
ABSTRACT
Objectives
Artificial intelligence-powered tools, such as ASReview, could reduce the burden of title and abstract screening. This study aimed to assess the accuracy and efficiency of using ASReview in a health economic context.
Methods
A sample from a previous systematic literature review containing 4,994 articles was used. Previous manual screening resulted in 134 articles included for full-text screening (FT) and 50 for data extraction (DE). Here, accuracy and efficiency was evaluated by comparing the number of identified relevant articles with ASReview versus manual screening. Pre-defined stopping rules using sampling criteria and heuristic criteria were tested. Robustness of the AI-tool’s performance was determined using 1,000 simulations.
Results
Considering included stopping rules, median accuracy for FT articles remained below 85%, but reached 100% for DE articles. To identify all relevant articles, a median of 89.9% of FT articles needed to be screened, compared to 7.7% for DE articles. Potential time savings between 49 and 59 hours could be achieved, depending on the stopping rule.
Conclusions
In our case study, all DE articles were identified after screening 7.7% of the sample, allowing for substantial time savings. ASReview likely has the potential to substantially reduce screening time in systematic reviews of health economic articles.
1. Introduction
Traditionally, systematic reviews in health economics have been valuable to synthesize published evidence, to identify knowledge gaps, and to inform decision-analytic model development [Citation1]. However, the workload of performing systematic reviews is high, as generally large numbers of articles need to be screened, especially when broad search terms are applied. Over the last decades, the number of newly published articles has been growing steadily [Citation2]. Within healthcare, ever growing demands and limited resources emphasize the need for efficient resource allocation [Citation3]. This need in turn further stimulates performing health economic evaluations leading to an increasing number of newly published health economic articles [Citation4]. This sharp growth increases the efforts needed to perform systematic reviews, which may have a negative impact on researchers’ willingness to conduct systematic reviews, or may lead to search strategies that are too narrow when prioritizing time constraints over quality.
Recently, artificial intelligence (AI)-powered tools that support title and abstract screening have been developed [Citation5]. Using machine learning algorithms, these tools estimate the relevance of an article based on a (small) training set of prelabelled articles. Evaluation studies of such tools in the field of health economics are, however, lacking. One such AI-powered tool is the open source-software ASReview [Citation6]. ASReview (hereafter referred to as ‘AI-tool’) currently runs as Python package and has a web browser interface. The AI-tool dynamically presents the most relevant article to screen to the reviewer based on information previously supplied by the reviewer. In brief, the initial order of articles for title and abstract screening is created by informing the software with prior knowledge, i.e. at least one relevant and one irrelevant article. Prior knowledge can be manually selected from the identified articles when known to the reviewer, or selected by randomly screening articles until at least one relevant and one irrelevant article are found. After the selection of prior knowledge, the software uses machine learning to rank the articles on relevance and presents the most relevant article to the reviewer. After screening this article, the content of the abstract and its classification (being relevant or irrelevant) is added to the prior knowledge and the ranking is updated based on all information. The next most relevant article is then presented to the reviewer. For the remainder of the screening process, the order is updated iteratively each time the highest ranked article is screened.
The AI-tool has no built-in mechanism deciding when to stop screening. Therefore, title and abstract screening continues until the reviewer decides to stop, typically whenever a certain prespecified stopping rule has been satisfied. Whenever satisfied, the remaining (unassessed) articles are discarded as ‘very likely irrelevant,’ thereby reducing the number of articles to screen and saving time. Different stopping rules have previously been proposed, such as sampling criteria (i.e. screening until a prespecified proportion of titles and abstracts has been screened), heuristic criteria (i.e. screening until a series of consecutive irrelevant articles have been found), and pragmatic criteria (i.e. screening for a prespecified amount of time), but no consensus has been reached on the most appropriate stopping rule [Citation7]. According to the developers of the AI-tool, between 8% and 33% of the articles included for title and abstract screening need to be screened manually to find 95% of all relevant articles [Citation8,Citation9]. Although they used systematic reviews performed in multiple disciplines to support their statement, the field of health economics was not included. Therefore, it is unknown how the AI-tool performs in screening for health economic evaluations. This study aimed to assess the performance of the AI-tool for health economic systematic reviews using post-hoc analysis based on a sample of articles from a previously performed systematic review [Citation10].
2. Methods
2.1. Data sample
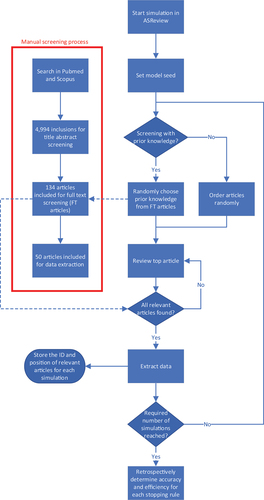
To assess the performance of the AI-tool compared to ‘classical’ manual screening, a sample of 4,994 articles was identified from the PubMed/MEDLINE and Scopus databases through a broad search on health economic evaluations of early detection strategies for cardiovascular disease published between 2016 and April 2022 [Citation10]. Manual title and abstract screening was performed in Covidence [Citation11] resulting in 134 articles included for full text assessment (FT articles) and, after full text assessment, 50 articles included for data extraction (DE articles). The process of manual screening and applying the AI-tool is visualized in . The following data was extracted from each article: title, authors, abstract, publication year, DOI, inclusion for full text screening, and inclusion for data extraction. The extracted data was collected in a comma separated file using Excel [Citation12] and used as input for the AI-tool.
Figure 1. Flowchart visualizing the screening and simulations of screening with ASReview. The manual screening in red was performed prior to the simulations. After each iterations, article ID and corresponding position were saved and the simulation was stopped when the required number of iterations was reached.
2.2. Data analysis
The performance of the AI-tool was defined as a trade-off between accuracy (i.e. the proportion of articles known to be relevant that would have been found) and efficiency (i.e. the amount of time that could have been saved by using the AI-tool) and was assessed through simulation. Simulations were performed using the ‘Makita’ (make it automatic) extension of the AI-tool and all screening decisions were based on manual screening outcomes. All simulation settings were kept at default (i.e. Naïve Bayes as classifier, term frequency-inverse document frequency as feature extraction, double as balance strategy, and maximum as query strategy). A model seed was set to ensure reproducibility of simulations. Subsequently, simulation data was extracted and data analysis was performed in R [Citation13].
Three distinct starting scenarios were assessed in this study:
the reviewer did not have any prior knowledge and has to start screening random articles to find one relevant and one irrelevant article, thus zero prior knowledge (PK0);
the reviewer already knows one relevant article and one irrelevant article as prior knowledge, prior knowledge 1 (PK1);
the reviewer already has five relevant articles and five irrelevant articles as prior knowledge (PK5).
All scenarios were simulated a 1,000 times with different prior knowledge chosen at random from the FT articles, or a different order in which the articles are presented to the reviewer in the scenario the reviewer did not have any prior knowledge. The position where each relevant article was found during the iterative screening was extracted and stored per iteration. Thereafter, the accuracy per number of articles screened was determined for each iteration and the proportion needed to screen (PNS) to obtain an accuracy of 100% was calculated.
Moreover, the performance of applying two types of stopping rules to the title and abstract screening was assessed per iteration. The first type of stopping rule was based on sampling criteria meaning that only a predefined proportion of the highest ranked articles was screened. The second type of stopping rule was based on heuristic criteria meaning that screening was stopped after a series of consecutive irrelevant articles of predefined length was found. After a stopping rule was satisfied during prospective screening, the remainder of articles were labeled ‘irrelevant.’ Screening was always performed in the dynamic order supplied by the AI-tool and different thresholds were set for each type of stopping rule as follows:
Sampling criteria: screening was stopped after screening the 5%, 7.5%, 10%, 15%, and 20% of highest ranked articles;
Heuristic criteria: screening was stopped when 50, 100, 150, and 200 consecutive irrelevant articles were found. In the PK0 scenario, screening always continued until at least one relevant article was identified.
Post hoc analysis was performed on the extracted data and the stopping rules were applied retrospectively on the extracted data. Performance of each stopping rule was assessed by calculating the median accuracy and efficiency for each starting scenario and the 95% range (i.e. 2.5th−97.5th percentile range) was calculated to show the variation between simulations. For efficiency, the PNS to satisfy the stopping rule was calculated per simulation. Thereafter, the time that could be saved by using a specific stopping rule could be calculated by multiplying the PNS by the time required for screening one title and abstract. It has been suggested that an experienced reviewer is able to screen two abstracts per minute [Citation14]. However, this could increase to several minutes per abstract when the abstract is complex. In this review, the assumption was made that a reviewer needs an average of 45 seconds to screen one abstract. In this case, screening decisions were still based on the manual screening outcomes, thus including all FT articles when screened, but only the (positions of) DE articles were considered to calculate the accuracy. Therefore, accuracy could differ between FT articles and DE articles, but the PNS, and thus efficiency, was always the same as for the FT articles.
3. Results
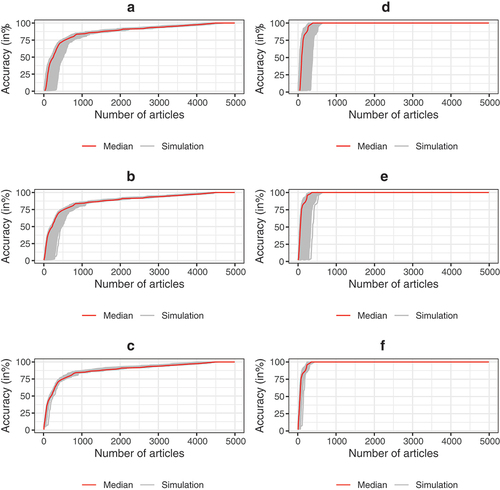
The proportion of relevant articles found per number of screened articles is shown per simulation and as a median value (in red) of all simulations in for PK0, PK1, and PK5 for both FT articles and DE articles. These results show that larger amounts of prior knowledge reduces the variation between simulations, but has limited impact on the median PNS. Screening with PK0 led to a median PNS of 89.9% (95% range: 87.3–92.6%) to reach an accuracy of 100% for FT articles resulting in potential time savings of 6.3 hours (95% range: 4.6–7.9 hours) compared to manual screening. Screening with PK5 led to a median PNS of 89.9% (95% range: 87.9–91.2%) to reach an accuracy of 100% for FT articles. This accounts for potential time savings of 6.3 hours (range: 5.5–7.9 hours). All DE articles were generally found much earlier than all FT articles. To reach an accuracy of 100% for DE articles, a median PNS of 7.7% (95% range: 6.4–11%) was found when screening with PK0, whereas a median PNS of 7.1% (95% range: 5.9–8.2%) when screening with PK5. This accounts for potential time savings of 57.6 hours (95% range: 55.6–58.4 hours) to 58.1 hours (range: 57.4–58.8 hours), respectively.
Figure 2. Accuracy of screening per number of articles screened when considering all FT articles was shown in: A when screening with PK0 (no prior knowledge known), B when screening with PK1 (1 relevant article and 1 irrelevant article as prior knowledge), and C when screening with PK5 (5 relevant articles and 5 irrelevant articles as prior knowledge). Accuracy of screening per number of screened when considering all DE articles was shown in: D for screening with PK0, E for screening with PK1, and in F for screening with PK5. Each gray line represents one of 1,000 simulations and the red line represents the median accuracy per number of screened articles.
Outcomes for accuracy per stopping rule are shown in for both FT articles (A) and DE articles (B). When using sampling criteria based stopping rules for FT articles, the median accuracy of screening the highest 5% was 54.5% (95% range: 32.1–56.7%) for PK0 and 56.7% (95% range: 54.5–59.7%) for PK5. Screening the highest ranked 20% resulted in a median accuracy of 83.6% (95% range: 83.6–85.1%) for PK0 and 84.3% (95% range: 83.6–85.8%) for PK5. Considering DE articles only, the median when screening the highest 5% was 96% (95% range: 64–98%) for PK0 and 96% (95% range: 90–98%) for PK5. Moreover, the median when screening 20% resulted in 100% (95% range: 100–100%) for both screening strategies, i.e. PK0 and PK5. The percentile range was larger for stopping rules that generally screened fewer articles and was smaller for stopping rules that generally screened more articles.
Figure 3. Median accuracy with 2.5th−97.5th percentile range per stopping rule and for each screening strategy. Figure a shows accuracy for FT articles, whereas Figure B shows accuracy for DE articles. s5–s20 means sampling criteria 5% up to 20% and h50–h200 means heuristic criteria 50 up to 200.
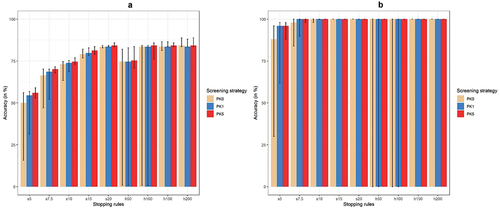
When assessing the accuracy of stopping rules using heuristic criteria for FT articles, the median of screening until 50 consecutive irrelevant articles were screened was 74.6% (95% range: 0–82.1%) for PK0 and 75.4% (95% range: 70.9–83.6%) for PK5. Furthermore, when stopping screening after 200 consecutive irrelevant articles were found, the median with its percentile range were identical for PK0 and PK5: 84.3% (95% range: 83.6–88.8%). When only DE articles are considered and screening is stopped after 50 consecutive irrelevant articles were found, the median for screening with PK0 was 100% (95% range: 0–100%), whereas the median was also 100% (95% range: 100–100%) when screening with PK5. When screening is stopped after 100 or more consecutive irrelevant articles, the median was 100% (95% range: 100–100%) for all screening strategies.
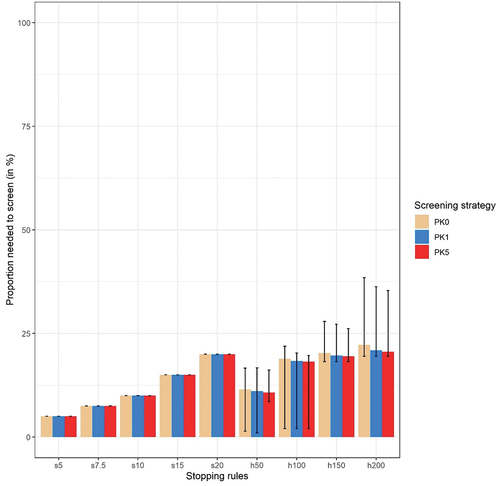
In , the PNS is shown per stopping rule and per screening strategy. Given the sampling criteria assessed, the time that could be saved ranged from 59.3 hours when screening the highest ranked 5% to 49.9 hours when screening the highest ranked 20%. Considering stopping rules using heuristic criteria, the PNS could change per prior knowledge scenario. The median PNS when stopping after 200 consecutive irrelevant articles were screened was 21.1% (95% range: 19.5–37.1%) for screening with PK0 and 20.4% (95% range 19–35.2%) for screening with PK5. This means that the median potential time that could be saved was 49.2 hours (95% range: 39.3–50.3 hours) for screening with PK0 and 49.7 hours (95% range: 40.5–50.6 hours) for screening with PK5. When stopping after 50 consecutive articles, the median of the PNS was 10.7% (95% range: 1–15.6%) for screening with PK0 and 10.6% (range: 8.4–16%) for screening with PK5. The median potential time that could be saved was 55.7 hours (95% range: 52.7–61.8 hours) for screening with PK0 and 55.8 hours (95% range: 52.4–57.2 hours) for screening with PK5. All data for screening with PK0, PK1, and PK5 can also be found in Appendix 1, Appendix 2, and Appendix 3, respectively.
Figure 4. Median proportion needed to screen (PNS) with 2.5th−97.5th percentile range for heuristic criteria for all three screening strategies. s5–s20 means sampling criteria 5% up to 20% and h50–h200 means heuristic criteria 50 up to 200.
4. Discussion
In our case study, ASReview (the AI-tool) could have considerably reduced title and abstract screening time while maintaining high accuracy, particularly regarding DE articles. This holds for stopping rules using both sampling criteria and heuristic criteria. Considering the accuracy of FT articles, median accuracy did not exceed 85%, regardless of the stopping rule, meaning that several articles labeled as ‘relevant’ during manual screening were consistently missed when applying the different sampling and heuristic based stopping rules. However, considering data extraction articles, the median accuracy of both types of stopping rules was substantially higher. Screening 89.8% of all articles would have been needed to achieve 100% accuracy of FT articles with PK0 resulting in a potential time saving of over 6 hours. However, to find all DE articles, screening a median of 7.7% of all articles would have been sufficient, resulting in time savings of 57.4 hours. The estimated time of a full manual screening would be 62.4 hours meaning that time savings could be 10.1% for FT articles and 92.3% for DE articles. This also indicates that DE articles were generally found rather early during screening with the AI-tool. For screening with PK0, median outcomes appeared to be comparable to screening with default prior knowledge and PK5, but differences between simulations, and thus variation, were larger. Overall, more prior knowledge did not lead to better accuracy, particularly using stopping rules that required higher number of articles to be screened.
Naïve Bayes was used as classification technique during the simulation, as this was the default in the AI-tool. When using Naïve Bayes, words in an abstract are scored based on their frequency in relevant articles. Words that occur frequently in relevant abstracts receive a high score and words that do not receive a low score. To predict the relevance of an abstract with Naïve Bayes, the score of all words are combined and the highest scoring abstract is deemed most relevant. Substantial differences in median accuracy between FT articles and DE articles were found for both types of stopping rules. Therefore, this suggests that certain words were found relatively more often in titles and abstracts of DE articles compared to FT articles in general and that the titles and abstracts of some FT articles did not include (many) high scoring words as they were consistently found late in the screening process. In retrospect, these articles were likely included during the manual screening process for ‘safety’ considerations: they were unlikely to be relevant but still included to avoid missing potentially relevant articles. Moreover, the percentile ranges for heuristic stopping rules for both accuracy and efficiency were large. Due to the large number of articles and potential low number of relevant articles at the start, particularly when screening with PK0, the stopping rule could have already been satisfied before any relevant article was found. For example, when using heuristic stopping rules and screening with PK0, 36.5% (stopping after 50 consecutive irrelevant articles) to 1.5% (stopping after 200 consecutive irrelevant articles) of all simulations stopped before any relevant article was found. In practice, however, it is unlikely that researchers would stop the screening process when no relevant articles are found based on a subset of articles. Rather, they would likely extend the subset and continue screening until one or more a relevant articles are found. Therefore, a stopping rule could only be satisfied as long as at least one relevant article was identified, either as prior knowledge or during the screening when screening with PK0.
Whereas the performance of the AI-tool has been evaluated using systematic reviews from multiple fields, such as the fields of next-generation sequencing in livestock, fault prediction in software engineering, machine learning in symptom detection for post-traumatic stress, and pharmacological efficacy of angiotensin converting enzyme inhibitors [Citation9], this case study is, to our knowledge, the first evaluation within the field of health economics. These results are highly relevant for health economic model developers and information specialists, since performing systematic reviews of health economic studies require researchers to review a large number of heterogeneous studies, due to the often broad search terms used in systematic reviews of health economic studies. The AI-tool seems promising in reducing this burden by focusing review efforts toward the most relevant studies. Previously, the developers estimated that between 8% and 33% of articles needed to be screened to find 95% of the DE articles [Citation8,Citation9]. In this case study, 64.7% needed to be screened to find 95% of all FT articles for the scenario PK0. When considering DE articles only in the same scenario, however, a median of 7.7% needed to be screened to find 100% of all relevant articles. Therefore, our results seem in line with earlier reported proportions needed to screen and they suggest that the PNS found in prior simulation studies with the AI-tool may also apply to systematic reviews focusing on health economic articles. Furthermore, screening with prior knowledge does not perform substantially better than screening without prior knowledge. Therefore, we suggest to use prior knowledge when readily available to the researcher when starting a review, but otherwise not to invest much additional time in generating prior knowledge before using the AI-tool.
This study also has some limitations. First, this study included a single health economic systematic review. Therefore, caution should be taken to generalize these results to the entire health economics discipline. Second, only two types of stopping rules were assessed, whereas novel automatic types of stopping rules, for example based on the BM25 algorithm [Citation15,Citation16], have been developed. However, their effectiveness has not consistently been proven, the level of recall has not been consistent [Citation7] and these stopping rules have not been integrated in the AI-tool. Therefore, these stopping rules were not used in this study. Stopping rules using combinations between sampling criteria and heuristic criteria may also be implemented, but these were outside the scope of this study.
After further confirmation of the accuracy of the AI-tool, its use could improve systematic review quality. A more efficient review process would, amongst others, allow broader literature searches, expanding search terms or the included time period, without increasing the workload substantially. Using the AI-tool during screening for systematic reviews could substitute full manual screening of title and abstract for one or two reviewers, thereby making the screening process less time-consuming. Even when it may not be desirable or acceptable to fully substitute manual screening by screening with the AI-tool, this may still support reviews performed by less experienced researchers, act as a second reviewer (after full manual screening by the first reviewer), or being used to update existing reviews with limited efforts. Additionally, the assumption that the time needed to screen one title and abstract is 45 seconds may be too low. Particularly when the reviewer is less experienced in title and abstract screening, the realistic time to screen a title and abstract may be higher. This means that the actual time saved using the AI-tool could be much higher in those situations with lesser experienced reviewers. Previous research has shown that single-reviewer screening misses 13% of relevant articles (and double reviewer screening misses 3%) [Citation17]. However, the AI-tool may reduce the number of articles missed by a reviewer, as reviewing a smaller proportion of identified articles containing relatively more relevant articles may improve concentration and motivation. This was outside the scope of this study and should be a topic for future research.
Future research should validate the accuracy and efficiency of ASReview within the field of health economics. For example, by performing similar assessments on other systematic reviews, preferably across a range of disease or innovation domains, and with varying expertise of the reviewers initially performing a full manual review. Next to the AI-tool used in this study, multiple other AI-powered tools, such as Abstrackr [Citation18], Rayyan [Citation19], and SWIFT-Active Screener [Citation20], have been developed to assist title and abstract screening for (systematic) reviews. Currently, it is unknown how the performance of AI-tools compares to each other. Further research should inform researchers on performance of different tools, and which tools may be preferred within health economics. Future validation studies, including multiple samples of health economic systematic reviews and multiple AI-tools, could provide these valuable insights.
5. Conclusion
In our case study, all DE articles were identified using the AI-tool by screening approximately 8% of all articles leading to potential time savings of 57 hours of work. the AI-tool likely has the potential to substantially reduce screening time in systematic reviews of health economic articles, while maintaining good accuracy.
Declaration of interest
The authors have no relevant affiliations or financial involvement with any organization or entity with a financial interest in or financial conflict with the subject matter or materials discussed in the manuscript. This includes employment, consultancies, honoraria, stock ownership or options, expert testimony, grants or patents received or pending, or royalties.
Reviewer disclosures
Peer reviewers on this manuscript have no relevant financial or other relationships to disclose.
Open science statement
Analysis was performed in R [Citation13] and all scripts and data will be published upon publication of the manuscript.
Earlier presentations
Part of the work has been presented in the form of a poster on the 8 November at ISPOR Europe 2022 in Vienna
Supplemental Material
Download Zip (42.6 KB)Supplementary Material
Supplemental data for this article can be accessed online at https://doi.org/10.1080/14737167.2023.2234639
Additional information
Funding
References
- Jacobsen E, Boyers D, Avenell A. Challenges of systematic reviews of economic evaluations: a review of recent reviews and an obesity case study. Pharmacoeconomics. 2020 Mar;38(3):259–267. doi: 10.1007/s40273-019-00878-2
- Bornmann L, Mutz R. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. J Assoc Inf Sci Tech. 2015 Nov;66(11):2215–2222. doi: 10.1002/asi.23329
- Jakovljevic M, Yamada T. Editorial: role of health economic data in policy making and reimbursement of new medical technologies. Front Pharmacol. 2017;8:662. doi: 10.3389/fphar.2017.00662
- Jakovljevic MM, Pejcic AV. Growth of global publishing output of health economics in the twenty-first century: a bibliographic insight. Front Public Health. 2017;5:211. doi: 10.3389/fpubh.2017.00211
- Blaizot A, Veettil SK, Saidoung P, et al. Using artificial intelligence methods for systematic review in health sciences: A systematic review. Res Synth Methods. 2022 May;13(3):353–362. doi: 10.1002/jrsm.1553
- ASReview LAB developers. Asreview LAB - A tool for AI-assisted systematic reviews. 2022. doi: 10.5281/zenodo.8159165
- Callaghan MW, Muller-Hansen F. Statistical stopping criteria for automated screening in systematic reviews. Syst Rev-London. 2020 Dec 28;9(1). doi: 10.1186/s13643-020-01521-4
- Ferdinands G, Schram R, de Bruin J, et al. Performance of active learning models for screening prioritization in systematic reviews: a simulation study into the average time to discover relevant records. Syst Rev. 2023 Jun 20;12(1):100. doi: 10.1186/s13643-023-02257-7
- van de Schoot R, de Bruin J, Schram R, et al. An open source machine learning framework for efficient and transparent systematic reviews. Nat Mach Intell. 2021 Feb;3(2):125–133. doi: 10.1038/s42256-020-00287-7
- Oude Wolcherink MJ, Behr CM, Pouwels X, et al. Health economic research assessing the value of early detection of cardiovascular disease: a systematic review. Pharmacoeconomics. 2023 Jun 16. doi: 10.1007/s40273-023-01287-2
- Veritas Health Innovation. Covidence research software. Melbourne (Australia); 2022. https://www.covidence.org/
- Microsoft Corporation. Microsoft Excel. 2018.
- R Core Team R Foundation for statistical computing. R: a language and environment for statistical computing. 2022. https://www.R-project.org/
- Wallace BC, Trikalinos TA, Lau J, et al. Semi-automated screening of biomedical citations for systematic reviews. BMC Bioinf. 2010 Jan 26; 11;11(1). doi: 10.1186/1471-2105-11-55
- Di Nunzio GM. A study of an automatic stopping strategy for technologically assisted medical reviews. Lect Notes Comput Sc. 2018;10772:672–677. doi: 10.1007/978-3-319-76941-7_61
- Yu Z, Menzies T. FAST(2): An intelligent assistant for finding relevant papers. Expert Syst Appl. 2019 Apr 15;120:57–71. doi: 10.1016/j.eswa.2018.11.021
- Gartlehner G, Affengruber L, Titscher V, et al. Single-reviewer abstract screening missed 13 percent of relevant studies: a crowd -based, randomized controlled trial. J Clin Epidemiol. 2020 May;121:20–28. doi: 10.1016/j.jclinepi.2020.01.005
- Gates A, Johnson C, Hartling L. Technology-assisted title and abstract screening for systematic reviews: a retrospective evaluation of the Abstrackr machine learning tool. Syst Rev-London. 2018 Mar 12;7(1). doi: 10.1186/s13643-018-0707-8
- Ouzzani M, Hammady H, Fedorowicz Z, et al. Rayyan-a web and mobile app for systematic reviews. Syst Rev. 2016 Dec 5;5(1):210. doi: 10.1186/s13643-016-0384-4
- Howard BE, Phillips J, Tandon A, et al. SWIFT-Active screener: accelerated document screening through active learning and integrated recall estimation. Environ Int. 2020 May;138:105623. doi: 10.1016/j.envint.2020.105623