
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Many asset pricing models assume that expected returns are driven by common factors. We formulate a model where returns are driven by a string, and no-arbitrage restricts each expected return to capture the asset's granular exposure to all other asset returns: a correlation premium. The model predicts fresh properties for big stocks, which display higher connectivity in bad times, but also work as correlation hedges: they contribute to a negative fraction of the correlation premium, and portfolios that are more exposed to them command a lower premium. The string model performs at least as well as many existing linear factor models.
1. Introduction
The inability of the CAPM to explain the cross-section of expected returns has led to a proliferation of models driven by factors that have recently been the focus of criticism and renewed rigorous statistical scrutiny (see, e.g. Harvey et al. Citation2016). This paper proposes a new arbitrage pricing model in which the cross-section of expected returns links to arguably one amongst the simplest concepts in financial economics: correlation. The distinguishing feature of our approach is that we avoid making reference to factors while explaining asset correlations. Instead, correlations of each asset return with all remaining asset returns are the building block in our framework. That is, in our model, correlations do not result from the assumption of exogenously given ‘pricing factors’. Rather, all correlations are the primitives of the model, and they jointly determine the whole set of no-arbitrage restrictions amongst all asset returns.
Correlation has a long history in asset pricing, although the typical approach has predominantly been to model asset returns in frameworks where correlation and volatility are intimately related. Consider, for example, the seminal Merton (Citation1971) model, in which asset returns are driven by Brownian motions. In that model, the assets correlations are pre-determined by the assumptions made on the assets betas; that is, the price of correlation risk is a function of the ‘lambdas’. Ideally, instead, we would like to disentangle the price of correlation from these lambdas, that is, we would like to disentangle volatility from correlation.
An alternative model is one in which asset returns are driven by shocks that enable one to separate volatility from correlation. We rely on random field models, or stochastic string models, to think about correlation as being determined in this independent way.Footnote1 Random field models were introduced in finance by Kennedy (Citation1994, Citation1997) to model the term structure of interest rates, and Goldstein (Citation2000) and Santa-Clara and Sornette (Citation2001) provide extensions or a more general framework in this domain. Tsoulouvi (Citation2005) applies random field models to derivative pricing. Our paper analyzes how random field models can be employed to explain the cross-section of the expected equity returns. Compared to other approaches, ours proposes, then, a new way to model asset returns. Our model is not built up around factors (be they observed or not). We model assets correlations directly, as explained. String models are particularly useful to achieve this goal.
The model works as follows. Asset returns are driven by the realizations of a string. These realizations lead asset returns to co-move, and these co-movements become sources of priced risk: for any asset, the co-movements of its returns with all remaining asset returns receive a compensation. We derive the arbitrage restrictions amongst all asset returns and characterize this compensation: the expected excess return on each asset is the sum of the correlations of this return with all the remaining returns, weighted by some ‘premium function’.
Thus, the expected excess return on any asset reflects an average premium required to compensate for the asset returns granular exposure to all remaining returns. We term the result correlation premium. We test whether, indeed, the cross-section of the expected returns is explained by the cross-section of the correlation premia. We find that the model provides a reasonable match of the cross-section of the expected returns, for a number of portfolios sorted through book-to-market, momentum and additional standard characteristics, at least comparable to well-known four- or five- linear factor models (e.g. Fama and French Citation2015). Furthermore, our model displays additional properties regarding returns predictability and the time-series of assets correlations, both realized and risk-adjusted, as we now explain.
In principle, our model does not require time-varying correlations: even if asset correlations were all constant, the cross-section of the expected excess returns would be a set of non-zero correlation premia. However, in practice, correlations change over time. We model time-variation in these correlations as being driven by a pro-cyclical state variable,Footnote2 such that correlations increase in bad times, i.e. for low realizations of this state variable. The cross-section of correlation premia and, then, the expected excess returns, are predictable, driven by the state variable. We reconstruct the dynamics of the state variable as a by-product of the model estimation method, based on moment conditions solved in closed-form. The model predicts that, for many portfolios, the cross-section of expected excess returns are countercyclical and asymmetrically related to market conditions: they increase more in bad times than they decrease in good times. We also discuss instances where this relation is reversed: in these cases, some assets may be particularly good hedges in bad times, and portfolios that are particularly exposed to them may command premia that decrease in times of increased market correlations. We find that big size stocks display such properties. More generally, we find that big stocks contribute to a negative fraction of the average correlation premium, such that portfolios that are more exposed to them command a lower premium.
Our moment conditions are based on time-series properties including both realized and option-implied correlations. The model, then, provides additional predictions regarding the random nature of assets correlations. In particular, the risk of changing correlations may lead, and our empirical findings suggest that they do lead, to a premium for correlation risk, the difference between risk-adjusted (i.e. option-implied) and realized correlations on S&P 500, a ‘global premium for correlation risk’.Footnote3
Our model predicts that realized correlations and premia for correlation risk are inversely related. In other words, risk-adjusted correlations move, on average, less than realized correlations in reaction to a changing market environment. This conclusion rationalizes the framework of analysis in the empirical literature of option-implied heterogenous correlations (see, e.g. Buss and Vilkov Citation2012, Mueller et al. Citation2017 in the foreign exchange space) and it, thus, stands, as a fact that differs from the evidence available from equity volatility markets (reviewed in Section 4.4), by which volatility risk premia are countercyclical. We emphasize that we provide a theoretical model for the premium for correlation risk and that this model also provides predictions on the term structure of premia for correlation risk.
Remarkably, then, our model is able to fit both the premium for correlation risk resulting in derivative markets (on S&P 500), and cross-sections of asset returns that are not directly related to S&P 500. For example, the model is given a comfortable support within the international stock universe, such as the global ME-BTM 5×5 portfolio. Therefore, the model displays potential to explain premia for other asset classes, by just relying on our global premium for correlation risk. In one of the technical appendixes, we focus on supplying additional evidence in the equity space, on a variety of S&P 500 sectors and index-based portfolios. The evidence confirms that our model performance is at least as good as many well-known linear factor models.
Our paper links to several strands of the asset pricing literature. First, and perhaps most important, our paper offers a complementary view to the rich field of factor modeling and testing of the cross-section of expected returns. Since Ross' (Citation1976) seminal paper on arbitrage pricing, the number of published factors has exceeded several hundreds (as reported by Harvey et al. Citation2016). As a result, researchers now carefully concentrate on designing tests to evaluate the asset pricing implications of new factors (see, e.g. Feng et al. Citation2020, amongst others). Our contribution is complementary to this new trend, as we are not proposing new factors, but simply developing a granular account of asset correlations.
By investigating the cross-sectional pricing implications of a string model, we also provide a fresh interpretation of size characteristics (Banz Citation1981) and the related SMB factor (Fama and French Citation1993).Footnote4 We find that in bad times, big stocks are those all other stocks become more connected to, as discussed; because big stocks are also safer than others, assets that are more exposed to big stocks command a lower premium. Small stocks display opposite properties. Thus, a size premium may be seen as a ‘correlation wedge’ that small stocks have with respect to big stocks.
We model the riskiness of a security by relating this same security returns to all other available securities returns. This property, ‘connectivity’, suggests a parallel with the empirical literature of networks in finance, whereby firms in the financial marketplace are interlinked through network effects. A number of papers study the effects of firm-level shocks and their propagation through the economic system (see, e.g. Acemoglu et al. Citation2012, Barrot and Sauvagnat Citation2016, Herskovic Citation2018; amongst others). Network effects have also been suggested to explain contagion in financial markets (see, e.g. the early survey of Allen and Babus (Citation2009)) or correlated trading (e.g. Colla and Mele Citation2010, Ozsoylev et al. Citation2014), and motivated new and several gauges of systemic risk (e.g. Billio et al. Citation2012) as well as asset pricing models that incorporate network effects (Billio et al. Citation2017). Our approach differs from these models due to our emphasis on modeling stochastic correlations based on strings rather than on the traditional input-output network models.
Modeling correlation in financial markets has been the focus of an extensive research agenda over the last decades. Engle (Citation2009) provides an early survey on methods and applications. Our model, based on strings, treats the dynamics of correlations in a simple, parsimonious way, assuming correlations are driven by a common, unobserved force. While simple, our model deals with correlation dynamics under both the physical and risk-neutral probabilities, and predicts an empirically plausible premium for correlation risk. Note that the literature on the premium for correlation risk in equity and option markets is quite large and goes back to at least Driessen et al. (Citation2009). Buss and Vilkov (Citation2012), Buraschi et al. (Citation2014) and Mueller et al. (Citation2017) provide relatively more recent contributions, and Faria et al. (Citation2022) contain a long list of additional relevant contributions to this topic. Finally, our paper assigns correlation a central role in explaining asset exposure and cross-sectional pricing properties, which go beyond those already studied in option markets. An area of future research is to integrate good parametric and non-parametric models of correlations into our string-based asset pricing framework.
The paper is organized as follows. The next section contains high level assumptions and general no-arbitrage restrictions. Section 3 provides model specifications for the purpose of empirical work. Section 4 develops cross-equation restrictions and contains our empirical results. Section 5 concludes. Appendix 1 contains technical details omitted from the main text, Appendix 2 develops model extensions, and Appendix 3 provides additional empirical evidence not discussed in the main text.
2. Asset prices as strings
2.1. Primitives
We consider a market with a continuum of assets in , and assume that each asset return is exposed to all remaining asset returns through the realization of a ‘string’. Previous models with a continuum of assets include those formulated by Al-Najjar (Citation1998) in a static exact factor framework and Gagliardini et al. (Citation2016) in a conditional approximate factor setting, amongst others. Our approach is novel precisely because we are not relying on any factor structure, but on strings.
The basic economic intuition underlying a string model for asset returns is that, in this model, each asset return is driven by its own source of uncertainty without implying that all asset returns are uncorrelated. Precisely, let be the price of the i-th asset at t and
be its instantaneous dividend. We assume that the realized returns on each asset-i are solutions to
(1)
(1)
where
is the cumulative return on asset-i,
, the string, is a process continuous in i and t, and such that
,
, and
, for some function ρ taking values in
, and some state vector
, to be discussed below; the volatility term,
is a continuous function of
and i, and
, a ‘string correlation function’, is also continuous; finally,
is the expected return, determined below (see Proposition 2.1). The function
summarizes the asset-i return exposure to how the very same asset return co-varies with all remaining asset returns. It, thus, plays a role similar to the familiar ‘beta’ in traditional factor models.
The notable feature of the model is that returns are risky because the realization of the string leads all asset returns to co-move; in standard models, instead, asset returns co-move, driven by the realization of common factors. In the next section, we explain how the random fluctuations of the string become priced sources of risk, that is, how the expected return on any asset relates to the price of risk of correlation with all other assets. Furthermore, Section 2.4 explains that our model is quite distinct from the standard CAPM, which also predicts that each asset expected returns relate to all other assets' returns (through the market portfolio).
What makes a string model a good model compared to a standard Brownian model? The property mentioned at the beginning of this section: each asset return is driven ‘by its own shock’ and, yet, each asset return may well be correlated with all other asset returns. This property, we now explain, enables us to free up the notion of correlation from that of volatility. Note, indeed, that according to the string model (Equation1(1)
(1) ), the (square of) volatility of any asset-i is
(2)
(2)
and the correlation between any two assets i and j is
(3)
(3)
That is, a string model relies on two distinct definitions of volatility and correlation: volatility and correlation are disentangled. This property does not hold for a Brownian model. To review this, consider an asset market driven by Brownian motions, by which
(4)
(4)
where
is a d-dimensional standard Brownian motion,
is the expected return for asset-i and, finally,
is the exposure of the asset-i returns to
, i.e. volatility. In this model, it is impossible to have each asset return driven ‘by its own Brownian motion’, except of course in the uninteresting case where asset returns are all mutually uncorrelated. The correlation between asset i and j returns is indeed
where
denotes the ℓ-th element of vector
. Note, further, that the correlation matrix is degenerate as soon as m>d.
As already pointed out by Santa-Clara and Sornette (Citation2001), it is very difficult to specify both volatilities and correlations in a Brownian model, without restricting any of these quantities: the assumptions on simultaneously determine both of them. Consider, for example, a market where the volatilities of two assets, say assets a and b, are
and
, for three constants
and
, and where
is a l-dimensional vector of zeros. The correlation between these assets returns and the squared volatility of asset b are
That is, asset returns volatilities determine asset returns correlations. By contrast, a string model always makes volatility and correlation two separate objects: see equations (Equation2
(2)
(2) ) and (Equation3
(3)
(3) ).
To illustrate a more complex case, assume that correlations are random but volatilities are constant, as with the string models that we focus on empirically (see Section 4). Equation (Equation4(4)
(4) ) is consistent with these assumptions when (i) at least one element of
is random and (ii)
is constant for all k. Conditions (i)-(ii) are very difficult to satisfy, but may hold very simply with equation (Equation1
(1)
(1) ), as
and
may potentially be driven by different sets of state variables.
Finally, and returning to the description of our string model, one may formulate several assumptions regarding the state vector . For example,
is another string in one extension of our model developed in Appendix A.3. In our empirical work, we shall assume it is a diffusion process, solution to
for some vector and diffusion matrix
and
. The role of
in this paper is to generate time-variation in assets' return correlations–not in asset returns, which are driven by strings. In other words, we are considering a string model for the first moments of asset returns, with (for simplicity) a more standard formulation regarding higher moments. We shall rely on this state vector mostly to model the joint behavior of asset correlations. We now provide a description of a pricing kernel that enables one to derive cross-sectional restrictions on each asset expected return.
2.2. The pricing kernel
In the absence of arbitrage, there exists a pricing kernel that prices all the assets. We assume that it is solution to
(5)
(5)
where r is the instantaneous interest rate,
is a vector valued function, including the unit prices of risk related to the fluctuations of the Brownian motion
, and
is the collection of the unit prices of risk related to the fluctuations of the string
. We assume that these prices of risk are continuous functions of the state vector
and i. From now on, we focus on the asset pricing implications of the pure string component and, accordingly, we shall refer the collection
as the string premium. Appendix 2 contains extensions that allow for the existence of a priced Brownian risk. We now turn to the cross-sectional restrictions on each asset expected return.
2.3. Conditional CAPM and the correlation premium
In a frictionless market, the expected return on each asset-i satisfies the following standard restriction
(6)
(6)
We have
(7)
(7)
Replacing these results into equation (Equation6
(6)
(6) ) leaves the following restrictions on the cross-section of expected returns:
Proposition 2.1
(Correlation premium)
The expected return on asset-i,
, satisfies
(8)
(8)
where
(9)
(9)
The term in this proposition summarizes the evaluation of the asset-i granular exposure to the market, and we are referring to it as the correlation premium for asset-i. The proposition provides a novel theory of the cross-section of the expected returns, based on this correlation premium. Equation (Equation8
(8)
(8) ) tells us that each asset expected excess return i is the premium required to compensate an investor for the exposure of the asset-i return to all remaining asset returns. The contribution of asset-j return to the premium for asset-i, when the state is
, is
. That is,
is the correlation between asset-i and asset-j returns, correlation arising from the realization of the string;
is the unit risk premium that compensates for any risk correlated with the asset-j return; finally,
defines the size of the overall exposure of the asset-i return to the whole string, as explained in Section 2.1.
To illustrate Proposition 2.1, consider the following heuristic example based on a J-asset market, as summarized by table . Consider, say, asset-i. Its returns are exposed to the risk of co-movements with returns on asset-1, a risk summarized by the correlation, ; then,
is the risk of co-variation that returns on asset-i have with returns on asset-1. We term this co-variation ‘exposure’, in analogy with standard asset pricing terminology. Now, there are obviously J such exposures resulting from the realization of the string, including the variation of the very same asset-i returns. According to the model, each of these exposures receives a compensation. The correlation premium is the average premium,
, as summarized by table , i.e. the counterpart to equation (Equation9
(9)
(9) ) in this heuristic example.
Table 1. This table provides a heuristic construction of the expected return required to hold any asset i. The second column indicates how asset-i is exposed to fluctuations of any asset j. The second column is the unit risk premium required to bear a given exposure to any asset j, . The correlation premium,
, is the average of the exposures weighted by the unit risk premia.
This example illustrates that, in the model, exposures are the counterparts to the familiar ‘betas’ in standard factor models. That is, betas are asset returns sensitivities to changes in common factors; instead, in our model, exposures result from the asset returns sensitivities to changes in all the asset returns that arise through the realization of the string. Similarly, compensations are the counterparts to ‘lambdas’. But while lambdas are unit risk premia relating to the fluctuations of common and exogenous factors, compensations are, in our model, unit premia rewarding an investor for how each asset return co-varies with all remaining asset returns: there exists, then, a compensation for the exposure to each asset return in the assets universe. In Section 3, we formulate assumptions that help deal with these infinite dimensional problems, rendering our model tractable for empirical purposes. Prior to this formulation, we highlight some properties of the model that help distinguish it from the standard CAPM.
2.4. Relations with the standard CAPM
In the standard CAPM, the expected excess returns on each asset link to the market portfolio and, hence, to all assets' expected returns. What makes our model different? Heterogeneity: the property that the realized returns on each asset (to which any asset returns may be exposed to) are risks that require ‘their own’ compensation. In our model, then, the premium for investing in any risky asset compensates for the granular exposure of this asset returns to shocks in all other asset returns, as equations (Equation8(8)
(8) )-(Equation9
(9)
(9) ) predict. By contrast, the standard CAPM predicts that the cross-section of risk-premia reflects exposures to a common factor (the market portfolio), such that each of the assets in the market portfolio requires the same compensation for risk, mechanically adjusted for its market cap.
To highlight these differences, we analyze the cross-sectional difference of the expected returns by focusing on two arbitrary assets. For simplicity, we consider the simple case in which correlations, volatilities and unit string-premia are constant. Note that the standard CAPM predicts that, for any asset-i,
where
denotes the covariance between two portfolio returns, i and j,
is market cap of asset-i and, finally,
, and
. In order to focus on our theme in this paper–correlations–assume, next, that volatilities are constant in the cross-section,
(say). Then, the difference in premia for any two assets,
, is
where
is the standard unit risk premium, the Sharpe ratio. That is, the difference in premia is a weighted sum of the difference in correlations of the two assets' returns with respect to all remaining assets' returns. But crucially, in this model, each of the assets' returns receives the same compensation, λ.
Our string model works differently. By equations (Equation8(8)
(8) )–(Equation9
(9)
(9) ), the differences in premia required to invest in a and b are
For the string, the difference in correlations with asset-j is weighted by
, which varies over
: the returns of each security contribute to the overall risk of any asset and requires ‘its own’ compensation, which is proportional to
, as explained in table . In other words, in the string model, there is a risk-premium related to each security j; in the standard CAPM, there is a unique premium, λ, for all securities.
Now, analytically, and under all the assumption in this section, the string model collapses to the CAPM under the razor's edge condition by which , for all i. However, this condition bears little economic meaning: the terms
are string-premia (that is, compensations for risk), whereas,
are, more mechanically, cap weights. The next section explains that, in Appendix 2, we have developed a consumption-based string model where the string-premium relating to any asset-j may be increasing in the dividend share of this asset. While dividend shares could be a possible proxy for firm size, they are however quite distinct from market caps. Even more crucially, the condition that high string-premia increase with firm size is strongly rejected by data (see Section 4) as our empirical analysis suggests a quite complicated structure for these string-premia. In Section 3, we proceed with the formulation of additional modeling details of the string-premia in the general random environment,
, which we rely on while estimating our cross-sectional restrictions.
2.5. Consumption-based correlation risk
What would a consumption-based model predict regarding the correlation premium? In Appendix 2, we study Euler's conditions in a string economy and identify the correlation premium that results in this economy. This premium is proportional to a weighted average of all the assets' dividend volatilities (weighted by the asset dividends' shares), where the proportionality factor is the CRRA (see equation (EquationA15(A15)
(A15) )). One additional property of this economy is that the returns on each asset depend on the asset specific shock (as in equation (Equation1
(1)
(1) )) but also, indirectly, on the realization of the whole string (see equation (EquationA16
(A16)
(A16) )). This property arises due to market clearing, as equilibrium asset prices do in general depend on the realization of the whole share process, a complication well-known since previous work on consumption-based multi-asset models (see, e.g. Menzly et al. Citation2004). This property justifies an extension of the model in this section, whereby any asset-i returns are driven by a ‘compound string’, that is, by the realization of a convex functional of the whole string (i.e. not only by
). The reader will find details regarding formulation, solution and economic interpretation of the compound string model in Appendix 2. We now formulate additional assumptions regarding the main model we focus in this paper–the Conditional CAPM string model of this section–with the purpose of taking it to data.
3. A model with random correlations
This section provides model specifications that account for the salient empirical properties of (i) asset return correlations and (ii) the premia required to bear time-variation in these correlations.
It is well-known that asset correlations do indeed vary over time (see, e.g. Figure ). Initially, however, it is instructive to focus on our model implications in the simple case where correlations, variances and premia are all constant. Assume, then, that for all ,
for some constants
,
,
and a vector of constants
. Given these assumptions, Proposition 2.1 predicts that the expected excess returns on each asset-i are
(10)
(10)
We call
global correlation exposure (GCE) for asset-i, consistent with terminology in Section 2.3 (see table ): the risk premium on asset-i equals the product of a risk exposure,
, times the unit price of string-risk,
. We refer to
as ‘global’ because it is the average correlation of asset-i returns with all other asset returns. This decomposition of the expected returns is neat, but obtains due to the assumption that the unit prices of risk are constant in the cross-section. We now generalize the insights from this basic model and account for both time-variation in correlations and cross-sectional variations in the unit risk premia.
Figure 1. This picture depicts the average correlation exposure for 25 Size and Book-to-Market sorted portfolios, defined as , where
is the realized correlation between portfolios j and i, obtained through a rolling window equal to 22 days.
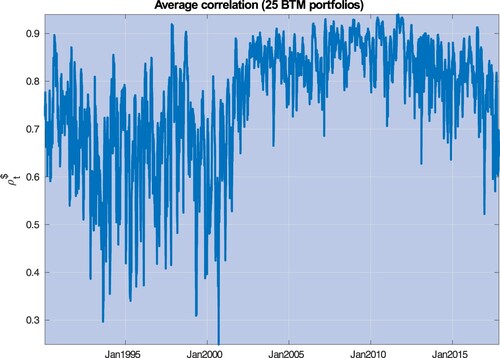
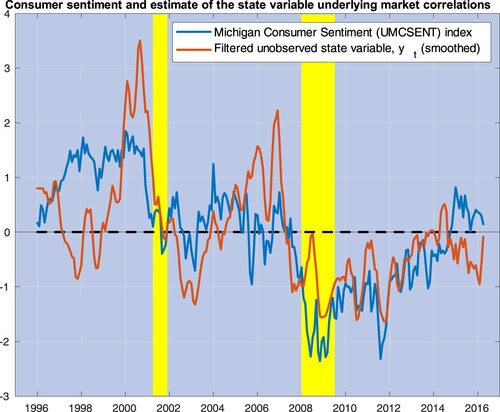
Figure 2. This figure plots three-month moving averages of the estimates of , the state variable driving market correlations (red line), along with the University of Michigan Consumer Sentiment (UMCSENT) index (blue line). Both variables are de-meaned and standardized by their own standard deviations. The yellow shaded areas cover recession episodes as determined by the National Bureau of Economic Research.
3.1. A factor model of asset correlations
Figure summarizes well-known evidence regarding time-variation in asset correlations. We consider 25 Size and Book-to-Market sorted portfolios and calculate realized correlations for each portfolio pair through one-month rolling windows estimates. Consider the empirical counterpart to the global correlation exposures in equation (Equation10
(10)
(10) ),
, where
denotes the realized correlation between portfolios j and i, and n = 25. We find that nearly 90% of the variability in these correlation exposures is explained by the first principal component. Figure plots the average correlation exposure, defined as
. Section 4.2 provides a detailed description of the historical episodes leading to the main spikes experienced by additional measures of correlation exposures (see figure and table ).
The fact that a large portion of the correlation exposures is driven by a single principal component suggests that a parsimonious model may help explain time-variation in these correlations. We now proceed with such a model while still assuming that correlation is priced in accordance with the string model of Section 2. We assume that the asset correlations are driven by a diffusion process , a scalar. To keep the model as simple as possible, we still assume that the exposures to strings are constant and independent of i, i.e.
; and we assume that the string correlation function is
(11)
(11)
where
and
are matrix coefficients independent of time, and such that
and
, and
is solution to a square root process
(12)
(12)
for three positive constants κ, m and η. Under standard parameter restrictions,
stays strictly positive, hence, this specification for
bounds
to be inside the unit circle as soon as
.
Note that a string model for pairwise correlations may well be an alternative to the modeling assumptions underlying equations (Equation11(11)
(11) ) and (Equation12
(12)
(12) ). However, we adopt the assumptions of this section because our main focus is on the cross-section of expected returns and last, but not least, for the sake of simplicity. The formulation in (Equation11
(11)
(11) ) is both analytically convenient and intuitive: correlations are made up of a constant and a dynamic component, with sensitivities to changes in
,
, which vary across all asset pairs. For the purpose of identifying the model, we need to fix the sign of
, and we work with
. We shall, then, refer
to as a pro-cyclical variable: correlations are down when
is up. Note, however, that correlations are not always linked to the business cycle. There might be correlation spikes during periods of financial distress, but such episodes may well be transitory and occurring during a favorable phase of the business cycle, as in the instances identified and discussed in Section 4 (see Figure ).
In other words, our model merely defines bad times as times of high correlations. Is there a more precise interpretation of our unobserved factor? Figure plots monthly estimates of obtained in Section 4 against the University of Michigan Consumer Sentiment (UMCSENT) index; both series are de-meaned and standardized by their own standard deviation. This index is known to track reasonably well the long swings in consumers' ‘sentiment’ around business cycle fluctuations. Our extracted variable correlates with this index at approximately 60%. In previous work, Corradi et al. (Citation2013) have noticed that long-run movements in stock market fluctuations link to this index. It is remarkable that market correlations (Wall Street) and consumer sentiment (Main Street) are also statistically quite closely related.
3.2. The correlation premium
The next corollary summarizes cross-section restrictions resulting from the assumptions formulated in Section 3.1.
Corollary 3.1
(One-factor correlation premia)
Assume that the correlation function satisfies equation (Equation11(11)
(11) ), where
is solution to equation (Equation12
(12)
(12) ), and that each asset return variance is constant and equal to
for asset-i. Then, the expected excess returns in Proposition 2.1 (equations (Equation8
(8)
(8) )-(Equation9
(9)
(9) )) are
(13)
(13)
Thus, the cross-section of the expected excess returns is driven by a single, pro-cyclical state variable, . Moreover, under conditions on
discussed in a moment, expected excess returns are decreasing and convex in
, that is, they are countercyclical and react asymmetrically to
: they increase in bad times more than they lower in good. This property is known to hold, empirically, at the aggregate level, and at a business cycle frequency (see Mele Citation2007). However, a similar property may not necessarily hold for the model in this paper because correlations may well spike in good times, as discussed in the previous section.
Furthermore, some assets may display a few desirable properties due to their ability of being more resilient to systemic shocks: while a very few assets may occasionally withstand to a widespread turmoil where there is ‘no place to hide’ (see, e.g. Buraschi et al. (Citation2014)), some assets' performance, a subset say, may still suffer relatively much less than others' in bad times. This property makes these assets natural ‘hedges’: now, asset returns that have more exposure to those in
may require a lower premium. In Section 4, we provide evidence that big stocks display such hedging property, and that some portfolio returns particularly exposed to them may, then, be even pro-cyclical, under conditions (see Section 4.3).
We now proceed with specifying three functional forms for the string premia that we use in our empirical work.
(I) Constant premia. The correlation premium is constant both in time and in the cross-section, that is, . In this case, the correlation premium in equation (Equation13
(13)
(13) ) collapses to
(14)
(14)
where
, q = 0, 1. This model specification is a very minimal generalization of the constant correlation model in equation (Equation10
(10)
(10) ), whereby the global correlation exposure (GCE),
, is replaced with its dynamic counterpart,
. Still, the properties of
play an important role in the interpretation of our empirical results (see Section 4.3).
(II) Cross-sectional variation. The correlation premium for shocks on the asset return-j links to the dynamic GCE in (Equation14(14)
(14) ) for the same asset,
, according to
, for two constants
and
. The correlation premium for asset-i in Corollary 3.1 is
(15)
(15)
(III) Time series and cross-sectional variation. The correlation premium for shocks on asset-j links to
, according to
, for three constants
,
and
, such that the correlation premium for asset-i is
(16)
(16)
The rationale behind the specifications in (II) and (III) is the following. A parsimonious modeling assumption is that the premium
for exposure to asset returns-j reflects information on the dynamic GCE for the very same asset,
. In these formulations, then, this premium reflects both the unconditional part of
, i.e.
, and the exposure of
to movements in the state variable
,
. The difference between (II) and (III) is that the latter reflects both cross-sectional information (i.e. on
and
) and time series information (i.e. on the state of
). Note that the specification (III) encompasses (II), namely for
.
The following proposition gathers the expressions for the cross-section of the unconditional expected returns in the three specifications formulated above.
Proposition 3.2
(Unconditional correlation premia)
The unconditional expected returns predicted by (I) the constant premia model, (II) the cross-sectional variation model, and (III) the time series and cross-sectional variation model, are
(17)
(17)
where
,
,
,
, and
In Section 4, we estimate our string model while relying on its unconditional version predicted by Proposition 3.2, similarly as with standard methodology used with the Conditional CAPM (e.g. Jagannathan and Wang Citation1996, Lettau and Ludvigson Citation2001. We now develop additional cross-equation restrictions that we use while estimating the model. We address the question: is a source of priced risk?
3.3. The premium for correlation risk
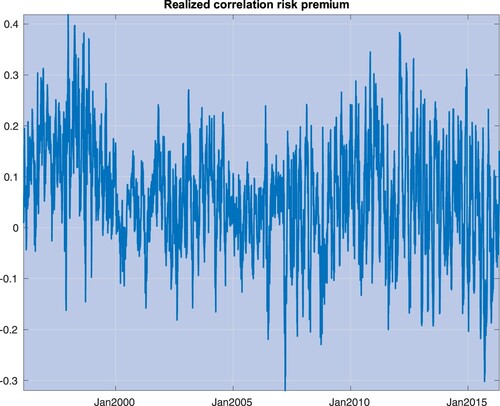
A key concept that has been extensively investigated in the empirical literature is the premium for correlation risk, defined as the difference between the expected integrated correlation under the risk-neutral probability and the physical probability, denoted hereafter as Q and P, respectively. If correlation was not a priced risk, this difference would always be zero. Figure depicts the realized premium for correlation risk for S&P 500 stocks, defined as the difference between option implied integrated correlations (that is, correlations expected under Q) and realized correlations (proxies for expectations under P). Section 4 contains a detailed description of our input data and computations used in figure .
Figure 3. This picture plots the realized premium for correlation risk for S&P 500 stocks, defined as the difference between (i) risk-adjusted expectations of one-month average correlations, and implied by option prices, and (ii) realized correlations, calculated throughout a one-month window.
Consistent with the empirical evidence, we assume that time-variation in correlations is a priced risk. Our point of departure is the string correlation function in equation (Equation11
(11)
(11) ). Let us integrate this function twice with respect to all asset pairs, obtaining the average correlation amongst all asset returns,
(18)
(18)
where we have defined
and
, q = 0, 1. The model-implied premium for correlation risk is defined as the difference between the average expected integrated correlation
in (Equation18
(18)
(18) ) under Q and that under P
(19)
(19)
where
denotes the expectation under Q given information at time-t, and T−t is a given time horizon.
In words, the premium for correlation risk compensates an investor for the fluctuations in the asset correlations. Note, also, that this definition is distinct from the correlation premium, i.e. in Proposition 2.1, as emphasized in the Introduction (see footnote 3). The correlation premium,
, compensates for any asset return exposure to all remaining asset returns. The premium for correlation risk,
, compensates for randomness in this exposure. Furthermore, note that
, the factor driving this random exposure, is not priced in the cross-section of the expected returns. Appendix B indicates how to proceed under the assumption that
is also priced in the cross-section of the expected returns. However, to keep the model as simple as possible, we do not consider this extension.
To render equation (Equation19(19)
(19) ) operational, we specify the unit risk premium for
. We assume that
for some constant ν, such that, under the risk neutral probability, Q,
(20)
(20)
where
is a standard Brownian motion under Q, and
Because
is interpreted as a pro-cyclical variable, we expect, and find, empirically (see Section 4.2), that
, meaning that
is more frequently in bad times under Q than under P (see Proposition A.1 in Appendix 1).
Let , where
denotes the parameter vector under the physical probability. Accordingly, denote with
the model-based premium for correlation risk in equation (Equation19
(19)
(19) ) for a given set of parameter values
. The next proposition, proved in Appendix 1, provides motivation for this notation as well as some properties of this premium for correlation risk.
Proposition 3.3
(Premium for correlation risk)
Assume that the premium related to Brownian fluctuations is . Then, the premium for correlation risk is
(21)
(21)
where
(22)
(22)
Moreover, for
, the premium for correlation risk is (i) strictly positive; and is (ii) increasing and concave in
for all
lower than some
; and (iii) decreasing and convex in
for all
higher than some
.
Proposition 3.3 tells us that, provided correlation risk is positively priced, , the premium for this risk achieves a maximum. In good times, when the pro-cyclical variable
is high, the premium for correlation risk rises as
lowers. As times deteriorate further, additional drops in
lead to a fall in this premium. This fall reflects that fact that, in bad times, correlations under P and under Q are already very high; because they are obviously both bounded, then, as
lowers, their difference tends to vanish. These properties are illustrated by the left panel in figure , which plots the premium for correlation risk
in equation (Equation21
(21)
(21) ), and its unconditional expectation, based on the parameter estimates obtained in Section 4.
Figure 4. This picture plots the one-month premium for correlation risk in equation (Equation21
(21)
(21) ) against the state variable
(left panel) and the average correlation predicted by the model,
in equation (Equation18
(18)
(18) ) (right panel). Parameter values are set equal to their estimates obtained in Section 4 (see table ). The red line is the unconditional expected value of the premium for correlation risk predicted by the model, i.e.
in equation (Equation26
(26)
(26) ).
![Figure 4. This picture plots the one-month premium for correlation risk P(yt;ϑ) in equation (Equation21(21) P(yt;ϑ)=ϱ1T−t∫tT(u(yt,τ−t;θ,ν)−u(yt,τ−t;θ,0))dτ,(21) ) against the state variable yt (left panel) and the average correlation predicted by the model, ρ(yt;ϱ) in equation (Equation18(18) ρ(yt;ϱ)=∬i,j∈[0,1]2ρ(yt;i,j)didj=ϱ0+ϱ1e−yt,(18) ) (right panel). Parameter values are set equal to their estimates obtained in Section 4 (see table 2). The red line is the unconditional expected value of the premium for correlation risk predicted by the model, i.e. E(P(yt;ϑ)) in equation (Equation26(26) E(P(yt;ϑ))=ϱ1T−t∫0T−t(u¯(x;θ,ν)−u¯(x;θ,0))dx,(26) ).](/cms/asset/ea56810d-3d88-4838-b415-c8ae6b7b12a9/rquf_a_2357189_f0004_oc.jpg)
The right panel of figure depicts the premium for correlation risk against the average correlation predicted by the model estimates, in equation (Equation18
(18)
(18) ), obtained while varying the state variable
driving them. The descending part of the curve in this right panel does correspond to the ascending part of the curve in the left panel. The model prediction, then, is that for most values of the instantaneous correlation, correlations and the premium for correlation risk are inversely related, with the premium achieving its maximum when correlation is about as low as 25%.Footnote5 These predictions are useful because, while
is not observed, we may estimate correlations and the premium for correlation risk based on observable quantities. Section 4 provides additional details on the testable implications of the model in this dimension, and evidence of a strong negative relation between correlations and the premium for correlation risk, consistent with the model predictions (see figure in Section 4.4).
4. Empirical analysis
4.1. Data and preparation of variables
4.1.1. Sources
For the model calibration, we require data on a wide panel of individual stocks belonging to a large index with traded options, and also data on a smaller panel of realized returns for a set of test assets. The first large panel is used to estimate the correlation state variable, and the smaller panels are then used to test our cross-sectional predictions. We rely on a daily data sample that runs from January 1996 until April 2016. For the smaller panels, we use returns on standard Fama-French portfolios. We calculate second moments (volatilities, correlations, and factor betas) based on daily returns, and then proceed to estimate risk premia relying on monthly portfolios returns.
As a broad sample of individual stocks, we select all constituents of a market-wide index, namely, S&P500. The composition of S&P500 index is obtained from Compustat and merged with CRSP through the CCM Linking Table using GVKEY and IID to link to PERMNO, following the second best method from Dobelman et al. (Citation2014). The data on daily returns and market capitalization are obtained from CRSP, and as a proxy for index weights on each day, we use the relative market cap of each stock in an index from the previous day.
For the cross-sectional tests, we use a number of standard portfolios, sorted by characteristics such as market equity (ME), book-to-market (BTM), investment (INV), operating profitability (OP), momentum (MOM), and reversal (REV). We obtain daily and monthly returns for these portfolios from Kenneth French data library. The cross-sectional pricing results are based on six sets of portfolios, each with 25 assets stemming from different two-way sorting procedures. We use the following data sets: 5×5 ME-BTM, 5×5 ME-INV, 5×5 ME-MOM, 5×5 ME-REV, 5×5 ME-OP, and 5×5 ME-BTM Global portfolios.
We would like our model to deliver not only cross-sectional pricing performance, but also to be consistent with the premium for correlation risk. To help achieve the second task, we rely on option data on the S&P500 index and all its constituents and compute the time series of the implied correlations and the premia for correlation risk, defined below. Implied correlations are estimated by comparing the index variance with the variance of the portfolio of index components. To compute the option-based variables, we rely on the Surface File from OptionMetrics, selecting for each underlying the options with 30, 91 and 365 days to maturity and deltas in the out-the-money range (that is, absolute delta weakly less than 0.5). While the surface data is not suitable for testing trading rules due to extensive inter- and extrapolations of market data, it proves to be a valuable source of information that can be used in asset pricing tests or in generating signals for trading.
4.1.2. Model inputs
The estimation of our model requires calibrating the string correlation function in (Equation11(11)
(11) ) to its empirical counterparts. We calibrate the model in a way that the correlation state variable
reproduces model dynamics for the average correlation in (Equation18
(18)
(18) ) and its risk-neutral equivalent (defined in a moment) that match as closely as possible their empirical counterparts. As for these empirical counterparts, we rely on average correlations obtained through the equicorrelation amongst all S&P500 components. Equicorrelation is a useful measure of the average level of market-wide correlations and, hence, it may reasonably be based upon for the purpose of proxying the dynamics of our state-variable. Equicorrelations are computed assuming that, in each day, all pairwise correlations are equal.Footnote6
Consider a basket of assets with a variance equal to at time-t:
where
are the asset portfolio weights. Given a time-series of variances of this basket,
, of its components
, and the index weights,
, equicorrelations are obtained as the single number
calculated in each day t as
(23)
(23)
Note that the resulting correlation matrix of the assets in the basket is positive-definite, provided the equicorrelation is non-negative, which is the case in our empirical implementation of (Equation23
(23)
(23) ). In the sequel, we refer to ‘implied correlation’ for the risk-neutral, and ‘realized correlation’ for the realized equicorrelations.
Option-implied variances are computed as model-free implied variances (Dumas Citation1995, Britten-Jones and Neuberger Citation2000, Bakshi et al. Citation2003). We compute realized variances using daily returns and a window length equal to one month. Thus, after plugging the implied or realized variances into equation (Equation23(23)
(23) ), we end up with the monthly implied or realized correlations, respectively. The premium for correlation risk is calculated as in Driessen et al. (Citation2005) as an implied correlation at the end of day-t minus 22-day moving averages of the realized correlations under P calculated through (Equation23
(23)
(23) ). We denote the estimate of this premium at time-t with
. Likewise, let
denote the realized correlation at time-t. As primary data series for calibrating the parameters governing the dynamics of
, we use one-month realized correlation,
, and such is, then, the time horizon of the corresponding premium for correlation risk,
. To calibrate the string correlation function (i.e.
and
in (Equation11
(11)
(11) )), we calculate equation (Equation23
(23)
(23) ) using realized standard deviations on each single asset. Pairwise correlations are computed from daily returns by relying on standard formulas. Finally, the cross-sectional tests of our models are based on monthly realized excess returns of test portfolios. The excess returns are computed as realized monthly returns minus the one-month Treasury bill rate (from Ibbotson Associates) obtained from the Kenneth French data library.
4.2. Cross-equation restrictions and state variable estimates
We develop moment conditions that we use to estimate , the parameter vector related to the dynamics of the pro-cyclical state variable
under P (see Section 3), the correlation exposures
and
, and the coefficient ν of the premium for correlation risk. Finally, we explain how we proceed to recover estimates of the pro-cyclical state variable for each date in our sample.
4.2.1. Matching correlations and the premium for correlation risk
The next proposition provides moment conditions that we use to estimate .
Proposition 4.1
(Correlation moment conditions)
For any integer n, the n-th uncentered unconditional moment of is
(24)
(24)
For any fixed Δ, the unconditional covariance of
with
is
(25)
(25)
Provided the state variable is mean-reverting (
), the auto-covariance of the integrated correlation,
, is strictly positive and vanishes to zero, eventually. The higher κ, the higher the vanishing rate, just as for the original state variable
. Note, also, that m, the unconditional mean of
, can be identified with enough moment conditions. Intuitively, the variance of a square root process is level-dependent, such that the whole autocovariance function of
is level-dependent too.
Proposition 4.1 helps reconstructing the dynamics of under the physical probability. Moreover, we may rely on the model-implied premium for correlation risk in Proposition 3.3 and derive additional parameter restrictions. In Appendix 1, we show that the unconditional mean of
is
(26)
(26)
where
We use a moment condition based on equation (Equation26
(26)
(26) ) as an additional cross-equation restriction for
. Note that we do not need this restriction in order to estimate the cross-section of expected returns. However, it helps pinning down the level of the premium for correlation risk to its historical average, through the parameter ν. (The horizontal, red lines in figure are the values of
implied by our parameter estimates.) Precisely, let
and let N denote the sample size. Define
where N subscripts indicate empirical moment estimates and, finally,
denotes the set of lags chosen while calibrating the model-implied autocovariance function to its data counterparts: two weeks, one month and two months. Our GMM estimator is obtained as
(27)
(27)
where
is a weighting matrix that minimizes the asymptotic variance of the estimator, which we estimate, recursively, as
.
Therefore, we rely on 7 moment conditions to estimate 6 parameters. Table contains parameter estimates and associated t-statistics. All parameter estimates are highly statistically significant.
Table 2. GMM estimates of in (Equation27
(27)
(27) ) and t-stats.
4.2.2. Estimates of correlation exposures
To implement cross-sectional estimates of the model in (Equation13(13)
(13) ), we need to estimate the asset return correlation exposures in equation (Equation11
(11)
(11) ),
and
and, thus, build up estimates of the state. We rely on estimates of
obtained while minimizing a distance of the model predictions to the data proxies
and
,
(28)
(28)
where
is defined in (Equation18
(18)
(18) ) and
denotes the model counterpart to
.Footnote7 Therefore, we are using option data for the purpose of extracting information on the state variable that drives the assets' correlations. This objective is not strictly needed while only focussing on the cross-section of expected returns–we could have omitted the second term of the minimand in (Equation28
(28)
(28) ). However, option data may provide additional and useful information for the purpose of estimating both correlation premia and the cross-section of expected returns.
Estimates of the correlation exposures, say and
are, then, obtained while regressing data proxies,
say, onto a constant and
, under the restriction that the coefficient estimates sum up to the GMM estimates in (Equation27
(27)
(27) ), viz
Finally, we use
and
in equation (Equation13
(13)
(13) ) and implement cross-sectional estimates of the prices of risk
while fitting the unconditional version of the model predicted by Proposition 3.2 in its three versions, as implied by (Equation14
(14)
(14) ), (Equation15
(15)
(15) ), and (Equation16
(16)
(16) ). Section 4.3 discusses results on these estimates.
Figure depicts the estimates of the state obtained through (Equation28(28)
(28) ) as well as a comparison of the average correlations predicted by the model with those in the data. Model predictions are obtained as 22-day rolling window averages of
, and average correlations in the data are obtained in the same way from S&P 500 stocks. The model tracks all the major episodes of spikes in correlations that occurred during our sample period (defined as the nine episodes in which model-based correlations reached their highest levels). Table provides a succinct description of the events leading to these spikes.
Figure 5. The top panel depicts estimates of the pro-cyclical state variable, , obtained by matching the model predictions on realized correlations and the premium for correlation risk, as in equation (Equation28
(28)
(28) ). The bottom panel depicts the average correlation in the data (solid, blue line) and the average correlation predicted by the model (dashed, red line). The numbered circles identify events described in table .
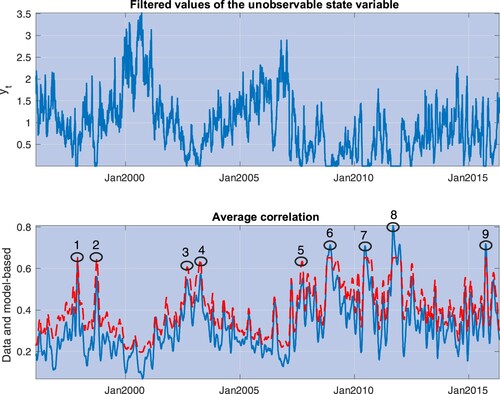
Table 3. This table provides descriptions of the major events leading to the spikes in correlation depicted in Figure .
We now turn to provide cross-sectional estimates of the price of risk and discuss the model implications on the cross-section of expected returns.
4.3. Cross-sectional pricing
We test the unconditional version of the asset pricing model (Equation13(13)
(13) ), implied by the three dynamic specifications of the premium for correlation risk predicted by Proposition 3.2: (I) constant premium
both in time and cross-sections, (II) premium with cross-sectional variation
, for two constants
and
, and (III) premium with time and cross-sectional variation
, for three constants
,
and
.
We employ a two-pass Fama-MacBeth (Citation1973) procedure to estimate the coefficients of the string premium . We estimate these coefficients by regressing the cross-section of the test portfolio realized returns onto the cross-sectionally exogenous variables appearing on the R.H.S. of equation (Equation17
(17)
(17) ) (e.g.
, for x = 0, 1, 2, for Model III). Note that the three specifications are all linear in the premium coefficients, which facilitates calculations and statistical inference. Specifically, for each portfolio i in a given set of test portfolios, we compute the model-based expected return using as inputs the estimate of the volatility parameter
, the estimates of the unconditional moments of the correlation level
,
, and the estimates of the correlation exposures
and
. We gauge the overall model fit by comparing the unconditional model-based average returns with the realized returns for the whole sample period. Tables to provide parameter estimates and adjusted-
for the three models on six sets of test portfolios.
Table 4. This table provides parameter estimates of in the constant string premium Model I,
(with t-stats below), and the pricing performance expressed as the average pricing error (α is annualized) across a given set of portfolios, and the fit of the model (adjusted-
,
) from this regression.
Table 5. This table provides parameter estimates of and
in the cross-sectional variation premium Model II,
(with t-stats below) and the pricing performance expressed as the average pricing error (α is annualized) across a given set of portfolios, and the fit of the model (adjusted-
,
) from this regression.
Table 6. This table provides parameter estimates of ,
and
in the time and cross-sectional variation premium Model III,
(with t-stats below), and the pricing performance expressed as the average pricing error (α is annualized) across a given set of portfolios, and the fit of the model (adjusted-
,
) from this regression.
For comparison, table provides adjusted- for a number of unconditional linear factor models fitted to the same portfolio returns of tables through : the CAPM, and 3- (Fama and French Citation1993), 4- (Carhart Citation1997) and 5- (Fama and French Citation2015) factor models. As with our string models, these measures of fit are obtained by fitting average excess returns of the test assets through the average returns predicted by the models. Our Models II and III seem to provide a quite reasonable fit and, with the exception of one case (5×5 ME-INV), certainly better than the linear factor models. Consider the following heuristic calculations. If we average the
across all portfolios in table , we obtain 0.222 (CAPM), 0.125 (3-F), 0.403 (4-F) and 0.397 (5-F). In comparison, the average
in table for the string Model III is 0.611, a performance much better than that of the 4-F model. Appendix 3 contains results regarding S&P 500 sectors and index-based portfolios, and achieves to equally encouraging conclusions: on average, our string models perform essentially the same as the 4-F model, but better than others. We now discuss our results on string models in detail.
Table 7. This table provides adjusted- from linear factor model regressions across the portfolios analzyed in tables through . The four columns provide the adjusted-
for the CAPM, the 3-F model (market, value, and size), the 4-F model (market, value, size, and momentum), and the 5-F model (market, size, value, profitability, and investment factors).
The helicopter view at the models' estimates tells us that the constant risk premium in both cross-sectional and time-series dimensions does not seem to do a good job: the estimate of the string risk premium is not significant and, sometimes, comes with a counterintuitive negative sign. In fact, a negative sign of for some asset j may turn out to be an interesting property, as discussed below; however, Model I estimates imply that, for certain test portfolios,
is negative, implying that the unit risk-premium is negative for all j. Furthermore, for half of the test portfolios, there is an insignificant relation between predicted and realized returns. Finally, the unconditional pricing performance is quite poor, with
ranging from negative to less than 20%. Allowing for variation in the premium in the cross-sectional dimension turns out to be very important, producing significant parameter estimates of
and
. For all the test portfolios, the model has a reasonable pricing fit, with cross-sectional
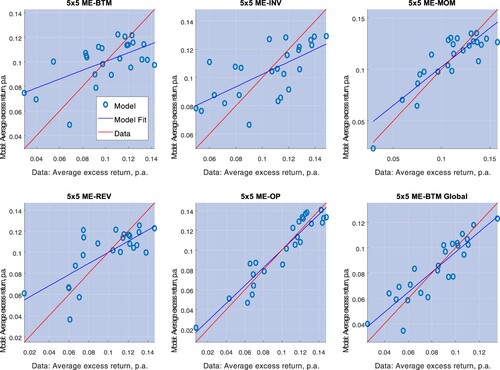
varying from 20% to nearly 80%, with the best fit displaying at the level of the global ME-OP portfolios. Time-variation in the string risk premium (Model III) provides a marginally improved performance (see table ), with results very similar to those of Model II. Figure provides scatterplots of the unconditional expected returns predicted by Model III against average realized returns.
Figure 6. This picture depicts average excess returns and Model III predictions on the unconditional expected excess returns (the unconditional correlation premium of Proposition 3.2), for 5×5 ME-BTM, 5×5 ME-INV, 5×5 ME-MOM, 5×5 ME-REV, 5×5 ME-OP, and 5×5 ME-BTM Global portfolios.
Which portfolios contribute to the unconditional premia displayed in figure ? What are the model predictions on the correlation premia conditional on the realization of (say,
in equation (Equation16
(16)
(16) ))? Figure plots average unit string premia,
, for each portfolio test, across all portfolios j comprising that test, obtained while fixing the state variable at the sample value taken by
over the sample size. In each test, the first 5 portfolios correspond to those with the smallest size (i.e. in the first quantile) and are ordered from the lowest to the highest characteristics (for example, in the case of the 5×5 ME-OP portfolio test, from the lowest to the highest operating profitability); portfolios from 5i + 1 through
are ordered similarly, with i = 1 identifying portfolios with the second smallest size quantile, and i = 4 identifying portfolios with the biggest size. The picture also depicts average returns on all portfolios.
Figure 7. This picture depicts average excess returns and the unit risk premia for each portfolio, with the latter estimated from Model III. The estimates are performed for 5×5 ME-BTM, 5×5 ME-INV, 5×5 ME-MOM, 5×5 ME-REV, 5×5 ME-OP, and 5×5 ME-BTM Global portfolios.
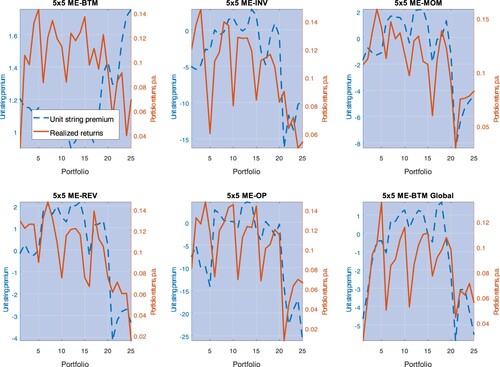
The unit string premia track the ‘shark-tooth’ pattern of the portfolios' expected returns quite well: with the exception of the first portfolio test (5×5 BE-BTM), the higher the average return on portfolio-j, the higher in general. Furthermore,
is negative for both small and big size portfolios. To facilitate the interpretation of these findings, recall the heuristic explanations in table . The contribution of portfolio-j to the premium of portfolio-i is proportional to
, where
is the risk of co-variation that portfolio-i returns have with j, and
is the unit risk premium commanded by any asset for the exposure to portfolio-j returns. Thus, portfolios with negative
may be interpreted as ‘correlation-hedges’, in that assets more exposed to them require lower overall expected returns. Figure shows very clearly that small size and big size portfolios are such correlation hedges. However, exposure to middle size portfolios commands positive unit string premia. We shall return to the correlation-hedge properties of big size portfolios in a moment.
We qualify our findings: How do conditional premia relate to the average market correlation? The key relation is that between the unit string premium and ,
, the portfolios' exposures to the average market correlation (see Section 3.2):
These two exposures have a natural interpretation. Note that the dynamic GCE introduced in (Equation14
(14)
(14) ),
(29)
(29)
is a measure of total connectivity of portfolio-j to all remaining assets in a given test. Now, the parameter estimates in Table suggest that
, that is, the unit string premium
for portfolio-j increases with the constant connectivity component of portfolio-j,
. The only exception is the first portfolio test, which, from now on, we shall not comment on.
More subtle is the relation between the unit string premium and the variable part of in (Equation29
(29)
(29) ), i.e. the conditional connectivity of portfolio-j. Note that
measures the sensitivity of portfolio-j total connectivity to changes in
. Table estimates suggest that
for all
, such that the unit string premium
decreases with
for all of our test portfolios. That is, portfolios with higher
provide better correlation hedges. Figure shows that portfolios with the highest
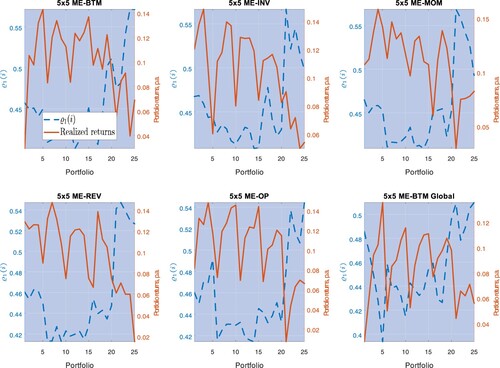
tend to be big size, and that these portfolios also command lower average returns. Note that these properties are specific to big stocks: in Appendix 3, we find that the unit string premium generally increases with
for S&P 500 sectors and index-based portfolios. Furthermore, note that for some of the test portfolios in Table ,
; in these cases, the previous effects become stronger in bad times: the lower
, the stronger the inverse relation between the unit string premium and conditional connectivity. Now, big stocks provide ‘dynamic correlation-hedges’: after a negative shock in
, assets that are more exposed to stocks with higher conditional connectivity (i.e. assets i with a higher
) require a lower premium in bad times.
Figure 8. This picture depicts average excess returns and the sensitivity of the conditional sensitivity, , for each portfolio, with the latter estimated from Model III. The estimates are performed for 5×5 ME-BTM, 5×5 ME-INV, 5×5 ME-MOM, 5×5 ME-REV, 5×5 ME-OP, and 5×5 ME-BTM Global portfolios.
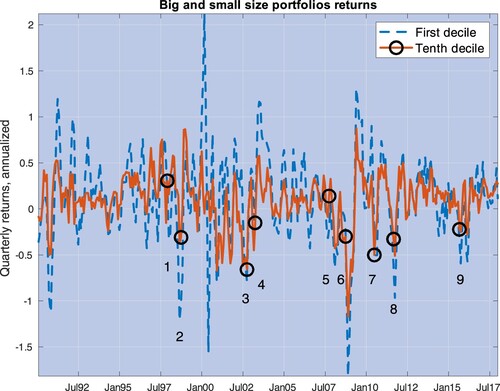
These correlation-hedge properties suggest one interpretation of the low average returns that big stocks display: big stocks provide some hedging properties, which manifest through the previous correlation-hedge channel; investors seek exposure to them, and these stocks, then, provide low average returns. It remains an open question as to why big stocks' connectivity increases in bad times, and why investors seek exposure to them–that is, why big stocks have such hedging properties. A natural explanation is that big stocks are likely to be resilient to systemic shocks (i.e. shocks by which market correlations become high), and that these stocks are also the most interconnected with the rest of the economy. Consistent with this hypothesis, we find that big size portfolios are more resilient than small during systemic events, and quite substantially. Precisely, we calculate quarterly returns for portfolios in the first (small) and tenth (big) decile and find that, while these returns average 12.72% and 10.13%, respectively, big size portfolios realized (annualized) returns are on average 12.40% higher than small across the nine systemic events identified in figure (see table ). Figure depicts these returns in our sample, along with these systemic events.
Figure 9. This picture depicts quarterly realized returns of portfolios sorted by size in the first decile (dashed, blue line) and the tenth decile (‘big size’) (dashed, blue line). The numbered circles identify the same events in figure (see table ) and are placed around the realization of big size portfolios returns.
When , assets that are more exposed to big stocks even require a lower premium in bad times. These properties imply that some test portfolios, i.e. those for which there is a sufficiently high exposure to big size portfolios, may exhibit a cross-section average premium that is pro-cyclical: their expected returns decrease in times of high market correlations. Figure shows that this is the case of the 5×5 ME-REV and 5×5 ME-BTM Global test portfolios. Figure also shows that, in the remaining cases, expected returns may be both counter-cyclical (5×5 ME-INV and 5×5 ME-OP) or non-monotonic in
(5×5 ME-MOM).
Figure 10. This picture depicts the relation between the conditional correlation premium predicted by Model III (equally weighted across all portfolios) and the state variable regarding 5×5 ME-BTM, 5×5 ME-INV, 5×5 ME-MOM, 5×5 ME-REV, 5×5 ME-OP, and 5×5 ME-BTM Global portfolios. The red, horizontal line is the unconditional premium for each of these portfolios.
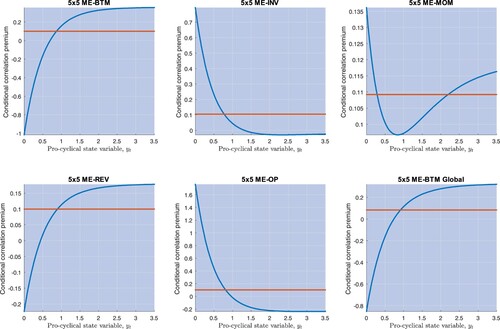
4.4. Premium for correlation risk
Next, we examine the model predictions on the premium for correlation risk. Proposition 3.3 (see Section 3) suggests a theoretical relation between realized correlations and the premium for correlation risk. In Section 3 we explained that, given our parameter estimates, this relation should be roughly inverse for most of the time (see figure ). We calculate data counterparts to this relation. We approximate the premium for correlation risk with its realized counterpart, defined as the difference between average correlations (implied and historical) over the past 22 days. We also compute the model-implied realized premium for correlation risk, estimating P-correlations through the average correlations calculated over the last 22 days, and relying on the estimates of the state
in Section 4.2.
Figure plots the results. The model predicts that the premium for correlation risk is statistically inversely related to realized correlations, as in the data. In terms of the explanations of Proposition 3.3 in Section 3, in bad times, when implied and realized correlations are both high, the premium for correlation risk decreases: implied correlations are obviously bounded and, then, a further increase in both correlations may translate into a decreasing difference between implied and realized correlations. Figure shows that this effect is so strong that the premium for correlation risk is negatively related to realized correlations.
Figure 11. This picture depicts scatterplots of realized premium for correlation risk for S&P 500 stocks against one-month realized correlations. Blue and red dots identify pairs in the data and pairs predicted by the model, respectively.
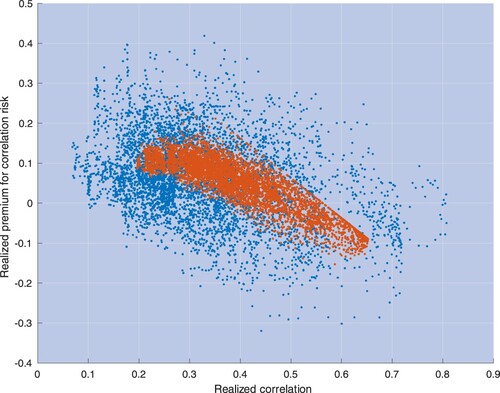
Figure 12. This picture depicts the unconditional premium for correlation risk calculated for horizons equal to 1, 3, 6, 9, and 12 months. The circles are data estimates, computed as described in the main text. The solid curve depicts model predictions, obtained while fixing parameter values at the GMM estimates in (Equation27(27)
(27) ), which rely on one moment condition based on one-month unconditional premium.
Because implied correlations are on average higher than realized, we might, then, also expect that implied correlations move less than one-to-one with realized correlations. It is indeed the case. Table reports regression estimates that reveal this property holds both in the data and for the model. These properties are in contrast with the empirical evidence in the equity volatility space, where volatility risk-premia do actually increase in bad times (see Corradi et al. Citation2013).Footnote8
Table 8. This table provides estimates (with standard errors in parenthesis) and adjusted- for the coefficients a and b in the linear regression
, where
is the one-month expected correlation for S&P 500 stocks under the risk-neutral probability, Q, and
is the one-month realized correlation.
Finally, we examine the model implications on the term structure of unconditional premia for correlation risk. The GMM estimator in (Equation27(27)
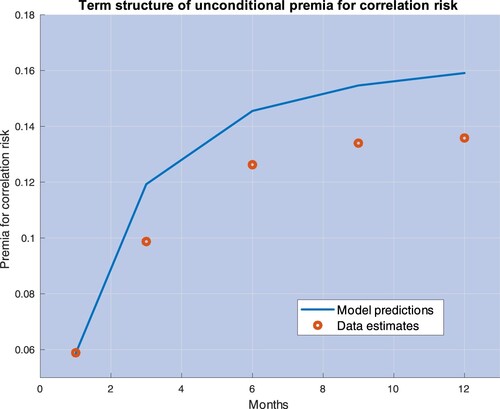
(27) ) relies on moment conditions that include the unconditional one-month premium for correlation risk. Yet our model allows us to consider any arbitrary horizon. Figure plots the average premium for correlation risk estimated from data along with the expression for
in (Equation26
(26)
(26) ), calculated with parameter values based on our GMM estimates. The model reproduces the upward sloping curve in the data and comes close to quantitatively match the unconditional premia for correlation risk estimated on data at all horizons up to one year.
5. Conclusion
This paper introduces an arbitrage pricing model by which the cross-section of expected returns relates to the granular exposure of each asset return with respect to all remaining returns. That is, we model asset risk premia as being directly driven by the very same assets' correlations, and not by a number of a pre-determined factors. More precisely, our model takes asset returns to be driven by the realization of a string, which, then, determines returns co-movements and the whole set of correlations amongst asset returns. In this setup, ‘risk’ is, thus, determined by the joint fluctuations of asset returns in a given universe of securities, and the cross-section of expected returns reflects the exposures of any given asset price fluctuations to the fluctuations of the remaining asset prices. The cross-section of expected returns is simply given by these exposures, weighted through a premium functional.
Within this theoretical framework, we specify a number of models that we use in empirical work. We assume that the assets correlations in the string are random. While our econometric methodology only requires asset returns to estimate the cross-section of expected returns, we also use the cross-section of options on individual S&P500 components and extract information on the unobserved state underlying realized correlations at any given point in time. We develop method-of-moments conditions that we employ to estimate our model. With our estimates of the state, we reconstruct the dynamics of average correlations and premium for correlation risk, and, naturally, the cross-section of expected returns that are predicted by the model.
The model predicts the empirical patterns of premia for correlation risk, but also explains cross-sectional pricing in a number of portfolios, both in the U.S. and in the international stock universe, with a performance that is often better than that of standard linear factor models. The model predictions shed new light into the empirical properties of big shocks. Big stocks are correlation-hedges, in that assets that are more exposed to them require lower expected returns. Under conditions, portfolios particularly exposed to big stocks may even require lower returns in bad times (when all assets' correlations spike) than in good. The string model and its granular methodology provide a flexible and a complementary framework to the standard factor structure that may be used for cross-sectional asset pricing and also for quantifying risks that any individual portfolio may have in common with the whole cross-section of asset returns.
Acknowledgments
We wish to thank one Associate Editor and two anonymous referees for their comments and suggestions. We are also indebted to Yacine Aït Sahalia, Torben Andersen, Andrea Buraschi, Robert Kosowski and Fabio Trojani for discussions and comments.
Data availability
The authors confirm that the data supporting the findings of this study are available within its supplementary materials (available upon request).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 If Brownian motions can be thought of as particles that move randomly over time, a two-parameter random field can be thought of as the random motion of a string. A three-parameter random field is also known as a membrane. This paper deals with strings.
2 Thus, we rely on a factor model for asset returns correlations. The point of the paper is that we do not rely on a factor model for the cross-section of asset returns.
3 The premium for correlation risk compensates for the risk that correlations are random. Furthermore, in this paper, we are referring to the cross-section of expected returns (our main focus) as correlation premia to emphasize the role correlation plays within our string model. As noted earlier, our model predicts correlation premia could be non-zero even if correlations are constant (in which case the premium for correlation risk would be zero).
4 Numerous studies have devoted their attention to size characteristics and variations of the related factor. To name just a few, both Chan et al. (Citation1985), and Chan and Chen (Citation1991) looked at characteristics of small and large firms and the firm size effect; Fama and French (Citation1992) analyzed the cross-section of stock returns versus characteristics; Fama and French (Citation1995) connected size effects to the properties of firms' earnings. Later studies such as Campbell et al. (Citation2008) more specifically focussed on rationalizing size effects by connecting them to financial distress risk.
5 One instance of such an inverse relation is documented by Mueller et al. (Citation2017) in the foreign exchange market.
6 Elton and Gruber (Citation1973) are amongst the first to suggest this notion of correlation under the physical probability. Driessen et al. (Citation2005) and Skinzi and Refenes (Citation2005) extended this notion to the risk-neutral space to measure an average option-implied correlation representative of a universe of stocks.
7 Precisely, is the one-month realized average of
in (Equation21
(21)
(21) ) evaluated at the estimated parameter vector
.
8 Corradi et al. (Citation2013) (Section 4.2.5) provide such evidence relying on ex-ante volatility risk-premia, within a no-arbitrage model for equity volatility. In the interest rate volatility space, Mele et al. (Citation2015) and Mele and Obayashi (Citation2015) study some properties of the volatility risk-premium, without addressing the issue of the premium sensitivity to market conditions.
References
- Acemoglu, D., Carvalho, V.M., Ozdaglar, A. and Tahbaz-Salehi, A., The network origins of aggregate fluctuations. Econometrica, 2012, 80, 1977–2016.
- Al-Najjar, N.I., Factor analysis and arbitrage pricing in large asset economies. J. Econ. Theory., 1998, 78, 231–262.
- Allen, F. and Babus, A., Networks in finance. In Network-Based Strategies and Competencies, edited by P. Kleindorfer and J. Wind, pp. 367–382, 2009 (Wharton School Publishing: Philadelphia, PA).
- Bakshi, G., Kapadia, N. and Madan, D., Stock return characteristics, skew laws, and the differential pricing of individual equity options. Rev. Financial Stud., 2003, 16, 101–143.
- Banz, R., The relationship between return and market value of common stocks. J. Financ. Econ., 1981, 9, 3–18.
- Barrot, J.-N. and Sauvagnat, J., Input specificity and the propagation of idiosyncratic shocks in production networks. Q. J. Econ., 2016, 131, 1543–1592.
- Billio, M., Caporin, M., Panzica, R. and Pelizzon, L., The impact of network connectivity on factor exposures, asset pricing and portfolio diversification.” SAFE Working Paper Series 166, Leibniz Institute for Financial Research SAFE, 2017.
- Billio, M., Getmansky, M., Lo, A.W. and Pelizzon, L., Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J. Financ. Econ., 2012, 104, 535–559.
- Britten-Jones, M. and Neuberger, A., Option prices, implied price processes, and stochastic volatility. J. Finance, 2000, 55, 839–866.
- Buraschi, A., Kosowski, R. and Trojani, F., When there is no place to hide: Correlation risk and the cross-section of hedge fund returns. Rev. Financial Stud., 2014, 27, 581–616.
- Buss, A. and Vilkov, G., Measuring equity risk with option-implied correlations. Rev. Financial Stud., 2012, 25, 3113–3140.
- Campbell, J., Hilscher, J. and Szilagyi, J., In search of distress risk. J. Finance, 2008, 63, 2899–2939.
- Carhart, M., On persistence of mutual fund performance. J. Finance, 1997, 52, 57–82.
- Chan, K. and Chen, N., Structural and return characteristics of small and large firms. J. Finance, 1991, 46, 467–1484.
- Chan, K., Chen, N. and Hsieh, D., An exploratory investigation of the firm size effect. J. Financ. Econ., 1985, 14, 451–471.
- Colla, P. and Mele, A., Information linkages and correlated trading. Rev. Financial Stud., 2010, 23, 203–246.
- Corradi, V., Distaso, W. and Mele, A., Macroeconomic determinants of stock volatility and volatility premiums. J. Monet. Econ., 2013, 60, 203–220.
- Dobelman, J.A., Kang, H.B. and Park, S.W., WRDS index data extraction methodology. Technical Report TR-2014-01, Rice University, Department of Statistics, 2014.
- Driessen, J., Maenhout, P. and Vilkov, G., The price of correlation risk: Evidence from equity options. J. Finance, 2009, 64, 1377–1406.
- Driessen, J., Maenhout, P. and Vilkov, G., Option-implied correlations and the price of correlation risk. Working paper INSEAD, 2005.
- Dumas, B., The meaning of the implicit volatility function in case of stochastic volatility. HEC Working Paper, 1995.
- Elton, E.J. and Gruber, M.J., Estimating the dependence structure of share prices. J. Finance, 1973, 28, 1203–1232.
- Engle, R., Anticipating Correlations, 2009 (Princeton University Press: Princeton).
- Fama, E.F. and French, K., The cross-section of expected stock returns. J. Finance, 1992, 47, 427–465.
- Fama, E.F. and French, K., Common risk factors in the returns on stocks and bonds. J. Financ. Econ., 1993, 33, 3–56.
- Fama, E.F. and French, K., Size and book-to-market factors in earnings and returns. J. Finance, 1995, 50, 131–155.
- Fama, E.F. and French, K., A five-factor asset pricing model. J. Financ. Econ., 2015, 116, 1–22.
- Fama, E.F. and MacBeth, J.D., Risk, return, and equilibrium: empirical tests. J. Political Econ., 1973, 81, 607–636.
- Faria, G., Kosowski, R. and Wang, T., The correlation risk premium: International evidence. J. Banking Finance, 2022, 136, 1–14.
- Feng, G., Giglio, S. and Xiu, D., Taming the factor zoo: A test of new factors. J. Finance, 2020, 75, 1327–1370.
- Gagliardini, P., Ossola, E. and Scaillet, O., Time-varying risk premium in large cross-sectional equity data sets. Econometrica, 2016, 84, 985–1046.
- Goldstein, R.S., The term structure of interest rates as a random field. Rev. Financial Stud., 2000, 13, 365–384.
- Harvey, C.R., Liu, Y. and Zhu, H., …and the cross-section of expected returns. Rev. Financial Stud., 2016, 29, 5–68.
- Herskovic, B., Networks in production: Asset pricing implications. J. Finance, 2018, 73(4), 1785–1818.
- Jagannathan, R. and Wang, W., The conditional CAPM and the cross-section of stock returns. J. Finance, 1996, 51, 3–53.
- Karatzas, I. and Shreve, S.E., Brownian Motion and Stochastic Calculus, 1991 (Springer Verlag: New York).
- Kennedy, D.P., The term structure of interest rates as a Gaussian random field. Math. Finance, 1994, 4, 247–258.
- Kennedy, D.P., Characterizing Gaussian models of the term structure of interest rates. Math. Finance, 1997, 7, 107–118.
- Lettau, M. and Ludvigson, S., Resurrecting the (C)CAPM: A cross-sectional test when risk premia are time-varying. J. Political Econ., 2001, 109, 1238–1287.
- Mele, A., Asymmetric stock market volatility and the cyclical behavior of expected returns. J. Financ. Econ., 2007, 86, 446–478.
- Mele, A., Financial Economics, 2022 (MIT Press: Cambridge, Mass).
- Mele, A. and Obayashi, Y., The Price of Fixed Income Market Volatility, Springer Finance Series, 2015 (Springer Verlag: New York).
- Mele, A., Obayashi, Y. and Shalen, C., Rate fears gauges and the dynamics of fixed income and equity volatilities. J. Banking Finance, 2015, 52, 256–265.
- Menzly, L., Santos, T. and Veronesi, P., Understanding predictability. J. Political Econ., 2004, 112, 1–47.
- Merton, R.C., Optimum consumption and portfolio rules in a continuous-time model. J. Econ. Theory., 1971, 3, 373–413.
- Mueller, Ph., Stathopoulos, A. and Vedolin, A., International correlation risk. J. Financ. Econ., 2017, 126, 270–299.
- Ozsoylev, H., Walden, J., Yavuz, D. and Bildik, R., Investor networks in the stock market. Rev. Financial Stud., 2014, 27, 1323–1366.
- Ross, S.A., The arbitrage theory of capital asset pricing. J. Econ. Theory., 1976, 13, 341–360.
- Santa-Clara, P. and Sornette, D., The dynamics of the forward interest rate curve with stochastic string shocks. Rev. Financial Stud., 2001, 14, 149–185.
- Skinzi, V.D. and Refenes, A.-P.N., Implied correlation index: A new measure of diversification. J. Futures Markets, 2005, 25, 171–197.
- Tsoulouvi, H., Essays on stochastic volatility and random-field models in finance. PhD Thesis, London School of Economics, 2005.
Appendices
Appendix 1.
Proofs
Proof
(Proof of Proposition 3.2)
Consider, first, the following preliminary result: for any given ℓ,
(A1)
(A1)
where
Equation (EquationA1
(A1)
(A1) ) follows by a mere change in notation in a result to be stated below (see equation (EquationA5
(A5)
(A5) )). Taking the limits leaves
where
is defined in the proposition. The expressions for the unconditional expected returns in Proposition 3.2 immediately follow.
Before providing the proof of Proposition 3.3, we prove a statement given in the main text regarding the dynamics of the state variable under the risk-neutral probability.
Proposition A.1
(Dynamics of y under Q)
Consider two diffusion processes, , i = 1, 2, solutions to equation (Equation20
(20)
(20) ), viz
where
. Then,
a.s.
Proof.
The drift of is strictly less than the drift of
, and the proposition follows by a comparison theorem (e.g. Karatzas and Shreve (Citation1991, pp. 291–295)).
Proof of Proposition 3.3.
We provide details regarding the function in equation (Equation22
(22)
(22) ), as those regarding
follow through a change in notation. The function
satisfies the following partial differential equation
where subscripts denote partial derivatives. The boundary condition is
. Conjecture that
and plug this suggested function into the previous partial differential equation. The result is that α and b satisfy the following ordinary differential equations: for all
,
subject to the boundary conditions
and
. The solution for b and α follow by standard integration arguments and details are available upon request. Equation (Equation22
(22)
(22) ) and, then, equation (Equation21
(21)
(21) ) follow by taking the exponential,
, and noting that
.
Next, we show that, for ,
is (i) strictly positive, (ii) increasing and concave in y for low y, and (iii) decreasing and convex in y for high y. (Note, also that the arguments below would equally go through if
and
.)
The first property directly follows by Proposition A.1. However, we provide an alternative proof based on an argument that will be used to deal with the other proofs of the proposition. Note that the function is solution to the following partial differential equation
(A2)
(A2)
where
, and subject to the boundary condition
. Therefore, by the maximum principle for partial differential equations, we have that the sign of
is the same as the sign of
. Since
is strictly decreasing in y for any finite T, it follows that
is strictly positive, and so is
.
Regarding the second property (increasing and concave for low y) and the third (decreasing and convex for high y), differentiate equation (EquationA2(A2)
(A2) ) two times with respect to y, and denote with
and
the first and the second partial of
with respect to y. The result is that
and
are solutions to the following partial differential equations
(A3)
(A3)
and
(A4)
(A4)
subject to the boundary conditions
and
.
Equation (EquationA3(A3)
(A3) ) can be rearranged to yield
where
denotes the expectation is taken under the probability
, defined as
By the no-crossing property of a diffusion, the expectation
is increasing in the initial condition
and, thus, there exists a threshold
(resp.,
) such that for all
(resp.,
),
is positive (resp., negative). Based on equation (EquationA4
(A4)
(A4) ), we can make a similar argument and conclude that there exists a threshold
(resp.,
) such that for all
(resp.,
),
is negative (resp., positive).
Proof of Proposition 4.1.
The n-th conditional moment of is
where the second line follows by the binomial formula. Now, by Itô's lemma,
is solution to
where
and
. Therefore, by the expression for the conditional expectation of
in Proposition 4.1,
(A5)
(A5)
where, and using the fact that
,
Equation (Equation24
(24)
(24) ) follows by taking the limit
.
Next, we determine the following unconditional uncentered covariance
(A6)
(A6)
We have
By the Law of Iterated Expectations, and the expression for the conditional expectation of
in Proposition 3.3,
where
and
and
and
are as in equation (Equation22
(22)
(22) ) of Proposition 3.3. Applying again the expression for the conditional expectation of
in Proposition 4.1 and relying on arguments nearly identical to those used to derive the conditional moment in equation (EquationA5
(A5)
(A5) ),
where
Hence,
Therefore, the limit in (EquationA6
(A6)
(A6) ) is obtained as
Equation (Equation25
(25)
(25) ) follows by rearranging terms in
where the expression for
is obtained through equation (Equation24
(24)
(24) ) of the proposition.
Proof
Proof of equation (Equation26 (26) (26) )
(26) (26) )
We have, for l>t, and for fixed ,
(A7)
(A7)
By Proposition 4.1, and arguments similar to those leading to equation (EquationA5
(A5)
(A5) ),
where
Equation (Equation26
(26)
(26) ) follows by calculating the limits in (EquationA7
(A7)
(A7) ), using the definition of
and
in Proposition 4.1, and rearranging terms.
Appendix 2.
Extensions
A.1. A string-and-factor model of asset returns
We extend the model in Section 2 to a market in which asset returns are strings, but they are also affected by systematic factors driven by Brownian motions, assuming that
(A8)
(A8)
where
is a standard multidimensional Brownian motion,
, is a continuous function, in
and i, and represents the asset returns exposures to the systematic factors, the ‘betas.’ Remaining notation is as in equation (Equation1
(1)
(1) ).
The pricing kernel is still as in equation (Equation5(5)
(5) ), such that repeating the arguments leading to Proposition 3.3, but relying on equation (EquationA8
(A8)
(A8) ), leaves the following expression for the expected excess returns on any asset-
(A9)
(A9)
where
is as in equation (Equation9
(9)
(9) ). Compared to Proposition 2.1, this formulation adds a standard factor-risk premium to the explanation of the cross-section of asset returns,
.
A.2. Compound strings
We consider the following extension to equation (Equation1(1)
(1) )
(A10)
(A10)
where
for some functions
and
. The additional term,
, is a linear functional of the whole string, and will be referred to as compound string in the sequel. Note that the state,
, may not necessarily be a diffusion process. It may be a string, as in the example developed in Appendix A.3.
This extension accounts for economies in which each asset return reacts to shocks in the fundamentals pertaining to all remaining asset returns, that is, not only to ‘its own point-i’ of the string , but also to
for all j, directly. For example, in the illustrative model of Appendix A.3 , each asset return is driven by a shock on its dividend and, due to market clearing, on those affecting all the dividend shares (i.e. the proportions of aggregate dividends paid by each asset), leading to price dynamics that are a special case of equation (EquationA10
(A10)
(A10) ).
By arguments similar to those leading to Proposition 2.1, the expected excess returns on each asset are now given by (A11)
(A11)
The first term on the R.H.S. of equation (EquationA11
(A11)
(A11) ) is the expected return predicted by Proposition 2.1. The second term captures the premium due to the compound string in equation (EquationA10
(A10)
(A10) ). In our empirical work, we rely on the simple specification of the model that gives rise to Proposition 2.1. However, we now provide an example of a Consumption-based CAPM that leads to the assumptions underlying the predictions of equation (EquationA11
(A11)
(A11) ).
A.3. Example: A consumption-based CAPM
We consider a string version of a multi-asset economy in Mele (Citation2022, Section 9.9.1, p. 499), that is, an infinite horizon economy with a continuum of long-lived securities in . Each of these securities delivers an instantaneous dividend
at time-t, solution to
(A12)
(A12)
where
is a string, and
and
are asset-i dividend growth and volatility. We denote the string correlation function with
, as usual.
We assume that there is a single agent with instantaneous utility and constant relative risk aversion equal to γ, and subjective discount rate equal to δ. The model may well be extended throughout more general specifications of preferences, including habit formation.
Aggregate consumption and pricing kernel. Denote the aggregate dividends with . They satisfy
(A13)
(A13)
where
denotes the ‘dividend share’ of asset-i. In equilibrium, aggregate dividends equal aggregate consumption,
say, i.e.
. By Itô's lemma,
satisfies
(A14)
(A14)
where, denoting
and
,
It is easy to see that
, such that
.
In this economy, the stochastic discounting factor is . It satisfies
(A15)
(A15)
Note that
in equation (EquationA15
(A15)
(A15) ) is the compensation required to hold any asset, the returns of which are exposed to co-movements with the dividends paid by asset-j. Due to the nature of the model that we are dealing with (consumption-CAPM), the functional form for
in equation (EquationA15
(A15)
(A15) ) resembles that of the unit risk-premia arising within a multi-asset Brownian economy (see Mele (Citation2022, equation (9.120))). Because the model in this section relies on strings, this analogy is only formal: in the model of this appendix, the unit premium for asset dividend-j compensates for the risk that any other asset returns are exposed to; in the Brownian model, unit premia compensate for each Brownian motion that asset returns are exposed to.
Asset returns. We make a few simplifying assumptions to render the model analytically tractable. We assume that the representative agent has log-utility, , and that the drift of each share process in (EquationA14
(A14)
(A14) ) is linear in
. These assumptions lead to an affine model for the inverse of the price-dividend ratio,
say, similar as in Menzly et al. (Citation2004) (MSV, in the sequel) (see equation (EquationA17
(A17)
(A17) ) below). Asset returns are, then, shown to be
(A16)
(A16)
where
, a compound string.
Equation (EquationA16(A16)
(A16) ) is then a special case of equation (EquationA10
(A10)
(A10) ): the state is
, the collection of all the share processes, and the compound string is
, with
. That is, while each asset return depends on its own share process, each share process is driven by the realization of the whole string (see equation (EquationA14
(A14)
(A14) )). Therefore, in equilibrium, asset returns are also driven by a compound string. In this economy, the volatility of asset-i returns originates from two forces. The first is the volatility of the asset dividend growth,
. The second stems from fluctuations in its price-dividend ratio,
, which, in turn, originate from those in the dividend share,
: the higher the semi-elasticity of
, the more significant is this second source of volatility. The term
reflects both dividend volatility and price-dividend ratio volatility. Instead,
only reflects price-dividend volatility. Note, also, that the price-dividend volatility determines how the realization of the compound string affects asset returns.
Expected returns on each asset, , can now be determined through correlations and volatility, based on equation (EquationA11
(A11)
(A11) ). These details are in Proposition A.2 below, and in its proof. First, we derive the price-dividend ratios in this economy under the assumptions formulated so far, and additional ones.
Price-dividend ratios. Consider the general formulation for the price-dividend ratio for each asset
That is, in principle, the price-dividend ratio of any asset depends on the future paths of aggregate dividends, which, in turn, depend on the collection of all the shares process,
. This dimensionality problem simplifies when
, in which case, the price-dividend ratio on asset-i only depends on the asset relative share. Under the additional assumption that, in (EquationA14
(A14)
(A14) ),
, for some
and β, we have that
, where
(A17)
(A17)
The constants
satisfy
, and β is constant in time and across assets, such that the shares sum up to one for all t. Note that the price-dividend ratio has the same functional form as in MSV. However, the model implications on the correlation of asset returns and the cross-section of expected returns are distinct, as we now explain.
Let and
. We have:
Proposition A.2
(Correlation and expected returns)
We have
(A18)
(A18)
where
(A19)
(A19)
Proof.
By equation (EquationA11(A11)
(A11) ), and the expression for the unit prices of risk,
, the cross-section of expected excess returns is
(A20)
(A20)
where the term indicated in the brackets coincides with
due to the expression of
predicted by this model,
. Replacing the expressions for
(see equation (EquationA16
(A16)
(A16) )) into (EquationA20
(A20)
(A20) ), leaves
where the last line follows by the expression for
. equation (EquationA18
(A18)
(A18) ) follows by the definition of
and by a direct calculation.
The first term on the R.H.S. of equation (EquationA18(A18)
(A18) ),
, is the standard single Lucas' tree prediction. The second term can take either sign. For any asset-i such that the values of
across j make this second term positive, the expected excess returns are increasing in
. Intuitively, asset-i is not a good hedge if its share is positively correlated with a sufficiently large set of the assets' dividends. In this case, the expected return on asset-i is increasing in
, as this asset pays a larger portion of consumption. This conclusion is reversed (that is, the second term of the R.H.S. in (EquationA18
(A18)
(A18) ) is negative) when the covariance between asset-i share is negatively correlated with a sufficiently large set of the assets' dividends.
Note that in multi-asset economies with dividends driven by Brownian motions, expected excess returns that go beyond the standard Lucas' tree prediction are also explained by the covariance of the share process with aggregate consumption, just as in (EquationA18(A18)
(A18) ) (see Mele (Citation2022, equation (9.129), p. 502)). However, the Brownian model does not disentangle volatilities from correlations: if m and d denote the number of assets and Brownian motions, it is possible to show that
, but the covariance term,
includes dividends' exposures to Brownian motions, the d-dimensional vectors
(the counterparts to the components of
in equation (Equation4
(4)
(4) ) of the main text), which do not separate dividends' volatility from correlation, as in the string model (see (EquationA19
(A19)
(A19) )). Finally, the model in this section is distinct from that in MSV for two reasons: (i) in our model, aggregate consumption is not I.I.D., but results from aggregation (see equation (EquationA13
(A13)
(A13) )); (ii) ours is a string model.
Appendix 3.
Additional empirical evidence
Table A1 provides parameter estimates and adjusted- of Model III (see Proposition 3.2, equation (Equation17
(17)
(17) )) for S&P 500 sectors and index-based portfolios. Table provides adjusted-
for linear factor models fitted to the same portfolios in table A1.
Table D1. This table provides parameter estimates of ,
and
in the time and cross-sectional variation premium Model III,
(with t-stats below), and the pricing performance expressed as the average pricing error (α is annualized) across a given set of portfolios, and the fit of the model (adjusted-
,
) from this regression. The first column provides the number of stocks in each portfolio (J). The last line provides the average adjusted-
across all portfolios for each model.
Table D2. This table provides adjusted- from linear factor model regressions across the portfolios in Table A1. The first column provides the number of stocks in each portfolio (J). The second through the fourth provide adjusted-
for the CAPM, the 3-F model (market, value, and size), the 4-F model (market, value, size, and momentum), and the 5-F model (market, size, value, profitability, and investment factors). The last line provides the average adjusted-
across all portfolios for each model.
