
Abstract
Objectives
In the personalisation of hearing-aid fittings, gain is often adjusted to suit patient preferences using live speech. When using brief sentences as stimuli, the minimum gain adjustments necessary to elicit consistent preferences (“preference thresholds”) were previously found to be much greater than typical adjustments in current practice. The current study examined the role of duration on preference thresholds.
Design
Participants heard 2, 4 and 6-s segments of a continuous monologue presented successively in pairs. The first segment of each pair was presented at each individual’s real-ear or prescribed gain. The second segment was presented with a ±0–12 dB gain adjustment in one of three frequency bands. Participants judged whether the second was “better”, “worse” or “no different” from the first.
Study sample
Twenty-nine adults, all with hearing-aid experience.
Results
The minimum gain adjustments needed to elicit “better” or “worse” judgments decreased with increasing duration for most adjustments. Inter-participant agreement and intra-participant reliability increased with increasing duration up to 4 s, then remained stable.
Conclusions
Providing longer stimuli improves the likelihood of patients providing reliable judgments of hearing-aid gain adjustments, but the effect is limited, and alternative fitting methods may be more viable for effective hearing-aid personalisation.
Introduction
In the treatment of hearing loss, clinicians fit hearing-aids to reach a balance between audibility and comfort for each patient. The balancing begins with prescribed gains across frequency based on each patient’s pure-tone thresholds. These prescribed gains, based on average data, are then personalised through adjustments made by the clinician using patient feedback (Anderson, Arehart, and Souza Citation2018; Jenstad, Van Tasell, and Ewert Citation2003; Kuk and Ludvigsen Citation1999; Thielemans et al. Citation2017). The patient’s feedback is often based solely on the effect the adjustments have on the perception of the clinician’s voice, the most readily available stimulus in any clinic.
We have previously investigated what gain adjustments are discriminable for short sentences presented in quiet. Median just-noticeable differences (JNDs) for increases in gain (increments) in broad low-, mid- and high-frequency bands were 4, 4, and 7 dB, respectively (Caswell-Midwinter and Whitmer Citation2019). Gain adjustments less than these JNDs will, on average, not be readily perceived. A clinician may still receive feedback from a patient, but such feedback may not be based on the auditory perception of these adjustments, but other factors (cf. placebo effects without adjustment; Bentler et al. Citation2003; Dawes, Hopkins, and Munro Citation2013; Naylor et al. Citation2015). Using the same speech corpus, we have subsequently investigated what gain adjustments are necessary to elicit consistent preferences (Caswell-Midwinter and Whitmer, Citation2021). Median preference thresholds, the minimum adjustment to elicit a preference, ranged from 4 to 12 dB for gain decrements and 5–9 dB for increments in the same broad low-, mid-, and high-frequency bands. In Caswell-Midwinter and Whitmer (Citation2019), it was posited that the greater JNDs for speech in quiet than for speech-shaped noise were due to the spectro-temporal sparsity of the speech. That is, for a given gain adjustment in any given band, the clean speech signal provided a smaller number of glimpses of the adjustment than same-spectrum noise. In Caswell-Midwinter and Whitmer (Citation2021), it was further speculated that the large preference thresholds were due in part to the short duration of the stimuli. The current study tested this by measuring preference thresholds for gain adjustments across various stimulus durations. Although patients typically make quick comparisons on adjustments in the clinic, audiologists may talk for longer, which might elicit more frequent and reliable preferences.
Previous psychophysical research provides some evidence that speaking longer would lead to more consistent preferences: level discrimination improves with increasing duration, albeit mostly limited to short pure-tone stimuli. Increasing the duration of a 0.25, 1, or 8-kHz tone up to 0.5, 1, or 2 s, respectively, can improve level discrimination for normal-hearing listeners (Florentine Citation1986). Further, duration can improve pure-tone level discrimination in fixed and roving pedestal level but not across-frequency conditions (Oxenham and Buus Citation2000). For the discrimination of a tone’s relative level within a complex (i.e. profile analysis), performance improves up to a duration of at least 100 ms (Green, Mason, and Kidd Citation1984; Dai and Green Citation1993). The ability to discriminate a gain adjustment in particular band(s) of speech bears partial resemblance to increment detection, the detection of an increase or “bump” in the level of an ongoing sound. Valente, Patra, and Jesteadt (Citation2011) showed that increasing the duration of an ongoing 0.5 or 4.0-kHz tone increased the detectability of a time-centred bump in the tone’s level more so than increasing the duration of the bump. There is some evidence of a duration effect with broadband stimuli: studying the detection of an 8-dB peak at 3.5 kHz in a broadband noise, Farrar et al. (Citation1987) found that thresholds decreased as duration increased up to 300 ms, the maximum duration tested. Isarangura et al. (Citation2019) found that the detection of spectral modulation in a broadband noise carrier also improved with increasing duration but reached asymptote by 200 ms. For speech stimuli, measures of duration effects on level discrimination are scant; in a study of overall level discrimination of speech, the threshold for words (mean duration 450 ms) was only significantly worse (greater) than for sentences (mean duration 1533 ms) when participants were aided (Whitmer and Akeroyd Citation2011).
In sound-quality evaluations such as comparing hearing-aid settings, a balance must be struck in sound-sample duration. The sample must be long enough to allow perception of the acoustic changes, but short enough to allow comparison of the adjusted sound with the previous (reference) sound. The International Telecommunication Union (ITU) recommendations for subjective sound-quality evaluations note that, for paired comparisons, durations should not exceed 15–20 s due to “short-term human memory limitations”, but can be “a few seconds” (International Telecommunication Union, Radiocommunication Sector Citation2019, p. 6; cf. Cowan Citation1984). These memory limitations – the ability to maintain features of the first sound for comparison to the second – are often measured by assessing the effect of the inter-stimulus interval (ISI) behaviourally (Pollack Citation1972; Winkler and Cowan Citation2005) or physiologically (Bartha-Doering et al. Citation2015). In the clinic, the adjustment is often done without any gaps other than the natural pauses in ongoing speech. The memory limitation for comparing ongoing stimuli has previously been modelled as an exponential decay over many seconds, albeit for pure-tone stimuli (Durlach and Braida Citation1969; Massaro Citation1970). Despite qualitative recommendations and a long history of auditory memory research (cf. Cowan Citation1984), the effect of duration on preferences for speech stimuli, as assessed in the clinic during hearing-aid adjustments, is not known.
On the basis of the foregoing evidence, we hypothesised that increasing the duration of the stimuli would elicit more consistent and reliable preferences for gain adjustments. The current study used most of the same methods, including most of the same participants, as Caswell-Midwinter and Whitmer (Citation2021) did when measuring preferences for gain adjustments. The main difference is the primary experimental contrast: stimulus duration. To avoid potential memory confounds, the maximum stimulus duration was 6 s (cf. International Telecommunication Union, Telecommunication Standardization Sector Citation2003); the minimum was 2 s (vs. 0.855–2.3 s in the previous study). To better mimic elements of a clinical session, there were five other methodological differences. First, the stimuli were consecutive segments from a continuous story instead of repeated (within a trial) sentences. Second, the gain adjustment was always made for the second stimulus on each trial, rather than randomised. Third, the number of gain steps was reduced from six (±4, 8, and 12 dB) to four (±6 and 12 dB). Fourth, there was no ISI. Finally, given the lack of agreement or reliability in using descriptors (e.g. “tinny”) to describe the effect of a gain adjustment reported by Caswell-Midwinter and Whitmer (Citation2021), the current study only measured preferences.
Methods
Participants
Twenty-nine adults (14 female) were recruited from a sample who had previously participated in a gain-discrimination experiment (Caswell-Midwinter and Whitmer Citation2019). The median age was 68 years (range 51–74 years). The median better-ear four-frequency (0.5, 1, 2, and 4 kHz) pure-tone threshold average (BE4FA) was 35 dB HL (range 12–56 dB HL; see left panel of ). None of the participants had a conductive loss (i.e. all participants’ average air-bone threshold differences were less than 20 dB; British Academy of Audiology Citation2016).
Figure 1. The left panel shows median pure-tone thresholds as a function of frequency (circles, solid line) and interquartile ranges (error bars), with the individual thresholds for the three lowest and highest average thresholds (dotted lines). The right panel shows median sensation levels (approximated from pure-tone thresholds and applied gain) as a function of frequency (circles, solid line) and interquartile ranges (error bars), with the individual values for the three lowest and highest average sensation levels (dotted lines).
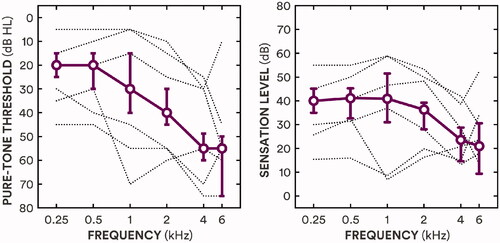
For the 19 participants who habitually wore hearing-aids at the time of the study, the real-ear insertion gain provided by their hearing-aids in their better ear was measured with 65 dB broadband noise input (ICRA URGN-M-N; Dreschler et al. Citation2001) and used as their gain prescription. For the ten participants who were not currently wearing hearing-aids, linear NAL-R gain prescriptions (Byrne and Dillon Citation1986) for their better ear were used. Sensation level (SL) of the stimuli was approximated from pure-tone thresholds and applied gain; the median sensation level for amplified stimuli, averaged across 0.5, 1, 2, and 4 kHz, was 35 dB SL (range 15–51 dB SL; see right panel of ). All participants had previously been fit with hearing-aids; the median hearing-aid experience was 10 years (range 2-35 years). Twenty-six of the 29 participants took part 18 months earlier in the preference experiment with short sentences (Caswell-Midwinter and Whitmer Citation2021).
All participants had also performed visual letter and digit monitoring tasks during a previous study (at least 18 months prior to the current study) to provide an estimate of their cognitive abilities (specifically working memory; Gatehouse, Naylor, and Elberling Citation2006). The tasks involved identifying triplet digit and letter sequences at two different ISIs (1 and 2 s); a full description is in Caswell-Midwinter and Whitmer (Citation2019). The resulting d′ measures were averaged across digit and letter tasks and ISIs to give a single cognitive score.
Stimuli
The stimuli were consecutive segments of a Sherlock Holmes story read by a professional male actor with a Southern English accent (“The Naval Treaty”; Doyle Citation2011). The original stimuli were converted from stereo to mono and resampled to 24 kHz from an original sample rate of 44.1 kHz. Any silent gaps greater than 250 ms were truncated to 250 ms. On each trial, two consecutive segments were presented to the participants’ better ear, both with the same duration of either 2, 4 or 6 s. For each segment, 50-ms linear onset and offset ramps were applied. To better mimic adjustments in the clinic, the standard stimulus was always the first stimulus in the pair, and there was no ISI beyond the offset and onset gating.
For the standard stimulus, real-ear or prescribed gain was applied across six frequency bands: a low-pass band with an upper cut-off of 0.25 kHz, four octave bands centred at 0.5, 1, 2, and 4 kHz, and a high-pass band with a lower cut-off of 6 kHz. For the target stimulus, additional gain (ΔGain) of either −12, −6, 0, +6, and +12 dB was applied in one of three broad frequency bands: a low-frequency band combining 0.25 (low-pass) and 0.5 kHz (octave) bands (LF), a mid-frequency band combining 1 and 2 kHz octave bands (MF), and a high-frequency band combining the 4 kHz and 6 kHz (high-pass) bands (HF). Stimuli were generated by convolving each segment with a 140-tap finite impulse response filter optimised for NAL-R equalisation at 24-kHz sample rate by Kates and Arehart (Citation2010). The overall long-term A-weighted presentation level was 60 dB SPL to approximate in-quiet conversational level (Olsen, 1998). The presentation level was verified with an artificial ear and sound level metre (Brüel & Kjaer 4152 and 2260), prior to any prescription or gain adjustment. The audibility of the segments was confirmed with each participant after the first trial.
We additionally analysed the effect of the natural variation in power within bands across the consecutive segments of each trial (i.e. when ΔGain = 0). There were significant mean absolute level differences within bands between the two segments in any given trial as a function of both frequency band and segment duration [F(2,56) = 13.06 and 19.41, respectively]. The differences, however, were small; absolute differences in band-specific level increased from 0.2 dB for the LF band to 0.3 dB for MF and HF bands [t(28) = 4.76; p ≪ 0.001], and absolute level differences decreased from 0.3 to 0.2 to 0.1 dB when the duration increased from 2 to 4 to 6 s, respectively [t(28) = −2.58 and −4.39; p = 0.015 and 0.0002, respectively].
Procedure
Participants were seated in a sound-isolated booth (IAC Acoustics), and listened to the stimuli through circumaural headphones (AKG K702) without hearing-aids. The change in stimulus within each trial from first to second segment was indicated on a touch screen in front of the participant. Participants were asked on each trial to indicate “How did the second sound compare to the first sound?” by selecting either the “better”, “worse” or “no difference” button on the touch screen.
There were three segment durations (2, 4 and 6 s) and 13 gain adjustments (±6 and ±12 dB adjustments in the LF, MF and HF bands plus a no-adjustment control), resulting in 39 stimulus conditions. Each stimulus condition was repeated ten times, resulting in 390 trials (3 × 13 × 10). The order of presentation was randomised for each participant. The trial run was broken into equal blocks of 130 trials with breaks between. Prior to testing, each participant completed 12 practice trials consisting of one trial each of 2-s and 6-s segments with ±12 dB gain adjustments in each of the three bands.
Ethical approval for the study was given by the West of Scotland research ethics committee (18/WS/0007) and NHS Scotland R&D (GN18EN094). All participants provided written informed consent prior to testing.
Results
Preferences
The proportions of “better” (B), “worse” (W) and “no difference” (ND) judgments were calculated for each gain adjustment in each frequency band (). A repeated-measures analysis of variance (RMANOVA) was run on the entire dataset (5 gain adjustments × 3 frequency bands × 3 segment durations) using combined “better” and “worse” proportions [P(B or W)] as the dependent variable (). Amount of gain adjustment, frequency band and duration all showed significant main effects on better-and-worse preferences. Better and worse judgments increased with increasing duration, from 2 to 4 s [t(28) = 8.44; p ≪ 0.001] and 4 to 6 s [t(28) = 2.80; p = 0.0092]. The greatest rates of “better” and “worse” responses were for LF adjustments.
Figure 2. Mean proportion of preferences as a function of gain adjustment for low-frequency (LF; ≤0.5 kHz), mid-frequency (MF; 1–2 kHz) and high-frequency (HF; ≥4 kHz) bands (left, middle and right panels, respectively) for 2-s, 4-s and 6-s durations (short-dashed, long-dashed and solid lines, respectively; red, green and blue online). Better, worse and no difference preferences are shown as upward triangles, downward triangles and circles, respectively. Grey dotted lines and symbols show results using short sentences from Caswell-Midwinter and Whitmer (Citation2021).
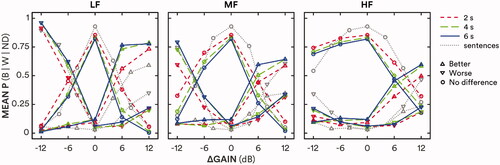
Table 1. Results of a repeated-measures analysis of variance on proportions of preferences, showing degrees of freedom (df), F-statistics and p values and partial eta-squared effect sizes.
As the current methods shared many aspects, including participants, with Caswell-Midwinter and Whitmer (Citation2021), the current study’s preference data were compared to the preferences elicited for short sentences in that previous study (grey triangles and dotted lines in ). In the current study there were more “better” and less “worse” ratings for +12-dB adjustments in the MF band [t(59) = 3.11 and −3.10 for better and worse, respectively; Holm-Bonferroni corrected p′ = 0.0028 and 0.0030] and HF band [t(59) = 5.32 and −3.77, respectively; both p′ <0.001]. There were also more “better” and less “worse” ratings for the LF band for +12 dB adjustments in the current study compared to the previous (compare grey with coloured triangles in the left panel of ), but these differences were not statistically significant [t(59) = 1.99 and −1.60; both p > 0.05].
Participants were less prone to choose “no difference” when there was no gain adjustment in the current study compared to the previous study. The proportion of no difference responses at ΔGain = 0 was 0.84 across segment durations compared to 0.94 previously for short sentences [t(56) = 3.31; p = 0.0017].
Preference thresholds
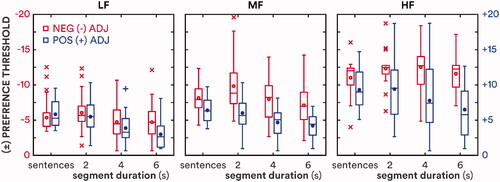
The minimum gain adjustment required to elicit either a “better” or “worse” preference – the preference threshold – was estimated by fitting a logistic function to each individual’s P(B or W) as a function of ΔGain. Separate functions were fitted for negative and positive gain adjustments (i.e. decrements and increments) for each frequency band. The threshold was defined as P(B or W) = 0.55 [P(ND) = 0.45] which corresponds to d′ = 1 for an unbiased differencing observer in a same-different discrimination task (Macmillan and Creelman Citation2005). Shapiro-Wilk tests of normality were violated for three of the 18 conditions: 4-s and 6-s LF increment and 2-s MF decrement thresholds (W = 0.91, 0.87 and 0.88, respectively; p = 0.018, 0.0034 and 0.0064); nevertheless, Tukey boxplots (Tukey, 1977) are used in to show the range of preference thresholds for each condition. All statistical probabilities reported for pairwise comparisons and correlations were corrected for multiple comparisons using the Holm-Bonferroni method (Holm Citation1979); corrected probabilities are indicated by p′.
Figure 3. Boxplots of preference thresholds for each stimulus duration: sentences (average duration 1.6 s; Caswell-Midwinter and Whitmer Citation2021), 2 s, 4 s, and 6 s. Preference thresholds for negative and positive gain adjustments are shown in red and blue, respectively. Circles show means; lines show medians; boxes show interquartile ranges (IQR); whiskers show 1.5·IQR; crosses and pluses show outliers for negative and positive adjustments, respectively.
An RMANOVA based on the preference thresholds showed main effects of frequency band, direction of gain adjustment and segment duration (). Preference thresholds decreased with increasing segment duration, increased with increasing centre frequency and were greater for decrements than increments. There was a significant interaction of frequency band and gain direction; decrement thresholds increased more than increment thresholds with increasing centre frequency. There was also a significant albeit modest (η2 = 0.11) interaction between gain direction and duration; preference thresholds decreased with increasing duration more for increments than decrements. There was additionally a significant but modest three-way interaction in the RMANOVA: preference thresholds for the MF band decreased with increasing segment duration more for decrements than for increments.
Table 2. Results of a repeated-measures analysis of variance on preference thresholds (see for description of terms).
Mean thresholds with 95% repeated-measures confidence intervals (Loftus and Masson Citation1994) are shown in . Thresholds significantly decreased with increasing duration for gain increments in the LF, MF and HF frequency bands, and for gain decrements in the LF and MF bands; the thresholds for decrements in the HF band (12.1 dB) did not significantly change across durations. The overall rate of change in preference threshold (i.e. the difference in mean thresholds not including HF decrements divided by the difference in duration) decreased with increasing duration from −0.8 dB/s at 4 s to −0.4 dB/s at 6 s. That is, preference thresholds decreased more between 2 and 4 s than between 4 and 6 s.
Table 3. Mean preference thresholds (dB) with 95% confidence intervals in brackets for all conditions (“-” = decrements; “+” = increments) including mean data from Caswell-Midwinter and Whitmer (Citation2021), denoted “sentences.”
The preference thresholds measured here for 2-s consecutive segments of a continuous story were similar to the thresholds for short sentences reported by Caswell-Midwinter and Whitmer (Citation2021) with the exception of MF and HF decrements, for which the current thresholds were significantly greater (t = 2.75 and 2.49; p′ = 0.011 and 0.030, respectively). Thresholds for 2-s stimuli, averaged across frequency bands, were positively correlated with thresholds in the previous study for both increments and decrements (ρ = 0.55 and 0.72, respectively; both p′ ≪ 0.001). Preference thresholds were not correlated with age, BE4FA, or hearing-aid experience (all p′ > 0.05). HF increment preference thresholds were positively correlated with HF pure-tone thresholds (ρ = 0.48; p′ = 0.049), and negatively correlated with HF sensation level (ρ = −0.50; p′ = 0.038) and cognitive score (r = −0.62; p′ = 0.0020). Individual 2-s preference thresholds were correlated with individual decreases in threshold with duration, characterised as the slope in dB/s (r = −0.57; p′ = 0.0035). Individual 2-s, 4-s or 6-s preference thresholds were not correlated with individual cognitive scores (r = −0.37, −0.13 and 0.03, respectively; all p′ > 0.05), but slopes (dB/s) were correlated with cognitive scores (r = 0.50; p = 0.0057). Controlling for the variance shared with 2-s thresholds, individual slopes were still correlated with cognitive scores (r = 0.38; p = 0.047). That is, thresholds decreased more with duration (i.e. greater negative slope) for those with lesser letter/digit-monitoring ability. Based on this correlation, the RMANOVA of preference thresholds was re-run with centred cognitive scores as a covariate. As expected, the covariate reduced the error term, increasing the F statistics and η2 effect sizes, but did not change the pattern of results shown in .
Preference agreement and reliability
Fleiss’ κ (Fleiss Citation1971) was used to measure inter-participant agreement, comparing participants’ most frequent judgement (better, worse or no different) for each adjustment condition. To simplify the analysis, judgments were collapsed across adjustments for each direction and frequency band; judgments for the ΔGain = 0 condition were not included in the analysis. Fleiss’ κ was 0.39 [0.36–0.42 95% confidence intervals (CI)], 0.50 (0.47–0.53) and 0.50 (0.47–0.53) for segments of 2-s, 4-s and 6-s duration, respectively, representing “fair” (2 s) and “moderate” (4 and 6 s) agreement. That is, agreement significantly increased from 2 to 4 s, but not from 4 to 6 s.
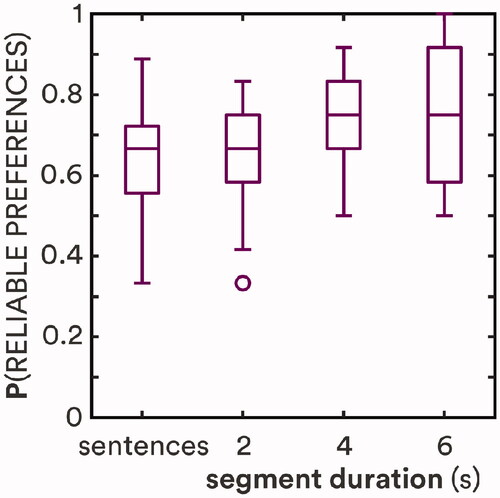
A participant’s judgments (“better”, “worse” or “no difference”) for a given gain adjustment in a given frequency band were considered reliable if seven or more of those judgments were identical, a reliability threshold based on binomial probability theory (Kuk and Lau Citation1995). Individual reliabilities were averaged across conditions; judgments for the ΔGain = 0 condition were not included. Because the proportions of reliable preferences in the current study were not normally distributed based on Shapiro-Wilk tests (W = 0.92, 0.90 and 0.92 for 2-s, 4-s and 6-s stimuli), non-parametric tests were used to compare reliability across conditions. shows individual proportions of adjustments with reliable preferences. Reliability increased significantly from a median value of 67% for short sentences and 2-s segments to 75% for 4-s and 6-s segments [χ2 = 11.10; p = 0.011]. There was no significant difference in reliability between sentences and 2-s segments (z = 0.65; p = 0.51) nor between 4-s and 6-s segments (z = 0.72; p = 0.47). The percentage of participants with ≥90% reliable preferences, however, did increase from 14% at 4 s to 28% at 6 s. Individual reliabilities for short sentences and 2-s stimuli were not correlated, but reliabilities for 4-s and 6-s stimuli were (r = 0.61; p = 0.0004).
Figure 4. Proportion of reliable preferences as a function of stimulus duration. Horizontal lines show medians; boxes show interquartile ranges (IQR); whiskers show 1.5·IQR; circles show outliers. Sentence data are from Caswell-Midwinter and Whitmer (Citation2021).
Discussion
By having participants compare and judge consecutive segments of a single-narrator story, we have shown that longer durations promote more frequent and reliable “better” or “worse” preference judgments for gain adjustments in broad frequency bands. That is, the gain adjustments required to elicit consistent preferences decreased with increasing stimulus duration. The proportions of better or worse preferences were greater, so preference thresholds were smaller, for increments than for decrements, in agreement with Caswell-Midwinter and Whitmer (Citation2021) as well as previous psychophysical literature (Ellermeier Citation1996; Moore, Oldfield, and Dooley Citation1989; Moore et al. Citation1997). Better and worse preferences were less frequent with increasing centre frequency of the adjustment band, as previously shown for short sentences (Caswell-Midwinter and Whitmer Citation2021).
Despite differences in the method, the median preference thresholds in the current study for 2-s segments were similar to the thresholds for 1.6-s average duration sentences in our previous study (Caswell-Midwinter and Whitmer Citation2021), and individual preference thresholds were correlated with the previous thresholds. As with the previous study, the strongest preferences were for increased LF gain and against decreased LF gain, as found in self-fitting studies (Keidser and Convery Citation2018; Nelson et al. Citation2018; Vaisberg et al. Citation2021). The long-term spectrum of the stimuli had its greatest power in the LF band; this may have influenced the discriminability of LF adjustments (Jesteadt et al. Citation2017), increasing preferences and reliability. There were preference differences between the two studies, with increases in “better” vs. “worse” judgments for MF and HF increments in the current study. The long-term spectrum in the HF band for the current monologue segments was 5.6 dB less than for the previous sentence stimuli. Increases in HF gain may have then been judged more favourably in the current study because of the greater audibility in that band. There were, though, no spectral differences to explain the MF increment preference discrepancy; further work is needed to better understand to what extent particular stimulus attributes (e.g. vocal timbre) and context (e.g. monologue vs. unconnected sentences) affect gain preferences.
Participants were less likely to respond “no difference” in the current study when consecutive segments were presented without gain adjustments compared to the previous study (Caswell-Midwinter and Whitmer Citation2021) where the same sentence was presented twice on each trial. This difference can be attributed to the comparison of two different speech segments; the naturally occurring differences in the spectrotemporal patterns between the two segments (without gain adjustments) could decrease the likelihood of a “no difference” response (Mason et al. Citation1984; Kidd, Mason, and Green Citation1986). The effect of this decrease in no-difference responses on threshold estimation was minimal; fitting logistic functions to the current data using the no-difference responses from the previous study increased threshold estimates by only 0.4 dB on average. Nevertheless, the change demonstrates a limitation of using sequential stimuli for comparison.
The use of an ongoing story, as opposed to hearing the same utterance twice, anecdotally provided a greater degree of participant engagement with the material, engagement as might occur in the clinic, where the responses of the patient will affect real-world use. Any greater engagement with the stimulus content, however, may have been detrimental to performing the task. Beyond the decrease in no-difference responses, the effect of comparing different stimuli (two consecutive segments) versus comparing identical stimuli was small. Using non-repeating segments introduces variability in the level and spectrum in the comparison, which can decrease detectability (Kidd, Mason, and Green Citation1986), thus increasing preference thresholds. In the present experiment, the use of the same talker throughout would have reduced signal uncertainty and thus reduced any effect of non-repeating segments on thresholds. To check the potential influence of extreme spectral variations between segment pairs, preference thresholds were recalculated excluding the 10% of trials with the greatest absolute difference in any band for each participant. The only significant effects of this recalculation were modest increases in the preference thresholds for 6-s MF and 2-s HF increment stimuli (Δthreshold = 0.2 and 0.3 dB; z = 2.72 and 2.13; p = 0.0065 and 0.032, respectively); all other threshold differences were not significantly different from zero (z = 0.14–1.22; all p > 0.05). Further, excluding trials based on extreme variation between their consecutive segments did not have any effect on the rate of change of preference thresholds as a function of duration. Thus, there is scant evidence that the natural variation in the consecutive stimuli affected the pattern of results.
The delivery of stimuli used for appraisal by the patient in the clinic may be different to paired or sequential comparisons. Rather, the appraisal may take the form of a single interval. Single interval ratings of hearing-aid sound quality have shown moderate test-retest reliability (Narendran and Humes Citation2003) and good inter-rater reliability (Gabrielsson et al. Citation1990), but these studies used stimulus durations of 50-60 s. Using such long stimuli for clinical fine-tuning may not be feasible
It is not known if durations > 6 s would provide even greater discriminability and more reliable preferences. While the thresholds across most conditions decreased significantly from 4 s to 6 s, the effect was small. The overall rate of change decreased from −0.8 dB/s between 2 and 4 s to −0.4 dB/s at 6 s, resembling the exponential decay in memory-based models of the effects of duration on pairwise comparison (e.g. Durlach and Braida Citation1969). There was a correlation between participants’ monitoring-task cognitive scores and the rate of decrease in their preference thresholds with increasing duration. That is, the worse their cognitive scores, the stronger the effect of stimulus duration on preference thresholds. This suggests that there is a limit to the effect of duration in the judgement of gain adjustments, and further suggests that the greatest effect is for those with lesser cognitive capacity. The mean preferences were very similar for 4-s and 6-s stimuli (), and there was no increase from 4 to 6 s in inter-participant agreement or intra-participant reliability (). It is therefore unlikely for thresholds to decrease, or reliability to increase, much further beyond the results here for 6-s stimuli (cf. Bartha-Doering et al. Citation2015). It is also not known how fast-acting compression, as delivered by many current hearing-aids, would affect results. The short-term variation in speech would interact with the compressor, potentially generating different preferences. The dynamic compression of speech, however, has previously not been found to have an effect on overall level discrimination of words and sentences (Whitmer and Akeroyd Citation2011), hence would not be expected to lead to more consistent preferences with duration.
The improvement in thresholds and reliability with increasing stimulus duration was small relative to the thresholds and reliabilities themselves. Talking or presenting stimuli for 6 s to a hearing-aid wearer in the clinic would help elicit consistent preferences for adjustments, but those adjustments would still need to be large: 3-6 dB for increments, 5-12 dB for decrements. These thresholds are well above common troubleshooting adjustments, especially for adjustments at higher frequencies. A patient may indeed state an immediate preference when a smaller adjustment has been made, but such a preference should be treated with caution, as it may not be based on the acoustical percept of the adjustment, and is therefore likely to be unreliable. For the personalisation of hearing-aids in the clinic, it is therefore important not only to say more than a few words (e.g. “how’s that sound?”) immediately following an adjustment, but also to ensure that the adjustment is large enough to elicit a consistent effect. Given these constraints, alternative methods of fitting, such as self-adjustments (Mackersie et al., 2019 ; Nelson et al. Citation2018), which have resulted in similar gains to those prescribed and fit by a clinician (cf. Sabin et al. Citation2020), may be more viable for effective hearing-aid personalisation, although further study is warranted.
Acknowledgments
The authors would like to thank David McShefferty for his assistance in conducting the study, as well as Dr. Gitte Keidser, Professor Brian C. J. Moore and two anonymous reviewers for their helpful comments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Anderson, M. C., K. H. Arehart, and P. E. Souza. 2018. “Survey of Current Practice in the Fitting and Fine-Tuning of Common Signal-Processing Features in Hearing Aids for Adults.” Journal of the American Academy of Audiology 29 (2): 118–124. doi:10.3766/jaaa.16107.
- Bartha-Doering, L., D. Deuster, V. Giordano, A. Am Zehnhoff-Dinnesen, and C. Dobel. 2015. “A Systematic Review of the Mismatch Negativity as an Index for Auditory Sensory Memory: From Basic Research to Clinical and Developmental Perspectives.” Psychophysiology 52(9): 1115-1130. doi:10.1111/psyp.12459.
- Bentler, R. A., D. P. Niebuhr, T. A. Johnson, and G. A. Flamme. 2003. “Impact of Digital Labelling on Outcome Measures.” Ear Hearing 24 (3): 215–224. doi:10.1097/01.AUD.0000069228.46916.92.
- British Academy of Audiology 2016. “Guidance for Audiologists: Onward Referral of Adults with Hearing Difficulty Directly Referred to Audiology Services.” https://www.baaudiology.org/app/uploads/2019/07/BAA_Guidance_for_Onward_Referral_of_Adults_with_Hearing_Difficulty_Directly_Referred_to_Audiology_2016_-_minor_amendments.pdf.
- Byrne, D., and H. Dillon. 1986. “The National Acoustic Laboratories' (NAL) New Procedure for Selecting the Gain and Frequency Response of a Hearing Aid.” Ear and Hearing 7 (4): 257–265. doi:10.1097/00003446-198608000-00007
- Caswell-Midwinter, B., and W. M. Whitmer. 2019. “Discrimination of Gain Increments in Speech.” Trends in Hearing 23: 2331216519886684. doi:10.1177/2331216519886684.
- Caswell-Midwinter, B., and W. M. Whitmer. 2021. “The Perceptual Limitations of Troubleshooting Hearing-Aids Based on Patients' Descriptions.” International Journal of Audiology 60 (6): 427–437. doi:10.1080/14992027.2020.1839679.
- Cowan, N. 1984. “On Short and Long Auditory Stores.” Psychological Bulletin 96 (2): 341–370. doi:10.1037/0033-2909.96.2.341.
- Dai, H., and D. M. Green. 1993. “Discrimination of Spectral Shape as a Function of Stimulus Duration.” The Journal of the Acoustical Society of America 93 (2): 957–965. doi:10.1121/1.405456.
- Dawes, P., R. Hopkins, and K. J. Munro. 2013. “Placebo Effects in Hearing-Aid Trials Are Reliable.” International Journal of Audiology 52 (7): 472–477. doi:10.3109/14992027.2013.783718.
- Doyle, A. C. 2011. The Memoirs of Sherlock Holmes (D. Jacobi, Narr.) [Audiobook]. London: AudioGO Ltd.
- Dreschler, W. A., H. Verschuure, C. Ludvigsen, and S. Westermann. 2001. “ICRA Noises: Artificial Noise Signals with Speech-like Spectral and Temporal Properties for Hearing Instrument Assessment.” International Journal of Audiology 40 (3): 148–157. doi:10.3109/00206090109073110.
- Durlach, N. I., and L. D. Braida. 1969. “Intensity Perception. I. Preliminary Theory of Intensity Resolution.” Journal of the Acoustical Society of America. 46 (2): 373–383. doi:10.1121/1.1911699.
- Ellermeier, W. 1996. “Detectability of Increments and Decrements in Spectral Profiles.” Journal of the Acoustical Society of America. 99 (5): 3119–3125. doi:10.1121/1.414797.
- Farrar, C. L., C. M. Reed, Y. Ito, N. I. Durlach, L. A. Delhorne, P. M. Zurek, and L. M. Braida. 1987. “ Spectral-Shape Discrimination. I. Results from Normal-Hearing Listeners for Stationary Broadband Noises.” The Journal of the Acoustical Society of America 81 (4): 1085–1092. doi:10.1121/1.394628.
- Fleiss, J. L. 1971. “Measuring Nominal Scale Agreement among Many Raters.” Psychological Bulletin 76 (5): 378–382. doi:10.1037/h0031619.
- Florentine, M. 1986. “Level Discrimination of Tones as a Function of Duration.” The Journal of the Acoustical Society of America 79 (3): 792–798. doi:10.1121/1.393469.
- Gabrielsson, A., B. Hagerman, T. Bech-Kristensen, and G. Lundberg. 1990. “Perceived Sound Quality of Reproductions with Different Frequency Responses and Sound Levels.” The Journal of the Acoustical Society of America 88 (3): 1359–1366. doi:10.1121/1.399713
- Gatehouse, S., G. Naylor, and C. Elberling. 2006. “Linear and Nonlinear Hearing Aid fittings-2. Patterns of candidature.” International Journal of Audiology 45 (3): 153–171. doi:10.1080/14992020500429484.
- Green, D. M., C. R. Mason, and G. Kidd. 1984. “Profile Analysis: Critical Bands and Duration.” The Journal of the Acoustical Society of America 75 (4): 1163–1167. doi:10.1121/1.390765.
- Greenhouse, S. W., and S. Geisser. 1959. “On Methods in the Analysis of Profile Data.” Psychometrika 24 (2): 95–112. doi:10.1007/BF02289823.
- Holm, S. 1979. “A Simple Sequentially Rejective Multiple Test Procedure.” Scandinavian Journal of Statistics. 6: 65–70.
- International Telecommunication Union, Radiocommunication Sector. 2019. General Methods for the Subjective Assessment of Sound Quality. Recommendation ITU-R BS.1284-2, International Telecommunications Union, Geneva, Switzerland.
- International Telecommunication Union, Telecommunication Standardization Sector. 2003. Subjective Test Methodology for Evaluating Speech Communication Systems that Include Noise Suppression Algorithm. Recommendation ITU-T P.835, International Telecommunications Union, Geneva, Switzerland.
- Isarangura, S., A. C. Eddins, E. J. Ozmeral, and D. A. Eddins. 2019. “The Effects of Duration and Level on Spectral Modulation Perception.” Journal of Speech, Language, and Hearing Research 62 (10): 3876–3886. doi:10.1044/2019_JSLHR-H-18-0449.
- Jenstad, L. M., D. J. Van Tasell, and C. Ewert. 2003. “Hearing Aid Troubleshooting Based on Patients’ Descriptions.” Journal of the American Academy of Audiology 14 (7): 347–360.
- Jesteadt, W., S. M. Walker, A. O. Oluwaseye, B. Ohlrich, K. E. Brunette, M. Wróblewski, and K. K. Schmid. 2017. “Relative Contributions of Specific Frequency Bands to the Loudness of Broadband Sounds.” The Journal of the Acoustical Society of America 142 (3): 1597–1610. doi:10.1121/1.5003778.
- Kates, J. M., and K. H. Arehart. 2010. “The Hearing-Aid Speech Quality Index (HASQI).” Journal of the Audio Engineering Society. 58: 363–381.
- Keidser, G., and E. Convery. 2018. “Outcomes with a Self-Fitting Hearing Aid.” Trends Hear 22: 1–12. doi:10.1177/2331216518768958.
- Kidd, G., C. R. Mason, and D. M. Green. 1986. “Auditory Profile Analysis of Irregular Sound Spectra.” The Journal of the Acoustical Society of America 79 (4): 1045–1053. doi:10.1121/1.393376.
- Kuk, F. K., and C. Lau. 1995. “The Application of Binomial Probability Theory to Paired Comparison Responses.” American Journal of Audiology 4 (1): 37–42. doi:10.1044/1059-0889.0401.37.
- Kuk, F. K., and C. Ludvigsen. 1999. “Variables Affecting the Use of Prescriptive Formulae to Fit Modern Nonlinear Hearing Aids.” Journal of American Academy of Audiology 10: 453–465.
- Loftus, G. R., and M. E. J. Masson. 1994. “Using Confidence Intervals in within-Subject Designs.” Psychonomic Bulletin & Review 1 (4): 476–490. doi:10.3758/BF03210951.
- Mackersie, C. L., A. Boothroyd, and A. Lithgow. 2019. “A "Goldilocks" Approach to Hearing Aid Self-Fitting: Ear-Canal Output and Speech Intelligibility Index.” Ear and Hearing 40 (1): 107–115. doi:10.1097/AUD.0000000000000617.
- Macmillan, N. A., and C. D. Creelman. 2005. Detection Theory: A User’s Guide (2nd ed.). Mahwah, NJ: Lawrence Erlbaum Associates.
- Massaro, D. W. 1970. “Perceptual Processes and Forgetting in Memory Tasks.” Psychological Review 77: 557–567.
- Mason, C. R., G. Kidd, T. E. Hanna, and D. M. Green. 1984. “Profile Analysis and Level Variation.” Hearing Research 13 (3): 269–275. doi:10.1016/0378-5955(84)90080-7.
- Moore, B. C. J., S. R. Oldfield, and G. J. Dooley. 1989. “Detection and Discrimination of Spectral Peaks and Notches at 1 and 8 kHz.” The Journal of the Acoustical Society of America 85 (2): 820–836. doi:10.1121/1.397554.
- Moore, B. C., R. W. Peters, A. Kohlrausch, and S. van de Par. 1997. “Detection of Increments and Decrements in Sinusoids as a Function of Frequency, Increment, and Decrement Duration and Pedestal Duration.” The Journal of the Acoustical Society of America 102 (5 Pt 1): 2954–2965. doi:10.1121/1.420350.
- Narendran, M. M., and L. E. Humes. 2003. “Reliability and Validity of Judgments of Sound Quality in Elderly Hearing Aid Wearers.” Ear and Hearing 24 (1): 4–11. doi:10.1097/01.AUD.0000051745.69182.14.
- Naylor, G., M. Öberg, G. Wänström, and T. Lunner. 2015. “Exploring the Effects of the Narrative Embodied in the Hearing Aid Fitting Process on Treatment Outcomes .” Ear and Hearing 36 (5): 517–526. doi:10.1097/AUD.0000000000000157.
- Nelson, P. B., T. T. Perry, M. Gregan, and D. Van Tasell. 2018. “Self-Adjusted Amplification Parameters Produce Large between-Subject Variability and Preserve Speech Intelligibility.” Trends in Hearing 22: 2331216518798264. doi:10.1177/2331216518798264.
- Oxenham, A. J., and S. Buus. 2000. “Level Discrimination of Sinusoids as a Function of Duration and Level for Fixed-Level, Roving-Level, and across-Frequency Conditions.” The Journal of the Acoustical Society of America 107 (3): 1605–1614. doi:10.1121/1.428445.
- Pollack, I. 1972. “Memory for Auditory Waveform.” The Journal of the Acoustical Society of America 52 (4): 1209–1215. doi:10.1121/1.1913234.
- Sabin, A. T., D. J. Van Tasell, B. Rabinowitz, and S. Dhar. 2020. “Validation of a Self-Fitting Method for over-the-Counter Hearing Aids.” Trends in Hearing 24: 2331216519900589 doi:10.1177/2331216519900589.
- Thielemans, T., D. Pans, M. Chenault, and L. Anteunis. 2017. “Hearing Aid fine-tuning based on Dutch descriptions .” International Journal of Audiology 56 (7): 507–515. doi:10.1080/14992027.2017.1288302.
- Vaisberg, J. M., S. Beaulac, D. Glista, E. A. Macpherson, and S. D. Scollie. 2021. “Perceived Sound Quality Dimensions Influencing Frequency-Gain Shaping Preferences for Hearing Aid-Amplified Speech and Music.” Trends in Hearing 25: 2331216521989900. doi:10.1177/2331216521989900.
- Valente, D. L., H. Patra, and W. Jesteadt. 2011. “Relative Effects of Increment and Pedestal Duration on the Detection of Intensity Increments.” The Journal of the Acoustical Society of America 129 (4): 2095–2103. doi:10.1121/1.3557043.
- Whitmer, W. M., and M. A. Akeroyd. 2011. “Level Discrimination of Speech Sounds by Hearing-Impaired Individuals with and without Hearing Amplification.” Ear and Hearing 32 (3): 391–398. doi:10.1097/AUD.0b013e318202b620.
- Winkler, I., and N. Cowan. 2005. “From Sensory to Long-Term Memory: Evidence from Auditory Memory Reactivation Studies.” Experimental Psychology 52 (1): 3–20. doi:10.1027/1618-3169.52.1.3.