
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We develop a product functional quantization of rough volatility. Since the optimal quantizers can be computed offline, this new technique, built on the insightful works by [Luschgy, H. and Pagès, G., Functional quantization of Gaussian processes. J. Funct. Anal., 2002, 196(2), 486–531; Luschgy, H. and Pagès, G., High-resolution product quantization for Gaussian processes under sup-norm distortion. Bernoulli, 2007, 13(3), 653–671; Pagès, G., Quadratic optimal functional quantization of stochastic processes and numerical applications. In Monte Carlo and Quasi-Monte Carlo Methods 2006, pp. 101–142, 2007 (Springer: Berlin Heidelberg)], becomes a strong competitor in the new arena of numerical tools for rough volatility. We concentrate our numerical analysis on the pricing of options on the VIX and realized variance in the rough Bergomi model [Bayer, C., Friz, P.K. and Gatheral, J., Pricing under rough volatility. Quant. Finance, 2016, 16(6), 887–904] and compare our results to other benchmarks recently suggested.
1. Introduction
Gatheral et al. (Citation2018) recently introduced a new framework for financial modelling. To be precise—according to the reference website https://sites.google.com/site/roughvol/home—almost 2400 days have passed since instantaneous volatility was shown to have a rough nature, in the sense that its sample paths are α-Hölder-continuous with . Many studies, both empirical (Bennedsen et al. Citation2017, Fukasawa Citation2021, Fukasawa et al. Citation2022) and theoretical (Alòs et al. Citation2007, Fukasawa Citation2011), have confirmed this, showing that these so-called rough volatility models are a more accurate fit to the implied volatility surface and to estimate historical volatility time series.
On equity markets, the quality of a model is usually measured by its ability to calibrate not only to the SPX implied volatility but also VIX Futures and the VIX implied volatility. The market standard models had so far been Markovian, in particular the double mean-reverting process (Gatheral Citation2008, Huh et al. Citation2018), Bergomi's model (Bergomi Citation2005) and, to some extent, jump models (Carr and Madan Citation2014, Kokholm and Stisen Citation2015). However, they each suffer from several drawbacks, which the new generation of rough volatility models seems to overcome. For VIX Futures pricing, the rough version of Bergomi's model was thoroughly investigated in Jacquier et al. (Citation2018a), showing accurate results. Nothing comes for free though and the new challenges set by rough volatility models lie on the numerical side, as new tools are needed to develop fast and accurate numerical techniques. Since classical simulation tools for fractional Brownian motions are too slow for realistic purposes, new schemes have been proposed to speed it up, among which the Monte Carlo hybrid scheme (Bennedsen et al. Citation2017, McCrickerd and Pakkanen Citation2018), a tree formulation (Horvath et al. Citation2019), quasi Monte-Carlo methods (Bayer et al. Citation2020) and Markovian approximations (Abi Jaber and El Euch Citation2019, Chen et al. Citation2021).
We suggest here a new approach, based on product functional quantization (Pagès Citation2007). Quantization was originally conceived as a discretization technique to approximate a continuous signal by a discrete one (Sheppard Citation1897), later developed at Bell Laboratory in the 1950s for signal transmission (Gersho and Gray Citation1992). It was, however, only in the 1990s that its power to compute (conditional) expectations of functionals of random variables (Graf and Luschgy Citation2007) was fully understood. Given an -valued random vector on some probability space, optimal vector quantization investigates how to select an
-valued random vector
, supported on at most N elements, that best approximates X according to a given criterion (such as the
-distance,
). Functional quantization is the infinite-dimensional version, approximating a stochastic process with a random vector taking a finite number of values in the space of trajectories for the original process. It has been investigated precisely (Luschgy and Pagès Citation2002, Pagès Citation2007) in the case of Brownian diffusions, in particular for financial applications (Pagès and Printems Citation2005). However, optimal functional quantizers are in general hard to compute numerically and instead product functional quantizers provide a rate-optimal (so, in principle, sub-optimal) alternative often admitting closed-form expressions (Pagès and Printems Citation2005, Luschgy and Pagès Citation2007).
In section 2, we briefly review important properties of Gaussian Volterra processes, displaying a series expansion representation, and paying special attention to the Riemann–Liouville case in section 2.2. This expansion yields, in section 3, a product functional quantization of the processes, that shows an -error of order
, with N the number of paths and H a regularity index. We then show, in section 3.1, that these functional quantizers, although sub-optimal, are stationary. We specialize our setup to the generalized rough Bergomi model in section 4 and show how product functional quantization applies to the pricing of VIX Futures and VIX options, proving in particular precise rates of convergence. Finally, section 5 provides a numerical confirmation of the quality of our approximations for VIX Futures and Call Options on the VIX in the rough Bergomi model, benchmarked against other existing schemes. In this section, we also discuss how product functional quantization of the Riemann–Liouville process itself can be exploited to price options on realized variance.
Notations We set as the set of strictly positive natural numbers. We denote by
the space of real-valued continuous functions over
and by
the Hilbert space of real-valued square integrable functions on
, with inner product
, inducing the norm
, for each
.
denotes the space of square integrable (with respect to
) random variables.
2. Gaussian Volterra processes on 
For clarity, we restrict ourselves to the time interval . Let
be a standard Brownian motion on a filtered probability space
, with
its natural filtration. On this probability space, we introduce the Volterra process
(1)
(1)
and we consider the following assumptions for the kernel K:
Assumption 2.1
There exist and
continuously differentiable, slowly varying at 0, that is, for any t>0,
, and bounded away from 0 function with
, for
, for some C>0, such that
This implies in particular that , so that the stochastic integral (Equation1
(1)
(1) ) is well defined. The Gamma kernel, with
, for
and
, is a classical example satisfying assumption 2.1. Straightforward computations show that the covariance function of Z reads
Under assumption 2.1, Z is a Gaussian process admitting a version which is ε-Hölder continuous for any
and hence also admits a continuous version (Bennedsen et al. Citation2017, Proposition 2.11).
2.1. Series expansion
We introduce a series expansion representation for the centered Gaussian process Z in (Equation1(1)
(1) ), which will be key to develop its functional quantization. Inspired by Luschgy and Pagès (Citation2007), introduce the stochastic process
(2)
(2)
where
is a sequence of i.i.d. standard Gaussian random variables,
denotes the orthonormal basis of
:
(3)
(3)
and the operator
is defined for
as
(4)
(4)
Remark 2.2
The stochastic process Y in (Equation2(2)
(2) ) is defined as a weighted sum of independent centered Gaussian variables, so for every
the random variable
is a centered Gaussian random variable and the whole process Y is Gaussian with zero mean.
We set the following assumptions on the functions :
Assumption 2.3
There exists such that
there is a constant
there exists a constant
Note that under these assumptions, the series (Equation2(2)
(2) ) converges both almost surely and in
for each
by Khintchine–Kolmogorov Convergence Theorem (Chow and Teichner Citation1997, theorem 1, section 5.1).
It is natural to wonder whether assumption 2.1 implies assumption 2.3 given the basis functions (Equation3(3)
(3) ). This is far from trivial in our general setup and we provide examples and justifications later on for models of interest. Similar considerations with slightly different conditions can be found in Luschgy and Pagès (Citation2007). We now focus on the variance–covariance structure of the Gaussian process Y.
Lemma 2.4
For any , the covariance function of Y is given by
Proof.
Exploiting the definition of Y in (Equation2(2)
(2) ), the definition of
in (Equation4
(4)
(4) ) and the fact that the random variable
's are i.i.d. standard Normal, we obtain
Remark 2.5
Note that the centered Gaussian stochastic process Y admits a continuous version, too. Indeed, we have shown that Y has the same mean and covariance function as Z and, consequently, that the increments of the two processes share the same distribution. Thus Bennedsen et al. (Citation2017, proposition 2.11) applies to Y as well, yielding that the process admits a continuous version. This last key property of Y can be alternatively proved directly as done in appendix A.2.
Lemma 2.4 implies that for all
. Both Z and Y are continuous, centered, Gaussian with the same covariance structure, so from now on we will work with Y, using
(5)
(5)
2.2. The Riemann–Liouville case
For , with
, the process (Equation1
(1)
(1) ) takes the form
where we add the superscript H to emphasize its importance. It is called a Riemann–Liouville process (henceforth RL) (also known as Type II fractional Brownian motion or Lévy fractional Brownian motion), as it is obtained by applying the Riemann–Liouville fractional operator to the standard Brownian motion, and is an example of a Volterra process. This process enjoys properties similar to those of the fractional Brownian motion (fBM), in particular being H-self-similar and centered Gaussian. However, contrary to the fractional Brownian motion, its increments are not stationary. For a more detailed comparison between the fBM and
we refer to Picard (Citation2011, theorem 5.1). In the RL case, the covariance function
is available (Jacquier et al. Citation2018b, proposition 2.1) explicitly as
where
denotes the Gauss hypergeometric function (Olver Citation1997, chapter 5, section 9). More generally, Olver (Citation1997, chapter 5, Section 11), the generalized hypergeometric functions
are defined as
(6)
(6)
with the Pochammer's notation
and
, for
, where none of the
are negative integers or zero. For
the series (Equation6
(6)
(6) ) converges for all z and when p = q + 1 convergence holds for
and the function is defined outside this disk by analytic continuation. Finally, when
the series diverges for nonzero z unless one of the
's is zero or a negative integer.
Regarding the series representation (Equation2(2)
(2) ), we have, for
and
,
(7)
(7)
Assumption 2.3 holds in the RL case here using (Luschgy and Pagès Citation2007, lemma 4) (identifying
to
from Luschgy and Pagès (Citation2007, equation (3.7))). Assumption 2.3 (B) implies that, for all
,
and therefore the series (Equation2
(2)
(2) ) converges both almost surely and in
for each
by Khintchine–Kolmogorov Convergence Theorem (Chow and Teichner Citation1997, theorem 1, section 5.1).
Remark 2.6
The expansion (Equation2(2)
(2) ) is in general not a Karhunen–Loève decomposition (Pagès and Printems Citation2005, section 4.1.1). In the RL case, it can be numerically checked that the basis
is not orthogonal in
and does not correspond to eigenvectors for the covariance operator of the Riemann–Liouville process. In his PhD Thesis (Corlay Citation2011), Corlay exploited a numerical method to obtain approximations of the first terms in the K–L expansion of processes for which an explicit form is not available.
3. Functional quantization and error estimation
Optimal (quadratic) vector quantization was conceived to approximate a square integrable random vector by another one
, taking at most a finite number N of values, on a grid
, with
. The quantization of X is defined as
, where
denotes the nearest neighbor projection. Of course the choice of the N-quantizer
is based on a given optimality criterion: in most cases
minimizes the distance
. We recall basic results for one-dimensional standard Gaussian, which shall be needed later, and refer to Graf and Luschgy (Citation2007) for a comprehensive introduction to quantization.
Definition 3.1
Let ξ be a one-dimensional standard Gaussian on a probability space . For each
, we define the optimal quadratic n-quantization of ξ as the random variable
, where
is the unique optimal quadratic n-quantizer of ξ, namely the unique solution to the minimization problem
and
is a Voronoi partition of
, that is a Borel partition of
that satisfies
where the right-hand side denotes the closure of the set in
.
The unique optimal quadratic n-quantizer and the corresponding quadratic error are available online, at http://www.quantize.maths-fi.com/gaussian_database for
.
Given a stochastic process, viewed as a random vector taking values in its trajectories space, such as , functional quantization does the analogue to vector quantization in an infinite-dimensional setting, approximating the process with a finite number of trajectories. In this section, we focus on product functional quantization of the centered Gaussian process Z from (Equation1
(1)
(1) ) of order N (see Pagès Citation2007, section 7.4 for a general introduction to product functional quantization). Recall that we are working with the continuous version of Z in the series (Equation5
(5)
(5) ). For any
, we introduce the following set, which will be of key importance all throughout the paper:
(8)
(8)
Definition 3.2
A product functional quantization of Z of order N is defined as
(9)
(9)
where
, for some
, and for every
is the (unique) optimal quadratic quantization of the standard Gaussian random variable
of order
, according to definition 3.1.
Remark 3.3
The condition in equation (Equation8
(8)
(8) ) motivates the wording ‘product’ functional quantization. Clearly, the optimality of the quantizer also depends on the choice of m and
, for which we refer to proposition 3.6 and section 5.1.
Before proceeding, we need to make precise the explicit form for the product functional quantizer of the stochastic process Z:
Definition 3.4
The product functional -quantizer of Z is defined as
for
and
for each
Remark 3.5
Intuitively, the quantizer is chosen as a Cartesian product of grids of the one-dimensional standard Gaussian random variables. So, we also immediately find the probability associated to every trajectory : for every
,
where
is the jth Voronoi cell relative to the
-quantizer
in definition 3.1.
The following, proved in appendix A.1, deals with the quantization error estimation and its minimization and provides hints to choose . A similar result on the error can be obtained applying (Luschgy and Pagès Citation2007, theorem 2) to the first example provided in the reference. For completeness we preferred to prove the result in an autonomous way to further characterize the explicit expression of the rate optimal parameters. Indeed, we then compare these rate optimal parameters with the (numerically computed) optimal ones in section 5.1. The symbol
denotes the lower integer part.
Proposition 3.6
Under assumption 2.3, for any , there exist
and C>0 such that
where
and with, for each
,
Furthermore
.
Remark 3.7
In the RL case, the trajectories of are easily computable and they are used in the numerical implementations to approximate the process
. In practice, the parameters m and
are chosen as explained in section 5.1.
3.1. Stationarity
We now show that the quantizers we are using are stationary. The use of stationary quantizers is motivated by the fact that their expectation provides a lower bound for the expectation of convex functionals of the process (remark 3.9) and they yield a lower (weak) error in cubature formulae (Pagès Citation2007, page 26). We first recall the definition of stationarity for the quadratic quantizer of a random vector (Pagès Citation2007, definition 1).
Definition 3.8
Let X be an -valued random vector on
. A quantizer Γ for X is stationary if the nearest neighbor projection
satisfies
(10)
(10)
Remark 3.9
Taking expectation on both sides of (Equation10(10)
(10) ) yields
Furthermore, for any convex function
, the identity above, the conditional Jensen's inequality and the tower property yield
While an optimal quadratic quantizer of order N of a random vector is always stationary (Pagès Citation2007, proposition 1(c)), the converse is not true in general. We now present the corresponding definition for a stochastic process.
Definition 3.10
Let be a stochastic process on
. We say that an N-quantizer
, inducing the quantization
, is stationary if
, for all
.
Remark 3.11
To ease the notation, we omit the grid in
, while the dependence on the dimension N remains via the superscript
(recall (Equation9
(9)
(9) )).
As was stated in section 2.1, we are working with the continuous version of the Gaussian Volterra process Z given by the series expansion (Equation5(5)
(5) ). This will ease the proof of stationarity below (for a similar result in the case of the Brownian motion (Pagès Citation2007, proposition 2)).
Proposition 3.12
The product functional quantizers inducing in (Equation9
(9)
(9) ) are stationary.
Proof.
For any , by linearity, we have the following chain of equalities:
Since the
-Gaussian
's are i.i.d., by definition of optimal quadratic quantizers (hence stationary), we have
, for all
, and therefore
Thus we obtain
Finally, exploiting the tower property and the fact that the σ-algebra generated by
is included in the σ-algebra generated by
by definition 3.2, we obtain
which concludes the proof.
4. Application to VIX derivatives in rough Bergomi
We now specialize the setup above to the case of rough volatility models. These models are extensions of classical stochastic volatility models, introduced to better reproduce the market implied volatility surface. The volatility process is stochastic and driven by a rough process, by which we mean a process whose trajectories are H-Hölder continuous with . The empirical study (Gatheral et al. Citation2018) was the first to suggest such a rough behavior for the volatility, and ignited tremendous interest in the topic. The website https://sites.google.com/site/roughvol/home contains an exhaustive and up-to-date review of the literature on rough volatility. Unlike continuous Markovian stochastic volatility models, which are not able to fully describe the steep implied volatility skew of short-maturity options in equity markets, rough volatility models have shown accurate fit for this crucial feature. Within rough volatility, the rough Bergomi model (Bayer et al. Citation2016) is one of the simplest, yet decisive frameworks to harness the power of the roughness for pricing purposes. We show how to adapt our functional quantization setup to this case.
4.1. The generalized Bergomi model
We work here with a slightly generalized version of the rough Bergomi model, defined as
where X is the log-stock price,
the instantaneous variance process driven by the Gaussian Volterra process Z in (Equation1
(1)
(1) ),
and B is a Brownian motion defined as
for some correlation
and
orthogonal Brownian motions. The filtered probability space is therefore taken as
,
. This is a non-Markovian generalization of Bergomi's second generation stochastic volatility model (Bergomi Citation2005), letting the variance be driven by a Gaussian Volterra process instead of a standard Brownian motion. Here,
denotes the forward variance for a remaining maturity t, observed at time T. In particular,
is the initial forward variance curve, assumed to be
-measurable. Indeed, given market prices of variance swaps
at time T with remaining maturity t, the forward variance curve can be recovered as
, for all
, and the process
is a martingale for all fixed t>0.
Remark 4.1
With ,
, for
, and
, we recover the standard rough Bergomi model (Bayer et al. Citation2016).
4.2. VIX Futures in the generalized Bergomi
We consider the pricing of VIX Futures (www.cboe.com/tradable_products/vix/) in the rough Bergomi model. They are highly liquid Futures on the Chicago Board Options Exchange Volatility Index, introduced on March 26, 2004, to allow for trading in the underlying VIX. Each VIX Future represents the expected implied volatility for the 30 days following the expiration date of the Futures contract itself. The continuous version of the VIX at time T is determined by the continuous-time monitoring formula (11)
(11)
similarly to Jacquier et al. (Citation2018a), where Δ is equal to 30 days, and we write
(dropping the subscript when T = 0). Thus the price of a VIX Future with maturity T is given by
where the process
is given by
To develop a functional quantization setup for VIX Futures, we need to quantize the process
, which is close, yet slightly different, from the Gaussian Volterra process Z in (Equation1
(1)
(1) ).
4.3. Properties of
To retrieve the same setting as above, we normalize the time interval to , that is
. Then, for T fixed, we define the process
as
which is well defined by the square integrability of K. By definition, the process
is centered Gaussian and Itô isometry gives its covariance function as
Proceeding as previously, we introduce a Gaussian process with same mean and covariance as those of
, represented as a series expansion involving standard Gaussian random variables; from which product functional quantization follows. It is easy to see that the process
has continuous trajectories. Indeed,
, by conditional Jensen's inequality since
. Then, applying tower property, for any
,
and therefore the H-Hölder regularity of Z (section 2) implies that of
.
4.3.1. Series expansion
Let be an i.i.d. sequence of standard Gaussian and
the orthonormal basis of
from (Equation3
(3)
(3) ). Denote by
the operator from
to
that associates to each
,
(12)
(12)
We define the process
as (recall the analogous (Equation2
(2)
(2) )):
The lemma below follows from the corresponding results in remark 2.2 and lemma 2.4:
Lemma 4.2
The process is centered, Gaussian and with covariance function
To complete the analysis of , we require an analogue version of assumption 2.3.
Assumption 4.3
Assumption 2.3 holds for the sequence on
with the constants
and
depending on T.
4.4. The truncated RL case
We again pay special attention to the RL case, for which the operator (Equation12(12)
(12) ) reads, for each
,
and satisfies the following, proved in appendix A.4.
Lemma 4.4
The functions satisfy assumption 4.3.
A key role in this proof is played by an intermediate lemma, proved in appendix A.3, which provides a convenient representation for the integral ,
, in terms of the generalized Hypergeometric function
.
Lemma 4.5
For any , the representation
holds, where
and
,
and
(13)
(13)
Remark 4.6
The representation in lemma 4.5 can be exploited to obtain an explicit formula for ,
and
:
with
and
,
in (Equation13
(13)
(13) ). We shall exploit this in our numerical simulations.
4.5. VIX derivatives pricing
We can now introduce the quantization for the process , similarly to definition 3.2, recalling the definition of the set
in (Equation8
(8)
(8) ):
Definition 4.7
A product functional quantization for of order N is defined as
where
, for some
, and for every
is the (unique) optimal quadratic quantization of the Gaussian variable
of order
.
The sequence denotes the orthonormal basis of
given by
and the operator
is defined for
as
Adapting the proof of proposition 3.12, it is possible to prove that these quantizers are stationary, too.
Remark 4.8
The dependence on Δ is due to the fact that the coefficients in the series expansion depend on the time interval .
In the RL case for each , we can write, using remark 4.6, for any
:
We thus exploit
to obtain an estimation of
and of VIX Futures through the following:
(14)
(14)
Remark 4.9
The expectation above reduces to the following deterministic summation, making its computation immediate:
where
is the (unique) optimal quadratic quantization of
of order
,
is the jth Voronoi cell relative to the
-quantizer ( definition 3.1), with
and
. In the numerical illustrations displayed in section 5, we exploited Simpson rule to evaluate these integrals. In particular, we used simps function from scipy.integrate with 300 points.
4.6. Quantization error of VIX derivatives
The following -error estimate is a consequence of assumption 4.3 (B) and its proof is omitted since it is analogous to that of proposition 3.6:
Proposition 4.10
Under assumption 4.3, for any , there exist
, C>0 such that
for
and with, for each
,
Furthermore
.
As a consequence, we have the following error quantification for European options on the VIX:
Theorem 4.11
Let be a globally Lipschitz-continuous function and
for some
. There exists
such that
(15)
(15)
Furthermore, for any
, there exist
and
such that, with
,
(16)
(16)
The upper bound in (Equation16(16)
(16) ) is an immediate consequence of (Equation15
(15)
(15) ) and proposition 4.10. The proof of (Equation15
(15)
(15) ) is much more involved and is postponed to appendix A.5.
Remark 4.12
When
Since the functions
5. Numerical results for the RL case
We now test the quality of the quantization on the pricing of VIX Futures in the standard rough Bergomi model, considering the RL kernel in remark 4.1.
5.1. Practical considerations for m and
Proposition 3.6 provides, for any fixed some indications on
and
(see (Equation8
(8)
(8) )), for which the rate of convergence of the quantization error is
. We present now a numerical algorithm to compute the optimal parameters. For a given number of trajectories
, the problem is equivalent to finding
and
such that
is minimal. Starting from (EquationA1
(A1)
(A1) ) and adding and subtracting the quantity
, we obtain
(17)
(17)
where
denotes the optimal quadratic quantization error for the quadratic quantizer of order
of the standard Gaussian random variable
(see appendix A.1 for more details). Note that the last term on the right-hand side of (Equation17
(17)
(17) ) does not depend on m, nor on
. We therefore simply look for m and
that minimize
This can be easily implemented: the functions
can be obtained numerically from the Hypergeometric function and the quadratic errors
are available at www.quantize.maths-fi.com/gaussian_database, for
. The algorithm therefore reads as follows:
fix m;
minimize
minimize
The results of the algorithm for some reference values of are available in table , where
represents the number of trajectories actually computed in the optimal case. In table , we compute the rate optimal parameters derived in proposition 3.6: the column ‘Relative error’ contains the normalized difference between the
-quantization error made with the optimal choice of
and
in table and the
-quantization error made with
and
of the corresponding line of the table, namely
. In the column
we display the number of trajectories actually computed in the rate-optimal case. The optimal quadratic vector quantization of a standard Gaussian of order 1 is the random variable identically equal to zero and so when
the corresponding term is uninfluential in the representation.
Table 1. Optimal parameters.
Table 2. Rate-optimal parameters.
5.2. The functional quantizers
The computations in sections 2 and 3 for the RL process, respectively the ones in sections 4.3 and 4.4 for , provide a way to obtain the functional quantizers of the processes.
5.2.1. Quantizers of the RL process
For the RL process, definition 3.4 shows that its quantizer is a weighted Cartesian product of grids of the one-dimensional standard Gaussian random variables. The time-dependent weights are computed using (Equation7
(7)
(7) ), and for a fixed number of trajectories N, suitable
and
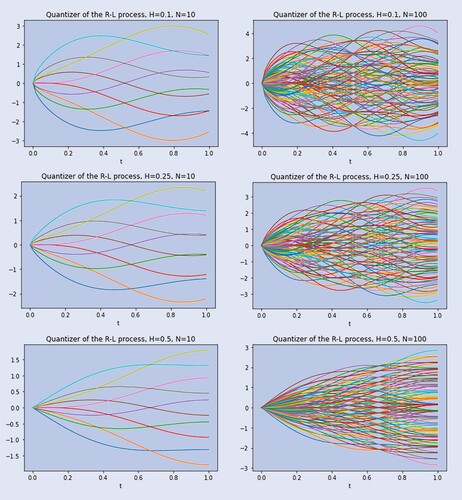
are chosen according to the algorithm in section 5.1. Not surprisingly, figure shows that as the paths of the process get smoother (H increases) the trajectories become less fluctuating and shrink around zero. For H = 0.5, where the RL process reduces to the standard Brownian motion, we recover the well-known quantizer from Pagès (Citation2007, figures 7–8). This is consistent as in that case
, and so
is the Karhuenen–Loève expansion for the Brownian motion (Pagès Citation2007, section 7.1).
Figure 1. Product functional quantizations of the RL process with N-quantizers, for , for N = 10 and N = 100.
5.2.2. Quantizers of
A quantizer for is defined analogously to that of
using Definition 3.4. The weights
in the summation are available in closed form, as shown in Remark 4.6. It is therefore possible to compute the N-product functional quantizer, for any
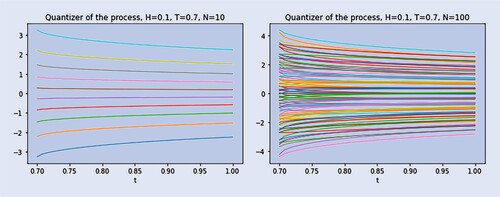
, as figure displays.
Figure 2. Product functional quantization of via N-quantizers, with H = 0.1, T = 0.7, for
.
5.3. Pricing and comparison with Monte Carlo
In this section, we show and comment some plots related to the estimation of prices of derivatives on the VIX and realized variance. We set the values H = 0.1 and for the parameters and investigate three different initial forward variance curves
, as in Jacquier et al. (Citation2018a):
Scenario 1.
Scenario 2.
Scenario 3.
The choice of such ν is a consequence of the choice , consistently with Bennedsen et al. (Citation2017), and of the relationship
. In all these cases,
is an increasing function of time, whose value at zero is close to the square of the reference value of 0.25.
5.3.1. VIX Futures pricing
One of the most recent and effective way to compute the price of VIX Futures is a Monte-Carlo-simulation method based on Cholesky decomposition, for which we refer to Jacquier et al. (Citation2018a, section 3.3.2). It can be considered as a good approximation of the true price when the number M of computed paths is large. In fact, in Jacquier et al. (Citation2018a) the authors tested three simulation-based methods (Hybrid scheme + forward Euler, Truncated Cholesky, SVD decomposition) and ‘all three methods seem to approximate the prices similarly well’. We thus consider the truncated Cholesky approach as a benchmark and take trajectories and 300 equidistant point for the time grid.
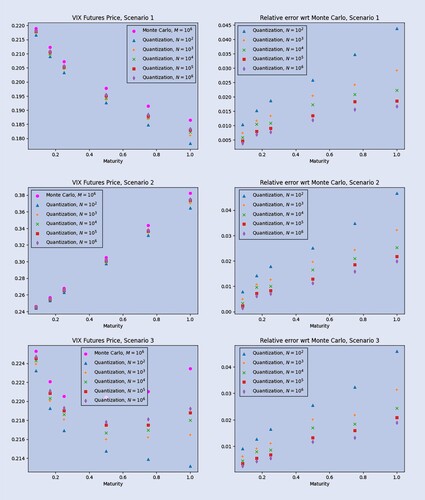
In figure , we plot the VIX Futures prices as a function of the maturity T, where T ranges in months (consistently with actual quotations) on the left, and the corresponding relative error w.r.t. the Monte Carlo benchmark on the right. It is clear that the quantization approximates the benchmark from below and that the accuracy increases with the number of trajectories.
Figure 3. VIX Futures prices (left) and relative error (right) computed with quantization and with Monte-Carlo as a function of the maturity T, for different numbers of trajectories, for each forward variance curve scenario.
We highlight that the quantization scheme for VIX Futures can be sped up considerably by storing ahead the quantized trajectories for , so that we only need to compute the integrations and summations in remark 4.9, which are extremely fast.
Furthermore, the grid organization time itself is not that significant. In table , we display the grid organization times (in seconds) as a function of the maturity (rows) expressed in months and of the number of trajectories (columns). From this table, one might deduce that the time needed for the organization of the grids is suitable to be performed once per day (say every morning) as it should be for actual pricing purposes. It is interesting to note that the estimations obtained with quantization (which is an exact method) are consistent in that they mimick the trend of benchmark prices over time even for very small values of N. However, as a consequence of the variance in the estimations, the Monte Carlo prices are almost useless for small values of M. Moreover, improving the estimations with Monte Carlo requires to increase the number of points in the time grid with clear impact on computational time, while this is not the case with quantization since the trajectories in the quantizers are smooth. Indeed, the trajectories in the quantizers are not only smooth but also almost constant over time, hence reducing the number of time steps to get the desired level of accuracy. Note that here we may refer also to the issue of complexity related to discretization: a quadrature formula over n points has a cost , while the simulation with a Cholesky method over the same grid has cost
. Finally, our quantization method does not require much RAM. Indeed, all the simulations performed with quantization can be easily run on a personal laptop,Footnote1 while this is not the case for the Monte Carlo scheme proposed here.Footnote2 For the sake of completeness, we also recall that combining Monte Carlo pricing of VIX futures/options with an efficient control variate speeds up the computations significantly (Horvath et al. Citation2020).
Table 3. Grid organization times (in seconds) as a function of the maturity (rows, in months) and of the number of trajectories (columns).
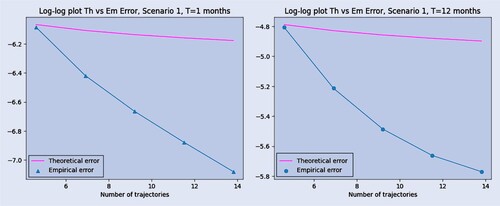
In figure , we show some plots comparing the behavior of the empirical error with the theoretically predicted one. We have decided to display only a couple of maturities for the first scenario since the other plots are very similar. The figures display in a clear way that the order of convergence of the empirical error should be bigger than the theoretically predicted one: in particular, we expect it to be .
Figure 4. Log–log (natural logarithm) plot of the empirical absolute error with the theoretically predicted one for scenario 1, with months.
5.3.2. VIX options pricing
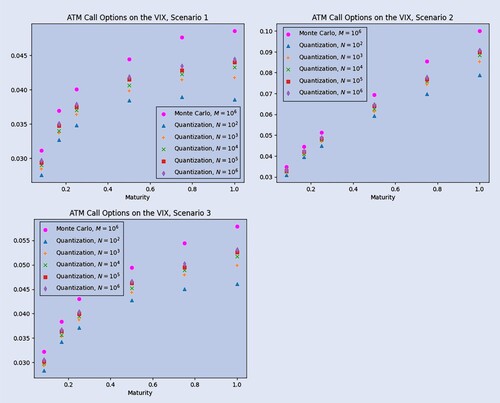
To complete the discussion on VIX Options pricing, we present in figure the approximation of the prices of ATM Call Options on the VIX obtained via quantization as a function of the maturity T and for different numbers of trajectories against the same price computed via Monte Carlo simulations with trajectories and 300 equidistant point for the time grid, as a benchmark. Each plot represents a different scenario for the initial forward variance curve. For all scenarios, as the number N of trajectories goes to infinity, the prices in figure are clearly converging, and the limiting curve is increasing in the maturity, as it should be.
Figure 5. Prices of ATM Call Options on the VIX via quantization.
5.3.3. Pricing of continuously monitored options on realized variance
Product functional quantization of the process can be exploited for (meaningful) pricing purposes, too. We first price variance swaps, whose price is given by the following expression:
Let us recall that, in the rough Bergomi model,
where
,
is an endogenous constant and
being the initial forward variance curve. Thus, exploiting the fact that, for any fixed
,
is distributed according to a centered Gaussian random variable with variance
, the quantity
can be explicitly computed:
This is particularly handy and provides us a simple benchmark. The price
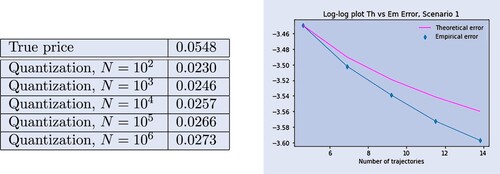
is, then, approximated via quantization through
Numerical results are presented in figure . On the left-hand side, we display a table with the approximations (depending on N, the number of trajectories) of the price of a swap on the realized variance in Scenario 1, for T = 1, and the true value
. On the right-hand side a log–log (natural logarithm) plot of the error against the function
, with c being a suitable positive constant. For variance swaps the error is not performing very well. It is indeed very close to the upper bound
that we have computed theoretically. One possible theoretical motivation for this behavior lies in the difference between strong and weak error rates. Weak error and strong error do not necessarily share the same order of convergence, being the weak error faster in general. See Bayer et al. (Citation2021, Citation2022) and Gassiat (Citation2022) for recent developments on the topic in the rough volatility framework. For pricing purposes, we are interested in weak error rates. Indeed, the pricing error should in principle have the following form
, where
is the process that we are using to approximate the original
and f is a functional that comes from the payoff function and that we can interpret as a test function. Thus the functional f has a smoothing effect. On the other hand, the upper bound for the quantization error we have computed is a strong error rate. This theoretical discrepancy motivates the findings in figure when pricing VIX Futures and other options on the VIX: the empirical error seems to converge with order
, while the predicted order is
. The different empirical rates that are seen in figure for VIX futures (roughly
)) and in figure for variance swaps (much closer to
) could be also related to the different degree of pathwise regularity of the processes Z and
. While
is a.s.
-Hölder, for fixed T, the trajectories
of
are much smoother when
and t is bounded away from T. When pricing VIX derivatives, we are quantizing almost everywhere a smooth Gaussian process (hence error rate of order
, while when pricing derivatives on realized variance, we are applying quantization to a rough Gaussian process (hence error rate of order
), resulting in a deteriorated accuracy for the prices of realized volatility derivatives such as the variance swaps in figure .
Figure 6. Prices and errors for variance swaps.
Furthermore, it can be easily shown that, for any and for any
, with m<N,
always provides a lower bound for the true price
. Indeed, since the quantizers
of the process
are stationary (cfr. proposition 3.12), an application of remark 3.9 to the convex function
together with the positivity of
, for any
, yields
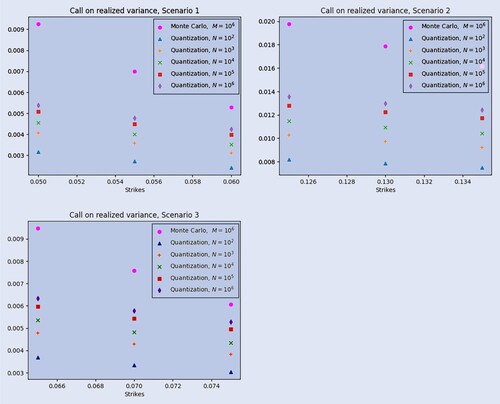
To complete this section, we plot in figure approximated prices of European Call Options on the realized variance via quantization with
trajectories and via Monte Carlo with
trajectories, as a benchmark. In order to take advantage of the trajectories obtained, we compute the price of a realized variance Call option with strike K and maturity T = 1 as
and we approximate it via quantization through
The three plots in figure display the behavior of the price of a European Call on the realized variance as a function of the strike price K (close to the ATM value) for the three scenarios considered before.
Figure 7. Prices of European Call Option on realized variance computed via Monte Carlo with trajectories and via quantization with
trajectories, as a function of K.
5.3.4. Quantization and MC comparison
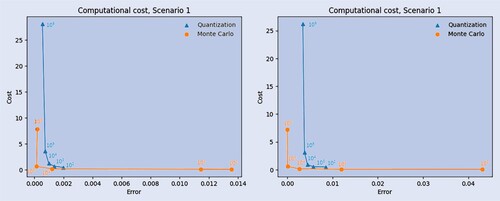
To make a fair comparison between quantization and Monte Carlo simulations, we present a figure to display, for each methodology, the computational work needed for a given error tolerance for the pricing of VIX Futures. The plots in figure should be read as follows. First, for any , we have computed the corresponding pricing errors:
and
where
is the Monte Carlo price obtained via truncated Cholesky with M trajectories,
is the price computed via quantization with N trajectories and
comes from the lowerbound in equation
in Jacquier et al. (Citation2018a) and the associated computational time in seconds
and
, respectively for Monte Carlo simulation and quantization. Then, each point in the plot is associated either to a value of M in case of Monte Carlo (the circles in figure ), or N in case of quantization (the triangles in figure ), and its x-coordinate provides the absolute value of the associated pricing error, while its y-coordinate represents the associated computational cost in seconds.
Figure 8. Computational costs for quantization versus Monte Carlo for Scenario 1, with T = 1 month (left-hand side) and T = 12 months (right-hand side). The number of trajectories, M for Monte Carlo and N for quantization, corresponding to a specific dot is displayed above it.
These plots lead to the following observations:
For quantization, which is an exact method, the error is strictly monotone in the number of trajectories.
When a small number of trajectories is considered, quantization provides a lower error with respect to Monte Carlo, at a comparable cost.
For large numbers of trajectories Monte Carlo overcomes quantization both in terms of accuracy and of computational time.
To conclude, quantization can always be run with an arbitrary number of trajectories and furthermore for it leads to a lower error with respect to Monte Carlo, at a comparable computational cost, as it is visible from figure . This makes quantization particularly suitable to be used when dealing with standard machines, i.e. laptops with a RAM memory smaller or equal to 16GB.
6. Conclusion
In this paper we provide, on the theoretical side, a precise and detailed result on the convergence of product functional quantizers of Gaussian Volterra processes, showing that the -error is of order
, with N the number of trajectories and H the regularity index.
Furthermore, we explicitly characterize the rate optimal parameters, and
, and we compare them with the corresponding optimal parameters,
and
, computed numerically.
In the rough Bergomi model, we apply product functional quantization to the pricing of VIX options, with precise rates of convergence, and of options on realized variance, comparing those—whenever possible—to standard Monte Carlo methods.
The thorough numerical analysis carried out in the paper shows that unfortunately, despite the conceptual promise of functional quantization, while the results on the VIX are very promising, other types of path-dependent options seem to require machine resources way beyond the current requirements of standard Monte Carlo schemes, as shown precisely in the case of variance swaps. While product functional quantization is an exact method, the analysis provided here does not however promise a bright future in the context of rough volatility. It may nevertheless be of practical interest when machine resources are limited and indeed the results for VIX Futures pricing are strongly encouraging in this respect. Functional quantization for rough volatility can, however, be salvaged when used as a control variate tool to reduce the variance in classical Monte Carlo simulations.
Acknowledgments
The authors would like to thank Andrea Pallavicini and Emanuela Rosazza Gianin for fruitful discussions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 The personal computer used to run the quantization codes has the following technical specifications: RAM: 8.00 GB, SSD memory: 512 GB, Processor: AMD Ryzen 7 4700U with Radeon Graphics 2.00 GHz.
2 The computer used to run the Monte Carlo codes is a virtual machine (OpenStack/Nova/KVM/Qemu, www.openstack.org) with the following technical specifications: RAM: 32.00 GB, CPU: 8 virtual cores, Hypervisor CPU: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz, RAM 128GB, Storage: CEPH cluster (www.ceph.com).
References
- Abi Jaber, E. and El Euch, O., Multifactor approximation of rough volatility models. SIAM J. Financ. Math., 2019, 10(2), 309–349.
- Adler, R.J. and Taylor, J.E., Random Fields and Geometry. Springer Monographs in Mathematics, 2007 (Springer-Verlag: New York).
- Alòs, E., León, J.A. and Vives, J., On the short-time behavior of the implied volatility for jump-diffusion models with stochastic volatility. Finance Stoch., 2007, 11(4), 571–589.
- Bayer, C., Friz, P.K. and Gatheral, J., Pricing under rough volatility. Quant. Finance, 2016, 16(6), 887–904.
- Bayer, C., Hammouda, C.B. and Tempone, R., Hierarchical adaptive sparse grids and quasi Monte Carlo for option pricing under the rough Bergomi model. Quant. Finance, 2020, 20(9), 1457–1473.
- Bayer, C., Hall, E.J. and Tempone, R., Weak error rates for option pricing under linear rough volatility, arXiv preprint, 2021. https://arxiv.org/abs/2009.01219.
- Bayer, C., Fukasawa, M. and Nakahara, S., On the weak convergence rate in the discretization of rough volatility models, ArXiV preprint, 2022. https://arxiv.org/abs/2203.02943.
- Bennedsen, M., Lunde, A. and Pakkanen, M.S., Hybrid scheme for Brownian semistationary processes. Finance Stoch., 2017, 21, 931–965.
- Bergomi, L., Smile dynamics II, Risk, 2005, pp. 67–73.
- Carr, P.P. and Madan, D.B., Joint modeling of VIX and SPX options at a single and common maturity with risk management applications. IIE Trans., 2014, 46(11), 1125–1131.
- Chen, W., Langrené, N., Loeper, G. and Zhu, Q., Markovian approximation of the rough Bergomi model for Monte Carlo option pricing. Mathematics, 2021, 9(5), 528.
- Chow, Y.S. and Teichner, E., Probability Theory. Springer Texts in Statistics, 1997 (Springer-Verlag: New York).
- Corlay, S., Quelques aspects de la quantification optimale, et applications en finance (in English, with French summary). PhD Thesis, Université Pierre et Marie Curie, 2011.
- Fukasawa, M., Asymptotic analysis for stochastic volatility: Martingale expansion. Finance Stoch., 2011, 15(4), 635–654.
- Fukasawa, M., Volatility has to be rough. Quant. Finance, 2021, 21, 1–8.
- Fukasawa, M., Takabatake, T. and Westphal, R., Consistent estimation for fractional stochastic volatility model under high-frequency asymptotics (Is Volatility Rough?). Math. Finance., 2022, 32, 1086–1132.
- Gassiat, P., Weak error rates of numerical schemes for rough volatility, arXiv preprint, 2022. https://arxiv.org/abs/2203.09298.
- Gatheral, J., Consistent Modelling of SPX and VIX Options. Presentation, 2008 (Bachelier Congress: London).
- Gatheral, J., Jaisson, T. and Rosenbaum, M., Volatility is rough. Quant. Finance, 2018, 18(6), 933–949.
- Gersho, A. and Gray, R.M., Vector Quantization and Signal Compression, 1992 (Kluwer Academic Publishers: New York).
- Graf, S. and Luschgy, H., Foundations of Quantization for Probability Distributions. Lecture Notes in Mathematics, 1730, 2007 (Springer: Berlin Heidelberg).
- Horvath, B., Jacquier, A. and Muguruza, A., Functional central limit theorems for rough volatility, 2019. arxiv.org/abs/1711.03078.
- Horvath, B., Jacquier, A. and Tankov, P., Volatility options in rough volatility models. SIAM J. Financ. Math., 2020, 11(2), 437–469.
- Huh, J., Jeon, J. and Kim, J.H., A scaled version of the double-mean-reverting model for VIX derivatives. Math. Financ. Econom., 2018, 12(4), 495–515.
- Jacquier, A., Martini, C. and Muguruza, A., On VIX futures in the rough Bergomi model. Quant. Finance, 2018a, 18(1), 45–61.
- Jacquier, A., Pakkanen, M.S. and Stone, H., Pathwise large deviations for the rough Bergomi model. J. Appl. Probab., 2018b, 55(4), 1078–1092.
- Kallenberg, O., Foundations of Modern Probability. 2nd edn, Probability and Its Applications, 2002 (Springer-Verlag: New York).
- Karp, D.B., Representations and inequalities for generalized Hypergeometric functions. J. Math. Sci. (N.Y.), 2015, 207, 885–897.
- Kokholm, T. and Stisen, M., Joint pricing of VIX and SPX options with stochastic volatility and jump models. J. Risk Finance, 2015, 16(1), 27–48.
- Luke, Y.L., The Special Functions and Their Approximations, Vol. 1, 1969 (Academic Press: New York and London).
- Luschgy, H. and Pagès, G., Functional quantization of Gaussian processes. J. Funct. Anal., 2002, 196(2), 486–531.
- Luschgy, H. and Pagès, G., High-resolution product quantization for Gaussian processes under sup-norm distortion. Bernoulli, 2007, 13(3), 653–671.
- McCrickerd, R. and Pakkanen, M.S., Turbocharging Monte Carlo pricing for the rough Bergomi model. Quant. Finance, 2018, 18(11), 1877–1886.
- Olver, F.W.J., Asymptotics and Special Functions, 2nd ed., 1997 (A.K. Peters/CRC Press: New York).
- Pagès, G., Quadratic optimal functional quantization of stochastic processes and numerical applications. In Monte Carlo and Quasi-Monte Carlo Methods 2006, pp. 101–142, 2007 (Springer: Berlin Heidelberg).
- Pagès, G. and Printems, J., Functional quantization for numerics with an application to option pricing. Monte Carlo Methods Appl., 2005, 11(4), 407–446.
- Picard, J., Representation formulae for the fractional Brownian motion. In Séminaire de Probabilités XLIII, Lecture Notes in Mathematics, 2006, pp. 3–70, 2011 (Springer-Verlag: Berlin Heidelberg).
- Sheppard, W.F., On the calculation of the most probable values of frequency-constants, for data arranged according to equidistant division of a scale. Proc. Lond. Math. Soc. (3), 1897, 1(1), 353–380.
- Steele, J.M., The Cauchy-Schwarz Master-Class, 2004 (Cambridge University Press: New York).
Appendices
Appendix 1.
Proofs
A.1. Proof of proposition 3.6
Consider a fixed and
for
. We have
(A1)
(A1)
using Fubini's Theorem and the fact that
is a sequence of i.i.d. Gaussian and where
. The Extended Pierce Lemma (Pagès Citation2007, theorem 1(b)) ensures that
for a suitable positive constant L. Exploiting this error bound and the property (B) for
in assumption 2.3, we obtain
(A2)
(A2)
with
. Inspired by Luschgy and Pagès (Citation2002, section 4.1), we now look for an ‘optimal’ choice of
and
. This reduces the error in approximating Z with a product quantization of the form in (Equation9
(9)
(9) ). Define the optimal product functional quantization
of order N as the
which realizes the minimal error:
From (EquationA2
(A2)
(A2) ), we deduce
(A3)
(A3)
For any fixed
we associate to the internal minimization problem the one we get by relaxing the hypothesis that
:
For this infimum, we derive a simple solution exploiting the arithmetic-geometric inequality using lemma A.3. Setting
, with
, we get
and note that the sequence
is decreasing. Since ultimately the vector
consists of integers, we use
,
. In fact, this choice guarantees that
Furthermore, setting
for each
, we obtain
Ordering the terms, we have
, for each
. From this we deduce the following inequality (notice that the left-hand side term is defined only if
):
(A4)
(A4)
Hence, we are able to make a first error estimation, placing in the internal minimization of the right-hand side of (EquationA3
(A3)
(A3) ) the result of inequality in (EquationA4
(A4)
(A4) ).
(A5)
(A5)
where
and the set
(A6)
(A6)
which represents all m's such that all
are positive integers. This is to avoid the case where
holds only because one of the factors is zero. In fact, for all
,
is a positive integer if and only if
. Thanks to the monotonicity of
, we only need to check that
First, let us show that
, defined in (EquationA6
(A6)
(A6) ) for each
, is a non-empty finite set with maximum given by
of order
. We can rewrite it as
, where
We can now verify that the sequence
is increasing in
:
which is obviously true. Furthermore the sequence
diverges to infinity since
and
. We immediately deduce that
is finite and, since
, it is also non-empty. Hence
. Moreover, for all
,
, which implies that
.
Now, the error estimation in (EquationA5(A5)
(A5) ) can be further simplified exploiting the fact that, for each
,
The last inequality is a consequence of the fact that
by definition. Hence,
(A7)
(A7)
for some suitable constant
.
Consider now the sequence , given by
. For
,
so that the sequence is decreasing and the infimum in (EquationA7
(A7)
(A7) ) is attained at
. Therefore,
A.2. Proof of Remark 2.5
This can be proved specializing the computations done in Luschgy and Pagès (Citation2007, page 656). Consider an arbitrary index For all
, exploiting assumption 2.3, we have that, for any
,
where
Therefore
(A8)
(A8)
Notice that
when
so that (EquationA8
(A8)
(A8) ) implies
In particular,
As noticed in Remark 2.2 the process Y is centered Gaussian. Hence, for each
so is
. Proposition A.2 therefore implies that, for any
,
where
, yielding existence of a continuous version of Y since choosing
such that
, Kolmogorov continuity theorem (Kallenberg Citation2002, theorem 3.23) applies directly.
A.3. Proof of Lemma 4.5
Let . Using Karp (Citation2015, corollary 1, equation (12)) (with
), the identity
holds for all r>0, where G denotes the Meijer-G function, generally defined through the so-called Mellin–Barnes type integral (Luke Citation1969, equation (1), section 5.2)) as
This representation holds if
,
and
, for integers m, n, p, q, and
, for
and
. The last constraint is set to prevent any pole of any
from coinciding with any pole of any
. With a>0,
and
, since
, we can therefore write
(A9)
(A9)
Similarly, using integration by parts and properties of generalized Hypergeometric functions,
(A10)
(A10)
where the last step follows from the definition of generalized sine function
. Indeed, exploiting (Equation6
(6)
(6) ), we have
Letting
,
, and mapping v: = t−u,
and
, we write
(A11)
(A11)
where
.
We therefore write, for , using (EquationA9
(A9)
(A9) )–(EquationA10
(A10)
(A10) ),
, and identifying
,
since
,
and
. Plugging these into (EquationA11
(A11)
(A11) ), we obtain
where
and
and
as defined in the lemma.
A.4. Proof of lemma 4.4
We first prove (A). For each and all
, recall that
with the change of variables v = t−u. Assume
. Two situations are possible:
If
If
This proves (A).
To prove (B), recall that, for and
, the function
reads
(A12)
(A12)
with the change of variable
. Denote from now on
. From (EquationA12
(A12)
(A12) ), we deduce, for each
and
,
(A13)
(A13)
To end the proof of (B), it therefore suffices to show that
is uniformly bounded since, in that case we have
for some
, proving (B). The following guarantees the uniform boundedness of
in (EquationA13
(A13)
(A13) ).
Proposition A.1
For any , there exists C>0 such that
for all
,
.
Proof.
For x>0, we write
Using the representation in lemma 4.5, we are thus left to prove that the maps
and
, defined in (Equation13
(13)
(13) ), are bounded on
by, say
and
. Indeed, in this case,
The maps
and
are both clearly continuous. Moreover, as z tends to infinity
converges to a constant
, for
. The identities
hold (this can be checked with Wolfram Mathematica for example) and therefore,
where, in the second line, we used the change of variables
. In particular, as z tends to infinity, this converges to
. Analogously, for
,
with the same change of variables as before. This converges to
as z tends to infinity. For k>0,
at zero. Since
, the two functions are continuous and bounded and the proposition follows.
A.5. Proof of theorem 4.11
We only provide the proof of (Equation15(15)
(15) ) since, as already noticed, that of (Equation16
(16)
(16) ) follows immediately. Suppose that
is Lipschitz continuous with constant M. By definitions (Equation11
(11)
(11) ) and (Equation14
(14)
(14) ), we have
For clarity, let
,
,
and
, with
We can therefore write, using the Lipschitz property of F (with constant M) and lemma A.4,
Now, an application of Hölder's inequality yields
where
. It remains to show that
is a strictly positive finite constant. This follows from the fact that
does not explode in finite time (and so does not its quantization
either). The identity
and Hölder's inequality imply
We only need to show that
and
are finite. Since h is a positive continuous function on the compact interval
, we have
(A14)
(A14)
with
. The inequality (EquationA14
(A14)
(A14) ) implies
since
and Z have the same law. The process
is a continuous centered Gaussian process defined on a compact set. Thus, by theorem 1.5.4 in Adler and Taylor (Citation2007), it is almost surely bounded there. Furthermore, exploiting Lemma A.5 and Borel-TIS inequality (Adler and Taylor Citation2007, Theorem 2.1.1), we have
(A15)
(A15)
with
and
. The change of variable
in the last term in (EquationA15
(A15)
(A15) ) yields
since
, and hence
is finite. Now, note that, in analogy to the last line of the proof of proposition 3.12, for any
, we have
(A16)
(A16)
since the sigma-algebra generated by
is included in the sigma-algebra generated by
. Now, exploiting, in sequence, (EquationA16
(A16)
(A16) ), the conditional version of
, conditional Jensen's inequality together with the convexity of
, for
and the tower property, we obtain
Thus we have
which is finite because of the proof of the finiteness of
, above.
Exploiting Fubini's theorem we rewrite as
Since
is centered Gaussian with covariance
, then
, with
and therefore
is finite since both h and g are continuous on compact intervals. Finally, for
we have
where we have used the fact that for all
,
is a stationary quantizer for
and so
since
is a convex function (see remark 3.9 in section 3.1). Therefore
is finite and the proof follows.
Appendix 2.
Some useful results
We recall some important results used throughout the text. Straightforward proofs are omitted.
Proposition A.2
For a Gaussian random variable ,
We recall (Steele Citation2004, Problem 8.5), correcting a small error, used in the proof of Proposition 3.6:
Lemma A.3
Let and
positive real numbers. Then
where the infimum is attained for
, for all
.
Proof.
The general arithmetic-geometric inequalities imply
since
by assumption. The right-hand side does not depend on
, so
Choosing
, for all
, we obtain
which concludes the proof.
Lemma A.4
The following hold:
For any x, y>0,
Set C>0. For any
Lemma A.5
For a positive random variable X on ,
.