
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this study, we respond to the criticism that the value-at-risk (VaR) measure fails during financial crises and is only applicable during periods without asset price bubbles. We propose a new dating mechanism that is based on the work of Phillips (2015) to date-stamp the origination and termination of the asset price bubbles. Our method relaxed the minimum bubble duration constraint in the original model, and the empirical application statistically identified the bubbles periods in nine stock markets (Australia, Canada, China, Germany, Spain, Hong Kong, Japan, the United Kingdom, and the United States). We choose the two most widely adopted VaR models (RiskMetrics and RiskMetrics 2006) to test the performance. Our results show that the RiskMetrics model fails in most periods, whereas the RiskMetrics 2006 performs efficiently in the periods with asset price bubbles. These results prove the criticism that all the VaR models fail during crises as invalid.
1. Introduction
Financial markets have experienced several crises over the last two decades. The Asian financial crisis in 1997, the dot-com bubble burst in 2001, the subprime mortgage crisis in 2008, and the European sovereign debt crisis in 2009 have driven the financial institutions to use better measures to manage downside risk. The losses caused by these financial crises were tremendous; the 2008 subprime mortgage crisis costed the US economy up to 14 USD trillion (Atkinson, Luttrell, & Rosenblum, Citation2013), which is equivalent to the average annual output of the entire US economy. Furthermore, the global economy has become more integrated and the cross-border financial flows have steadily increased. This widens the contagion effect and complicates the effects of the financial crisis further.
Financial crises are predominantly caused by the burst of asset price bubbles. An asset price bubble is formed when the asset’s price deviates from its fundamental value. During the bubble booming period, an asset’s price grows at an explosive rate. Blanchard and Watson (Citation1982) suggest that asset bubbles last only till the market realizes it and makes corrections. The correction is usually associated with a large sale force that causes a plunge in the stock price. This process is commonly referred as a bubble burst. However, it is difficult to identify bubbles and date-stamp the bursts.
The losses from the financial crises have led the practitioners and regulators to actively look for risk models that measure the downside risks. Over the past decade, value-at-risk (VaR) has emerged as one of the most popular methods for measuring the downside risks of financial investments. The downside risk of a financial investment predicts the minimum loss of a portfolio’s value for a period with a certain probability. After the subprime mortgage crisis in 2008, practitioners and regulators criticised the VaR models for failing to reveal the underlying risk, which led many financial institutions to suffer unexpected losses well above the VaR value and resulted in a credit crunch. However, most criticism stems from the lack of statistical analysis, which leads to false conclusions on the efficiency of VaR models.
Although a considerable body of research criticises VaR for performing poorly during turbulent financial periods (see Mertzanis, Citation2013; Lockwood, Citation2015), most literature classifies crisis and non-crisis periods unclearly by its own subjective judgment. Halbleib and Pohlmeier (Citation2012) proposed a data-driven VaR method that combines quantile forecasts to improve VaR’s performance during a crisis. They formed three portfolios to represent small-, middle-, and large-cap stocks in the Dow Jones index and evaluated the performance in the claim period (1 January 2007 to 17 July 2007), crisis period (18 July 2007 to 1 July 2009), and crash period (1 September 2008 to 1 July 2009). The results show that the method performs well in the crisis periods. However, the crisis and non-crisis periods were defined arbitrarily without a statistical basis. Chen, Gerlach, Lin, and Lee (Citation2012) studied the RiskMetrics models (Riskmetrics, Citation1996) and several generalised autoregressive conditional heteroscedasticity (GARCH) (Bollerslev, Citation1986) family VaR models under Bayesian forecasting tests in Japan, Hong Kong, Korea, and the US markets. Their study ranks the RiskMetrics model last among all models, and shows that all VaR models underestimate the risk level during a crisis period. However, similar to the work of Halbleib and Pohlmeier (Citation2012), the crisis and non-crisis periods were defined arbitrarily and the crisis periods were considered to be the same across different stock markets with different characteristics, which is debatable.
Our study contributes to the literature that responds to these limitations, by empirically testing the VaR models’ performance in periods with and without asset price bubbles, particularly in the periods of financial crisis after the bubbles burst. Against the background of criticism for VaR models, we perform a series of backtests to statistically evaluate its performance. Following Phillips, Shi, and Yu (Citation2015), we use the backward supremum augmented Dickey–Fuller (BSADF) test to date-stamp the origination and termination of the bubbles. However, we modify the date-stamping algorithm to suit backtesting. We define three periods for the tests: the pre-bubble period, bubble period, and post-burst period. The bubble period is bounded by the bubble’s origination and termination dates and the pre- and post-burst periods are defined as 2 years before and 2 years after the termination date, respectively. Our date-stamping method allows researchers to evaluate the financial models that may behave differently at different stages of a bubble.
Though VaR is a popular means to quantify downside risk, there is little consensus on the preferred VaR model. Köksal and Orhan (Citation2013) tested a VaR model based on a simple autoregressive conditional heteroscedasticity (ARCH) setting in the developed and emerging markets during financial crisis. Their results show that VaR performs more inefficiently in developed countries than in emerging countries and, overall, fails to reveal the downside risk. However, their results may only be true for the ARCH-based VaR model. Bams, Blanchard, and Lehnert (Citation2017) compared VaR’s performance in the S&P 500, Dow Jones Industrial Average, and Nasdaq 100 indices. The results show that the VaR based on historical volatility measure outperforms other parametric VaR models. Lee, Chiou, and Lin (Citation2006) employed Engle (Citation2002) dynamic conditional correlation (DCC) estimators to estimate a portfolio’s VaR. The authors found that VaR performance at a portfolio level may be unreliable due to the difficulty in forecasting the dynamic correlation among assets. For better modeling of a portfolio’s volatility, Chiriac and Voev (Citation2011) developed a multivariate vector fractionally integrated ARMA (VARFIMA) process that models the long memory characteristics of financial volatility. Furthermore, Engle, Ledoit, and Wolf (Citation2019) proposed a new standard of DCC model that applies nonlinear shrinkage in the estimation of the portfolios of large dimensions. Recent studies such as Fiszeder, Fałdziński, and Molnár (Citation2019) and Law, Li, and Yu (Citation2020) incorporate the state-of-the-art volatility estimation method in the calculation of portfolio VaR. The results show that the choice of volatility model significantly impacts the accuracy of the VaR estimates.
We follow Campbell and Shiller (Citation1989) and Phillips et al. (Citation2015) to consider the explosive behaviour in log price–dividend ratio for the detection of asset price bubble. To understand the VaR performance in different markets, we examine nine stock markets (Australia, Canada, China, Germany, Spain, Hong Kong, Japan, the UK, and the US, and proxy each of the market portfolios by its respective market index. In light of this, our analysis focuses on univariate VaR models and uses the two widely adopted univariate VaR models – RiskMetrics (Riskmetrics, Citation1996) and RiskMetrics 2006 (Zumbach, Citation2007) – in our empirical tests in response to the criticism of VaR failure. To evaluate the performance of the VaR models in different periods, we conduct the unconditional coverage tests (Kupiec, Citation1995), the independence tests (Christoffersen & Pelletier, Citation2004), and the joint coverage tests. The empirical results of both the conditional and unconditional coverage tests suggested that the RiskMetrics 2006 model adequately described the downside risks in all the nine markets during the bubble periods. However, one weakness noted in the RiskMetrics 2006 model was its tendency to occasionally overstate the downside risk after a market turbulence. Further, the RiskMetrics 2006 model reported zero VaR violations in post-burst periods in Australia, Canada, Japan, and the UK. The empirical results of the conditional coverage tests, unconditional coverage tests, and Fisher’s exact tests suggested that the RiskMetrics 2006 model performs efficiently in most periods, rendering the criticism against VaR models statistically invalid.
The remainder of this paper is organised as follows: Section 2 discusses the rationale of using the log price/dividend ratio as an indicator of asset price bubbles. Section 3 explains the SADF and generalised SADF (GSADF) tests used to identify asset price bubbles and the date-stamping mechanism. Section 4 describes the RiskMetrics and RiskMetrics 2006 VaR models, as well as the backtesting methods. The empirical results of the GSADF tests, identification of the bubble periods, and VaR backtesting results for the sample markets are presented in Section 5. Section 6 concludes the study.
2. Asset prices and bubbles
Asset price bubbles are usually driven by speculative behaviours that bid up the asset prices beyond their fundamental values. The fundamental value of an asset is the sum of the discounted future cash flows. In the presence of bubbles, asset prices behave explosively. The log price of a security is defined as
where is the log price at a time
,
is the fundamental value, and
is the bubble component (Campbell & Shiller, Citation1989).
In this Equationequation 1(1)
(1) , the value of
is the fundamental component of the stock price as it depends on the expected dividends. In contrast,
is the speculative component as it is based on the future expectations on the stock price. The stock price will be explosive if the bubble component
in the Equationequation 1
(1)
(1) is non-zero.
The log price–dividend ratio is the summation of a series of log dividend differences and the bubble components (Campbell & Shiller, Citation1989; Phillips et al., Citation2015). If the log dividend is stationary after differencing, an explosive behaviour of the log price–dividend ratio would be caused by the presence of a non-zero bubble component . Thus, we can detect if asset price bubbles exist by examining any explosive behaviour in the log price–dividend ratio series and non-explosive behaviour in the first difference log dividend series.
3. SADF and GSADF tests
Previous studies have suggested using a supremum of a set of recursive right-tailed augmented Dickey–Fuller (ADF) tests to detect the presence of stock bubbles (Dickey & Fuller, Citation1979). This SADF test applies the right-tailed ADF test with the null hypothesis of a unit root () and the alternative hypothesis of an explosive root (
).
The regression model used in the SADF test is
where is the lag order and
is the random error.
The SADF test begins with testing the first fraction of the observations. It is followed by repeated ADF tests till
is increased to 1, which is denoted by
. The forward sequence of the regression starts from observation 1 and ends with
, where
is the integer part of the argument,
is the total number of observations, and
is the fraction of the observations. The SADF statistic is
The corresponding asymptotic distribution of the SADF test is discussed by Phillips, Shi, and Yu (Citation2014). The asymptotic distribution of the SADF test statistic for the null hypothesis that the true process is a random walk without drift is
where is a Wiener process.
We determine if the behaviour of the data series is explosive by comparing the SADF statistic of the data series with the asymptotic distribution of the Dickey–Fuller t-statistic in Equationequation 3(3)
(3) . We perform a backward ADF (BADF) test to date-stamp the explosion. The BADF test performs the ADF test repeatedly by fixing the starting point of the sample at the first observation, and rolling the ending point from
to
. For example, if the testing sequence starts from
(
in the BADF test) and ends at
, the corresponding BADF test statistic would be
. The BADF test statistic is denoted by
because the first observation is the starting point.
The explosion originates at when it is the first occurrence after the
statistic exceeds the critical value. Phillips, Wu, and Yu (Citation2011) impose the conditions that the bubble duration must be longer than
and the termination date of the explosion (
) must be the first occurrence after the observation
, when the
statistic is below the critical value.
Phillips et al. (Citation2011) further recommended that the critical value should vary with the number of observations in the testing window for it to diverge to infinity and eliminate type I errors for large
; specifically, they suggested setting
. The test using the bubble date-stamping method of equation 4 is referred to as the PWY test in this paper.
The disadvantage of the PWY test is the possible failure when multiple bubbles are present in the sample. Phillips et al. (Citation2015) proposed the generalised version of SADF (i.e., the GSADF test) to address this issue for its flexibility in allowing changes to the starting point of the testing window. The GSADF statistic is defined as
The asymptotic distribution of the GSADF test is elaborated by Phillips et al. (Citation2014).
The date-stamping method used in the GSADF test is an extended version of the one used in the BADF statistic. The BSADF test performs an SADF test by rolling the starting point of the test window from observation
to the first observation. The BSADF statistic for a testing sequence that starts at
and ends at
is defined as
Similar to the PWY test, the origination date of a bubble in the GSADF test is , when
is the first occurrence after the
statistic exceeds the critical value. The minimum bubble duration in the BSADF statistic is generalised to
, where
is a frequency-dependent parameter. Furthermore, the termination date of explosion
is the first occurrence after the observation
, when the
statistic is below the critical value. The bubble date-stamping method of equation 5 is referred to as the PSY test in this paper.
The bubble origination date in the GSADF test is date-stamped using Equationequation 5a(5a)
(5a) , which is the ending point
of the testing window in the BSADF statistic. The PSY date-stamping method picks the ending point in an explosive series as the bubble origination date. Though this gives confidence in forward tests, it might miss the bubble formation period, which is crucial for a backtest. Alternately, we examine the bubble origination date by considering the starting point as
instead of
of the explosive series. Thereby, we modify the date-stamping method for the bubble origination date as in Equationequation 6a
(6a)
(6a) . The new bubble origination date is
.
, in Equationequation 6a
(6a)
(6a) , is the end of the testing sequence in the BSADF test for bubble origination. We use this ending point as a starting point to detect the termination date of the explosion
in Equationequation 6b
(6b)
(6b) . The minimum length of the bubble duration is the size of the testing window when the bubble origination date starts at
. Thus, we address the minimum bubble duration
constraint in the PSY test to obtain the bubble termination date. The differences between the PSY date-stamping method and the modified method are presented in section 5.2. This new date-stamping method for the bubble origination date, presented in equation 6, is used throughout the study.
4. VaR models and backtests
We compute daily 1% VaRs by using the RiskMetrics (Riskmetrics, Citation1996) and RiskMetrics 2006 (Zumbach, Citation2007) models to compare the performance of VaR in the pre-bubble, bubble, and post-burst periods. The RiskMetrics model assumes that the asset returns are normally distributed with mean
and variance
. Using the standard normal cumulative distribution function
and the cumulative distribution function of the asset return
, the
percent one-day VaR can be obtained using equation 7. The estimated values of
and
are computed from an estimation window of size
, which is set to 250 days in this study. As the Student’s
-distribution is another prominent distribution to describe financial asset returns, further from the original RiskMetrics model, we study a variant model that uses cumulative
-distribution
with
degree of freedom to compute the
percent one-day VaR, and the formula is shown in Equationequation 8
(8)
(8) .
RiskMetrics estimates the volatility by using the second central moment of the asset returns
. In contrast, RiskMetrics 2006 allocates a heavier weight to recent observations, while preserving the long-lasting impact of shocks. Towards this end, RiskMetrics 2006 introduces a hyperbolic decay factor
, based on the geometric time horizon factor
defined using Equationequation 9
(9)
(9) .
Here is an operationalised parameter. RiskMetrics 2006 obtains the volatility
using Equationequation 10
(10)
(10) , by summing the
historical volatilities
(defined in Equationequation 11a)
(11a)
(11a) with logarithmic decay weights
derived using Equationequation 11b
(11b)
(11b) .
where C is kept constant to ensure that the sum of the weights is equal to 1 (i.e.,
). The long memory RiskMetrics 2006 model is controlled by three parameters: the logarithmic decay factor
, lower cut-off
, and upper cut-off
. We set
,
days,
days,
days, and
following Zumbach (Citation2007).
We define as the total number of observations in the data set,
as the size of the estimation window, and
as the size of the testing window for VaR violations. A VaR violation (
) is recorded when the loss on a trading day
exceeds the calculated VaR value. The total number of VaR violations
in the testing period
is calculated using Equationequation 12
(12)
(12) ;
, calculated using Equationequation 13
(13)
(13) , indicates the number of days without violations.
We employ three categories of backtests to test the accuracy of the VaR models: the unconditional, conditional, and joint coverage tests. Unconditional coverage tests evaluate the VaR models by testing the number of violations at a given confidence level. In the unconditional coverage tests, we employ Kupiec (Citation1995) proportion of failures (POF) test and time until first failure (TUFF) test to assess the VaR values. The POF test is a likelihood ratio test that examines if a VaR failure rate (number of violations divided by the number of observations) is consistent with the VaR confidence level. The TUFF test assesses the time for the first violation to occur in a sample. Both methods test the hypothesis that assumes that the violation rate is equal to the significance level . Further, based on the frequency of the violations (unconditional coverage), independence of the violations (conditional coverage) is considered to hold equal importance when assessing a VaR model. Ideally, the probabilities of VaR violations of time
and
should show no dependences. Christoffersen and Pelletier (Citation2004) developed an interval forecast test using a binary first-order Markov chain and a transition probability matrix to test the independence of the violations. However, the Christoffersen’s independence test has a limited ability in assessing violations between two consecutive trading days. The mixed-Kupiec independence test (Hass, Citation2001) overcame this limitation with the mixed-Kupiec independence test, which considers the timing of the violations without the use of first-order Markov chain. Both the conditional coverage tests examine the hypothesis that assume that no violation clustering effect (consecutive violations) exists. Furthermore, we employ the Christoffersen’s joint test (a likelihood ratio test which combines POF test and Christoffersen’s independence test) and mixed-Kupiec joint test (a likelihood ratio test, which combines TUFF test and mixed-Kupiec independence test) to test the hypotheses that the true violation rate is
and the violations are independent. The details of the coverage tests are provided in Appendix A.
4.1. Fisher’s exact test
We perform the Fisher’s exact test (Fisher, Citation1922) to examine the significance of associations between the VaR failure rates in different crisis periods. We perform the Fisher’s exact test in this study due to the small sample size of VaR violations (1% VaR represents 5 violations of 500 observations). We use a contingency table to represent the number of VaR violations in different periods. For instance, in , for
days in period
, the VaR measure performed well for
days but failed for
(
) days. Under the null hypothesis, the VaR failures in different periods are stochastically independent. The VaR failure rates show no significant difference between the crisis and non-crisis periods. The alternative hypothesis is that the systematic difference in VaR failures compared to the expectation in different periods is coincidental.
Table 1. Contingency table of fisher’s exact test for VaR measures in different periods
5. Data and empirical results
The nine stock markets employed in our empirical analysis represent both the developed and emerging markets. The selection was based on the market capitalisation and trading time zones, shown in .
Table 2. Stock exchanges and the respective indices used
Monthly price and dividend data were used in the bubble tests and daily price data were used in the VaR backtests. The data were obtained from Bloomberg.
5.1. Pre-bubble, bubble, and post-burst periods
shows the GSADF tests of the log price–dividend ratio and log dividend difference series of the nine markets. The finite sample of critical values used in the GSADF tests was obtained from 2,000 simulations. We followed Phillips et al. (Citation2015) in determining the minimum window size of the test based on the rule , where
is the corresponding sample size. As the GSADF test statistic of all the log price–dividend ratios exceeded their corresponding 10% right-tail critical values, the summary test showed an explosive behaviour in the log price–dividend ratio and a non-explosive behaviour in the log dividend difference series. This provided evidence for explosive sub-periods in the nine markets.
Table 3. GSADF tests for the log price–dividend ratio and log dividend difference in the nine markets
We performed both the PSY test and the modified test to date-stamp the origination and termination of the bubbles using equations 5 and 6, respectively. shows the bubble date-stamping results from these methods in the nine stock markets. The estimated bubble origination dates were close to the termination dates in most cases and the bubble duration was short in the PSY date-stamping method. The average duration of the bubble period was 7 months. Although all the tests identified asset price bubbles around the subprime mortgage crisis, they exhibited a time lag. For the stock markets in Australia, Canada, Germany, Spain, Japan, the UK, and the US, the PSY method suggested that the bubbles originated in late 2008 and terminated in mid-2009. The origination dates were close to the original bubble burst, that is, when Lehman Brothers filed for the largest bankruptcy protection in the US history on 15 September 2008. The reason for the short durations of asset price bubbles indicated by the PSY test, contrary to general agreement that it takes time for the bubble to form, is the date-stamping strategy, which is based on choosing the ending point of the testing window when the whole sample is explosive. We believe that a more appropriate choice for the bubble origination date would be the starting point of the testing window, instead of the ending point.
Table 4. Bubble periods obtained by the PSY test and the modified date-stamping method
The bubble origination dates identified by the modified method are from late 2002 to mid-2005 and the termination dates are from early 2009. Our results agree with those from the previous studies (Brown, Stein, & Zafar, Citation2015; Demyanyk & Van Hemert, Citation2011; Lewis, Citation2009; Mian & Sufi, Citation2009; Sanders, Citation2008).
To illustrate the differences between the two date-stamping methods, we used the Hong Kong stock market as an example. The PSY approach identified a five-month bubble from November 2007 to March 2018; this is illustrated in , with the bubble period highlighted in grey. In contrast, the bubble period identified by the modified method was from April 2004 to October 2007 as shown in . Unlike the PSY approach, the result of the modified method did not indicate shorter durations and agreed well with the asset price bubble cycles of the subprime mortgage crisis (see Dell’ariccia, Igan, & Laeven, Citation2012; Lewis, Citation2009; Tridico, Citation2012).
Figure 1. Bubble identification results for the hong kong stock market.
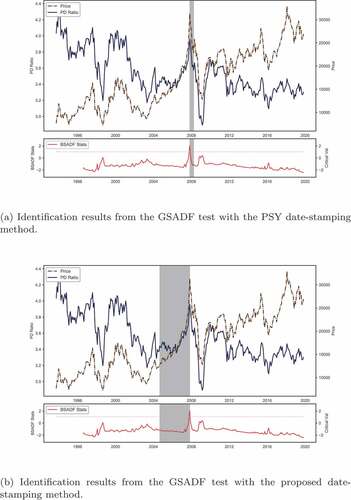
5.2. Backtesting results
We defined the pre-bubble and post-burst periods as 2 years before and after the bubble.
Here is the time frequency-dependent parameter;
for the monthly data and
for the daily data (we assume 250 trading days per year). The pre-bubble period extended from September 2002 to August 2004 and the post-burst period from November 2007 to October 2009 for a bubble period identified from September 2004 to October 2007, when Hong Kong was used as an example. Further, we define the period not covered by the pre-bubble, bubble, and post-burst periods as ”normal periods.” For example, two normal periods of September 1993 to August 2002 and November 2009 to October 2019 were defined from the entire period considered for the Hong Kong market (September 1993 to October 2019). shows the bubble periods identified for the nine stock markets. One bubble period was identified each for Australia, Canada, China, Germany, Hong Kong, Japan, and the UK, and two each for Spain and the US. The reason for the additional bubble period in Spain and the US could be the extent of data available. Spain’s data starts from January 1991 and the US’s data from February 1978.
Table 5. Full, pre-bubble, bubble, post-burst, and normal periods for the bubbles examined in the nine stock markets
show the results of the RiskMetrics VaR backtests, and show the results of RiskMetrics 2006 in different periods. In all the hypothesis tests, we tested the null hypotheses at a significance level of 5%. For the periods where no VaR violation was observed, we have not reported the value for the independence tests as the results of the violation clustering test were ambiguous (see an example of the independence test and joint test results in the normal period for the UK (period 1) in ). In the coverage tests, to deem a case as a ”failure,” the null hypotheses should be rejected in both coverage tests. An analogous criterion was also adopted for the independence tests and joint tests.
Table 6. Backtest results of riskmetrics VaR in the pre-bubble, bubble, and post-burst periods
Table 7. Backtest results of riskmetrics VaR in the normal and full periods
Table 8. Backtest Results of RiskMetrics 2006 VaR in the Pre-bubble, Bubble, and Post-burst Periods
Table 9. Backtest results of riskmetrics 2006 VaR in the full and normal periods
shows that RiskMetrics performed poorly around turbulent financial times. Both the RiskMetrics models with normal distribution and -distribution had analogous results. Minor differences were found in Canada and the UK but such have no impact on the results in the hypothesis tests. Within the large estimation window size used in the RiskMetrics model the fitted
-distribution approaches the normal. Further, RiskMetrics performed effectively only in the coverage tests for the pre-bubble period. We could not reject the null hypothesis because the probability of a violation was the same as the coverage rate for Australia, Canada, China, Spain, Hong Kong, Japan, and the US markets. The exceptions were Germany (p-value was 0.028 in the TUFF test) and the UK markets (p-value was 0.003 in the POF test). Violation clustering was also noted with Canada, Germany, the UK, and the US, which led to rejecting the null hypotheses in these markets in all the joint tests.
RiskMetrics performed inadequately in the bubble period as well. The null hypotheses of the POF coverage tests were rejected in all the nine markets. Although the Christoffersen’s independence test showed no significant consecutive violations, the violation clustering was severe leading to the null hypotheses being rejected by the mixed-Kupiec independence test and all the joint tests. However, RiskMetrics performed noticeably better in the post-burst period as it rejected the null hypotheses only for China, Hong Kong, and Japan. The coverage tests (with a p-value of 0.001 in the POF test, and 0.011 in the TUFF test) showed that the number of violations in China was misspecified. The independence tests showed that the Japanese market exhibited violation clusters (with a p-value of 0.035 in the Christoffersen test and 0.005 in the mixed-Kupiec test). In the post-burst period, RiskMetrics underestimated the downside risk in China, Hong Kong, and Japan. Further, shows that RiskMetrics presented inaccurate downside risk measures for both the normal and full periods. Similar to the results for the bubble period, the null hypotheses were rejected in most of the POF coverage tests, independence tests, and joint tests. We found that RiskMetrics failed to reveal the downside risk in most cases.
The results in provide convincing evidence to show that RiskMetrics 2006 works efficiently in a period of market turbulence. In the pre-bubble period, we could not reject the null hypotheses in all the tests, except for China and the US. In China, the null hypothesis was rejected by both coverage tests (the p-value was 0.002 in the POF test and 0.033 in the TUFF test). In the US, both the independence tests (period 1) rejected the null hypothesis (with p-values of 0.034 and 0.020). Further, RiskMetrics 2006 performed efficiently in the bubble period. It failed only in the coverage tests and joint tests for the US market in period 2, defined in . However, the long memory RiskMetrics 2006 behaved conservatively in the post-burst period although no violation was found in Australia, Canada, Japan, the UK, and the US (period 2). In the normal period, RiskMetrics 2006 performed efficiently; failing only in period 2 of the independence tests for Australia (with a p-value of 0.008 in the Christoffersen test and 0.004 in the mixed-Kupiec test), Japan (with a p-value of 0.008 in the Christoffersen test and 0.008 in the mixed-Kupiec test), and the US (with a p-value of 0.002 in the Christoffersen test and 0.000 in the mixed-Kupiec test).
RiskMetrics 2006 behaved conservatively in overestimating the downside risk after the bubbles. However, in the total duration considered, the number of VaR violations were 34, 57, 49, 23, 45, 43, 43, 25, and 77 in Australia, Canada, China, Spain, Hong Kong, Japan, the UK, and the US, respectively. These violation numbers were significantly lower than those found by the RiskMetrics model, which were 100, 172, 112, 129, 139, 140, 146, 108, and 212, respectively, as shown in . Although RiskMetrics 2006 may require financial institutions to allocate more capital than necessary to manage risks, it performed efficiently in most periods.
5.3. VaR performance in pre-bubble, bubble, and post-burst periods
We conducted the Fisher’s exact tests for both the RiskMetrics and RiskMetrics 2006 models to gain further insight on their performance in different crisis periods. We performed 10 Fisher’s exact tests to compare the VaR performance in each of the nine markets during the full, pre-bubble, bubble, post-burst, and normal periods. The results are shown in . shows that unlike RiskMetrics, the RiskMetrics 2006 has a consistent performance regardless of the periods in all the nine markets. In each panel, the lower triangular matrix contain the p-values of the RiskMetrics tests, while the upper triangular matrix contains the p-values of the RiskMetrics 2006 tests. A p-value of Fisher test greater than 5% is indicative of no statistically significant relationship of the VaR failure rates between two chosen periods. Panels 10(a), 10(g), and 10(h) show that the performance of RiskMetrics VaR differed in the bubble periods. The null hypotheses were rejected in the tests between the bubble period and the pre-bubble, post-burst, and full periods. After combining the results in , the performance of RiskMetrics was found to be inconsistent in different periods, with the frequency of failure being higher in the bubble periods. Panel 10(i) shows considerable difference with RiskMetrics in the US post-burst period when compared to other periods. Comparing this with the results in , we observe that the RiskMetrics model failed in all the periods in the US except for the post-burst period. Similarly, panel 10(c) shows that it only performed well in the pre-bubble period in China. The overall results suggested a significant difference in the RiskMetrics performance across different countries in different crisis periods.
Table 10. Fisher exact test for the significance level of the difference of VaR failure rate by time period
Contrary to RiskMetrics, RiskMetrics 2006 did not show extensive performance differences in different periods. The VaR performance seen panel 10(d), panel 10(e), panel 10(f), panel 10(i) shows no significant difference, whereas occasional inconsistencies are observed in panel 10(b), 10(g), and 10(h). Specifically, the inconsistency in these three panels was between the bubble and the post-burst periods. The Fisher’s test results support our finding previously mentioned in section 5.2 that though RiskMetrics 2006 occasionally overstated the downside risk in post-burst periods, it performed efficiently in most periods.
6. Summary and conclusions
In this study, we conducted empirical tests to respond to the criticism that VaR models fail during financial crises when asset bubbles burst. Our empirical tests on the nine markets, namely Australia, Canada, China, Spain, Hong Kong, Japan, the UK, and the US, were conducted using data from the earliest available dates to October 2019. Asset price bubbles were date-stamped using the modified PSY tests on the log price-dividend ratios of these nine markets. However, as the date-stamping method of the original PSY test is forward-looking, it selects the ending point of the testing window as the bubble origination date. To suit our need for a backward-looking date-stamping method for the backtests, we modified the date-stamping method by choosing the starting point of the testing window. Our results show that the original date-stamping method has time lag and indicates a shorter duration for the bubble period. It date-stamps the bubble start near the end of a true bubble and the average duration of the bubble periods detected is 8 months. The results also show that our modified method addressed both the time lag and shorter duration issues present in the original date-stamping method and, thus, more suitable for backtesting.
The empirical test results of the nine backtests allowed us to draw two main conclusions. First, the RiskMetrics 2006 model outperforms the RiskMetrics model. Specifically, the former works well in pre-bubble, bubble, and normal periods but behaves conservatively in the post-burst period, which may overestimate the downside risk. Second, the criticism that all VaR models fail in crisis or bubble periods is statistically invalid. The power of VaR is affected by the modelling practices adopted by different financial institutions.
An interesting direction for future research would be to examine parametric and non-parametric VaR approaches. Non-parametric approaches comprise historical and Monte Carlo simulations, whereas parametric approaches include GARCH, GJR-GARCH (Glosten, Jagannathan, & Runkle, Citation1993), and the multivariate DCC (Engle, Citation2002) approach.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Raymond Kwong
Raymond Kwong is a Senior Lecturer in the College of Professional and Continuing Education, the Hong Kong Polytechnic University. He received his PhD in Economics from the Newcastle University, United Kingdom. His research focuses on issues of asset price bubbles, market microstructure, price discovery and risk management in equity market.
Helen Wong
Helen Wong is a Principal Lecturer in the College of Professional and Continuing Education, the Hong Kong Polytechnic University (HKPU). She has devoted her research study in customer relationship building, corporate social responsibility, accounting and finance. Prior joining HKPU, Helen has worked in several renowned corporations in Hong Kong and Canada, such as PricewaterhouseCoopers, Hong Kong Stock Exchange, University of Toronto, and Bank of Montreal.
References
- Atkinson, T., Luttrell, D., & Rosenblum, H. (2013). Assessing the costs and consequences of the 2007–09 financial crisis and its aftermath. Economic Letter, 8(7). Retrieved from https://ideas.repec.org/a/fip/feddel/y2013isepnv.8no.7.html
- Bams, D., Blanchard, G., & Lehnert, T. (2017). Volatility measures and Value- at-Risk. International Journal of Forecasting, 33(4), 848–863. Retrieved from http://www.sciencedirect.com/science/article/pii/S0169207017300511
- Blanchard, O. J., & Watson, M. W. (1982, july). Bubbles, rational expectations and financial markets (Working Paper No. 945). National Bureau of Economic Research. Retrieved from http://www.nber.org/papers/w0945
- Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31(3), 307–327. Retrieved from http://econpapers.repec.org/RePEc:eee:econom:v:31:y:1986:i:3:p:307-327
- Brown, M., Stein, S., & Zafar, B. (2015). The impact of housing markets on consumer debt: Credit report evidence from 1999 to 2012. Journal of Money, Credit and Banking, 47(S1), 175–213. Retrieved from https://onlinelibrary.wiley.com/doi/abs/10.1111/jmcb.12198
- Campbell, J. Y., & Shiller, R. J. (1989). The dividend-price ratio and expectations of future dividends and discount factors. The Review of Financial Studies, 1(3), 195–228.
- Chen, C. W. S., Gerlach, R., Lin, E. M. H., & Lee, W. C. W. (2012, December). Bayesian forecasting for financial risk management, pre and post the global financial crisis. Journal of Forecasting, 31(8), 661–687.
- Chiriac, R., & Voev, V. (2011, September). Modelling and forecasting multivariate realized volatility. Journal of Applied Econometrics, 26(6), 922–947.
- Christoffersen, P., & Pelletier, D. (2004). Backtesting value-at-risk: A duration- based approach. Journal of Financial Econometrics, 2(1), 84–108. Retrieved from http://jfec.oxfordjournals.org/content/2/1/84.abstract
- Dell’ariccia, G., Igan, D., & Laeven, L. (2012). Credit booms and lending standards: Evidence from the subprime mortgage market. Journal of Money, Credit and Banking, 44(2–3), 367–384. Retrieved from https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1538-4616.2011.00491.x
- Demyanyk, Y., & Van Hemert, O. (2011). Understanding the subprime mortgage crisis. Review of Financial Studies, 24(6), 1848–1880.
- Dickey, D. A., & Fuller, W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74(366a), 427–431.
- Engle, R. (2002). Dynamic conditional correlation. Journal of Business & Economic Statistics, 20(3), 339–350.
- Engle, R., Ledoit, O., & Wolf, M. (2019, April). Large dynamic covariance matrices. Journal of Business & Economic Statistics, 37(2), 363–375.
- Fisher, R. A. (1922, June). On the interpretation of χ2 from contingency tables, and the calculation of P. Journal of the Royal Statistical Society, 85(1), 87–94. Retrieved from http://www.jstor.org/stable/2340521
- Fiszeder, P., Fałdziński, M., & Molnár, P. (2019). Range-based DCC models for covariance and value-at-risk forecasting. Journal of Empirical Finance, 54, 58–76. Retrieved from http://www.sciencedirect.com/science/article/pii/S0927539819300696
- Glosten, L. R., Jagannathan, R., & Runkle, D. E. (1993, December). On the relation between the expected value and the volatility of the nominal excess return on stocks. The Journal of Finance, 48(5), 1779–1801.
- Halbleib, R., & Pohlmeier, W. (2012). Improving the value at risk forecasts: Theory and evidence from the financial crisis. Journal of Economic Dynamics and Control, 36(8), 1212–1228. Retrieved from http://www.sciencedirect.com/science/article/pii/S0165188912000887
- Hass, M. (2001). New methods in backtesting. Retrieved from www.ime.usp.br/rvicente/risco/haas.pdf
- Köksal, B., & Orhan, M. (2013). Market risk of developed and emerging countries during the global financial crisis. Emerging Markets Finance and Trade, 49(3), 20–34.
- Kupiec, P. H. (1995). Techniques for verifying the accuracy of risk measurement models. The Journal of Derivatives, 3(2), 85–93. Retrieved from http://ideas.repec.org/p/fip/fedgfe/95-24.html
- Law, K., Li, W. K., & Yu, P. (2020). An empirical evaluation of large dynamic covariance models in portfolio value-at-risk estimation. Journal of Risk Model Validation, 14(2), 21–39.
- Lee, M.-C., Chiou, J.-S., & Lin, C.-M. (2006, May). A study of value-at-risk on portfolio in stock return using DCC multivariate GARCH. Applied Financial Economics Letters, 2(3), 183–188.
- Lewis, M. K. (2009). The origins of the sub-prime crisis: Inappropriate policies, regulations, or both? Accounting Forum, 33(2), 114–126.
- Lockwood, E. (2015). Predicting the unpredictable: Value-at-risk, performativity, and the politics of financial uncertainty. Review of International Political Economy, 22(4), 719–756.
- Mertzanis, C. (2013). Risk management challenges after the financial crisis. Economic Notes, 42(3), 285–320. Retrieved from https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1468-0300.2013.12011.x
- Mian, A., & Sufi, A. (2009). The consequences of mortgage credit expansion: Evidence from the U.S. mortgage default crisis*. The Quarterly Journal of Economics, 124(4), 1449–1496.
- Phillips, P., Shi, S., & Yu, J. (2014). Specification sensitivity in right-tailed unit root testing for explosive behaviour. Oxford Bulletin of Economics and Statistics, 76(3), 315–333. Retrieved from https://onlinelibrary.wiley.com/doi/abs/10.1111/obes.12026
- Phillips, P., Shi, S., & Yu, J. (2015). Testing for multiple bubbles: Historical episodes of exuberance and collapse in the S&P 500. International Economic Review, 56(4), 1043–1078.
- Phillips, P., Wu, Y., & Yu, J. (2011). Explosive behavior in the 1990S Nasdaq: When did exuberance escalate asset values?*. International Economic Review, 52(1), 201–226.
- Riskmetrics, T. M. (1996). JP morgan technical document. JP Morgan: New York.
- Sanders, A. (2008, December). The subprime crisis and its role in the financial crisis. Journal of Housing Economics, 17(4), 254–261. Retrieved from https://www.sciencedirect.com/science/article/pii/S1051137708000363
- Tridico, P. (2012). Financial crisis and global imbalances: Its labour market origins and the aftermath. Cambridge Journal of Economics, 36(1), 17–42.
- Zumbach, G. (2007). The riskmetrics 2006 methodology (Tech. Rep.). University of Applied Sciences Western Switzerland.
Appendix A.
Technical details of VaR backtests
A.1. Unconditional Coverage Tests
The POF test examines whether the observed fail rate (number of VaR violations) is significantly different from the selected failure rate . The null hypothesis of the POF test is
, and equation A.1 defines the likelihood ratio test statistic of the POF test. Under the null hypothesis, the likelihood ratio test statistic
is asymptotically
-distributed with 1 degree of freedom.
The TUFF test assesses the time it takes for the first violation to occur. It assumes that the first violation occurs in days. For the 1% VaR calculation, a violation is expected to occur every 100 days. The null hypothesis of the TUFF test is
. Equation A.2 defines the likelihood ratio test statistic of the TUFF test. Similar to the POF test, under the null hypothesis, the likelihood ratio test statistic
is asymptotically
-distributed with 1 degree of freedom.
A.2. Conditional Coverage Tests
Christoffersen’s independence test uses a binary first-order Markov chain and a transition probability matrix to test the independence of the violations.
Indicator variable takes the value 1 when a VaR violation occurs and 0 otherwise, and
. Christoffersen and Pelletier (Citation2004) suggested that the likelihood function for the violation sequence is Bernoulli-distributed and follows the first-order Markov chain of equation A.4.
where is the total number of observations occurring after
, until
. The unrestricted form of the maximum likelihood estimates for the log-likelihood functions
are simply ratios of the counts of the respective cells as shown in equation A.5.
If the violations are independent, the violation on day is independent from that on day
; thus, the probability
should be equal to
. Equation A.6 shows the transition probability matrix under the null hypothesis
and equation A.7 shows the restricted form of the maximum likelihood estimates for the log-likelihood function
.
where . Equation A.8 shows the likelihood ratio test statistic for independence,
, which is asymptotically
-distributed with 1 degree of freedom under the null hypothesis of the restricted model being the preferred model.
Hass (Citation2001) proposed the mixed-Kupiec independence test, which combined the ideas of Christoffersen and Kupiec, to consider the timing of different occurrences to test the independence of the violations. The mixed-Kupiec test overcomes the limitation of Christoffersen’s independence test in which the first-order Markov chain considers only the dependence between two consecutive trading days. Equation A.9 shows the likelihood ratio statistic of the mixed-Kupiec test.
where is the time between VaR violations
and
, and
is the number of exceptions in the testing period.
A.3. Joint Coverage Tests
The joint test considers both the coverage and the independence of the violations by combining the likelihood ratios of both the tests. The Christoffersen joint test combines the likelihood ratios of the POF test and the Christoffersen’s independence test, whereas the mixed-Kupiec joint test combines the likelihood ratios of the TUFF test and the mixed-Kupiec independence test.
The Christoffersen joint test of coverage and independence can be performed by combining the and
statistics. The null hypothesis is that there are no coverage and clustering issues. Under the null hypothesis, the conditional coverage
statistic, shown in equation A.10, is asymptotically
-distributed with 2 degrees of freedom.
Similarly, the mixed-Kupiec joint test combines the and
statistics into the conditional coverage
statistic. This statistic, shown in equation A.11, is asymptotically
-distributed with
degrees of freedom under the null hypothesis.