
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Objective
The “Marginal benefit from acoustic amplification” version 2 (MBAA2) sentence test has been used in France in the routine evaluation of cochlear implant (CI) users for 20 years. Here we present four studies that characterise and validate the test, and compare it with the French matrix sentence test.
Design and sample
An analytic method was developed to obtain speech recognition threshold in noise (SNR50) from testing at a fixed signal to noise ratios (SNRs). Speech recognition was measured at several fixed SNRs in 18 normal-hearing listeners and 15 CI listeners. Then, the test–retest reliability of the MBAA2 was measured in an additional 15 CI listeners. Finally, list equivalence was evaluated in eight CI listeners.
Results
The MBAA2 test produced lower SNR50s and SNR50s were obtained in more CI listeners than with the French matrix test. For the MBAA2, the standard deviation of test–retest differences in CI listeners was around 1 dB SNR. Three lists had deviant difficulty and nine low item-to-total correlations.
Conclusions
We propose to reduce the number of MBAA2 test lists to reduce variability. The MBAA2 test has high test–retest reliability for percent correct and SNR50, and is suitable for the assessment of cochlear implant patients.
Introduction
The understanding of everyday common phrases or sentences has long been a measure of functional hearing capacity. Speech understanding can be tested with or without prosthetic assistance from acoustic amplification or, for example, cochlear implants (CI). In addition, to mimic everyday situations, background noise may be added.
To further replicate a natural situation, multi-talker babble or “cocktail party” noise can be used, rather than synthetic white or speech-spectrum shaped noise, so that the noise contains amplitude modulations which may allow listeners to “listen in the gaps” (Wilson, Carnell, and Cleghorn Citation2007; Theunissen, Swanepoel, and Hanekom Citation2009). The French language Marginal Benefit from Acoustic Amplification (MBAA) test was devised in the 1990s by Xavier Cormary of the Service ORL, Hôpital Purpan, Toulouse, to evaluate functional speech recognition performance in CI recipients, both before and after surgery (Fraysse et al. Citation1998). At the time, no other similar test was available in French. The format and content of the test were borrowed from the English City University of New York (CUNY) test developed by Boothroyd et al. (Citation1988). Originally, there were 20 MBAA lists composed of 15 “everyday” sentences of three to fifteen words, with no particular rules of the composition except that there were 100–103 words per list.
Initially, the test was used with live voice presentations by experienced speech-language therapists. However, due to the need for systematic calibration of presentation levels, a recording was made of the speech material in 2003 along with an interfering masker noise. In addition, 16 lists were added and the original lists were modified because some of the language was considered to be antiquated or there were too few or too many words. This second recorded version was named the MBAA2 and was used with French CI recipients in studies of the expansion of indications for cochlear implantation at the time (Fraysse et al. Citation2006). Recordings of the test were distributed to CI centres all over France in the form of compact disc audio recordings with fixed signal-to-noise ratios (SNR) so that errors in presentation levels could be largely avoided. However, no systematic evaluation and validation of the MBAA2 test have been performed.
At about the same time, the Canadian French adaptation of the hearing in noise test (HINT) was developed (Vaillancourt et al. Citation2005), and slightly later the French intelligibility sentence test (FIST) (Luts et al. Citation2008). More recently, the French matrix sentence test was developed (Jansen et al. Citation2012). This test is based on Hagerman's (Citation1982) closed response set with permutations of ten words for five different word positions per sentence. One desirable quality of the matrix test format is that listeners are unable to use semantic context to aid them in the recall. However, Jansen et al. (Citation2012) did report that two practice lists should be used before the actual test lists to reduce variability arising from learning effects. As the French matrix sentence test was the most recently validated test, we evaluated it as a potential test to replace the MBAA2 test in our centre for the routine evaluation of speech recognition in noise for CI patients. Similar tests had been developed or are under development in many other languages (Kollmeier et al. Citation2015) and thus results could more easily be compared or combined across languages.
The matrix sentence tests and the HINT tests, as well as others, were developed with an eye to using adaptive procedures to estimate a “speech reception threshold” in quiet or in noise. The SNR50 is the SNR allowing 50% correct speech recognition. These adaptive procedures are similar to those first developed by Plomp and Mimpen (Citation1979) using everyday Dutch sentences. Speech recognition across test sentences is evaluated and made approximately equivalent by adjusting the recorded level of the speech. However, deviations in the loudness of individual words or sentences may sound unnatural and disturb listeners. Adaptive procedures also assume that listeners can recognise most or nearly all of a test sentence under ideal (i.e. no noise) conditions, which is often not the case for CI listeners (e.g. see James et al. Citation2019). When this condition is not fulfilled, the adaptive algorithm may not converge to the SNR50, or the result may be very variable (due to the shallow slope of the psychometric function near 50%). An alternative to adaptive SNR50 testing is to test at several fixed SNRs and fit a psychometric function to the data. This may require using more sentences than with adaptive testing, but it has the benefit of always obtaining an SNR50, providing >50% comprehension can be obtained in quiet.
We implemented a procedure for testing multiple fixed SNRs to obtain SNR50 and used this with the MBAA2 sentences. The method only requires an estimate of the maximum score (i.e. 100% correct, or the score in quiet) and two additional scores at fixed SNRs. An analytical formula is used to obtain the parameters of the psychometric function and to derive the SNR50 from the three scores.
In the first of the four studies reported here, speech recognition thresholds (SNR50) were established for the MBAA2 and the French matrix test in the same group of normal-hearing listeners. This work was part of the study to validate the French matrix sentence test, but it was not reported in Jansen et al. (Citation2012). In the second study, speech recognition scores, as a function of SNR for the MBAA2, were compared with those obtained with the validated French matrix sentence test in CI listeners. In our third study, test–retest reliability of the MBAA2 was quantified for the analytical method to obtain SNR50s in another group of CI listeners, using a method suitable for everyday clinical practice. Finally, it had been noted by us and some other MBAA2 users that there appeared to be some variability in difficulty between lists (Ambert-Dahan 2020). Therefore list equivalence was evaluated in CI recipients in the fourth study to detect and quantify any differences.
Materials and methods
The MBAA2 sentence-in-noise test
The MBAA2 corpus consists of 36 lists of 15 everyday sentences, each with a total of 100–103 words. List numbers 1 and 2 were always considered practice lists and were only used in Study 4. All test lists are available as complementary material (Supplemental Online Material 1). The MBAA2 lists are scored by word with a maximum score of 100: Common liaisons are counted as single words (e.g. “avez-vous,” “il y a”). For lists with more than 100 separate words (there are not more than 103 in any list), any count >100 correct is scored as 100%. A score out of 100 is the percent correct score.
The MBAA2 sentence material was recorded with a single female French speaker with a neutral Parisian accent (author N.C.). A Neumann U87 microphone was placed at a distance of ∼30 cm at a slightly higher level than the speaker’s mouth during recording. A digital recording was made with a 44,100 Hz sampling rate. The first half of each sentence list was recorded first for all lists, followed by the second half to improve vocal consistency across lists. Editing and processing of the recorded speech were performed using Goldwave software (version circa 2003). The recordings were high-pass filtered at 75 Hz to remove any non-speech frequencies, using a second-order finite-impulse-response filter. Each sentence was isolated with 20 ms leading and trailing silences. The root-mean-square (RMS) amplitude of all resulting digital files was equalised to −25 dB re. full-scale deflection (FSD). To create the recorded lists, the sentences were concatenated with 5.5 s of silence between each sentence. Each list recording is 2 min 7 s long (including additional trailing silence as necessary) and begins with the spoken list number (e.g. “Liste une”) before the first sentence. The mean speaking rate is 3.4 (SD = 0.6) words per second.
The MBAA2 masker signal was composed of the reading voices of two French men and two French women with differing voice pitches. Any pauses were reduced to 200 ms, leaving ∼8 min per speaker. The recordings for the four speakers were equalised at −25 dB RMS re. FSD and then mixed together. Subjectively, one male speaker’s voice was more prominent in the mix, and so the level of his voice was reduced by 1 dB. The resulting four-talker mixture was then looped and doubled to produce an eight-talker mixture of 12 min. The RMS level of this mixture was reduced to −25 dB re. FSD to define 0 dB SNR with respect to the sentence level. One-third of octave band levels for the speech and noise material are shown in Supplementary Figure 1. Band levels for the noise were ∼10 dB lower than for speech at >2000 Hz, and ∼10 dB greater at <160 Hz.
Reduction of scores to SNR50
Performance intensity functions were modelled using a logistic sigmoid function (EquationEquation (1)(1)
(1) ).
(1)
(1)
Expressed as a function of SNR, score P was dependent on three variables: the maximum score (Pmax; for example, attained in quiet), the position of the centre of the sigmoid function A (in dB), and a slope constant B (e.g. ). When the maximum score is 100%, the value A corresponds to SNR50. However, if this is not the case, the fitted function needs to be inverted (SNR as a function of score) to compute SNR50.
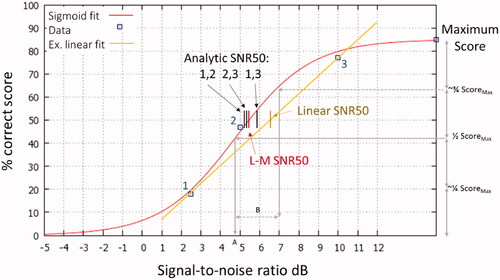
Figure 1. Examples of reduction of fixed-SNR testing data points to obtain the SNR50: The sigmoid (red curve) was fitted using an iterative, least-squares Levenburg-Marquart (L-M) method from all four points, three intermediate and the maximum, to give the SNR50 (short red line); three analytic sigmoid estimates of the SNR50 were calculated from two intermediate points and maximum (short black lines); the linear fit gives a large error in estimating the SNR50 when using intermediate data points 1 and 3 (e.g. short gold line).
The sigmoid function parameters can be found either via curve fitting, or analytically using the three measurable parameters Pmax and the scores P1 and P2 for two fixed SNRs: S1 and S2. The slope constant B can then be calculated:
(2)
(2)
Then using B, the SNR for the target score PSNR (e.g. 50 for SNR50) can be estimated:
(3)
(3)
Three methods for estimating SNR50 from scores for fixed SNRs are illustrated in using real scores as an example. There are four measured scores: for 2.5, 5, and 10 dB SNRs marked 1–3, and the maximum score Pmax measured in quiet. The resulting SNRs are indicated by short vertical lines for the following: all four points with an iterative Levenburg-Marquart sigmoid fit (EquationEquation (1)(1)
(1) ); three analytic fits using two of the three SNR points and Pmax (using EquationEquations (2)
(2)
(2) and Equation(3)
(3)
(3) ); and a linear fit for the two extreme SNRs (those marked 1 and 3).
The three analytic sigmoid fits result in SNR50 estimates that lie within a 1 dB margin of the iterative fit. However, the linearly fitted SNR50 is >1 dB distant. This is due to the linear function not being sufficiently representative of the underlying sigmoid function. The other differences between analytic estimates are due to either the underlying PI function not being exactly a sigmoid or because of random variability in the scores.
The slope of an individual performance intensity function, expressed as %/dB, was defined as the difference in score over 1 dB around its mid-point [the difference between substituting 0.5 and −0.5 for (SNR-A) in EquationEquation (1)(1)
(1) ]. The resulting slopes are within ∼1% of the values calculated using the logistic slope definition of Brand and Kollmeier (Citation2002) over the range 5–20%/dB. An Excel 2013 (Microsoft Corporation) spreadsheet file was developed to facilitate the calculations (Supplemental Online Material 2).
Study 1: MBAA2 and French matrix tests compared in normal hearing listeners
Participants
Normal-hearing (NH) listeners were 18 French native speakers (13 women, five men). Their mean age was 28 years (range 21–42 years). All participants underwent pure tone audiometry screening to verify normal hearing. They all presented with normal pure-tone thresholds <15 dB HL across the octave frequencies from 250 to 8000 Hz.
Procedures
MBAA2 sentence lists were randomly selected per participant and per condition from the 34 test lists available. Individual sentence lists were only used once in any individual participant. Part of a practice list (list 1 or list 2) was used to familiarise the participant with every SNR condition before testing. Signals were presented using the same setup and calibration as described by Jansen et al. (Citation2012) via a Sennheiser HDA200 headphone to a single ear (with left and right ear presentation balanced across participants). Using the headphone, the speech level was fixed at 60 dB SPL.
For the MBAA2 test, one practice list was presented in quiet, followed by a single test list in quiet, and then one list at −5.0 dB SNR. If the score was <50% correct the SNR was increased to −2.5 dB, or otherwise decreased to −7.5 dB. The two scores obtained were reduced to a single SNR50 measure using the analytical method described below. The French matrix test measurements were part of the data reported in Jansen et al. (Citation2012); two adaptive runs of the French matrix test were performed in both stationary noise and fluctuating noise to obtain SNR50s. We report here only the results for the stationary long-term average speech spectrum (LTASS) noise used in standard clinical practice.
Study 2: MBAA2 and French matrix tests compared in CI listeners
Participants
In Study 2, CI listeners were 15 French native speakers (six men and nine women). Their mean age was 59 years (range 39–79 years). All CI speech processors had been activated for at least 6 months (range 0.5–11 years). Twelve participants used Nucleus CIs, two had Advanced Bionics, and one a MED-EL. Eight participants used contralateral hearing aids and these were kept on for testing. The function of the hearing aids was not verified.
Procedures
MBAA2 sentence lists were randomly selected, for each participant and for each condition, from the 34 test lists available. Sentence lists were only used once for any participant. Part of a practice list (list 1 or list 2) was used to familiarise the participant with each SNR condition before testing. The sentence presentation level was fixed at 65 dB SPL (fast, unweighted) at the listening position. All stimuli were presented via a single (Studio Lab SLB sat 200) loudspeaker placed 1.5 m in front of participants, in a 3 by 3 m sound-proof room. CI listeners used their usual hearing configuration. For the MBAA2 test, speech and noise were recorded on left and right channels, on a compact audio disc, and played via a Madsen Itera 2 audiometer, to fix the SNR. For the French matrix test, speech and noise were played using the Oldenburg Measurement System (OMA) software and an M-Audio Delta 1010 T sound card. For the French matrix test, the LTASS noise was used as a masker and the OMA software was used to control the SNR.
For the MBAA2 test, one practice list was presented in quiet, followed by a single test list in quiet, and then one list at 10 dB SNR, then at 5, 2.5, and 0 dB. Testing was stopped when word-in-sentence scores were <20%. The same conditions were used with the French matrix test, with one list of 20 sentences for the practice and one list to test in quiet, and one list per SNR. In addition to the fixed SNR testing, two adaptive SNR runs of the French matrix test were performed, with two practice lists presented before the adaptive testing to reduce learning effects (Jansen et al. Citation2012).
Test order varied across participants in an ABBA fashion such that eight participants began (A) with the MBAA2 test and seven with the French matrix test. Then the test type was changed (B), then repeated (B), and finally, the first test type was retested (A).
Study 3: MBAA2 test–retest evaluation in CI listeners
Participants
A different group of CI listeners was tested in Study 3; they were 15 French native speakers: 10 women and 5 men. Their mean age was 54.5 years (range 35–74 years). All speech processors had been activated for at least 6 months (range 1.1–4.2 years). Participants were selected from the centre’s population based on obtaining >80% correct on the MBAA2 test at 10 dB SNR in a previous clinical testing session. Twelve participants used Nucleus CIs and three MED-EL. The use of contralateral hearing aids was not recorded.
Procedures
Sentences were presented to the subjects in the same way as for Study 2.
Here in Study 3, we estimated test–retest reliability for SNR50 with the MBAA2 test in CI listeners, following a procedure that is easily applicable to everyday clinical testing. Half a practice list was presented in quiet to familiarise the participant with the speaker’s voice. Then, one test list was presented at 10 dB SNR and one at 5 dB SNR. If the score at 5 dB SNR was <80% correct the next list was presented at 2 dB SNR if >80% then at 0 dB. If the score at 10 dB SNR was <50% correct then the next list was tested at 15 dB SNR. This procedure was designed to generate at least one score greater than, and one score <50% correct. This procedure was repeated within the same session for each participant.
Study 4: MBAA2 list equivalence in CI users
Participants
In Study 4, CI listeners were 8 French native speakers (three women, five men). Their mean age was 59 years (range 29–73 years). All speech processors had been activated for at least 6 months (range 0.5–4 years). Four participants used Nucleus CIs and four MED-EL. The use of contralateral hearing aids was not recorded.
Procedures
Presentation methods were the same as for Study 2.
Each participant was presented with all 36 lists, including the original practice lists 1 and 2. The total test time was ∼2 h. To control for presentation order, where practice and/or fatigue effects may influence performance, the lists were divided into four blocks of nine lists. The presentation order of the four blocks was permutated across participants such that each block was presented equally as often in the same position (i.e. twice in first, twice in second, etc.). Then “within each block” the order of lists was randomised across participants.
A relatively easy level was chosen for each CI listener to minimise the effects of fatigue so that the SNR was fixed individually for each participant. Based on the subjects’ previous clinical tests, the SNR was chosen to achieve a score of 50–90% correct. A relatively high scoring range was chosen to reduce the fatigue of participants who would normally only be tested with up to four lists in a clinical session. The individualised SNRs ranged from 2 to 10 dB.
Statistical analysis
For studies 1 and 3, Pmax was set to 100. We had previously noted that NH listeners scored at or very close to 100% in quiet, and the CI listeners chosen for Study 3 scored >80% correct at 10 dB SNR and thus at, or close to, 100% in quiet. For analytic curve fitting in Study 2, the obtained score in quiet was used for Pmax and the SNRs S1 and S2 were chosen from the tested SNRs such that the associated scores were closest to 50% correct, with one score >50 and the other <50. For Study 3, separate analytic fits were generated for the test and the retest sequences.
Summary statistics and paired t-tests were used to compare measures between tests for the same participants in Study 1 and Study 2. In Study 1, for evaluating the differences between different methods for obtaining SNR50, and in Study 3 for test–retest reliability, we estimated the standard deviation of differences in % correct scores or SNR50 across individual participants. These analyses were performed using Excel 2013 (Microsoft Corporation) software.
In Study 4, linear mixed models were used to determine the effect of list number or order of presentation on scores. In addition, item to total correlations (ITC) was computed for each list. The overall consistency of results across sets of lists was evaluated using the intra-class correlation coefficients (ICC, Shrout and Fleiss Citation1979); both for consistency and agreement. We used R software (R Core Team Citation2017), with extension packages “lme4,” “emmeans,” “psy,” and “multilevel,” for these analyses (Bates et al. Citation2015; Lenth Citation2019; Falissard Citation2012; Bliese Citation2016).
Results
Study 1: MBAA2 and French matrix tests compared in normal-hearing listeners
All NH listeners have only presented lists at −7.5 and −5.0 dB SNR, since none of them obtained scores <50 at −5.0 dB SNR. However, the SNR50 obtained for one NH listener was identified as an outlier as his or her SNR50 was −10.4 dB. This NH listener scored 70% correct even at the lower SNR, and 83% at the higher SNR, producing an unusually low slope. Mean SNR50s obtained with the remaining 17 NH listeners were −7.1 dB (range −8.5 to −5.8) for the MBAA2 and −5.5 dB (range −6.7 to −3.8) for the adaptive French matrix test.
SNR50s measured by the French matrix test were significantly higher than those for MBAA2 (Student’s paired t-test t[16] = 6.5, p < 0.001). Furthermore, SNR50s of the French matrix test and the MBAA2 test were not significantly correlated (Pearson’s r = 0.011, F[16] = 0.002, p = 0.965): Standard deviations of SNR50s were very low (0.8 for the MBAA2 and 0.7 for the adaptive French matrix test), possibly indicating that random errors in measurements were larger than intra-participant differences. The mean slope for the MBAA2 was 20.1%/dB (SD = 5.4%/dB). The slope for the French matrix sentence test was not measured in our experiment but for comparison has been previously reported as 14.0%/dB for NH listeners by Jansen et al. (Citation2012).
Study 2: MBAA2 and French matrix tests compared in CI listeners
gives summary statistics for SNR50s obtained with the French matrix test using either fixed or adaptive SNR testing. Five CI listeners scored <50% correct in quiet and were suspected to obtain unreasonably high SNR50s in adaptive testing with SNRs ranging from +32 to +93 dB on the first run. We note these SNRs were indicated by the software, and the latter was not physically realisable. The remaining ten CI listeners obtained adaptive SNR50s <15 dB, between −1 and +12 dB. We therefore only used these 10 listeners’ scores to estimate the test–retest reliability for the French matrix adaptive testing in CI listeners (). There were no significant differences between SNR50s obtained using the adaptive version of the French matrix test and the SNR50s obtained by iterative curve fitting to French matrix scores obtained at fixed SNRs (Paired t[9] = 1.66, p = 0.13).
Table 1. Summary statistics for 15 CI listeners in Study 2 using the French matrix and MBAA2 sentence tests.
Table 2. Summary statistics for 15 CI listeners in Study 3 using MBAA2.
also shows SNR50s obtained by iterative fitting to scores obtained at fixed SNRs with the MBAA2 test. One CI listener scored <50% correct in quiet on the MBAA2 test, and thus this listener’s data was removed for calculations of SNR50. SNR50 calculations used scores for 10 and 5 dB SNR in four CI listeners, 5 and 2.5 dB SNR in five listeners, and 2.5 and 0 dB SNR in five listeners. Overall, CI listeners had significantly lower SNR50s for the MBAA2 compared with the French matrix test (Paired t[9] = 3.35, p < 0.01), and the two were correlated (Pearson’s r = 0.78, F[9] = 12.7, p < 0.01). Next, we analysed the ten CI listeners obtaining SNR50 < 15 dB SNR on the French matrix test. This group had a lower mean SNR50 in the MBAA2 test of 1.4 dB SNR (SD = 2.6) compared with 4.4 dB SNR (SD = 4.4) for the French matrix test.
The analytic fitting method was also applied to obtain SNR50s from scores obtained with the MBAA2 at fixed SNRs. There was zero mean difference between SNR50s obtained using iterative curve fitting to all fixed SNR scores and those using the analytic fit with the maximum score (in quiet) and two scores bracketing 50% ().
Study 3: MBAA2 test–retest evaluation in CI listeners
Test–retest reliability of SNR50s calculated using the analytic fitting method with the MBAA2 was evaluated in 15 CI listeners with a relatively narrow range of performance. All CI listeners have presented test lists at 10 and 5 dB SNR, six were additionally tested at 2 dB, and the nine others were tested at 0 dB SNR. Of those tested at 0 dB SNR, one participant scored >50: they obtained 43 in the test and 55 at retest. No CI listener tested at 2 dB scored >50. Test scores were similar for lists presented at 2 and 0 dB and therefore these scores were combined to calculate test–retest reliability statistics (). The mean score, for 2 and 0 dB combined, was 33.8 points (SD = 9.6). As expected, test–retest reliability reduced with decreasing SNR: that is, the standard deviation of test–retest differences increased with increasing test difficulty (, Fixed SNR testing). Test–retest confidence intervals were approximately ±8.5 points at 10 dB SNR, increasing to ±18 points at 5 dB SNR, and ±29 points at 2/0 dB SNR.
Mean analytic SNR50 was 2.1 dB, with a mean test–retest difference of 0.1 dB, and therefore very little learning or practice effect. The mean slope was 13 points per dB (SD = 4.1). The test–retest differences were not statistically significant (Student’s paired t-test t[14] = 0.409, p = 0.689).
SNR50s and the test–retest differences were evenly distributed around their means (Supplementary Figure 2). For 11 of the 15 CI listeners, absolute test–retest differences were <1.3 dB. The standard deviation of the differences was 1.2 dB, resulting in a 95% confidence interval of ±2.3 dB. The standard deviation of differences can be used in power calculations to determine sample sizes in studies and the confidence interval for interpreting individual differences.
Study 4: MBAA2 list equivalence in CI users
The percent correct scores, obtained by eight CI listeners for all lists, were analysed using linear mixed models. In the first model, order of presentation was entered as a fixed effect, along with list number; with the listener as the random effect. Order of presentation was not statistically significant (Type II Wald test, chi2[35] = 37.211, p = 0.368), and therefore was dropped from the model. In the simplified model, there was a significant effect of list number on scores (chi2[35] = 103.9, p < 0.001). Using sum contrasts to measure the deviation of mean list scores from the grand mean of 82.9% (standard error of the mean, SEM = 2.6), four lists were identified as being significantly easier or more difficult (marginal mean differences 6.9, −5.9, 6.2, −13.3% points, SEM = 2.3) with a t statistic criterion of >2.5.
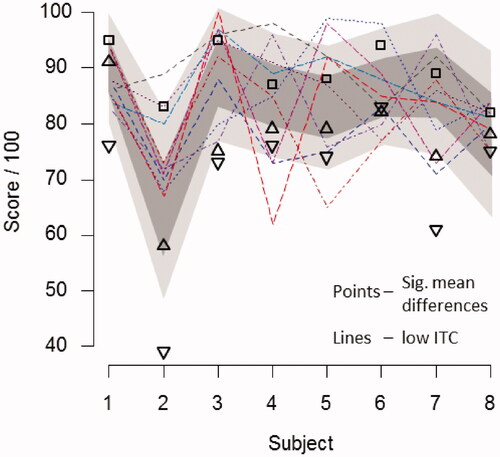
In addition, we computed item to total correlations (ITC) for each list: nine lists had ITCs <0.63 (range 0.16–0.62), and the remaining had ITCs from 0.65 to 0.96. We note that for N = 8 listeners, an r value <0.63 constitutes a non-significant correlation (p > 0.05). One list with ITC <0.63 also significantly deviated in the mean score from the grand mean. Scores obtained with individual lists with ITCs <0.63 are indicated in with lines, and those only deviating from the grand mean as points. The 95% confidence intervals of scores for individual listeners are indicated by the shaded region. Low ITC indicates a deviation from the overall pattern of scores in (contour of shading), whereas deviation from the grand mean is indicated by overall vertical displacement from the centre of the shaded area.
Figure 2. Scores for three lists exhibiting significant differences in mean scores (points) compared to all lists, and those nine having low item to total correlation (lines): Confidence intervals of scores for individual listeners are represented by the darker (68%) and lighter (95%) shading.
The lists can be described as “raters” of the performance of the listeners. Removing lists with low ITCs will tend to improve the intra-class correlation (ICC) consistency of the set. Removing those lists with absolute deviation from the mean also increases the ICC agreement. That is that the lists as “raters” will give more similar scores for a given listener (Shrout and Fleiss Citation1979). In , we compare the characteristics of the full set of 36 lists with the reduced set of 24; with lists 1, 2, 3, 4, 5, 8, 17, 22, 24, 28, 31, and 35 removed (We note that lists 1 and 2 were already considered as practice lists). Removing those twelve lists, the variance in scores across lists was reduced by 50%, and ICC agreement improved from 0.49 to 0.64. Decreasing the threshold for deviance from the grand mean and/or increasing the threshold for ITC did not improve ICC agreement greatly without considerably reducing the number of lists in the set. Finally, the grand mean score for the reduced set of 24 lists (83.0%) was very close to that of the complete set (82.9%).
Table 3. Summary statistics for the full original set of 36 MBAA2 lists, and the reduced set of 24 lists.
Discussion
Assessing speech recognition in noise can remove ceiling and floor effects and thus accommodate the wide range of performance levels seen in CI listeners. In clinical practice, it is common to use a test repeatedly across sessions to follow-up the performance of individual CI patients and measure progression over time (James et al. Citation2019). Equally, drops in performance can be identified, which may signal problems with sound processor fitting or function. In Studies 1 and 2, we investigated the use of an efficient fixed SNR testing method with the analytical estimation of the SNR50, applied it to the MBAA2 test, and specifically evaluated it with CI listeners in Study 3. In Study 4, we identified twelve lists from the MBAA2 test which may be more likely to produce spurious test results, and therefore induce unnecessary diagnostic or therapeutic activities.
In Study 2, SNR50 could not be obtained in 5/15 CI listeners using the French matrix test due to them scoring <50% in quiet, as opposed to only one using the MBAA2. Thus the MBAA2 test appears to be easier for CI listeners, and this is further supported with mean SNR50s being lower than with the French matrix test. A similar difference was found for normal-hearing listeners in Study 1. Previously, in a series of 118 of our CI patients (James et al. Citation2019), about 75% of them scored >70% correct at three months post-activation on the MBAA2 test; this increased to 90% of patients at 9 months. Thus an SNR50 measure should be obtainable using the MBAA2 test in the large majority of patients. In practice, therefore, the MBAA2 test appears more useful than the French matrix test for routine evaluation across a large range of performance levels in CI listeners. The MBAA2 test is probably easier, and produced lower SNR50 because more context in the sentences is available compared with the French matrix test. The slight mismatch of speech spectrum and babble noise spectrum may also contribute to the lower mean SNR50 found with the MBAA2 test (Supplementary Figure 1).
In a study by Hey et al. (Citation2014), CI users were first selected based on obtaining scores of 75% or greater with the German OLSA Matrix sentence test, in quiet at 65 dB SPL. However, they did not state what proportion of their total CI population might reach this criterion. Nine of the 38 (23%) CI listeners they tested obtained <90% correct in quiet, and in two of them convergence to SNR50 was not reached by the adaptive OLSA test in noise. Thus SNR50 data loss, in this case, would be at least 5%, and we assume it to be even greater in the general CI population. One benefit of fixed SNR testing is that some measure of performance is always obtained, even if scores are close to, or at, zero. It is problematic in clinical practice and in clinical trials to have missing data due to “could not test” events that may be produced by wrongly- or non-converging adaptive tracks.
Our new hybrid MBAA dB method allows for the use of fixed SNR testing and it has a simple method to obtain SNR50 from those scores. The analytic fitting may also be applied to retrospective fixed-level data to facilitate analysis, and it can be used with many types of fixed SNR tests. Similarly, in an adaptive test track, the scores for sentences (e.g. out of 5 in the French matrix test) presented at different SNRs could be used to provide more information about the performance intensity function in addition to the SNR50.
Test–retest reliability of the French matrix adaptive test has previously been established for normal-hearing listeners and moderately hearing-impaired listeners (Jansen et al. Citation2012), but not for CI users. We established test–retest reliability in CI listeners for the French matrix adaptive test in Study 2, and for the MBAA2 in dB SNR in Study 3. Test–retest reliability was similar for the two tests, with little evidence of learning effects. We note that we used the standard French matrix sentence test protocol and ran two practice lists before testing. For the MBAA2, the test we ran half a practice list before testing. Overall, the adaptive French matrix sentence test took more time than the MBAA dB test method to obtain SNR50. We note that the total test time using the French matrix test could potentially be reduced to below that for the MBAA dB where several listening conditions are tested in one session without additional practice lists.
A more difficult French-language sentence test for the evaluation of CI listeners, the French version (“FrBio”) of the Arizona State University AzBio test, was recently developed by Bergeron et al. (Citation2019). Test–retest reliability was established in NH listeners via a binomial simulation (Thornton and Raffin Citation1978) with a 95% confidence interval of 18% points around 50% correct. The test–retest reliability we observed for the MBAA2 in CI listeners was similar to that of the FrBio for scores at 90 and 70%, being ∼10 and ∼20%, however, we saw a larger value of 30 points for scores of ∼35% in Study 3 at 2 dB and 0 dB SNRs. It is unclear whether the increasing test–retest differences seen with increasing level of difficulty is a characteristic of CI listeners or some error of the assumptions in the binomial approximation. It will be useful to see results with the FrBio test in CI listeners.
Some of the MBAA2 sentence material was recently integrated into a QuickSIN-style sentence test in noise (Leclercq, Renard, and Vincent Citation2018), called the vocale rapide dans le bruit (VRB). SNR50 values found for NH listeners in speech-envelope modulated noise were similar to those found here for 8-talker babble; −7.1 dB (SD = 0.8) for MBAA dB vs. −6.6 dB (SD = 1.47) for the VRB. The mean SNR50 measured with the MBAA2 was also similar to that for the FIST (Luts et al. Citation2008). It would be of interest to understand the effect of the different noise types on SNR50s using VRB and MBAA dB test paradigms, as well as the effect of differences in the test setup. In addition, test–retest reliability should be established for both tests in NH and hearing-impaired listeners, especially using the reduced set of 24 test lists for the MBAA dB.
We evaluated list equivalence in eight CI listeners in Study 4 with all the MBAA2 lists. Only four lists were significantly more or less difficult compared to all lists for these CI listeners. However, nine lists produced scores with low correlation to the average scores of listeners. Removal of twelve lists with low item-to-total correlation or high deviation from the mean increased intra-class correlation agreement to a moderate to good level Koo and Li (Citation2016). This maintains a sufficiently large set of 24 test lists to avoid content learning between sessions and for use in clinical studies where several combinations of conditions may necessitate a large number of test lists.
Conclusions
The test–retest characteristics of the MBAA2 speech recognition in noise test were similar to that of the French matrix sentence test, except that the MBAA2 test was easier for cochlear implant listeners, even in quiet. Overall, our results confirm that an MBAA2 test is a useful tool for routine clinical evaluation of CI listeners who have a wide range of performance. We presented a simple method to obtain the SNR50 from three fixed SNR presentations, with high test–retest reliability. We further propose to reduce the MBAA2 set to 24 test lists to improve list equivalence and reduce variability.
Author contributions
C.J., C.K., C.N., M-L.L., and M.M. designed the material and studies and drafted the report. C.J. and C.K. analyzed the data. M-L.L, C.A., C.N., and M.T. managed CI patients, and supervised data collection by master’s students. O.D. and B.F. approved the manuscript.
Supplemental Material
Download MS Excel (11.4 KB)Supplemental Material
Download PDF (165 KB)Supplemental Material
Download TIFF Image (60.1 KB)Supplemental Material
Download TIFF Image (40.7 KB)Acknowledgements
We would like to thank master’s students Alice Lamy, Maria Perrault, and Audrey Georges for collecting some of the data as part of their dissertations. The MBAA test material is freely available at https://tinyurl.com/y2dsp7vu. We thank Marielle Bazo, Cochlear France, for providing this web page. Portions of this work were previously presented at conferences, including the Workshop on Speech in Noise, Glasgow, January 2018; and the Meeting of the Acoustical Society of America, Minneapolis, May 2018.
Disclosure statement
There are no relevant financial or non-financial competing interests to report.
References
- Ambert-Dahan, E. 2020. Personal Communication on the Use of the MBAA Test at the Service ORL. Paris: Hôpital Pitié-Salpêtrière.
- Bates, D., M. Mächler, B. Bolker, and S. Walker. 2015. “Fitting Linear Mixed-Effects Models Using lme4.” Journal of Statistical Software 67 (1): 1–48. http://www.jstatsoft.org/v67/i01/
- Bergeron, François, Aurore Berland, Elizabeth M. Fitzpatrick, Christophe Vincent, Annie Giasson, Kevin Leung Kam, Walid Chafiq, et al. 2019. “Development and Validation of the FrBio, An International French Adaptation of the AzBio Sentence Lists.” International Journal of Audiology 58 (8): 510–515. doi:10.1080/14992027.2019.1581950.
- Bliese, P. 2016. Multilevel: Multilevel Functions. https://cran.r-project.org/package=multilevel
- Boothroyd, A., T. Hnath-Chisolm, L. Hanin, and L. Kishon-Rabin. 1988. “Voice Fundamental Frequency as an Auditory Supplement to the Speechreading of Sentences.” Ear Hear 9 (6): 306–312. doi:10.1097/00003446-198812000-00006
- Brand, T., and B. Kollmeier. 2002. “Efficient Adaptive Procedures for Threshold and Concurrent Slope Estimates for Psychophysics and Speech Intelligibility Tests.” The Journal of the Acoustical Society of America 111 (6): 2801–2810. doi:10.1121/1.1479152.
- Falissard, B. 2012. psy: Various procedures used in psychometry. https://cran.r-project.org/package=psy
- Fraysse, B., Á. R. Macías, O. Sterkers, S. Burdo, R. Ramsden, O. Deguine, T. Klenzner, et al. 2006. “Residual Hearing Conservation and Electroacoustic Stimulation with the Nucleus 24 Contour Advance Cochlear Implant.” Otology & Neurotology 27 (5): 624–633. doi:10.1097/01.mao.0000226289.04048.0f.
- Fraysse, B., N. Dillier, T. Klenzner, R. Laszig, M. Manrique, C. Morera Perez, A. H. Morgon, et al. 1998. “Cochlear Implants for Adults Obtaining Marginal Benefit from Acoustic Amplification: A European Study.” American Journal of Otolaryngology 19: 591–597.
- Hagerman, B. 1982. “Sentences for Testing Speech Intelligibility in Noise.” Scandinavian Audiology 11 (2): 79–87. doi:10.3109/01050398209076203.
- Hey, M., T. Hocke, J. Hedderich, and J. Müller-Deile. 2014. “Investigation of a Matrix Sentence Test in Noise: Reproducibility and Discrimination Function in Cochlear Implant Patients.” International Journal of Audiology 53 (12): 895–902. doi:10.3109/14992027.2014.938368.
- James, Chris J., Chadlia Karoui, Marie-Laurence Laborde, Benoît Lepage, Charles-Édouard Molinier, Marjorie Tartayre, Bernard Escudé, et al. 2019. “Early Sentence Recognition in Adult Cochlear Implant Users.” Ear & Hearing 40 (4): 905–917. doi:10.1097/AUD.0000000000000670.
- Jansen, Sofie, Heleen Luts, Kirsten Carola Wagener, Birger Kollmeier, Matthieu Del Rio, René Dauman, Chris James, et al. 2012. “Comparison of Three Types of French Speech-in-Noise Tests: A Multi-Center Study.” International Journal of Audiology 51 (3): 164–173. doi:10.3109/14992027.2011.633568.
- Kollmeier, Birger, Anna Warzybok, Sabine Hochmuth, Melanie A. Zokoll, Verena Uslar, Thomas Brand, Kirsten C. Wagener, et al. 2015. “The Multilingual Matrix Test: Principles, Applications, and Comparison across Languages: A Review.” International Journal of Audiology 54 (sup2): 3–16. doi:10.3109/14992027.2015.1020971.
- Koo, T. K., and M. Y. Li. 2016. “A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research.” Journal of Chiropractic Medicine 15 (2): 155–163. doi:10.1016/j.jcm.2016.02.012.
- Leclercq, F., C. Renard, and C. Vincent. 2018. “Speech Audiometry in Noise: Development of the French-Language VRB (Vocale Rapide Dans le Bruit) Test.” European Annals of Otorhinolaryngology, Head and Neck Diseases 135 (5): 315–319. doi:10.1016/j.anorl.2018.07.002.
- Lenth, R. 2019. emmeans: Estimated Marginal Means, aka Least-Squares Means. https://cran.r-project.org/package=emmeans
- Luts, H., E. Boon, J. Wable, and J. Wouters. 2008. “FIST: A French Sentence Test for Speech Intelligibility in Noise.” International Journal of Audiology 47 (6): 373–374. doi:10.1080/14992020801887786.
- Plomp, R., and A. M. Mimpen. 1979. “Improving the Reliability of Testing the Speech Reception Threshold for Sentences.” Audiology 18 (1): 43–52. doi:10.3109/00206097909072618.
- R Core Team. 2017. R: A Language and Environment for Statistical Computing. https://www.r-project.org/
- Shrout, P. E., and J. L. Fleiss. 1979. “Intraclass Correlations: uses in Assessing Rater Reliability.” Psychological Bulletin 86 (2): 420–428. doi:10.1037/0033-2909.86.2.420.
- Theunissen, M., D. W. Swanepoel, and J. Hanekom. 2009. “Sentence Recognition in Noise: Variables in Compilation and Interpretation of Tests.” International Journal of Audiology 48 (11): 743–757. doi:10.3109/14992020903082088.
- Thornton, A. R., and M. J. M. Raffin. 1978. “Speech-Discrimination Scores Modeled as a Binomial Variable.” Journal of Speech and Hearing Research 21 (3): 507–518. doi:10.1044/jshr.2103.507.
- Vaillancourt, Véronique, Chantal Laroche, Chantal Mayer, Cynthia Basque, Madeleine Nali, Alice Eriks-Brophy, Sigfrid D. Soli, et al. 2005. “Adaptation of the HINT (Hearing in Noise Test) for Adult Canadian Francophone Populations.” International Journal of Audiology 44 (6): 358–369. doi:10.1080/14992020500060875.
- Wilson, R. H., C. S. Carnell, and A. L. Cleghorn. 2007. “The Words-in-Noise (WIN) Test with Multitalker Babble and Speech-Spectrum Noise Maskers.” Journal of the American Academy of Audiology 18 (6): 522–529. doi:10.3766/jaaa.18.6.7.