
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We present a fast algorithm for generating Laguerre diagrams with cells of given volumes, which can be used for creating RVEs of polycrystalline materials for computational homogenisation, or for fitting Laguerre diagrams to EBSD or XRD measurements of metals. Given a list of desired cell volumes, we solve a convex optimisation problem to find a Laguerre diagram with cells of these volumes, up to any prescribed tolerance. The algorithm is built on tools from computational geometry and optimal transport theory which, as far as we are aware, have not been applied to microstructure modelling before. We illustrate the speed and accuracy of the algorithm by generating RVEs with user-defined volume distributions with up to 20,000 grains in 3D. We can achieve volume percentage errors of less than 1% in the order of minutes on a standard desktop PC. We also give examples of polydisperse microstructures with bands, clusters and size gradients, and of fitting a Laguerre diagram to 3D EBSD measurements of an IF steel.
1. Introduction
1.1. State of the art
Voronoi diagrams and their generalisations are often used to represent the microstructure of polycrystalline metals and foams, e.g. [Citation1–14], with individual Voronoi cells representing grains in metals and pores or bubbles in foams. They can be used to generate complex microstructures quickly using a relatively small number of parameters, and they are often used as representative volume elements (RVEs) for computational homogenisation, e.g. [Citation15–17].
In this paper, we focus on the class of weighted Voronoi diagrams known as Laguerre diagrams (or power diagrams or radical Voronoi tessellations), which provide a more accurate description of the geometry of polycrystalline materials than classical Voronoi diagrams [Citation8,Citation14]. However, Laguerre diagrams share the limitation of Voronoi diagrams that there is not an explicit relation between their generators and their geometric properties, such as the volumes of their cells. Consequently, an active area of research is to develop algorithms for generating Laguerre diagrams with prescribed geometric properties.
One popular method for approximately controlling the grain size distribution of Laguerre diagrams is using random close packing of spheres and ellipsoids [Citation4,Citation8,Citation10,Citation18]. This method is inexact, however, since it is impossible to tessellate Euclidean space with spheres or ellipsoids.
Several authors have developed methods for fitting Laguerre diagrams to image data (EBSD, XRD) of polycrystals. Here, geometric properties such as grain size, centroid location, and aspect ratio are fitted by minimising a measure of the fitting error using deterministic and stochastic optimisation methods, e.g. [Citation3,Citation9,Citation11,Citation19,Citation20]. While optimisation methods can give very accurate results, they can also be computationally expensive. Heuristic methods such as [Citation13] trade-off fidelity against speed.
Recently, several authors have generated RVEs with curved boundaries and non-convex cells grains using generalisations of Laguerre diagrams such as generalised balanced power diagrams [Citation1,Citation12,Citation13,Citation21] and multilevel Voronoi diagrams [Citation5,Citation17]. Complex geometries can also be created using the open-source software DREAM.3D [Citation22] and Neper [Citation23].
We will discuss some of these methods in more detail and compare them with ours in the Discussion section.
1.2. Goal of this paper
The goal of this paper is to develop algorithms for creating Laguerre diagrams with user-defined cell size distributions. Our motivation comes from steel modelling. We wish to generate realistic RVEs of single- and multi-phase steels for computational homogenisation simulations. Unlike much of the literature on Laguerre modelling of polycrystals [Citation1,Citation12,Citation13,Citation24], our primary aim is not to fit Laguerre diagrams to EBSD or XRD data, but rather to create a tool for generating a rich family of (possibly never-observed) microstructures, which can be combined with multiscale simulations to optimise grain geometries and lead to the development of new alloys. Having said that, our algorithms are also very well suited for generating Laguerre diagrams with texture intensities that match EBSD data, as we demonstrate in Example 5.3. With these applications to steel in mind, we often refer to Laguerre cells as grains, although our results can be applied more generally to other polycrystalline metals and to foams.
1.3. Contributions and outline of the paper
In Section 2, we recall the definition and some important properties of Laguerre diagrams. In particular, Property 2.3 forms the basis of our work. Section 3 includes our main result, Algorithm 2, for generating ‘regularised’ Laguerre diagrams with grains of prescribed volumes, up to any given tolerance. We also provide Algorithm 1 that can be used for fitting a Laguerre diagram to EBSD measurements of grain volumes and centroids (Example 5.3). We discuss practical issues about how the algorithms can be implemented in Section 4. Section 5 includes some large examples (10,000+ grains) and run-time tests in 3D, including examples of RVEs of Interstitial Free (IF) steels.
The theory underlying the algorithms presented in Section 2 uses results from computational geometry and optimal transport theory [Citation25,Citation26], a field of mathematics that has recently enormously grown in importance and found applications in a wide range of areas including data science, economics, image processing, partial differential equations and statistics. We believe however that this is its first application in the steel industry.
2. Laguerre diagrams
2.1. Notation and definitions
Let be the region occupied by a metal. We consider both the 2- and 3-dimensional cases (
and
). For simplicity, we assume that
is a convex polygon if
or a convex polyhedron if
. In principle, the algorithms below can be used for non-convex regions with curved boundaries, but they become harder to implement. In all our examples below, we take
to be a rectangular box. If
is a subset of
, let
denote its area if
or its volume if
.
Definition 2.1
([Citation27], [Citation28]):
Let be distinct points in
and
be real numbers (not necessarily positive). The Laguerre diagram or power diagram generated by the weighted points
is the tessellation
of
defined by
(1)
(1) We refer to the sets
as Laguerre cells or grains.
Laguerre diagrams have the following basic properties [Citation27,Citation28]:
Laguerre cells are convex polygons if
or convex polyhedra if
The Laguerre cells tessellate
If all the weights are equal,
Adding a constant to all the weights does not affect the Laguerre diagram, i.e. the weighted points
A generator
There can be empty Laguerre cells,
Now, we recall two advanced properties of Laguerre diagrams, Properties 2.2 and 2.3. These are the key ingredients for generating RVEs with grains of given sizes (given areas if or given volumes if
). Property 2.2 states that there always exists a Laguerre diagram with grains of given sizes. Property 2.3 gives a constructive way of finding one.
Property 2.2
([27, p. 96, Corollary 6.1], [29]):
Let be distinct points in
. Let
be positive numbers with
. Then there exist weights
such that the Laguerre diagram
generated by
has cells of size
:
(2)
(2)
The weights in Property 2.2 can be computed using the following result.
Property 2.3
([27, pp. 98–100], [29], [30, Theorem 2]):
Let be distinct points in
. Let
be positive numbers with
. Define the function
by
(3)
(3) where
is the Laguerre diagram generated by
. Then
The function
The gradient of
If
Property 2.3 forms the basis of Algorithms 1 and 2. It means that if we want to generate a Laguerre diagram with grains of given sizes, then we just need to find critical points of . Since
is concave, this is equivalent to maximising
, or to minimising
, which is a smooth, unconstrained, convex optimisation problem. Fast numerical methods are available for solving this [Citation31].
2.2. Controlling the spatial distribution of grains
Property 2.3 not only allows one to control the size distribution of grains, it also gives some control over the spatial distribution. Given positive numbers with
, there are infinitely many Laguerre diagrams
such that
for all
. This can be seen from Property 2.3(iii); any choice of distinct points
can give a Laguerre diagram with grains of size
. In Section 4.3.1, we will show how to choose
to control the spatial distribution of the grains.
2.3. Connection with optimal transport theory
Properties 2.2 and 2.3 can also be stated in the language of semi-discrete optimal transport theoryFootnote1; see, e.g. [Citation26, Sec. 6.4.2], [Citation30], [Citation32]. This connection provides a way of finding critical points of using fast modern methods from optimal transport theory [Citation32,Citation33]. We discuss this connection further at the end of Section 3.2.3.
3. Main results
3.1. Statement of the algorithms
For concreteness we state the algorithms in three dimensions, but they can also be used in two dimensions (by substituting volume with area and polyhedron with polygon wherever they appear in Algorithms 1 and 2). Our main result is Algorithm 2. First, however, we consider a simplified version, Algorithm 1, which will help us to understand the importance of the regularisation step in Algorithm 2. Algorithm 1 can also be used for data-driven modelling to fit a Laguerre diagram to EBSD or XRD measurements of grain volumes and centroids (see Example 5.3). Algorithm 1 is not new and goes back at least as far as [Citation29]. Our role is simply to bring it to the attention of the microstructure modelling community.
Algorithm 1: Generate a Laguerre diagram with grains of given volumes.
Input: A convex polyhedron representing a sample of metal, a list of volumes
such that
and
, and a relative error tolerance
.
Output: The generators of a Laguerre diagram
such that grain
has volume
up to
relative error, i.e.
, for all
.
Method:
Initialisation. Choose or randomly select distinct points
in
.
Optimisation step. Use a numerical optimisation method to find that maximises the function
defined in equation (Equation3
(3)
(3) ). Initialise the optimisation method using the initial guess
and terminate it using the stopping criterion
.
Example 3.1
(Example of Algorithm 1):
shows an example of Algorithm 1 implemented in MATLAB with grains in the square domain
. The grains have target areas
for
and
for
, where
so that the total area of all the grains equals the area of
. The actual areas of the grains returned by Algorithm 1 are correct to within
error (
). The initialisation step of Algorithm 1 was performed using the MATLAB function rand to select
(pseudo)randomly from a uniform distribution. While the grains have the correct areas to within
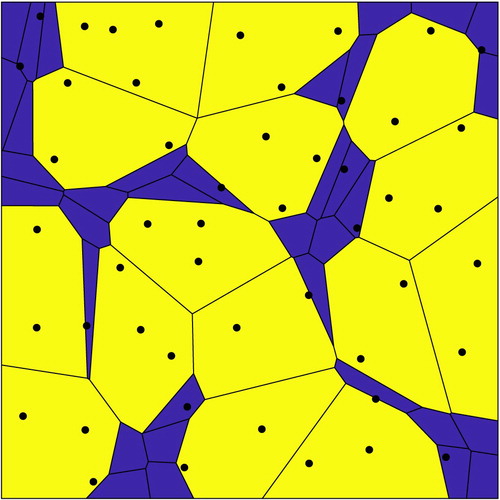
, the microstructure is somewhat irregular and unrealistic, with some highly elongated grains. This leads us to Algorithm 2, which produces more regular microstructures; compare and (i).
Algorithm 2: Generate a regularised Laguerre diagram with grains of given volumes.
Input: A convex polyhedron representing a sample of metal, a list of volumes
such that
and
, a relative error tolerance
, and the number of regularisation steps
.
Figure 1. An example of Algorithm 1 with grains in the unit square
. There are 35 small grains and 15 large grains. The small grains have area
and the large grains have area
to within
error, where
. The black dots are the locations of the generators
. Notice that not every grain contains its own generator.
Output: The generators of a regularised Laguerre diagram
such that grain
has volume
up to
relative error, i.e.
, for all
.
Method:
Initialisation. Choose or randomly select distinct points
in
. Initialise the weights to be zero:
.
Iteration. For do:
(1) Regularisation step. For
(2) Optimisation step. Use a numerical optimisation method to find
Figure 2. An example of iterations of Algorithm 2 with
grains in the unit square
. There are 35 small grains and 15 large grains. The small grains have area
and the large grains have area
to within
error, where
. The black dots are the locations of the generators
. In figure (i), the generators
are located at the centroids of their cells
to within a distance of 0.002. (a) Iteration
. (b) Iteration
. (c) Iteration
. (d) Iteration
. (e) Iteration
. (f) Iteration
. (g) Iteration
. (h) Iteration
. (i) Iteration
.

Example 3.2
(Example of Algorithm 2):
shows an example of Algorithm 2, using iterations, implemented in MATLAB with
grains in the square domain
. The grains have target areas
for
and
for
, where
so that the total area of all the grains equals the area of
. The actual areas of the grains returned by Algorithm 2 are correct to within
error (
). For the initialisation step we used exactly the same points
that were used for the initialisation step in Example 3.1. Observe from how the Laguerre diagram becomes more regular as the number of iterations
increases, and how it appears to be converging. The diagram already looks quite regular after just 4 or 5 iterations and the user may be happy to take far fewer than
iterations. We discuss how to choose
in the following section.
3.1.1. Periodic Laguerre diagrams
Algorithms 1 and 2 can be modified to create periodic Laguerre diagrams for use as RVEs for computational homogenisation (RVEs are usually taken to be periodic to avoid artificial boundary effects). To create periodic diagrams in a rectangular box of side lengths
, modify Algorithms 1 and 2 as follows. Define the periodic distance between
by
(8)
(8) In Algorithms 1 and 2 replace the Laguerre cells
by periodic Laguerre cells
, which are defined by
(9)
(9) In Algorithm 2 replace
by
(10)
(10) Replace
in Algorithm 2 is an analogous way.
3.2. Properties of the algorithms
3.2.1. Convergence of algorithm 2: centroidal Laguerre diagrams
In the appendix we prove that, under a generic assumption, Algorithm 2 converges as . This means that the generator locations
settle down with increasing iterations, like we see in . To be more precise, there exist
such that
for all
. By taking the limit
in equation (Equation6
(6)
(6) ), we see that
(11)
(11) Therefore, the generator
is the centroid of its own Laguerre cell
for all
. Such a Laguerre diagram is known as a centroidal Laguerre diagram or a centroidal power diagram, a term introduced in [Citation34]; see also [Citation35,Citation36]. Centroidal Laguerre diagrams tend to be more regular than non-centroidal Laguerre diagrams, as illustrated by (i) (centroidal) and (non-centroidal).
3.2.2. Connection with Lloyd's algorithm
If we omit the optimisation step in Algorithm 2 and set the weights to be zero for all iterations, for all
, then we obtain the well-known Lloyd's algorithm for computing centroidal Voronoi tessellations (Voronoi diagrams where each generator is the centroid of its own Voronoi cell) [Citation37]. Therefore, Algorithm 2 can be interpreted as a generalised Lloyd algorithm with capacity constraints where cell
is constrained to have volume
. An alternative method for generating centroidal Laguerre diagrams with capacity constraints is given in [Citation36, Section 4].
3.2.3. Energy-decreasing property of Algorithm 2
Algorithm 2 can also be interpreted as an energy-decreasing optimisation method. Given with
, define
(12)
(12) Here, the minimum is taken over all possible partitions of
, not just Laguerre diagrams. This is an example of an optimal transport problem. For example, in two dimensions
could represent the minimum (squared) cost of transporting the recyclable waste generated by a population uniformly distributed over a country
to recycling centres located at
with capacities
. It can be shown [Citation27, Section 6.4.1] that
(13)
(13) where
is the Laguerre diagram with generators
, where
is a maximum point of
(defined in (Equation3
(3)
(3) )). In other words,
is the solution of the optimal transport problem and all the recyclable waste generated in region
should be sent to the recycling centre
.
We could further ask what are the best locations of the recycling centres by considering the optimisation problem(14)
(14) This is known as the optimal location problem in the economics literature [Citation38] and the quantisation problem in the discrete geometry [Citation39], electrical engineering [Citation40] and probability literature [Citation41]. It can be shown that
(15)
(15) See, for example, [Citation36]. Therefore,
if and only if
generate a centroidal Laguerre diagram.
Thanks to its regularisation step, Algorithm 2 is energy-decreasing in the sense that(16)
(16) Moreover, under the generic assumption (EquationA5
(A5)
(A5) ), the sequence
converges to a critical point of
(to a local minimum point or saddle point). In other words, it converges to a centroidal Laguerre diagram. We prove these statements in the appendix. In general, Algorithm 2 does not converge to a global minimum point of
since
is highly non-convex with many critical points; illustrates four different (approximate) critical points of
, corresponding to different choices of
.
An alternative method for finding local minima of is given in [Citation36, Section 4] where, instead of updating
using our regularisation step, they update it using a quasi-Newton (L-BFGS) optimisation step applied to
.
4. Implementation
In this section, we discuss different options for implementing Algorithms 1 and 2, which we did using MATLAB and Voro++ [Citation42].
4.1. Computing Laguerre diagrams
One of the main expenses of Algorithms 1 and 2 is the computation of Laguerre diagrams. This happens whenever the objective function or
is evaluated, which could happen many times within a single optimisation step. A Laguerre diagram of
generators can be computed in
flops in 2D and
flops in 3D [Citation27, p. 85]. (Note that these are worst-case optimal run times and in practice the complexity may be better, as we observed in Example 5.1. For example, the complexity can be better if each cell has only
faces instead of the worst-case
[Citation27, Theorem 6.1].) In applications
could be 10,000 or more, and hundreds or thousands of Laguerre diagrams could be computed in a single run of either algorithm. Therefore, it is important to use efficient software.
For our 2D computations we used the MATLAB function power_bounded from the MATLAB File Exchange [Citation43], which implements Aurenhammer's lifting method [Citation44] and crops the diagram to a rectangular box .
The function power_bounded is limited to 2D, and so for our 3D computations we used (a slightly modified version of) the C++ library Voro++ [Citation42] combined with a MEX file so that we could run Voro++ via MATLAB. In 3D, we also tried the MATLAB function powerDiagramWrapper from the MATLAB File Exchange [Citation45], combined with our own code to crop the diagram to a cuboid , but we found Voro++ to be faster. Another advantage of Voro++ is that it can create periodic Laguerre diagrams.
We also used Tata Steel's own in-house Laguerre diagram code to visualise Laguerre diagrams in 2D and 3D.
4.2. Optimisation methods
The other main expense of Algorithms 1 and 2 is the optimisation step. For each algorithm this is a smooth, unconstrained, concave maximisation problem and so is very tractable. We used the MATLAB function fminunc to minimise and
(and hence maximise
and
), which uses the BFGS quasi-Newton method by default [Citation31]. This requires an initial guess
for the minimum point.
4.2.1. Choice of the initial guess
For Algorithm 1, we recommend the initial guess . For data fitting (like Example 5.3, where the seeds
are taken from EBSD measurements), if the target grains are relatively spherical, then a better choice may be
in 2D or
in 3D. In other words,
where
is the radius of a ball of area
in 2D or volume
in 3D. This is motivated by sphere-packing methods [Citation4,Citation8,Citation10,Citation18].
For Algorithm 2, the initial guess should depend on the iteration . For the first iteration
we recommend
. For iterations
we recommend
, the solution of the optimisation step from the previous iteration. As the number of iterations increases and the points
converge, the initial guess
becomes better and better and consequently the optimisation step becomes quicker and quicker. This is illustrated in , which shows the relative run time of each iteration for an example in which the relative sizes and relative proportions of small and large grains are the same as in Example 3.2 but the number of grains is
. We see that the total runtime of the algorithm is not proportional to the number of iterations
; most of the expense is in the first few iterations.
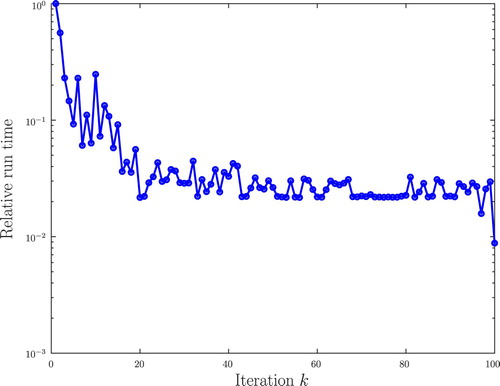
Figure 3. The relative run times for each optimisation step of Algorithm 2. In this example, the parameters are the same as those in Example 3.2, except that the number of grains is . The relative proportion of small and large grains is the same as in Example 3.2 and the ratio of the size of the largest grain to the size of the smallest grain is 10. The initial seed locations are randomly distributed in the unit square. The y-axis displays
, where
is the run time for the optimisation step of iteration
. After 12 iterations the time per iteration falls to below one-tenth the time of the first iteration, and after 18 iterations it falls to below one-twentieth. This is because the initial guess for the weights in the inner iteration is taken from the output of the previous outer iteration, and the quality of this guess improves as the number of iterations increases.
Note that for the first iteration, , the initial guess
does not incorporate any information about the locations
. It is possible to improve the speed of the first iteration by using a more sophisticated choice of
, e.g. using the multilevel methods of Mérigot [Citation30] and Lévy [Citation32], which generate a good initial guess
by solving a sequence of smaller optimisation problems with fewer grains. (For example, you can obtain a good initial guess
for
grains by first solving a coarser problem with
grains; you can obtain a good initial guess for
grains by first solving a coarser problem with
grains, etc.) We found that Mérigot's multilevel method [Citation30] in 2D could halve the run time of iteration
when there are
grains. It is reported that Lévy's multilevel program GEOGRAM can handle one million grains in 3D [Citation32, Table 4].
It is also possible to obtain a better initial guess for iterations
as follows. The Lloyd step (Equation6
(6)
(6) ) of Algorithm 2 could be replaced with a damped Lloyd step of the form
(17)
(17) where λ is a damping parameter between 0 and 1. The choice
corresponds to the Lloyd step (Equation6
(6)
(6) ). The closer
is to 0, the closer
is to
, and so the better the associated initial guess
. Therefore, the optimisation step is faster for smaller
. On the other hand, the regularisation step has less effect for smaller
, and it is necessary to increase the number of iterations
to achieve the same amount of regularisation. For our purposes, the full Lloyd step
was sufficiently fast and so we did not try to optimise the choice of
.
4.2.2. Choice of the tolerance
For simplicity, we chose the tolerance of the optimisation step of Algorithm 2 to be fixed at each iteration
(recall that the optimisation step terminates when
). The algorithm could be sped up, however, by taking
to depend on
. In order for Algorithm 2 to produce a Laguerre diagram with grains of given volumes up to a relative error of
, we only need the tolerance to be
at the final iteration,
. For previous iterations, we could use a cruder tolerance:
. It is tempting to think that the larger the tolerance, the faster the optimisation step. On the other hand, if
is larger than
, then the initial guess
at iteration
may be worse, and the optimisation step at iteration
may be slower. So the tolerances
must be chosen carefully. The choice of fixed tolerance
for all
is a simple, reliable option, which is why we used it.
4.2.3. Choice of the optimisation algorithm
The speed of the optimisation step depends of course not only on the choice of the initial guess and the tolerance
, but also on the choice of the optimisation algorithm. For example, instead of using a quasi-Newton method as we did, one could use Newton's method. Newton's method tends to converge faster than quasi-Newton methods (quadratically rather than superlinearly), although it is harder to implement since it requires the second derivative of
(whereas quasi-Newton methods only require the first derivative) [Citation31].
It can be shown (see, e.g. [Citation35]) that(18)
(18) where
is the area of the face between cell
and cell
and
is the index set of the neighbours of cell
(that is
if and only if cell
and cell
share a face). The pseudo-inverse of this Hessian matrix is used in a damped Newton method in [Citation33, Algorithm 1], where fractions of a full Newton step are used in order to control the error reduction and the minimum volume of a cell (to stop cells disappearing). The authors prove that their damped Newton method converges globally with order 1 and locally with order 2 [Citation33, Theorem 1.5].
4.3. Initialisation: effect on the spatial distribution
In this section, we discuss the initialisation step of Algorithms 1 and 2.
4.3.1. Initialisation of the seeds
The locations of the generators at the termination of Algorithm 2 are a strong function of the initial choice
. This simple observation gives us a great deal of control over the spatial distribution of the different sized grains. Examples of Algorithm 2 with different initial distributions of the generators
are shown in . In these examples,
and there are
grains. There are
grains of size
and
grains of size
. The tolerance is
and the number of iterations of Algorithm 2 is
. The figure shows the output of Algorithm 2. The final spatial distribution of grains has some features in common with the spatial distribution of the initial generator locations.
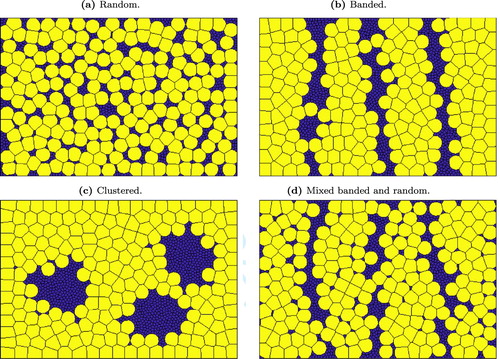
Figure 4. Examples of more advanced microstructures: Coupling of size and spatial distributions with Algorithm 2. This figure shows the output of Algorithm 2 after iterations with different initial distributions for the seed locations. In all cases there are
grains with
grains of size
and
grains of size
. (a) Random distribution of initial locations. Here the initial generator locations of the large and small grains are uniformly distributed over
. (b) Banded distribution of initial locations. Here, the different sized grains have initial generator locations that lie inside bands within
. The sizes of the bands have been chosen so that there are approximately equal numbers of small grains within each small-grain band and approximately equal numbers of large grains within each large-grain band. (c) Clustered distribution of initial locations. Here, the smaller grains have initial generator locations that lie inside non-overlapping discs. (d) A mixed distribution: the initial generators are such that the larger grains are arranged in bands and the smaller grains are a combination of the banded and random distributions.
A further example of controlling the spatial distribution of grains can be seen in . In this example, grains have areas drawn from a random distribution such that the ratio of the largest to the smallest grain size is at most 100. The Laguerre diagram in (a) has the property that the grain sizes tend to increase from left to right. A variety of spatial distributions of grain sizes can be simulated by first distributing the seed locations appropriately. (b) shows how a more complicated distribution can be produced.
Figure 5. Experiments to demonstrate a gradient in the distribution of grain sizes. Here, grains have areas drawn from a uniform distribution such that the ratio of the largest to the smallest grain size is at most 100. The domain is
. The results are shown after
iterations and the grains are coloured according to their area. (a) The initial seed locations
are distributed such that the
-coordinate increases with grain size. (b) The initial seed locations are distributed such that the larger grains are found in the middle of
.
![Figure 5. Experiments to demonstrate a gradient in the distribution of grain sizes. Here, n=1000 grains have areas drawn from a uniform distribution such that the ratio of the largest to the smallest grain size is at most 100. The domain is Ω=[0,3]×[0,2]. The results are shown after K=20 iterations and the grains are coloured according to their area. (a) The initial seed locations x1(0),…,xn(0) are distributed such that the x-coordinate increases with grain size. (b) The initial seed locations are distributed such that the larger grains are found in the middle of Ω.](/cms/asset/4fc444b6-1b9d-46ab-b130-b7fa3d444523/tphm_a_1790053_f0005_oc.jpg)
4.3.2. Initialisation of the weights
The choice of in the initialisation step of Algorithm 2 is also important. One should choose
so that the Laguerre diagram generated by
has no empty Laguerre cells. If there are empty cells then the regularisation step is not defined (there is division by zero in equation (Equation6
(6)
(6) ) if
is empty). A good choice is
since then the Laguerre diagram generated by
is a Voronoi diagram and so has no empty cells, whatever the choice of
.
4.4. Stopping criteria
In Algorithm 2, the user must specify the number of regularisation steps . As we discussed in Section 3.1, for large values of
the Laguerre diagram resulting from Algorithm 2 is approximately a centroidal Laguerre diagram, which means that each seed
is approximately the centre of mass of its Laguerre cell
. Centroidal Laguerre diagrams tend to have very regular-shaped cells, e.g. in 2D if the grains all have the same target areas,
, and if
and
are large, then the Laguerre diagram looks locally like a regular hexagonal tiling. Indeed for steel microstructures, we found that if
is too large, then Algorithm 2 tends to produce grains that are too ‘round’ compared to EBSD measurements of grain aspect ratios.
Instead of fixing the number of steps in advance, the user could terminate the algorithm whenever some measure of the maximum grain aspect ratio falls below a critical threshold. For example, the aspect ratio of grain can be measured using the ratio of its largest and smallest principal moments of inertia, or using the ratio of the radii of circumscribed and inscribed balls, or using its sphericity [Citation46], which is the ratio of the surface area of the volume-equivalent sphere to the surface area of the grain.
The user may also want to terminate the algorithm if the distance moved by the seeds from one iteration to the next falls below some threshold. The Laguerre diagram
tends to evolve slowly with
when
is large, as illustrated in , and the evolution can slow down dramatically when there is a T1 topological transition (to borrow a term from foam dynamics). This topological transition involves a change of cell neighbour relations; in 2D this is via coalescence of two triple junctions of cell boundaries. So, in general, there is little to be gained from performing a large number of regularisation steps, especially since our aim is not to produce a centroidal Laguerre diagram, but rather to produce a physically realistic microstructure. (If on the other hand, the user's aim is to produce centroidal Laguerre diagrams, then it would be better to use the quasi-Newton method of [Citation36], which converges superlinearly as opposed to the linear convergence of Lloyd's algorithm.)
5. Examples
This section includes some large examples in 3D to illustrate the capabilities of our algorithms.
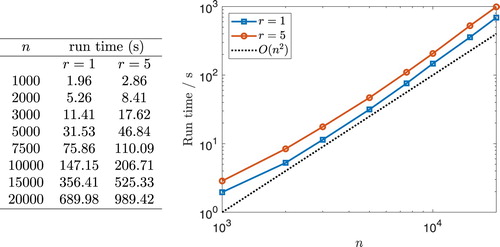
Example 5.1
(Run time tests):
gives some run times of Algorithm 2 for creating monodisperse and polydisperse periodic Laguerre diagrams in 3D. Here Algorithm 2 has been used to create grains of volume
and
grains of volume
, for
and
, in a cube of side length 100 with error tolerance
. We see that the run time grows roughly quadratically in the range
to
, for both the monodisperse (single phase) case
and the polydisperse (dual phase) case
. This could be expected since the cost of each iteration of the BFGS method used by fminunc is
(a matrix-vector multiplication). Also the worst-case optimal time it takes to compute a Laguerre diagram of
cells is
in 3D, although we found that in these examples the cost of computing the Laguerre diagrams was sub-quadratic (but super-linear); see also the discussion in Section 4.1. For
the run time grows a little faster than
. Observe also from that it is about 50% more expensive to compute dual phase RVEs (
) than single phase RVEs (
).
Figure 6. Run times in seconds of Algorithm 2 for creating monodisperse (single phase) and polydisperse (dual phase) periodic RVEs in 3D. There are grains of volume
and
grains of volume
in a cube of side length 100 with at most
error (
) in the volumes of the grains (
corresponds to a single phase material,
corresponds to a dual phase material,
is chosen such that the total volume of the grains equals the volume of the box). We used
regularisation steps, and the initial seed locations
were chosen randomly from a uniform distribution. The simulations were performed on an Intel Xeon E5-1620V3 (3.5 GHz, 4 cores, 8 threads). The graph on the right has a log–log scale. The black dotted line is the graph of the function
, where
is a constant. It is included to illustrate how the run times grow with
.
Example 5.2
(Generating a periodic RVE of an IF steel):
shows an example of a periodic Laguerre diagram created using Algorithm 2. The target volumes are taken from a 3D EBSD measurement of an IF (interstitial free) steel (EN 10130 grade DC06). There are
grains in a box of dimensions
. We took the initial seed locations
to be the centres of mass of the grains from the EBSD data, and performed
regularisation steps with a tolerance of
(
). The grains in are coloured according to their lattice orientations by mapping the three Euler angles linearly to RGB values. The orientations were taken from the EBSD data. shows that the volumes of all the grains are correct to within
, and most volumes are correct to within
.
Figure 7. A periodic RVE of an IF steel with grains, generated using Algorithm 2 (see Example 5.2). The grains are coloured according to their lattice orientations.

Figure 8. The complementary cumulative number distribution of the percentage error of the volumes of the grains for Example 5.2. For a percentage error , we plot the number of grains that have a volume percentage error at least
. Most of the grain volumes have percentage error less than
, which is an order of magnitude below the tolerance of
(
). In this example, the maximum percentage error is
.
Example 5.3
(Fitting a Laguerre diagram to EBSD measurements):
The main aim of this paper is to create Laguerre diagrams with given volume distributions for use in computational homogenisation simulations. We briefly mention, however, how Algorithm 1 can be used to fit a Laguerre diagram to EBSD data of grain volumes and centroids. is an example of a non-periodic Laguerre diagram fitted to a 3D EBSD measurement of an IF steel (EN 10130 grade DC06) with grains in a box of dimensions
(this is the same EBSD data used in the previous example). In the initialisation step of Algorithm 1, we took
to be the centroids of the grains from the EBSD data. The target volumes
were also taken from the EBSD data. We used a tolerance of
(
). As in the previous example, the grains in are coloured according to their lattice orientation. Observe that is less regular than , which is because Algorithm 1 is missing the regularisation steps of Algorithm 2. shows that the volumes of all the grains are correct to within
, and most volumes are correct to within
. shows the complementary cumulative number distribution of the relative errors of the centroids. The relative error for grain
is defined by
(19)
(19) where
is the centroid of grain
from the EBSD data,
is the centroid of the Laguerre cell
, and
is the radius of a sphere of volume
, where
is the target volume of grain
. This definition of relative error was proposed by [Citation9]. As expected, the centroid errors are higher than the volume errors since Algorithm 1 does not directly try to fit the centroids. To be precise, the optimisation step of Algorithm 1 only minimises the fitting error of the volumes; the centroid fitting error is not minimised (the centroids do not appear in the objective function
). However, the centroid measurements are used in the initialisation step of Algorithm 1. The relative error of 79% of the grain centroids is less than 1 and the relative error of 93% of the grain centroids is less than 2.The run time for this example was 376 s on an Intel Xeon E5-1620V3 (3.5 GHz, 4 cores, 8 threads) with the initial guess
, which was inspired by sphere-packing methods [Citation4,Citation8,Citation10,Citation18].
Figure 9. A non-periodic Laguerre diagram fitted to 3D EBSD data of an IF steel using Algorithm 1 (see Example 5.3). The grains are coloured according to their lattice orientations. The volume distribution has a fitting error of less than . The texture intensity inherits the same fitting error.

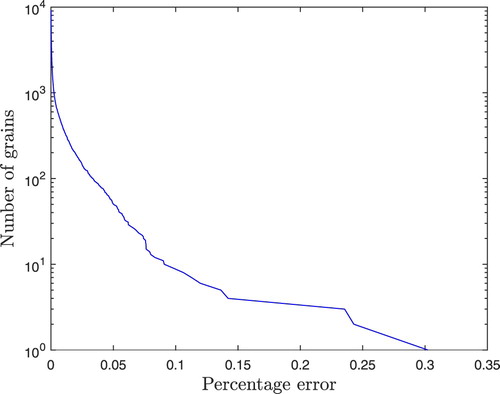
Figure 10. The complementary cumulative number distribution of the percentage error of the volumes of the grains for Example 5.3. For a percentage error , we plot the number of grains with volume percentage error at least
. The largest percentage error is
and the second largest is
. All the other percentage errors are below
.
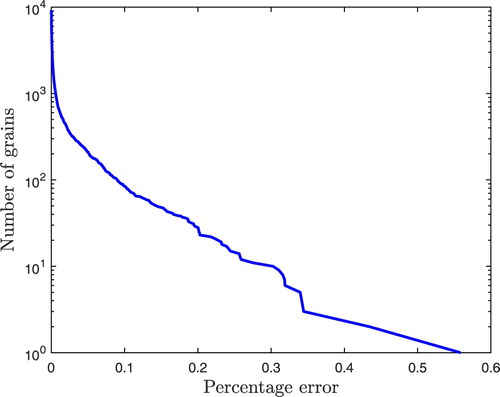
Figure 11. The complementary cumulative number distribution of the relative error of the centroids of the grains for Example 5.3. For a relative error , we plot the number of grains with centroid relative error at least
. The maximum relative error is 11.16%, which is worse than the result given in [Citation9, Figure 9], although for most of the grains the relative errors are comparable: 7278 of the 9211 grains have a relative error less than 1, and 8596 of the 9211 grains have a relative error less than 2.
![Figure 11. The complementary cumulative number distribution of the relative error of the centroids of the grains for Example 5.3. For a relative error x, we plot the number of grains with centroid relative error at least x. The maximum relative error is 11.16%, which is worse than the result given in [Citation9, Figure 9], although for most of the grains the relative errors are comparable: 7278 of the 9211 grains have a relative error less than 1, and 8596 of the 9211 grains have a relative error less than 2.](/cms/asset/2d8ab61b-9e74-4a31-84d6-3f88d21b79ca/tphm_a_1790053_f0011_oc.jpg)
Example 5.4
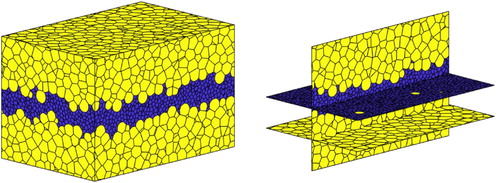
(Generating a dual phase RVE with a banded microstructure):
shows an example of a periodic, dual phase Laguerre diagram with a band of small grains in the centre, generated using Algorithm 2. There are grains: 8000 grains of volume
and 2000 grains of volume
(where
was chosen so that the total volume of the grains equals the volume of the box). We used
regularisation steps and a volume tolerance of
. The grains are coloured according to their volume. In order to obtain the banded structure, we placed the initial seeds
at random within bands of the correct volume. We see from that these bands were largely preserved by the regularisation steps.
Figure 12. A periodic RVE of a dual phase material with a banded microstructure (see Example 5.4).
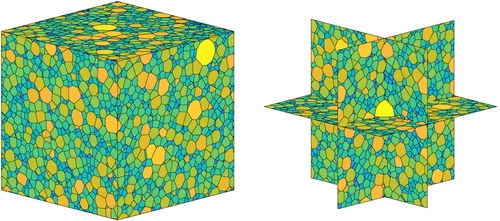
Example 5.5
(Generating an RVE with a log-normal distribution of grain volumes):
shows an example of a periodic Laguerre diagram generated by Algorithm 2, in which the grains have volumes that are log-normally distributed. There are grains. We used
regularisation steps and a volume tolerance of
. The grains are coloured by their volume, using a log scale. We placed the initial seeds
at random. The target volumes were generated by drawing 10,000 samples
from a log-normal distribution with mean 1 and standard derivation 0.35 (these correspond to the log-normal parameters
and
). The target volumes were defined by
(20)
(20) where the
are the side-lengths of the domain
. For large
these target volumes are approximately log-normally distributed with coefficient of variation (the ratio of standard variation to mean) of
(21)
(21) The algorithm took 669 s using the same machine as above. Observe from Example 5.1 that Algorithm 2 took only 147 s to produce a monodisperse RVE and 207 s to produce a dual phase RVE with the same number of grains (
) and the same number of regularisation steps (
). Therefore, the run time of Algorithm 2 increases as the RVE becomes more polydisperse.
Figure 13. An RVE in which the grain volumes have approximately log-normal distribution (see Example 5.5). There are grains in the cubic cell. The coefficient of variation of the volumes (the ratio of the standard deviation to the mean) is 1.4. Cross-sections of the cell are also shown, showing the distribution of sizes throughout the cell.
6. Discussion
The advantages of our method are
it is fast;
it can create Laguerre diagrams with grains of exact volumes, in principle of any desired tolerance up to machine precision;
it gives some control over the spatial distribution of the grains;
it can create periodic and non-periodic Laguerre diagrams.
The disadvantages of our method are
it provides no direct control over the centroids of the grains or their morphology, e.g. their aspect ratio;
it is currently limited to Laguerre diagrams and so the grains cannot have curved boundaries or be non-convex.
We now discuss these advantages and disadvantages in more detail, give evidence in support of our claims, and compare our method with others in the literature.
6.1. Controlling grain volumes: speed and accuracy
shows that we can create Laguerre diagrams in 3D with up to 20,000 grains in around 10 min on a standard desktop PC (without using parallel computation), where the volumes of the grains are correct to within . For 10,000 grains, we require as little as 2.5 min (see ), although the time depends on the regularity of the microstructure and whether the material is monodisperse or polydisperse; in Example 5.3 it took 6.25 min for 9211 grains and in Example 5.5 it took about 11 min for 10,000 grains.
In our implementation of Algorithm 2, we simply used MATLAB's all-purpose fminunc optimisation algorithm. With modern, customised optimal transport optimisation algorithms such as [Citation32,Citation33] it should be possible to use our method to generate Laguerre diagrams with given volume distributions with 100,000 grains in a few minutes [Citation32, Table 3] or even one million grains in less than an hour [Citation32, Table 4].
We now compare this with the speed of other algorithms. It is difficult to make a direct comparison in some cases since different methods fit different geometric properties.
In [Citation9], a stochastic optimisation method (the cross-entropy method) is used to solve a non-convex optimisation problem to fit a Laguerre diagram to 3D XRD measurements of grain volumes and centroids. The authors report simulation times (performed using parallel computation) of 19.2 h for 1439 grains and 122.3 h for 8063 grains. Note that it is hard to compare their run times with ours since they also fitting centroids; their method does not try to fit the volumes exactly like we do, but rather obtain a good fit for both volumes and centroids, and their method can produce empty Laguerre cells (grains with volume zero). While the main focus of our paper is to fit volumes only, we gave an example of fitting volumes and centroids in Example 5.3, where we fit a Laguerre diagram to 3D EBSD measurements of an IF steel with 9211 grains. The run time is 6.25 min and the volumes are correct to within . The centroid errors of most of the grains are comparable to those given in [Citation9, Figure 9], although overall our method does worse than [Citation9] at centroid fitting, as expected.
Sphere-packing methods are popular for fitting Laguerre diagrams to volume distributions [Citation4,Citation8,Citation10,Citation18]. For non-overlapping spheres
with centres
and radii
, the Laguerre diagram with seeds
and weights
has the property that cell
contains sphere
. Therefore, the volume of
is at least the volume of
. The idea of sphere-packing methods is that if the spheres are close-packed, then the volumes of the Laguerre cells are approximately equal to the volumes of the solid spheres. The disadvantage of this method is that it is inexact and computationally expensive since the sphere-packing problem is NP hard [Citation47]. Nevertheless, this method provided us with inspiration for a good initial guess for the optimisation simulation in Example 5.3 (see also Section 4.2.1).
In [Citation1], a method is proposed for fitting grain measurements with generalised balanced power diagrams (GBPDs), which are a generalisation of Laguerre diagrams. GBPDs are generated by triples of seeds
, weights
, and positive definite matrices
; the matrices
give some control over the aspect ratio of the generalised Laguerre cells; the case
for all
corresponds to a standard Laguerre diagram. The advantage of GBPDs is that they give a high degree of control over the morphology of the grains [Citation1, Figures 1–6]. The disadvantage is that they are hard to compute. In [Citation1], the authors approximate GBPDs by voxels, and they fit discretised GBPDs to grain measurements by solving a high-dimensional linear programming problem, where the number of unknowns equals the number of grains multiplied by the number of voxels. It is reported that to fit a discretised GBPD to 109 grains in 3D took around 6 h on a standard laptop (this involved solving a linear programming problem with over 77 million variables and 78 million constraints) [Citation1, Section 5.3]. Again, it is not possible to make a direct comparison of these run times with the ones presented here since grain volumes and morphology are fitted in [Citation1], not only grain volumes like here.
A heuristic method for approximately fitting GBPDs to measurements of grain volumes, centroids and aspect ratios was proposed in [Citation13]. Their method entirely avoids solving an optimisation problem; it includes explicit formulas for the generators in terms of the data. It is reported in [Citation13] that the method is comparable in accuracy with the optimisation methods of [Citation1,Citation11,Citation21] but takes a small fraction of the computation time. No run times or volume errors are reported in [Citation13] precluding a more precise comparison with our method. Like the sphere-packing method, this heuristic method could be used for generating good initial guesses for optimisation methods.
6.2. Controlling grain geometry
The main goal of our method is to fit grain volumes quickly and accurately. Unlike other methods [Citation1,Citation9,Citation11–13,Citation21,Citation24], it is not specifically designed for fitting grain morphology. We now discuss to what extent we can control the geometry of Laguerre diagrams.
Our method gives some control over the spatial distribution of the grains, as shown in Figures , and , where we create microstructures with bands, clusters, and size gradients.
Several authors use grain centroids as a measure of fitting-error when fitting Laguerre diagrams to data measurements, e.g. [Citation9,Citation13]. We show how we can approximately fit grain centroids to 3D EBSD data in Example 5.3, although the accuracy is much lower than the volume accuracy.
In its current form, our method gives no direct control over the aspect ratio of the grains. Like the sphere-packing method, Algorithm 2 tends to produce grains that are too round compared to grains typically seen in metals; see Section 4.4.
Nevertheless, there are several ways how our method could be generalised to give more control over the morphology of the grains. For example, by combining our method with multilevel Voronoi diagrams [Citation5,Citation17] we could maintain control over the volume of the grains while producing more realistic RVEs with non-convex and elongated grains. The idea would be to first use Algorithm 2 to create a Laguerre diagram with ‘micro-grains’ of equal volume for large
. Then we would glue together the micro-grains into non-convex ‘macro-grains’. By choosing which micro-grains to glue, we would control the volume and the morphology of the macro-grains. (The multilevel Voronoi method glues together two micro-grains if their generators lie in the same Voronoi cell of a ‘coarser’ Voronoi diagram with fewer generators.)
In principle, our algorithms can also be generalised very easily to produce GBPDs with grains of given volumes (up to any desired tolerance) by modifying the objective functions and
in Algorithms 1 and 2 (simply replace the Laguerre cells
with generalised Laguerre cells, and replace the isotropic distances
with anisotropic distances
). This would again allow us to control both the volumes and the aspect ratio of the grains. In practice, however, it is expensive to compute GBPDs to high accuracy; discretising them with voxels greatly increases the cost of the algorithm. Without developing new computational geometry algorithms for the efficient computation of GBPDs, this limits the method to a small number of grains or greatly increases the run time (cf. the run time of 6 h for 109 grains in 3D in [Citation1]).
Since our method is currently limited to Laguerre diagrams, the grains cannot have curved boundaries or be non-convex. Curved grain boundaries can be created using additively weighted Voronoi diagrams (Apollonius diagrams) [Citation27], anisotropic diagrams [Citation2], or GBPDs [Citation1,Citation12,Citation13,Citation21], although these are all more costly to compute than Laguerre diagrams. Algorithms 1 and 2 can also be modified to produce Apollonius diagrams with grains of given volumes (in the definition of the objective functions and
simply replace the Laguerre cells
with Apollonius cells, and replace the squared distances
with non-squared distances
) but again the implementation cost is an obstacle at the present time. We plan to explore this and the above generalisations in a future paper.
7. Conclusions
In this paper, we introduced a fast optimisation method for generating Laguerre diagrams with user-defined grain size distributions. The volumes of the grains can be controlled exactly (to within any given tolerance). We produced industrially relevant examples of RVEs with up to 20,000 grains with only volume error in the order of minutes on a standard desktop PC. We also demonstrated how the spatial and texture distribution of the grains can be partially controlled. Our algorithms can create both non-periodic Laguerre diagrams (for data fitting) and periodic Laguerre diagrams (for generating RVEs of polycrystalline metals or solid foams for computational homogenisation).
Acknowledgments
The authors would like to thank Carola Celada-Casero for useful discussions.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 Technical remark: It can be shown that evaluating the optimal transport (Wasserstein) distance between the Lebesgue measure and a discrete measure generates a partition of
into Laguerre cells of size
.
References
- A. Alpers, A. Brieden, P. Gritzmann, A. Lyckegaard, and H.F. Poulsen, Generalized balanced power diagrams for 3D representations of polycrystals, Philos. Mag. 95 (2015), pp. 1016–1028. Available at https://doi.org/10.1080/14786435.2015.1015469.
- H. Altendorf, F. Latourte, D. Jeulin, M. Faessel, and L. Saintoyant, 3D reconstruction of a multiscale microstructure by anisotropic tessellation models, Image Anal. Stereol. 33 (2014), pp. 121–130. Available at https://www.ias-iss.org/ojs/IAS/article/view/1090. doi: 10.5566/ias.v33.p121-130
- J. Barker, G. Bollerhey, and J. Hamaekers, A multilevel approach to the evolutionary generation of polycrystalline structures, Comput. Mater. Sci. 114 (2016), pp. 54–63. Available at http://www.sciencedirect.com/science/article/pii/S0927025615007259. doi: 10.1016/j.commatsci.2015.11.018
- D. Depriester and R. Kubler, Radical Voronoi tessellation from random pack of polydisperse spheres: prediction of the cells' size distribution, Computer-Aided Des. 107 (2019), pp. 37–49. Available at https://doi.org/10.1016/j.cad.2018.09.001.
- P.J.J. Kok and F.N.M. Korver. Modelling of complex microstructures in multi-phase steels: geometric considerations for building an RVE, Proceedings of the 10th International Conference on Computational Plasticity, Barcelona, 2009.
- A. Liebscher, Laguerre approximation of random foams, Philos. Mag. 95 (2015), pp. 2777–2792. Available at https://doi.org/10.1080/14786435.2015.1078511.
- A. Leonardi, P. Scardi, and M. Leoni, Realistic nano-polycrystalline microstructures: beyond the classical Voronoi tessellation, Philos. Mag. 92 (2012), pp. 986–1005. Available at https://doi.org/10.1080/14786435.2011.637984.
- A. Lyckegaard, E.M. Lauridsen, W. Ludwig, R.W. Fonda, and H.F. Poulsen, On the use of Laguerre tessellations for representations of 3d grain structures, Adv. Eng. Mater. 13 (2011), pp. 165–170. Available at https://onlinelibrary.wiley.com/doi/abs/10.1002/adem.201000258.
- L. Petrich, J. Staněk, M. Wang, D. Westhoff, L. Heller, P. Šittner, C.E. Krill III, V. Beneš, and V. Schmidt, Reconstruction of grains in polycrystalline materials from incomplete data using Laguerre tessellations, Microsc. Microanal. 25 (2019), pp. 743–752. Available at https://doi.org/10.1017/S1431927619000485.
- I. Pérez, M. Muniz de Farias, M. Castro, R. Roselló, C. Recarey Morfa, L. Medina, and E. Oñate, Modeling polycrystalline materials with elongated grains, Int. J. Numer. Methods. Eng. 118 (2019), pp. 121–131. Available at https://onlinelibrary.wiley.com/doi/abs/10.1002/nme.6004.
- A. Spettl, T. Brereton, Q. Duan, T. Werz, C.E. Krill III, D.P. Kroese, and V. Schmidt, Fitting Laguerre tessellation approximations to tomographic image data, Philos. Mag. 96 (2016), pp. 166–189. Available at https://doi.org/10.1080/14786435.2015.1125540.
- O. Šedivý, D. Westhoff, J. Kopeček, C.E. Krill III, and V. Schmidt, Data-driven selection of tessellation models describing polycrystalline microstructures, J. Stat. Phys. 172 (2018), pp. 1223–1246. Available at https://doi.org/10.1007/s10955-018-2096-8.
- K. Teferra and D.J. Rowenhorst, Direct parameter estimation for generalised balanced power diagrams, Philos. Mag. Lett. 98 (2018), pp. 79–87. Available at https://doi.org/10.1080/09500839.2018.1472399.
- Y. Wu, J. Cao, and Z. Fan, Chord length distribution of Voronoi diagram in Laguerre geometry with lognormal-like volume distribution, Mater. Charact. 55 (2005), pp. 332–339. Available at http://www.sciencedirect.com/science/article/pii/S1044580305001695. doi: 10.1016/j.matchar.2005.07.005
- J. Alsayednoor, P. Harrison, and Z. Guo, Large strain compressive response of 2-D periodic representative volume element for random foam microstructures, Mech. Mater. 66 (2013), pp. 7–20. Available at http://www.sciencedirect.com/science/article/pii/S016766361300118X. doi: 10.1016/j.mechmat.2013.06.006
- S. Ghosh and D. Dimiduk, Computational Methods for Microstructure-Property Relationships, Springer, New York, 2011.
- S. Yadegari, S. Turteltaub, A.S.J. Suiker, and P.J.J. Kok, Analysis of banded microstructures in multiphase steels assisted by transformation-induced plasticity, Comput. Mater. Sci. 84 (2014), pp. 339–349. Available at http://www.sciencedirect.com/science/article/pii/S0927025613007519. doi: 10.1016/j.commatsci.2013.12.002
- Y. Wu, W. Zhou, B. Wang, and F. Yang, Modeling and characterization of two-phase composites by Voronoi diagram in the Laguerre geometry based on random close packing of spheres, Comput. Mater. Sci. 47 (2010), pp. 951–961. Available at http://www.sciencedirect.com/science/article/pii/S092702560900439X. doi: 10.1016/j.commatsci.2009.11.028
- Q. Duan, D. Kroese, T. Brereton, A. Spettl, and V. Schmidt, Inverting Laguerre tessellations, Comput. J. 57 (2014), pp. 1431–1440. doi: 10.1093/comjnl/bxu029
- K. Teferra and L. Graham-Brady, Tessellation growth models for polycrystalline microstructures, Comput. Mater. Sci. 102 (2015), pp. 57–67. Available at https://doi.org/10.1016/j.commatsci.2015.02.006.
- O. Šedivý, T. Brereton, D. Westhoff, L. Polívka, V. Beneš, V. Schmidt, and A. Jäger, 3D reconstruction of grains in polycrystalline materials using a tessellation model with curved grain boundaries, Philos. Mag. 96 (2016), pp. 1926–1949. Available at https://doi.org/10.1080/14786435.2016.1183829.
- M. Groeber and M. Jackson, DREAM.3D: A digital representation environment for the analysis of microstructure in 3D, Integrating Mater. 3 (2014), pp. 56–72. Available at https://doi.org/10.1186/2193-9772-3-5.
- R. Quey and L. Renversade, Optimal polyhedral description of 3d polycrystals: Method and application to statistical and synchrotron X-ray diffraction data, Comput. Methods. Appl. Mech. Eng. 330 (2018), pp. 308–333. Available at http://www.sciencedirect.com/science/article/pii/S0045782517307028. doi: 10.1016/j.cma.2017.10.029
- O. Šedivý, J. Dake, C.E. Krill III, V. Schmidt, and A. Jäger, Description of the 3D morphology of grain boundaries in aluminum alloys using tessellation models generated by ellipsoids, Image Anal. Stereol. 36 (2017), pp. 5–13. Available at https://www.ias-iss.org/ojs/IAS/article/view/1656. doi: 10.5566/ias.1656
- B. Lévy and E.L. Schwindt, Notions of optimal transport theory and how to implement them on a computer, Comput. Graph. 72 (2018), pp. 135–148. Available at http://www.sciencedirect.com/science/article/pii/S0097849318300098. doi: 10.1016/j.cag.2018.01.009
- F. Santambrogio, Optimal Transport for Applied Mathematicians, Birkhäuser/Springer, Basel, 2015. Available at https://doi.org/10.1007/978-3-319-20828-2.
- F. Aurenhammer, R. Klein, and D.-T. Lee, Voronoi Diagrams and Delaunay Triangulations, World Scientific, Singapore, 2013. Available at https://doi.org/10.1142/8685.
- A. Okabe, B. Boots, K. Sugihara, and S.N. Chiu, Spatial Tessellations: Concepts and Applications of Voronoi Diagrams. 2nd ed. Wiley, Chichester, 2000. Available at https://doi.org/10.1002/9780470317013.
- F. Aurenhammer, F. Hoffmann, and B. Aronov, Minkowski-type theorems and least-squares clustering, Algorithmica 20 (1998), pp. 61–76. Available at https://doi.org/10.1007/PL00009187.
- Q. Mérigot, A multiscale approach to optimal transport, Comput. Graph. Forum. 30 (2011), pp. 1583–1592. Available at https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1467-8659.2011.02032.x.
- S. Boyd and L. Vandenberghe, Convex Optimization, Cambridge University Press, Cambridge, 2004. Available at https://doi.org/10.1017/CBO9780511804441.
- B. Lévy, A numerical algorithm for L2 semi-discrete optimal transport in 3D, ESAIM. Math. Model. Numer. Anal. 49 (2015), pp. 1693–1715. Available at https://doi.org/10.1051/m2an/2015055.
- J. Kitagawa, Q. Mérigot, and B. Thibert, Convergence of a Newton algorithm for semi-discrete optimal transport, J. Eur. Math. Soc. 21 (2019), pp. 2603–2651. Available at https://doi.org/10.4171/JEMS/889.
- A. Brieden and P. Gritzmann, On optimal weighted balanced clusterings: Gravity bodies and power diagrams, SIAM J. Discrete Math. 26 (2012), pp. 415–434. Available at https://doi.org/10.1137/110832707.
- D.P. Bourne and S.M. Roper, Centroidal power diagrams, Lloyd's algorithm, and applications to optimal location problems, SIAM. J. Numer. Anal. 53 (2015), pp. 2545–2569. Available at https://doi.org/10.1137/141000993.
- S.-Q. Xin, B. Lévy, Z. Chen, L. Chu, Y. Yu, C. Tu, and W. Wang, Centroidal power diagrams with capacity constraints: Computation, applications, and extension, ACM. Trans. Graph. 35 (2016), pp. 244:1–244:12. Available at http://doi.acm.org/10.1145/2980179.2982428.
- Q. Du, V. Faber, and M. Gunzburger, Centroidal Voronoi tessellations: applications and algorithms, SIAM Rev. 41 (1999), pp. 637–676. Available at https://doi.org/10.1137/S0036144599352836.
- B. Bollobás and N. Stern, The optimal structure of market areas, J. Econ. Theory. 4 (1972), pp. 174–179. Available at https://doi.org/10.1016/0022-0531(72)90147-0.
- P.M. Gruber, Optimum quantization and its applications, Adv. Math. (N. Y.) 186 (2004), pp. 456–497. Available at https://doi.org/10.1016/j.aim.2003.07.017.
- R.M. Gray and D.L. Neuhoff, Quantization, IEEE Trans. Inform. Theory 44 (1998), pp. 2325–2383. Available at https://doi.org/10.1109/18.720541, Information theory: 1948–1998.
- S. Graf and H. Luschgy, Foundations of Quantization for Probability Distributions, Springer, Berlin, Heidelberg, 2000. Vol. 1730. Available at https://doi.org/10.1007/BFb0103945.
- C.H. Rycroft, VORO++: A three-dimensional Voronoi cell library in C++, Chaos: An Interdiscip. J. Nonlinear Sci. 19 (2009), p. 041111. Available at https://doi.org/10.1063/1.3215722
- Firman, Fast bounded power diagram. Available at https://uk.mathworks.com/matlabcentral/fileexchange/56633-fast-bounded-power-diagram, MATLAB Central File Exchange.
- F. Aurenhammer, Power diagrams: properties, algorithms and applications, SIAM J. Comput. 16 (1987), pp. 78–96. Available at https://doi.org/10.1137/0216006.
- F. McCollum, Power diagrams, Available at https://uk.mathworks.com/matlabcentral/fileexchange/44385-power-diagrams, MATLAB Central File Exchange.
- A. Spettl, T. Werz, C. Krill III, and V. Schmidt, Parametric representation of 3d grain ensembles in polycrystalline microstructures, J. Stat. Phys. 154 (2014), pp. 913–928. Available at https://doi.org/10.1007/s10955-013-0893-7.
- M. Hifi and R. M'Hallah, A literature review on circle and sphere packing problems: models and methodologies, Adv. Oper. Res. 2009 (2009), pp. 150624:1–150624:22.
- M. Emelianenko, L. Ju, and A. Rand, Nondegeneracy and weak global convergence of the Lloyd algorithm in Rd, SIAM. J. Numer. Anal. 46 (2008), pp. 1423–1441. Available at https://doi.org/10.1137/070691334.
- D. Luenberger and Y. Ye, Linear and Nonlinear Programming. 3rd ed. Springer, Cham, 2008.
- Q. Du, M. Emelianenko, and L. Ju, Convergence of the Lloyd algorithm for computing centroidal Voronoi tessellations, SIAM. J. Numer. Anal. 44 (2006), pp. 102–119. Available at https://doi.org/10.1137/040617364617364. doi: 10.1137/040617364
Appendix. Proof that Algorithm 2 is energy-decreasing and convergent
Throughout this section, we assume that is compact.
First, we prove that Algorithm 2 is energy-decreasing, Equation (Equation16(16)
(16) ). Recall that if
is a compact subset of
with centroid
, then
(A1)
(A1) This follows from the fact that the function
is strictly convex with unique critical point
. By Equation (Equation13
(13)
(13) ) and by the way
is constructed using Algorithm 2,
(A2)
(A2) where
is the Laguerre diagram with generators
. Therefore,
(A3)
(A3) This proves (Equation16
(16)
(16) ). The inequalities above are strict unless
for all
, which means that
is a fixed point of Algorithm 2.
Next, we prove a weak global convergence result of the form [Citation48, Theorem 3.8], where convergence of the classical Lloyd algorithm was proved. Weak global convergence means that as
and that any convergent subsequence of
converges to a critical point of
, namely to a centroidal Laguerre diagram. This convergence is called weak because it does not guarantee convergence of the whole sequence
(different subsequences could converge to different critical points).
By construction is the centroid of the convex set
, which has volume
. Therefore, by [Citation48, Lemma 3.2], the distance between
and
has a lower bound of
where
. Therefore, the closest that two generators
and
can be is
where
. Note that this bound is independent of the iteration number
. Therefore, the iterates
lie in the compact set
(A4)
(A4) Owing to this compactness and the energy-decreasing property of Algorithm 2, we have weak global convergence of
; see the Global Convergence Theorem in [Citation49, p. 206] or [Citation35, proof of Theorem 3.3].
Finally, we prove a strong convergence result, namely that the whole sequence produced by Algorithm 2 converges to a critical point of
. We are only able to prove this, however, under the following generic assumption: There are only finitely many centroidal Laguerre diagrams with the same energy
. More precisely, we assume that, for all
,
(A5)
(A5) This assumption is expected to hold for ‘generic’ domains
and masses
[Citation35, Remark 3.4], [Citation50, p. 107], however, there are examples where it fails. For example, if
is a disc,
and
, then there are infinitely many critical points of
with the same energy by the rotational symmetry of
. Note that if
satisfies the generic condition of being a Morse function (having no degenerate critical points), then its critical points are isolated. Since they lie in the compact set (EquationA4
(A4)
(A4) ) there are only finitely many of them, and so assumption (EquationA5
(A5)
(A5) ) is satisfied.
The Monotone Convergence Theorem implies that the whole sequence converges (because Algorithm 2 is energy-decreasing and
is bounded below by zero). In addition
is continuous, and so every accumulation point of
has the same energy
. Moreover, by the global weak convergence result above, every accumulation point is a critical point of
. Therefore, assumption (EquationA5
(A5)
(A5) ) ensures there are only finitely many accumulation points.
We now complete the proof following the idea from [Citation50, proof of Theorem 2.5]. Assume for contradiction that the sequence does not converge. Since it only has finitely many accumulation points, there exist distinct accumulation points
,
and distinct subsequences
,
such that
,
, and
, i.e. the sequence
‘jumps’ between the two subsequences infinitely many times. (Note that such subsequences may not exist if there are infinitely many accumulation points.) Let
and let
denote the continuous map that sends
to
, where
is the Laguerre diagram with seeds
and cells of volume
. In other words,
. Moreover,
and
. Then
(A6)
(A6) By taking
in the right-hand side, and using the continuity of
, we find that
, which is a contradiction. Therefore, the whole sequence
converges to a critical point of
. Moreover, this critical point must a local minimum point or a saddle point of
by the energy-decreasing property. This completes the proof.