
1. Introduction
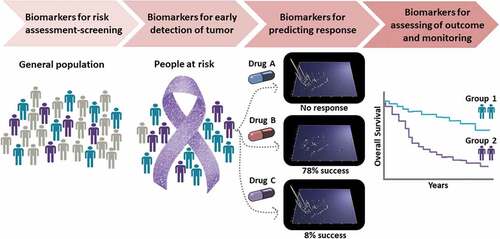
The use of biomarkers in oncology has revolutionized diagnosis, monitoring and treatment in many cancer types by promoting the concept of a personalized approach to guide treatment decision making and monitoring [Citation1]. Cancer biomarkers can assist in risk estimation, detection of a tumor or its recurrence, prediction of response to available treatments for the specific cancer type and assessment of treatment outcome, as illustrated in . The huge variability among patients with the same cancer type, as well as heterogeneity even within the same tumor specimens, necessitates a tailored cancer care according to individual patient or tumor characteristics.
Figure 1. Main applications of biomarkers in oncology.
2. State-of-the art in biomarker research and development
Considerable progress has been recently made regarding the implementation of biomarkers in cancer therapies, with approximately 55% of all oncology clinical trials in 2018 involving the use of biomarkers as stratification means [Citation1]. In addition, more than 25% of patients with cancer may receive a therapy following a prior biomarker testing [Citation1]. Some examples of biomarkers that are currently used in clinical practice to select patients that will benefit from a therapy include, among others, BRAF V600E or V600K mutations to guide treatment with vemurafenib plus cobimetinib in patients with unresectable or metastatic melanoma [Citation2]; BRCA1/2 mutations to guide treatment with olaparib in breast cancer [Citation3]; RAS mutational status as a negative predictor factor for the benefit of anti-EGFR monoclonal antibody to treat colorectal cancer [Citation4]. Nevertheless, and although there are thousands of studies reporting on biomarker application in oncology, only very few of them have finally achieved success: clinical implementation. A main factor attributing to low cancer biomarker clinical applicability appears to be the fact that statistics are often neglected or underappreciated. This becomes evident even when searching in PubMed; of the approximately 300,000 studies reporting in the title or abstract cancer and biomarkers [keywords: (cancer) AND (biomarker*)] only 10% mention statistics [((cancer) AND (biomarker*)) AND (statistic*)].
3. Statistical considerations
3.1. Study design and sample power
Several key considerations should be observed to fill the gaps of insufficient or poor use of statistics in biomarker discovery and validation. A correct study design is critical for the successful clinical application of the biomarkers and depends on, among others, the selection of the proper target population, sufficient statistical power and consideration of the influence of possible confounding variables [Citation5]. Power calculations are needed to ensure that an adequate number of samples/events are investigated, in relation to the specific clinical context of use, the specific cancer type prevalence, and the targeted performance improvement over current standards. Standard operating procedures and sampling standardization must be established prior to the initiation of sample collection for the study, to minimize the impact of experimental/analytical variability. Multiple confounding factors (e.g. sex, age, body mass index, or comorbidities) must also be accounted for to ensure the correct estimation of the biomarker performance. Statistical approaches such as inverse probability weighting or Bayesian methods can be used to reduce selection bias to the findings [Citation6]. Biases during patient selection/specimen collection and patient evaluation can be further reduced with randomization and blinding.
3.2. Data missingness and false discovery rate control
Due to the complexity of cancer, omics platforms are often applied for biomarker discovery and validation. Omics aims at the holistic/collective characterization and simultaneous quantification of multiple molecules depicting structural, functional, and dynamic statuses of an organism at a given timepoint. A common burden in omics datasets are missing data as a result of biological (feature is not present in the sample) or technical factors (detection limits of the technology). Although no golden rule exists and the best method to handle the missing data remains controversial, it seems that the optimal approach in fact is treating missing values as what they are (missing) and hence the dataset cannot be used for interpretation. However, such approach obviously reduces the number of datasets (and power). Therefore, multiple efforts to develop imputation algorithms for guiding missing value imputation have been made [Citation7], including random forest (RF), k-nearest neighbors imputation (KNN), singular value decomposition-based imputation (SVD), Bayesian principal component analysis (BPCA), and others. Omics data complexity indicates that frequently nonparametric statistical tests, such as a Wilcoxon rank sum test, should be utilized since in most of the cases omics data do not meet the underlying assumptions for normality (a standard t-test can be applied only if the data follow a normal distribution) [Citation6]. Moreover, given the intrinsic variances particularly for proteomics/metabolomics, adjustment for multiple testing is required to reduce false-positive identifications. Very rigorous correction as suggested by Bonferroni, although apparently ideal, preserves only little statistical power and consequently may result in no significant findings. Therefore, less stringent methods controlling false discovery rate (FDR) like Benjamini–Hochberg correction are widely used. Multiple additional methods controlling the FDR are available [Citation6,Citation8]. Data filtering, transformation, or scaling may be also needed for multivariate modeling and dimensionality reduction. This can be achieved by applying low-dimensional visualizations to the processed data such as principal coordinate analysis, t-distributed stochastic neighbor embedding (t-SNE), and uniform manifold approximation and projection (UMAP) as well as machine learning and deep learning algorithms [Citation9].
3.3. Multidimensionality and integrative models
Discovery studies based on omics datasets can result in the identification of numerous (hundreds) biomarker candidates. Frequently statistical significance and fold change between cases and controls are the main criteria for biomarker candidate prioritization. However, not every feature with a change in its distribution between healthy individuals and cancer patients represents a useful cancer biomarker. For instance, interleukins are highly upregulated in cancer, but similar upregulation can be found in inflammatory diseases. Consequently, interleukins are generally not used as biomarkers in oncology [Citation10]. Biomarker prioritization depends on the application of statistical methods, machine or deep learning as well as functional enrichment analyses. The high dimensionality of omics data, as a result of the so-called p > > n problem (larger number of omic features than samples needed to detect biologically relevant attributes), is a major challenge as it can result in statistically unstable overfitted models. Machine learning techniques such as logistic regression, random forests, and support vector machines can be employed to develop multivariate biomarker panels [Citation6]. An improved performance may be achieved when using a panel of biomarkers over single markers. After demonstrating benefits in well-powered trials, multi-gene biomarkers have been already endorsed by ASCO to guide decisions of adjuvant endocrine and chemotherapy in patients with early stage breast cancer [Citation11]. Biomarkers can be also integrated with clinical variables using mathematic formulas to construct predictive models such as nomograms [Citation12]. To develop predictive nomograms, regression analysis (for example logistic or multiple regression) can be performed, based on clinical characteristics that are correlated with e.g. patients’ overall survival and fulfilling the statistical selection criteria. Irrespective of the approach, validation of the model performance in independent datasets, ideally including patients from multiple clinical centers, must be undertaken prior to clinical implementation.
3.4. Performance metrics
One of the main challenges in biomarker research is distinguishing between a potential biomarker and a reliable biomarker that can guide important clinical decisions. To be clinically meaningful and provide guidance as well as a benefit over standard criteria, biomarkers must be specified for a specific context of use. During clinical validation, the performance of the biomarker can be estimated in terms of diagnostic sensitivity, specificity, positive predictive value (PPV) and negative predictive value (NPV), receiver operating characteristics (ROC) curve, and area under the ROC curve (AUCROC) [Citation13]. Kaplan–Meier survival curves and log rank test can be applied to compare survival differences among groups, a concordance index (C-index) enables estimating the similarity between the true survival time and predicted risk score. For clinical application a cutoff must be defined. Among the different methods that can be chosen to define the cutoff point from a ROC curve, Youden index is frequently used. Although high sensitivity and specificity indicate a good biomarker, PPV and NPV represent important probabilities for the successful implementation of the biomarkers. Several blood-based biomarkers have been used in clinical practice such as prostate-specific antigen (PSA) for prostate cancer, carcinoembryonic antigen (CEA) for colorectal cancer, carbohydrate antigen 19–9 (CA19-9) for pancreatic cancer, and cancer antigen 125 (CA125) for ovarian cancer [Citation13]. However, not all of them reach the standards of sufficiently high specificity and sensitivity. For example, the application of PSA as a screening tool is being debated for more than a decade, due to low accuracy in distinguishing individuals with benign prostatic hyperplasia from those with malignant prostate cancer. High false-positive rate is also a common issue for many FDA approved urine biomarker assays (e.g. in bladder cancer), thus leading to overdiagnosis [Citation14]. These examples further demonstrate that the application of proper statistical analysis is crucial for biomarker research.
4. Conclusions
Up to date, unfortunately most published biomarker studies are inconclusive or not reproducible as a result of dismissing important factors during study design and execution (including statistics). Apart from the neglected statistics, restricted access to appropriate number of specimens, limited funding options, the necessity to validate biomarkers utility in clinical trials, as well as the poor communication of all parties involved represent additional challenges [Citation15]. However, even a successfully clinically validated biomarker may not reach implementation at clinical practice; as demonstrated by the large number of available valid biomarkers that are not yet included in clinical guidelines and/or approved by regulatory agencies. In fact, in many European countries availability and reimbursement of biomarker tests are restricted, ultimately resulting in avoidable poor outcome (death) for tumor patients [Citation1]. The dedicated strategies and methods to address these challenges have been proposed a decade ago [Citation15]. Following these (and similar) suggestions should enable increased implementation of biomarkers in oncology, expected to significantly improve treatment outcome and reduce mortality in oncology.
Declaration of interest
Marika Mokou and Maria Frantzi are employed by Mosaiques Diagnostics GmbH. Harald Mischak holds ownership interest in Mosaiques Diagnostics GmbH. The authors have no relevant affiliation or financial involvement with any organization or entity with a financial interest in or financial conflict with the subject matter or materials discussed in the manuscript. This includes employment, consultancies, honoraria, stock ownership or options, expert testimony, grants or patents received or pending, or royalties.
Reviewers disclosure
Peer reviewers on this manuscript have no relevant financial relationships or otherwise to disclose.
Additional information
Funding
References
- Normanno N, Apostolidis K, Wolf A, et al. Access and quality of biomarker testing for precision oncology in Europe. Eur J Cancer. 2022;176:70–77.
- Seth R, Messersmith H, Kaur V, et al. Systemic therapy for melanoma: ASCO guideline. J Clin Oncol. 2020;38(33):3947–3970.
- Gennari A, Andre F, Barrios CH, et al. ESMO clinical practice guideline for the diagnosis, staging and treatment of patients with metastatic breast cancer. Ann Oncol. 2021;32(12):1475–1495.
- Cervantes A, Adam R, Rosello S, et al. Metastatic colorectal cancer: ESMO clinical practice guideline for diagnosis, treatment and follow-up. Ann Oncol. 2023;34(1):10–32.
- Ou FS, Michiels S, Shyr Y, et al. Biomarker discovery and validation: statistical considerations. J Thorac Oncol. 2021;16(4):537–545.
- Nakayasu ES, Gritsenko M, Piehowski PD, et al. Tutorial: best practices and considerations for mass-spectrometry-based protein biomarker discovery and validation. Nat Protoc. 2021;16(8):3737–3760.
- Wang S, Li W, Hu L, et al. NAguideR: performing and prioritizing missing value imputations for consistent bottom-up proteomic analyses. Nucleic Acids Res. 2020;48(14):e83.
- Lualdi M, Fasano M. Statistical analysis of proteomics data: a review on feature selection. J Proteomics. 2019;198:18–26.
- Diaz-Uriarte R, Gomez de Lope E, Giugno R, et al. Ten quick tips for biomarker discovery and validation analyses using machine learning. PLoS Comput Biol. 2022;18(8):e1010357.
- Briukhovetska D, Dorr J, Endres S, et al. Interleukins in cancer: from biology to therapy. Nat Rev Cancer. 2021;21(8):481–499.
- Andre F, Ismaila N, Allison KH, et al. Biomarkers for adjuvant endocrine and chemotherapy in early-stage breast cancer: ASCO guideline update. J Clin Oncol. 2022;40(16):1816–1837.
- Hendrix SB, Mogg R, Wang SJ, et al. Perspectives on statistical strategies for the regulatory biomarker qualification process. Biomark Med. 2021;15(9):669–684.
- Sarhadi VK, Armengol G. Molecular biomarkers in cancer. Biomolecules. 2022;12:8.
- Ng K, Stenzl A, Sharma A, et al. Urinary biomarkers in bladder cancer: a review of the current landscape and future directions. Urol Oncol. 2021;39(1):41–51.
- Mischak H, Ioannidis JP, Argiles A, et al. Implementation of proteomic biomarkers: making it work. Eur J Clin Invest. 2012;42(9):1027–1036.