
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Objective: To clinically evaluate ForwardFocus in noise with experienced Nucleus® cochlear implant (CI) recipients.
Design: Listening performance with ForwardFocus was compared against the best in class directional microphone program (BEAM®). Speech comprehension was tested with the Oldenburg sentence test with competing signals (stationary, three, six and 18-talker babble) in both co-located and spatially-separated listening environments. Additionally, normal hearing participants were tested monaurally in the same listening environments as a reference and to promote cross-study comparisons between CI clinical study outcomes.
Study sample: Post-lingually deaf adult CI recipients (n = 20) who were experienced users of the Nucleus sound processor (Cochlear Limited).
Results: Improved speech comprehension was found with the ForwardFocus program compared to the BEAM program in a co-located frontal listening environment for both stationary and fluctuating competing signals. In spatially-separated environments ForwardFocus provided significant speech reception threshold (SRT) improvements of 5.8 dB for three-talker competing signals, respectively.
Conclusions: ForwardFocus was shown to significantly improve speech comprehension in a wide range of listening environments. This technology is likely to provide significant improvements in real-world listening for CI recipients, given the clinically relevant performance outcomes in challenging dynamic noise environments, bringing their performance closer to their normal hearing peers.
Introduction
Hearing in noise is hard for cochlear implant recipients
The majority of cochlear implant (CI) recipients are able to achieve high levels of open-set speech perception in quiet (Hey et al. Citation2016; Fetterman and Domico Citation2002; Holden et al. Citation2013). In noisy environments, however, CI recipients speech understanding deteriorates rapidly as the level of background noise increases (Müller-Deile, Schmidt, and Rudert Citation1995). A common measure of the ability of a listener to understand speech in noise is the speech reception threshold (SRT), defined as the signal-to-noise ratio (SNR) where 50% of the speech is correctly understood. Compared to normal-hearing listeners, the SRT achievable for CI recipients is typically 6–25 dB poorer (Spriet et al. Citation2007; Wouters and Vanden Berghe Citation2001; Hochberg et al. Citation1992; Rader, Fastl, and Baumann Citation2013).
CI performance decreases, while normal hearing performance increases in dynamic noise
Fluctuating competing signals have been found to be a very difficult noise type impacting speech understanding for CI recipients. In a clinical investigation by Rader, Fastl, and Baumann (Citation2013), post-lingually deafened CI recipients were tested in Oldenburg noise (a SWN stationary noise type), CCITT-noise (speech shaped stationary noise; according to ITU-T Rec. G.227 (11/88) Conventional telephone signal) and Fastl-noise (1-talker babble based on CCITT noise). Results showed SRTs of approximately −0.5, 3 and 6 dB, respectively. Similar decrements in performance in babble noise in contrast to stationary noise have been found in other CI speech perception studies (Ye et al. Citation2013; Hu et al. Citation2007; Goehring et al. Citation2017; Hersbach et al. Citation2012; Mauger et al. Citation2014). In contrast, normal hearers find it easier to listen in fluctuating babble noise compared to more stationary noises, the opposite to CI users. For example, Rader, Fastl, and Baumann (Citation2013) tested normal listeners with Oldenburg-noise, CCITT-noise, and Fastl-noise, with results showing SRT’s of −7, −9 and −15 dB, respectively.
Improved performance of normal hearers in dynamic noise environments is likely due to the hearing phenomenon called “glimpsing”, where they can “listen in the gaps” found in dynamic noise conditions. Normal hearers are thought to glimpse due to their comparatively higher spectro-temporal signal resolution (Nelson, Carney, and Nelson Citation2003; Fu and Nogaki Citation2005).
CI performance compared to normal listening peers
Dynamic noises such as babble noise is a difficult listening condition which CI recipients have the most disadvantage compared to their normal hearing peers. For speech and noise presented from the front, CI users have an approximate SRT disadvantage of 6 dB in constant SWN noise, a 12 dB decrement in CCITT noise, and a 21 dB decrement in a single-talker babble noise (Rader, Fastl, and Baumann Citation2013). Similarly, in a spatial-noise configuration with speech from the front and noise from ±27 and ±153 degrees, SRTs disadvantage for CI recipients were found to be 5, 14 and 16 dB for SWN, CCITT and Fastl noise, respectively.
So although CI recipients are able to perform well in quiet, they are still operating a significant disadvantage in competing noise. In particularly, they will struggle in the presence of fluctuating babble noise types, commonly found in environments such as schools, restaurants, parties and shopping centres.
Improving speech comprehension in constant noise environments
Noise reduction technologies have been shown to provide significant performance benefit in noise (Hochberg et al. Citation1992; Wolfe et al. Citation2015; Dawson, Mauger, and Hersbach Citation2011; Mauger et al. Citation2014; Müller-Deile et al. Citation2008). The advantage of these technologies is that they are not dependant on the directionality of the noise, as shown in studies where co-located speech and noise is presented from a single loudspeaker in front of the listener (Hey et al. Citation2016). Although these technologies have been able to produce significant and meaningful improvements, the improvements are typically restricted to constant (non-fluctuating) noise environments such as SWN, car noise, and party noise (Dawson, Mauger, and Hersbach Citation2011). While some benefit has been shown for multi-talker babble (20-talker babble) (Mauger, Arora, and Dawson Citation2012), the benefit reduces as the number of competing speakers decreases, such as in dynamic four-talker babble environments (Mauger, Arora, and Dawson Citation2012; Mauger et al. Citation2014).
Improving speech comprehension in spatial noise environments
Directional microphones are a group of technologies which rely on the speech input from the front and spatially-separated noise (Spriet et al. Citation2007; Hersbach et al. Citation2012). Such spatially-separated listening environments occur often in real-world environments. In unilateral systems like a behind-the-ear (BTE) sound processor, fixed and adaptive directional microphones use the inputs of two close spaced omnidirectional microphones to attenuate sounds arriving from the sides and behind. Audiological booth testing to represent spatial-listening scenes is typically conducted with a target speaker in front, and competing signals presented from the side (90 degrees) or from behind (180 degrees) (Kompis et al. Citation2004; Wimmer, Caversaccio, and Kompis Citation2015). When the speech and noise are separated in these conditions, directional microphones have been reported to provide performance benefits in babble noise (Wimmer et al. Citation2016). To represent a more realistic spatial listening scenario, the number of loudspeakers can be increased, presenting competing noise from multiple directions. For example, a common speaker arrangement uses four loudspeakers with speech presented from in front of the listener, and noise from the sides and behind (90, 180 and 270 degrees) (Dillier and Lai Citation2015; Mauger et al. Citation2014; Van Den Bogaert et al. Citation2009). Using a seven-speaker rear-half spatial-configuration, Hersbach et al. (Citation2012) found significant SRT benefit with an adaptive directional microphone (BEAM®) compared to a moderately omnidirectional microphone (Standard) (Patrick, Busby, and Gibson Citation2006) in SWN, 20-talker babble, and four-talker babble of 6.0, 5.1 and 5.0 dB, respectively. Since directional microphone technologies attenuate noise according to the direction of sound arrival, similar performance benefits irrespective of noise type are expected.
Spatial and dynamic noise environment research
A number of research technologies have been developed to provide additional benefit over and above that achieved with fixed highly directional microphones or adaptive directional microphones for CI recipients. Bilateral systems that use sound processors located behind both ears have been able to provide some additional speech understanding benefits. Early research with two microphones, one located on each ear (van Hoesel and Clark Citation1995, Hamacher et al. Citation1997) demonstrated the performance capabilities with bilateral microphone technologies. A system using a moderately directional microphone on each ear (Audallion BEAMformer) was shown to provide similar benefit to a unilateral moderately directional microphone (Spriet et al. Citation2007). With two sound processors connected with a bi-directional wireless link, bilaterally implemented directional microphones (Büchner et al. Citation2014) or bilateral masking-based technologies (Qazi et al. Citation2012) have shown moderate improvements compared to unilateral adaptive beamforming. However, these systems require two sound processors to be worn, and impact battery life due to the power requirements of the wireless link.
Unilateral systems using the conventional BTE sound processor, with two closely spaced microphones on the same ear provide additional performance benefit over directional microphones alone. This promising group of technologies are in the spatial post filter class. Using a coherence-based spatial filter, Yousefian and Loizou (Citation2011) were able to demonstrate significant improvements in some listening conditions compared to a fixed directional microphone and suggested its suitability for CI sound processors. Another spatial post-filtering algorithm based on phase-differences has also demonstrated improved performance compared to omnidirectional and dipole directional microphones in a spatial noise environment (Goldsworthy et al. Citation2014). A subsequent study using the spatial post-filter algorithm investigated performance in a range of reverberant environments and with a range of noise sources showing benefit in reverberant and complex multiple noise source environments (Goldsworthy Citation2014). These spatial post-filter technologies have demonstrated the possibility of significantly improved performance compared to best in class directional microphones. They also have the advantages of being able to be implemented on a unilateral sound processor and not impact battery life.
ForwardFocus is a new sound processing technology in the CP1000 sound processor introduced in the Nucleus® 7 system, and aims to provide additional benefits over directional microphones. ForwardFocus is a spatial post-filter technology, and is implemented on a unilateral conventional BTE sound processor. Compared to an adaptive directional microphone (BEAM) which adaptively steers its null towards the dominant noise source, ForwardFocus is described as able to attenuate noise sources arriving from multiple locations. A fixed highly directional microphone (zoom) has a fixed null at 210 degrees to provide optimal directivity index, where ForwardFocus does not have a null point but similarly applies attenuation to the sides and behind the listener. Where Standard, zoom and BEAM directional microphone technologies are activated automatically by the automatic scene classifier (SCAN), ForwardFocus is a user controlled technology. This technology is recommended for use in noisy environments where a target talker is located in front of the listener, with noises coming from a range of other directions. An example of such a noisy environment would be talking face-to-face with someone at a social event or in an office, while to the sides or behind other competing conversations are occurring. As a noise reduction technology, ForwardFocus is not recommended for use in quiet situations. In the commercial implementation, access to ForwardFocus is enabled for use by the audiologist using Custom Sound® or Nucleus Fitting software. The user then controls the activation and deactivation of ForwardFocus via the Nucleus Smart App on their SmartPhone, without the need to change listening programmes.
Clinical testing and comparison
Sound processing technologies used in CI systems are able to provide speech understanding benefits, but are usually limited to specific environments. For instance, noise reduction technologies provide most performance benefit in constant (non-fluctuating) competing noise, while directional microphones provide most benefit in spatially-separated noise environments. Although some booth test scenarios are relatively common, there are still a wide range of spatially-separated tests used, resulting in a range of reported performance outcomes. There is also a range of competing signals used in CI testing, further adding to differences. For instance, CI recipients perform significantly worse in dynamic babble noise compared to constant speech weighted noise presented at the same sound pressure level (SPL). Different sentence tests typically used in noise testing also have a range of performance outcomes. Differences in the spatially separated scenes, noise types, and sentence test types make it difficult to compare outcomes across the published literature.
With the performance improvements of CIs over the last thirty years, there has also been a progression of tests used for outcome evaluation. Initially, CIs were introduced as an aid to lip reading, and as such, the tests used for assessment of performance were simple, often closed-set, and administered with and without visual cues. As the technology advanced in sophistication and patient candidacy criteria expanded, so too did performance outcomes, enabling a shift towards the use of open-set speech tests such as words and sentences in quiet, and eventually even more challenging speech in noise tests. Currently, many CI recipients can communicate successfully in listening environments which are challenging even to people with normal levels of hearing (Hey et al. Citation2016).
To improve the ability to compare and contrast outcomes across clinical studies using different spatial tests, noise types and sentence types, we suggest using a relative comparison to normal listeners. This metric shifts the focus from performance outcome assessment of CI technology, towards a relative comparison against a control group of normal hearing peers. This relative metric will also elucidate the areas of largest performance decrement, and therefore the areas of greatest development need, and will be a theme throughout this article.
This study
This study investigates the ForwardFocus technology, which has recently been released in the Nucleus 7 system (CP1000 sound processor). This new CI sound processing technology is available on a single unilateral sound processor, and is designed to maintain input signals coming from in front of the listener, while reducing signals from behind the listener. ForwardFocus overrides the directional microphone setting, while maintaining other SmartSound® technologies which may be enabled in the users programme (i.e. SNR-NR, ADRO and ASC). This clinical evaluation will investigate this technology implemented for research on the Nucleus 6 Sound Processor. Clinical evaluation will compare its performance to the best in class adaptive beamformer (BEAM), in a range of spatial acoustic configurations and temporally modulated noise types.
Along with evaluating the clinical performance of this new technology, relative performance to normal listeners in the same listening scenarios will be conducted as a reference. Given the largest difference in performance between CI recipients and their normal hearing peers is in everyday babble noise environments, this study will include a spatially separated dynamic noise environment much like a cocktail-party setting (Pollack and Pickett Citation1957). We also discuss a relative performance metric able to compare outcomes across studies, which focuses on the listening scenes CI recipients find most difficult compared to their normal hearing peers.
Materials and methods
Research participants
A group consisting of 20 research participants (28 ears) from the clinical patient pool took part in this investigation. The investigation was approved and carried out in accordance with local ethics approval (D 467/16). All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Selection criteria of the CI research patients for this study were post-lingual onset of deafness, implantation with a Nucleus CI24RE or CI500 series CI (Cochlear Limited, Sydney, Australia), adult (>18 years), and user of a CP900 series sound processor. Participants all had more than six months experience with their CI system. Additionally, participants had to demonstrate speech comprehension scores of 80% or more with their sound processor in the Oldenburg sentence test in quiet at 65 dB SPL. Bilateral implantation was not an exclusion criterion. All patients had a full insertion of their electrode array with all 22 electrodes activated, except for one subject (#3) who had 21 electrodes activated.
Preoperatively, all subjects had demonstrated a speech intelligibility level, as measured by the Freiburg Monosyllable Test (Hahlbrock 1953), of 40% or less in both ears at 65 dB SPL with their optimally adjusted hearing aids. Participants mean age was 60 years (minimum 43 years and maximum 80 years). All participants had at least 18 month experience with their CI, with a group mean of 6 years (minimum 1.5 years and maximum 11 years). All were using the ACE coding strategy with individually fitted stimulation rate and number of maxima. summarises biographical details for research participants in this study.
Table 1. Recipients biographical data. Stimulus rate reported in pulses per second (pps).
For further normal hearing comparison, ten normal hearing adult participants were also recruited. Audiometry assessment of each of these participants was conducted to ensure they had normal hearing (ISO Citation2012, EN 8253-3) in the frequency range 250–8,000 Hz.
Test procedures
This study used a single-subject, repeated measures design. Testing was conducted across three test sessions spaced between two and three weeks apart. Measurements in normal hearing subjects provide a reference. This could be useful comparing these results to referenced studies (Rader, Fastl, and Baumann Citation2013; Weissgerber, Rader, and Baumann Citation2017).
All tests were conducted in an audiometric sound treated test booth of the size 6 × 4×2.5 m3 via calibrated loudspeakers which were 1.3 m from the patient. The room was acoustically shielded and complies with ISO 8253:2. This room had a T20 = 0.1 s and an Early Decay Time = 0.06 s for 400–1250 Hz. Research participants implanted on both ears were fitted bilaterally and used the appropriate maps for take-home acclimatisation, but they were tested unilaterally on each side with the contralateral sound processor being switched off (no auditory input).
Sentences in noise were presented through a computer-based implementation of the Oldenburg sentence test (Equinox audiometer; Interacoustics, Middelfart, Denmark and evidENT 3 software; Merz Medizintechnik, Metzingen, Germany) to control the recording and to calculate the SRT. A German version of the so-called Matrix test with fixed syntactic structure and the same set of words in all test lists was used for speech comprehension in noise: the Oldenburg sentences (Wagener et al. Citation1999). This test was administered in continuous background noise using lists of 30 sentences. The SRT was measured by using an adaptive procedure (Brand and Kollmeier Citation2002), starting at a SNR of 0 dB SNR. This noise was fixed at a constant presentation level of 65 dB SPL. The SRT was defined as the SNR resulting in a 50% words correct score. All CI recipients were accustomed to the test procedure, having been previously assessed three or more times as part of our clinical routine (both in quiet and in noise, listening to at least 80 sentences each time) in alignment with the training practice. To further ensure sufficient familiarity with the Oldenburg sentence test (Hey et al. Citation2014), a training session was performed immediately before testing in noise, by administering 30 recorded sentences in quiet at a presentation level of 65 dB SPL in every test session. Speech signals were presented from in front in all cases.
The Oldenburg noise is a speech-spectrum shaped noise (SWN), a stationary noise type (Wagener et al. Citation1999). The International Collegium for Rehabilitative Audiology (ICRA) noises are a set of noises designed for audiological evaluation developed by the Hearing Aid Clinical Test Environment Standardization (HACTES) group (Dreschler et al. Citation2001). These signals are defined by spectral and temporal characteristics representing everyday speech signals. The different signals represent typical temporal modulation of speech for one, two and six talkers. When presenting three noise signals simultaneously in this study, the signals were delivered asynchronously with a temporal shift to prevent coherence. Prior to the first test session, CI recipient’s sound processors were tested to ensure correct operation. If a problem was identified, the given component was replaced.
The following audiometric test protocols were used ():
Figure 1. Schema of the test conditions comparing BEAM and ForwardFocus for the two speaker configurations and for the different noise types.
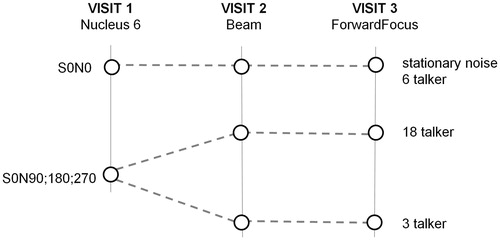
S0N0 – speech and noise signals presented from the front.
Oldenburg noise (SWN, OlNoise).
ICRA7 six-talker babble noise (Babble normal).
S0N90,180, 270 – speech from front and noise signals from 90, 180 and 270 degrees.
ICRA9 six-talker babble noise (Babble normal) from three loudspeakers (18-talker babble total).
ICRA5 one-talker babble noise (One-speaker male) from each loudspeaker (three-talker babble total).
In-booth testing used the default SmartSound technologies (Adro & SNR-NR and ASC) as in take-home testing, but with BEAM adaptive directional microphone enabled. BEAM is the technology which SCAN (automatic scene classifier system) chooses in babble noise (Mauger et al. Citation2014), and having a fixed programme ensured that adaptation was not a factor in outcomes. BEAM also served as the baseline condition in this study, being the best performing current technology for spatially separated babble noise scenes (Mauger et al. Citation2014) and represents Nucleus 6 outcomes. A second programme using the same SmartSound settings was created, but with the ForwardFocus technology also enabled, and represents Nucleus 7 expected outcomes. In the second visit participants were tested with the BEAM program after two weeks acclimatisation with the programme and sound processor. In the third visit patients were tested with the ForwardFocus program after acclimatisation with this programme for two weeks. In this investigation, ForwardFocus was tested as a research programme enabled on the Nucleus 6 (CP900 series) sound processor, and evaluated with in-booth and take home situations.
Data analysis
To determine the relative performance of ForwardFocus compared to BEAM, paired comparison analyses were performed, where each participant served as their own control. In all cases, a significance level of 0.05 was used to determine significance for two-tailed analyses. Statistical analysis of the data was performed with OriginLab (Northampton, MA).
Paired t-tests were used to determine the effect of technology, as separate patient groups were used. Paired t-tests were also used for normal hearing comparisons.
Results
Speech comprehension for co-located speech and noise
Group mean SRT scores for CI recipients in stationary noise were −0.2 and −1.9 dB and in six-talker babble were 3.8 and 1.9 dB for BEAM and ForwardFocus, respectively, in the S0N0 speaker configuration. Results are presented in . A significant SRT improvement with ForwardFocus of 1.7 dB in stationary noise (p < 0.001), and of 1.9 dB in six-talker babble (p < 0.001) was found compared to BEAM.
Figure 2. Boxplots of SRT for the Oldenburger sentences in S0N0 across different noise types for normal hearing participants and CI participants. CI recipient testing compared BEAM and ForwardFocus (FF) technologies, both using the same base default SmartSound technologies. Box plot shows median (solid mid line), 25th and 75th percentile interval (box limits), 5th and 95th percentile interval (whiskers). Mean values are also shown (squares).
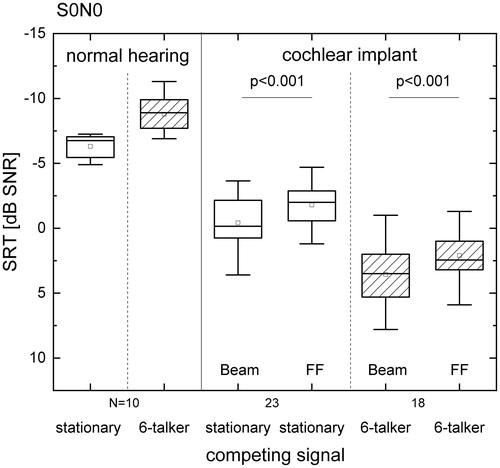
Group mean SRT scores for normal hearing participants in stationary noise were −6.3 dB, which is in accordance with the reference reported by Wagener et al. (Citation1999). In six-talker babble, mean SRT scores for normal hearers were −8.8 dB. A paired t-test found a significant difference in SRT scores between the two noise types for normal hearers (p < 0.001).
Speech comprehension for spatially separated speech and noise
Group mean SRT scores for CI recipients in 18-talker babble were −6.1 and −7.4 dB for BEAM and ForwardFocus, respectively, for the spatially-separated speaker configuration (). A paired t-test found no significant difference between the technology type in 18-talker babble (p = 0.1). Group mean SRT scores for CI recipients in three-talker babble were −12.7 and −18.6 dB for BEAM and ForwardFocus, respectively, for the spatially-separated speaker configuration. A paired t-test found a significant difference between the technology type in three-talker babble (p < 0.001). This shows a significant SRT improvement with ForwardFocus of 5.8 dB in three-talker babble compared to BEAM.
Figure 3. Boxplots of SRT for the Oldenburg sentences in S0N90; 180; 270 across different noise types for normal hearing participants and CI participants. CI recipient testing compared BEAM and ForwardFocus (FF) technologies, both using the same base default SmartSound technologies. Box plot shows median (solid mid line), 25th and 75th percentile interval (box limits), 5th and 95th percentile interval (whiskers). Mean values are also shown (squares).
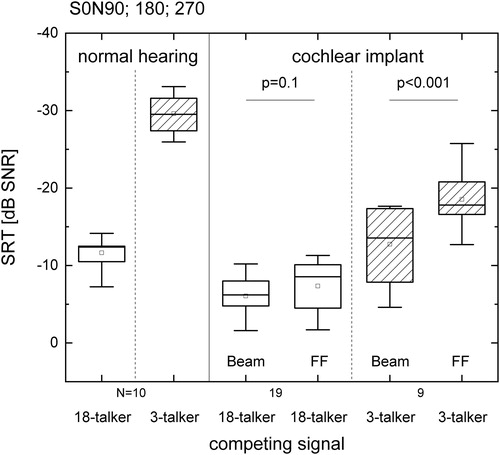
Group mean SRT scores for normal hearing participants in stationary noise were −11.6 and −29.6 dB for 18-talker babble and three-talker babble, respectively. A paired t-test found a significant difference in SRT scores between the two noise types for normal hearers (p < 0.001). This shows that normal hearers can tolerate a significant increase of 18.0 dB SPL in three-talker babble noise compared to 18-talker babble noise to achieve the same level (50%) of speech comprehension.
Discussion
This study investigated a new CI sound processing technology called ForwardFocus, which is described as able to provide benefit in challenging listening environments with multiple spatially distributed and fluctuating noise sources such as classrooms and restaurants. This study evaluated the ForwardFocus technology against the best in class adaptive directional microphone technology (BEAM) for such challenging noise environments.
Speech comprehension discussion
The Nucleus 6 Sound Processor has an automatic scene classifier, SCAN, which selects a suitable directional microphone configuration for each listening environment. In difficult dynamic listening environments such as babble noise, BEAM provides the best speech perception outcomes, and is automatically selected by SCAN (Mauger et al. Citation2014). Since ForwardFocus was described as providing benefit in these challenging environments, BEAM was chosen as the control condition for this study. To represent a challenging spatial listening environment, speech was presented from in front and noise from speakers located at the sides and behind the listener. In three-talker babble, a large SRT improvement of 5.8 dB was found; however, there was no significant difference in 18-talker babble for ForwardFocus compared to BEAM. This technology demonstrates significant improvements in the challenging temporally fluctuating competing signal.
This benefit is clinically relevant and is expected to translate into significant real-world benefits. Compared to the additive benefits reported from the introduction of previous technologies such as BEAM (Patrick, Busby, and Gibson Citation2006) to the then default technologies, results in this study show that ForwardFocus is able to provide similar and probably larger additive performance improvements, in this case in addition to BEAM. For patients upgrading from the Nucleus 6 system to the Nucleus 7 system which includes the ForwardFocus technology, significant SRT improvements of 5.8 dB in three-talker competing noise and 1.3 dB in multi-talker babble are expected. Anecdotal results from take-home acclimatisation with ForwardFocus indicate that these clinically relevant performance outcome translate into significant real-world benefit in noisy environments.
Large performance improvements in fluctuating noise was a finding of particular interest. This outcome is in contrast to directional microphone technologies which, in comparison to Standard or omnidirectional microphones, reported similar performance improvements across a range of noise types, and possible larger improvements in constant noise environments. Mauger et al. (Citation2014) reported a 4.7 dB improvement in SWN and a 4.5 dB improvement in four-talker babble with BEAM compared to a Standard directional microphone. Another study (Hersbach et al. Citation2012) reported an SRT improvement of approximately 6 dB in SWN and a smaller improvement of approximately 5 dB in four-talker babble. Similarly, Weissgerber, Rader, and Baumann (Citation2017) reported that directional microphones provide less benefit to CI recipients in fluctuating noise. In their investigation of bilateral and bimodal CI recipients, they found a “limited effect of sophisticated beamforming strategies on SRT in real life listening” and saw a desire for signal processing to further improve the SRT in those listening situations (Weissgerber, Rader, and Baumann Citation2017). Although the adaptive directional microphone (BEAM) is able to better attenuate noise by steering its null towards a dominant noise location, results in this study in fluctuating noise indicating that ForwardFocus is better able to attenuate multiple noise locations and provide improved listening outcomes.
Testing in co-located speech and noise was also performed as it is a common test condition, but also to ensure that signals are not degraded from in front. In both stationary noise and in six-talker babble, a significant improvement with ForwardFocus compared to BEAM was found. This was not expected as both technologies retain signals from in-front of the listener. Although no difference in directional microphones are often reported with co-located testing (Mauger et al. Citation2014; Hey et al. Citation2016), some studies found a difference of approximately 1 dB between Standard and BEAM programmes (Wesarg et al. Citation2018; Müller-Deile et al. Citation2009). This improvement with ForwardFocus may suggest that it does not require sensitivity compensation and subsequent increased noise floor at low frequencies common to directional microphones (Wesarg et al. Citation2018). Since ForwardFocus provides performance improvement in spatial listening, it may be able to attenuate reverberations found even in a sound booth from co-located speech and noise, and therefore, provide performance improvement in this condition. In either case, results confirm that there was no degradation of co-located speech and noise with ForwardFocus.
Two possible biases in this study are noted. BEAM was tested in an earlier session than ForwardFocus for all participants, introducing a possible learning bias, but is very small, being previously quantified by Hey et al. (Citation2014) as 0.2 dB. Participants used BEAM prior to the study, but had no prior exposure to ForwardFocus, introducing an acclimatisation bias, but is also expected to be small as two weeks is considered appropriate for acclimatisation. These two possible biases favour one technology each, and are very small particularly in relation to those of the technology improvement.
Speech testing with CI recipients has changed dramatically over time as speech performance outcomes have improved. Early assessments in quiet were closed-set tests administered with and without visual cues to assess CIs as an aid to lip reading. Today tests in quiet are open-set and require low presentation levels to become suitably sensitive as many CI recipients receive above 90% scores (Hey, Hocke, and Ambrosch Citation2017). Similarly, testing in noise has become common, both to represent real-world listening stimulations as well as to deliver a suitably sensitive test. However, current speech in noise testing outcomes are difficult to contextualise. The SRT scores are not able to fully reflect the patients performing in everyday listening situations (Ramakers et al. Citation2017). The main goal of each and every hearing therapy is to minimise the disadvantage of the hearing impairment compared to normal hearing. To assess CI recipients against this goal, performance of normal hearing participants is required. We suggest a metric for speech testing in which CI performance is reported relative to the performance of normal hearers in the same listening environment (Rader, Fastl, and Baumann Citation2013; Weissgerber, Rader, and Baumann Citation2017). Outcomes reporting accompanied with a measure of how dynamic the noise type is with a metric such as Crest Factor is also an important factor. Although speech testing can be quite varied, by using a normal hearing relative measure, the speech corpus and precise locations and arrangement of speakers in a diffuse noise presentation becomes less critical in cross-study comparisons. Additionally, this metric would elucidate the areas of disadvantage and focus future development to minimise this performance decrement relative to normal listeners.
In this study, normal unilateral hearers were tested in the same audiological booth and with the same speech and noise conditions used for CI testing. As found in numerous previous studies, normal hearer’s performance improves in more fluctuating environments (Rader, Fastl, and Baumann Citation2013). In this study, normal hearers could tolerate 18.0 dB more noise in three-talker babble than in 18-talker babble when tested in the spatially-separated noise environment. Compared to normal hearing participants, CI recipient’s had a 5.6 dB disadvantage in spatially-separated 18-talker babble with BEAM compared to normal hearing listeners. This is in contrast to the even larger 16.9 dB disadvantage in fluctuating three-talker babble. When using ForwardFocus, the SRT disadvantage in three-talker babble reduced to 11.1 dB compared to their normal hearing peers. This outcome clearly demonstrates the difficulty CI recipients have compared to their normal hearing peers in fluctuating noise environments, and has been consistently reported (Rader, Fastl, and Baumann Citation2013; Weissgerber, Rader, and Baumann Citation2017; Hu et al. Citation2007; Hersbach et al. Citation2012; Ye et al. Citation2013; Goehring et al. Citation2017). Although any improvement in speech understanding for CI recipients is desired, particularly improvements in fluctuating noise environments are important in closing the gap in performance with their normal hearing peers. In co-located noise (S0N0), CI recipient data showed a similar trend with 5.9 dB poorer SRTs in stationary noise and 12.4 dB poorer dB in six-talker babble. Although some improvement was found with ForwardFocus in this co-located condition, a disadvantage in fluctuating noise for CI recipients compared to their normal hearing peers remains. Due to the synthetic co-located presentation of speech and noise, as well as the relatively low reverberation of test booths, this testing type is less representative of situations found in the real-world.
Clinical considerations
Counselling is an important consideration with the introduction of new technologies, and is a factor for the introduction and clinical practice with ForwardFocus. As released in the Nucleus 7 CI system, ForwardFocus is activated by the patients Apple or Android SmartPhone based Nucleus Smart App. This is in contrast to automatic control of technologies with SCAN. Although significant performance is achieved where the talker is in front of the listener, the converse is also true, where signals from the sides and behind are attenuated. Although ForwardFocus provides significant benefit in difficult multi-talker noise situations (Cocktail party noise), it may be difficult to know which talker the recipient wants to listen to or what is of interest to the recipient in these complex listening environments. Although requiring user interaction, allowing the recipient to enable ForwardFocus in a challenging listening environments, where the talker of interest is positioned in front of them, ensures the technology is used in the desired situations. Results from this study indicate that particularly multi-talker babble noise environments, where the noise comes from the sides or behind the listener, would provide the most benefit. Counselling from audiologists should discuss suitable listening scenarios encountered in the recipient’s life where it will provide benefit, as well as encourage users to experiment with the technology in a range of listening scenes to broaden their experience and understanding of the technology.
Future ForwardFocus studies should investigate acceptance and real-world usage with this technology. We understand that the implementation of ForwardFocus in Nucleus 6 in this study is the same as in Nucleus 7. To achieve further knowledge on real-world acceptance, Data Logging with the Nucleus 7 system may serve as a valuable tool to investigate both usage (Oberhoffner et al. Citation2018) and acoustic environment (Busch, Vanpoucke, and van Wieringen Citation2017; Hey, Hocke, and Ambrosch Citation2017) where ForwardFocus is used. When the usage, preferred listening scenarios, and effectiveness are better understood, more specific counselling or further developments in user interaction and automation may be realized.
Cross study comparisons
Results from this study show two aspects of CI listening environments contributing significantly to the performance outcomes. The first is the impact of fluctuations in the competing signal, ranging from stationary SWN noise to highly dynamic three-talker babble noise. The second is the spatial distribution of competing signals, ranging from co-located to spatially separated.
Although performance outcomes for CI recipients are known to be related to how dynamic the noise is, comparing outcomes between studies is difficult. For instance, there are many types of babble noise types which differ in how dynamic they are, which is generally related to the number of talkers. Energetic babble maskers in the same class such as different ICRA noises have large differences in performance outcomes as seen in this study. Even for the well-defined stationary SWN noises, there are multiple versions such as Oldenburg Noise and CCITT noise that will have similar but not identical levels of fluctuations, and therefore likely result in different performance outcomes. It is clear that since each speech test and language have their commonly used noise types, comparison between studies, particularly of those with different fluctuating noise, is challenging.
To aid in comparing dynamic noise types between studies, a measure of how dynamic the signal is would be useful. One such characterisations of the temporal fluctuations in a signal is the median Crest Factor based on the samples
defined here as
where
represents the time domain samples in each 0.4 s segment, and k represents the number of consecutive segments in a noise signal. The window length of 0.4 s was derived from the typical length of items in the test material. We have used Crest Factor to characterise differences in temporal fluctuations of the noises used in this study. Even though the absolute value of
for each analysed signal depends on the windows length, it allows for a qualitative differentiation of the applied competing signals and, therefore, might be used for within comparisons of different stationary signals with respect to their temporal characteristics. The order on the x-axis in and is not affected by the windows length. Oldenburg noise, ICRA7, and ICRA5 had median Crest Factors of 3.1, 4.4 and 5.4, respectively. For four other studies using the Oldenburg sentence test (Rader, Fastl, and Baumann Citation2013; Weissgerber, Rader, and Baumann Citation2017; Hey et al. Citation2014; Wesarg et al. Citation2018), the Crest Factor of common noise types is displayed in . This figure shows the increasing Crest Factor for stationary SWN, through six-talker, to one-talker babble.
Figure 4. A summary of the different test conditions used in recent studies, all using the Oldenburg sentence test. Speaker configuration is presented on the y-axis, from noise from the front, through diffuse noise environments, to noise from behind. Competing signals are described by their crest factors. Median crest factors are indicated by ticks on the top x-axis together with their interquartile range.
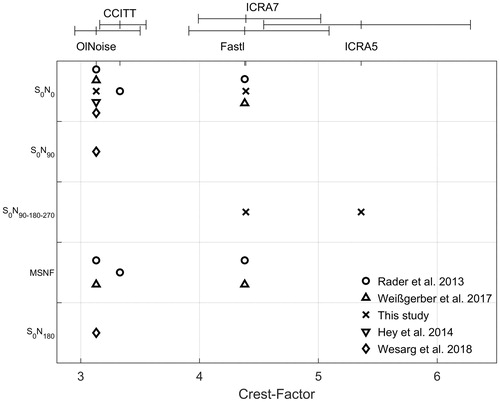
Figure 5. SRT results from this study and interpreted from two other studies plotted relative to performance of normal listeners in the same test environment. The x-axis shows the Crest Factor for each noise type. Spatial configuration of speakers is presented for each curve. All studies presented used the Oldenburg sentence test. Mean results are presented in all cases. Arrows marked with ForwardFocus (FF) indicate the improvement of FF compared to BEAM for the two spatial conditions. It should be noted that this study uses unilateral CI users compared to unilateral and normal listeners, where Rader et al. and Weissgerber et al. both refer to bilateral CI recipients compared to bilateral normal hearing listeners.
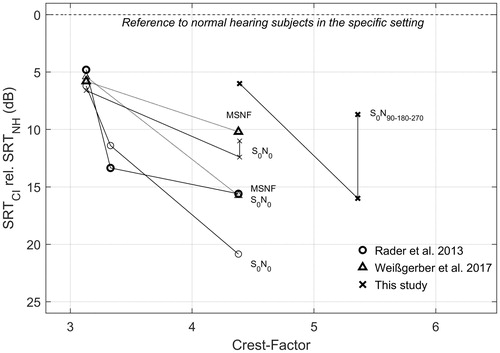
Comparing the outcome of CI patients to normal listeners has the disadvantage of not being a paired comparison and, therefore, reduced statistical power. However, the referencing to normal hearing listeners enables easier comparison of less common spatial configurations such as S0N90;180;270 with ICRA multi-talker babble. The inclusion of normal listening data in this study allowed the clear difficulty of CI patients in temporally fluctuating noise to be shown, and to substantiate this via comparison to other groups. As it is our aim to improve understanding for patients not only in stationary noise, but also in demanding situations, this normal listener comparison elucidates the benefits with a dedicated processing algorithm.
Current CI performance in some stationary noise types shows exceptional outcomes for some CI recipients, approaching the performance of normal hearers. However, in dynamic noise they have significant relative performance decrement. A measure of temporal fluctuations is, therefore, important to explain, and focus on, the specific characteristic of noise which provides this difficulty. This metric is able to characterise temporal fluctuations in noise, and elucidates the actual decrement of CI users compared to their normal hearing peers as an anchor point. The key advantages of this metric are:
Includes a metric (Crest Factor), needed to categorise temporal fluctuations.
Enables comparison across different speech corpi due to its relation to normal hearing persons.
Allows the comparison between studies in a range of speech and noise settings.
Another limitation with comparing studies is the spatial configuration of noise sources. Typical spatial localisations are S0N0 (speech and noise from front), S0N90 (speech from front and noise from 90 degrees on the CI side) and S0N180 (speech from front and noise from behind). Using co-located speech and noise has the advantage of only requiring a single loudspeaker, but has the major limitation of not being a good representation of a real-world spatial listening environment. With two loudspeakers, the S0N90 and S0N180 speaker configurations are able to represent a simple spatial scene; however, a single noise source is also not a good representative of a real-world listening environment. To overcome these limitations, four or more loudspeakers have been used to create an approximate diffuse noise field with noises coming from a range of directions (Hersbach et al. Citation2012; Rader, Fastl, and Baumann Citation2013; Weissgerber, Rader, and Baumann Citation2017; Dillier and Lai Citation2015; Büchner et al. Citation2014). To assess the range of spatial configurations, we suggest placing configurations in categorical groups, and order them from noise from the front, through approximate diffuse spatial noise scenes, through to noise from behind. An example of this is provided in . Although this does not provide a continuous scale, as four or more speakers present a diffuse environment simulating a real-world environment, we believe that the general categorisation significantly aids in determining similar test configurations. Future studies should investigate the contribution of speaker arrangements, possibly analogous to the directivity index used in determining a single characteristic for directional microphone polar patterns.
To demonstrate cross study comparisons, this study, and two other CI studies which also reported results of normal hearing listeners are investigated. CI SRT results relative to normal hearing outcomes are plotted against the Crest Factor of noise signals used in each study (). Each spatial configuration is plotted as a separate curve. Results from the S0N0 configuration in this study show a decreasing SRT from −6.6 dB with a Crest Factor of 3.8 (SWN) to −12.4 dB at Crest Factor of 5.6 (six-talker babble) relative to normal hearers. Results from the studies of Rader, Fastl, and Baumann (Citation2013) and Weissgerber, Rader, and Baumann (Citation2017) are also plotted in . Although these two studies have different approaches in the noise types used, as well as the spatial configurations, they do have sufficient similarities for comparison. Both studies have normal hearing outcomes in each test scene, use an adaptive Oldenburg sentence speech in noise test, and use common and openly available noise sources for which the Crest Factor can be calculated.
At a Crest Factor of 3.8 (SWN) all three studies have similar results with S0N0 in the range of 5–7 dB lower than normal hearers. In this noise type, mean results show strong performance, indicating that some individuals receive exceptional performance approaching the performance of normal listeners. However, in dynamic noises with Crest Factors above 5, all studies show significantly decreased performance compared to normal hearers. Comparison between dynamic noises can also be made, for instance, babble noises at 5.5 and 5.6 have similar Crest Factors, and therefore are expected to result in similar performance outcomes. Also, the range of dynamic noise types can be seen, ranging from stationary SWN noise to dynamic three-talker babble. By measuring CI outcomes relative to normal hearers, and characterising fluctuations of the signals, the area of most decrement for CI users compared to their normal hearing peers in diffuse hearing environments can be seen. A challenge for future studies should be to consider covering a range of dynamic signals, and also include diffuse spatial configurations, even where the assessment of signal processing is not the primary focus.
Conclusion
ForwardFocus provides improvement to CI recipients in challenging listening environments with spatially distributed and temporal fluctuating (high Crest Factor) competing signals.
Using normal hearing outcomes as a reference for CI recipient’s outcomes in specific listening situations (spatial distribution and temporal characteristics of competing signal) and introducing a one-dimensional measure to characterise the temporal fluctuations of the competing signal (Crest Factor) may improve comparability of speech understanding over different studies.
Acknowledgements
We wish to cordially thank all the patients who kindly took time to participate in the investigations. Our special thanks go to the medical-technical assistants at the Kiel University ENT Clinic, whose conscientious and efficient working schedule made a significant contribution to the success of this study.
Disclosure statement
The authors report no other potential or actual conflict of interest. The authors alone are responsible for the content and writing of this article.
Additional information
Funding
References
- Brand, T., and B. Kollmeier. 2002. “Efficient Adaptive Procedures for Threshold and Concurrent Slope Estimates for Psychophysics and Speech Intelligibility Tests.” Journal of the Acoustical Society of America 111 (6): 2801–2810. doi:10.1121/1.1479152.
- Büchner, A., K. H. Dyballa, P. Hehrmann, S. Fredelake, and T. Lenarz. 2014. “Advanced Beamformers for Cochlear Implant Users: Acute Measurement of Speech Perception in Challenging Listening Conditions.” PLoS One 9 (4): e95542. doi:10.1371/journal.pone.0095542.
- Busch, T., F. Vanpoucke, and A. van Wieringen. 2017. “Auditory Environment Across the Life Span of Cochlear Implant Users: Insights From Data Logging.” Journal of Speech, Language, and Hearing Research 60 (5): 1362–1377. doi:10.1044/2016_jslhr-h-16-0162.
- Dawson, P. W., S. J. Mauger, and A. A. Hersbach. 2011. “Clinical Evaluation of Signal-to-noise ratio-based Noise Reduction in Nucleus® Cochlear Implant Recipients.” Ear and Hearing 32: 382–390. doi:10.1097/AUD.0b013e318201c200.
- Dillier, N., and W. K. Lai. 2015. “Speech Intelligibility in Various Noise Conditions with the Nucleus® 5 CP810 Sound Processor.” Audiology Research 5: 69–75. http://www.audiologyresearch.org/index.php/audio/article/view/132.
- Dreschler, W. A., H. Verschuure, C. Ludvigsen, and S. Westermann. 2001. “ICRA Noises: Artificial Noise Signals with Speech-like Spectral and Temporal Properties for Hearing Aid Assessment.” Audiology, 40, 148–157. doi:10.3109/00206090109073110.
- Fetterman, B. L., and E. H. Domico. 2002. “Speech Recognition in Background Noise of Cochlear Implant Patinets.” Otolaryngology–Head and Neck Surgery 126: 257–263. doi:10.1067/mhn.2002.123044.
- Fu, Q. J., and G. Nogaki. 2005. “Noise Susceptibility of Cochlear Implant Users: The Role of Spectral Resolution and Smearing.” Journal of the Association for Research in Otolaryngology 6: 19–27. doi:10.1007/s10162-004-5024-3.
- Goehring, T., F. Bolner, J. J. M. Monaghan, B. van Dijk, A. Zarowski, and S. Bleeck. 2017. “Speech Enhancement Based on Neural Networks Improves Speech Intelligibility in Noise for Cochlear Implant Users. Hearing Research 344: 183–194. doi:10.1016/j.heares.2016.11.012.
- Goldsworthy, R. L. 2014. “Two-microphone Spatial Filtering Improves Speech Reception for Cochlear-implant Users in Reverberant Conditions with Multiple Noise Sources.” Trends in Hearing 18: pii: 2331216514555489. doi:10.1177/2331216514555489.
- Goldsworthy, R. L., L. A. Delhorne, J. G. Desloge, and L. D. Braida. 2014. “Two-microphone Spatial Filtering Provides Speech Reception Benefits for Cochlear Implant Users in Difficult Acoustic Environments.” Journal of the Acoustical Society of America 136 (2): 867–876. doi:10.1121/1.4887453.
- Hamacher, V., W. H. Doering, G. Mauer, H. Fleischmann, and J. Hennecke. 1997. “Evaluation of Noise Reduction Systems for Cochlear Implant Users in Different Acoustic Environment.” American Journal of Otolaryngology 18(6): S46–S49.
- Hersbach, A. A., K. Arora, S. J. Mauger, and P. W. Dawson. 2012. “Combining Directional Microphone and Single-Channel Noise Reduction Algorithms.” Ear and Hearing 33: e13–e23. doi:10.1097/AUD.0b013e31824b9e21.
- Hey, M., T. Hocke, and P. Ambrosch. 2017. “Speech Audiometry and Data Logging in CI Patients: Implications for Adequate Test Levels.” HNO 66 (1): 22–27. doi:10.1007/s00106-017-0419-8.
- Hey, M., T. Hocke, J. Hedderich, and J. Müller-Deile. 2014. “Investigation of a Matrix Sentence Test in Noise: Reproducibility and Discrimination Function in Cochlear Implant Patients.” International Journal of Audiology 53: 895–902. doi:10.3109/14992027.2014.938368.
- Hey, M., T. Hocke, S. Mauger, and J. Müller-Deile. 2016. “A Clinical Assessment of Cochlear Implant Recipient Performance: Implications for Individualized Map Settings in Specific Environments.” European Archives of Oto-Rhino-Laryngology 273: 4011–4020. doi:10.1007/s00405-016-4130-2.
- Hochberg, I., A. Boothroyd, M. Weiss, and M. S. Sharon. 1992. “Effects of Noise and Noise Suppression on Speech Perception by Cochlear Implant Users.” Ear and Hearing 13: 263–271. doi:10.1097/00003446-199208000-00008.
- Holden, L. K., C. C. Finley, J. B. Firszt, T. A. Holden, C. Brenner, L. G. Potts, B. D. Gotter, et al. 2013. “Factors Affecting Open-Set Word Recognition in Adults with Cochlear Implants.” Ear and Hearing 34: 342–360. doi:10.1097/AUD.0b013e3182741aa7.
- Hu, Y., P. C. Loizou, N. Li, and K. Kasturi. 2007. “Use of a Sigmoidal-shaped Function for Noise Attenuation in Cochlear Implants.” Journal of the Acoustical Society of America 122: EL128–EL134. doi:10.1121/1.2772401.
- ISO. 2012. Acoustics – Audiometric test Methods – Part 3: Speech Audiometry. 8253-3. Berlin: Beuth publishing DIN.
- Kompis, M., M. Bettler, M. Vischer, P. Senn, and R. Häuslera. 2004. “Bilateral Cochlear Implantation and Directional Multi-microphone Systems.” International Congress Series 1273: 447–450. doi:10.1016/j.ics.2004.08.081.
- Mauger, S. J., K. Arora, and P.W. Dawson. 2012. “Cochlear Implant Optimized Noise Reduction.” Journal of Neural Engineering 9: 65007. doi:10.1088/1741-2560/9/6/065007.
- Mauger, S. J., C. D. Warren, M. R. Knight, M. Goorevich, and E. Nel. 2014. “Clinical Evaluation of the Nucleus® 6 Cochlear Implant System: Performance Improvements with SmartSound iQ.” International Journal of Audiology 53: 564–576. doi:10.3109/14992027.2014.895431.
- Müller-Deile, J., T. Kortmann, U. Hoppe, H. Hessel, and A. Morsnowski. 2009. “Improving Speech Comprehension Using a New Cochlear Implant Speech Processor. HNO 57 (6): 567–574. doi:10.1007/s00106-008-1781-3.
- Müller-Deile, J., J. Kiefer, J. Wyss, J. Nicolai, and R. Battmer. 2008. “Performance Benefits for Adults Using a Cochlear Implant with Adaptive Dynamic Range Optimization (ADRO): A Comparative Study.” Cochlear Implants International 9: 8–26. doi:10.1179/cim.2008.9.1.8.
- Müller-Deile, J., B. J. Schmidt, and H. Rudert. 1995. “Effects of Noise on Speech Discrimination in Cochlear Implant Patients. The Annals of Otology, Rhinology & Laryngology Supplement 166: 303–306.
- Nelson, P. B., A. E. Carney, and D. A. Nelson. 2003. “Understanding Speech in Modulated Interference: Cochlear Implant Users and Normal-hearing Listeners.” Journal of the Acoustical Society of America 113, 961–968. doi:10.1121/1.1531983.
- Oberhoffner, T., U. Hoppe, M. Hey, D. Hecker, H. Bagus, P. Voigt, S. Schicktanz, A. Braun, and T. Hocke. 2018. “Multicentric Analysis of the Use Behavior of Cochlear Implant Users.” Laryngorhinootologie 97 (5): 313–320. doi:10.1055/a-0574-2569.
- Patrick, J. F., P. A. Busby, and P. J. Gibson. 2006. “The Development of the Nucleus Freedom Cochlear Implant System.” Trends in Amplification 10 (4): 175–200. doi:10.1177/1084713806296386.
- Pollack, I., and J. M. Pickett. 1957. “Cocktail Party Effect.” Journal of the Acoustical Society of America 29: 1262. doi:10.1121/1.1919140.
- Qazi O., B. van Dijk, M. Moonen, and J. Wouters. 2012. “Speech Understanding Performance of Cochlear Implant Subjects Using Time-frequency Masking-based Noise Reduction.” IEEE Transactions on Bio-Medical Engineering 59 (5): 1364–1373. doi:10.1109/TBME.2012.2187650.
- Rader, T., H. Fastl, and U. Baumann. 2013. “Speech Perception with Combined Electric-acoustic Stimulation and Bilateral Cochlear Implants in a Multisource Noise Field.” Ear and Hearing 34: 324–332. doi:10.1097/AUD.0b013e318272f189.
- Ramakers, G. G. J., Y. E. Smulders, A. van Zon, G. A. Van Zanten, W. Grolman, and I. Stegeman. 2017. “Correlation between Subjective and Objective Hearing Tests after Unilateral and Bilateral Cochlear Implantation. BMC Ear, Nose and Throat Disorders 17: 10. doi:10.1186/s12901-017-0043-y.
- Spriet, A., L. Van Deun, K. Eftaxiadis, J. Laneau, M. Moonen, B. van Dijk, A. van Wieringen, J. Wouters. 2007. “Speech Understanding in Background Noise with the Two-microphone Adaptive Beamformer BEAM in the Nucleus Freedom Cochlear Implant System.” Ear and Hearing 28: 62–72. doi:10.1097/01.aud.0000252470.54246.54.
- Van den Bogaert, T., S. Doclo, J. Wouters, and M. Moonen. (2009). “Speech Enhancement with Multichannel Wiener Filter Techniques in Multimichrophone Binaural Hering Aids.” Journal of the Acoustical Society of America 125: 360–371. doi:10.1121/1.3023069.
- van Hoesel, R. J., and G. M. Clark. 1995. “Evaluation of a Portable Two-microphone Adaptive Beamforming Speech Processor with Cochlear Implant Patients.” Journal of the Acoustical Society of America 97: 2498–2503. doi:10.1121/1.411970.
- Wagener, K., T. Brand, V. Kühnel, and B. Kollmeier. 1999. “Entwicklung und Evaluation Eines Satztests in Deutscher Sprache I–III: Design, Optimierung und Evaluation des Oldenburger Satztests.” Zeitschrift für Audiologie 38 (1–3): 4–15.
- Weissgerber, T., T. Rader, and U. Baumann. 2017. “Effectiveness of Directional Microphones in Bilateral/Bimodal Cochlear Implant Users-impact of Spatial and Temporal Noise Characteristics.” Otology & Neurotology 38 (10): e551–e557. doi:10.1097/mao.0000000000001524.
- Wesarg, T., B. Voss, F. Hassepass, R. Beck, A. Aschendorff, R. Laszig, and S. Arndt. 2018. “Speech Perception in Quiet and Noise With an Off the Ear CI Processor Enabling Adaptive Microphone Directionality.” Otology & Neurotology 39(4): e240–e249. doi:10.1097/MAO.0000000000001749.
- Wimmer, W., M. Caversaccio, and M. Kompis. 2015. “Speech Intelligibility in Noise with a Single-unit Cochlear Implant Audio Processor.” Otology & Neurotology 36, 1197–1202. doi:10.1097/MAO.0000000000000775.
- Wimmer, W., S. Weder, M. Caversaccio, and M. Kompis. 2016. “Speech Intelligibility in Noise with a Pinna Effect Imitating Cochlear Implant Processor.” Otology & Neurotology 37, 19–23. doi:10.1097/MAO.0000000000000866.
- Wolfe, J., S. Neumann, M. Marsh, E. Schafer, L. Lianos, J. Gilden, L. O’Neill, et al. 2015. “Benefits of Adaptive Signal Processing in a Commercially Available Cochlear Implant Sound Processor.” Otology & Neurotology 36 (7):1181–1190. doi:10.1097/MAO.0000000000000781.
- Wouters, J., and J. Vanden Berghe. 2001. “Speech Recognition in Noise for Cochlear Implantees with a Two-Microphone Monaural Adaptive Noise Reduction System.” Ear and Hearing 22, 420–430. doi:10.1097/00003446-200110000-00006.
- Ye, H., G. Deng, S. J. Mauger, A. A. Hersbach, P. W. Dawson, and J. M. Heasman. 2013. “A Wavelet-Based Noise Reduction Algorithm and Its Clinical Evaluation in Cochlear Implants.” PLoS One 8, e75662. doi:10.1371/journal.pone.0075662.
- Yousefian, N., and P. C. Loizou. 2011. “A Dual-Microphone Speech Enhancement Algorithm Based on the Coherence Function.” IEEE Transactions on Audio, Speech and Language Processing 20 (2): 599–609.