
Introduction
Sport scientists could benefit from knowing about the processes underpinning machine learning (ML) and its practical applications, as it has substantial implications for our field. ML has already had an impact on:
the devices used to acquire data (optimisation of inertial sensor readings (Jamil et al., Citation2020)),
the information extracted from data acquired by devices (3d kinematic and vertical ground reaction forces might be soon predicted via 2D videos (Morris et al., Citation2020; Weir et al., Citation2019), barbell movement trajectories and mass have been used to predict joint moments (Kipp et al., Citation2018)),
the processing of data acquired by devices (classification models are able to split data in to meaningful packages that would have previously placed large time demands on sport scientists (Ahmadi et al., Citation2014)) and
the utility of processed data to enhance our understandings of sports performance and injury risk prediction (classification models can facilitate objective decision making with respect to rehabilitation practices and injury prevention (Richter et al., Citation2019; Rommers et al., Citation2020)).
In this editorial we illustrate how ML has been used successfully to characterise aberrant movement profiles in injured athletes and how this data can subsequently inform rehabilitation practices (see references: Franklyn-Miller et al., Citation2016; Richter et al., Citation2019; Rommers et al., Citation2020). Furthermore, we outline the advantages of ML, as well as the challenges that sport scientists are likely to encounter when reading about or endeavouring to implement ML models. Let’s start with the most important question: ‘What is machine learning?’
ML is the creation and use of models that have learned from data (Grues, Citation2015) and involves the process of programming a computer to perform a classification or magnitude estimation without being ‘told’ how it is done (; the most basic and commonly used example is fitting a regression model). During this classification or magnitude estimation the computer (i.e., the machine) ‘experiments’ with different model parameters and prediction features (independent variables) and identifies (learns), which combination of parameters and prediction features best replicate (i.e., predict) the target (dependent variable). The advantage conferred over traditional statistical methodologies is that this process allows interdependency of data points and facilitates the detection of previously hidden clusters (e.g., athletes that respond differently to one stimuli) without any subjective magnitude/dependency settings, whilst also providing a clear error estimation. However, as with traditional statistical methodologies it is important to exert caution when interpreting ML outcomes because explanatory and predictive modelling are not the same (Shmueli, Citation2010)—if a ML model is trained with erroneous data the model will not generalise and will generate false conclusions—hence the phrase ‘errors in, errors out’. While it is not necessary for sport scientists to comprehend the mathematical and statistical principles underpinning ML, it is important that they understand certain key concepts (data capture/processing, feature selection, modelling and evaluation), before using it as a component of their research toolkit.
Figure 1. Illustration of the processes of feature-based machine learning and the potential challenges associated with each of these processes.
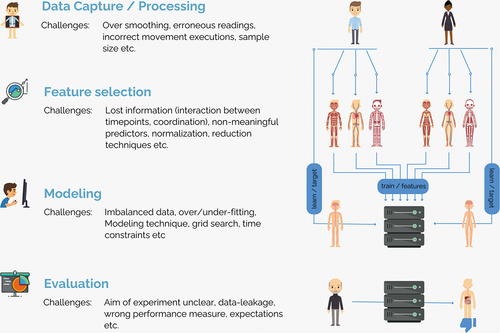
Data capture/processing
When utilising ML, it is critically important to capture a sufficiently large dataset. Unfortunately, power calculations are not applicable to ML models, and it can’t be known a priori as to how many data samples are ‘sufficient’. In most instances, the more data the better, as this will provide the model with ‘more’ opportunities to learn. We would suggest that sharing of datasets amongst sports scientists should be considered to facilitate the development of robust ML models. Previous studies using injury prediction ML models have used >400 or >700 data samples (Richter et al., Citation2019; Rommers et al., Citation2020). If datasets are shared amongst sport scientists, it should be noted that it is highly probable that data captured from different laboratories are likely to have different noise characteristics or have been processed using different frameworks. Such dataset artefacts might result in a ML model that has learned an erroneous pattern (predictions are made on measures that describe noise rather than movement patterns), and hence efforts will be required to harmonise the data.
Feature selection
Regardless of how much data were collected, the features extracted from a dataset are possibly more important than the sample size of the dataset used, because if the prediction features inputted to a ML model hold no meaningful information it will never perform well. While a ML model could be trained on all the available data collected, models that seek to guide rehabilitation programmes, injury prevention initiatives, movement quality assessments and training load optimisation should be built using only a small selection of features—to aid interpretability. Traditionally, studies in sports science have used a subjective selection of features (e.g., a signal’s maximal value) that can potentially result in important information being discarded. Recently, data-driven approaches were introduced and are being used more frequently (e.g., principal component analysis [PCA]). For an optimal and robust collection of features, sports scientists should combine objective and domain-specific knowledge-based features because even a data-driven feature extraction does not guarantee that all information that is contained within the data is used. For example, Richter et al. (Citation2019) sought to develop a ML model that could differentiate between the operated and non-operated limb of an athlete undergoing rehabilitation following anterior cruciate ligament reconstruction and the limb of a non-injured healthy control athlete using kinematic and kinetic measures (time normalised waveforms) recorded during a variety of exercises. To extract prediction features, a PCA was used, as it captures the variability within the dataset. However, this approach may have resulted in missed information on potential benefit to the model, as variability of the dataset does not necessarily correspond to differentiation/classification ability.
Modelling
Following the completion of the feature selection, an ML approach needs to be selected, which can be tricky—as many techniques exist that differ in their abilities to learn (regression, decision-tree, neural networks etc., see: Hastie & Tibshirani, Citation2002). It is important to note that feature normalisation (transforming a features magnitude into for example, z-scores) may be required (depending on the ML technique) and that many ML models perform better when the training data is well balanced across different predictive outcomes of importance (data can be balanced using synthetic minority over-sampling (Chawla et al., Citation2002)). When building a model, it is important to consider the danger of overfitting that could be caused by an inappropriate ratio between input features and observations within the dataset. To avoid this, a feature-selection can be undertaken to identify the most useful features (O’Reilly et al., Citation2017), which unfortunately could result in the loss of information. To interpret/refine the output of a model, different visualisation approaches can be used to understand the importance of a feature and the predictions made (Liu et al., Citation2017). When seeking to develop a ML model it is common practice to evaluate multiple ML techniques and feature combinations to find the most appropriate model.
Evaluation
To estimate the performance of a ML model, it is important to use a criterion that aligns with the ML task. An often-used measure to evaluate the performance of a ML model is accuracy, which can be used if there is a balance across possible outcomes. Accuracy, however, should never be used if there is an imbalance across possible outcomes. Using accuracy in an injury prediction study is likely to yield an ‘excellent’ result, even if the model has learned nothing (e.g., 98% accuracy can be achieved by always predicting ‘no injury’ if 2% of the observations get injured). For classification problems, many performance measures can be computed from the confusion matrix (; a receiver operating curve can give information about different decision thresholds), while magnitude predicting ML models should use measures such as: mean-average-errors, root-mean-square-error, Bland-Altman plots or regression analyses (r2).
Table 1. Illustration of a binary classification confusion matrix and measures that can be directly calculated from it. Criteria that could be computed from the listed measures are also positive and negative likelihood ratio, diagnostic ratio and F1 score.
To ensure the generalisability of a model, it should be evaluated by estimating its robustness. The best practice is to set aside a portion of the data, which is only used for the evaluation of the model (testing data) and for cross-validation during the fitting process ( lists possible options). This process can highlight if a model is under- (too rigid to learn pattern of training) or over-fitted (too flexible—learned noise of training data; Halilaj et al., Citation2018; Hastie & Tibshirani, Citation2002). Data from the same athlete should never be used simultaneously in training and testing data, as this can greatly overestimate a model’s performance (called data-leakage). Unfortunately, evaluation is not yet commonly used in sports science studies.
Table 2. List of common cross-validation methods.
Discussion and implications
Over the next decade, ML is likely to greatly enhance the objectivity of decision making in sports science (Franklyn-Miller et al., Citation2016; Richter et al., Citation2019; Rommers et al., Citation2020). Studies have demonstrated that ML can: predict future injuries (85% precision, 85% recall) based on pre-season measures (Rommers et al., Citation2020); identify movement strategies within a cohort—enabling the identification of movement-specific injury risk factors (Franklyn-Miller et al., Citation2016); and identify uninjured individuals who demonstrate movement patterns that are similar to injured individuals (Richter et al., Citation2019). However, substantial challenges need to be overcome (). There are many pitfalls that must be avoided, when developing a ML model. Successful ML model creation and assessment require comprehensive interdisciplinary expertise including domain experts with experience and knowledge of statistics and ML. To enable ML techniques to have a widespread positive impact in our field, it is recommended that coding and ML modules are integrated into sports science educational courses and that widespread international collaboration is adopted in the aggregation and harmonisation of ‘open access’ datasets.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Ahmadi, A., Mitchell, E., Richter, C., Destelle, F., Gowing, M., O’Connor, N. E., & Moran, K. (2014). Toward automatic activity classification and movement assessment during a sports training session. IEEE Internet of Things Journal, 2(1), 98–103. https://doi.org/10.1109/BSN.2014.29
- Chawla, N., Bowyer, K., Hall, L., & Kegelmeyer, W. (2002). SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16, 321–357. https://doi.org/10.1613/jair.953
- Franklyn-Miller, A., Richter, C., King, E., Gore, S., Moran, K., Strike, S., & Falvey, E. C. (2016). Athletic groin pain (part 2): A prospective cohort study on the biomechanical evaluation of change of direction identifies three clusters of movement patterns. British Journal of Sports Medicine, 51(5), 460–68. https://doi.org/10.1136/bjsports-2016-096050
- Grues, J. (2015). Data science from scratch: First principles with python. O’Reilly.
- Halilaj, E., Rajagopal, A., Fiterau, M., Hicks, J. L., Hastie, T. J., & Delp, S. L. (2018). Machine learning in human movement biomechanics: Best practices, common pitfalls, and new opportunities. Journal of Biomechanics, 81, 1–11. https://doi.org/10.1016/j.jbiomech.2018.09.009
- Hastie, T., & Tibshirani, R. (2002). Elements of statistical learning. Springer.
- Jamil, F., Iqbal, N., Ahmad, S., & Kim, D. H. (2020). Toward accurate position estimation using learning to prediction algorithm in indoor navigation. Sensors (Switzerland), 20(16), 1–27. https://doi.org/10.3390/s20164410
- Kipp, K., Giordanelli, M., & Geiser, C. (2018). Predicting net joint moments during a weightlifting exercise with a neural network model. Journal of Biomechanics, 74, 225–229. https://doi.org/10.1016/j.jbiomech.2018.04.021
- Liu, S., Wang, X., Liu, M., & Zhu, J. (2017). Towards better analysis of machine learning models: A visual analytics perspective. Visual Informatics, 1(1), 48–56. https://doi.org/10.1016/j.visinf.2017.01.006
- Morris, C., Mundt, M., Goldacre, M., & Jacqueline, A. (2020). Predict ground reaction forces from 2D video. https://twitter.com/JacquelineUWA/status/1327971555029073924
- O’Reilly, M. A., Johnston, W., Buckley, C., Whelan, D., & Caulfield, B. C. (2017). The influence of feature selection methods on exercise classification with inertial measurement units. In IEEE 14th International Conference on Wearable and Implantable Body Sensor Networks (BSN) (Vol. 14, pp. 193–196).
- Richter, C., King, E., Strike, S., & Franklyn-Miller, A. (2019). Objective classification and scoring of movement deficiencies in patients with anterior cruciate ligament reconstruction. Plos One, 14(7), e0206024. https://doi.org/10.1371/journal.pone.0206024
- Rommers, N., Rössler, R., Verhagen, E., Vandecasteele, F., Verstockt, S., Vaeyens, R., Lenoir, M., D’hondt, E., & Witvrouw, E. (2020). A machine learning approach to assess injury risk in elite youth football players. Medicine & Science in Sports & Exercise, Publish Ah, 52(12), 1745–1751. https://doi.org/10.1249/mss.0000000000002305
- Shmueli, G. (2010). To explain or to predict? Statistical Science, 25(3), 289–310. https://doi.org/10.1214/10-STS330
- Weir, G., Alderson, J., Smailes, N., Elliott, B., & Donnelly, C. (2019). A reliable video-based ACL injury screening tool for female team sport athletes. International Journal of Sports Medicine, 40(3), 191–199. https://doi.org/10.1055/a-0756-9659