until the estimates and the log-likelihood reach convergence.
Finally, we select the number of long-term sentiment q using the AIC and BIC indicators.
3. Data
The approaches to sentiment analysis can be broadly classified into three categories. The first class is based on (mostly supervised) Machine Learning techniques. Three steps are typically considered. The first one is to collect textual data forming the training dataset. The second one is to select the text features for classification and to pre-process the data according to the selection. The final step is to apply a classification algorithm to the textual data. As an example, Pang et al. (Citation2002) compare the performance of Naive Bayes, support vector machines, and maximum entropy algorithm to classify positive or negative movie reviews. The second category is the lexicon-based approach. It also typically consists of three steps. The first step is the selection of a dictionary of N words that could be relevant to a specific topic (e.g. the word great is considered as a positive word to review a movie). The second one consists in tokenizing the textual data and, for each word in the dictionary, count how many times it appears in the text. This process can be visualized with a vector of length N where the ith element represents the number of times the ith word of the dictionary is mentioned in the text. Finally, a measure takes the vector of length N as an input and gives a quantitative score as an output. One can refer to Loughran and McDonald (Citation2011) for a relevant example in the financial literature. The third and last approach is a combination of methodologies coming from the first and second approach. For an overview of textual data treatments and computational techniques, we refer to the review paper (Vohra and Teraiya Citation2013) and the book (Liu Citation2015).
In this paper, we use a pre-classified index named The TRMI sentiment index. It is constructed using over 700 primary sources, divided into news and social media, and collects more than two million articles per day. For every article, a ‘bag-of-words’ technique is used to create a sentiment score, which lies between and
, a buzz variable,Footnote† and one or more asset codes, which in our case refer to companies. The time resolution of the sentiment data is one minute.
For any asset a, minute s, and day t we denote as the sentiment score and as
the buzz variable. The variable
can be specific for news or social sentiment. In this paper, we use both the series but analyze them separately. Since the following empirical analysis are performed using daily data, we need to aggregate the TRMI series on a daily basis. TRMI user guide suggests to use the following equation
(15)
(15)
where
refers to the daily sentiment at day t, evaluated on a 24-hour window between the 4:00 PM of day t−1 (
) and the 4:00 PM of day t (
). Note that the TRMI server provides a daily frequency sentiment, where they use equation (Equation15
(15)
(15) ) with a 24-hours window from 3:30 PM to 3:30 PM of the day after. However, since we want to relate the sentiment series with close-to-close returns, we construct the daily sentiment series aggregating the high-frequency sentiment according to the trading closing hour of the NYSE (4:00 PM). For more details, please refer to Peterson (Citation2016).
For the empirical analysis, we consider the TRMI sentiment index of 27 out of 30 stocksFootnote† of the Dow Jones Industrial Average (DJIA) over the period 03/01/2006–29/12/2017. The companies that we considered are the components of the DJIA as of December 29, 2017. Since the TRMI index divides the news sentiment from the social sentiment, we have a total of 54 time series. A description of tickers, sectors and summary statistics is available in Sector A of the online material. Finally, the MLSS model, in its current specification, does not manage missing values in data, while some of the sentiment time series present missing observations. The EM algorithm is naturally designed to handle missing observations. However, since the number of missing values is small,Footnote‡ we fill them using the rolling mean over the last 5 days.
4. Empirical analysis
In this section, we present the results of the estimation of the MLSS model for the investigated stocks, providing an economic interpretation of the long- and short-term component of the sentiment. In the analyses, we consider separately the case of news and social sentiment indicator.
The first quantity to fix is the number q of long-term sentiment factors. Using the Bayesian information criteria (BIC) we select and
. An additional criterion for the selection of the number of long-term sentiment is provided in section C of the online material.
Table reports the values of Φ and Λ with the estimation errors.Footnote§ Bold values indicate parameters which are significantly different from 0 with a p-value smaller than 0.05. We notice that most of the estimated parameters are statistically significant.
Table 1. Static parameters of model (Equation6(6)
(6) ) for news sentiment.
As an illustrative example, the top panel of figure shows how the filter works for the Goldman Sachs news sentiment series. We observe that a high fraction of the sentiment daily variation is captured by the filter. In section D of the online material, we quantify more in detail the signal-to-noise ratio of the proposed filter. We find that the MLSS model has a signal-to-noise ratio approximately 20 times larger than the MLNSL. Moreover, the noise in social media is generally higher than the noise in newspapers. The bottom panel of figure reports separately the long-term and short-term components of the filtered sentiment signal.
Figure 1. Goldman Sachs sentiment series. In the top panel, the blue line is the observed sentiment and the orange line is the filtered sentiment including both long-term and short-term component. In the bottom panel, we decompose the contribution of the long-term sentiment (in orange, RHS scale) and the short-term sentiment (in blue, LHS scale).
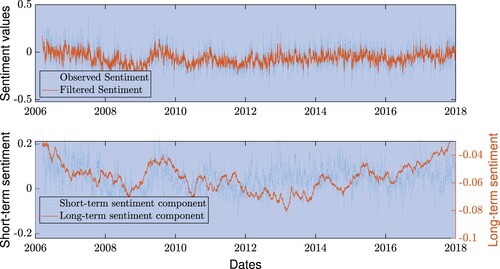
The MLSS approach considers two new quantities extracted from the observed sentiment. The first novelty is the long-term sentiment, which, by construction, represents the series of common trends in a particular basket of sentiment time series. The second novelty is the multivariate structure of sentiment, extracted using the symmetric matrix . In the next sections, we separately analyze the relation between these two quantities and the stock market prices. To this end, we extract the market factors from the stock prices of these assets. Denote as
the vector of demeaned close-to-close log-returns and evaluate the unconditional covariance matrix
and the unconditional correlation matrix
. We extract the factor loading matrix
using the PCA on the matrix
and define the return factors
. We also define the market factors as
, where
is the vector of log-prices. In the following analysis, we consider
and name the first market factor Fixed Dow 27.Footnote¶
4.1. Long-term sentiment
We first investigate a possible economic interpretation of the long-term sentiment. Since we estimate model (Equation6(6)
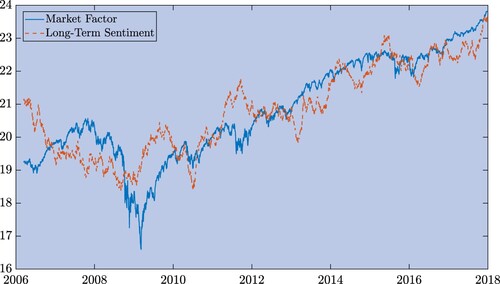
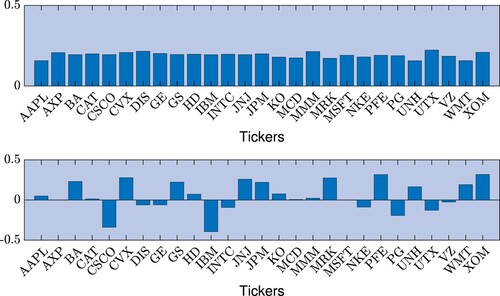
(6) ) separately for the news and social sentiment, the total number of long-term sentiment series is four. However, two of them are specific for the news sentiment while the other two are specific for the social sentiment. Using the Engle-Granger test (Engle and Granger Citation1987), we observe that one of the factors of the news long-term sentiment is cointegrated with the Fixed Dow 27. Figure shows the cointegration relation, pointing out that the main driver of the prices and the driver of the sentiment time series reflect the same common information. Since, at daily scale, the news from which the sentiment is extracted could in general reflect the performance of the market, the existence of such a co-integration relation sounds very reasonable and not so surprising. However, figure shows the standardized weights of the cointegrated factors. The weights of the market factor are very homogeneous across assets, as shown in the top panel, while the weights of the cointegrated factor of the long-term sentiment are very heterogeneous, as shown in the bottom panel. The values of the elements of the factor loading matrix
reported in table are either positive or negative.Footnote‖ Then, some firm's sentiment positively affects the common sentiment factors, while some other firm's sentiment negatively affects them. We checked whether the heterogeneity of weights were related to the number of news of a given asset, or with the buzz index, but we found no significant evidence. Unravelling the origin of the detected heterogeneity is an interesting research question, that could be probably answered by looking at the contents of the articles from which the sentiment was computed. Unfortunately, we do not have access to this kind of information.
Figure 2. Co-integration between Fixed Dow 27, in blue, and the second factor of the news long-term sentiment, in orange. Time series are scaled. The Fixed Dow 27 is the first market factor built using log-prices.
We do not have a clear interpretation for the other news long-term sentiment component. The loadings of this factor are reported in the second column of table . We see that all the companies are positively related with the factor with the only exceptions of two financial stocks (GS and JPM). In addition, the two social long-term sentiment are not cointegrated with the Fixed Dow 27 and, even in this case, the loadings do not provide a clear association between the factors and the market or a specific sector.
Figure 3. Values of the standardized factor loadings of the cointegrated series. Top panel: loadings of the Fixed Dow 27 index. Bottom panel: loadings of the second factor of the news long-term sentiment.
4.2. Short-term sentiment
The second novelty of the MLSS model is the multivariate structure of the short-term sentiment series. The question we want to address in this section is whether the correlation structure of the short-term sentiment is (linearly) related with the correlation structure of the daily returns. In the previous section, we observed that one of the factors of the long-term sentiment is cointegrated with the first market factor. We therefore expect the short-term sentiment to capture asset-specific features, i.e. we expect a close relation with the idiosyncratic dynamic of the returns.Footnote† To test this intuition for the correlation structure, we compare the results of the MLSS model with the results of the MLNSL model which, by construction, does not disentangle the factors from the sentiment series. If the intuition is correct, the correlation matrix of the sentiment extracted using the MLSS model should be linearly related with the return correlations and with the idiosyncratic return correlations. On the contrary, the correlation matrix of the sentiment extracted using the MLNSL model, which only captures the slowly changing dynamics of the sentiment series, and thus of the first market factor, should be linearly related with the returns correlation but mildly correlated with the idiosyncratic returns correlations. Finally, to test whether the filtering procedure is a crucial step in our approach, the correlation matrix of the observed sentiment is also considered.
We define as the correlation matrix associated with the covariance matrix
,
the correlation matrix associated with the covariance matrix Q of equation (Equation2
(2)
(2) ),
the unconditional correlation of the first difference of the observed sentiment, and
the unconditional correlations matrix of the stock returns. We search for a linear element-wise relation between
and
, where
is one of
,
, or
. The results are reported for the news case only, but the conclusions are similar for the social sentiment.
We perform a standard ordinary least squares estimation on the model
(16)
(16)
where
is the operator which collects the lower triangular elements of matrix X in a column vector. We compare the results obtained using the MLSS model (
), with the results obtained using the MLNSL model (
) and using the Observed sentiment (
). In addition, since the unconditional correlation between two assets is higher when they belong to the same sector, we separately consider two cases. In the first case, we estimate model (Equation16
(16)
(16) ) considering all the pairs of assets. In the second case, we estimate model (Equation16
(16)
(16) ) considering only the pairs of assets belonging to the same economic sector according to table A.1.
The top left panel of table shows the results with all the correlation pairs. In the first column, we report the of the regression; in the second column, we report the F-statistic and the relative p-value is reported in the third column. The regressions with
and
have high and significant p-values, while the regression with
is not statistically different from the model with the intercept only. This finding has two implications. The first one is that the sentiment innovations have a similar correlation structure as that of the returns' innovations. In particular, if the returns of two assets are relatively highly correlated, then also the increment of the filtered sentiment of the news about these assets are relatively highly correlated. The second implication is that, if a filtering procedure is not applied to the observed sentiment data, the noise is too large to find significant results. In the top right panel of table , we report the results of the model (Equation16
(16)
(16) ) applied to the pairs of assets belonging to the same sector. We observe that the
increases for all models. This result is expected since it is well known that the return correlation is higher and more significant between two assets of the same sector. However, even if the
increases, the number of pairs decreases. For this reason, the increment in the
does not lead to an increment in the F-statistic, which fails to reject the null hypothesis for the
. This result confirms that the
matrix is not a significant regressor for
.
Table 2. Top rows: Results from the linear regression (Equation16(16)
(16) ).
Comparing the top panels of table , we note that the increment in the is higher for the MLSS model rather than the MLNSL model. This evidence is consistent with the intuition that the short-term sentiment series, extracted using the MLSS model, are more related with the idiosyncratic returns. Indeed the correlation induced by the market factor is predominant in the first case, reported in the top left panel, where all the assets are considered, rather than the second case, reported in the top right panel, where the co-movements are not only driven by the first market factor, but they are also driven by sector-specific factors.
Now we extract the Fixed Dow 27 return from the asset returns using a one-factor model. We repeat the analysis comparing the matrices ,
and
with the unconditional correlation of the idiosyncratic returns. We extract the market factor
from the returns using the factor model
(17)
(17)
where
. We then compute the cross-correlation matrix
from the covariance matrix
and estimate the following model
(18)
(18)
The bottom panels of table report the results. In the bottom left panel, we show the results for the model (Equation18
(18)
(18) ), where all the correlation pairs are considered. The first evidence is that the MLNSL
dramatically decreases, while the MLSS
remains almost the same. This finding suggests that almost all the return correlations explained by the
matrix are associated with the market factor
, while the matrix
, which represents the fast trends on the sentiment data, also captures different dynamics.
In the bottom right panel, we show the results for the model (Equation18(18)
(18) ), where we consider only the correlation pairs for assets belonging to the same sector. In this case, the differences between the MLSS and MLNSL are more severe. Indeed, the MLSS model still has a high and highly significant
, while the F-statistic for the MLNSL model fails to reject the null that
, defined in equation (Equation18
(18)
(18) ), is equal to 0. Again, the model with the observed sentiment has no significant p-values.
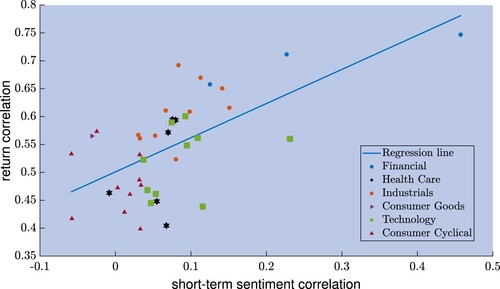
As a last observation, we see the different behavior of the sectors in this regression exercise. Figure reports the scatter plot of the elements of versus the corresponding values of
when the two stocks belong to the same economic sector, characterized by a specific marker. We also superimpose the regression line obtained from equation (Equation16
(16)
(16) ). Note that the behavior is different among sectors. The financial sector, marked with blue dots, is the one with highest linear relation and the three assets belonging to this sector have all high returns and sentiment correlations. On the contrary, the consumer cyclical sector, marked with garnet-red triangles, has a high dispersion among the correlations of the 5 assets.
Figure 4. Scatter plot of the news short-term sentiment correlations and the return correlations for pairs of assets in the same sector. The line corresponds to the regression (Equation16(16)
(16) ).
In summary, sections 4.1 and 4.2 support the intuition behind the MLSS model. Indeed, the slowly changing components of the sentiment are effectively captured by the long-term sentiment. We successfully confirmed this hypothesis in section 4.1. At the same time, the short-term sentiment effectively describes the firm-specific behavior of the returns. Section 4.2 shows that the MLSS model can capture different features of the returns, while the MLNSL mainly captures the sentiment component associated with the market.
5. Contemporaneous and lagged relations
The goal of this section is to assess the explanatory power of the sentiment with respect to the market returns using the different filters presented in the previous sections. In particular, we show that both the extraction of long-term and short-term sentiment components and the multivariate specification of the model are crucial ingredients to capture the synchronous and lagged effects.
We consider the asset prices of the 27 stocks of the Fixed Dow 27 and construct the equally weighted portfolio
(19)
(19)
as a representative portfolio and denote with
its log-returns. We consider a representative portfolio for two reasons. Firstly, Beckers (Citation2018) shows that the predictability returns using sentiment indicators is higher when using market indexes rather than single stocks. Secondly, using a representative portfolio, we can compare different filtering techniques which do or do not consider the multivariate structure.
We define and
as the sentiment associated with the representative portfolio. We consider six different filtering techniques defined as follows:
In summary, the six models allow us to separate the effect of the different components. The MLSS model exploits all the possible information from the multivariate time series and all the relevant factors are considered. The average across assets is computed at a later stage on the short-term sentiment. For this reason, it does not affect the long-term components. The LSS model computes the cross-sectional average as a first step and does not exploit the multivariate structure. Then, both the short-term and long-term components are different from one of the MLSS model. The MLNSL and LNSL models differ only on the step of the aggregation. The first model applies the filter on the multivariate time series, while the second model applies the filter on the aggregated time series. The SDFM model uses a non-parametric PCA to extract the common features and ignores the possible presence of a short-term sentiment component. The advantage of this model is that, similarly to the MLSS model, it extracts the main factors starting from the row data without aggregating them. Finally, the Obs model works as a benchmark.
5.1. Quantile regression
In this section, we investigate the lagged relation between sentiment and market returns. The recent literature for the DJIA (Garcia Citation2013) and for the gold futures (Smales Citation2014) found that the reaction to news is more pronounced during recessions. For this reason, we use the quantile regression in place of a simple linear regression to obtain a more comprehensive analysis of the relationship between variables. In section E of the online material we report the investigation on the contemporaneous relation between sentiment and returns.
5.1.1. Lagged relations
We consider the following quantile regression
(20)
(20)
where model denotes one of the six filtering models presented above and
for
. According to Koenker and Machado (Citation1999), we can compare the explanatory power of a selected model according to the
measure. In particular, if we consider the functional expression for the quantile regression
(21)
(21)
where
, we can define the quantile
measure as
(22)
(22)
where
is evaluated restricting equation (Equation21
(21)
(21) ) with the intercept parameter and the market return at time t−h. In contrast with the
measure of the linear models,
is a local measure of goodness of fit and only applies to a particular quantile. In addition, Koenker and Machado (Citation1999) show that using
we can test the significance of the
parameters. However, the likelihood ratio test introduced in Koenker and Machado (Citation1999) assumes that the residuals of the quantile regression are i.i.d. while the observed residuals show heteroskedasicity. For this reason, we perform a multivariate Wald test where the covariance structure of the estimators is estimated using a block bootstrap. For an introduction to confidence intervals estimations with bootstrap methods refer to MacKinnon (Citation2006). To maintain the autocorrelation structure of the data, the block bootstrap length is set to 22 days (one month in financial time).
As a first step, we consider the lag h = 1. We evaluate the statistic and test the significance using the
Wald-test.
Table reports the values and significance of the measure. A finding is common among all models: the values of
are higher in the tails and lower close to the median. In addition, what we observe is extremely promising for the Long-Short modeling approach. The significance of the noisy sentiment is zero for almost all quantile levels. Filtering the time series is essential to recover predictability. However, filtering alone is not sufficient. Indeed, neither the predictability of the LSNL model nor of the multivariate extension MLSNL is statistically significant except for some case. Significance is recovered only when the filtered sentiment is decomposed into the short-run and long-run components. This is true for extreme returns, both positive and negative. The result is stronger when the LSS model is replaced by the MLSS, meaning that the cross-sectional dependence is an important ingredient to enhance predictability. It is worth noticing that the values of
presented in table come from models with different number of regressors, therefore, an adjustment with respect to the number of regressors should be applied. However, given that the number of observations used to evaluate the measures is T = 3020, a correction in the spirit of the adjusted
would be of order
and would not affect the results.
A further advantage of the long-short decomposition is that we can properly asses the relative contribution of the two components. In particular, we use a bootstrap Wald test to assess the significance of the parameters in the MLSS model. Considering the , the significance of the parameter
and
can be tested using
(23)
(23)
and
(24)
(24)
As before, we use a Wald test based on block bootstrap resampling to assess the significance of
and
.
Table 3. The measure across the value τ for the one-lag quantile regression.
We report the p-values of the Wald test statistics in table .
Table 4. p-values for the Wald test statistics.
The contribution given by the short-term sentiment is strongly significant, in particular for extreme quantiles. On the contrary, the long-term sentiment is not significant in 6 out of 9 quantiles. The results support the intuition that, if today a very high or very low return appears, it can be partially explained by the yesterday's rapidly changing mood, while the permanent trend in the sentiment series have almost no impact.
The experiments performed in the contemporaneous (see section E in the online material) and one-lag cases show that the MLSS model is the best model to capture the return variations. For this reason, for the multi-period analysis, we will only consider the MLSS model.
Considering a general h, we wonder if extra lags can add explanatory power to the regression exercise. Using the functional form
(25)
(25)
we separate the contributions given by the first and higher order lags. The bootstrap Wald test can be used to assess the null hypothesis that
.
Following Tetlock (Citation2007) and Garcia (Citation2013), we fix a maximum number of h = 5 and table reports the p-values for the different values of h.
Table 5. p-values for the Wald statistics for different values of h.
The h-lagged sentiment series are uninformative in the median region, where the one lag sentiment has less explanatory power too. However, in agreement with Garcia (Citation2013), the lagged sentiment remains informative for few days and, in our case, this is true for the 5%, 10%, 90%, and 95% quantile levels. It is worth noticing that the 1% and 99% quantiles are unaffected by higher-order lags. This shows that, in case of very good or very bad days, the returns are strongly driven by very fresh news (h = 1) while the older news have no informative power.
6. Portfolio allocation with sentiment data
This section details an economic application of the MLSS model in portfolio selection and benckmarks the results against a buy-and-hold strategy. We consider the equally weighted portfolio in equation (Equation19(19)
(19) ) and the six filtered signals
,
,
,
,
and
introduced in the previous section. It is worth noticing that Beckers (Citation2018) and Garcia (Citation2013) showed that the predictability power of the sentiment series declined after 2007. For this reason, we want to challenge the filtering techniques to predict the future daily returns in the time window 2007–2019.
In the first part of this section, we use the sentiment signals as exogenous variables to build a simple classifier and we introduce six trading strategies based on the six sentiment time series. Then, we test these strategies in February 2007–June 2017 window. This period offers a large series with different economic conditions. The sentiment models are estimated in the same time window. The estimation of multivariate models (MLSS and MLNLS) employs a backward-looking technique based on smoothing recursions. Then, one may argue that for the multivariate case the estimation technique may introduce some sort of forward looking bias. We test that this bias, if any, is not likely to be the dominant effect. We perform a robustness check where we use the parameter values from February 2007–June 2017 period to filter the TRMI sentiment series from July 2017 to December 2019. In this way, the trading signals cannot be affected by any forward-looking bias. The results in the out-of-sample period confirm those from February 2007–June 2017, showing that the trading strategies built on the MLSS model are the best performers. The details of the robustness check can be found in section G of the online material.
6.1. Trading strategies
In the financial literature, several papers support the strong out-of-sample performance of the equally weighted portfolio (e.g. DeMiguel et al. Citation2009). The 1/n portfolio without rebalancing is used as a baseline for our trading strategies and the long passive position in this portfolio is called buy-and-hold strategy. Given that the buy-and-hold portfolio offers a good out-of-sample performance, we assume an investor who only deviates from the baseline strategy if a strong signal which predicts a negative return arrives from the sentiment series. For this reason, the criterion variable needs to capture the behavior of the left tail of returns distribution. We define the criterion binary variable as
(26)
(26)
where
is the 1/3 Gaussian quantile and
are the standardized market returns with the realized variance,
, evaluated by means of 5-minute intraday returns. The standardization of the returns is crucial to eliminate possible effects due to the persistence of volatility. The choice of the
quantile is consistent with the findings of section 5.1.1. Moreover, it is a balance between a more conservative choice—a smaller quantile only sensitive to more extreme and predictive events—and a larger quantile, which provides a larger number of selling signals but less predictive power.
Since the goal of this paper is to show that the choice of the filtering procedure is essential, a simple classification technique is used. As a classifier, we consider the following conditional logit model
(27)
(27)
where
and
. We recall that
is a vector whose dimension depends on the filtering model. For further details see the first part of section 5.
The predicted binary value is defined as
(28)
(28)
The main advantages of the conditional logit model are twofold. On the one hand, the conditional logit model can be easily estimated using MLE. On the other hand, we can easily assess the fitness of the model on the data using the Mc Fadden's
measure defined in McFadden (Citation1973) as
represents the maximum likelihood of the complete model (Equation27
(27)
(27) ) and
is the maximum likelihood of the bare model based only on the intercept. The models are estimated using overlapping rolling windows of 6 months (126 observations). We verified that this choice is sufficient to capture the time-varying nature of the explanatory power of the sentiment series. Figure shows the value of
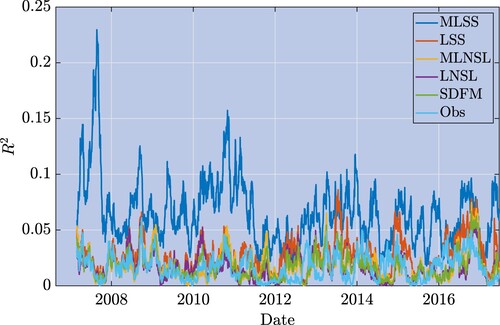
over the February 2007–June 2017 period. The MLSS model has the highest
w.r.t the other models, which typically translates into a higher predictive power. In addition, the MLSS
has a high variability, suggesting that the predictive power changes through time. This latter finding suggests that the sentiment signal can be a good returns predictor in certain periods and a poor predictor in others. This intuition will be exploited later to generate trading strategies based on the
. In equation (Equation28
(28)
(28) ), we have used a naive threshold of 0.5 to generate a trading signal. The choice of the optimal or a dynamic threshold is discussed in section I of the online material.
Figure 5. McFadden's for the different filtering methods using negative abnormal returns.
The estimated defined in (Equation28
(28)
(28) ) translates in the trading signal
(29)
(29)
where
(
) represents a buy (sell) signal in the equally weighted portfolio (Equation19
(19)
(19) ). On any day t, at the closing time of the trading day, the investor uses the sentiment signal
and the standardized realized daily returns
to forecast the binary variable
and the relative trading signal. Naming
the number of shares bought or sold in any transaction, there are three possible scenarios
Please notice that the only exception is for because we initialized
. In this case, the equally weighted portfolio is bought when
and it is short sold when
. The investor's portfolio is then built as
(30)
(30)
where cost is the percentage trading cost and
is defined in (Equation19
(19)
(19) ). The first equation in (Equation30
(30)
(30) ) shows that the value of the portfolio is composed of the value of the invested amount
plus the cash position. The latter increases when
, meaning that the investor sells the portfolio and receives cash, and decreases when
, meaning that the investor buys and erodes the cash position. The second equation includes the impact of the transaction costs. Specifically, every time that a transaction happens, i.e.
, the investor pays an extra cost proportional to the current value of the equally weighted portfolio
.
We fix the starting point ,
and the parameter
. In the paper, we only report the results for the case with trading costs, while the results with zero trading costs are reported in section F of the online material. From now on, we refer to without trading costs when the portfolio in equation (Equation30
(30)
(30) ) is evaluated with cost
and to with trading costs when costs
as in Gilli and Schumann (Citation2009) and Avellaneda and Lee (Citation2010). In the following sections, the number of transactions is evaluated as
and the transaction costs are evaluated as
. It is worth noticing that the change of signal effectively produces two transactions. For instance, if the signal moves from
to
, the first transaction is the liquidation of the long position and the second transaction is the short position on the asset. In addition, most of the time, the selling signal appears for only one day and disappears the day after. Then, the typical path of a selling signal is given by
,
and
producing a total of four transactions.
The transaction costs can strongly depress the overall performance of the portfolio. To partially mitigate this drawback, we can decrease the number of transactions using the McFadden's as a measure of the reliability of the signal
. We compute the empirical quantile
of the McFadden
over the time window
. The quantile
is
-measurable and does not introduce a forward-looking bias. We can reduce the number of trades conditioning the selling signal at time t on the level of the McFadden's
evaluated in the previous 6 months. The
adjusted trading signal is then defined as follows
(31)
(31)
The value α determines the reduction in the number of trades. The higher α is, the smaller is the number of transactions. The parameter α should be considered as a subjective transaction cost of the investor. The six strategies, together with the buy-and-hold strategy itself, are evaluated according to six measures, the annual return, the annual volatility, the annual negative volatility, the Sharpe ratio, the Sortino ratio, and the maximum drawdown (MDD). In the next section, in the first step, the portfolios with the trading signals (Equation29
(29)
(29) ) with and without trading cost are analyzed. Then, we assess the impact and the performance of the trade reduction strategy based on (Equation31
(31)
(31) ).
6.2. Empirical application: February 2007–June 2017
The 2007–2009 crisis and the 2009–2017 bull market are good backtesting periods for the sentiment portfolios because we can test the return predictability during different market conditions.
Table reports the performances of the six sentiment strategies together with the buy-and-hold portfolio with trading costs. The sentiment-based strategies have, excluding the LNSL and the Obs, a smaller volatility and MDD than the buy-and-hold portfolio. In addition, the MLSS portfolio produces returns similar to the buy-and-hold strategy, lower negative volatility, and consequently higher Sharpe and Sortino ratios than all the other strategies.Footnote† The lower performance for the annual returns is due to the higher transaction costs. Indeed in section F of the online material, we show that, when the trading costs are not considered, the MLSS strategy produces higher annual returns than all the other strategies. In addition, when we compare without trading costs experiment with the with trading costs experiment, the excessive number of transactions for the MLSS strategy reduces the Sharpe ratio gain with respect to the buy-and-hold portfolio from to
and the Sortino ratio gain from
to
. In section H of the online material, we show that the selling signal generated by the MLSS sentiment series corresponds to statistically significant returns predictability.
Table 6. Performances of the seven strategies with transaction cost for the period February 2007–June 2017.
The transaction costs incurred by the MLSS portfolio throughout the nine years amount in total to of the starting capital. For this reason, we employ the trading signal
defined in equation (Equation31
(31)
(31) ), which penalizes signals with moderate McFadden's
. Table reports the performances of the strategies based on the penalized signal for different values of α. As expected, the higher the value of α and the lower the number of transactions is. In addition, the
-based signal produces higher quality signal and effectively increases the performance of the portfolios. The number of transactions decreases almost linearly but the Sharpe and Sortino ratios strongly increase. They reach a maximum value when
. These findings further corroborate the intuition that the MLSS sentiment strongly anticipates future returns during the financial crisis, given that the
values in figure are higher than the unconditional average during the 2007–2009 period. Again this feature is peculiar for the MLSS filter, while no evidence of return predictability is reported for the other filtering techniques. Again, the statistical significance of these strategies is reported in section H of the online material.
7. Conclusions
In this paper, we presented a novel way to filter multivariate sentiment time series. The approach is very general and encompasses previous models discussed in the literature. Using a dynamic factor model, we were able to identify two different sentiment components. The first one, named long-term sentiment and modeled as a random walk, captures the common trends which drive the long-term dynamics. The second component, dubbed short-term sentiment and modeled as a VAR(1) process, captures short-term swings in market mood. An extensive empirical section investigates the different features of the two sentiment components. In a first analysis, we pointed out that one of the long-term sentiment factors co-integrates with the first principal component of the market. Quite surprisingly, the structure of the sentiment factor loadings does not mimic the typical uniform profile of the market factor. Some assets are over-expressed and contribute to the factor with a positive or negative sign, while others are under-expressed. Concerning the short-term sentiment, its multivariate dependence structure explains a sizable fraction of the residual covariance in a single-factor market model. This result suggests that the short-term component captures transient and rapidly changing trends associated with the idiosyncratic components of the market. In a second analysis, based on quantile regression, we showed that the Multivariate Long-Short Sentiment model provides the highest explanatory power of lagged and contemporaneous returns. Essential to achieve statistical significance are the multivariate nature of the approach and the separation of the sentiment signal in a long and a short component. In particular, disentangling the short-term sentiment is crucial to capture the behavior of extreme returns. In a further analysis, we observed that newspapers and social media react differently to negative and positive returns. Specifically, they can effectively explain abnormal returns from one to five days in advance, but they almost immediately digest the positive market realizations while they echo negative realizations for several days to come.
Table 7. Performances of the MLSS-based strategies built from equation (Equation31(31)
(31) ) for different values of
.
It is worth noting that Tetlock (Citation2007) and Garcia (Citation2013) reported results similar to ours for the unfiltered sentiment focusing on period before 2007. Using the TRMI dataset, Beckers (Citation2018) showed that the forecasting power on returns of the sentiment dropped dramatically after 2007. Our results suggest that the filtering procedures are more important nowdays than in the past. Consistently, in a final investigation, we performed an asset allocation exercise where the selling signal are based on the sentiment series. In line with the results from the quantile regression, the portfolio based on the MLSS filter significantly outperforms the benchmark buy-and-hold strategy and the other strategies based on different filtering techniques.
Supplemental Material
Download PDF (484 KB)Acknowledgements
The authors thank Thomson Reuters for kindly providing Thomson Reuters MarketPsych Indices time series. They benefited from discussion with Giuseppe Buccheri, Fulvio Corsi, Luca Trapin, as well as with conference participants to the Quantitative Finance Workshop 2019 at ETH in Zurich and the AMASES XLIII Conference in Perugia.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Supplemental data
Supplemental data for this article can be accessed online at http://dx.doi.org/10.1080/14697688.2022.2119159.
Additional information
Funding
Notes
† In the empirical application, we find that the Gaussian assumption is appropriate for the investigated data
† Detailed results are available upon request.
† ‘The buzz field represents a sum of entity-specific words and phrases used in TRMI computations. It can be non-integer when any of the words/phrases are described with a minimizer, which reduces the intensity of the primary word or phrase. For example, in the phrase “less concerned” the score of the word “concerned is” mitigated by “less”. Additionally, common words such as “new” may have a minor but significant contribution to the Innovation TRMI. As a result, the scores of common words/phrases with minor TRMI contributions can be minimized’. See TRMI user guide.
† We only consider 27 assets because one is missing in the Thomson Reuters dataset and two have a high ratio of missing values at the beginning of the sample.
‡ 47 out of 54 sentiment series have less than of missing observations. All the series have a percentage of missing which is smaller than
. For more information on the sentiment series, we refer to section A of the online material.
§ Note that the Λ matrices, as discussed in the supplementary material, have the upper triangular submatrix equal to zero.
¶ Since we are not re-balancing the index to track the real composition of the Dow Jones, we fix the composition as of December 29, 2017 and name the index Fixed Dow 27.
‖ The elements of the factor loading matrix are available upon request.
† We define idiosyncratic returns as the market returns where the first market factor is removed using the factor model (Equation17(17)
(17) )
† We have also tested a simple strategy where we remove the first factor, extracted with PCA, from the observed sentiment. However, this procedure is not sufficient to remove all the observation noise and to extract an effective trading signal. The performances of this strategy are Annual return , Annual volatility
, and Sharpe ratio 0.459 (against 0.469 for the BH strategy and 0.519 for the MLSS-based strategy).
References
- Algaba, A., Ardia, D., Bluteau, K., Borms, S. and Boudt, K., Econometrics meets sentiment: An overview of methodology and applications. J. Econ. Surv., 2020, 34(3), 512–547.
- Allcott, H. and Gentzkow, M., Social media and fake news in the 2016 election. J. Econ. Perspect., 2017, 31, 211–236.
- Allen, D., McAleer, M. and Singh, A., Machine news and volatility: The Dow Jones industrial average and the TRNA real-time high-frequency sentiment series. In Handbook of High Frequency Trading, pp. 327–344, 2015 (Academic Press: San Diego).
- Antweiler, W. and Frank, M.Z., Is all that talk just noise? The information content of internet stock message boards. J. Finance, 2004, 59, 1259–1294.
- Appel, G., Become your own technical analyst: How to identify significant market turning points using the moving average convergence-divergence indicator or macd. J. Wealth Manag., 2003, 6, 27–36.
- Audrino, F. and Tetereva, A., Sentiment spillover effects for US and European companies. J. Bank. Financ., 2019, 106, 542–567.
- Avellaneda, M. and Lee, J.H., Statistical arbitrage in the US equities market. Quant. Finance, 2010, 10, 761–782.
- Banbura, M. and Modugno, M., Maximum likelihood estimation of factor models on datasets with arbitrary pattern of missing data. J. Appl. Econom., 2014, 29, 133–160.
- Beckers, S., Do social media trump news? The relative importance of social media and news based sentiment for market timing. J. Portf. Manag., 2018, 45, 58–67.
- Bork, L., Estimating US monetary policy shocks using a factor-augmented vector autoregression: An EM algorithm approach, 2009. Available at SSRN 1358876.
- Borovkova, S., The role of news in commodity markets, 2015. Available at SSRN 2587285.
- Borovkova, S. and Mahakena, D., News, volatility and jumps: The case of natural gas futures. Quant. Finance, 2015, 15, 1217–1242.
- Borovkova, S., Garmaev, E., Lammers, P. and Rustige, J., SenSR: A sentiment-based systemic risk indicator. Technical Report 553, De Nederlandsche Bank, 2017.
- Calomiris, C.W. and Mamaysky, H., How news and its context drive risk and returns around the world. J. Financ. Econ., 2019, 133, 299–336.
- Cavaliere, G. and Xu, F., Testing for unit roots in bounded time series. J. Econom., 2014, 178, 259–272. Recent advances in time series econometrics.
- Chen, I., Kelkar, Y.D., Gu, Y., Zhou, J., Qiu, X. and Wu, H., High-dimensional linear state space models for dynamic microbial interaction networks. PLoS ONE, 2017, 12, e0187822–e0187822.
- Corsi, F., Peluso, S. and Audrino, F., Missing in asynchronicity: A Kalman-EM approach for multivariate realized covariance estimation. J. Appl. Econom., 2015, 30, 377–397.
- Da, Z., Engelberg, J. and Gao, P., In search of attention. J. Finance, 2011, 66, 1461–1499.
- DeMiguel, V., Garlappi, L. and Uppal, R., Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Rev. Financ. Stud., 2009, 22, 1915–1953.
- Dempster, A.P., Laird, N.M. and Rubin, D.B., Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.), 1977, 39(1), 1–22.
- Durbin, J. and Koopman, S.J., Time Series Analysis by State Space Methods, 2012 (Oxford University Press: Oxford).
- Engle, R.F. and Granger, C.W.J., Co-integration and error correction: Representation, estimation, and testing. Econometrica, 1987, 55, 251–276.
- Feuerriegel, S. and Gordon, J., News-based forecasts of macroeconomic indicators: A semantic path model for interpretable predictions. Eur. J. Oper. Res., 2019, 272, 162–175.
- Garcia, D., Sentiment during recessions. J. Finance, 2013, 68, 1267–1300.
- Gerber, A.S., Gimpel, J.G., Green, D.P. and Shaw, D.R., How large and long-lasting are the persuasive effects of televised campaign ads? Results from a randomized field experiment. Amer. Polit. Sci. Rev., 2011, 105, 135–150.
- Gilli, M. and Schumann, E., An empirical analysis of alternative portfolio selection criteria. Swiss Finance Institute Research Paper Series, Swiss Finance Institute, 2009.
- Groß-Klußman, A. and Hautsch, N., When machines read the news: Using automated text analytics to quantify high frequency news-implied market reactions. J. Empir. Finance, 2011, 18, 321–340.
- Harvey, A.C., Estimation, Prediction and Smoothing for Univariate Structural Time Series Models, pp. 168–233, 1990 (Cambridge University Press: Cambridge).
- Hill, S.J., Lo, J., Vavreck, L. and Zaller, J., How quickly we forget: The duration of persuasion effects from mass communication. Polit. Commun., 2013, 30, 521–547.
- Huynh, T.L.D., Foglia, M., Nasir, M.A. and Angelini, E., Feverish sentiment and global equity markets during the covid-19 pandemic. J. Econ. Behav. Organ., 2021, 188, 1088–1108.
- Jiao, P., Veiga, A. and Walther, A., Social media, news media and the stock market. J. Econ. Behav. Organ., 2020, 176, 63–90.
- Jungbacker, B. and Koopman, S.J., Likelihood-based analysis for dynamic factor models. Tinbergen Institute Discussion Papers, Tinbergen Institute, 2008.
- Kalman, R.E., A new approach to linear filtering and prediction problems. Trans. ASME–J. Basic Eng., 1960, 82, 35–45.
- Kim, S.H. and Kim, D., Investor sentiment from internet message postings and the predictability of stock returns. J. Econ. Behav. Organ., 2014, 107, 708–729. Empirical behavioral finance.
- Koenker, R. and Machado, J.A.F., Goodness of fit and related inference processes for quantile regression. J. Am. Stat. Assoc., 1999, 94, 1296–1310.
- Lillo, F., Micciché, S., Tumminello, M., Piilo, J. and Mantegna, R.N., How news affect the trading behavior of different categories of investors in a financial market. Quant. Finance, 2015, 15, 213–229.
- Liu, B., Sentiment Analysis: Mining Opinions, Sentiments, and Emotions, 2015 (Cambridge University Press: Cambridge).
- Loughran, T. and McDonald, B., When is a liability not a liability? Textual analysis, dictionaries, and 10-ks. J. Finance, 2011, 66, 35–65.
- MacKinnon, J.G., Bootstrap methods in econometrics. Econ. Rec., 2006, 82, S2–S18.
- Mai, F., Tian, S., Lee, C. and Ma, L., Deep learning models for bankruptcy prediction using textual disclosures. Eur. J. Oper. Res., 2019, 274, 743–758.
- McFadden, D., Conditional logit analysis of qualitative choice behaviour. In Frontiers in Econometrics, edited by P. Zarembka, pp. 105–142, 1973 (Academic Press: New York).
- Nyman, R., Kapadia, S. and Tuckett, D., News and narratives in financial systems: Exploiting big data for systemic risk assessment. J. Econ. Dyn. Contr., 2021, 127, 104119.
- Pang, B., Lee, L. and Vaithyanathan, S., Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing, pp. 79–86, 2002 (Prague).
- Peterson, R., Trading on Sentiment: The Power of Minds Over Markets, 2016 (John Wiley & Sons, Ltd: Hoboken).
- Ranco, G., Aleksovski, D., Caldarelli, G., Grcar, M. and Mozetic, I., The effects of Twitter sentiment on stock price returns. PLoS ONE, 2015, 10, e0138441.
- Ranco, G., Bordino, I., Bormetti, G., Caldarelli, G., Lillo, F. and Treccani, M., Coupling news sentiment with web browsing data improves prediction of intra-day price dynamics. PLoS ONE, 2016, 11, e0146576.
- Schnaubelt, M., Fischer, T.G. and Krauss, C., Separating the signal from the noise - financial machine learning for twitter. J. Econ. Dyn. Contr., 2020, 114, 103895.
- Shumway, R.H. and Stoffer, D.S., An approach to time series smoothing and forecasting using the EM algorithm. J. Time Ser. Anal., 1982, 3, 253–264.
- Smales, L.A., News sentiment in the gold futures market. J. Bank. Financ., 2014, 49, 275–286.
- Smales, L.A., Asymmetric volatility response to news sentiment in gold futures. J. Int. Financ. Mark. Inst. Money, 2015, 34, 161–172.
- Sun, L., Najand, M. and Shen, J., Stock return predictability and investor sentiment: A high-frequency perspective. J. Bank. Financ., 2016, 73, 147–164.
- Tetlock, P.C., Giving content to investor sentiment: The role of media in the stock market. J. Finance, 2007, 62, 1139–1168.
- Thorsrud, L.A., Words are the new numbers: A newsy coincident index of the business cycle. J. Bus. Econ. Statist., 2018, 38(2), 393–409.
- Vohra, S. and Teraiya, J., A comparative study of sentiment analysis techniques. J. JIKRCE, 2013, 2, 313–317.
- Wu, L.S.Y., Pai, J.S. and Hosking, J., An algorithm for estimating parameters of state-space models. Stat. Probab. Lett., 1996, 28, 99–106.
Appendices
Appendix 1. Filter and smoother recursions
In this section, we report Kalman Filter and Smoother recursions ancillary to the EM algorithm. The derivation of the formulas which follow can be found in Shumway and Stoffer (Citation1982).
Starting from system (Equation7(7)
(7) ), we calculate recursively the Kalman Filter as:
where we take
and
. Now, using backward recursions
we derive the Smoother as
(A1)
(A1)
where
.
Appendix 2. Expectation maximization
The log-likelihood of the model (Equation7(7)
(7) ) is
where a and Σ are the parameters s.t.
.
A.1. E-step
The objective function to maximize is, from Shumway and Stoffer (Citation1982),
where
denotes the conditional expectation relative to a density containing the mth iterate values
and
. Using now the Kalman smoother (EquationA1
(A1)
(A1) ) we can derive
lead to
where
(A2)
(A2)
A.2. M-step
The resulting update equations are
(A3)
(A3)
(A4)
(A4)
(A5)
(A5)
(A6)
(A6)
For simplicity, in our estimations, we impose
.